
Abstract
In this paper we describe the efficient numerical implementation of Fractional HBVMs, a class of methods recently introduced for solving systems of fractional differential equations. The reported arguments are implemented in the Matlab\(^{\copyright } \) code fhbvm, which is made available on the web. An extensive experimentation of the code is reported, to give evidence of its effectiveness.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Fractional differential equations have become a common description tool across a variety of applications (see, e.g., the classical references [23, 36] for an introduction). For this reason, their numerical solution has been the subject of many researches (see, e.g. [1, 24, 25, 34, 35, 37, 38]), with the development of corresponding software (see, e.g., [21, 27, 28]). In this context, the present contribution is addressed for solving initial value problems for fractional differential equations (FDE-IVPs) in the form
where, for the sake of brevity, we have omitted the argument t for f. Here, for \(\alpha \in (0,1)\), \(y^{(\alpha )}(t) \equiv D^\text{\AA }y(t)\) is the Caputo fractional derivative:Footnote 1
The Riemann-Liouville integral associated to (2) is given by:
Consequently, the solution of (1) can be formally written as:
The numerical method we shall consider, relies on Fractional HBVMs (FHBVMs), a class of methods recently introduced in [8], as an extension of Hamiltonian Boundary Value Methods (HBVMs), special low-rank Runge-Kutta methods originally devised for Hamiltonian problems (see, e.g., [10, 11]), and later extended along several directions (see, e.g., [2, 4, 6, 8, 9, 12]), including the numerical solution of FDEs. A main feature of HBVMs is the fact that they can gain spectrally accuracy, when approximating ODE-IVPs [3, 19, 20], and such a feature has been recently extended to the FDE case [8].
With this premise, the structure of the paper is as follows: in Section 2 we recall the main facts about the numerical solution of FDE-IVPs proposed in [8]; in Section 3 we provide full implementation details for the Matlab\(^{\copyright }\) code fhbvm used in the numerical tests; in Section 4 we report an extensive experimentation of the code, providing some comparisons with another existing one; at last, a few conclusions are given in Section 5.
2 Fractional HBVMs
To begin with, in order to obtain a piecewise approximation to the solution of the problem, we consider a partition of the integration interval in the form:
where \(h_n>0\), \(n=1,\dots ,N\), and such that
Further, by setting
the restriction of the solution of (1) on the interval \([t_{n-1},t_n]\), and taking into account (4) and (5–6), one obtains, for \(t\equiv t_{n-1}+ch_{n}\), \(c\in [0,1]\),
To make manageable the handling of the ratios \(h_i/h_\nu \), \(i=\nu ,\dots ,n\), \(\nu =1,\dots ,n-1\), we shall hereafter consider the following choices for the mesh (5–6):
-
Graded mesh. In order to cope with possible singularities in the derivative of the vector field at the origin, we consider the graded mesh
$$\begin{aligned} h_n = r h_{n-1} \equiv r^{n-1} h_1, \qquad n=1\dots ,N, \end{aligned}$$(9)where \(r>1\) and \(h_1>0\) satisfy, by virtue of (5–6),
$$\begin{aligned} h_1\frac{r^N-1}{r-1} = T. \end{aligned}$$(10)As a result, one obtains that (8) becomes:
$$\begin{aligned} y_n(ch_n)= & y_0~ + \nonumber \\ & \frac{h_1^\alpha }{\varGamma (\alpha )}\sum _{\nu =1}^{n-1} r^{\alpha (\nu -1)} \int _0^1 \left( \frac{r^{n-\nu }-1}{r-1}+cr^{n-\nu }-\tau \right) ^{\alpha -1}f(y_\nu (\tau r^{\nu -1}h_1))\textrm{d}\tau \nonumber \\ & \qquad + ~\frac{h_1^\alpha r^{\alpha (n-1)}}{\varGamma (\alpha )} \int _0^c (c-\tau )^{\alpha -1}f(y_n(\tau r^{n-1}h_1))\textrm{d}\tau \nonumber \\=: & ~\phi _{n-1}^\alpha (c;h_1,r,y) \,+\, \frac{h_1^\alpha r^{\alpha (n-1)}}{\varGamma (\alpha )} \int _0^c (c-\tau )^{\alpha -1}f(y_n(\tau r^{n-1}h_1))\textrm{d}\tau , \nonumber \\ & \qquad \qquad c\in [0,1]. \end{aligned}$$(11) -
Uniform mesh. This case is equivalent to allowing \(r=1\) in (9). Consequently, from (5–6) we derive
$$\begin{aligned} h_n \equiv h_1 := \frac{T}{N}, \quad n=1,\dots ,N, \quad \Rightarrow \quad t_n = nh_1, \quad n=0,\dots ,N. \end{aligned}$$(12)As a result, (8) reads:
$$\begin{aligned} y_n(ch_n)\equiv & y_n(ch_1) \nonumber \\= & y_0 + \frac{h_1^\alpha }{\varGamma (\alpha )}\sum _{\nu =1}^{n-1} \int _0^1 \left( n-\nu +c-\tau \right) ^{\alpha -1}f(y_\nu (\tau h_1))\textrm{d}\tau \nonumber \\ & \qquad + ~\frac{h_1^\alpha }{\varGamma (\alpha )} \int _0^c (c-\tau )^{\alpha -1}f(y_n(\tau h_1))\textrm{d}\tau \nonumber \\\equiv & ~\phi _{n-1}^\alpha (c;h_1,1,y) \,+\, \frac{h_1^\alpha }{\varGamma (\alpha )} \int _0^c (c-\tau )^{\alpha -1}f(y_n(\tau h_1))\textrm{d}\tau , \nonumber \\ & \qquad \qquad c\in [0,1]. \end{aligned}$$(13)
Remark 1
As is clear, in order to obtain an accurate approximation of the solution, it is important to establish which kind of mesh (graded or uniform) is appropriate. Besides this, also a proper choice of the parameters \(h_1\), r, and N in (9–10) is crucial. Both aspects will be studied in Section 3.1.
