
Abstract
The adsorption process was investigated using the ANFIS, ANN, and RSM models. The adaptive neuro-fuzzy inference system (ANFIS), artificial neural network (ANN), and response surface methodology (RSM) were used to develop an approach for assessing the Cr(VI) adsorption from wastewater using cellulose nanocrystals and sodium alginate. The adsorbent was characterized using Fourier transform infrared spectroscopy and thermogravimetric analysis. Initial pH of 6, contact time of 100 min, initial Cr(VI) concentration of 175 mg/L, sorbent dose of 6 mg, and adsorption capacity of 350.23 mg/g were the optimal condition. The Cr(VI) adsorption mechanism was described via four mechanistic models (film diffusion, Weber and Morris, Bangham, and Dumwald-Wagner models), with correlation values of 0.997, 0.990, and 0.989 for ANFIS, ANN, and RSM, respectively, and predicted the adsorption of the Cr(VI) with incredible accuracy. Statistical error tasks were additionally applied to relate the adequacy of the models. Using the central composite design (CCD), the significance of operating factors such as time, adsorbent dose, pH, and initial Cr(VI) concentration was investigated. The same concept was used to create a training set for ANN where the Levenberg–Marquardt, variable learning rate, and Polak Ribiere conjugate algorithms were used. Further statistical indices supported ANFIS as the best prediction model for adsorption compared to ANN and RSM. The efficient algorithm was used to optimize the process, which resulted in a 350 mg/g adsorption capacity. Film diffusion was identified as the rate-limiting process via mechanistic modeling.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Heavy metals have a more than 5 g/cm3 density and atomic weights ranging from 63.0 to 200.0. Water pollution caused by the discharge of heavy metals into the ecosystem metals has been a source of concern across the world [1]. Heavy metals are primarily found in wastewater from various chemical industries such as the production of steel, chemical manufacturing, fertilizer, mining, pulp, and pesticides, as well as metallurgy, mining, coal power, leather industries, and the manufacture of various polymers such as polyvinyl chloride [2]. The significant growth in industrialization has significantly contributed to releasing contaminants into the environment. Heavy metals, unlike organic pollutants, accumulate in human organisms since they are not biodegradable. Arsenic, chromium, copper, cadmium, lead, nickel, zinc, and mercury are toxic heavy metals of crucial significance in industrial wastewater treatment [3].
Chromium is considered one of the earth crust’s most abundant elements and is estimated to be the sixth most abundant transition metal. Chromium is a metal found in natural deposits as ores containing other elements such as crocoite, ferric chromite, and chrome ochre [4]. It is a well-known, very poisonous metal that may be found in drinking water. Chromium exists in various oxidation states, including 2+ , 3+ , and 6+ , with the most stable being trivalent Cr(III) and hexavalent Cr(VI). Cr(III) is much less harmful than Cr(VI) because it is an essential component of human organisms [1]. Cr(VI), however, is exceedingly hazardous and may be found in various industrial wastewater, causing severe nausea, vomiting, lung congestion, and liver and kidney problems [5]. Leather tanning, textile industries, metal polishing, electroplating, and chromate preparation all require chromium metal [4].
As a result, industrial effluent discharge into the environment is a possible source of chromium pollution in wastewater. Industrial sources include refrigeration tower blowdown, electrolysis, mineral processing, and coating activities. Dichromate (Cr2O72) and chromate (CrO42−) ions are the most common forms of Cr(VI) [6]. Cr(VI) can exist in water as chromate ion (CrO42−), dichromate (Cr2O72) ions, chromic acid (H2CrO4), and hydrogen chromate ion (HCrO4−) depending on the pH of the solution. As a result of these detrimental impacts, the United States Environmental Protection Agency (USEPA) has categorized all chromium(VI) compounds as potential health hazards and set the allowable contaminant level in water at 0.1 mg/L. Because of the strict rules limiting the emission of this dangerous pollutant into water bodies, numerous solutions must be developed to decrease chromium(VI) to the permissible limit [7].
Chemical precipitation, electrolysis, ion exchange, coagulation, membrane separation, and adsorption are all well-known and efficient traditional sewage treatment procedures [3]. However, because of constraints such as low efficacy, high operating costs, and the danger of secondary contamination, most of these technologies could not be widely deployed. The adsorption process has been extensively researched and widely implemented on a large scale because of its high efficiency, low cost, easy operation, and lack of polluting by-products [8]. Various authors [4, 7] have reported methods for adsorbing Cr(VI) from solution, including ion exchange, electrolysis, chemical precipitation, membrane separation, and adsorption. Of these methods, the adsorption process seems to have great potential due to its ability to remove heavy metal ions from water and wastewater, its simplicity, easy operation, and the potential to be regenerated by some desorption processes.
Adsorbents based on natural polymers, in particular, are gaining much interest. Many of them were developed to address the disadvantages of synthetic polymers, such as their high cost of manufacture and challenges in regeneration. On the other hand, natural polymers can be highly effective, biodegradable, cost-effective, and recyclable, with no sludge formation and complete pollution reduction [9, 10]. Cellulose nanocrystals is a biopolymer with a large surface area that is renewable and sustainable. Cellulose nanocrystals are derived from natural cellulose by acid hydrolysis and are commonly applied in three industrial sectors: energy electronics, biomedical, and wastewater treatment [11]. Cellulose nanocrystals and various active OH groups have been physically and chemically modified using grafting, composite synthesis, and carboxylation [12]. The last step is to soak cellulose nanocrystals in citric acid anhydrous. The resulting carboxylated cellulose nanocrystals retain cellulose's fundamental structure while displaying beneficial properties such as high specific surface area, hardness, and excellent stability.
Alginate is a naturally present biopolymer of mannuronic acid and guluronic acid residues obtained from brown algae [13]. Alginate is a potential biopolymer for various applications, such as drug administration, surgical dressing, and wastewater treatment. It has several desirable characteristics, including non-toxicity, biodegradability, biocompatibility, and low cost. Alginate may be modified physically and chemically to increase its structural performance and durability and generate new adsorptive structural features. Graft polymerization, composite, and developing hydrogel beads are the most frequent ways of improving alginate's adsorption properties [14].
One factor at a time (OFAT) is used in experimental design where one variable is varied while keeping all other factors constant. This approach aims to investigate the effect of each factor on the system or process being studied. This method is simple and easy to use but has limitations [15]. OFAT assumes that the factors under investigation are independent, and that their effects on the system or process are linear and additive. However, in many cases, the factors are interdependent, and their effects are nonlinear and interactive. Therefore, OFAT may be unable to identify the optimal conditions for a process or system and may miss significant interactions among the factors [16].
OFAT may not be effective regarding heavy metal ions removal because the factors affecting heavy metal removal are often interdependent and nonlinear. For example, the pH, temperature, and concentration of the heavy metals in the water can all affect the removal efficiency of a given method [17]. However, these factors do not act independently, and their effects on removal efficiency may be nonlinear and interactive. Therefore, by varying one factor at a time, OFAT may not capture the system’s true nature and identify the optimal conditions for effective heavy metals removal. As a result, a more comprehensive and systematic approach, such as response surface methodology or factorial design, may be required to optimize the heavy metals removal process [18].
Unlike one factor at a time, the response surface methodology (RSM) is a statistical method for optimizing a process in which many independent input variables impact a dependent output variable. The response is the name of the output variable. As an improved systematic approach to experimentation, RSM evaluates all process variables simultaneously while predicting an outcome. One of the most critical aspects of RSM is the central composite design (CCD). The central composite design is a three-level experimental design that combines the axial and factorial design points in the experiments conducted. One of its key benefits is that it just requires a few experimental runs to determine the optimal experimental conditions [19].
The artificial neural network (ANN) is a computational model that estimates the processing data of biological neurons. In addition to input and output layers, most neural network models have one or more hidden layers, the number is affected by the type of investigation. A neural network's main characteristic is its capacity to perform internal computations to determine the targeted output from input information [20]. Since it is reliable and efficient in representing the nonlinear interactions among the variables and responses of diverse processes, ANN may be applied in complex systems. Through training in the multiple input–output networks algorithm, the ANN can also assess multifactorial nonlinear and complicated processes given sufficient data [21].
ANFIS is a neural network that is built on mathematical computation. Its operation is based on the Takagi–Sugeno fuzzy inference system, which allows it to handle complex and nonlinear problems. It consists of a mixed system of neural networks and fuzzy systems which work together to provide accurate and better predictions from recorded input information. The fuzzy inference mechanism enhances the system’s reliability and dependability, while the neural network regulates its flexibility [22]. In recent years, there has been a growth in interest in using ANFIS in various processes. ANFIS was used by [23] to investigate the indium(III) removal from leachates of LCD screens [24]. ANFIS based on a hairpin RNA genetic algorithm for simulating overhead cranes.
This study used modified cellulose nanocrystals and sodium alginate to remove Cr(VI) from the aqueous solution by adsorption. The research's novelty is based on the modeling and analysis of Cr(VI) adsorption capacity using artificial neural networks (ANN), response surface methodology (RSM), and adaptive neuro-fuzzy interference system (ANFIS), as well as the relationship between the output variable and four input variables, including adsorption time, dosage, pH, and adsorbate concentration. The performance of ANN, RSM, and ANFIS techniques is compared to the statistically significant nonlinear error functions that measure the error distribution. However, most Cr(VI) removal research focused on (OFAT) the one-factor-at-a-time technique. One factor at a time requires a long time to evaluate. It cannot be used to predict the desired optimal adsorption efficiency as a series of contact between process variables. There has been no comparative investigation of Cr(VI) removal using complex modeling methods such as the adaptive neuro-fuzzy inference system (ANFIS), artificial neural network (ANN), and the response surface approach (RSM). As a result, our research is aimed toward reaching that goal. In addition, four mechanistic models (Weber and Morris, Dumwald-Wagner film diffusion, and Bangham models) have been explored to establish the rate-controlling phase in the adsorption process. The coefficient of correlation was used to evaluate the models. As a result, the following are the goals of this work: (1) CNC-modified adsorbent preparation and characterization; (2) modeling the adsorption capacity of Cr (VI) using ANFIS, ANN, and RSM; (3) comparison of the three models predictive capacities; and (4) determining the rate-controlling phase of the adsorption process using four mechanistic models.
2 Material and Method
2.1 Materials and Equipment
Cellulose nanocrystals were hydrolyzed from waste papers (≥ 90%). Calcium chloride (> 99%), sodium hydroxide (> 99%), hydrochloric acid (> 99%) and potassium dichromate (> 99%) were all purchased from Sigma-Aldrich. The pH of the solution was controlled using a pH meter (Hanna HI 8421). Distilled water was produced using the Ultima 888 water distiller. Using induced coupled plasma, the quantity of metal ions adsorbed was assessed (ICP, Icap7000). The functional groups available in the CNC-Alg were explored using Fourier transform infrared spectroscopy (FTIR, PerkinElmer UATR), and the morphological surface was examined using scanning electron microscopy (SEM, Philips XL30FEG).
2.2 Preparation of CNC-Alg Adsorbent
This experiment created a colloidal solution by adding alginate to water and agitating it at 60 °C for 60 min. Cellulose nanocrystals were dispersed using ultrasound and added to the alginate solution to achieve a uniform diffusion. The blended solution was then agitated at a continuous high speed for 120 min. The resulting mixture was injected into a CaCl2 solution and mechanically stirred for 45 min. The cellulose nanocrystals and sodium alginate particles were then transferred to a 0.2% CaCl2 solution to solidify. After 36 h, the particles were removed from the solution and rinsed with distilled water. Finally, the chemical structure of the particles was analyzed using Gaussian 6.0 software, and the optimized structure is represented in Fig. 1. The optimization process involves calculating the potential energy surface of the material, which describes the energy of the system as a function of the positions of the atoms. The software then iteratively adjusts the positions of the atoms in the material until the lowest energy configuration is found. This process is repeated until the system's energy converges to a minimum, indicating that the geometry and structure of the material have been optimized.

