
Abstract
This paper defines and characterizes the concept of an increase in inverse downside inequality and show that, when the Lorenz curves of two income distributions intersect, how the change from one distribution to the other is judged by an inequality index exhibiting inverse downside inequality aversion often depends on the relative strengths of its aversion to inverse downside inequality and inequality aversion. For the class of linear inequality indices, of which the Gini coefficient is a member, a measure characterizing the strength of an index’s aversion to inverse downside inequality against its own inequality aversion is shown to determine the ranking by the index of two distributions whose Lorenz curves cross once. The precise condition under which the same result generalizes to the case of multiple-crossing Lorenz curves is also identified.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The Lorenz curve as an analytical tool has played a central role in the studies of income inequality as the Lorenz criterion (i.e., whether the Lorenz curve of one distribution lies above that of another) coincides precisely with the Pigou–Dalton “principle of transfers”, which says that an income transfer from a poorer to a richer person worsens inequality and captures our usual concept of inequality. It is however well-known that in empirical studies of real-world income distributions e.g., Atkinson (1973) and Davies and Hoy (1985) the Lorenz criterion can typically provide a ranking for only a small minority of all possible pairwise comparisons. This led many authors to propose to strengthen it with the additional principle of “transfer sensitivity” (Shorrocks and Foster 1987) or equivalently “aversion to downside inequality” (Davies and Hoy 1995).Footnote 1 These authors argue that, for a fixed income gap, the same amount of income transfer from a poorer to a richer person should be considered more disequalizing the lower it occurs in the distribution. The concept parallels that of downside risk aversion proposed by Menezes et al. (1980) since an inequality index exhibiting such transfer sensitivity always assigns a higher value to a distribution that has “more downside inequality” than another in the sense that the former can be obtained from the latter by a sequence of what Menezes et al. (1980) term “mean-variance preserving transformations”, each of which combines a “mean-preserving spread” (equivalently a regressive transfer) with a “mean-preserving contraction” (equivalently a progressive transfer) occurring at higher income levels in a way that the variance is preserved. Using empirical data, Shorrocks and Foster (1987) show that such a strengthening does significantly increase the ranking success rate.
These authors have thus treated downside inequality aversion as a secondary criterion to strengthen the principle of transfers. Chiu (2007) highlights the conceptual distinction between inequality aversion and downside inequality aversion by showing, first of all, that when the Lorenz curves of two distributions intersect, one distribution can often be obtained from the other by a combination of an increase in downside inequality and a decrease in Pigou–Dalton inequality (i.e., a sequence of progressive transfers) and secondly that the inequality aversion and the downside inequality aversion of a given inequality index can work against, as well as reinforce, each other in determining the ranking of two distributions. In the case of additive inequality indices, it is shown that a measure characterizing the strength of an index’s downside inequality aversion against its own inequality aversion determines the ranking by the index of two income distributions whose difference can be decomposed into an increase downside inequality and a decrease in Pigou–Dalton inequality with the former “preceding” the latter. These results however do not apply to the arguably best known and most-widely used inequality index, namely the Gini coefficient, which is well-known not to exhibit transfer sensitivity.
This paper considers the class of linear inequality indices, of which the Gini coefficient is a member, and the alternative concept of transfer sensitivity proposed by Mehran (1976), known as “positional transfer sensitivity” (Zoli 1999) or “the principle of dual diminishing transfers” (Chateauneuf et al. 2002). We first define the notion of “mean-Gini-preserving transformation” in a way analogous to how Menezes et al. (1980) define “mean-variance-preserving transformation” and that an income distribution is an increase in “inverse downside inequality” of another if the former can be obtained from the latter by a finite sequence of mean-Gini-preserving transformations. We show that a distribution is judged to be worse than another by all linear indices exhibiting positional transfer sensitivity, or equivalently aversion to inverse downside inequality, if and only if the former is an increase in inverse downside inequality of the latter. Furthermore, in the case where the Lorenz curves of two distributions intersect, results analogous to those in Chiu (2007) obtain. Specifically, a measure characterizing the strength of a linear index’s aversion to inverse downside inequality against its own inequality aversion determines the ranking by the index of two income distributions whose Lorenz curves cross only once. In the case where the Lorenz curves of two distributions cross more than once, since the difference between the two distributions may or may not be decomposable into a change in inverse downside inequality and a change in Pigou–Dalton inequality, we identify the precise condition under which the measure can determine the ranking of two distributions by a linear inequality index.Footnote 2
The rest of the paper is organized as follows. Section 2 introduces the basic concepts and characterizes the concept of an increase in inverse downside inequality. Section 3 considers the empirically important case of single-crossing Lorenz curves. Section 4 establishes the characterizations in the general case where the Lorenz curves can cross more than once. Section 5 concludes.
2 Preliminaries and inverse downside inequality
Let \(X=[0,\bar{x}]\) where \(\bar{x}<\infty \) be an interval of real-valued income levels. \(\Omega \) denotes the set of cumulative probability (or frequency) distributions over X and \(\mu (F)\) the mean of \(F\in \Omega \). For \(F\in \Omega \), the inverse distribution function \(F^{-1}(p)\equiv \inf \{x: F(x)\ge p\}\) gives the income of an individual at the \(100p\hbox {th}\) percentile of the distribution. A (Pigou–Dalton) inequality index is a function \(I: \Omega \rightarrow R\) such that for \(F, G \in \Omega \), \(I(F)< I(G)\) if G is obtained from F by a sequence of regressive transfers. The Lorenz curve of distribution F at \(p\in (0,1)\) is given by
which, for \(p\in (0,1)\), gives the proportion of the total wealth held by the bottom \(100p\%\) of the population. It is well-known that \(L_F(p)\ge L_G(p)\) for all \(p\in (0,1)\) and the inequality is strict for some subinterval(s) if and only if G is obtained from F by a sequence of regressive transfers.
In what follows, to streamline presentation, a weak inequality (i.e., \(\ge \) or \(\le \)) being true of a function (e.g., \(\int ^{p}_0 [G^{-1}(q)-F^{-1}(q)]dq\le 0\)) or two functions (e.g., \(L_F(p)\ge L_G(p)\)) for all p in an interval, say [0, 1], implicitly indicates that the inequality is strict for p in some subinterval(s) of [0, 1].
Among the best known and most widely used inequality indices is the Gini coefficient. The Gini coefficient of a distribution F is given by
In this paper, we will focus primarily on the class of linear indices [axiomatized and characterized by Yaari (1988)], which are generalizations of the Gini coefficient, i.e., \(I, J: \Omega \rightarrow R\) such that
It is well-known that these indices are inequality indices if and only if \(\nu _I' (\;\;)>0\) and \(\nu _J' (\;\;)>0\). Both Mehran (1976) “linear measure of inequality”
and (Donaldson and Weymark 1983) “single-parameter-Gini”, or “S-Gini”, indices
are clearly positive linear transformations of indices in this class and thus ordinally equivalent to them.
