
Abstract
Background
Polymorphisms in the CYP1A2 genes have the potential to affect the individual capacity to convert pre-carcinogens into carcinogens. With these comprehensive meta-analyses, we aimed to provide a quantitative assessment of the association between the published genetic association studies on CYP1A2 single nucleotide polymorphisms (SNPs) and the risk of cancer.
Methods
We searched MEDLINE, ISI Web of Science and SCOPUS bibliographic online databases and databases of genome-wide association studies (GWAS). After data extraction, we calculated Odds Ratios (ORs) and 95 % confidence intervals (CIs) for the association between the retrieved CYP1A2 SNPs and cancer. Random effect model was used to calculate the pooled ORs. Begg and Egger tests, one-way sensitivity analysis were performed, when appropriate. We conducted stratified analyses by study design, sample size, ethnicity and tumour site.
Results
Seventy case-control studies and one GWA study detailing on six different SNPs were included. Among the 71 included studies, 42 were population-based case-control studies, 28 hospital-based case-control studies and one genome-wide association study, including total of 47,413 cancer cases and 58,546 controls. The meta-analysis of 62 studies on rs762551, reported an OR of 1.03 (95 % CI, 0.96–1.12) for overall cancer (P for heterogeneity < 0.01; I2 = 50.4 %). When stratifying for tumour site, an OR of 0.84 (95 % CI, 0.70–1.01; P for heterogeneity = 0.23, I2 = 28.5 %) was reported for bladder cancer for those homozygous mutant of rs762551. An OR of 0.79 (95 % CI, 0.65–0.95; P for heterogeneity = 0.09, I2 = 58.1 %) was obtained for the bladder cancer from the hospital-based studies and on Caucasians.
Conclusions
This large meta-analysis suggests no significant effect of the investigated CYP1A2 SNPs on cancer overall risk under various genetic models. However, when stratifying according to the tumour site, our results showed a borderline not significant OR of 0.84 (95 % CI, 0.70–1.01) for bladder cancer for those homozygous mutant of rs762551. Due to the limitations of our meta-analyses, the results should be interpreted with attention and need to be further confirmed by high-quality studies, for all the potential CYP1A2 SNPs.
Similar content being viewed by others


Background
Cancer is a complex disease that develops as a result of the interactions between environmental factors and genetic inheritance. In 2012 there were 14.1 million new cancer cases and 8.2 million cancer deaths worldwide [1]. Endogenous or exogenous xenobiotics are activated or inactivated through two metabolic steps by phase I and phase II enzymes [2]. The majority of chemical carcinogens require activation to electrophilic reactive forms to produce DNA adducts and this is mainly catalyzed by phase I enzymes. Although there are some exceptions, phase II enzymes, in contrast, detoxify such intermediates through conjugative reactions. The consequent formation of reactive metabolites and their binding to DNA to give stable adducts are considered to be critical in the carcinogenic process. It might therefore be expected that individuals with increased activation or low detoxifying potential have a higher susceptibility for cancer [3].
Cytochrome P450 1A2 (CYP1A2) enzyme is a member of the cytochrome P450 oxidase system and is involved in the phase I metabolism of xenobiotics. In humans, the CYP1A2 enzyme is encoded by the CYP1A2 gene [4]. In vivo, CYP1A2 activity exhibits a remarkable degree of interindividual variations, as the gene expression is highly inducible by a number of dietary and environmental chemicals, including tobacco smoking, heterocyclic amines (HAs), coffee and cruciferous vegetables. Another possible contributor to interindividual variability in CYP1A2 activity is the occurrence of polymorphisms in the CYP1A2 gene [5], which have the potential for determining individual’s different susceptibility to carcinogenesis [6]. CYP1A2 is expressed mainly in the liver, but also, expression of the CYP1A2 enzyme in pancreas and lung has been detected. The CYP1A2 gene consists of 7 exons and is located at chromosome 15q22-qter. More than 40 single nucleotide polymorphisms (SNPs) of the CYP1A2 gene have been discovered so far [7, 8].
High in vivo CYP1A2 activity has been suggested to be a susceptibility factor for cancers of the bladder, colon and rectum, where exposure to compounds such as aromatic amines and HAs has been implicated in the etiology of the disease [5, 6]. Additionally, it has been reported that among the CYP1A2 polymorphisms, CYP1A2*1C (rs2069514) and CYP1A2*1 F (rs762551) are associated with reduced enzyme activity in smokers [5].
In recent years, efforts have been put into investigating the association of CYP1A2 polymorphisms and the risk of several cancers, among them, colorectal [9–23], lung [7, 24–32], breast [33–46], bladder [4, 47–52], and other in different population groups, with inconsistent results. Therefore, with these meta-analyses we aimed to provide a quantitative assessment of the association between all CYP1A2 polymorphisms and risk of cancer at various sites.
Methods
Selection criteria
Identification of the studies was carried out through a search of MEDLINE, ISI Web of Science and SCOPUS databases up to February 15th, 2015, by two independent researchers (R.A. and V.V.). The following terms were used: [(Cytochrome P450 1A2) OR (CYP1A2)] AND (Cancer) AND (Humans [MeSH]), without any restriction on language. All eligible studies were retrieved, and their bibliographies were hand-searched to find additional eligible studies. We only included published studies with full-text articles available.
Also, detail search of several publically available databases of genome-wide association studies (GWAS) - GWAS Central, Genetic Associations and Mechanisms in Oncology (GAME-ON), the Human Genome Epidemiology (HuGE) Navigator, National Human Genome Research Institute (NHGRI GWAS Catalog), The database of Genotypes and Phenotypes (dbGaP), The GWASdb, VarySysDB Disease Edition (VaDE), The genome wide association database (GWAS DB), was carried out up to February 15th, 2015 for the association between CYP1A2 and various cancers using the combinations of following terms: (Cytochrome P450 1A2) OR (CYP1A2) OR (Chromosome 15q24.1) AND (Cancer). Additional consultation of principal investigators (PI) of the retrieved GWAS was undertaken in order to obtain the primary data and include them in the analyses.
Studies were considered eligible if they were assessing the frequency of any CYP1A2 gene polymorphism in relation to the number of cancer cases and controls, according to the three variant genotypes (wild-type homozygous (wtwt), heterozygous (wtmt) and homozygous mutant (mtmt)). Case-only and case series studies with no control population were excluded, as well as studies based only on phenotypic tests, reviews, meta-analysis and studies focused entirely on individuals younger than 16 years old. When the same sample was used in several publications, we only considered the most recent or complete study to be used in our meta-analyses. Meanwhile, for studies that investigated more types of cancer, we counted them as individual data only in a subgroup analysis by the tumour type, while when they reported different ethnicity or location within the same study, we considered them as a separate studies.
