
Abstract
We prove that when suitably normalized, small enough powers of the absolute value of the characteristic polynomial of random Hermitian matrices, drawn from one-cut regular unitary invariant ensembles, converge in law to Gaussian multiplicative chaos measures. We prove this in the so-called \(L^2\)-phase of multiplicative chaos. Our main tools are asymptotics of Hankel determinants with Fisher–Hartwig singularities. Using Riemann–Hilbert methods, we prove a rather general Fisher–Hartwig formula for one-cut regular unitary invariant ensembles.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
1.1 Main result
Log-correlated Gaussian fields, namely Gaussian random generalized functions whose covariance kernels have a logarithmic singularity on the diagonal, are known to show up in various models of modern probability and mathematical physics—e.g. in combinatorial models describing random partitions of integers [35], random matrix theory [31, 34, 60], lattice models of statistical mechanics [41], the construction of conformally invariant random planar curves such as stochastic Loewner evolution [4, 63], and growth models [9] just to name a few examples. A recent and fundamental development in the theory of these log-correlated fields has been that while these fields are rough objects—distributions instead of functions—their geometric properties can be understood to some degree. For example, one can describe the behavior of the extremal values and level sets of the fields in a suitable sense—see e.g. [58, Section 4 and Section 6.4].
A fundamental tool in describing these geometric properties of the fields is a class of random measures, which can be formally written as an exponential of the field. As these fields are distributions instead of functions, exponentiation is not an operation one can naively perform, but through a suitable limiting and normalization procedure, these random measures can be rigorously constructed and they are known as Gaussian multiplicative chaos measures. These objects were introduced by Kahane in the 1980s [37]. For a recent review, we refer the reader to [58] and for a concise proof of existence and uniqueness of these measures we refer to [6].
A typical example of how log-correlated fields show up can be found in random matrix theory. For a large class of models of random matrix theory, the following is true: when the size of the matrix tends to infinity, the logarithm of the characteristic polynomial behaves like a log-correlated field. This is essentially equivalent to a suitable central limit theorem for the global linear statistics of the random matrix—see [31, 34, 60] for results concerning the GUE, Haar distributed random unitary matrices, and the complex Ginibre ensemble.
One would thus expect that the characteristic polynomial and powers of it should behave asymptotically like a multiplicative chaos measure. A related question was explored thoroughly though non-rigorously in [30, 32]. The issue here is that the construction of the multiplicative chaos measure goes through a very specific approximation of the Gaussian field and typically uses things like independence and Gaussianity very strongly. In the random matrix theory situation these are present only asymptotically. Thus the precise extent of the connection between the theory of log-correlated processes and random matrix theory is far from fully understood. For rigorous results concerning multiplicative chaos and the study of extrema of approximately Gaussian log-correlated fields in random matrix theory we refer to [2, 12, 46, 47, 57, 67].
In this article we establish a universality result showing that for a class of random Hermitian matrices, small enough powers of the absolute value of the characteristic polynomial can be described in terms of a Gaussian multiplicative chaos measure. More precisely, we prove the following result (for definitions of the relevant quantities, see Sect. 2).
Theorem 1.1
Let \(H_N\) be a random \(N\times N\) Hermitian matrix drawn from a one-cut regular, unitary invariant ensemble whose equilibrium measure is normalized to have support \([-1,1]\). Then for \(\beta \in [0,\sqrt{2})\), the random measure
on \((-1,1)\), converges in distribution with respect to the topology of weak convergence of measures on \((-1,1)\) to a Gaussian multiplicative chaos measure which can be formally written as \(e^{\beta X(x)-\frac{\beta ^2}{2}\mathbb {E}X(x)^2}dx\), where X is a centered Gaussian field with covariance kernel
We note that in particular, this result holds for the Gaussian Unitary Ensemble (GUE) of random matrices, with a suitable normalization. The proof here is a generalization of that in [67] by the second author and relies on understanding the large N asymptotics of quantities which can be written in the form \(\mathbb {E}[e^{\mathrm {Tr}\ \mathcal {T}(H_N)}\prod _{j=1}^k |\det (H_N-x_j)|^{\beta _j}]\) for a suitable function \(\mathcal {T}:\mathbb {R}\rightarrow \mathbb {R}, x_j\in (-1,1)\) and \(\beta _j\ge 0\).
It is easy to see, and we will recall the relevant derivations below, that such expectations can be written in terms of Hankel determinants with Fisher–Hartwig symbols, and while such quantities (and corresponding Toeplitz determinants) have been studied in great detail [14, 19, 20, 42], it seems that in the generality we require for Theorem 1.1, many of the results are lacking. Thus we give a proof of such results using Riemann–Hilbert techniques; see Proposition 2.10 for the precise result. This settles some conjectures due to Forrester and Frankel—see Remark 2.11 and [28, Conjecture 5 and Conjecture 8] for further information about their conjectures.
1.2 Motivations and related results
One of the main motivations for this work is establishing multiplicative chaos measures as something appearing universally when studying the global spectral behavior of random matrices. This is a new type of universality result in random matrix theory and also suggests that it should be possible to establish some of the geometric properties of log-correlated fields in the setting of random matrix theory as well. Perhaps on a more fundamental level, a further motivation for the work here is a general picture of when does the exponential of an approximation to a log-correlated field converge to a multiplicative chaos measure. Naturally we don’t answer this question here, but the fact that our approach works so generally, suggests that part of this argument is something that transfers beyond random matrix theory to general models where one expects multiplicative chaos measures to play a role.
