
Abstract
In this paper, the robust optimal filtering problem is discussed for time-varying networked systems with randomly occurring quantized measurements via the variance-constrained method. The stochastic nonlinearity is considered by statistical form. The randomly occurring quantized measurements are expressed by a set of Bernoulli distributed random variables, where the quantized measurements are described by the logarithmic quantizer. The objective of this paper is to design a recursive optimal filter such that, for all randomly occurring uncertainties, randomly occurring quantized measurements and stochastic nonlinearity, an optimized upper bound of the estimation error covariance is given and the desired filter gain is proposed. In addition, the boundedness analysis problem is studied, where a sufficient condition is given to ensure the exponential boundedness of the filtering error in the mean-square sense. Finally, simulations with comparisons are proposed to demonstrate the validity of the presented robust variance-constrained filtering strategy.
Similar content being viewed by others


1 Introduction
Over the past few years, the state estimation or filtering problems have been widely discussed owing to its practical applications in various fields, such as in navigation system, dynamic positioning, tracking of objects in computer vision, and so on [1,2,3,4,5,6,7]. In particular, based on a series of observed measurements over time, the Kalman filtering known as a linear optimal estimation algorithm can provide the globally optimal estimation for linear stochastic systems [8]. Regarding the complex dynamics systems with higher performance requirements, the traditional Kalman filtering method might not achieve satisfactory accuracy especially when the systems are contaminated with the nonlinear disturbances. Thus, a large number of filtering approaches under different performance constraints have been given, such as Kalman filtering [9], extended Kalman filtering [10,11,12], variance-constrained filtering [13,14,15], unscented Kalman filtering [16], \(H_{\infty}\) filtering [17, 18], and security-guaranteed filtering [4, 5]. More specifically, some security-guaranteed filtering methods have been presented in [4, 5] for complex systems under different performance indices. In [17], a robust \(H_{\infty}\) filtering algorithm has been designed to cope with the effects of the randomly occurring nonlinearities, parameter uncertainties and signal quantization. In [10, 11], the robust extended Kalman filtering methods have been proposed for time-varying nonlinear systems, and the related performance analyses concerning the boundedness of the filtering errors have been provided. In recent years, the variance-constrained method has been presented in [13, 14] to handle the filtering problems for time-varying nonlinear networked systems with missing measurements under deterministic/uncertain occurrence probabilities, where the authors have obtained the optimized upper bounds of estimation error covariance and proposed the expression forms of the time-varying filter gains via the stochastic analysis technique. Subsequently, the variance-constrained state estimation problem has been discussed in [15] for time-varying complex networks and a new time-varying estimation algorithm has been given based on the results in [13, 14].
As it is well known, the existence of the uncertainties would deteriorate the whole performance of addressed systems [19,20,21,22]. Accordingly, it is necessary to propose appropriate means to reduce the influence from uncertainties onto the filtering algorithm performance [23, 24]. Up to now, a variety of results have been reported concerning the filtering problems for uncertain time-varying systems [25,26,27]. To mention a few, a robust recursive filter has been designed in [25] for uncertain systems with missing measurements, where a sufficient criterion has been given such that the exponential mean-square stability of filtering error has been ensured. In the networked environment, the uncertainties might emerge in a random way with certain probability [28]. For example, the state estimation scheme has been proposed in [28] for discrete time-invariant networked systems subject to distributed sensor delays and randomly occurring uncertainties, under which the sufficient criterion has been given such that the stability of the resulted estimation error dynamics has been guaranteed. It is worthwhile to point out that it is necessary to compensate the negative effects caused by randomly occurring uncertainties for time-varying systems and propose more efficient filtering scheme with improved algorithm accuracy.
In a networked setting, the signals before transmission might be quantized due to the limited data-processing capacity of the transmission channels [29], hence the quantization errors should be properly addressed in order to reduce the resulted effects on the filtering algorithm performance [13]. Generally, the logarithmic quantization and uniform quantization are commonly discussed [29, 30]. So far, a large amount of efforts have been made to discuss the filtering/control problems subject to signal quantization; see e.g. [13, 17, 29, 31, 32]. Accordingly, a great deal of attention has been given with respect to the quantization errors. For instance, the sector-bound approach has been employed in [33] to convert the quantization errors into the sector-bound uncertainties, and such a method has been widely utilized when handling the control and filtering problems for networked systems with quantization effects. For example, a robust \({H_{\infty}}\) filtering algorithm under variance constraint has been proposed in [31] for nonlinear time-varying systems with randomly varying gain perturbations as well as quantized measurements, where the pre-defined estimation error variance constraint and \({H_{\infty}}\) performance have been discussed by proposing the sufficient condition. In [34], an \({H_{\infty}}\) filtering problem has been addressed for time-varying systems and a new algorithm has been given to handle the effects of signal measurements and non-Gaussian noises, moreover, the applicability of the proposed filtering scheme has been illustrated by means of a mobile robot localization scenario. So far, most of available filtering methods can be applied to tackle the deterministic quantization effects only. However, there is a need to take the randomly occurring quantization effects into account in order to further reflect the unreliable networked environments with communication constraints. Hence, new filtering approach is desirable for addressing the filtering problem of time-varying systems in the simultaneous presence of randomly occurring uncertainties and quantized measurements under variance constraint. Accordingly, it is very necessary to provide efficient analysis criterion to evaluate the proposed filtering algorithm. As such, the objective of this paper is to shorten the gap by proposing a robust variance-constrained filtering method under certain optimization criterion and conducting the desired algorithm performance analysis issue.
