
Abstract
Background
Predicting impact of plant tissue culture media components on explant proliferation is important especially in commercial scale for optimizing efficient culture media. Previous studies have focused on predicting the impact of media components on explant growth via conventional multi-layer perceptron neural networks (MLPNN) and Multiple Linear Regression (MLR) methods. So, there is an opportunity to find more efficient algorithms such as Radial Basis Function Neural Network (RBFNN) and Gene Expression Programming (GEP). Here, a novel algorithm, i.e. GEP which has not been previously applied in plant tissue culture researches was compared to RBFNN and MLR for the first time. Pear rootstocks (Pyrodwarf and OHF) were used as case studies on predicting the effect of minerals and some hormones in the culture medium on proliferation indices.
Results
Generally, RBFNN and GEP showed extremely higher performance accuracy than the MLR. Moreover, GEP models as the most accurate models were optimized using genetic algorithm (GA). The improvement was mainly due to the RBFNN and GEP strong estimation capability and their superior tolerance to experimental noises or improbability.
Conclusions
GEP as the most robust and accurate prospecting procedure to achieve the highest proliferation quality and quantity has also the benefit of being easy to use.
Similar content being viewed by others

Background
Graft incompatibility and fruit quality are the present and future challenges that pear orchards are facing with them [1, 2]. In this framework, Pyrodwarf and OHF dwarfing rootstocks acquired from Pyrus communis were used. Pyrodwarf a hybrid of “Old Home” and “Gute Luise” is particularly tolerant to winter cold temperatures, calcareous soils and has a highly significant compatibility with all pear varieties. Moreover, it is characterized by a high precocity, good productivity, and producing uniform in size fruits with pear cultivars [3]. OHF as a cross between “Old Home” and “Farmingdale” cultivars, has reasonably resistance to fireblight, excellent anchorage and is compatible with all pear cultivars [4, 5]. Therefore, many problems with pear orchards are largely overcome by use of these rootstocks, and based on the above reasons, both rootstocks are recommended for high-density planting systems. Classic methods for propagation of pear such as cutting and layering which have been mostly used, are too expensive, time consuming and labor intensive [6]. Micropropagation is a reliable technique that plays a decisive role in rapid propagation of pear and researchers have claimed considerable success with this approach. The responses of pear cultivars to micropropagation are significantly variable, so that some cultivars have exhibited disorders like shoot tip necrosis [7], hyperhydricity [8,9,10], fascination [11] and hooked leaves [9], while some of them grow well [12].
According to the previous studies, [13] (MS) is a very common medium in pear micropropagation but it is not appropriate medium in all cases. That is why recent investigations have focused on optimization of the culture medium [10, 14, 15]. Several studies have been done on modifying MS medium by changing the level of plant growth regulators (PGRs) [8, 12, 16,17,18]. Wada et al. [19] found that increasing mesos nutrients content of MS medium improves multiplication rate in several pear cultivars and alleviates some physiological disorders. Reed et al. [7] adjusted MS medium by increasing mesos levels (1.5 × MS) and reducing nitrogen compounds (0.5–0.8 × MS) to produce shoots without physiological abnormalities in some pear genotypes. Wada et al. [20] found that some pear cultivars require high NO3− (52 to 60 mM), low to moderate NH4+ (data not shown) and high mesos concentrations (1.5 × MS) for the best growth results. Another approach for optimization of MS medium was performed by [21] who suggested that adding meta-topolin (6–9 µM), an aromatic cytokinin, to MS medium increases significantly the multiplication rate and shoot quality in OHF-333 (another clonal selection of Old Home × Farmingdale).
Due to various nutrition necessities of different plant species, it is difficult to obtain an optimized culture medium. Therefore, it is important to employ a trustworthy modeling system to achieve the highest growth performance [15].
Biological systems are difficult to understand and model, largely due to the complexities of their system and non-linear nature; moreover, their dynamic characteristics are poorly understood. Usually, it is difficult to clarify biological interactions by traditional models and algorithms, particularly in the complex and noisy data set. Additionally, many studies have demonstrated that plant biology needs more attempts to find developing platforms for combining multidimensional data in order to draw biological interactions.
In recent decades, several meta-modeling techniques have been emerged as promising methods for modeling high dimensional and non-linear processes. Artificial neural networks (ANN) [22, 23], gene expression programming (GEP) [24,25,26], fuzzy logic (FL) [27] and statistical methodologies [20] are the best examples. Previous investigations have demonstrated that artificial intelligence (AI) based modeling approaches are vastly superior in modeling process to all other techniques [15, 28].
The capability to quickly and effectively emulate nonlinear trends in data operation have helped setting up AI technology as a reliable meta-modeling platform for surrogate modeling in a wide variety of practical assignment, including science and engineering, because of their ability to utilize learning algorithm and detect input–output relationships in intricate, nonlinear processes. Among the numerous aspects of the AI paradigms, ANN technique has a wide range of applications in the field of plant biology and prediction of bioprocess quantitative properties. Successful applications of this approach have been reported in many studies. Among others, ANN was found as a promising technique to assess the effects of mineral nutrients on plant growth and productivity [29]. ANN and Response surface method (RSM) were utilized to model and optimize fermentation media and the results showed that ANN performed significantly better than the RSM methodology [30]. ANN models superiority to traditional statistical analysis was confirmed for assessing the plant biological processes [31]. ANN was applied to model the effects of cultivar and exogenous auxin on in vitro rooting and acclimatization of some grapevine genotypes [32]. Culture media composition was modeled by using a hybrid ANN-genetic algorithm (ANN-GA) method and compared with regression techniques [10] and the superiority of the ANN-GA over the traditional methodology was proved. ANN was found as a very accurate method in modeling and predicting the composition of G × N15 rootstock proliferation culture medium [15].
Radial basis function neural network (RBFNN) is one of the most popular feed-forward ANN architectures in the literature for forecasting problems, among which the back-propagation (BP) algorithm is the most extensively used, and is a supervised learning model. The RBFNN can be considered as a special three-layer feed forward network which has certain advantages including better approximation capabilities, fast learning algorithms, simple network structures, and will not encounter the local minima problems [33, 34]. RBFNN can illuminate the complex law between the inputs and outputs through a fitting process that allows it to approximate any nonlinear function [35,36,37,38].
Although the reported approaches are fitting for modeling culture media, no approaches have been reported to provide effective and clear modeling results as well as explicit formulations of the studied phenomenon without presuming previous shape of the relationship [39, 40]. This induces us to use and suggest a novel method to bridge these gaps among contemporary paradigms. Genetic programming (GP) [41] is a fairly new soft computing approach for the behavior modeling of structural engineering problems. GP is an extension of GA which searches a program space instead of a data space. The main advantage of the GP-based approaches is their ability to generate prediction equations without assuming prior form of the relationship. Many researchers have employed GP and its variants to discover any complex relationships among experimental data [42,43,44]. Gene expression programming (GEP) [45] is a recent extension to GP. GEP evolves computer programs of different sizes and shapes encoded in linear chromosomes of fixed length. The GEP chromosomes are composed of multiple genes, each gene encoding a smaller subprogram [42]. The GEP approach is shown to be an efficient alternative to the traditional GP [45, 46].