On a more speculative level, we also mention as motivation the connection to two-dimensional quantum gravity. It is well known that random matrix theory is related to a discretization of two-dimensional quantum gravity, namely the analysis of random planar maps—see e.g. [25] for a mathematically rigorous discussion of this connection. On the other hand, multiplicative chaos measures play a significant role in the study of Liouville quantum gravity [16, 24] which is in some instances known to be the scaling limit of a suitable model of random planar maps [48, 50, 52,53,54]. The appearance of multiplicative chaos measures from random matrix theory seems like a curious coincidence from this point of view, and one that deserves further study.
One interpretation of Theorem 1.1 is that it gives a way of probing the (random fractal) set of points x where the recentered log characteristic polynomial \(\log |\det (H_N-x)|-\mathbb {E}\log |\det (H_N-x)|\) is exceptionally large. In analogy with standard multiplicative chaos results (see e.g. [58, Theorem 4.1] or the approach of [6]), one would expect that Theorem 1.1 implies that asymptotically, \(\frac{|\det (H_N-x)|^\beta }{\mathbb {E}|\det (H_N-x)|^\beta } dx\) lives on the set of points x where
We emphasize that this really means that the (approximately Gaussian) random variable \(\log |\det (H_N-x)|-\mathbb {E}\log |\det (H_N-x)|\) would be of the order of its variance instead of its standard deviation—as the variance is exploding, this is what motivates the claim of the log-characteristic polynomial taking exceptionally large values. Moreover, as it is known that the measure \(\mu _\beta \) vanishes for \(\beta \ge 2\), this connection suggests that for \(\beta >2\), there are no points where (1.1) is satisfied and that \(\beta =2\) corresponds to the scale of where the maximum of the field lives (note that it is rigorously known through other methods that the maximum is indeed on the scale of two times the variance of the field—see [47] and see also [2, 12, 57] for analogous results in the case of ensembles of random unitary matrices). This suggests that suitable variants of Theorem 1.1 should provide a tool for studying extremal values of the characteristic polynomial, or even that more generally, existence of multiplicative chaos measures can be used to study the extremal behavior of log-correlated field. This is significant because maxima of logarithmically correlated fields (such as the log characteristic polynomial) are believed to display universality, and have as such been extensively studied in recent years (see e.g. [29] and references below). In fact, the construction of Gaussian multiplicative chaos measures supported on points where the value of the field is a given fraction of the maximal value, may be viewed as part of the programme of establishing universality for such processes. While our results do not extend to the full range of values of \(\beta \) where one expects the result to be valid (roughly, we examine only the \(L^2\) regime in Gaussian multiplicative chaos terminology), we believe that an appropriate modification of the methods of this paper eventually will yield the result in its full generality (for instance by combining it with a suitable modification of the approach in [6]).
Regarding this programme, we mention the papers of Arguin et al. [2] which verify the leading order of the maximum of the CUE log characteristic polynomial, as well as Paquette and Zeitouni [57] which refined this to obtain the second order, doubly logarithmic (“Bramson”) correction. This is consistent with a prediction of Fyodorov et al. [29]. In turn this was subsequently refined and generalized to the so-called circular \(\beta \)-ensemble by [13] where tightness of the centered maximum was proved. For a large class of random Hermitian matrices, the leading order behavior was established recently by Lambert and Paquette [47], while in the case of the Riemann zeta function, the first order term was obtained (assuming the Riemann hypothesis) by Najnudel [55] as well as (unconditionally) by Arguin et al. [3]. In the case of the discrete Gaussian free field in two dimensions, the convergence in law of the recentered maximum was obtained recently in an important paper of Bramson et al. [8]. As for Gaussian multiplicative chaos measures (in the \(L^2\)-phase), the construction in the case of CUE random matrices was achieved by Webb [67]. Very recently, a related construction of a Gaussian multiplicative chaos measure was obtained by Lambert et al. [46] in the full \(L^1\) regime of CUE random matrices, but for a slightly regularized version of the logarithm of the characteristic polynomial which is closer to a Gaussian field.
1.3 Organisation of the paper
The outline of the article is the following: in Sect. 2, we describe our model and objects of interest, our main results, and an outline of the proof. After this, in Sect. 3, we recall how the relevant moments can be expressed as Hankel determinants as well as how these determinants are related to orthogonal polynomials on the real line and Riemann–Hilbert problems. In this section we also recall from [20] a differential identity for the relevant determinants. Then in Sect. 4 we go over the analysis of the relevant Riemann–Hilbert problem. This is very similar to the corresponding analysis in [20, 42], but for completeness and due to slight differences in the proofs, we choose to present details of this in appendices. After this, in Sect. 5 we use the solution of the Riemann–Hilbert problem to integrate the differential identity to find the asymptotics of the relevant moments. Finally in Sect. 6, we put things together and prove our main results.
We have chosen to defer a number of technical proofs to the end of the paper in the form of multiple appendices. These contain proofs of results which might be considered in some sense routine calculations by experts in random matrix and integrable models, but which would require significant effort to readers not familiar with these techniques. Since we hope that the paper will be of interest to different communities, we have chosen to keep them in the paper at the cost of increasing its length.
2 Preliminaries and outline of the proof
In this section, we describe the main objects we shall discuss in this article, state our main results, and give an outline of the proof of them.