2.1 Quasi-polynomial approximation
We now discuss a piecewise quasi-polynomial approximation to the solution of (1),
such that
is the approximation to \(y_n(ch_n)\), defined in (7). According to [8], such approximation will be derived through the following steps:
-
1.
expansion of the vector field, in each sub-interval \([t_{n-1},t_n]\), \(n=1,\dots ,N\), (recall (5–6)) along a suitable orthonormal polynomial basis;
-
2.
truncation of the infinite expansion, in order to obtain a local polynomial approximation.
Let us first consider the expansion of the vector field along the orthonormal polynomial basis, w.r.t. the weight function
resulting into a scaled and shifted family of Jacobi polynomials:Footnote 2
such that
In so doing, for \(n=1,\dots ,N\), one obtains:
with (see (15))
Consequently, the FDE (1), can be rewritten as:
The approximation is derived by truncating the infinite series in (17) to a finite sum with s terms, thus replacing (19) with a series of local problems, whose vector field is a polynomial of degree s:
with \(\gamma _j(\sigma _n)\) defined similarly as in (18):
As a consequence, (11) will be approximated as:
where (see (3))
is the Riemann-Liouville integral of \(P_j(c)\), and, for \(x\ge 1\):
The efficient numerical evaluation of the integrals (23) and (24) will be explained in detail in Section 3.2.
Remark 2
We observe that, for \(c=x=1\), by virtue of (15–16) one has:
Similarly, when using a uniform mesh, by means of similar steps as above, (13) turns out to be approximated by:
In both cases, the approximation at \(t_n\) is obtained, by setting \(c=1\) and taking into account (25), as:
which formally holds also in the case of a uniform mesh (see (12)) by setting \(r=1\).
2.2 The fully discrete method
Quoting Dahlquist and Björk [22], “as is well known, even many relatively simple integrals cannot be expressed in finite terms of elementary functions, and thus must be evaluated by numerical methods”. In our framework, this obvious statement means that, in order to obtain a numerical method, at step n the Fourier coefficients \(\gamma _j(\sigma _n)\) in (21) need to be approximated by means of a suitable quadrature formula. Fortunately enough, this can be done up to machine precision by using a Gauss-Jacobi formula of order 2k based at the zeros of \(P_k(c)\), \(c_1,\dots ,c_k\), with corresponding weights (see (15))
by choosing a value of k, \(k\ge s\), large enough. In other words,
where \(\,\doteq \,\) means equal within machine precision. Because of this, and for sake of brevity, we shall continue using \(\sigma _n\) to denote the fully discrete approximation (compare with (22), or with (26), in case \(r=1\)):Footnote 3
As is clear, the coefficientes \(\gamma _j^\nu \), \(j=0,\dots ,s-1\), \(\nu =1,\dots ,n-1\), needed to evaluate \(\phi _{n-1}^{\alpha ,s}(c;h_1,r,\sigma )\), have been already computed at the previous time-steps.
We observe that, from (28), in order to compute the (discrete) Fourier coefficients, it is enough evaluating (29) only at the quadrature abscissae \(c_1,\dots ,c_k\). In so doing, by combining (28) and (29), one obtains a discrete problem in the form:
Once it has been solved, according to (27), the approximation of \(y(t_n)\) is given by:
It is worth noticing that the discrete problem (30) can be cast in vector form, by introducing the (block) vectors
and the matrices
as:
with the obvious notation for the function f, evaluated in a vector of (block) dimension k, of denoting the (block) vector of dimension k containing the function f evaluated in each (block) entry. As observed in [8], the (block) vector
appearing at the r.h.s. in (32) as argument of f, satisfies the equation
obtained combining (32) and (33). Consequently, it can be regarded as the stage vector of a Runge-Kutta type method with Butcher tableau
Remark 3
Though the two formulations (32) and (34) are equivalent each other, nevertheless, the former has (block) dimension s independently of the considered value of k (\(k\ge s\)), which is the (block) dimension of the latter. Consequently, in the practical implementation of the method, the discrete problem (32) is the one to be preferred, since it is independent of the number of stages.
