
Abstract
Background
Numerous studies have demonstrated that the high-order features (HOFs) of blood test data can be used to predict the prognosis of patients with different types of cancer. Although the majority of blood HOFs can be divided into inflammatory or nutritional markers, there are still numerous that have not been classified correctly, with the same feature being named differently. It is an urgent need to reclassify the blood HOFs and comprehensively assess their potential for cancer prognosis.
Methods
Initially, a review of existing literature was conducted to identify the high-order features (HOFs) and classify them based on their calculation method. Subsequently, a cohort of patients diagnosed with non-small cell lung cancer (NSCLC) was established, and their clinical information prior to treatment was collected, including low-order features (LOFs) obtained from routine blood tests. The HOFs were then computed and their associations with clinical features were examined. Using the LOF and HOF data sets, a deep learning algorithm called DeepSurv was utilized to predict the prognostic risk values. The effectiveness of each data set’s prediction was evaluated using the decision curve analysis (DCA). Finally, a prognostic model in the form of a nomogram was developed, and its accuracy was assessed using the calibration curve.
Results
From 1210 documents, over 160 blood HOFs were obtained, arranged into 110, and divided into three distinct categories: 76 proportional features, 6 composition features, and 28 scoring features. Correlation analysis did not reveal a strong association between blood features and clinical features; however, the risk value predicted by the DeepSurv LOF- and HOF-models is significantly linked to the stage. Results from DCA showed that the HOF model was superior to the LOF model in terms of prediction, and that the risk value predicted by the blood data model could be employed as a complementary factor to enhance the prognosis of patients. A nomograph was created with a C-index value of 0.74, which is capable of providing a reasonably accurate prediction of 1-year and 3-year overall survival for patients.
Conclusions
This research initially explored the categorization and nomenclature of blood HOF, and proved its potential in lung cancer prognosis.
Similar content being viewed by others


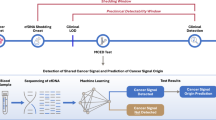
Introduction
Lung cancer is a global, chronic disease with a poor prognosis. The tumor–lymph node–metastasis (TNM) staging system is the most commonly used and accurate prognostic model [1], and patients may experience enhanced treatment results after obtaining the suitable treatment based on the stage. To accurately ascertain the TNM stage, patients must undergo a range of tests, such as histopathological tests, CT scans, MRI scans, and/or PET-CT scans [2]. In order to take these examinations, patients must fulfill certain criteria depending on their physical condition. Prolonged investigations in a clinical setting can often be a challenge for both patients and medical professionals, as they can last anywhere from a week to a month.
The accuracy of TNM staging in diagnosing is estimated to be around 70% [3], which is insufficient to meet the demands of clinical practice; thus, researchers are endeavoring to supplement it with easily available data. Routine blood test is distinct from other clinical examination procedures because of their ease, speed, repeatability, and capacity to track alterations over time [4, 5]. The aforementioned attributes render it a crucial factor in the diagnosis and prediction of numerous diseases, including the current COVID-19 pandemic [6]. It has been demonstrated that certain features obtained from routine blood tests, such as the Neutrophil-to-Lymphocyte Ratio (NLR), the Glasgow Prognosis Score (GPS), and the Systemic Immune-Inflammation Index (SII), can be used to predict cancer prognosis [7,8,9].
Researchers have discovered and continue to discover numerous complex blood features. To differentiate between the original features and the derived complex features, we can refer to them as low-order features (LOF) and high-order features (HOF) respectively. The LOF have an established naming system for their abbreviations, such as WBC (White Blood Cell Count), CRP (C-Reactive Protein), RBC_SD (RBC Distribution Width Standard Deviation), and MPV (Mean Platelets Volume). However, no such systematic system exists for HOF abbreviations, which has caused confusion in the utilization of the abbreviations of these HOFs in existing reports. For instance, the calculation formula of Systemic inflammatory marker (SIM) [10] and Systemic inflammation response index (SIRI) [7], the lung immune prognostic index (LIPI) [11] and the dNLR combined with LDH index (LNI) [12], Onodera’s prognostic nutritional index (OPNI) [13] and (Prognostic nutrition index) PNI [14] are identical, whereas the only distinction between Glasgow prognostic score (GPS) [9] and modified Glasgow prognostic score (mGPS) [14], the systemic inflammation score (SIS) and modified SIS (mSIS) [15] is their cutoff values. Moreover, the values of Lymphcyte-to-Monocyte ratio (LMR) [7] and Monocyte-to-Lymphcyte ratio (MLR) [16], Fibrinogen-to-Albumin ratio (AFR) [17] and Albumin-to-Fibrinogen ratio (FAR) [18] are inversely proportional to each other, yet their importance for prognosis remains the same when it comes to data analysis. What is more, naming with single-letter abbreviations can lead to conflicts, GLR is used as an abbreviation for Gran/Lymph [19], GGT/Lymph [20] and Glc/Lymph [21] in different documents, while LLR is an acronym for both WBC/Lymph [14] and LDH/Lymph [23].
The primary objective of this paper is to introduce the concept of high-order blood HOF and to conduct a thorough investigation of existing literature to determine its potential in predicting NSCLC prognosis.
Methods
Document retrieval
In order to identify as many blood HOFs as possible, a comprehensive search of articles published between January 2018 and October 2022 on PubMed was conducted. The search query was: ((“Blood Cell Count“[MeSH Terms]) OR (Complete Blood Count[Title/Abstract]) OR (“Laboratory Tests“[Title/Abstract]) OR (blood routine[Title/Abstract])) AND ((“Risk Factors“[MeSH Terms]) OR (Prognosis[MeSH Terms]) OR (Biomarkers[MeSH Terms])) AND ((complex index[Title/Abstract]) OR (ratio[Title/Abstract])) AND ((Cancer[MeSH Terms]) OR (Inflammation[Title/Abstract])) NOT ((review[Title/Abstract]) OR (Meta-analysis[Title/Abstract])).
Patients
This research included 1,423 individuals who had been identified with lung cancer and were admitted to the Sichuan Cancer Hospital between 2015 and 2017. In line with the Chinese Medical Association’s clinical diagnosis and treatment guidelines for lung cancer [24], the treatment options for all patients were determined according to the same guidelines. This study excluded patients who had not been diagnosed with primary lung cancer or had a combination of other primary carcinomas, lacked blood test data prior to treatment, or had received anti-tumor therapy in other hospitals.
Data collection
This study was granted approval by the Medical Ethics Committee of the Sichuan Cancer Hospital (SCCHEC-02-2021-064). Clinical and laboratory data of the patients were retrospectively obtained; histological examination was employed to verify the pathological type; and the American Joint Committee on Cancer (AJCC) Eighth Edition staging system [25] was utilized for tumor staging. The LOFs and HOFs that we used are covered in Additional Table 1. The LOFs comprise reference intervals that are considered normal.