Many of our results that follow are stated in terms of the number of times a function crosses another. The formal definition is given as follows.
Definition 1
A function \(\bar{\Psi } (p)\) crosses another \(\hat{\Psi } (p)\) n times first from below if there exists a series of “crossings”, \(p_i\), \(i=1,2,\ldots , n\), \(p_0\equiv 0\), \(p_{n+1}\equiv 1\), and \(0<p_1<p_2<\cdots<p_n<1\) such that for i even (odd):
-
(i)
\(\bar{\Psi } (p)\ge (\;\le \;) \hat{\Psi } (p)\) for \(p\in [p_{i-1},p_i]\) and there exists some \(\epsilon >0\) such that \(\bar{\Psi } (p)> (\;<\;) \hat{\Psi } (p)\) for \(p\in (p_i-\epsilon , p_i)\);
-
(ii)
\(\bar{\Psi } (p)\le (\;\ge \;)\hat{\Psi } (p)\) for \(p\in [p_{i},p_{i+1})\).
Following Menezes et al. (1980),Footnote 3 we define the concept of a mean-preserving spread as follows.
Definition 2
Letting f(x) be any probability or density function, a function s(x) on \([0,\bar{x}]\) is a mean-preserving spread (MPS) if
-
(i)
\( \int ^x_0 [f(x)+s(y)]dy \in \Omega \);
-
(ii)
\(\int ^{ \bar{x} }_0xs(x)dx=0\);
-
(iii)
There exist \(0<a<b<\bar{x}\) such that
A function c(x) on \([0,\bar{x}]\) is a mean-preserving contraction (MPC) given \(g(x)\equiv f(x)-c(x)\) being a probability or density function if \(-c(x)\) is an MPS.
An MPS is thus a function that transforms a probability or density function into another [(i)] by shifting probability (or mass) from the center to the tails of a distribution [(iii)] while keeping the mean the same [(ii)]. A distribution G is defined to be a “mean-preserving increase in inequality” (MPII) of F and F a “mean-preserving decrease in inequality” (MPDI) of G if G can be obtained from F by a finite sequence of MPSs. It has been shown by Rothschild and Stiglitz (1970) and Machina and Pratt (1997) that G is an MPII of F if and only if
-
(i)
\(\int ^{\bar{x}}_0 [G(y)-F(y)]dy=0\);
-
(ii)
\(\int ^{x}_0 [G(y)-F(y)]dy\ge 0\) for all \(x\in [0,\bar{x}]\).
which imply and are implied by the following conditions in terms of the inverse distribution functions
-
(i’)
\(\int ^{1}_0 [G^{-1}(q)-F^{-1}(q)]dq=0;\)
-
(ii’)
\(\int ^{p}_0 [G^{-1}(q)-F^{-1}(q)]dq\le 0\) for all \(p \in [0,1]\).
It is well-known that, for F and G being discrete income distributions, G being an MPII of F is equivalent to G being obtainable from F by a sequence of regressive transfers. An MPII is thus equivalent to an increase in Pigou–Dalton inequality and an MPDI a decrease in Pigou–Dalton inequality.
We now define the notion of a “mean-Gini-preserving transformation” in a way analogous to how Menezes et al. (1980) define a “mean-variance-preserving transformation” (MVPT).
Definition 3
Letting f(x) be any probability or density function, a function t(x) is a mean-Gini-preserving transformation (MGPT) if
-
(i)
\(t(x)=\sum s(x)+\sum c(x)\) where \(\sum s(x)\) is an MPII and \(\sum c(x)\) an MPDI;
-
(ii)
\(G(x)\equiv \int ^x_0 [f(y)+t(y)]dy=F(x)+\int ^x_0 t(y)dy\in \Omega \);
-
(iii)
\(\int ^{1}_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq=0\);
-
(iv)
\(\int ^p_0 G^{-1}(q) dq \) crosses \(\int ^p_0 F^{-1}(q) dq \) only once from below.
(i) says that an MGPT is a combination of an MPII and an MPDI and thus will leave the mean unchanged. (ii) stipulates that \(f(x)+t(x)\) is still a probability (or density) function and denotes the cumulative distribution functions of f(x) and \(f(x)+t(x)\) respectively by F and G. (iii) ensures that the Gini coefficients of F and G are the same. In view of (iii) and the properties of an MPII and an MPDI, (iv) means that the MPII occurs at lower income levels than the MPDI. That is, an MGPT, like an MVPT, shifts dispersion from higher to lower income levels but leaves the overall dispersion as measured by the Gini coefficient, not the variance, unchanged. We define one distribution to have more “inverse downside inequality” than another if it can be obtained from the other by a sequence of probability transfers which unambiguously shift dispersion from higher to lower income levels without changing the mean or the Gini coefficient.
Definition 4
G is an increase in inverse downside inequality (IDII) of F if G can be obtained from F by a sequence of MGPTs.
The following result sets out the necessary and sufficient distribution condition for an IDII.
Proposition 1
G is an IDII of F if and only if
-
(i)
\(\int ^{1}_0 [G^{-1}(q)-F^{-1}(q)]dq=0\);
-
(ii)
\(\int ^{1}_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq=0\);
-
(iii)
\(\int ^p_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p \in [0,1]\).
It is clear from this characterization of an IDII that G is an IDII of F if and only if the means and Gini coefficients of F and G are the same and F dominates G via “third-degree inverse stochastic dominance” as defined by Muliere and Scarsini (1989).
The “diminishing transfer principle” proposed by Mehran (1976), later named “positional transfer sensitivity” (Zoli 1999) or “the principle of dual diminishing transfers” (Chateauneuf et al. 2002)—to distinguish it from Shorrocks and Foster (1987) notion of transfer sensitivity, which is also known as “the principle of diminishing transfers”—stipulates that “a small positive transfer from a richer to a poorer individual, with a given proportion of the population in between them, decreases the inequality and the decrease is larger the poorer the recipient”. To state it formally, denote a generic discrete income distribution by \(\tilde{x}=(x_1, x_2, \ldots , x_N)\in R_+^N\) where \(0\equiv x_0< x_1< x_2< \cdots< x_N< x_{N+1}\equiv \bar{x}\). Its cumulative distribution F on X is then given by \(F(x)=\frac{i}{N}\) for \(x\in [x_i,x_{i+1})\) for \(i=0, 1, 2,\ldots , N\) and \(F(\bar{x})=1\). Let \(\tilde{e}_i\) denote the n-tuple \((0,\ldots ,0,1,\ldots ,0)\) whose only non-zero element occurs in the i-th position.
