
Abstract
This study extends existing research on the implications of advanced analytics. Drawing on organizational information processing theory (OIPT), hypotheses are developed for the relationships between information technology orientation, the use of advanced analytical techniques, the ability of information to be utilized in a decision context, and data-driven decision-making. Using survey data from 176 medium-sized and large firms, a mediator model was proposed and tested with structural equation modelling. The data show that the significant direct effect of technology orientation on analytical practice is greatly enhanced by the digital orientation of the firms. As suggested by OIPT, controllers are argued to act as integrators in the sense-making of data-centric mechanisms. The results of the model indicate that the added value of controllers mediates the effect of advanced analytics on the ability of analytical information to be utilized in a decision context. Importantly, the data did not corroborate any relationship between the extent to which available information is able to support decision making and reliance on this information in the decision-making process. It suggests that the strengthening of data-driven decision-making does not overshadow intuition, as assumed based on the expected opposite movement of the two variables. This finding shows the importance of a more detailed and theoretically grounded investigation on how advances in analytical capabilities are (not) changing managerial decision-making processes.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recent developments in information technology (IT) shape several professions, among others the professions of controllersFootnote 1 (Andreassen, 2020). These developments affect not only the tasks carried out by controllers and the methods used by them but also how they act in an organization and how they support management (Knudsen, 2020). To support managerial decision making, controllers' practice used to be limited to analyzing historical, aggregated and accounting-based data. Nowadays, much of the change is linked to the fact that the range of data captured by and available for firms have enormously expanded, while data remained the foundation of controllers’ practice (Knauer et al., 2020).
With the help of mathematical-statistical techniques and continuously improved information processing capacities, the growing datasets can be extensively analyzed. Whether and how the adoption of these advanced analytics approaches influence organizations is of interest to both researchers and practitioners (Chen et al., 2012; Davenport & Harris, 2017), especially after companies are heavily investing in it. Though the IT productivity paradox—suggesting that productivity payoff of an IT investment lags in many cases—has been resolved for the payoffs from computerization (Brynjolfsson & Yang, 1996) and ERP implementation (Botta-Genoulaz et al., 2005), this does not mean that all companies realize benefits from their investments and the resolution cannot be automatically applied for analytics-related investments (Gupta & George, 2016). To establish the link between analytics and corporate benefits, the positive effect of good analytical practice was justified in areas such as the firm’s agility (Ashrafi et al., 2019), sustainability in supply chains (Dubey et al., 2019) or innovation capabilities (Mikalef et al., 2019). A link to firm performance was also established and repeatedly investigated in prior research (Cao & Duan, 2017; Davenport & Harris, 2007; Gupta & George, 2016; LaValle et al., 2011). Nevertheless, the impact of digitalization and analytics on financial results should be treated with caution, as better-performing companies can already devote more resources to these initiatives, which can falsely give the impression that better economic performance is a consequence and not a precedent (Knudsen, 2020).
Instead of searching for a direct link between performance gains and advanced analytics approaches, it should be understood in detail how data analytics can create value for an organization (Gillon et al., 2014; Seddon et al., 2017). As Sharma et al. (2014) proposed, the first-order effect of advanced analytical practice is on the decision making processes that might be or might not be followed by improvements in organizational performance. Accordingly, data analytics was often argued to affect decision making in some ways, as high-quality information allows better-informed decision making (Cao et al., 2019; Kowalczyk & Gerlach, 2015) if the information is not only available but utilized by the managers in decision contexts (Popovič et al., 2012). In line with this, our study is driven by the question of whether and how the use of advanced analytics promotes data-driven decision making.
We ground our study on organizational information processing theory (OIPT). The OIPT claims that organizations coping with uncertainty and equivocality need quality information that in turn requires adequate information processing (Galbraith, 1974; Tushman & Nadler, 1978; Weick, 1979). OIPT suggests that companies need mechanisms that facilitate information processing, where effective organizing and use of information enables informed managerial decision making (Cao et al., 2019). This position made OIPT popular in theorizing data analytics related studies that focus on the consequences of analytics, such as improved firm performance (Aydiner et al., 2019), supply chain transparency (Zhu et al., 2018) or resilience (Dubey et al., 2021). It is argued here that the use of advanced analytics enables the information processing capability of contemporary companies. Simple adoption of advanced data analytics techniques is insufficient; companies need to have a combination of organizational and technological means to gain proper information processing capabilities (Zack, 2007). Accordingly, the establishment of adequate technological infrastructure and suitable organizational characteristics are argued as antecedents for leveraging the benefits of analytics in transforming the decision making process (Kowalczyk & Gerlach, 2015; Popovič et al., 2012; Sharma et al., 2014). Thus, we propose here that a firm’s information technology orientation and digital orientation are important predictors for the use of advanced analytics, which in turn increases the extent to which available information is able to support decision making. It is hypothesized that valuable analytical results support their use in the decision making process.
Analytical work and data-based decision support used to be the territory of management accounting. Recently, the integration of various new data streams and the ongoing increase in the volume of internal data challenges this field (Appelbaum et al., 2017). New technologies in data collection and analytics affect not only the tasks but also the configuration of related organizational roles (Arnaboldi et al., 2017). Occupational boundaries are blurred as other occupational groups claim jurisdiction over the control of information processes and data analysis is far from being the sole responsibility of controllers (Andreassen, 2020; Knudsen, 2020). Thus, while investigating the use of advanced analytics techniques, we cannot limit this to the use by controllers. Although competition between occupational groups has received much attention in previous research, there has been much less talk about how controllers can add value and maintain their organizational relevance in data analytics.
Informed by the OIPT, the study draws attention to an organizational information processing mechanism, namely the role of integrators who are able to support decision-makers while interpreting the data. We argue that controllers can act as integrators in the organization, enabling analytical results to inform business decisions, and playing a key role in converting data analytics into business impacts (Quinn, 2014). Along with these propositions, a set of related hypotheses has been developed and tested. The mediation model was tested by PLS path modelling, using survey data from 176 medium-sized and large organizations. In order to avoid common method bias, variables of the exogenous construct technology orientation were obtained separately from endogenous construct variables: the former is part of the operations management questionnaire, and the latter was built in the general management questionnaire, both of them addressing senior executives of the companies surveyed.
As a result of path modelling, it is verified that the proposed positive effect of technology orientation on the use of advanced analytics is mediated by digital orientation. The use of advanced analytics increases the extent to which available information is able to support decision making, and the added value of controllers mediates this positive influence. Most interestingly, this perceived value of available information does not strengthen the reliance on data in decision making.
Our study extends current literature in many ways. First, we contribute to the literature by directing attention to both data-centric and organizational mechanisms when it comes to enhanced information processing needs. Second, besides the importance of information technology, digital orientation is emphasized as an important predictor of advanced analytics. Third, this study provides insights into how controllers can utilize their combined business and analytical knowledge in an age where analytics becomes the territory of other professional groups. A new integrator role is evidenced for controllers in organizational information processing, which has not yet been explicitly explored according to our knowledge. Fourth, we provide a possible explanation for the missing link between the ability of provided information to be utilized in decision context and actual use of analytical results in decision context: data-centric and organizational information processing mechanisms are able to deliver information that is valuable for decision support, but this – per se – will not ensure that decisions are really made as the result of comprehensive data analyses.
The remainder of the paper is organized as follows. First, OIPT as the theoretical lens of this study is introduced, the data-centric mechanism of advanced analytics and the organizational mechanism of integrators are described. The link between data analytics and decision making is conceptualized, followed by a discussion on the role of information technology and digitalization as predictors of advanced data analytics. After developing the hypotheses, the research model is introduced and tested with mediator analysis. The focus of the discussion section is on why it might remain an illusion that decision making becomes more data-driven.
2 Literature review and hypotheses development
2.1 Organizational information processing theory
OIPT views organizations as information processing systems facing uncertainty (Galbraith, 1974). This uncertainty is understood as the absence of information, and it can stem from the subunits’ task complexity, task environment, and intra- and inter-unit task interdependence (Tushman & Nadler, 1978). As the uncertainty of various sources increases, a higher amount of information is needed to manage the uncertainty that in turn requires higher information processing capacity, where "information processing refers to the gathering, interpreting, and synthesis of information” (Tushman & Nadler, 1978, p. 614). The ongoing increase of information processing capacities drew the attention of researchers and practitioners to identify mechanisms that make organizations capable of coping with this challenge. Recently, researchers proved that analytics capability, i.e. the use of analytics techniques could enable firms to increase their information processing capacity, which in turn may help in the decision making process (Cao et al., 2015; Srinivasan & Swink, 2018). This argument made OIPT a valid theoretical basis to discuss the organizational implications of data analytics.
The original focus of OIPT on uncertainty was extended with the aspect of equivocality (Weick, 1979) that can be interpreted as "ambiguity, the existence of multiple and conflicting interpretations about an organizational situation” (Daft & Lengel, 1986, p. 556). At the same time, Zack (2007, p. 1665) differentiates equivocality from ambiguity: the former means “having several competing or contradictory conceptual frameworks”, the latter is about “not having a conceptual framework for interpreting information”, where the framework is built on the knowledge of the individual.
At that point, we need to make a clear distinction between data, information, and knowledge. Data is a set of discrete facts such as records of transactions (Davenport & Prusak, 1998) that is raw and unpunctuated (Zack, 2007). Data needs to be cognitively processed to serve as information (Zack, 2007) that is relevant, accurate, timely, and concise (Tushman & Nadler, 1978). Information is a message that has a sender and a receiver, and it aims to have an impact on the receiver: it affects and alters existing knowledge of the receiver (Davenport & Prusak, 1998). Knowledge is a unique mix of former experience and values which is held at the individual level (Kogut & Zander, 1992). Information not only alters existing knowledge, but a sufficient pre-knowledge is also required on the part of a receiver for understanding and interpreting the received information (Zack, 2007). In sum, data is transformed into information that enriches knowledge.
Uncertainty is linked to the shortage of information derived from data; accordingly, it can be reduced by obtaining and processing additional data (Galbraith, 1974). Complexity is experienced when a high amount of information loads the processing. In both cases, the focus should be on optimizing the amount of available information (Kowalczyk & Buxmann, 2014) that requires enhanced information processing driven by information technology that is applied by the firms (Zack, 1993). This proposition makes the focus on information technology an important proxy for the companies’ information processing mechanism.
Ambiguity and equivocality are not linked to the amount of information but to the problems of interpretive knowledge frames. Therefore these cannot be managed by bigger datasets and require an increase of the richness of information that can reduce confusion and enhance understanding (Daft & Lengel, 1986). In ambiguous situations, the receiver of the information is not able to interpret the message as he or she lacks proper knowledge. In the case of equivocality, the multiple interpretations lead to confusion (Zack, 2007). In both cases, the organization needs less structured personal media that makes repeated interpretation and interactive discussions possible (Mintzberg et al., 1976).
Decision contexts can be characterized by a certain level of ambiguity, equivocality, uncertainty, and complexity (Kowalczyk & Buxmann, 2014; Zack, 2007) that needs to be handled at the same time. Daft and Lengel (1986) proposed a continuum of seven mechanisms to handle uncertainty and equivocality. Their framework was later adapted and reworked by Kowalczyk and Buxmann (2014) in their study focusing on analytics-supported decision processes and distinguishing four data-centric and four organizational information processing mechanisms. Data-centric mechanisms cover diverse types of data analysis that serve primarily as tools for the resolution of uncertainty problems. Organizational mechanisms cover different types of joint efforts of organizational members, such as planning, direct contacts or group meetings, focusing on mitigating problems arising from equivocality.
As one of the organizational mechanisms, firms employ integrators who carry the role of integrating and distributing information in the organization to reduce equivocality and, therefore, overcome disagreement arising from interpretation problems (Daft & Lengel, 1986; Kowalczyk & Buxmann, 2014). The role of such integrators might be vital if data-centric mechanisms are well developed because a high level of analytic elaboration might hinder the understanding of the results, mainly when decision makers have limited analytics knowledge (Kowalczyk & Gerlach, 2015; LaValle et al., 2011). The mediating role of an integrator was proved to be important in both uncertain and non-routine decision contexts (Kowalczyk & Buxmann, 2014). As data scientists or analytics experts with deep knowledge in technology and analytic methods are not necessarily experts in the business domain, this might hinder them from being integrators (Kowalczyk & Buxmann, 2014). It is proposed here that another occupational group can effectively take this role. Controllers having both analytical competencies and business knowledge can effectively decrease ambiguity by supporting the interpretation of numbers and handle equivocality by consulting and carrying information across departments.
Recently, researchers have been anxiously watching the latest developments in controllers’ work: the previously emphasized broadening role seems to be narrowed due to the increasing use of digital technology (Andreassen, 2020). While their competence has not been questioned in the past concerning analysis based on financial and management accounting data, this monopoly is lost in the analysis of new types of data where the boundaries between disciplines are blurred (Arnaboldi et al., 2017). Previously, a vertical power shift has been reported as the effect of implementing transactional systems. The consequence of recent trends of adopting advanced analytics may be a horizontal power shift: from the controllers’ domain to the business domains that are not only the subject of data analysis but also implement analytics on their own (Knudsen, 2020). It also means that the designer of management reporting systems might no longer be the controllers, but they will help end-users to select and interpret data relevant to the decision (Rikhardsson & Yigitbasioglu, 2018). This new focus of controllers’ work fits the above-described role of an integrator.