The final follow-up, conducted in May 2021, measured overall survival (OS), which is the time from diagnosis to death caused by any cause or loss to follow-up.
DeepSurv
To analyze both linear and nonlinear data, the DeepSurv algorithm [26], which is based on deep learning, can be employed to predict the probability of death for a particular patient. This algorithm was implemented using Python 3.7.6; for further information on the method and project code, please refer to the references [3, 26].
The input layer was set to the same dimensionality as the input data, while the three hidden layers comprised of 512, 1024, and 512 neurons respectively, and the output layer was one neuron. The experiment was trained for 500 epochs with an initial learning rate of 0.067, Adam optimizer, a decay rate of 0.06494, a discard layer loss rate of 0.2, and an L2 regularization coefficient of 0.005. The reliability of the model was evaluated using five-fold cross-validation.
To increase the DeepSurv model’s interpretability, the Shapley Additive exPlanations (SHAP) [27] approach is being utilized. The estimated importance of the features for the model was determined by using the SHAP method. For each patient, the DeepSurv model generated a predicted risk value, and a SHAP value was assigned to each feature of the patient, demonstrating the influence of each feature on the model’s output risk value.
Statistical analysis and plotting
Statistical analysis was conducted using R version 4.0.2 (2020-06-22). Spearman’s method was applied to assess the correlation between features. The patient characteristics were generated with the help of the package “TableOne”. The “ggDCA” package was used to create decision curve analysis (DCA) curves, and “rms” nomogram was used to generate nomogram and calibration curves. Concordance index (C-index) values were used to compare the prediction and true values.
Results
HOFs categorize
After conducting a literature screening strategy, 1558 articles were identified, of which 1210 were suitable for analysis after filtering out those deemed unsuitable based on title and abstract screening. Through manual reading of the literature, we screened 160 HOFs and then merged them into 110 according to their calculation formula. This suggests that HOFs can be classified into three groups according to calculation method: basic proportional type (e.g. NLR and LMR), composite type (e.g. derived NLR (dNLR) and PNI), and scoring type based on the first two types (e.g. GPS and LIPI). Within this study, we identified 76 proportional (Table 1), 6 composite (Table 2), and 28 scoring (Table 3) HOFs, respectively.
To avoid similar issues in the future, we have proposed a set of rules for the naming of blood HOFs, with the aim of providing researchers with a consistent and accurate nomenclature. These rules include, but are not limited to:
-
1.
Preference should be given to the abbreviations reported in Tables 1, 2 and 3 of this article, and it is advised to use the abbreviations with more reports in the left column, rather than the reverse proportional mode on the right.
-
2.
Use abbreviations of terms related to clinical relevance. Although both the Lung Immune Prognostic Index (LIPI) and the dNLR combined with LDH index (LNI) are identical, it is suggested to use the LIPI due to its more accurate representation.
-
3.
The product type feature is denoted by the initial letter of the feature, whereas the proportion type feature is indicated by the combination of the initial letter and the suffix ‘R’, indicating Ratio. For example, LA stands for the product of lymphocytes and albumin, while LAR is the ratio of lymphocytes to albumin.
-
4.
The nomenclature of proportional features shall be based on the order of obtaining the ratio that is greater than one. It is important to note that multiplying the coefficient should be avoided when adjusting the value, as this will not alter the significance of this feature in data analysis.
-
5.
In the event of a clash in naming with a single acronym, the second letter or full name of the conflicting feature should be employed. When the abbreviation of GLR is unclear, GlcLR can be used to signify the Glucose-to-Lymphocyte ratio and GranLR for the Granulocyte -to-Lymphocyte ratio.
-
6.
It is advisable to limit the number of abbreviated names to between 3 and 6 characters to avoid confusion.
Patient characteristics
Following the acquisition of HOFs, we immediately collected patient data for validation. The cohort included 1423 individuals with NSCLC, with 945 having adenocarcinoma and 478 having squamous cell carcinoma. At diagnosis, the majority of patients were in the later stages, with 482 in stage III and 595 in stage IV. Approximately 36% (51/1423) of the patients were either current or former smokers. The number of men (945) being almost double that of women (478). The median age was 62 years (IQR: 52–67), median follow-up was 499 days (IQR: 189-1162.5). Upon follow-up, 675 (47.4%) patients had died. The baseline characteristics of the study cohort are outlined in Additional Table 2.
Correlation analysis
Having thoroughly explored the reported HOFs, we proceeded to investigate whether there is any correlation between each blood feature and other clinical characteristics, including sex, age, staging, smoking status, and pathological type, in order to gain further understanding. It should be noted that, as many patients in our cohort did not have a blood biochemical test prior to treatment, the HOFs in Tables 1, 2 and 3 cannot be included in the analysis (Additional Table 1). To carry out a correlation analysis, we evaluated patients based on the other four parameters. The screening criteria and the features of the patients who meet the criteria are outlined in Table 4. The Spearman method was utilized to conduct correlation analysis, with a confidence interval of 0.95. All groups, except for the smoking group, consisted of 60 patients, and the correlation coefficient threshold (Rs) was set at an absolute value of 0.305. The smoking group comprised 52 patients, with a Rs of 0.321. The analysis results indicate that sex is associated with MCHC and WRPI in LOFs. The calculation formulas for the two HOFs that are related to Age already include Age, rendering their significance insignificant. Smoking can lead to an increase in neutrophils and a decrease in albumin, with a greater impact on HOFs. There was no observed correlation between blood features and pathological types. It is noteworthy that no significant correlation was observed between any LOFs and stage, but after high-order transformation, eight features were found to be related to stage. The most highly correlated feature is GGLR (GGT/Lymph), with a correlation coefficient of 0.4041. All the characteristics that exhibit correlation coefficients greater than Rs are grouped together in the final row of Table 4.
DeepSurv Analysis
To evaluate the importance of LOF and HOF data on the prognosis of lung cancer patients, models were constructed with DeepSurv algorithm and the prediction accuracy was measured by C-index. The Table 5 shows that the LOF model is relatively stable, with C-index values in the train set and the test set not significantly different. On the other hand, the HOF model can achieve a C-index value of more than 0.7 on the train set, which is comparable to the effect of staging. However, maybe due to high correlation among many HOF features, it is prone to overfitting, thereby performing poorly in the test set. Given that age, sex, and smoking status are readily available data that can be conveniently gathered during routine clinical assessments, we have grouped these three variables together as ASS. The addition of ASS (Age + Sex + Smoking) features does not enhance the prediction model’s performance significantly.
To evaluate the impact of each feature in the model, we have utilized SHAP algorithm for visual analysis. As illustrated in Fig. 1, feature value reflects the real value of each feature, and SHAP value reflects the contribution to the individual prognosis model, with a negative value indicating a negative contribution. Figure 1 A reveals that WBC, MPV, Mono_ratio, Baso_ratio, and Lymph_ratio are the five features that have the most significant influence on the LOF model; an increase in WBC and Mono_ratio values is associated with a poor prognosis, whereas the other three have the opposite effect. Figure 1B indicates that among the top five most important features, a rise in FIB4, GlcLR and Neu values is linked to a negative prognosis for patients, whilst the MPVLR and BLR are the opposite.