The researches mentioned above exhibit the potential of AI methodologies as appropriate modeling tools for plant tissue culture. However, the literature survey revealed that no investigation has been done to use GEP for predicting new culture medium. This gave new impetus to the present study.
The purpose of this paper is to apply two soft computing techniques namely RBFNN and GEP and to compare their prediction accuracy to Multiple Linear Regression (MLR) method as well as using GA algorithm aiming to predict and optimize pear culture media. The main contributions of this paper are as follows:
-
Investigating the application of the GEP and RBFNN for modeling the effects of macronutrients and hormones on in vitro culture of Pyrodwarf and OHF rootstocks.
-
Development of GEP-GA models in order to evaluate how Pyrodwarf and OHF microshoots respond to the mineral medium based on the number and length of new formed shoots obtained from the design of Box-behnken.
-
Finding the optimal culture medium composition for maximizing the proliferation rate (PR), the average shoot length (SL), the quality index (QI), and minimizing shoot tip necrosis (STN) and vitrification (Vitri) by optimizing the obtained model using GA.
Results
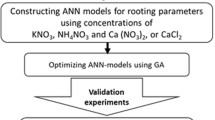
This section evaluates the performances of the proposed models by analyzing the accuracy of each modelling approach for predicting the plant tissue culture media composition to studied fruit tree rootstocks micropropagation. Then GA-optimization of the most accurate modeling approach results is evaluated to achieve the most appropriate media compositions for each studied parameter. A framework of the performed experiments to achieve the best model is presented in Fig. 1.

Framework of the performed experiments
Comparison of MLR, RBFNN and GEP prediction models
The models were developed using MLR, RBFNN and GEP methods considering the media components variables that mainly affect the explant proliferation parameters. The MLR predictive model could not explain high variability of growth parameters due to the interaction of the variables considered, which may cover the media components effects. The mathematical equations obtained from GEP method that best approximate the growth parameters are given in Table 1. Moreover, the R2, RMSE, MARE and MBE statistics of each developed model are given in Table 2.
Results of the calculated statistics for output variables (PR, SL, Vitri, STN and QI) corresponding to the GEP and RBFNN showed a substantially higher accuracy of prediction than for MLR models. As, the amounts of calculated R2 for GEP and RBFNN vs. MLR models were: PR = 0.992 and 0.957 vs. 0.583, SL = 0.974 and 0.990 vs. 0.904, STN = 0.961and 0.882 vs. 0.674, Vitri = 0.969 and 0.883 vs. 0.511 and QI = 0.943 and 0.891 vs. 0.668 in OHF and PR = 0.994 and 0.908 vs. 0.315, SL = 0.978 and 0.924 vs. 0.357, STN = 0.954 and 0.906 vs. 0.855, Vitri = 0.936 and 0.901 vs. 0.909 and QI = 0.944 and 0.923 vs. 0.902 in Pyrodwarf, respectively (Table 2).
Comparing the accuracy results of GEP and RBFNN (Table 2) showed that GEP is more accurate in case of all studied parameters in both rootstocks except SL in OHF (R2 = 0.974 and 0.990, RMSE = 0.14 and 0.22, MARE = 0.034 and 0.058 and MBE = 0.012 and 0.040 for RBFNN and GEP, respectively). Therefore, to find the optimized medium for achieving the highest quality and quantity in proliferation, we optimized constructed GEP models using GA technique.
GEP models optimization
Finally, the GEP models were analyzed to find the optimum levels of NH4NO3, KNO3, mesos nutrients, micro-nutrients and 6-benzylaminopurine (BA) and indole-3-butyric acid (IBA) hormones to be used in the culture medium for achieving the maximum PR, SL and QI, as well as the minimum STN and Vitri occurrence in Pyrus rootstocks. The predicted values and the optimization of studied growth parameters by the GEP models are presented in Table 3.
Comparing observed and predicted outputs showed the behavior of the constructed models from investigating inputs. The GA optimization analysis on the GEP model showed that media containing 1.56 NH4NO3, 1.19 KNO3, 1.75 mesos nutrients, 3.28 micro-nutrients, 2.08 BA and 0.13 IBA could lead to optimal PR in Pyrodwarf (13.0) and media containing 2.00 NH4NO3, 1.19 KNO3, 0.62 mesos nutrients, 2.13 micro-nutrients, 1.59 BA and 0.17 IBA resulted in optimal PR in OHF (9.4). The optimal SL in pyrodwarf (5.0 cm) could be obtained with media comprising 1.83 NH4NO3, 0.51 KNO3, 1.74 mesos nutrients, 2.60 micro-nutrients, 0.60 BA and 0.16 IBA and in OHF (5.0) with media containing 0.90 NH4NO3, 1.35 KNO3, 2.04 mesos nutrients, 3.45 micro-nutrients, 1.81 BA and 0.10 IBA. Results of our study exhibited that media containing 0.93 NH4NO3, 0.50 KNO3, 2.30 mesos nutrients, 0.64 micro-nutrients, 0.51 BA and 0.07 IBA and 1.08 NH4NO3, 0.51 KNO3, 1.58 mesos nutrients, 2.36 micro-nutrients, 1.93 BA and 0.15 IBA could lead to minimum STN in pyrodwarf (0.00) and OHF (0.02), respectively. In Pyrodwarf rootstock (4.0), media with 0.50 NH4NO3, 0.50 KNO3, 2.50 mesos nutrients, 2.76 micro-nutrients, 0.50 BA and 0.05 IBA could result in the optimal point for Vitri, whereas in OHF rootstock (0.02) the optimal point for Vitri could be achieved with media supplemented with 0.50 NH4NO3, 1.27 KNO3, 1.49 mesos nutrients, 1.52 micro-nutrients, 1.31 BA and 0.14 IBA. Lastly, the optimization results of RBFNN models revealed that media containing 0.89 NH4NO3, 0.50 KNO3, 2.50 mesos nutrients, 4.0 micro-nutrients, 0.50 BA and 0.05 IBA in Pyrodwarf (4.99) and 0.99 NH4NO3, 0.53 KNO3, 1.88 mesos nutrients, 2.12 micro-nutrients, 2.59 BA and 0.18 IBA in OHF could produce optimal explant quality.
The media components suggested by the optimized GEP model revealed that although decrease in NH4NO3, KNO3 and micro-nutrients and BA and IBA hormones and increase in mesos nutrients may reduce PR but it also may reduce STN and Vitri occurrences which cause the higher QI of in vitro multiplied Pyrodwarf rootstock. But it was a little different for OHF rootstock as decrease in NH4NO3 and KNO3 and increase in mesos nutrients and BA hormone caused lower STN and higher QI, but decrease in KNO3 was not effective on Vitri reduction. The positive effect of reduction in NO3− and NH4+ concentrations on PR has also been previously reported [15] on G × N15 rootstock. In addition, the effective role of higher concentration of some mesos components like CaCl2 has also been stated b by [47].
