
Abstract
The recent global focus on big data in medicine has been associated with the rise of artificial intelligence (AI) in diagnosis and decision-making following recent advances in computer technology. Up to now, AI has been applied to various aspects of medicine, including disease diagnosis, surveillance, treatment, predicting future risk, targeted interventions and understanding of the disease. There have been plenty of successful examples in medicine of using big data, such as radiology and pathology, ophthalmology cardiology and surgery. Combining medicine and AI has become a powerful tool to change health care, and even to change the nature of disease screening in clinical diagnosis. As all we know, clinical laboratories produce large amounts of testing data every day and the clinical laboratory data combined with AI may establish a new diagnosis and treatment has attracted wide attention. At present, a new concept of radiomics has been created for imaging data combined with AI, but a new definition of clinical laboratory data combined with AI has lacked so that many studies in this field cannot be accurately classified. Therefore, we propose a new concept of clinical laboratory omics (Clinlabomics) by combining clinical laboratory medicine and AI. Clinlabomics can use high-throughput methods to extract large amounts of feature data from blood, body fluids, secretions, excreta, and cast clinical laboratory test data. Then using the data statistics, machine learning, and other methods to read more undiscovered information. In this review, we have summarized the application of clinical laboratory data combined with AI in medical fields. Undeniable, the application of Clinlabomics is a method that can assist many fields of medicine but still requires further validation in a multi-center environment and laboratory.
Similar content being viewed by others


Introduction
The technology of “omics” (genomics, proteomics, transcriptomics, metabolomics, etc.) is an emerging practice. We can more accurately predict and understand disease risks and formulate treatments for more specific and homogeneous populations by using big data, technologies, and methods [1, 2] (Fig. 1A). Since the advent of high-throughput and ultra-high-throughput sequencing technologies, clinicians and molecular biologists share the concern of discovering individual differences in disease based on the individual genome and transcriptome, which enables better clinical management [3,4,5]. Due to the discovery of specific proteins associated with human disease, the field of protein chemistry and subsequent proteomics devote to the search for new or better disease markers and therapeutic targets [6, 7]. In addition to the development of fundamental omics, clinical omics are also improving. For example, the application of emerging radiomics supported personalized clinical decisions and individualized treatment choices. A high-throughput method was used to extract and analyze a large number of image features from radiographic images to develop diagnostic, predictive, or prognostic imaging models [8, 9].

A The technology of “omics” e.g. genomics, proteomics, transcriptomics, metabolomics radiomics etc. can be used for more accurate predicting and understanding disease risks and formulating treatments for more specific and homogeneous populations by machine learning and statistical approaches. B Differences in the data structure between the different omics
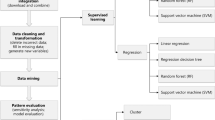
The clinical laboratory is the department that provides valuable test results and auxiliary clinical diagnosis by using visual observation, physical, biochemical, or molecular biological methods to examine specimens of patients, such as blood, urine, effusion, and tumor tissue [10]. Although current clinical laboratory testing indexes are less than the variables of transcriptomics, genomics, and even radiomics. The data dimension of Clinlabomics is lower than other omics. However, the clinical laboratory produces a large amount of data every day and many diseases currently need the assistance of the clinical laboratory test results. Besides, the clinical laboratory data also is quantitative. The clinical data collected by the clinical laboratory are larger and more intuitive than the imaging data (Fig. 1B). Therefore, we speculate that it is possible to develop clinical laboratory medicine omics models for promoting the development of all areas of medicine by integrating the test data information. By 2021, searches using "AI" and "Medicine" in PubMed would produce nearly 6,000 articles compared to 4,000 articles in 2020. We used search pattern: ("Artificial Intelligence"[Title/Abstract] OR "Artificial Intelligence"[MeSH Terms] OR "Machine Learning"[Title/Abstract] OR "Machine Learning"[MeSH Terms] OR "Data Mining"[Title/Abstract] OR "Data Mining"[MeSH Terms] OR "Deep Learning"[MeSH Terms] OR "Big Data"[MeSH Terms] OR "Big Data"[Title/Abstract] OR "Deep Learning"[Title/Abstract] OR "Data Science"[MeSH Terms] OR "Data Science"[Title/Abstract]) AND ("clinical laboratory"[Title/Abstract] OR "laboratories, clinical"[MeSH Terms] OR "clinical laboratories"[Title/Abstract] OR "laboratory medicine"[Title/Abstract] OR "Medical Laboratory Science"[MeSH Terms] OR "Clinical Laboratory Information Systems"[MeSH Terms] OR "laboratory science medical"[Title/Abstract] OR "clinical biochemistry"[Title/Abstract] OR "blood routine"[Title/Abstract] OR "urine routine"[Title/Abstract] OR "coagulation test"[Title/Abstract] OR "pretransfusion tests"[Title/Abstract] OR "clinical immunoassay"[Title/Abstract] OR "Blood Coagulation Tests"[MeSH Terms] OR "clinical microbiology"[Title/Abstract]) to retrieval relevant articles in PubMed from 2010 to 2022 and approximately got 445 papers. Through manual title and abstract review, we finally identify related articles of the clinical laboratory in combination with AI and some articles in references for review and the workflow see Fig. 2. We excluded some laboratory work that did not belong to the hospital clinical laboratory department combined with AI work, including pathology, iconography and other laboratories combined with AI work research.

The workflow for searching and filtering articles
Progress in clinical laboratory medicine
The development of laboratory technology has created conditions for the establishment of Clinlabomics (Fig. 3). In the past decade, clinical laboratory medicine has progressed in four distinct areas.

The development of the time has created conditions for the establishment of Clinlabomics. Mainly include the advantage of the development of clinical laboratory and the coming of the era of big data
Development of medical equipment
Before the 1980s, clinical laboratory equipment was relatively straightforward. And this situation led to the type of clinical laboratory test indexes being limited [11]. Whereas, with the continuous development and the progress of society and science, clinical laboratory medicine has reached an unprecedented prosperous stage from the era of manual medical tests to semi-automatic and full-automatic analysis. Now, clinical blood, biochemistry, and microbial testing in the clinical laboratory have been automated [12,13,14]. Automated equipment rapidly and efficiently increased the throughput of a laboratory and has enabled us to monitor and manage the raw data produced more effectively than before [11, 15]. In brief, the renewal of laboratory equipment increases the efficiency of clinical tests so that we can get more data from clinical laboratory testing.
Clinical laboratory standardization
For clinical laboratory test data, the quality of the data is as crucial as the quantity of data [16, 17]. In the past, most medical institutions carried out clinical laboratory tests by medical institutions themselves and there was no global quality assurance guideline. Until the international quality assurance of the ISO15189 standard was accepted. The ISO15189 is still the internationally accepted standard that has high credibility in quality management systems for all fields of laboratory medicine [18, 19]. The standardization of clinical laboratory test methods and the unified quality control standards make the clinical laboratory test results of different clinical laboratories more comparable [20]. A correct diagnosis and treatment decision is based on accurate clinical laboratory test results.