In this paper, we aim to design the robust variance-constrained optimal filtering algorithm for time-varying networked systems with randomly occurring uncertainties and quantized measurements. Both the randomly occurring uncertainties and the quantized measurements are modeled by Bernoulli distributed random variables. Owing to the existence of the randomly occurring uncertainties, signal quantization and stochastic nonlinearity, it is difficult to obtain the accurate value of the estimation error covariance. Therefore, we aim to propose a new robust variance-constrained filtering method under certain optimization criterion. In particular, we need to find a locally optimal upper bound of estimation error covariance and design proper filter gain at each sampling step. The main contributions of this paper lie in: (1) a new variance-constrained filtering algorithm is given for addressed networked systems with stochastic nonlinearity, randomly occurring uncertainties and signal quantization; (2) the obtained upper bound of resulting filtering error covariance can be minimized by properly designing the filtering gain, under which the stochastic analysis techniques are used; and (3) the detailed boundedness analysis of filtering error is discussed and a sufficient condition is given. Finally, we utilize the simulations to illustrate the validity of main results.
Notations
The notations in this paper are standard. \(\mathbb {R}^{n}\) and \(\mathbb{R}^{n\times m}\), denote the n-dimensional Euclidean space and the set of \(n\times m\) matrices, respectively. \(\mathbb{E}\{x\}\) represents the expectation of the random variable x. \(P^{T}\) and \(P^{-1}\) stand for the transpose and inverse of matrix P. We use \(P\geq0\) (\(P>0\)) to depict that P is symmetric positive semi-definite (symmetric positive definite). The \(\operatorname{diag}\{Y_{1}, Y_{2}, \ldots, Y_{m}\}\) represents a block-diagonal matrix with \(Y_{1}, Y_{2}, \ldots, Y_{m}\) in the diagonal. I represents an identity matrix with appropriate dimension. ∘ is the Hadamard product.
2 Problem formulation and preliminaries
In this paper, we consider the following class of discrete time-varying systems with randomly occurring uncertainties and stochastic nonlinearity:
where \(x_{k}\in{\mathbb{R}}^{n}\) is the system state vector to be estimated and its initial value \(x_{0}\) has mean \(\bar{x}_{0}\) and covariance \(P_{0|0}>0\), \(y_{k}\in{\mathbb{R}^{m}}\) denotes the measurement output, \(\xi_{k}\in{\mathbb{R}}\) is a zero-mean Gaussian white noise, \(\omega_{k}\in{\mathbb{R}^{l}}\) and \(\nu_{k}\in{\mathbb {R}^{m}}\) are the zero-mean noises with covariance \(Q_{k}>0\) and \(R_{k}>0\), respectively. \(A_{k}\), \(B_{k}\) and \(C_{k}\) are known and bounded matrices.
The uncertain matrix \(\Delta A_{k}\) has the following form:
where \(H_{k}\) and \(M_{k}\) are known matrices, and uncertain matrix \(F_{k}\) satisfies \(F^{T}_{k}F_{k}\leq I\).
The Bernoulli distributed random variable \(\alpha_{k}\in{\mathbb{R}}\), which is used to model the phenomenon of the randomly occurring uncertainties, takes the values of 0 or 1 with
where \(\bar{\alpha}_{k}\in[0,1]\) is a known scalar. The function \(f(x,\xi_{k})\) represents the stochastic nonlinearity with \(f(0,\xi _{k})=0\) and has the following statistical properties for all \(x_{k}\):
where \(s>0\) is a known integer, \(\varPi_{i}\) and \(\varGamma_{i}\) (\(i=1,2,\ldots,s\)) are known matrices with suitable dimensions.
Remark 1
In fact, it is not always possible to obtain the accurate system model during the system modeling, hence there is a need to address the modeling errors and discuss their effects on the desired performance. On the other hand, it could be the case that the modeling errors undergo the random changes, thus the randomly occurring uncertainties are characterized by introducing the random variable \(\alpha_{k}\) with known occurrence probability as in (4), which is used to cater the practical feature especially in the networked environment.
