
Abstract
There could be another scalar in nature quasi-degenerate with the observed one (\(h_{125}\)). This is possible in models such as the Next-to-Minimal Supersymmetric Standard Model (NMSSM). The scenario(s) with a single Higgs boson can be compared to that with multiple ones, all near \(125 \,\text {GeV}\). In order to assess the extent to which the current set of collider, cold dark matter relic density and direct detection limits are capable of discriminating these scenarios, we perform, for the first-time, global fits of a weak-scale phenomenological NMSSM with 26 free parameters using the nested sampling implementation in PolyChord, a next-generation tool for Bayesian inference. The analyses indicate that the data used shows a moderate tendency for supporting the scenario with an additional scalar much lighter than \(h_{125}\) with mass distribution centred below the W-boson mass. More stringent constraints are, however, needed for decisive inference regarding an additional Higgs boson with mass much less than or near \(125 \,\text {GeV}\).
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The Standard Model (SM) of particle physics predicted the existence of a neutral scalar particle, the Higgs boson, with an unknown mass. After decades of technological and experimental developments since the prediction, eventually such a particle with mass near 125 GeV was discovered at the Large Hadron Collider (LHC) [1, 2]. This discovery completed the SM as a successful quantum field theory description of the electroweak and strong interactions. However, to date, there remained observations and theoretical indications of physics beyond the SM (BSM).
Supersymmetry(SUSY)-based BSM, such as the Next-to-Minimal Supersymmetric Standard Model (NMSSM) [3,4,5], have spectra with multiple neutral scalar particles. A lot of theoretical and phenomenological work within the NMSSM framework have been done by various groups. To mention a non-exhaustive selection, these include global fits of the model’s sub-spaces along experimental constraints [6,7,8,9,10], studies on its relation to baryogenesis [11,12,13,14], phenomenological comparisons [15,16,17,18] and vacuum stability analyses [19,20,21]. In this article we analyse, for the first time, a weak-scale NMSSM with many free parameters in contrast to the analogue at the grand unification theory scale which have been typically studied the most. We call this scenario the “phenomenological NMSSM” (pNMSSM), as it is constructed with similar motivations to the well-studied pMSSM [22,23,24,25,26].
Within the pNMSSM, various Higgs sector scenarios can be considered depending on how the observed 125 GeV scalar at the LHC, which we shall label as \(h_{125}\), is identified and on how the other Higgs boson masses are restricted. Within the literature, the scenario studied the most is the ordinary case for which the lightest CP-even scalar, \(h_1\), is identified as \(h_{125}\). Here we consider three scenarios, \(\mathcal{H}_0\), \(\mathcal{H}_1\), and \(\mathcal{H}_2\), which are defined as follows:
-
\(\mathcal{H}_0\): \(h_1 \equiv h_{125}\). pNMSSM points were discarded if \(m_{h_1} \notin [122, 128] \,\text {GeV}\). To make \(\mathcal{H}_0\) mutually exclusive to \(\mathcal{H}_{1,2}\), \(m_{h_2} \notin [122, 128] \,\text {GeV}\) is required for this scenario. No restrictions on the other Higgs bosons were imposed.
-
\(\mathcal{H}_1\): \(h_1 \equiv h_{125}\) with \(m_{h_2} \in @@[122, 128] \,\text {GeV}\).
-
\(\mathcal{H}_2\): \(h_2 \equiv h_{125}\). To make \(\mathcal{H}_2\) mutually exclusive to \(\mathcal{H}_{0,1}\), \(m_{h_1} \notin [122, 128] \,\text {GeV}\) is required. No restrictions on the other Higgs boson masses were imposed.
-
\(\mathcal{H}_3\): \(h_1 \equiv h_{125}\) with the restriction that \(m_{h_2} \sim m_{h_3} \sim m_{h_1}\). This and other potentially interesting further possibilities will not be addressed in this article.
Here \(h_i\), with \(i = 1,2,3\), represent the three mass-ordered CP-even Higgs bosons. Our proposal is that by using Bayesian models comparison technique, one can find out which of the alternative hypotheses is supported most and, from another perspective, one can assess the status of the pNMSSM in light of the experimental data used. This method has been successfully applied in various particle physics phenomenology [26,27,28,29,30,31,32,33,34,35,36,37] and to greater extent in cosmology and astro-particles research. For instance, see [38,39,40,41] and their citations. For our analyses, we use the PolyChord [41, 42] “next-generation” (to MultiNest [40]) nested sampling implementation for making the comparisons.
The aim of this article is to determine which of the scenarios, \(\mathcal{H}_0\) , \(\mathcal{H}_1\) and \(\mathcal{H}_2\), is supported most by current data. Performing such a comparison analyses will add new directions to previous studies concerning quasi-degenerate Higgs boson scenarios such as in [9, 16, 43,44,45,46]. Likewise, the strength of the data in constraining the pNMSSM can be quantified. New benchmarks and perhaps experimentally unexplored pNMSSM regions can be extracted for future investigations along the searches for BSM physics. In the sections that follow, we first describe the Bayesian models comparison technique which makes the base for our analyses. This will be followed by a description of the weak-scale parametrisation, the procedure for fitting the parameters to data, and then the results of the comparisons made. The article ends with a Conclusions section.
2 Bayesian model selection
Using the nested sampling algorithm, the Bayesian evidence based on a given set of data can be readily computed and thereafter used for comparing alternative physics scenarios. With this algorithm, the parameters estimation is a by-product of the evidence computation. This is a unique advantage of nested sampling in contrast to traditional Monte Carlo techniques.
There are various possibilities for performing Bayesian models comparison. One can perform a comparison between two completely different physics models based on a common set of data. For example in [28] various SUSY-breaking mediation mechanisms were compared. Another possibility is the comparison of alternative physics scenarios within a single model. Examples of this can be found in [27, 29]. In [29], the comparison was between the MSSM scenario whereby the neutralino lightest sparticle (LSP) is considered to make all of the observed cold dark matter relic density compared to the alternative for which the LSP accounts for only part, not all, of the observed relic density. Along this line of thought, the pNMSSM scenarios \(\mathcal{H}_0\), \(\mathcal{H}_1\) and \(\mathcal{H}_2\), can be compared among one another based on a common set of experimental data. In the subsections that follow we briefly describe Bayes’ theorem, the Bayes factors which were used for the comparisons, and the similarities/differences between PolyChord and MultiNest.
2.1 Bayes theorem and Bayes factors
For a given context, \(\mathcal {H}\), based on a model with a set of N parameters, \( \theta \), the a priori assumed values which the parameters can take is encoded in the prior probability density distribution, \(p( \theta )\). The support a given hypothesis could draw from a data set is quantified by the probability density of observing the data set given the hypothesis,
This can be obtained directly from Bayes’ theorem,
Here \(p( d| \theta , \mathcal{{H}})\) is the likelihood, a measure of the probability for obtaining the data set d from a given set of the model parameters. To compare between say, \(\mathcal{{H}}_{0}\) and \(\mathcal{{H}}_{1}\) the Bayes factor, \(K = \frac{\mathcal {Z}_1}{\mathcal {Z}_0}\), should be computed. This could be done via the the posterior odd ratios:
For the case where the two hypotheses are a priori equally likely, \(p(\mathcal{{H}}_{1})/p(\mathcal{{H}}_{0}) = 1\), then the logarithm of the Bayes factor can be obtained as the logarithm of the posterior odd factors:
Getting \(\mathcal {Z}_1/\mathcal {Z}_0 > 1\) will infer that the data supports \(\mathcal{{H}}_1\) more compared to \(\mathcal{{H}}_0\) and vice versa if the ratio is less than one. The Jeffrey’s scale shown in Table 1 calibrates the significance of the Bayes factors. Next we are going to explain what the Bayes factors describe within the context of the pNMSSM global fits to data.
From a point of view, the Bayes factor encodes information about the scenarios’ posterior masses as measured by the chosen priors. It can tell which scenario is more plausible based on a given set of data. To see this, let the pNMSSM posterior without restricting to any of the \(\mathcal{H}_{0}\), \(\mathcal{H}_{1}\), or \(\mathcal{H}_{2}\) scenarios be
Assuming that the scenarios represent mutually exclusive volumes, \(\Omega _0, \Omega _1\) and \(\Omega _2\) respectively, in the “full” \(\theta \)-space then the corresponding posterior probability masses can be computed. For instance,
The global evidence, \(\mathcal{Z}\), will cancel out when computing the ratios, such as \(\frac{\mathcal{Z}_0^{'}}{\mathcal{Z}_1^{'}} = \frac{\mathcal{Z}_0}{\mathcal{Z}_1}\). So the evidence and posterior mass ratios are equivalent. As such, the priors for scenarios \(\mathcal{H}_{0,1,2}\) are not free to be chosen arbitrarily. They are rather set by the prior distribution \(p(\theta )\), with the relative priors such as \(\frac{p(\mathcal{H}_0)}{p(\mathcal{H}_1)}\) constrained to match the corresponding integrations of \(p(\theta |\mathcal{H}_{0,1})\) over the domains \(\Omega _{1,2}\). The prior ratios can be estimated by scanning over the pNMSSM parameters without imposing the likelihoods or scenario requirements and then find the number of survived points after imposing the Higgs boson(s) mass restrictions. Thus \(p(\mathcal{H}_i)\), \(i = 0, 1, 2\) can be considered to be the fraction of the survived points.
