
Abstract
The main objective of this study is to understand the overall impact of earthquake in upper Indrawati Watershed, located in the high mountainous region of Nepal. Hence, we have assessed the relationship between the co-seismic landslide and underlying causative factors as well as performed landslide susceptibility mapping (LSM) to identify the landslide susceptible zone in the study area. We assessed the landslides distribution in terms of density, number, and area within 85 classes of 13 causal factors including slope, aspect, elevation, formation, land cover, distance to road and river, soil type, total curvature, seismic intensity, topographic wetness index, distance to fault, and flow accumulation. The earthquake-induced landslide is clustered in Northern region of the study area, which is dominated by steep rocky slope, forested land, and low human density. Among the causal factors, 'slope' showed positive correlation for landslide occurrence. Increase in slope in the study area also escalates the landslide distribution, with highest density at 43%, landslide number at 4.34/km2, and landslide area abundance at 2.97% in a slope class (> 50°). We used logistic regression (LR) for LSM integrating with geographic information system. LR analysis depicts that land cover is the best predictor followed by slope and distance to fault with higher positive coefficient values. LSM was validated by assessing the correctly classified landslides under susceptibility categories using area under curve (AUC) and seed cell area index (SCAI). The LSM approach showed good accuracy with respective AUC values for success rate and prediction rate of 0.843 and 0.832. Similarly, the decreasing SCAI value from very low to very high susceptibility categories advise satisfactory accuracy of the LSM approach.
Similar content being viewed by others

Background and introduction
Landslides, either triggered by an earthquake or rainfall (García-Rodríguez et al. 2008), pose costly and deadly threats to the mountainous country (Nowicki et al. 2014; Robinson et al. 2017). It subsequently damages the houses and basic infrastructures, economics, and human prosperity (Corominas et al. 2014) and is considered as vital geological hazard in the high mountainous regions (Nefeslioglu et al. 2008). Earthquake alone triggers a lot of landslides (Xu and Xu 2012; Xu et al. 2013a) in the mountainous region (Kamp et al. 2008; Fan et al. 2019) consequently remarked as subordinate hazards of an earthquake (Keefer 1994, 2002; Li et al. 2014). Notably, the 25 April 2015 Gorkha earthquake of Nepal and its aftershock not only responsible for the death of nine thousand people and economic losses of billions of US dollars (GoN 2015) but also triggered more than 25,000 landslides (Roback et al. 2018), which included small-scale rock falls to valley blocking landslides in several areas (Kargel et al. 2016). The landslides obstructed the accessibility to earthquake-affected areas hindering the post-earthquake relief activities (Kargel et al. 2016) multiplying the effects of the earthquake.
Despite, earthquake, an external factor, triggered many landslides (Pourghasemi and Rahmati 2018), several conditioning factors are responsible for occurrence of landslides including topography, geology, and environmental parameters (Süzen and Kaya 2012). Anthropogenic interactions including rapid infrastructure development (Petley et al. 2007) in combination with ground shaking becomes a major triggering factor for landslide occurrence (Süzen and Kaya 2012) in mountainous region (Robinson et al. 2017). In this regards, detailed analysis of earthquake-triggered landslide following an earthquake supplements the knowledge to understand the total impact of the earthquake (Marzorati et al. 2002; Robinson and Davies 2013). Landslide susceptibility mapping (LSM) identifies landslide sensitive areas considering the relationship between causal factors and landslide (Fell et al. 2008), it is a key step for landslide hazard monitoring and mitigation (Pourghasemi and Rahmati 2018). Furthermore, LSM is important for safety planning, disaster management, and future planning of earthquake stuck areas (Xu et al. 2013a).
Many of the developed countries have adopted different technologies to understand the landslide risk of the earthquake which has been lacking in the Nepalese context (Merghadi et al. 2020). Despite several studies have been conducted regarding the landslides and their distribution after an earthquake (e.g., Collins and Jibson 2015; Goda et al. 2015; Gallen et al. 2017; Kargel et al. 2016; Robinson et al. 2017; Roback et al. 2018), there is still a gap in research regarding landslide and its damages due to the earthquake (Kamp et al. 2008) mostly in developing countries including Nepal.
Multiple approaches have been adopted for LSM (Corominas et al. 2014) including heuristic approach (e.g., van Westen et al. 1999; Yalcin and Bulut 2007; Kouli et al. 2010), statistical approach (e.g. Ayalew and Yamagishi 2005; Kamp et al. 2008; Bai et al. 2010; Mancini et al. 2010; Xu et al. 2013a, b), and deterministic approach (e.g. Zhou et al. 2003). Broadly, it can be classified as qualitative and quantitative approach (Ayalew and Yamagishi 2005; García-Rodríguez et al. 2008; Corominas et al. 2014). In the heuristic analysis, the weight assignment is based on the expert opinion (Fell et al. 2008; Xu et al. 2013b; Corominas et al. 2014) as a qualitative approach (Ayalew and Yamagishi 2005). Both deterministic and statistical methods are quantitative approaches and are based on numerical expression of causal factors and landslides (García-Rodríguez et al. 2008). The statistical method is based on the quantitative analysis of relationships between causal factors and landslide events (Ayalew and Yamagishi 2005; Fell et al. 2008).
Several statistical approaches including bivariate probabilistic (e.g. Magliulo et al. 2008; Yilmaz 2009), multivariate as logistic regression (LR; e.g. Dai and Lee 2003; Ayalew and Yamagishi 2005; Lee and Pradhan 2007; García-Rodríguez et al. 2008; Kamp et al. 2008; Bai et al. 2010; Mancini et al. 2010; Pradhan and Lee 2010; Xu et al. 2013a; Aditian et al. 2018), artificial neural network (ANN; e.g. Nefeslioglu et al. 2008; Yilmaz 2009; Pradhan and Lee 2010; Bui et al. 2012; Aditian et al. 2018), and support vector machine (SVM; e.g. Yao et al. 2008; Xu et al. 2012; Gautam et al. 2021) are commonly used for LSM. However, the consensus regarding best suiting method for mapping has yet to be established (García-Rodríguez et al. 2008; Corominas et al. 2014). Among them, LR can define the multivariate relationship of causal factors and landslide (Ayalew and Yamagishi 2005; Lee and Pradhan 2007) which logically can assign the weight depicting the most influencing causal factor as well as disregarding the less significant factors during the mapping process (Budimir et al. 2015). Hence, it produces more reliable results (Nandi and Shakoor 2010). It is for that reason, LR approach is considered to be more suitable and is common in LSM (Nandi and Shakoor 2010; Budimir et al. 2015) especially on regional scale (e.g., Mancini et al. 2010; Pradhan and Lee 2010; Xu et al. 2013a; Corominas et al. 2014).
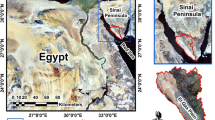
In the wake of Gorkha earthquake (Mw 7.8 at the epicenter of N 28.1470° and E 84.7080°—Fig. 1), we studied the earthquake-induced landslides in Upper Indrawati Watershed of Nepal which is severely affected by the earthquake. The study area is in the North of the small town called Melamchi (see in Fig. 2), where the effects due to the quake were reported severe in the study by Goda et al. (2015). Thus, our research aims to assess the impact of causal factors for the occurrence of landslides and susceptibility mapping to identify landslide sensitivity of the study area. We used descriptive statistics and logistic regression approach integrating with GIS for LSM (e.g., García-Rodríguez et al. 2008; Kamp et al. 2008; Bai et al. 2010; Aditian et al. 2018). This study could also be replicated in other catchment areas of high mountainous regions for susceptibility mapping.



