
Abstract
Uniaxial compressive strength (UCS) is the most fundamental physico–mechanical parameter used for any rock mass classification in geotechnical and geological engineering. However, determining UCS is a very tough, expensive, time consuming and destructive method and requires experienced workers. On the other hand, P-wave velocity (VP) determination is cheap, precise, non-destructive and easy. There are many established relationships between UCS and VP but mostly are low in range or proposed for multiple rock types of different origin. In this paper, the correlation of UCS with VP has been assessed based on the rocks' lithology. The methodology used in this analysis was centred on the previous studies database, lithology-based data disintegration and data integration to establish lithology based simple regression (SR) equations. A total of 37 previous studies databases were processed, and 12 characteristic regression equations have been determined based on the lithology. The lithological control was also determined using the principal component analysis (PCA), which categorised the data into diverse rock types. Artificial neural network (ANN) has been used as a robust predictive tool to estimate the UCS using the VP and rock type information.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Uniaxial compressive strength (UCS) is the primary physico–mechanical parameter that is essentially required to assess the field conditions for any geotechnical or civil engineering constructions. Rock mass and other classification systems such as rock mass rating (RMR) proposed by Bieniawski (1973), slope mass rating (SMR) offered by Romana (1985), Q-slope offered by Bar and Barton (2017) etc. which are being used in various geotechnical, geological and civil purposes, fundamentally requires UCS as a primary physico-mechanical parameter. However, standards proposed by the International Society of Rock Mechanics (ISRM) (1979) and the American Society of Testing and Materials (ASTM) (2000) are very tough, time-consuming, expensive and destructive. Therefore, estimating the UCS using various indirect tests has become popular. UCS has been correlated with physical parameters such as density, porosity etc. and physico-mechanical parameters such as point load strength index (PLSI), rebound number (NR), Brazilian tensile strength (BTS) and VP. In the present study, the correlation of UCS with the VP has been assessed based on the previous studies database. The VP depends on the density and elastic properties of the material. The standards suggested by ASTM (2002) and ISRM (1978) for the determination of VP is straightforward, easy, non-destructive, cheap and precise.
Many researchers have proposed a general regression for multiple types of rocks (Kahraman 2001; Karakus et al. 2005; Sharma and Singh 2008; Kilic and Teymen 2008; Sarkar et al. 2012; Karakul and Ulusay 2013; Teymen and Menguc 2020 etc.), whereas some researchers have proposed regression equations for single rock types (Tugrul and Zarif 1999; Yasar and Erdogan 2004; Chary et al. 2006; Vasconcelos et al. 2007; Minaeian and Ahangari 2011; Rahman et al. 2020 etc.). In this paper, an attempt has been made to propose a generalised regression equation based on the lithology and evaluate the statistical acceptance of regression equations proposed for particular rock types. A specific characteristic regression equation has been offered for each rock type (a total of 12) based on previous studies database.
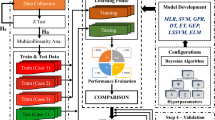
Principal component analysis (PCA) and ANN are the most common unsupervised and supervised learning algorithm in machine learning, respectively. ANN is a modern predictive tool that many researchers have used, while PCA has been generally used for data-processing and classification or categorisation of the dataset. Sarkar et al. (2010) used ANN to predict the UCS and shear strength with three input parameters such as VP, PLSI, slake durability index (SDI) and density for four different rock types. Sharma et al. (2017) compared the accuracy of adaptive neuro-fuzzy inference system, multiple regression analysis and ANN to predict the UCS using three input parameters (density, VP and SDI). In this paper, PCA has been used to validate the lithological control on the estimation of UCS from the VP by categorising the database into 12 rock types, whereas ANN has been trained to predict the UCS from VP and rock type information using three different training function algorithms and the regression fit obtained from simple regression analysis have been compared with each other.