Definition 5
I exhibits positional transfer sensitivity if \(I(G)<I(F)\) where F(x) and G(x) are the distribution functions of \(\tilde{x}+\epsilon (\tilde{e}_{i_1}-\tilde{e}_{i_2})\) and \(\tilde{x}+\epsilon (\tilde{e}_{i_3}-\tilde{e}_{i_4})\) respectively, \(i_1<i_3\), \(i_3-i_4=i_1-i_2<0\) and \(\epsilon >0\) is such that \(x_{i_1}+\epsilon \le x_{i_1+1}\), \(x_{i_2-1}\le x_{i_2 }-\epsilon \), \(x_{i_3}+\epsilon \le x_{i_3+1}\), \(x_{i_4-1}\le x_{i_4 }-\epsilon \).
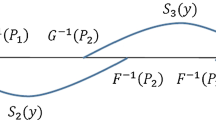
Letting H(x) be the distribution function of \(\tilde{x} \), both G(x) and F(x) are clearly MPCs of H(x) and
That is, \([G^{-1}(p)-H^{-1}(p)]\) is an upward shift of \([F^{-1}(p)-H^{-1}(p)]\) by \(\frac{i_3-i_1}{N}\) and G can be obtained from F by a combination of an MPS and an MPC occurring at higher income levels as illustrated graphically in Fig. 1 below. It can thus be easily verified that \([G^{-1}(p)-F^{-1}(p)]\) satisfies the conditions for an MGPT.

A mean-Gini-preserving transformation
Aversion to IDII thus implies positional transfer sensitivity. Mehran (1976) also shows that a linear index I exhibits positional transfer sensitivity if and only if \(\nu _I''<0\). We can show that a distribution is judged to be worse than another by all linear indices exhibiting positional transfer sensitivity if and only if the former is an increase in inverse downside inequality of the latter.
Proposition 2
\(\int ^1_0\nu (p) F^{-1}(p) dp <\int ^1_0\nu (p) G^{-1}(p) dp\) for all \(\nu (\;\;)\) such that \(\nu ''<0\) if and only if G is an IDII of F.
For linear inequality indices, positional transfer sensitivity is therefore equivalent to aversion to IDII in essentially the same way transfer sensitivity, as pointed out by Davies and Hoy (1995), is equivalent to aversion to downside inequality for additive inequality indices. In the case of discrete income distributions, Zoli (2002) defines a “favorable composite positional transfer” to be a combination of a rank-preserving progressive and a rank-preserving regressive transfer from the same donor that leave the Gini coefficient unchanged and show that F dominates G via third-degree inverse stochastic dominance if and only if F can be obtained from G by a finite sequence of progressive transfers and/or favorable composite positional transfers. In view of this and our preceding characterizations, it is clear that in the case of discrete distributions, if a distribution is an MGPT of another, then the latter can be obtained from the former by a finite sequence of favorable composite positional transfers. In this sense, a favorable composite positional transfer is a more elementary probability transformation than MGPT. However, the concept of a favorable composite positional transfer is well-defined only in the case of discrete distributions. As the concepts and characterizations in this paper are meant to be applicable to all probability distributions, we elect to base the definition of an IDII on a probability transformation that is well-defined whether or not the distributions are discrete.Footnote 4
In the reminder of this paper, to avoid unnecessary technical and notational complications, we consider the subset \(\Omega ^c\) of \(\Omega \) containing only continuous probability (or frequency) distributions over X whose cumulative distribution functions are strictly increasing over their supports and hence the inverse function of a \(F\in \Omega ^c\) is well-defined and coincides with \(F^{-1}(p)\). Following Shorrocks and Foster (1987) and (Davies and Hoy 1995), we will also focus on distributions with the same mean, i.e., \(\Omega _{\mu }^c\equiv \{F\in \Omega ^c, \mu (F)=\mu \}\subset \Omega ^c\). In applied comparisons where the means of the distributions are not the same, the axiom of scale invariance can be imposed and the results thus apply to the distributions of relative incomes.
We next establish useful characterizations of two distributions whose difference can be decomposed into a change in inverse downside inequality and a change in Pigou–Dalton inequality.
Proposition 3
For \(F,G\in \Omega _{\mu }^c\),
-
(i)
There exists \(H\in \Omega _{\mu }^c\) such that G(x) is an IDII of H(x) and H(x) is an MPDI of F(x) if and only if \(\int ^1_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq> 0\), and \(\int ^1_p\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq\ge 0\) for all \(p\in [0,1]\).
-
(ii)
There exists \(H\in \Omega _{\mu }^c\) such that G(x) is an IDII of H(x) and H(x) is an MPII of F(x) if and only if \(\int ^1_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq< 0\), and \(\int ^p_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p\in [0,1]\).
The result thus allows for definitive identification of two distributions whose relative ranking by an inequality index is determined by the index’s inequality aversion and aversion to inverse downside inequality. Importantly, as will be shown in more detail in the next section, it implies as a corollary that in the empirically important special case of single-crossing Lorenz curves, one distribution can always be obtained from the other by a combination of a change in inverse downside inequality and a change in Pigou–Dalton inequality.Footnote 5
3 Single-crossing Lorenz curves
Using Kuznets (1963) data, Atkinson (1973) shows that 24% of the 66 possible pairwise country comparisons can be ranked on the basis of Lorenz dominance, while a further 71% involve single-crossing Lorenz curves and mere 5% of them involve multiple-crossing Lorenz curves. A broadly similar pattern emerges from a similar analysis by Davies and Hoy (1985) of the data developed by Sawyer (1976) and those by Budd (1970). The simple special case of single-crossing Lorenz curves thus has a outsized significance in empirical studies. We show in this case very clearcut results can be obtained.
If the Gini coefficient of F is smaller than that of G, which is equivalent to \(\int ^1_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq< 0\), then by Proposition 3 (ii), there exists \(H\in \Omega _{\mu }^c\) such that G(x) is an IDII of H(x) and H(x) is an MPII of F(x). We therefore have, for I being a linear inequality index exhibiting inverse downside inequality aversion,
since (given \(\nu _I' >0\) and \(\nu _I'' <0\)) both terms are clearly positive. (If \(\Gamma (F)=\Gamma (G)\), then \([G(x)-F(x)]\) is an IDII.) We thus have the following.
Proposition 4
(Zoli 1999) For \(F,G\in \Omega _{\mu }^c\), if \(L_G(p)\) crosses \(L_F(p)\) once from below and \(\Gamma (F)\le \Gamma (G)\), then \(I(F)< I(G)\) for any linear inequality index \(I(\;\;)\) exhibiting aversion to inverse downside inequality.