Data extraction
Two investigators (C.I. and V.V.) independently extracted the data from each article using a structured sheet and entered them into the database. The following items were considered: rs number, first author, year and location of the study, tumour site, ethnicity, study design, number of cases and controls, number of heterozygous and homozygous individuals for the CYP1A2 polymorphisms in the compared groups. We used widely accepted National Center for Biotechnology Information (NCBI) CYP classification [53] to determine which specific genotype should be considered as wtwt, wtmt and mtmt. We also ranked studies according to their sample size, where studies with minimum of 200 cases were classified as small and above 200 cases as large.
Statistical analysis
The estimated Odds Ratios (ORs) and 95 % confidence interval (CI) for the association between each CYP1A2 SNP and cancer were defined as follows:
-
wtmt vs wtwt (OR1)
-
mtmt vs wtwt (OR2).
According to the following algorithm on the criteria to identify the best genetic model [54] for each SNP:
-
Recessive model (mtmt versus wt carriers): if OR2 ≠ 1 and OR1 = 1
-
Dominant model (mt carriers versus wtwt): if OR2 = OR1 ≠ 1,
we used the dominant model of inheritance for rs2069514, rs2069526 and rs35694136 and recessive model for rs762551, rs2470890 and rs2472304 in the meta-analysis. Random effect model was used to calculate the pooled ORs, taking into account the possibility of between studies heterogeneity [55], that was evaluated by the χ2-based Q statistics and the I2 statistics [56], where I2 = 0 % indicates no observed heterogeneity, within 25 % regarded as low, 50 % as moderate, and 75 % as high [57]. A visual inspection of Begg’s funnel plot and Begg’s and Egger’s asymmetry tests [58] were used to investigate publication bias, where appropriate [59]. To determinate the deviation from the Hardy-Weinberg Equilibrium (HWE) we used a publicly available program (http://ihg.gsf.de/cgi-bin/hw/hwa1.pl ). Additionally, the Galbraith’s test [60] was performed to evaluate the weight each study had on the overall estimate and its contribution on Q-statistics. We also performed a one-way sensitivity analysis to explore the effect that each study had on the overall effect estimate, by computing the meta-analysis estimates repeatedly after every study has been omitted.
Studies whose allele frequency in the control population deviated significantly from the Hardy-Weinberg Equilibrium (HWE) at the p-value ≤ 0.01 were excluded from the meta-analyses, given that this deviation may represent bias. We conducted stratified analysis by study design, ethnicity, sample size and tumour site to investigate the potential sources of heterogeneity across the studies. Statistical analyses were performed using the STATA software package v. 13 (Stata Corporation, College 162 Station, TX, USA), and all statistical tests were two-sided.
Results
Characteristics of the studies
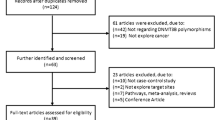
We identified a total of 2541 studies through MEDLINE, ISI Web of Science and SCOPUS online databases. One thousand and sixteen studies were left after duplicates removal, and after carefully reading the titles, only 175 studies were assessed for eligibility. After reviewing the abstracts, 120 full text articles were obtained for further eligibility. By not fulfilling the inclusion criteria, 61 full text articles were excluded, leaving 59 studies for quantitative synthesis. Additional hand-search of the reference lists of 59 included studies was done and 11 new eligible studies were found, resulting in 70 included studies.
Eleven GWASs on the association between CYP1A2 SNPs and cancer risk were identified after detail search of GWAS online databases. Studies did not report full data on investigated SNPs, so we contacted principal investigators (PIs) to retrieve the information and include into our analyses. After 3 repeated solicitations, only one PI provided us with the full data on CYP1A2 SNPs of breast cancer cases and controls, and by this making total of 71 studies included in our meta-analyses [4, 7–52, 61–84]. Figure 1 shows the process of literature search and study selection.

Flowchart depicting literature search and study selection. *GWAS data bases searched: GWAS Central, Genetic Associations and Mechanisms in Oncology (GAME-ON), the Human Genome Epidemiology (HuGE) Navigator, National Human Genome Research Institute (NHGRI GWAS Catalog), The database of Genotypes and Phenotypes (dbGaP), The GWASdb, VarySysDB Disease Edition (VaDE), The genome wide association database (GWAS DB)
Among the 71 included studies, 42 were population-based case-control studies, 28 hospital-based case-control studies and one genome-wide association study, including total of 47,413 cancer cases and 58,546 controls (Table 1). The total investigated SNPs were six, of which 62 studies on the rs762551 [4, 7–21, 23, 24, 26–46, 48–50, 52, 61–65, 67, 68, 72–75, 77–79, 81–84]. Thirty five studies out of 62 were conducted on Caucasians (56.5 %), 17 on mixed populations (27.4 %) and 10 on Asians (16.1 %), including 33,181 cancer cases and 40,195 controls. Among them, 15 were on breast cancer, 14 studies on colorectal, and 9 on lung cancer.
Twenty studies investigated the rs2069514 [9, 16, 18, 22–27, 29–32, 34, 47, 51, 61, 66, 71, 76], of which 11 were conducted on Caucasians (55 %) and 9 on Asians (45 %). Eight studies investigated the effect on lung cancer (40 %), 5 studies on colorectal cancer (25 %), 2 on liver cancer (10 %), 2 on bladder (10 %) and by 1 study on stomach (5 %), breast (5 %) and pleura (5 %), totaling for 4562 cancer cases and 6399 controls (Table 1).
The remaining four SNPs were investigated by a reduced number of studies and details are presented in Table 1. Genotype frequencies in all control groups did not deviate from values predicted by HWE (Table 1). As some studies on different cancer types shared the same control group [35], these studies were aggregated when performing the meta-analyses, except when stratified by tumour site.
Quantitative synthesis
As the crude analysis for rs762551 provided an OR1 of 1.03 (95 % CI 0.98–1.07) and an OR2 of 1.06 (95 % CI 0.97–1.16), for rs2470890 OR1 1.03 (95 % CI 0.93–1.14) and OR2 of 1.14 (95 % CI 0.97–1.34) and for rs2472304 OR1 of 0.98 (95 % CI 0.79–1.22) and OR2 of 0.89 (95 % CI 0.66–1.22) according to the criteria proposed in the methods section, we applied the recessive model of inheritance for the meta-analyses. On the other hand, for rs2069514, rs2069526 and rs35694136 original papers did not report enough data to calculate OR1 and OR2, so we were able only to apply the dominant model for the data analyses.
The Figs. 2 and 3 depict the forest plots of the ORs of the six CYP1A2 SNPs and cancer. By pooling 62 studies on rs762551, the meta-analysis reported an OR of 1.03 (95 % CI 0.96–1.12) for overall cancer (P for heterogeneity < 0.01; I2 = 50.4 %). Egger test and the Begg’s correlation method did not provide statistical evidence of publication bias (P = 0.19 and P = 0.39, respectively) (Fig. 4). To explore the potential sources of heterogeneity, we performed the Galbraith’s test which identified the study of Shimada N. (b) [45] and Sangrajrang S. [44], as the main contributors to heterogeneity (graph not shown). In the one-way sensitivity analysis, these two outlying studies were omitted from meta-analysis and the overall OR slightly changed to 1.03 (95 % CI 0.96–1.11), with a reduced heterogeneity (P for heterogeneity <0.01; I2 = 43.0 %).