For the nested sampling implementation in PolyChord, parameter points were sampled from a flat prior distribution, \(p( \theta )\), which integrates to 1 over the “full” pNMSSM \(\theta \)-space. This “global” prior is used for each of the three scenarios considered. So PolyChord is run once for each of the scenarios. From the sampled parameter points, the \(\mathcal{H}_0\), \(\mathcal{H}_1\), or \(\mathcal{H}_2\) cuts on the Higgs boson masses were applied. For instance, in the case of the PolyChord run for \(\mathcal{H}_0\) the sampled pNMSSM points were discarded if \(m_{h_1} \notin [122, 128] \,\text {GeV}\) and \(\mathcal{H}_{1,2}\), \(m_{h_2} \notin [122, 128] \,\text {GeV}\). As such the evidence value returned by PolyChord will be
with \(\int \, p(\theta ) \, d\theta = 1\), since in principle \(p(\theta )\) can be expanded as \(p(\theta ) = p(\theta | \mathcal{H}_0) \, p(\mathcal{H}_0) + p(\theta | \mathcal{H}_1) \, p(\mathcal{H}_1) + p(\theta | \mathcal{H}_2) \, p(\mathcal{H}_2)\). This way, the ratios such as \(\frac{\mathcal{Z}_0^{''}}{\mathcal{Z}_1^{''}} = \frac{\mathcal{Z}_0}{\mathcal{Z}_1} \,\, \frac{p(\mathcal{H}_0)}{p(\mathcal{H}_1)}\) represents the full posterior mass ratio as in Eq. (3). Thus the Bayes factor, K can be obtained from what PolyChord returns (the \(\mathcal{Z}^{''}\)s) as
2.2 PolyChord versus MultiNest
Here we briefly describe the similarities and contrast between the relatively new PolyChord [41, 42] and the MultiNest algorithm [40, 49] which we have used in the past for similar analyses. Both MultiNest and PolyChord are effective Bayesian evidence calculators that perform as excellent multi-modal posterior samplers. At their core, “nested sampling” algorithm [38] is implemented. They differ on how a new set of model parameters is generated over sampling iterations. MultiNest is based on rejection sampling or, alternatively, importance sampling. On the other hand, PolyChord is based on slice sampling method.
We used PolyChord because of its improved scaling with dimensionality, D, as illustrated in [42]. For the multi-dimensional Gaussian problem analysed in [42], the number of likelihood calculations needed for the run to converge scales as \(\mathcal{O}(D^3)\) at worst using PolyChord instead of the approximately exponential scaling that emerges for higher dimensions (greater than around 20) as is expected for the rejection sampling method (see Sect. 29.3 of [50]). The 26-dimensional pNMSSM considered for the analysis presented in this article is more complicated in comparison to the toy Gaussian problem.
There are two tuning parameters for running PolyChord, namely the number of live points maintained throughout the nested sampling implementation, \(n_{live}\), and the length of the slice sampling chain, \(n_{repeats}\), used for generating new live points. With \(n_{live} = 200\) and \(n_{repeats} = 26\), running PolyChord on the pNMSSM parameters space finished with 700208 likelihood calculations using 96 core-hours of computing time. This compares to 11344428 likelihood calculations for the same pNMSSM model with MultiNest tuning parameters \(n_{live} = 5000\) and \(efr = 0.1\) using 4480 core-hours. Making \(n_{live} = 1000\) instead of \(n_{live} = 200\), the amount of time and likelihood calculations needed to finish the PolyChord run increased drastically but ends up with similar results for the Bayesian evidence. It took 6272 core-hours and 3492331 likelihood calculations. Setting \(n_{repeats} = 2 \times 26\) instead of \(n_{repeats} = 26\), PolyChord finished with 1632936 likelihood calculations and 512 core-hours. These basic comparison between PolyChord and MultiNest are summarised in Table 2. Given the experience in using MultiNest for large parameter models (order 20 to 30), especially the difficulties in getting runs to finish over tightly constrained or models with high number of parameters, we decide to use PolyChord.Footnote 1
3 The phenomenological NMSSM
The NMSSM, for reviews see e.g. [3,4,5], has phenomenological advantages over the MSSM. These include the solution of the \(\mu \)-problem [51]. The vacuum expectation value of an additional gauge-singlet (S) can generate superpotential \(\mu \)-term dynamically. It also has a richer Higgs-sector. There are three CP-even Higgs bosons, \(h_{1,2,3}\), and two CP-odd Higgs bosons \(a_{1,2}\) which are mixtures of the MSSM-like Higgs doublet fields and respectively the real or imaginary part of S. For our analyses, we shall consider an R-parity conserving NMSSM with minimal CP and flavour violating free parameters and superpotential,
where \(W_{MSSM'}\) is the MSSM-like superpotential without the \(\mu \)-term,
Here, the chiral superfields have the following \(SU(3)_C\otimes SU(2)_L\otimes U(1)_Y\) quantum numbers,
The corresponding soft SUSY-breaking terms are
with the trilinear and bilinear contributions given by
A tilde-sign over the superfield symbol represents the scalar component. However, an asterisk over the superfields as in, for example, \(\tilde{u}_R^*\) represents the scalar component of \(\bar{U}\). The \(SU(2)_L\) fundamental representation indices are donated by \(a,b=1,2\) while the generation indices by \(i,j=1,2,3\). \(\epsilon _{12}=\epsilon ^{12}=1\) is a totally antisymmetric tensor. In a similar approach to the pMSSM [22, 24,25,26] construction, the pNMSSM parameters are defined at the weak scale. For suppressing sources of unobserved CP-violation and flavour-changing neutral currents, the sfermion mass and trilinear scalar coupling parameters were chosen to be real and diagonal. For the same motivation, the first and second generation sfermion mass parameters were set to be degenerate. The gaugino mass parameters were reduced to be real by neglecting CP-violating phases. These lead to a non-Higgs sector set of parameters
Here, \(M_{1,2,3}\) and \(m_{\tilde{f}}\) are respectively the gaugino and the sfermion mass parameters. \(A_{t,b,\tau }\) represent the trilinear scalar couplings, with \(T_{ij} \equiv A_{ij} Y_{ij}\) (no summation over i, j). So \(A_{t,b,\tau }\) is equivalent to the \(A_{33}\) corresponding, respectively, to the diagonalised matrices \(T_{U}\), \(T_{D}\), and \(T_{L}\). Here Y represent the Yukawa matrices. After electroweak symmetry breaking, the vacuum expectation value (vev) of S, \(v_s\), develops an effective \(\mu \)-term, \(\mu _\mathrm {eff} = \lambda \, v_s\). This and the ratio of the MSSM-like Higgs doublet vevs, \(\tan \beta =\left<H_2\right>/\left<H_1\right>\), are free parameters which together with mass of the Z-boson, \(m_Z\), can be used for computing \(m^2_{H_{1,2},S}\) via minimisation of the scalar potential. With these, the tree-level Higgs sector parameters are
Adding to the list of parameters in Eqs. (15) and (16), four SM nuisance parameters, namely, the top and bottom quarks \(m_{t,b}\), \(m_Z\) and the strong coupling constant, \(\alpha _s\), makes the 26 free parameters of the pNMSSM:
\(M_{1,2}\) strongly affect the electroweak gaugino masses for which a wide range of values, GeV to TeV, is possible. We let \(M_1 \in [-4, 4] \,\text {TeV}\) and same for \(M_2\) but fixed to be positive without loss of generality (see e.g. [52]). A strong sensitivity of the pNMSSM Higgs sector on the gluino and the 1st/2nd generation squark mass parameters is not anticipated. However we choose to let them vary since the limits from searches for SUSY will be part of the experimental data to be used. As such, following the work in [24, 26] we let the gluino and squark mass parameters vary within \([100 \,\text {GeV}, 4 \,\text {TeV}]\) and the trilinear scalar couplings within \([-8 \,\text {TeV}, 8 \,\text {TeV}]\). \(\tan \beta \) is allowed to vary between 2 and 60. With the aim of minimising fine-tuning, we subjectively choose to vary the effective \(\mu \)-parameter, \(\mu _\mathrm {eff} = \lambda \, v_s\), to be within 100 to 400 GeV and not (orders of magnitude) far away from the \(m_Z\). The remaining Higgs-sector parameters were allowed in ranges as summarised in Table 3. For all the parameters, except the SM ones, flat prior probability density distribution was assumed. For the experimentally measured SM nuisance parameters, Gaussian distributions around the measured values were used.
Checking the prior-dependence of results is useful for assessing the strength of the data in constraining the model in an unambiguous manner. The priors can be chosen to be flat or logarithmic with the latter favouring lower regions of the parameter ranges. There are two bottle-necks concerning our attempts for sampling the pNMSSM parameters with logarithmic priors. On one hand, the absence of signatures for SUSY at the LHC pushes sparticle mass lower bounds towards or well into the multi-TeV regions. Therefore, sampling the phenomenologically viable parameters according to a logarithmic prior will be difficult and computationally expensive. For the attempted log-prior fits, only parameters that do not cross zero were sampled logarithmically. Those that have the possibility of being zero were sampled uniformly. On the other hand, for the nested sampling algorithm in PolyChord to get started, a 200-points sample of the 26-parameters pNMSSM is required. By using logarithmic priors, it was not possible to generate the 200 model points within the maximal possibility of 3072 CPU core-hours per run at our disposal.Footnote 2 Thus we restrict our analyses to the flat priors only. The conclusions presented in this article are valid only within this context.
Another issue concerning our pNMSSM parametrisation is related to “naturalness” or the avoidance of excessive fine-tuning associated with obtaining the correct weak-scale (\(m_Z\)). With the naturalness prior parametrisation [53], the fine-tuning can be avoided by directly scanning the parameters \(m_Z\) and \(\tan \beta \) rather than \(m_{H_1}\) an \(m_{H_2}\). Moreover it was shown [37] that naturalness prior parametrisation could significantly affect the Bayesian evidence values. For the analyses presented in this article, such parametrisation was not considered. Rather, a Gaussian prior for \(m_Z\) centred on the measured value was used. Doing this injects information about what the weak scale is into the prior. In addition, \(\mu _{eff}\) were chosen to be near the electroweak symmetry breaking scale, between 100 to 400 GeV, since one of our aims is to show that there are still vast regions in parameter space with low mass gauginos and BSM Higgs bosons which are not ruled out by current data. It is accepted that fine-tuning penalisation manifests implicitly and automatically within Bayesian global fits as presented in [33, 54, 55]. The same applies to the fact that fine-tuning limits could be imposed during fits by using the various fine-tuning measures [53, 56,57,58,59,60,61]. Using any of these is not within the scope of our present analyses given the deliberate target to regions with low mass electroweak gauginos.