2 Previous Studies
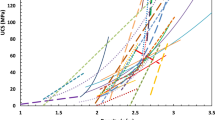
A plethora of research was conducted to estimate the UCS using the VP (Table 1). Tugrul and Zarif (1999) proposed a regression equation to predict the UCS using VP of 19 granitic rocks collected from different Turkey locations. Kahraman (2001) proposed a power correlation of UCS with the VP of 27 different rock types, including sandstones, carbonates, tuffs etc., collected from different parts of Turkey. Yasar and Erdogan (2004) suggested a linear regression equation to predict the VP using UCS, which was used for vice versa. They used 13 samples of carbonate rocks collected from different parts of Turkey. Karakus et al. (2005) used 9 samples of carbonate and igneous rocks to propose a multivariate linear regression to predict the Poisson’s ratio and Young’s modulus from NR, VP and porosity. Sousa et al. (2005) suggested a power correlation to estimate the UCS from VP of 9 different granitic rocks procured from NE Portugal. Entwisle et al. (2005) suggested an exponential correlation equation to estimate the UCS from VP of 171 samples of Volcanites procured from the UK NIREX off-site core characterisation programme. Chary et al. (2006) used sandstone samples from two different coalfields, namely SCCL and NLC, where they suggested regression equations separately for SCCL and NLC, to predict the UCS from VP. Vasconcelos et al. (2007) used 19 samples to evaluate granites' behaviour in dry and saturated conditions. Kilic and Teymen (2008) proposed a power regression equation to predict the UCS of 19 samples of 10 different rock types using the VP. Sharma and Singh (2008) suggested a common regression equation for 49 samples of 6 different rock types collected from India's different parts. Cobanoglu and Celik (2008) used cement mortar, limestone and sandstone core samples of different diameter and proposed a common correlation equation for all types of materials used based on sets of different diameters. Moradian and Behnia (2009) used 64 samples of marlstone, sandstone, and limestone to produce a common correlation between the samples' UCS and VP. In contrast, Diamantis et al. (2009) suggested a linear regression equation for 32 serpentinite rocks from Central Greece. Torok and Vasarhelyi (2010) used 40 travertine samples from Hungary to study the influence of moisture and fabric on the rock's physico-mechanical properties. They also suggested a power regression equation to predict the UCS from VP. The UCS and VP database of Sarkar et al. (2010) with 40 samples of 4 rock types was also used in the study. Kurtulus et al. (2010) investigated the mechanical and physical properties of andesite rocks of Gokceada Island near Turkey mainland. A power correlation was offered by Yagiz (2011) for 3 types of rocks including mica-schist, travertine and carbonate. Kurtulus et al. (2012) investigated the physical and mechanical properties of serpentinites from NW Turkey. They proposed a linear regression between UCS and VP along and across foliation planes with excellent R2 values. The regression for across foliation tests was included for the present study. Minaeian and Ahangari (2011) proposed a linear regression equation to estimate the UCS of weak conglomerates using VP. Sarkar et al. (2012) used 94 samples of 13 rock types from India and proposed a common correlation for all rock types. Babacan et al. (2012) suggested a linear regression equation between UCS and VP for 15 samples of limestone. Karakul and Ulusay (2013) studied the variation in the physico-mechanical properties at varying degree of saturation and suggested a correlation equation to predict the physico-mechanical parameters from VP. Azimian et al. (2013) studied 40 samples of marl from Iran and proposed a linear correlation between the UCS and VP. Mishra and Basu (2013) suggested separate regression equations for granite, chlorite-schist and sandstone because they could not find a common correlation for all rock types used. Beiki et al. (2013) used genetic programming to estimate the UCS and elastic modulus of various carbonate rocks using VP, porosity and density. Karaman and Kesimal (2015) correlated the NR with the UCS and VP of 46 rocks samples. Goh et al. (2014) investigated 77 Malaysian granite samples and suggested a power correlation between the UCS and VP. Mohamad et al. (2014) suggested a common correlation equation for 3 types of rocks, including shale, old alluvium and iron pan. Goh et al. (2015) used 26 Malaysian schist samples and proposed a power correlation between UCS and VP. Jamshidi et al. (2015) studied the effect of diameter size of the core specimen of 15 travertine rocks of Iran on the UCS and VP and suggested a relation for 5 different diameter size. For the present study, the relationship of UCS and VP for dry rock samples and 54 mm diameter size was considered. Kurtulus et al. (2015) used 96 samples of 3 rock types from Turkey and proposed correlations between VP and different mechanical and physical properties. Selçuk and Nar (2016) used 42 samples of 8 rock types, and Kurtulus et al. (2016) used 32 samples of limestone to suggest a correlation equation between UCS and VP. Awang et al. (2016) also proposed a correlation between UCS and VP for shale rocks of Malaysia. Nespereira et al. (2019) used serpentinite rocks of NW Spain to propose a linear regression to predict the UCS from VP. Teymen and Menguc (2020) used 93 samples of different rock types and suggested a common regression equation. Rahman et al. (2020) used Lower Gondwana sandstone and shale rocks and suggested separate regression equations for the 2 rock types, and recommended that each rock type follow a characteristic regression curve. The regression equations obtained by different researchers used in this study have been plotted and compared in Fig. 1, which is suggestive that there is no common and reliable regression equation that could be used for the prediction of UCS with the VP. Hence, the study becomes very significant and important.

Previous studies regression equations between UCS and VP
3 Data Processing
3.1 Data Disintegration
The samples of different rock types used by various researchers in the previous studies were disintegrated on the basis of lithology irrespective of the proposed regression equation (Fig. 2). A total of 12 types of rocks have been identified using the previous studies database on the basis of lithology. A general overall trend, including all the rock types, have been proposed with a good R2 value of 0.5657 and an exponential equation as follows (Eq. 1).