Forest plot of the CYP1A2 rs762551 and cancer meta-analysis under recessive models of inheritance. The diamonds and horizontal lines correspond to the study-specific odds ratio (OR) and 95 % confidence interval (CI)

Forest plot of the remaining five CYP1A2 SNPs and cancer meta-analyses under different models of inheritance. The diamonds and horizontal lines correspond to the study-specific odds ratio (OR) and 95 % confidence interval (CI)

Funnel plot for publication bias for studies with CYP1A2 rs762551. Each point represents an individual study for the indicated association
Results of the stratified meta-analyses are reported in the Table 2. When stratifying the results of meta-analysis for rs762551 by ethnicity, we found no significant effect of CYP1A2 on cancer risk for Caucasians (OR = 1.03; 95 % CI 0.94–1.13), Asians (OR = 0.95; 95 % CI 0.72–1.27) nor among a mixed population (OR = 1.05; 95 % CI 0.89–1.25). When stratifying according to the tumour site, results showed an OR of 0.84 (95 % CI 0.70–1.01; P for heterogeneity = 0.23, I2 = 28.5 %) for bladder cancer for those homozygous mutant types of rs762551 (Table 2). We further examined the association between the CYP1A2 polymorphism and cancer risk according to ethnicity, source of controls and sample size and then stratified by cancer type. We found a significant OR of 0.79 (95 % CI 0.65–0.95; P for heterogeneity = 0.09, I2 = 58.1 %) for bladder cancer among the hospital-based population and among Caucasians. There was no significant association among Caucasians for breast cancer (OR = 1.71; 95 % CI 0.94–3.10; P for heterogeneity < 0.01, I2 = 83.4 %), lung cancer (OR = 1.07; 95 % CI 0.79–1.44; P for heterogeneity = 0.07, I2 = 48.1 %,) or colorectal cancer (OR = 1.05, 95 % CI 0.94–1.16; P for heterogeneity = 0.49, I2 = 0.0 %). Among Asians, when stratifying for cancer type, we obtained an OR of 0.76 (95 % CI 0.47–1.22; P for heterogeneity = 0.48, I2 = 0.0 %) for colorectal cancer and OR = 1.27 (95 % CI 0.75–2.16; P for heterogeneity <0.01, I2 = 83.6 %) for breast cancer.
When pooling the 20 studies on rs2069514, the meta-analysis provided an OR of 0.99 (95 % CI 0.81–1.21) for overall cancer (P for heterogeneity <0.01; I2 = 60 %) (Fig. 2). Egger test and the Begg’s correlation method provided no statistical evidence of publication bias (P = 0.86 and P = 0.56, respectively). We performed the Galbraith’s test to explore the source of heterogeneity and accordingly singled out the study of B’chir F. et al. [24] as the main contributor to heterogeneity (graph not shown). In the one-way sensitivity analysis, the study of B’chir F. et al. [24] was omitted from the overall meta-analysis and the heterogeneity dropped down to 14 % (P = 0.28), with the OR of 0.93 (95 % CI 0.82–1.06).
We evaluated the effect of the rs2069514 polymorphism according to the tumour site and obtained an OR of 0.96 (95 % CI 0.65–1.43; P for heterogeneity = 0.07, I2 = 53.2 %) for colorectal cancer, an OR of 1.29 (95 % CI 0.60–2.79; P for heterogeneity = 0.00; I2 = 82.1 %) for lung cancer (Table 2). Analyses on different ethnicity and study design did not provide any significant results (Caucasians OR = 1.16; 95 % CI 0.63–2.14; I2 = 75.7 %, P < 0.01, for Asians OR = 0.96; 95 % CI 0.86–1.07, I2 = 0.0 %; P = 0.86 and Hospital-based study design OR = 1.01; 95 % CI 0.73–1.40; I2 = 73.7 %, P < 0.01, for Population-based design OR = 0.94; 95 % CI 0.78–1.14; I2 = 10.6 %, P = 0.35). We did not observe any significant association between rs2069514 polymorphism and cancer risk when subgrouping data according to ethnicity, source of controls and sample size and then stratified by cancer type. Among Caucasians, we obtained an OR of 1.28 (95 % CI 0.55–2.98; I2 = 80.9 %, P < 0.01) for lung cancer, while among Asians OR = 0.94 (95 % CI 0.68–1.31; I2 = 0.0 %, P = 0.44) for lung and OR = 0.94 (95 % CI 0.71–1.24; I2 = 28.8 %, P = 0.25) for colorectal cancer.
We performed meta-analysis of 11 studies on rs2470890 which provided an OR of 1.11 (95 % CI 0.96-1.28) for the overall cancer risk (P for heterogeneity 0.09; I2 = 39 %) (Fig. 2). Egger test and the Begg’s correlation method provided no statistical evidence of publication bias (P = 0.42 and P = 0.59, respectively). The Galbraith’s test singled out the study of Anderson LN et al. [33] as the main contributor to heterogeneity (graph not shown). In one-way sensitivity analysis, this study was omitted from the overall meta-analysis and the heterogeneity dropped down to 6 % (P = 0.39), with still not significant OR of 1.06 (95 % CI, 0.94–1.19). The effect of rs2470890 polymorphism according to the tumour site was also evaluated and was obtained non-significant result of OR of 1.10 (95 % CI, 0.94–1.28) P for heterogeneity = 0.51, I2 = 0.0 % for colorectal cancer and an OR of 1.20 (95 % CI, 0.83–1.74), P for heterogeneity = 0.09; I2 = 65.7 % for cancer of upper aero-digestive tract (UADT) (Table 2). Subgroups analyses by different ethnicity showed a significant association between rs2470890 polymorphism and cancer for Mixed population OR = 1.44; 95 % CI 1.16–1.80; I2 = 0.0 %, P = 0.41, while not among Caucasians (OR = 1.07; 95 % CI 0.96–1.20; I2 = 0.0 %, P = 0.41) nor Asians (OR = 0.77; 95 % CI 0.37–1.64; I2 = 55.4 %, P = 0.13).
Results of the remaining three SNPs of CYP1A2 are presented in the Fig. 3 and the Table 2. Absence of significant association with overall risk of cancer was reported. Only for rs2472304 we rendered an OR of 0.72 (95 % CI 0.52–0.99) I2 = 0.0 %, P = 0.61 for Caucasians, when doing a subgroup analyses on ethnicity. No evidence of significant heterogeneity was detected (data not shown).
When the meta-analyses were performed excluding small sample size studies for all examined SNPs, there were still no significant results obtained for the association between CYP1A2 SNPs and cancer risk (Table 2).
