
Abstract
The focus in this paper is interior-point methods for bound-constrained nonlinear optimization, where the system of nonlinear equations that arise are solved with Newton’s method. There is a trade-off between solving Newton systems directly, which give high quality solutions, and solving many approximate Newton systems which are computationally less expensive but give lower quality solutions. We propose partial and full approximate solutions to the Newton systems. The specific approximate solution depends on estimates of the active and inactive constraints at the solution. These sets are at each iteration estimated by basic heuristics. The partial approximate solutions are computationally inexpensive, whereas a system of linear equations needs to be solved for the full approximate solution. The size of the system is determined by the estimate of the inactive constraints at the solution. In addition, we motivate and suggest two Newton-like approaches which are based on an intermediate step that consists of the partial approximate solutions. The theoretical setting is introduced and asymptotic error bounds are given. We also give numerical results to investigate the performance of the approximate solutions within and beyond the theoretical framework.
Similar content being viewed by others

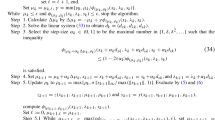

Avoid common mistakes on your manuscript.
1 Introduction
This work is intended for bound-constrained nonlinear optimization problems on the form
where \(f: {\mathbb {R}}^n \rightarrow {\mathbb {R}}\) is twice continuously differentiable, \(\nabla ^2 f(x)\) is locally Lipschitz continuous and \(l, u\in \left\{ {\mathbb {R}} \cup \{ -\infty , \infty \} \right\} ^n\) are such that \(l< u\). However, to make the work and its ideas more comprehensible, we initially describe the theoretical framework and the corresponding results for problems on the form
For completeness, analogous results for problems on the form of (NLP) together with complementary remarks are given in “Appendix A”.
Bound-constrained optimization problems appear in many different applications and are frequently subproblems in augmented Lagrangian methods. For a general overview of solution methods, see [15] and e.g., the introduction in [18] for a thorough review of previous work. Common solution techniques are: active-set methods, which aim to determine the active constraints and solve a reduced problem with the inactive variables, e.g., [8, 18]; methods involving projections onto the feasible set such as projected-gradient methods, e.g., [1, 27], projected-Newton or trust-region methods, e.g., [2, 6, 7, 22] and projected quasi-Newton methods, e.g., [4, 21, 34]. We are not aware of any primal-dual interior-point methods specialized for bound-constrained optimization except for more general methods, e.g., [9, 12, 28,29,30]. Other techniques that are related to trust-region and interior methods are affine-scaling interior-point methods, which are based upon a reformulation of the first-order necessary optimality conditions combined with a Newton-like method, e.g., [5, 19, 20].
In contrast, we consider the classical primal-dual interior-point framework. This means solving or approximately solving a sequence of systems of nonlinear equations for which we consider Newton’s method as the model method. As interior methods converge, the Newton systems typically become increasingly ill-conditioned due to large diagonal elements in the Schur complement. This is not harmful for direct solvers but it may deteriorate the performance of iterative solvers. We propose a strategy for generating approximate solutions to Newton systems, which in general involves solving smaller systems of linear equations. In the ideal case, these systems do not become increasingly ill-conditioned due to the barrier parameter approaching zero. The specific approximate solutions, and the size of the system that needs to be solved at each iteration, are determined by estimates of the active and inactive constraints at the solution. However, in general these sets are unknown and have to be estimated as the iterations proceed. In this work we use basic heuristics to determine the considered sets but other approaches may also be used, e.g., approaches similar to those in [8, 18]. In addition, we motivate and suggest two Newton-like approaches which utilize an intermediate step in combination with the solution of a Newton-like system. The intermediate step partially consists of the proposed partial approximate solutions.
The work is meant to contribute to the theoretical and numerical understanding of approximate solutions to systems of linear equations arising in interior-point methods. The approach is mainly intended for, but not limited to, bound-constrained problems, e.g., the work may also be interpreted in the framework of linear complementarity problems, see e.g., [32]. We envisage the use of the approximate solution procedure as an accelerator for a direct solver. In particular, when solving a sequence of Newton systems for a given value of the barrier parameter \(\mu\). E.g., when the direct solver and the approximate solution procedure can be run in parallel. To give an indication of the potential of the approximate solutions, we show numerical simulations on randomly generated problems as well as problems from the CUTEst test collection [16].
The manuscript is organized as follows; Sect. 2 contains a brief background to primal-dual interior-point methods and an introduction to the theoretical framework; in Sect. 3 we propose partial and full approximate solutions to Newton systems arising in interior-point methods, as well as motivate two Newton-like approaches; Sect. 4 contains numerical results on convex bound-constrained quadratic optimization problems, both randomly generated and problems from the CUTEst test collection; finally in Sect. 5 we give some concluding remarks.
2 Background
We are interested in the asymptotic behavior of primal-dual interior-point methods in the vicinity of a local minimizer \(x^*\) and its corresponding multipliers \(\lambda ^*\). In particular, we assume that the iterates of the method converge to a vector \(\left( x^{*T}, \lambda ^{*T} \right) ^T \triangleq (x^*,\lambda ^*)\) that satisfies
where “\(\cdot\)” is defined as the component-wise operator and \(Z(x^*)\) is a matrix whose columns span the nullspace of the Jacobian corresponding to the constraints with a strictly positive multiplier, \(\lambda ^*\). Equations (1a)–(1d) constitute first-order necessary optimality conditions for a local minimizer of (P). These conditions together with (1e) form second-order sufficient conditions [17]. For the theoretical framework we also assume that \((x^*, \lambda ^*)\) satisfies (1f). We are particularly interested in the function \(F_{\mu }:{\mathbb {R}}^{2n} \rightarrow {\mathbb {R}}^{2n}\) defined by
where \(\mu \in {\mathbb {R}}\) is the barrier parameter, \(X \in {\mathbb {R}}^{n \times n}, \varLambda \in {\mathbb {R}}^{n \times n}\), \(X=\text {diag}(x)\), \(\varLambda = \text {diag}(\lambda )\) and e is a vector of ones of appropriate size. A vector \((x,\lambda )\) with \(x\ge 0\), \(\lambda \ge 0\) and \(F_{\mu }(x, \lambda ) = 0\) for \(\mu =0\) satisfies the first-order optimality conditions (1a)–(1d). Primal-dual interior-point methods aim to solve or approximately solve \(F_{\mu }(x,\lambda ) = 0\) for a decreasing sequence of \(\mu >0\), while maintaining \(x>0\) and \(\lambda > 0\). This is typically done with Newton-like methods which means solving a sequence of systems of linear equations on the form
where \(F': {\mathbb {R}}^{2n} \rightarrow {\mathbb {R}}^{2n}\) is the Jacobian of \(F_{\mu }\). The Jacobian is given by
where \(H=\nabla ^2 f(x)\) and the subscript \(\mu\) is omitted since \(F'\) is independent of the barrier parameter. For each \(\mu\), iterations are performed until a specified measure of improvement is achieved, thereupon \(\mu\) is decreased and the process is repeated. A natural measure in our setting is \(\Vert F_{\mu }(x,\lambda ) \Vert _2\) where \(\Vert F_{\mu }(x,\lambda ) \Vert _2 =0\) gives the exact solution. To improve efficiency many algorithms seek approximate solutions, a basic condition for the reduction of \(\mu\) is \(\Vert F_{\mu }(x,\lambda ) \Vert _2 < \mu\) [24, Ch. 17, p. 572]. Herein, we consider a possibly weaker version, namely \(\Vert F_{\mu }(x,\lambda ) \Vert _2 < C_1 \mu\) for some constant \(C_1 >0\). Moreover, it will throughout be assumed that all considered vectors \((x,\lambda )\) satisfy \(x>0\) and \(\lambda > 0\). The subscript in the norms will hereafter be omitted since all considered norms in this work are of type 2-norm.
Definition 1
(Order-notation) Let \(\alpha\), \(\gamma \in {\mathbb {R}}\) be two positive related quantities. If there exists a constant \(C_2>0\) such that \(\gamma \ge C_2 \alpha\) for sufficiently small \(\alpha\), then \(\gamma = \varOmega (\alpha )\). Similarly, if there exists a constant \(C_3>0\) such that \(\gamma \le C_3 \alpha\) for sufficiently small \(\alpha\), then \(\gamma = {\mathcal {O}}(\alpha )\). If there exist constants \(C_2, C_3 > 0\) such that \(C_2 \alpha \le \gamma \le C_3 \alpha\) for sufficiently small \(\alpha\) then, \(\gamma = \varTheta (\alpha )\).
Definition 2
(Neighborhood) For a given \(\delta >0\), let the neighborhood around \((x^*, \lambda ^*)\) be defined by \({\mathcal {B}}( (x^*, \lambda ^*), \delta ) = \{ (x,\lambda ) : \Vert (x,\lambda )-(x^*, \lambda ^*) \Vert \leq \delta \}\).
Assumption 1
(Strict local minimizer) The vector \((x^*, \lambda ^*)\) satisfies (1), i.e., second-order sufficient optimality conditions and strict complementarity.
The following two results provide the theoretical framework and additional definitions of various quantities. In particular, the existence of a neighborhood where the Jacobian is nonsingular and there exists a Lipschitz continuous barrier trajectory which is parameterized by the barrier parameter \(\mu\). The results are well known and can be found in e.g., the work of Ortega and Rheinboldt [26] and Byrd et al. [3] whose setting is similar to the one in this work.