Remark 2
The stochastic nonlinearity \(f(\cdot)\) satisfying the statistical features (5)–(7) could cover many known nonlinearities addressed in the literature. For example, it could describe the functions in some linear systems with the state-multiplicative noises \(x_{k}\xi_{k}\), where \(\xi_{k}\) is a zero-mean noise with bounded second moment; and the nonlinearities in some nonlinear systems with random disturbances (e.g. \(\operatorname{sgn}(\psi (x_{k}))x_{k}\xi_{k}\) with sgn representing the signum function). In this paper, the effects induced by the stochastic nonlinearity will be examined later and the available information (e.g. \(\varPi_{i}\) and \(\varGamma_{i}\)) will be reflected in the main results.
Owing to the limited bandwidth and the unreliable link of the network communication, the signal quantizations maybe occur in a random way. Firstly, the map of the quantization process is expressed by
For each \(q_{j}(\cdot)\) (\(j=1,2,\ldots,m\)), the following set of quantization levels are considered:
where \(\chi^{(j)}\) (\(j=1,2,\ldots,m\)) characterizes the quantization density. According to [33, 35], we use the following logarithmic quantizer:
where \(\delta_{j}=\frac{1-\chi^{(j)}}{1+\chi^{(j)}}\). It is not difficult to verify that \(q_{j}(y^{j}_{k})= (1+\Delta ^{(j)}_{k} )y^{j}_{k}\) with \(|\Delta^{(j)}_{k}|\leq\delta_{j}\). Letting \(\mathcal{F}_{k}=\Delta_{k}\varUpsilon^{-1}\), \(\varUpsilon=\operatorname{diag}\{\delta_{1}, \delta_{2},\ldots,\delta_{m}\}\) and \(\Delta _{k}=\operatorname{diag}\{\Delta^{(1)}_{k},\Delta^{(2)}_{k},\ldots,\Delta ^{(m)}_{k}\}\), we can know that \(\mathcal{F}_{k}\) is an unknown real-valued matrix satisfying \(\mathcal{F}_{k}\mathcal {F}^{T}_{k}=\mathcal{F}^{T}_{k}\mathcal{F}_{k}\leq I\).
The following model is introduced to describe the real measurement signals received by the remoter filter side:
where \(\varLambda_{k}:=\operatorname{diag}\{\lambda_{k,1},\lambda_{k,2},\ldots ,\lambda_{k,m}\}\), and \(\lambda_{k,i}\) (\(i=1,2,\ldots,m\)) are random variables satisfying
with \(\bar{\lambda}_{k,i}\) being known scalars. Meanwhile, suppose that \(\xi_{k}\), \(\alpha_{k}\), \(\omega_{k}\), \(\lambda_{k,i}\), \(\nu_{k}\) as well as \(x_{0}\) are all mutually independent.
In this paper, the following time-varying filter is designed:
where \(\hat{x}_{k|k}\) is the state estimate of \(x_{k}\) at time k, \(\hat{x}_{k+1|k}\) is the one-step prediction at time k, \(\bar{\varLambda }_{k+1}={\mathbb{E}}\{\varLambda_{k+1}\}\), and \(K_{k+1}\) is the filter gain to be determined.
The purpose of this paper mainly has three aspects. Firstly, we seek the upper bound of the filtering error covariance by using inequality technique. Secondly, we design the filter gain \(K_{k+1}\) so as to minimize the upper bound. In addition, we will propose a sufficient condition to guarantee the exponential boundedness of the filtering error in the mean-square sense.
For later derivations, the following lemmas are introduced.
Lemma 1
For p, q \(\in\mathbb{R}^{n}\) and scalar \(\varepsilon>0\), the inequality
holds.
Lemma 2
([36])
For matrices A, B, C, D (\(CC^{T}\leq I\)), if the matrix \(X>0\) and scalar \(\mu>0\) satisfy
one has
Lemma 3
([37])
For a real-valued matrix \(A=[a_{ij}]_{n\times n}\) and a stochastic matrix \(B=\operatorname{diag}\{b_{1},b_{2},\ldots,b_{n}\}\), we have
with ∘ being the Hadamard product.
3 Design of optimal filtering algorithm
In this section, an optimized upper bound of the filtering error covariance is obtained based on the matrix theory and stochastic analysis technique. Moreover, we derive the desired filter gain based on the solutions to recursive matrix equations.
Firstly, let us calculate the one-step prediction error and filtering error. Define \(\tilde{x}_{k+1|k}=x_{k+1}-\hat{x}_{k+1|k}\) and \(\tilde {x}_{k+1|k+1}=x_{k+1}-\hat{x}_{k+1|k+1}\), respectively. Subtracting (10) from (1) yields
where \(\tilde{\alpha}_{k}=\alpha_{k}-\bar{\alpha}_{k}\). Similarly, we have
where \(\tilde{\varLambda}_{k+1}=\varLambda_{k+1}-\bar{\varLambda}_{k+1}\) and \(\boldsymbol {\varLambda}_{k+1}=I-\bar{\varLambda}_{k+1}\).
Now, the following theorems provide the desired recursions of the one-step prediction error covariance and filtering error covariance via the above definitions.