New clinical significance of traditional test items
The sensitivity and specificity of different clinical laboratory test indexes for diagnosing a particular disease are different, so each item has its default clinical significance. In addition to the further study of various diseases and a deeper understanding of the physiological and pathological changes caused by diseases, some conventional clinical laboratory items have been found to possess more undiscovered clinical significance. For example, platelets were widely known to play a key role in hemostasis and thrombosis disorders [21, 22]. But now, it is known that platelets also contribute to immune and inflammatory activities in health and disease, including cancer progression [23,24,25]. For many years, prealbumin has been used as a measure of body nutritional status [26]. Now, the prognostic role of prealbumin in some tumor patients is recognized. A Study proved that for early relapse lung cancer patients, perioperative serum prealbumin levels were significantly lower than those in non-recurrence lung cancer patients and the serum prealbumin level can be used as a biomarker to predict early recurrence of lung cancer [27]. Besides, serum prealbumin level has also been confirmed as an independent prognostic factor for the patients of postoperative esophageal squamous cell carcinoma [28], liver cancer[29], and gastric cancer [30]. Notably, the practical markers cannot be found in time during the global outbreak of Coronavirus (COVID-19) infection in 2020. Many researchers have had to shift their focus to routine blood tests in the hope of finding cheap and accessible tests [31,32,33]. Brandon et al. found that some hematologic, biochemical, and immunologic biomarkers have discriminative ability. These clinical laboratory test items include interleukins 6 (IL-6) and 10 (IL-10) and serum ferritin which all potential aid in predicting severe and fatal COVID-19 were identified [34]. Moreover, other clinical studies also have shown significant changes in blood parameters in patients with COVID-19. These clinical laboratory items, include lactate dehydrogenase (LDH), white blood cell (WBC), C reactive protein (CRP), aspartate transaminase (AST), and alanine transaminase (ALT), which can play a crucial role in COVID-19 diagnosis and prognosis [35].
Clinical significance of combined blood test items
Over the past several decades, the combinations of clinical laboratory test data also have gradually been applied to clinical diagnosis and treatment choices. Clinical evaluations of disease progression have even used combinations of test items as a score. For example, many studies found that the change of the ratio of AST/ALT is not only an item of hepatocyte injury but suitable for more diseases. Zhou et al. have shown that the high AST/ALT ratio can increase the pathogenetic risk of prostate cancer [36]. Besides, studies have reported a significant association between the pre-treatment AST/ALT ratio and survival in oropharyngeal squamous cell carcinoma patients [37], non-metastatic renal cancer patients [38], urothelial carcinoma [39], and metastatic renal cell carcinoma [40]. The combined neutrophil-to-lymphocyte ratio (NLR) also has been confirmed that is an adverse prognostic factor in many diseases at present, especially malignant tumors, including gastric cancer [41], and colorectal cancer [42], and non-small cell lung cancer [43, 44]. And the score of clinical evaluation of disease development composed of some routine test items is also widely used. The modified Glasgow prognostic score (mGPS) is an inflammation-based prognostic score that consists of CRP and albumin (ALB). The score is not only an independent prognostic factor in early esophageal cancer patients [45] but is considered an essential prognostic indicator in a study on prognostic factors in colon cancer [46]. The control nutritional status (CONUT) score consists of serum albumin, cholesterol, and total lymphocyte count. It is associated with the postoperative survival of patients undergoing hepatectomy [47] and gastric cancer resection [48], and can predict the survival of patients with hypertension over 80 years old [49]. It is not difficult to find that the combination of inexpensive, available and routine clinical test items seems to play an increasingly important role in clinical diagnosis and treatment.
Combining AI with clinical laboratory
AI is a field of computer science that is designed to mimic human thinking processes, learning abilities, and knowledge storage [50]. In the age of big data, AI technology can use sizeable clinical data sets to support clinical decisions, uncover occult disease subtypes, associations, and prognostic indicators, and generate new testable hypotheses. AI is gradually changing the way that doctors make clinical decisions and diagnoses. AI has now been applied to several aspects of medicine, from diagnostic applications in radiology and pathology [51, 52] and the classification of various eye diseases in ophthalmology [53] to more therapeutic and interventional applications in cardiology and surgery [54, 55].
Machine learning (ML), is a significant branch of AI, and one of its advantages is learning from data [56, 57]. ML and deep learning (DL) techniques can handle large, complex, nonlinear, and multidimensional data better than conventional statistical methods [58, 59]. The development of clinical laboratory automation and the unification of data standardization have gradually transformed the clinical laboratory department into a large and credible clinical database in medicine. In addition, in the clinical laboratory department and the potential diagnostic value of clinical testing data and the value of the joint diagnosis of clinical testing items are gradually explored [60]. Therefore, the multifaceted development of clinical laboratories and the development of AI provide the conditions for their combination in the era of big data [61].
From routine blood or body fluid test data, Clinlabomics extracts, analyzes, screens, and identifies certain reproducible and prominent clinical laboratory test indexes for patients with clinically relevant diseases. A relationship is then analyzed between the selected characteristic test items and the diagnosis and treatment results. Through in-depth ML of a large amount of data and the establishment of predictive models for related diseases, the aim is to provide accurate disease diagnosis, risk stratification, and prognosis (Fig. 4). Analysis of clinical laboratory test data can provide additional information not currently available. Furthermore, Clinlabomics can evaluate the added value of routine laboratory test items to common predictors of related diseases. The use of Clinlabomics can reduce unnecessary expenses and the time for diagnosing and treating clinical diseases. However, with a lack of such definitions as transcriptomics, metabolomics, radiomics, and other complete keywords, many research projects cannot be classified very well, which does not support the development of the field. We propose a concept of Clinlabomics to summarize some of these studies for diagnosing, treating, and predicting diseases by using clinical laboratory data along with AI.

The Clinlabomics workflow. Collecting blood or body fluid sample and testing. From this clinical laboratory data to extract the features e.g. features based on range of clinical test data from healthy or patient with various diseases. These features are used for analysis, e.g. the features are assessed for their diagnostic prognostic power or linked with stage. Ultimately, it could lead to precision medicine and personalized medicine
At present, using clinical laboratory testing data combined with AI to perform disease diagnosis, prediction, monitoring, and prognosis research is booming [62, 63]. In the following sections, we summarized some relevant studies obtained using Clinlabomics (Table 1).
The application of clinlabomics
Clinlabomics and clinical prediction
The prediction of biological aging has been widely concerned. However, there are currently no informative tests to assess the impact of smoking on biological aging rates. Researchers collected data from 149,000 fully anonymized individual records. They trained a set of supervised feed-forward deep neural networks (DNNs) on the non-smokers to predict their chronological age. Then, they included smoking status as one of the input features and performed a feature importance analysis. Eventually they trained a set of supervised feed-forward deep neural networks to predict the smoking status of patients using only their sex and blood feature, including 66 kinds of blood biochemistry items and cell count markers. The model demonstrated that smoking accelerates human aging, and that smoking status could also be predicted from blood biochemical and cell count results. Although this blood aging clock model proved to be less accurate than predictors based on DNA methylation, it is cheaper and more practical, and only involves standard blood tests [64]. Additionally, Putin designed a modular ensemble of 21 DNNs of varying depth, structure and optimization to predict human chronological age using a basic blood test and used over 60,000 samples from common blood biochemistry and cell count tests from routine health exams to train DNNs. The best performing DNNs achieved an accuracy of 81.5% when testing human chronological age. Moreover, they found that albumin, glucose, alkaline phosphatase, urea, and red blood cells were five of the most important markers of predicting chronological age [65].