2.2 Data analytics and organizational decision making
As part of the data-centric mechanism, data analysis is receiving increasing attention among practitioners and researchers. While the term ‘analysis’ refers to the activity itself, ‘analytics’ is understood as the body of knowledge or principles (Power et al., 2018). The terms business analytics and data analytics are usually treated as synonyms, as business analytics is the general term for data analytics in business problems (Duan & Xiong, 2015). We consistently use here data analytics. There is no clear position in the literature on how this relates to the concept of business intelligence (BI), which is defined as the use of technology to collect and use information for business improvement (Sahay & Ranjan, 2008). Analytics is often viewed as an integrated part of BI (Gudfinnsson et al., 2015), as “an advanced discipline within business intelligence” (Laursen & Thorlund, 2016, p. xxiv) that goes beyond the simple technical reporting solution by extending it with a vast volume of data, new software solutions and intensified use of analytical models. Others argue that recent developments in analytics have shown its importance and suggest not to use BI and analytics interchangeably but to refer to it as BI&A (Božič & Dimovski, 2019; Chen et al., 2012; Kowalczyk & Gerlach, 2015).
The umbrella term BI&A is interpreted as a set of technologies and processes that use data to analyze and interpret business performance and provide information for decision support purposes (Rikhardsson & Yigitbasioglu, 2018). The field of BI&A can be examined along with the aspects of infrastructure, data management, the nature of information provision, and data analysis (Rikhardsson & Yigitbasioglu, 2018). Of these aspects, this article deals with data analysis that can be characterized along three dimensions: the area that indicates the context in which the analysis is applied; the technique that covers a range of qualitative techniques to quantitative methods of varying complexity; and the orientation of the analysis that refers to the direction of thinking (Holsapple et al., 2014). Orientation can be (1) descriptive, where the analysis is based on past, and present data, (2) predictive, that covers analysis inferring from past data to the future, (3) prescriptive, including analysis that proposes actions based on complex models, and (4) autonomous, where analysis is based on models that continuously learn from the data (Davenport & Harris, 2017).
Descriptive data analytics is considered as a basic analytics capability, analytics with predictive, prescriptive, and autonomous orientation are referred to as advanced analytics that includes comprehensive functionalities of statistical analysis, simulation, optimization methods, and data mining (Davenport & Harris, 2007; Kowalczyk & Buxmann, 2014; Watson, 2010). However, a companys' advanced analytics capability alone is not enough; additional human and organizational conditions must be met in order to not only analyze but also utilize the data (Lismont et al., 2017), i.e. use and incorporate analytical results into decision making. If these conditions are met, data analysis is able to change the decision making, which is designated in the literature as fact-based, data-based, analytical, or data-driven decision making (Brynjolfsson & McElheran, 2016; LaValle et al., 2011; Popovič et al., 2012). Decision making is understood as a process, a set of actions "that begins with the identification of a stimulus for action and ends with the specific commitment to action” (Mintzberg et al., 1976, p. 246) and data-driven decision making is understood as the extent of relying on data-based insights during the organizational decision making process (Cao et al., 2015). Prior research linked advanced analytics with diverse facets of decision making, such as the effectiveness (Cao et al., 2015) or the quality (Janssen et al., 2017) of it. The findings show that enhanced quality and effectiveness are essential gains from the use of data analytics, but the realization of these benefits is not straightforward. Not only the quality of the source data, the processing of the data and method of data transfer influence the quality of decision making (Janssen et al., 2017), but an adequate data-driven environment is also required: strategy and policies that guide business analytics activities, an enabling organizational structure, integration of analytics activities into business processes and prioritizing related investments (Cao et al., 2015).
2.3 Technology orientation and digital orientation
The development of information processing capacity has been long an issue for companies, but databases and analytics have been used only for the last couple of decades (Galbraith, 2014). Hence, the development of the information technological (IT) background – software, hardware, and personnel – is not a new phenomenon. Growing out of the strategic management literature, technology orientation is conceptualized as one of the possible strategic orientations and is widely used in marketing research (Gao et al., 2007; Voss & Voss, 2000). Technology orientation is denoted here as the firm's "ability and will to acquire a substantial technological background" (Gatignon & Xuereb, 1997, p. 78). Information system (IS) research narrowed this concept to information technology. It introduced the related term of information systems strategic orientation, restricting it to the actual activities of the companies by measuring the realized investments instead of intentions (Cao & Schniederjans, 2004; Chan et al., 1997). Here, we limit technology orientation to information technology in line with IS research and conceptualize it as a firm’s will and ability to acquire and develop substantial IT background. In that sense, technology-oriented firms are willing to devote their resources to IT development, a prerequisite for building and maintaining adequate infrastructure and processes capable of meeting the ever-increasing information processing capacity needs.
After several subsequent and overlapping innovations in the history of IT, such as personal computing in the 1980s or internet computing in the 1990s, recent developments are referred to as digitalization (Riedl et al., 2017). It includes diverse innovations such as cloud computing, embedded internet of things devices, enterprise ecosystems, and social media platforms (Bhimani, 2020) that can alter business strategies, processes, products, services, and key interfirm relationships (Bharadwaj et al., 2013). Because of the speed of the technological transition and the scale of related business change, the developments are often argued to be revolutionary (Brynjolfsson & McAfee, 2011).
Digital innovations enabled the extreme expansion of information processing capacity as they changed the fields of data collection, storage, processing, and use, thus drastically reducing their costs. In addition to the vast and ever-increasing amount of structured data, unstructured data is collected in a short time and is available to organizations (Knudsen, 2020). Traditional systems designed to capture, process, and store transactional data are not able to process and analyze new types of data; these require new technologies, innovative forms of information processing (Cao et al., 2015). Accordingly, mere focus on information technology is not enough. Companies need to be digitally oriented to use and make use of new technologies: they need to be "well-positioned to take advantage of the opportunities presented by digital technologies" (Quinton et al., 2018). Although digital orientation is interpreted along several dimensions in the literature (Kindermann et al., 2020; Saunila et al., 2020), here we conceptualize digital orientation as the firm’s commitment toward using digital technology (Khin & Ho, 2018).
2.4 Interplay of technology, data analytics, management support and managerial information processing
Information technology, management support and managerial information processing have always gone hand in hand. Implementing information technology solutions is argued to be ‘an effective environmental pull factor’ (Heinzelmann, 2018), an’exogenous shock’ (Vitale et al., 2020) that alters how controllers can execute their task and support managerial decision making. Decades ago, the implementation of transactional systems modified (integrated and standardized) information flows, and line managers had not only greater overview of and responsibility for the financial aspects of their operations and but they needed more intensive support of controllers to interpret the various information newly available in the system (Scapens & Jazayeri, 2003). The technology changed managerial information processing that in turn required from controllers enhanced support of management instead of a simple focus on information provision.
Recent improvements in technology and data analytics reshape information processing in organizations again and "have the potential to make a lasting difference to the ways that accounting … is carried out" (Bergmann et al., 2020, p. 26). Evidence provided for the interplay between technological disruptions and controllers (Heinzelmann, 2018) is not primarily reasoned by altering management accounting techniques, rather by the greater emphasis on analysis and management support that has been long argued as an integral part of the controllers' work (Burns & Baldvinsdottir, 2005; Byrne & Pierce, 2007; Goretzki et al., 2013; Pasch, 2019). As both business intelligence and analytics (BI&A) technologies and management accounting activities are designed to support decision making, there is an unambiguous link between them (Rikhardsson & Yigitbasioglu, 2018). In the next part of the paper, we develop our hypotheses explaining the suggested interplay of technology, data analytics and controllers’ work with managerial information processing.
2.5 Hypotheses development
As suggested by the OIPT, organizations build and maintain a unique combination of data-centric and organizational information processing mechanisms to cope with uncertainty and equivocality. Formerly, the management accounting activities produced the primary information base with the aim of enhancing clarity and certainty in managerial decision making (Bhimani, 2020), and as a reaction to new information needs, new management accounting techniques had been developed (Johnson & Kaplan, 1987). Recently, the relevance of former, accounting-based information structures seems to be lost again, and companies try to make use of the vastness of newly available data. Instead of repeated advancement within the management accounting domain, “enterprises today exercise data reach and plurality of information usages to inform enterprise action” (Bhimani, 2020, p. 12) and develop their analytical competencies.
The establishment of novel practices of data collection and analytics goes hand in hand with a solid commitment to IT development for two reasons. Firstly, newly available datasets are collected, processed, and stored by IT solutions far beyond traditional transactional systems that need to be acquired, developed, and maintained. Secondly, to make use of new datasets, advanced analytics techniques need to be widely applied that might require increased computational power (Appelbaum et al., 2017). The necessity of advances in information technology was argued by researchers for the precursors of advanced analytics, such as enterprise systems, as well (Sharma et al., 2014). With respect to analytics, the proposed link between the focus on IT and the use of advanced analytics is supported by OECD (2013), reporting that the data-intensive sectors tend to have a high information and communication technology (ICT) intensity since they invest in technology to be able to collect and process data holdings. Moreover, evidence was found that using and investing in data analytics is associated with company-wide advancements in technology as well (Sena & Ozdemir, 2020). Based on these findings, we propose that technology orientation and advanced data analytics are positively related to each other.
H1a: The technology orientation of the company is positively associated with the use of advanced analytics.
As current advancements in information technology cannot remain divorced from developments of digital technology, and novel information structures and processing modes are linked with digital innovations, we posit that firms’ digital orientation also plays a crucial role. Even though technology orientation is argued to be not a sufficient condition for success in digitalization (Kindermann et al., 2020), it proved to be a relevant supporting factor. Al-Ansari et al. (2013) found that having a high commitment to technology is highly important in responding to the ever changing technological conditions. Focusing on and investing in information technology as an operational backbone remains crucial for success in using digital technologies as it gives “the foundational capabilities that are needed to enable its digital services platform” (Sebastian et al., 2017, p. 207). These findings suggest that the firm’s commitment to technology is positively associated with their digital orientation.
H1b: The technology orientation of the company is positively associated with its digital orientation.
Even if taking advantage of the opportunities offered by new digital technologies is underpinned by substantial technology focus, there is more to digital-oriented companies: they have an attitude that supports openness to new ideas, techniques and generation and use of new information (Quinton et al., 2018). This openness to and adoption of digital technologies can quickly redesign the former information processing mechanism and boost the use of advanced analytical techniques as innovative technologies offer new ways of data generation and exploitation easily accessible for companies of all sizes, also for those with typically limited financial resources (Moeuf et al., 2020). Thus, we propose that digitally orientated firms are ahead in the use of advanced data analytics.
H1c: The digital orientation of the company is positively associated with the use of advanced analytics.
While the ongoing increase of information processing capacities requires substantial IT background, the new ways of data generation and exploitation are offered more by new innovative technologies (Moeuf et al., 2020). Accordingly, we expect that the catalyst effect of technology orientation on the use of analytical techniques is explained mainly by digital orientation. The proposed mediator effect of digital orientation calls forth a related hypothesis.
H1d: The digital orientation of the company mediates between the technology orientation of the company and its use of advanced analytics.
Information base used to inform managerial actions undergoes fundamental changes. Whereas basic descriptive analytics of financial and basic operational data has been part of the toolset of companies for a long while, recently predictive and prescriptive techniques are also widely adopted by firms (Davenport, 2013; Davenport et al., 2019). How these advanced analytical techniques of data create value for the adopter is of high interest to researchers, but in many cases, indirect second-, or third-order effects are investigated without understanding the steps of value creation (Gillon et al., 2014; Seddon et al., 2017). The direct value of data analytics stems from whether analytics can provide new and valuable information usable in many different ways (Grover et al., 2018). If products of advanced analytics are not perceived at all or perceived as non-usable by managers, utilization of analytical information fails, and the business value lags. Accordingly, we assume that the ‘ability to be used’ precedes utilization; thus, a first and direct link is proposed from the use of advanced analytics to the ability of generated information to be utilized in the decision context.
H2a: The use of advanced analytics is positively associated with the extent to which available information is able to support decision making.
Utilizing the outputs of advanced analytics is often hindered by missing or wrong interpretation of the data due to the lack of time and knowledge of the executives (Arnaboldi, 2018). Facilitating the interpretation of the numbers requires less technical but more business knowledge (Kowalczyk & Buxmann, 2014) and calls for value-added management services traditionally provided by controllers. While providing value-added services – often referred to as business partner role (Goretzki & Messner, 2014; Hartmann & Maas, 2011; Pasch, 2019) – controllers they not only provide good quality information to managers (Sathe, 1983), but help a deep understanding of this information (Quinn, 2014), are able to make suggestions (Byrne & Pierce, 2007), and are involved in both the strategic and operational decision making processes of organizations (Byrne & Pierce, 2007; Zoni & Merchant, 2007). Accordingly, the emerging need in interpreting new data can again divert managerial attention to controllers. Thus, we propose that advanced analytical practice can enhance the perceived value of controllers.