Data disintegration of the databases proposed by various researchers in the previous studies based on lithology
Many authors such as Kahraman (2001), Sharma and Singh (2008), Sarkar et al. (2012) etc., used multiple rock types and suggested an ordinary regression equation. Therefore, to propose a characteristic regression equation for a particular lithology, the method of data disintegration was used. For example, Kurtulus et al. (2015) used 96 samples of 3 rock types, including 10 samples of Kızderbent volcanic, 8 samples of Sopali arkose (T35-1), 36 samples of Korfez sandstone (T35-2), 20 samples of Derince sandstone (T35-3) and 22 samples of Akveren limestone. These rock types were disintegrated from the study and grouped as per the lithology under the heading of Volcanite (T35), Sandstone (T35-1, T35-2, T35-3) or Carbonate (T35).
3.2 Data Integration
In this section, all the lithology grouped after data disintegration has been analysed. The rock types shown in Fig. 3 (Group I: sandstone, carbonate, volcanite and granite) include \(> \;100\) data points from the previous studies database. These rocks have been well studied in the past and suggest a characteristic regression trend-line with excellent R2 values, while the rock types shown in Fig. 4 (Group II: shale, mica schist, ignimbrite and travertine) include \(< \;100\) data points from the previous studies databases. The previous studies databases integrated on the basis of lithology suggested characteristic regression trend lines with excellent R2 values. On the contrary, Group III rocks (conglomerate, slate/phyllite, chlorite schist and serpentinite) have not been well studied in the previous studies. These rocks belong to a grey area in the subject and are very difficult to prepare samples and test in the laboratory or field because of the presence of structural anisotropy. Hence, the rock types analysed and the regression proposed in Figs. 3 and 4 are more reliable and accurate than the group III rock types analysed in Fig. 5. Different lithology groups identified from data integration have been discussed below.

Lithology based regression equations on predicting UCS from VP obtained by integration of data published in previous studies; a sandstone, b carbonate, c volcanite, d plutonic rocks

Lithology based regression equations on predicting UCS from VP obtained by integration of data published in previous studies; a shale, b mica schist, c ignimbrite, d travertine

Lithology based regression equations on predicting UCS from VP obtained by integration of data published in previous studies; a conglomerate, b slate/phyllite, c chlorite schist, d serpentinite
3.2.1 Sandstone
A total of 14 previous studies database were used to obtain a characteristic regression equation for sandstone (Fig. 3a). An exponential curve has been proposed with a good R2 value of 0.6627 (Eq. 2).
Many previous studies database regressions are parallel or even overlapping with the proposed overall trend line. T11 and T21 have a similar regression line with a gradient much higher than the achieved overall trend line. T41, T35-3 and T13 are almost overlapping the overall trend-line. T39, T35-2 and T12 + T23 lie above the overall trend-line, which would predict a much higher value of UCS for corresponding VP values. T8 and T35-1 lie below the overall trend-line. T7 shows an extraordinary regression which suggests drastic changes in UCS prediction within a very small range of VP; hence the gradient of the regression is very steep.
3.2.2 Carbonate
The carbonates described in this section include limestone, marlstone, marble and dolomite rocks. The database used for carbonate rocks includes 15 previous studies (Fig. 3b). A power correlation equation (Eq. 2) has been suggested with a moderate R2 value of 0.5613.
T24, T29 and T35 are similar but show a steeper gradient than the overall trend line. T2, T3, and T13 regressions agree with the proposed overall trend line with slight deviations. T16 shows a parallel regression to the overall trend line but estimates much higher values of UCS for the corresponding VP values while T4 and T22 lie below the overall trend line, which predicts underestimated values of UCS with a gentle slope gradient. T12, T18and T39 have very steep regression trend line and does not agree with the overall trend line with steep gradient regression slopes.
3.2.3 Volcanite
Volcanites are rocks that have solidified on the surface of the Earth. Rocks included in this section for analysis are dacite, andesite, basalt, rhyolite etc. A total of 10 previous studies database were used to suggest a characteristic regression equation for volcanites (Fig. 3c). For volcanites, two overall regression trend-lines have been suggested based on the inclusion of the T6 database. As the database is very large (database extraction problems due to overlapping data points), it has a greater influence on the proposed trend-line. The regression trend line without the T6 database (trend-A) shows an excellent R2 value of 0.7683 (Eq. 4), while the overall trend with the T6 database (trend-B) shows a very small R2 value of 0.4954 (Eq. 5).
T29, T34 and T39 regression trend-lines agree with the overall trend-line (trend-A and trend-B). The T17 trend-line do not agree with the overall trend but lies within the field of the overall database. T11 and T21 databases lie parallel to the proposed overall regressions but predict higher values of UCS for the corresponding VP values.