a Landslide causative factor's map of the study area. b Landslide causative factor's map of the study area
Study area
This research is conducted in Upper Indrawati Watershed (85°33′N–85°44′N; 27°49′E–28°07′E) of Sindhupalchok district, located 40 km north-east of Kathmandu, Nepal (Fig. 1). We did not analyze the area with an altitude of more than 4000 m because of the lack of geological data (no detailed data available in the Department of Mines and Geology, Nepal), and unavailability of qualitative satellite images because of cloudy weather condition and snow-capped areas. Therefore, the altitude of the area we analyzed ranges from 796 to 4000 m with a coverage of 364 km2 area. The slope gradient ranges from 0° to 73° with the mean slope of 31.6°.
The study area belongs to higher Himalayan zone (Pre-Cambrian) geology dominated by Sermanthang formation and Dhad Khola gneiss formation covering 35% and 24% area respectively (DMG 2021). Sermanthang formation mostly covers the high-altitude region of the study area which includes lithology of interbedded feldspathic schist, augen gneiss, quartzite, and biotic-feldspathic schist. However, Dhad Khola gneiss covers the lower altitudinal region including porphyroblastic gneiss, augen gneiss with a thin band of quartzite and schist, and migmatitic gneiss lithology. The study area located in between the Main Central Thrust (MCT) which passes throughout the Himalayan range in Nepal (Dahal 2006) and is a part of Main Himalayan Thrust where the Gorkha earthquake of magnitude Mw7.8 occurred on April 24, 2015, followed by hundreds of aftershocks including Mw7.3 at ~ 120 km east of the epicenter (Sakai et al. 2016—Fig. 1). These tremors increased the earthquake severity considerably in the study area (Goda et al. 2015) which amplified likely occurrences of landslide. The study area is located nearly 30 km east of the MCT that traced throughout the Himalayan region and (3–6) km northwest of another local MCT (Dhital et al. 2002; DMG 2021) (Fig. 1). A normal fault (southern side of the study area as in Fig. 1) and local thrusts (reverse fault) are located within the study area (DMG 2021).
Landslide distribution
Gorkha earthquake followed by hundreds of aftershocks (Parameswaran et al. 2015) triggered many landslides in the study area. Landslide inventory is key to understand the mechanism of landslide occurrences and preparation of landslide hazard map (Fan et al. 2019). Field observation, on-screen detection of aerial photographs, visual interpretation, and on-screen digitization of high-resolution satellite images are effective and applicable for co-seismic landslide detection (Keefer 2002; Harp et al. 2011; Corominas et al. 2014; Xu et al. 2015). This is because the number, area, and volume of coseismic landslides are extensive (e.g., Keefer 1994; Marc et al. 2016), and landslides location are spatially distributed over the larger areas (Dai et al. 2011). Even though its time consuming, it is more accurate than point-based on susceptibility mapping (Xu et al. 2012; Fan et al. 2019). Thus, we conducted onscreen digitization of post-earthquake satellite imageries available on Google Earth after the Gorkha earthquake and its aftershock in polygon format. We avoided the inclusion of rainfall-induced landslides in the study by comparing the pre-and post-earthquake satellite imageries (Roback et al. 2018). In doing so, the inventory of rainfall-induced landslides of the Gautam et al. (2021) were overlaid in the Google Earth and only the landslide triggered by ground shaking were digitize manually on Google Earth satellite imageries from 2nd to 25th May 2015 (Fig. 1). We mapped 402 co-seismic landslides covering total area of 2.75 km2 in polygon format having an average area of 6891.83 m2 with minimum and maximum area of 169.62 m2 and 158,313 m2, respectively. Furthermore, it was aided by field observation from Nov. 15 to Dec. 5, 2015.
Landslide distribution was expressed by landslide relative density (LRD) (Ayalew and Yamagishi 2005), landslide number abundance (LNA) (Keefer 2000; Xu et al. 2015), and landslide area abundance (LAA) (Dai et al. 2011; Xu et al. 2014, 2015) which helps to understand the effects of causal factors on landslide occurrences. LRD is the ratio of the frequency ratio value (FRV) of a class to the total FRV of that causal factor and is calculated as suggested by Ayalew and Yamagishi (2005). LNA is the number of landslides per square kilometer, and LAA is the percentage of area affected by landslides (Xu et al. 2015).
Landslide causal factors
The occurrence of landslides depends upon multiple causal factors. Even though seismic shaking is the driving force for the earthquake-triggered landslides, local (natural and anthropogenic) factors play a dominant role (Kamp et al. 2008; Fan et al. 2019). Selection of the appropriate causal factors is essential for susceptibility mapping (Xu et al. 2013a; Merghadi et al. 2020), and there are not any agreed criteria (Budimir et al. 2015). Casual factors should be measurable, varies spatially (Ayalew and Yamagishi 2005; Budimir et al. 2015), and have a certain degree of compatibility with the dependent variable (García-Rodríguez et al. 2008). Hence, we selected 13 factors for mapping which includes slope angle, aspect, elevation, geological formation, land cover, distance to river, distance to road, soil type, total curvature, seismic intensity (PGA), topographic wetness index (TWI), distance to fault, and flow accumulation (Table 1). All the causal factors except categorical variables were categorized from four to ten classes to understand their effect for landslide occurrences due to earthquake (Table 1), whereas we preserved the category of all the categorical variables (aspect, formation, land cover, soil type, and PGA).
The categorical factors were dealt by creating dummy variables whereas the non-categorical factors with continuous data were dealt as they are (Nefeslioglu et al. 2008) for the purpose of susceptibility mapping (Fig. 2). As the scales of the input variables (casual factors) are different, the input data was normalized from 0 and 1 in order to increase the speed and accuracy of data processing, using Eq. 1 following the study of Nefeslioglu et al. (2008).
where Xnorm is normalized value of Xi input data, Xi is the input data that should be normalized, Xmax is the maximum value of the input data, and Xmin is the minimum value of the input data.
Preparation of training and validation landslide
All the inventoried landslides were divided as training landslide and validation landslide for LR modeling to perform susceptibility mapping and validating to access the quality of the model, respectively (Aditian et al. 2018; Ba et al. 2018; Huang and Zhao 2018). As there are no agreed criteria for the selection of training and validation landslides (Xu et al. 2013b), most of the researcher employed a random selection approach for susceptibility mapping (e.g., Ayalew and Yamagishi 2005; Mancini et al. 2010; Chen et al. 2016; Aditian et al. 2018; Pourghasemi and Rahmati 2018; Huang and Zhao 2018). Hence, we employed random selection approach with a ratio of 80:20 for the training and validation landslides (e.g., Bai et al. 2010; Gautam et al. 2021) (Fig. 3).

Distribution of training landslides and validation landslides
All the mapped 402 co-seismic landslides polygon were rasterized in GIS platform in 12.5 m pixels for analysis, resembling the causal factors resolution as determined by DEM. Among 17,554 pixels of landslide, 14,043 (80%) were used as training data to train the model whereas 3511 pixels (20%) were used to validate the model. As LSM needs the representation of no landslide areas, the equal number of landslides absence pixel (0) from no-landslide zone of the study area for both training and validation datasets were selected randomly (Xu et al. 2013a).