The top 20 important features in LOF- and HOF-model chosen by SHAP algorithm. A: LOF model. B: HOF model
Model comparison
The previous analysis leads us to believe that the risk value output by the DeepSurv model can be used to supplement the staging system, thereby improving the prediction efficiency. To more clearly illustrate the comparison of the prediction effects of each data combination, a DCA decision curve was utilized. The decision curve employs a horizontal axis labeled as risk threshold, with the “none” horizontal line signifying that patients are devoid of any risk. The model’s net benefit is zero in this scenario. However, if all patients are at risk, the net benefit takes the form of a negative slope backslash, as depicted by the “All” line.
As illustrated in Fig. 2, the risk prediction ability of HOF model is superior to that of LOF model, and the addition of ASS features can enhance the prediction efficiency of both models. However, the feature combination of DS_LOF + DS_HOF + ASS was not as effective as that of Stage + Pathotype in terms of prediction efficiency. All features (Stage + Pathotype + DS_LOF + DS_HOF + ASS)combined can provide the best prediction efficiency. It can evident that blood features can be employed as an additional factor in forecasting the risk of lung cancer patients.

The DCA curve of different feature combinations. “DS_” means the output risk value of DeepSurv model. ASS present the combination of Age + Sex + Smoking features. All feature contains Stage + Pathotype + DS_LOF + DS_HOF + ASS features
Nomogram Model
Finally, a nomogram was established based on these features to obtain a more intuitive prognosis model. Figure 3 A shows that stage is still the most significant prognostic factor, followed by DS_ HOF, age, DS_ LOF, sex, pathological type and smoking status. The C-index of the model is 0.744 and the calibration curve, as seen in Fig. 3B, demonstrates its good predictive effect on lung cancer patients in 1 year and 3 years.

The Nomogram on OS and calibration curve of the final prognosis model. A: Nomogram for 1-, 3-, and 5-year OS. B: Calibration curve of nomogram predicting 1-, 3- and 5-year OS
Discussion
To sustain the exploration of HOFs with clinical application value and further deepen this research direction of blood test data, a sustainable expansion system needs to be established. This is the first systematic review of the blood HOF, which aims to sort and classify the existing HOFs, and to propose rules for their nomenclature.
Tables 1, 2 and 3 demonstrate that the main direction of HOF mining is to acquire features from inflammation and nutrition, such as NLR, SII, GPS, SIS and other significant HOFs which are all based on Neu, CRP, Lymph, Alb, Plt. However, for early cancer patients, their nutritional and inflammatory status may not serve as a crucial indicator. Therefore, it is suggested to start from the viewpoint of the pro- and anti-tumor balance. Tracking the changes during the treatment process could help to identify such features quickly [85]. Previous research has demonstrated that the alterations of NLR throughout treatment have a more reliable prognostic value for patients than NLR at a single point in time [79, 119].
The correlation analysis findings reveal that low-order features have little correlation with clinical features, whereas a multitude of high-order features demonstrate a correlation with clinical features. This implies that high-order features hold substantial clinical significance in cancer diagnosis and treatment. In terms of medical applications, MLR can provide insights into the likelihood of prostate cancer [16], while NLR and PLR can be utilized to predict chemotherapy response [114] and the potential for metastasis [82]. Additionally, LWR and MWR have proven to be effective in forecasting the prognosis of gastric cancer [58].
Despite numerous reports of HOFs, the clinical significance of most of them remains uncertain and the interpretability is still unsatisfactory. This study proposes that the output risk value can be utilized in addition to the staging information to optimize the prognostic efficiency, demonstrating that this usage is possible. Despite the integration of the SHAP algorithm, the inexplicable of deep learning remains unresolved. We can only ascertain the influence of the chosen features on the model’s formation, yet the weight and calculation process of each feature remain unknown.
Conclusion
This paper’s most remarkable achievement is the sorting of reported blood HOFs, which can be used as an index for further research, and a systematic evaluation of its prediction of OS in NSCLC. However, there may still be many HOFs that have not been retrieved and included, and there is no systematic scheme for the subsequent blood HOFs mining, which will be the main goal of the research group.
Availability of data and materials
The datasets and codes used in this study are accessible from the first author or corresponding author upon reasonable request.
Abbreviations
- AJCC:
-
The American Joint Committee on Cancer
- ASS:
-
Age + Sex + Smoking
- AUC:
-
Area under the curve
- C-index:
-
Concordance index
- CT:
-
Computed Tomography
- DCA:
-
Decision curve analysis
- DS:
-
DeepSurv
- HOF:
-
High-order feature
- IQR:
-
Interquartile range
- LOF:
-
Low-order feature
- MRI:
-
Magnetic Resonance Imaging
- NSCLC:
-
Non-small cell lung cancer
- OS:
-
Overall survival
- Pathotype:
-
Pathological Type
- PET:
-
Positron Emission Tomography
- SHAP:
-
Shapley Additive exPlanations
- TNM:
-
Tumor-lymph node-metastasis
References
Wang Q, Wang S, Sun Z, et al. Evaluation of log odds of positive lymph nodes in predicting the survival of patients with non-small cell lung cancer treated with neoadjuvant therapy and surgery: a SEER cohort-based study. BMC Cancer. 2022;22(1):801. https://doi.org/10.1186/s12885-022-09908-3.
Xu Y, Zheng M, Guo Q, et al. Clinical features and survival outcome of early-stage primary pulmonary MALT lymphoma after surgical treatment. Front Surg. 2021;8:713748. 10.33 89/fsurg.2021.713748.
She Y, Jin Z, Wu J, et al. Development and validation of a deep learning model for non-small cell lung cancer survival. JAMA Netw Open. 2020;3(6):e205842. https://doi.org/10.1001/jamanetworkopen.2020.5842.
Wen X, Leng P, Wang J, et al. Clinlabomics: leveraging clinical laboratory data by data mining strategies. BMC Bioinformatics. 2022;23(1):387. https://doi.org/10.1186/s12859-022-04926-1.
Wang Q, Cao B, Peng L, et al. Development and validation of a practical prognostic coagulation index for patients with esophageal squamous cell cancer. Ann Surg Oncol. 2021;28(13):8450–61. https://doi.org/10.1245/s10434-021-10239-z.
Tahir Huyut M, Huyut Z, İlkbahar F, et al. What is the impact and efficacy of routine immunological, biochemical and hematological biomarkers as predictors of COVID-19 mortality? Int Immunopharmacol. 2022;105:108542. https://doi.org/10.1016/j.intimp.2022.108542.