Clinlabomics also can predict many diseases, including cancer [66,67,68,69]. As everyone knows, diabetes is a global epidemic, chronic and incurable and long-term exposure to hyperglycemia can cause chronic damage to various tissues [70]. Early prediction can drastically reduce the risk of diabetes occurrence. Yang collected 1,507,563 physical examination data from healthy individuals and diabetes patients, as well as 387,076 physical examination data from the follow-up records. They fused three types of physical examination data: laboratory values (fasting blood glucose (FBG), high-density lipoprotein (HDL), low-density lipoprotein (LDL), serum creatinine (SC), triglyceride (TG), total cholesterol (TC), blood urea nitrogen (BUN), urine glucose (UGLU)) demographics, and vital signs in their computational model. They used mutual information, analysis of variance and Gini impurity to rank the features, and then, the incremental feature selection strategy was combined with XGBoost. Finally, they created a diabetes risk assessment model with high accuracy in detecting diabetes (AUC = 0.8763)[71]. This study result showed that the application of Clinlabomics could help the high-risk group take medicine or change lifestyle timely and reasonably so they can effectively reduce the risk of diabetes and prevent diabetes effectively. Besides, Chen developed a method based on a support vector machine combined with the blood routine indexes feature selection technique to accurately predict toxic paraquat (PQ) poisoning risk status. The results showed that there are significant differences in blood routine indexes between dead and living PQ-poisoned individuals (p value < 0.01) and the most important correlated indexes are WBCs and neutrophils [72]. Therefore, the toxicity or prognosis of PQ poisoning can be preliminarily predicted by blood routine testing. Finally, a simple decision tree model was constructed by applying the Minimum Redundancy-Maximum Relevance feature selection method to the 235 patients' data (89 benign ovarian tumors and 146 ovarian cancer samples). The results demonstrated that the decision tree model had strong predictive power for distinguishing ovarian cancer from benign ovarian tumors, and human epididymis protein 4 (HE4) and carcinoembryonic antigen (CEA) were valuable markers for ovarian cancer prediction [73]. Clinlabomics has good potential for providing predictive models for complex diseases, using the cheaper and more practical standard blood tests to support some clinical predictions.
Clinlabomics and clinical diseases diagnosis
Clinlabomics not only plays a great role in clinical prediction, but also plays a significant role in clinical diagnosis. Recently, the research on the application of Clinlabomics in the diagnosis of clinical diseases has gradually increased. Muhsen summarized the application of ML in the field of hematology diagnosis, including Clinlabomics [74]. Azarkhish developed an artificial neural network (ANN) and an adaptive neuro-fuzzy inference system (ANFIS) to diagnose iron deficiency anemia (IDA) and to predict serum iron levels based on four accessible laboratory data (Mean corpuscular volume (MCV), Mean corpuscular hemoglobin (MCH), Mean corpuscular hemoglobin concentration (MCHC), Hemoglobin /red-blood-cell (Hb/RBC)) [75]. The ANN was the best model for diagnosing IDA with an accuracy of 97% for patients with IDA and 96% for patients without it.
Zhan used 14 routine blood test data (basophil count, eosinophil count, lymphocyte ratio, lymphocyte count, mean corpuscular hemoglobin, mean corpuscular hemoglobin concentration, monocyte ratio, monocyte count, mean platelet volume, platelet distribution width, platelet count, red blood cell count, red blood cell distribution width, and white blood cell count) from healthy individuals to construct a Mahalanobis space (MS). To ensure the efficiency of MS, they calculated Mahalanobis distances of blood data from 355 asthma patients and 1480 healthy individuals. Orthogonal arrays and signal-to-noise ratios were used to optimize blood biomarker variables the receiver operating characteristic (ROC) curve was used to determine the threshold value. Ultimately Mahalanobis-Taguchi system (MTS) correctly classified 94.15% of patients. In addition, 97.20% of healthy individuals were correctly classified [76]. Due to there being no gold standard for asthma diagnosis currently, we can see that the use of Clinlabomics offers the potential to simplify diagnostic complexity and optimize clinical efficiency.
Chronic kidney disease (CKD) severity can be assessed using urine protein concentration, but it can be inconvenient to collect 24-h urine for follow-up. 9 models were developed and compared using 13 routine blood test indexes and five demographic characteristics. These models as non-uretic clinical variables combine statistical, machine learning, and neural network methods to predict urinary protein progression in patients with chronic kidney disease. Their results showed that linear models including Elastic Net, lasso regression, ridge regression and logistic regression have overall predictive power, with an average AUC and precision above 0.87 and 0.8, respectively. Among them, LR obtained the highest AUC value of 0.873 [77].
Clinlabomics is also extremely important for detecting COVID-19 [78]. Based on hematochemical values from routine blood tests, Brinati developed two machine-learning classification models whose accuracy ranges between 82 and 86%, and sensitivity ranges between 92 and 95% [79]. Besides, Domínguez-Olmedo also developed a model to predict the mortality of patients with COVID-19, which can assess mortality from laboratory values with a high degree of accuracy [80].
In addition, Clinlabomics also plays a vital role in the diagnosis of some cancers. Simon used the routine blood tests from 15,176 neurological patients via the smart blood analytics (SBA) ML algorithm to build a machine learning predictive model for brain tumor diagnosis. Moreover, they validated the model by retrospective analysis of 68 consecutive brain tumors and 215 control patients presenting to the neurological emergency service. The sensitivity and specificity of the adapted tumor model in the validation group were 96% and 74%, respectively [81]. That result demonstrated the feasibility of brain tumor diagnosis by routine blood tests combined with machine learning. At the same time, it proved that the application of Clinlabomics can compensate for the low accuracy and expensive disadvantage of computed tomography (CT) imaging in the diagnosis of brain tumors. Similarly, Wu used a random forest machine-learning algorithm to build an identification model between routine blood indexes and lung cancer. A correlation between 19 regular blood indexes and lung cancer patients was found, and lung cancer patients could be identified from other patients, especially those with tuberculosis (which has similar symptoms to lung cancer), with a sensitivity of 96.3%, specificity of 94.97%, and accuracy of 95.7% for the cross-validation results, respectively [82]. Li also used laboratory data, including liver enzymes, lipid profiles, complete blood counts, and tumor biomarkers to develop five machine learning models to identify colorectal cancer (CRC). The results showed that the logistic regression model achieved the highest performance in identifying CRC (AUC: 0.865, sensitivity: 89.5%, specificity: 83.5%, PPV: 84.4%, NPV: 88.9%) [83]. Studies of Clinlabomics in diagnosing disease have increased, both in general and severe diseases, and have achieved remarkable diagnostic results. In addition to facilitating more convenient and accurate diagnostic methods, it also decreases the cost of diagnosing related diseases. In the age of big data, we can see that Clinlabomics is becoming more and more important for precision medicine. The routine blood test results contained much more information than is usually recognized even by the most experienced clinicians.