Discussion
The current meta-analysis included 71 studies with more than 47,000 cancer cases and 58,000 controls, detailing on all the CYP1A2 gene polymorphisms and risk of cancer, shows no significant effect of investigated CYP1A2 SNPs on cancer overall risk under various genetic models. Meta-analysis is a common tool for summarizing different studies to resolve the problem of small size statistical power and discrepancy in genetic association studies [85] and also it provides more reliable results than a single case-control study. To the best of our knowledge, this is the largest and most comprehensive meta-analysis on CYP1A2 SNPs and cancer performed so far. Several previous meta-analyses have been reported on the association between CYP1A2 gene polymorphisms and risk of cancer [86–95]. Deng et al. [87] reported no association between CYP1A2 rs762551 polymorphism and lung cancer risk by including 1675 cases and 2393 controls. In the paper of Xue et al. [94], combined mutational homozygous and wild type homozygous genotype compared with mutational heterozygous genotype, had protective effect against gastric cancer by including 383 cases and 1229 controls. Wen-Xia Sun et al. [91] reported a significant protective effect of homozygous mutant of rs762551 CYP1A2 SNP on bladder cancer in Caucasian population. Based on 19 studies, Wang et al. [93] found a borderline significantly increased risk of overall cancer among homozygous mutant of CYP1A2 rs762551, mainly in Caucasians. The meta-analysis of 46 case-control studies by Tian et al. [92] suggested that the wild-type allele of CYP1A2 rs762551 polymorphism might be associated with breast and ovarian cancer risk, especially among Caucasians. These inconclusive results could be explained by differences in study design, sample size, ethnicity, and cancer subtypes included.
The CYP1A2 gene is a member of the CYP1 family and is involved in metabolism of carcinogens and estrogens. In particular, it plays an essential role in the metabolic activation of pro-carcinogens, such as polycyclic aromatic hydrocarbons (PAHs) and heterocyclic aromatic amines (HAA) [93]. Therefore, increased levels of this enzyme could explain the association with increased risk for cancer [16]. The wild genotype of CYP1A2*1 F represents a highly inducible genotype, and this high CYP1A2 activity may increase the hydroxylated forms as proximate carcinogens, from HCAs and aryl-amines [29].
In our meta-analyses, we showed that none of the investigated CYP1A2 polymorphisms were significantly associated with overall risk of cancer at various sites. These results confirm the findings of a recent meta-analysis from Li Zhenzhen et al. [95] where was reported no significant associations with cancer risk in any genetic model (allele contrast, codominant, dominant, or recessive model) in terms of rs2069514 and rs3569413. For rs762551, they found that carriers of C-allele have an increased overall risk of developing cancer in allele genetic model (C-allele vs. A-allele) while not in other models. Their further subgroup analyses demonstrated that rs762551 polymorphism was associated with an increased risk of cancer in Caucasians under dominant model, while we investigated rs762551 under recessive model and did not obtain significant association. Moreover, their meta-analysis included only 37 case-control studies of rs762551 involving 16,825 cancer cases and 21,513 controls. Our meta-analysis may be the most comprehensive meta-analysis of the relationship between the CYP1A2 rs762551 polymorphisms and the risk of cancer, to date.
When stratifying according to tumour site, our results showed a borderline not significant OR of 0.84 (95 % CI, 0.70–1.01) for bladder cancer for those homozygous mutant of rs762551 with total of 3430 cases and 3242 controls included (Table 2), thus confronting the previous evidence from Wen-Xia Sun et al. [91] that reported an OR = 0.79 (95 % CI 0.66–0.94) from 2415 cases and 2208 controls, and suggesting that on even bigger number of subjects investigated, this significance might disappear. Pavanello et al. [96] stressed that polymorphisms of rs762551 might be the crucial modulating factor along the continuum from the exposure to relevant environmental and occupational factors, in increased CYP1A2 activity of smokers measured by the urinary caffeine metabolic ratio.
We also found a significant decreased risk for bladder cancer for mutant carriers of rs762551 among the hospital-based population. Hospital-based studies have certain biases since those controls may have some benign diseases which can progress and also may not be representative of the general population. Using a population-based control would reduce the chance of bias in these studies.
In one recent meta-analysis by Zhi-Bin Bu et al. [86] on the association between CYP1A2 rs762551, rs2069514, rs2069526, and rs2470890 polymorphisms and lung cancer risk, there was no evidence of significant association between lung cancer risk and CYP1A2 rs2069514, s2470890, and rs2069526 polymorphisms. They found increased lung cancer risk for rs762551 polymorphism in Caucasians from 3 studies, while in our analysis there was no such connection on a bigger sample of studies [24, 26–28, 30–32].
Lastly, when stratifying our results for breast and colorectal cancer, we did not report any significant association between rs762551 and these cancers, thus confirming previous meta-analyses of Li-Xin Qiu et al. [90] on breast and Xiao-Feng He et al. [88] on colorectal cancer risk. Other meta-analysis by Jianbing Hu et al. [89] also suggested that CYP1A2 rs762551 polymorphism was not a risk factor for colorectal cancer susceptibility, since no association was detected after all studies were pooled together nor in a subgroup analysis by ethnicity or source of controls, in all genetic models. The influence of the different CYP1A2 SNPs might be camouflaged by the presence of some yet unidentified causal genes involved in many other types of cancer.
When stratifying the results according to ethnicity, the protective effect of rs2472304 in our study was restricted only to Caucasians, while for rs2470890, we noticed an increased risk among a mixed population. A possible explanation for these results could be that the same polymorphisms may play different roles in cancer susceptibility in different ethnic populations as well as different tumour positions, due to a difference in genetic backgrounds, the environment they live in, lifestyle and migrations, which all may have a critical role in cancer pathogenesis [97]. Also, some low penetrance genetic effects of single polymorphism could be determined by their interaction with other polymorphisms and/or a specific environmental exposure.
No other relevant results were reported for the remaining SNPs, however there were available only few studies regarding these associations, involving relatively small number of participants.
In interpreting the results, some limitations of our study should be considered. Firstly, only published studies were included, so there was space for publication bias, which in fact was confirmed by formal statistical tests. Secondly, the study size for most of the CYP1A2 polymorphisms was limited to perform any meaningful subgroup analyses. Thirdly, it would have been valuable to stratify the results according to environmental effect modifiers, though this was not possible, as the original data sets were not available. Indeed, due to lack of access to original data used in included studies, our meta-analyses are based on the unadjusted data, so the effects might be confounded or modified by relevant covariates. Fourthly, beside breast cancer, there are no genome-wide association studies of the effects of CYP1A2 polymorphisms on cancer risk. We were able to include only one breast cancer GWAS into our analyses, therefore our results might be affected by additional publication bias.
Despite these limitations, our meta-analyses also have some advantages. First, the statistical power of the analyses was noticeably increased as a huge number of cases and controls were pooled from different studies and has more statistical powerful than any single case-control study. Secondly, in our analyses, we included more studies than any previously published meta-analysis on the association between CYP1A2 polymorphism and cancer risks and investigated 6 different CYP1A2 SNPs.
Conclusions
In conclusion, our meta-analysis suggests that investigated CYP1A2 polymorphisms are not associated with cancer susceptibility under various genetic models. In order to reach a more definitive conclusion, there is a necessity for further gene-gene and gene-environment interaction studies to be conducted on different populations and larger sample size, for diverse CYP1A2 SNPs.