2.1 One-cut regular ensembles of random Hermitian matrices
The basic objects we are interested in are \(N\times N\) random Hermitian matrices \(H_N\) whose distribution can be written as
where \(dH_N=\prod _{j=1}^N dH_{jj}\prod _{1\le i<j\le N}d(\mathrm {Re}H_{ij})d(\mathrm {Im}H_{ij})\) denotes the Lebesgue measure on the space of \(N\times N\) Hermitian matrices, \(\mathrm {Tr}V(H_N)\) denotes \(\sum _{j=1}^N V(\lambda _j)\), where \((\lambda _j)\) are the eigenvalues of \(H_N\) (we drop the dependence on N from our notation), the potential \(V:\mathbb {R}\rightarrow \mathbb {R}\) is a smooth function with nice enough growth at infinity so that this makes sense, and \({\widetilde{Z}}_N(V)\) is a normalizing constant. Perhaps the simplest model of such form is the Gaussian Unitary Ensemble for which \(V(x)=2x^2\). This corresponds to the diagonal entries of \(H_N\) being i.i.d. centered normal random variables with variance 1 / (4N), and the entries above the diagonal being i.i.d. random variables whose real and imaginary parts are centered normal random variables with variance 1 / (8N) and are independent of each other and of the diagonal entries. The entries below the diagonal are determined by the condition that the matrix is Hermitian.
The distribution (2.1) induces a probability distribution for the eigenvalues of \(H_N\). In analogy with the GUE (see e.g. [1]) one finds that the distribution of the eigenvalues (on \(\mathbb {R}^N\)) is given by
where \(Z_N(V)\) is a normalizing constant called the partition function. Our main goal will be to describe the large N behavior of the characteristic polynomial of \(H_N\), and more generally a power of this characteristic polynomial. To do this, we will have to impose further constraints on the function V. A general family of functions V for which our argument works is the class of one-cut regular potentials. We will review the relevant concepts here, but for more details, see [43].
First of all, we assume that V is real analytic on \(\mathbb {R}\) and \(\lim _{x\rightarrow \pm \infty }V(x)/\log |x|=\infty \). Further conditions on V are rather indirect as they are statements about the associated equilibrium measure \(\mu _V\) which is defined as the unique minimizer of the functional
on the space of Borel probability measures on \(\mathbb {R}\). For further information about \(\mu _V\), see e.g. [21, 61]. The measure \(\mu _V\) can also be characterized in terms of Euler–Lagrange equations:
for some constant \(\ell _V\) depending on V.
Our first constraint on V is that the support of \(\mu _V\) is a single interval, and we normalize it to be \([-1,1]\). In this case, on \([-1,1], \mu _V\) can be written as
where d is real analytic in some neighborhood of \([-1,1]\)—see [21]. For one-cut regularity, we further assume that d is positive on \([-1,1]\) and that the inequality (2.4) is strict. We collect this all into a single definition.
Definition 2.1
(One-cut regular potentials) We say that the potential \(V:\mathbb {R}\rightarrow \mathbb {R}\) is one-cut regular (with normalized support of the equilibrium measure) if it satisfies the following conditions:
-
1.
V is real analytic.
-
2.
\(\lim _{x\rightarrow \pm \infty }V(x)/\log |x|=\infty \).
-
3.
The support of the equilibrium measure \(\mu _V\) is \([-1,1]\).
-
4.
The inequality (2.4) is strict.
-
5.
The real analytic function d from (2.5) is positive on \([-1,1]\).
The condition that the support is \([-1,1]\) instead of say [a, b] is not a real constraint since the general case can be mapped to this with a simple transformation. Moreover, note that the support of the equilibrium measure is where the eigenvalues accumulate asymptotically, as the size of the matrix tends to infinity. So in this limit, we expect that nearly all of the eigenvalues of \(H_N\) are in \([-1,1]\).
We also point out that this is a non-empty class of functions V, since for the GUE (\(V(x)=2x^2\)), it is known that all of the conditions of Definition 2.1 are satisfied—in particular \(d(x)=2/\pi \) in this case.
2.2 The characteristic polynomial and powers of its absolute value
As mentioned, our main goal is to describe the large N behavior of the characteristic polynomial of \(H_N\). There are several possibilities for what one might want to say. One could consider the characteristic polynomial at a single point, say inside the support of the equilibrium measure, in which case one might expect in analogy with random unitary matrices [40] that the logarithm of the characteristic polynomial should, as a linear statistic of eigenvalues, be asymptotically a Gaussian random variable with exploding variance. One could consider the behavior of the characteristic polynomial in a microscopic neighborhood of a fixed point, where one might expect it to be asymptotically a random analytic function as it is for the CUE—see [13], or one could consider the logarithm of the absolute value of the characteristic polynomial on a macroscopic scale inside or outside the support of the equilibrium measure. For the GUE, on the macroscopic scale and in the support of the equilibrium measure, it is known [31] that the recentered logarithm of the absolute value of the characteristic polynomial behaves like a random generalized function which is formally a Gaussian process with a logarithmic singularity in its covariance.
Our goal is to “exponentiate” this last statement. (Note that since the limiting process describing the logarithm of a the characteristic polynomial is only a generalized function, and not an actual function defined pointwise, taking its exponential is a priori highly nontrivial). More precisely, we make the following definitions.
Definition 2.2
For \(N\in \mathbb {Z}_+\), let \(H_N\) be distributed according to (2.1). For \(x\in \mathbb {C}\), define
Moreover, let
and for \(\beta >0\), define the following measure on \((-1,1)\):
While exponentiating a generalized function in general is impossible, it turns out that in our setting, the correct description of such a procedure is in terms of random measures known as Gaussian multiplicative chaos measures. We now describe some of the basics of the relevant theory.
2.3 Gaussian multiplicative chaos
Gaussian multiplicative chaos is a theory going back to Kahane [37] with the aim of defining what the exponential of a Gaussian random (possibly generalized) function should mean when the covariance kernel of the Gaussian process has a suitable structure, as well as describing some geometric properties of these Gaussian processes.
