
Abstract
In this work, the performances of two recently developed finite-rate dynamic scale similarity (SS) sub-grid scale (SGS) combustion models (named DB and DC) for non-premixed turbulent combustion are a priori assessed based on three Direct Numerical Simulation (DNS) databases. These numerical experiments feature temporally evolving syngas jet flames with different Reynolds (Re) numbers (2510, 4487 and 9079), experiencing a high level of local extinction. For comparison purposes, the predicting capability of these models is compared with three classical non-dynamic SS models, namely the scale similarity resolved reaction rate model (SSRRRM or A), the scale similarity filtered reaction rate model (SSFRRM or B), and a SS model derived by the “test filtering” approach (C), as well as an existing dynamic version of SSRRRM (DA). Improvements in the prediction of heat release rates using a new dynamic model DC are observed in high Re flame case. By decreasing Re, dynamic procedures produce results roughly similar to their non-dynamic counterparts. In the lowest Re, the dynamic methods lead to higher errors.
Similar content being viewed by others

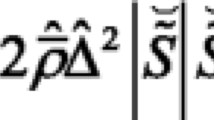
Avoid common mistakes on your manuscript.
1 Introduction
In the governing equations of Large Eddy Simulation (LES) of reactive flows with detailed kinetics, transport equations of the filtered species mass fractions are solved. The equation for k th species, has a filtered production/consumption rate, i.e. \(\overline {\dot {\omega } }_{k}\left (\boldsymbol {\varphi } \right ) \), which needs to be modeled. In \(\overline {\dot {\omega } }_{k}\left (\boldsymbol {\varphi } \right ) \), φ is the composition vector together with the temperature (T) and pressure (p), and \(\overline {(.)} \) a filtering operator in LES. Since the net formation rates of species are non-linear functions of φ,the equality \(\overline {\dot {\omega }}_{k}\left (\boldsymbol {\varphi } \right )=\dot {\omega }(\overline {\boldsymbol {\varphi }}^{f} ) \), which is called the “no model” or “quasi laminar” approach, in many conditions does not hold. In the previous statement, \(\overline {(.)}^{f} \) is a Favre filtering operator defined as \(\overline {\rho (.)}/\overline {\rho }\) with ρ the density. Sub-grid scale (SGS) combustion models try to include the effects of turbulence on chemistry in such a way that \(\overline {\dot {\omega }}_{k}\left (\boldsymbol {\varphi } \right )\) can be computed by using \(\overline {\boldsymbol {\varphi }}^{f}\).
Sub-grid scale (SGS) combustion models may be divided into two main classes [1, 2], namely the flamelet-based and finite-rate combustion models. The assumption of mixed is burnt (in non-premixed flames) leads to the widely used flamelet-based combustion models, treating a turbulent flame as an ensemble of thin laminar flames called flamelets. The consideration of turbulent conditions is achieved by using a probability density function (PDF) of parametrized progress variables, e.g., a conserved scalar like mixture fraction where a presumed form is usually applied. A transport equation for the PDF can also be solved but remains computationally expensive. The main challenges in the flamelet-based models are in the two steps of building the table and accounting for the effects of turbulence-chemistry interactions (TCI) for which a priori knowledge of the flow and the flame behavior is needed. Furthermore, for concurrent non-premixed and premixed combustion regimes, the flamelet approach requires suitable but complex modifications, as reported in [3,4,5].
In contrast to the flamelet-based models, the finite-rate combustion models in LES try to evaluate \(\overline {\dot {\omega } }_{k}\left (\boldsymbol {\varphi } \right )\) as a function of filtered quantities which are available after LES solution. In finite-rate combustion models, which are the focus of the present study, there is no assumption about the flow or flame, but instead, they attempt to model the low-pass filtered net formation rates [1]. Models in this class are the Thickened Flame Model (TFM) [6, 7], the Transported PDF (TPDF) models [8, 9], the Eddy Dissipation Concept (EDC) model [10], the Partially Stirred Reactor (PaSR) model [11, 12], and the Scale Similarity (SS) models [13, 14]. The TFM was developed primarily for turbulent premixed flames. The TPDF models can deal with premixed, non-premixed and multi-regime combustion, but they are reported to be computationally very expensive. The EDC and PaSR, which have been developed for Reynolds Average Naiver Stokes (RANS), are now being extended to LES.
In their general form (i.e., Bardina’s approach [15] for the closure of the SGS stress field), Scale Similarity models are soft deconvolution methods [16, 17], which use low order approximations to reconstruct the exact field based on filtered fields. In Bardina et al. [15] approach, the exact velocity field in the SGS tensor is replaced by its “grid filtered” counterpart. In other words, the SGS stress tensor is replaced by the modified Leonard stress in Germano’s decomposition [18]. Liu et al. [19], based on the decomposition of the velocity field in logarithmic bands, used test filters (filters with larger withds than the grid) instead, in the definition of the modeled SGS stress.Footnote 1 SS models of these types were found to capture well the locations where the contribution of the SGS stress field is high, using a priori assessments (see, e.g. [15]), as well as experimental data analyses (see, e.g. [19]). However, the drawback of the original models was their slight dissipative characters. It is argued that the SS models are actually low order soft deconvolution models and the information which are lost by the inherent grid filter is un-recoverable in LES [17]. So each soft deconvolution model needs a complementary model to handle the lost data. This is the idea behind “mixed models” which take the advantages of both the SS models and the eddy viscosity type models.
In SGS combustion modeling, first, DesJardin and Frankel [13] used the SS idea to model \(\overline {\dot {\omega }}_{k}\left (\boldsymbol {\varphi } \right )\) in LES. They proposed two SS combustion models, namely the scale similarity resolved reaction rate model (SSRRRM), hereafter model A, and the scale similarity filtered reaction rate model (SSFRRM), hereafter model B, which will be presented in detail in Section 3. In their formulations, they were inspired by the original approach proposed by Bardina et al. [15] however, the models also contain complementary parts to account for the lost data. Germano et al. [20] proposed the third model, model C, which will be better explained in Section 3. The three mentioned SS models hereafter will be called non-dynamic SS models. In [21], a comprehensive a priori study of the three mentioned non-dynamic SS models was performed using a DNS database of a temporally evolving jet flame experiencing a high level of local extinction. The analysis was carried out using different filter widths in two instants of extinction and re-ignition. It was observed that the non-dynamic SS models can capture correctly the locations where the SGS combustion effects prevail. In particular, the SS models following Bardina’s “grid filtering” approach (models A and B) were found to have lower errors than the SS model derived according to Germano’s “test filtering” approach (model C).
In the non-dynamic scale similarity formulations, the model coefficient is by default set to one (see e.g., [13, 21, 22]). Jaberi and James [14] extended the non-dynamic model A by proposing a dynamic version. In the dynamic model, hereafter called DA2, the similarity coefficient is evaluated based on Germano’s identity. The model was tested merely using a DNS database of homogeneous isotropic compressible reacting turbulent flow with one step Arrhenius reaction. The results were reported to be in a good agreement with those obtained by the DNS.
From this short review, following inferences can be drawn:
The non-dynamic finite-rate SS SGS combustion models were found to yield good predictions for the direct closure of the filtered species production/consumption and heat release rates [13, 21]. One way to check if the models can be improved is through the dynamic evaluation of the SS coefficients. The first version of Jaberi and James [14] (the dynamic SSRRRM or DA2) was tested in an ideal test case of homogeneous isotropic turbulence with one step reaction. There has been no comprehensive study of the performance of the model in practical combustion regimes like jets with multi-species/multi-reactions.
Of particular interest is the development of dynamic version of model B since the non-dynamic B was found to predict well minor species [21].
Since the dynamic SS models include explicit filtering (sometimes up to 4 stages), which is computationally not easy to implement and also time-consuming in LES, it is important to understand whether the dynamic procedures are effective or not.
The present paper aims therefore at:
developing dynamic versions of finite-rate SS SGS models B and C,
assessing their prediction capability by using 3 DNS databases of complex 3D temporal non-premixed jets in which the flames experience a high level of local extinction. A skeletal mechanism (similar to the reference DNS) with 11 species and 21 reactions [23] is used in the current study, which made possible the direct assessment of the models in prediction of the filtered source terms of major species as well as radicals.
For comparison purposes, three classical non-dynamic finite-rate SS SGS combustion models are selected: the two proposed in [13] (i.e. SSRRRM and SSFRRM) and the one developed based on Germano’s test filtering approach [20, 21]. In particular, the effect of Reynolds number (changing the normalized filter width) on the performance of the models is studied. This is done by using three DNS databases with similar configurations and different initial jet Reynolds numbers.
The paper is organized as follows. The DNS databases are introduced in the next section. The non-dynamic SS SGS finite-rate combustion models are presented in Section 3, followed by a detailed derivation of new dynamic models. The comparison metrics used in the current study are introduced in Section 4 and an a priori DNS assessment is carried out in Section 5. Finally, conclusions will be drawn in the last section.
2 A priori Analysis and the DNS Databases
DNS databases of reactive flows with relatively detailed chemistry, which are now available thanks to massively large parallel computational resources, can be utilized to assess combustion models for LES of reactive flows. The two main ways of DNS data utilization are through a priori and a posteriori tests [24]. In this work, an a priori analysis is adopted by comparing “modeled” targets (i.e., filtered combustion and heat release rates) with the “exact” filtered ones from DNS databases. Modeled targets make use of directly filtered quantities from DNS databases. The main drawback in a priori analyses is their inability to predict the time properties of sub-grid closures [25]. It is not guaranteed that if a model performs well in a priori analyses it will also perform well in a real LES. The opposite is also possible, this means that some models may fail in a priori DNS analyses while in LES giving acceptable results (see, e.g. [26]). On the other hand, the advantage of a priori analyses is that target models can be assessed in an isolated system, to a good extent, free from errors or uncertainties caused by other models. In a special case of SGS combustion modeling, uncertainties regarding applied turbulence models are skipped and one can focus directly on the performance of a combustion model itself. If a model is considered as a system with inputs and outputs, it is of interest to study the outputs while the inputs are free from errors. Considering a relatively small computational time required for the a priori analysis, it is a very good choice for comparing the models’ performance. Many previous studies have been performed a priori analyses to study the performance of SGS combustion models [27,28,29,30,31,32]. Scale Similarity combustion models have been a priori tested in a 2D DNS/LES of a spatial jet [13] and a 3D DNS/LES of isotropic decaying reactive flow [14], both using small LES grid filters \({\overline {\Delta }}\) (\({\overline {\Delta }}=3{\Delta }_{\text {DNS}}\) in [13] and \({\overline {\Delta }}=4{\Delta }_{\text {DNS}}\) in [14]) and also a single step chemistry. In the present study, SS models (will be introduced in the next Section) are tested using a larger filter width of \({\overline {\Delta }}=12{\Delta }_{\text {DNS}}\) and also in challenging test flames experiencing a high level of local extinction.
The DNS databases used in the current study are DNS of temporal evolution of syngas non-premixed jets [23]. Three flames (L, M, and H cases) with different initial Reynolds numbers are selected. Reynolds number is defined as Re = UH/νfuel, with H the initial fuel jet width, U the difference between fuel (CO/H2) and oxidizer (O2/N2) streams velocities and νfuel the kinematic viscosity of fuel stream [23]. Initially, the fuel and the oxidizer jet streams have equal stream-wise velocities, but in the opposite directions. In Table 1, the three DNS databases are introduced in detail. These flames experience first extinction up to about 20tj and then re-ignition, where tj is the “transient jet time”, computed as tj = H/U = 5μs [23] in all the three cases. In Fig. 1a, the maximum of Favre averaged temperature (\(\underline {T}_{f}\)) is plotted versus the normalized simulation time for the three cases considered in this study. In the paper, Reynolds averaged quantities are denoted by \(\underline {(.)}\), while Favre averaged quantities are defined as \(\underline {\rho (.)}/\underline {\rho }\) and denoted by \(\underline {(.)}_{f}\). The transient extinction/re-ignition phenomenon is clearly observed in Fig. 1a. The vertical red line is approximately the time instant with maximum local extinction in the three flames which is selected to be analyzed in the current work. In Fig. 1b, c and d, the Favre average Kolmogorov, Taylor and integral length scales are depicted, respectively, for the three DNS databases. The spacial averages are calculated using the data on statistically homogeneous planes (Oxz planes) at different crosswise (Oy) heights. On these plots the data are confined to Oxz planes on which the Favre averaged mixture fraction is above 0.02. Different length scales are defined using the DNS databases. The Favre averaged Kolmogorov length scale, \(\underline {\eta }_{f}\) is defined as:
where \(\underline {\nu }_{f}\) is the Favre averaged kinematic viscosity, viz. \(\underline {\nu }_{f}={\underline {\mu }}/{\underline {\rho }}\) and \(\underline {\varepsilon }_{f}\) the Favre averaged turbulence dissipation rate. \(\underline {\varepsilon }_{f}\) is defined as:
with \(u^{\prime \prime }_{i}\) the Favre fluctuation of velocity, viz. \(u^{\prime \prime }_{i} \equiv u_{i}-\underline {u_{i}}_{f}\) and \(\tau _{ij}^{\prime }\) the fluctuation of viscous stress tensor, viz. \(\tau _{ij}^{\prime } \equiv \tau _{ij}-\underline {\tau _{ij}} \). The viscous stress tensor is defined as:
with Sij the strain-rate tensor, viz. \(S_{ij}\equiv \frac {1}{2}\left (\frac {\partial {u_{i}}}{\partial {x_{j}}}+\frac {\partial {u_{j}}}{\partial {x_{i}}} \right )\), Δv = Sii the flow dilatation and δij the Kronecker delta. The Taylor length scale is defined as:
with \(u_{int}\equiv \sqrt {\frac {1}{3}\underline {u^{\prime \prime }_{i} u^{\prime \prime }_{i}}_{f}}=\sqrt {\frac {2}{3}\underline {k}_{f}}\). The integral length scale is defined as:

Favre averaged statistics of the three DNS databases, a maximum of Favre averaged temperature during the simulation, b Kolmogorov’s length scale, c Taylor’s length scale, d the integral length scale. The vertical red dashed line in a is the time instant of maximum local extinction which is used in the current study, i.e. t = 20tj. The other three figures show the statistics at this time instant
Comparing the scales in Fig. 1b, c and d and the filter size from Table 1, one can conclude that the filter size is about the Taylor length scale. Based on Fig. 1, the \({\Delta }/\underline {\lambda }_{f}\) increases from the low Re case (L) to the high Re case (H). In [33], an a posteriori analysis carried out using the DNS databases L and H. They chose \({\overline {\Delta }=8{\Delta }_{DNS}}\). In [34] they did LES of the H case and used two filter sizes of \({\overline {\Delta }=8{\Delta }_{\text {DNS}}}\) and \({\overline {\Delta }=16{\Delta }_{\text {DNS}}}\). In [35], they studied LES-LEM of the M case DNS, using non-uniform grids with the minimum resolutions of \(5\underline {\eta }_{f}\) and \(2.5\underline {\eta }_{f}\), translating these to our notations gives Δ ≈ 5ΔDNS and Δ ≈ 2.5ΔDNS, respectively. In [21], the turbulent kinetic energy (TKE) spectrum of the H case DNS was constructed at the mid plane of the jet at the same time instant used in this study. The locations of the spectral cutoff filters with the same filter width as top-hat kernels are shown on a log-log diagram of the compensated energy spectrum for \({\overline {\Delta }=8,12,18{\Delta }_{\text {DNS}}}\). The location of the cut off filters found to lie in the inertial range, although the range is very narrow because the Re of the DNS cases is not high. Also, the fraction of the resolved Favre mean turbulent kinetic energy was depicted using the mentioned filter widths. It was observed that using \({\overline {\Delta }/{\Delta }_{\text {DNS}}=8}\), more than 80% of the TKE is resolved. This fraction is reduced by increasing the filter width to 70% for Δ/ΔDNS = 12 and 60% for \({\overline {\Delta }/{\Delta }_{\text {DNS}}=18}\). With this brief review, \({\overline {\Delta }/{\Delta }_{DNS}=12}\) seems to be a proper choice for the current study. The filter width is also suitable for the future a posteriori analyses. The chemical kinetic mechanism is the same as the one used in the DNS and has 11 species and 21 elementary reactions [23]. The computational domain of the DNS is a box with lengths 12H × 14H × 8H in Ox (stream-wise), Oy (transverse), and Oz (span-wise) directions, respectively. The DNS mesh is a uniform grid with the size of ΔDNS which is mentioned in Table 1. Periodic boundary conditions are used in Ox and Oz directions so that the flame is statistically 1D and Oxz planes at each Oy location can be considered as the statistically homogeneous planes to extract the statistical first and second moments.
3 Scale Similarity Closures for Reactive Flows
3.1 Non-dynamic finite-rate scale similarity SGS combustion models
The first non-dynamic scale similarity model for \(\overline {\dot {\omega } }_{k}\left (\boldsymbol {\varphi } \right )\), originally called SSRRRM (hereafter denoted as model A), was proposed by Desjardin and Frankel [13]. According to that model:

where \(C_{A}^{\overline {\Delta }}\) is a coefficient to be evaluated dynamically according to the approach described in Section 3.2 and set equal to 1 in the case of the non-dynamic approach. \({{}}_{{\dot {\omega }}^{A}}\) is the residual field representing the SGS effects. If one filters Eq. 6 and uses the same decomposition for the residual field as in Eq. 6, it ends in Eq. 7 for the residual field in the first filtering level. As it can be seen, a “double Favre filtered” field  is introduced.Footnote 2 The way to compute this type of fields using explicit filters and OpenSMOKE++ open source library [36] has been explained in [21] and also in detail in Appendix A. Note that \(\overline {(.)}\) (thin bar) and
is introduced.Footnote 2 The way to compute this type of fields using explicit filters and OpenSMOKE++ open source library [36] has been explained in [21] and also in detail in Appendix A. Note that \(\overline {(.)}\) (thin bar) and  (thick bar) are virtually the same filters with the same filter widths, however, since the numerical implementations are different, different notations have been used (see Appendix A for more details).
(thick bar) are virtually the same filters with the same filter widths, however, since the numerical implementations are different, different notations have been used (see Appendix A for more details).
The second model, originally called SSFRRM [13] and hereafter denoted as model B, uses the filtered formation rate of filtered fields instead of resolved ones in the first decomposition step, which results in Eq. 8:

where \(C_{B}^{\overline {\Delta }}\) is the coefficient of similarity which is set to 1 for model B, to be evaluated dynamically in model DB which will be introduced in Section 3.2. The same procedure previously described is carried out to find an expression for the residual field \({{}}_{{\dot {\omega }}^{B}}\), which ends in Eq. 9:

Liu et al. [19] proposed to use a filter (say \(\widehat {{\Delta }}\)) larger than the grid filter in the similarity model formulation for the SGS stress field. By the extension of this idea to the formation rates of species, a non-dynamic model C is introduced:
where \(\widehat {{\Delta }}=2\overline {{\Delta }}\) in this study. The non-dynamic similarity coefficient (\(C_{C}^{\overline {\Delta }}\)) is set equal to 1 and will be evaluated dynamically for model DC in Section 3.2.
3.2 Dynamic finite-rate scale similarity SGS combustion models
To derive the dynamic versions of the previous models, the generalized Germano identity [37] can be used. A non-linear operator \(\mathcal {N}(\boldsymbol {\varphi })\) is defined, where in general \(\mathcal {N}(\boldsymbol {\varphi }) \neq \mathcal {N}(\overline {\boldsymbol {\varphi }})\). The difference between these two is the contribution of the sub-grid scales [38]. One may try to write the difference in additive form i.e., \(\overline {\mathcal {N}}(\boldsymbol {\varphi }) ={\mathcal {N}}(\overline {\boldsymbol {\varphi }})+{}_{F}\), where the “model” \({}_{F}\) can be of any type and the subscript F is used to remark that the model is defined at the F filter level, \(\overline {(.)}\), with cutoff \(\overline {{\Delta }}\). A second filter called “test filter”, at G level, with cutoff larger than F level, i.e. \(\widehat {{\Delta }}>\overline {{\Delta }}\), is introduced, which is denoted by \(\widehat {(.)}\). If one filters the non-linear operator using the test filter, the operator at the FG level is derived, i.e., \(\widehat {\overline {\mathcal {N}}}(\boldsymbol {\varphi }) =\widehat {\mathcal {N}}(\overline {\boldsymbol {\varphi }})+\widehat {{}_{F}}\). On the other hand, the non-linear operator can be directly defined at the FG level, i.e., \(\widehat {\overline {\mathcal {N}}}(\boldsymbol {\varphi }) ={\mathcal {N}}(\widehat {\overline {\boldsymbol {\varphi }}})+{}_{FG}\). The generalized Germano identity is defined by equating the two expressions of \(\mathcal {N}(\boldsymbol {\varphi }) \) at the FG level, i.e., \(\widehat {\mathcal {N}}(\overline {\boldsymbol {\varphi }})+\widehat {{}_{F}}={\mathcal {N}}(\widehat {\overline {\boldsymbol {\varphi }}})+{}_{FG} \) [38]. The identity can be used to evaluate the coefficients in the “model” part of the filtered operator. Here it should be noted that \({}_{FG}\) is by definition the scale similarity model defined at the FG level [39]. Some authors proposed to use the information at the F level instead of FG level to reduce model complexity [14, 40]. Below, this will be further investigated.
In the context of scale similarity models in reactive flows, \( \mathcal {N}(\boldsymbol {\varphi } )=\dot {\omega }(\boldsymbol {\varphi }) \) and \({}_{F}=C{}_{\dot {\omega }} \) defined above. Replacing the definitions in the generalized Germano identity, dynamic models will be derived.
3.2.1 DA: Dynamic formulation of SSRRRM (model A)
The dynamic version of model A will be named DA and categorized with respect to the filtering level to be used. So, DA1 will refer to the use of FG level while DA2 to the F level. To derive \(\dot {\omega }^{DA1}\), we start from writing the Germano identity explained above:

In Eq. 12, the second term on the left hand side is the residual field filtered using the test filter (\({\widehat {{}}}_{{\dot {\omega }}^{A}}\)) and the second term on the right hand side is the scale similarity model A defined at the FG level (ΛA1). The coefficient in each level is also marked by the corresponding filter width. It should be mentioned that \(C^{\overline {{{\Delta } }}}_{DA1}\) is actually \(\widehat {C}^{\overline {{{\Delta } }}}_{DA1}\) so in Eq. 12 and also all the following applications of Germano’s identity it is implicitly assumed that \( C^{\overline {{{\Delta } }}} = \widehat {C}^{\overline {{{\Delta } }}}\). The effect of this simplification might be quite strong and it can be a topic of the future studies. Rearranging Eq. 12 leads to:

which can be written in a compact form as:
where ΥA is the resolved covariance:
and \({\mathcal {X}}_{A1}\) is