Proposed structure of CNC-Alg particles
2.3 Adsorption Experimental
Batch experiments were used to develop the adsorption method. Batch studies were carried out in 200-mL glass-stoppered flasks reactors holding test solutions at the appropriate required Cr(VI) concentration, contact time, adsorbent dose, and pH at room temperature (27 ± 2 °C). The amounts of a solution with a particular concentration of Cr(VI) were placed in the reactor. To maintain a consistent pH throughout the experiment, the pH of the solution was controlled using 0.1 M NaOH or HCl. A shaker was used to agitate the solution at 180 rpm, adding the appropriate weight of adsorbent in the prescribed dose. The mixed phases were then centrifugated for 10 min at 1500 rpm.
The quantity of Cr(VI) adsorbed onto CNC-Alg (qe) was determined using the equation below.
where Ci (mg/L) denotes the starting concentration, Ceq (mg/L) denotes the equilibrium concentration, M (mg) denotes the mass of the nanocomposite used, and V (L) is the volume of the solution.
2.4 Response Surface Methodology
RSM investigation of the adsorption process was performed using a central composite design (CCD). The four parameters employed as independent variables at a constant volume of 100 ml and a temperature of (27 ± 2 °C) were adsorbent dosage, contact time, concentration, and pH. The three levels of variance for these components are shown in Table 1 (− 1, 0, + 1). Based on the findings of the experiments and past research, the experimental limit was determined [25]. The response variable was the adsorbent capacity (mg/g). The RSM analysis examined 21 experimental data sets, including six central points. The core points ensured that the higher and lower values varied equally, the axial points ensured that the model prediction deviation was equal from the design center, and the center point facilitated data repeatability. The studies were carried out randomly to avoid systematic mistakes [26].
The response was estimated using an empirical relationship of the second-order polynomial, as shown in Eq. 2.
where Y is the expected response, γ0 is the model constant, A, B, C, and D are independent variables, γa, γb, γc and γd are linear coefficients, and γab, γac γad γbc and γcd are cross-product coefficients, and γaa, γbb γcc and γdd are the quadratic coefficients.
Design Expert version 13 was employed for the experimental design, regression analysis, analysis of variance, and optimization of process factors in the adsorption of Cr(VI). The regression coefficient (R2) and the ANOVA p-value were used to assess the model’s acceptability. By plotting the response variable on the z-axis and two independent variables on the x- and y-axis, the three-dimensional diagram can visualize how changes in the independent variables affect the response variable. This visualization can help researchers to identify the optimal combination of independent variables that will result in the desired response and understand the nature of the relationship between the variables. In addition to providing a visual representation of the relationship between variables, a three-dimensional diagram can be useful for communicating results to others. It allows researchers to see the results in a clear and easily understandable way, making it a valuable tool for presenting and sharing scientific findings. When the relationship between the input and output variables is nonlinear, RSM may not accurately capture the underlying relationship, which can result in suboptimal solutions. Researchers have explored using artificial neural networks (ANN) as an alternative modeling approach to address this issue.
2.5 Artificial Neural Network
According to [27], the RSM-generated experimental data set may be exploited to evaluate the ANN model correctly. Therefore, given a huge number of data sets, ANN modeling performs better. ANN can learn and model nonlinear and complex interactions, which is significant since many of the relationships between inputs and outputs in real life are nonlinear and complex [28]. ANN can generalize—after learning from the original inputs and their relationships, it can also estimate unseen relationships on unseen data, allowing the model to generalize and predict unseen data. Unlike many other prediction algorithms, ANN imposes no constraints on the input variables. Furthermore, several studies have demonstrated that ANNs can better predict data with high volatility and non-constant variance due to their capacity to learn hidden correlations without imposing any fixed relationships in the data [29]. The procedure for optimization by ANN is presented in Fig. 2.