Kahane proved, that if the covariance kernel has a logarithmic singularity, but otherwise has a particularly nice form, then with a suitable limiting and normalizing procedure, the exponential of the corresponding generalized function can be indeed understood as a random multifractal measure, known as a Gaussian multiplicative chaos measure. For a recent review of the theory, see [58] and for a concise proof for existence and uniqueness, see [6].
Recently, these measures have found applications in constructing random SLE-like planar curves through conformal welding [4, 63], quantum Loewner evolution [51], the random geometry of two-dimensional quantum gravity [16, 24]—see also the lecture notes [7, 59], and even in models of mathematical finance [5]. Complex variants of these objects are also connected to the statistical behavior of the Riemann zeta function on the critical line [62]. Perhaps their greatest importance is the role they are believed to play in describing the scaling limits of random planar maps embedded conformally—see [52,53,54] and [7]. In all of these cases, the covariance kernel of the Gaussian field has a logarithmic singularity on the diagonal.
In this section we will give a brief construction of the measures which are relevant to us. The random distribution we will be interested in is the whole-plane Gaussian free field restricted to the interval \((-1,1)\) with a suitable choice of additive constant. Formally we will want to consider a Gaussian field X defined on \((-1,1)\) such that it has a covariance kernel \(\mathbb {E}X(x)X(y)=-\frac{1}{2}\log [2|x-y|]\). It can be shown that it is possible to construct such an object as a random variable taking values in a suitable Sobolev space of generalized functions, see [31]. However, we will only need to work with approximations to this distribution which are well defined functions, so we will not need this fact. To motivate our definitions, we first recall a basic fact about expanding \(\log |x-y|\) for \(x,y\in (-1,1)\) in terms of Chebyshev polynomials—see e.g. [56, Appendix C], [27, Exercise 1.4.4], or [33, Lemma 3.1] for a proof.
Lemma 2.3
Let \(x,y\in (-1,1)\) and \(x\ne y\). Then
where \(T_n\) is a Chebyshev polynomial of the first kind, i.e. it is the unique polynomial of degree n satisfying \(T_n(\cos \theta )=\cos n\theta \) for all \(\theta \in [0,2\pi ]\).
Thus formally, if \((A_k)_{k=1}^\infty \) were i.i.d. standard Gaussians and one defined
then one would have \(\mathbb {E}\mathcal {G}(x)\mathcal {G}(y)=-\frac{1}{2}\log [2|x-y|]\). Motivated by this, we make the following definition.
Definition 2.4
Let \((A_k)_{k=1}^\infty \) be i.i.d. standard Gaussian random variables. For \(x\in (-1,1)\) and \(M\in \mathbb {Z}_+\), let
We then want to understand \(e^{\beta \mathcal {G}}\) (for suitable \(\beta \)) as a limit related to \(e^{\beta \mathcal {G}_M}\) as \(M\rightarrow \infty \). The precise statement is the following:
Lemma 2.5
Consider the random measure
on \((-1,1)\). For \(\beta \in (-\sqrt{2},\sqrt{2}), \mu _{\beta }^{(M)}\) converges weakly almost surely (when the i.i.d. Gaussians are realized on the same probability space) to a non-trivial random measure \(\mu _\beta \) on \((-1,1)\), as \(M\rightarrow \infty \).
This measure \(\mu _\beta \) is the limiting object in Theorem 1.1. The basic idea is that the sequence \(\mu _\beta ^{(M)}\) is a measure-valued martingale, and it turns out that for \(\beta \in (-\sqrt{2},\sqrt{2})\), it is bounded in \(L^2\) so by standard martingale theory it has a non-trivial limit. The \(L^2\)-boundedness is somewhat non-trivial and we will return to the details later.
Remark 2.6
The measure \(\mu _\beta \) exists actually for larger values of \(|\beta |\) as well. It essentially follows from the standard theory of multiplicative chaos, or alternatively the approach of [6], that a non-trivial limiting measure exists for \(\beta \in (-2,2)\). In fact, comparing with other log-correlated fields, it is natural to expect that with a suitable deterministic normalization, that differs from ours for some values of \(\beta \), it is possible to construct a non-trivial limiting object for all \(\beta \in \mathbb {C}\). However, for complex \(\beta \), the limit might not be in general a measure (not even a signed measure), but only a distribution. We refer to [45] for a study in complex multiplicative chaos and to [49] for defining \(\mu _\beta \) for large real \(\beta \). Our approach for proving convergence relies critically on calculating second moments and it is known for example that the total mass of the measure \(\mu _\beta \) has a finite second moment only for \(\beta \in (-\sqrt{2},\sqrt{2})\), so our approach is not directly possible for proving a corresponding result in the full range of values of \(\beta \) where we would expect the result to hold. However, combining our results, those of [15], and the approach of [46] should yield the result for \(\beta \in (0,2)\). This being said, we wish to point out that while the limiting object \(\mu _\beta \) should exist for all complex \(\beta \), one should not expect that \(\mu _{N,\beta }\) converges to it if the real part of \(\beta \) is too negative—e.g. if \(\beta \le -1\), then with overwhelming probability, \(\int _{-1}^1 f(x)|P_N(x)|^{\beta }dx\) will be infinite and one can not hope for convergence. To avoid this type of complications, we focus on non-negative \(\beta \).