Qi WX, Xiang Y, Zhao S, Chen J. Assessment of systematic inflammatory and nutritional indexes in extensive-stage small-cell lung cancer treated with first-line chemotherapy and atezolizumab. Cancer Immunol Immunother. 2021;70(11):3199–206. https://doi.org/10.1007/s00262-021-02926-3.
Winther-Larsen A, Aggerholm-Pedersen N, Sandfeld-Paulsen B. Inflammation-scores as prognostic markers of overall survival in lung cancer: a register-based study of 6,210 danish lung cancer patients. BMC Cancer. 2022;22(1):63. https://doi.org/10.1186/s12885-021-09108-5.
Toyokawa T, Muguruma K, Yoshii M, et al. Clinical significance of prognostic inflammation-based and/or nutritional markers in patients with stage III gastric cancer. BMC Cancer. 2020;20(1):517. https://doi.org/10.1186/s12885-020-07010-0.
Cantiello F, Russo GI, Vartolomei MD, et al. Systemic inflammatory markers and oncologic outcomes in patients with high-risk non-muscle-invasive urothelial bladder cancer. Eur Urol Oncol. 2018;1(5):403–10. https://doi.org/10.1016/j.euo.2018.06.006.
Mezquita L, Auclin E, Ferrara R, et al. Association of the lung immune prognostic index with immune checkpoint inhibitor outcomes in patients with advanced non-small cell lung cancer. JAMA Oncol. 2018;4(3):351–7. https://doi.org/10.1001/jamaoncol.2017.4771.
Li L, Ai L, Jia L, et al. High score of LDH plus dNLR predicts poor survival in patients with HER2-positive advanced breast cancer treated with trastuzumab emtansine. BMC Cancer. 2022;22(1):29. https://doi.org/10.1186/s12885-021-09131-6.
Tojek K, Banaś W, Czerniak B, et al. Total blood lymphocyte count as a prognostic factor among unselected inpatients. Adv Med Sci. 2020;65(1):141–8. https://doi.org/10.1016/j.advms.2020.01.001.
Paydas S, Lacin S, Dogan M, et al. Easier and more explanatory indices by integrating leukocyte lymphocyte ratio (LLR) and prognostic nutritional index (PNI) to IPS systems in cases with classical Hodgkin lymphoma. Leuk Res. 2021;107:106586. https://doi.org/10.1016/j.leukres.2021.106586.
Lin JX, Lin JP, Xie JW, et al. Prognostic importance of the preoperative modified systemic inflammation score for patients with gastric cancer. Gastric Cancer. 2019;22(2):403–12. https://doi.org/10.1007/s10120-018-0854-6.
Xu Z, Zhang J, Zhong Y, et al. Predictive value of the monocyte-to-lymphocyte ratio in the diagnosis of prostate cancer. Med (Baltim). 2021;100(38):e27244. https://doi.org/10.1097/MD.0000000000027244.
Du JH, Lu J. Circulating CEA-dNLR score predicts clinical outcome of metastatic gallbladder cancer patient. J Clin Lab Anal. 2019;33(2):e22684. https://doi.org/10.1002/jcla.22684.
An Q, Liu W, Yang Y, Yang B. Preoperative fibrinogen-to-albumin ratio, a potential prognostic factor for patients with stage IB-IIA cervical cancer. BMC Cancer. 2020;20(1):691. https://doi.org/10.1186/s12885-020-07191-8.
Gialluisi A, Di Castelnuovo A, Bracone F, et al. Associations between systemic inflammation and somatic depressive symptoms: findings from the Moli-sani study. Depress Anxiety. 2020;37(9):935–43. https://doi.org/10.1002/da.23070.
Wang JJ, Li H, Li JX, et al. Preoperative gamma-glutamyltransferase to lymphocyte ratio predicts long-term outcomes in intrahepatic cholangiocarcinoma patients following hepatic resection. World J Gastroenterol. 2020;26(13):1501–12. https://doi.org/10.3748/wjg.v26.i13.1501.
Yilmaz H, Nigdelioglu B, Aytac A, et al. The prognostic importance of glucose-to-lymphocyte ratio and uric acid in metastatic breast cancer patients treated with cdk 4/6 inhibitors. Future Oncol. 2022;18(27):3043–53. https://doi.org/10.2217/fon-2022-0464.
Paydas S, Lacin S, Dogan M, et al. Easier and more explanatory indices by integrating leukocyte lymphocyte ratio (LLR) and prognostic nutritional index (PNI) to IPS systems in cases with classical Hodgkin lymphoma. Leuk Res. 2021;107:106586. https://doi.org/10.1016/j.leukres.2021.
Li T, Li H, Xie S, et al. Lactate dehydrogenase-to-lymphocyte ratio represents a powerful prognostic tool of metastatic renal cell carcinoma patients treated with tyrosine kinase inhibitors. Pathol Oncol Res. 2020;26(2):1319–24. https://doi.org/10.1007/s12253-019-00707-z.
Chinese Medical Association, Oncology Society of Chinese Medical Association, Chinese Medical Association Publishing House. Chinese Medical Association guidelines for clinical diagnosis and treatment of lung cancer (2019 edition). Zhonghua Zhong Liu Za Zhi. 2020;23(4):257–87. https://doi.org/10.3760/cma.j.cn112152-20200120-00049. (In Chinese).
Detterbeck FC, Boffa DJ, Kim AW, et al. The Eighth Edition Lung Cancer Stage classification. Chest. 2017;151(1):193–203. https://doi.org/10.1016/j.chest.2016.10.010.
Katzman JL, Shaham U, Cloninger A, et al. DeepSurv: personalized treatment recommender system using a Cox proportional hazards deep neural network. BMC Med Res Methodol. 2018;18(1):24. https://doi.org/10.1186/s12874-018-0482-1. (DeepSurv code. https://github.com/czifan/DeepSurv.pytorch.
Lundberg SM, Lee S-I. A unified approach to interpreting model predictions. In Proceedings of the 31st international conference on neural information processing systems. 2017. (SHAP code: https://github.com/slundberg/shap.)
Turker S, Cilbir E, Guven DC, et al. The relation between inflammation-based parameters and survival in metastatic pancreatic cancer. J Cancer Res Ther. 2021;17(2):510–5. https://doi.org/10.4103/jcrt.JCRT_773_19.
Okugawa Y, Toiyama Y, Fujikawa H, et al. Cumulative perioperative lymphocyte/C-reactive protein ratio as a predictor of the long-term outcomes of patients with colorectal cancer. Surg Today. 2021;51(12):1906–17. https://doi.org/10.1007/s00595-021-02291-9.
García-Núñez A, Jiménez-Gómez G, Hidalgo-Molina A, et al. Inflammatory indices obtained from routine blood tests show an inflammatory state associated with disease progression in engineered stone silicosis patients. Sci Rep. 2022;12(1):8211. https://doi.org/10.1038/s41598-022-11926-x.