When \(\alpha =1\), the Runge-Kutta method (35) reduces to a HBVM(k, s) method [3, 5, 9,10,11,12, 19, 20]. Consequently, we give the following definition [8].
Definition 1
The method defined by (35) (i.e., (31–32)) is called fractional HBVM with parameters (k, s). In short, FHBVM(k, s).
The efficient numerical solution of the discrete problem (32) will be considered in Section 3.4.
3 Implementation issues
In this section we report all the implementation details used in the Matlab\(^{\copyright }\) code fhbvm, which will be used in the numerical tests reported in Section 4.
3.1 Graded or uniform mesh?
The first relevant problem to face is the choice between a graded or a uniform mesh and, in the former case, also choosing appropriate values for the parameters r, N, and \(h_1\) in (9–10). We start considering a proper choice of this latter parameter, i.e., \(h_1\) which, in turn, will allow us to choose the type of mesh, too. For this purpose, the user is required to provide, in input, a convenient integer value \(M>1\), such that, if a uniform mesh is appropriate, then the stepsize is given by:
It is to be noted that, since the code is using a method with spectral accuracy in time, the value of M should be as small as possible. That said, we set \(h_1^0=h\) and apply the code on the interval \([0,h_1^0]\) both in a single step, and by using a graded mesh of 2 sub-intervals defined by a value of \(r:=\hat{r}\equiv 3\). As a result, the two sub-intervals, obtained by solving (10) for \(h_1\), with
are Footnote 4
In so doing, we obtain two approximations to \(y(h_1^0)\), say \(y_1\) and \(y_2\). According to the analysis in [8], if Footnote 5
with tol a suitably small tolerance,Footnote 6 then this means the stepsize \(h_1:=h_1^0\) is appropriate. Moreover, in such a case, a uniform mesh with \(N\equiv M\) turns out to be appropriate, too.
Conversely, the procedure is repeated on the sub-interval \([0,h_1^1] \equiv [0,h_1^0/4]\), and so forth, until a convenient initial stepsize \(h_1\) is obtained. This process can be repeated up to a suitable maximum number of times that, considering that at each iteration the current guess of \(h_1\) is divided by 4, allows for a substantial reduction of the initial value (36). Clearly, in such a case, a graded mesh is needed. At the end of this procedure, we have then chosen the initial stepsize \(h_1\) which, if the procedure ends at the \(\ell \)-th iteration, for a convenient \(\ell >1\), is given by:
We need now to appropriately choose the parameters r and N in (9–10). To simplify this choice, we require that the last stepsize in the mesh be equal to (36). Consequently, we would ideally satisfy the following requirements:
which, by virtue of (38), become
Combining the two equations then gives:
As is clear, this value of N is not an integer, in general, so that we shall choose, instead:
Remark 4
From (40), and considering that \(Nh_1<T\) (conversely, a uniform mesh could have been used) and, by virtue of (38), one has:
As is clear, using the value of N in (40) in place of that in (39) implies that we need to recompute r, so that the requirement (now \(h_1\), N, and T are given)
is again fulfilled. Equation (42) can be rewritten as
thus inducing the iterative procedure
As a convenient choice for \(r_0\), one can use the guess for r defined in (39). The following result can be proved.
Theorem 1
There exists a unique \(\bar{r}>1\) satisfying \(\bar{r}=\psi (\bar{r})\), and the iteration (44) globally converges to this value over the interval \((1, +\infty )\).
Proof
A direct computation shows that:
From (45) we deduce that the (positive) mapping \(\psi (r)\) is strictly increasing and admits \((1,+\infty )\) as invariant set, since \(r>1\) implies \(\psi (r)>\psi (1)=1\).
From (46) we additionally deduce that \(\psi (r)\) is concave and \(\psi (r)>r\) for \(r\in (1,1+\varepsilon )\), with \(\varepsilon >0\) sufficiently small. These properties and the fact that \(\psi '(r) \rightarrow 0\), for \(r\rightarrow +\infty \), imply that:
-
the equation \(r=\psi (r)\) admits a unique solution \(\bar{r}>1\) and \(\psi '(\bar{r})<1\);
-
\(\psi \big ((1,\bar{r})\big ) \subset (1,\bar{r})\) and \(\psi \big ((\bar{r},+\infty )\big ) \subset (\bar{r},+\infty )\) (since \(\psi \) is increasing);
-
\(\psi (r)>r\) for \(1<r<\bar{r}\) and \(\psi (r)<r\) for \(r>\bar{r}\).
From the two latter properties we conclude that, for any \(r_0>1\), the sequence generated by (44) converges monotonically to \(\bar{r}\). \(\square \)
Consequently, we have derived the parameters \(h_1\) in (38), N in (40), and r satisfying (42) of the graded mesh (9–10), the latter one obtained by a few iterations of (44).
Remark 5
In the actual implementation of the code, we allow the use of a uniform mesh also when \(\ell =2\) steps of the previous procedure are required, provided that M has a moderate value (say, \(M\le 5\)). Consequently, for the final mesh, \(h_1=h/4\), \(r=1\), and \(N=4M\).