Clinlabomics and clinical laboratory management
Clinlabomics also correctly conducts laboratory management to some extent, including laboratories formulate reference ranges, clinical laboratory quality control, and automated interpretation of laboratory testing results. Clinlabomics has the potential to improve laboratory efficiency and quality in a setting of limited staff resources [84]. One concerning the type of preanalytic error in laboratory medicine is the wrong blood in the tube (WBIT) error because blood specimens collected from one patient occasionally get mislabeled with identifiers from another patient. Continuous monitoring of specimen acceptability, collection and transport can result in the prompt identification and correction of problems, leading to improved patient care and a reduction in unnecessary redraws and delays in reporting results [85,86,87,88]. Rosenbaum simulated WBIT errors within sets of routine inpatient chemistry test results to develop, train, and evaluate five machines learning based WBIT detection algorithms. The results showed a best-performing WBIT detection algorithm based on a support vector machine to identify WBIT errors before test reporting. This algorithm achieved an area under the curve of 0.97 and considerably outperformed traditional single-analyte delta checks [85]. For evaluating the performance of identifying mislabeled samples, Farrell developed eight different machine learning models using different algorithms: artificial neural networks, extreme gradient boosting, support vector machines, random forests, logistic regression, k-nearest neighbors, and two decision trees (one complex and one simple). Moreover, it was compared with the ability to manually identification of mislabeled samples. The best performing machine learning model, the artificial neural network (92.1% accuracy), outdistanced human performance for identifying mislabeled samples(77.8% accuracy) [86]. Serum quality is also a key consideration in the pre-analytical phase of a laboratory analysis [89]. Fang retrospectively retrieved the coagulation test results (Activated partial thromboplastin time (APTT), Prothrombin time (PT), Thrombin time (TT), Fibrinogen (Fbg), and D-dimer) of 192 clot samples and 2889 clot-free test (NCD) samples to form a training and test dataset. Standard and momentum back-propagation neural networks (BPNNs) were trained and validated using training datasets and five-fold cross-validation methods to verify the feasibility of identifying clot specimens through machine learning. Surprisingly, the result confirmed that the standard and momentum BPNNs could identify the sample status (clotted and NCD) with areas under the ROC curves of 0.966 (95% CI 0.958–0.974) and 0.971 (95% CI 0.9641–0.9784), respectively [90].
Auto verification and auto-explanation systems might have greatly improved laboratory efficiency. Wilkes retrospectively collected 4619 urine steroid profile data to train and test various ML classifiers’ abilities to differentiate profiles. The results showed the best performing binary classifier could predict the interpretation of profiles with a mean area under the ROC curve of 0.955 (95% CI 0.949–0.961). In addition, the best performing multiclass classifier could predict the individual abnormal profile interpretation with a mean balanced accuracy of 0.873 (0.86–0.880) [91]. This provided a proof-of-concept application of ML algorithms to complex clinical laboratory data. Salama developed deep neural networks (DNN) to improve the efficiency of clinical laboratories in detecting minimal residual disease (MRD) in chronic lymphocytic leukemia (CLL) by flow cytometric immunophenotyping. The result showed that there was an excellent correlation between their DNN and expert analysis when CLL cells were reported as a percentage of total white blood cells. In addition, gating time was dramatically reduced to 12 s/case by DNN from 15 min/case by the manual process. The proposed DNN demonstrated high accuracy in CLL MRD detection and significantly improved workflow efficiency [92].
In addition, reference intervals are critical for the interpretation of laboratory results and Clinlabomics also can help to establish the reference interval [93, 94]. Ma validated five data mining algorithms using thyroid-related hormones test data from clinical laboratories to establish reference intervals of thyroid hormones for older adults. The results showed that the transformed Hoffmann, transformed Bhattacahrya, Kosmic, and refineR algorithms were the more suitable algorithms to establish reference intervals for thyroid-related hormones in older adults and an Expectation maximization (EM) algorithm combined with Box-Cox transformation was recommended for data with obvious skewness [95]. Poole developed LIMIT, an unsupervised learning method to extract reference intervals from the electronic medical record. Results showed that LIMIT produces usable reference intervals for sodium, potassium and hemoglobin laboratory results. From the above research, we conclude that Clinlabomics represents a fast and inexpensive solution for calculating reference intervals, and showed that it is possible to establish reference intervals by using laboratory results and AI [96].
The urine samples from patients suspected of urinary tract infection (UTI) generate the highest workload in routine clinical microbiology diagnostic laboratories [97]. However, the actual situation was that many urine samples produce negative culture results. There were no significant bacterial isolates or mixed culture results indicating sample contamination [98]. The reduction in the number of suspect samples that must be cultured will allow diagnostic services to focus on actual microbial infections, which will reduce the workload in the laboratory. Burton retrospectively analyzed a total of 212,554 urine microscopy, culture, and sensitivity urine reports. He compared the two classification methods: a heuristic model using a combination of white blood cell count and bacterial count and a machine learning approach testing three algorithms (Random Forest (RF), Neural Network (NN), and Extreme Gradient Boosting (XGboost)). The clinical laboratory items included in the machine learning approach include urine items of microscopic analysis, and biochemical dip-stick testing such as NIT, WBCUF, EC, and haematuria. Based on their initial findings, the machine learning algorithms outperformed the heuristic model in terms of relative workload reduction at a classification sensitivity above 95%. Using this method has a potential decrease of about 41% in the cultivation workload. XGboost achieved the highest AUC of 0.910among the three machine learning approaches [99].
From the above research, we concluded that Clinlabomics can help with clinical laboratory management and improve the efficiency of clinical diagnosis. Besides, Clinlabomics also may improve service efficiency when demand exceeds the resources of public health service providers.
The challenge and opportunity of clinlabomics
The 2016 World Economic Forum listed the open AI ecosystem as one of the top 10 most important emerging technologies [100]. Since 2017, China, the United States, and the European Union have successively issued national-level artificial intelligence (AI) strategic development plans, in the field of clinical laboratory testing, the explosive growth of AI theories and technologies also provides a new direction for the development of medical testing theory, methods and applications [101,102,103,104].
By reviewing some recent studies of ML applications in the field of clinical laboratory medicine. It was not difficult to find that Clinlabomics in the clinical laboratory can conduct more rapid and efficient analytical processing of complex detection data. Not only that, Clinlabomics can correctly conduct laboratory management to some extent, which can play an important role in the future development and construction of laboratory medicine. Besides, Clinlabomics will certainly go further beyond its current boundaries in the field of clinical laboratory medicine. Just as during the global period of COVID-19 spread, Clinlabomics can further expand the scope of disease diagnostic tools, which is particularly promising to make up for the lack of skilled laboratory staff and adequate testing instruments in developing countries [32, 35, 79, 80, 105].
It is undeniable that the development of artificial intelligence has brought opportunities to the development of Clinlabomics but there are still a series of challenges and problems in the development process of Clinlabomics [106, 107].
On the one hand, although the current Clinlabomics to improve the efficiency of clinical laboratory testing and supplementary diagnosis of clinical diseases has great potential [108], a lot of clinical laboratory technicians for big data age and AI combined with clinical laboratory test data understanding is not deep [109]. In addition, the replacement of human labor with technological development has caused panic in the whole society, and clinical laboratory personnel also have the same concern [14, 109]. The clinical laboratory staff has not willing to further study and develop Clinlabomics resulting laboratory’s lack of bioinformatics professional knowledge, leading to this field is limited and the development slow. On the other hand, ML models rely on the type and quality of the data used for training, and often tend to perform better on data from the same cohort than on the new data. Different regions, different people, and even different hospitals' laboratory equipment, and methods may result in instability in Clinlabomics-related diagnosis models. The development of Clinlabomics requires the standardization of testing methods and data for each region, each country, each species, and each laboratory. Biological variation data and external validation is a necessary practice in Clinlabomics evaluation [110,111,112,113]. Besides, laboratory medicine, like other areas of medicine, is obliged to adhere to high ethical standards [114,115,116,117]. Informed consent is essential to maintaining patient autonomy [118]. However, it is sometimes difficult to balance patient autonomy with the idea of contributing to the development of medicine [119]. The use of remaining or stored samples is essential for research and the development of Clinlabomics, but it creates problems with consent. There is no doubt that this is a huge project for the current situation.