If, on the other hand, the Gini coefficient of F is larger than that of G while the Lorenz curve of G still single-crosses that of F from below, then Proposition‘3 (i) implies the existence of \(H\in \Omega _{\mu }^c\) such that G(x) is an IDII of H(x) and H(x) is an MPDI of F(x). We can thus write, for I being a linear inequality index exhibiting aversion to inverse downside inequality,
Since the two terms are of opposite signs, whether the change from F to G reduces the value of I depends on the relative strengths of its inequality aversion and aversion to inverse downside inequality. The next result shows that the function \(-\frac{\nu _I'' (p)}{\nu _I' (p)}\) measures, in the special case of single-crossing Lorenz curves, the strength of I’s aversion to inverse downside inequality against its own inequality aversion and determines I’s ranking of F and G as a result.
Proposition 5
Suppose I and J are linear inequality indices and, for \(F,G\in \Omega _{\mu }^c\), \(L_G(p)\) crosses \(L_F(p)\) once from below and \(\Gamma (F)>\Gamma (G)\). Then (i), (ii), and (iii) are equivalent.
The result says that in the special case of single-crossing Lorenz curves if G can be obtained from F by a combination of an inverse downside risk increase and a Pigou–Dalton inequality decrease and G is judged “equally unequal” by an inequality index I, then another index J with \(-\frac{\nu _J'' (p)}{\nu _J' (p)}\) uniformly larger than \(-\frac{\nu _I'' (p)}{\nu _I' (p)}\) must judge G “more unequal” than F. The function \(-\frac{\nu _I'' (p)}{\nu _I' (p)}\) thus has the interpretation of measuring the strength of I’s aversion to inverse downside inequality against its own inequality aversion. Furthermore since the condition of \(-\frac{\nu _J'' (p)}{\nu _J' (p)}\) being uniformly larger than \(-\frac{\nu _I'' (p)}{\nu _I' (p)}\) is equivalent to \(\nu _J (p)\) being a concave transformation of \(\nu _I (p)\), we can also say that “the degree of concavity” of \(\nu _I (p)\) determines the strength of I’s aversion to inverse downside inequality against its own inequality aversion.
4 Multiple-crossing Lorenz curves
While multiple-crossing Lorez curves are rare in comparisons of empirical income distributions, this considerably more complex case is more important conceptually for its generality and for the insights it gives into the results in the special case of single-crossing Lorenz curves.
Suppose distributions F and G have the same mean and the Lorenz curve of F crosses that of G more than once first from above. If \(\int ^1_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq< 0\), and \(\int ^p_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p\in [0,1]\), then, by Proposition 3 (ii), we clearly still have, for I being a linear inequality index exhibiting inverse downside inequality aversion,
where G(x) is an IDII of H(x) and H(x) an MPII of F(x) and hence under our assumptions on \(\nu _I(\;\;)\) both terms are clearly positive.
Recall that in the simple case of single-crossing Lorenz curves where the difference between the two distributions is always a combination of a change in inverse downside inequality and a change in Pigou–Dalton inequality (i.e., an MPDI or an MPII). By contrast, if the Lorenz curves cross more than once and the difference between the two distributions cannot be decomposed into an IDII and an MPII, it may not, first of all, be a combination of an IDII and an MPDI and, secondly, even if the change is a combination of an IDII and an MPDI, the result in Proposition 5 may or may not generalize.
We show in Propositions 6 and 7 that the following condition is the precise condition under which the result in Proposition 5 does generalize.
Condition PI. \(\int _0^{1} \int _0^q [G^{-1}(r)-F^{-1}(r)]drdq> 0\) and \(\exists z\in (0,1)\) such that \(\int _0^{p} \int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for \(p\le z\) and \(\int _0^p [G^{-1}(q)-F^{-1}(q)]dq\ge 0\) for \(p\ge z\).
As illustrated below, the condition requires the function \(\int _0^{p} \int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\) to be non-positive up to z and non-decreasing from that point onwards (i.e., the graph of \(\int _0^{p} \int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\) never slopes downwards from z onwards) since \(\int _0^p [G^{-1}(q)-F^{-1}(q)]dq\) is required to be non-negative (Fig. 2).

The graph of \(\int _0^{p} \int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\) satisfying Condition PI
Proposition 6
Suppose I and J are linear inequality indices. Then for \(F,G\in \Omega _{\mu }^c\) satisfying Condition PI, (i), (ii), and (iii) are equivalent.
Proposition 7
Suppose I and J are linear inequality indices and
and for \(F,G\in \Omega _{\mu }^c\), it is not true that \(\int _0^{p} \int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p\in [0,1]\). Then
if and only if F and G satisfy Condition PI.
Condition PI clearly implies, but is not implied by, the condition (in Proposition 3 (i)) for the change from one distribution to another to be a combination of an IDII and an MPDI. In other words, the change from F to G satisfying Condition PI is a special combination of an IDII and an MPDI. Such a special combination has the interpretation that the component IDII “precedes” the component MPDI.Footnote 6 The measure \(-\nu _I'' /\nu _I' \) can thus be interpreted as measuring the index I’s strength of aversion to inverse downside inequality against its own inequality aversion in such a special case.
The results give a novel interpretation to the parameter \(\theta \) of Donaldson and Weymark’s (1983) S-Gini indices. Since, for \(F\in \Omega \), the S-Gini indices
are ordinally equivalent to
and
\(-\theta \) has the interpretation of measuring the strength of \(\Gamma _{\theta } \)’s aversion to inverse downside inequality against its own inequality aversion. Our results thus facilitate both the use of these indices in empirical or applied studies and the interpretation of results from such studies. Specifically, for two distributions F and G satisfying Condition PI (or whose Lorenz curves single-cross, as is most common in empirical studies), there is a critical value for the parameter \(\theta \), \(\theta ^{FG}\), such that \(\Gamma _{\theta }(G)\ge \Gamma _{\theta }(F)\) for all \(\theta \le \theta ^{FG}\) and \(\Gamma _{\theta }(G)\le \Gamma _{\theta }(F)\) for all \(\theta \ge \theta ^{FG}\). This, among other things, obviates the need to perform exhaustive robustness exercises in applied work.
Supposing \(L_G(p)\) crosses \(L_F(p)\) n times first from below and \(p_1, p_2,\ldots , p_n\) are the crossings, we next consider an alternative characterization of Condition PI in terms of the Gini coefficients of distributions within subpopulation \([0,p_i]\), \(i=1,2,\ldots , n\). Specifically, the distributions of \(F, G\in \Omega _{\mu }^c\) within the subpopulation \([0,p_i]\) are given by
and their Gini coefficients are denoted by \(\Gamma ^i(F)\) and \(\Gamma ^i(G)\).Footnote 7 An alternative characterization of Condition PI can be given as follows.