Now, coming back to the Higgs sector potential, the details concerning the NMSSM Higgs mass matrices and couplings can be found in the literature, for example see [4, 62,63,64,65,66]. The \(\mathbb {Z}_3\)-invariant NMSSM Higgs potential can be obtained from the SUSY gauge interactions, soft-breaking and F- terms as
Here \(g_1\) and \(g_2\) denotes the \(U(1)_Y\) and SU(2) gauge couplings, respectively. Out of the 22 non-SM pNMSSM parameters, six, compared to two for the pMSSM, are directly from the Higgs sector. After electroweak symmetry breaking, replacement of the Higgs sector fields with corresponding fluctuations on top of the vevs,
leads to the realisation of CP-even Higgs boson mixing matrix
Here the physical Higgs fields have indices R for the CP-even, and indices I for the CP-odd states. \(h_i^{\text {weak}} = (H_{1R}, H_{2R}, S_R)\) represents the interaction, and \(h_i^{\text {mass}}\), the mass-ordered, eigenstates. The mixing of the SU(2) doublets with the singlet state affects the phenomenology of the Higgs bosons. For instance, the reduced couplings (see, e.g. [66])
of the 3 CP-even mass-eigenstates \(h_i\) to the electroweak gauge bosons can be very small in some regions of parameter space. The sum rule \(\sum _{i=1}^3 \xi _i^2 = 1\) is always satisfied. The reduced couplings are inputs to the Lilith [67] program for comparing the pNMSSM signal strengths to the experimentally measured values.
4 Experimental constraints and fit procedure
During the global fits, the experimental constraints used were those implemented in NMSSMTools [68,69,70,71,72,73], Lilith [67], and MicrOMEGAs [74,75,76,77,78,79,80,81,82,83]. The set of experimental constraints, d, shown in Table 4 were used to associate each pNMSSM point, \(\{ \theta , \mathcal{{H}}\}\), with a likelihood \(p( d| \theta , \mathcal{{H}})\). The likelihood as a function of the parameters is explained as follows.
In modelling the likelihood, the set of constraints used during the global fits are divided into the three groups:
-
Constraints on the Higgs boson mass \(m_h\), the neutralino cold dark matter (CDM) relic density \(\Omega _{CDM} h^2\), anomalous magnetic moment of the muon \(\delta a_\mu \) and B-physics related limits summarised in the upper part of Table 4 form the first part of the data set, d. The likelihood is computed from the pNMSSM predictions, \(O_i\), corresponding to the constraints i, with experimental central values \(\mu _i\) and uncertainties \(\sigma _i\), as
$$\begin{aligned} p( d| \theta , \mathcal{{H}}) = \prod _i \, \frac{ \exp \left[ - (O_i - \mu _i)^2/2 \sigma _i^2\right] }{\sqrt{2\pi \sigma _i^2}}. \end{aligned}$$(22)Here the index i runs over the relevant experimental constraints in Table 4.
-
Signal strength measurements from Tevatron [103], ATLAS [98, 100, 104,105,106,107,108,109,110,111,112] and CMS [99, 101, 102, 113,114,115,116,117,118,119] as implemented in Lilith v1.1 (with data version 15.09) [67] represent the second part of the data set. For each pNMSSM point, the returned likelihood from Lilith is combined with the product in Eq. (22). The likelihood can be computed via either the Higgs boson signal strengths or their reduced couplings with respect to the SM. For the first case, a pNMSSM point with corresponding signal strength \(\mu _i\) is associated with the likelihood
$$\begin{aligned}&-2L_{lilith}( \theta ) = - 2 \sum _i \log L(\mu _i) \nonumber \\&\quad = \sum _{i} \left( \frac{\mu _i(\theta ) - \hat{\mu }_i}{\Delta \mu _i}\right) ^2. \end{aligned}$$(23)Here i runs over the various categories of Higgs boson production and decay modes combinations. \(\hat{\mu }_i \pm \Delta \hat{\mu }_i\) represents the experimentally determined signal strengths. Theoretically, the signal strength associated to a model point can be computed, for a given production mode X and decay mode Y as
$$\begin{aligned} \mu = \sum _{X,Y} \epsilon _{X,Y} \frac{ \sigma (X) \, BR(H \rightarrow Y)}{\left[ \sigma (X) \, BR(H \rightarrow Y) \right] ^{SM}}. \end{aligned}$$(24)Here \(\epsilon _{X,Y}\) are the experimental efficiencies, \(X \in \{ ggH, VH, VBF, ttH\}\) and \(Y \in \{ \gamma \gamma , VV^{(*)}, b \bar{b}, \tau \tau , ttH\}\). For a proton-proton collider, the elements in X represent: the gluon-gluon fusion (ggH), associated production with a boson (VH), vector boson fusion (VBF) or associated production with top quarks (ttH). The elements in Y represent the Higgs diphoton (\(\gamma \gamma \)), W or Z bosons (VV), bottom quarks (bb) or tau leptons (\(\tau \tau \)) decay modes.
Now, computing \(\mu \) as in Eq. (24) could be impractical since for a meaningful theory versus experiment comparison, the non-SM predictions in the numerator should be computed using the same prescriptions such as the order in perturbation, implementation of parton distribution functions etc. The second approach, whereby the input to Lilith are the reduced couplings does not suffer from this problem. BSM physics effects can be parametrised in terms of the reduced couplings. The cross section (or partial decay width) for each production process X (or decay mode Y) can be scaled [158] with a factor of \(C_X^2\) and \(C_Y^2\) respectively such that
$$\begin{aligned} \sigma (X) = C_X^2 \, \sigma (X)^{SM} \quad \text { and } \quad \Gamma (Y) = C_Y^2 \, \Gamma (Y)^{SM}. \end{aligned}$$(25)The reduced couplings computed from the NMSSMTools together with their invisible and undetectable decay branching ratios can then be passed to Lilith for computing the likelihood based on
$$\begin{aligned} \mu= & {} ( 1 - BR(H \rightarrow \, undetected) \nonumber \\&- BR(H \rightarrow \, invisible) ) \frac{ \sum _{X,Y} \epsilon _{X,Y} C_X^2 \, C_Y^2}{\sum _Y \, C_Y^2 \, BR(H \rightarrow Y)^{SM}}\nonumber \\ \end{aligned}$$(26)and the table of likelihood values as a function of \(\mu \) within the Lilith database of experimental results. This procedure is valid only for Higgs bosons with mass between 123 to 128 GeV. For the multi-Higgs case with masses within this range, such as for \(\mathcal{H}_1\), the combined [159] signal strengths were used.
-
The third set of constraints in d is the CDM direct detection limits. These are from searches for the elastic scattering of CDM with nucleons. The recoil energy deposited on nuclei in a detector can be measured. In the absence of discovery, upper limits on the scattering cross section can be determined. The cross sections can be either spin-independent (SI) or spin-dependent (SD) depending on whether the LSP-nucleon coupling is via scalar or axial-vector interaction. For the fits with the direct detection limits imposed, only parameter points that pass the SI [120,121,122] and SD [123,124,125,126] limits were accepted.
Another set of limits were used for fitting the pNMSSM. These were not included during the global fit samplings. Instead, the limits implemented in SModelS [136,137,138,139,140,141,142,143,144,145,146] and HiggsBounds [127, 128] were applied to the posterior samples from the pNMSSM fits to the data on the upper section of Table 4. The inclusion of SModelS constraints during the fits will slow the exploration of the pNMSSM space beyond tolerance. For this reason, the “post-processing” procedure was used. The “post-processing” means passing the posterior sample points, in SLHA[160] format, to SModelS and HiggsBounds for imposing the experimental 95% confidence limits from ATLAS and CMS SUSY bounds [147,148,149,150,151,152,153,154,155,156,157] and the Tevatron and LHC Higgs physics bounds [98,99,100,101,102, 127,128,129,130,131,132,133,134,135] respectively. The ruled out points were taken out of the samples and the evidence values re-weighted accordingly. The impact of SModelS and HiggsBounds on the evidence values is rather insignificant since the ruled-out points do not saturate the likelihood space.
5 Results
5.1 Bayesian evidences
The results for the Bayesian comparisons between the hypotheses considered are shown in Table 5. There are three sets of results demarcated by the double horizontal lines. In the first set, the CDM direct detection (DD), \(Br(B_s \rightarrow \mu ^+ \mu ^-)\), \(Br(B_u \rightarrow \tau \nu )\) and \(\delta a_{\mu }\) limits were not included during the fits. For the third set, all the observables were included. The Bayesian evidence (\(\log _e \mathcal{Z}\)) values returned by PolyChord for each of the scenarios are shown in the second column. The Bayes factors, K, for the comparisons between \(\mathcal{H}_i\) and \(\mathcal{H}_j\) scenarios are shown on the third column while the corresponding remarks are displayed on the fourth column. The priors \(p(\mathcal{H}_i)\), \(i = 0, 1, 2\) were estimated via a random scan of 2156295 pNMSSM points without any of the \(\mathcal{H}_i\) constraints imposed. Out of these, 1867739, 128, and 7646 points respectively survived the \(\mathcal{H}_0\), \(\mathcal{H}_1\), and \(\mathcal{H}_2\) requirements. This way, \(p(\mathcal{H}_0) = 8.6618 \times 10^{-1}\), \(p(\mathcal{H}_1) = 5.9361 \times 10^{-5}\), and \(p(\mathcal{H}_2) = 3.5459 \times 10^{-3}\). As expected, the stronger the data set is, the better the discrimination between the scenarios becomes. But this depends on whether all the elements in the set pull the posterior mass towards a common region. The addition of two sets of data with tendencies for pulling the posterior in opposite directions will dilute the discrimination strength of the combined set. This characteristic behaviour can be seen in going from the second to the third set of results shown in Table 5. the \(Br(B_s \rightarrow \mu ^+ \mu ^-)\), \(Br(B_u \rightarrow \tau \nu )\) and \(\delta a_{\mu }\) set tends to prefer lighter SUSY states. The inclusion of this set diluted the discrimination power of the combined data set. Without the \(Br(B_s \rightarrow \mu ^+ \mu ^-)\), \(Br(B_u \rightarrow \tau \nu )\) and \(\delta a_{\mu }\) limits, the conclusions drawn are Moderate or Strong. These changed to Inconclusive or Moderate when the mentioned set of data are included as can be seen for the third set of results in Table 5. For the third set of the results, we discuss the comparisons between the scenarios as follows.
