
Abstract
Introduction
Endoxifen—the principal metabolite of tamoxifen—is subject to a high inter-individual variability in serum concentration. Numerous attempts have been made to explain this, but thus far only with limited success. By applying predictive modeling, we aimed to identify factors that determine the inter-individual variability. Our purpose was to develop a prediction model for endoxifen concentrations, as a strategy to individualize tamoxifen treatment by model-informed dosing in order to prevent subtherapeutic exposure (endoxifen < 16 nmol/L) and thus potential failure of therapy.
Methods
Tamoxifen pharmacokinetics with demographic and pharmacogenetic data of 303 participants of the prospective TOTAM study were used. The inter-individual variability in endoxifen was analyzed according to multiple regression techniques in combination with multiple imputations to adjust for missing data and bootstrapping to adjust for the over-optimism of parameter estimates used for internal model validation.
Results
Key predictors of endoxifen concentration were CYP2D6 genotype, age and weight, explaining altogether an average-based optimism corrected 57% (95% CI 0.49–0.64) of the inter-individual variability. CYP2D6 genotype explained 54% of the variability. The remaining 3% could be explained by age and weight. Predictors of risk for subtherapeutic endoxifen (< 16 nmol/L) were CYP2D6 genotype and age. The model showed an optimism-corrected discrimination of 90% (95% CI 0.86–0.95) and sensitivity and specificity of 66% and 98%, respectively. Consecutively, there is a high probability of misclassifying patients with subtherapeutic endoxifen concentrations based on the prediction rule.
Conclusion
The inter-individual variability of endoxifen concentration could largely be explained by CYP2D6 genotype and for a small proportion by age and weight. The model showed a sensitivity and specificity of 66 and 98%, respectively, indicating a high probability of (misclassification) error for the patients with subtherapeutic endoxifen concentrations (< 16 nmol/L). The remaining unexplained inter-individual variability is still high and therefore model-informed tamoxifen dosing should be accompanied by therapeutic drug monitoring.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Globally, breast cancer is the most frequent cancer among women and also the most frequent malignancy overall impacting 2.26 million cases annually [1].In approximately 70% of primary breast cancer, the tumor is estrogen- receptor positive (ER+) and is dependent on estrogen for its proliferation [2]. Tamoxifen is a widely used selective estrogen receptor modulator (SERM) against ER+ breast cancer in the adjuvant setting [3]. Tamoxifen substantially reduces the risk of recurrence, breast cancer mortality, and also overall mortality [4,5,6,7].
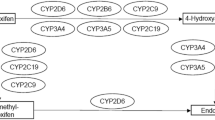
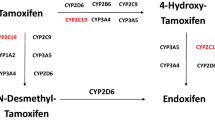
Tamoxifen is a prodrug and is mainly metabolized by the cytochrome P450 (CYP) enzymes 2D6 and 3A4 into its most clinically relevant metabolite endoxifen (Fig. 1) [8]. Endoxifen is characterized by a high inter-individual variability partly due to its complex metabolism [9,10,11]. To ensure optimal treatment efficacy, a therapeutic endoxifen threshold of 14–16 nmol/L (5.22–5.97 ng/mL) is proposed [9, 12]. However, one out of five patients do not reach therapeutic endoxifen concentrations and thus may fail to retain optimal treatment efficacy [9, 12, 13].

Simplistic representation of biotransformation of tamoxifen into its most clinically relevant metabolite endoxifen
Genetic polymorphisms of the cytochrome P450 (CYP) system—and especially the polymorphic enzyme CYP2D6—are prominently involved in tamoxifen metabolism and consecutively in its high variability in pharmacokinetics [9, 12, 14, 15]. Therefore, numerous studies and guidelines have focused on CYP2D6 genotype as a predictive marker for individualization of tamoxifen therapy. However, based on the current literature CYP2D6 genotype accounts for approximately 30–40% of the total variability of endoxifen concentration which calls for further individualization strategies [15,16,17].
Consequently, several studies have investigated other factors contributing to the inter-individual variability. An important factor explaining the inter-individual variability in endoxifen plasma concentration is adherence to tamoxifen treatment. One-year adherence based on biochemical definition (tamoxifen < 100 nmol/L) and self-reported adherence showed non-adherence in 16% and 12% of the population, respectively [18, 19]. However, real-life estimates range from 15 to 72% non-adherence over 5 years of tamoxifen therapy; with a tamoxifen adherence cut-off in the range of 100–160 nmol/L [20,21,22].
In the past, age, weight, and body mass index (BMI), amongst others, have been identified as predictors, however, only marginal effects regarding the inter-individual variability in endoxifen concentrations were found. Concurrent medication inhibiting or inducing CYP2D6 enzymatic activity are known to affect endoxifen concentrations and therefore are of clinical value. Nonetheless, with this knowledge, the one-dose-fits-all strategy is still current practice [12, 15, 19, 22,23,24,25,26].