Lemma 1
Under Assumption 1 there exists \(\delta >0\) such that \(F'(x,\lambda )\) is continuous and nonsingular for \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\) and
for some constant \(M>0\).
Proof
See [26, p. 46]. \(\square\)
Lemma 2
Let Assumption 1 hold and let \({\mathcal {B}}((x^*, \lambda ^*), \delta )\) be defined by Lemma 1. Then there exists \({\hat{\mu }}>0\) such that for each \(0<\mu \le {\hat{\mu }}\) there is a Lipschitz continuous function \((x^{\mu },\lambda ^{\mu }) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\) that satisfies \(F_{\mu }(x^{\mu },\lambda ^{\mu }) = 0\) and
where \(C_4 = \inf _{(x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )} \Vert F'(x,\lambda ) ^{-1}\frac{ \partial F_{\mu } (x,\lambda )}{\partial \mu } \Vert\).
Proof
The result follows from the implicit function theorem, see e.g., [26, p. 128].\(\square\)
The next lemma relates the measure \(\Vert F_\mu (x,\lambda ) \Vert\) to the distance between the barrier trajectory and vectors \((x,\lambda )\) that are sufficiently close. An analogous result is given by Byrd et al. [3].
Lemma 3
Under Assumption 1, let \({\mathcal {B}}((x^*, \lambda ^*), \delta )\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. For \(0<\mu \le {\hat{\mu }}\) and \((x,\lambda )\) sufficiently close to \((x^{\mu },\lambda ^{\mu }) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\) there exist constants \(C_5, C_6 > 0\) such that
Proof
See [3, p. 43]. \(\square\)
Recall that the reduction of \(\mu\) can be determined with the condition \(\Vert F_\mu (x,\lambda )\Vert <C_1 \mu\), for some constant \(C_1>0\). It can be shown that vectors \((x,\lambda )\), which satisfy this condition and are sufficiently close to the barrier trajectory, have their individual components bounded within certain intervals at sufficiently small \(\mu\). The individual components can be partitioned into two sets of indices which depend on how close the iterate is to its feasibility bound, see Definition 3. The order of magnitude of the individual components, which are given in Lemma 4 below, will be of importance in the derivation of various approximate solutions to (2).
Definition 3
(Active/inactive constraint) For a given \(x^* \ge 0\) constraint \(i\in \{1, \dots , n \}\) is defined as active if \(x_i^* = 0\) and inactive if \(x_i^* > 0\). The corresponding active and inactive set are defined as \({\mathcal {A}} = \{i\in \{1, \dots , n \} : x^*_i = 0 \}\), and \({\mathcal {I}}=\{i\in \{1,\dots ,n\}:x^*_i>0\}\) respectively.
Lemma 4
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {{\bar{\mu }}}\) and \((x,\lambda )\) sufficiently close to \((x^{\mu }, \lambda ^{\mu }) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\) so that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\) it holds that
Proof
Under Assumption 1 it holds that
where \(c_i = \varTheta (1)\), \(i = 1,\dots , n\). The function \((x^{\mu }, \lambda ^{\mu })\) is Lipschitz continuous and hence for each \(\mu \le {\hat{\mu }}\) it holds that \((x^{\mu }, \lambda ^{\mu }) \in {\mathcal {B}}\left( (x^*, \lambda ^*), L_{F'} \mu \right)\), where \(L_{F'}\) is the Lipschitz constant of \(F'\) on \({\mathcal {B}}((x^*, \lambda ^*), \delta )\). There exist \({\bar{\mu }}_1\), with \(0 < {\bar{\mu }}_1 \le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}_1\) it holds that
The condition \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\) implies that there exists a constant \(C_1>0\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert \le C_1 \mu\). Lemma 3 and \(\Vert F_{\mu } (x,\lambda ) \Vert \le C_1 \mu\) give
which implies that \((x,\lambda ) \in {\mathcal {B}}\left( (x^\mu , \lambda ^\mu ), \frac{C_1}{ C_5} \mu \right)\). Similarly here, there exists \({\bar{\mu }}_2\), with \(0 < {\bar{\mu }}_2 \le {\hat{\mu }}\), such that the result follows for \(0<\mu \le {\bar{\mu }}\) with \({\bar{\mu }}= \min \{{\bar{\mu }}_1, {\bar{\mu }}_2 \}\). \(\square\)
The result of Lemma 4 shows two regions which depend on \(\mu\). The first region, \(0<\mu \le {\hat{\mu }}\), defines where the barrier trajectory \((x^\mu , \lambda ^\mu )\) exists and the second region, \(0 < \mu \le {\bar{\mu }}\le {\hat{\mu }}\), defines where asymptotic behavior occurs.
3 Approximate solutions
This section initially contains an introduction to the groundwork of the ideas which precede the results. It is followed by a subsection that contains approximate solutions for specific components of the solution of (2) together with related results. The last subsection contains procedures for approximating the full solution of (2), as well as related results. Under Assumption 1 it holds that
in consequence, the Schur complement of X in (2) becomes increasingly ill-conditioned as \(\mu \rightarrow 0\). These properties have been utilized by several authors before, e.g., in the development of preconditioners [10, 13]. The idea in this work is to exploit them and the additional property that (P) only has bound constraints to obtain partial or full approximate solutions of (2). In particular, by utilization of structure and the asymptotic behavior of coefficients in the arising systems of linear equations. With the partition \((\varDelta x^N, \varDelta \lambda ^N) = (\varDelta x_{\mathcal {A}}^N, \varDelta x_{\mathcal {I}}^N, \varDelta \lambda _{\mathcal {A}}^N, \varDelta \lambda _{\mathcal {I}}^N)\), (2) can be written as
where the first and second set in the matrix subscripts give the indices of rows and columns respectively. The Schur complement of \(X_{{\mathcal {A}} {\mathcal {A}}}\) and \(X_{{\mathcal {I}} {\mathcal {I}}}\) in (5) is
By continuity of \((x^{\mu }, \lambda ^{\mu })\) it follows that \(x_i \rightarrow 0\), \(i\in {\mathcal {A}}\), and \(\lambda _i \rightarrow 0\), \(i\in {\mathcal {I}}\), as \(\mu \rightarrow 0\). In consequence, \(X_{{\mathcal {I}} {\mathcal {I}}}\) and \(\varLambda _{{\mathcal {A}} {\mathcal {A}}}\) dominate the coefficients of the third and fourth block of (5) for sufficiently small \(\mu\) under strict complementarity. Similarly \(X_{{\mathcal {A}} {\mathcal {A}}} ^{-1}\varLambda _{{\mathcal {A}} {\mathcal {A}}}\) dominates the coefficients of the first block of (6). Consequently, approximate solutions of \(\varDelta x_{\mathcal {A}}^N\) and \(\varDelta \lambda _{\mathcal {I}}^N\) can be obtained from the third and fourth block of (5), and of \(\varDelta x_{\mathcal {A}}^N\) from the first block of (6). These approximates can then be inserted into (5), or (6), to obtain a reduced system of size \(| {\mathcal {I}} |\) \(\times\) \(| {\mathcal {I}} |\) that involves \(H_{{\mathcal {I}} {\mathcal {I}}}\). The solution of this system gives an approximation of \(\varDelta x_{\mathcal {I}}^N\). These observations together with Lemma 4 and Lemma 5 below provide the foundation for the results. The essence of Lemma 5 is that the norm of the solution of (2) is bounded by a constant times \(\mu\).
Lemma 5
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. For \(0< \mu \le {\hat{\mu }}\) and \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), let \((\varDelta x^N, \varDelta \lambda ^N)\) be the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). If \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu }) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\) then
Proof
By (2) it holds that
Continuity of \(F'\) on \({\mathcal {B}}((x^*, \lambda ^*), \delta )\) implies that \(F_{\mu ^+}\) is Lipschitz continuous. Moreover, both \((x,\lambda )\) and \((x^{\mu ^+}, \lambda ^{\mu ^+})\) belong to \({\mathcal {B}}((x^*, \lambda ^*), \delta )\). Lipschitz continuity of \(F_{\mu ^+}\) and Lemma 1 yield
Addition and subtraction of \((x^\mu , \lambda ^\mu )\) in the norm of the right-hand side give
where the second last inequality follows from Lemma 3 and Lipschitz continuity of \((x^{\mu }, \lambda ^{\mu })\). The last inequality follows from \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\), i.e., there exists a constant \(C_1>0\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert \le C_1 \mu\). \(\square\)
3.1 Partial approximate solutions
In this section we initially propose an approximate solution of \(\varDelta x_{\mathcal {A}}^N\) which originates from the Schur complement form (6). This approximate solution will be labeled with superscript “S” due to its origin. As \(\mu \rightarrow 0\), the diagonal elements of the (1,1)-block become large and dominate the coefficients of the matrix under strict complementarity. In Proposition 1 we show that an approximate solution of \(\varDelta x_{\mathcal {A}}^N\) can be obtained by neglecting all off-diagonal coefficients in the the first block of (6). Thereafter, we propose another approximate solution of \(\varDelta x_{\mathcal {A}}^N\), as well as one of \(\varDelta \lambda _{\mathcal {I}}^N\), which originate from the complementarity blocks of (5). These approximate solutions will be labeled with superscript “C” due to their origin. The solutions are obtained by neglecting the coefficients in the complementarity blocks which approach zero as \(\mu \rightarrow 0\), i.e., those in \(X_{{\mathcal {A}} {\mathcal {A}}}\) and \(\varLambda _{{\mathcal {I}} {\mathcal {I}}}\). The resulting partial approximate solutions are given below in Proposition 2. The essence of both results is that, under certain conditions, the asymptotic component error bounds are in the order of \(\mu ^2\). Finally we motive and propose two Newton-like approaches which we later on investigate numerically.