Landslide susceptibility mapping
We used LR, a multivariate statistical approach for LSM in the study area (eg., Ayalew and Yamagishi 2005; García-Rodríguez et al. 2008; Bai et al. 2010; Mancini et al. 2010; Xu et al. 2013a; Abedini et al. 2017; Aditian et al. 2018). LR is also called as generalized linear model (GLM) for binary response variables (Hosmer and Lemeshow 2000). It allows describing the effect of all the independent variables on dependent variables in the form of a linear regression equation (Atkinson and Massari 1998). It has a distinct advantage in which the independent variables can be either continuous or (and) discrete as if the link function is added to usual linear regression model (Bai et al. 2010), and not necessarily needed to normally distributed (García-Rodríguez et al. 2008; Bai et al. 2010). LR analysis is based on the analysis of dependency of a binary dependent variable having possible outcome of either 1 (landslide) or 0 (no landslide) to independent variables (landslide causal factors) (Mancini et al. 2010; Budimir et al. 2015). It calculates the probability of specific event occurrences, landslide occurrence in this case as in the study by Ayalew and Yamagishi (2005) which can be expressed as in Eq. (2).
where P is the probability of landslide occurrence, e is the exponential function and Z is the logit value which is expressed by a linear equation as;
where b0 is the intercept, b1, b2,…bn are the coefficient of landslide causal factors x1, x2,…xn respectively, n is the number of causal factors. The linear model is logistic regression and represents the presence and absence of landslides on independent variables (Bai et al. 2010).
A data matrix is devised including 40 variables with eight continuous and 32 classes of five categorical variables in binary format to perform the LR. The data were arranged in such a way that each row datum represents an individual case expressed in pixel, and columnar data show the dependent and independent variables (Gautam et al. 2021). The "glm" package in R 3.5.2 was employed for GLM (Team 2019). Provided results were the coefficient of causal factors by the process of maximum likelihood criterion (Mancini et al. 2010).
Susceptibility scale of the region is relative (Fell et al. 2008) hence, obtained probability value were categorized in five discrete classes as susceptibility categories (very low, low, medium, high, and very high) using the natural breaks (Jenks) method in ArcGIS (e.g., Chalkias et al. 2014; Aditian et al. 2018; and Gautam et al. 2021).
Map validation
The overall performance of the mapping approach is assessed by identifying the correctly classified landslides under the susceptibility categories of LSM (Xu et al. 2013b). The area under the curve (AUC) value was calculated to predict the accuracy of the model quantitatively (Akgun 2012; Abedini et al. 2017; Ba et al. 2018; Gautam et al. 2021). The AUC value suggests the model's quality for reliable prediction of the existence and non-existence landslides (Aditian et al. 2018). The larger the AUC values, the higher the accuracy of the model's performance (Corominas et al. 2014). Additionally, the values close to 1.0 indicating perfect fit is the ideal condition whereas, close to 0.5 indicates the random fit (Carvalho et al. 2014).
We compared the LSM with both training and validation landslides (Gautam et al. 2021). The curve obtained by overlaying susceptibility map with training landslide suggests the model's capability of classifying the area (Mancini et al. 2010; Xu et al. 2012) and also called as success rate curve (Chung and Fabbri 2003; Aditian et al. 2018; Ba et al. 2018); and with validation landslide, it is called prediction rate curve (Lee and Pradhan 2007; Ba et al. 2018) suggesting the model's ability of landslide prediction (Chung and Fabbri 2003; Aditian et al. 2018). The AUC value generated from the success rate curve also indicates the correlation between dependent and independent variables in LR analysis (Mancini et al. 2010).
Furthermore, we used seed cell area index (SCAI) to validate the susceptibility map (Suzen and Doyuran 2004; Abedini et al. 2017; Nicu and Asăndulesei 2018). The SCAI illustrates the landslide density on susceptibility class (Suzen and Doyuran 2004) and is the ratio of the percentage of the area in the susceptibility category to the percentage area of landslides in that category (Abedini et al. 2017). The SCAI reflects the accuracy of the mapping approach qualitatively (Abedini et al. 2017). In an ideal situation, the SCAI value is decreasing form very low to very high susceptibility classes (Kincal et al. 2009; Sdao et al. 2013; Chen et al. 2016; Abedini et al. 2017; Nicu and Asăndulesei 2018).
Landslides distribution
Landslides in the study area were clustered within the Northern part (Fig. 4). This is because of the dominated steeper slope and higher elevation topology in the northern region. Most of the earthquake-induced landslides are rock and debris falls following the category of Varnes (1978) classification (Owen et al. 2008). We found an adequate number of rockfalls in the study area as the landslide concentration is higher in the northern part which is subjugated by the rocky slope. In this study, we did not include the debris flows, following the study of Varnes (1978) as the mechanism of debris flow is entirely different from other types of mass movement. Our study support that the distribution of earthquake-induced landslides and rainfall-induced landslide is comparable as earthquake-induced landslides is clustered along the sharper slope, whereas the rainfall-induced landslides distributed evenly throughout the flatter slope where higher anthropogenic pressure is observed (Gnyawali et al. 2020; Gautam et al. 2021).

Landslide density (number [#] of landslide per km2) of the study area due to the Gorkha earthquake of 2015
We assessed the concentration of co-seismic landslides in this study corresponding to the study of Kargel et al. (2016). We categorized the area into eight categories considering the landslide number per km2. Nearly 40% of the area is not affected by earthquake-induced landslides; with a frequency less than 0.5/km2 (Fig. 4). Only 5% of the area had landslide density (expressed regarding landslides number/km2) of more than 40 (Fig. 4), indicating the higher landslide zone. However, the area having landslides 10–20 per km2 and 20–40 per km2 covered the considerable area with 11% and 7% respectively.
The LRD, LNA, and LAA of the classes of causal factors are presented in Fig. 5a–m. LRD, LAA, and LNA are increased with slope angle reaching a maximum of 44%, 2.97%, and 4.34/km2 respectively at a slope class more than 50 degree (Fig. 5a). The LRD, LAA, and LNA of southern aspect (southeast, south, and southwest) were higher with the value reaching maximum of 21%, 1.25%, and 1.83/km2 respectively (Fig. 5b). The relationship of elevation and landslide frequency showed that the higher LRD (= 31%), LAA (= 1.15%) and LNA (= 1.68/km2) were found in the elevation range (2400–3000) m and were decreased in either lesser or higher elevation classes (Fig. 5c). Both concave and convex curvature had higher landslide distribution with slightly more elevated in concave curvature reaching a maximum value of LRD (= 25%), LAA (= 1.79) and LNA (= 2.61/km2) in curvature class (= -34.56 to -3.99) among the 6 classes generated in ArcGIS using natural breaks method (Fig. 5k).