H2b: The use of advanced analytics is positively associated with the added value of controllers.
A good understanding of the business and the general analytical and IT skills have been long mentioned as crucial characteristics of controllers (Byrne & Pierce, 2007; Jablonsky et al., 1993; Pierce & O’Dea, 2003). Analytics experience has recently received more emphasis in controller-related studies (Bhimani & Willcocks, 2014; Oesterreich et al., 2019; Payne, 2014), although data analytics is not a privilege of controllers anymore (Knudsen, 2020). Their experience in analytical work does not primarily stem from expertise with new analytical tools; this is instead "the 'nose for the numbers' – tacit knowledge which supports the ability to spot patterns and anomalies and ask the right questions” (Payne, 2014, p. 494). This qualifies controllers for being helpful in interpreting analytical information. Thus, we assume that controllers’ added value can facilitate how information based on advanced analytics is sensed in the decision context.
H2c: The added value of controllers is positively associated with the extent to which available information is able to support decision making.
Kowalczyk and Buxmann (2014) showed the importance of interpreting analytical information in organizational information processing. "Within the set of organizational information processing mechanisms, the analytic integrator role is particularly noteworthy, as it is utilized throughout the different decision types to bridge understanding gaps between decision makers and analytics experts" (Kowalczyk & Buxmann, 2014, p. 276). In line with this finding, we propose that controllers can act as integrators if they are able to shift away from basic data collection and provision and take a more substantial role as described above. Thus, it is argued here that the added value of controllers mediates between the use of advanced analytics and the ability of provided information to be utilized in a decision context.
H2d: The added value of controllers mediates between the use of advanced analytics and the extent to which available information is able to support decision making.
Information available for decision makers is processed by a dual system: a fast, holistic and unconscious system and a slower, cognitively effortful system (Salas et al., 2010), referred to as intuitive and analytic by Hammond (1996). Analytic information processing starts with collecting, collating, analyzing, and interpreting the available information, and it consciously arrives at a logical choice. Consciously-derived rational choices require unambiguous, sufficient 'hard' data that is immediately to hand (Sadler-Smith & Shefy, 2004). Although numerous diverse factors influence organizational decision making processes, we can reasonably expect that high-quality information (i.e. cognitively processed data) at hand will be utilized by decision makers to a greater extent, possibly also moving into new territories which have been seen as reliant on human judgment so far (Brynjolfsson & McAfee, 2011). Namely, the ability of provided information to be utilized in decision context will improve the extent of relying on this information during organizational decision making process (Sharma et al., 2014), referred to as data-driven decision making (Cao et al., 2015).
H3: The ability of information to be utilized in decision context is positively associated with data-driven decision making.
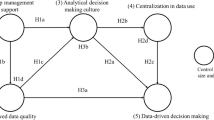
This set of hypotheses is summarized in the research model that consists of one exogenous (1) and five endogenous constructs (2–6) and proposes cause-effect relationships between them described by seven paths (pxy) (see Fig. 1). To rule out the confounding effect of company size and industry, the model includes these control variables by assessing their effects on each endogenous construct: (2) digital orientation, (3) use of advanced analytics, (4) added value of controllers, (5) the extent to which available information is able to support decision making (shortly referred to as ‘decision support’) and (6) data-driven decision making.

Research model
3 Research method
3.1 Data collection and sample
The data collectionFootnote 2 took place between October 2018 and July 2019, targeting medium and large companies registered in Hungary across several industries displayed in Table 1. Small and micro firms were excluded as information technology, analytical practice (Lyver & Lu, 2018) and management accounting systems (Mitchell & Reid, 2000) are in an early stage of development in this segment. The non-existence of developed formal systems can be the result of a deliberate choice, but the reasons are often argued to be possibility-based (e.g. no financial resource), awareness-based (e.g. lack of knowledge) or need-based (e.g. felt irrelevant due to simple operation) (Choudhury, 1988; Taipaleenmäki, 2014).
Reflecting the diversity of the population, stratified random sampling was executed, stratifying by company size (defined based on the number of employees) and industry. Out of the 4295 companies in the sampling frame, over 2000 companies were randomly selected and first contacted by phone during this sampling process. Following a positive response from 234 companies, the interviewers personally visited them. An initial short face-to-face survey with the top executive was followed by longer self-administered paper and pencil questionnaires addressing (1) general management issues and (2) operations management, including technology-related questions. Although this study does not use variables relying on the face-to-face survey questions, the first personal contact with the top executives is seen as necessary in terms of motivating the respondents to participate seriously and aiming to achieve a better quality of data (Heerwegh & Loosveldt, 2008). The research purpose was detailed and face-to-face communicated to the top executives with a promise of feedback about the research results.
The self-administered questionnaires were completed and returned adequately by 209 companies. Each company's perception-based survey data was completed with balance sheets and profit and loss statements obtained via Bisnode database for 5 years (2013–2018). Eighteen companies needed to be excluded because their reported number of full-time employees was under 50. Excluding small size enterprises from the research is justified by our assumption that they do not have extensive practice in the topics on which the research is based. The sample of 191 cases was further reduced to 176 cases due to missing values exceeding 15%, as suggested by Hair et al., (2016, p. 51). The concentration of missing values in specific sets of questions about advanced analytics and available information showed that respondents might have felt the questions irrelevant to their organization. In the reduced sample, missing values per variable range from 0% to 4.5% (see appendix II) except for the machine learning variable (60.8%), which had to be dropped from the model. Missing values were treated by mean value replacement that is reported not to have major effects on the results (Hair et al., 2016). Table 1 contains characteristics of the final sample compared with the sampling frame.
Our response rates of 10.45% (n = 209) and 8.80% for the reduced sample (n = 176) can be considered as average compared to surveys in this research area. Recent studies linking digitalization, data analytics with management accounting and decision support report about very similar effective response rates of 8%(Bergmann et al., 2020) and 9.38% (Knauer et al., 2020). We tested for a potential non-response bias by comparing the target population and the final sample of respondents (Knauer et al., 2020). As the null-hypothesis of normality was rejected for our data based the Shapiro–Wilk test (p < 0.001), the non-parametric Mann–Whitney U test was applied here. The result (p = 0.457 > 0.05) shows that we can accept the null hypothesis that the final and target samples do not differ significantly in terms of company size. Based on the Pearson chi-square test (p = 0.463 > 0.05), we conclude that there is no significant difference between the groups in terms of the industry either. The results suggest an absence of response bias.
Harman's Single Factor Test was used for assessing common method bias. As the total variance extracted by one factor (43.78%) does not exceed the threshold of 50%, it is not reported to be a critical issue. To mitigate common method bias and avoid reporting false, accelerated relationships between causes and outcomes, we followed Podsakoff and Organ (1986; 2012) in designing the survey. Measures with different scaling formats were applied, and separation of measurement was established. Scale properties vary among the variables: it uses both attitude scales and frequency scales, and in the case of the dependent construct 6 variables cover reversely worded items. Separation of measurement was secured by developing two questionnaires. Questions related to each endogenous construct were raised in the general management survey, and questions related to the exogenous construct of technology orientation were answered within the operations management survey. At the initial personal interview, companies were asked to address the surveys to the responsible managers competent in answering the questions, preferably the top executive and head of operations or technology – if this position exists separately at the company. There are two main reasons why clean pairs could not be reached for 62 companies: due to the company's size, the same person was responsible for all the topics targeted, or the responsible managers in charge were not available at the time of the survey. Table 2 shows the characteristics of the respondents.
Adapting to the respondents, the language of the survey was Hungarian, translated into English later. After a thorough review of the scales by academics, the questionnaires were pre-tested by the interviewers of the research institute carrying out the questionnaire survey. Interviewers conducting the face-to-face interviews acted as test respondents to ensure that the questions were easy to interpret and unambiguously worded.
3.2 Operationalization and measurement properties
The research model presented in Fig. 1 relies on terms investigated in prior studies at the fields of information systems, marketing, management accounting and control, and decision processes. For operationalization of most of these constructs, we decided to develop our own measurement scales that best fit the study's purpose. Two reasons support this choice. First, the fast-growing literature is not short of interpretations of terms but commonly agreed definitions rarely exist. The lack of commonly agreed definitions did not allow for the widespread use of validated scales. Rather researchers develop their conceptualization and fit the items to that. After a thorough literature review, we delivered clear definitions for each construct. These definitions built on the work of several different authors guided us in providing scales that can capture the essence of the constructs. Second, in line with the argumentation of Bergmann et al. (2020), the validity of self-developed or adopted measures always remains a sensitive issue; however, the difficulties are more in the measurement of personality variables, attitudes and self-reported behaviours, the areas with possibly high social-desirability bias (Fisher & Katz, 2000). As our items refer mainly to the existence of practices and the use of specific techniques, we do not expect that the items' wording critically deflects the items’ value.
To limit the length of the survey, some items merge different but closely linked facets of a phenomenon, such as 'challenges and opportunities',' plan and implement', 'analyze and provide'. This kind of global measure allows the respondents to consider all aspects at once. At the same time, they may tend to disregard some aspects and focus on those relevant in their organization, leading to a different weighting of aspects in the case of different respondents (Diamantopoulos et al., 2012). Variables were typically answered on five-point scales as presented in the appendix.
Technology-orientated firms will and are able to acquire a substantial technological background (Gatignon & Xuereb, 1997). In contrast to the new product development-focused scales of technology orientation in marketing research, we operationalized the ‘will and ability’ of technology orientated firms (1) by the amount of their IT investments, (2) by the knowledge of people in this field, and (3) by the organizational significance of IT. Investment in information technology measured by the IT budget as a percentage of revenue has been long proposed as a significant predictor of the organizational impact of IT (it_1) (Mahmood & Mann, 1993). This comprehensive measure is relevant regardless of industry, does not limit the focus on any solutions, and has been used as an important explanatory variable in later information management studies (Luftman et al., 2013). Beyond software and hardware investments, companies need to acquire and develop technical support staff with IT knowledge that is understood as the extent to which a firm possesses a body of technical knowledge (Tippins & Sohi, 2003). Outstanding IT staff in terms of capacity and knowledge (it_2) alongside their adequate knowledge about basic activities of the company (it_3) are required to operate and utilize technology the company invested in. Moreover, in order for IT to play a strategic role, organizational members responsible for IT need to move from backroom to boardroom (Romanczuk & Pemberton, 1997). Accordingly, a direct line to the CEO as a measure of organizational significance was expected to be a crucial aspect of technology orientation. This variable was not retained in the final model, as the items’ outer loading (0.664) was below the suggested threshold of 0.708 (Hair et al., 2016).
Digital orientation was conceptualized in line with technology orientation. Therefore adequate financial resources (digi_3) and digital technological knowledge (digi_4) are seen as critical organizational aspects here as well. As digital orientation assesses a firm’s commitment to using digital technologies, it requires an attitude of being open to new innovations and challenges and adequate behaviour. These are terms that describe several further layers of digital orientation and were handled first by the digital maturity models developed close to practice (Gill & VanBoskirk, 2016; Ifenthaler & Egloffstein, 2020; Kane et al., 2017). Similar to the Digital Business Global Executive Survey (Kane et al., 2017), we supplemented the organizational aspects with several items of attitudes and behaviour and included a good understanding of digital challenges (digi_1), clearly defined digital strategic directions (digi_2), capability for rapid change (digi_5), risk-tolerance (digi_6), the constant search for new solutions (digi_7) in the model. A total of 11 items were measured, resulting in a construct with extremely high reliability measures (composite reliability of 0.9672 and Chronbach’s alfa value of 0.9625) signalling semantically redundant items. As redundant items might boost error term correlations (Hair et al., 2016), four items overlapping with digi_2 (non-accidental project implementation and embracing digitalization ideas) and digi_7 (testing new digital technologies and being ahead of competitors in digital technology innovation) were not retained in the final model.
The construct of advanced analytics is measured by Davenport’s and Harris’ typology (2007) of predictive (aa_1), prescriptive (aa_2), and autonomous analysis (machine learning). The high item non-response for machine learning (60.8%) is interpreted as missing knowledge about models that are constantly learning from data. Compensating for item non-response by imputation was rejected here. A mean imputation (replacing missing values with mean values) would distort the variable as we expect that non-respondents are all non-users. Applying the only plausible value (1 = not used at all) as a replacement, we arrive at a variable with a very low variance that is not able to contribute to the explanation of the advanced analytics construct. Accordingly, we decided not to involve this variable in the model, even if this limits the concept of advanced analytics to predictive and prescriptive analytics.
While measuring the added value of controllers, we recognized controllers’ involvement in both the operating and the strategic processes (Sathe, 1982; Zoni & Merchant, 2007). Controllers’ added value is evaluated by their involvement in preparing analysis and interpreting of information (co_1), recommending actions (co_2), and advising in decision making (co_3) not only in operating decisions but in strategic decision context as well (co_4, co_5, co_6). Unlike many studies investigating controllers' activities, skills or involvement based on their self-picture (Emsley, 2005; Loo et al., 2011; Pasch, 2019), this study aims to measure the perceptions of top executives. This choice is reasoned by the fact that answering the questions (co_1-6) do not require technical knowledge of the profession, and perception gaps between controllers and managers (Byrne & Pierce, 2007; Pierce & O’Dea, 2003) can be avoided. Most importantly, managers’ perceptions matter here: it cannot be expected that the invisible work of controllers, not perceived by the manager, will help him/ her to interpret analytical information and facilitate information processing.