Proposition 1
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1and Lemma 2respectively. For \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), let \((\varDelta x^N, \varDelta \lambda ^N)\) be the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). If the search direction components are defined as
then
Assume in addition that \(0 < \mu \le {\hat{\mu }}\) and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
and
Proof
The solution of (2) for \(\varDelta x^N\) is equivalent to the solution of (6) where the i’th, \(i=1,\dots ,n\), row is
If \(x_i \left[ \nabla ^2 f(x)\right] _{ii} + \lambda _i \ne 0\) then (11) can be written as
Subtraction of (12) from (7) gives (8). By Lemma 4 there exists \({\bar{\mu }}_3\), with \(0<{\bar{\mu }}_3 \le {\hat{\mu }}\) such that the components of \((x,\lambda )\) satisfy (4). Due to the boundedness of f on \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) there exists \({\bar{\mu }}_4\), with \(0<{\bar{\mu }}_4 \le {\hat{\mu }}\), such that (9) holds for \(0<\mu \le {\bar{\mu }}\) with \({\bar{\mu }}= \min \{{\bar{\mu }}_3, {\bar{\mu }}_4\}\). The result of (10) follows from application of Lemma 4 and Lemma 5 to (8) while taking (9) into account.\(\square\)
The approximate solution \(\varDelta x^S\) in (7) of Proposition 1 and its corresponding component error (8) may be undefined for certain components. However, the essence is that the expressions are well-defined sufficiently close to the barrier trajectory for sufficiently small \(\mu\), as shown by (9). In particular the component errors of (10) are bounded by a constant times \(\mu ^2\) only for components \(i \in {\mathcal {A}}\), although the expressions (7) and associated errors (8) hold for all components \(i=1,\dots ,n\). An approximate solution that is guaranteed to have all its components well-defined can be obtained from the complementarity blocks of (5). This approximate solution, and in addition an approximate solution of \(\varDelta \lambda _{\mathcal {I}}^N\), are given in the proposition below.
Proposition 2
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1and Lemma 2 respectively. For \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), let \((\varDelta x^N, \varDelta \lambda ^N)\) be the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). If the search direction components are defined as
then
Assume in addition that \(0 < \mu \le {\hat{\mu }}\) and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
Proof
The i’th, \(i=1,\dots ,n\), row in the second block of (2) is
For \(x_i > 0\), \(\lambda _i > 0\), \(i,\dots , n\), it holds that
Subtraction of (16a) from (13a) and subtraction of (16b) from (13b) gives (14a) and (14b) respectively. By Lemma 4 there exists \({\bar{\mu }}\), with \(0<{\bar{\mu }}\le {\hat{\mu }}\) such that the components of \((x,\lambda )\) satisfy (4) for \(0<\mu \le {\bar{\mu }}\). The result of (15) then follows from application of Lemma 5 to (16) while taking (4) into account.\(\square\)
The expressions for \(\varDelta x^C_i\) and \(\varDelta \lambda ^C_i\), (13a) and (13b) respectively, and their associated component errors (14a) and (14b) respectively, hold for all components. The essence of the results in Proposition 2 is that the component errors are bounded by a constant times \(\mu ^2\) only for certain components. Specifically, for \(\varDelta x^C_i\), \(i \in {\mathcal {A}}\), and \(\varDelta \lambda _i^C\), \(i \in {\mathcal {I}}\). Both \(\varDelta x^S_i\) given by (7) and \(\varDelta x^C_i\) given by (13a) provide approximate solutions of \(\varDelta x_i^N\), \(i \in {\mathcal {A}}\), with similar asymptotic error bounds. Note that the order of the approximation error, \(\Vert \varDelta x_{\mathcal {A}} - \varDelta x_{\mathcal {A}}^N \Vert\), is maintained even if some components \(i \in {\mathcal {A}}\) are updated with (7) and others with (13a). Which expression to use can hence be chosen individually for each index \(i \in {\mathcal {A}}\). The factors in front of \(\varDelta x_i^N\) and \(\varDelta \lambda _i^N\), \(i =1,\dots , n\), in the component errors of (8) and (14) respectively may be used as an indicator for which of the approximations to use, and also whether either expression is likely to provide an accurate approximation. Note also that the approximate solution \(\varDelta x^C\) given by (13a) does not take into account any information from the first block equation of (2), whereas \(\varDelta x^S\) given by (7) includes information from both blocks.
Provided that the norm of the combined steps \(\varDelta x_{\mathcal {A}}^N\) and \(\varDelta \lambda _{\mathcal {I}}^N\) is not smaller than the approximation error, then stepping in these components with (7) or (13) give a vector which is not further from the Newton iterate. This is formalized in Proposition 3 below.
Proposition 3
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2respectively. For \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), define \((x_+^{N},\lambda _+^{N})=(x,\lambda )+ (\varDelta x^N,\varDelta \lambda ^N)\) where \((\varDelta x^N, \varDelta \lambda ^N)\) is the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). Moreover, let \((x_+, \lambda _+) = (x,\lambda ) + (\varDelta x, \varDelta \lambda )\) where
with \(\varDelta x_i^C\), \(\varDelta \lambda _i^C\) and \(\varDelta x_i^S\) given by (13) and (7) respectively. Assume that \(0 < \mu \le {\hat{\mu }}\), \(\Vert (\varDelta x_{\mathcal {A}}^N, \varDelta \lambda _{\mathcal {I}}^N) \Vert =\varOmega ( \mu ^\gamma )\) for \(0\le \gamma < 2\), and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
Proof
With \((\varDelta x, \varDelta \lambda )\) defined as in (17) of the proposition it holds that
By Proposition 1 and Proposition 2 there exists \({\bar{\mu }}_5\) and \({\bar{\mu }}_6\) respectively, with \(0 < {\bar{\mu }}_i \le {\hat{\mu }}\), \(i=5,6,\) such that for \(\varDelta x_i\) equal to \(\varDelta x_i^S \text{ or } \varDelta x_i^C\) it holds that \(| \varDelta x_i - \varDelta x_i^N | ={\mathcal {O}}(\mu ^2)\), \(i \in {\mathcal {A}}\), for \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). By Proposition 2 it also holds that \(| \varDelta \lambda _i^C - \varDelta \lambda _i^N | = {\mathcal {O}}(\mu ^2)\), \(i \in {\mathcal {I}}\), for \(0 < \mu \le {\bar{\mu }}_6\). Hence, for \(0<\mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\), there exist constants \(C_7>0\) and \(C_8>0\), where \(C_8\) comes from the condition \(\Vert (\varDelta x_{\mathcal {A}}^N, \varDelta \lambda _{\mathcal {I}}^N) \Vert =\varOmega ( \mu ^\gamma )\), \(0\le \gamma < 2\), such that
The right-hand side of (20) is non-positive for \(0<\mu \le (C_8/C_7)^{\frac{1}{2-\gamma }}\), \(0\le \gamma < 2\). Combining (19)–(20) with \({\bar{\mu }}= \min \{{\bar{\mu }}_5, {\bar{\mu }}_6, (C_8/C_7)^{\frac{1}{2-\gamma }} \}\) gives the result. \(\square\)
The partial approximate solution (17) of Proposition 3 is computationally inexpensive compared to solving (2). In consequence, (18) motivates the study of Newton-like approaches which make use of (17). We will construct two such approaches where the idea is to utilize the intermediate iterate
with \((\varDelta x^E, \varDelta \lambda ^E)\) as in (17). It is thus only the active components of x and inactive components of \(\lambda\) that is updated in the step to \((x^E, \lambda ^E)\). For simplicity we describe the ideas for unit step length, in practice the iterates would be required to be strictly feasible.
The first approach is based on the fact that solving a Newton system from the iterate \((x^E,\lambda ^E)\) provides potential improvement, provided that \((x^E, \lambda ^E)\) is strictly feasible and lies in \({\mathcal {B}}((x^*, \lambda ^*), \delta )\). A full iteration in the approach consists of the approximate intermediate step (21) together with the solution of
and the step \((x^E + \varDelta x, \lambda ^E + \varDelta \lambda )\).
The idea of the second approach is to update the coefficients in the complementarity blocks of the matrix in (2). The approach may hence under strict complementarity be interpreted as an approximate higher-order method. A full iteration consists of the step (21), the solution of
where \(\varLambda ^E = \text{ diag }(\lambda ^E)\) and \(X^E = \text{ diag }(x^E)\), together with the step \((x+\varDelta x, \lambda +\varDelta \lambda )\). The approach may hence also be interpreted as a modified Newton method where the Jacobian of each Newton system is altered.