Discussion and conclusion
In general, routine clinical laboratory test results usually contain more information than is usually recognized. Even the most expert clinicians are challenged to extract all the information contained in routine clinical laboratory tests [60, 63]. According to the relevant representative research reports in this review, it is not difficult to see that combining AI and clinical laboratory data has been applied, including disease prediction, diagnosis, and monitoring of disease status. Besides, it also is very conducive to laboratory management. Therefore, our proposed Clinlabomics is a new concept aimed at collecting valuable information obtained from routine laboratory tests. Although the research of combining AI and clinical laboratory data is still in its infancy, most studies focus on details information on routine testing items in the blood. From some research we summarized, combining blood-related testing items data and AI have achieved some results in the diagnosis, monitoring, and prognosis evaluation of clinical diseases and their conclusions. Many authors presented opportunities related to combining clinical laboratory data and AI methods, and some also made their algorithms available. However, extensive data clinical trials are still lacking to verify and the establishment of standardization. On the other hand, there are few studies combining AI with body fluid-related detection items (such as urine, and cerebrospinal fluid) in the clinical laboratory. In the future, we can carry out disease diagnosis and treatment-related research on body fluid-related detection items through the deep learning method. In addition, there are many studies combining AI and other medical fields, especially imaging and pathology. Therefore, using patient clinical information and laboratory data, combining data from other diagnostic facilities (such as pathology and radiology) and pharmacies) has the potential to further improve the accuracy and reliability of the diagnostic model.
As seen in the previous section, many studies use different models for comparison, the best model or algorithm used in combining AI and clinical laboratory data is different whether in disease prediction and diagnosis or laboratory management. Clinical laboratory data must be analyzed with appropriate models and algorithms to solve different problems. Logistic regression (LR) is one of the traditional models, its clarity, simplicity and great interpretability of the model are the reasons why LR was frequently chosen [63]. However, due to the simple form of the LR model (very similar to the linear model), it is difficult to fit the real distribution of data, so the accuracy is not high. Therefore, the LR model is currently widely used to predict the factors of disease pathogenesis [77, 83]. We can use the LR model to analyze and predict disease risk through clinical laboratory testing items. We also found that the Random Forest (RF) model was frequently used in studies we reviewed [73, 79, 82]. From a technical point of view, RF is an ensemble algorithm that relies on a collection of decision trees that are trained on mutually independent subsets of the original data to obtain a classifier with lower variance and/or lower bias [79]. This class of models also has generally high accuracy as well as interpretable output [63]. These are some reasons why RF is chosen. As a result of its merits, especially high accuracy, we think the RF model may be suitable for some applications related to disease diagnosis. A support vector machine (SVM) is a dichotomous model that is supported by strict mathematical theory and has strong explanatory power. It does not rely on statistical methods, thus simplifying the usual classification and regression problems. SVM has been applied to myriad classification tasks and has been demonstrated to be particularly effective for medical diagnosis [72]. Studies have reported that NN models (such as ANNs and DNNs) are widely used in control and optimization, prediction and management, pattern recognition and image processing [63, 65]. Since NN models extract features automatically, they require more training resources (time and data volume) than traditional ML models [64, 65, 86, 92]. For this reason, we think NN models may be more effective at integrating data from different laboratories to extract feature test items.
In this article, there are a few limitations. Due to the differences in keywords, some related articles may be overlooked since our search query only contains words commonly used in the area we intend to study. In addition, we conducted our search only using PubMed and focused on nearly 10 years of related research. Finally, we only compared the performance of commonly used models in the research we reviewed. We did not discuss some of the less commonly used models specifically.
In conclusion, we believe Clinlabomics, with its advantages of low cost, effectiveness, avoiding unnecessary treatment, and toxicity risk can provide a new way for personalized medicine in the future. The potential of Clinlabomics, which applies machine learning to laboratory data for diagnostic and prognostic purposes deserves more attention from clinicians-scientists who wish to take advantage of this new computer-based pathology and laboratory medical support. In the future, the establishment of relevant databases through standardized and standard clinical test data features in various medical institutions will provide us with high-quality medical help for accurate diagnosis and treatment, thus taking a concrete step towards the realization of precision medicine.
Availability of data and materials
Not applicable.
References
Monti C, Zilocchi M, Colugnat I, Alberio T. Proteomics turns functional. J Proteom. 2019;198:36–44.
Prodan Žitnik I, Černe D, Mancini I, Simi L, Pazzagli M, Di Resta C, et al. Personalized laboratory medicine: a patient-centered future approach. Clin Chem Lab Med. 2018;56:1981–91.
Pareek CS, Smoczynski R, Tretyn A. Sequencing technologies and genome sequencing. J Appl Genet. 2011;52:413–35.
Olfson E, Cottrell CE, Davidson NO, Gurnett CA, Heusel JW, Stitziel NO, et al. Identification of medically actionable secondary findings in the 1000 genomes. PLoS ONE. 2015;10:e0135193.
Harel T, Lupski JR. Genomic disorders 20 years on-mechanisms for clinical manifestations. Clin Genet. 2018;93:439–49.
Cifani P, Kentsis A. Towards comprehensive and quantitative proteomics for diagnosis and therapy of human disease. Proteomics. 2017;17:155.
Zheng J, Haberland V, Baird D, Walker V, Haycock PC, Hurle MR, et al. Phenome-wide Mendelian randomization mapping the influence of the plasma proteome on complex diseases. Nat Genet. 2020;52:1122–31.
Kumar V, Gu Y, Basu S, Berglund A, Eschrich SA, Schabath MB, et al. Radiomics: the process and the challenges. Magn Reson Imaging. 2012;30:1234–48.
Lambin P, Rios-Velazquez E, Leijenaar R, Carvalho S, van Stiphout RGPM, Granton P, et al. Radiomics: extracting more information from medical images using advanced feature analysis. Eur J Cancer. 2012;48:441–6.
Bayot ML, Brannan GD, Naidoo P. Clinical laboratory. StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2022 [cited 2022 Jan 20]. http://www.ncbi.nlm.nih.gov/books/NBK535358/.
Park JY, Kricka LJ. One hundred years of clinical laboratory automation: 1967–2067. Clin Biochem. 2017;50:639–44.
Bailey AL, Ledeboer N, Burnham C-AD. Clinical microbiology is growing up: the total laboratory automation revolution. Clin Chem. 2019;65:634–43.
Naugler C, Church DL. Automation and artificial intelligence in the clinical laboratory. Crit Rev Clin Lab Sci. 2019;56:98–110.
Nakamine Y. Reflections on the activities of the past year. Public health nursing activities and evaluation. Hokenfu Zasshi. 1987;43:1061.
Thomson RB, McElvania E. Total laboratory automation: what is gained, what is lost, and who can afford it? Clin Lab Med. 2019;39:371–89.
Ma C, Wang X, Wu J, Cheng X, Xia L, Xue F, et al. Real-world big-data studies in laboratory medicine: current status, application, and future considerations. Clin Biochem. 2020;84:21–30.
Vesper HW, Myers GL, Miller WG. Current practices and challenges in the standardization and harmonization of clinical laboratory tests. Am J Clin Nutr. 2016;104(Suppl 3):907S-S912.