Discussion
AI has recently been successfully and progressively applied in plant bio-researches [48] as well as for predicting the optimal plant tissue culture conditions [49] and media components [10, 15, 50, 51]. The in vitro plant tissues development is under control of the culture media nutrients. As the optimization of the media mineral composition is a laborious and time-consuming job, so predicting the favorable growth media composition is very helpful for achieving maximum efficiency. Developing neural models to investigate the effect of sucrose and light on the in vitro proliferation of kiwifruit (Actinidia deliciosa) [31] and the effect of macronutrients content in the culture media on the G × N15 explant growth [15] are some examples. In our previous work on pear rootstocks (OHF and Pyrodwarf), we modeled the effect of the eight macronutrients concentrations on explant growth parameters by evaluating the optimal structure of the multilayer perceptron neural network (MLPNN) [10]. The mentioned study showed that ANN-based analyses are promising in predicting the required macronutrients concentrations for maximizing the explant PR and SL and minimizing the explant STN, chlorosis, and Vitri which was not possible using linear regression analysis [10].
In the present study, we used RBFNN as a more robust predicting tool than MLPNN due to working as an interpolator in multidimensional space whereas MLPNN works in stochastic manner. In the other words, RBFNN is more ‘function approximator’ than ‘pattern recognizer’ whilst MLPNN is the contrary [52]. GEP also was used as an expansion of GA and GP to predict the relationship between input and output. The MLR was also used to compare the power of new above mentioned methods in predicting the optimal points of plant tissue culture media components for achieving the most appropriate results in proliferation of Pyrus rootstocks.
The main advantage of ANN-based models is that they do not require a preceding specification of appropriate fitting function so; they have a general approximation capability to estimate practically all types of non-linear functions. This flexibility characteristic may benefit the modeler to construct a model with the highest probable prediction accuracy.
One of the most important advantages of using GP-based methods like GEP, over other approaches is their ability for production of prediction equations without any assumption for prior form of the relationship. GP as well as its variants have been employed by many researchers to discover any complex relationships which fit various experimental data [53,54,55]. A population of individuals is used in this method and then, better individuals are selected by employing genetic variations and fitness function. Genetic operators introduce the genetic variations. GEP as a learning machine is supposed to learn the relationship between variables in groups of data. The difference between GEP and its precursors GP and GA is in the way of individual programming as in GEP, individuals are programmed as fixed length linear strings (chromosomes) which are shown eventually by expression trees which are a simple diagram presentation. While, individuals are expressed in GP and GA as fixed length linear strings (chromosomes) and nonlinear entities of different shapes (parse trees) and sizes, respectively. Genetic operators work at the chromosome level in GEP making creation of genetic diversity very simple, which is considered as one of its strengths over GP and GA. The unique, multi-genic nature of GEP is its other significant point allowing more complex programs with several sub-programs to be evolved. The benefits of both GP and GA are combined in GEP, while some of their limitations are met [39].
Our previous results on the same Pyrus rootstocks showed that the performance of explant in response to macronutrients concentrations varies according to the pear rootstock genotype, as well. So that, NO3− was found to be critical for OHF explant while NH4+ was found to be critical nutrient for Pyrodwarf explant growth and therefore, we suggested that the use of ANN-based model analyses would lead us to detect the optimized macronutrient concentrations essential to maximize the PR and SL and minimize the occurrence of STN and Vitri [10]. Due to the complicated interactions between medium components, determining minerals and hormones optimum levels for a special genotype is very difficult [56]. Moreover, different media are needed for optimal growth of Pyrus genotypes because of the incidence of the physiological disorders like hyperhydricity and necrosis at the explant multiplication stage. In order to design an optimized culture medium, use of a trustworthy mathematical modeling and optimization technique is necessary to achieve an optimal and efficient growth [10, 15, 50, 51]. Diverse statistical techniques have been used previously to design new and effective plant tissue culture media [10, 15, 32, 50, 51, 57]. RSM and MLR have been constantly applied to optimize new in vitro media for pear genotypes [10, 19]. The studies reported that ANN-GA models had a significantly higher accuracy of prediction than RSM and MLR [10, 58]. It has been reported that RSM and MLR alone could not be reliable methods for estimating non-polynomial or non-linear relationships among variables [10, 59].
Briefly, we found different RBFNN-based models with optimization algorithm to integrate the obtained data set of the in vitro responses of Pyrus rootstocks to nutrients and hormones concentrations. These optimized models could reveal the importance of each studied nutrient or hormone in increasing or decreasing each studied feature. Previous studies using ANN-GA models on G × N15 Prunus rootstock from a gathered data proposed that the role of NH4+, NO3−, PO42−, Ca2+, and K+ were more important than SO42−, Mg2+, and Cl− in in vitro proliferation [15]. Here, we found from the GEP optimized models that increasing proliferation may lead to less plantlet quality. So, we did GEP analysis to find the best medium resulting to high quality proliferated plantlets and lowest losses.
NH4NO3 and KNO3 are the major sources of nitrogen and potassium for Pyrus rootstocks micropropagation. The importance of the ratio between NO3− and NH4+ concentrations has been widely discussed in literatures [60,61,62,63]. The present results are in coincidence with many previous reports on different plant species [60, 61, 64, 65]. The medium macro-nutrients contents are major determinants of the explant growth responses. The pear rootstock responses to in vitro nutrients has been reported that varies with the macro-nutrients levels in the culture medium [10]. Comparison of our comprehensive results to the previous results [10, 15, 50, 51] showed for the first time that the concentrations of macro- and micro-nutrients depend highly on the concentrations of used hormones as their interaction could determine the quality of plantlets. Arab et al. [15] predicted and maximized the number and length of in vitro regenerated shoots by decreasing NH4+ concentration and optimizing NO3− concentration, simultaneously. But they predicted that enhancing the NH4+ concentration will increase SL while producing non-healthy shoots while reducing its amount will increase the quality of plantlets. It has been suggested that an optimized culture medium would produce a higher number and length of shoots. Andreu and Marín [66] reported that reducing nitrogen content had a proper effect on proliferation rate. Our results using optimized RBFNN and GEP modeling (Table 3) also showed that a lower nitrogen concentration content in the medium will produce higher quality plantlets which is consistent with the previous results [60, 67, 68]. The purpose of our recent studies [10, 15, 50, 51] was to present a more and more precise approach for prediction of an optimized culture medium. Here, techniques of RBFNN and GEP combined with GA were applied to pear rootstocks proliferation experiment data sets for finding the best proliferation results. Comparing the present results with the previous ones [10, 15, 50, 51] shows that using both methods together leads us to more accurate consequences. As, comparing these two techniques results showed the effect of each medium component increasing or decreasing the measured parameter (Tables 2, 3).