A strategy for individualizing tamoxifen treatment involves the quantification of predictors for endoxifen steady-state concentrations [15,16,17]. Therefore, the aim of this study was: (i) to quantify the inter-individual variability in endoxifen concentrations in breast cancer patients treated with tamoxifen; (ii) to identify possible predictors of the inter-individual variability in endoxifen concentration; and (iii) to develop a predictive model for endoxifen concentration as a strategy to individualize tamoxifen treatment by model-informed precision dosing.
Methods
Study design and population
Participants included in this analysis are selected from the TOTAM study. The TOTAM study is an open-label, single arm, monocentric clinical trial performed at the Erasmus MC – Cancer Institute in Rotterdam, the Netherlands. The primary aim of the TOTAM study is to prove that therapeutic drug monitoring (TDM) of endoxifen for tamoxifen precision dosing is feasible in patients with hormone-sensitive breast cancer in clinical practice. A secondary aim is to develop a model to predict the endoxifen plasma concentration in tamoxifen users. The study protocol is registered in the Netherlands Trial Registry (www.trialregister.nl; NL6918). The TOTAM study prospectively enrolled 314 participants between January 2018 and November 2020. Eligible participants for analysis were ER+ breast cancer patients who initiated a tamoxifen treatment dose of 20 mg administered once daily and reached steady-state concentration (at least 2.5 months of treatment before the first endoxifen measurement). Participants with tamoxifen plasma concentrations < 100 nmol/L were considered non-eligible for analysis due to non-adherence. All participants provided a written informed consent before enrolment.
Data collection
Data from the first outpatient hospital visit were used, including participants’ demographics, medical history, serum biochemistry, pharmacokinetic sample, and pharmacogenetics. Concurrent use of co-medication or supplements known to strongly inhibit or induce CYP2D6 and CYP3A4 were categorized in weak, moderate and strong inhibitors/inducers, respectively. Tamoxifen-related adverse events were monitored and graded via the Common Terminology Criteria for Adverse Events (CTCAE) version 5 [27]. Adherence to tamoxifen treatment was quantified by the validated 8-item Morisky Medication Adherence Scale; a widely used self-report questionnaire resulting in a high (score 8), medium (score 6–7) or low (score < 5) adherence rate [28].
Pharmacokinetics of tamoxifen and endoxifen
Pharmacokinetic blood samples were drawn at steady state to quantify tamoxifen- and endoxifen plasma concentration. Blood samples for the quantification of tamoxifen and endoxifen were all analyzed at the laboratory of Translational Pharmacology, Erasmus MC Cancer Institute, Rotterdam, The Netherlands, using a validated liquid chromatography tandem mass spectrometry method [29].
Pharmacogenetics of CYP2D6 and CYP3A4*22
Participants were CYP2D6 and CYP3A4*22 genotyped using the Infiniti Biofilm Microarray (Autogenomics Carlsbad, USA) and the Quantstudio test (ThermoFisher Scientific Waltham, USA). CYP2D6 phenotype was assayed in the laboratory on the genetic variants *2 to *10, *12, *14, *17, *29, and *41; thereafter, patients were classified into four phenotypes based on enzyme function. Consecutively, the CYP2D6 activity score (AS) was calculated according to their allele combination and according to the sum of the AS, participants were assigned to four phenotypes: poor metabolizer (PM; AS = 0), intermediate metabolizer (IM; AS ≥ 0.5 to ≤ 1.0), normal metabolizer (NM; AS ≥ 1.5 to ≤ 2.5), and ultra-rapid metabolizer (UM; AS ≥ 3.0). Additionally, all participants were assigned to a phenotype based on their allele combination, including PM/PM, IM/PM, IM/IM, NM/PM, NM/IM, and NM/NM. All participants were genotyped for CYP3A4*22 for wild type (CC), heterozygous (CT), and homozygous (TT). Activity score calculations and phenotyping were in agreement with the Clinical Pharmacogenetic Implementation Consortium guidelines [30].
Statistical analysis
To summarize baseline characteristics of the study participants, descriptive statistics were computed. Differences between groups were calculated by means of appropriate parametric or non-parametric tests. All tests for differences were two-sided and based on a significance level of 5%. Multiple linear regression was used to model the association between predictors and endoxifen concentration. A logarithmic transformation was applied to endoxifen concentrations to adjust for non-normality. The following variables were included in the regression analysis: age (years), weight (kg), BMI (kg/m2), CYP2D6, CYP3A4*22, co-medication (CYP2D6 and CYP3A4/5 inhibitors/inducers), intake-with-food, time-of-intake and adherence to tamoxifen.
In order to account for missing data, Multiple Imputation by Chained Equations (MICE) to create multiple complete datasets was performed. A standard Multiple Imputation (MI) scheme was considered and consisted of (i) imputation of all the missing data m times, (ii) analysis of m imputed datasets, and (iii) pooling of the parameters across m analyses according to Rubin’s Rules [31, 32]. Imputation of missing data was according to a full conditional specification approach as variables with missing data were measured at different scales. To incorporate model selection in the MI scheme, a stepwise selection procedure was implemented.