Abbreviations
- 95 % CI:
-
95 % confidence interval
- CYP1A2:
-
cytochrome P450 1A2
- dbGaP:
-
The database of Genotypes and Phenotypes
- GAME-ON:
-
Genetic Associations and Mechanisms in Oncology
- GWAS:
-
genome-wide association studies
- GWAS DB:
-
The genome wide association database
- HAA:
-
heterocyclic aromatic amines
- HAs:
-
heterocyclic amines
- HuGE:
-
the Human Genome Epidemiology Navigator
- HWE:
-
Hardy-Weinberg Equilibrium
- mtmt:
-
homozygous mutant genotype
- NCBI:
-
National Center for Biotechnology Information
- NHGRI:
-
National Human Genome Research Institute Catalog
- ORs:
-
Odds Ratios
- PAHs:
-
polycyclic aromatic hydrocarbons
- PIs:
-
principal investigators
- SNPs:
-
single nucleotide polymorphisms
- VaDE:
-
VarySysDB Disease Edition
- wtmt:
-
wild-type mutant-type heterozygous genotype
- wtwt:
-
wild-type homozygous genotype
References
Boffetta P, Boccia S, La Vecchia C. A Quick Guide to Cancer Epidemiology. Springer International Publishing; 2014. p. 11–4.
Heller F. Genetics/genomics and drug effects. Acta Clin Belg. 2013;68(2):77–80.
Raunio H, Husgafvel-Pursiainen K, Anttila S, Hietanen E, Hirvonen A, Pelkonen O. Diagnosis of polymorphisms in carcinogen-activating and inactivating enzymes and cancer susceptibility--a review. Gene. 1995;159(1):113–21.
Altayli E, Gunes S, Yilmaz AF, Goktas S, Bek Y. CYP1A2, CYP2D6, GSTM1, GSTP1, and GSTT1 gene polymorphisms in patients with bladder cancer in a Turkish population. Int Urol Nephrol. 2009;41(2):259–66.
Sachse C, Bhambra U, Smith G, Lightfoot TJ, Barrett JH, Scollay J, et al. Polymorphisms in the cytochrome P450 CYP1A2 gene (CYP1A2) in colorectal cancer patients and controls: allele frequencies, linkage disequilibrium and influence on caffeine metabolism. Br J Clin Pharmacol. 2003;55(1):68–76.
Nakajima M, Yokoi T, Mizutani M, Kinoshita M, Funayama M, Kamataki T. Genetic polymorphism in the 5′-flanking region of human CYP1A2 gene: effect on the CYP1A2 inducibility in humans. J Biochem. 1999;125(4):803–8.
Aldrich MC, Selvin S, Hansen HM, Barcellos LF, Wrensch MR, Sison JD, et al. CYP1A1/2 haplotypes and lung cancer and assessment of confounding by population stratification. Cancer Res. 2009;69(6):2340–8.
Li D, Jiao L, Li Y, Doll MA, Hein DW, Bondy ML, et al. Polymorphisms of cytochrome P4501A2 and N-acetyltransferase genes, smoking, and risk of pancreatic cancer. Carcinogenesis. 2006;27(1):103–11.
Bae SY, Choi SK, Kim KR, Park CS, Lee SK, Roh HK, et al. Effects of genetic polymorphisms of MDR1, FMO3 and CYP1A2 on susceptibility to colorectal cancer in Koreans. Cancer Sci. 2006;97(8):774–9.
Cleary SP, Cotterchio M, Shi E, Gallinger S, Harper P. Cigarette smoking, genetic variants in carcinogen-metabolizing enzymes, and colorectal cancer risk. Am J Epidemiol. 2010;172(9):1000–14.
Cotterchio M, Boucher BA, Manno M, Gallinger S, Okey AB, Harper PA. Red meat intake, doneness, polymorphisms in genes that encode carcinogen-metabolizing enzymes, and colorectal cancer risk. Cancer Epidemiol Biomarkers Prev. 2008;17(11):3098–107.
Dik VK, van Oijen MG, Uiterwaal C, van Gils C, van Duijnhoven FJ, Cauchi S, et al. Coffee consumption, genetic polymorphisms in CYP1A2 and NAT2, and colorectal cancer risk. Gastroenterology. 2013;144(5):S589–90.
Kiss I, Orsos Z, Gombos K, Bogner B, Csejtei A, Tibold A, et al. Association between allelic polymorphisms of metabolizing enzymes (CYP 1A1, CYP 1A2, CYP 2E1, mEH) and occurrence of colorectal cancer in Hungary. Anticancer Res. 2007;27(4C):2931–7.
Kobayashi M, Otani T, Iwasaki M, Natsukawa S, Shaura K, Koizumi Y, et al. Association between dietary heterocyclic amine levels, genetic polymorphisms of NAT2, CYP1A1, and CYP1A2 and risk of colorectal cancer: a hospital-based case-control study in Japan. Scand J Gastroenterol. 2009;44(8):952–9.
Kury S, Buecher B, Robiou-du-Pont S, Scoul C, Sebille V, Colman H, et al. Combinations of cytochrome P450 gene polymorphisms enhancing the risk for sporadic colorectal cancer related to red meat consumption. Cancer Epidemiol Biomarkers Prev. 2007;16(7):1460–7.
Landi S, Gemignani F, Moreno V, Gioia-Patricola L, Chabrier A, Guino E, et al. A comprehensive analysis of phase I and phase II metabolism gene polymorphisms and risk of colorectal cancer. Pharmacogenet Genomics. 2005;15(8):535–46.
Rudolph A, Sainz J, Hein R, Hoffmeister M, Frank B, Forsti A, et al. Modification of menopausal hormone therapy-associated colorectal cancer risk by polymorphisms in sex steroid signaling, metabolism and transport related genes. Endocr Relat Cancer. 2011;18(3):371–84.
Sachse C, Smith G, Wilkie MJ, Barrett JH, Waxman R, Sullivan F, et al. A pharmacogenetic study to investigate the role of dietary carcinogens in the etiology of colorectal cancer. Carcinogenesis. 2002;23(11):1839–49.
Saebo M, Skjelbred CF, Brekke Li K, Bowitz Lothe IM, Hagen PC, Johnsen E, et al. CYP1A2 164 A-->C polymorphism, cigarette smoking, consumption of well-done red meat and risk of developing colorectal adenomas and carcinomas. Anticancer Res. 2008;28(4C):2289–95.
Sainz J, Rudolph A, Hein R, Hoffmeister M, Buch S, von Schonfels W, et al. Association of genetic polymorphisms in ESR2, HSD17B1, ABCB1, and SHBG genes with colorectal cancer risk. Endocr Relat Cancer. 2011;18(2):265–76.
Wang J, Joshi AD, Corral R, Siegmund KD, Marchand LL, Martinez ME, et al. Carcinogen metabolism genes, red meat and poultry intake, and colorectal cancer risk. Int J Cancer. 2012;130(8):1898–907.