Landslide distribution according to the classes of causal factors (a slope [< 10, 10–20, 20–30, 30–40, 40–50, > 50], b aspect [North, NE, East, SE, South, SW, West, NW], c elevation [794–1300, 1300–1800, 1800–2400, 2400–3000, 3000–3600, > 3600], d geological formation [Sermanthang, Simpani, Hadi Khola, Dhad Khola, Gyalthung, Pangang], e land cover [Needle leaved closed forest, Needle leaved open forest, Broad leaved closed forest, Broad leaved open forest, Shrubland, Grassland, Agriculture], f distance to the river [< 100, 100–200, 200–400, > 400], g distance to road [< 678, 678–1733, 1733–2869, 2869–3965, 3965–5216, 5216–6573, 6573–7930, 7930–9338, 9338–10955, 10955-13303], h soil type [Humic cambisols, Gelic leptisols, Eutric regosols, Gleyic cambisols, Eutric cambisols, Chromic cambisols], i peak ground acceleration, [< 20%, 20–30%, 30–40%, 40–50%] j topographic wetness index [0–88–4.12, 4.12–5.38, 5.38–6.85, 6.85–9.20, 9.20–18.00], k curvature [–34 to –3.99, –3.99 to –1.37, –1.37 to 0.38, 0.38 to 2.41, 2.41 to 6.20, 6.20 to 39.39], l distance to fault [< 1088, 1088–2520, 2520–4180, 4180–6070, 6070–8188, 8188–10707, 10707–14544], and m flow accumulation[< 220, 220–329, 329–549, 549–993, 993–1885, 1885–3618, 3618–7297, 7297–14575, 14575–29225, 29225–58714]). The bar graph represents the LRD in percent shown in the primary y-axis. The dotted line with round marker represents LAA (%), and line with triangular marker represents LNA (landslide #/km2); depicted in the secondary y-axis
Pangang formation of higher Himalayan zone (Pre-Cambrian) is found in the northernmost area of the watershed (Fig. 3), which has higher landslide distribution as LRD (= 41%), LAA (= 1.71%), and LNA (= 2.50/km2) followed by Sermanthang formation (Fig. 5d). Hence, gneiss, schist and quartzite lithology of the higher Himalayan group were highly susceptible due to the earthquake-induced landslide in the study area. Humic cambisols, among the 6 category of soil types found in the study area, has higher distribution of landslides with LRD, LAA, and LNA value of 34%, 1%, and 1.45/km2 respectively followed by Eutric regosols (Fig. 5h).
Distribution of earthquake-induced landslides in the open forest is higher in the study area followed by shrubland reaching the maximum value of 31%, 1.16%, and 1.70/km2 for LRD, LAA, and LNA respectively (Fig. 5e). Landslide frequency in the closed forest was also considerably higher compared to agricultural land in the study area. The reason behind this could be most of the forested area is distributed throughout the higher slope gradient as we overlaid the land cover class with slope gradient.
Among the four classes of distance to the river, class (100–200) m has higher landslide distribution with the value of 38%, 1.11%, and 1.62/km2 for LRD, LAA, and LNA respectively followed by the class (200–400) m (Fig. 5f). Landslide distribution is increasing with increasing distance to road until 6500 m, reaching LRD (= 21%), LAA (1.76%), and LNA (= 2.56/km2) and is decreasing further (Fig. 5g). In case of causal factor distance to the fault, class (3.3–4.2) km out of ten classes generated in ArcGIS (natural breaks method), have higher LRD, LAA and LNA with respective value of 50%, 3.03% and 4.43/km2 with gradually decreasing on either side of the classes (Fig. 5l).
As we were mapping seismic induced landslides susceptibility, we considered seismic intensity, which varied spatially throughout the study area, as a causal factor. LRD (= 42%), LAA (= 0.99%) and LNA (= 1.45/km2) were found higher in the area which had low seismic intensity (20% peak ground acceleration, PGA) followed by the PGA class 50% (Fig. 5h) among the four classes.
The distribution of landslides were gradually decreasing with increasing value of TWI (Fig. 5j). The TWI class with lesser index ranging from 0.9 to 4.1 has the highest LRD (= 29%), LAA (= 0.96%), and LNA (= 0.88/km2) suggesting that the chances of landslide occurring within that class is higher. We found similar trend with flow accumulation (Fig. 5m).
Landslide susceptibility modelling
All together 19 variables of causal factors slope, distance to fault, TWI, aspect, landcover, soil type (one class), and PGA (one class) show the positive association for landslide occurrences in the study area among the 40 variables of 13 causal factors (Table 2). We found that landcover (except bare area) classes and slope were the best predictors for landslide occurrences with the coefficient value of >10 and 5.35, respectively.
Even though many of these landslides would not occur any time soon without the earthquake shaking, we found that only two classes of PGA (PGA 20% = 0.66 and PGA 40% = -2.64) have shown association (statistically) for landslide occurrence in the study area. The negative association on PGA class 40% is the second most important variables having negative association for landslide occurrences after elevation (− 4.37).
The probability values of landslide occurrences in each pixel were ranges from 0.001 to 0.987. The final susceptibility map with susceptibility categories–very low, low, medium, high, and very high–is presented in Fig. 6. The area coverage according to the five susceptibility categories are 50.16% (182.76 km2), 22.55% (82.18 km2), 13.79% (50.24 km2), 9.34% (34.04 km2), and 4.16% (15.17 km2), respectively from very low to very high.

Simplified map of landslide susceptibility due to earthquake depicting the susceptibility classes in the study area
The land having higher slope gradient with elevation ranges from 2400 to 3000 m are highly sensitive for an earthquake-induced landslide in future (Fig. 6). Similarly, Pangang and Sermanthang formation of higher Himalayan (Pre-Cambrian) geology including schist, quartzite and gneiss lithology are highly susceptible. Last but not least, the area having less population density is highly vulnerable to the landslides due to the earthquake.
Map validation
The AUC values of the success rate and prediction rate curves were 0.843 and 0.832 respectively (Fig. 7) suggesting good accuracy. The AUC value of success rate curve suggests that the approach have the capability of 84.3% to classify landslide correctly under the susceptibility categories as well as there exists a good correlation between dependent (landslide) and independent (causal factors) variables. The AUC value of the prediction rate curve represents that LSM approach able to correctly predict future landslides by 83.2%. The SCAI values are decreasing from very low to very high susceptibility classes (Table 3) suggesting the mapping approach produces a susceptible map with satisfactory accuracy.

Success rate (a) and prediction rate (b) curves with AUC values
Discussion
Understanding overall impact of earthquake hazards require the understanding of several features of co-seismic landslide (Robinson and Davies 2013). It includes the landslide number, area, and volume (e.g., Keefer 1984; Marc et al. 2016) and the location of landslides (e.g., Dai et al. 2011). Hence, we studied the distribution of co-seismic landslide (landslide number, area, and volume and spatial location of landslides) caused by earthquake and employed the landslide susceptibility mapping approach using LR considering several causal factors in a catchment of mountainous area of Nepal.
Landslide susceptibility differs from quake to quake (Kargel et al. 2016). This study concurred with the study of García-Rodríguez et al. (2008) that the landslide density is increasing with the slope gradient. Likewise, the recent study by Kargel et al. (2016) of Nepal found that the earthquake frequencies are higher in the area where slope gradient is more than 300 which is similar to our study. In addition, the topographical variables including slope found to be significant variables for co-seismic landslides in the study by Fan et al. (2021). However, our study contradicts the study from Kamp et al. (2008) as they found that the landslide relative density is higher in slope 25°–35° and decrease on either side. Similarly, the study from Roback et al. (2018) also did not found any correlation between landslide occurrences and steepest slopes. Different surficial geology, mostly dominated by a rocky hill which is brittle and more susceptible for shaking, and land cover in the steepest slope gradient might play an essential role for increasing landslide distribution in steeper slope in this study. This study also concurs with the study of García-Rodríguez et al. (2008) that landslide distribution is low at the lower elevation because of the gentle terrain. Likewise, the landslide distribution with respect to elevation is similar with the study by Roback et al. (2018) where the mid elevation has higher frequencies of landslides. Similarly, our study found an analogous result with Kamp et al. (2008) that southeast, south, and southwest aspect have higher landslides distribution.