Thelen MHM, Vanstapel FJLA, Kroupis C, Vukasovic I, Boursier G, Barrett E, et al. Flexible scope for ISO 15189 accreditation: a guidance prepared by the European Federation of Clinical Chemistry and Laboratory Medicine (EFLM) Working Group Accreditation and ISO/CEN standards (WG-A/ISO). Clin Chem Lab Med. 2015;53:1173–80.
Huisman W. European medical laboratory accreditation. Present situation and steps to harmonisation. Clin Chem Lab Med. 2012;50:1147–52.
Schreier J, Feeney R, Keeling P. Diagnostics reform and harmonization of clinical laboratory testing. J Mol Diagn. 2019;21:737–45.
Koupenova M, Clancy L, Corkrey HA, Freedman JE. Circulating platelets as mediators of immunity, inflammation, and thrombosis. Circ Res. 2018;122:337–51.
Holinstat M. Normal platelet function. Cancer Metastasis Rev. 2017;36:195–8.
In’t Veld SGJG, Wurdinger T. Tumor-educated platelets. Blood. 2019;133:2359–64.
Zu R, Yu S, Yang G, Ge Y, Wang D, Zhang L, et al. Integration of platelet features in blood and platelet rich plasma for detection of lung cancer. Clin Chim Acta. 2020;509:43–51.
Best MG, Wesseling P, Wurdinger T. Tumor-educated platelets as a noninvasive biomarker source for cancer detection and progression monitoring. Cancer Res. 2018;78:3407–12.
Smith SH. Using albumin and prealbumin to assess nutritional status. Nursing. 2017;47:65–6.
Kawai H, Ota H. Low perioperative serum prealbumin predicts early recurrence after curative pulmonary resection for non-small-cell lung cancer. World J Surg. 2012;36:2853–7.
Wei J, Jin M, Shao Y, Ning Z, Huang J. High preoperative serum prealbumin predicts long-term survival in resected esophageal squamous cell cancer. Cancer Manag Res. 2019;11:7997–8003.
Qiao W, Leng F, Liu T, Wang X, Wang Y, Chen D, et al. Prognostic value of prealbumin in liver cancer: a systematic review and meta-analysis. Nutr Cancer. 2020;72:909–16.
Zu H, Wang H, Li C, Xue Y. Preoperative prealbumin levels on admission as an independent predictive factor in patients with gastric cancer. Medicine (Baltimore). 2020;99:e19196.
Tomo S, Karli S, Dharmalingam K, Yadav D, Sharma P. The clinical laboratory: a key player in diagnosis and management of COVID-19. EJIFCC. 2020;31:326–46.
Chen Z, Xu W, Ma W, Shi X, Li S, Hao M, et al. Clinical laboratory evaluation of COVID-19. Clin Chim Acta. 2021;519:172–82.
Hong KH, Lee SW, Kim TS, Huh HJ, Lee J, Kim SY, et al. Guidelines for laboratory diagnosis of coronavirus disease 2019 (COVID-19) in Korea. Ann Lab Med. 2020;40:351–60.
Henry BM, de Oliveira MHS, Benoit S, Plebani M, Lippi G. Hematologic, biochemical and immune biomarker abnormalities associated with severe illness and mortality in coronavirus disease 2019 (COVID-19): a meta-analysis. Clin Chem Lab Med. 2020;58:1021–8.
Goudouris ES. Laboratory diagnosis of COVID-19. J Pediatr (Rio J). 2021;97:7–12.
Zhou J, He Z, Ma S, Liu R. AST/ALT ratio as a significant predictor of the incidence risk of prostate cancer. Cancer Med. 2020;9:5672–7.
Knittelfelder O, Delago D, Jakse G, Reinisch S, Partl R, Stranzl-Lawatsch H, et al. The AST/ALT (De Ritis) ratio predicts survival in patients with oral and oropharyngeal cancer. Diagnostics (Basel). 2020;10:E973.
Bezan A, Mrsic E, Krieger D, Stojakovic T, Pummer K, Zigeuner R, et al. The preoperative AST/ALT (De Ritis) ratio represents a poor prognostic factor in a cohort of patients with nonmetastatic renal cell carcinoma. J Urol. 2015;194:30–5.
Hu X, Yang W-X, Wang Y, Shao Y-X, Xiong S-C, Li X. The prognostic value of De Ritis (AST/ALT) ratio in patients after surgery for urothelial carcinoma: a systematic review and meta-analysis. Cancer Cell Int. 2020;20:39.
Ishihara H, Kondo T, Yoshida K, Omae K, Takagi T, Iizuka J, et al. Evaluation of preoperative aspartate transaminase/alanine transaminase ratio as an independent predictive biomarker in patients with metastatic renal cell carcinoma undergoing cytoreductive nephrectomy: a propensity score matching study. Clin Genitourin Cancer. 2017;15:598–604.
Sahin AG, Aydin C, Unver M, Pehlivanoglu K. Predictive value of preoperative neutrophil lymphocyte ratio in determining the stage of gastric tumor. Med Sci Monit. 2017;23:1973–9.
Haram A, Boland MR, Kelly ME, Bolger JC, Waldron RM, Kerin MJ. The prognostic value of neutrophil-to-lymphocyte ratio in colorectal cancer: a systematic review. J Surg Oncol. 2017;115:470–9.
Diem S, Schmid S, Krapf M, Flatz L, Born D, Jochum W, et al. Neutrophil-to-Lymphocyte ratio (NLR) and Platelet-to-Lymphocyte ratio (PLR) as prognostic markers in patients with non-small cell lung cancer (NSCLC) treated with nivolumab. Lung Cancer. 2017;111:176–81.
Russo A, Russano M, Franchina T, Migliorino MR, Aprile G, Mansueto G, et al. Neutrophil-to-lymphocyte ratio (NLR), platelet-to-lymphocyte ratio (PLR), and outcomes with nivolumab in pretreated non-small cell lung cancer (NSCLC): a large retrospective multicenter study. Adv Ther. 2020;37:1145–55.
Sakai M, Sohda M, Saito H, Ubukata Y, Nakazawa N, Kuriyama K, et al. Comparative analysis of immunoinflammatory and nutritional measures in surgically resected esophageal cancer: a single-center retrospective study. In Vivo. 2020;34:881–7.
Rossi S, Basso M, Strippoli A, Schinzari G, D’Argento E, Larocca M, et al. Are markers of systemic inflammation good prognostic indicators in colorectal cancer? Clin Colorectal Cancer. 2017;16:264–74.
Takagi K, Yagi T, Umeda Y, Shinoura S, Yoshida R, Nobuoka D, et al. Preoperative controlling nutritional status (CONUT) score for assessment of prognosis following hepatectomy for hepatocellular carcinoma. World J Surg. 2017;41:2353–60.
Kuroda D, Sawayama H, Kurashige J, Iwatsuki M, Eto T, Tokunaga R, et al. Controlling Nutritional Status (CONUT) score is a prognostic marker for gastric cancer patients after curative resection. Gastric Cancer. 2018;21:204–12.
Sun X, Luo L, Zhao X, Ye P. Controlling Nutritional Status (CONUT) score as a predictor of all-cause mortality in elderly hypertensive patients: a prospective follow-up study. BMJ Open. 2017;7:e015649.
Holmes JH, Sacchi L, Bellazzi R, Peek N. Artificial intelligence in medicine AIME 2015. Artif Intell Med. 2017;81:1–2.