Yeh CC, Sung FC, Tang R, Chang-Chieh CR, Hsieh LL. Polymorphisms of cytochrome P450 1A2 and N-acetyltransferase genes, meat consumption, and risk of colorectal cancer. Dis Colon Rectum. 2009;52(1):104–11.
Yoshida K, Osawa K, Kasahara M, Miyaishi A, Nakanishi K, Hayamizu S, et al. Association of CYP1A1, CYP1A2, GSTM1 and NAT2 gene polymorphisms with colorectal cancer and smoking. Asian Pac J Cancer Prev. 2007;8(3):438–44.
B’Chir F, Pavanello S, Knani J, Boughattas S, Arnaud MJ, Saguem S. CYP1A2 genetic polymorphisms and adenocarcinoma lung cancer risk in the Tunisian population. Life Sci. 2009;84(21–22):779–84.
Chiou HL, Wu MF, Chien WP, Cheng YW, Wong RH, Chen CY, et al. NAT2 fast acetylator genotype is associated with an increased risk of lung cancer among never-smoking women in Taiwan. Cancer Lett. 2005;223(1):93–101.
Gemignani F, Landi S, Szeszenia-Dabrowska N, Zaridze D, Lissowska J, Rudnai P, et al. Development of lung cancer before the age of 50: the role of xenobiotic metabolizing genes. Carcinogenesis. 2007;28(6):1287–93.
Gervasini G, Ghotbi R, Aklillu E, San Jose C, Cabanillas A, Kishikawa J, et al. Haplotypes in the 5′-untranslated region of the CYP1A2 gene are inversely associated with lung cancer risk but do not correlate with caffeine metabolism. Environ Mol Mutagen. 2013;54(2):124–32.
Mikhalenko AP, Krupnova EV, Chakova NN, Chebotareva NV, Demidchik YE. Assessment of the relationship between combinations of polymorphic variants of xenobiotic-metabolizing enzyme genes and predisposition to lung cancer. Cytol Genet. 2014;48(2):111–6.
Osawa Y, Osawa KK, Miyaishi A, Higuchi M, Tsutou A, Matsumura S, et al. NAT2 and CYP1A2 polymorphisms and lung cancer risk in relation to smoking status. Asian Pac J Cancer Prev. 2007;8(1):103–8.
Pavanello S, Fedeli U, Mastrangelo G, Rota F, Overvad K, Raaschou-Nielsen O, et al. Role of CYP1A2 polymorphisms on lung cancer risk in a prospective study. Cancer Genet. 2012;205(6):278–84.
Singh AP, Pant MC, Ruwali M, Shah PP, Prasad R, Mathur N, et al. Polymorphism in cytochrome P450 1A2 and their interaction with risk factors in determining risk of squamous cell lung carcinoma in men. Cancer Biomark. 2010;8(6):351–9.
Zienolddiny S, Campa D, Lind H, Ryberg D, Skaug V, Stangeland LB, et al. A comprehensive analysis of phase I and phase II metabolism gene polymorphisms and risk of non-small cell lung cancer in smokers. Carcinogenesis. 2008;29(6):1164–9.
Anderson LN, Cotterchio M, Mirea L, Ozcelik H, Kreiger N. Passive cigarette smoke exposure during various periods of life, genetic variants, and breast cancer risk among never smokers. Am J Epidemiol. 2012;175(4):289–301.
Ayari I, Fedeli U, Saguem S, Hidar S, Khlifi S, Pavanello S. Role of CYP1A2 polymorphisms in breast cancer risk in women. Mol Med Rep. 2013;7(1):280–6.
Gulyaeva LF, Mikhailova ON, PustyInyak VO, Kim IV, Gerasimov AV, Krasilnikov SE, et al. Comparative analysis of SNP in estrogen-metabolizing enzymes for ovarian, endometrial, and breast cancers in Novosibirsk, Russia. Adv Exp Med Biol. 2008;617:359–66.
Hopper JL, Dite GS, Jenkins MA, Southey MC, Hocking JS, Giles GG, et al. Familial risks, early-onset breast cancer, and BRCA1 and BRCA2 germline mutations. J Natl Cancer Inst. 2003;95(6):448–57.
Khvostova EP, Pustylnyak VO, Gulyaeva LF. Genetic polymorphism of estrogen metabolizing enzymes in Siberian women with breast cancer. Genet Test Mol Biomarkers. 2012;16(3):167–73.
Kotsopoulos J, Ghadirian P, El-Sohemy A, Lynch HT, Snyder C, Daly M, et al. The CYP1A2 genotype modifies the association between coffee consumption and breast cancer risk among BRCA1 mutation carriers. Cancer Epidemiol Biomarkers Prev. 2007;16(5):912–6.
Le Marchand L, Donlon T, Kolonel LN, Henderson BE, Wilkens LR. Estrogen metabolism-related genes and breast cancer risk: the multiethnic cohort study. Cancer Epidemiol Biomarkers Prev. 2005;14(8):1998–2003.
Lee HJ, Wu K, Cox DG, Hunter D, Hankinson SE, Willett WC, et al. Polymorphisms in xenobiotic metabolizing genes, intakes of heterocyclic amines and red meat, and postmenopausal breast cancer. Nutr Cancer. 2013;65(8):1122–31.
Long JR, Egan KM, Dunning L, Shu XO, Cai Q, Cai H, et al. Population-based case-control study of AhR (aryl hydrocarbon receptor) and CYP1A2 polymorphisms and breast cancer risk. Pharmacogenet Genomics. 2006;16(4):237–43.
Lowcock EC, Cotterchio M, Anderson LN, Boucher BA, El-Sohemy A. High coffee intake, but not caffeine, is associated with reduced estrogen receptor negative and postmenopausal breast cancer risk with no effect modification by CYP1A2 genotype. Nutr Cancer. 2013;65(3):398–409.
Marie-Genica C. Genetic polymorphisms in phase I and phase II enzymes and breast cancer risk associated with menopausal hormone therapy in postmenopausal women. Breast Cancer Res Treat. 2010;119(2):463–74.
Sangrajrang S, Sato Y, Sakamoto H, Ohnami S, Laird NM, Khuhaprema T, et al. Genetic polymorphisms of estrogen metabolizing enzyme and breast cancer risk in Thai women. Int J Cancer. 2009;125(4):837–43.
Shimada N, Iwasaki M, Kasuga Y, Yokoyama S, Onuma H, Nishimura H, et al. Genetic polymorphisms in estrogen metabolism and breast cancer risk in case-control studies in Japanese, Japanese Brazilians and non-Japanese Brazilians. J Hum Genet. 2009;54(4):209–15.
Takata Y, Maskarinec G, Le Marchand L. Breast density and polymorphisms in genes coding for CYP1A2 and COMT: the Multiethnic Cohort. BMC Cancer. 2007;7:30.
Cui X, Lu X, Hiura M, Omori H, Miyazaki W, Katoh T. Association of genotypes of carcinogen-metabolizing enzymes and smoking status with bladder cancer in a Japanese population. Environ Health Prev Med. 2013;18(2):136–42.