Theorem 1
The covariance \(P_{k+1|k}\) of the one-step prediction error satisfies
Proof
According to (14) and the independent properties of random variables, we can get (16) easily. □
Theorem 2
The recursion of the filtering error covariance \(P_{k+1|k+1}\) can be given by
where
Proof
In terms of (15) and Lemma 3, it is easy to see that
where
Notice that \(\nu_{k+1}\) and \(\varLambda_{k+1}\) are mutually independent and the expectation of \(\tilde{\varLambda}_{k+1}\) is a zero matrix, then we know that \(\mathcal{N}_{i}\) (\(i=1,2,\ldots,18\)) are zero terms. Consequently, the result in (17) can be obtained easily. □
Remark 3
Generally, it could be better if a global optimal filtering method can be given. Unfortunately, it is impossible to attain this objective due to the existence of the parameter uncertainties, nonlinearity and randomly occurring quantized measurements. In view of these obstacles, we decide to derive an upper bound of filtering error covariance and minimize this upper bound by designing proper filtering gain matrix at each time step, which is acceptable with certain admissible estimation accuracy.
So far, we have provided the recursions of the one-step prediction error covariance and the filtering error covariance. Next, we are ready to obtain the desired upper bound of filtering error covariance and choose the filter gain properly.
Theorem 3
Let \(\gamma_{k+1,1}\) and \(\varepsilon_{i}\) \((i=1,2,\ldots,6)\) be positive scalars. If the following two recursive matrix equations:
and
under the constraint \(\gamma^{-1}_{k+1,1}I-\varUpsilon\varUpsilon>0\) and initial condition \(\varSigma_{0|0}=P_{0|0}>0\), have solutions \(\varSigma _{k+1|k}>0\) and \(\varSigma_{k+1|k+1}>0\), then \(P_{k+1|k+1}\leq\varSigma_{k+1|k+1}\). Moreover, if we choose the following form of the filter gain matrix \(K_{k+1}\):
it is shown that \(\operatorname{tr} (\varSigma_{k+1|k+1})\) can be minimized, where
Proof
To prove this theorem, we resort to the mathematical induction method. By considering (16) and Lemma 1, we can deduce that
where \(\varepsilon_{1}\) is a positive scalar. So, we can get
Next, we get
where \(\varepsilon_{2}\) is a positive scalar. Noticing the norm-bounded parameter uncertainties defined in (3), the following term can be tackled:
Finally, it follows from (23)–(25) that
Secondly, it is easy to see that
where \(\varepsilon_{3}>0\) is a scalar. Next, we tackle the uncertain terms in (17). According to Lemma 1 and (27), we can arrive at
where \(\varepsilon_{i}>0\) (\(i=4,5,6\)) are scalars. Based on (28), one has
Noting \(\Delta_{k+1}=\mathcal{F}_{k+1}\varUpsilon\) (\(\mathcal {F}_{k+1}\mathcal{F}^{T}_{k+1}\leq I\)), together with Lemma 2 and the property of trace, we have
where \(\gamma_{k+1,1}\) is a positive scalar. Taking (30)–(31) into account, we arrive at
Then it follows from (18), (19), (26) and (32) that \(P_{k+1|k+1} \leq\varSigma_{k+1|k+1}\).
Finally, we aim to minimize the trace of the upper bound \(\varSigma _{k+1|k+1}\) and determine the corresponding filter gain. Firstly, calculating the partial derivative of the trace of (19) with respect to \(K_{k+1}\) leads to
where \(\bar{\varPi}_{k+1}\) and \(\varPsi_{k+1}\) are defined in (21). Let the derivative in (33) be zero, we can obtain the following optimal filter gain \(K_{k+1}\):
which is the same as in (20). Therefore, the proof is complete. □
Remark 4
As shown in Theorem 3, the obtained upper bound of filtering error covariance can be minimized by the filter gain \(K_{k+1}\) in (34) at each sampling instant. It is worth pointing out that the value of \(\gamma_{k+1,1}\) can be chosen firstly according to the constraint condition \(\gamma ^{-1}_{k+1,1}I-\varUpsilon\varUpsilon>0\). Then we can adjust the value of \(\gamma_{k+1,1}\) to improve the solvability of the new filtering scheme under certain estimation accuracy requirement. Besides, the randomly occurring uncertainties, quantized measurements as well as the stochastic nonlinearity are all examined, and the corresponding information is reflected in main results. In particular, the scalar \(\bar{\alpha}_{k}\) and the matrices \(H_{k}\), \(M_{k}\) correspond to the randomly occurring uncertainties, the matrices \(\varPi_{i}\) and \(\varGamma _{i}\) reflect the variance information of the stochastic nonlinearity \(f(x_{k},\xi_{k})\) in (1), and the scalar \(\bar{\lambda }_{k,i}\) as well as matrix ϒ refer to the randomly occurring quantized measurements addressed in the paper. Moreover, it is worthwhile to note that the newly proposed robust variance-constrained filtering scheme has the recursive feature, which is suitable for online applications particularly in the networked environments.