Consistent with the argument of LaValle et al. (2011) – that the available information from data analytics should be able to guide both day-to-day and strategic decisions – the ability of information to support decision making was measured both for day-to-day business decisions (ds_2) and for business development decisions (ds_1). As information systems (IS) contain various information, we cannot expect all types of information to be affected by advanced analytics. By a global rating of information available in IS, respondents provide a complete picture while “respondents tend to ignore aspects that are not relevant to their situations” (Diamantopoulos et al., 2012, p. 445). Accordingly, we can expect that respondents ignore aspects of IS that are not relevant to decision support.
Data-driven decision making is operationalized as the extent to which the organization depends on data-based insights for decision making. The measurement tool developed by Covin et al. (2001) was readapted by assessing whether decisions result from extensive quantitative analysis of data (ddd_1) or experience-based intuition (ddd_2, ddd_3). As the composite reliability value of the construct 6 was above the threshold of 0.95 and items ‘c’ and ‘d’ proved to measure the same phenomenon, it suggested removing the superfluous variable from the model (Diamantopoulos et al., 2012). Thus, we operationalized data-driven decision making by the tendency to rely on the data analysis in decisions (ddd_1) and an opposing tendency to rely on experience-based intuition (ddd_2)—arriving at a measurement model suggested by LaValle et al. (2011) in their data analytics related study. The suggested opposition of variables means that when an executive prefers to decide based on data, he/she is less intuitive. If a respondent gives a score of 4 for each variable on a scale of 1 to 5, it means that data-based and intuition-based decision making have the same frequency. That says nothing about preference. To clearly indicate preference, the data were centered across the second mode: original values are transformed into deviation scores by subtracting the average value for each case calculated for the set of variables. This data transformation method is used for reducing systematic errors of Likert scale measurement, which arise from the respondents' individual propensity for a uniformly better or worse grading (Bro & Smilde, 2003). The value of the transformed variables thus indicates that intuition and data-based decision making are used at a rate below or above the respondent’s own average preference. As the latent variable assesses reliance on data, the scale of the variable ddd_2 was reversed before involving in the calculation.
The confounding variable of company size was involved in the model. Out of the wide range of size measures, the continuous variable of the number of full-time employees in 2018 was chosen as it is considered as a common proxy for the span of control in an organization (Becker-Blease et al., 2010), an aspect of company size that is the most relevant for our research purposes. Out of the 176 companies in the sample, 99 are active in the processing industry; thus the effect of processing was ruled out by involving a confounding industry variable as a dummy variable showing that the company is active in the processing industry or not.
The study is based on the method of partial least squares structural equation modelling (PLS-SEM) and the model was calculated using the software package SmartPLS 2.0. PLS-SEM is willingly used by researchers in fields related to this paper, such as information management (Hair et al., 2017) and management accounting (Nitzl, 2016), also in the European context (Richter et al., 2016). The choice of PLS-SEM is reasoned by the fact that it enables simultaneous estimates of the interrelationships between complex constructs under study, and it has a predictive power (Shmueli et al., 2016). The predictive relationships can be considered as casual relationships if they are theoretically strongly supported (Hair et al., 2016).
The proposed model applies two -or three-item scales, and PLS-SEM allows for the unrestricted use of a small number of items in construct measurement. Even single-items (SI) (as the lowest possible number of items) are very often used in PLS-SEM models (Ringle et al., 2012). Although multi-item (MI) scales usually outperform SI in terms of predictive validity, there are some conditions when SI scales or small number of items are acceptable (Diamantopoulos et al., 2012). The construct' use of advanced analytics' is judged to be very concrete here; it is reasonable to assume that there is an agreement among respondents about predictive and prescriptive analytics. Overall evaluations are similarly considered as concrete; thus construct 5 evaluating the company's information system can be measured by a single global measure (Rossiter, 2002). Furthermore, in the case of 'data-driven decision making' the dimensionality of the measure have been reduced to two as items measuring intuition and experience-based decision making proved to be very homogenous, a further condition when SI and MI scales are likely to match up (Diamantopoulos et al., 2012).
4 Research results
The’10 times rule’ (Barclay et al., 1995) suggests ten times the largest number of structural paths directed at any latent variable as the minimum sample size, that is 20 in this case. This rough guideline was criticized many times as it can accept samples of small size that show unacceptably low levels of statistical power (Henseler et al., 2009; Kock & Hadaya, 2018). The ‘minimum R‐squared method’ that builds on Cohen’s work (1992) relies again on the maximum number of arrows pointing at a construct anywhere in the model (here: 2), but it also addresses statistical power and effect size issues. It suggests that at least 75 observations are needed for detecting an R2 value of at least 0.25 at a significance level of 1%, assuming a statistical power of 80% (Hair et al., 2016). Our number of cases (n = 176) far above this required minimum can help with minimizing PLS-SEM bias, i.e., underestimating structural model relationships and overestimating measurement model relationships.
4.1 Measurement model assessment
The PLS algorithm was run with a path weighting scheme in order to maximize R2 values for the endogenous constructs. Initial weights were set at + 1.0 with a maximum number of 300 iterations and a stop criterion of 10–5. The measurement model (outer model) that specifies the relationship between observable and latent variables is operationalized reflectively. As suggested by Hair et al. (2019), the reflective outer model is assessed by the evaluation of (A) indicator reliability, (B) internal consistency reliability, (C) convergent validity, and (D) discriminant validity.
As reported in Table 3, indicator reliability is established by outer loadings above 0.708, a threshold that stems from the requirement that each of the latent constructs should explain over 50% of each item's variance, meaning that the square of outer loadings should be at least 0.7082 = 0.5 (Hair et al., 2016). Item reliability, understood as the consistency of a set of variables, shows to what extent the items measure the same phenomenon. Cronbach’s alpha is the widely used measure of item reliability assessing the internal consistency of the variables (Dunn et al., 2014). Values over 0.7 reported for the six constructs (0.75—0.93) are a good sign that the sets of indicators measure the uni-dimensional constructs well (Nunnally & Bernstein, 1994). As an alternative measure of consistency reliability, composite reliability (CR) values are reported in the range of 0.85 and 0.95. According to Hair et al. (2019), values of reliability measures above 0.95 are reported to be problematic in PLS-SEM models. Increased level of composite reliability and Cronbach’s alpha values may occur when a measure is highly homogenous, indicative of semantic redundancy. The CR value of construct 3 exceeds this less rigorous threshold of 0.95. The construct involves two indicators: predictive and prescriptive analytics that are theoretically strongly supported and distinguished from each other; they do not measure the same phenomenon. As Diamantopoulos et al., (2012, p. 445) also noted, “inter-item correlations should not automatically be equated with semantically redundant items, because items measuring different aspects of a construct may also be highly related”.
Convergent validity on the construct level is established by the high values of average variance extracted (AVE), the sum of squared loadings divided by the number of items. The values reported in Table 3 show that 66.5–91.5% of each indicators’ variance is explained by the related latent variable. Discriminant validity is measured by the cross-loadings of the indicators reported in Table 4. As none of the cross-loadings exceeds the indicators' outer loading, each construct proved to be distinct from all other constructs. As an alternative and more conservative measure of reflective constructs' dissimilarity, calculation of the Fornell-Larcker criterion shows in Table 5 that the square root of AVE for each construct exceeds its highest correlation with any other constructs (Götz et al., 2010).
4.2 Structural model assessment
Before assessing the structural model, collinearity problems among the predictor latent variables were excluded. As each value of the variance inflation factor (VIF) (1.711 for the predictors of the use of advanced analytics and 1.476 for the predictors of decision support) is below the recently proposed and more rigorous threshold value of 3 (Hair et al., 2019), collinearity is not an issue in the model. Overall, the quality of the reflective measurement model is acceptable based on the results presented above.
The mediator model was assessed in two subsequent steps. First, the significance of direct effects was tested without the mediator variables (2) and (4) in the model. Second, the model was newly assessed after including the mediator variables. Although the significance of the direct effects is not needed to establish mediation, we propose a complementary mediation model meaning that we hypothesize both direct effects (effects to be mediated) and indirect effects pointing in the same direction (Zhao et al., 2010). In line with recent suggestions (Hair et al., 2021; Ramayah et al., 2017), Preacher and Hayes (2008) bootstrapping procedure was used for testing the model.
First, the significance of direct path coefficients was assessed by running bootstrapping procedure with 5000 bootstrap samples, 176 cases, and no sign changes. Considering that the critical t-value for two-tailed test is 2.57 (⍺ = 0.01), paths with empirical t-values exceeding this threshold are significant at a significance level of 1% (Hair et al., 2016). The direct path (p13) from technology orientation to advanced analytics proved to be significant (t value = 10.029), similar to the direct path (p35) from the use of advanced analytics to decision support (t-value = 8.961). Accordingly, hypotheses H1a and H2a are supported. The path coefficient (p56) between decision support and data-driven decision making with a t-value of 0.19 is not significant; hypothesis H3 is rejected. It means that technology orientation is an antecedent of the use of advanced analytics, which in turn helps managers perceive the information adequate for decision support, without any significant effect on the use of the information in a decision context.
In the second step, the bootstrapping procedure was repeatedly carried out for the mediator model to test the significance of both direct and indirect effects and evaluate the strength of the significant relationships. While p56 remains insignificant (t = 0.1956), all other empirical t-values are larger than the critical value of 2.47 for a 1% probability of error (see Fig. 2). Consequently, with one exception, all relationships are significant at a level of 1%.

Structural path model coefficients and t-values
While Götz et al. (2010) argued that there are no commonly accepted thresholds for the evaluation of path coefficients’ (ß) strength, Cohen’s (2013) suggestions are widely used: the values of 0.50, 0.30, or 0.15, represent strong, medium, and weak relationship. Accordingly, the ß values shown in Fig. 2 reflect the high relevance of how technology orientation enhances the digital orientation of the company (H1b). It also reflects that the use of advanced analytic techniques considerably improves the perceived added value of the controllers (H2b) and supports that the added value of controllers is highly positively associated with the extent to which available information is able to support decision making (H2c). Medium effects of similar size are depicted for how technology orientation and digital orientation are associated with the use of advanced analytics (H1a and H1c) and for the influence of advanced analytics on the ability of information to be utilized in a decision context (H2a).
The assessment of indirect effect sizes – calculated as the product of the direct path coefficients – needed to be tested again to discern whether these can be treated as significant (see Table 6). The empirical t-value of the indirect effect results from the indirect effect size divided by bootstrapping standard error (Hair et al., 2016). As both t-values (3.47 and 4.76) exceed the threshold of 2.47, both indirect effects via mediator are significant at a level of 1%. Therefore, hypotheses H1d and H2d describing the mediator effect are accepted: digital orientation mediates between technology orientation and the use of advanced analytics, and the added value of controllers mediates the relationship between the use of advanced analytics and decision support. Measured by the ratio of the indirect-to-total effect (also referred to as variance accounted for, VAF), that is, the fraction of direct effect and total effect (Nitzl et al., 2016), the strength of mediation is medium in both cases as VAF value is reported being between 20 and 80% (Hair et al., 2016). Mediator digital orientation explains 36.95% of the effect of technology orientation on advanced analytics, whereas mediator added value of the controller explains 50.45% of the effect of advanced analytics on decision support (see Table 6).
The model needed to be tested against the confounding effects of control variables. In a second model involving both company size and industry, the control variables were related to all endogenous variables (2–6). The significance and strength of the estimated path coefficients remained unchanged, proving that neither the effect of company size nor the industry distorts the results. While the industry is not significantly associated with any of the endogenous variables, the effect of company size on decision support is significant at a 10% significance level as the empirical t-value (t = 1.76) exceeds the critical value of 1.65. The close to zero but negative path coefficient (ß = -0.094) indicates that executives tend to perceive the available information as less adequate for decision support with growing company size.
R2 reflects the model’s in-sample explanatory power by measuring the level of each endogenous construct’s explained variance. While in some research fields R2 values are considered substantial at a value of 0.75, moderate at a value of 0.5, and weak at a value of 0.25 (Henseler et al., 2009), R2 values of 0.1–0.2 have also been reported as relevant in exploratory management accounting research (Hartmann & Maas, 2011). The R2 value of zero for data-driven decision making shows that the model has no predictive power for that latent variable. R2 values reported between 0.323 and 0.423 for other endogenous constructs are considered here as moderate.
The explanatory value of predictor constructs is often assessed by the effect size f2, measured as the change in the value of the coefficient of determination after omitting an independent latent variable from the model. As Hair et al. (2019) recently reported, the size of exogenous constructs’ influence on the dependent latent variable moves together with the value of path coefficients, and therefore reports on effect size f2 generally do not provide additional information. Instead, the focus is on the predictive accuracy assessed by Q2 values that use blindfolding procedure based on cross-validated redundancy approach (Shmueli et al., 2016). Except for data-driven decision making, Q2 values of all reflective endogenous constructs are considerable above zero. The values in the range between 0.25 and 0.5 depict a medium level of predictive relevance for these latent variables (see Table 7).