Figueroa JD, Malats N, Garcia-Closas M, Real FX, Silverman D, Kogevinas M, et al. Bladder cancer risk and genetic variation in AKR1C3 and other metabolizing genes. Carcinogenesis. 2008;29(10):1955–62.
Guey LT, Garcia-Closas M, Murta-Nascimento C, Lloreta J, Palencia L, Kogevinas M, et al. Genetic susceptibility to distinct bladder cancer subphenotypes. Eur Urol. 2010;57(2):283–92.
Pavanello S, Mastrangelo G, Placidi D, Campagna M, Pulliero A, Carta A, et al. CYP1A2 polymorphisms, occupational and environmental exposures and risk of bladder cancer. Eur J Epidemiol. 2010;25(7):491–500.
Tsukino H, Kuroda Y, Nakao H, Imai H, Inatomi H, Osada Y, et al. Cytochrome P450 (CYP) 1A2, sulfotransferase (SULT) 1A1, and N-acetyltransferase (NAT) 2 polymorphisms and susceptibility to urothelial cancer. J Cancer Res Clin Oncol. 2004;130(2):99–106.
Villanueva CM, Silverman DT, Murta-Nascimento C, Malats N, Garcia-Closas M, Castro F, et al. Coffee consumption, genetic susceptibility and bladder cancer risk. Cancer Causes Control. 2009;20(1):121–7.
National Center for Biotechnology Information. dbSNP Home Page. [cited 2015 02/15]. Available from: http://www.ncbi.nlm.nih.gov/SNP/index.html. Accessed 15 Feb 2015.
Attia J, Thakkinstian A, D’Este C. Meta-analyses of molecular association studies: methodologic lessons for genetic epidemiology. J Clin Epidemiol. 2003;56(4):297–303.
DerSimonian R, Laird N. Meta-analysis in clinical trials. Control Clin Trials. 1986;7(3):177–88.
Deeks J, Altman D, Bradburn M. Statistical methods for examining heterogeneity and combining results from several studies in meta-analysis. In: Egger M, Davey Smith G, Altman D, editors. Systematic reviews in health care: meta-analysis in context. 2nd ed. London: BMJ Books; 2001. p. 285–312.
Higgins JP, Thompson SG, Deeks JJ, Altman DG. Measuring inconsistency in meta-analyses. BMJ. 2003;327(7414):557–60.
Egger M, Davey Smith G, Schneider M, Minder C. Bias in meta-analysis detected by a simple, graphical test. BMJ. 1997;315(7109):629–34.
Ioannidis JP, Trikalinos TA. The appropriateness of asymmetry tests for publication bias in meta-analyses: a large survey. CMAJ. 2007;176(8):1091–6.
Galbraith RF. A note on graphical presentation of estimated odds ratios from several clinical trials. Stat Med. 1988;7(8):889–94.
Agudo A, Sala N, Pera G, Capella G, Berenguer A, Garcia N, et al. Polymorphisms in metabolic genes related to tobacco smoke and the risk of gastric cancer in the European prospective investigation into cancer and nutrition. Cancer Epidemiol Biomarkers Prev. 2006;15(12):2427–34.
Ashton KA, Proietto A, Otton G, Symonds I, McEvoy M, Attia J, et al. Polymorphisms in genes of the steroid hormone biosynthesis and metabolism pathways and endometrial cancer risk. Cancer Epidemiol. 2010;34(3):328–37.
Barbieri RB, Bufalo NE, Cunha LL, Assumpcao LV, Maciel RM, Cerutti JM, et al. Genes of detoxification are important modulators of hereditary medullary thyroid carcinoma risk. Clin Endocrinol. 2013;79(2):288–93.
Canova C, Hashibe M, Simonato L, Nelis M, Metspalu A, Lagiou P, et al. Genetic associations of 115 polymorphisms with cancers of the upper aerodigestive tract across 10 European countries: the ARCAGE project. Cancer Res. 2009;69(7):2956–65.
Canova C, Richiardi L, Merletti F, Pentenero M, Gervasio C, Tanturri G, et al. Alcohol, tobacco and genetic susceptibility in relation to cancers of the upper aerodigestive tract in northern Italy. Tumori. 2010;96(1):1–10.
Chen X, Wang H, Xie W, Liang R, Wei Z, Zhi L, et al. Association of CYP1A2 genetic polymorphisms with hepatocellular carcinoma susceptibility: a case-control study in a high-risk region of China. Pharmacogenet Genomics. 2006;16(3):219–27.
De Roos AJ, Gold LS, Wang S, Hartge P, Cerhan JR, Cozen W, et al. Metabolic gene variants and risk of non-Hodgkin’s lymphoma. Cancer Epidemiol Biomarkers Prev. 2006;15(9):1647–53.
Doherty JA, Weiss NS, Freeman RJ, Dightman DA, Thornton PJ, Houck JR, et al. Genetic factors in catechol estrogen metabolism in relation to the risk of endometrial cancer. Cancer Epidemiol Biomarkers Prev. 2005;14(2):357–66.
Eom SY, Yim DH, Zhang Y, Yun JK, Moon SI, Yun HY, et al. Dietary aflatoxin B1 intake, genetic polymorphisms of CYP1A2, CYP2E1, EPHX1, GSTM1, and GSTT1, and gastric cancer risk in Korean. Cancer Causes Control. 2013;24(11):1963–72.
Ferlin A, Ganz F, Pengo M, Selice R, Frigo AC, Foresta C. Association of testicular germ cell tumor with polymorphisms in estrogen receptor and steroid metabolism genes. Endocr Relat Cancer. 2010;17(1):17–25.
Gemignani F, Neri M, Bottari F, Barale R, Canessa PA, Canzian F, et al. Risk of malignant pleural mesothelioma and polymorphisms in genes involved in the genome stability and xenobiotics metabolism. Mutat Res. 2009;671(1–2):76–83.
Ghoshal U, Tripathi S, Kumar S, Mittal B, Chourasia D, Kumari N, et al. Genetic polymorphism of cytochrome P450 (CYP) 1A1, CYP1A2, and CYP2E1 genes modulate susceptibility to gastric cancer in patients with Helicobacter pylori infection. Gastric Cancer. 2014;17(2):226–34.
Goodman MT, McDuffie K, Kolonel LN, Terada K, Donlon TA, Wilkens LR, et al. Case-control study of ovarian cancer and polymorphisms in genes involved in catecholestrogen formation and metabolism. Cancer Epidemiol Biomarkers Prev. 2001;10(3):209–16.
Goodman MT, Tung KH, McDuffie K, Wilkens LR, Donlon TA. Association of caffeine intake and CYP1A2 genotype with ovarian cancer. Nutr Cancer. 2003;46(1):23–9.
Hirata H, Hinoda Y, Okayama N, Suehiro Y, Kawamoto K, Kikuno N, et al. CYP1A1, SULT1A1, and SULT1E1 polymorphisms are risk factors for endometrial cancer susceptibility. Cancer. 2008;112(9):1964–73.