2.4 Outline of the proof
In this section we define the main objects we analyze in the proof of Theorem 1.1, and state the main results we need about them. Motivated by the approach in [67], we will consider an approximation to \(\mu _{N,\beta }\), and we will denote this by \({\widetilde{\mu }}_{N,\beta }^{(M)}\), where M is an integer parametrizing the approximation. Using known results about the linear statistics of one-cut regular ensembles, it will be clear that as \(N\rightarrow \infty \) for fixed \(M, {\widetilde{\mu }}_{N,\beta }^{(M)}\rightarrow \mu _{\beta }^{(M)}\) in distribution. Thus our goal is to control the difference \(\mu _{N,\beta }-{\widetilde{\mu }}_{N,\beta }^{(M)}\), when we first let \(N\rightarrow \infty \) and then \(M\rightarrow \infty \).
Let us begin by defining our approximation \({\widetilde{\mu }}_{N,\beta }^{(M)}\). It is essentially just truncating the Fourier-Chebyshev series of \(X_N\), but we have to be slightly careful as the eigenvalues can be outside of \([-1,1]\) with non-zero probability.
Definition 2.7
Fix \(M\in \mathbb {Z}_+\) and \(\epsilon >0\) (small and possibly depending on M). Let \({\widetilde{T}}_j(x)\) be a \(C^\infty (\mathbb {R})\)-function with compact support such that \({\widetilde{T}}_j(x)=T_j(x)\) for each \(x\in (-1-\epsilon ,1+\epsilon )\). Then define for \(x\in (-1,1)\)
and
Remark 2.8
Our reasoning here is that if we pretended that all of the \(\lambda _j\) are in the interval \((-1,1)\), we could make use of Lemma 2.3. Then \(X_N\) would coincide with the above expansion for \(M=\infty \) and \({\widetilde{T}}_j\) replaced by \(T_j\). Outside of the interval, we have to use \({\widetilde{T}}_k\) instead of \(T_k\), as otherwise \(\mathbb {E}e^{\beta {\widetilde{X}}_{N,M}(x)}\) might not exist for all values of x and M.
We will break our main statement down into parts now. The statement of our Theorem 1.1 is equivalent to saying that for each bounded continuous \(\varphi :(-1,1)\rightarrow [0,\infty ), \mu _{N,\beta }(\varphi ):=\int _{-1}^1\varphi (x)\mu _{N,\beta }(dx)\) converges in distribution to \(\mu _\beta (\varphi )\). It will actually be enough to assume that \(\varphi \) has compact support in \((-1,1)\), i.e. to prove vague convergence. We will be more detailed about these statements in the actual proof in Sect. 6. The way we will prove vague convergence is to write
By using standard central limit theorems for linear statistics of one-cut regular ensembles, and the definition of \(\mu _\beta \), we will see that the second term here tends to \(\mu _\beta (\varphi )\) in the limit where first \(N\rightarrow \infty \), and then \(M\rightarrow \infty \). Our main result will then follow from showing that the second moment of the first term tends to zero in the same limit. We formulate this as a proposition.
Proposition 2.9
If we first let \(N\rightarrow \infty \) and then \(M\rightarrow \infty \), then for \(\beta \in (0,\sqrt{2})\) and each compactly supported continuous \(\varphi :(-1,1)\rightarrow [0,\infty ), {{\widetilde{\mu }}}_{N,\beta }^{(M)}(\varphi )\) converges in distribution to \(\mu _\beta (\varphi )\), and
Proving the second statement takes up most of this article. Expanding the square, we see that what is critical is having uniform asymptotics for \(\mathbb {E}e^{\beta X_N(x)}, \mathbb {E}e^{\beta {\widetilde{X}}_{N,M}(x)}\), \(\mathbb {E}e^{\beta (X_N(x)+X_N(y))}, \mathbb {E}e^{\beta ({\widetilde{X}}_{N,M}(x)+{\widetilde{X}}_{N,M}(y))}\), and \(\mathbb {E}e^{\beta (X_N(x)+{\widetilde{X}}_{N,M}(y))}\). More precisely, we have:
Each of these expectations here can be expressed as \(\mathbb {E}\prod _{j=1}^Nh(\lambda _j)\) for a suitable function \(h:\mathbb {R}\rightarrow \mathbb {R}\). For instance,
As we will recall in Sect. 3, such quantities can be expressed in terms of Hankel determinants. Moreover, all of these Hankel determinants have a very specific type of symbol: one with so-called Fisher–Hartwig singularities. To explain what this means here, a Hankel matrix is a matrix in which the skew-diagonals are constant. They are closely related to Toeplitz matrices where the diagonals themselves are constant (these arise typically in the study of CUE and related random matrix ensembles rather than the GUE-type ensembles considered in this paper). In the case we will be interested in, the (i, j)th coefficient of the Hankel matrix will be of the form \(\int _\mathbb {R}x^{i+j}h(x) e^{-NV(x)}dx\) where h is as above. When h is smooth enough and doesn’t have any roots, then the asymptotic analysis of such determinants would follow from the classical strong Szegő theorem (actually this theorem applies in the Toeplitz case rather than the Hankel case, but here this isn’t a crucial distinction). However in our situation h typically contains at least one root of the form \(|x-x_i|^{\beta _i}\), which greatly complicates the task of analysing the corresponding determinant. This type of behavior is an example of a Fisher–Hartwig singularity. (In general a Fisher–Hartwig singularity might also include a jump at \(x_i\) corresponding to the symbol also having a term of the form \(e^{\gamma \mathrm {Im} \log (x- x_i)}\)).
The asymptotics of Hankel determinants with Fisher–Hartwig singularities is still very much a subject of active research, and much information is already available using the steepest descent technique due to Deift and Zhou [23]; see in particular the papers [14, 19, 20, 42] which play an important role in our proof. Yet results in the generality we need seem to still be lacking in the literature. What suffices for us is the following result (which we will only use with \(k=1\) or \(k=2\), but since there is no added difficulty in proving it for a general value of k we will do so).