As Xu et al. (2015) suggested in their study that only seismogenic faults affect a co-seismic landslide, this study also found the similar result that there is no clear correlation between the distance to the fault line and landslide distribution. The distribution of landslides are random without considering the physical properties of the fault. However, landslide frequencies are increased as the distance from faults line decrease (Xu et al. 2015) because the rock strength weakens due to the fault line (Osmundsen et al. 2009).
We found types of metamorphic rock including schist, quartzite, and gneiss of Pangang formation of the higher Himalayan zone have a higher frequency of landslides which is harmonize with the study by Kargel et al. (2016). The schist of the higher Himalayan zone along with Proterozoic phyllite, amphibolite, meta-sandstone of lesser Himalaya has higher landslide frequency due to the Gorkha earthquake (Kargel et al. 2016). In general, soft sediment (metamorphic rock) usually amplifies the energy of seismic waves (Chamlagain and Gautam 2015) and amplifies frequencies of the landslide. As weaker soil types have low elasticity and can amplify seismic waves and undergo a greater displacement (Hovius and Meunier 2012), our study find the similar result that the delicate soil type of mountainous regions including Humic Cambisols and Eutric Regosols (Driessen 1991) have higher density of landslide.
The landslide abundance is positively correlated with the seismic intensity (Xu et al. 2015) and is considered as the important factor for landslide occurrence due to the earthquake (Wang et al. 2003; Xu et al. 2014). Hence, we used PGA, a triggering factor of earthquake-induced landslides, as a causal factor for landslide study and susceptibility mapping which has been scarcely used in LR based LSM despite it is the reason for earthquake-induced landslide (Budimir et al. 2015). However, as in the study by Xu et al. (2015), Fan et al. (2021), and Roback et al. (2018), our study found that there is no correlation between the PGA and landslide distribution in the study area. The PGA is slightly reduced with steeper slope in our study which coincides with the study by Roback et al. (2018) where they found the modelled PGA of Gorkha earthquake reduces slightly for the steepest terrain and is weakly constrained for landslide occurrences. The landslide frequencies in this study area are higher in lower PGA as in the study by Roback et al. (2018). However, the study by Xu et al. (2014) suggests that the landslide density increases with increasing PGA. Relatively steeper slope and diverse lithology is the significant attributes of the study area where PGA value is lower and has experienced the majority of landside with higher density. Hence, the higher slope, steeper relief, and increased terrain roughness is positively correlated to the seismic landslide distribution (Roback et al. 2018).
Regarding the association of land cover classes and landslide, we found that the forested area has a higher frequency of landslide which is contrasting with the result of the study by Kamp et al. (2008) as they found that grassland and agricultural land have higher earthquake-triggered landslide densities than forest land. The reason for this contrasting result might be dependent with slope distribution as the forested area have higher slope. In addition, temporal change in land cover induced by human activities could be another reason. However, we have not consider the land cover changes from 2010 to 2015 (earthquake date) in our analysis despite landslide occurrences is significantly attributed by the land cover change trajectories as per the study by Guns and Vanacker (2013).
Even though, LSM is the key for hazard mitigation and Nepal ranked among the top of the list with the highest percentage of the landslide reports, it is not listed among the top 18 countries where machine learning (ML) approaches including LR for LSM studies have been used (Merghadi et al. 2020). Hence, we conducted LSM using LR among the different ML approaches available in the literature (Budimir et al. 2015; Merghadi et al. 2020). Among the ML approaches, LR belonged among the 10 most popular and has been considered widely by the researchers (Nowicki et al. 2014), despite several new computing techniques have been in use. In addition, LR is simple and easy techniques and has been popular and widely used in recent times as the integration of GIS in susceptibility mapping has eased the process and improved the effectiveness (Budimir et al. 2015; Huang and Zhao 2018). LR even produced better result than that of high computing techniques including the study by Xu et al. (2012) where LR outperforms ANN, SVM and bivariate statistics methods. In the study by Gautam et al. (2021) LR produced the map with better accuracy than SVM. Similarly, the LR accomplished over 0.9 in AUC values in some studies (e.g., Kavzoglu et al. 2015). Hence, we used LR for LSM in the study of high mountainous region of Nepal.
In LR analysis, the highest coefficient describes the best predictor which depends upon the trends of the landslide distribution within the classes of each causal factor (Mancini et al. 2010). If there are definite trends as in the causal factors: land cover classes and slope of this study; their coefficient is positive and higher, which show the positive correlation for landslide occurrences as suggested by the study from Abedini et al. (2017) and vice versa. We found that the land cover classes were the best predictor among the causal factors followed by slope and distance to fault which align with the study of Mancini et al. (2010) and Roback et al. (2018). However, our study contrast with the result of Xu et al. (2013a): they found slope and distance from the fault has a negative association for landslide occurrence. It is also believed that landslide frequency often decreases with increasing distance to the fault (Xu et al. 2015), however, in this study, there is no clear correlation. Various researcher found different factors as the best predictor in their studies such as slope (Ohlmacher and Davis 2003; Lee and Pradhan 2007; Yilmaz 2009; Xu et al. 2013a; Abedini et al. 2017); soil type (Gautam et al. 2021); distance to road (Ayalew and Yamagishi 2005); terrain roughness and lithology (García-Rodríguez et al. 2008); aspect (Aditian et al. 2018). In the study of Bai et al. (2010), curvature was the best predictor. However, we found that curvature is the less essential factor. Similarly, we found the correlation of PGA in landslide occurrence is weaker compared to other causal factor; even though, the seismic intensity is the reason for land sliding in the region. The triggering factor (either rainfall or earthquake) for landslides (García-Rodríguez et al. 2008) and selection of causal factors could be the reason for such variance in results.
The appearance of the validation landslides in the high susceptibility category determined the performance of the LSM approach which differs among the researchers. Choice of the independent variables (causal factors) (Pradhan and Lee 2010); mapping approaches used (Nefeslioglu et al. 2008); and local factors as well as the method of selecting training and validation landslides (Xu et al. 2012) could result in the varying accuracy of validation in LSM studies. The map validation result of SCAI-decreasing from very low to very high susceptible categories concurs with the study from Kincal et al. (2009), Sdao et al. (2013), Chen et al. (2016), Abedini et al. (2017), and Nicu and Asăndulesei (2018). The prediction AUC value of 83.2% in this study suggest that the LR approach predict the future landslides with satisfactory accuracy. Performance of our study resembles the study by Merghadi et al. (2020) on LSM using LR among the other ML approaches which produced the LSM by LR with satisfactory accuracy (AUC values more than 80%). Considering its simplicity, easiness, highly interpretable capacity, quick processing ability, and ability to calculate probability directly, the LR approach is the best option among the different ML approaches (Merghadi et al. 2020) and produced a result with more than acceptable accuracy (as in our study).
Concluding remarks
To realize the overall impact of the earthquake in the high mountainous regions of Nepal, we studied the landslide distribution, its relationship with causal factors (13 factors), and landslide susceptibility due to co-seismic landslides in Upper Indrawati watershed which is highly impacted by Gorkha earthquake and its aftershocks. It is a critical aspect of hazard mitigation (Merghadi et al. 2020).
The study provided the insight that the landslide occurrences show the apparent positive correlation with the slope as landslide abundance increased with slope angle. The causal factors: fault distance, slope, aspect, landcover, a class of PGA, and soil type showed some trends for landslide occurrences resulting in the positive coefficient in LR analysis. From the study, the region belongs to elevation range (2400–3600) m, higher slope, and forested area are highly susceptible to landslides due to the earthquake. Most of such region belongs to the northern part of the study area where lithology of Pangang formation is dominant and have relatively low population density.