Imaizumi T, Higaki Y, Hara M, Sakamoto T, Horita M, Mizuta T, et al. Interaction between cytochrome P450 1A2 genetic polymorphism and cigarette smoking on the risk of hepatocellular carcinoma in a Japanese population. Carcinogenesis. 2009;30(10):1729–34.
Jang JH, Cotterchio M, Borgida A, Gallinger S, Cleary SP. Genetic variants in carcinogen-metabolizing enzymes, cigarette smoking and pancreatic cancer risk. Carcinogenesis. 2012;33(4):818–27.
Kobayashi M, Otani T, Iwasaki M, Natsukawa S, Shaura K, Koizumi Y, et al. Association between dietary heterocyclic amine levels, genetic polymorphisms of NAT2, CYP1A1, and CYP1A2 and risk of stomach cancer: a hospital-based case-control study in Japan. Gastric Cancer. 2009;12(4):198–205.
Mochizuki J, Murakami S, Sanjo A, Takagi I, Akizuki S, Ohnishi A. Genetic polymorphisms of cytochrome P450 in patients with hepatitis C virus-associated hepatocellular carcinoma. J Gastroenterol Hepatol. 2005;20(8):1191–7.
Olivieri EH, da Silva SD, Mendonca FF, Urata YN, Vidal DO, Faria Mde A, et al. CYP1A2*1C, CYP2E1*5B, and GSTM1 polymorphisms are predictors of risk and poor outcome in head and neck squamous cell carcinoma patients. Oral Oncol. 2009;45(9):e73–9.
Prawan A, Kukongviriyapan V, Tassaneeyakul W, Pairojkul C, Bhudhisawasdi V. Association between genetic polymorphisms of CYP1A2, arylamine N-acetyltransferase 1 and 2 and susceptibility to cholangiocarcinoma. Eur J Cancer Prev. 2005;14(3):245–50.
Rebbeck TR, Troxel AB, Wang Y, Walker AH, Panossian S, Gallagher S, et al. Estrogen sulfation genes, hormone replacement therapy, and endometrial cancer risk. J Natl Cancer Inst. 2006;98(18):1311–20.
Shahabi A, Corral R, Catsburg C, Joshi AD, Kim A, Lewinger JP, et al. Tobacco smoking, polymorphisms in carcinogen metabolism enzyme genes, and risk of localized and advanced prostate cancer: results from the California Collaborative Prostate Cancer Study. Cancer Med. 2014;3(6):1644–55.
Suzuki H, Morris JS, Li Y, Doll MA, Hein DW, Liu J, et al. Interaction of the cytochrome P4501A2, SULT1A1 and NAT gene polymorphisms with smoking and dietary mutagen intake in modification of the risk of pancreatic cancer. Carcinogenesis. 2008;29(6):1184–91.
Munafo MR, Flint J. Meta-analysis of genetic association studies. Trends Genet. 2004;20(9):439–44.
Bu ZB, Ye M, Cheng Y, Wu WZ. Four polymorphisms in the cytochrome P450 1A2 (CYP1A2) gene and lung cancer risk: a meta-analysis. Asian Pac J Cancer Prev. 2014;15(14):5673–9.
Deng SQ, Zeng XT, Wang Y, Ke Q, Xu QL. Meta-analysis of the CYP1A2 -163C>A polymorphism and lung cancer risk. Asian Pac J Cancer Prev. 2013;14(5):3155–8.
He XF, Wei J, Liu ZZ, Xie JJ, Wang W, Du YP, et al. Association between CYP1A2 and CYP1B1 polymorphisms and colorectal cancer risk: a meta-analysis. PLoS One. 2014;9(8), e100487.
Hu J, Liu C, Yin Q, Ying M, Li J, Li L, et al. Association between the CYP1A2-164 A/C polymorphism and colorectal cancer susceptibility: a meta-analysis. Mol Genet Genomics. 2014;289(3):271–7.
Qiu LX, Yao L, Mao C, Yu KD, Zhan P, Chen B, et al. Lack of association of CYP1A2-164 A/C polymorphism with breast cancer susceptibility: a meta-analysis involving 17,600 subjects. Breast Cancer Res Treat. 2010;122(2):521–5.
Sun WX, Chen YH, Liu ZZ, Xie JJ, Wang W, Du YP, et al. Association between the CYP1A2 polymorphisms and risk of cancer: a meta-analysis. Mol Genet Genomics. 2015;290(2):709–25.
Tian Z, Li YL, Zhao L, Zhang CL. Role of CYP1A2 1F polymorphism in cancer risk: evidence from a meta-analysis of 46 case-control studies. Gene. 2013;524(2):168–74.
Wang H, Zhang Z, Han S, Lu Y, Feng F, Yuan J. CYP1A2 rs762551 polymorphism contributes to cancer susceptibility: a meta-analysis from 19 case-control studies. BMC Cancer. 2012;12:528.
Xue H, Lu Y, Xue Z, Lin B, Chen J, Tang F, et al. The effect of CYP1A1 and CYP1A2 polymorphisms on gastric cancer risk among different ethnicities: a systematic review and meta-analysis. Tumour Biol. 2014;35(5):4741–56.
Zhenzhen L, Xianghua L, Ning S, Zhan G, Chuanchuan R, Jie L. Current evidence on the relationship between three polymorphisms in the CYP1A2 gene and the risk of cancer. Eur J Cancer Prev. 2013;22(6):607–19.
Pavanello S, Pulliero A, Lupi S, Gregorio P, Clonfero E. Influence of the genetic polymorphism in the 5′-noncoding region of the CYP1A2 gene on CYP1A2 phenotype and urinary mutagenicity in smokers. Mutat Res. 2005;587(1–2):59–66.
Hirschhorn JN, Lohmueller K, Byrne E, Hirschhorn K. A comprehensive review of genetic association studies. Genet Med. 2002;4(2):45–61.
Acknowledgements
The Authors would like to thank Professor John Hopper and his working team from the Centre for Epidemiology and Biostatistics, Melbourne School of Population and Global Health, The University of Melbourne, for providing us with the primary GWAS data from their study of association between CYP1A2 SNPs and breast cancer risk. Also, would like to thank the ERAWEB mobility programme, under the European Commission, for financially supporting the work of VV., the Fondazione Veronesi for supporting the work of Emanuele Leoncini, and the Associazione Italiana per la Ricerca sul Cancro (AIRC) for supporting the work of Roberta Pastorino.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
VV, MRG, SB made concept and design of the study. VV, RA, CI, MRG, SB developed the methodology and contributed to data extraction. Statistical analysis and interpretation of data was done by VV, EL, RP and SB. Drafting the manuscript was done by VV, CI, RP, SB. All authors read and approved the final manuscript
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Vukovic, V., Ianuale, C., Leoncini, E. et al. Lack of association between polymorphisms in the CYP1A2 gene and risk of cancer: evidence from meta-analyses. BMC Cancer 16, 83 (2016). https://doi.org/10.1186/s12885-016-2096-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12885-016-2096-5