Proposition 2.10
Let \(\mathcal {T}\in C^\infty (\mathbb {R})\) be real analytic in some neighborhood of \([-1,1]\) and have compact support. Let \(k\in \mathbb {Z}_+\) be fixed, and let \(\beta _1,{\ldots },\beta _k\in [0,\infty )\) be fixed. Moreover, let \(x_1,{\ldots },x_k\in (-1,1)\) be distinct. Finally let \(H_N\) be a \(N\times N\) random Hermitian matrix drawn from a one-cut regular unitary invariant ensemble with potential V. Then for \(C(\beta )=2^{\frac{\beta ^2}{2}}\frac{G(1+\beta /2)^2}{G(1+\beta )}\), where G is the Barnes G function, we have as \(N \rightarrow \infty \),
uniformly on compact subsets of \(\lbrace (x_1,{\ldots },x_k)\in (-1,1)^k: x_i\ne x_j \ \mathrm {for} \ i\ne j\rbrace \). Here \(P.V.\int \) denotes the Cauchy principal value integral. Moreover, if there exists a fixed \(M\in \mathbb {Z}_+\), such that in some fixed neighborhood of \([-1,1], \mathcal {T}(x)=\sum _{j=1}^M \alpha _j T_j(x)\), then the above asymptotics are uniform also in compact subsets of \(\lbrace (\alpha _1,{\ldots },\alpha _M)\in \mathbb {R}^M\rbrace \).
Remark 2.11
As mentioned in the introduction, this settles some conjectures due to Forrester and Frankel—see [28, Conjecture 5 and Conjecture 8] for more details. In terms of the potential V, we actually improve on the conjectures as these are only stated for polynomial V, but concerning the functions \(\mathcal {T}\), our results are not as general as those appearing in the conjectures of Forrester and Frankel. This being said, one could easily relax some of our regularity assumptions on \(\mathcal {T}\). In fact, the compact support or smoothness outside of a neighborhood of the interval \([-1,1]\) play essentially no role in our proof, but as this is a simple and clear way of stating the result, we do not attempt to state things in their greatest generality. Moreover, using techniques from [20], one could attempt to generalize our estimates and prove a corresponding result when \(\mathcal {T}\) is less smooth also on \([-1,1]\). Again, this is not necessary for our main goal, so we don’t pursue this further.
We also mention that after the first version of this article appeared, Charlier [11] proved an extension of this result to the case where the symbol can also have jump-type singularities.
We prove our results through Riemann–Hilbert methods. In particular, we first show that with a suitable differential identity, and some analysis of a Riemann–Hilbert problem, we can relate the \(\mathcal {T}=0\) case to the \(\mathcal {T}\ne 0\) case. Then with another differential identity (and further analysis of another Riemann–Hilbert problem) we relate the \(\mathcal {T}=0\), general V -case to the GUE with \(\mathcal {T}=0\). The asymptotics in the \(\mathcal {T}=0\) case for the GUE have been obtained by Krasovsky [42]. Using these, we are able to prove Proposition 2.10.
As we will need uniform asymptotics for \(\mathbb {E}e^{\beta X_N(x)+\beta X_N(y)}\) and other terms, Proposition 2.10 is not quite enough for us. For uniform estimates, we will rely on a recent result of Claeys and Fahs [14], which combined with Proposition 2.10 will let us prove Proposition 2.9.
Next we review the connection between expectations of the form (2.15), Hankel determinants, and Riemann–Hilbert problems.
3 Hankel determinants and Riemann–Hilbert problems
In this section, we recall how the expectations we are interested in can be written as Hankel determinants, which are related to orthogonal polynomials, which in turn can be encoded into a Riemann–Hilbert problem. We also recall certain differential identities we will need for analyzing the expectations we are interested in. While our discussion is very similar to that in e.g. [19, 20], there are some minor differences as we are dealing with Hankel determinants instead of Toeplitz ones. We choose to give some details for the convenience of a reader with limited experience with Riemann–Hilbert problems.
3.1 Hankel determinants and orthogonal polynomials
Terms of the form \(\mathbb {E}\prod _{j=1}^N f(\lambda _j)\) can be written in determinantal form due to Andreief’s identity—for a proof, one can use e.g. [1, Lemma 3.2.3] with the functions \(f_i(x)=f(x)e^{-NV(x)}x^{i-1}\) and \(g_i(x)=x^{i-1}\) as well as the product representation of the Vandermonde determinant.
Lemma 3.1
Let \(f:\mathbb {R}\rightarrow \mathbb {R}\) be a nice enough function (measurable and nice enough decay that all the relevant integrals converge absolutely). Then
where \(Z_N(V)\) is as in (2.2).
Let us introduce some notation for the Hankel determinant here.
Definition 3.2
For nice enough functions \(f:\mathbb {R}\rightarrow \mathbb {R}\), (so that the integrals exist) let
As the notation suggests, we will suppress the dependence on V when it’s convenient. We suppress the dependence on N always.
It is a well known result in the theory of orthogonal polynomials, that such determinants can be written in terms of orthogonal polynomials. For the convenience of the reader, we offer a proof for the following result.