Numerical results for the approximate intermediate step and the approximate higher-order approach are shown in Sect. 4. The results are for bound-constrained quadratic optimization problems where strict complementarity typically does not hold. The complexity of each iteration in both approaches is the same as with Newton’s method. The hope is thus to reduce the total number of iteration necessary for convergence. See the work by Gondzio and Sobral [14] for quasi-Newton approaches for quadratic problems where each iteration is inexpensive in comparison to the approaches above.
3.2 Full approximate solution
In this section we propose approximate solutions of (2) that, in the considered framework, have an asymptotic error bound in the order of \(\mu ^2\). The full approximate solutions are obtained by utilizing either of the partial approximate solutions of \(\varDelta x_{\mathcal {A}}^N\) in Proposition 1 or Proposition 2 while exploiting structure in the systems that arise. Specifically, suppose that an approximate \(\varDelta x_{{\mathcal {A}}}\) is given, e.g., \(\varDelta x^S_{\mathcal {A}}\) given by (7) or \(\varDelta x^C_{\mathcal {A}}\) given by (13a). Insertion of the approximate \(\varDelta x_{{\mathcal {A}}}\) into (5) yields
where the solution is given the superscript “ls” since it will lead to a least squares system. The second and fourth block of (24) provide unique solutions of \(\varDelta x^{ls}_{\mathcal {I}}\) and \(\varDelta \lambda ^{ls}_{\mathcal {I}}\) which satisfy
The solution of (25) can be obtained by first solving with the Schur complement of \(X_{{\mathcal {I}} {\mathcal {I}}}\)
and then
Note that (26) can also be obtained by insertion of the given \(\varDelta x_{\mathcal {A}}\) into the second block of (6). The matrix of (26) is by Assumption 1 a symmetric positive definite \(( |{\mathcal {I}}|\) \(\times\) \(|{\mathcal {I}}| )\)-matrix. Moreover, the matrix does not become increasingly ill-conditioned due to large elements in \(X^{-1}\varLambda\), under strict complementarity as \(\mu \rightarrow 0\), in contrast to the matrix of (6). The remanding part of the solution of (24), that is \(\varDelta \lambda _{\mathcal {A}}^{ls}\), is then given by
If the approximate \(\varDelta x_{\mathcal {A}}\) is exact, i.e., if \(\varDelta x_{\mathcal {A}} = \varDelta x_{\mathcal {A}}^N\), then \(\varDelta x_{\mathcal {I}}^{ls}= \varDelta x_{\mathcal {I}}^N\) by (26). In consequence, the over-determined system (28) has a unique solution that satisfies all equations, i.e., \(\varDelta \lambda _{\mathcal {A}}^{ls}\) is the corresponding part of the solution to (2). The solutions corresponding to the first and second block equation of (28) will be assigned superscripts “b” and “−” respectively. These are given by
and
Alternatively, \(\varDelta \lambda _{A}^{ls}\) can be obtained as the least squares solution of (28) that is
In Theorem 1 it is shown that, under certain conditions, both \(\varDelta \lambda _{\mathcal {A}}^b\) given by (29a) and \(\varDelta \lambda _{\mathcal {A}}^{ls}\) given by (30) can be used to approximate \(\varDelta \lambda _{\mathcal {A}}^N\) without affecting the order of the asymptotic error. Note however that this is not true for \(\varDelta \lambda _{\mathcal {A}}^{-}\) given by (29b) due to the last term that contains \(X_{\mathcal {A} \mathcal {A}} ^{-1}\) in combination with approximation error.
Theorem 1
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. For \(0< \mu \le {\hat{\mu }}\) and \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), let \((\varDelta x^N, \varDelta \lambda ^N)\) be the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). Moreover, let the search direction components be defined as
where \(\varDelta x_i^S\) is given by (7), \(\varDelta x_i^C\) by (13a), \(\varDelta x_i^{ls}\) by (26), \(\varDelta \lambda _i^{ls}\) by (30), \(\varDelta \lambda _i^b\) by (29a), \(\varDelta \lambda _i^{ls}\) by (27) and \(\varDelta \lambda _i^C\) by (13b). Assume that \(0 < \mu \le {\hat{\mu }}\) and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
Proof
Similarly as in the proof of Proposition 3. By Proposition 1 and Proposition 2 there exists \({\bar{\mu }}_5\) and \({\bar{\mu }}_6\) respectively, with \(0 < {\bar{\mu }}_i \le {\hat{\mu }}\), \(i=5,6,\) such that for \(\varDelta x_i\) equal to \(\varDelta x_i^S \text{ or } \varDelta x_i^C\) it holds that \(| \varDelta x_i - \varDelta x_i^N | ={\mathcal {O}}(\mu ^2)\), \(i \in {\mathcal {A}}\), for \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). In consequence it follows that \(\Vert \varDelta x_{\mathcal {A}} - \varDelta x_{\mathcal {A}}^N \Vert = {\mathcal {O}}(\mu ^2)\), \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). By Proposition 2 it also holds that \(| \varDelta \lambda _i^C - \varDelta \lambda _i^N | = {\mathcal {O}}(\mu ^2)\), \(i \in {\mathcal {I}}\), \(0 < \mu \le {\bar{\mu }}_6\). The backward error with \(\varDelta x^{ls}_{\mathcal {I}}\) as given in (26) is
which gives
Due to the assumption on f the elements of \(H_{{\mathcal {I}} {\mathcal {A}}}\) are bounded. Moreover, the smallest singular value of \(H_{{\mathcal {I}} {\mathcal {I}}} + X_{{\mathcal {I}} {\mathcal {I}}} ^{-1}\varLambda _{{\mathcal {I}} {\mathcal {I}}}\) is bounded away from zero since the matrix is positive definite by Assumption 1. Hence it follows that \(\| \varDelta x^{ls}_{\mathcal {I}} - \varDelta x_{\mathcal {I}}^N \| = {\mathcal {O}}(\mu ^2)\), \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). Note that \(\varDelta \lambda _{\mathcal {I}}^N\) is the solution of (27) with \(\varDelta x_{\mathcal {I}}^N\). Subtraction of (27), with \(\varDelta x_{\mathcal {I}}^N\), from (27) with the approximated solution \(\varDelta x_{\mathcal {I}}^{ls}\) gives \(\varDelta \lambda ^{ls}_{\mathcal {I}} - \varDelta \lambda ^{N}_{\mathcal {I}} = -X_{\mathcal {I} {\mathcal {I}}} ^{-1}\varLambda _{{\mathcal {I}} {\mathcal {I}}} \left( \varDelta x_{\mathcal {I}}^{ls} - \varDelta x^{N}_{\mathcal {I}} \right)\), and hence
By Lemma 4 it holds that \(\Vert X_{{\mathcal {I}} {\mathcal {I}}} ^{-1}\varLambda _{{\mathcal {I}} {\mathcal {I}}} \Vert = {\mathcal {O}}(\mu )\), \(0 < \mu \le \max \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). With \(\| \varDelta x^{ls}_{\mathcal {I}} - \varDelta x_{\mathcal {I}}^N \| = {\mathcal {O}}(\mu ^2)\), \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\) it then follows that \(\Vert \varDelta \lambda ^{ls}_{\mathcal {I}} - \varDelta \lambda _{\mathcal {I}}^N \Vert = {\mathcal {O}}(\mu ^3)\), and also \(| \varDelta \lambda ^{ls}_i - \varDelta \lambda _i^N| = {\mathcal {O}}(\mu ^3)\), \(i \in {\mathcal {I}}\), \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). Similarly, \(\varDelta \lambda ^N_{\mathcal {A}}\) is the solution to (30) with \(\varDelta x^N_{\mathcal {A}}\) and \(\varDelta x^N_{\mathcal {I}}\). Subtraction of (30), with \(\varDelta x^N_{\mathcal {A}}\) and \(\varDelta x^N_{\mathcal {I}}\), from (30) with the approximated solutions gives
The the largest singular value of \(\left( I_{\mathcal {A} \mathcal {A}} + X_{\mathcal {A} \mathcal {A}}^2 \right) ^{-1}\) is bounded by 1 and hence
The elements of \(H_{\mathcal {A} \mathcal {A}}\) and \(H_{\mathcal {A} \mathcal {I}}\) are bounded and by Lemma 4 it holds that \(\Vert X_{\mathcal {A} \mathcal {A}} \varLambda _{\mathcal {A} \mathcal {A}} \Vert = {\mathcal {O}}(\mu )\), \(0 < \mu \le \max \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). Thus it follows that \(\Vert \varDelta \lambda ^{ls}_{\mathcal {A}} - \varDelta \lambda _{\mathcal {A}}^N \Vert = {\mathcal {O}}(\mu ^2)\), and also \(| \varDelta \lambda ^{ls}_i - \varDelta \lambda _i^N| = {\mathcal {O}}(\mu ^2)\), \(i \in {\mathcal {A}}\), \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). Similarly, (29a) gives the backward error
Hence
from which it follows that \(\Vert \varDelta \lambda ^b_{\mathcal {A}} - \varDelta \lambda _{\mathcal {A}}^N \Vert = {\mathcal {O}}(\mu ^2)\), and also \(| \varDelta \lambda ^b_i - \varDelta \lambda _i^N | = {\mathcal {O}}(\mu ^2)\), \(i \in {\mathcal {A}}\), \(0 < \mu \le \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). Thus the result holds for \({\bar{\mu }}= \min \{ {\bar{\mu }}_5, {\bar{\mu }}_6 \}\). \(\square\)
Information is discarded in the calculation of the components \(\varDelta x^S_i\), \(\varDelta x_i^C\), \(i\in {\mathcal {A}}\), and \(\varDelta \lambda _i^C\), \(i \in {\mathcal {I}}\), with (7) and (13) respectively. The equations for the approximate solution in Theorem 1 show that it is essential to obtain a good approximate solution of \(\varDelta x_{\mathcal {A}}^N\). It is the error in the approximate solution of \(\varDelta x_{\mathcal {A}}^N\) that propagates through the suggested solutions labeled with ls and b. In contrast to all other components of the proposed full approximate solution, \(\varDelta \lambda _i^{ls}\), \(i\in {\mathcal {I}}\), actually have asymptotic component error bounds in the order of magnitude \(\mu ^3\), as can be seen in the proof of Theorem 1.