Nooh HA, Abdellateif MS, Refaat L, et al. The role of inflammatory indices in the outcome of COVID-19 cancer patients. Med Oncol. 2021;39(1):6. https://doi.org/10.1007/s12032-021-01605-8.
Yazgan SC, Yekedüz E, Utkan G, Ürün Y. Prognostic role of pan-immune-inflammation value in patients with metastatic castration-resistant prostate cancer treated with androgen receptor-signaling inhibitors. Prostate. 2022;82(15):1456–61. https://doi.org/10.1002/pros.24419.
Afify SM, Tabll A, Nawara HM, et al. Five fibrosis biomarkers together with serum ferritin level to diagnose liver fibrosis and cirrhosis. Clin Lab. 2018;64(10):1685–93. https://doi.org/10.7754/Clin.Lab.2018.180502.
Li L, Mo F, Hui EP, et al. The association of liver function and quality of life of patients with liver cancer. BMC Gastroenterol. 2019;19(1):66. https://doi.org/10.1186/s12876-019-0984-2.
Ypma PF, van Geloven N, Kerkhoffs JLH, et al. The association between haemorrhage and markers of endothelial insufficiency and inflammation in patients with hypoproliferative thrombocytopenia: a cohort study. Br J Haematol. 2020;189(1):171–81. https://doi.org/10.1111/bjh.16291.
Said NM. Three gold indicators for breast cancer prognosis: a case-control study with ROC analysis for novel ratios related to CBC with (ALP and LDH). Mol Biol Rep. 2019;46(2):2013–27. https://doi.org/10.1007/s11033-019-04650-9.
Casadei Gardini A, Foschi FG, Conti F, et al. Immune inflammation indicators and ALBI score to predict liver cancer in HCV-patients treated with direct-acting antivirals. Dig Liver Dis. 2019;51(5):681–8. https://doi.org/10.1016/j.dld.2018.09.016.
Yugawa K, Maeda T, Nagata S, et al. A novel combined prognostic nutritional index and aspartate aminotransferase-to-platelet ratio index-based score can predict the survival of patients with hepatocellular carcinoma who undergo hepatic resection. Surg Today. 2022;52(7):1096–108. https://doi.org/10.1007/s00595-021-02440-0.
Shi JY, Sun LY, Quan B, et al. A novel online calculator based on noninvasive markers (ALBI and APRI) for predicting post-hepatectomy liver failure in patients with hepatocellular carcinoma. Clin Res Hepatol Gastroenterol. 2021;45(4):101534. https://doi.org/10.1016/j.clinre.2020.09.001.
Wang Y, Zhou N, Zhu R, et al. Circulating activated immune cells as a potential blood biomarkers of non-small cell lung cancer occurrence and progression. BMC Pulm Med. 2021;21(1):282. https://doi.org/10.1186/s12890-021-01636-x.
Toyokawa T, Muguruma K, Yoshii M, et al. Clinical significance of prognostic inflammation-based and/or nutritional markers in patients with stage III gastric cancer. BMC Cancer. 2020;20(1):517. https://doi.org/10.1186/s12885-020-07010-0.
Nozoe T, Kono M, Kuma S, et al. New scoring system to create a prognostic criteria in colorectal carcinoma based on serum elevation of C-reactive protein and decrease in lymphocyte in peripheral blood. J Med Invest. 2019;66(34):264–8. https://doi.org/10.2152/jmi.66.264.
Nishikawa M, Miyake H, Kurahashi T, Fujisawa M. Significance of multiple preoperative laboratory abnormalities as prognostic indicators in patients with urothelial carcinoma of the upper urinary tract following radical nephroureterectomy. Int J Clin Oncol. 2018;23(1):151–7. https://doi.org/10.1007/s10147-017-1184-0.
Zhang B, Wu S, Zhang Y, et al. Analysis of risk factors for gleason score upgrading after radical prostatectomy in a chinese cohort. Cancer Med. 2021;10(21):7772–80. https://doi.org/10.1002/cam4.4274.
Şan İ, Gemcioğlu E, Davutoğlu M, et al. Which hematological markers have predictive value as early indicators of severe COVID-19 cases in the emergency department? Turk J Med Sci. 2021;51(6):2810–21. https://doi.org/10.3906/sag-2008-6.
Huyut MT, İlkbahar F. The effectiveness of blood routine parameters and some biomarkers as a potential diagnostic tool in the diagnosis and prognosis of Covid-19 disease. Int Immunopharmacol. 2021;98:107838. https://doi.org/10.1016/j.intimp.2021.107838.
Holub K, Biete A. New pre-treatment eosinophil-related ratios as prognostic biomarkers for survival outcomes in endometrial cancer. BMC Cancer. 2018;18(1):1280. https://doi.org/10.1186/s12885-018-5131-x.
Zhao X, Zhang N, Zhang H, et al. High fibrinogen-albumin ratio index predicts poor prognosis for lung adenocarcinoma patients undergoing epidermal growth factor receptor-tyrosine kinase inhibitor treatments. Med (Baltim). 2020;99(46):e23150. https://doi.org/10.1097/MD.0000000000023150.
Wakatsuki K, Matsumoto S, Migita K, et al. Prognostic value of the fibrinogen-to-platelet ratio as an inflammatory and coagulative index in patients with gastric cancer. Surg Today. 2019;49(4):334–42. https://doi.org/10.1007/s00595-018-1734-8.
Zhao L, Li S, Ju J, et al. Gamma-glutamyl transpeptidase to platelet ratio is a novel and independent prognostic marker for resectable lung cancer: a propensity score matching study. Ann Thorac Cardiovasc Surg. 2021;27(3):151–63. https://doi.org/10.5761/atcs.oa.20-00247.
Bostancı MT, Yılmaz I, Seki A, et al. Haematological inflammatory markers for indicating ischemic bowel in patients with incarcerated abdominal wall hernias. Hernia. 2022;26(1):349–53. https://doi.org/10.1007/s10029-021-02518-1.
Nanava N, Betaneli M, Giorgobiani G et al. Complete blood count derived inflammatory biomarkers in patients with hematologic malignancies. Georgian Med News. 2020;(302):39–44.
Yamamoto T, Kawada K, Hida K, et al. Combination of lymphocyte count and albumin concentration as a new prognostic biomarker for rectal cancer. Sci Rep. 2021;11(1):5027. https://doi.org/10.1038/s41598-021-84475-4.
Zhu Y, Xu D, Zhang Z, et al. A new laboratory-based algorithm to predict microvascular invasion and survival in patients with hepatocellular carcinoma. Int J Surg. 2018;57:45–53. https://doi.org/10.1016/j.ijsu.2018.07.011.
Huang X, Huan Y, Liu L, et al. Preoperative low absolute lymphocyte count to fibrinogen ratio correlated with poor survival in nonmetastatic colorectal cancer. World J Surg Oncol. 2022;20(1):309. https://doi.org/10.1186/s12957-022-02775-z.