The LR approach used for LSM in the study area shows the good accuracy with AUC value for success and prediction rate curves of 0.843 and 0.832 respectively, and SCAI values higher in very low susceptible category and are descending toward very high susceptible category. Hence, the map could be used for slope improvement and generalized planning of the study area. As the rehabilitation and development of the area has been ongoing, this map could be an asset for the managers including government and private sectors. Site-specific consideration of local factors need to be addressed before implementation. This study added an extra value to the literature for the much-needed clarity and consistency in methodology for selection of causal factors for LR analysis, despite LR has been widely used for LSM (Budimir et al. 2015).
Availability of data and materials
Data will be provided upon request.
Abbreviations
- ANN:
-
Artificial neural network
- AUC:
-
Area under curve
- DEM:
-
Digital elevation model
- FRV:
-
Frequency ratio value
- GIS:
-
Geographic information system
- GLM:
-
Generalized linear model
- LAA:
-
Landslide area abundance
- LNA:
-
Landslide number abundance
- LR:
-
Logistic regression
- LRD:
-
Landslide relative density
- LSM:
-
Landslide susceptibility mapping
- ML:
-
Machine learning
- PGA:
-
Peak ground acceleration
- SCAI:
-
Seed cell area index
- SVM:
-
Support vector machine
References
ASF DAAC (2015) ALOS PALSAR_Radiometric_Terrain_Corrected_high_res; Includes Material © JAXA/METI 2007. Accessed through ASF DAAC 11 May 2021. https://doi.org/10.5067/Z97HFCNKR6VA
Abedini M, Ghasemyan B, Mogaddam MR (2017) Landslide susceptibility mapping in Bijar city, Kurdistan Province, Iran: a comparative study by logistic regression and AHP models. Environ Earth Sci 76(8):308
Aditian A, Kubota T, Shinohara Y (2018) Comparison of GIS-based landslide susceptibility models using frequency ratio, logistic regression, and artificial neural network in a tertiary region of Ambon, Indonesia. Geomorphology 318:101–111
Atkinson PM, Massari R (1998) Generalized linear modeling of susceptibility to landsliding in the Central Apennines, Italy. Comput Geosci 24(4):373–385
Akgun A (2012) A comparison of landslide susceptibility maps produced by logistic regression multi-criteria decision and likelihood ratio methods: a case study at İzmir, Turkey. Landslides 9(1):93–106. https://doi.org/10.1007/s10346-011-0283-7
Ayalew L, Yamagishi H (2005) The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 65(1):15–31
Ba Q, Chen Y, Deng S, Yang J, Li H (2018) A comparison of slope units and grid cells as mapping units for landslide susceptibility assessment. Earth Sci Inf 11(3):373–388
Bai SB, Wang J, Lü GN, Zhou PG, Hou SS, Xu SN (2010) GIS-based logistic regression for landslide susceptibility mapping of the Zhongxian segment in the Three Gorges area, China. Geomorphology 115(1):23–31
Brabb EE (1984) Innovative approaches to landslide hazard and risk mapping. Publisher not identified
Budimir MEA, Atkinson PM, Lewis HG (2015) A systematic review of landslide probability mapping using logistic regression. Landslides 12(3):419–436
Bui DT, Pradhan B, Lofman O, Revhaug I, Dick OB (2012) Landslide susceptibility assessment in the Hoa Binh province of Vietnam: a comparison of the Levenberg–Marquardt and Bayesian regularized neural networks. Geomorphology 171:12–29
Chalkias C, Ferentinou M, Polykretis C (2014) GIS-based landslide susceptibility mapping on the Peloponnese Peninsula, Greece. Geosciences 4(3):176–190. https://doi.org/10.3390/geosciences4030176
Chamlagain D, Gautam D (2015) Seismic hazard in the Himalayan intermontane basins: an example from Kathmandu Valley, Nepal. In: Nibanupudi HK, Shaw R (eds) Mountain hazards and disaster risk reduction. Springer, Tokyo, pp 73–103
Chen W, Li W, Chai H, Hou E, Li X, Ding X (2016) GIS-based landslide susceptibility mapping using analytical hierarchy process (AHP) and certainty factor (CF) models for the Baozhong region of Baoji City, China. Environ Earth Sci 75(1):63
Chung CJF, Fabbri AG (2003) Validation of spatial prediction models for landslide hazard mapping. Nat Hazards 30(3):451–472
Collins BD, Jibson RW (2015) Assessment of existing and potential landslide hazards resulting from the April 25, 2015 Gorkha, Nepal earthquake sequence (No. 2015–1142). US Geological Survey
Corominas J, van Westen C, Frattini P, Cascini L, Malet JP, Fotopoulou S, Catani F, Van Den Eeckhaut M, Mavrouli O, Agliardi F, Pitilakis K (2014) Recommendations for the quantitative analysis of landslide risk. Bull Eng Geol Environ 73(2):209–263
Dahal RK (2006) Geology for technical students: a textbook for bachelor level students: environmental science, civil engineering, forestry and earth hazard. Bhrikuti Academic Publications, Kathmandu
Dai FC, Lee CF (2002) Landslide characteristics and slope instability modeling using GIS, Lantau Island, Hong Kong. Geomorphology 42(3):213–228
Dai FC, Lee CF (2003) A spatiotemporal probabilistic modeling of storm-induced shallow landsliding using aerial photographs and logistic regression. Earth Surf Proc Land 28(5):527–545
Dai FC, Xu C, Yao X, Xu L, Tu XB, Gong QM (2011) Spatial distribution of landslides triggered by the 2008 Ms 8.0 Wenchuan earthquake, China. J Asian Earth Sci 40(4):883–895
Delgado J, Garrido J, López-Casado C, Martino S, Peláez JA (2011) On far field occurrence of seismically induced landslides. Eng Geol 123(3):204–213
Dhital MR, Sunuwar SC, Shrestha R (2002) Geology and structure of the Sundarijal-Melamchi area, central Nepal. J Nepal Geol Soc 27:1–10
Dijkshoorn JA, Huting JRM (2009) Soil and terrain database for Nepal (1.1 million) (No. 2009/01). ISRIC-World Soil Information
DMG (2021) Department of Mine and Geology, Nepal. https://www.dmgnepal.gov.np. Accessed 11 May 2021
Driessen PM (ed) (1991) The major soils of the world: lecture notes on their geography, formation, properties and use. Agricultural University
Duncan JM, Wright SG, Brandon TL (2014) Soil strength and slope stability. Wiley, Hoboken
Fan X, Scaringi G, Korup O, West AJ, Westen CJ, Tanyas H, Hovius N, Hales TC, Jibson RW, Allstadt KE, Zhang L, Evans SG, Xu C, Li G, Pei X, Xu Q, Huang R (2019) Earthquake-induced chains of geologic hazards: Patterns, mechanisms, and impacts. Rev Geophys 57(2):421–503
Fan X, Yunus AP, Scaringi G, Catani F, Siva Subramanian S, Xu Q, Huang R (2021) Rapidly evolving controls of landslides after a strong earthquake and implications for hazard assessments. Geophys Res Lett 48(1):e2020GL090509
Fell R, Corominas J, Bonnard C, Cascini L, Leroi E, Savage WZ (2008) Guidelines for landslide susceptibility, hazard and risk zoning for land-use planning. Eng Geol 102(3):99–111