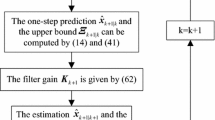
Summarizing the result in Theorem 3, the robust variance-constrained filtering (RVCF) algorithm can be provided as follows:
Algorithm RVCF
- Step 1::
-
Set \(k = 0\) and select the initial values.
- Step 2::
-
Compute the one-step prediction \(\hat{x}_{k+1|k}\) based on (10).
- Step 3::
-
Calculate the value of \(\varSigma_{k+1|k}\) by (18).
- Step 4::
-
Solve the estimator gain matrix \(K_{k+1}\) by (20).
- Step 5::
-
Compute the filtering update equation \(\hat{x}_{k+1|k+1}\) by (11).
- Step 6::
-
Obtain \(\varSigma_{k+1|k+1}\) by (19).
- Step 7::
-
Set \(k = k + 1\), and go to Step 2.
4 Boundedness analysis
In this section, the desired boundedness analysis concerning the filtering error is conducted. Before proceeding, the concept of exponential boundedness of stochastic process is firstly given.
Definition 1
([38])
If there exist real numbers \(\rho>0\), \(\nu>0\), and \(0 <\vartheta<1\) such that
holds for every \(k\geq0\), then the stochastic process \(\zeta_{k}\) is said to be exponentially mean-square bounded.
In order to conduct the boundedness analysis about the filtering error, we need the following assumption.
Assumption 1
For every \(1\leq i \leq m\) and \(k\geq0\), there exist positive numbers a̅, \(\underline{c}\), c̅, h̅, m̅, \(\overline{l}_{1}\), \(\overline{l}_{2}\) f̅, \(\underline{b}_{1}\), \(\overline{b}_{1}\), \(\underline{\omega}\), ω̅, ν̅, \(\underline{\lambda}\), λ̅ such that
Furthermore, the inequality
holds.
Theorem 4
Consider the time-varying systems (1)–(2) and the filter (10)–(11). Under the Assumption 1, the filtering error \(\tilde{x}_{k|k}\) is exponentially mean-square bounded.
Proof
Substituting (14) into (15) leads to
where
Based on (20) and Assumption 1, it is not difficult to obtain
and
Then we have
According to Lemma 1 and Assumption 1, the following inequality holds:
where \(\sigma_{1}\) is a positive scalar and \(\delta=\max\{\delta _{1},\delta_{2},\ldots,\delta_{m}\}\). Similarly, we can show
where \(\sigma_{2}\) as well as \(\sigma_{3}\) are positive scalars and \(\hat{\lambda}=\max\{1-\underline{\lambda},\overline{\lambda}\}\).
Next, we consider the following iterative matrix equation with respect to \(\varTheta_{k}\):
with the initial condition \(\varTheta_{0}=B_{0}Q_{0}B^{T}_{0}\). It is not difficult to find that
By iteration, we obtain
From (36), we have \(0 < \overline{a}_{1} < 1\) and then we arrive at
Due to the positive definite property of \(\varTheta_{k}\), it is obvious that
In view of (39) and (40), it follows that there exist \(\underline{\theta}>0\) and \(\overline{\theta}>0\) satisfying \(\underline {\theta}I \leq\varTheta_{k}\leq\overline{\theta}I\) for every \(k\geq0\).
According to (38) and the matrix inversion lemma, we have
Let \(\eta_{0}= [\frac{ \overline{a}^{2}_{1}\overline{\theta} }{ \underline{b}_{1}\underline{\omega} }+1 ]^{-1}\) and \(V_{k}(\tilde {x}_{k|k})=\tilde{x}^{T}_{k|k}\varTheta^{-1}_{k}\tilde{x}_{k|k}\). Then it is not difficult to see that \(\eta_{0} \in(0,1)\), and there exists \(\beta>0\) satisfying \(\eta=(1-\eta_{0})(1+\beta)<1\). Thus, it follows from (12) and (37) that
where \(\tau=\frac{(1+\beta^{-1})\overline{r}^{2}+\overline {z}^{2}}{\underline{\theta}}\). Accordingly, we know that
By iteration and \(\frac{ 1 }{ \overline{\theta} }I \leq\varTheta ^{-1}_{k} \leq\frac{ 1 }{ \underline{\theta} }I\), the following inequality holds:
under \(0<\eta<1\). Then it follows from Definition 1 that the stochastic process \(\tilde{x}_{k|k}\) is exponentially mean-square bounded. □
Remark 5
By utilizing the stochastic analysis technique, a new sufficient condition under certain assumption has been given in Theorem 4 to testify the exponentially mean-square boundedness of the filtering error, which provides a helpful method to evaluate the performance of the proposed optimal variance-constrained filtering scheme.