3.2.4 Plutonic Rocks
In Fig. 3d, all the previous studies database were observed to follow the proposed characteristic regression curve. The plutonic rock group mainly includes granites with other plutonic rocks of the T39 database such as diorite, granodiorite, gabbro, syenite etc. A total of 6 previous studies database were used to propose a characteristic power regression equation (Eq. 6) with an excellent R2 value of 0.8103.
T1, T9, T30 and T39 database agrees with overall regression trend-line. In contrast, the T25 database lies in the general field of the overall trend-line. It depicts a steeper gradient regression slope that might underestimate or overestimate the UCS for granites with lower or higher VP, respectively. The T5 database trend-line is parallel to the overall trend but predicts higher UCS values for the corresponding VP values.
3.2.5 Shale
A power regression equation (Eq. 7) was proposed with an impeccable R2 value of 0.8195. Out of 5 previous studies databases used for this rock group, 4 of the databases were observed to follow the general trend (Fig. 4a).
The regression proposed by the database of T11 and T21 has a linear trend that predicts underestimated UCS values for higher VP values if used beyond the proposed range. T31 and T40 have a polynomial and exponential regression trend, respectively, which agrees with the overall regression trend for shale rocks. T37 does not agree with the overall trend-line and estimates lower values of UCS for the corresponding VP values with a gentler regression slope.
3.2.6 Mica Schist
Only 4 previous studies databases were used to propose the overall regression equation (Fig. 4b). An exponential curve has been suggested with an excellent R2 value of 0.7946 (Eq. 8).
T11 and T16 databases extend for a very low range of VP and overlap each other. T32 database suggests a power regression trend-line that agrees with the overall regression, whereas T18 database regression predicts lower values of UCS for corresponding VP values.
3.2.7 Ignimbrite
A total of 4 previous studies database were used to propose a characteristic regression equation for ignimbrite and tuff rocks (Fig. 4c). A linear regression equation (Eq. 9) with a good R2 value of 0.5927 was suggested.
T10, T23 and T39 databases lie parallel to the overall regression trend-line. T34 database suggested a trend-line with a gentler gradient than the overall trend-line. Therefore, predicting UCS using the T34 regression trend-line would give underestimated results for higher values of VP.
3.2.8 Travertine
A total of 5 previous studies databases have been included, in which the majority of the data was incorporated from T15 and T33 databases. T15 database suggested a power regression that is parallel and close to the overall regression trend. T33 database suggested a linear regression that extends for the lower range of values and shows a slightly lower gradient, while the T18 database offers a linear regression with a higher slope than the overall trend of the proposed regression. Other studies (T10 and T39) have a very small database but lie in the field of the suggested regression. A power regression equation (Eq. 10) with an excellent R2 value of 0.7568 was obtained for the overall database (Fig. 4d).
3.2.9 Conglomerate
Only T19 previous study database could be found to obtain the characteristic regression equation. A linear correlation equation (Eq. 11) was obtained with an excellent R2 value of 0.9027 (Fig. 5a).
3.2.10 Slate and Phyllite
A linear regression equation (Eq. 12) with an impeccable R2 value of 0.9949 was obtained (Fig. 5b). Only 2 previous studies databases (T11 and T16) were incorporated to propose the characteristic regression equation.
3.2.11 Chlorite Schist
Only the T26 database could be found to propose an exponential regression equation (Eq. 13) with a below-average R2 value of 0.5184 (Fig. 5c).
3.2.12 Serpentinite
T14 and T20 database proposed linear regression equations with excellent R2 values of 0.81 and 0.92 for serpentinite rocks of Greece and Turkey, respectively. T38 database suggested a linear regression with a poor R2 value of 0.29 to predict UCS from VP for serpentinite rocks of Spain. The database from previous studies does not agree with each other. Hence, an unreliable exponential regression equation (Eq. 14) was obtained with a poor R2 value of 0.1583 (Fig. 5d).
4 Results and Discussion
4.1 Simple Regression Analysis and Validation
In this paper, a simple bivariate regression analysis has been performed, and the best fit curve was evaluated to be linear \((y = mx + c\)), power \((y = mx^{c}\)) or exponential \((y = me^{x}\)). Where \(x\) is the independent variable, \(y\) is the dependent variable, and \(c\) is constant. The best-fit regression equation and R2 values of the obtained 12 rock types under analysis have been shown in Table 2. The statistical credibility of the obtained regression equations was also analysed using the Student’s t test (Eq. 15).