The first step incorporated performing model selection on each imputed dataset separately by means of multiple linear regression with backwards selection based on two stopping rules—namely a significance level of p < 0.10 and the Akaike Information Criteria (AIC) [32,33,34]. Consecutively, a majority rule is applied, i.e., predictors are included in the final model when they were selected in at least 50% of the intermediate models across all MI datasets. Wald-based statistics were computed for variables with selection probabilities between 0.4 and 0.6 to compare two nested models for improvement and thereby yield the exclusion of non-predictive variables [32, 35]. A non-parametric bootstrap procedure was nested within MI approach to correct for model optimism due to overfitting. After creating m completed datasets 5000 bootstrap samples were drawn, for each dataset, before the results were pooled [32, 36, 37]. Consecutively, pooled parameter estimates and average-based optimism-adjusted R2 values were calculated including average bootstrap-based 95% confidence intervals (CIs). The mice package (R Statistics) was used to estimate model parameters. More information regarding model selection procedure can be found in the supplementary material (sects. 5.1 and 5.2).
As a sensitivity analysis, a complete case analysis (CCA) was performed by means of multiple linear regression with backwards selection based on two stopping rules—namely a significance level of p < 0.10 and AIC [33, 34]. In order to formally test for improvement in nested models, a Wald test was applied [34]. Again, to adjust for model optimism, a non-parametric bootstrap including 5000 bootstrap samples was performed to estimate parameters and optimism-adjusted R2 with accompanying 95% CIs. Goodness-of-fit plots were computed to assess model performance and to check model assumptions such as normality, linearity, no or minimal multicollinearity, and heteroscedasticity of residuals.
Finally, key predictors for subtherapeutic risk of endoxifen concentration (< 16 nmol/L) were identified by means of multiple logistic regression. The likelihood ratio test was used to identify the best fitting model, thereby excluding non-predictive variables. The area under the receiver operator curve (AUC) was computed and a bootstrap approach was considered to estimate optimism-adjusted predictive performance measures. All statistical analyses were carried out using the statistical software package R (R statistics. Foundation of Statistical Computing©, version 3.5.4.).
Results
Patients and data
Between January 2018 and November 2020, 314 early breast cancer patients were enrolled in the TOTAM study. Of those patients, 11 patients were excluded from this analysis due to (i) non-adherence (n = 1) and (ii) non-steady-state endoxifen concentration (n = 10). Geno- and phenotyping was successfully performed in almost all of the patients and conform Hardy–Weinberg equilibrium (p < 0.05). Hot flashes (61%), arthralgia (19%), fatigue (11%), vaginal dryness (8%), and mood swings (6%) were the most commonly reported tamoxifen-related adverse events (all CTCAE grade 1) during the first six months after initiation of tamoxifen treatment. Patients’ characteristics are shown in Table 1. No statistically significant differences were found between the full cohort (n = 303) and patients with complete information (n = 281) concerning patient characteristics. Tamoxifen and endoxifen plasma concentrations were measured from patients prescribed 20 mg once daily and who reached steady-state concentration. Median (IQR) steady-state trough plasma concentration of tamoxifen and endoxifen were 308 (248.0–385.5) nmol/L and 26.2 (17.0–35.3) nmol/L, respectively.
Impact of genetic polymorphisms on blood plasma concentrations
Inter-individual variability in plasma concentration was observed for tamoxifen and endoxifen, ranging from 127 to 881 nmol/L and 3.4–82.8 nmol/L, respectively. The median endoxifen concentration in patients with an NM 31.5 (22.9–40.3) nmol/L was statistically significantly higher than in patients with an IM 21.5 (13.9–30.2) nmol/L and PM phenotype 7.6 (6.6–9.0) nmol/L; p < 0.001, respectively. Results of different pharmacokinetic profiles are depicted in both Fig. 2A (stratified on CYP2D6 phenotype) and Fig. 2B (stratified on CYP2D6 activity score) Consecutively, based on CYP2D6 phenotype 100% of PMs, 32% of IMs, and 7% of NMs had endoxifen concentration (< 16 nmol/L, a threshold often used in the literature).