Thus:
It should be mentioned that in Eq. 16, ΛA1 is a similarity closure for FG level based on the fields defined at FG level. This is the mathematically consistent formulation suggested by Vreman [39] in computations of SGS stress fields using SS models. In this paper, it is applied to non-linear chemical formation rates to see its effects.
To derive \(\dot {\omega }^{DA2}\), one needs to define the similarity model in Eq. 13 at the FG level using the fields at F level. It is inspired by the work of Zang et. al. [40] for SGS stress field. It reads:

which again in a compact form reads:
where

Thus:
As it can be seen, the difference between \({\overline {\dot {\omega }}}^{DA1}\) and \({\overline {\dot {\omega }}}^{DA2}\) models is only in the definition of ΛA in \({\mathcal {X}}_{A}\). Using scale invariance assumption between F level and FG level, i.e. \(C^{\widehat {{\Delta } }}=C^{\overline {{\Delta } }}\), \({\mathcal {X}}_{A1}\) is simplified to:

and \({\mathcal {X}}_{A2}\) is simplified to:

which is the model derived by Jaberi and James [14]. Some issues exist in numerical implementation of \({\mathcal {X}}_{A1}\) in a consistent manner proposed in [19]. Indeed, \({\overline {\boldsymbol {\varphi }}}^{f}\) is computed based on DNS field, i.e., φ is defined on a fine DNS grid and should be sampled on a coarse grid of mesh size \(\overline {{\Delta } }=N{{\Delta } }_{DNS}\), where N is an integer defining the filter width. Further, \({\widehat {\overline {\boldsymbol {\varphi }}}}^{f}\) should be computed based solely on the \({\overline {\boldsymbol {\varphi }}}^{f}\) field and then sampled on a coarser grid of mesh size \(\widehat {{\Delta } }=2N{{\Delta } }_{DNS}\). Now the problem is in the evaluation of terms  or
or  which again (after two consecutive filtering at F and G level) needs filtering on F level, which is not possible for the data defined on grid points of mesh \(\widehat {{\Delta } }=2N{{\Delta } }_{DNS}\). To remedy this, one has two options: i) to write the similarity model (ΛA) using the fields at the F level instead of FG level (by doing this, \({\mathcal {X}}_{A2}\) will be recovered); ii) to skip the sampling step after evaluation of \({\widehat {\overline {\boldsymbol {\varphi }}}}^{f}\), which means that both \({\widehat {\overline {\boldsymbol {\varphi }}}}^{f}\) and \({\overline {\boldsymbol {\varphi }}}^{f}\) will be defined on a grid with mesh size \(\overline {{\Delta } }=N{{\Delta } }_{DNS}\).
which again (after two consecutive filtering at F and G level) needs filtering on F level, which is not possible for the data defined on grid points of mesh \(\widehat {{\Delta } }=2N{{\Delta } }_{DNS}\). To remedy this, one has two options: i) to write the similarity model (ΛA) using the fields at the F level instead of FG level (by doing this, \({\mathcal {X}}_{A2}\) will be recovered); ii) to skip the sampling step after evaluation of \({\widehat {\overline {\boldsymbol {\varphi }}}}^{f}\), which means that both \({\widehat {\overline {\boldsymbol {\varphi }}}}^{f}\) and \({\overline {\boldsymbol {\varphi }}}^{f}\) will be defined on a grid with mesh size \(\overline {{\Delta } }=N{{\Delta } }_{DNS}\).
3.2.2 DB: Dynamic formulation of SSFRRM (model B)
Following similar notations as in Section 3.2.1, models of type DB1 and DB2 will be obtained. Relying on Eq. 13 one can obtain:

which can be written in a compact form as:
where ΥB is

and \({\mathcal {X}}_{B1}\) is

Thus:

Again, if one evaluates the similarity model at the FG level (the first term on the right hand side of Eq. 24) using fields at F level, it results in the fourth dynamic similarity model which reads:

which again in a compact form reads:
where:

Thus:

Using scale invariance assumption between F level and FG level i.e., \(C^{\widehat {{\Delta } }}=C^{\overline {{\Delta } }}\), \({\mathcal {X}}_{B1}\) is simplified to:

and \({\mathcal {X}}_{B2}\) is simplified to:

3.2.3 DC: Dynamic formulation of model C
The same procedure can be used to evaluate the similarity coefficient of model C dynamically. Following [41] and writing the Germano identity for the two filter levels for model C, one finds:
where \(\overbrace {(.)}\) represents a spatial filter at scale \(4{\overline {\Delta }} \). In a compact form:
where ΥC and \({\mathcal {X}}_{C1}\) are:
It should be emphasized that ΥC = ΥA for two models A and C. This is because both models decompose the non-linear term \(\overline {\mathcal {N}}\left (\boldsymbol {\varphi }\right )\) in a similar way i.e. \(\overline {\mathcal {N}}\left (\boldsymbol {\varphi }\right )=\mathcal {N}\left (\overline {\boldsymbol {\varphi }}\right )+{}_{F}\). The difference between the models comes from the way they treat the residual field i.e. \({}_{F}\).
Using the scale invariance assumption between F level and FG level, i.e., \(C^{\widehat {{\Delta } }}=C^{\overline {{\Delta } }}\), \({\mathcal {X}}_{C1}\) is:
Again, if the fields at the F level are used to evaluate ΛC1, the second dynamic version of model C is derived as below:
Thus:
In all models above \(C^{\overline {{\Delta } }}_{DA1}\), \(C^{\overline {{\Delta } }}_{DA2}\), \(C^{\overline {{\Delta } }}_{DB1}\), \(C^{\overline {{\Delta } }}_{DB2}\), \(C^{\overline {{\Delta } }}_{DC1}\), and \(C^{\overline {{\Delta } }}_{DC2}\) (in compact form \(C^{\overline {{\Delta } }}_{Dij}\), where i is A, B or C and j is 1 or 2) are evaluated using the least square method to minimize the error of scale similarity assumption at the FG level as below (no summation over repeated indexes):
where, as mentioned before, \(\underline {(.)}\) is the averaging operator which can be over Oxz planes with Ox and Oz the homogeneous directions in the case considered. This will give only one value of the coefficient on each statistically homogeneous plane. Since Eqs. 15, 19, 25, 30, 36 and 41 are scalar equations, alternatively one can directly solve for the dynamic similarity coefficients, i.e. \(C^{\overline {{\Delta } }}_{Dij}={{\Upsilon }}_{\mathrm {i}}/{\mathcal {X}}_{ij}\ \)locally at each grid point or to evaluate the coefficients in an average form \(C^{\overline {{\Delta } }}_{Dij}=\underline {{{\Upsilon }}_{i}}/\underline { {\mathcal {X}}_{ij}} \) in statistically homogeneous directions (e.g. time or space coordinates). However, the results obtained by these two alternatives (not reported here) shows large oscillations which deteriorates the final results even in average. The best results are obtained by least square error minimization (42) and only this method has been exploited in the results shown in the next section. The summary of the models used in the current study is presented in Table 2.
4 Metrics for Statistical Analysis
The first and the second moments of quantities will be used as the first metric to compare the modeled and the exact fields by the DNS data. As mentioned before, since two homogeneous stream-wise (Ox) and span-wise (Oz) directions exist, the first moment is defined as the planar average (on Oxz planes) at different crosswise (Oy) heights. The spatial average is denoted by \(\underline {(.)}\). The second moment is the “RMS” and is computed for an arbitrary quantity “q” using:
Spatial averages suffer from error cancellation, to better compare the models, the Root Mean Square Error (RMSE) is used:
This metric provides one of the most stringent tests, since local point-wise errors can be made even if the exact field obtained by DNS and the modeled data have similar means and PDFs [42]. Beside the filtered combustion rates, another important quantity is the filtered heat release rate in the filtered energy equation which reads:
where \({\Delta } {h_{k}^{0}}\) is the enthalpy of formation of species k. In this work, the conditional means (conditioned on the mixture fraction) of heat release rate computed using different models are compared with the exact filtered heat release rates from DNS databases. The conditional means are computed by the conditional Probability Density Functions (PDFs). Moreover, extended conditional statistics, conditioned on species mass fraction and temperature, as well as scatter plots have been studied but the results are only provided in the supplementary plots (see Online Resource 1).
5 Results and Discussions
5.1 Performance of different variants of dynamic models
As stated before, there are two procedures to dynamically compute the similarity coefficients of models A, B and C. The two procedures explained in Section 3.2 result in two version of dynamic models for each SS model, namely models DA1 and DA2 for model A, models DB1 and DB2 for model B, and models DC1 and DC2 for model C. In Fig. 2 the mean and RMS of specie H2O is depicted along with their relative errors compared to the exact filtered DNS for two versions of model A at t = 20tj for the high Reynolds number (H) case using a filter with \({\overline {\Delta }} =12{{\Delta } }_{DNS}\). The horizontal axis is the distance of statistically homogeneous planes, used to compute mean and RMS, from the center of the jet (Oy= 0). As it can be clearly seen in Fig. 2c and d, the error remains almost similar for both models in the shear layers. However, the error of model DA1 is much higher than model DA2 in the core of the jet (the region between two vertical blue lines) and outside of the jet (the regions with distance more than 2 mm from the center of the jet). The same behavior is observed for all the species in the mechanism and for the purpose of brevity only the results for H2O is shown. Moreover, DB1 and DB2 show similar results. However, for model C it is found that DC1 produce better results. The plots can be found in Online Resource 1.