Procedure for optimization by ANN
The ANN was truly tested using the abovementioned parameters, the slope, the validation test variable used to determine the ANN's validity, and data analysis regression, which reveals how the ANN plots. The connection was examined, and the weights were re-initialized and modified if they were too tight or loose. The process of training, testing, validating, and regression was repeated until the fit was satisfactory. The outcome and error data were collected when the fitting was satisfactory, and the targets and outputs were compared [30]. To develop ANN, [25] state that the following crucial characteristics must be determined: (1) Back-propagation training method selection, (2) data distribution, (3) ANN structure selection, and (4) starting weight selection[21].
2.5.1 Algorithm for BP Training Selection
Three back-propagation training algorithms were examined to determine the best back-propagation training method, as shown in Table 2. The ANN Toolbox was used to import the data’s laboratory findings. Most back-propagation training techniques used a three-layer NN with a linear transfer function at the output layer and a tangential sigmoid transfer function at the hidden layer. The Levenberg–Marquardt back-propagation training method was chosen because it has the minimum mean squared error, indicating that the algorithm's error is very low. The regression correlation and the MSE were determined for NN cross-validation. The Levenberg–Marquardt back-propagation BP technique was used to build the NN model for the experimental data. The neural network was trained using these data. The outcome matrix was generated via a forward pass (feed-forward back-propagation NN) during training. The input matrix was sent forward through the network to generate each unit's output.
As a result, the RSM collected data sets were doubled yielding forty-two (42) data sets for the ANN analysis. For the ANN computation, MATLAB software 2015 was employed. The network was trained using a multi-layer perceptron (MPL). For modeling, the Levenberg–Marquardt back-propagation, Polak Ribiere conjugate gradient back-propagation, and variable learning rate back-propagation algorithm were used (Table 2). The Levenberg–Marquardt (LM) algorithm, often known as the damped least squares approach, handles nonlinear least squares problems [31]. The variable learning approach is computationally cheap since it does not require many operations to assess the Hessian matrix and calculate the associated inverse. Each iteration generates an approximation value to the inverse Hessian matrix. It is calculated using just the first derivatives of the loss function[32]. The conjugate gradient algorithm, which is a hybrid of gradient descent and Newton’s technique, might be regarded as one of the strategies for improving the convergence rate of an artificial neural network.
Trial and error were used to determine the number of neurons in the hidden layer that would give the lowest mean square error (MSE) and the highest correlation coefficient. This was done to guarantee that the model's predictions were as near as possible to the experimental data and to avoid over-fitting. Large and small numbers of neurons were avoided since they might result in complex over-fitting and increased convergence speed [24]. About 70% of the data sources were chosen to train the neural network, 15% to test the neural network, and the other 15% to confirm the output. Trainlm was utilized as the training method to normalize the bias value. To eliminate network error, the input parameters and response were standardized between 0 and 1 [33]. However, ANNs have limitations, such as the potential for overfitting and difficulty interpreting the learned model. To address these issues, researchers have developed ANFIS (adaptive neuro-fuzzy inference system), which combines the power of ANNs with the interpretability of fuzzy logic.
2.6 Adaptive Neuro-Fuzzy Inference System
ANFIS has been shown to outperform traditional RSM and ANN models in various applications, mainly when the relationships between the input and output variables are highly nonlinear. ANFIS combines the qualitative approach of fuzzy logic with the quantitative approach of neural networks. Integrating adaptive capabilities into a single system has certain drawbacks and benefits. A trial-and-error method defines membership parameters and rules in a fuzzy system [34]. The ANFIS model was generated using the fuzzy inference approach. The first and last layers of the ANFIS structure, respectively, represent the input parameters and the output variable. The model corresponded to first-order Sugeno inference systems in the second layer, which fuzzify input parameters by converting them into membership values using membership function parameters (MF). In the third layer, the model output was derived using a set of logical principles. In the third layer, the model output was computed using logical rules. The defuzzification of the inferred result to the actual target value was achieved in the fourth layer by applying the output membership function [26]. In the fifth layer, only one node displayed all received signals as the total output, which is the adsorbent capacity [35]. The procedure for optimization by ANFIS is shown in Fig. 3.