3.2 Approximating the fractional integrals
The practical implementation of the method requires the evaluation of the following integrals (recall (30) and the definitions (23–24)):
and
in case a graded mesh is used, or
in case a uniform mesh is used.
It must be emphasized that all such integrals ((47) and (48), or (47) and (49)), can be pre-computed once for all, for later use. For their computation, in the first version of the software, we adapted an algorithm based on [5] which, however, required a quadruple precision, for the considered values of k and s. In this respect, the use of the standard vpa of Matlab\(^{\copyright }\), which is based on a symbolic computation, turned out to be too slow. For this reason, hereafter we describe two new algorithms for computing the above integrals, which result to be quite satisfactory, when using the standard double precision IEEE. Needless to say that, since vpa is no more required, they turn out to be much faster than the previous ones.
Let us describe, at first, the computation of (47). One has, by considering that \(k\ge s\) and \(c_i\in (0,1)\):
where the last equality holds because the Jacobi quadrature formula has order 2k. Clearly, for each \(i=1,\dots ,k\), all the above integrals can be computed in vector form in “one shot”, by using the usual three-term recurrence to compute the Jacobi polynomials.
Concerning the integrals (48-49), let us now consider the evaluation of a generic \(J_j^\alpha (x)\), \(j=0,\dots ,s-1\), for \(x>1\). In this respect, there is numerical evidence that, for \(x\ge 1.1\), a high-order Gauss-Legendre formula is able to approximate the required integral to full machine precision. Since we will use a value of \(s=20\), we consider, for this purpose, a Gauss-Legendre formula of order 60, which turns out to be fully accurate. Instead, for \(x\in (1,1.1)\), one has:
again, due to the fact that the quadrature is exact for polynomials of degree at most \(s-1\). Also in this case, for each fixed \(x>1\), all the integrals can be computed in “one shot” by using the three-term recurrence of the Jacobi polynomials.
We observe that the previous expression is exact also for \(x=1\), since \(J_j^\alpha (1)=\delta _{j0}/\varGamma (\alpha +1)\).
3.3 Error estimation
An estimate of the global error can be derived by computing the solution on a doubled mesh. In other words, if (see (31))
with \(t_n\) as in (5–6), are the obtained approximations, then
where \(\hat{y}_n\approx y(\hat{t}_n)\), \(n=0,\dots ,2N\), is the solution computed on a doubled mesh.
When a uniform mesh (12) is used, the doubled mesh is simply given by:
Conversely, when a graded mesh (9–10) is considered, the doubled mesh is given by:
with \(\hat{t}_0=0\), and
The choice of \(\hat{h}_1\) is done for having
according to (10).
3.4 The nonlinear iteration
At last, we describe the efficient numerical solution of the discrete problem (32), which has to be solved at the n-th integration step. As is clear, the very formulation of the problem induces a straightforward fixed-point iteration:
which can be conveniently started from \(\gamma ^{n,0}=\textbf{0}\). The following straightforward result holds true.
Theorem 2
Assume f be Lipchitz with constant L in in the interval \([t_{n-1},t_n]\). Then, the iteration (50) is convergent for all timesteps \(h_n\) such that
Proof
See [8, Theorem 2].\(\square \)
Nevertheless, as is easily seen, also the simple equation
whose solution is almost everywhere close to 0, after an initial transient, suffers from stepsize limitations, if the fixed-point iteration (50) is used, since it has to be everywhere proportional to \(\lambda ^{-1/\alpha }\).
In order to overcome this drawback, a Newton-type iteration is therefore needed. Hereafter, we consider the so-called blended iteration which has been at first studied in a series of papers [7, 14, 16, 17]. It has been implemented in the Fortran codes BIM [15], for ODE-IVPs, and BIMD [18], for ODE-IVPs and linearly implicit DAEs, and in the Matlab code hbvm [10, 13], for solving Hamiltonian problems. We here consider its adaption for solving (32). By neglecting, for sake of brevity, the time-step index n, we then want to solve the equation:
By setting \(f_0'\) the Jacobian of f evaluated at the first entry of \(\phi ^{\alpha ,s}\), \(I=I_s\otimes I_m\), and
the application of the simplified Newton method then reads:
Even though this iteration has the advantage of using a coefficient matrix which is constant at each time-step, nevertheless, its dimension may be large, when either s or m are large. To study a different iteration, able to get rid of this problem, let us decouple the linear system into the various eigenspaces of \(f_0'\), thus studying the simpler problem
with all involved vectors of dimension s, and \(\mu \in \sigma (f_0')\) a generic eigenvalue of \(f_0'\), and an obvious meaning of \(g(\gamma ^\ell )\). By setting \(q=h^\alpha \mu \), the iteration then reads:
Hereafter, we consider the iterative solution of the linear system in (54). A linear analysis of convergence (in the case the r.h.s. is constant) is then made, as at first suggested in [31,32,33], and later refined in [14, 17]. Consequently, skipping the iteration index \(\ell \), let us consider the linear system to be solved:
and its equivalent formulation, derived considering that matrix (52) is nonsingular, and with \(\xi >0\) a parameter to be later specified,
Further, we consider the blending of the previous two equivalent formulations with weights \(\theta (q)\) and \(I_s-\theta (q)\), where, by setting \(O\in \mathbb {R}^{s\times s}\) the zero matrix,
In so doing, one obtains the linear system
with the coefficient matrix,
such that [14]:
This naturally induces the splitting matrix
defining the blended iteration
This latter iteration converges iff the spectral radius of the iteration matrix,
The iteration is said to be A-convergent if (58) holds true for all \(q\in \mathbb {C}^-\), the left-half complex plane, and L-convergent if, in addition, \(\rho (q)\rightarrow 0\), as \(q\rightarrow \infty \). Since [14]
the blended iteration is L-convergent iff it is A-convergent. For this purpose, we shall look for a suitable choice of the positive parameter \(\xi >0\). Considering that \(\theta (q)\) is well defined for all \(q\in \mathbb {C}^-\), the following statement easily follows from the maximum modulus theorem.