A Pharmacokinetic profile of endoxifen steady-state concentrations (n = 301) stratified based on CYP2D6 phenotype, median (IQR). PM poor metabolizer 7.6 (6.6–9.0); IM, intermediate metabolizer 21.5 (13.9–30.2); NM, normal metabolizer 31.5 (22.9–40.3). B Pharmacokinetic profile of endoxifen steady-state concentrations (n = 301) stratified on CYP2D6 activity score (AS) based on their allele combination, median (IQR). PM/PM 7.6 (6.6–9.0), IM/PM 11.2 (9.1–12.4), IM/IM 15.2 (13.3–24.1), NM/PM 26.6 (19.0–32.8), NM/IM 26.6 (19.2–32.8), NM/NM 34.1 (25.6–44.3)
CYP3A4*22 genotyping showed no statistically significant difference in median endoxifen concentrations between CYP3A4*22 carriers CT/TT and wildtype CC (p = 0.31). Nevertheless, a statistically significant difference was found in median tamoxifen concentrations in CYP3A4*22 carriers 386 (296.0–455.8) nmol/L compared to wildtype 303 (242.0–378.0) nmol/L)—indicating carriers had a higher tamoxifen concentration (p < 0.001).
Predictors of blood plasma concentrations
Multiple linear regression was performed to determine statistically significant predictors of endoxifen. To adjust for potential bias due to missing data, MICE was considered and presented as primary analysis. Approximately seven percent of all patients had missing information. The missingness mechanism was assumed to be missing at random (MAR). Given the limited amount of missing data, the number of imputed datasets was chosen to be m = 10 [32, 38]. Adherence to tamoxifen treatment was left out in the primary analysis due to low representation of the study population; adherence was only questioned in the first 145 participants of the trial. However, adherence to tamoxifen treatment was found high in 91% of all participants, and 5% and 4% of those showed medium and low adherence, respectively.
The variable selection procedure across all intermediate MI datasets identified age, weight, BMI, and CYP2D6 as statistically significant predictors. Comedication (CYP2D6/ CYP3A4 inducers or inhibitors), intake with food and CYP3A4*22 genotype were excluded, see Supplementary material (Sect. 5.1) for more details of the selection procedure. Wald statistics were computed to assess significance of variables in our variable selection procedure. Therefore, two nested models including and excluding BMI and intake-time-of-the-day were compared, leading to BMI and intake-time-of-the-day being excluded from the final model, as the Wald-based test statistics were non-significant (p = 0.14; p = 0.56). Pooled parameter estimates from the imputed datasets and accompanying average bootstrap-based 95% CIs of the model parameter estimates and average-based optimism-adjusted R2 values were summarized in Table 2.
Thus, the final model included age, weight, and CYP2D6 genotype to be statistically significant predictors of endoxifen concentration. Altogether, these predictors explained 57% (95% CI 0.49–0.64) of the total inter-individual variability. CYP2D6 genotype accumulated for approximately 54%, whereas in addition age and weight only explained 1.8% and 1.5% of the inter-individual variability, after adjusting for CYP2D6 genotype status, respectively. Complete case analysis identified, similarly, age, weight, and CYP2D6 genotype as statistically significant predictors. However, no meaningful difference was found in parameter estimates and optimism-adjusted R2 values between primary analysis and CCA (Table 3). Details with regard to model selection and diagnostics are presented in the supplementary material (Sect. 5.1 and 5.2).
Predictors of subtherapeutic blood plasma concentration
The extent of missing information in key predictors found by multiple linear regression was approximately 0.6%. Therefore, an imputation model was not considered, and analysis was performed accordingly. Key predictors for subtherapeutic risk of endoxifen (< 16 nmol/L) were age and CYP2D6 genotype. A bootstrap-based area under the curve (AUC) was computed and showed an optimism-adjusted AUC of 90% (95% CI 0.86–0.95; Fig. 3). Considering an optimal cut-off probability of 0.8, sensitivity, and specificity of the model were estimated to be 66% and 98%, respectively. A goodness-of-fit test indicated a good model fit given the Hosmer–Lemeshow test statistic was non-significant (p = 0.28). Parameter estimates by logistic multiple regression model and accompanying bootstrap-based 95% CIs were depicted in Table 4.

Receiver operator curve and area under the curve
Discussion
Our data showed a high inter-individual variability in both tamoxifen and endoxifen concentrations. Age, weight, and CYP2D6 genotype were identified as statistically significant predictors of endoxifen plasma concentrations. Consequently, a large proportion of the variability remains unexplained by the model at hand, suggesting the presence of additional unobserved predictors affecting true patient-specific endoxifen concentrations. By means of logistic regression, ROC analyses showed an optimism-adjusted AUC of 90% (95% CI 0.86–0.95), thereby indicating an excellent predictive accuracy of subtherapeutic endoxifen concentration (< 16 nmol/L) with CYP2D6 genotype and age as statistically significant predictors. However, the model showed a sensitivity and specificity of 66 and 98 percent, respectively, indicating a high probability of (misclassification) error for the patients with subtherapeutic endoxifen concentrations. Consecutively, those patients will have a high false negative rate and thereby potentially misclassified.