In general the active and inactive sets at the optimal solution are unknown and have to be estimated as the iterations proceed. The quality of the approximate solution of \(\varDelta x_{\mathcal {A}}^N\) will hence also depend on these estimates. There is a trade-off when estimating the set of active constraints. A restrictive strategy may lead to a more accurate approximate \(\varDelta x_{\mathcal {A}}\). However, it increases the cardinality of the inactive set and in consequence the size of the system (26) that needs to be solved at each iteration. In theory, the cardinality of the inactive set is determined by the number of inactive constraints at the solution of the specific problem, whereas in practice it is determined by the estimate. The size of the system that needs to be solved at each iteration may thus range from 0 to n. A restrictive strategy may also increase the size of some coefficients in the diagonal of the matrix of (26), or (43) in the general case, which may increase the condition number. A generous strategy on the other hand, decreases the size of the system that has to be solved but may increase the error in the approximate \(\varDelta x_{\mathcal {A}}\), which then propagates to other components of the approximate solution. In the ideal case with the true inactive set, then (25) and (26) are composed by the inactive parts of (2), or equivalently (5), and (6) respectively. Consequently, the inactive part of the Schur complement in (26) does not become increasingly ill-conditioned due to \(\mu\) approaching zero, in contrast to the complete Schur complement in (6). However, in practice the behavior will be dependent on an estimate of the inactive set.
Note also that the system that needs to be solved for the full approximate solution has the same structure as the original one. In consequence, our analysis may be interpreted in the framework of previous work on stability and effects of finite-precision arithmetic for interior-point methods, e.g., [11, 31,32,33]. In the case of quadratic problems, see also [23].
To increase the comprehensibility of the work we have described the theoretical foundation for problems on the form (P). Analogous results for problems on the more general form (NLP) together with complementary remarks are given in “Appendix A”.
4 Numerical results
As an initial numerical study we consider convex quadratic optimization problems with lower and upper bounds. In particular, randomly generated problems and a selection from the corresponding class in the CUTEst test collection [16]. The minimizers of the randomly generated problems satisfy strict complementarity, whereas the minimizers of the CUTEst problems typically do not. The simulations were done in Julia and all systems of linear equations were solved by its built-in solver. Moreover, the benchmark problems were initially processed using the packages CUTEst.jl and NLPmodels.jl by Orban and Siqueira [25].
The purpose of the first part of this section is to compare the proposed approximate solutions in Theorem 2. The intent is also to give a rough indication of how the approximation errors develop for practical values of \(\mu\). A setting is considered where the vector \((x,\lambda )\), that satisfies \(\Vert F_{\mu }(x,\lambda ) \Vert < \mu\), is found by an interior-point method. Thereafter, \(\mu\) is decreased by a factor \(\sigma = 0.1\) to \(\mu ^+=\sigma \mu\) and the approximate solution of (2) is calculated. This procedure was then repeated for different values of \(\mu\). Mean errors with one standard deviation error bars for the proposed approximate solutions are shown in Fig. 1. As mentioned, the results are for the approximate solutions given in Theorem 2 of “Appendix A” since the problems in general include lower and upper bounds. In order to avoid double subscripts in the approximates, we have throughout this section omitted the second subscript. Furthermore, \(\varDelta x^{S}_{\mathcal {A}}\) was used in the equations which require an initial approximation of \(\varDelta x_{\mathcal {A}}^N\). Figure 1 also shows the mean improvement in terms of the measure \(\Vert F_{\mu ^+} \Vert\) for two new iterates \((x_+^S, \lambda ^S_+)\) and \((x_+^C, \lambda ^C_+)\) defined by
with step lengths \(\alpha ^P\) and \(\alpha ^D\) as in Algorithm 1. Specifically, the search direction is composed by (35) or (36) combined with (43), (47) and (44). The figure also contains the mean improvement of the Newton iterate \((x^{N}_+, \lambda ^{N}_+)\), which is defined analogously. The results are for \(10^2\) randomly generated problems, with \(10^3\) variables, whose minimizers satisfy (31). For each problem, both the specific bounds as well as the specific active and inactive constraints were chosen by random. Moreover, the elements of the Hessian were uniformly distributed around zero with a sparsity level corresponding to approximately 40% non-zero elements. The condition numbers were in the order of magnitude \(10^7\)–\(10^{10}\) and the largest singular values in the order of magnitude of \(10^3\).

Mean approximation error and mean progress with measure \(\Vert F_{\mu ^+}\Vert\) with one standard deviation error bars for randomly generated quadratic problems. The top and the bottom correspond to problems where approximately 3/4 and 1/4 of the variables respectively are inactive at the solution
The least accurate approximate solutions in Fig. 1 are those corresponding to active \(\lambda\) and inactive x. This is anticipated as their error bounds rely more heavily on the size of the elements of H. Moreover, it can be seen that \(\varDelta \lambda _{\mathcal {I}}^{ls}\) is favorable over \(\varDelta \lambda _{\mathcal {I}}^C\) for the problems considered. This is anticipated as \(\varDelta \lambda _{\mathcal {I}}^{ls}\) has asymptotic error bounds in the order of magnitude \(\mu ^3\), in contrast to the bounds corresponding to \(\varDelta \lambda _{\mathcal {I}}^C\) which is in the order of magnitude \(\mu ^2\), as mentioned in Sect. 3.2. In general, Fig. 1 gives an indication of what equation that is favorable for each partial approximate solution if one is to be chosen. However, as mentioned, more sophisticated choices can be made by carefully considering the known quantities in the individual error terms for specific components. The right side of Fig. 1 shows that the iterates \((x_+^S, \lambda ^S_+)\) and \((x_+^C, \lambda ^C_+)\) perform similar to \((x_+^N, \lambda ^N_+)\) in terms of the measure \(\Vert F_{\mu ^+} \Vert\) for a wide range of \(\mu\). The error bars show that the results are not sensitive to changes in specific bounds, which of the constraints are active/inactive or different initial solutions. Numerical simulations have shown, as the theory also predicts, that the results can be improved (or dis-improved) by increasing (or decreasing) the size of the coefficients of the matrix H as well as its sparsity level.
Next we show results for a selection of problems in the CUTEst test collection in the analogous setting. In the problems with variable options, the number of primal variables, \(n_x\), was typically chosen to approximately 5000, resulting in a total number of primal-dual variables in the order of \(10^4\). The number of primal variables of each specific problem is shown in Table 1. Each problem was initially solved by an interior-point method with stopping criterion \(\Vert F_{0} (x,\lambda )\Vert < 10^{-14}\), i.e., the first-order optimality conditions given by (32) for \(\mu = 0\). This was to determine the selection of problems as well as estimates of the active and inactive sets. Problems with an unconstrained optimal solution or an optimal solution with only degenerate active constraints were not considered. In the first case the proposed approximate solutions are equivalent to the true solution. In the second case it is not clear how to deduce active/inactive sets. A constraint was considered as active if the corresponding variable was closer than \(10^{-10}\) to its bound. An active constraint was deemed degenerate if the corresponding multiplier value was below \(10^{-6}\). An exception was made for problem ODNAMUR, due to its larger size, for which the tolerances above were increased by a factor of \(10^1\) and \(10^2\). Figure 2 shows mean errors with the approximate solutions of Theorem 2 on each CUTEst problem. The results are for three different values of \(\mu\) with 10 different random initial solutions. The figure also shows the measure \(\Vert F_{\mu ^+} \Vert\) for \((x,\lambda )\), \((x_{+}^S, \lambda _{+}^S)\), \((x_{+}^C, \lambda _{+}^C)\) and \((x^{N}_+, \lambda ^{N}_+)\). Simulations with the set estimation heuristic above have shown that the behavior of the approximate solution varies in three different regions depending on \(\mu\). These regions are approximately, \([10^2,10^{-2})\), \([10^{-2}, 10^{-6}]\) and \((10^{-6},0)\). The \(\mu\)-values in Fig. 2 correspond to representative behavior in their respective region. The problems are ordered such that the fraction of estimated active constraints at the solution decreases from left to right.