Theorem 3
The blended iteration is L-convergent iff the maximum amplification factor,
The following result also holds true.
Theorem 4
The eigenvalues of the iteration matrix \(I_s-\theta (q)M(q)\) are given by:
Consequently, the maximum amplification factor is given by:
Proof
See [14, Theorem 2 and (25)], by considering that
is obtained at \(x=\xi ^{-1}\), so that (59) follows. \(\square \)
Slightly generalizing the arguments in [14], we then consider the following choice of the parameter \(\xi \),
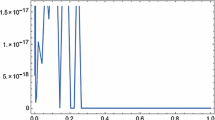
which is computed once forall, and always provides, in our experiments, an L-convergent iteration. In particular, the code fhbvm uses, at the moment, \(k=22\) and \(s=20\): the corresponding maximum amplification factor (59) is depicted in Fig. 1, w.r.t. the order \(\alpha \) of the fractional derivative, thus confirming this.

Coming back to the original problem (53), starting from the initial guess \(\varDelta \gamma ={\varvec{0}}\), and updating the r.h.s. as soon as a new approximation to \(\gamma \) is available, one has that the iteration (55–57) simplifies to:
with \(\xi \) chosen according to (60), and
Consequently, only the factorization of one matrix, having the same dimension m of the problem, is needed. Moreover, the initial guess \(\gamma ^0={\varvec{0}}\) can be conveniently considered in (61).
Remark 6
It is worth mentioning that, due to the properties of the Kronecker product, the iteration (61) can be compactly cast in matrix form, thus avoiding an explicit use of the Kronecker product. This implementation has been considered in the code fhbvm used in the numerical tests.
Actually, according to Theorem 2, in the code fhbvm we automatically switch between the fixed-point iteration (50) or the blended iteration (61), depending on the fact that
with \(tol<1\) a suitable tolerance.
4 Numerical Tests
In this section we report a few numerical tests using the Matlab\(^{\copyright }\) code fhbvm: the code implements a FHBVM(22,20) method using all the strategies discussed in the previous section. The calling sequence of the code is:
[t,y,stats,err] = fhbvm( fun, y0, T, M )
In more details,
-
In input:
-
fun is the identifier (or the function handling) of the function evaluating the r.h.s. of the equation (also in vector mode), its Jacobian, and the order \(\alpha \) of the fractional derivative (see help fhbvm for more details);
-
y0 is the initial condition;
-
T is the final integration time;
-
M is the parameter in (36) (it should be as small as possible);
-
-
In output:
-
t,y contain the computed mesh and solution;
-
stats (optional) is a vector containing the following time statistics:
-
1.
the pre-processing time for computing the parameters \(h_1\), r, and N (see Section ()) and the fractional itegrals (47), and (48) or (49);
-
2.
the time for solving the problem;
-
3.
the pre-processing time for computing the fractional itegrals (47), and (48) or (49) for the error estimation;
-
4.
the time for solving the problem on the doubled mesh, for the error estimation;
-
1.
-
err (optional), if specified, contains the estimate of the absolute error. This estimate, obtained on a doubled mesh, is relatively costly: for this reason, when the parameter is not specified, the solution on the doubled mesh is not computed.
-
For the first two problems, we shall also make a comparison with the Matlab\(^{\copyright }\) code flmm2 [27],Footnote 7 in order to emphasize the potentialities of the new code. All numerical tests have been done on a M2-Silicon based computer with 16GB of shared memory, using Matlab\(^{\copyright }\) R2023b.
The comparisons will be done by using a so called Work Precision Diagram (WPD), where the execution time (in sec) is plotted against accuracy. The accuracy, in turn, is measured through the mixed error significant computed digits (mescd) [39], defined, by using the same notation seen in (37), as Footnote 8
being \(t_i\), \(i=0,\dots ,N\), the computational mesh of the considered solver, and \(y(t_i)\) and \(\bar{y}_i\) the corresponding values of the solution and of its approximation.