Proposition 8
Suppose \(F,G\in \Omega _{\mu }^c\) and \(L_G(p)\) crosses \(L_F(p)\) n times first from below and n is odd. \(\Gamma ^i(F)\le \Gamma ^i(G)\) for \(i=2, 4, 6,\ldots , n-1\) and \(\Gamma (F)>\Gamma (G)\) if and only if F and G satisfy Condition PI.
5 Conclusion
This paper shows that, defining an income distribution to be an increase in inverse downside inequality of another if the former can be obtained from the latter by a sequence of probability transfers which unambiguously shift dispersion from higher to lower income levels without changing the mean or the Gini coefficient, an inequality index’s aversion to inverse downside inequality implies its positional transfer sensitivity. It is further shown that when the Lorenz curves of two income distributions intersect, how the change from one distribution to the other is judged by an inequality index exhibiting inverse downside inequality aversion often depends on the relative strengths of its aversion to inverse downside inequality and inequality aversion. For the class of linear inequality indices where positional transfer sensitivity is shown to also imply aversion to inverse downside inequality, a useful measure is shown to characterize the strength of an index’s aversion to inverse downside inequality relative to its own inequality aversion and determine the ranking of two distributions by the index if one distribution can be obtained from the other by a special combination of an increase in inverse downside inequality and an inequality decrease. The conceptual clarity given by the analysis to the empirically most relevant case of single-crossing Lorenz curves is particularly striking: in this case the change from one distribution to the other can always be decomposed into a change in inverse downside inequality and a change in Pigou–Dalton inequality and how a linear inequality index judges between two distributions is fully characterized by a single measure. Furthermore, an interpretation implied by our results of the parameter of Donaldson and Weymark (1983) “S-Gini” indices allows us to theoretically predict (and understand), from the ranking of two distributions by one member of the family, the rankings by many other members of the family, obviating the need to perform exhaustive robustness exercises in applied studies.
Notes
As with the results in Chiu (2007), these results are particularly relevant in the context of tax reforms since two tax schedules rarely intersect each other more than twice and (Dardanoni and Lambert 1988) show that, given the same pre-tax income distribution, if two tax schedules generating the same tax revenue cross twice, the Lorenz curves of the two after-tax income distributions cross each other once. Moreover, in analyzing the effect on inequality of moving from an income tax with a graduated rate tax schedule to one with a single marginal rate levied on the same base and a personal allowance adjusted to maintain an equal tax revenue, (Davies and Hoy 2002) show that, for any inequality index, there exists a critical value such that a reform of this kind is judged desirable by the index if and only if the marginal tax rate of the flat-rate tax is higher than the critical value. We can show that this critical marginal tax rate for a linear inequality index exhibiting aversion to inverse downside inequality is determined by the strength of the index’s aversion to inverse downside inequality against its own inequality aversion. The derivation of these results is not explicitly given in this paper as it is fairly analogous to that of the analogous results in Chiu (2007). Readers who are nevertheless interested in the detailed derivation can find it in an earlier version of this paper (Chiu 2019).
This is also essentially the more general definition of a mean-preserving spread put forward by Machina and Pratt (1997).
To address the problem of intersecting Lorenz curves, Aaberge (2009) proposes the concept of higher-degree Lorenz dominance. Readers familiar with the work will recognize from Proposition 3 (i) that, for \(F,G\in \Omega _{\mu }^c\), there exists \(H\in \Omega _{\mu }^c\) such that G(x) is an IDII of H(x) and H(x) is an MPDI of F(x) if and only if the Lorenz curve of F “second-degree downward dominates” that of G. Proposition 3 (i) thus also serve to shed light on the result (Aaberge (2009, Theorem 2.2B)) that the Lorenz curve of F “second-degree downward dominates” that of G if and only if \(I(F)<I(G)\) for I being any linear inequality index with \(\nu _I''(\;\;)>0\). Aaberge (2009) notion of “second-degree upward dominance”, on the other hand, coincides with third-degree inverse stochastic dominance in the case of distributions with the same mean.
That is, the IDII occurs at lower income levels than the MPDI. This can perhaps be seen intuitively in the fact that the change from F(x) to G(x) satisfies the condition for an IDII up to z and for \(p\ge z\) it satisfies the condition for an MPDI. Chiu (2005) develops the notion of precedence relations on stochastic dominant changes, which generalizes the concept of an MPS “coming before” an MPC used by Menezes et al. (1980) in defining a mean-variance-preserving transformation. An analogous precedence relation for “inverse stochastic dominant changes” can formalize the relation between the component IDII and the component MPDI of a change in distribution satisfying Condition PI.
Such definitions immediately imply, by Proposition 3 (ii), that, assuming \(F,G\in \Omega _{\mu }^c\) and \(L_G(p)\) crosses \(L_F(p)\) n times first from below and n is even, \(\Gamma ^i(F)\le \Gamma ^i(G)\) for \(i=2, 4, 6,\ldots , n \) and \(\Gamma (F)\le \Gamma (G)\) if and only if \(I(F)<I(G)\) for any linear inequality index \(I(\;\;)\) exhibiting positional transfer sensitivity, which is what obtains in Proposition 5 in Zoli (1999) in the case of distributions with the same mean.