Interactions between plant hormones make a critical complexity in regulating plant growth processes. Cytokinin has been shown that regulates cell proliferation [69] and auxin increases the sensitivity of the less mitotically active cells of apical meristem to cytokinin [70]. The ratio of cytokinin to auxin is a crucial signal which determines phenotype [71]. The effects of hormones depend on plant species. The results of [50] on Prunus rootstock showed that using cytokinin and auxin together in the medium will make higher shooting than using each alone. They indicated that the concentration and interaction of hormones are two important factors on in vitro shooting. In accordance with these results and the findings of [11, 72], we used different concentrations of BA and IBA in our protocol formulation. As auxin and cytokinin have roles in DNA replication and cell cycle regulation, respectively [73]. The adverse results of [50] was reported to be due to the interaction of many factors like genotype and the composition of culture medium [74] with hormones. So, in the present study, we assessed the interaction of hormones and medium nutrients on proliferation. Since the high concentration of hormonal combinations may result in low SL and regenerated shoots quality and low concentrations of auxin may prompt cell division but its higher concentrations may inhibit axillary bud growth [75], we considered BA and IBA concentrations in a reasonable range to achieve the most effective protocol. Our experiments analyses using GA optimized GEP modeling procedure showed that this technique can be used as an effective method for studying the interaction of many factors on growth parameters in proliferation stage. So, GEP is introduced for the first time as a great tool in optimizing higher quality and efficiency plant tissue culture protocols in less time.
In general, the use of ANN-based models such as RBFNN leads to the high accuracy of estimation whereas GEP models are easier in the use to give it an explicit mathematical equation in prediction of explant growth parameters as well as being more accurate than RBFNN method. No studies have been done on the superiority of RBFNN or GEP approaches for estimating in vitro explant proliferation parameters with optimal use of media components. Therefore, according to the current results, the approaches presented here would allow more accurate estimations without the need for the availability of all data.
Conclusions
The main objective of this paper was to compare the performance of MLR, RBFNN and GEP models for predicting the concentrations of in vitro medium components to achieve the optimal growth parameters. Different combinations of the nutrients and hormones were used as inputs for the MLR, RBFNN and GEP techniques. The proliferation parameters were estimated from the GEP equations. PR, SL, Vitri, STN and QI were chosen as the main indices of proliferation state. Our results suggested that using RBFNN and GEP techniques leads to more accurate results. The optimized GEP models gave us the most appropriate formulation for each studied parameter so, these results can cause finding the most efficient protocol. The GEP constructed models were the most accurate models as well as being easier to apply, as they estimate growth parameters using explicit statistical equations. Using further optimization techniques are suggested for future studies on predicting and optimizing plant tissue culture media by GEP modeling procedure to achieve the most appropriate results.
Methods
MLR, RBFNN and GEP modeling procedures were used to construct models by using different combinations of minerals and hormones concentrations as inputs and various measured proliferation parameters as outputs. The GEP models were applied to find the optimized models using GA. Two case studies were performed using two pear rootstocks which have described details of the used techniques to realize the optimized inputs compositions as follows.
Case studies
Pear rootstocks Pyrodwarf (“Old Home” × “Gute Luise”) and OHF (“OldHome” × “Farmingdel”) from in vitro cultures were grown in modified macro- and micro-nutrient MS media supplemented with 30 g/l sucrose, 8 g/l agar (DuchefaH) and different concentrations of cytokinin and auxin hormones. Media pH was adjusted to 5.7, distributed into 250 ml jam jars with polyethylene caps and autoclaved at 1 kg cm−2 s−1 (121 °C) for 15 min. All cultures were incubated at 25 ± 2 °C with a 16-h light period (80 µmol m2 s−1) of white fluorescent light for 4 weeks. Afterwards, variables including PR, SL, Vit, STN and QI were recorded. In each set of experiments, each treatment consisted of 10 replicates (jam jars) and each replication included four explants for both Pyrodwarf and OHF rootstocks.
Box–Behnken experimental design as an invaluable tool for optimization of explant growth parameters
In recent years, multivariate experimental designs such as Central Composition and Box–Behnken designs (BBD) have been frequently used for evaluating the effects of variables in many processes. The most important advantage of these designs is decrease in the number of experiments essential to conduct the studies, which results in saving time and cost as well as a decrease in materials and reagents consumption. Additionally, the statistical analysis carried out on the results is quickly realized and the percentage amount of experimental error is diminished [76,77,78,79]. In the present investigation, Box–Behnken statistical screening design with 6 variables, 3 levels and 48 runs was applied to assess accurately the main and quadratic effects of independent variables on dependent variables. BBD is a useful and formidably effective tool for optimizing process in a way that variables and their interactions could be recognized with a minimum in the number of experimental trials [79, 80]. It is a very complicated design with a practical combination of two-level factorial designs with incomplete block designs [79, 81, 82]. Furthermore, previous researches have demonstrated that BBD is more powerful and efficient than the three-level factorial and Central Composition designs [83, 84].
In the present experiment, KNO3, NH4NO3, Mesos, minors, BAP and IBA were determined as independent (input) variables and PR, SL, Vit, STN and QI were selected as dependent (target) variables. Different concentrations of independent variables were determined based on their content in MS medium (1 × MS concentration) (Table 4).
After establishing the range of independent variables at three levels in a coded form: − 1 (low), 0 (mid) and + 1 (high) (Table 5), the experimental trials based on a BBD were set up (Table 6). The actual values and observed results for the three levels of the variables studied are presented in Tables 7 and 8.
At least 10 replicates were used for each experimental run. 357 experimental sets (70% of all available patterns) were randomly selected among 510 sets in order to train the modeling procedures and the other 153 sets (30% of all patterns) were used to test the models generalization capacity.
Modeling systems
Multiple linear regression
MLR analysis is considered as a multivariate statistical technique to analyze the relationship between a dependent single variable and a group of independent variables. Prediction and explanation are two main objectives of MLR. The prediction of MLR involves the extent to which the dependent variables can be predicted by the independent variables. The explanation of MLR evaluates the regression coefficients, their sign, statistical interface and magnitude, for each independent variable [85].
Linear regression is characterized as the oldest statistical technique in regression and it is thought to be a benchmark method to be employed by new techniques. Like other regression techniques, MLR models the relationships between two or more independent variables and a response variable; this is accomplished a linear equation fitted to the observed data. In this approach, every value assigned to the independent variable k is associated with a value assigned to the dependent variable M. The regression line of population for n input variables × 1, × 2, …, kn is as follows:
M is the dependent variable, α0 denotes a constant named intercept, k = (× 1, …, kn) represents an input variables vector and α denotes the regression coefficients vector, each of which belongs for each explanatory variable. The observed values of Y have different means and are assumed with the equal standard deviation ε. The software package of SPSS 19 was utilized in the MLR model.
Radial basis function neural network
The RBFNN is able to simulate the brain of human to accomplish several different tasks easily. It can also crystallize the complex relation between the inputs and outputs using a fitting process which leads it to an approximation of any nonlinear function [35, 36, 86, 87].