Procedure for optimization by ANFIS
2.7 Model Performance Indicator
The ANFIS, ANN, and RSM modeling findings were compared to performance indicators to provide a classification that identified the model with the highest predictive potential concerning the results obtained. The analysis used five high-performance statistical error functions (Eqs. 3–7). The assessment indices that were chosen were based on the characteristics of the data set that was used. A comparative parity analysis was also performed, which indicated particular deviation spots between the ANFIS, ANN, and RSM model predictions from the experimental results [36].
where the number of observations is N, the number of variables in the model is P, qe(pred), and qe(exp) are predicted and experimental adsorbent capacity, respectively.
2.8 Mechanism Modeling
Four mechanistic models were explored to reveal the rate-controlling phase in removing the Cr(VI) (see Table 3). In mechanistic modeling, the Bangham model, the film diffusion (Boyd) model, the Dumwald-Wagner model, and the Weber and Morris (intra-particle) diffusion model were used[26].
Kd is the rate constant, and A is the diffusion coefficient for the liquid film diffusion. KX is the rate constant for Weber and Morris, and Cx is the equilibrium adsorbent capacity. Kdw is the rate constant, A is the coefficient, and V is the volume required for the Dumwald-Wagner model. Kb is the rate constant, β is the coefficient, m is the mass, qmax is the maximum adsorption capacity, and C is the concentration for Bangham model.
3 Results and Discussion
3.1 Characterization of the Cellulose Nanocrystals-Alginate Nanocomposites
3.1.1 FTIR Analysis
As shown in Fig. 4, the peaks at 3300, 1650, and 1400 cm−1 indicate the stretched vibration of O–H, the asymmetric vibration of C=O, and the symmetric vibrations of the carboxyl group, respectively. The C–H stretching vibration peak was between 3000 and 2600 cm−1, and the C–O stretching vibration peak was at 1200 cm−1. The cellulose nanocrystals include a lot of COOH and OH, whereas Alginate has a lot of OH but very little COOH. This might imply that Alginate was successfully coated with cellulose nanocrystals while retaining some OH and COOH in the composite. The stretching vibration of CH2 is responsible for the peak at 1350 cm−1. Other bands include 1020 cm−1 for morphological change in C–O and 850 cm−1 for the normal cellulose structure with glycoside connections in the glucose ring [37].

FTIR vibrational spectra of the cellulose nanocrystals and alginate
3.1.2 TGA Analysis
The TGA curves of cellulose nanocrystals–sodium alginate samples produced in an N2 atmosphere at a 10 C min−1 heating rate are shown in Fig. 5. The weight loss for cellulose nanocrystals–sodium alginate was rapid at 150–200 °C, followed by a more gradual reduction at 200–380 °C. The breakdown of the pyranose rings in CCN’s backbone is correlated with a distinctive degradation between 250 and 320 C. The last degradation stage occurred at 400–600 °C, resulting in a 10% weight loss, which was consistent with the disintegration of alginate and cellulose nanocrystals and demonstrated the effective synthesis process[37].

TGA curve of the cellulose nanocrystals and alginate
3.2 Experimental Design Result
An experimental design was adopted to investigate the individual and interacting impacts of the process factors. Most of the responses from different runs were considered exceptional, demonstrating that the input parameters considerably impacted the response. At a contact time of 180 min, an adsorbent dose of 2 g, a solution pH of 6, and a concentration of 50 mg/L, the maximum adsorption capacity of 265 mg/g was recorded.
3.2.1 Response Surface Method Plots
Graphical representations such as three-dimensional (3-D) and contour surface plots may be used to explore the interaction effects of the combination of input factors and response[33]. Figure 6 shows these plots. The graphs were used to demonstrate how the combined impacts of the process parameters on the adsorbent capacity of CNC-alginate adsorbent for Cr(VI) removal. The surface plots were developed by changing any two variables within the experimental region while keeping the other independent factors constant at their center points.

Three-dimensional surface and contour plots of Cr(VI) adsorption
Figure 6a, b shows the interaction impact of contact time and dosage at a constant concentration of 175 mg/L and pH of 6. It was discovered that as both contact time and dosage expanded simultaneously, the adsorption capacity was raised to 466 mg/g. This is due to the availability of additional active adsorption sites for Cr(VI) capture, and the presence of sufficient time for the adsorption process is responsible for the increase in Cr(VI) [6]. This was corroborated by the contour plot, which revealed that the optimal predicted adsorption capacity was 466 mg/g at a contact period of 180 min and a dosage of 2 g. The 3D plot’s design showed a high interaction relationship between time and dosage.
Figures 6c, d demonstrates the combined effects of pH and concentration at a contact time and dosage at CenterPoint of 150 min and 150 mg/L, respectively. The contour plot resembled a vertical line, indicating that the pH and concentration interacted. Within the pH range used, the adsorption capacity dropped as pH increased. Lower pH and high concentration increased the adsorption capacity. This was because, at acidic pH, the hydrogen bond degree of the CNCs/Alginate resulted in greater mobility and, as a result, an increase in adsorption due to electrostatic charge [38].
3.2.2 Response Surface Modeling and ANOVA Analysis
The Design Expert software’s central composite design (CCD) was used in the RSM model study. The two-factor interactions, linear, cubic, and quadratic models, were compared using statistical model results to explain the interaction between the output and input variables. A high regression coefficient (R2) and a low standard variation were used to find the optimum model for the adsorption process [39]. As shown in Table 4, the best model for describing Cr(VI) removal was a quadratic model with an R2 value of 0.989 and a standard deviation of 1.62. Furthermore, the quadratic model’s adjusted R2 of 0.992 was close to the R2, indicating strong significance and acceptable agreement between the input and output values [40]. The adjusted R2 value was close to the predicted R2, suggesting that the model and data were adequate [6].
3.2.3 Anova (Analysis of Variance)
The findings of the analysis of variance are summarized in Table 7. It was used to determine the significance of the quadratic model and design variables. The p-value was used to determine the significance of each term in the quadratic model. A 95% confidence level was employed in the p-value probability analysis. This implies that variables with p-values more than or equal to 0.05 are insignificant, and terms with p-values less than or equal to 0.05 are significant.
The magnitude of the model’s relevance and each of the quadratic model's independent input data were both determined using Fisher’s F-test values. The ratio between the model's mean square was determined to achieve this. The greater the F-value for each significant model term, the greater the term’s impact on the response. The p-value was less than 0.0001, and the F-value was 93.45, suggesting that the quadratic model recommended was acceptable [41].
The variables time (A), dosage (B), pH (C), and concentration (D) were significant, as were the interacting variables of AB, BC, AC, CD, AD, and BD, as well as the exponential variables of A2, C2, B2, and D2. For the interactive and exponential variables, Time had the most singularly significant influence, followed by the concentration on the adsorption of the Cr(VI). In contrast, the dose and the combination of pH and dosage had the most significant effects. The RSM process’s coefficient of variation was 2.10%, indicating that the model equation was adequately predictable. The coefficient of variation was calculated by dividing the standard deviation by the mean of the output variable. A model is considered highly replicable if the coefficient of variation is below 10%, according to [42]. Equation 12 shows the quadratic model equation that relates the response of Cr(VI) removal to the independent input variables (pH, time, dosage, and initial concentration).
The model equation might predict the response for a given set of variables. It was also important to compare the variables’ coefficients to see how they influenced the results. Any model term with a positive sign had a synergistic effect, whereas those with a negative value had an antagonistic effect. AD and CD were negligible in the ANOVA analysis in Table 5. Equation 13 shows the complete model equation after removing the negligible component.
The observed values were compared to predicted values obtained by the model in Fig. 8a, while residual values are shown in Fig. 7b. The points were quite close to the straight line, showing that the actual and predicted response values are very well-connected. According to the residuals plot, most data points were between − 1.0 and + 1.0 points. The majority of residuals were negligible, according to these findings. In Fig. 8c, the perturbation plot depicted the variation from the reference point for input parameters. The mean at 300 mg/g adsorption capacity was the reference point for this variation[25]. Table 6 compares the three models with the experimental data set.