As summarized in Table 8, the significant paths of strong to medium strengths with a medium level of explanatory power on the model level support the original casual chain of how technology and digital orientation helps using advanced analytical techniques that, together with the added value of controllers alter information perception in a decision context. At the same time, the model leaves the link to data-driven decision making unexplained.
5 Discussion
Drawing on OIPT, this study proposed a set of causal relationships between technology orientation, advanced analytics, the ability of analytical information to be used for decision support, and reliance on this information in the decision making process. It was argued that digital orientation and the role of controllers are mediating factors in this logic. The findings of the structural model supported that the firm’s technology orientation plays a crucial role in the use of advanced analytics. That is in line with prior studies emphasizing that the application of information systems supports the information processing ability of firms (Mani et al., 2010) and managerial perception of IT positively influence organizations’ achievement in analytics (Chen & Nath, 2018). A mere focus on information technology might be scarce, as the effect of technology orientation on analytical practice is mainly explained by the firm’s digital orientation. The high effect size reveals that technology orientation is a prerequisite for digital orientation, but digital orientation is more than simply focusing on information technology: besides adequate knowledge and financial resources, it implicates attitudes and behaviours of senior management. Top executives’ beliefs on the benefits of digital technology have a domino effect on the attitude of other organizational members and strongly influence technology adoption (Jones et al., 2014; Quinton et al., 2018).
The significant impact of using advanced analytics on decision support reveals that the organizational achievements in developing analytical practice strengthen the perceived value of processed information, as Bergmann et al. (2020) also demonstrated the positive effect of the analytical practice on managerial satisfaction with the budgeting process. Nevertheless, the medium strength of this relationship suggests that improvements in managerial perception are lagging behind the developments in analytics. Cao et al. (2015) justified this on the grounds that developing firms’ information processing capability needs not only data analytics, but it requires the adequate design of processes, structure, policy, and strategy—factors not measured by our model. Moreover, exceeding basic descriptive analytics is often argued to require specialized knowledge of data analysts or scientists, at the same time the results might be less easily understandable and assessable for decision makers (Davenport & Harris, 2017). Interpretation of analytic results requires a good combination of analytic approach and business knowledge. We proposed that the controllers in their advocated role of business partner (Quinn, 2014) can help disseminate and interpret analytical information and support decision-makers to utilize it in a decision context. The model validated this complementary mediation hypothesis of the controllers' added value, in line with the expectations toward the role of controllers in assisting data-driven decisions (Stransky et al., 2019). Especially if highly elaborated analytics approaches are used, the trustworthiness of organizational members disseminating the information is a major factor in influencing analytics utilization (Kowalczyk & Gerlach, 2015). The position of controllers empowers them to build this trust (Busco et al., 2006; Scapens, 2006), thus enabling them to facilitate the acceptance of new analytical practices and information, even if they do not fully comply with the requirements towards advanced analytics competencies (Oesterreich & Teuteberg, 2019).
The insignificant path with a close to 0 path coefficient between the decision support and data-driven decision making destroyed the last link in the research model. Even if decision makers consider the available information adequate for decision support, this positive perception does not strengthen the reliance on analytical results during the decision making. Thus, a company with strong digital and technology orientation and outstanding use of advanced analytics might not necessarily exploit the data they have. LaValle et al. (2011) argued that getting the right amount and quality of data is not the primary challenge of companies. The leading obstacle is rather that organizations do not know how to use analytics results to develop their business. Thus, the available information based on advanced analytics can be outstanding, yet the lack of understanding about the utilization can hinder the use of information in the decision making process. This justifies the missing link between the ability of information to be used in decision making and the reliance on this information during the decision making process. The missing relationship is problematic in two respects. Neglecting analytical information in decision making while mastering advanced analytics seems to be a waste of resources, and it can create a company-wide scepticism towards the value of advanced analytics (LaValle et al., 2011). This scepticism will not help overcome the organizational inertia that is needed to realize the benefits from business analytics (Seddon et al., 2017).
Kowalczky and Gerlach (2015) found that the systematic processing behaviour, i.e. reliance on data analytics results, is determined by decision maker motivation. Likewise, it was reported by other studies that the adoption barriers are mostly managerial (Kane et al., 2017; Schoemaker & Tetlock, 2017). As LaValle et al., (2011, p. 25) noted, "it’s extraordinary hard for people to change from making decisions based on personal experience to making them to data – especially when the data counters the prevailing common wisdom”. Quattrone (2016) emphasized that this change is not only hard but probably also undesirable. He drew attention to the danger that, thanks to convincingly substantiated numbers and effective visualization, the results of analysis might be blindly accepted as truth by managers, and data analysis completely displaces human (common sense) judgment. The root cause of problems is that data analysis allows to detect statistical patterns, but while focusing only on the revealed patterns, the “why” is pushed into the background (Lycett, 2013; Rikhardsson & Yigitbasioglu, 2018).
OIPT suggests that information processing mitigates problems arising from uncertainty and equivocality. As information processing mechanisms, calculative practices result in numbers based on a procedure. Calculations gradually reduce confusion by simplifying the world into a two-dimensional space, but they are just one possible representation of the real three-dimensional world (Mouritsen, 2018). Numbers are not the reality; they take the place of reality and "are too smooth to help management all the way” (Mouritsen, 2018, p. 139). Thus, creating clarity by numbers will not necessarily erase uncertainty or ambiguity. That also means we cannot accept far-reaching changes in managerial behaviour due to adopting a data-centric mechanism. If different calculations are different representations of the real world, they can be hardly interpreted as facts. The reported tension between data reliance and intuition is apparent from that viewpoint. Mixing data-based and intuitive decision making can lead to better results than applying only one or the other, especially as intuition can play an essential role in shaping analytical practice as well (Ransbotham et al., 2017).
6 Conclusions and limitations
The rise of data analytics raises not only interesting organizational and technological issues, but it draws attention to behavioural consequences such as the change in managerial decision making processes. Data-transformed companies not only analyzing data but using it intensively in decision making are reported to outperform other companies (LaValle et al., 2011). This performance effect suggests that being data-centric is a recipe for success. Our study demolishes the illusion that a data-centric practice necessarily has organizational consequences beyond analytical resources such as technology and analytical techniques. Analytics elaboration—defined as the extent to which a firm uses advanced analytical practices and approaches in order to advance a better understanding of business and support decision making (Kowalczyk & Gerlach, 2015) – seems to be hindered in the companies involved in the research. Previous studies argued that not only the giants can excel in the adoption of digital technology that supports data gathering and processing, but in many cases, they struggle to adapt to changes as they lack managerial expertise (Quinton et al., 2018). As an alternative explanation, we proposed that the expected increase in data-based decision making lags behind for another reason: reliance on analytical information does not replace intuition, but the two are completing and shaping each other.
Although the impact of data analytics was anticipated on decision support and decision making, there is limited interest in the current literature on whether and how these developments affect the management accounting domain (Rikhardsson & Yigitbasioglu, 2018) and whether and how controllers can execute their task of decision support. This study revealed the importance of their role in interpreting analytical information in times when other organizational functions grow their own analytical competencies, and the narrowing role of controllers is threatening (Andreassen, 2020).
Implications for practice can be derived from these results. Developing analytical capabilities is costly, and managers have a legitimate expectation to see the benefits of these investments realized. If it fails, the IT productivity paradox will be on the agenda again, this time for data and analytics (Gupta & George, 2016). Of course, avoidance of wasting IT resources is of high priority. However, while paying attention only to immediate payoffs, we do not consider that technology, data, and human analytical skills are necessary but not sufficient conditions to transform processes such as decision making. Perhaps it is the manager responsible for return that hinders the realization of the expected benefits by not making a change on his own. Thus, key challenges for the near future are the acceptance of new analytical tools and trust in data; and as argued earlier, the position of controllers empowers them to build this trust (Busco et al., 2006; Scapens, 2006).
When evaluating the results, it should be taken into account that our research model did not distinguish decision types, although different decision contexts were reported to require different combinations of information processing mechanisms (Kowalczyk & Buxmann, 2014). Accordingly, our research was unable to explain the possible differences in the use of analytical information due to diverse decision contexts. There are additional limitations to this research. The data may suffer from biases induced by the cross-sectional survey procedure. One of the biggest risks to validity is self-selection bias that arose as many companies refused to participate in the survey. The effective sample closely resembles the target population on key characteristics of size and industry, but a follow-up survey for collecting further information from non-respondents has been not done. Therefore, we do not know the reasons for refusal, and we cannot characterize non-respondents along the variables examined in the survey (such as their use of advanced analytical techniques or data-driven nature of their decision making process). Albeit the reasons for non-response remain unknown, we can rightly assume that certain types of survey respondents are underrepresented. Executives who are less confident with or less interested in the topic might miss the survey.
We could not ensure clean pairs for the separate measurement of the exogenous and endogenous constructs in each case, which increases the chance of natural correlation. Although the integrator role of the controllers is an important mediating variable in the model, controllers were not explicitly surveyed; consequently, their view is not represented here. As the sample excluded micro and small companies and was limited to Hungary-based enterprises, the results might be only cautiously generalizable for companies of all sizes and may not be transferable to other regions. Future research can overcome these limitations by involving companies of all sizes from further regions in the research and carefully exploring whether non-responding companies significantly differ from the sample in any of the key characteristics. The possibility of using validated multi-item scales for each factor could increase the validity of the research. Differentiation of decision situations and establishing whether our findings hold in every decision context would also contribute to existing knowledge.
Availability of data and material
The datasets generated analysed during the current study are available from the corresponding author on reasonable request. Database available in sav and.csv format.
Code availability
SmartPLS 2.0
Notes
Here, ‘controller’ is used as a job title that is the established term of the management accounting profession in continental Europe; nevertheless, the title 'management accountant' is more common in Anglo-Saxon countries.
The data was collected as part of the Hungarian Competitiveness Research survey detailed analyzed by Wimmer and Csesznák (2021), available in the Hungarian language. The datasets are available from the Competitiveness Research Centre upon reasonable request.
References
Al-Ansari, Y., Altalib, M., & Sardoh, M. (2013). Technology orientation, innovation and business performance: A study of Dubai SMEs. The International Technology Management Review, 3(1), 1–11.
Andreassen, R.-I. (2020). Digital technology and changing roles: A management accountant’s dream or nightmare? Journal of Management Control, 31(3), 209–238. https://doi.org/10.1007/s00187-020-00303-2
Appelbaum, D., Kogan, A., Vasarhelyi, M., & Yan, Z. (2017). Impact of business analytics and enterprise systems on managerial accounting. International Journal of Accounting Information Systems, 25, 29–44. https://doi.org/10.1016/j.accinf.2017.03.003
Arnaboldi, M. (2018). The Missing Variable in Big Data for Social Sciences: The Decision-Maker. Sustainability, 10(10), 3415. https://doi.org/10.3390/su10103415
Arnaboldi, M., Busco, C., & Cuganesan, S. (2017). Accounting, accountability, social media and big data: Revolution or hype? Accounting, Auditing & Accountability Journal, 30(4), 762–776. https://doi.org/10.1108/AAAJ-03-2017-2880
Ashrafi, A., Zare Ravasan, A., Trkman, P., & Afshari, S. (2019). The role of business analytics capabilities in bolstering firms’ agility and performance. International Journal of Information Management, 47, 1–15. https://doi.org/10.1016/j.ijinfomgt.2018.12.005
Aydiner, A. S., Tatoglu, E., Bayraktar, E., Zaim, S., & Delen, D. (2019). Business analytics and firm performance: The mediating role of business process performance. Journal of Business Research, 96, 228–237. https://doi.org/10.1016/j.jbusres.2018.11.028
Barclay, D. W., Higgins, C., & Thompson, R. (1995). The partial least squares approach to causal modeling personal computer adoption and use as an illustration. Technology Studies, 2(2), 285–309.
Becker-Blease, J. R., Kaen, F. R., Etebari, A., & Baumann, H. (2010). Employees, Firm Size and Profitability of U.S. Manufacturing Industries. Investment Management and Financial Innovations, 7(2), 19.
Bergmann, M., Brück, C., Knauer, T., & Schwering, A. (2020). Digitization of the budgeting process: Determinants of the use of business analytics and its effect on satisfaction with the budgeting process. Journal of Management Control, 31(1), 25–54. https://doi.org/10.1007/s00187-019-00291-y
Bharadwaj, A., El Sawy, O. A., Pavlou, P. A., & Venkatraman, N. (2013). Digital Business Strategy: Toward a Next Generation of Insights. MIS Quarterly, 37(2), 471–482.