Mean approximation error and mean progress with measure \(\Vert F_{\mu ^+}\Vert\) with one standard deviation error bars for a collection of CUTEst test problems
The partial approximate solution errors in Fig. 2 are significantly larger compared to those of Fig. 1. This is expected since the optimal solutions of the CUTEst test problems typically do not satisfy strict complementarity. Moreover, with the above strategy for determining the active and inactive sets, the smallest active multipliers may be in the order of \(10^{-5}\). Small active multipliers may cause inaccurate components in the approximate solution of \(\varDelta x_{\mathcal {A}}^N\). Nevertheless, the approximate solutions perform asymptotically similar to the Newton solution in terms of the measure \(\Vert F_{\mu ^+} \Vert\), as shown in Fig. 2. The figure also shows that the approximation error and the progress measure are not particularly sensitive to different initial solutions for smaller \(\mu\), whereas some effects can be seen for larger \(\mu\). The results may be improved and dis-improved depending on how the estimation of the active constraints at the solution is made. We chose to give the results for the strategy described above which gives a potentially significant reduction in the computational iteration cost.
In practice the active constraints at the optimal solution are unknown and have to be estimated as the iterations proceed. The purpose of the following simulations is to give an initial indication of the performance of the proposed approximate solutions within a primal-dual interior-point framework. In particular, we focus on the behavior on problems that do not satisfy the assumptions for which the theoretical results are valid, but also on the robustness in regards to how the set of active constraints is estimated. Algorithm 1 and 2 were considered with the aim of not drowning, or combining, approximation effects with other effects from more advanced features in more sophisticated methods. Algorithm 1 should here be seen as the reference method as it only contains Newton steps.


At iteration k of Algorithm 1 and Algorithm 2, \(\alpha ^P_{max,k}\) and \(\alpha ^D_{max,k}\) are the maximum feasible step lengths for \(x_k\) along \(\varDelta x_k\) and \(\lambda _k\) along \(\varDelta \lambda _k\) respectively. Table 1 contains a comparison of Algorithm 1 and two versions of Algorithm 2 which differ in how \(\varDelta x_{\mathcal {A}}\) is computed. The versions are denoted by \(\texttt {aN}^\texttt {S}\) and \(\texttt {aN}^\texttt {C}\) as they use the approximates \(\varDelta x_{\mathcal {A}}^S\) and \(\varDelta x_{\mathcal {A}}^C\) respectively. In Algorithm 2, a constraint was considered active if the distance to its bound was smaller than the value of its multiplier and a threshold \(\tau _{\mathcal {A}}\). The procedure is thus a basic heuristic aimed at determining the non-degenerate active constraints. In essence, the heuristic gives an estimate of set \({\mathcal {A}}_x\), compare to Definition 4 in the theoretical setting. The thresholds of the two versions \({\texttt {aN}}^{\texttt {S}}\) and \({\texttt {aN}}^{\texttt {C}}\) were chosen to \(\tau _{\mathcal {A}} = \mu ^{2/3}\) and the more restrictive \(\tau _{\mathcal {A} }= \mu ^{3/4}\) respectively. This was done to show the effects of two different thresholds \(\tau _{\mathcal {A}}\), but also because numerical experiments have shown that steps with Schur-based approximation are more robust at larger \(\mu\), see Fig. 2. Table 1 gives a comparison of the number of iterations for different values of \(\mu\) as well as the average cardinality of \({\mathcal {I}}_x\), the set of indices corresponding to the estimated inactive components of x, i.e., the size of the systems that has to be solved in every iteration. The symbol “–” denotes the situation when the method failed to converge within 50 iterations for the corresponding \(\mu\). If the method failed at a specific \(\mu\) then Newton steps were performed instead until \(\Vert F_\mu (x,\lambda ) \Vert < \mu\). The order of the problems is the same as in Fig. 2.
The results in Table 1 display similar characteristics as the results in Fig. 2. The version associated with the Schur-based approximate solution, \(\texttt {aN}^\texttt {S}\) of Algorithm 2, makes sufficient progress at \(\mu \in [10^2,10^{-2})\), often at a relatively low computational cost. Version \(\texttt {aN}^\texttt {S}\) converges at \(\mu \in [10^{-2}, 10^{-6}]\), however, often while solving relatively large systems due to the difficulty of estimating \({\mathcal {A}}_x\). At \(\mu \in (10^{-6},0)\) the asymptotic behavior becomes more pronounced. Consequently, \(\texttt {aN}^\texttt {S}\) does similar in terms of iteration count to Algorithm 1 while solving systems of reduced size. Version \(\texttt {aN}^\texttt {S}\) converges at all considered \(\mu\) in all problems of Table 1, except on HARKERP2 for larger \(\mu\). The version associated with the complementarity-based approximate solution, \(\texttt {aN}^\texttt {C}\) of Algorithm 2, tend to perform poorly overall for \(\mu \in [10^2,10^{-2})\) and parts of \([10^{-2}, 10^{-6}]\). Although \(\texttt {aN}^\texttt {C}\) converges for large \(\mu\), this is often at the expense of either solving relatively large systems or performing many iterations. In general, \(\texttt {aN}^\texttt {C}\) performs similar to Algorithm 1 for \(\mu\) in the approximate region \([10^{-5},0)\) while solving systems of reduced size. The versions \(\texttt {aN}^\texttt {S}\) and \(\texttt {aN}^\texttt {C}\) have similar asymptotic performance, however in general, \(\texttt {aN}^\texttt {S}\) performs better for larger values of \(\mu\), as also indicated by previous results in Fig. 2.
Finally we show results for the two Newton-like approaches, mentioned in Sect. 3.1, in a simple primal-dual interior-point setting. The approximate intermediate step method and the approximate higher-order method are described in Algorithm 3 and Algorithm 4 respectively. In contrast to Sect. 3.1, here the intermediate iterate is required to be strictly feasible. The total number of iterations required at different intervals of \(\mu\) with the two Newton-like approaches is shown in Fig. 3. The figure shows results for three different choices of \((\varDelta x^E, \varDelta \lambda ^E)\). Moreover, the selection of which components to update was done as the iterations proceeded similarly as above. Note however that it is not necessary to label each constraint and each component of \(\lambda\) as active or inactive in this case, some may be defined as neither. The set of indices corresponding to active constraints, \({\mathcal {A}}_x\), was estimated as above and the sets of indices corresponding to inactive \(\lambda\), \({\mathcal {I}}_l\) and \({\mathcal {I}}_u\), see Definition 4, were estimated analogously. I.e., a multiplier was considered inactive if its value was smaller than the distance of the corresponding x to its feasibility bound and a threshold \(\tau _{\mathcal {I}}\). Table 2 shows how the nonzero components of \((\varDelta x^E, \varDelta \lambda ^E)\) were chosen in the different versions of the approaches as well as the different thresholds \(\tau _{\mathcal {A}}\) and \(\tau _{\mathcal {I}}\).


In Algorithm 3 and Algorithm 4 at iteration k, \(\alpha ^P_{max,k}\), \(\alpha ^D_{max,k}\), \(\alpha ^{E,P}_{max,k}\) and \(\alpha ^{E,D}_{max,k}\) are for the prescribed steps defined analogously as in Algorithm 1.

Number of iterations required at different intervals of \(\mu\) for three versions of the Newton-like approaches and Algorithm 1, (Newton)
The total iteration count for \(\mu \in [10^1,\> 10^{-10}]\) in Fig. 3 shows that the approximate higher-order approach requires the same, or fewer iterations, compared to the approach with the approximate intermediate step. The iteration count for the approaches with the Schur-based approximate is similar to that of Algorithm 1 for this range of \(\mu\). Also here, numerical experiments show indications of three regions. For \(\mu\) in the approximate region \([10^1,10^{-2})\), the versions with the Schur-based approximate yield a potentially reduced number of iterations. Their performance varies in the region of intermediate sized \(\mu\). However, it can not be discarded that this is an effect of the relatively simple set estimation heuristics. On all problems, with the exception of ODNAMUR, in Fig. 3 for \(\mu \in [10^{-5},\> 10^{-10}]\) all versions of both approaches give an iteration count less or equal to Algorithm 1, hence providing potential savings in computation cost. The results may be improved with a flexible set estimation heuristics, e.g., more restrictive thresholds for intermediate sized \(\mu\). However, we chose not to include another layer of detail and instead give the results for a relatively simple setting to obtain an initial evaluation of the potential performance.
5 Conclusions
In this work we have given approximate solutions to systems of linear equations that arise in interior point methods for bound-constrained optimization; in particular, partial approximate solutions, where the asymptotic component error bounds are in the order of \(\mu ^2\), and full approximate solutions with asymptotic error bounds in the order of \(\mu ^2\). Numerical simulations on randomly generated bound-constrained convex quadratic optimization problems, whose minimizers satisfy strict complementarity, have shown that the approximate solutions perform similarly to Newton solutions for sufficiently small \(\mu\). Simulations on convex bound-constrained quadratic problems from the CUTEst test collection, whose minimizers typically do not satisfy strict complementarity, has shown that the predicted asymptotic behavior still occurs, however at significantly smaller values of \(\mu\).
We have performed numerical simulations in a simple yet more realistic setting. Specifically, in a primal-dual interior-point framework where the active and inactive sets were estimated with basic heuristics as the iterations proceeded. These simulations were done on a selection of CUTEst benchmark problems. The results showed that the behavior roughly varied with three regions determined by the size of \(\mu\). The Schur-based approximate solutions showed potential in the region for larger \(\mu\), in the region of intermediate sized \(\mu\) the performance varied, partly due to difficulties in determining the active and inactive sets. For sufficiently small \(\mu\) the approximate solutions showed performance similar to our reference method while solving systems of reduced size.