-
The data shows an inconclusive result for the comparison between \(\mathcal{H}_0\) against \(\mathcal{H}_1\). This an indication that the CDM DD limits on one hand, versus the \(Br(B_s \rightarrow \mu ^+ \mu ^-)\), \(Br(B_u \rightarrow \tau \nu )\) and \(\delta a_{\mu }\) set of limits on another are sensitive to these scenarios but in opposite directions. This can be seen by noting that the support for \(\mathcal{H}_1\) against \(\mathcal{H}_0\) changed from Strong to Moderate and then to Inconclusive in going from the first to the second and then third set of results shown in Table 5.
-
Similarly, the data demonstrates a moderate evidence in support of \(\mathcal{H}_2\) against \(\mathcal{H}_1\). For the \(\mathcal{H}_2\) versus \(\mathcal{H}_1\) comparison the evidence changes from Moderate to Strong upon the inclusion of CDM direct detection limits. This can be understood as being due to the presence of relatively much lighter \(h_1\) in the \(\mathcal{H}_2\) scenario (see Fig. 1, first-row left plot). Lighter \(h_1\) leads to bigger LSP-nucleon cross sections and thus more likely to be ruled out by the direct detection limits.
-
The data has a Moderate support for \(\mathcal{H}_2\) relative to \(\mathcal{H}_0\). Over the first two sets of results, the support for \(\mathcal{H}_2\) against \(\mathcal{H}_0\) is Strong. The inclusion of the \(Br(B_s \rightarrow \mu ^+ \mu ^-)\), \(Br(B_u \rightarrow \tau \nu )\) and \(\delta a_{\mu }\) limits diluted the conclusion to a Moderate one.
All together, there is a Moderate support for \(\mathcal{H}_2\) against \(\mathcal{H}_0\) and the latter may be considered as being ranked first in comparison to \(\mathcal{H}_0\) or \(\mathcal{H}_1\) which can be simultaneously ranked second. The hypothesis with a single Higgs boson around \(125 \,\text {GeV}\) is not decisively supported. The data has a tendency towards preferring the \(\mathcal{H}_2\) scenario which permits the possibility of having an additional but much lighter (than \(125 \,\text {GeV}\)) scalar.
5.2 Posterior distributions related to CP-even Higgs bosons

Marginalised one- (top) and two-dimensional (bottom) posterior distributions for the first-two lightest CP-even Higgs bosons. The dashed/green (H0), dash-dotted/red (H1) and solid/black (H2) lines represent respectively the hypotheses \(\mathcal{{H}}_0\), \(\mathcal{{H}}_1\) and \(\mathcal{{H}}_2\). The top-right plot shows the \(m_{h_2}\) distribution for \(\mathcal{{H}}_0\) which is not visible on the top-left plot. For the plot on the bottom, \(m_{h_2}\) for \(\mathcal{{H}}_0\) scenario (H0, on the legend) is re-scaled
To complement the Bayes’ factors reported on Table 5, in this subsection we describe the posterior distributions of the first two light Higgs boson masses and couplings. The plots Footnote 3 in Fig. 1 show respectively the one- and two-dimensional mass distributions within each of the scenarios considered. For \(\mathcal{{H}}_2\), \(m_{h_1}\) distribution is peaked at a value much less than 125 GeV. This is because of the interplay between the large electron-positron (LEP) and LHC constraints. With respect to the position of the peak, the lower mass region is suppressed by LEP constraints such as upper limits on the cross section of \(e^- \, + \, e^+ \rightarrow h_1 \, Z\) [161, 162]. The heavier mass region beyond the peak gets ruled out by the upper limits on the reduced production cross sections, at the LHC, such as for \(p\,p \rightarrow h_1 \rightarrow a_1 a_1\) [163], \(ggF \rightarrow h_1 \rightarrow \gamma \, \gamma \) [164], and \(ggF \rightarrow h_1 \rightarrow \tau \, \tau \) [165, 166] processes.
The nature of the two lightest CP-even Higgs bosons in each of the three scenarios can be determined by considering their reduced couplings to fermions (up-type, u and down-type, d) and gauge bosons (W, Z, and \(\gamma \)). As shown in Fig. 2, for \(\mathcal{{H}}_0\) (dashed/green line), \(h_1\) is completely SM-like. For \(\mathcal{{H}}_1\) (dash-dotted/red line), \(h_2\) is mostly SM-like when \(h_1\) is not and vice versa. This due to the so-called “sharing of couplings” effect. \(h_1\) is almost completely non SM-like within \(\mathcal{{H}}_2\) (solid/black line) for which \(h_2\) is identified as \(h_{125}\). These features stem from the combined effects of the various limits imposed on the pNMSSM parameter space. The most pronounced of these for \(h_1\) are the LHC limits on the signal strengths which are directly proportional to the reduced couplings, and subsequently to the elements of the Higgs mixing matrix.

Marginalised posterior distributions for the first-two lightest CP-even Higgs bosons (\(h_j\), \(j = 1\) or 2) reduced couplings, \(C_i^{h_j}\), to matter and gauge particles \(i = u, d, V, \gamma \) (respectively up-type, and down-type matter particles, W, Z, and photon). The dashed/green line (H0), dash-dotted/red line (H1) and solid/black (H2) lines represent respectively the hypotheses \(\mathcal{{H}}_0\), \(\mathcal{{H}}_1\) and \(\mathcal{{H}}_2\)

Marginalised posterior distributions for the neutralino LSP content. Here \(p_1 = N_{11}^2 + N_{12}^2\), \(p_2 = N_{13}^2 + N_{14}^2\), and \(p_3 = N_{15}^2\) quantifies the gaugino, Higgsino, and singlino content of the LSP. The dashed/green (H0), dash-dotted/red (H1) and solid/black (H2) lines represent the hypotheses \(\mathcal{{H}}_0\), \(\mathcal{{H}}_1\) and \(\mathcal{{H}}_2\) respectively
5.3 Posterior distributions related to neutralino CDM candidate
The LSP is identified as a candidate for explaining the observed CDM relic density. Here we show the posterior distributions for the neutralino composition and direct detection cross sections are presented. The nature of the LSP is one of the most important factors affecting its relic density and scattering cross sections. The relevant part of the Lagrangian for the neutralino is
Here \(\lambda _1\), \(\lambda _2^i\) (with \(i=1, 2, 3\)), and \(\lambda _3^a\) (with \(a=1, \dots , 8\)) represents respectively the \(U(1)_Y\), \(SU(2)_L\) and \(SU(3)_c\) gaugino fields. \(\lambda _1\) and \(\lambda _2^3\) mix with the neutral Higgsinos \(H_1^0, H_2^0, S\) to form a symmetric \(5 \times 5\) mass matrix \(\mathcal{M}_0\). With \(\psi ^0 = (-i\lambda _1 , -i\lambda _2^3, H_1^0, H_2^0, S)\), the neutralino mass term takes the form \(\mathcal{L} = - \frac{1}{2} (\psi ^0)^T \mathcal{M}_0 (\psi ^0) + \mathrm {H.c.}\). \(\mathcal{M}_0\) can be diagonalised by an orthonormal matrix \(N_{ij}\) such that the five mass-ordered eigenstates are superpositions of \(\psi ^0_j\):
The neutralino LSP is considered to be gaugino-, Higgsino- or singlino-like when \(p_1 = N_{11}^2 + N_{12}^2\), \(p_2 = N_{13}^2 + N_{14}^2\), or \(p_3 = N_{15}^2\) dominates respectively. The posterior distributions for these are shown in Fig. 3. It resulted in the fact that for \(\mathcal{{H}}_0\) (dashed/green line), the LSP is mixed gaugino-Higgsino with approximately zero singlino content. The case is different for \(\mathcal{{H}}_2\), for which the LSP is mixed Higgsino-singlino but with dominantly singlino and zero gaugino content. Instead, in the case for \(\mathcal{{H}}_1\) the LSP is dominantly Higgsino.
The nature of the neutralino LSP composition determines what leading role the annihilation and co-annihilation processes (see, e.g., Ref. [4]) play for getting the relic density around the experimental value, \(\Omega _{CDM} h^2 = 0.12\) [97]. It also determines the processes that could be involved for the direct detection of the dark matter candidate. Concerning the latter, the dominant processes are the t-channel Z or Higgs boson exchange for spin dependent or independent interactions, respectively. For instance, highly singlino-like LSP leads to small spin dependent cross section. The application of the dark matter direct detection limit will therefore lead to a posterior distribution with dominantly singlino LSP as is the case within \(\mathcal{{H}}_2\).
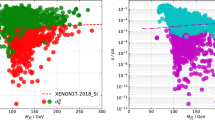
In Fig. 4 (first-row) the posterior distributions of the spin-independent and spin-dependent LSP-proton scattering cross sections compatible with all the considered collider, astrophysical, including the CDM direct detection bounds reported in [120,121,122,123,124,125,126], and flavour physics constraints are shown. The sudden suppressions in the direct detection cross sections occur at points for which there are cancellations from the neutralino-neutralino-Higgs interaction terms [167].