4.1 Example 1
The first problem [28] is given by:
whose solution is
We consider the value \(\alpha =0.3\), and use the codes with the following parameters, to derive the corresponding WPD:
-
flmm2 : \(h=10^{-1}2^{-\nu }\), \(\nu =1,\dots ,20\);
-
fhbvm : \(M=2,3,4,5\).
Figure 2 contains the obtained results: as one may see, flmm2 reaches less than 12 mescd, since by continuing reducing the stepsize, at the 15-th mesh doubling the error starts increasing. On the other hand, the execution time essentially doubles at each new mesh doubling. Conversely, fhbvm can achieve full machine accuracy by employing a uniform mesh with stepsize \(h_1=1/M\), with M very small, thus using very few mesh points. As a result, fhbvm requires very short execution times.

Work-precision diagram for problem (62), \(\alpha =0.3\)
4.2 Example 2
We now consider the following linear problem:
having solution
with \(E_{0.5}\) the Mittag-Leffler function.Footnote 9 We use the codes with the following parameters, to derive the corresponding WPD:
-
flmm2 : \(h=10^{-1}2^{-\nu }\), \(\nu =1,\dots ,20\);
-
fhbvm : \(M=5,\dots ,10\).
Figure 3 contains the obtained results, from which one deduces that flmm2 achieves about 5 mescd (with a run time of about 85 sec), whereas fhbvm has approximately 13 mescd, with an execution time of about 1 sec. Further, in Fig. 4, we plot the true and estimated (absolute) errors for fhbvm in the case \(M=10\) (corresponding to a computational mesh made up of 251 mesh-points, with an initial stepsize \(h_1\approx 7.3\cdot 10^{-12}\), and a final stepsize \(h_{250}\approx 2\)): as one may see from the figure, there is a substantial agreement between the two errors.

Work-precision diagram for problem (63)

True and estimated absolute errors for fhbvm solving problem (63), \(M=10\)
4.3 Example 3
We now consider the following nonlinear problem [8]:
having solution
This problem is relatively simple and, in fact, both flmm2 and fhbvm solve it accurately. We use it to show the estimated error by using fhbvm with parameter \(M=2\), which produces a graded mesh with 41 mesh-points, with \(h_1\approx 1.8\cdot 10^{-12}\) and \(h_{40}\approx 0.49\). The absolute errors (true and estimated) for each component are depicted in Fig. 5, showing a perfect agreement for both of them.
In this case, the evaluation of the solution requires \(\approx 0.04\) sec, and the error estimation requires \(\approx 0.11\) sec.

True and estimated absolute errors for fhbvm solving problem (64), \(M=2\)
4.4 Example 4
At last, we consider the following fractional Brusselator model:
By solving this problem using fhbvm with parameter \(M=5\), a graded mesh of 46 points is produced, with \(h_1\approx 6.1\cdot 10^{-5}\) and \(h_{45}\approx 0.98\). The maximum estimated error in the computed solution is less than \(3.5\cdot 10^{-13}\), whereas the phase-plot of the solution is depicted in Fig. 6.
In this case, the evaluation of the solution requires \(\approx 0.04\) sec, and the error estimation requires \(\approx 0.14\) sec.

Phase-plot of the computed solution by using fhbvm solving problem (65), \(M=5\)
5 Conclusions
In this paper we have described in full details the implementation of the Matlab\(^{\copyright }\) code fhbvm, able to solving systems of FDE-IVPs. The code is based on a FHBVM(22,20) method, as described in [8]. We have also provided comparisons with another existing Matlab\(^{\copyright }\) code, thus confirming its potentialities. In fact, due to the spectral accuracy in time of the FHBVM(22,20) method, the generated computational mesh, which can be either a uniform or a graded one, depending on the problem at hand, requires relatively few mesh points. This, in turn, allows to reduce the execution time due to the evaluation of the memory term required at each step.
We plan to further develop the code fhbvm, in order to provide approximations at prescribed mesh points, as well as to allow selecting different FHBVM(k, s), \(k\ge s\), methods [8]. At last, we plan to extend the code to cope with values of the fractional derivative, \(\alpha \), greater than 1.
Data Availability
All data reported in the manuscript have been obtained by the Matlab\(^{\copyright }\) code fhbvm, Rel. 2024-03-06, available at the url [40].
Notes
As is usual, \(\varGamma \) denotes the Euler gamma function, such that, for \(x>0\), \(x\varGamma (x)=\varGamma (x+1)\).
Here, \(\overline{P}_j^{\,(a,b)}(x)\) denotes the j-th Jacobi polynomial with parameters a and b, in \([-1,1]\).
Hereafter, we shall use \(h_n\) in place of \(h_1r^{n-1}\).
It is to be noticed that the division by 4 is done without introducing round-off errors.
Here, ./ means the componentwise division between two vectors, and \(|y_2|\) denotes the vector with the absolute values of the entries of \(y_2\).
In view of the spectral accuracy of the method, this tolerance is only slightly larger than the machine epsilon.
In particular, the BDF2 method is selected (method=3), with the parameters tol=1e-15 and itmax=1000.