Case H, at t = 20tj using \({\overline {\Delta }}\)/ΔDNS= 12: comparison of dynamic models DA1 and DA2 performance with exact filtered \({\dot {\omega }}_{\mathrm {H}_{\mathrm {2}}\mathrm {O}}\) extracted from DNS database. a mean, b RMS, c relative error of mean profiles and d relative error of RMS profiles. The vertical blue lines are the location of the planes of maximum mean turbulent kinetic energy (TKE). Vertical green lines represent the plane of mean stoichiometric mixture fraction, while the vertical red lines show the planes in which the maximum mean fluctuations of density occurs
It is also useful to look at the mean local errors in predictions using two versions of dynamic models. The RMSE is plotted in Fig. 3. As it can be seen, the RMSE of models DA1 in Fig. 3a and DB1 in Fig. 3b is higher than models DA2 and DB2 respectively. However, model DC1 has lower locally incurred error than model DC2. The behavior of two dynamic versions of models A, B and C is the same for all the species and cases studied in the present work. So in the following only the results of dynamic models DB2, DA2 and DC1 will be presented.

Case H, at t = 20tj using \({\overline {\Delta }}\)/ΔDNS= 12: comparison of dynamic models performance using RMSE metric in predicting locally exact filtered \({\dot {\omega }}_{\mathrm {H}_{\mathrm {2}\mathrm {O}}}\) extracted from DNS database. a DA1 and DA2, b DB1 and DB2 and c DC1 and DC2 dynamic scale similarity models
5.2 Comparison of different SS SGS combustion models for flows with different Re
In this section, the data of three flames at t = 20tj with different Reynolds numbers are used to assess the performance of dynamic and non-dynamic scale similarity models introduced in Table 2 to model filtered production/consumption rate of species. As mentioned before, increasing Reynolds number from case L to H is equivalent to the increase of \({\overline {\Delta }}/\underline {\lambda }_{f}\). The analysis is a priori testing of models using filter width \({\overline {\Delta }}/{\Delta }_{\text {DNS}}\)= 12. The time instant for case H and M is when the flame experiences maximum local extinction and for case L is close to it (as also shown in Fig. 1a). The flames at this time instant are in the fully turbulent, self-similar regime [43]. H2 (fuel) is selected as major specie, whereas O and OH are selected to assess the performance of models in prediction of radicals net production rates. The results for other species are presented in Online Resource 1. Different metrics have been used to compare the performances of different SS models. These include the point-wise metrics together with conditional means in composition space. The data were confined to a region where \({\underline {Z}}_{f}\ge 0.02\), with \({\underline {Z}}_{f}\) being the Favre mean mixture fraction. The “quasi laminar” or “no model” approach is also used as the base model. In the “no model” approach, SGS effects are neglected and \({\dot {\omega }}^{noModel}\left (\boldsymbol {\varphi }\right )=\dot {\omega }({\overline {\boldsymbol {\varphi }}}^{f})\).
In Fig. 4, the RMSE in the prediction of filtered \({\dot {\omega }}_{\mathrm {H_{2}}}\) (fuel) in the three DNS cases (cases L, M, and H) is depicted. As it can be seen, the local error of all models decreases with increasing the Reynolds number (increasing \({\overline {\Delta }}/\underline {\lambda }_{f}\)). This is consistent with observations in scatter plots (see Online Resource 1). This shows that similarity models are more effective in high Reynolds numbers (higher \({\overline {\Delta }}/\underline {\lambda }_{f}\)).

Comparison of dynamic and non-dynamic models performance using RMSE metric in predicting locally exact filtered \({\dot {\omega }}_{\mathrm {H_{2}}}\) extracted from DNS database at t = 20tj using \({\overline {\Delta }}\)/ΔDNS= 12. a case L, b case M and c case H
Regarding model A, the error of its dynamic version becomes comparable to its non-dynamic version by increasing Reynolds number (increasing \({\overline {\Delta }}/\underline {\lambda }_{f}\)), especially in the core of the jet. It is seen that in some locations DA2 produces larger mean local errors. Moreover, the error of DA2 is comparable to the “no model” approach in low and medium Reynolds numbers. The results show that the dynamic version of model A has no advantage over its non-dynamic version for these test cases.
Regarding model B, the performance of DB2 is worse than non-dynamic model B, especially in low and medium Reynolds number. The error of model DB2 is even higher than the “no model” approach, while non-dynamic model B has lower error than the “no model” approach in the shear layers. In the core of the jet, both models DB2 and B show large errors, higher than the “no model” approach. Again, the results show that the dynamic version of model B has no advantage over its non-dynamic version.
Regarding model C, in the low and medium Reynolds numbers, the SS models C and DC1, produce large local errors. However, in the high Reynolds number case (Fig. 4c) the error of model DC1 becomes comparatively low. This shows that using Germano’s test filtering approach in derivation of SS model C is more suitable for high Reynolds numbers.
Finally, as it can be seen for the fuel (H2) net production rate, regardless of the Reynolds number, the non-dynamic model A has the lowest locally incurred error among all tested models. All dynamic models (except model DC1 in high Reynolds case H) locally produce larger errors than their non-dynamic counterparts. The same behavior is observed for H2O (product). The analysis is also carried out for CO2. The comparisons are extensively reported in Online Resource 1. In summary, in agreement with what observed for H2 and H2O, there is no major improvement observed by applying dynamic versions of the three similarity models studied in this paper. Furthermore, among all the models, the non-dynamic model A has the lowest mean of locally incurred errors among all the models studied. The same behavior is observed for CO (fuel) and O2 (oxidizer).
The performance of the dynamic and non-dynamic SS models in the prediction of the production/consumption rates of radicals is summarized in Fig. 5 where the RMSEs in the prediction of filtered \({\dot {\omega }}_{\mathrm {O}}\) and \({\dot {\omega }}_{\text {OH}}\) are shown. Regarding model A, its dynamic version, i.e. DA2, has always larger errors than A. The error of model A is always lower than the “no model” approach, while DA2 in the low Reynolds case shows similar error to the “no model” approach. The behavior is similar to what is observed for major species. Regarding model B, the error is always lower than its dynamic version, DB2. This is the same as what already observed for major species. Similar to the previous results, the performance of both C and DC1 are better in the high Reynolds number case (Fig. 5e) compared to the low and medium Reynolds number cases. A difference between the performance of SS models for radicals and major species is observed for model B. It is observed that model B has the lowest error among all models for radicals (Fig. 5). This behavior was reported in [21] for case H using different filter widths. In the current analysis it is observed that the behavior is the same in cases L and M. This is the same for other radicals not shown here for the purpose of brevity and can be found in Online Resource 1. It is interesting to see that, compared to Fig. 4, the error of B and DB2 remains low in the core of the jet.