References
Aaberge R (2009) Ranking intersecting Lorena curves. Soc Choice Welf 33:235–259
Atkinson AB (1970) On the measurement of inequality. J Econ Theory 2:244–263
Atkinson AB (1973) More on the measurement of inequality. mimeo
Budd EC (1970) Postwar changes in the size of distribution of income in the US. Am Econ Rev 60:247–260
Chateauneuf A, Gajdos T, Wilthien P (2002) The principle of strong diminishing transfer. J Econ Theory 103:311–333
Chiu WH (2005) Skewness preference, risk aversion, and the precedence relations on stochastic changes. Manag Sci 51:1812–1828
Chiu WH (2007) Intersecting Lorenz curves, the degree of downside inequality aversion, and tax reforms. Soc Choice Welf 28:375–399
Chiu WH (2019) Intersecting Lorenz curves, aversion to inverse downside inequality, and tax reforms, mimeo
Dardanoni V, Lambert P (1988) Welfare rankings of income distributions: a role for the variance and some insights for tax reform. Soc Choice Welf 5:1–17
Davies JB, Hoy M (1985) Comparing income distributions under aversion to downside inequality. mimeo
Davies JB, Hoy M (1995) Making inequality comparisons when Lorenz curves intersect. Am Econ Rev 85:980–986
Davies JB, Hoy M (2002) Flat rate taxes and inequality measurement. J Publ Econ 84:33–46
Donaldson D, Weymark JA (1983) Ethically flexible gini indices for income distributions in the continuum. J Econ Theory 29:353–358
Kolm S (1976) Unequal inequalities: I. J Econ Theory 12:416–42
Kuznets S (1963) Quantitative aspects of economic growth of nations. Econ Dev Cult Change 11:1–80
Machina M, Pratt JW (1997) Increasing risk: some direct construction. J Risk Uncertainty 14:103–127
Mehran F (1976) Linear measures of income inequality. Econometrica 44:805–809
Menezes C, Geiss C, Tressler J (1980) Increasing downside risk. Am Econ Rev 70:921–932
Muliere, Scarsini (1989) A note on stochastic dominance and inequality measures. J Econ Theory 49:314–323
Rothschild M, Stiglitz JE (1970) Increasing risk: I. A definition. J Econ Theory 2(3):225–243
Sawyer M (1976) Income distribution in OECD countries. OECD Economic Outlook, Occasional Studies, Paris
Sen A (1973) On economic inequality. Oxford University Press, Oxford
Shorrocks AF, Foster JE (1987) Transfer sensitive inequality measures. Rev Econ Stud 54:485–97
Yaari ME (1988) A controversial proposal concerning inequality measurement. J Econ Theory 44:381–397
Zoli C (1999) Intersecting generalized Lorenz curves and the Gini index. Soc Choice Welf 16:183–196
Zoli C (2002) Inverse stochastic dominance, inequality measurement and Gini indices. J Econ 9:119–161
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Proofs.
Proof of Proposition 1
If G can be obtained from F by a sequence of MGPTs, (i)–(iii) follow immediately from the properties of an MGPT.
To prove the converse, define \(\phi (p)\equiv \int _0^p [G^{-1}(q)-F^{-1}(q)]dq\). (ii) and (iii) imply that \(\int ^p_0\phi (r)dr\) is negative on (0, 1). Hence \(\phi (p)\) must cross the p-axis at least once at one point on (0, 1). Let \(0=p_0<p_1<\cdots <p_n=1\) be the finite number of crossings and let \(A_i\) denote the area between \(\phi (p)\) and the p-axis on interval \(I_i=[p_{i-1}, p_i]\), for \(i=1, \ldots , n\). (ii) and (iii) imply that \(\phi (p)\) is negative on the interval \((p_0,p_1)\) and alternates in sign thereafter on successive intervals and n is an even number. Furthermore
where the last equality is by (iii). Define
By (1), there exists an \(\alpha _1\in (0,1]\) such that \(\alpha _1 A_1=A_2\). Hence, \(\phi _1(p)\) corresponds to an MGPT.
Define
By (2), \((1-\alpha _1)A_1+A_3\ge A_4\). Hence there exists an \(\alpha _2\in (0,1]\) such that \(\alpha _2[(1-\alpha _1)A_1+A_3]=A_4\). Hence \(\phi _2(p)\) corresponds to an MGPT.
The pattern of construction should now be obvious. We construct \(\phi _1(p)\) to exhaust \(A_2\), \(\phi _2\) to exhaust \(A_4\). Similarly, \(\phi _3 (p),\ldots , \phi _{n/2}(p)\) can be constructed to exhaust \(A_6, \ldots , A_n\). The proof is completed by noting that (4) guarantees that \(\sum _{i=1}^{n/2}\phi _i(p)=\phi (p)\) for all \(p\in [0,1]\). \(\square \)
Proof of Proposition 2
Since repeated integration by parts yields
conditions (i), (ii) and (iii) in Proposition 1 clearly imply \(\int _0^{1} \nu (p)G^{-1}(p)dp>\int _0^{1} \nu (p)F^{-1}(p)dp\).
To prove the converse, consider first the following pair of functions \(\hat{\nu } =\theta p^2+1\) and \(\breve{\nu } =\theta p^2-1\) where \(\theta <0\). Since
and
letting \(\theta \rightarrow 0\), we have \(\int _0^{1} [G^{-1}(p)-F^{-1}(p)]dp\ge 0\) and \(-\int _0^{1} [G^{-1}(p)-F^{-1}(p)]dp\ge 0\), which implies condition (i) in Proposition 1. Consider secondly the functions \(\bar{\nu } =\theta p^2+p\) and \(\check{\nu } =\theta p^2-p\) where \(\theta <0\). Since (by integration by parts)
and
letting \(\theta \rightarrow 0\), we have \(-\int _0^{1} \int _0^p[G^{-1}(q)-F^{-1}(q)]dqdp\ge 0\) and \(\int _0^{1} \int _0^p[G^{-1}(q)-F^{-1}(q)]dqdp\ge 0\), which implies condition (ii) in Proposition 1. Now suppose (iii) in Proposition 1 is false at \(p_0\in (0,1)\). By continuity, there exists an interval \((p_1,p_2)\) containing \(p_0\) such that \(\int ^p_0 \int ^q_0[G^{-1}(r)-F^{-1}(r)] drdq>0\) for all \(p\in (p_1,p_2)\). Letting
Applying conditions (i) and (ii) in Proposition 1 to (5), we have
That is, we have \(\ddot{\nu }''(p) <0\) but \(\int ^1_0\ddot{\nu } (p) F^{-1}(p) dp >\int ^1_0\ddot{\nu } (p) G^{-1}(p) dp\). \(\square \)
Proof of Proposition 3
(i)
(\(\Rightarrow \)) Since \(\int _0^{1}\int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq= 0\) and \(\int _0^p\int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq\le 0\) for all p, we have \(\int _p^1 \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq\ge 0\) for all p, which together with \(\int _0^p [H^{-1}(q)-F^{-1}(q)] dq\ge 0\) for all p, implies \(\int ^1_0\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq> 0\), and \(\int ^1_p\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq\ge 0\) for all \(p\in [0,1]\).
(\(\Leftarrow \)) Suppose \(\int _0^p G^{-1}(q)dq\) crosses \(\int _0^p F^{-1}(q)dq\) n times and \(p_1, p_2,\ldots , p_n\) are the crossings. \(\int ^1_p\int ^q_0 [G^{-1}(r)-F^{-1}(r)]drdq\ge 0\) for all \(p\in [0,1]\) clearly implies that \(\int _0^p G^{-1}(q)dq\ge \int _0^p F^{-1}(q)dq\) for \(p\in [p_n, 1]\) and \(\int _0^p G^{-1}(q)dq\le \int _0^p F^{-1}(q)dq\) for \(p\in [p_{n-1}, p_n]\).