This definition corresponds to set atol=rtol in the definition used in [39].
We have used the Matlab\(^{\copyright }\) function ml [26] for its evaluation.
References
Aceto, L., Magherini, C., Novati, P.: Fractional convolution quadrature based on generalized Adams methods. Calcolo 51, 441–463 (2014). https://doi.org/10.1007/s10092-013-0094-4
Amodio, P., Brugnano, L., Iavernaro, F.: Spectrally accurate solutions of nonlinear fractional initial value problems. AIP Conf. Proc. 2116, 140005 (2019). https://doi.org/10.1063/1.5114132
Amodio, P., Brugnano, L., Iavernaro, F.: Analysis of spectral hamiltonian boundary value methods (SHBVMs) for the numerical solution of ODE problems. Numer. Algorithms 83, 1489–1508 (2020). https://doi.org/10.1007/s11075-019-00733-7
Amodio, P., Brugnano, L., Iavernaro, F.: Arbitrarily high-order energy-conserving methods for poisson problems. Numer. Algoritms 91, 861–894 (2022). https://doi.org/10.1007/s11075-022-01285-z
Amodio, P., Brugnano, L., Iavernaro, F.: A note on a stable algorithm for computing the fractional integrals of orthogonal polynomials. Appl. Math. Lett. 134, 108338 (2022). https://doi.org/10.1016/j.aml.2022.108338
Amodio, P., Brugnano, L., Iavernaro, F.: (Spectral) Chebyshev collocation methods for solving differential equations. Numer. Algoritms 93, 1613–1638 (2023). https://doi.org/10.1007/s11075-022-01482-w
Brugnano, L.: Blended block BVMs (B\(_3\)VMs): a family of economical implicit methods for ODEs. J. Comput. Appl. Math. 116, 41–62 (2000). https://doi.org/10.1016/S0377-0427(99)00280-0
Brugnano, L., Burrage, K., Burrage, P., Iavernaro, F.: A spectrally accurate step-by-step method for the numerical solution of fractional differential equations. J. Sci. Comput. 99, 48 (2024). https://doi.org/10.1007/s10915-024-02517-1
Brugnano, L., Frasca-Caccia, G., Iavernaro, F., Vespri, V.: A new framework for polynomial approximation to differential equations. Adv. Comput. Math. 48, 76 (2022). https://doi.org/10.1007/s10444-022-09992-w
Brugnano, L., Iavernaro, F.: Line Integral Methods for Conservative Problems. Chapman et Hall/CRC, Boca Raton, FL, USA (2016)
Brugnano, L., Iavernaro, F.: Line integral solution of differential problems. Axioms 7(2), 36 (2018). https://doi.org/10.3390/axioms7020036
Brugnano, L., Iavernaro, F.: A general framework for solving differential equations. Ann. Univ. Ferrara Sez. VII Sci. Mat. 68,243–258 (2022). https://doi.org/10.1007/s11565-022-00409-6
Brugnano, L., Iavernaro, F., Trigiante, D.: A note on the efficient implementation of hamiltonian BVMs. J. Comput. Appl. Math. 236, 375–383 (2011). https://doi.org/10.1016/j.cam.2011.07.022
Brugnano, L., Magherini, C.: Blended implementation of block implicit methods for ODEs. Appl. Numer. Math. 42, 29–45 (2002). https://doi.org/10.1016/S0168-9274(01)00140-4
Brugnano, L., Magherini, C.: The BiM code for the numerical solution of ODEs. J. Comput. Appl. Math. 164–165, 145–158 (2004). https://doi.org/10.1016/j.cam.2003.09.004
Brugnano, L., Magherini, C.: Blended implicit methods for solving ODE and DAE problems, and their extension for second order problems. J. Comput. Appl. Math. 205, 777–790 (2007). https://doi.org/10.1016/j.cam.2006.02.057
Brugnano, L., Magherini, C.: Recent advances in linear analysis of convergence for splittings for solving ODE problems. Appl. Numer. Math. 59, 542–557 (2009). https://doi.org/10.1016/j.apnum.2008.03.008
Brugnano, L., Magherini, C., Mugnai, F.: Blended implicit methods for the numerical solution of DAE problems. J. Comput. Appl. Math. 189, 34–50 (2006). https://doi.org/10.1016/j.cam.2005.05.005
Brugnano, L., Montijano, J.I., Iavernaro, F., Randéz, L.: Spectrally accurate space-time solution of hamiltonian PDEs. Numer. Algorithms 81, 1183–1202 (2019). https://doi.org/10.1007/s11075-018-0586-z
Brugnano, L., Montijano, J.I., Randéz, L.: On the effectiveness of spectral methods for the numerical solution of multi-frequency highly-oscillatory hamiltonian problems. Numer. Algorithms 81, 345–376 (2019). https://doi.org/10.1007/s11075-018-0552-9
Cardone, A., Conte, D., Paternoster, B.: A Matlab code for fractional differential equations based on two-step spline collocation methods. In: Fractional Differential Equations, Modeling, Discretization, and Numerical Solvers, Cardone, A., et al. (eds.) Springer INDAM Series, vol. 50, pp. 121–146 (2023). https://doi.org/10.1007/978-981-19-7716-9_8