Comparison of dynamic and non-dynamic models performance using RMSE metric in predicting locally exact filtered \({\dot {\omega }}_{\mathrm {O}}\) (left) and \({\dot {\omega }}_{\text {OH}}\) (right) extracted from DNS database at t = 20tj using \({\overline {\Delta }}\)/ΔDNS= 12 for case L (top), case M (middle), case H (bottom). Legends are the same as in Fig. 4
To sum up, the error of DC1 decreases by increasing the Re. In case H (the highest Re in the three cases), for some major species, the error becomes lower than non-dynamic model C. It is interesting to see that in the flame regions (the regions between vertical blue and red lines in the plots) DC1 produces less local errors for medium and high Re cases almost for all species (see Figs. 4 and 5). DB2 shows local errors higher than (for radicals) or at most equal (for major species) to model B. This can be due to four filtering levels in the mathematical formulation of DB2; little information is remained to be used for the prediction of the true coefficient (see Eq. 33). Similar to DC1, the mean local error of DA2 decreases by increasing the Re, however, unlike DC1, here the local errors approaches to those of model A.
The scatter plots (see Online Resource 1), comparing the modeled source terms for different species plotted versus the exact filtered source terms from the three DNS databases, also show the same results. By increasing the Re, improvements can be observed. The improvement is more pronounced in major species than radicals (see Online Resource 1.). In most species, between a non-dynamic model and its non-dynamic counterpart, except for model C, no visible improvement was observed. For major species the correlation coefficients are already high. However, for radicals it seems that non of the models perform well when looking at the scatter plots.
In Fig. 6, the conditional means of H2 and H conditioned on the mixture fraction are plotted. The results for other species can be found in Online Resource 1. The failure of the “no model” approach is obvious for H radical.

Comparison of dynamic and non-dynamic models performances in predicting conditional mean filtered source terms of H2[kg/m3/s] (left), and H (right), conditioned on the mixture fraction at t = 20tj using \({\overline {\Delta }}\)/ΔDNS = 12. (Top:) case L, (Middle:) case M and (Bottom:) case H
In Fig. 7, the conditional mean of O2 (conditioned on the mass fraction of O2 ) and O (conditioned on the temperature) are plotted. The results for other species can be found in Online Resource 1. It should be mentioned that since the flames are in extinction mode, the lack of data was observed in high temperatures. So the last bins of the joint histograms were omitted in the final plots of conditional means. The improvements compared to the “no model” approach can be observed. Moreover, all models can capture the trends in the composition space, especially in higher Reynolds cases M and H.

Comparison of dynamic and non-dynamic models performances in predicting conditional mean filtered source terms [kg/m3/s] of O2 conditioned on the mass fraction of O2 (left), and conditional mean filtered source terms of O conditioned on the temperature [K] (right), at t = 20tj using \({\overline {\Delta }}\)/ΔDNS= 12 for case L (top), case M (middle), and case H (bottom)
In Fig. 8, the conditional mean heat release rates (conditioned on the mixture fraction) are plotted and compared with the exact filtered values from the DNS databases. Since the heat release rate contains the contribution of all species production rates (see Eq. 45), this is a good measure for the overall effect of SGS combustion models. It is clearly seen that the “no model” approach overpredicts the heat release rates. On the other hand, the SS models A and B improved the results in the whole composition space. It is observed that C and its dynamic version DC1, have a high error in the low Reynolds number case (Fig. 8a); by increasing the Reynolds number the error of both becomes lower. Further, it is seen that for the medium and high Reynolds number cases (Fig. 8a and b) the results of C are improved by using the dynamic coefficient. This is not the case for the other two models. Model DB2 has a higher error than B and DA2 produces almost similar results compared to its non-dynamic version A.