RSM plots predicted vs actual (a), normal plot (b) and perturbation (c)

Training, validation, and test for the Levenberg–Marquardt algorithm
3.3 Modeling of Artificial Neural Network
The outcome matrix was then matched to the required matrix, providing an error signal for each output. Appropriate modifications were performed for each network's weights to reduce the inaccuracy. After several rounds, the discrepancies between training and validation errors began to increase; the training was terminated. The algorithms Levenberg–Marquardt, variable learning rate, and Polak Ribiere conjugate are shown in Figs. 8, 9, and 10.

Training, validation, and test for variable learning rate algorithm

Training, validation, and test for Polak Ribiere conjugate algorithm
The best method for training, testing, and validation was Levenberg–Marquardt, as illustrated in Fig. 11. The R-value for the Levenberg–Marquardt back-propagation method was 0.994 for training, 0.998 for validation, 0.999 during testing, and 0.990 for all phases. This suggests that the network's predicted output is substantially identical to the laboratory analyses' result, as seen by the lower MSE. Because it had the minimum MSE value, this approach was chosen to provide the best structure. This indicates that the Levenberg–Marquardt algorithm is appropriate for training the ANN Toolbox to predict Cr (VI) removal.

Performance of the Levenberg–Marquardt algorithm
The ideal network architecture has to be developed to identify the best performance of the NN structure. The number of hidden neurons was calculated based on the training and prediction sets' minimal MSE values. Using the Levenberg–Marquardt back-propagation algorithm, the minimal value of MSE. The ideal structure: in the input layer (four neurons), in the hidden layer (six neurons), and the output layer (one neuron). The network was discovered to be completely linked. This indicates that every neuron for each layer was connected to each neuron in the next layer, as seen in Fig. 12.

ANN architecture of the adsorption process
According to the literature, a key issue faced when training ANN was determining the correct beginning values for the connection weights. These weights are adjusted during use to meet a performance requirement [43]. ANN adds the signal from its inputs and multiplies it by the weights. If the result exceeds the threshold, the neuron can fire and transmit a signal at the output through a transfer function. Effective weight initiation is related to performance factors such as the time required to successfully train the network and the generalization ability of the trained network. The incorrect selection of initial weights might cause an increase in training time or possibly non-convergence of the training algorithm. The Garson equation was used to calculate the initial weight for NN training [44]. Using the Levenberg–Marquardt back-propagation technique, the initial weights to layer one from input one were as follows: [1.325; 1.656; 1.442; 1.463; 0.913; 1.717; 1.417; 0.179; 1.853; 1.611; 1.753; 0.056; 0.561; 1.968; 1.252]. These weights led to using the Levenberg–Marquardt back-propagation method (trainlm). The best algorithm was chosen because it produced an MSE of 0.002. After evaluating ten methods, the MSE with this algorithm and weights produced the least MSE, indicating that this algorithm's error is very low. These weights also reduced training duration. It produced a clean straight line with R values of 0.990 for training, validation, and testing.
3.4 Modeling of Adaptive Neuro-Fuzzy Inference System
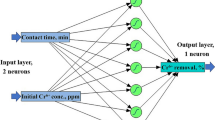
The ANFIS model was generated as a five-layered neural network using a fuzzy inference system approach. Figure 13 shows the ANFIS structure, with the input parameters (time, dosage, pH, and concentration) and the response or outcome variable (adsorption capacity) represented by the first and last layers, respectively. The model is related to first-order Sugeno inference systems in the second layer, which fuzzify input parameters by transforming them to membership values using membership functions (MF). In the third layer, a set of logical rules were used to determine the model's output. Output membership functions were used in the fourth layer to defuzzify the inferential output to actual output values. In the fifth layer, only one node was used, and the overall output was the total of all input variables [2, 24].

Architecture of ANFIS model
The ANFIS model’s data prediction capacity is shown in Fig. 14 (rule viewer). For illustration, the absorption capacity for pH 6.14, the concentration of 175 mg/L, contact time of 100 min, and dosage of 12.5 is about 350 mg/g. The model can predict all output data for every input parameter within the data range. Simultaneously, the inputs for a necessary output may be selected using the rule viewer. As a consequence, the model can predict output data (absorption capacity) based on input variables (Cr(VI) concentration, time, pH, and adsorbent dose) and vice versa.

Rule viewer of the ANFIS model
Three membership functions (MFs) were assigned to each element in the input layer to create the FIS (Fig. 15). The ANFIS modeling yielded a high correlation value of 0.997, indicating that the fuzzy inference system network is capable of predicting the absorption of Cr(VI) from solution using modified cellulose nanocrystals. The main advantage of ANFIS is that it reduces error by augmenting fuzzy controllers with self-learning abilities [22]. After seven epochs of training, the fuzzy network exhibited an error magnitude of 0.0005, confirming its suitability for modeling the removal of Cr(VI). Also, the low MSDE value indicated that the training procedure was not overfitting, and that the ANFIS model can accurately predict the removal of Cr(VI) using adsorption.