Marginalised two-dimensional posterior distributions for the neutralino LSP mass versus its spin-independent (1st-row left) and spin-dependent (1st-row right) scattering cross-section with proton. The green (H0), red (H1) and black (H2) regions represent \(\mathcal{{H}}_1\), \(\mathcal{{H}}_1\) and \(\mathcal{{H}}_2\) scenarios respectively. Inner and outer contours respectively enclose \(68\%\) and \(98\%\) Bayesian credibility regions of the posteriors. The blue/dotted contour lines on the left- and right-hand side plots show respectively the XENON1T [121] and PICO-2L [124] which represents the most constraining of the CDM direct detection limits used. The XENONnT and PICO-500 black/dotted contours show possible sensitivity of future upgrades of the experiments. The posterior distributions of the neutralino relic densities for each of the three pNMSSM scenarios are shown on the last plot (3rd-row). The dashed/green, dash-dotted/red and solid/black lines respectively represent the \(\mathcal{H}_0\), \(\mathcal{H}_1\) and \(\mathcal{H}_2\) scenarios. For parameter points with relic densities (in logarithmic scale) to the left of the mark near \(-1.0\), the direct detection constraints were rescaled to account for the neutralino dark matter under-production

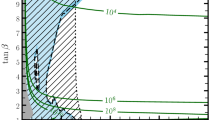
Marginalised posterior distribution for the NMSSM parameters \(\lambda \) and \(\kappa \). The green (H0), red (H1) and black (H2) regions represent the hypotheses \(\mathcal{{H}}_1\), \(\mathcal{{H}}_1\) and \(\mathcal{{H}}_2\), respectively. Inner and outer contours respectively enclose \(68\%\) and \(98\%\) Bayesian credibility regions
The second-row of plots in Fig. 4 show the DM direct detection limits used for the global fits. Regions above the contour lines are excluded at 95% C.L.. Possible sensitivity of the experiments’ future upgrades are also shown (XENONnT and PICO-500). These should probe better the pNMSSM parameter space, although the situation depends very much on the neutralino CDM relic density. Under-production of the relic density makes the direct detection limits less constraining. For instance the regions above the blue/dots line in Fig. 4 (first-row left) would have been excluded. They were not excluded because the relic densities at those points are much less than the experimentally measured central value around 0.1 as shown in Fig. 4 (third/last plot).
6 Conclusions
The nested sampling technique [38] implementation in PolyChord [41, 42] has been applied for computing the Bayesian evidence within a 26-parameters pNMSSM. The evidence values are based on limits from collider, astrophysical bounds on dark matter relic density and direct detection cross sections, and low-energy observables such as muon anomalous magnetic moment and flavour physics observables. These were used for comparing between three pNMSSM hypotheses:
-
\(\mathcal{H}_0\): The scenario for which the observed scalar around \(125 \,\text {GeV}\) is identified as the lightest CP-even Higgs boson, \(h_1\). \(m_{h_1}\) were allowed according to a Gaussian distribution with \(3 \,\text {GeV}\) standard deviation.
-
\(\mathcal{H}_1\): This is the same as \(\mathcal{H}_0\) but with the restriction that \(m_{h_2}\) be within 122–\(128 \,\text {GeV}\).
-
\(\mathcal{H}_2\): The scenario for which the observed scalar around \(125 \,\text {GeV}\) is identified as the second lightest Higgs boson, \(h_2\).
Using the Jeffreys’ scale for interpreting the evidence values (see Table 1), the analyses indicate that \(\mathcal{H}_2\) could be considered as being ranked first, with a Moderate support, amongst the three hypotheses. \(\mathcal{H}_0\) and \(\mathcal{H}_1\) can be considered as ranked second at the same time. That is, the current data used for the Bayesian comparisons favours the hypothesis with the possibility of having an additional but much lighter (than \(125 \,\text {GeV}\)) scalar. The lightest scalar within \(\mathcal{H}_2\) turned out to have mass distribution centred below the W-boson mass as shown in Fig. 1. Due to the “sharing of couplings” effect, \(h_2\) is SM-like while \(h_1\) is dominantly singlet-like.
From the posterior distributions presented, pNMSSM benchmark points could be constructed for further analyses with regards to non SM-like Higgs bosons. For instance, consider the two-dimensional posterior distribution on the (\(\lambda \), \(\kappa \)) plane shown in Fig. 5. For the \(\mathcal{H}_2\) hypothesis, the plane is well constrained and approximately reduced to a line. The model points along the line could be excellent benchmarks for testing non-SM Higgs scenarios.
Other possible directions for further investigations can be described as follows. In this article, the composition of the LSP was not fixed. The only requirement was that the relic density and the elastic cross section with nucleons be within the experimentally allowed range. One can go beyond this by demanding, a priori, a particular LSP composition. That is, one could require, in addition to what the masses of the light CP-even Higgs bosons could be, that only a specific LSP composition be allowed during the pNMSSM parameter space explorations. Next, there are experimental measurements which could possibly probe, in a better way, the pseudo-degenerate Higgs scenario. These include the precise determination of the Higgs boson’s total decay width. An update of the analyses presented here to include these ideas could shed more light about the pseudo-degenerate Higgs scenario.
There are caveats within our analyses. One is concerning the uncertainty of the Higgs mass prediction. Here we have used the traditional, and possibly too optimistic uncertainty of \(3 \,\text {GeV}\). A more careful analysis and systematic treatment of the uncertainties, see e.g. [168, 169], could significantly impact the Bayesian evidence values. This is also the case should naturalness priors be used for the analyses. In [37], it was shown that imposing naturalness requirements significantly affect the evidence. The correlations among the various observables were not included. Whenever available, the inclusion of correlations could possibly alter the pNMSSM posteriors. For instance, the measurements of the Higgs boson mass and couplings could come from a single experiment and therefore likely to be correlated. Finally, the inclusion of SUSY limits, such as in SmodelS, during the fits and using logarithmic priors should lead to more robust conclusions about the pNMSSM.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: The datasets generated and/or analysed during the current study are not publicly available due to their size but are available from the corresponding author on request.].
Notes
Note: for the comparison performed here, the aim is about getting correct evidence values. No special attention were made for comparing the uncertainties on the Evidence coming from the codes. The PolyChord’s “precision criterion” used is \(10^{-3}\) while the MultiNest’s “tolerance” parameter was set to 0.5. These code parameters affect, but in different ways (see Sect. 5.4 of [40]), the stopping criterion for the nested sampling and the error on the evidence. For the basic comparison made here between the codes no attempt were made for achieving similar deviations on the evidence values.
This limitation is because PolyChord requires live points to be generated and then the start of nested sampling all over a single run of the program.
These were made using GetDist, github.com/cmbant/getdist.
References
G. Aad et al., [ATLAS Collaboration], Phys. Lett. B 716, 1 (2012). https://doi.org/10.1016/j.physletb.2012.08.020. arXiv:1207.7214 [hep-ex]
S. Chatrchyan et al., [CMS Collaboration], Phys. Lett. B 716, 30 (2012). https://doi.org/10.1016/j.physletb.2012.08.021. arXiv:1207.7235 [hep-ex]