The \(t\) test is a statistical tool to differentiate between the means of two populations. The test was conducted for each regression equation with a confidence interval (CI) of 0.95, significance level \(\left( \alpha \right)\) of 0.05 \(\left( {CI + \alpha = 1.0} \right),\) degree of freedom \(\left( {n {-} 2} \right),\) where n is the number of samples and R2 is the coefficient of determination. The regression is accepted when the alternate hypothesis \(\left( {H_{1} } \right)\) is accepted, and the null hypothesis \(\left( {H_{0} } \right)\) is rejected. The \(H_{1}\) is accepted and \(H_{0}\) is rejected when the calculated \(t\) value \(\left( {t_{C} } \right)\) is greater than the tabulated \(t\) value \(\left( {t_{T} } \right).\)
In Fig. 6, all the regression equations obtained from the database-disintegration and -integration methodology of the previous studies have been compared and analysed. It was surprising that shale rocks show the steepest trend-line gradient while conglomerate has the lowest trend-line slope as compared to other rock types. The sandstone regression has an intermediate slope between shale and conglomerate. Among these rocks, it was striking to see that the shale rocks which are composed of clay-sized particles, have the highest gradient, sandstone which is constituted of sand-sized particles, have intermediate gradient and conglomerate, which are composed of gravel-sized particles, shows the lowest gradient of the regression slope. Similarly, in igneous rocks, the volcanite rocks composed of fine-grained crystals have a higher regression gradient than the regression of the coarse-grained plutonic rocks.

Lithology-based regressions for different rock types
Carbonate rocks show an intermediate gradient of the regression slope. Travertine rocks regression have a very steep gradient comparable to that of volcanite rock regression, but travertine rocks are confined to the high VP region and estimated lower values of UCS than volcanite rock regression for corresponding VP values. Ignimbrites, mica schist and sandstone have a similar regression gradient, but the ignimbrites extend for very small VP values while mica-schist extends to very high VP values. The slate/phyllite regression line extends for intermediate values of VP with a slope gradient similar to that of sandstone and serpentinite. The chlorite schist and serpentinite rocks regressions have a similar gradient, but serpentinite regression yields higher UCS values at lower VP values.
4.2 Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is the most commonly used unsupervised learning algorithm in machine learning. It is a linear transformation method that transforms n-dimensional space to another space with a reduced number of dimensions with minimal loss of information. This technique processes high-dimensional data and uses the dependencies between the variables to represent it in a more amenable and low-dimensional form. In this paper, a classification approach has been used to identify the regressions to predict the UCS from the VP on the basis of lithology (Fig. 7). Here, PCA has been particularly used as a classification tool and not as a predictive tool. In a similar manner, Mahmoudi et al. (2020) used PCA to study the spread rate of COVID-19 in different countries and compared them.

PCA analysis to classify the rocks based on lithology
The PCA projects the multi-dimensional data onto an orthogonal coordinate system so that the variability is maximum along with the first component (PC1) axis. A data matrix is first defined as follows (Eq. 16).
where \(\overrightarrow{{{d_{i} }}}\) is the row vector which consists of \(m\) values from the ith observation. To generate a modified data matrix \(X\) with data vectors \(\overrightarrow{{{d_{l} }}} ^{\prime }\), where \(l = 1, 2, \ldots , n\) and column-wise zero mean, we first subtract the \(1 \times m\) vector \(\overrightarrow{{\mu }}\) containing the mean of each column of \(X_{D}\) from each of the rows of \(X_{D}\) for transformation to the principal components. The PCA builds an orthogonal set of vectors \(\overrightarrow{{{w_{k} }}}\) with \(k = 1, 2, \ldots , m\) in such a way that \(\overrightarrow{{{w_{1} }}}\) maximises the variance of the data vector projections \(t_{l}^{\left( 1 \right)} = \overrightarrow{{{d_{l} }}} ^{\prime } \cdot \overrightarrow{{{w_{1} }}}\). The obtained data vector projection is called the first principal component scores. Similarly, the second principal component (PC2) is projected orthogonally to the \(\overrightarrow{{{w_{1} }}}\) in the \(m - 1\) dimensional subspace and so on. This operation is equivalent to maximising
Subject to \(\overrightarrow{{w}}^{T} \overrightarrow{{w}}\) = 1. Introducing Lagrange multipliers and varying with respect to \(\overrightarrow{{w}}\) yields
where \(\lambda_{i}\) is the eigenvalue that quantify the variance of the corresponding scores. For the present study, VP has been considered as the PC1 and UCS as the PC2. The two-dimensional \(\left( m \right)\) scatter plot has been reduced or transformed into an \(m - 1\) dimension plot. Hence, the dimensionality of the dataset has been reduced while the variance was maximised, as shown in Fig. 7.