Li C, Li W, Xu G, et al. Relationship between the absolute lymphocyte count/absolute monocyte count ratio, soluble interleukin 2 receptor level, serum programmed cell death 1 level, and the prognosis of patients with diffuse large B-cell lymphoma. Ann Palliat Med. 2021;10(10):10938–45. https://doi.org/10.21037/apm-21-2551.
Feng Y, Wang Z, Cui R, et al. Clinical analysis and artificial intelligence survival prediction of serous ovarian cancer based on preoperative circulating leukocytes. J Ovarian Res. 2022;15(1):64. https://doi.org/10.1186/s13048-022-00994-2.
Feng F, Sun L, Zheng G, et al. Low lymphocyte-to-white blood cell ratio and high monocyte-to-white blood cell ratio predict poor prognosis in gastric cancer. Oncotarget. 2017;8(3):5281–91. https://doi.org/10.18632/oncotarget.14136.
Karantanos T, Karanika S, Seth B, Gignac G. The absolute lymphocyte count can predict the overall survival of patients with non-small cell lung cancer on nivolumab: a clinical study. Clin Transl Oncol. 2019;21(2):206–12. https://doi.org/10.1007/s12094-018-1908-2.
Suzuki S, Akiyoshi T, Oba K, et al. Comprehensive comparative analysis of prognostic value of systemic inflammatory biomarkers for patients with stage II/III colon cancer. Ann Surg Oncol. 2020;27(3):844–52. https://doi.org/10.1245/s10434-019-07904-9.
Belviranli S, Oltulu R, Gundogan AO, et al. Evaluation of the systemic inflammation in patients with pterygium: monocyte-to- high-density lipoprotein cholesterol ratio and hematologic indexes of inflammation. Middle East Afr J Ophthalmol. 2022;28(4):211–5. https://doi.org/10.4103/meajo.meajo_75_21.
Elalfy H, Besheer T, El-Maksoud MA, et al. Monocyte/granulocyte to lymphocyte ratio and the MELD score as predictors for early recurrence of hepatocellular carcinoma after trans-arterial chemoembolization. Br J Biomed Sci. 2018;75(4):187–91. https://doi.org/10.1080/09674845.2018.1494769.
Shi WR, Wang HY, Chen S, et al. The impact of monocyte to high-density lipoprotein ratio on reduced renal function: insights from a large population. Biomark Med. 2019;13(9):773–83. https://doi.org/10.2217/bmm-2018-0406.
Chen Z, He Y, Su Y, et al. Association of inflammatory and platelet volume markers with clinical outcome in patients with anterior circulation ischaemic stroke after endovascular thrombectomy. Neurol Res. 2021;43(6):503–10. https://doi.org/10.1080/01616412.2020.1870359.
Divsalar B, Heydari P, Habibollah G, Tamaddon G. Hematological parameters changes in patients with breast cancer. Clin Lab. 2021;67(8):10. https://doi.org/10.7754/Clin.Lab.2020.201103.
Tekin YK, Tekin G. Mean platelet volume-to-platelet count ratio, mean platelet volume-to-lymphocyte ratio, and red blood cell distribution width-platelet count ratio as markers of inflammation in patients with ascending thoracic aortic aneurysm. Braz J Cardiovasc Surg. 2020;35(2):175–80. https://doi.org/10.21470/1678-9741-2019-0348.
Tirumala V, Klemt C, Xiong L, et al. Diagnostic utility of platelet count/lymphocyte count ratio and platelet count/mean platelet volume ratio in periprosthetic joint infection following total knee arthroplasty. J Arthroplasty. 2021;36(1):291–7. https://doi.org/10.1016/j.arth.2020.07.038.
Su R, Zhu J, Wu S, et al. Prognostic significance of platelet (PLT) and platelet to mean platelet volume (PLT/MPV) ratio during apatinib second-line or late-line treatment in advanced esophageal squamous cell carcinoma patients. Technol Cancer Res Treat. 2022;21:15330338211072974. https://doi.org/10.1177/15330338211072974.
Hlapčić I, Somborac-Bačura A, Popović-Grle S, et al. Platelet indices in stable chronic obstructive pulmonary disease - association with inflammatory markers, comorbidities and therapy. Biochem Med (Zagreb). 2020;30(1):010701. https://doi.org/10.11613/BM.2020.010701.
Uludag SS, Sanli AN, Zengin AK, Ozcelik MF. Systemic inflammatory biomarkers as surrogate markers for stage in colon cancer. Am Surg. 2022;88(6):1256–62. https://doi.org/10.1177/0003134821995059.
Zapała Ł, Ślusarczyk A, Garbas K, et al. Complete blood count-derived inflammatory markers and survival in patients with localized renal cell cancer treated with partial or radical nephrectomy: a retrospective single-tertiary-center study. Front Biosci (Schol Ed). 2022;14(1):5. https://doi.org/10.31083/j.fbs1401005.
Zhao R, Shan J, Nie L, et al. The predictive value of the ratio of the product of neutrophils and hemoglobin to lymphocytes in non-muscular invasive bladder cancer patients with postoperative recurrence. J Clin Lab Anal. 2021;35(8):e23883. https://doi.org/10.1002/jcla.23883.
Kou T, Luo H, Yin L. Relationship between neutrophils to HDL-C ratio and severity of coronary stenosis. BMC Cardiovasc Disord. 2021;21(1):127. https://doi.org/10.1186/s12872-020-01771-z.
Yanagisawa M, Gingrich AA, Judge S, et al. Serum c-reactive protein and neutrophil/lymphocyte ratio after neoadjuvant radiotherapy in soft tissue sarcoma. Anticancer Res. 2018;38(3):1491–7. https://doi.org/10.21873/anticanres.12376.
Zhou T, Zheng N, Li X, et al. Prognostic value of neutrophil- lymphocyte count ratio (NLCR) among adult ICU patients in comparison to APACHE II score and conventional inflammatory markers: a multi center retrospective cohort study. BMC Emerg Med. 2021;21(1):24. https://doi.org/10.1186/s12873-021-00418-2.
Morga R, Dziedzic T, Moskala M, et al. Clinical relevance of changes in peripheral blood cells after intracranial aneurysm rupture. J Stroke Cerebrovasc Dis. 2020;29(12):105293. https://doi.org/10.1016/j.jstrokecerebrovasdis.2020.105293.
Yıldız D, Seferoğlu M, Güneş A, et al. Epicardial adipose thickness and neutrophil lymphocyte ratio in acute occlusive cerebrovascular diseases. J Stroke Cerebrovasc Dis. 2020;29(11):105203. https://doi.org/10.1016/j.jstrokecerebrovasdis.2020.105203.