Predicted and experimental data of the adsorption for ANFIS
When it comes to advantages in adsorption results analysis, ANFIS has the advantage of being able to handle both numerical and linguistic input variables. This makes it useful for modeling systems where some input variables are challenging to quantify or where there is uncertainty in the data. ANFIS can also provide insights into the relationships between the input and output variables, which can be useful for understanding the underlying mechanisms of the system being studied.
3.5 Error Analysis
To further investigate the model accuracy abilities, five statistical error functions were used for the model predictions with the data reported in Table 7. The RMSE, ARE, SSE, MSE, and MPSD error functions were used to evaluate each model. The low values of these error functions proved the model’s potential to predict. According to the findings, all of the models displayed insignificant error levels. The value of R2 must be more than 0.8, according to [24], to establish a satisfactory correlation between predicted and experimental data. To see if the R2 was overstated, the adjusted-R2 was used, and the findings were satisfactory for all models, demonstrating their significance. According to the statistical findings, the RSM and ANN were the least successful models in predicting the accuracy of the Cr(VI) adsorption process. The ANFIS model performed slightly better than the other two. The results of the current study were consistent with those of [2, 34, 45], and all reported that ANFIS was more reliable than ANN in predicting efficiency.
The choice between ANFIS, ANN, and RSM depends on the application's specific needs. ANFIS helps handle linguistic input variables and provides insights into the underlying mechanisms of the system. ANN is suitable for recognizing patterns and making predictions based on historical data, while RSM is useful for identifying optimal conditions and optimizing processes for maximum efficiency. However, ANFIS may require more computational effort than the other two methods.
3.6 Mechanistic Modeling
Table 8 summarizes the model constants. The plotting of ln (1 − A) versus time was used to assess the liquid film diffusion model. The rate factor was determined using the linear plot’s gradient. The R2 of 0.987 indicates that Cr(VI) removal was controlled by film diffusion, with time and proportionate approach to optimum being linearly related [46]. The plotting of qt versus t0.5 was used to explore the Weber and Morris model. With increasing duration of solute uptake, the rate constant Kd dropped. The intra-particle diffusion model has a correlation value of 0.954. Since C is not equal to 0, this shows that intra-particle diffusion was not the only limiting rate in the Cr(VI) removal. This is likely due to a discrepancy in the Cr(VI) starting and ending mass transfer rates from solution to adsorbent [47]. The Dumwald-Wagner model was investigated using log plotting (1 − A2) as a function of time t. The Dumwald-Wagner model is an intra-particle model. The high fit of the near linear fit indicated that pore dispersion was implicated in the removal mechanism. The line did not pass through the origin, showing that Cr(VI) adsorption onto adsorbent pores was not the only limiting rate step. These studies revealed that while pore diffusion had a part in the adsorption process, film dispersion was the most important rate-controlling phase of the adsorption process [3]. The Bangham method was assessed using the log (Ca/Ca − qmax) as a factor of log t. The model was used to analyze if pore dispersion was the only rate-limiting step in the adsorption mechanism. A good model fit was shown by a high correlation value of 0.979, indicating that pore dispersion was involved in the adsorption mechanism. The lack of a perfect linear line in the double logarithm plot suggests that pore dispersion was not the primary rate-limiting phase [48].
3.7 Comparison with Other Adsorbents
Table 9 compares the current study's findings with previously published chromium removal data from other researchers who used commonly accessible and low-cost adsorbents. The adsorption capacities of the adsorbents were employed as the basis. The present study’s results were similar to those of other adsorbents. It has a reasonably high adsorption capacity of 270 mg/g. Based on the findings, it was determined that the cellulose nanocrystals and sodium alginate were low-cost and efficient adsorbent for removing Cr(VI)from an aqueous solution.
4 Conclusion
Traditional time series prediction algorithms are incapable of handling complicated nonlinear forecasts. ML prediction approaches cannot accommodate the known unknown complicated prediction processes required to include the complex attitudinal features of the outcome. Furthermore, such approaches cannot lower the computational cost of a huge data collection without losing significant information. This research offers a unique prediction model that incorporates the RSM, ANN, and ANFIS prediction abilities in modeling Cr(VI) removal using cellulose nanocrystals and sodium alginate which was investigated in this work. OH and COOH imply that alginate was successfully coated with cellulose nanocrystals. The consistency in the disintegration of alginate and cellulose nanocrystals demonstrated the effective synthesis process by FTIR and TGA analyses. Increases in contact time, adsorbent dose, and concentration led to higher adsorption capacity, but increases in pH above 6 resulted in lower adsorption capacity. The interaction impacts of the process variables and their optimal conditions were identified. Initial pH of 6, contact time of 100 min, initial Cr(VI) concentration of 175 mg/L, sorbent dose of 6 mg, and adsorption capacity of 350.23 mg/g were the optimal condition. ANN approaches with the BP algorithm are described and compared to experimental data. The Levenberg–Marquardt algorithm (4-6-1) with a tangent sigmoid transfer function at the hidden layer and a linear transfer function at the output layer produced the minimum MSE. In terms of predicting Cr(VI) uptake, ANFIS, ANN, and RSM were shown to be accurate and similar. According to five statistical error indicators, the ANFIS model has the most outstanding quality and reliability, followed by the ANN and RSM model. The most likely rate-controlling phase of the removal process was film diffusion, according to mechanistic modeling. The cellulose nanocrystals were shown to be suitable adsorbents in this investigation.
Data Availability
The data supporting this study's findings are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