Dahlquist, G., Björk, Å.: Numerical Methods in Scientific Computing. SIAM, Philadelphia, PA, USA (2008)
Diethelm, K.: The analysis of fractional differential equations. An application-oriented exposition using differential operators of Caputo type. Lecture Notes in Math, 2004. Springer-Verlag, Berlin, (2010)
Diethelm, K., Ford, N.J., Freed, A.D.: A predictor-corrector approach for the numerical solution of fractional differential equations. Nonlinear Dyn. 29, 3–22 (2002). https://doi.org/10.1023/A:1016592219341
Diethelm, K., Ford, N.J., Freed, A.D.: Detailed error analysis for a fractional adams method. Numer. Algorithms 36, 31–52 (2004). https://doi.org/10.1023/B:NUMA.0000027736.85078.be
Garrappa, R.: Numerical evaluation of two and three parameter mittag-leffler functions. SIAM J. Numer. Anal. 53 No. 3, 1350–1369 (2015). https://doi.org/10.1137/140971191
Garrappa, R.: Trapezoidal methods for fractional differential equations: theoretical and computational aspects. Math. Comput. Simul. 110, 96–112 (2015). https://doi.org/10.1016/j.matcom.2013.09.012
Garrappa, R.: Numerical solution of fractional differential equations: a survey and a software tutorial. Math. 6(2), 16 (2018). https://doi.org/10.3390/math6020016
Gu, Z.: Spectral collocation method for nonlinear riemann-liouville fractional terminal value problems. J. Compt. Appl. math. 398, 113640 (2021). https://doi.org/10.1016/j.cam.2021.113640
Gu, Z., Kong, Y.: Spectral collocation method for caputo fractional terminal value problems. Numer. Algorithms 88, 93–111 (2021). https://doi.org/10.1007/s11075-020-01031-3
van der Houwen, P.J., de Swart, J.J.B.: Triangularly implicit iteration methods for ODE-IVP solvers. SIAM J. Sci. Comput. 18, 41–55 (1997). https://doi.org/10.1137/S1064827595287456
van der Houwen, P.J., de Swart, J.J.B.: Parallel linear system solvers for runge-kutta methods. Adv. Comput. Math. 7(1–2), 157–181 (1997). https://doi.org/10.1023/A:1018990601750
van der Houwen, P.J., Sommeijer, B.P., de Swart, J.J.: Parallel predictor-corrector methods. J. Comput. Appl. Math. 66, 53–71 (1996). https://doi.org/10.1016/0377-0427(95)00158-1
Li, C., Yi, Q., Chen, A.: Finite difference methods with non-uniform meshes for nonlinear fractional differential equations. J. Comput. Phys. 316, 614–631 (2016). https://doi.org/10.1016/j.jcp.2016.04.039
Lubich, Ch.: Fractional linear multistep methods for abel-volterra integral equations of the second kind. Math. Comp. 45 No. 172, 463–469 (1985). https://doi.org/10.1090/S0025-5718-1985-0804935-7
Podlubny, I.: Fractional differential equations. An introduction to fractional derivatives, fractional differential equations, to methods of their solution and some of their applications. Academic Press, Inc., San Diego, CA, (1999)
Stynes, M., O’Riordan, E., Gracia, J.L.: Error analysis of a finite difference method on graded meshes for a time-fractional diffusion equation. SIAM J. Numer. Anal. 55, 1057–1079 (2017). https://doi.org/10.1137/16M1082329
Zayernouri, M., Karniadakis, G.E.: Exponentially accurate spectral and spectral element methods for fractional ODEs. J. Comput. Phys. 257, 460–480 (2014). https://doi.org/10.1016/j.jcp.2013.09.039
Mazzia, F., Magherini, C.: Test Set for Initial Value Problem Solvers. Release 2.4, February 2008, Department of Mathematics, University of Bari and INdAM, Research Unit of Bari, Italy, available at: https://archimede.uniba.it/~testset/testsetivpsolvers/
Acknowledgements
The authors are members of the Gruppo Nazionale Calcolo Scientifico-Istituto Nazionale di Alta Matematica (GNCS-INdAM).
Funding
Open access funding provided by Universitá degli Studi di Firenze within the CRUI-CARE Agreement. No grants were received for conducting this study.
Author information
Authors and Affiliations
Contributions
All authors contributed equally to this work.
Corresponding author
Ethics declarations
Conflicts of Interest/Competing Interests
The authors declare no conflict of interests, nor competing interests.
Ethical Approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Brugnano, L., Gurioli, G. & Iavernaro, F. Numerical solution of FDE-IVPs by using fractional HBVMs: the fhbvm code. Numer Algor (2024). https://doi.org/10.1007/s11075-024-01884-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11075-024-01884-y
Keywords
- Fractional differential equations
- Fractional integrals
- Caputo derivative
- Jacobi polynomials
- Fractional hamiltonian boundary value methods
- FHBVMs