Gallen SF, Clark MK, Godt JW, Roback K, Niemi NA (2017) Application and evaluation of a rapid response earthquake-triggered landslide model to the 25 April 2015 Mw 7.8 Gorkha earthquake, Nepal. Tectonophysics 714:173–187
García-Rodríguez MJ, Malpica JA, Benito B, Díaz M (2008) Susceptibility assessment of earthquake-triggered landslides in El Salvador using logistic regression. Geomorphology 95(3):172–191. https://doi.org/10.1016/j.geomorph.2007.06.001
Gautam P, Kubota T, Sapkota LM, Shinohara Y (2021) Landslide susceptibility mapping with GIS in high mountain area of Nepal: a comparison of four methods. Environ Earth Sci 80(9):1–18
Gnyawali KR, Zhang Y, Wang G, Miao L, Pradhan AMS, Adhikari BR, Xiao L (2020) Mapping the susceptibility of rainfall and earthquake triggered landslides along China–Nepal highways. Bull Eng Geol Environ 79(2):587–601. https://doi.org/10.1007/s10064-019-01583-2
Goda K, Kiyota T, Pokhrel RM, Chiaro G, Katagiri T, Sharma K, Wilkinson S (2015) The 2015 Gorkha Nepal earthquake: insights from earthquake damage survey. Front Built Environ 1:8
Government of Nepal (2015) Nepal Earthquake 2015, Post Disaster Needs Assessment, Vol. B: sector reports. Government of Nepal, National Planning Commission, Kathmandu. Accessed at: https://www.npc.gov.np/images/category/PDNA_volume_BFinalVersion.pdf
Guns M, Vanacker V (2013) Forest cover change trajectories and their impact on landslide occurrence in the tropical Andes. Environ Earth Sci 70(7):2941–2952
Harp EL, Keefer DK, Sato HP, Yagi H (2011) Landslide inventories: the essential part of seismic landslide hazard analyses. Eng Geol 122(1):9–21
Hasegawa S, Dahal RK, Nishimura T, Nonomura A, Yamanaka M (2009) DEM-based analysis of earthquake-induced shallow landslide susceptibility. Geotech Geol Eng 27(3):419–430
HDX (2015) Road Network of Nepal. https://www.data.humdata.org/dataset/nepal-road-network. Assessed 11 May 2021
Hosmer DW, Lemeshow S (2000) Applied logistic regression. Wiley, New York
Hovius N, Meunier P (2012) Earthquake ground motion and patterns of seismically induced landsliding. Landslides: types, mechanisms and modeling. Cambridge University Press, Cambridge, pp 24–36
Huang Y, Zhao L (2018) Review on landslide susceptibility mapping using support vector machines. CATENA 165:520–529
ICIMOD (2013) Land cover of Nepal 2010. Kathmandu, Nepal: ICIMOD. http://apps.geoportal.icimod.org/ArcGIS/rest/services/Nepal/Landcover2010/MapServer/0. Assessed 11 May 2021
Kamp U, Growley BJ, Khattak GA, Owen LA (2008) GIS-based landslide susceptibility mapping for the 2005 Kashmir earthquake region. Geomorphology 101(4):631–642
Kargel JS, Leonard GJ, Shugar DH, Haritashya UK, Bevington A, Fielding EJ, Fujita K, Geertsema M, Miles ES, Steiner J, Anderson E (2016) Geomorphic and geologic controls of geohazards induced by Nepal’s 2015 Gorkha earthquake. Science 351(6269):aac8353 (1–10)
Kavzoglu T, Sahin EK, Colkesen I (2015) Selecting optimal conditioning factors in shallow translational landslide susceptibility mapping using genetic algorithm. Eng Geol 192:101–112. https://doi.org/10.1016/j.enggeo.2015.04.004
Keefer DK (1984) Landslides caused by earthquakes. Geol Soc Am Bull 95(4):406–421
Keefer DK (1994) The importance of earthquake-induced landslides to long-term slope erosion and slope-failure hazards in seismically active regions. In: Morisawa M (ed) Geomorphology and natural hazards, pp 265–284
Keefer DK (2000) Statistical analysis of an earthquake-induced landslide distribution—the 1989 Loma Prieta, California event. Eng Geol 58(3–4):231–249
Keefer DK (2002) Investigating landslides caused by earthquakes–a historical review. Surv Geophys 23(6):473–510
Kincal C, Akgun A, Koca MY (2009) Landslide susceptibility assessment in the Izmir (West Anatolia, Turkey) city center and its near vicinity by the logistic regression method. Environ Earth Sci 59(4):745–756
Kouli M, Loupasakis C, Soupios P, Vallianatos F (2010) Landslide hazard zonation in high risk areas of Rethymno Prefecture, Crete Island. Greece Nat Hazards 52(3):599–621
Lee S, Pradhan B (2007) Landslide hazard mapping at Selangor, Malaysia using frequency ratio and logistic regression models. Landslides 4(1):33–41
Li G, West AJ, Densmore AL, Jin Z, Parker RN, Hilton RG (2014) Seismic mountain building: Landslides associated with the 2008 Wenchuan earthquake in the context of a generalized model for earthquake volume balance. Geochem Geophys Geosyst 15(4):833–844
Magliulo P, Di Lisio A, Russo F, Zelano A (2008) Geomorphology and landslide susceptibility assessment using GIS and bivariate statistics: a case study in southern Italy. Nat Hazards 47(3):411–435
Mancini F, Ceppi C, Ritrovato G (2010) GIS and statistical analysis for landslide susceptibility mapping in the Daunia area, Italy. Nat Hazard 10(9):1851–1864. https://doi.org/10.5194/nhess-10-1851-2010
Marc O, Hovius N, Meunier P, Gorum T, Uchida T (2016) A seismologically consistent expression for the total area and volume of earthquake-triggered landsliding. J Geophys Res Earth Surf 121(4):640–663
Marzorati S, Luzi L, De Amicis M (2002) Rock falls induced by earthquakes: a statistical approach. Soil Dyn Earthq Eng 22(7):565–577
McAdoo BG, Quak M, Gnyawali KR, Adhikari BR, Devkota S, Rajbhandari PL, Sudmeier-Rieux K (2018) Roads and landslides in Nepal: how development affects environmental risk. Nat Hazard 18(12):3203–3210
Merghadi A, Yunus AP, Dou J, Whiteley J, ThaiPham B, Bui DT, Avtar R, Abderrahmane B (2020) Machine learning methods for landslide susceptibility studies: a comparative overview of algorithm performance. Earth Sci Rev 207:103225
Meusburger K, Alewell C (2008) Impacts of anthropogenic and environmental factors on the occurrence of shallow landslides in an alpine catchment (Urseren Valley, Switzerland). Nat Hazard 8:509–520
Montgomery DR, Schmidt KM, Greenberg HM, Dietrich WE (2000) Forest clearing and regional landsliding. Geology 28(4):311–314
Nandi A, Shakoor A (2010) A GIS-based landslide susceptibility evaluation using bivariate and multivariate statistical analyses. Eng Geol 110(1):11–20
Nefeslioglu HA, Gokceoglu C, Sonmez H (2008) An assessment on the use of logistic regression and artificial neural networks with different sampling strategies for the preparation of landslide susceptibility maps. Eng Geol 97(3):171–191
Nicu IC, Asăndulesei A (2018) GIS-based evaluation of diagnostic areas in landslide susceptibility analysis of Bahluieț River Basin (Moldavian Plateau, NE Romania). Are Neolithic sites in danger? Geomorphology 314:27–41
Nowicki MA, Wald DJ, Hamburger MW, Hearne M, Thompson EM (2014) Development of a globally applicable model for near real-time prediction of seismically induced landslides. Eng Geol 173:54–65
Ohlmacher GC, Davis JC (2003) Using multiple logistic regression and GIS technology to predict landslide hazard in northeast Kansas, USA. Eng Geol 69(3):331–343