Abbreviations
- ANN:
-
Artificial neural network
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- CCD:
-
Central composite design
- CNC–Alg:
-
Cellulose nanocrystals and alginate
- RMSE:
-
Root-mean-square errors
- ARE:
-
Average relative errors
- MSE:
-
Mean square errors
- BP:
-
Back-propagation
- LM:
-
Levenberg–Marquardt model
- ML:
-
Multilayer perceptron
- MPSD:
-
Derivative of Marquardt’s percent standard deviation
- XRF:
-
X-ray fluorescence
- FTIR:
-
Infrared spectroscopy
- SEM:
-
Scanning electron microscope
References
Ihsanullah; Abbas, A.; Al-Amer, A.M.; Laoui, T.; Al-Marri, M.J.; Nasser, M.S.; Khraisheh, M.; Atieh, M.A.: Heavy metal removal from aqueous solution by advanced carbon nanotubes: critical review of adsorption applications. Sep. Purif. Technol. 157, 141–161 (2016)
Dolatabadi, M.; Mehrabpour, M.; Esfandyari, M.; Alidadi, H.; Davoudi, M.: Modeling of simultaneous adsorption of dye and metal ion by sawdust from aqueous solution using of ANN and ANFIS. Chemom. Intell. Lab. Syst. 181, 72–78 (2018)
Kabuba, J.; Banza, M.: Modification of clinoptilolite with dialkylphosphinic acid for the selective removal of cobalt (II) and nickel (II) from hydrometallurgical effluent. Can. J. Chem. Eng. 99, S168–S178 (2021)
Zaman, H.A.; Sharif, S.; Kim, D.W.; Idris, M.H.; Suhaimi, M.A.; Tumurkhuyag, Z.: Machinability of cobalt-based and cobalt chromium molybdenum alloys: a review. Procedia Manuf. 11, 563–570 (2017)
Nordin, A.H.; Wong, S.; Ngadi, N.; Zainol, M.M.; Aien, N.; Abd, F.; Nabgan, W.: Surface functionalization of cellulose with polyethyleneimine and magnetic nanoparticles for efficient removal of anionic dye in wastewater. J. Environ. Chem. Eng. 9(1), 104639 (2021)
Shahnaz, T.; Mohamed Madhar Fazil, S.; Padmanaban, V.C.; Narayanasamy, S.: Surface modification of nanocellulose using polypyrrole for the adsorptive removal of Congo red dye and chromium in binary mixture. Int. J. Biol. Macromol. 151, 322–332 (2020)
Igberase, E.; Osifo, P.; Ofomaja, A.: Chromium(VI) ion adsorption by grafted cross-linked chitosan beads in aqueous solution—a mathematical and statistical modeling study. Environ. Technol. 00, 1–11 (2017)
Fosso-kankeu, E.: Hybridized technique applied for AMD treatment. Phys. Chem. Earth 105(January), 170–176 (2018)
Shojaeiarani, J.; Bajwa, D.; Shirzadifar, A.: A review on cellulose nanocrystals as promising biocompounds for the synthesis of nanocomposite hydrogels. Carbohydr. Polym. 216(March), 247–259 (2019)
Leudjo Taka, A.; Klink, M.J.; Yangkou Mbianda, X.; Naidoo, E.B.: Chitosan nanocomposites for water treatment by fixed-bed continuous flow column adsorption: a review. Carbohydr. Polym. 255(November 2020), 117398 (2021)
Kargarzadeh, H.; Sheltami, R.M.; Ahmad, I.; Abdullah, I.; Dufresne, A.: Cellulose nanocrystal : a promising toughening agent for unsaturated polyester nanocomposite. Polymer (Guildf.) 56, 346–357 (2015)
Kaboorani, A.; Riedl, B.: Surface modification of cellulose nanocrystals (CNC) by a cationic surfactant. Ind. Crop. Prod. 65, 45–55 (2015)
Thomas, D.; Latha, M.S.; Thomas, K.K.: Synthesis and in vitro evaluation of alginate-cellulose nanocrystal hybrid nanoparticles for the controlled oral delivery of rifampicin. J. Drug Deliv. Sci. Technol. 46, 392–399 (2018)
Hu, Z.; Mohamed, A.; Yu, D.: Fabrication of carboxylated cellulose nanocrystal/sodium alginate hydrogel beads for adsorption of Pb(II) from aqueous solution. Int. J. Biol. Macromol. 108, 149–157 (2018)
Ashraf, M.; Aslam, Z.; Ramzan, N.; Anwar, A.; Aslam, U.; Khan Durrani, A.; Ullah Khan, R.; Naseer, S.; Zeeshan Azam, M.: Non-isothermal thermo-kinetics and empirical modeling: comparative pyrolysis of cow and Buffalo manure. Therm. Sci. Eng. Prog. 37, 101568 (2023)
Banza, M.; Rutto, H.; Seodigeng, T.: Application of artificial neural network and shrinking core model for copper(Ii) and lead(Ii) leaching from contaminated soil using ethylenediaminetetraacetic acid. Soil Sediment Contam. Int. J. 00, 1–21 (2023)
Akhtar, A.; Akram, K.; Aslam, Z.; Ihsanullah, I.; Baig, N.; Bello, M.M.: Photocatalytic degradation of p-nitrophenol in wastewater by heterogeneous cobalt supported ZnO nanoparticles: modeling and optimization using response surface methodology. Environ. Prog. Sustain. Energy (2022). https://doi.org/10.1002/ep.13984
Akhtar, A.; Aslam, Z.; Asghar, A.; Bello, M.M.; Raman, A.A.A.: Electrocoagulation of Congo Red dye-containing wastewater: optimization of operational parameters and process mechanism. J. Environ. Chem. Eng. 8(5), 104055 (2020)
Samuel, O.D.; Okwu, M.O.; Oyejide, O.J.; Taghinezhad, E.; Afzal, A.; Kaveh, M.: Optimizing biodiesel production from abundant waste oils through empirical method and grey wolf optimizer. Fuel 281, 118701 (2020)
Ashraf, M.; Aslam, Z.; Ramzan, N.; Aslam, U.; Durrani, A.K.; Khan, R.U.; Ayaz, S.: Pyrolysis of cattle dung: model fitting and artificial neural network validation approach. Biomass Convers. Biorefin. 56, 23 (2021). https://doi.org/10.1007/s13399-021-02051-2
Cojocaru, C.; Humelnicu, A.C.; Pascariu, P.; Samoila, P.: Artificial neural network and molecular modeling for assessing the adsorption performance of a hybrid alginate-based magsorbent. J. Mol. Liq. 337, 116406 (2021)
Arora, S.; Keshari, A.K.: ANFIS–ARIMA modelling for scheming re-aeration of hydrologically altered rivers. J. Hydrol. 601, 126635 (2021)
Franco, D.S.P.; Duarte, F.A.; Salau, N.P.G.; Dotto, G.L.: Analysis of indium(III) adsorption from leachates of LCD screens using artificial neural networks (ANN) and adaptive neuro-fuzzy inference systems (ANIFS). J. Hazard. Mater. 384, 121137 (2020)
Zhu, X.; Wang, N.: Hairpin RNA genetic algorithm based ANFIS for modeling overhead cranes. Mech. Syst. Signal Process. 165, 108326 (2022)
Kabuba, J.; Banza, M.: Results in engineering ion-exchange process for the removal of Ni(II) and Co(II) from wastewater using modified clinoptilolite : modeling by response surface methodology and artificial neural network. J. Results Eng. 8, 100189 (2020)
Onu, C.E.; Nwabanne, J.T.; Ohale, P.E.; Asadu, C.O.: Comparative analysis of RSM, ANN and ANFIS and the mechanistic modeling in eriochrome black-T dye adsorption using modified clay. S. Afr. J. Chem. Eng. 36, 24–42 (2021)
Souza, P.R.; Dotto, G.L.; Salau, N.P.G.: Artificial neural network (ANN) and adaptive neuro-fuzzy interference system (ANFIS) modelling for nickel adsorption onto agro-wastes and commercial activated carbon. J. Environ. Chem. Eng. 6(6), 7152–7160 (2018)
Igwilo, C.N.; Ude, N.C.; Onoh, I.M.; Enekwe, C.B.; Alieze, B.A.: RSM, ANN and ANFIS applications in modeling fermentable sugar production from enzymatic hydrolysis of Colocynthis Vulgaris Shrad seeds shell. Bioresour. Technol. Rep. 18(3), 31–36 (2022)