M. Maniatis, Int. J. Mod. Phys. A 25, 3505 (2010). https://doi.org/10.1142/S0217751X10049827. arXiv:0906.0777 [hep-ph]
U. Ellwanger, C. Hugonie, A.M. Teixeira, Phys. Rept. 496, 1 (2010). https://doi.org/10.1016/j.physrep.2010.07.001. arXiv:0910.1785 [hep-ph]
U. Ellwanger, Eur. Phys. J. C 71, 1782 (2011). https://doi.org/10.1140/epjc/s10052-011-1782-3. arXiv:1108.0157 [hep-ph]
K. Kowalska, S. Munir, L. Roszkowski, E.M. Sessolo, S. Trojanowski, Y.L.S. Tsai, Phys. Rev. D 87, 115010 (2013). https://doi.org/10.1103/PhysRevD.87.115010. arXiv:1211.1693 [hep-ph]
C. Balazs, D. Carter, JHEP 1003, 016 (2010). https://doi.org/10.1007/JHEP03(2010)016. arXiv:0906.5012 [hep-ph]
F. Mahmoudi, J. Rathsman, O. Stal, L. Zeune, Eur. Phys. J. C 71, 1608 (2011). https://doi.org/10.1140/epjc/s10052-011-1608-3. arXiv:1012.4490 [hep-ph]
B. Das, S. Moretti, S. Munir, P. Poulose, Eur. Phys. J. C 77(8), 544 (2017). https://doi.org/10.1140/epjc/s10052-017-5096-y. arXiv:1704.02941 [hep-ph]
S. Baum, K. Freese, N.R. Shah, B. Shakya, Phys. Rev. D 95(11), 115036 (2017). https://doi.org/10.1103/PhysRevD.95.115036. arXiv:1703.07800 [hep-ph]
K. Cheung, T.J. Hou, J.S. Lee, E. Senaha, Phys. Lett. B 710, 188 (2012). https://doi.org/10.1016/j.physletb.2012.02.070. arXiv:1201.3781 [hep-ph]
S. Akula, C. Balázs, L. Dunn, G. White, JHEP 1711, 051 (2017). https://doi.org/10.1007/JHEP11(2017)051. arXiv:1706.09898 [hep-ph]
K. Cheung, T.J. Hou, J.S. Lee, E. Senaha, Phys. Rev. D 82, 075007 (2010). https://doi.org/10.1103/PhysRevD.82.075007. arXiv:1006.1458 [hep-ph]
K. Cheung, T.J. Hou, J.S. Lee, E. Senaha, Phys. Rev. D 84, 015002 (2011). https://doi.org/10.1103/PhysRevD.84.015002. arXiv:1102.5679 [hep-ph]
J.J. Cao, Z.X. Heng, J.M. Yang, Y.M. Zhang, J.Y. Zhu, JHEP 1203, 086 (2012). https://doi.org/10.1007/JHEP03(2012)086. arXiv:1202.5821 [hep-ph]
M. Guchait, J. Kumar, Int. J. Mod. Phys. A 31(12), 1650069 (2016). https://doi.org/10.1142/S0217751X1650069X. arXiv:1509.02452 [hep-ph]
C. Beskidt, W. de Boer, D.I. Kazakov, Phys. Lett. B 726, 758 (2013). https://doi.org/10.1016/j.physletb.2013.09.053. arXiv:1308.1333 [hep-ph]
R. Benbrik, M.Gomez Bock, S. Heinemeyer, O. Stal, G. Weiglein, L. Zeune, Eur. Phys. J. C 72, 2171 (2012). https://doi.org/10.1140/epjc/s10052-012-2171-2. arXiv:1207.1096 [hep-ph]
Y. Kanehata, T. Kobayashi, Y. Konishi, O. Seto, T. Shimomura, Prog. Theor. Phys. 126, 1051 (2011). https://doi.org/10.1143/PTP.126.1051. arXiv:1103.5109 [hep-ph]
T. Kobayashi, T. Shimomura, T. Takahashi, Phys. Rev. D 86, 015029 (2012). https://doi.org/10.1103/PhysRevD.86.015029. arXiv:1203.4328 [hep-ph]
J. Beuria, U. Chattopadhyay, A. Datta, A. Dey, JHEP 1704, 024 (2017). https://doi.org/10.1007/JHEP04(2017)024. arXiv:1612.06803 [hep-ph]
A. Djouadi et al., [MSSM Working Group], arXiv:hep-ph/9901246
S. Profumo, C.E. Yaguna, Phys. Rev. D 70, 095004 (2004). https://doi.org/10.1103/PhysRevD.70.095004. arXiv:hep-ph/0407036
S.S. AbdusSalam, [AIP Conf. Proc.] 1078, 297 (2009). https://doi.org/10.1063/1.3051939. arXiv:0809.0284 [hep-ph]
C.F. Berger, J.S. Gainer, J.L. Hewett, T.G. Rizzo, JHEP 0902, 023 (2009). https://doi.org/10.1088/1126-6708/2009/02/023. arXiv:0812.0980 [hep-ph]
S.S. AbdusSalam, B.C. Allanach, F. Quevedo, F. Feroz, M. Hobson, Phys. Rev. D 81, 095012 (2010). https://doi.org/10.1103/PhysRevD.81.095012. arXiv:0904.2548 [hep-ph]
F. Feroz, B.C. Allanach, M. Hobson, S.S. AbdusSalam, R. Trotta, A.M. Weber, JHEP 0810, 064 (2008). https://doi.org/10.1088/1126-6708/2008/10/064. arXiv:0807.4512 [hep-ph]
S.S. AbdusSalam, B.C. Allanach, M.J. Dolan, F. Feroz, M.P. Hobson, Phys. Rev. D 80, 035017 (2009). https://doi.org/10.1103/PhysRevD.80.035017. arXiv:0906.0957 [hep-ph]
S.S. AbdusSalam, F. Quevedo, Phys. Lett. B 700, 343 (2011). https://doi.org/10.1016/j.physletb.2011.02.065. arXiv:1009.4308 [hep-ph]
J. Bergstrom, JHEP 1208, 163 (2012). https://doi.org/10.1007/JHEP08(2012)163. arXiv:1205.4404 [hep-ph]
J. Bergstrom, JHEP 1302, 093 (2013). https://doi.org/10.1007/JHEP02(2013)093. arXiv:1212.4484 [hep-ph]
J. Bergstrom, D. Meloni, L. Merlo, Phys. Rev. D 89(9), 093021 (2014). https://doi.org/10.1103/PhysRevD.89.093021. arXiv:1403.4528 [hep-ph]
A. Fowlie, Phys. Rev. D 90, 015010 (2014). https://doi.org/10.1103/PhysRevD.90.015010. arXiv:1403.3407 [hep-ph]
A. Fowlie, Eur. Phys. J. C 74(10), 3105 (2014). https://doi.org/10.1140/epjc/s10052-014-3105-y. arXiv:1407.7534 [hep-ph]
A. Fowlie, C. Balazs, G. White, L. Marzola, M. Raidal, JHEP 1608, 100 (2016). https://doi.org/10.1007/JHEP08(2016)100. arXiv:1602.03889 [hep-ph]
A. Fowlie, Eur. Phys. J. Plus 132(1), 46 (2017). https://doi.org/10.1140/epjp/i2017-11340-1. arXiv:1607.06608 [hep-ph]
P. Athron, C. Balazs, B. Farmer, A. Fowlie, D. Harries, D. Kim, JHEP 1710, 160 (2017). https://doi.org/10.1007/JHEP10(2017)160. arXiv:1709.07895 [hep-ph]
J. Skilling, Bayesian Anal. 1, 833 (2006). https://doi.org/10.1214/06-BA127
R. Trotta, Mon. Not. R. Astron. Soc. 378, 72 (2007). https://doi.org/10.1111/j.1365-2966.2007.11738.x. arXiv:astro-ph/0504022
F. Feroz, M.P. Hobson, M. Bridges, Mon. Not. R. Astron. Soc. 398, 1601 (2009). https://doi.org/10.1111/j.1365-2966.2009.14548.x. arXiv:0809.3437 [astro-ph]
W.J. Handley, M.P. Hobson, A.N. Lasenby, Mon. Not. R. Astron. Soc. 450(1), L61 (2015). https://doi.org/10.1093/mnrasl/slv047. arXiv:1502.01856 [astro-ph.CO]
W.J. Handley, M.P. Hobson, A.N. Lasenby, Mon. Not. R. Astron. Soc. 453(4), 4384 (2015). https://doi.org/10.1093/mnras/stv1911
U. Ellwanger, C. Hugonie, Adv. High Energy Phys. 2012, 625389 (2012). https://doi.org/10.1155/2012/625389. arXiv:1203.5048 [hep-ph]
J.F. Gunion, Y. Jiang, S. Kraml, Phys. Rev. D 86, 071702 (2012). https://doi.org/10.1103/PhysRevD.86.071702. arXiv:1207.1545 [hep-ph]
J.F. Gunion, Y. Jiang, S. Kraml, Phys. Rev. Lett. 110(5), 051801 (2013). https://doi.org/10.1103/PhysRevLett.110.051801. arXiv:1208.1817 [hep-ph]
N. Chen, Z. Liu,. arXiv:1607.02154 [hep-ph]
H. Jeffreys, The Theory of Probability, 3rd ed., Oxford University Press, p. 432 (1961)
R.E. Kass, A.E. Raftery, J. Am. Stat. Assoc. 90(430), 791 (1995). https://doi.org/10.2307/2291091
F. Feroz, M.P. Hobson, Mon. Not. R. Astron. Soc. 384, 449 (2008). https://doi.org/10.1111/j.1365-2966.2007.12353.x. arXiv:0704.3704 [astro-ph]
D.J.C. Mackay, Information Theory, Inference and Learning Algorithms (Cambridge University Press, Cambridge, 2003)
J.E. Kim, H.P. Nilles, Phys. Lett. 138B, 150 (1984). https://doi.org/10.1016/0370-2693(84)91890-2
S.Y. Choi, J. Kalinowski, G.A. Moortgat-Pick, P.M. Zerwas, Eur. Phys. J. C 22, 563 (2001). (Addendum: [Eur. Phys. J. C 23, 769 (2002)]) https://doi.org/10.1007/s100520100808
B.C. Allanach, Phys. Lett. B 635, 123 (2006). https://doi.org/10.1016/j.physletb.2006.02.052. arXiv:hep-ph/0601089
M.E. Cabrera, J.A. Casas, R. Ruiz de Austri, JHEP 0903, 075 (2009). https://doi.org/10.1088/1126-6708/2009/03/075. arXiv:0812.0536 [hep-ph]
D.M. Ghilencea, G.G. Ross, Nucl. Phys. B 868, 65 (2013). https://doi.org/10.1016/j.nuclphysb.2012.11.007. arXiv:1208.0837 [hep-ph]
J.R. Ellis, K. Enqvist, D.V. Nanopoulos, F. Zwirner, Mod. Phys. Lett. A 1, 57 (1986). https://doi.org/10.1142/S0217732386000105
R. Barbieri, G.F. Giudice, Nucl. Phys. B 306, 63 (1988). https://doi.org/10.1016/0550-3213(88)90171-X
R. Harnik, G.D. Kribs, D.T. Larson, H. Murayama, Phys. Rev. D 70, 015002 (2004). https://doi.org/10.1103/PhysRevD.70.015002. arXiv:hep-ph/0311349
R. Kitano, Y. Nomura, Phys. Lett. B 631, 58 (2005). https://doi.org/10.1016/j.physletb.2005.10.003. arXiv:hep-ph/0509039
H. Baer, V. Barger, D. Mickelson, Phys. Rev. D 88(9), 095013 (2013). https://doi.org/10.1103/PhysRevD.88.095013. arXiv:1309.2984 [hep-ph]
S.S. AbdusSalam, L. Velasco-Sevilla, Phys. Rev. D 94(3), 035026 (2016). https://doi.org/10.1103/PhysRevD.94.035026. arXiv:1506.02499 [hep-ph]