Finally we showed numerical results for two Newton-like approaches, which include an approximate intermediate step consisting of partial approximate solutions, on the considered CUTEst benchmark problems. The simulations showed similar characteristics as the previous results and also a potential for reducing the overall iteration count of interior-point methods.
The results of this work are meant to contribute to the theoretical and numerical understanding for approximate solutions to systems of linear equations that arise in interior-point methods. We hope that the work can lead to further research on approximate solutions and approximate higher-order methods for optimization problems with linear inequality constraints.
References
Bertsekas, D.P.: On the Goldstein-Levitin-Polyak gradient projection method. IEEE Trans. Automatic Control AC–21(2), 174–184 (1976). https://doi.org/10.1109/tac.1976.1101194
Bertsekas, D.P.: Projected Newton methods for optimization problems with simple constraints. SIAM J. Control Optim. 20(2), 221–246 (1982). https://doi.org/10.1137/0320018
Byrd, R.H., Liu, G., Nocedal, J.: On the local behavior of an interior point method for nonlinear programming. Numerical analysis, pp. 37–56. Addison-Wesley-Longman, Boston (1998)
Byrd, R.H., Lu, P., Nocedal, J., Zhu, C.Y.: A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput. 16(5), 1190–1208 (1995). https://doi.org/10.1137/0916069
Coleman, T.F., Li, Y.: On the convergence of interior-reflective Newton methods for nonlinear minimization subject to bounds. Math. Program. 67(2 Ser. A), 189–224 (1994). https://doi.org/10.1007/BF01582221
Conn, A.R., Gould, N.I.M., Toint, P.L.: Global convergence of a class of trust region algorithms for optimization with simple bounds. SIAM J. Numer. Anal. 25(2), 433–460 (1988). https://doi.org/10.1137/0725029
Conn, A.R., Gould, N.I.M., Toint, P.L.: Trust region methods. Society for Industrial and Applied Mathematics (2000). https://doi.org/10.1137/1.9780898719857. URL https://epubs.siam.org/doi/abs/10.1137/1.9780898719857
Facchinei, F., Júdice, J., Soares, Ja: An active set Newton algorithm for large-scale nonlinear programs with box constraints. SIAM J. Optim. 8(1), 158–186 (1998). https://doi.org/10.1137/S1052623493253991
Forsgren, A., Gill, P.E.: Primal-dual interior methods for nonconvex nonlinear programming. SIAM J. Optim. 8(4), 1132–1152 (1998). https://doi.org/10.1137/S1052623496305560
Forsgren, A., Gill, P.E., Griffin, J.D.: Iterative solution of augmented systems arising in interior methods. SIAM J. Optim. 18(2), 666–690 (2007)
Forsgren, A., Gill, P.E., Shinnerl, J.R.: Stability of symmetric ill-conditioned systems arising in interior methods for constrained optimization. SIAM J. Matrix Anal. Appl. 17(1), 187–211 (1996). https://doi.org/10.1137/S0895479894270658
Forsgren, A., Gill, P.E., Wright, M.H.: Interior methods for nonlinear optimization. SIAM Rev. 44(4), 525–597 (2002). https://doi.org/10.1137/S0036144502414942
Gill, P.E., Murray, W., Ponceleón, D.B., Saunders, M.A.: Preconditioners for indefinite systems arising in optimization. SIAM J. Matrix Anal. Appl. 13, 292–311 (1992)
Gondzio, J., Sobral, F.N.C.: Quasi-Newton approaches to interior point methods for quadratic problems. Comput. Optim. Appl. 74(1), 93–120 (2019). https://doi.org/10.1007/s10589-019-00102-z
Gould, N., Orban, D., Toint, P.: Numerical methods for large-scale nonlinear optimization. Acta Numer. 14, 299–361 (2005). https://doi.org/10.1017/S0962492904000248
Gould, N.I.M., Orban, D., Toint, P.L.: CUTEst: a constrained and unconstrained testing environment with safe threads for mathematical optimization. Comput. Optim. Appl. 60(3), 545–557 (2015). https://doi.org/10.1007/s10589-014-9687-3
Griva, I., Nash, S., Sofer, A.: Linear and nonlinear optimization, 2nd edn. Society for Industrial and Applied Mathematics, London (2009)
Hager, W.W., Zhang, H.: A new active set algorithm for box constrained optimization. SIAM J. Optim. 17(2), 526–557 (2006). https://doi.org/10.1137/050635225
Heinkenschloss, M., Ulbrich, M., Ulbrich, S.: Superlinear and quadratic convergence of affine-scaling interior-point Newton methods for problems with simple bounds without strict complementarity assumption. Math. Program. 86(3 Ser. A), 615–635 (1999). https://doi.org/10.1007/s101070050107
Kanzow, C., Klug, A.: On affine-scaling interior-point Newton methods for nonlinear minimization with bound constraints. Comput. Optim. Appl. 35(2), 177–197 (2006). https://doi.org/10.1007/s10589-006-6514-5
Kim, D., Sra, S., Dhillon, I.: Tackling box-constrained optimization via a new projected quasi-newton approach. SIAM J. Scientific Computing 32, 3548–3563 (2010). https://doi.org/10.1137/08073812X
Lin, C.J., Moré, J.J.: Newton’s method for large bound-constrained optimization problems. SIAM J. Optim. (1999). https://doi.org/10.1137/S1052623498345075. Dedicated to John E. Dennis, Jr., on his 60th birthday
Morini, B., Simoncini, V.: Stability and accuracy of inexact interior point methods for convex quadratic programming. J. Optim. Theory Appl. 175(2), 450–477 (2017). https://doi.org/10.1007/s10957-017-1170-8
Nocedal, J., Wright, S.J.: Numerical optimization. Springer Series in Operations Research and Financial Engineering, 2nd edn. Springer, New York (2006)
Orban, D., Siqueira, A.S.: JuliaSmoothOptimizers: Infrastructure and solvers for continuous optimization in Julia (2019). https://doi.org/10.5281/zenodo.2655082. URL https://juliasmoothoptimizers.github.io
Ortega, J.M., Rheinboldt, W.C.: Iterative Solution of Nonlinear Equations in Several Variables. Society for Industrial and Applied Mathematics, Philadelphia, PA, USA (2000)
Schwartz, A., Polak, E.: Family of projected descent methods for optimization problems with simple bounds. J. Optim. Theory Appl. 92(1), 1–31 (1997). https://doi.org/10.1023/A:1022690711754
Vanderbei, R.J., Shanno, D.F.: An interior-point algorithm for nonconvex nonlinear programming. Computational optimization (1999). https://doi.org/10.1023/A:1008677427361. A tribute to Olvi Mangasarian, Part II
Wächter, A., Biegler, L.T.: On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. Math. Program. 106(1 Ser. A), 25–57 (2006). https://doi.org/10.1007/s10107-004-0559-y
Waltz, R.A., Morales, J.L., Nocedal, J., Orban, D.: An interior algorithm for nonlinear optimization that combines line search and trust region steps. Math. Program. 107(3 Ser. A), 391–408 (2006). https://doi.org/10.1007/s10107-004-0560-5
Wright, M.H.: Ill-Conditioning and computational error in interior methods for nonlinear programming. SIAM J. Optim. 9(1), 84–111 (1999). https://doi.org/10.1137/S1052623497322279
Wright, S.J.: Stability of linear equations solvers in interior-point methods. SIAM J. Matrix Anal. Appl. 16(4), 1287–1307 (1995). https://doi.org/10.1137/S0895479893260498
Wright, S.J.: Effects of finite-precision arithmetic on interior-point methods for nonlinear programming. SIAM J. Optim. 12(1), 36–78 (2001). https://doi.org/10.1137/S1052623498347438
Zhu, C., Byrd, R.H., Lu, P., Nocedal, J.: Algorithm 778: L-BFGS-B: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. 23(4), 550–560 (1997). https://doi.org/10.1145/279232.279236
Acknowledgements
We thank the anonymous referees for many helpful suggestions which significantly improved the presentation. Research partially supported by the Swedish Research Council (VR).
Funding
Open Access funding provided by Royal Institute of Technology. Funding is provided by Vetenskapsrådet (Grant No. 621-2014-4772).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: The general case
Appendix A: The general case
Consider problems on the form of (NLP). In this situation the Lagrange multiplier vector at a local minimizer \(x^*\) takes the form \(\lambda ^* = \begin{pmatrix} \lambda ^{l*} \\ \lambda ^{u*} \end{pmatrix}\), where \(\lambda ^{l*}\) and \(\lambda ^{u*}\) are the multiplier vectors corresponding to lower and upper bounds respectively. The second-order conditions sufficient optimality conditions together with strict complementarity take the form
Similarly as in Sect. 2, define the function \(F_{\mu }:{\mathbb {R}}^{3n} \rightarrow {\mathbb {R}}^{3n}\) by
where \(L= \text {diag} (l)\), \(U = \text {diag}(u)\), \(\varLambda ^l=\text {diag}(\lambda ^l)\) and \(\varLambda ^u=\text {diag}(\lambda ^u)\). The corresponding Jacobian \(F' : {\mathbb {R}}^{3n} \rightarrow {\mathbb {R}}^{3n}\) is
For the case with upper and lower bounds it is useful to distinguish whether a specific component of \(x^*\) is active with respect to an upper or a lower bound.