The results of this study confirm that CYP2D6 genotype accounts for a large proportion of the variability and has high predictive properties for identifying subtherapeutic endoxifen concentrations. Comparable results were found in estimates and R2 values by colleagues Teft et al. and Schroth et al. explaining 39 to 58 percent of the inter-individual variability in endoxifen concentrations [15, 39]. Additionally, other iso-enzymes of the cytochrome P450 system significantly affects endoxifen formation [16, 19, 26]. Puszkiel et al. investigated the effects of CYP3A4*22, CYP2C19*2, and CYP2B6*6 on endoxifen concentrations. CYP3A4*22 homozygous and heterozygous patients were associated with a 16–25% higher endoxifen concentration compared to wild type, irrespective of CYP2D6 genotype. However, no significant differences were found. CYP2C19*2 and CYP2B6*6 showed only marginal effects on endoxifen concentrations, indicating minimal clinical value [40]. Thus, CYP2D6 is evidently an important factor in predicting endoxifen concentrations.
Age and weight were identified as statistically significant predictors, but only explained an small (1.8 and 1.5) percent of the total variability with small effect sizes after adjusting for CYP2D6 genotype, respectively. Our data implied a positive association between age and endoxifen—which corresponds with other published model-based analyses [25, 41]—yet only explained an additional 1.8 percent of the total inter-individual variability including small effect sizes (0.006; 95% CI 0.003–0.010). Puszkiel and colleagues reported a negative association between age and endoxifen leading to a lower endoxifen exposure if age increased. [37] However, taking into account their substantial sample size (> 900), only approximately 5% of the population was above 65 years old and therefore limits the interpretation in other populations. Consequently, conflicting results regarding the impact of age with either no association, increased endoxifen concentrations or decreased endoxifen concentrations in older patients have been reported [39,40,41].
Weight has been described as a significant predictor for the formation of endoxifen. In the analysis by Mueller-Schoell et al., body weight was found to be negatively correlated with endoxifen concentrations [25]. Additionally, body weight was also in other analyses identified as relevant covariate and a risk factor for subtherapeutic concentrations [9, 40]. Our data also implied a negative association in the multiple linear regression analysis between body weight and endoxifen concentration and only explained an additional ≈ 1.5% of the total variability including small effect sizes (− 0.005; 95% CI − 0.008 to − 0.002). Interestingly, Mueller-Schoell et al. identified participants with high body weight at increased risk of subtherapeutic endoxifen. Up to 13-fold differences in endoxifen concentration were found in heavy young (22 years, 150 kg) and light elderly (95 years, 39 kg). However, analysis was done across extreme values and the risk shrunk after averaging across the population [25]. Additionally, and similarly, after multivariate analysis CYP2D6 genotype, age, and weight were identified as significant predictors. However, the unexplained variability in endoxifen remains high and therefore predictions—as made by various models—may deviate in real life [25, 40, 41].
A strength of this study lies in the statistical analysis. MI was used to minimalize bias by missing data (under the assumption of MAR) and results of both primary analysis and CCA were presented. Additionally, by incorporating MI, the statistical power increased by using the full extent of the dataset. This approach favors CCA as primarily used in the methodologies in other relevant prediction studies. Mixed-effect association methods—used by Mueller-Schoell et al., and Klopp-Schulze et al., to predict endoxifen concentration—may prevent false positive associations and increase power in comparison to multiple regression analysis [25, 41]. Nonetheless, in our model selection procedures across multiple imputed datasets the probability of type-I error is decreased by the application of validated techniques (SM: Sect. 5.1 and 5.2). Moreover, our prediction model performance was quantified relying on a bootstrap approach to reduce model optimism and to function as internal validation of the prediction model thereby providing a more realistic estimate of its performance estimates. The results of the primary analysis and the CCA showed marginal differences. These marginal differences are likely caused by the low proportion of missing data (≈ 7%) in the total dataset and even an even lower proportion of missing data (≈ 1%) amongst the predictors included in the model.
Earlier research showed, fairly extensive use of important inhibitors and inducers in the general ER+ breast cancer population. Primarily, concurrent treatment with CYP2D6 inducers may significant decrease endoxifen concentration and should be monitored, e.g., selective serotonin reuptake inhibitors (SSRI) are known to decrease endoxifen concentration [15, 16, 19]. Therefore, concurrent treatment with, especially, CYP2D6 inhibitors should be monitored and possibly intervened accordingly—to sustain tamoxifen efficacy.
Additionally, 91% of our population showed high adherence to tamoxifen treatment whereas five and four percent of the participants showed medium and low adherence, respectively. Likely, this was an advantage for model building as under these conditions a low proportion of the variability is likely to be attributed by the degree of adherence. However, these results lack external validity as adherence is a major issue in the adjuvant treatment with tamoxifen. Pistilli et al. [18] showed that after one-year the adherence to tamoxifen is 86% based on serum concentration and self-declared adherence (95% CI 84–88%). Nevertheless, real-life adherence estimations range from 15 to 72% non-adherence over 5 years of tamoxifen therapy [20, 21].