J.R. Ellis, J.F. Gunion, H.E. Haber, L. Roszkowski, F. Zwirner, Phys. Rev. D 39, 844 (1989). https://doi.org/10.1103/PhysRevD.39.844
M. Drees, Int. J. Mod. Phys. A 4, 3635 (1989). https://doi.org/10.1142/S0217751X89001448
F. Franke, H. Fraas, Int. J. Mod. Phys. A 12, 479 (1997). https://doi.org/10.1142/S0217751X97000529. arXiv:hep-ph/9512366
D.J. Miller, R. Nevzorov, P.M. Zerwas, Nucl. Phys. B 681, 3 (2004). https://doi.org/10.1016/j.nuclphysb.2003.12.021. arXiv:hep-ph/0304049
U. Ellwanger, J.F. Gunion, C. Hugonie, JHEP 0502, 066 (2005). https://doi.org/10.1088/1126-6708/2005/02/066. arXiv:hep-ph/0406215
J. Bernon, B. Dumont, Eur. Phys. J. C 75(9), 440 (2015). https://doi.org/10.1140/epjc/s10052-015-3645-9. arXiv:1502.04138 [hep-ph]
U. Ellwanger, C. Hugonie, Comput. Phys. Commun. 177, 399 (2007). https://doi.org/10.1016/j.cpc.2007.05.001. arXiv:hep-ph/0612134
U. Ellwanger, C. Hugonie, Comput. Phys. Commun. 175, 290 (2006). https://doi.org/10.1016/j.cpc.2006.04.004. arXiv:hep-ph/0508022
A. Djouadi, J. Kalinowski, M. Spira, Comput. Phys. Commun. 108, 56 (1998). https://doi.org/10.1016/S0010-4655(97)00123-9. arXiv:hep-ph/9704448
G. Degrassi, P. Slavich, Nucl. Phys. B 825, 119 (2010). https://doi.org/10.1016/j.nuclphysb.2009.09.018. arXiv:0907.4682 [hep-ph]
F. Domingo, U. Ellwanger, JHEP 0712, 090 (2007). https://doi.org/10.1088/1126-6708/2007/12/090. arXiv:0710.3714 [hep-ph]
F. Domingo, Eur. Phys. J. C 76(8), 452 (2016). https://doi.org/10.1140/epjc/s10052-016-4298-z. arXiv:1512.02091 [hep-ph]
E. Boos et al., [CompHEP Collaboration], Nucl. Instrum. Methods A 534, 250 (2004). https://doi.org/10.1016/j.nima.2004.07.096. arXiv:hep-ph/0403113
A. Semenov, Comput. Phys. Commun. 180, 431 (2009). https://doi.org/10.1016/j.cpc.2008.10.012. arXiv:0805.0555 [hep-ph]
G. Belanger, N.D. Christensen, A. Pukhov, A. Semenov, Comput. Phys. Commun. 182, 763 (2011). https://doi.org/10.1016/j.cpc.2010.10.025. arXiv:1008.0181 [hep-ph]
A. Pukhov et al., arXiv:hep-ph/9908288
A. Belyaev, N.D. Christensen, A. Pukhov, Comput. Phys. Commun. 184, 1729 (2013). https://doi.org/10.1016/j.cpc.2013.01.014. arXiv:1207.6082 [hep-ph]
G. Belanger, F. Boudjema, A. Pukhov, A. Semenov, Comput. Phys. Commun. 185, 960 (2014). https://doi.org/10.1016/j.cpc.2013.10.016. arXiv:1305.0237 [hep-ph]
G. Belanger, F. Boudjema, A. Pukhov, A. Semenov, Nuovo Cim. C 033N2, 111 (2010). https://doi.org/10.1393/ncc/i2010-10591-3. arXiv:1005.4133 [hep-ph]
G. Belanger, F. Boudjema, A. Pukhov, A. Semenov, Comput. Phys. Commun. 180, 747 (2009). https://doi.org/10.1016/j.cpc.2008.11.019. arXiv:0803.2360 [hep-ph]
G. Belanger, F. Boudjema, A. Pukhov, A. Semenov, Comput. Phys. Commun. 176, 367 (2007). https://doi.org/10.1016/j.cpc.2006.11.008. arXiv:hep-ph/0607059
D. Barducci, G. Belanger, J. Bernon, F. Boudjema, J. Da Silva, S. Kraml, U. Laa, A. Pukhov, Comput. Phys. Commun. 222, 327 (2018). https://doi.org/10.1016/j.cpc.2017.08.028. arXiv:1606.03834 [hep-ph]
G. Aad et al., [ATLAS and CMS Collaborations], Phys. Rev. Lett. 114, 191803 (2015). https://doi.org/10.1103/PhysRevLett.114.191803. arXiv:1503.07589 [hep-ex]
C. Bobeth, M. Misiak, J. Urban, Nucl. Phys. B 567, 153 (2000). https://doi.org/10.1016/S0550-3213(99)00688-4. arXiv:hep-ph/9904413
A.J. Buras, A. Czarnecki, M. Misiak, J. Urban, Nucl. Phys. B 631, 219 (2002). https://doi.org/10.1016/S0550-3213(02)00261-4. arXiv:hep-ph/0203135
Y. Amhis et al., [Heavy Flavor Averaging Group (HFAG)], arXiv:1412.7515 [hep-ex]
R. Aaij et al., [LHCb Collaboration], Phys. Rev. Lett. 118(19), 191801 (2017). https://doi.org/10.1103/PhysRevLett.118.191801. arXiv:1703.05747 [hep-ex]
C. Bobeth, M. Gorbahn, T. Hermann, M. Misiak, E. Stamou, M. Steinhauser, Phys. Rev. Lett. 112, 101801 (2014). https://doi.org/10.1103/PhysRevLett.112.101801. arXiv:1311.0903 [hep-ph]
A.J. Buras, P.H. Chankowski, J. Rosiek, L. Slawianowska, Nucl. Phys. B 659, 3 (2003). https://doi.org/10.1016/S0550-3213(03)00190-1. arXiv:hep-ph/0210145
P. Ball, R. Fleischer, Eur. Phys. J. C 48, 413 (2006). https://doi.org/10.1140/epjc/s10052-006-0034-4. arXiv:hep-ph/0604249
R. Barate et al., [ALEPH Collaboration], Eur. Phys. J. C 19, 213 (2001). https://doi.org/10.1007/s100520100612. arXiv:hep-ex/0010022
B. Aubert et al., [BaBar Collaboration], Phys. Rev. Lett. 95, 041804 (2005). https://doi.org/10.1103/PhysRevLett.95.041804. arXiv:hep-ex/0407038
A. Gray et al., [HPQCD Collaboration], Phys. Rev. Lett. 95, 212001 (2005). https://doi.org/10.1103/PhysRevLett.95.212001. arXiv:hep-lat/0507015
A.G. Akeroyd, S. Recksiegel, J. Phys. G 29, 2311 (2003). https://doi.org/10.1088/0954-3899/29/10/301. arXiv:hep-ph/0306037
G.W. Bennett et al., [Muon g-2 Collaboration], Phys. Rev. D 73, 072003 (2006). https://doi.org/10.1103/PhysRevD.73.072003. arXiv:hep-ex/0602035
P.A.R. Ade et al., [Planck Collaboration], Astron. Astrophys. 594, A13 (2016). https://doi.org/10.1051/0004-6361/201525830. arXiv:1502.01589 [astro-ph.CO]
G. Aad et al., [ATLAS Collaboration], Phys. Rev. Lett. 112, 201802 (2014). https://doi.org/10.1103/PhysRevLett.112.201802. arXiv:1402.3244 [hep-ex]
S. Chatrchyan et al., [CMS Collaboration], Eur. Phys. J. C 74, 2980 (2014). https://doi.org/10.1140/epjc/s10052-014-2980-6. arXiv:1404.1344 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Phys. Lett. B 738, 68 (2014). https://doi.org/10.1016/j.physletb.2014.09.008. arXiv:1406.7663 [hep-ex]
V. Khachatryan et al., [CMS Collaboration], Eur. Phys. J. C 75 5, 212 (2015). https://doi.org/10.1140/epjc/s10052-015-3351-7. arXiv:1412.8662 [hep-ex]
V. Khachatryan et al., [CMS Collaboration], Eur. Phys. J. C 74 10, 3076 (2014). https://doi.org/10.1140/epjc/s10052-014-3076-z. arXiv:1407.0558 [hep-ex]
T. Aaltonen et al., [CDF and D0 Collaborations], Phys. Rev. D 88(5), 052014 (2013). https://doi.org/10.1103/PhysRevD.88.052014. arXiv:1303.6346 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Eur. Phys. J. C 76(1), 6 (2016) . https://doi.org/10.1140/epjc/s10052-015-3769-y. arXiv:1507.04548 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Phys. Rev. D 90(11), 112015 (2014) . https://doi.org/10.1103/PhysRevD.90.112015. arXiv:1408.7084 [hep-ex]
G. Aad et al., [ATLAS Collaboration], JHEP 1508, 137 (2015). https://doi.org/10.1007/JHEP08(2015)137. arXiv:1506.06641 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Phys. Rev. D 91(1), 012006 (2015). https://doi.org/10.1103/PhysRevD.91.012006. arXiv:1408.5191 [hep-ex]
G. Aad et al., [ATLAS Collaboration], JHEP 1504, 117 (2015). https://doi.org/10.1007/JHEP04(2015)117. arXiv:1501.04943 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Phys. Lett. B 749, 519 (2015). https://doi.org/10.1016/j.physletb.2015.07.079. arXiv:1506.05988 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Eur. Phys. J. C 75(7), 349 (2015). https://doi.org/10.1140/epjc/s10052-015-3543-1. arXiv:1503.05066 [hep-ex]
G. Aad et al., [ATLAS Collaboration], JHEP 1501, 069 (2015). https://doi.org/10.1007/JHEP01(2015)069. arXiv:1409.6212 [hep-ex]
The ATLAS collaboration [ATLAS Collaboration], ATLAS-CONF-2015-004
S. Chatrchyan et al., [CMS Collaboration], JHEP 1401, 096 (2014). https://doi.org/10.1007/JHEP01(2014)096. arXiv:1312.1129 [hep-ex]
S. Chatrchyan et al., [CMS Collaboration], Phys. Rev. D 89(9), 092007 (2014). https://doi.org/10.1103/PhysRevD.89.092007. arXiv:1312.5353 [hep-ex]
S. Chatrchyan et al., [CMS Collaboration], JHEP 1405, 104 (2014). https://doi.org/10.1007/JHEP05(2014)104. arXiv:1401.5041 [hep-ex]
S. Chatrchyan et al., [CMS Collaboration], Phys. Rev. D 89(1), 012003 (2014). https://doi.org/10.1103/PhysRevD.89.012003. arXiv:1310.3687 [hep-ex]
V. Khachatryan et al., [CMS Collaboration], JHEP 1409, 087 (2014) (Erratum: [JHEP 1410 (2014) 106]). https://doi.org/10.1007/JHEP09(2014)087. https://doi.org/10.1007/JHEP10(2014)106. arXiv:1408.1682 [hep-ex]
V. Khachatryan et al., [CMS Collaboration], Eur. Phys. J. C 75(6), 251 (2015). https://doi.org/10.1140/epjc/s10052-015-3454-1. arXiv:1502.02485 [hep-ex]