Consider first the case where \(\int _0^p G^{-1}(q)dq\) crosses \(\int _0^p F^{-1}(q)dq\) first from below. H(x) is constructed as follows: (a) \(H^{-1}(p)=F^{-1}(p)\) for \(p\le p_1\), (b) If \(\int _0^{p_1} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq+\int _{p_1}^{p_2} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq> 0\), then for \(p\in [p_1, p_2]\), let \(H^{-1}(p)\) be such that \(\min \{F^{-1}(p), G^{-1}(p)\}\le H^{-1}(p)\le \max \{F(p)^{-1}, G^{-1}(p)\}\), \(\int _0^p G^{-1}(q)dq \ge \int _0^p H^{-1}(q)dq\ge \int _0^p F^{-1}(q)dq\), and \(\int ^{p_2}_{p_1} \int ^q_0[H^{-1}(r)-G^{-1}(r)]drdq=\int ^{p_1}_{0} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq\); otherwise, \(H^{-1}(p)=F^{-1}(p)\). (c) for \(p\in [p_2, p_3]\), \(H^{-1}(p)=F^{-1}(p)\), (d) If \(\int _0^{p_3} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq+ \int _{p_3}^{p_4} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq> 0\), then for \(p\in [p_3, p_4]\), let \(H^{-1}(p)\) be such that \(\min \{F^{-1}(p), G^{-1}(p)\}\le H^{-1}(p)\le \max \{F^{-1}(p), G^{-1}(p)\}\), \(\int _0^p G^{-1}(q)dq \ge \int _0^p H^{-1}(q)dq\ge \int _0^p F^{-1}(q)dq\), and \(\int ^{p_4}_{p_3} \int ^q_0[H^{-1}(r)-G^{-1}(r)]drdq=\int ^{p_3}_{0} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq\); otherwise, \(H^{-1}(p)=F^{-1}(p)\).... for \(p\in [p_{n-1}, p_n]\), \(H^{-1}( p)=F^{-1}(p)\).
(Such construction and \(\int _p^{1} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\ge 0\) for all p imply that \(\int _0^{p_n} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq +\int _{p_n}^{1} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\ge 0\) since, by the construction, there exists a crossing \(p_m\le p_{n-1}\) of \(\int _0^p G^{-1}(q)dq\) and \(\int _0^p F^{-1}(q)dq\) such that \(\int _{0}^{p_{m}} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq=0\) and \(H^{-1}(p)=F^{-1}(p)\) for \(p\in [p_m, p_n]\), which, together with \(\int _{p_{m}}^{1} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\ge 0\), gives \(\int _0^{p_n} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq +\int _{p_n}^{1} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq =\int _0^{p_m} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq +\int _{p_m}^{1} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq \ge 0\).)
For \(p\in [p_n, 1]\), let \(H^{-1}(p)\) be such that \(\min \{F^{-1}(p), G^{-1}(p)\}\le H^{-1}(p)\le \max \{F^{-1}(p), G^{-1}(p)\}\), \(\int _0^p G^{-1}(q)dq \ge \int _0^p H^{-1}(q)dq\ge \int _0^p F^{-1}(q)dq\), and \(\int ^{1}_{p_n} \int ^q_0[H^{-1}(r)-G^{-1}(r)]drdq=\int ^{p_n}_{0} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq\). We thus have \(\int _0^p \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq\le 0\) for all p, \(\int _0^{1} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq= 0\), and \(\int ^{1}_0 [G^{-1}(q)-H^{-1}(q)]dq=0\) (by our construction \(\int ^{1}_0 H^{-1}(q)dq=\int ^{1}_0 G^{-1}(q)dq=\int ^{1}_0 F^{-1}(q)dq\) given that G(x) and F(x) have the same mean), \(\int ^p_0[H^{-1}(q)-F^{-1}(q)]dq\ge 0\) for all p and \(\int ^{1}_0[H^{-1}(q)-F^{-1}(q)]dq= 0\). That is, G(x) is an IDII of H(x) and H(x) is an MPDI of F.
If \(\int _0^p G^{-1}(q)dq\) crosses \(\int _0^p F^{-1}(q)dq\) first from above, let \(\hat{p}_1\) and \(\hat{p}_2\) be two consecutive crossings of \(G^{-1}(p)\) and \(F^{-1}(p)\) such that \(\hat{p}_1<p_1<\hat{p}_2\) and \(G^{-1}(p)-F^{-1}(p)\le 0\) for \(p \in [\hat{p}_1,\hat{p}_2]\). H(x) is constructed as follows: (a) for \(p\le \hat{p}_1, H^{-1}(p)=G^{-1}(p)\), (b) for \(p\in [\hat{p}_1, \hat{p}_2]\), let H(x) be such that \(F^{-1}(p)\ge H^{-1}(p)\ge G^{-1}(p)\), and \(\int ^{\hat{p}_2}_{\hat{p}_1}[H^{-1}(q)-F^{-1}(q)]dq=-\int ^{\hat{p}_1}_{0}[G^{-1}(q)-F^{-1}(q)]dq\) (c) for \(p\in [\hat{p}_2, p_2], H^{-1}(p)=F^{-1}(p)\), (d) if \(\int _0^{p_2} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq+\int _{p_2}^{p_3} \int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq> 0\), then for \(p\in [p_2, p_3]\), let H(x) be such that \(\min \{F^{-1}(p), G^{-1}(p)\}\le H^{-1}(p)\le \max \{F^{-1}(p), G^{-1}(p)\}\), \(\int _0^p G^{-1}(q)dq \ge \int _0^p H^{-1}(q)dq\ge \int _0^p F^{-1}(q)dq\), and \(\int ^{p_3}_{p_2} \int ^q_0[H^{-1}(r)-G^{-1}(r)]drdq=\int ^{p_2}_{0} \int ^q_0[G^{-1}(r)-H^{-1}(r)]drdq\), otherwise, \(H^{-1}(p)=F^{-1}(p)\). The rest of the proof is the same as the case where \(\int _0^p G^{-1}(q)dq\) crosses \(\int _0^p F^{-1}(q)dq\) first from below.
-
(ii)
is proved analogously.
\(\square \)
Proof of Proposition 5
A special case of Proposition 6 that follows. \(\square \)
Proof of Propositions 6 and 7
First note that if F and G have the same mean, i.e., \(\int _0^{1} [G^{-1}(p)-F^{-1}(p)]dp=0\), then integration by parts yields
The rest of the proofs is implied by Lemmas 4–6 that follow. \(\square \)
Lemma 1
Suppose
-
(a)
\(\int _0^{1} [G^{-1}(p)-F^{-1}(p)]dp=0\),
-
(b)
\(\int _0^{p} \nu _I' (q)\int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p\in [0,1]\).