Alternatively, the therapeutic drug monitoring (TDM) strategy might be of benefit for this population as pragmatic approach [42]. Personalizing tamoxifen treatment by dose adjustments based on measured steady-state concentration may benefit the population at risk for subtherapeutic endoxifen. Currently, endoxifen concentration is not a validated biomarker for tamoxifen efficacy. Ideally, to demonstrate the clinical benefit of TDM it is desirable to perform a randomized controlled trial. However, the feasibility of such a study is very low given the extreme high number of patients required and the long follow-up period and required endpoints i.e., death and recurrence [43]. On the other hand, positive results of a tamoxifen feasibility study and cost-effectiveness evaluations are encouraging for multidisciplinary discussions about implementation in clinical practice [44]. Klopp-Schulze et al. identified CYP2D6, drug-drug interactions and age as significant predictors of endoxifen. However, and similarly, the unexplained inter-individual variability in endoxifen concentration remained large (47.2%) and therefore they concluded that therapeutic drug monitoring may be a beneficial strategy.
A combination of CYP2D6 predicted phenotype-guided dosing and therapeutic drug monitoring at steady-state concentration was proposed, including Bayesian forecasting to test different doses (off label; > 40 mg tamoxifen once daily) [41]. Our published primary TOTAM data indicating that PMs might benefit with a maximal daily dose of 40 mg as described in the tamoxifen drug label combined with TDM; and IMs might benefit with the standard dose combined with TDM. For NMs 20 mg, once daily tamoxifen might be sufficient without TDM for most of the tamoxifen users [45]. As a result of earlier research, almost all concomitant moderate and strong CYP2D6 inhibitors are included in the medication monitoring system of Dutch pharmacies as a monitoring signal [46]. Hence, minimal use of concomitant CYP2D6 inhibitors was noticed in our population thereby no association between endoxifen concentration and comedication was found likely due lack of statistical power.
In conclusion, the inter-individual variability of endoxifen concentration is largely explained by CYP2D6 genotype and for a small proportion by age and weight. However, small effect sizes accompanied with a high remaining unexplained inter-individual variability were found. Furthermore, our prediction model showed a sensitivity and specificity of 66 and 98%, respectively, thereby indicating that other yet unknown parameters influence endoxifen plasma steady-state concentrations. In other words, this analysis shows that only model-guided tamoxifen dosing is not sufficient in clinical practice for tamoxifen precision dosing. Therefore, we recommend model-guided tamoxifen dosing in combination with therapeutic drug monitoring—by directly measuring endoxifen concentration—as a practical tool to personalize tamoxifen treatment.
References
Sung H, Ferlay J, Siegel RL, Laversanne M, Soerjomataram I, Jemal A (2021) Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin 71(3):209–249
Maximov PY, Lee TM, Jordan VC (2013) The discovery and development of selective estrogen receptor modulators (SERMs) for clinical practice. Curr Clin Pharmacol 8(2):135–155
Jordan VC (2021) 50th Anniversary of the first clinical trial with ICI 46,474 (tamoxifen): then what happened? Endocr Relat Cancer 28(1):R11-30
Early Breast Cancer Trialists’ Collaborative Group (EBCTCG) (2005) Effects of chemotherapy and hormonal therapy for early breast cancer on recurrence and 15-year survival: an overview of the randomised trials. Lancet 365(9472):1687–1717
Early Breast Cancer Trialists’ Collaborative Group (EBCTCG), Davies C, Godwin J, Gray R, Clarke M, Cutter D (2011) Relevance of breast cancer hormone receptors and other factors to the efficacy of adjuvant tamoxifen: patient-level meta-analysis of randomised trials. Lancet 378(9793):771–784
Davies C, Pan H, Godwin J, Gray R, Arriagada R, Raina V (2013) Long-term effects of continuing adjuvant tamoxifen to 10 years versus stopping at 5 years after diagnosis of oestrogen receptor-positive breast cancer: ATLAS, a randomised trial. Lancet 381(9869):805–816
Howlader N, Chen VW, Ries LAG, Loch MM, Lee R, DeSantis C (2014) Overview of breast cancer collaborative stage data items–their definitions, quality, usage, and clinical implications: a review of SEER data for 2004–2010. Cancer 120:3771–3780