Remark 6
Note that some effective filtering methods have been presented in [39, 40] for networked systems with energy bounded noises, where the envelope-constrained \(H_{\infty}\) filtering and distributed event-triggered set-membership filtering schemes have been given. Compared with the results in [39, 40], we have developed a new RVCF algorithm with performance evaluation under variance-constrained index for addressed uncertain time-varying nonlinear systems subject to randomly occurring quantized measurements and stochastic noises with known statistical properties. In particular, it should be noted that the advantages of the proposed filtering lie in its local optimality in the minimum variance sense and the online implementations. Moreover, it could be possible to extend the proposed method to handle the mean-square consensus problem for time-varying multi-agent systems as in [41], which could be expected in a near future.
5 An illustrative example
In this section, we use numerical simulations to demonstrate the usefulness of the proposed variance-constrained filtering algorithm.
The system parameters in (1)–(2) are given by
The state vector is \(x_{k}=[x_{1,k}\ x_{2,k}]^{T} \). The noises \(\omega_{k}\) and \(\nu_{k}\) are zero-mean noises with covariances 0.05 and 0.075, respectively.
The stochastic nonlinearity \(f(x_{k},\xi_{k})\) is given as follows:
where \(\xi_{i,k}\) (\(i=1,2\)) are zero-mean noises with unity covariances. It is easy to check that \(f(x_{k},\xi_{k})\) satisfies (5)–(7) with
The parameters of the logarithmic quantizer are chosen \(u^{1}_{0}=0.5\) and \(\chi^{(1)}=0.01\). Other parameters are given by \(\varepsilon _{1}=0.01\), \(\varepsilon_{2}=1\), \(\varepsilon_{3}=0.1\), \(\varepsilon _{4}=0.01\), \(\varepsilon_{5}=0.01\), \(\varepsilon_{6}=1\), \(\gamma _{k+1,1}=0.68\), \(\bar{\alpha}_{k}=0.59\) and \(\bar{\varLambda}_{k}=0.35\). From (18)–(19), we can obtain the filter gain at each sampling step and plot the relevant simulation results in Figs. 1–5 with the initial conditions \(x_{0}=\hat {x}_{0|0}=[ 1.8 \ 2.5]^{T} \) and \(\varSigma_{0|0}=2.5I_{2}\), where MSEi (\(i=1,2\)) denote the mean-square errors for the estimations of the states \(x_{i,k}\) (\(i=1,2\)).

\(y_{k}\) without and with randomly occurring signal quantization
In the simulations, Fig. 1 plots the measurement outputs with and without randomly occurring signal quantization. In order to propose the comparison with existing method, the states are plotted and the state estimations are also provided in Figs. 2–3 based on the developed recursive variance-constrained filtering method and Kalman filter (KF) strategy. The obtained upper bound and \(\log(\mathrm{MSE}i)\) (\(i=1,2\)) are described in Figs. 4–5, which confirm that the upper bound is indeed above the mean-square errors. The \(\log(\mathrm{MSE}i)\) (\(i=1,2\)) caused by the robust variance-constrained filtering algorithm in this paper and the KF strategy are shown in Figs. 6–7, in which we can see that the filtering algorithm presented in this paper possesses smaller error than the conventional KF method.

State \(x_{1,k}\) and its estimation \(\hat{x}_{1,k|k}\)

State \(x_{2,k}\) and its estimation \(\hat{x}_{2,k|k}\)

\(\log(\mbox{MSE}1)\) and its upper bound

\(\log(\mbox{MSE}2)\) and its upper bound

\(\log(\mbox{MSE}1)\) in different methods

\(\log(\mbox{MSE}2)\) in different methods
In addition, for the purpose of illustration of the effects from the randomly occurring quantization effects, the traces of the upper bounds are depicted in Fig. 8 under different occurrence probabilities \(\bar{\varLambda}_{k}=0.35\), \(\bar{\varLambda}_{k}=0.85\), \(\bar {\varLambda}_{k}=0.95\) and \(\bar{\varLambda}_{k}=1\). From the simulations, we can see that the filtering algorithm performance can be improved if less quantized measurements are used in the filter side, i.e., more original measurements are transmitted to the remote filter and the filtering algorithm accuracy is better.

\(\log(\operatorname{trace}(\varSigma_{k|k}))\) under different occurrence probabilities
6 Conclusions
In this paper, we have investigated the robust variance-constrained filtering problem for networked time-varying systems subject to stochastic nonlinearity, randomly occurring uncertainties and quantized measurements. The phenomena of the randomly occurring uncertainties and signal quantization have been modeled by a set of mutually independent Bernoulli random variables. A recursive variance-constrained filtering algorithm has been proposed, where the filter gain has been designed to minimize the obtained upper bound of the filtering error covariance. Moreover, we have given a sufficient condition to ensure the exponential mean-square boundedness of the filtering error. Finally, we have provided the simulations to demonstrate the validity and feasibility of the obtained filtering algorithm. It should be noted that the effects induced by the stochastic nonlinearity has been examined in the conducted topic. When the other types of nonlinearities (e.g. continuous differentiable nonlinearities or Lipschitz nonlinearities) exist in the system model, the proposed filtering method can also be applicable as long as the Taylor expansion or matrix inequality technique are utilized. Accordingly, the desirable filtering algorithm can be given along the same lines as provided in this paper.