Osmundsen PT, Henderson I, Lauknes TR, Larsen Y, Redfield TF, Dehls J (2009) Active normal fault control on landscape and rock-slope failure in northern Norway. Geology 37(2):135–138
Owen LA, Kamp U, Khattak GA, Harp EL, Keefer DK, Bauer MA (2008) Landslides triggered by the 8 October 2005 Kashmir earthquake. Geomorphology 94(1):1–9
Parameswaran RM, Natarajan T, Rajendran K, Rajendran CP, Mallick R, Wood M, Lekhak HC (2015) Seismotectonics of the April–May 2015 Nepal earthquakes: an assessment based on the aftershock patterns, surface effects and deformational characteristics. J Asian Earth Sci 111:161–174
Petley DN, Hearn GJ, Hart A, Rosser NJ, Dunning SA, Oven K, Mitchell WA (2007) Trends in landslide occurrence in Nepal. Nat Hazards 43(1):23-44. https://doi.org/10.1007/s11069-006-9100-3
Pourghasemi HR, Rahmati O (2018) Prediction of the landslide susceptibility: which algorithm, which precision? Catena 162:177–192
Pradhan B, Lee S (2010) Landslide susceptibility assessment and factor effect analysis: backpropagation artificial neural networks and their comparison with frequency ratio and bivariate logistic regression modelling. Environ Model Softw 25(6):747–759
Remondo J, González A, De Terán JRD, Cendrero A, Fabbri A, Chung CJF (2003) Validation of landslide susceptibility maps; examples and applications from a case study in Northern Spain. Nat Hazards 30(3):437–449
Roback K, Clark MK, West AJ, Zekkos D, Li G, Gallen SF, Chamlagain D, Godt JW (2018) The size, distribution, and mobility of landslides caused by the 2015 Mw7. 8 Gorkha earthquake, Nepal. Geomorphology 301:121–138
Robinson TR, Davies TRH (2013) Potential geomorphic consequences of a future great (Mw= 8.0+) Alpine Fault earthquake, South Island, New Zealand. Nat Hazards Earth Syst Sci 13(9):2279–2299
Robinson TR, Rosser NJ, Densmore AL, Williams JG, Kincey ME, Benjamin J, Bell HJ (2017) Rapid post-earthquake modelling of coseismic landslide magnitude and distribution for emergency response decision support. Nat Hazards Earth Syst Sci Discuss 17:1521–1540
Sakai H, Fujii R, Sugimoto M, Setoguchi R, Paudel MR (2016) Two times lowering of lake water at around 48 and 38 ka, caused by possible earthquakes, recorded in the Paleo-Kathmandu lake, central Nepal Himalaya. Earth Planets Space 68(1):1–10
Sdao F, Lioi DS, Pascale S, Caniani D, Mancini IM (2013) Landslide susceptibility assessment by using a neuro-fuzzy model: a case study in the Rupestrian heritage rich area of Matera. Nat Hazard 13(2):395–407
Suzen ML, Doyuran V (2004) A comparison of the GIS based landslide susceptibility assessment methods: multivariate versus bivariate. Environ Geol 45(5):665–679
Süzen ML, Kaya BS (2012) Evaluation of environmental parameters in logistic regression models for landslide susceptibility mapping. Int J Digit Earth 5(4):338–355. https://doi.org/10.1080/17538947.2011.586443
Team RC (2019) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
USGS (2015) United States Geological Survey's Shake map of M7.8–36 km E of Khudi. Nepal. https://earthquake.usgs.gov/earthquakes/eventpage/us20002926/shakemap/pga. Assessed 11 July 2020
Van Westen CJ, Seijmonsbergen AC, Mantovani F (1999) Comparing landslide hazard maps. Nat Hazards 20(2–3):137–158
Varnes DJ (1978) Slope movement types and processes. Transp Res Board Spec Rep 176:11–33
Xu C, Xu X (2012) Comment on “Spatial distribution analysis of landslides triggered by 2008.5. 12 Wenchuan Earthquake, China” by Shengwen Qi, Qiang Xu, Hengxing Lan, Bing Zhang, Jianyou Liu [Eng Geol 116 (2010) 95–108]. Eng Geol 133:40–42
Xu C, Xu X, Dai F, Saraf AK (2012) Comparison of different models for susceptibility mapping of earthquake triggered landslides related with the 2008 Wenchuan earthquake in China. Comput Geosci 46:317–329
Xu C, Xu X, Dai F, Wu Z, He H, Shi F, Wu X, Xu S (2013a) Application of an incomplete landslide inventory, logistic regression model and its validation for landslide susceptibility mapping related to the May 12, 2008 Wenchuan earthquake of China. Nat Hazards 68(2):883–900
Xu C, Xu X, Yao Q, Wang Y (2013b) GIS-based bivariate statistical modelling for earthquake-triggered landslides susceptibility mapping related to the 2008 Wenchuan earthquake, China. Q J Eng GeolHydrogeol 46(2):221–236
Xu C, Xu X, Yao X, Dai F (2014) Three (nearly) complete inventories of landslides triggered by the May 12, 2008 Wenchuan Mw 79 earthquake of China and their spatial distribution statistical analysis. Landslides 11(3):441–461
Xu C, Xu X, Shyu JBH (2015) Database and spatial distribution of landslides triggered by the Lushan, China Mw 6.6 earthquake of 20 April 2013. Geomorphology 248:77–92
Yalcin A (2008) GIS-based landslide susceptibility mapping using analytical hierarchy process and bivariate statistics in Ardesen (Turkey): comparisons of results and confirmations. Catena 72(1):1-12. https://doi.org/10.1016/j.catena.2007.01.003
Yalcin A, Bulut F (2007) Landslide susceptibility mapping using GIS and digital photogrammetric techniques: a case study from Ardesen (NE-Turkey). Nat Hazards 41(1):201–226
Yao X, Tham LG, Dai FC (2008) Landslide susceptibility mapping based on support vector machine: a case study on natural slopes of Hong Kong, China. Geomorphology 101(4):572–582
Yilmaz I (2009) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat—Turkey). Comput Geosci 35(6):1125–1138
Zhou G, Esaki T, Mitani Y, Xie M, Mori J (2003) Spatial probabilistic modeling of slope failure using an integrated GIS Monte Carlo simulation approach. Eng Geol 68(3):373–386
Acknowledgements
The study would not be possible without valuable suggestions and inputs from Dr. Andang Soma Suriyana, Dr. Prem Prasad Paudel and Mr. Lok Mani Sapkota. The authors also would like to thank anonymous reviewers for the constructive comments for the improvement of this manuscript. The authors were indebted to Roma for English checks.
Funding
This work is partially supported by Asian Development Bank (ADB)-Japanese Scholarship Program and Kyushu University.
Author information
Authors and Affiliations
Contributions
All authors have contributed for this paper. PG lead the development of this manuscript from study design, data collection and writing. AA contribute for reviewing the manuscript and provide essential feedbacks. TK supervise the study and manuscript development. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gautam, P., Kubota, T. & Aditian, A. Evaluating underlying causative factors for earthquake-induced landslides and landslide susceptibility mapping in Upper Indrawati Watershed, Nepal. Geoenviron Disasters 8, 30 (2021). https://doi.org/10.1186/s40677-021-00200-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40677-021-00200-3