V. Khachatryan et al., [CMS Collaboration], Phys. Rev. D 92(3), 032008 (2015). https://doi.org/10.1103/PhysRevD.92.032008. arXiv:1506.01010 [hep-ex]
D.S. Akerib et al., [LUX Collaboration], Phys. Rev. Lett. 118(2), 021303 (2017). https://doi.org/10.1103/PhysRevLett.118.021303. arXiv:1608.07648 [astro-ph.CO]
E. Aprile et al., [XENON Collaboration], Phys. Rev. Lett. 119(18), 181301 (2017). https://doi.org/10.1103/PhysRevLett.119.181301. arXiv:1705.06655 [astro-ph.CO]
A. Tan et al., [PandaX-II Collaboration], Phys. Rev. Lett. 117(12), 121303 (2016). https://doi.org/10.1103/PhysRevLett.117.121303. arXiv:1607.07400 [hep-ex]
C. Amole et al., [PICO Collaboration], Phys. Rev. D 93(5), 052014 (2016). https://doi.org/10.1103/PhysRevD.93.052014. arXiv:1510.07754 [hep-ex]
C. Amole et al., [PICO Collaboration], Phys. Rev. D 93(6), 061101 (2016). https://doi.org/10.1103/PhysRevD.93.061101. arXiv:1601.03729 [astro-ph.CO]
D.S. Akerib et al., [LUX Collaboration], Phys. Rev. Lett. 116(16), 161302 (2016). https://doi.org/10.1103/PhysRevLett.116.161302. arXiv:1602.03489 [hep-ex]
C. Fu et al., [PandaX-II Collaboration], Phys. Rev. Lett. 118(7), 071301 (2017) (Erratum: [Phys. Rev. Lett. 120(4), 049902 (2018)]). https://doi.org/10.1103/PhysRevLett.120.049902. https://doi.org/10.1103/PhysRevLett.118.071301. arXiv:1611.06553 [hep-ex]
P. Bechtle, O. Brein, S. Heinemeyer, G. Weiglein, K.E. Williams, Comput. Phys. Commun. 182, 2605 (2011). https://doi.org/10.1016/j.cpc.2011.07.015. arXiv:1102.1898 [hep-ph]
P. Bechtle, O. Brein, S. Heinemeyer, O. Stål, T. Stefaniak, G. Weiglein, K.E. Williams, Eur. Phys. J. C 74(3), 2693 (2014). https://doi.org/10.1140/epjc/s10052-013-2693-2. arXiv:1311.0055 [hep-ph]
G. Aad et al., [ATLAS Collaboration], Phys. Lett. B 732, 8 (2014). https://doi.org/10.1016/j.physletb.2014.03.015. arXiv:1402.3051 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Phys. Rev. D 92, 092004 (2015). https://doi.org/10.1103/PhysRevD.92.092004. arXiv:1509.04670 [hep-ex]
V. Khachatryan et al., [CMS Collaboration], JHEP 1510, 144 (2015). https://doi.org/10.1007/JHEP10(2015)144. arXiv:1504.00936 [hep-ex]
G. Aad et al., [ATLAS Collaboration], JHEP 1411, 056 (2014). https://doi.org/10.1007/JHEP11(2014)056. arXiv:1409.6064 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Eur. Phys. J. C 76 1, 45 (2016). https://doi.org/10.1140/epjc/s10052-015-3820-z. arXiv:1507.05930 [hep-ex]
G. Aad et al., [ATLAS Collaboration], Phys. Rev. Lett. 114 8, 081802 (2015). https://doi.org/10.1103/PhysRevLett.114.081802. arXiv:1406.5053 [hep-ex]
G. Aad et al., [ATLAS Collaboration], JHEP 1601, 032 (2016). https://doi.org/10.1007/JHEP01(2016)032. arXiv:1509.00389 [hep-ex]
F. Ambrogi et al., Comput. Phys. Commun. 227, 72 (2018). https://doi.org/10.1016/j.cpc.2018.02.007. arXiv:1701.06586 [hep-ph]
S. Kraml, S. Kulkarni, U. Laa, A. Lessa, W. Magerl, D. Proschofsky-Spindler, W. Waltenberger, Eur. Phys. J. C 74, 2868 (2014). https://doi.org/10.1140/epjc/s10052-014-2868-5. arXiv:1312.4175 [hep-ph]
A. Buckley, Eur. Phys. J. C 75(10), 467 (2015). https://doi.org/10.1140/epjc/s10052-015-3638-8. arXiv:1305.4194 [hep-ph]
T. Sjostrand, S. Mrenna, P.Z. Skands, JHEP 0605, 026 (2006). https://doi.org/10.1088/1126-6708/2006/05/026. arXiv:hep-ph/0603175
W. Beenakker, R. Hopker, M. Spira, P.M. Zerwas, Nucl. Phys. B 492, 51 (1997). https://doi.org/10.1016/S0550-3213(97)80027-2. arXiv:hep-ph/9610490
W. Beenakker, M. Kramer, T. Plehn, M. Spira, P.M. Zerwas, Nucl. Phys. B 515, 3 (1998). https://doi.org/10.1016/S0550-3213(98)00014-5. arXiv:hep-ph/9710451
A. Kulesza, L. Motyka, Phys. Rev. Lett. 102, 111802 (2009). https://doi.org/10.1103/PhysRevLett.102.111802. arXiv:0807.2405 [hep-ph]
A. Kulesza, L. Motyka, Phys. Rev. D 80, 095004 (2009). https://doi.org/10.1103/PhysRevD.80.095004. arXiv:0905.4749 [hep-ph]
W. Beenakker, S. Brensing, M. Kramer, A. Kulesza, E. Laenen, I. Niessen, JHEP 0912, 041 (2009). https://doi.org/10.1088/1126-6708/2009/12/041. arXiv:0909.4418 [hep-ph]
W. Beenakker, S. Brensing, M. Kramer, A. Kulesza, E. Laenen, I. Niessen, JHEP 1008, 098 (2010). https://doi.org/10.1007/JHEP08(2010)098. arXiv:1006.4771 [hep-ph]
W. Beenakker, S. Brensing, M n Kramer, A. Kulesza, E. Laenen, L. Motyka, I. Niessen, Int. J. Mod. Phys. A 26, 2637 (2011). https://doi.org/10.1142/S0217751X11053560. arXiv:1105.1110 [hep-ph]
[ATLAS Collaboration], ATLAS-CONF-2013-024
The ATLAS collaboration [ATLAS Collaboration], ATLAS-CONF-2013-047
The ATLAS collaboration [ATLAS Collaboration], ATLAS-CONF-2013-053
The ATLAS collaboration [ATLAS Collaboration], ATLAS-CONF-2013-061
CMS Collaboration [CMS Collaboration], CMS-PAS-SUS-13-018
CMS Collaboration [CMS Collaboration], CMS-PAS-SUS-13-023
S. Chatrchyan et al., [CMS Collaboration], Eur. Phys. J. C 73 9, 2568 (2013). https://doi.org/10.1140/epjc/s10052-013-2568-6. arXiv:1303.2985 [hep-ex]
V. Khachatryan et al., [CMS Collaboration], Eur. Phys. J. C 74 9, 3036 (2014). https://doi.org/10.1140/epjc/s10052-014-3036-7. arXiv:1405.7570 [hep-ex]
S. Chatrchyan et al., [CMS Collaboration]. JHEP 1406, 055 (2014). https://doi.org/10.1007/JHEP06(2014)055. arXiv:1402.4770 [hep-ex]
V. Khachatryan et al., [CMS Collaboration]. JHEP 1505, 078 (2015). https://doi.org/10.1007/JHEP05(2015)078. arXiv:1502.04358 [hep-ex]
S. Chatrchyan et al., [CMS Collaboration], Eur. Phys. J. C 73(12), 2677 (2013). https://doi.org/10.1140/epjc/s10052-013-2677-2. arXiv:1308.1586 [hep-ex]
S. Heinemeyer et al., [LHC Higgs Cross Section Working Group], https://doi.org/10.5170/CERN-2013-004. arXiv:1307.1347 [hep-ph]
P. Bechtle, S. Heinemeyer, O. Stal, T. Stefaniak, G. Weiglein, Eur. Phys. J. C 75(9), 421 (2015). https://doi.org/10.1140/epjc/s10052-015-3650-z. arXiv:1507.06706 [hep-ph]
P.Z. Skands et al., JHEP 0407, 036 (2004). https://doi.org/10.1088/1126-6708/2004/07/036. arXiv:hep-ph/0311123
D. Buskulic et al., [ALEPH Collaboration], Phys. Lett. B 313, 312 (1993). https://doi.org/10.1016/0370-2693(93)91228-F
J. Abdallah et al., [DELPHI Collaboration], Eur. Phys. J. C 38, 1 (2004). https://doi.org/10.1140/epjc/s2004-02011-4. arXiv:hep-ex/0410017
V. Khachatryan et al., [CMS Collaboration], Phys. Lett. B 752, 146 (2016). https://doi.org/10.1016/j.physletb.2015.10.067. arXiv:1506.00424 [hep-ex]
The ATLAS collaboration [ATLAS Collaboration], ATLAS-CONF-2014-031
The ATLAS collaboration [ATLAS Collaboration], ATLAS-CONF-2014-049
The ATLAS collaboration [ATLAS Collaboration], ATLAS-CONF-2016-085
J.R. Ellis, A. Ferstl, K.A. Olive, Phys. Lett. B 481, 304 (2000). https://doi.org/10.1016/S0370-2693(00)00459-7. arXiv:hep-ph/0001005
M.D. Goodsell, K. Nickel, F. Staub, Phys. Rev. D 91, 035021 (2015). https://doi.org/10.1103/PhysRevD.91.035021. arXiv:1411.4665 [hep-ph]
F. Staub, P. Athron, U. Ellwanger, R. Gröber, M. Mühlleitner, P. Slavich, A. Voigt, Comput. Phys. Commun. 202, 113 (2016). https://doi.org/10.1016/j.cpc.2016.01.005. arXiv:1507.05093 [hep-ph]
Acknowledgements
Thanks to W. Handley for support in using PolyChord; U. Ellwanger, C. Hugonie, and J. Bernon for NMSSMTools related issues; L. Aparicio, M.E. Cabrera and F. Quevedo for discussions about the NMSSM; and to A. Gatti for reading and suggestions for improving the manuscript. With support from F. Quevedo, this work was performed using ICTP’s ARGO and the University of Cambridge’s Darwin HPC facilities. The latter is provided by Dell Inc. using Strategic Research Infrastructure Funding from the Higher Education Funding Council for England and funding from the Science and Technology Facilities Council.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
AbdusSalam, S.S. Testing Higgs boson scenarios in the phenomenological NMSSM. Eur. Phys. J. C 79, 442 (2019). https://doi.org/10.1140/epjc/s10052-019-6953-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-019-6953-7