McIntosh RC, Lobo J, Paparozzi J, et al. Neutrophil to lymphocyte ratio is a transdiagnostic biomarker of depression and structural and functional brain alterations in older adults. J Neuroimmunol. 2022;365:577831. https://doi.org/10.1016/j.jneuroim.2022.577831.
Punjabi A, Barrett E, Cheng A, et al. Neutrophil-lymphocyte ratio and absolute lymphocyte count as prognostic markers in patients treated with curative-intent radiotherapy for non-small cell lung cancer. Clin Oncol (R Coll Radiol). 2021;33(8):e331–8. https://doi.org/10.1016/j.clon.2021.03.019.
Mika T, Ladigan S, Schork K, et al. Monocytes-neutrophils-ratio as predictive marker for failure of first induction therapy in AML. Blood Cells Mol Dis. 2019;77:103–8. https://doi.org/10.1016/j.bcmd.2019.04.008.
He X, Dai F, Zhang X, Pan J. The neutrophil percentage-to-albumin ratio is related to the occurrence of diabetic retinopathy. J Clin Lab Anal. 2022;36(4):e24334. https://doi.org/10.1002/jcla.24334.
Dogan M, Algin E, Guven ZT, et al. Neutrophil-lymphocyte ratio, platelet-lymphocyte ratio, neutrophil-platelet score and prognostic nutritional index: do they have prognostic significance in metastatic pancreas cancer? Curr Med Res Opin. 2018;34(5):857–63. https://doi.org/10.1080/03007995.2017.1408579.
Patel M, McSorley ST, Park JH, et al. The relationship between right-sided tumour location, tumour microenvironment, systemic inflammation, adjuvant therapy and survival in patients undergoing surgery for colon and rectal cancer. Br J Cancer. 2018;118(5):705–12. https://doi.org/10.1038/bjc.2017.441.
Sisti G, Faraci A, Silva J, Upadhyay R. Neutrophil-to-lymphocyte ratio, platelet-to-lymphocyte ratio, and routine complete blood count components in HELLP syndrome: a matched case control study. Med (Kaunas). 2019;55(5):123. https://doi.org/10.3390/medicina55050123.
Ramsay G, Ritchie DT, MacKay C, et al. Can haematology blood tests at time of diagnosis predict response to neoadjuvant treatment in locally advanced rectal cancer? Dig Surg. 2019;36(6):495–501. https://doi.org/10.1159/000493433.
Takeuchi H, Noda D, Abe M, et al. Evaluating the platelet distribution width-to-plateletcrit ratio as a prognostic marker for patients with breast cancer. Anticancer Res. 2020;40(7):3947–52. https://doi.org/10.21873/anticanres.14386.
Tao Y, He X, Qin Y, et al. Low platelet/platelet distribution width and high platelet/ lymphocyte ratio are adverse prognostic factors in patients with newly diagnosed advanced Hodgkin lymphoma. Leuk Lymphoma. 2021;62(13):3119–29. https://doi.org/10.1080/10428194.2021.
Bayir D, Seber S, Yetisyigit T. Prognostic values of various hematological variables as markers of systemic inflammation in metastatic lung cancer. J Cancer Res Ther. 2020;16(4):731–6. https://doi.org/10.4103/jcrt.JCRT_397_17.
Pierscianek D, Ahmadipour Y, Michel A, et al. Preoperative survival prediction in patients with glioblastoma by routine inflammatory laboratory parameters. Anticancer Res. 2020;40(2):1161–6. https://doi.org/10.21873/anticanres.14058.
Ge X, Zhu L, Li W et al. Red cell distribution width to platelet count ratio: a promising routinely available indicator of mortality for acute traumatic brain injury [published correction appears in J Neurotrauma. 2021;38(17):2487]. J Neurotrauma. 2022;39(1–2):159–171. https://doi.org/10.1089/neu.2020.7481.
Saiki O, Uda H. Ratio of serum amyloid A to C-reactive protein is constant in the same patients but differs greatly between patients with inflammatory diseases. Scand J Immunol. 2022;95(2):e13121. https://doi.org/10.1111/sji.13121.
Carpio-Orantes LD, García-Méndez S, Hernández-Hernández SN. Neutrophil-to-lymphocyte ratio, platelet-to-lymphocyte ratio and systemic immune-inflammation index in patients with COVID-19-associated pneumonia. Gac Med Mex. 2020;156(6):527–31. https://doi.org/10.24875/GMM.
Zhou ZQ, Pang S, Yu XC, et al. Predictive values of postoperative and dynamic changes of inflammation indexes in survival of patients with resected colorectal cancer. Curr Med Sci. 2018;38(5):798–808. https://doi.org/10.1007/s11596-018-1946-6.
Guclu K, Celik M. Prognostic value of inflammation parameters in patients with non-st elevation acute coronary syndromes. Angiology. 2020;71(9):825–30. https://doi.org/10.1177/0003319720936500.
Yang Z, Li S, Zhao L, et al. Serum uric acid to lymphocyte ratio: a novel prognostic biomarker for surgically resected early-stage lung cancer. A propensity score matching analysis. Clin Chim Acta. 2020;503:35–44. https://doi.org/10.1016/j.cca.2020.01.005.
Huyut MT, Huyut Z. Forecasting of Oxidant/Antioxidant levels of COVID-19 patients by using Expert models with biomarkers used in the Diagnosis/Prognosis of COVID-19. Int Immunopharmacol. 2021;100:108127. https://doi.org/10.1016/j.intimp.2021.108127.
Zheng HL, Lu J, Xie JW, et al. Exploring the value of new preoperative inflammation prognostic score: white blood cell to hemoglobin for gastric adenocarcinoma patients. BMC Cancer. 2019;19(1):1127. https://doi.org/10.1186/s12885-019-6213-0.
Weng Y, Gao Y, Zhao M, et al. The white blood cell count to mean platelet volume ratio for ischemic stroke patients after intravenous thrombolysis. Front Immunol. 2022;13:995911. https://doi.org/10.3389/fimmu.2022.995911.
Sandfeld-Paulsen B, Meldgaard P, Sorensen BS, et al. The prognostic role of inflammation-scores on overall survival in lung cancer patients. Acta Oncol. 2019;58(3):371–6. https://doi.org/10.1080/0284186X.2018.1546057.
Xiu WJ, Yang HT, Zheng YY, et al. ALB-dNLR score predicts mortality in coronary artery disease patients after percutaneous coronary intervention. Front Cardiovasc Med. 2022;9:709868. https://doi.org/10.3389/fcvm.2022.709868.
Abe T, Oshikiri T, Goto H, et al. Albumin-derived NLR score is a novel prognostic marker for esophageal squamous cell carcinoma. Ann Surg Oncol. 2022;29(4):2663–71. https://doi.org/10.1245/s10434-021-11012-y.
Salati M, Caputo F, Cunningham D, et al. The A.L.A.N. score identifies prognostic classes in advanced biliary cancer patients receiving first-line chemotherapy. Eur J Cancer. 2019;117:84–90. https://doi.org/10.1016/j.ejca.2019.05.030.