Hosny A, Parmar C, Quackenbush J, Schwartz LH, Aerts HJWL. Artificial intelligence in radiology. Nat Rev Cancer. 2018;18:500–10.
Salto-Tellez M, Maxwell P, Hamilton P. Artificial intelligence-the third revolution in pathology. Histopathology. 2019;74:372–6.
Ting DSW, Pasquale LR, Peng L, Campbell JP, Lee AY, Raman R, et al. Artificial intelligence and deep learning in ophthalmology. Br J Ophthalmol. 2019;103:167–75.
Johnson KW, Torres Soto J, Glicksberg BS, Shameer K, Miotto R, Ali M, et al. Artificial intelligence in cardiology. J Am Coll Cardiol. 2018;71:2668–79.
Hashimoto DA, Rosman G, Rus D, Meireles OR. Artificial intelligence in surgery: promises and perils. Ann Surg. 2018;268:70–6.
Lippi G. Machine learning in laboratory diagnostics: valuable resources or a big hoax? Diagnosis (Berl). 2019;8:133–5.
De Bruyne S, Speeckaert MM, Van Biesen W, Delanghe JR. Recent evolutions of machine learning applications in clinical laboratory medicine. Crit Rev Clin Lab Sci. 2021;58:131–52.
Deo RC. Machine learning in medicine. Circulation. 2015;132:1920–30.
Jiang T, Gradus JL, Rosellini AJ. Supervised machine learning: a brief primer. Behav Ther. 2020;51:675–87.
Ialongo C, Bernardini S. Total laboratory automation has the potential to be the field of application of artificial intelligence: the cyber-physical system and “Automation 4.0.” Clin Chem Lab Med. 2019;57:e279–81.
Cabitza F, Banfi G. Machine learning in laboratory medicine: waiting for the flood? Clin Chem Lab Med. 2018;56:516–24.
Rabbani N, Kim GYE, Suarez CJ, Chen JH. Applications of machine learning in routine laboratory medicine: Current state and future directions. Clin Biochem. 2022;103:1–7.
Ronzio L, Cabitza F, Barbaro A, Banfi G. Has the flood entered the basement? A systematic literature review about machine learning in laboratory medicine. Diagnostics. 2021;11:372.
Mamoshina P, Kochetov K, Cortese F, Kovalchuk A, Aliper A, Putin E, et al. Blood biochemistry analysis to detect smoking status and quantify accelerated aging in smokers. Sci Rep. 2019;9:142.
Putin E, Mamoshina P, Aliper A, Korzinkin M, Moskalev A, Kolosov A, et al. Deep biomarkers of human aging: application of deep neural networks to biomarker development. Aging (Albany NY). 2016;8:1021–33.
Tsai I-J, Shen W-C, Lee C-L, Wang H-D, Lin C-Y. Machine learning in prediction of bladder cancer on clinical laboratory data. Diagnostics (Basel). 2022;12:203.
Cao Y, Hu Z-D, Liu X-F, Deng A-M, Hu C-J. An MLP classifier for prediction of HBV-induced liver cirrhosis using routinely available clinical parameters. Dis Markers. 2013;35:653–60.
Qu Y, Deng X, Lin S, Han F, Chang HH, Ou Y, et al. Using innovative machine learning methods to screen and identify predictors of congenital heart diseases. Front Cardiovasc Med. 2021;8:797002.
Kurstjens S, de Bel T, van der Horst A, Kusters R, Krabbe J, van Balveren J. Automated prediction of low ferritin concentrations using a machine learning algorithm. Clin Chem Lab Med. 2022. https://doi.org/10.1515/cclm-2021-1194.
American Diabetes Association. Diagnosis and classification of diabetes mellitus. Diabetes Care. 2013;36(Suppl 1):S67-74.
Yang H, Luo Y, Ren X, Wu M, He X, Peng B, et al. Risk prediction of diabetes: big data mining with fusion of multifarious physical examination indicators. Inf Fusion. 2021;75:140–9.
Chen H, Hu L, Li H, Hong G, Zhang T, Ma J, et al. An Effective machine learning approach for prognosis of paraquat poisoning patients using blood routine indexes. Basic Clin Pharmacol Toxicol. 2017;120:86–96.
Lu M, Fan Z, Xu B, Chen L, Zheng X, Li J, et al. Using machine learning to predict ovarian cancer. Int J Med Inform. 2020;141:104195.
Muhsen IN, Shyr D, Sung AD, Hashmi SK. Machine learning applications in the diagnosis of benign and malignant hematological diseases. CHI. 2020;3:13.
Azarkhish I, Raoufy MR, Gharibzadeh S. Artificial intelligence models for predicting iron deficiency anemia and iron serum level based on accessible laboratory data. J Med Syst. 2012;36:2057–61.
Zhan J, Chen W, Cheng L, Wang Q, Han F, Cui Y. Diagnosis of asthma based on routine blood biomarkers using machine learning. Comput Intell Neurosci. 2020;2020:8841002.
Xiao J, Ding R, Xu X, Guan H, Feng X, Sun T, et al. Comparison and development of machine learning tools in the prediction of chronic kidney disease progression. J Transl Med. 2019;17:119.
Carobene A, Milella F, Famiglini L, Cabitza F. How is test laboratory data used and characterised by machine learning models? A systematic review of diagnostic and prognostic models developed for COVID-19 patients using only laboratory data. Clin Chem Lab Med. 2022. https://doi.org/10.1515/cclm-2022-0182.
Brinati D, Campagner A, Ferrari D, Locatelli M, Banfi G, Cabitza F. Detection of COVID-19 infection from routine blood exams with machine learning: a feasibility study. J Med Syst. 2020;44:135.
Domínguez-Olmedo JL, Gragera-Martínez Á, Mata J, Pachón ÁV. Machine learning applied to clinical laboratory data in Spain for COVID-19 outcome prediction: model development and validation. J Med Internet Res. 2021;23:e26211.
Podnar S, Kukar M, Gunčar G, Notar M, Gošnjak N, Notar M. Diagnosing brain tumours by routine blood tests using machine learning. Sci Rep. 2019;9:14481.
Wu J, Zan X, Gao L, Zhao J, Fan J, Shi H, et al. A machine learning method for identifying lung cancer based on routine blood indices: qualitative feasibility study. JMIR Med Inform. 2019;7:e13476.
Li H, Lin J, Xiao Y, Zheng W, Zhao L, Yang X, et al. Colorectal cancer detected by machine learning models using conventional laboratory test data. Technol Cancer Res Treat. 2021;20:153303382110583.
Ford BA, McElvania E. Machine learning takes laboratory automation to the next level. J Clin Microbiol. 2020;58:e00012-20.
Rosenbaum MW, Baron JM. Using machine learning-based multianalyte delta checks to detect wrong blood in tube errors. Am J Clin Pathol. 2018;150:555–66.
Farrell C-J. Identifying mislabelled samples: machine learning models exceed human performance. Ann Clin Biochem. 2021;58:650–2.
Tamimi W, Martin-Ballesteros J, Brearton S, Alenzi FQ, Hasanato R. Evaluation of biological specimen acceptability in a complex clinical laboratory before and after implementing automated grading serum indices. Br J Biomed Sci. 2012;69:103–7.
Farrell C-JL, Giannoutsos J. Machine learning models outperform manual result review for the identification of wrong blood in tube errors in complete blood count results. Int J Lab Hematol. 2022;44:497–503.