The RBFNN is comprised of three different layers: an input layer, a hidden layer and an output layer. The input–output relationship of this RBFNN network can be described by:
where \(\varphi\) denotes the radial basis function of the hidden unit j; \(x\) is the vector of input data; \(W_{ij}\) is a weighted connections between output layer and the radial basis function; and \(N_{h}\) represents the number of hidden-layer neurons. The constant term bi in Eq. (2) denotes a bias. As the activation function, an RBFNN hidden neuron has a Gaussian function.
where \({\text{c}}_{\text{i}}\) and \(\sigma_{\text{i}}\) represent centers and widths, respectively, and \(\left\| . \right\|\) denotes the Euclidean distance norm. The variances and centers are predefined and fixed for simplicity. From a point of view of design, the RBFNN networks training consists of finding the number of hidden layer nodes (neurons) Nh and the appropriate parameter set (\(\sigma_{\text{i}}\), \({\text{W}}_{\text{ij}}\) and \({\text{c}}_{\text{i}}\)) to map a given vector of input to a desired scalar of output efficiently with suitable accuracy and generalization. The supervised gradient-descent-based method [88, 89] was used for the network training.
Gene expression programming
GP is also utilized to model the behavior of structural engineering problems. It is a genetic algorithm extension which uses a program space for search, instead of employing a data space. One of the most important advantages of using GP-based methods over other approaches is their ability for production of prediction equations without any assumption for prior form of the relationship. GP as well as its variants have been employed by many researchers to discover any complex relationships which fit various experimental data [24, 25, 42] Researchers have introduced GEP as an efficient alternative approach to the traditional GP [45, 90]. Several different computer programs have been developed by GEP, through getting encoded in fixed length linear chromosomes, each of which composed of multiple encoding genes [45, 91].
GEP is rooted from evolutionary algorithms like GP and GA. A population of individuals is used in this method and then, better individuals are selected by employing genetic variations and fitness function. Genetic operators introduce the genetic variations. GEP as a learning machine, is supposed to learn the relationship between variables in groups of data. The difference between GEP and its precursors GP and GA is in the way of individual programming as in GEP, individuals are programmed as fixed length linear strings (chromosomes) which are shown eventually by expression trees which are a simple diagram presentation. However, individuals are expressed in GP and GA as fixed length linear strings (chromosomes) and nonlinear entities of different shapes (parse trees) and sizes, respectively. Genetic operators work at the chromosome level in GEP making creation of genetic diversity very simple, which is considered as one of its strengths over GP and GA. The unique, multi-genic nature of GEP is its other significant point allowing more complex programs with several sub-programs to be evolved. The benefits of both GP and GA are combined in GEP, while some of their limitations are met [39, 45, 92].
Architecture of GEP
In GEP the individuals are encoded as fixed size linear strings (chromosome), which are then shown as non-linear entities with different shapes and sizes, known as Expression Trees. For example, the expression of Eq. (4) can also be shown by an expression tree or diagram as represented in Fig. 2.

Gene expression programming diagram
The actual phenotype of GEP chromosome is this representation and the genotype can be easily explained from the phenotype as shown in Eq. (4)
As we read a page of text, the genotype is characterized as the straightforward reading of the expression tree from left to right and from top to bottom. The Eq. (5), for example, is an open reading frame which starts at ‘‘*’’ or position 0 and terminates at ‘‘d’’ or position 6. Karva notation or K-expression is the term describing these open reading frames [25, 93].
The GEP functional steps are shown in Fig. 2 [45]. The structure of GEP consists of function set, fitness function, terminal set, termination condition, and control parameters. As it can be seen in Fig. 2, an initial population is the start point of GEP. Then, the genes located on the chromosomes are expressed, and the fitness of each individual is analyzed. Subsequently, based on their fitness, the individuals are designated in order to reproduce with modification. The same process of development is performed on this new generation of individuals: the genomes expression, confrontation of the selection environment, and finally reproduction with modification. Altogether, this procedure is repeated for an exact number of generations or it is done until a termination condition is reached.
GEP system uses roulette wheel sampling with elitism to select and copy the individuals into the next generation based on the fitness. This guarantees that the best individuals are survived and cloned to the next generation. When single or several genetic operators are conducted on selected chromosomes, including rotation, mutation and cross over, variation is introduced in the population.
GEP methodology
The software package of GeneXpro was employed to run the GEP models. All parameters used in the GEP models are shown in Table 9.
The mathematical operators and functions chosen in the present study are illustrative and not conclusive as the plant modeling designer as the freedom to choose such functions so as suit the anatomy of the problem under study. The operators and functions were chosen with a perspective of invoking simplicity of the evolved model promising faster convergence. The population size (number of chromosomes) sets the number of programs in the population. Larger population size takes longer for an iteration run. A large number of chromosomes were tested to find models with minimum error. The program was run until there was no significant improvement in the performance of the models. The present study was undertaken to attain explicit relationship between response variables and decision variables. GEP explicit formulations for PR, SL, STN, Vit and QI were obtained as a function of experimental parameters as follows:
PR, SL, STN, Vit and QI = f (KNO3, NH4NO3, Mesos, Micro, BA and IBA).
Optimization of GEP models
Genetic algorithm model optimization
GA is another search heuristic algorithm that is inspired by biological evolution in nature as well as Darwin’s evolution theory. This algorithm was first introduced by [94], and its development goes back to 1960–1970 [94, 95]. It is one of the oldest, most well-known, and most-widely used evolution algorithms utilized by researchers in different fields for the optimization of intricate problems. The algorithmic structure, like any of the other evolution algorithms, is composed of a population, where each individual in it is considered to be a solution to the problem. An individual is called chromosome and is composed of different problem variables that act as genes in the algorithm [91] (Fig. 3).

Structure of the chromosome and gene
The search procedure in this algorithm is created by developing a random population of chromosomes, and producing the next generation of the population is accomplished through three operators [91]:
Selection Operator: in this phase, the best chromosomes of the society, which are the best solutions to the problem, are identified by calculating the fitness function of each chromosome. The chromosomes are then used as parents for producing offspring, new child chromosomes and, thus, the next generation. Crossover Operator: using this operator, we produce offspring that are new child chromosomes from two parent chromosomes and take measurements to make this chromosome have better fitness than its parents. The crossover operator is in fact a method that determines the structure and ratio of the child’s chromosome compared with its parents’ chromosomes. The crossover operator can be implemented with different methods, including Ranking Selection, N-Point, Cycle, Order, Uniform, Tournament, and partially mapped [96]. Since use of a uniform method, such as the Crossover operator, is common between researchers [97] this method is utilized in the current research (Fig. 4).

A crossover operator
Mutation Operator: this operator is utilized for searching new areas in the available dimension. The result makes the local optimum be not accepted as the best solution. To realize this goal, we need only to change some of the genes inside the chromosomes randomly (Fig. 5). Offspring new child chromosomes that are produced through these three operators are utilized as the next generation parents. The trend goes on as long as the termination condition determined by the researcher is met.