Sun H, Hu P, Shen H, et al. Albumin and neutrophil combined prognostic grade as a new prognostic factor in non-small cell lung cancer: results from a large consecutive cohort. PLoS ONE. 2015;10(12):e0144663. https://doi.org/10.1371/journal.pone.0144663.
Wang F, He W, Jiang C, et al. Prognostic value of inflammation-based scores in patients receiving radical resection for colorectal cancer. BMC Cancer. 2018;18(1):1102. 10.1186/s 12885-018-4842-3.
Li C, Zhang XY, Peng W, et al. Preoperative albumin-bilirubin grade plus platelet-to-lymphocyte ratio predict the outcomes of patients with BCLC stage a hepatocellular carcinoma after liver resection. Med (Baltim). 2018;97(29):e11599. https://doi.org/10.1097/MD.0000000000011599.
Wei Y, Zhang X, Wang G, et al. The impacts of pretreatment circulating eosinophils and basophils on prognosis of stage I-III colorectal cancer. Asia Pac J Clin Oncol. 2018;14(5):e243–51. https://doi.org/10.1111/ajco.12871.
Liu C, Li L, Lu WS, et al. A novel combined systemic inflammation-based score can predict survival of intermediate-to-advanced hepatocellular carcinoma patients undergoing transarterial chemoembolization. BMC Cancer. 2018;18(1):216. https://doi.org/10.1186/s12885-018-4121-3.
Hao Y, Li X, Chen H, et al. A cumulative score based on preoperative neutrophil-lymphocyte ratio and fibrinogen in predicting overall survival of patients with glioblastoma multiforme. World Neurosurg. 2019;128:e427–33. https://doi.org/10.1016/j.wneu.2019.04.169.
Deng Y, Li W, Liu X, et al. The combination of platelet count and lymphocyte to monocyte ratio is a prognostic factor in patients with resected breast cancer. Med (Baltim). 2020;99(18):e18755. https://doi.org/10.1097/MD.0000000000018755.
Lim JU, Yeo CD, Kang HS, et al. Prognostic value of platelet count and lymphocyte to monocyte ratio combination in stage IV non-small cell lung cancer with malignant pleural effusion. PLoS ONE. 2018;13(7):e0200341. https://doi.org/10.1371/journal.pone.0200341.
Wang Q, Huang T, Ji J, et al. Prognostic utility of the combination of pretreatment monocyte-to-lymphocyte ratio and neutrophil-to-lymphocyte ratio in patients with NMIBC after transurethral resection. Biomark Med. 2019;13(18):1543–55. https://doi.org/10.2217/bmm-2019-0398.
Kong W, Yang M, Zhang J, et al. Prognostic value of inflammation-based indices in patients with resected hepatocellular carcinoma. BMC Cancer. 2021;21(1):469. https://doi.org/10.1186/s12885-021-08153-4.
Huang Z, Liu Y, Yang C, et al. Combined neutrophil/platelet/lymphocyte/differentiation score predicts chemosensitivity in advanced gastric cancer. BMC Cancer. 2018;18(1):515. https://doi.org/10.1186/s12885-018-4414-6.
Hirahara T, Arigami T, Yanagita S, et al. Combined neutrophil-lymphocyte ratio and platelet-lymphocyte ratio predicts chemotherapy response and prognosis in patients with advanced gastric cancer. BMC Cancer. 2019;19(1):672. https://doi.org/10.1186/s12885-019-5903-y.
Nader Marta G, Isaacsson Velho P, Bonadio RRC, et al. Prognostic value of systemic inflammatory biomarkers in patients with metastatic renal cell carcinoma. Pathol Oncol Res. 2020;26(4):2489–97. https://doi.org/10.1007/s12253-020-00840-0.
Nakayama M, Gosho M, Hirose Y, et al. Modified combination of platelet count and neutrophil “to” lymphocyte ratio as a prognostic factor in patients with advanced head and neck cancer. Head Neck. 2018;40(6):1138–46. https://doi.org/10.1002/hed.25085.
Qin L, Yang XL, Li C, Luo YL. Predictive value of platelet to lymphocyte ratio and prognostic nutritional index on prognosis of hepatocellular carcinoma after liver resection. Sichuan Da Xue Xue Bao Yi Xue Ban. 2018;49(4):645–8. (In Chinese).
Shen Q, Liu W, Quan H, et al. Prealbumin and lymphocyte-based prognostic score, a new tool for predicting long-term survival after curative resection of stage II/III gastric cancer. Br J Nutr. 2018;120(12):1359–69. https://doi.org/10.1017/S0007114518002854.
Guo M, Li W, Li B, et al. Prognostic value of delta inflammatory biomarker-based nomograms in patients with inoperable locally advanced NSCLC. Int Immunopharmacol. 2019;72:395–401. https://doi.org/10.1016/j.intimp.2019.04.032.
Acknowledgements
Thanks to Professor Bangrong Cao and Kaijiong Zhang from Sichuan Cancer Hospital and Kaifu Yang from University of Electronic Science and Technology of China for their kindly guidance.
Funding
Key Projects of Sichuan Natural Science Foundation (2022NSFSC0051); Clinical Scientist Program of Sichuan Cancer Hospital (YB2022003); Chengdu Technology Innovation R&D Project (2021YF0501659SN); Sichuan cadre health research project CGY2023-804; Sichuan Provincial Science and Technology Plan Project (2020YJ0446).
Author information
Authors and Affiliations
Contributions
The contributions of authors are as follows: Funding acquisition & Supervision: Weidong Wang; Writing - Original Draft: Liping Luo; Conceptualization: Liping Luo, Weidong Wang, Yongjie Li, Wenjun Jiang; Methodology & Software & Formal analysis: Yubo Tan, Shixuan Zhao, Liping Luo, Huaichao Luo; Resources & Investigation: Man Yang, Yurou Che, Kezhen Li, Jieke Liu.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no interests that would conflict with the present work.
Ethical approval and consent to participate
This study was approved by the Medical Ethics Committee of Sichuan Cancer Hospital (No. SCCHEC-02-2021-064) and was conducted in accordance with the principles outlined in the Declaration of Helsinki. As this is a retrospective study, which does not involve any intervention in the treatment of patients, nor increase the treatment cost of patients, and does not study any identifiable individual characteristics of patients, SCCHEC is authorized to waive the need for filling in the informed consent form.
Consent to publication
Not applicable.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
As there are numerous abbreviations for blood features, please refer to the supplementary table for the abbreviations of LOFs and Table 1 for the abbreviations of HOFs.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Luo, L., Tan, Y., Zhao, S. et al. The potential of high-order features of routine blood test in predicting the prognosis of non-small cell lung cancer. BMC Cancer 23, 496 (2023). https://doi.org/10.1186/s12885-023-10990-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12885-023-10990-4