Brauch H, Jordan VC (2009) Targeting of tamoxifen to enhance antitumour action for the treatment and prevention of breast cancer: the ‘personalised’ approach? Eur J Cancer 45(13):2274–2283
Madlensky L, Natarajan L, Tchu S, Pu M, Mortimer J, Flatt SW (2011) Tamoxifen metabolite concentrations, CYP2D6 genotype, and breast cancer outcomes. Clin Pharmacol Ther 89(5):718–725
Klein DJ, Thorn CF, Desta Z, Flockhart DA, Altman RB, Klein TE (2013) PharmGKB summary: tamoxifen pathway, pharmacokinetics. Pharmacogenet Genomics 23(11):643–647
Mürdter TE, Schroth W, Bacchus-Gerybadze L, Winter S, Heinkele G, Simon W (2011) Activity levels of tamoxifen metabolites at the estrogen receptor and the impact of genetic polymorphisms of phase I and II enzymes on their concentration levels in plasma. Clin Pharmacol Ther 89(5):708–717
Saladores P, Mürdter T, Eccles D, Chowbay B, Zgheib NK, Winter S (2015) Tamoxifen metabolism predicts drug concentrations and outcome in premenopausal patients with early breast cancer. Pharmacogenomics J 15(1):84–94
Fox P, Balleine RL, Lee C, Gao B, Balakrishnar B, Menzies AM (2016) Dose escalation of tamoxifen in patients with low endoxifen level: evidence for therapeutic drug monitoring-the TADE study. Clin Cancer Res 22(13):3164–3171
Schroth W, Antoniadou L, Fritz P, Schwab M, Muerdter T, Zanger UM (2007) Breast cancer treatment outcome with adjuvant tamoxifen relative to patient CYP2D6 and CYP2C19 genotypes. J Clin Oncol 25(33):5187–5193
Teft WA, Gong IY, Dingle B, Potvin K, Younus J, Vandenberg TA (2013) CYP3A4 and seasonal variation in vitamin D status in addition to CYP2D6 contribute to therapeutic endoxifen level during tamoxifen therapy. Breast Cancer Res Treat 139(1):95–105
Binkhorst L, Mathijssen RHJ, Jager A, van Gelder T (2015) Individualization of tamoxifen therapy: much more than just CYP2D6 genotyping. Cancer Treat Rev 41(3):289–299
Sanchez-Spitman AB, Swen JJ, Dezentje VO, Moes DJ, Gelderblom H, Guchelaar HJ (2019) Clinical pharmacokinetics and pharmacogenetics of tamoxifen and endoxifen. Expert Rev Clin Pharmacol 12(6):523–536
Pistilli B, Paci A, Ferreira AR, Di Meglio A, Poinsignon V, Bardet A (2020) Serum Detection of Nonadherence to Adjuvant Tamoxifen and Breast Cancer Recurrence Risk. J Clin Oncol 38(24):2762–2772
Mulder TAM, de With M, DelRe M, Danesi R, Mathijssen RHJ, van Schaik RHN (2021) Clinical CYP2D6 genotyping to personalize adjuvant tamoxifen treatment in ER-positive breast cancer patients: current status of a controversy. Cancers 13(4):1–9
Murphy CC, Bartholomew LK, Carpentier MY, Bluethmann SM, Vernon SW (2012) Adherence to adjuvant hormonal therapy among breast cancer survivors in clinical practice: a systematic review. Breast Cancer Res Treat 134(2):459–478
Pagani O, Gelber S, Colleoni M, Price KN, Simoncini E (2013) Impact of SERM adherence on treatment effect: International Breast Cancer Study Group Trials 13–93 and 14–93. Breast Cancer Res Treat 142(2):455–459
Puszkiel A, Arellano C, Vachoux C, Evrard A, Le Morvan V, Boyer JC (2019) Factors affecting tamoxifen metabolism in patients with breast cancer: preliminary results of the French PHACS Study. Clin Pharmacol Ther 106(3):585–595
Ximenez JPB, de Andrade JM, Marques MP, Coelho EB, Suarez-Kurtz G, Lanchote VL (2019) Hormonal status affects plasma exposure of tamoxifen and its main metabolites in tamoxifen-treated breast cancer patients. BMC Pharmacol Toxicol 20(Suppl 1):81
Slanař O, Hronová K, Bartošová O, Šíma M (2021) Recent advances in the personalized treatment of estrogen receptor-positive breast cancer with tamoxifen: a focus on pharmacogenomics. Expert Opin Drug Metab Toxicol 17(3):307–321
Mueller-Schoell A, Klopp-Schulze L, Schroth W, Mürdter T, Michelet R, Brauch H (2020) Obesity alters endoxifen plasma levels in young breast cancer patients: a pharmacometric simulation approach. Clin Pharmacol Ther 108(3):661–670
Helland T, Alsomairy S, Lin C, Søiland H, Mellgren G, Hertz DL (2021) Generating a precision endoxifen prediction algorithm to advance personalized tamoxifen treatment in patients with breast cancer. J Pers Med. 11(3):1–9
National Cancer Institute. Common Terminology Criteria for Adverse Events (CTCAE) | Protocol Development | CTEP | Version 5.0. https://ctep.cancer.gov/protocoldevelopment/electronic_applications/ctc.htm#ctc_50
Morisky DE, Ang A, Krousel-Wood M, Ward HJ (2008) Predictive validity of a medication adherence measure in an outpatient setting. J Clin Hypertens Greenwich Conn 10(5):348–354