Comparison of dynamic and non-dynamic models performance in predicting conditional mean heat release rate [W/m3] (conditioned on the mixture fraction) at t = 20tj using \({\overline {\Delta }}\)/ΔDNS= 12. a case L, b case M and c case H
6 Summary and Conclusions
In this paper the finite-rate dynamic Scale Similarity (SS) SGS combustion models for LES were developed and a priori tested using the DNS databases of non-premixed turbulent syngas jet flames with varying degrees of extinction and different Reynolds numbers. An explicit top-hat filter with relatively large filter width (\({\overline {\Delta }}\)/ΔDNS = 12), compared to the previous studies on SS models, was applied to compute the exact LES-like filtered quantities from the DNS databases. Two variants of dynamic versions for each existing non-dynamic model were derived. In particular, three classical non-dynamic models were: (i) the SS models derived following Bardina’s grid filtering approach [15], namely the scale similarity resolved reaction rate model (model A), (ii) the scale similarity filtered reaction rate model (model B) proposed in [13], and (iii) a SS model derived using the test filtering approach [20, 21] (model C). Two versions of dynamic models (DA1, DA2, DB1, DB2 and DC1, DC2) resulted from using different filtering levels in the mathematical formulations. Comparing the two dynamic versions of each SS model, it was found that DA2, DB2 and DC1 produce better results. This demonstrates that the mathematically consistent formulation of the SS models for combustion does not always improve the results like what was seen before for SGS stress field [39]. It should be mentioned that among the three dynamic models, only DC1 was derived using the mathematically consistent formulation (see Section 3.2.3).
Comparisons were made with the non-dynamic models as well as the existing dynamic one (model DA2) [14]. The focus was on the assessment of the ability of different SS models in the prediction of filtered net formation rate of major species, radicals and also the filtered heat release rates in flames with extinction.
Considering the conditional mean heat release rates (see Fig. 8), the SS models could predict correctly (in mean) the filtered heat release rates, while in all three flames, the “no model” approach predicted higher heat release rates. It was observed that by increasing the Re (increasing \({\overline {\Delta }}/\underline {\lambda }_{f}\)), the error of both dynamic and non-dynamic models decreased. DC1 produced better results than the non-dynamic C for case H (see e.g. Fig. 8b and c). However, for the other two models, in the best case the dynamic procedure produced results similar to their non-dynamic counterparts. It should be mentioned that in these DNS cases, there is more extinction in the higher Re conditions than the lower Re one, showing progressively more flamelet-like behavior. So it is possibly the case that it is the flamelet-like behavior that is more challenging rather than lower Re. This needs to be further studied in the future. It seems that the specific test cases considered here are not suitable to reveal the true potentials of the new dynamic procedures. One may conclude that the dynamic models can at least converge to the best predictions which here resulted from the default similarity coefficient of 1. The optimal estimators concept [44] can be exploited to find the minimum achievable error by the SS models for these specific databases.
Regarding the strict metric of RMSE for individual species, three conclusions can be drawn:
- (i)
The error of DC1 decreased by increasing the Re and interestingly, in the flame regions, produced less mean local errors for medium and high Re cases. This is consistent with observations regarding the prediction of filtered heat release rate.
- (ii)
The mean local error of DA2 decreased by increasing the Re, however, unlike DC1, the local errors became similar to the non-dynamic A model. It seems that for the specific test cases considered in this study, using the default value of 1 for the similarity coefficient of model A produces the best results and the dynamic evaluation of the coefficient leads to the same mean local error.
- (iii)
DB2 showed local errors higher than or at most equal to B. No improvement was observed by increasing the Re. This can be due to four filtering levels in the mathematical formulation of DB2.
By the observed performance of the dynamic models:
- (i)
It is expected that the dynamic procedures presented in the current study, produce acceptable results in higher Reynolds than the ones considered here. The highest Re in this study is around 9000. One may argue that the encouraging results of the SS SGS combustion models observed in the current study may be due to the specific DNS test cases in which the scales are overlapped and there is possibly not enough scale separation. It is true that these DNS databases lack a distinct scale separation, however, one should also take this into account that in this study it was observed that the performance of the models are better in higher Reynolds cases M and H. Furthermore, by increasing the Re, the \({\overline {\Delta }}/\underline {\lambda }_{f}\) is also increasing. So it is reasonable to expect better performances in higher Reynolds numbers. It is so suggested to do this analysis to draw a solid conclusion on the effect of the Re on the performance of the new models.
- (ii)
It is of interest to study directly the effect of the width of the filter on the performance of the new dynamic models. Furthermore, the analyses should be expanded into the other regimes of non-premixed flames like re-ignition phases, or flames without any extinction.
- (iii)
The application of Germano’s identity for pure SS models seems to be unsuccessful in improving the performance in low Re flames. It will be interesting to use a combination of mixed models and Germano’s identity to compute the similarity coefficient dynamically like what is done for flame surface density closure in [45].
- (iv)
To complete the assessment, it is also suggested doing a posteriori DNS analyses of the new dynamic models. Although the models (especially DA2 and DC1) produced acceptable results in the a priori analysis, as mentioned earlier, it is not guaranteed that they show the same performance in a real LES.
Notes
The terms, “grid” and “test” filters will be defined more precisely later.
Strictly speaking, the name “double Favre filtered” may not be suitable in mathematical point of view since the second operator (thick bar) uses the filtered density in the formulations (see also Table 4). However, the operation is similar to what is done in LES codes where only filtered density is available. This is the reason the term “double Favre filtered” has been used.
References
Fedina, E., Fureby, C., Bulat, G., Meier, W.: Assessment of finite rate chemistry large eddy simulation combustion models. Flow Turbul. Combust. 99(2), 385–409 (2017)
Janicka, J., Sadiki, A.: Large Eddy simulation of turbulent combustion systems. Proc. Combust. Inst. 30(1), 537–547 (2005)
Fiorina, B., Gicquel, O., Vervisch, L., Carpentier, S., Darabiha, N.: Approximating the chemical structure of partially premixed and diffusion counterflow flames using fpi flamelet tabulation. Combust. Flame 140(3), 147–160 (2005)
Fureby, C.: Les of a multi-burner annular gas turbine combustor. Flow Turbul. Combust. 84(3), 543–564 (2010)
Knudsen, E., Pitsch, H.: A general flamelet transformation useful for distinguishing between premixed and non-premixed modes of combustion. Combust. Flame 156(3), 678–696 (2009)
Charlette, F., Meneveau, C., Veynante, D.: A power-law flame wrinkling model for les of premixed turbulent combustion part ii: dynamic formulation. Combust. Flame 131(1-2), 181–197 (2002)
Colin, O., Ducros, F., Veynante, D., Poinsot, T.: A thickened flame model for large eddy simulations of turbulent premixed combustion. Phys. Fluids 12 (7), 1843–1863 (2000)
Haworth, D.: Progress in probability density function methods for turbulent reacting flows. Prog. Energy Combust. Sci. 36(2), 168–259 (2010)
Pope, S.B.: Pdf methods for turbulent reactive flows. Prog. Energy Combust. Sci. 11(2), 119–192 (1985)
Ertesvåg, I.S., Magnussen, B.F.: The eddy dissipation turbulence energy cascade model. Combust. Sci. Technol. 159(1), 213–235 (2000)
Golovitchev, V., Chomiak, J.: Numerical modeling of high temperature air flameless combustion. In: Proceedings of the 4th International Symposium on High Temperature Air Combustion and Gasification (HiTACG), pp. 27–30 (2001)
Sabelnikov, V., Fureby, C.: Les combustion modeling for high re flames using a multi-phase analogy. Combust. Flame 160(1), 83–96 (2013)
DesJardin, P.E., Frankel, S.H.: Large eddy simulation of a nonpremixed reacting jet: application and assessment of subgrid-scale combustion models. Phys. Fluids 10 (9), 2298–2314 (1998)
Jaberi, F., James, S.: A dynamic similarity model for large eddy simulation of turbulent combustion. Phys. Fluids 10(7), 1775–1777 (1998)
Bardina, J., Ferziger, J., Reynolds, W.: Improved subgrid-scale models for Large-Eddy simulation. In: 13th Fluid and Plasmadynamics Conference, p 1357 (1980)
Garnier, E., Adams, N., Sagaut, P.: Large Eddy Simulation for Compressible Flows. Springer Science & Business Media, Berlin (2009)
Sagaut, P.: Large Eddy Simulation for Incompressible Flows: an Introduction. Springer Science & Business Media, Berlin (2006)
Germano, M.: A proposal for a redefinition of the turbulent stresses in the filtered Navier–Stokes equations. Phys. Fluids 29(7), 2323–2324 (1986)
Liu, S., Meneveau, C., Katz, J.: On the properties of similarity subgrid-scale models as deduced from measurements in a turbulent jet. J. Fluid Mech. 275, 83–119 (1994)
Germano, M., Maffio, A., Sello, S., Mariotti, G.: On the extension of the dynamic modelling procedure to turbulent reacting flows. In: Direct and Large-Eddy Simulation II, pp 291–300. Springer (1997)
Shamooni, A., Cuoci, A., Faravelli, T., Sadiki, A.: Prediction of combustion and heat release rates in non-premixed syngas jet flames using finite-rate scale similarity based combustion models. Energies 11(9), 2464 (2018)
Potturi, A., Edwards, J.R.: Investigation of subgrid closure models for finite-rate scramjet combustion. In: 43rd AIAA Fluid Dynamics Conference, p. 2461 (2013)
Hawkes, E.R., Sankaran, R., Sutherland, J.C., Chen, J.H.: Scalar mixing in direct numerical simulations of temporally evolving plane jet flames with skeletal co/h2 kinetics. Proceedings of the Combustion Institute 31(1), 1633–1640 (2007)
Trisjono, P., Pitsch, H.: Systematic analysis strategies for the development of combustion models from dns: a review. Flow Turbul. Combust. 95(2-3), 231–259 (2015)
Argyropoulos, C., Markatos, N.: Recent advances on the numerical modelling of turbulent flows. Appl. Math. Model. 39(2), 693–732 (2015)
Behzadi, J.J., Talei, M., Bolla, M., Hawkes, E.R., Lucchini, T., D’Errico, G., Kook, S.: A conditional moment closure study of chemical reaction source terms in scci combustion. Flow Turbul. Combust. 100(1), 93–118 (2018)
Allauddin, U., Klein, M., Pfitzner, M., Chakraborty, N.: A priori and a posteriori analyses of algebraic flame surface density modeling in the context of large eddy simulation of turbulent premixed combustion. Numerical Heat Transfer Part A: Applications 71(2), 153–171 (2017)
Ameen, M., Abraham, J.: A priori evaluation of subgrid-scale combustion models for diesel engine applications. Fuel 153, 612–619 (2015)
Ihme, M., Pitsch, H.: Prediction of extinction and reignition in nonpremixed turbulent flames using a flamelet/progress variable model: 1. a priori study and presumed pdf closure. Combust. Flame 155(1-2), 70–89 (2008)
Lapointe, S., Blanquart, G.: A priori filtered chemical source term modeling for les of high karlovitz number premixed flames. Combust. Flame 176, 500–510 (2017)
Lignell, D.O., Hewson, J.C., Chen, J.H.: A-priori analysis of conditional moment closure modeling of a temporal ethylene jet flame with soot formation using direct numerical simulation. Proc. Combust. Inst. 32(1), 1491–1498 (2009)
Vo, S., Stein, O., Kronenburg, A., Cleary, M.: Assessment of mixing time scales for a sparse particle method. Combust. Flame 179, 280–299 (2017)
Yang, Y., Wang, H., Pope, S.B., Chen, J.H.: Large-eddy simulation/probability density function modeling of a non-premixed co/h2 temporally evolving jet flame. Proc. Combust. Inst. 34(1), 1241–1249 (2013)
Gonzalez, E., Dasgupta, A., Arshad, S., Oevermann, M.: Effect of the turbulence modeling in Large-Eddy simulations of nonpremixed flames undergoing extinction and reignition. In: 55th AIAA Aerospace Sciences Meeting, p. 0604 (2017)
Sen, B.A., Hawkes, E.R., Menon, S.: Large eddy simulation of extinction and reignition with artificial neural networks based chemical kinetics. Combust. Flame 157 (3), 566–578 (2010)
Cuoci, A., Frassoldati, A., Faravelli, T., Ranzi, E.: Opensmoke++: an object-oriented framework for the numerical modeling of reactive systems with detailed kinetic mechanisms. Comput. Phys. Commun. 192, 237–264 (2015)
Germano, M.: Turbulence: the filtering approach. J. Fluid Mech. 238, 325–336 (1992)
Meneveau, C.: Germano identity-based subgrid-scale modeling: a brief survey of variations on a fertile theme. Phys. Fluids 24(12), 121301 (2012)
Vreman, B., Geurts, B., Kuerten, H.: On the formulation of the dynamic mixed subgrid-scale model. Phys. Fluids 6(12), 4057–4059 (1994)
Zang, Y., Street, R.L., Koseff, J.R.: A dynamic mixed subgrid-scale model and its application to turbulent recirculating flows. Phys. Fluids A: Fluid Dynamics 5 (12), 3186–3196 (1993)
Vinuesa, J.F., Porté-Agel, F.: Dynamic models for the subgrid-scale mixing of reactants in atmospheric turbulent reacting flows. J. Atmos. Sci. 65(5), 1692–1699 (2008)
Yang, S., Ranjan, R., Yang, V., Sun, W., Menon, S.: Sensitivity of predictions to chemical kinetics models in a temporally evolving turbulent non-premixed flame. Combust Flame 183, 224–241 (2017)
Gauding, M., Dietzsch, F., Goebbert, J.H., Thévenin, D., Abdelsamie, A., Hasse, C.: Dissipation element analysis of a turbulent non-premixed jet flame. Phys. Fluids 29(8), 085103 (2017)
Berger, L., Kleinheinz, K., Attili, A., Bisetti, F., Pitsch, H., Mueller, M.E.: Numerically accurate computational techniques for optimal estimator analyses of multi-parameter models. Combust. Theor. Model. 22(3), 480–504 (2018)
Knikker, R., Veynante, D., Meneveau, C.: A priori testing of a similarity model for large eddy simulations of turbulent premixed combustion. Proc. Combust. Inst. 29 (2), 2105–2111 (2002)
da Silva, C.B., Pereira, J.C.: Analysis of the gradient-diffusion hypothesis in large-eddy simulations based on transport equations. Phys. Fluids 19(3), 035106 (2007)
Acknowledgements
The authors would like to thank Professor Evatt Hawkes from The University of New South Wales for providing us the DNS validation databases.
Funding
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No 643134.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix A: On the Implementation
Appendix A: On the Implementation
In this Appendix the implemented filters and the different types of filtered quantities are explained. A “simple filtered” quantity \(\overline {q}\) in 3D is computed as:
Equivalently a Favre filtered quantity is given by:
where \(F\left (\mathbf {X}\right )\) represents the 3D filter kernel which is selected to be a top-hat filter:
where \({\overline {\Delta }}\) is the filter width and is equal to \({\overline {\Delta }}=N{{\Delta }^{\text {DNS}}}\), with N an integer. Therefore, Eq. 46 leads to:
The top-hat “simple filter” corresponds to the filter implicitly associated with the discretization using centered finite difference or finite volume codes which are used more often in LES [46].
The integral in Eq. 49 is computed by using the trapezoidal rule. In 1D, the final equation for structured meshes is given in the first row of Table 3. The 3D filtered data is computed by 3 consecutive applications of this formula in Ox, Oy, and Oz directions, respectively.
“Simple filter” is only applied to the original data so that the grid size is the DNS grid size, viz. \(\mathrm {{\Delta }^{*}={\Delta }_{\text {DNS}}}\). In a priori DNS analysis, this creates LES like quantities. In a posteriori DNS analysis or real LES, there is no need to apply the “simple filter” simply because the solution is already a “simple filtered” quantity. It must be mentioned that the “simple filtered” data will be sampled on a new grid. The size of the new grid will be N times the original DNS grid. This will be explained in detail later. The “1st test filter” and “2nd test filter” are simple filters with a fixed filter widths of 2 and 4 times the original grid size, respectively. The grid filter,  , is virtually the same filter as the “simple filter” with the same filter width, however, the implementation is different. The method introduced in [40] is used in the current study which can be seen in Table 3.
, is virtually the same filter as the “simple filter” with the same filter width, however, the implementation is different. The method introduced in [40] is used in the current study which can be seen in Table 3.
Other filters can be applied on top of a previously filtered quantity. For example the double grid filtered data is computed by:

where i + 1 and i − 1 are two neighboring points. The 3D filtered data are computed by 3 consecutive applications of 1D filters in Ox, Oy, and Oz directions. This reads:


1D graphical illustration of first filtering level (simple filter) of the DNS data and sampling step on a coarse grid. It is assumed that N is 4 for simplicity
It should be mentioned that in all equations above, it is assumed that the DNS mesh is uniform, i.e. ΔxDNS = ΔyDNS = ΔzDNS = ΔDNS, which is common in DNS setups. Also note that \(\overline {q}\) is an already sampled quantity on a coarse grid.
The Favre filtered quantities and the steps to compute them are explained in Table 4. Throughout the paper, a compact notation has been used for simplicity and the exact notations can be found in this table.
Care must be taken on handling the data after filtering. In this work it is tried to follow as much as possible the “consistent a priori DNS analysis” explained by Liu et al., [19]. In Fig. 9, the first step of producing LES like quantities from the DNS databases is illustrated in 1D. For simplicity, it is assumed that \({\overline {\Delta }=4{\Delta }_{\text {DNS}}}\) instead of \({\overline {\Delta }=12{\Delta }_{\text {DNS}}}\) and it should not be mistakenly interpreted as the “2nd test filter”. The DNS data is filtered using the “simple filter”, i.e. \(\overline {(.)}\), and then sampled and interpolated to a new grid. The new grid is a coarser grid with the grid size N = 4 times the DNS grid size. In this way, the filtered quantities, \(\overline {q}\), are only available on a coarse grid. However, for the next level filter, i.e., application of  , \(\widehat {(.)}\), and \(\overbrace {(.)}\) on \(\overline {q}\), no more sampling will be performed. The reason was already explained in Section 3.2.1.
, \(\widehat {(.)}\), and \(\overbrace {(.)}\) on \(\overline {q}\), no more sampling will be performed. The reason was already explained in Section 3.2.1.
The filtered source terms which are used in the current study are presented in Table 5. The steps to compute the multi-level filtered terms are also presented. In this work, OpenSMOKE++ (OS++) [36] is used to compute the Arrhenius source terms. Of course calculations can also be performed using Chemkin or Cantera. As can be seen, the input of OS++ is Favre filtered composition vector in different filtering levels.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Shamooni, A., Cuoci, A., Faravelli, T. et al. New Dynamic Scale Similarity Based Finite-Rate Combustion Models for LES and a priori DNS Assessment in Non-premixed Jet Flames with High Level of Local Extinction. Flow Turbulence Combust 104, 233–260 (2020). https://doi.org/10.1007/s10494-019-00060-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10494-019-00060-w