Definition 4
(Active/inactive sets) For a given \(x^*\) such that \(l \le x^* \le u\), define the sets
Throughout the remaining part of the manuscript, Assumption 1 means that the vector \((x^*, \lambda ^*)\) satisfies (31), i.e., second-order sufficient optimality conditions and strict complementarity. Bounds on individual components of the solution \((x, \lambda )\) in the region of asymptotic behavior is given the lemma below.
Lemma 6
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {{\bar{\mu }}}\) and \((x,\lambda )\) sufficiently close to \((x^{\mu }, \lambda ^{\mu }) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\) so that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\) it holds that
1.1 Partial approximate solutions
In this section we give results analogous to those given in Sect. 3.1 together with some complementary remarks. With \(F'(x,\lambda )\) and \(F_{\mu }(x,\lambda )\) defined as in (33) and (32) respectively the Schur complement of \((X-L)\) and \((U-X)\) in (2) is
For \(i \in {\mathcal {A}}_x\) either \((u_i-x_i) \rightarrow 0\) or \((l_i-x_i) \rightarrow 0\) as \(\mu \rightarrow 0\). In consequence, approximates of \(\varDelta x_i^N\), \(i \in {\mathcal {A}}_x\), can be obtained from the Schur complement (34). These approximate solutions are given below in Proposition 4 which is the result analogous to Proposition 1.
Proposition 4
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. For \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), let \((\varDelta x^N, \varDelta \lambda ^N)\) be the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). If the search direction components are defined as
for \(i=1,\dots , n\), then
Assume in addition that \(0 < \mu \le {\hat{\mu }}\) and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
and
Next we give results corresponding to those in Proposition 2. As \(\mu \rightarrow 0\) then \(\lambda _i^l \rightarrow 0\) for \(i \in {\mathcal {I}}_{l}\) and \(\lambda _i^u \rightarrow 0\) for \(i \in {\mathcal {I}}_{u}\). Consequently, approximations based on the complementarity blocks of \(F'(x,\lambda ) (\varDelta x^N, \varDelta \lambda ^N) = - F_{\mu }(x,\lambda )\) can be formed for \(\varDelta x_i^N, i \in {\mathcal {A}}_x\), \(\varDelta \lambda _i^{l,N}, i \in {\mathcal {I}}_{l}\) and \(\varDelta \lambda _i^{u,N}, i \in {\mathcal {I}}_{u}\).
Proposition 5
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. For \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), let \((\varDelta x^N, \varDelta \lambda ^N)\) be the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). If the search direction components are defined as
then
Assume in addition that \(0 < \mu \le {\hat{\mu }}\) and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
Finally we give the general result for the approximate intermediate step, i.e., for the case with lower and upper bounds.
Proposition 6
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. For \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), define \((x_+^{N},\lambda _+^{N})=(x,\lambda )+ (\varDelta x^N,\varDelta \lambda ^N)\) where \((\varDelta x^N, \varDelta \lambda ^N)\) is the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). Moreover, let \((x_+, \lambda _+) = (x,\lambda ) + (\varDelta x, \varDelta \lambda )\) where
Assume that \(0 < \mu \le {\hat{\mu }}\) and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\) and \(\Vert (\varDelta x_{\mathcal {A}}^N, \varDelta \lambda _{\mathcal {I}}^N) \Vert =\varOmega ( \mu ^\gamma )\) for \(\gamma < 2\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
1.2 Full approximate solutions
In this section we give results analogous to those given in Sect. 3.2 together with some complementary remarks. Note that \({\mathcal {I}}_x \cap {\mathcal {A}}_{l} = \emptyset\) and \({\mathcal {I}}_x \cap {\mathcal {A}}_{u}= \emptyset\). By partitioning \((\varDelta x^N, \varDelta \lambda ^N) = (\varDelta x_{{\mathcal {A}}_x}^N, \varDelta x_{{\mathcal {I}}_x}^N, \varDelta \lambda ^{l,N}_{{\mathcal {A}}_{l}}, \varDelta \lambda ^{l,N}_{{\mathcal {I}}_{l}}, \varDelta \lambda ^{u,N}_{{\mathcal {A}}_{u}}, \varDelta \lambda ^{u,N}_{{\mathcal {I}}_{u}})\), (2) can be written as
Suppose that an approximate solution of \(\varDelta x^N_{{\mathcal {A}}_x}\) is given, e.g., (35) or (36a) and (36b) of Proposition 4 and Proposition 5 respectively. Insertion of an approximate \(\varDelta x_{{\mathcal {A}}_x}\) into (40) yields
whose solution is labeled with “ls” since it will lead to least squares system, similarly as in Sect. 3.2. The second, fourth and sixth block of (41) provide unique solutions of \(\varDelta x^{ls}_{{\mathcal {I}}_x}\), \(\varDelta \lambda ^{l,ls}_{{\mathcal {I}}_l}\) and \(\varDelta \lambda ^{u,ls}_{{\mathcal {I}}_u}\) which satisfy
The solution of (42) can be obtained by first solving with the Schur complement of \((X-L)_{{\mathcal {I}}_{l} {\mathcal {I}}_{l}}\) and \((U-X)_{{\mathcal {I}}_{u} {\mathcal {I}}_{u}}\)
and then
Note that the matrix of (43) is by Assumption 1 a symmetric positive definite \(\left( |{\mathcal {I}}_x| \times |{\mathcal {I}}_x| \right)\)-matrix. The remanding part of the solution of (41), that is \(\varDelta \lambda ^{l,ls}_{{\mathcal {A}}_{l}}\) and \(\varDelta \lambda ^{u,ls}_{{\mathcal {A}}_{u}}\) are then given by
where \(\nabla _x {\mathcal {L}}(x,\lambda )_{{\mathcal {A}}_x} = \nabla f(x)_{{\mathcal {A}}_x} - \lambda ^l_{{\mathcal {A}}_x} + \lambda ^u_{{\mathcal {A}}_x}\). If the approximate \(\varDelta x_{{\mathcal {A}}_x}\) is exact then so is \(\varDelta x^{ls}_{{\mathcal {I}}_x}\) by (43). In consequence, the over-determined system (45) has a unique solution that satisfies all equations, i.e., \(\varDelta \lambda ^{ls}_{{\mathcal {A}}_x}\), or equvalently \(\varDelta \lambda ^{l,ls}_{{\mathcal {A}}_{l}}\) and \(\varDelta \lambda ^{u,ls}_{{\mathcal {A}}_{u}}\) since \({\mathcal {A}}_x = {\mathcal {A}}_{l} \cup {\mathcal {A}}_{u}\), are the corresponding parts of the solution to (2). The solutions corresponding to the first and second block equation of (45) will be labeled with superscript “b” and “−” respectively. These are given by
and
Alternatively, \(\varDelta \lambda ^{l,ls}_{{\mathcal {A}}_{l}}\) and \(\varDelta \lambda ^{u,ls}_{{\mathcal {A}}_{u}}\) can be obtained as the least squares solution of (45)
since \(I_{{\mathcal {A}}_x {\mathcal {A}}_{l}}^T I_{{\mathcal {A}}_x {\mathcal {A}}_{l}} = I_{{\mathcal {A}}_{l} {\mathcal {A}}_{l}}\), \(I_{{\mathcal {A}}_x {\mathcal {A}}_{u}}^T I_{{\mathcal {A}}_x {\mathcal {A}}_{u}} = I_{{\mathcal {A}}_{u} {\mathcal {A}}_{u}}\) and \(I_{{\mathcal {A}}_x {\mathcal {A}}_{l}}^T I_{{\mathcal {A}}_x {\mathcal {A}}_{u}} = I_{{\mathcal {A}}_x {\mathcal {A}}_{u}}^T I_{{\mathcal {A}}_x {\mathcal {A}}_{l}}=0\). The equations can also be written as
Finally, we state the main result which is analogous to the result of Theorem 1.
Theorem 2
Under Assumption 1, let \({\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) and \({\hat{\mu }}\) be defined by Lemma 1 and Lemma 2 respectively. For \(0< \mu \le {\hat{\mu }}\) and \((x,\lambda ) \in {\mathcal {B}}((x^*, \lambda ^*), \delta )\), let \((\varDelta x^N, \varDelta \lambda ^N)\) be the solution of (2) with \(\mu ^+ = \sigma \mu\), where \(0< \sigma < 1\). Moreover, let the search direction components be defined as
Assume that \(0 < \mu \le {\hat{\mu }}\) and \((x,\lambda )\) is sufficiently close to \((x^{\mu }, \lambda ^{\mu })\in {\mathcal {B}}\left( (x^*, \lambda ^*), \delta \right)\) such that \(\Vert F_{\mu } (x,\lambda ) \Vert = {\mathcal {O}}(\mu )\). Then there exists \({\bar{\mu }}\), with \(0 <{\bar{\mu }}\le {\hat{\mu }}\), such that for \(0 < \mu \le {\bar{\mu }}\) it holds that
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ek, D., Forsgren, A. Approximate solution of system of equations arising in interior-point methods for bound-constrained optimization. Comput Optim Appl 79, 155–191 (2021). https://doi.org/10.1007/s10589-021-00265-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-021-00265-8