4.3 Artificial Neural Network (ANN)
ANN is an artificial soft computing technology that has been extensively used in recent years. It offers a highly accurate predictive or modelling tool that mimics the function of a biological brain. It has information processing features such as non-linearity, noise tolerance, parallelism and learning-generalisation, which makes it better than other predictive methods. For the present study, the Neural Fitting App of MATLAB© was used. The structure of an ANN consists of a three-layer system (input-hidden-output) called the multi-layer perceptron model (Fig. 8). All three in-built training functions were used and compared with each other. Levenberg–Marquardt (LM) algorithm (trainlm) is a typically fast algorithm that requires more memory and less time to compute; Bayesian regularization (BR) algorithm (trainbr) generally is a slow processing algorithm that requires less memory but more time but can result in a good generalisation of some noisy and challenging dataset. In comparison, the scaled conjugate gradient (SCG) algorithm (trainscg) requires less memory, and the training automatically stops when the generalisation stops improving. These three training functions were used to train the ANN model with three hidden layers (logarithmic sigmoid transfer function), VP and rock-type as input layers and UCS as a target/output layer (tangent sigmoid transfer function). The network was trained for each rock type with its corresponding database. The best validation performance and regressions for different training functions of ANN have been shown in Fig. 9.

A general ANN structure for the present study

Showing the best validation performance and regression plot for different ANN models
4.4 Comparative Analysis
The results obtained from the regression and ANN model assessed on the basis of lithology were compared in the scatter plot for the measured and estimated UCS shown in Fig. 10. To analyse the predictive capacity of the model, the measured and estimated UCS values were drawn according to the x:y line (1:1). All the plots for different rock types were observed to show data points close to the x:y line (except for schist and serpentinite rocks), indicating that the proposed regression and ANN models on the basis of lithology are statistically acceptable.

Plots of estimated versus measured values for different rock types including simple regression and best ANN model; a sandstone, b carbonate, c volcanite, d plutonic rocks, e shale, f mica schist, g ignimbrite, h travertine, i conglomerate, j slate and phyllite, k chlorite schist and l serpentinite
The developed ANN models from different training functions were able to predict the UCS for different rock types very efficiently. The efficiency of the predictive ANN models was assessed by comparing the calculated Chi-squared (\(\chi^{2}\)) values for the SR and the ANN models (Table 3). The Chi-squared values have been calculated using Eq. 19 as follows.
where O is the observed value, and E is the estimated value for the ith sample, and k is the total number of samples. The above equation was used to quantify the difference between the observed and estimated values using simple regression (O-SR) and different ANN models (O-BR, O-LM, and O-SCG). Note that the equation was not used for hypothesis testing. Depending on the lowest \(\chi^{2}\) value, the ANN model was chosen to be plotted in the 1:1 plot for that particular rock. The BR-ANN model was selected for carbonate, volcanite, plutonic rocks, shale, mica schist and chlorite schist. Similarly, LM-ANN model was selected for sandstone, ignimbrite, travertine and slate/phyllite rocks, while the SCG-ANN model was selected for conglomerate and serpentinite rocks.
5 Conclusion
This study was aimed to establish a characteristic regression equation between UCS and VP for 12 rock types identified from the previous studies. It was observed that there was no general regression equation that could be used to predict the UCS from VP with high precision for multiple rock types. Hence, a separate characteristic regression equation was proposed for each rock type under study. It was observed that each rock type has its own characteristic regression curve, which could be used to predict the UCS from VP easily and precisely. Shale, sandstone and conglomerate exhibit characteristic regression curves, which could be attributed to the constituent grain-size particles. Similarly, the regression curve of plutonic rocks, which are coarse-grained rocks, predict lower values of UCS than volcanite, which are fine-grained rocks for corresponding values of VP. Therefore, it must be concluded that a common regression equation cannot be used to predict the UCS from VP for multiple rock types.
The regression equations for four rock types in group I, namely, sandstone, carbonate. volcanite, and plutonic rocks have been rigorously studied, while rocks of group II such as shale, mica schist ignimbrite and travertine exhibit characteristic regressions but require more study. The group III rocks (conglomerate, slate/phyllite, chlorite schist and serpentinite) have not been studied well in the past because of sample preparation and testing constraints due to structural anisotropy.
The lithological control for the studied relationship in this paper has also been validated using PCA, which validated the relationship based on the rock type. The proposed regression equations for 12 rock types have been statistically tested using the x:y (1:1) scatter plots and Student’s t test, where the \({H}_{0}\) was rejected and \({H}_{1}\) was accepted in all the cases. The ANN models generated using three different training function algorithms (BR, LM and SCG) have been compared with each other and the simple regression curves using the \(\chi^{2}\) method. The BR algorithm was able to generalise the dataset better than LM and SCG algorithms.
Availability of data and material
The authors declared that all the data generated or used during the study appear in the article.