Simsek, S.; Uslu, S.; Simsek, H.: Proportional impact prediction model of animal waste fat-derived biodiesel by ANN and RSM technique for diesel engine. Energy 239, 122389 (2022)
Ayoola, A.A.; Hymore, F.K.; Omonhinmin, C.A.; Babalola, P.O.; Fayomi, O.S.I.; Olawole, O.C.; Olawepo, A.V.; Babalola, A.: Response surface methodology and artificial neural network analysis of crude palm kernel oil biodiesel production. Chem. Data Collect. 28, 100478 (2020)
Ike, I.S.; Asadu, C.O.; Ezema, C.A.; Onah, T.O.; Ogbodo, N.O.; Godwin-Nwakwasi, E.U.; Onu, C.E.: ANN-GA, ANFIS-GA and thermodynamics base modeling of crude oil removal from surface water using organic acid grafted banana pseudo stem fiber. Appl. Surf. Sci. Adv. 9, 100259 (2022)
Agu, C.M.; Orakwue, C.C.; Menkiti, M.C.; Agulanna, A.C.; Akaeme, F.C.: RSM/ANN based modeling of methyl esters yield from Anacardium occidentale kernel oil by transesterification, for possible application as transformer fluid. Curr. Res. Green Sustain. Chem. 5, 100255 (2022)
David Samuel, O.; Adekojo Waheed, M.; Taheri-Garavand, A.; Verma, T.N.; Dairo, O.U.; Bolaji, B.O.; Afzal, A.: Prandtl number of optimum biodiesel from food industrial waste oil and diesel fuel blend for diesel engine. Fuel 285, 119049 (2021)
Ehteram, M.; Yenn Teo, F.; Najah Ahmed, A.; Dashti Latif, S.; Feng Huang, Y.; Abozweita, O.; Al-Ansari, N.; El-Shafie, A.: Performance improvement for infiltration rate prediction using hybridized adaptive neuro-fuzzy inferences system (ANFIS) with optimization algorithms. Ain Shams Eng. J. 12(2), 1665–1676 (2021)
Devaraj, R.; Mahalingam, S.K.; Esakki, B.; Astarita, A.; Mirjalili, S.: A hybrid GA-ANFIS and F-race tuned harmony search algorithm for multi-response optimization of non-traditional machining process. Expert Syst. Appl. 199, 116965 (2022)
Rezk, H.; Mohammed, R.H.; Rashad, E.; Nassef, A.M.: ANFIS-based accurate modeling of silica gel adsorption cooling cycle. Sustain. Energy Technol. Assess 50, 101793 (2022)
Banza, M.; Rutto, H.: Toxic/hazardous substances and environmental engineering continuous fixed-bed column study and adsorption modeling removal of Ni, Cu, Zn and Cd ions from synthetic acid mine drainage by nanocomposite cellulose hydrogel. J. Environ. Sci. Heal. Part A 0, 1–13 (2022)
Ahmadi, S.; Mesbah, M.; Igwegbe, C.A.; Ezeliora, C.D.; Osagie, C.; Khan, N.A.; Dotto, G.L.; Salari, M.; Dehghani, M.H.: Sono electro-chemical synthesis of LaFeO3 nanoparticles for the removal of fluoride: optimization and modeling using RSM, ANN and GA tools. J. Environ. Chem. Eng. 9(4), 105320 (2021)
Nosuhi, M.; Nezamzadeh-Ejhieh, A.: High catalytic activity of Fe(II)-clinoptilolite nanoparticales for indirect voltammetric determination of dichromate: experimental design by response surface methodology (RSM). Electrochim. Acta 223, 47–62 (2017)
Zolgharnein, J.; Dalvand, K.; Rastgordani, M.; Zolgharnein, P.: Adsorptive removal of phosphate using nano cobalt hydroxide as a sorbent from aqueous solution; multivariate optimization and adsorption characterization. J. Alloys Compd. 725, 1006–1017 (2017)
Derikvandi, H.; Nezamzadeh-Ejhieh, A.: Designing of experiments for evaluating the interactions of influencing factors on the photocatalytic activity of NiS and SnS2: focus on coupling, supporting and nanoparticles. J. Colloid Interface Sci. 490, 628–641 (2017)
Samuel, O.D.; Okwu, M.O.: Comparison of response surface methodology (RSM) and artificial neural network (ANN) in modelling of waste coconut oil ethyl esters production. Energy Sources Part A Recover. Util. Environ. Eff. 41(9), 1049–1061 (2019)
Nawaz, A.; Kumar, P.: Optimization of process parameters of Lagerstroemia speciosa seed hull pyrolysis using a combined approach of response surface methodology (RSM) and artificial neural network (ANN) for renewable fuel production. Bioresour. Technol. Rep. 18(April), 101110 (2022)
Ogedjo, M.; Kapoor, A.; Kumar, P.S.; Rangasamy, G.; Ponnuchamy, M.; Rajagopal, M.; Nath, P.: Modeling of sugarcane bagasse conversion to levulinic acid using response surface methodology (RSM), artificial neural networks (ANN), and fuzzy inference system (FIS): a comparative evaluation. Fuel 329, 125409 (2022)
Ahmad, M.; Rashid, K.; Tariq, Z.; Ju, M.: Utilization of a novel artificial intelligence technique (ANFIS) to predict the compressive strength of fly ash-based geopolymer. Constr. Build. Mater. 301(May), 124251 (2021)
Samadi, M.T.; Zarrabi, M.; Sepehr, M.N.; Ramhormozi, S.M.; Azizian, S.; Amrane, A.: Removal of fluoride ions by ion exchange resin: kinetic and equilibrium studies. Environ. Eng. Manag. J. 13(1), 205–214 (2014)
Race, M.; Marotta, R.; Fabbricino, M.; Pirozzi, F.; Andreozzi, R.; Cortese, L.; Giudicianni, P.: Copper and zinc removal from contaminated soils through soil washing process using ethylenediaminedisuccinic acid as a chelating agent: a modeling investigation. J. Environ. Chem. Eng. 4(3), 2878–2891 (2016)
Al-Qahtani, K.M.: Water purification using different waste fruit cortexes for the removal of heavy metals. J. Taibah Univ. Sci. 10(5), 700–708 (2016)
Igberase, E.; Ofomaja, A.; Osifo, P.O.: International Journal of Biological Macromolecules Enhanced heavy metal ions adsorption by 4-aminobenzoic acid grafted on chitosan/epichlorohydrin composite: kinetics, isotherms, thermodynamics and desorption studies. Int. J. Biol. Macromol. 123, 664–676 (2019)
Acknowledgements
The author would like to thank the Vaal University of Technology’s Department of Chemical & Metallurgical Engineering for providing continuous operating facilities.
Funding
Open access funding provided by Vaal University of Technology.
Author information
Authors and Affiliations
Contributions
MB involved in conceptualization, methodology, formal analysis, investigation, data curation, writing, and writing—original draft. TS involved in methodology, validation, formal analysis, investigation, and writing—reviewing and editing. HR involved in methodology, validation, formal analysis, and investigation, writing—reviewing and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competition for financial interests or personal relationships that could have influenced the work reported in this paper.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
banza, M., Seodigeng, T. & Rutto, H. Comparison Study of ANFIS, ANN, and RSM and Mechanistic Modeling for Chromium(VI) Removal Using Modified Cellulose Nanocrystals–Sodium Alginate (CNC–Alg). Arab J Sci Eng 48, 16067–16085 (2023). https://doi.org/10.1007/s13369-023-07968-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-023-07968-6