A mutation operator
Statistical indices
In order to evaluate and compare the precision of different models, four statistical indices including root mean squared error (RMSE), mean absolute relative error (MARE), mean bias error (MBE) and correlation coefficient (R2) were used with the following formulas:
where Oi and Pi are observed and predicted amounts, respectively; and \(\bar{O}_{i}\) and \(\bar{P}_{i}\) are mean observed and predicted amounts for N samples.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- MLPNN:
-
multi-layer perceptron neural networks
- MLR:
-
multiple linear regression
- RBFNN:
-
radial basis function neural network
- GEP:
-
gene expression programming
- GA:
-
genetic algorithm
- ANN:
-
artificial neural networks
- AI:
-
artificial intelligence
- GP:
-
genetic programming
- PR:
-
proliferation rate
- SL:
-
shoot length
- QI:
-
quality index
- STN:
-
shoot tip necrosis
- Vitri:
-
vitrification
- MS:
-
Murashige and Skoog (1962)
- BA:
-
6-benzylaminopurine
- IBA:
-
indole-3-butyric acid
References
Westwood MN, Cameron HR, Lombard PB, Cordy CB. Effects of trunk and rootstock on decline, growth, and performance of pear. Am Soc Hort Sci J. 1971;96:147–50.
Lombard PB, Westwood MN. Pear Rootstocks, Present and Future Usage. In: Willett M, Stebbins RL, editors. Pear Prod Pacific Northwest 1986 Proc Pacific Northwest Tree Fruit Short Course. Pullman: Washington State University; 1986. p. 2–21.
Jacob HB. Pyrodwarf, a new clonal rootstock for high density pear orchards. In: VII international symposium on pear growing 475. 1997. p. 169–78.
Bajaj YPS. Biotechnology in agriculture and forestry. Berlin: Springer; 1986.
Ikinci A, Bolat I, Ercisli S, Kodad O. Influence of rootstocks on growth, yield, fruit quality and leaf mineral element contents of pear cv. ‘Santa Maria’ in semi-arid conditions. Biol Res. 2014;47(1):71.
Al-Maarri K, Arnaud Y, Miginiac E. Micropropagation of Pyrus communis cultivar ‘Passe Crassane’ seedlings and cultivar ‘Williams’: factors affecting root formation in vitro and ex vitro. Sci Hortic (Amsterdam). 1994;58(3):207–14.
Reed BM, Wada S, DeNoma J, Niedz RP. Improving in vitro mineral nutrition for diverse pear germplasm. Vitr Cell Dev Biol. 2013;49(3):343–55.
Kadota M, Niimi Y. Effects of cytokinin types and their concentrations on shoot proliferation and hyperhydricity in in vitro pear cultivar shoots. Plant Cell Tissue Organ Cult. 2003;72(3):261–5.
Reed BM, Wada S, DeNoma J, Niedz RP. Mineral nutrition influences physiological responses of pear in vitro. Vitr Cell Dev Biol. 2013;49(6):699–709.
Jamshidi S, Yadollahi A, Ahmadi H, Arab MM, Eftekhari M. Predicting in vitro culture medium macro-nutrients composition for pear rootstocks using regression analysis and neural network models. Front Plant Sci. 2016;7:274.
Ružić D, Vujović T, Nikolić D, Cerović R. In vitro growth responses of the ‘Pyrodwarf’ pear rootstock to cytokinin types. Rom Biotechnol Lett. 2011;16(5):6631.
Aygun A, Dumanoglu H. In vitro shoot proliferation and in vitro and ex vitro root formation of Pyrus elaeagrifolia Pallas. Front Plant Sci. 2015;6:225.
Murashige T, Skoog F. A revised medium for rapid growth and bio assays with tobacco tissue cultures. Physiol Plant. 1962;15(3):473–97.
Poothong S, Reed BM. Optimizing shoot culture media for Rubus germplasm: the effects of NH4 +, NO3 −, and total nitrogen. Vitr Cell Dev Biol. 2016;52(3):265–75.
Arab MM, Yadollahi A, Shojaeiyan A, Ahmadi H. Artificial neural network genetic algorithm as powerful tool to predict and optimize in vitro proliferation mineral medium for G × N15 rootstock. Front Plant Sci. 2016;7:1526.
Yu X, Reed BM. A micropropagation system for hazelnuts (Corylus species). HortScience. 1995;30(1):120–3.
Hassanen SA, Mahdia FG. In vitro propagation of pear Pyrus betulaefolia rootstock. Am J Agric Environ Sci. 2012;12:484–9.
Rehman HU, Gill MIS, Sidhu GS, Dhaliwal HS. Micropropagation of Kainth (Pyrus pashia)-an important rootstock of pear in northern subtropical region of India. J Exp Biol Agric Sci. 2014;2(2):188–96.
Wada S, Niedz RP, DeNoma J, Reed BM. Mesos components (CaCl2, MgSO4, KH2PO4) are critical for improving pear micropropagation. Vitr Cell Dev Biol. 2013;49(3):356–65.
Wada S, Niedz RP, Reed BM. Determining nitrate and ammonium requirements for optimal in vitro response of diverse pear species. Vitr Cell Dev Biol. 2015;51(1):19–27.
Dimitrova N, Nacheva L, Berova M. Effect of meta-topolin on the shoot multiplication of pear rootstock OHF-333 (Pyrus communis L.). Hortorum Cultus Acta Sci Pol. 2016;15:43–53.
Roy S, Ghosh A, Das AK, Banerjee R. A comparative study of GEP and an ANN strategy to model engine performance and emission characteristics of a CRDI assisted single cylinder diesel engine under CNG dual-fuel operation. J Nat Gas Sci Eng. 2014;21:814–28.
Mostafa MM, El-Masry AA. Oil price forecasting using gene expression programming and artificial neural networks. Econ Model. 2016;54:40–53.
Dey P, Das AK. A utilization of GEP (gene expression programming) metamodel and PSO (particle swarm optimization) tool to predict and optimize the forced convection around a cylinder. Energy. 2016;95:447–58.
Gholampour A, Gandomi AH, Ozbakkaloglu T. New formulations for mechanical properties of recycled aggregate concrete using gene expression programming. Constr Build Mater. 2017;130:122–45.
Shiri J. Evaluation of FAO56-PM, empirical, semi-empirical and gene expression programming approaches for estimating daily reference evapotranspiration in hyper-arid regions of Iran. Agric Water Manag. 2017;188:101–14.
Xiang X, Yu C, Lapierre L, Zhang J, Zhang Q. Survey on fuzzy-logic-based guidance and control of marine surface vehicles and underwater vehicles. Int J Fuzzy Syst. 2018;20(2):572–86.
Pilkington JL, Preston C, Gomes RL. Comparison of response surface methodology (RSM) and artificial neural networks (ANN) towards efficient extraction of artemisinin from Artemisia annua. Ind Crops Prod. 2014;58:15–24.
Mehrotra S, Prakash O, Mishra BN, Dwevedi B. Efficiency of neural networks for prediction of in vitro culture conditions and inoculum properties for optimum productivity. Plant Cell Tissue Organ Cult. 2008;95(1):29–35.
Desai KM, Survase SA, Saudagar PS, Lele SS, Singhal RS. Comparison of artificial neural network (ANN) and response surface methodology (RSM) in fermentation media optimization: case study of fermentative production of scleroglucan. Biochem Eng J. 2008;41(3):266–73.