References
Caballero-Águila, R., Hermoso-Carazo, A., Linares-Pérez, J.: Distributed fusion filters from uncertain measured outputs in sensor networks with random packet losses. Inf. Fusion 34, 70–79 (2017)
Hu, L., Wang, Z., Han, Q.-L., Liu, X.: State estimation under false data injection attacks: security analysis and system protection. Automatica 87, 176–183 (2018)
Guo, R., Zhang, Z., Gao, M.: State estimation for complex-valued memristive neural networks with time-varying delays. Adv. Differ. Equ. 2018, Article ID 118 (2018)
Duan, H., Peng, T.: Finite-time reliable filtering for T–S fuzzy stochastic jumping neural networks under unreliable communication links. Adv. Differ. Equ. 2017, Article ID 54 (2017)
Wang, B., Zou, F., Cheng, J., Zhong, S.: Fault detection filter design for continuous-time nonlinear Markovian jump systems with mode-dependent delay and time-varying transition probabilities. Adv. Differ. Equ. 2017, Article ID 262 (2017)
Tuan, N.H., Tran, B.T., Long, L.D.: On a general filter regularization method for the 2D and 3D Poisson equation in physical geodesy. Adv. Differ. Equ. 2014, Article ID 258 (2014)
Park, J.H., Mathiyalagan, K., Sakthivel, R.: Fault estimation for discrete-time switched nonlinear systems with discrete and distributed delays. Int. J. Robust Nonlinear Control 26(17), 3755–3771 (2016)
Chen, D., Xu, L., Du, J.: Optimal filtering for systems with finite-step autocorrelated process noises, random one-step sensor delay and missing measurements. Commun. Nonlinear Sci. Numer. Simul. 32, 211–224 (2016)
Al-Gahtani, O., Al-Mutawa, J., El-Gebeily, M.: The interval versions of the Kalman filter and the EM algorithm. Adv. Differ. Equ. 2012, Article ID 172 (2012)
Xiong, K., Zhang, H., Liu, L.: Adaptive robust extended Kalman filter for nonlinear stochastic systems. IET Control Theory Appl. 2(3), 239–250 (2008)
Xiong, K., Liu, L., Liu, Y.: Robust extended Kalman filtering for nonlinear systems with multiplicative noises. Optim. Control Appl. Methods 32(1), 47–63 (2011)
Liu, S., Wei, G., Song, Y., Liu, Y.: Extended Kalman filtering for stochastic nonlinear systems with randomly occurring cyber attacks. Neurocomputing 207, 708–716 (2016)
Hu, J., Wang, Z., Shen, B., Gao, H.: Quantised recursive filtering for a class of nonlinear systems with multiplicative noises and missing measurements. Int. J. Control 86(4), 650–663 (2013)
Hu, J., Wang, Z., Alsaadi, F.E., Hayat, T.: Event-based filtering for time-varying nonlinear systems subject to multiple missing measurements with uncertain missing probabilities. Inf. Fusion 38, 74–83 (2017)
Hu, J., Wang, Z., Liu, S., Gao, H.: A variance-constrained approach to recursive state estimation for time-varying complex networks with missing measurements. Automatica 64, 155–162 (2016)
Li, L., Yu, D., Xia, Y., Yang, H.: Stochastic stability of a modified unscented Kalman filter with stochastic nonlinearities and multiple fading measurements. J. Franklin Inst. 354(2), 650–667 (2017)
Shen, B., Wang, Z., Shu, H., Wei, G.: Robust \(H_{\infty}\) finite-horizon filtering with randomly occurred nonlinearities and quantization effects. Automatica 46(11), 1743–1751 (2010)
Dong, H., Wang, Z., Ding, S.X., Gao, H.: Event-based \(H_{\infty}\) filter design for a class of nonlinear time-varying systems with fading channels and multiplicative noises. IEEE Trans. Signal Process. 63(13), 3387–3395 (2015)
Liu, G., Xu, S., Wei, Y., Qi, Z., Zhang, Z.: New insight into reachable set estimation for uncertain singular time-delay systems. Appl. Math. Comput. 320, 769–780 (2018)
Min, H., Xu, S., Li, Y., Chu, Y., Wei, Y., Zhang, Z.: Adaptive finite-time control for stochastic nonlinear systems subject to unknown covariance noise. J. Franklin Inst. 355, 2645–2661 (2018)
Hu, J., Wang, Z., Gao, H.: Joint state and fault estimation for uncertain time-varying nonlinear systems with randomly occurring faults and sensor saturations. Automatica 97, 150–160 (2018)
Kao, Y., Xie, J., Wang, C., Karimi, H.R.: A sliding mode approach to \(H_{\infty}\) non-fragile observer-based control design for uncertain Markovian neutral-type stochastic systems. Automatica 52, 218–226 (2015)
Ding, D., Han, Q.L., Xiang, Y., Ge, X., Zhang, X.M.: A survey on security control and attack detection for industrial cyber-physical systems. Neurocomputing 275, 1674–1683 (2018)