References
ASTM (American Society of Testing and Materials) (2000) Standard Test Method for Unconfined Strength of Intact Rock Core Specimens. ASTM Standard D2938-95. West Conshohocken, PA
ASTM (American Society of Testing and Materials) (2002) Standard test method for laboratory determination of pulse velocities and ultrasonic elastic constants of rock: ASTM Standard D2845–83. ASTM, West Conshohocken
Awang H, Rashidi NRA, Yusof M, Mohammad K (2016) Correlation between P-wave velocity and strength index for shale to predict uniaxial compressive strength value. MATEC Web Conf 103:07017. https://doi.org/10.1051/matecconf/201710307017
Azimian A, Ajalloeian R, Fatehi L (2013) An empirical correlation of uniaxial compressive strength with P-wave velocity and point load strength index on marly rocks using statistical method. Geotech and Geol Eng 32:205–214
Babacan AE, Ersoy H, Gelisli K (2012) Determination of physical, mechanical and elastic properties of the rocks with ultrasonic velocity technique and time-frequency analysis: a case study on the beige limestones (NE Turkey). Jeoloji Muhendisligi Dergisi 36(1):63–73
Bar N, Barton N (2017) The Q-slope method for rock slope engineering. Rock Mech Rock Eng 50(12):3307–3322. https://doi.org/10.1007/s00603-017-1305-0
Beiki M, Majdi A, Givshad AD (2013) Application of genetic programming to predict the uniaxial compressive strength and elastic modulus of carbonate rocks. Int J Rock Mech Min Sci 63:159–169
Bieniawski ZT (1973) Engineering classification of jointed rock masses. Civ Eng S Afr 15:335–344
Chary et al. (2006) Evaluation of engineering properties of rock using ultrasonic pulse velocity and uniaxial compressive strength. In: Proceeding of the National Seminar on Non-Destructive Evaluation. Indian Society for Non-Destructive Testing, Hyderabad, pp 379–385
Çobanoglu I, Çelik SB (2008) Estimation of uniaxial compressive strength from point load strength, Schmidt hardness and P-wave velocity. Bull Eng Geol Environ 67:491–498. https://doi.org/10.1007/s10064-008-0158-x
Diamantis K, Gartzos E, Migiros G (2009) Study on uniaxial compressive strength, point load strength index, dynamic and physical properties of serpentinites from Central Greece: Test results and empirical relations. Eng Geol 108(2009):199–207
Entwisle DC, Hobbs PRN, Jones LD, GunnD RMG (2005) The relationships between effective porosity, uniaxial compressive strength and sonic velocity of intact borrowdale volcanic group core samples from Sellafield. Geot Geol Eng 23(6):793–809. https://doi.org/10.1007/s10706-004-2143-x
Goh et al (2014) Empirical correlation of uniaxial compressive strength and primary wave velocity of Malaysian granites. Elect J Geotech Eng. 19(E):1063–1072
Goh et al (2015) Correlation of ultrasonic velocity slowness with uniaxial compressive strength of schists in Malaysia. Elect J Geotech Eng 20:12663–12670
ISRM (International Society of Rock Mechanics) (1978) Suggested method for determining sound velocity. Int J Rock Mech Min Sci Geomech Abstr 15(1978):A100
ISRM (International Society of Rock Mechanics) (1979) Suggested methods for determining the uniaxial compressive strength and deformability of rock materials. Int J Rock Mech Min Sci Geomech Abstr 16:135–140
Jamshidi A, Nikudel MR, Khamehchiyan M, Sahamieh Z (2015) The effect of specimen diameter size on uniaxial compressive strength, P-wave velocity and the correlation between them. Geomech Geoeng: An Int J 11(1):1–7
Kahraman S (2001) Evaluation of simple methods for assessing the uniaxial compressive strength of rock. Int J Rock Mech Min Sci 38:981–994
Karakul H, Ulusay R (2013) Empirical correlations for predicting strength properties of rocks from P-wave velocity under different degrees of saturation. Rock Mech Rock Eng. https://doi.org/10.1007/s00603-012-0353-8
Karakuş M, Kumral M, Kılıc O (2005) Predicting elastic properties of intact rocks from index tests using multiple regression modelling. Int J Rock Mech Min Sci 42:323–330
Karaman K, Kesimal A (2015) Correlation of Schmidt rebound hardness with uniaxial compressive strength and P-wave velocity of rock materials. Arab J Sci Eng 40:1897–1906
Kilic A, Teymen A (2008) Determination of mechanical properties of rocks using simple methods. Bull Eng Geol Environ 67:237–244. https://doi.org/10.1007/s10064-008-0128-3
Kurtulus C, Irmak TS, Sertcelik I (2010) Physical and mechanical properties of Gokceada: Imbros (NE Aegean Sea) Island andesites. Bull Eng Geol Environ 69:321–324
Kurtulus C, Bozkurt A, Endes H (2012) Physical and mechanical properties of serpentinised ultrabasic rocks in NW Turkey. Pure Appl Geophys 169:1205–1215
Kurtulus C, Sertcelik F, Sertcelik I (2015) Correlating physico-mechanical properties of intact rocks with P-wave velocity. Acta Geod Geoph. 51(3):571–583 https://doi.org/10.1007/s40328-015-0145-1