Gago J, Martínez-Núñez L, Landín M, Gallego PP. Artificial neural networks as an alternative to the traditional statistical methodology in plant research. J Plant Physiol. 2010;167(1):23–7.
Gago J, Landín M, Gallego PP. A neurofuzzy logic approach for modeling plant processes: a practical case of in vitro direct rooting and acclimatization of Vitis vinifera. Plant Sci. 2010;179:241–9.
Leon-Masich A, Valderrama-Blavi H, Bosque-Moncusi JM, Maixe-Altes J, Martinez-Salamero L. Sliding-mode-control-based boost converter for high-voltage–low-power applications. IEEE Trans Ind Electron. 2015;62(1):229–37.
Biricik S, Komurcugil H. Optimized sliding mode control to maximize existence region for single-phase dynamic voltage restorers. IEEE Trans Ind Inf. 2016;12(4):1486–97.
Han H-G, Qiao J-F, Chen Q-L. Model predictive control of dissolved oxygen concentration based on a self-organizing RBF neural network. Control Eng Pract. 2012;20(4):465–76.
Liu X, Jiang Y, Shen S, Luo Y, Gao L. Comparison of Arrhenius model and artificial neuronal network for the quality prediction of rainbow trout (Oncorhynchus mykiss) fillets during storage at different temperatures. LWT-Food Sci Technol. 2015;60(1):142–7.
Qiao J, Meng X, Li W. An incremental neuronal-activity-based RBF neural network for nonlinear system modeling. Neurocomputing. 2018;302:1–11.
Ortombina L, Tinazzi F, Zigliotto M. Magnetic modeling of synchronous reluctance and internal permanent magnet motors using radial basis function networks. IEEE Trans Ind Electron. 2018;65(2):1140–8.
Ferreira C. Gene expression programming: mathematical modeling by an artificial intelligence, vol. 21. Berlin: Springer; 2006.
Roy S, Ghosh A, Das AK, Banerjee R. Development and validation of a GEP model to predict the performance and exhaust emission parameters of a CRDI assisted single cylinder diesel engine coupled with EGR. Appl Energy. 2015;140:52–64.
Koza JR. Genetic programming: on the programming of computers by means of natural selection. Cambridge: MIT Press; 1994.
Gandomi AH, Alavi AH. A new multi-gene genetic programming approach to nonlinear system modeling. Part I: materials and structural engineering problems. Neural Comput Appl. 2012;21(1):171–87.
Sonebi M, Cevik A. Genetic programming based formulation for fresh and hardened properties of self-compacting concrete containing pulverised fuel ash. Constr Build Mater. 2009;23(7):2614–22.
Alemdag S, Gurocak Z, Cevik A, Cabalar AF, Gokceoglu C. Modeling deformation modulus of a stratified sedimentary rock mass using neural network, fuzzy inference and genetic programming. Eng Geol. 2016;203:70–82.
Ferreira C. Algorithm for solving gene expression programming: a new adaptive problems. Complex Syst. 2001;13(2):87–129.
Hosseini SSS, Gandomi AH. Short-term load forecasting of power systems by gene expression programming. Neural Comput Appl. 2012;21(2):377–89.
Nezami SR, Yadollahi A, Hokmabadi H, Eftekhari M. Control of shoot tip necrosis and plant death during in vitro multiplication of pistachio rootstock UCB1 (Pistacia integrima × P. atlantica). J Nuts. 2015;6(1):27–35.
Eftekhari M, Yadollahi A, Ahmadi H, Shojaeiyan A, Ayyari M. Development of an artificial neural network as a tool for predicting the targeted phenolic profile of grapevine (Vitis vinifera) foliar wastes. Front Plant Sci. 2018;9:837.
Zielinska S, Kepczynska E. Neural modeling of plant tissue cultures: a review. Biotechnol J Biotechnol Comput Biol Bionanotechnol. 2013;94:3.
Arab MM, Yadollahi A, Ahmadi H, Eftekhari M, Maleki M. Mathematical modeling and optimizing of in vitro hormonal combination for G × N15 vegetative rootstock proliferation using artificial neural network-genetic algorithm (ANN-GA). Front Plant Sci. 2017;8:1853.
Arab MM, Yadollahi A, Eftekhari M, Ahmadi H, Akbari M, Khorami SS. Modeling and optimizing a new culture medium for in vitro rooting of G × N15 prunus rootstock using artificial neural network-genetic algorithm. Sci Rep. 2018;8(1):9977.
Xie T, Yu H, Wilamowski B. Comparison between traditional neural networks and radial basis function networks. In: 2011 IEEE international symposium on industrial electronics (ISIE). IEEE; 2011. p. 1194–9.
Nazari A. Application of gene expression programming to predict the compressive damage of lightweight aluminosilicate geopolymer. Neural Comput Appl. 2012;31:1–10.
Nazari A, Riahi S. Predicting the effects of nanoparticles on compressive strength of ash-based geopolymers by gene expression programming. Neural Comput Appl. 2013;23(6):1677–85.
Dikmen E. Gene expression programming strategy for estimation performance of LiBr–H2O absorption cooling system. Neural Comput Appl. 2015;26(2):409–15.
Nas MN, Read PE. A hypothesis for the development of a defined tissue culture medium of higher plants and micropropagation of hazelnuts. Sci Hortic (Amsterdam). 2004;101(1–2):189–200.
Gallego PP, Gago J, Landín M. Artificial neural networks technology to model and predict plant biology process. In: Suzuki K, editor. Artificial neural networks-methodological advances and biomedical applications, vol. 11. Rijeka, Croatia: Intech Open Access; 2011. p. 197–217.
Sedghi M, Golian A, Soleimani-Roodi P, Ahmadi A, Aami-Azghadi M. Relationship between color and tannin content in sorghum grain: application of image analysis and artificial neural network. Rev Bras Ciência Avícola. 2012;14(1):57–62.
Moghri M, Shamaee H, Shahrajabian H, Ghannadzadeh A. The effect of different parameters on mechanical properties of PA-6/clay nanocomposite through genetic algorithm and response surface methods. Int Nano Lett. 2015;5(3):133–40.
Nowak B, Miczyński K, Hudy L. The effect of total inorganic nitrogen and the balance between its ionic forms on adventitious bud formation and callus growth of ‘Węgierka Zwykła’plum (Prunus domestica L.). Acta Physiol Plant. 2007;29(5):479–84.
Ivanova M, Van Staden J. Nitrogen source, concentration, and NH4 +: NO3 − ratio influence shoot regeneration and hyperhydricity in tissue cultured Aloe polyphylla. Plant Cell Tissue Organ Cult. 2009;99(2):167–74.
Damiano C, Monticelli S, Frattarelli A. Recent progress and protocols in the micropropagation of apricot. Italus Hortus. 2009;16(2):113–5.
Shirdel M, Motallebi-Azar A, Masiha S, Mortazavi N, Matloobi M, Sharafi Y. Effects of inorganic nitrogen source and NH4 +: NO3-ratio on proliferation of dog rose (Rosa canina). J Med Plants Res. 2011;5(18):4605–9.