Bhimani, A. (2020). Digital data and management accounting: Why we need to rethink research methods. Journal of Management Control, 31(1), 9–23. https://doi.org/10.1007/s00187-020-00295-z
Bhimani, A., & Willcocks, L. (2014). Digitisation, ‘Big Data’ and the transformation of accounting information. Accounting and Business Research, 44(4), 469–490. https://doi.org/10.1080/00014788.2014.910051
Botta-Genoulaz, V., Millet, P.-A., & Grabot, B. (2005). A survey on the recent research literature on ERP systems. Computers in Industry, 56(6), 510–522. https://doi.org/10.1016/j.compind.2005.02.004
Božič, K., & Dimovski, V. (2019). Business intelligence and analytics for value creation: The role of absorptive capacity. International Journal of Information Management, 46, 93–103. https://doi.org/10.1016/j.ijinfomgt.2018.11.020
Bro, R., & Smilde, A. K. (2003). Centering and scaling in component analysis. Journal of Chemometrics, 17, 16–33. https://doi.org/10.1002/cem.773
Brynjolfsson, E., & McAfee, A. (2011). Race against the machine: How the digital revolution is accelerating innovation, driving productivity, and irreversibly transforming employment and the economy. Brynjolfsson and McAfee.
Brynjolfsson, E., & McElheran, K. (2016). The Rapid Adoption of Data-Driven Decision-Making. American Economic Review, 106(5), 133–139. https://doi.org/10.1257/aer.p20161016
Brynjolfsson, E., & Yang, S. (1996). Information Technology and Productivity: A Review of the Literature. Advances in Computers, 179–214.
Burns, J., & Baldvinsdottir, G. (2005). An Institutional Perspective of Accountants’ New Roles – The Interplay of Contradictions and Praxis. European Accounting Review, 14(4), 725–757. https://doi.org/10.1080/09638180500194171
Busco, C., Riccaboni, A., & Scapens, R. W. (2006). Trust for accounting and accounting for trust. Management Accounting Research, 17(1), 11–41. https://doi.org/10.1016/j.mar.2005.08.001
Byrne, S., & Pierce, B. (2007). Towards a More Comprehensive Understanding of the Roles of Management Accountants. European Accounting Review, 16(3), 469–498. https://doi.org/10.1080/09638180701507114
Cao, G., & Duan, Y. (2017). How do top- and bottom-performing companies differ in using business analytics? Journal of Enterprise Information Management, 30(6), 874–892. https://doi.org/10.1108/JEIM-04-2016-0080
Cao, G., Duan, Y., & Cadden, T. (2019). The link between information processing capability and competitive advantage mediated through decision-making effectiveness. International Journal of Information Management, 44, 121–131. https://doi.org/10.1016/j.ijinfomgt.2018.10.003
Cao, G., Duan, Y., & Li, G. (2015). Linking Business Analytics to Decision Making Effectiveness: A Path Model Analysis. IEEE Transactions on Engineering Management, 62(3), 384–395. https://doi.org/10.1109/TEM.2015.2441875
Cao, Q., & Schniederjans, M. J. (2004). Empirical study of the relationship between operations strategy and information systems strategic orientation in an e-commerce environment. International Journal of Production Research, 42(15), 2915–2939. https://doi.org/10.1080/00207540410001691884
Chan, Y. E., Huff, S. L., Barclay, D. W., & Copeland, D. G. (1997). Business Strategic Orientation, Information Systems Strategic Orientation, and Strategic Alignment. Information Systems Research. https://doi.org/10.1287/isre.8.2.125
Chen, H., Chiang, R. H. L., & Storey, V. C. (2012). Business Intelligence and Analytics: From Big Data to Big Impact. MIS Quarterly, 36(4), 1165–1188. https://doi.org/10.2307/41703503
Chen, L., & Nath, R. (2018). Business analytics maturity of firms: An examination of the relationships between managerial perception of IT, business analytics maturity and success. Information Systems Management, 35(1), 62–77. https://doi.org/10.1080/10580530.2017.1416948
Choudhury, N. (1988). The seeking of accounting where it is not: Towards a theory of non-accounting in organizational settings. Accounting, Organizations and Society, 13(6), 549–557. https://doi.org/10.1016/0361-3682(88)90030-X
Cohen, J. (1992). A power primer. Psychological Bulletin, 112(1), 155–159. https://doi.org/10.1037/0033-2909.112.1.155
Cohen, J. (2013). Statistical Power Analysis for the Behavioral Sciences. Academic Press.
Covin, J. G., Slevin, D. P., & Heeley, M. B. (2001). Strategic decision making in an intuitive vs. technocratic mode: Structural and environmental considerations. Journal of Business Research, 52(1), 51–67. https://doi.org/10.1016/S0148-2963(99)00080-6
Daft, R. L., & Lengel, R. H. (1986). Organizational Information Requirements, Media Richness and Structural Design. Management Science, 32(5), 554–571.
Davenport, T. H. (2013). Analytics 3.0. Harvard Business Review(December), 65–72.
Davenport, T. H., & Harris, J. G. (2007). Competing on Analytics: The New Science of Winning (1st edition). Harvard Business Review Press.
Davenport, T. H., & Harris, J. G. (2017). Competing on Analytics: Updated, with a New Introduction: The New Science of Winning. Harvard Business Press.
Davenport, T. H., & Prusak, L. (1998). Working Knowledge: How Organizations Manage What They Know. Harvard Business Press.
Davenport, T., Smith, T., Guszcza, J., & Stiller, B. (2019). Analytics and AI-driven enterprises thrive in the Age of With. Deloitte Insights. https://www2.deloitte.com/us/en/insights/topics/analytics/insight-driven-organization.html
Diamantopoulos, A., Sarstedt, M., Fuchs, C., Wilczynski, P., & Kaiser, S. (2012). Guidelines for choosing between multi-item and single-item scales for construct measurement: A predictive validity perspective. Journal of the Academy of Marketing Science, 40(3), 434–449. https://doi.org/10.1007/s11747-011-0300-3
Duan, L., & Xiong, Y. (2015). Big data analytics and business analytics. Journal of Management Analytics, 2(1), 1–21. https://doi.org/10.1080/23270012.2015.1020891
Dubey, R., Gunasekaran, A., Childe, S. J., Fosso Wamba, S., Roubaud, D., & Foropon, C. (2021). Empirical investigation of data analytics capability and organizational flexibility as complements to supply chain resilience. International Journal of Production Research, 59(1), 110–128. https://doi.org/10.1080/00207543.2019.1582820
Dubey, R., Gunasekaran, A., Childe, S. J., Papadopoulos, T., Luo, Z., Wamba, S. F., & Roubaud, D. (2019). Can big data and predictive analytics improve social and environmental sustainability? Technological Forecasting and Social Change, 144, 534–545. https://doi.org/10.1016/j.techfore.2017.06.020
Dunn, T. J., Baguley, T., & Brunsden, V. (2014). From alpha to omega: A practical solution to the pervasive problem of internal consistency estimation. British Journal of Psychology, 105(3), 399–412. https://doi.org/10.1111/bjop.12046
Emsley, D. (2005). Restructuring the management accounting function: A note on the effect of role involvement on innovativeness. Management Accounting Research, 16(2), 157–177. https://doi.org/10.1016/j.mar.2005.02.002
Fisher, R. J., & Katz, J. E. (2000). Social-desirability bias and the validity of self-reported values. Psychology & Marketing, 17(2), 105–120. https://doi.org/10.1002/(SICI)1520-6793(200002)17:2%3c105::AID-MAR3%3e3.0.CO;2-9
Galbraith, J. R. (1974). Organization Design: An Information Processing View. Interfaces, 4(3), 28–36. https://doi.org/10.1287/inte.4.3.28
Galbraith, J. R. (2014). Organizational Design Challenges Resulting from Big Data (SSRN Scholarly Paper ID 2458899). Social Science Research Network. https://papers.ssrn.com/abstract=2458899
Gao, G. Y., Zhou, K. Z., & Yim, C. K. B. (2007). On what should firms focus in transitional economies? A study of the contingent value of strategic orientations in China. International Journal of Research in Marketing, 24(1), 3–15. https://doi.org/10.1016/j.ijresmar.2006.09.004.
Gatignon, H., & Xuereb, J.-M. (1997). Strategic Orientation of the Firm and New Product Performance. Journal of Marketing Research (JMR), 34(1), 77–90. https://doi.org/10.2307/3152066
Gill, M., & VanBoskirk, S. (2016). The Digital Maturity Model 4.0. 17.
Gillon, K., Aral, S., Lin, C.-Y., Mithas, S., & Zozulia, M. (2014). Business Analytics: Radical Shift or Incremental Change? Communications of the Association for Information Systems, 34(1). https://doi.org/10.17705/1CAIS.03413
Goretzki, D. L., & Messner, P. D. M. (2014). Business Partnering in der Praxis etablieren. Controlling & Management Review, 58(2), 7–15. https://doi.org/10.1365/s12176-014-0903-x
Goretzki, L., Strauss, E., & Weber, J. (2013). An institutional perspective on the changes in management accountants’ professional role. Management Accounting Research, 24(1), 41–63. https://doi.org/10.1016/j.mar.2012.11.002
Götz, O., Liehr-Gobbers, K., & Krafft, M. (2010). Evaluation of Structural Equation Models Using the Partial Least Squares (PLS) Approach. In V. Esposito Vinzi, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of Partial Least Squares: Concepts, Methods and Applications (pp. 691–711). Springer. https://doi.org/10.1007/978-3-540-32827-8_30
Grover, V., Chiang, R. H. L., Liang, T.-P., & Zhang, D. (2018). Creating Strategic Business Value from Big Data Analytics: A Research Framework. Journal of Management Information Systems, 35(2), 388–423. https://doi.org/10.1080/07421222.2018.1451951
Gudfinnsson, K., Strand, M., & Berndtsson, M. (2015). Analyzing business intelligence maturity. Journal of Decision Systems, 24(1), 37–54. https://doi.org/10.1080/12460125.2015.994287
Gupta, M., & George, J. F. (2016). Toward the development of a big data analytics capability. Information & Management, 53(8), 1049–1064. https://doi.org/10.1016/j.im.2016.07.004
Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2021). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM) (Third Edition). SAGE Publications. https://uk.sagepub.com/en-gb/eur/a-primer-on-partial-least-squares-structural-equation-modeling-pls-sem/book270548
Hair, J. F., Hult, G. T. M., Ringle, C., & Sarstedt, M. (2016). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM). SAGE Publications.
Hair, J. F., Risher, J. J., Sarstedt, M., & Ringle, C. M. (2019). When to use and how to report the results of PLS-SEM. European Business Review, 31(1), 2–24. https://doi.org/10.1108/EBR-11-2018-0203
Hair, J., Hollingsworth, C. L., Randolph, A. B., & Chong, A. Y. L. (2017). An updated and expanded assessment of PLS-SEM in information systems research. Industrial Management & Data Systems, 117(3), 442–458. https://doi.org/10.1108/IMDS-04-2016-0130
Hammond, K. R. (1996). Human Judgment and Social Policy: Irreducible Uncertainty, Inevitable Error. Oxford University Press.
Hartmann, F. G. H., & Maas, V. S. (2011). The effects of uncertainty on the roles of controllers and budgets: An exploratory study. Accounting and Business Research, 41(5), 439–458. https://doi.org/10.1080/00014788.2011.597656
Heerwegh, D., & Loosveldt, G. (2008). Face-to-Face versus Web Surveying in a High-Internet-Coverage Population: Differences in Response Quality. Public Opinion Quarterly, 72(5), 836–846. https://doi.org/10.1093/poq/nfn045
Heinzelmann, R. (2018). Occupational identities of management accountants: The role of the IT system. Journal of Applied Accounting Research, 19(4), 465–482. https://doi.org/10.1108/JAAR-05-2017-0059
Henseler, J., Ringle, C., & Sinkovics, R. (2009). The Use of Partial Least Squares Path Modeling in International Marketing. In Advances in International Marketing (Vol. 20. pp. 277–319). https://doi.org/10.1108/S1474-7979(2009)0000020014
Holsapple, C., Lee-Post, A., & Pakath, R. (2014). A unified foundation for business analytics. Decision Support Systems, 64, 130–141. https://doi.org/10.1016/j.dss.2014.05.013
Ifenthaler, D., & Egloffstein, M. (2020). Development and Implementation of a Maturity Model of Digital Transformation. TechTrends, 64(2), 302–309. https://doi.org/10.1007/s11528-019-00457-4
Jablonsky, S. F., Keating, P. J., & Heian, J. B. (1993). Business advocate or corporate policeman?: Assessing your role as a financial executive. Financial Executives Research Foundation, 1993. Financial Executives Research Foundation.
Janssen, M., van der Voort, H., & Wahyudi, A. (2017). Factors influencing big data decision-making quality. Journal of Business Research, 70, 338–345. https://doi.org/10.1016/j.jbusres.2016.08.007
Johnson, H. T., & Kaplan, R. S. (1987). Relevance lost: The rise and fall of managerial accounting. Harvard Business School Press.
Jones, P., Simmons, G., Packham, G., Beynon-Davies, P., & Pickernell, D. (2014). An exploration of the attitudes and strategic responses of sole-proprietor micro-enterprises in adopting information and communication technology. International Small Business Journal, 32(3), 285–306. https://doi.org/10.1177/0266242612461802
Kane, G. C., Palmer, D., Phillips, A. N., Kiron, D., & Buckley, N. (2017). Achieving Digital Maturity. MIT Sloan Management Review and Deloitte University Press, 31.