Kurtulus C, Cakir S, Yogurtcuoglu AC (2016) Ultrasound study of limestone rock physical and mechanical properties. Soil Mech Found Eng 52(6):348–354
Mahmoudi et al (2020) Principal component analysis to study the relations between the spread rates of COVID-19 in high risks countries. Alex Eng J 60:457–464
Minaeian B, Ahangari K (2011) Estimation of uniaxial compressive strength based on P-wave and Schmidt hammer rebound using statistical method. Arab J Geosci 6(6):1925–1931. https://doi.org/10.1007/s12517-011-0460-y
Mishra D, Basu A (2013) Estimation of uniaxial compressive strength of rock materials by index tests using regression analysis and fuzzy inference system. Eng Geol 160:54–68
Mohamad ET, Armaghani DJ, Momeni E, Abad SVANK (2014) Prediction of the unconfined compressive strength of soft rocks: a PSO-based ANN approach. Bull Eng Geol Environ. https://doi.org/10.1007/s10064-014-0638-0
Moradian OZ, Behnia M (2009) Predicting the unconfined compressive strength and static young’s modulus of intact sedimentary rocks using the ultrasonic tests. Int J Geomech 9:1–14
Nespereira J, Navarro R, Monterrubio S, Yenes M, Pereira D (2019) Sustainability serpentinite from moeche (Galicia, North Western Spain). A stone used for centuries in the construction of the architectural heritage of the region. Sustainability 11:2700
Rahman T, Sarkar K, Singh AK (2020) Correlation of geomechanical and dynamic elastic properties with the P-wave velocity of Lower Gondwana coal measure rocks of India. Int J Geomech 20(10):04020189. https://doi.org/10.1061/(ASCE)GM.1943-5622.0001828
Romana M (1985) New adjustment ratings for application of Bieniawski classification to slopes; In: Proceedings of International Symposium on Role of Rock Mech, ISRM, Zacatecas, Mexico. pp 49–53
Sarkar K, Tiwary A, Singh TN (2010) Estimation of strength parameters of rock using artificial neural networks. Bull Eng Geol Environ 69:599–606
Sarkar K, Vishal V, Singh TN (2012) An empirical correlation of index geomechanical parameters with the compressional wave velocity. Geotech Geol Eng 30:469–479
Selçuk L, Nar A (2016) Prediction of uniaxial compressive strength of intact rocks using ultrasonic pulse velocity and rebound-hammer number. Q J Eng Geol Hydrogeol 49(1):67–75
Sharma PK, Singh TN (2008) A correlation between P-wave velocity, impact strength index, slake durability index and uniaxial compressive strength. Bull Eng Geol Environ 67:17–22. https://doi.org/10.1007/s10064-007-0109-y
Sharma LK, Vishal V, Singh TN (2017) Developing novel models using neural networks and fuzzy systems for the prediction of strength of rocks from key geomechanical properties. Measurement 102:158–169
Sousa et al (2005) Influence of microfractures and porosity on the physic–mechanical properties and weathering of ornamental granites. Eng Geol 77:153–168. https://doi.org/10.1016/j.enggeo.2004.10.001
Teymen A, Mengüç EC (2020) Comparative evaluation of different statistical tools for the prediction of uniaxial compressive strength of rocks. Int J Min Sci Tech. https://doi.org/10.1016/j.ijmst.2020.06.008
Torok A, Vasarhelyi B (2010) The influence of fabric and water content on selected rock mechanical parameters of travertine, examples from Hungary. Eng Geol 115:237–245
Tugrul A, Zarif IH (1999) Correlation of mineralogical and textural characteristics with engineering properties of selected granitic rocks from Turkey. Eng Geol 51:303–317. https://doi.org/10.1016/S0013-7952(98)00071-4
Vasconcelos G, Lourenco PB, Alves CSA, Pamplona J (2007) Prediction of the mechanical properties of granites by ultrasonic pulse velocity and Schmidt hammer hardness. In: North American Masonry Conference, Missouri, 3–5 June, The Masonry Society, CO, pp 980–991
Yagiz S (2011) P-wave velocity test for assessment of geotechnical properties of some rock materials. Bull Mater Sci 34(4):947–953
Yasar E, Erdogan Y (2004) Correlating sound velocity with the density, compressive strength and Young’s modulus of carbonate rocks. Int J Rock Mech Min Sci 41:871–875. https://doi.org/10.1016/j.ijrmms.2004.01.012
Acknowledgements
The authors gratefully acknowledge the financial support from IIT (ISM) Dhanbad. Two anonymous learned reviewers are thanked for their critical evaluation and valuable comments on the research.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared that they have no known competing financial interests or personal relationships that could have appeared to influence the study reported in this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Rahman, T., Sarkar, K. Lithological Control on the Estimation of Uniaxial Compressive Strength by the P-Wave Velocity Using Supervised and Unsupervised Learning. Rock Mech Rock Eng 54, 3175–3191 (2021). https://doi.org/10.1007/s00603-021-02445-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00603-021-02445-8