Lemma 3.3
Let \(f:\mathbb {R}\rightarrow \mathbb {R}\) be positive Lebesgue almost everywhere, have nice enough regularity and growth at infinity, and let \((p_j(x;f,V))_{j=0}^\infty \) be the sequence of real polynomials which have a positive leading order coefficient and which are orthonormal with respect to the measure \(f(x)e^{-NV(x)}dx\) on \(\mathbb {R}\) (we will write \(p_j(x;f)\) when we wish to suppress the dependence on V and we will always suppress the dependence on N):
and \(p_j(x;f)=\chi _j(f)x^j+\mathcal {O}(x^{j-1})\) as \(x\rightarrow \infty \), where \(\chi _j(f)>0\). Then
Note that due to our assumptions on f, the above polynomials do exist as we can construct them by applying the determinantal representation associated with the Gram–Schmidt procedure to the monomials.
Proof
Consider the space of real polynomials, equipped with an inner product given by the \(L^2\) inner product on \(\mathbb {R}\) with weight \(f(x)e^{-NV(x)}\). A consequence of the Gram–Schmidt procedure applied to the sequence of monomials in this inner product space is the following: for \(j\ge 1\)
where for \(j=0\) the determinant is replaced by 1, and \(D_{-1}(f)=1\).
Note that from our assumption on f and an easy generalization of Lemma 3.1, \(D_j(f)>0\) for all \(j\ge 0\), so these polynomials exist. From (3.5) one sees that \(\chi _j(f)\)—the coefficient of \(x^j\) in \(p_j(x;f)\)—equals \(\sqrt{D_{j-1}(f)/D_j(f)}\). The claim then follows as the product has a telescopic form, and we defined \(D_{-1}(f)=1\). \(\square \)
3.2 Riemann–Hilbert problems and orthogonal polynomials
We now recall a result going back to Fokas, Its, and Kitaev [26] about encoding orthogonal polynomials on the real line into a Riemann–Hilbert problem. In our setting, the relevant result is formulated in the following way.
Proposition 3.4
(Fokas, Its, and Kitaev) Let \(\mathcal {T}\) be a real valued \(C^\infty (\mathbb {R})\) function with compact support, let \((\beta _j)_{j=1}^k\in [0,\infty )^k\) , \((x_j)_{j=1}^k\in (-1,1)^k\), and \(x_i\ne x_j\) for \(i\ne j\). Let V be some real analytic function on \(\mathbb {R}\) satisfying \(\lim _{x\rightarrow \pm \infty } V(x)/\log |x|=\infty \). For \(\lambda \in \mathbb {R}\), define
and let \(p_j(x;f)\) be as in Lemma 3.3, with the relevant measure being \(f(\lambda ) e^{-NV(\lambda )}d\lambda \) on \(\mathbb {R}\). Consider the \(2\times 2\) matrix-valued function
for \(z\in \mathbb {C}{\setminus } \mathbb {R}\). Then Y is the unique solution to the following Riemann–Hilbert problem: find a function \(Y:\mathbb {C}{\setminus } \mathbb {R}\rightarrow \mathbb {C}^{2\times 2}\) such that
-
1.
Y is analytic.
-
2.
On \(\mathbb {R}, Y\) has continuous boundary values \(Y_\pm \), i.e. \(Y_\pm (\lambda )=\lim _{\epsilon \rightarrow 0^+}Y(\lambda \pm i\epsilon )\) exists and is continuous for all \(\lambda \in \mathbb {R}\). Moreover, \(Y_\pm \) are related by the jump condition
$$\begin{aligned} Y_+(\lambda )=Y_-(\lambda ) \begin{pmatrix} 1 &{} f(\lambda ) e^{-NV(\lambda )}\\ 0 &{} 1 \end{pmatrix}, \qquad \lambda \in \mathbb {R}. \end{aligned}$$(3.8) -
3.
As \(z\rightarrow \infty \),
$$\begin{aligned} Y(z)=(I+\mathcal {O}(z^{-1}))\begin{pmatrix} z^j &{} 0\\ 0 &{} z^{-j} \end{pmatrix}. \end{aligned}$$(3.9)
Remark 3.5
Typically for Riemann–Hilbert problems related to Toeplitz and Hankel determinants with Fisher–Hartwig singularities (e.g. [14, 19, 20]) one says that the boundary values are continuous on the relevant contour minus the singularities \(x_j\), and then imposes conditions on the behavior of Y near the singularities. This is relevant when one of the \(\beta _j\) is negative or non-real, but as we will shortly mention, in our case the boundary values are truly continuous on \(\mathbb {R}\) and no further condition is needed.
Sketch of proof
The proof for uniqueness is the standard one: one first looks at some solution to the RHP, say Y. From the jump condition, it follows that \(\det Y\) is continuous across \(\mathbb {R}\), so it is entire. From the behavior of Y at infinity, it follows that \(\det Y\) is bounded, so by Liouville’s theorem and the behavior at infinity, one sees that \(\det Y=1\). In particular, (as a matrix) Y is invertible and the inverse matrix \(Y^{-1}\) is analytic in \(\mathbb {C}{\setminus } \mathbb {R}\). Now if \({\widetilde{Y}}\) is another solution, we see that \({\widetilde{Y}}Y^{-1}\) is analytic in \(\mathbb {C}{\setminus } \mathbb {R}\) and continuous across \(\mathbb {R}\), so it is entire. From the behavior at infinity, \({\widetilde{Y}}(z)Y(z)^{-1}\rightarrow I\) (the \(2\times 2\) identity matrix) as \(z\rightarrow \infty \), so again by Liouville, \({\widetilde{Y}}=Y\).