Chen, W., Hu, J., Yu, X., Chen, D.: Protocol-based fault detection for discrete delayed systems with missing measurements: the uncertain missing probability case. IEEE Access 6, 76616–76626 (2018)
Ma, L., Wang, Z., Hu, J., Bo, Y., Guo, Z.: Robust variance-constrained filtering for a class of nonlinear stochastic systems with missing measurements. Signal Process. 90(6), 2060–2071 (2010)
Hu, J., Wang, Z., Chen, D., Alsaadi, F.E.: Estimation, filtering and fusion for networked systems with network-induced phenomena: new progress and prospects. Inf. Fusion 31, 65–75 (2016)
Dong, H., Wang, Z., Gao, H.: Distributed \(H_{\infty}\) filtering for a class of Markovian jump nonlinear time-delay systems over lossy sensor networks. IEEE Trans. Ind. Electron. 60(10), 4665–4672 (2013)
Hu, J., Chen, D., Du, J.: State estimation for a class of discrete nonlinear systems with randomly occurring uncertainties and distributed sensor delays. Int. J. Gen. Syst. 43(3–4), 387–401 (2014)
Wei, L., Yang, Y.: A new approach to quantized stabilization of a stochastic system with multiplicative noise. Adv. Differ. Equ. 2013, Article ID 30 (2013)
Zou, L., Wang, Z., Han, Q.L., Zhou, D.: Ultimate boundedness control for networked systems with try-once-discard protocol and uniform quantization effects. IEEE Trans. Autom. Control 62(12), 6582–6588 (2017)
Lyu, M., Bo, Y.: Variance-constrained resilient \(H_{\infty}\) filtering for time-varying nonlinear networked systems subject to quantization effects. Neurocomputing 267, 283–294 (2017)
Liu, S., Wei, G., Song, Y., Ding, D.: Set-membership state estimation subject to uniform quantization effects and communication constraints. J. Franklin Inst. 354(15), 7012–7027 (2017)
Fu, M., Xie, L.: The sector bound approach to quantized feedback control. IEEE Trans. Autom. Control 50(11), 1698–1711 (2005)
Wang, Z., Dong, H., Shen, B., Gao, H.: Finite-horizon \(H_{\infty}\) filtering with missing measurements and quantization effects. IEEE Trans. Autom. Control 58(7), 1707–1718 (2013)
Elia, N., Mitter, S.K.: Stabilization of linear systems with limited information. IEEE Trans. Autom. Control 46(9), 1384–1400 (2001)
Wang, Y., Xie, L., de Souza, C.E.: Robust control of a class of uncertain nonlinear systems. Syst. Control Lett. 19(2), 139–149 (1992)
Horn, R.A., Johnson, C.R.: Topics in Matrix Analysis. Cambridge University Press, New York (1991)
Reif, K., Günther, S., Yaz, E., Unbehauen, R.: Stochastic stability of the discrete-time extended Kalman filter. IEEE Trans. Autom. Control 44(4), 714–728 (1999)
Ma, L., Wang, Z., Lam, H.K., Kyriakoulis, N.: Distributed event-based set-membership filtering for a class of nonlinear systems with sensor saturations over sensor networks. IEEE Trans. Cybern. 47(11), 3772–3783 (2017)
Ma, L., Wang, Z., Han, Q.-L., Lam, H.K.: Envelope-constrained \(H_{\infty}\) filtering for nonlinear systems with quantization effects: the finite horizon case. Automatica 93, 527–534 (2018)
Ma, L., Wang, Z., Han, Q.-L., Liu, Y.: Consensus control of stochastic multi-agent systems: a survey. Sci. China Inf. Sci. 60, Article ID 120201 (2017)
Availability of data and materials
Not applicable.
Funding
This work was supported in part by the Outstanding Youth Science Foundation of Heilongjiang Province of China under grant JC2018001, the National Natural Science Foundation of China under Grants 61673141, the Fok Ying Tung Education Foundation of China under Grant 151004, the University Nursing Program for Young Scholars with Creative Talents in Heilongjiang Province of China under grant UNPYSCT-2016029, and the Alexander von Humboldt Foundation of Germany.
Author information
Authors and Affiliations
Contributions
The two authors contributed equally to this paper. The two authors read and approved the final version of the paper.
Corresponding author
Ethics declarations
Competing interests
The two authors declared that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Jia, C., Hu, J. Variance-constrained filtering for nonlinear systems with randomly occurring quantized measurements: recursive scheme and boundedness analysis. Adv Differ Equ 2019, 53 (2019). https://doi.org/10.1186/s13662-019-2000-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13662-019-2000-0