Binkhorst L, Mathijssen RHJ, Ghobadi Moghaddam-Helmantel IM, de Bruijn P, van Gelder T, Wiemer EAC (2011) Quantification of tamoxifen and three of its phase-I metabolites in human plasma by liquid chromatography/triple-quadrupole mass spectrometry. J Pharm Biomed Anal 56(5):1016–1023
Goetz MP, Sangkuhl K, Guchelaar HJ, Schwab M, Province M, Whirl-Carrillo M (2018) Clinical Pharmacogenetics Implementation Consortium (CPIC) guideline for CYP2D6 and tamoxifen therapy. Clin Pharmacol Ther 103(5):770–777
Rubin TH (1990) Multiple imputation for nonresponse in surveys. Stat Pap 31(1):180–180
van Buuren S. Flexible Imputation of Missing data [Internet]. Second Edition. Chapman & Hall/CRC; 2018. https://stefvanbuuren.name/fimd/
Akaike H (1998) Information theory and an extension of the maximum likelihood principle. In: Parzen E, Tanabe K, Kitagawa G (eds) Redacteuren. Selected papers of Hirotugu Akaike. Springer, New York, pp 199–213
Chowdhury MZI, Turin TC (2020) Variable selection strategies and its importance in clinical prediction modelling. Fam Med Commun Health 8(1):e000262
Wood AM, White IR, Royston P (2008) How should variable selection be performed with multiply imputed data? Stat Med 27(17):3227–3246
Schomaker M, Heumann C (2018) Bootstrap inference when using multiple imputation. Stat Med 37(14):2252–2266
J.P.L. Brand (Jaap), Erasmus MC: University Medical Center Rotterdam, Erasmus MC: University Medical Center Rotterdam. Development, Implementation and Evaluation of Multiple Imputation Strategies for the Statistical Analysis of Incomplete Data Sets. http://hdl.handle.net/1765/19790
Graham JW, Olchowski AE, Gilreath TD (2007) How many imputations are really needed? Some practical clarifications of multiple imputation theory. Prev Sci 8(3):206–213
Schroth W, Winter S, Mürdter T, Schaeffeler E, Eccles D, Eccles B (2017) Improved prediction of endoxifen metabolism by CYP2D6 genotype in breast cancer patients treated with tamoxifen. Front Pharmacol 8:582
Puszkiel A, Arellano C, Vachoux C, Evrard A, Le Morvan V, Boyer JC (2021) Model-based quantification of impact of genetic polymorphisms and co-medications on pharmacokinetics of tamoxifen and six metabolites in breast cancer. Clin Pharmacol Ther 109(5):1244–1255
Klopp-Schulze L, Joerger M, Wicha SG, Ter Heine R, Csajka C, Parra-Guillen ZP (2018) Exploiting pharmacokinetic models of tamoxifen and endoxifen to identify factors causing subtherapeutic concentrations in breast cancer patients. Clin Pharmacokinet 57(2):229–242
Braal L, Jager A, Lommen KM, de Hoop EO, de Bruijn P, Vastbinder MB (2020) 191P Therapeutic drug monitoring of tamoxifen to improve adjuvant treatment of hormone sensitive breast cancer: the TOTAM study. Ann Oncol 31:S319
Braal CL, Beijnen JH, Koolen SLW, Oomen-de Hoop E, Steeghs N, Jager A (2019) Relevance of endoxifen concentrations: absence of evidence is not evidence of absence. J Clin Oncol 37(22):1980–1981
Groenland SL, Verheijen RB, Joerger M, Mathijssen RHJ, Sparreboom A, Beijnen JH (2021) Precision dosing of targeted therapies is ready for prime time. Clin Cancer Res 27(24):6644–6652
Braal CL, Jager A, de Hoop EO, Westenberg JD, Lommen KMWT, de Bruijn P (2022) Therapeutic drug monitoring of endoxifen for tamoxifen precision dosing: feasible in patients with hormone-sensitive breast cancer. Clin Pharmacokinet 61(4):527–537
Binkhorst L, Mathijssen RHJ, van Herk-Sukel MPP, Bannink M, Jager A, Wiemer EAC (2013) Unjustified prescribing of CYP2D6 inhibiting SSRIs in women treated with tamoxifen. Breast Cancer Res Treat 139(3):923–929
Nguyen CD, Carlin JB, Lee KJ (2017) Model checking in multiple imputation: an overview and case study. Emerg Themes Epidemiol 14(1):8
Acknowledgements
None declared.
Funding
This work was supported by an unrestricted MRACE grant [Erasmus MC, the Netherlands (Grant Number 2017-17108)].
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
The study was approved by the local ethics committee (Erasmus MC, Rotterdam Rotterdam; MEC 17-548) and was registered in the Dutch Trial Registry (NL6918).
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Braal, C.L., Westenberg, J.D., Buijs, S.M. et al. Factors affecting inter-individual variability in endoxifen concentrations in patients with breast cancer: results from the prospective TOTAM trial. Breast Cancer Res Treat 195, 65–74 (2022). https://doi.org/10.1007/s10549-022-06643-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10549-022-06643-y