Khin, S., & Ho, T. C. (2018). Digital technology, digital capability and organizational performance: A mediating role of digital innovation. International Journal of Innovation Science, 11(2), 177–195. https://doi.org/10.1108/IJIS-08-2018-0083
Kindermann, B., Beutel, S., Garcia de Lomana, G., Strese, S., Bendig, D., & Brettel, M. (2020). Digital orientation: Conceptualization and operationalization of a new strategic orientation. European Management Journal. https://doi.org/10.1016/j.emj.2020.10.009
Knauer, T., Nikiforow, N., & Wagener, S. (2020). Determinants of information system quality and data quality in management accounting. Journal of Management Control, 31(1), 97–121. https://doi.org/10.1007/s00187-020-00296-y
Knudsen, D.-R. (2020). Elusive boundaries, power relations, and knowledge production: A systematic review of the literature on digitalization in accounting. International Journal of Accounting Information Systems, 36, 100441. https://doi.org/10.1016/j.accinf.2019.100441
Kock, N., & Hadaya, P. (2018). Minimum sample size estimation in PLS-SEM: The inverse square root and gamma-exponential methods. Information Systems Journal, 28(1), 227–261. https://doi.org/10.1111/isj.12131
Kogut, B., & Zander, U. (1992). Knowledge of the Firm, Combinative Capabilities, and the Replication of Technology. Organization Science, 3(3), 383–397.
Kowalczyk, M., & Buxmann, P. (2014). Big Data and Information Processing in Organizational Decision Processes: A Multiple Case Study. Business & Information Systems Engineering, 6(5), 267–278. https://doi.org/10.1007/s12599-014-0341-5
Kowalczyk, M., & Gerlach, J. (2015). Business Intelligence & Analytics and Decision Quality—Insights on Analytics Specialization and Information Processing Modes. ECIS 2015 Completed Research Papers. https://doi.org/10.18151/7217398
Laursen, G. H. N., & Thorlund, J. (2016). Business Analytics for Managers: Taking Business Intelligence Beyond Reporting. John Wiley & Sons.
LaValle, S., Lesser, E., Shockley, R., Hopkins, M. S., & Kruschwitz, N. (2011). Big data, analytics and the path from insights to value. MIT Sloan Management Review, 52(2).
Loo, I. D., Verstegen, B., & Swagerman, D. (2011). Understanding the roles of management accountants. European Business Review, 23(3), 287–313. https://doi.org/10.1108/09555341111130263
Luftman, J., Zadeh, H. S., Derksen, B., Santana, M., Rigoni, E. H., & Huang, D. (2013). Key information technology and management issues 2012–2013: An international study. Journal of Information Technology, 28(4), 354–366. https://doi.org/10.1057/jit.2013.22.
Lycett, M. (2013). ‘Datafication’: Making sense of (big) data in a complex world. European Journal of Information Systems, 22(4), 381–386. https://doi.org/10.1057/ejis.2013.10
Lyver, M. J., & Lu, T.-J. (2018). Sustaining Innovation Performance in SMEs: Exploring the Roles of Strategic Entrepreneurship and IT Capabilities. Sustainability, 10(2), 442. https://doi.org/10.3390/su10020442
Mahmood, M. A., & Mann, G. J. (1993). Measuring the Organizational Impact of Information Technology Investment: An Exploratory Study. Journal of Management Information Systems, 10(1), 97–122. https://doi.org/10.1080/07421222.1993.11517992
Mani, D., Barua, A., & Whinston, A. (2010). An Empirical Analysis of the Impact of Information Capabilities Design on Business Process Outsourcing Performance. MIS Quarterly, 34(1), 39–62. https://doi.org/10.2307/20721414
Mikalef, P., Boura, M., Lekakos, G., & Krogstie, J. (2019). Big Data Analytics Capabilities and Innovation: The Mediating Role of Dynamic Capabilities and Moderating Effect of the Environment. British Journal of Management, 30(2), 272–298. https://doi.org/10.1111/1467-8551.12343
Mintzberg, H., Raisinghani, D., & Théorêt, A. (1976). The Structure of ‘Unstructured’ Decision Processes. Administrative Science Quarterly, 21(2), 246–275. https://doi.org/10.2307/2392045
Mitchell, F., & Reid, G. C. (2000). Editorial. Problems, challenges and opportunities: The small business as a setting for management accounting research. Management Accounting Research, 11(4), 385–390. https://doi.org/10.1006/mare.2000.0152
Moeuf, A., Lamouri, S., Pellerin, R., Tamayo-Giraldo, S., Tobon-Valencia, E., & Eburdy, R. (2020). Identification of critical success factors, risks and opportunities of Industry 4.0 in SMEs. International Journal of Production Research, 58(5), 1384–1400. https://doi.org/10.1080/00207543.2019.1636323
Mouritsen, J. (2018). From Numbers to Interventions and Back: How Do Accounting Facts and Management Concerns Interact? In L. Gårseth-Nesbakk & F. Mellemvik (Eds.), Dealing with Expectations and Traditions in Research (pp. 129–147). Cappelen Damm Akademisk. https://press.nordicopenaccess.no/index.php/noasp/catalog/book/42
Nitzl, C. (2016). The use of partial least squares structural equation modelling (PLS-SEM) in management accounting research: Directions for future theory development. Journal of Accounting Literature, 37, 19–35. https://doi.org/10.1016/j.acclit.2016.09.003
Nitzl, C., Roldan, J. L., & Cepeda, G. (2016). Mediation analysis in partial least squares path modeling: Helping researchers discuss more sophisticated models. Industrial Management & Data Systems, 116(9), 1849–1864. https://doi.org/10.1108/IMDS-07-2015-0302
Nunnally, J. C., & Bernstein, I. H. (1994). Psychometric tehory (3rd edition). McGraw-Hill.
OECD 2013 Exploring Data-Driven Innovation as a New Source of Growth: Mapping the Policy Issues Raised by ‘Big Data’ OECD Digital Economy Papers 222 https://doi.org/10.1787/5k47zw3fcp43-en
Oesterreich, T. D., & Teuteberg, F. (2019). The role of business analytics in the controllers and management accountants’ competence profiles: An exploratory study on individual-level data. Journal of Accounting & Organizational Change, 15(2), 330–356. https://doi.org/10.1108/JAOC-10-2018-0097
Oesterreich, T. D., Teuteberg, F., Bensberg, F., & Buscher, G. (2019). The controlling profession in the digital age: Understanding the impact of digitisation on the controller’s job roles, skills and competences. International Journal of Accounting Information Systems, 35, 100432. https://doi.org/10.1016/j.accinf.2019.100432
Pasch, T. (2019). Strategy and innovation: The mediating role of management accountants and management accounting systems’ use. Journal of Management Control, 30(2), 213–246. https://doi.org/10.1007/s00187-019-00283-y
Payne, R. (2014). Discussion of ‘Digitisation, “Big Data” and the transformation of accounting information’ by Alnoor Bhimani and Leslie Willcocks (2014). Accounting and Business Research, 44(4), 491–495. https://doi.org/10.1080/00014788.2014.910053
Pierce, B., & O’Dea, T. (2003). Management accounting information and the needs of managers: Perceptions of managers and accountants compared. The British Accounting Review, 35(3), 257–290. https://doi.org/10.1016/S0890-8389(03)00029-5
Podsakoff, P. M., MacKenzie, S. B., & Podsakoff, N. P. (2012). Sources of Method Bias in Social Science Research and Recommendations on How to Control It. Annual Review of Psychology, 63(1), 539–569. https://doi.org/10.1146/annurev-psych-120710-100452
Podsakoff, P., & Organ, D. (1986). Self-Report in Organizational Research. Journal of Management - J MANAGE, 12, 531–544. https://doi.org/10.1177/014920638601200408
Popovič, A., Hackney, R., Coelho, P. S., & Jaklič, J. (2012). Towards business intelligence systems success: Effects of maturity and culture on analytical decision making. Decision Support Systems, 54(1), 729–739. https://doi.org/10.1016/j.dss.2012.08.017
Power, D. J., Heavin, C., McDermott, J., & Daly, M. (2018). Defining business analytics: An empirical approach. Journal of Business Analytics, 1(1), 40–53. https://doi.org/10.1080/2573234X.2018.1507605
Preacher, K. J., & Hayes, A. F. (2008). Asymptotic and resampling strategies for assessing and comparing indirect effects in multiple mediator models. Behavior Research Methods, 40(3), 879–891. https://doi.org/10.3758/BRM.40.3.879
Quattrone, P. (2016). Management accounting goes digital: Will the move make it wiser? Management Accounting Research, 31, 118–122. https://doi.org/10.1016/j.mar.2016.01.003
Quinn, D. M. (2014). The Elusive Business Partner Controller. Controlling & Management Review, 58(2), 22–27. https://doi.org/10.1365/s12176-014-0905-8
Quinton, S., Canhoto, A., Molinillo, S., Pera, R., & Budhathoki, T. (2018). Conceptualising a digital orientation: Antecedents of supporting SME performance in the digital economy. Journal of Strategic Marketing, 26(5), 427–439. https://doi.org/10.1080/0965254X.2016.1258004
Ramayah, T., Hwa, C., Chuah, F., Ting, H., & Memon, M. (2017). PLS-SEM using SmartPLS 3.0: Chapter 12: Assessment of Mediation Analysis.
Ransbotham S., Kiron D., & Kirk Prentice P. (2017). Beyond the Hype: The Hard Work Behind Analytics Success. MIT Sloan Management Review, 57(3). https://search.proquest.com/openview/0ce6e2c0881920087f32d0ea7494ae52/1?pq-origsite=gscholar&cbl=26142
Richter, N. F., Cepeda, G., Roldán, J. L., & Ringle, C. M. (2016). European management research using partial least squares structural equation modeling (PLS-SEM). European Management Journal, 34(6), 589–597. https://doi.org/10.1016/j.emj.2016.08.001
Riedl, R., Benlian, A., Hess, T., Stelzer, D., & Sikora, H. (2017). On the Relationship Between Information Management and Digitalization. Business & Information Systems Engineering, 59(6), 475–482. https://doi.org/10.1007/s12599-017-0498-9
Rikhardsson, P., & Yigitbasioglu, O. (2018). Business intelligence & analytics in management accounting research: Status and future focus. International Journal of Accounting Information Systems, 29, 37–58. https://doi.org/10.1016/j.accinf.2018.03.001
Ringle, C. M., Sarstedt, M., & Straub, D. W. (2012). Editor’s Comments: A Critical Look at the Use of PLS-SEM in ‘MIS Quarterly.’ MIS Quarterly, 36(1), iii–xiv. https://doi.org/10.2307/41410402
Romanczuk, J. B., & Pemberton, J. M. (1997). The Chief Information Officer: Rise and fall? ARMA Records Management Quarterly, 36(2), 14–26.
Rossiter, J. R. (2002). The C-OAR-SE procedure for scale development in marketing. International Journal of Research in Marketing, 19(4), 305–335. https://doi.org/10.1016/S0167-8116(02)00097-6
Sadler-Smith, E., & Shefy, E. (2004). The intuitive executive: Understanding and applying ‘gut feel’ in decision-making. Academy of Management Perspectives, 18(4), 76–91. https://doi.org/10.5465/ame.2004.15268692
Sahay, B. S., & Ranjan, J. (2008). Real time business intelligence in supply chain analytics. Information Management & Computer Security, 16(1), 28–48. https://doi.org/10.1108/09685220810862733
Salas, E., Rosen, M. A., & DiazGranados, D. (2010). Expertise-Based Intuition and Decision Making in Organizations. Journal of Management, 36(4), 941–973. https://doi.org/10.1177/0149206309350084
Sathe, V. (1982). Controller involvement in management. Prentice-Hall.
Sathe, V. (1983). The Controller’s Role in Management. Organizational Dynamics, 11(3), 31–48.
Saunila, M., Nasiri, M., Ukko, J., & Rantala, T. (2020). Determinants of the Digital Orientation of Small Businesses. In S. H. Park, M. A. Gonzalez-Perez, & D. E. Floriani (Eds.), The Palgrave Handbook of Corporate Sustainability in the Digital Era (pp. 75-). Parlgrave Macmillan.
Scapens, R. W. (2006). Understanding management accounting practices: A personal journey. The British Accounting Review, 38(1), 1–30. https://doi.org/10.1016/j.bar.2005.10.002
Scapens, R. W., & Jazayeri, M. (2003). ERP systems and management accounting change: Opportunities or impacts? A Research Note. European Accounting Review, 12(1), 201–233. https://doi.org/10.1080/0963818031000087907
Schoemaker, P. J. H., & Tetlock, P. E. (2017). Building a More Intelligent Enterprise. MIT Sloan Management Review, 58(3), 12.