Ramage CM, Williams RR. Mineral nutrition and plant morphogenesis. Vitr Cell Dev Biol. 2002;38(2):116–24.
Niedz RP, Evens TJ. Regulating plant tissue growth by mineral nutrition. Vitr Cell Dev Biol. 2007;43(4):370–81.
Andreu P, Marín JA. In vitro culture establishment and multiplication of the Prunus rootstock ‘Adesoto 101’(P. insititia L.) as affected by the type of propagation of the donor plant and by the culture medium composition. Sci Hortic (Amsterdam). 2005;106(2):258–67.
Mansseri-Lamrioui A, Louerguioui A, Abousalim A. Effect of the medium culture on the micro cutting of material resulting from adult cuttings of wild cherry trees (Prunus avium L.) and of in vitro germination. Eur J Sci Res. 2009;25:345–52.
Petri C, Scorza R. Factors affecting adventitious regeneration from in vitro leaf explants of ‘Improved French’ plum, the most important dried plum cultivar in the USA. Ann Appl Biol. 2010;156(1):79–89.
Vanstraelen M, Benková E. Hormonal interactions in the regulation of plant development. Annu Rev Cell Dev Biol. 2012;28:463–87.
Schaller GE, Bishopp A, Kieber JJ. The yin-yang of hormones: cytokinin and auxin interactions in plant development. Plant Cell. 2015;27(1):44–63.
George EF, Hall MA, De Klerk G-J. Plant growth regulators I: introduction; auxins, their analogues and inhibitors. Plant propagation by tissue culture. Berlin: Springer; 2008. p. 175–204.
Hepaksoy S, Tanrisever A. Investigations on micropropagation of some cherry rootstocks II. Rooting and acclimatization. ZIRAAT Fak Derg. 2004;41(3):23.
Pasternak T, Miskolczi P, Ayaydin F, Mészáros T, Dudits D, Fehér A. Exogenous auxin and cytokinin dependent activation of CDKs and cell division in leaf protoplast-derived cells of alfalfa. Plant Growth Regul. 2000;32(2–3):129–41.
Molassiotis AN, Dimassi K, Therios I, Diamantidis G. Fe-EDDHA promotes rooting of rootstock GF-677 (Prunus amygdalus × P. persica) explants in vitro. Biol Plant. 2003;47(1):141–4.
Bagheri N, Babaeian-Jelodar N, Ghanbari A. Evaluation of effective factors in anther culture of Iranian rice (Oryza sativa L.) cultivars. Biharean Biol. 2009;3(2):119–24.
Aslan N, Cebeci Y. Application of Box–Behnken design and response surface methodology for modeling of some Turkish coals. Fuel. 2007;86(1–2):90–7.
Ahmadi MA, Zendehboudi S, James LA. Developing a robust proxy model of CO2 injection: coupling Box–Behnken design and a connectionist method. Fuel. 2018;215:904–14.
Ma S, Yang X, Wang C, Guo M. Effect of ultrasound treatment on antioxidant activity and structure of β-lactoglobulin using the Box–Behnken design. CyTA J Food. 2018;16(1):596–606.
Ali MBS, Mnif A, Hamrouni B. Modelling of the limiting current density of an electrodialysis process by response surface methodology. Ionics (Kiel). 2018;24(2):617–28.
Banerjee A, Verma PRP, Gore S. Application of Box–Behnken design to optimize the osmotic drug delivery system of metoprolol succinate and its in vivo evaluation in beagle Dogs. J Pharm Innov. 2016;11(2):120–33.
Montgomery DC. Design and analysis of experiments. 5th ed. New York: Wiley; 2001.
Ferreira SLC, Bruns RE, Ferreira HS, Matos GD, David JM, Brandao GC, et al. Box–Behnken design: an alternative for the optimization of analytical methods. Anal Chim Acta. 2007;597(2):179–86.
Kaiser S, Verza SG, Moraes RC, Pittol V, Peñaloza EMC, Pavei C, et al. Extraction optimization of polyphenols, oxindole alkaloids and quinovic acid glycosides from cat’s claw bark by Box–Behnken design. Ind Crops Prod. 2013;48:153–61.
Nam S-N, Cho H, Han J, Her N, Yoon J. Photocatalytic degradation of acesulfame K: optimization using the Box–Behnken design (BBD). Process Saf Environ Prot. 2018;113:10–21.
Babin B, Hair JF, Hair J, Anderson R, Black WC. Multivariate data analysis: a global perspective. New Jersey: Prentice Hall PTR; 2010.
Hsu C-F, Lin C-M, Yeh R-G. Supervisory adaptive dynamic RBF-based neural-fuzzy control system design for unknown nonlinear systems. Appl Soft Comput. 2013;13(4):1620–6.
Li B, Rui X. Vibration control of uncertain multiple launch rocket system using radial basis function neural network. Mech Syst Signal Process. 2018;98:702–21.
Poggio T, Girosi F. Networks for approximation and learning. Proc IEEE. 1990;78(9):1481–97.
Poggio T, Girosi F. A theory of networks for learning. Science (80-). 1990;247:978–82.
Gandomi AH, Roke DA. Assessment of artificial neural network and genetic programming as predictive tools. Adv Eng Softw. 2015;88:63–72.
Mitchell M. An introduction to genetic algorithms. Cambridge: MIT press; 1998.
Ferreira C. Gene expression programming in problem solving. Soft computing and industry. Berlin: Springer; 2002. p. 635–53.
Kaboli SHA, Fallahpour A, Selvaraj J, Rahim NA. Long-term electrical energy consumption formulating and forecasting via optimized gene expression programming. Energy. 2017;126:144–64.
Holland J. Adaptation in natural and artificial systems: an introductory analysis with application to biology. Control Artif Intell. 1975.
Goldberg DE. Messy genetic algorithms: motivation analysis, and first results. Complex Syst. 1989;4:415–44.
Saeidian B, Mesgari MS, Ghodousi M. Evaluation and comparison of genetic algorithm and bees algorithm for location–allocation of earthquake relief centers. Int J Disaster Risk Reduct. 2016;15:94–107.
Vekaria K, Clack C. Selective crossover in genetic algorithms: An empirical study. In: International Conference on Parallel Problem Solving from Nature. Springer; 1998. p. 438–47.
Funding
No funding was received.
Author information
Authors and Affiliations
Contributions
SJ: designing and performing the experiments, summing up, and writing. AY: designing and leading. MMA: designing and performing the experiments, summing up, and writing. MS: statistical analyzing and writing. ME: interpreting experiments, writing and revising the manuscript. HS: statistical analyzing and writing. ASh: designing and drafting the manuscript. JSh: statistical analyzing and revising manuscript. All authors listed, have made substantial, direct and intellectual contribution to the work. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Jamshidi, S., Yadollahi, A., Arab, M.M. et al. Combining gene expression programming and genetic algorithm as a powerful hybrid modeling approach for pear rootstocks tissue culture media formulation. Plant Methods 15, 136 (2019). https://doi.org/10.1186/s13007-019-0520-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13007-019-0520-y