Then the following are equivalent:
Proof
-
(ii)
\(\Longleftrightarrow \) (iii)
Since \(\nu _I \) and \(\nu _J \) are monotonic, \(T(\;\;)\equiv \nu _J (\nu _I ^{-1}(\;\;))\) is well-defined. We then have \(\nu _J (p)=T(\nu _I (p))\) and \(\nu _J' (p)=T'(\nu _I (p))\nu _I' (p)\).
gives
Hence given \(T'(\;\;)\ge 0\) and \(\nu _I' (\;\;)> 0\),
(i) \(\Longleftrightarrow \) (iii)
where the last inequality is true if \(I(G)\ge I(F)\) or equivalently \(\int _0^{1} \nu _I' (p)\int _0^p [G^{-1}(q)-F^{-1}(q)] dqdp\ge 0\). Clearly if \(T''(\;\;)\le 0\), given (b), \(J(G)-J(F)\ge 0\). Conversely, since (b) allows \(\int _0^{p} \nu _I' (q)\int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\) to take any non-positive value, positive values for \(T''(\nu _I )\) would permit a negative value for \([J(G)-J(F)]\) (assuming \([I(G)-I(F)]\) equals zero). That is, \(I(G)\ge I(F)\) does not imply \(J(G)\ge J(F)\). \(\square \)
Lemma 2
Suppose \(\int _0^{1} [G^{-1}(p)-F^{-1}(p)]dp=0\) and
Then \(I(G)\ge I(F)\) implies \(J(G)\ge J(F)\) if and only if \(\int _0^p \nu _I' (q)\int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p\in [0,1]\).
Proof
Assuming \([I(G)-I(F)]\) equals zero and using
(from the proof of Lemma 1) where \(\nu _J (p)=T(\nu _I (p))\) and \(T''(\;\;)\le 0\), since \(T''(\nu _I )\) can take any non-positive value, positive value for \(\int _0^p \nu _I' (q)\int _0^q [G^{-1}(r)-F^{-1}(r)]drdq\) would permit a negative value for \([J(G)-J(F)]\).
The converse is proved in Lemma 1. \(\square \)
Lemma 3
Suppose \(\int _0^{1} [G^{-1}(p)-F^{-1}(p)]dp=0\) and \(I(G)\ge I(F)\) but it is not true that \(\int ^p_0\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p\in [0,1]\). Then \(\int _0^p \nu _I' (q)\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for all \(p\in [0,1]\) if and only if \(\int ^1_0\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq> 0\) and there exists \(z\in (0,1)\) such that \(\int ^p_0\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for \(p\le z\) and \(\int ^p_0[G^{-1}(q)-F^{-1}(q)]dq\ge 0\) for \(p\ge z\).
Proof
(\(\Leftarrow \)) For \(p\le z\),
because both terms are clearly non-positive by the hypothesis, \(\nu _I' > 0\) and \(\nu _I'' < 0\). For \(p\in (z,1)\), since \(\nu _I' (p) \int ^p_0[G^{-1}(q)-F^{-1}(q)]dq\ge 0\), we have
Hence
(\(\Rightarrow \)) First note that (given \(\int _0^{1} [G^{-1}(p)-F^{-1}(p)]dp=0\))
\(\nu _I' (p)> 0\) and \(\nu _I'' (p)< 0\) for all p thus imply that if \(\int ^p_0 \int ^q_0[G^{-1}(r)-F^{-1}(r)] drdq\ge 0\) for all \(x\in [0,1]\), \(\int _0^{1} \nu _I(p) [G^{-1}(p)-F^{-1}(p)]dp<0\) (which contradicts the assumption \(I(G)\ge I(F)\)). Since we also rule out \(\int ^p_0 \int ^q_0[G^{-1}(r)-F^{-1}(r)] drdq\le 0\) for all \(p\in [0,1]\) by assumption, there always exists \(\hat{z}\in (0,1)\) such that \(\int ^{\hat{z}}_0\int ^q_0[G^{-1}(r)-F^{-1}(r)] drdq=0\). For such a \(\hat{z}\), since
and \(\nu _I'' \) can take any negative values, positive values for \(\int ^p_0\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\) for \(p\le \hat{z}\) would permit a negative value for \(\int _0^{\hat{z}} \nu _I' (q)\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\) and contradict the hypothesis.
Hence there exists \(z\in (0,1)\) such that \(\int ^p_0\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\le 0\) for \(p\in [0,z]\) and \(\int ^p_0\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq> 0\) for \(p\in (z,z_1]\) where \(z_1\in (z,1]\), which in turn implies \(\int ^p_0[G^{-1}(q)-F^{-1}(q)]dq> 0\) for \(p\in (z,z_2)\) where \(z_2\in (z,z_1]\). Now if there exist \(z_3\) and \(z_4\) such that \(z_2\le z_3<z_4<1\) and \(\int ^p_0[G^{-1}(q)-F^{-1}(q)]dq< 0\) for \(p\in (z_3,z_4)\) and \(\int ^p_0[G^{-1}(q)-F^{-1}(q)]dq\ge 0 \) for \(p\in (z, z_3)\), we can always choose the magnitude of \(\nu _I' (p)\) appropriately so that \(\int _{z_3}^{1} \nu _I' (q)\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq< 0\) without violating \(\nu _I'' (p)< 0\). At the same time, since \(\int _z^{z_3} \nu _I' (q)\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq>0\) and \(\int _0^{z} \nu _I' (q)\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq= -\int _0^{z} \{ \nu _I'' (q)\int ^q_0 \int ^r_0[G^{-1}(s)-F^{-1}(s)] dsdr\}dq\) and \(\nu _I'' (p)\) can take any negative value (however close to 0), we can choose the value of \(\nu _I'' (p)\) for \(p \in [0,z]\) so that
and
(i.e., \(\int _{0}^{1} \nu _I' (q)\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq\le 0\) or \(I(G)\ge I(F)\)). But \(\int _0^{z_3} \nu _I' (q)\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq>0\) violates the hypothesis. That is, we must have \(\int ^p_0[G^{-1}(q)-F^{-1}(q)]dq\ge 0\) for \(p\ge z\) and also \(\int ^1_0\int ^q_0[G^{-1}(r)-F^{-1}(r)]drdq> 0\) as a result. \(\square \)
Proof of Proposition 8
The characterization follows immediately from the definitions of \(\hat{F}^i(x)\) and \(\hat{G}^i(x)\) and the fact that \(L_G(p)\) crosses \(L_F(p)\) n times first from below and n is odd. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chiu, W.H. Intersecting Lorenz curves and aversion to inverse downside inequality. Soc Choice Welf 56, 487–508 (2021). https://doi.org/10.1007/s00355-020-01288-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00355-020-01288-6