Sebastian, I., Ross, J., Beath, C., Mocker, M., Moloney, K., & Fonstad, N. (2017). How Big Old Companies Navigate Digital Transformation. MIS Quarterly Executive, 16(3). https://aisel.aisnet.org/misqe/vol16/iss3/6
Seddon, P. B., Constantinidis, D., Tamm, T., & Dod, H. (2017). How does business analytics contribute to business value? Information Systems Journal, 27(3), 237–269. https://doi.org/10.1111/isj.12101
Sena, V., & Ozdemir, S. (2020). Spillover effects of investment in big data analytics in B2B relationships: What is the role of human capital? Industrial Marketing Management, 86, 77–89. https://doi.org/10.1016/j.indmarman.2019.05.016
Sharma, R., Mithas, S., & Kankanhalli, A. (2014). Transforming decision-making processes: A research agenda for understanding the impact of business analytics on organisations. European Journal of Information Systems, 23(4), 433–441. https://doi.org/10.1057/ejis.2014.17
Shmueli, G., Ray, S., Velasquez Estrada, J. M., & Chatla, S. B. (2016). The elephant in the room: Predictive performance of PLS models. Journal of Business Research, 69(10), 4552–4564. https://doi.org/10.1016/j.jbusres.2016.03.049
Srinivasan, R., & Swink, M. (2018). An Investigation of Visibility and Flexibility as Complements to Supply Chain Analytics: An Organizational Information Processing Theory Perspective. Production and Operations Management, 27(10), 1849–1867. https://doi.org/10.1111/poms.12746
Stransky, M., Reder, R., Huber, S., & Hauer, G. (2019). Change of the Role of a Controller through Business Analytics. In A. Lochmahr, P. Müller, P. Planing, & T. Popović (Eds.), Digitalen Wandel gestalten: Transdisziplinäre Ansätze aus Wissenschaft und Wirtschaft (pp. 75–86). Springer Fachmedien. https://doi.org/10.1007/978-3-658-24651-8_3.4
Taipaleenmäki, J. (2014). Absence and Variant Modes of Presence of Management Accounting in New Product Development – Theoretical Refinement and Some Empirical Evidence. European Accounting Review, 23(2), 291–334. https://doi.org/10.1080/09638180.2013.811065
Tippins, M. J., & Sohi, R. S. (2003). IT competency and firm performance: Is organizational learning a missing link? Strategic Management Journal, 24(8), 745–761. https://doi.org/10.1002/smj.337
Tushman, M. L., & Nadler, D. A. (1978). Information Processing as an Integrating Concept in Organizational Design. The Academy of Management Review, 3(3), 613–624. https://doi.org/10.2307/257550
Vitale, G., Cupertino, S., & Riccaboni, A. (2020). Big data and management control systems change: The case of an agricultural SME. Journal of Management Control, 31(1), 123–152. https://doi.org/10.1007/s00187-020-00298-w
Voss, G. B., & Voss, Z. G. (2000). Strategic Orientation and Firm Performance in an Artistic Environment. Journal of Marketing, 64(1), 67–83. https://doi.org/10.1509/jmkg.64.1.67.17993
Watson, H. J. (2010). Business analytics insight: Hype or here to stay? Journal of Business Intelligence, 16(1), 4–8.
Weick, K. E. (1979). The Social Psychology of Organizing, Second Edition. McGraw-Hill.
Wimmer, Á., & Csesznák, A. (2021). A hazai vállalatok versenyképességi jellemzői a negyedik ipari forradalom idején. Alinea Kiadó – BCE Versenyképesség Kutató Központ.
Zack, M. H. (1993). Interactivity and Communication Mode Choice in Ongoing Management Groups. Information Systems Research, 4(3), 207–239. https://doi.org/10.1287/isre.4.3.207
Zack, M. H. (2007). The role of decision support systems in an indeterminate world. Decision Support Systems, 43(4), 1664–1674. https://doi.org/10.1016/j.dss.2006.09.003
Zhao, X., Lynch, J. G., & Chen, Q. (2010). Reconsidering Baron and Kenny: Myths and Truths about Mediation Analysis. Journal of Consumer Research, 37(2), 197–206. https://doi.org/10.1086/651257
Zhu, S., Song, J., Hazen, B. T., Lee, K., & Cegielski, C. (2018). How supply chain analytics enables operational supply chain transparency: An organizational information processing theory perspective. International Journal of Physical Distribution & Logistics Management, 48(1), 47–68. https://doi.org/10.1108/IJPDLM-11-2017-0341
Zoni, L., & Merchant, K. A. (2007). Controller involvement in management: An empirical study in large Italian corporations. Journal of Accounting & Organizational Change, 3(1), 29–43. https://doi.org/10.1108/18325910710732849
Funding
Open access funding provided by Corvinus University of Budapest. The data collection was managed by TÁRKI Social Research Institute. Financial support for data collection was provided by the OTP Bank and the Business Economics Science and Education Foundation (Vállalatgazdaságtan Tudományos és Oktatási Alapítvány) of the Corvinus University of Budapest, Hungary.
Author information
Authors and Affiliations
Contributions
Not applicable.
Corresponding author
Ethics declarations
Conflict of interest
The author has no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Appendix I: Measurement scales
Questionnaire items | Constructs and variable names | Reference to literature | |
|---|---|---|---|
(1a) Approximately what proportion of the company's total sales revenue has the IT budget averaged over the past 3 years? | (1) Technology orientation | ||
1– 0.0–1.0%; 2– 1.1–2.0%; 3– 2.1–3.0%; 4– 3.1–5.0%; 5– 5.1–7.0%; 6– more than 7% | it_1 | Mahmood and Mann (1983) | |
To what extent do the following statements apply to your company? | |||
(1– not at all, 2– slightly, 3– moderately, 4– very, 5– completely) | |||
(1b) | The head of IT is in direct contact with the top management. a | Romanczuk and Pemberton, (1997) | |
(1c) | The composition of the staff of the IT organization is outstanding in terms of capacity and competence | it_2 | Tippins and Sohi (2003) |
(1d) | The employees of the IT organization have adequate knowledge of the basic activities of the organization | it_3 | |
(2) To what extent do the following statements apply to your company? | (2) Digital orientation | Kane et al. (2017) | |
(1– not at all, 2– slightly, 3– moderately, 4 – very, 5 – completely) | |||
(2a) | Corporate management understands the digital challenges and opportunities facing the company | digi_1 | |
(2b) | The leadership of our organization has clearly defined the digital business strategy of the organization | digi_2 | |
(2c) | Projects related to digital transformation are implemented in a specified manner (not accidentally). b | ||
(2d) | We have allocated adequate financial resources to plan and implement the digital business transformation | digi_3 | |
(2e) | Our organization has the technological knowledge and skills to transform the digital business | digi_4 | |
(2f) | In our organization, we have the opportunity to come up with and embrace digitalization ideas from below. b | ||
(2 g) | We can quickly change our digital solutions to meet business challenges | digi_5 | |
(2 h) | We are willing to take risks compared to our current practice by introducing innovative digital solutions | digi_6 | |
(2i) | We track industry-leading digital solutions | digi_7 | |
(2j) | We are consciously testing new digital technologies to investigate their applicability. b | ||
(2 k) | We are ahead of our competitors in digital technology innovation. b | ||
(3) To what extent are the following analytical tools used to support management? | (3) Use of Advanced Analytics | Davenport and Harris (2007) | |
(1– not used, 2– rarely used, 3– monthly, 4– weekly, 5– daily) | |||
(3a) | Predictive calculations | aa_1 | |
(3b) | Optimization calculations | aa_2 | |
(3c) | Machine learning c | ||
(4) Please describe the role (s) of controlling (or other related accounting, management accounting) activities in your company in supporting management decisions! | (4) Added value of controllers | ||
(1– not typical at all, 2– slightly typical, 3– moderately typical, 4– very typical, 5– completely typical) | |||
Controllers… | |||
(4a) | … Analyze the data and provide interpretative explanations | co_1 | |
(4b) | … Make suggestions for improving business performance | co_2 | |
(4c) | … Participate in decision making as advisory partners of the managers | co_3 | |
(4d) | … Provide data and analysis for strategy development and implementation | co_4 | |
(4e) | … Measure the achievement of goals and indicates deviations | co_5 | |
(4f) | … Make suggestions for reviewing the strategy | co_6 | |
(5) To what extent does your company's information system (information available at the company, from internal or external sources, statements, reports, etc.) support the following activities? | (5) Decision support | LaValle et al. (2011) | |
(1—not at all, 2—just usable, 3—appropriate, 4—helps the activity, 5—very effective) | |||
(5a) | Business development decisions | ds_1 | |
(5b) | Day-to-day business decisions | ds_2 | |
(6) When making the most important operational and strategy decisions, how characteristic is it for your company that these decisions … | (6) Data-driven decision making | Covin et al. (2001) | |
(1- never, 2—rarely, 3—sometimes, 4—often, 5—almost always) | |||
(6a) | … result from extensive quantitative analysis of data | ddd_1 | |
(6b) | … rely principally on experienced-based intuition (rather than quantitative analysis) | ddd_2 | |
(6c) | … are much more affected by industry experience and lessons learned than by the results of formal research and systematic evaluation of alternatives. d | ||
1.2 Appendix II: Descriptive statistics of questionnaire items
Item | Theoretical range | Min | Max | Mean | Std. Deviation | N | Missing | Variable name in the model | |
|---|---|---|---|---|---|---|---|---|---|
Count | Percent | ||||||||
(1a) | 1-6 | 1 | 6 | 2.99 | 1.595 | 168 | 8 | 4.5 | it_1 |
(1b) | 1-5 | 1 | 5 | 4.10 | 1.072 | 171 | 5 | 2.8 | |
(1c) | 1-5 | 1 | 5 | 3.68 | 1.213 | 170 | 6 | 3.4 | it_2 |
(1d) | 1-5 | 1 | 5 | 4.05 | 1.048 | 170 | 6 | 3.4 | it_3 |
(2a) | 1-5 | 1 | 5 | 4.09 | 1.010 | 174 | 2 | 1.1 | digi_1 |
(2b) | 1-5 | 1 | 5 | 3.66 | 1.105 | 170 | 6 | 3.4 | digi_2 |
(2c) | 1-5 | 1 | 5 | 3.52 | 1.119 | 171 | 5 | 2.8 | |
(2d) | 1-5 | 1 | 5 | 3.70 | 1.175 | 174 | 2 | 1.1 | digi_3 |
(2e) | 1-5 | 1 | 5 | 3.64 | 1.107 | 172 | 4 | 2.3 | digi_4 |
(2f) | 1-5 | 1 | 5 | 3.53 | 1.260 | 173 | 3 | 1.7 | |
(2g) | 1-5 | 1 | 5 | 3.49 | 1.200 | 171 | 5 | 2.8 | digi_5 |
(2h) | 1-5 | 1 | 5 | 3.62 | 1.257 | 175 | 1 | 0.6 | digi_6 |
(2i) | 1-5 | 1 | 5 | 3.66 | 1.198 | 173 | 3 | 1.7 | digi_7 |
(2j) | 1-5 | 1 | 5 | 3.49 | 1.276 | 171 | 5 | 2.8 | |
(2k) | 1-5 | 1 | 5 | 3.39 | 1.311 | 170 | 6 | 3.4 | |
(3a) | 1-5 | 1 | 5 | 3.34 | 1.159 | 176 | 0 | 0.0 | aa_1 |
(3b) | 1-5 | 1 | 5 | 3.41 | 1.202 | 176 | 0 | 0.0 | aa_2 |
(3c) | 1-5 | 1 | 5 | 2.17 | 1.014 | 69 | 107 | 60.8 | |
(4a) | 1-5 | 1 | 5 | 3.78 | 0.988 | 175 | 1 | 0.6 | co_1 |
(4b) | 1-5 | 1 | 5 | 3.60 | 1.047 | 174 | 2 | 1.1 | co_2 |
(4c) | 1-5 | 1 | 5 | 3.62 | 1.086 | 175 | 1 | 0.6 | co_3 |
(4d) | 1-5 | 1 | 5 | 3.75 | 1.073 | 175 | 1 | 0.6 | co_4 |
(4e) | 1-5 | 1 | 5 | 3.74 | 1.128 | 175 | 1 | 0.6 | co_5 |
(4f) | 1-5 | 1 | 5 | 3.59 | 1.194 | 175 | 1 | 0.6 | co_6 |
(5a) | 1-5 | 1 | 5 | 3.65 | 0.962 | 176 | 0 | 0.0 | ds_1 |
(5b) | 1-5 | 1 | 5 | 3.90 | 0.853 | 176 | 0 | 0.0 | ds_2 |
(6a) | 1-5 | 1 | 5 | 3.86 | 0.854 | 172 | 4 | 2.3 | ddd_1 |
(6b) | 1-5 | 1 | 5 | 3.19 | 1.065 | 172 | 4 | 2.3 | ddd_2 |
(6c) | 1-5 | 1 | 5 | 3.46 | 1.099 | 172 | 4 | 2.3 | |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Szukits, Á. The illusion of data-driven decision making – The mediating effect of digital orientation and controllers’ added value in explaining organizational implications of advanced analytics. J Manag Control 33, 403–446 (2022). https://doi.org/10.1007/s00187-022-00343-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00187-022-00343-w
Keywords
- Advanced analytics
- Data-driven decision making
- Technology orientation
- Digital orientation
- Controllers’ added value