Yang C, Li D, Sun D, Zhang S, Zhang P, Xiong Y, et al. A deep learning-based system for assessment of serum quality using sample images. Clin Chim Acta. 2022;531:254–60.
Fang K, Dong Z, Chen X, Zhu J, Zhang B, You J, et al. Using machine learning to identify clotted specimens in coagulation testing. Clin Chem Lab Med. 2021;59:1289–97.
Wilkes EH, Rumsby G, Woodward GM. Using machine learning to aid the interpretation of urine steroid profiles. Clin Chem. 2018;64:1586–95.
Salama ME, Otteson GE, Camp JJ, Seheult JN, Jevremovic D, Holmes DR, et al. Artificial intelligence enhances diagnostic flow cytometry workflow in the detection of minimal residual disease of chronic lymphocytic leukemia. Cancers. 2022;14:2537.
Katayev A, Fleming JK, Luo D, Fisher AH, Sharp TM. Reference intervals data mining: no longer a probability paper method. Am J Clin Pathol. 2015;143:134–42.
Yang D, Su Z, Zhao M. Big data and reference intervals. Clin Chim Acta. 2022;527:23–32.
Ma C, Zou Y, Hou L, Yin Y, Zhao F, Hu Y, et al. Validation and comparison of five data mining algorithms using big data from clinical laboratories to establish reference intervals of thyroid hormones for older adults. Clin Biochem. 2022;S0009–9120(22):00137.
Poole S, Schroeder LF, Shah N. An unsupervised learning method to identify reference intervals from a clinical database. J Biomed Inform. 2016;59:276–84.
LaRocco MT, Franek J, Leibach EK, Weissfeld AS, Kraft CS, Sautter RL, et al. Effectiveness of preanalytic practices on contamination and diagnostic accuracy of urine cultures: a laboratory medicine best practices systematic review and meta-analysis. Clin Microbiol Rev. 2016;29:105–47.
Íñigo M, Coello A, Fernández-Rivas G, Carrasco M, Marcó C, Fernández A, et al. Evaluation of the SediMax automated microscopy sediment analyzer and the Sysmex UF-1000i flow cytometer as screening tools to rule out negative urinary tract infections. Clin Chim Acta. 2016;456:31–5.
Burton RJ, Albur M, Eberl M, Cuff SM. Using artificial intelligence to reduce diagnostic workload without compromising detection of urinary tract infections. BMC Med Inform Decis Mak. 2019;19:171.
Hamet P, Tremblay J. Artificial intelligence in medicine. Metabolism. 2017;69:S36-40.
Vatansever S, Schlessinger A, Wacker D, Kaniskan HÜ, Jin J, Zhou M-M, et al. Artificial intelligence and machine learning-aided drug discovery in central nervous system diseases: State-of-the-arts and future directions. Med Res Rev. 2021;41:1427–73.
Zhou Q, Qi S, Xiao B, Li Q, Sun Z, Li L. Artificial intelligence empowers laboratory medicine in industry 4.0. Nan Fang Yi Ke Da Xue Xue Bao. 2020;40:287–96.
Salinas M, Flores E, Lopez-Garrigós M, Salinas CL. Artificial intelligence: a step forward in the clinical laboratory, a decision maker hub. Clin Biochem. 2022;S0009-9120(22)00134-5.
Greaves RF, Bernardini S, Ferrari M, Fortina P, Gouget B, Gruson D, et al. Key questions about the future of laboratory medicine in the next decade of the 21st century: a report from the IFCC-emerging technologies division. Clin Chim Acta. 2019;495:570–89.
Dai W, Ke P-F, Li Z-Z, Zhuang Q-Z, Huang W, Wang Y, et al. Establishing classifiers with clinical laboratory indicators to distinguish COVID-19 from community-acquired pneumonia: retrospective cohort study. J Med Internet Res. 2021;23:e23390.
Alaidarous MA. The emergence of new trends in clinical laboratory diagnosis. Saudi Med J. 2020;41:1175–80.
Herman DS, Rhoads DD, Schulz WL, Durant TJS. Artificial intelligence and mapping a new direction in laboratory medicine: a review. Clin Chem. 2021;67:1466–82.
Paranjape K, Schinkel M, Hammer RD, Schouten B, Nannan Panday RS, Elbers PWG, et al. The value of artificial intelligence in laboratory medicine. Am J Clin Pathol. 2021;155:823–31.
Ardon O, Schmidt RL. Clinical laboratory employees’ attitudes toward artificial intelligence. Lab Med. 2020;51:649–54.
Cabitza F, Campagner A, Soares F, García de Guadiana-Romualdo L, Challa F, Sulejmani A, et al. The importance of being external. Methodological insights for the external validation of machine learning models in medicine. Comput Methods Programs Biomed. 2021;208:106288.
Carobene A, Aarsand AK, Bartlett WA, Coskun A, Diaz-Garzon J, Fernandez-Calle P, et al. The European Biological Variation Study (EuBIVAS): a summary report. Clin Chem Lab Med. 2022;60:505–17.
Demirci F, Akan P, Kume T, Sisman AR, Erbayraktar Z, Sevinc S. Artificial neural network approach in laboratory test reporting: learning algorithms. Am J Clin Pathol. 2016;146:227–37.
Johnson PR, Shahangian S, Astles JR. Managing biological variation data: modern approaches for study design and clinical application. Crit Rev Clin Lab Sci. 2021;58:493–512.
Borovecki A, Mlinaric A, Horvat M, Supak SV. Informed consent and ethics committee approval in laboratory medicine. Biochem Med (Zagreb). 2018;28:030201.
Gronowski AM, Budelier MM, Campbell SM. Ethics for laboratory medicine. Clin Chem. 2019;65:1497–507.
Gruson D, Helleputte T, Rousseau P, Gruson D. Data science, artificial intelligence, and machine learning: opportunities for laboratory medicine and the value of positive regulation. Clin Biochem. 2019;69:1–7.
Pennestrì F, Banfi G. Artificial intelligence in laboratory medicine: fundamental ethical issues and normative key-points. Clin Chem Lab Med. 2022.
Véliz C. Medical privacy and big data: A further reason in favour of public universal healthcare coverage. In: de Campos TC, Herring J, Phillips AM, editors. Philosophical foundations of medical law [Internet]. Oxford (UK): Oxford University Press; 2019 [cited 2022 Jun 16]. http://www.ncbi.nlm.nih.gov/books/NBK550264/.
Ahmed Z, Mohamed K, Zeeshan S, Dong X. Artificial intelligence with multi-functional machine learning platform development for better healthcare and precision medicine. Database (Oxford). 2020;2020:baaa010.
Acknowledgements
Not applicable.
Funding
This study was supported by grants from Sichuan Medical Association Research project (S20087) and Sichuan cancer hospital Outstanding Youth Science Fund (YB2021033). The funding body did not play any role in the design of the study and collection, analysis, and interpretation of data, or in writing the manuscript.
Author information
Authors and Affiliations
Contributions
HCL, DSW and JH conceived of the studies. XXW prepared and wrote the manuscript. GSY, PL, RLZ, KJZ and JSW performed the literature review. JXJ and BAM reviewed drafts and edited the final copy. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Wen, X., Leng, P., Wang, J. et al. Clinlabomics: leveraging clinical laboratory data by data mining strategies. BMC Bioinformatics 23, 387 (2022). https://doi.org/10.1186/s12859-022-04926-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12859-022-04926-1