Consider then the statement that Y given in terms of the orthogonal polynomials is a solution. The analyticity condition is obvious. The continuity of the boundary values of the first column is obvious since we are dealing with polynomials. For the second column, the Sokhotski-Plemelj theorem implies that the boundary values of the second column can be expressed in terms of \(p_j f e^{-NV}\) (or \(p_j\) replaced by \(p_{j-1}\)) and its Hilbert transform (see e.g. [64, Chapter V] for an introduction to the Hilbert transform). The first term is obviously continuous. For the Hilbert transform, we note that \(p_j fe^{-NV}\) is Hölder continuous, so as the Hilbert transform preserves Hölder regularity (see [64, Chapter V.15]), we see that the boundary values of Y are continuous.
For the jump condition (3.8) and behavior at infinity (3.9), we refer to analogous problems in [18, Section 3.2 and Section 7]. \(\square \)
We next discuss how deforming V or \(\mathcal {T}\) changes \(D_{N-1}(f;V)\).
3.3 Differential identities
Let us fix our potential V (and drop dependence on it from our notation) and first consider how deforming \(\mathcal {T}\) changes \(D_{N-1}(f)\).
The proof of the following result is a minor modification of the proof of [20, Proposition 3.3], but for completeness, we give a proof in “Appendix A”. The role of this result is that if we know the asymptotics in the case \(\mathcal {T}=0\), instead of studying \(Y_j\) for all j, it’s enough to study \(Y_N\) though with a one-parameter family of deformations of \(\mathcal {T}\).
Lemma 3.6
Let \(\mathcal {T}:\mathbb {R}\rightarrow \mathbb {R}\) be a \(C^\infty \) function with compact support, let \((\beta _j)_{j=1}^k\in [0,\infty )^k\) , \((x_j)_{j=1}^k\in (-1,1)^k\), and \(x_i\ne x_j\) for \(i\ne j\). For \(t\in [0,1]\) and \(\lambda \in \mathbb {R}\), define
Let Y(z, t) be as in (3.7) with \(j=N, f=f_t\), and \(p_l(x;f)=p_l(x;f_t)\) the orthonormal polynomials with respect to the measure \(f_t(\lambda )e^{-NV(\lambda )}d\lambda \) on \(\mathbb {R}\). Then
where the indices of Y refer to matrix entries.
The object we are interested in is \(D_{N-1}(f_1)\) which we can analyze by writing
For the GUE, the asymptotics of \(D_{N-1}(f_0)\)—the case \(\mathcal {T}=0\)—were investigated in [42], so a consequence of Lemma 3.6 is that if we understand the asymptotics of Y(z, t) well enough, we are able to study the asymptotics of \(D_{N-1}(f_1)\) in the GUE case.
The other deformation we will consider is what happens when we interpolate between the potentials \(V_0(x)=2x^2\) (the GUE) and \(V_1(x)=V(x)\) in the \(\mathcal {T}=0\) case.
Lemma 3.7
Let \((\beta _j)_{j=1}^k\in [0,\infty )^k, (x_j)_{j=1}^k\in (-1,1)^k\), and \(x_i\ne x_j\) for \(i\ne j\). Let f be defined by (3.6) with \(\mathcal {T}=0\) and let \(V:\mathbb {R}\rightarrow \mathbb {R}\) be a real analytic function satisfying \(\lim _{x\rightarrow \pm \infty }V(x)/\log |x|=\infty \). Define for \(s\in [0,1]\)
Let us then write \(Y(z;V_s)\) for Y defined as in (3.7) with \(j=N, V=V_s\) and \(p_j(x;f)=p_j(x;f,V_s)\). Then using the notation of (3.2)
Again, we give a proof in “Appendix A”. The role of this differential identity is that if we understand the asymptotics of \(Y(z;V_s)\) well enough, then by integrating (3.13), we can move from the GUE asymptotics to the general ones.
We mention that both of these identities are of course true for a much wider class of symbols than what we state in the results (in particular, in Lemma 3.7 the condition \(\mathcal {T}=0\) is not necessary for anything). This is simply the generality we use them in. Next we move on to describing how to study the large N asymptotics of Y(z, t) and \(Y(z;V_s)\).
4 Solving the Riemann–Hilbert problem
In this section we will finally describe the asymptotic behavior of Y(z, t) and \(Y(z;V_s)\) as \(N\rightarrow \infty \). The typical way this is done is through a series of transformations to the RHP, ultimately leading to a RHP where the jump matrix is asymptotically close to the identity matrix as \(N \rightarrow \infty \), and the behavior at infinity is close to the identity matrix. Then using properties of the Cauchy-kernel, the final RHP can be solved in terms of a Neumann series solution of a suitable integral equation. Moreover, each term in the series expansion is of lower and lower order in N. We will go into further details about this part of the problem in Sect. 4.5, but we will start with transforming the problem.
While we never have both \(s,t\in (0,1)\), we will find it notationally convenient to consider Y(z) to be defined as in (3.7) with \(f=f_t\) and \(V=V_s\). We suppress all of this in our notation for Y. We will also focus on functions \(\mathcal {T}\) with the regularity claimed in Proposition 2.10 which was stronger than what we stated in the differential identities.
4.1 Transforming the Riemann–Hilbert problem
Let us introduce some further notation to simplify things later on. Let \(\mathcal {T}\) satisfy the conditions of Proposition 2.10, and let
so that in the notation of Lemma 3.6
and let us assume that the singularities are ordered: \(x_j<x_{j+1}\).
The series of transformations we will now start implementing is a minor modification of that in [42, Section 4].
4.1.1 The first transformation
Our first transformation will change the asymptotic behavior of the solution to the RHP so that it is close to the identity as \(z\rightarrow \infty \), as well as cause the distance between the jump matrix and the identity matrix to be exponentially small in N when we’re off of the interval \([-1,1]\). The proofs of the statements of this section are either elementary or straightforward generalizations of standard ones in the RHP-literature, but for the convenience of readers unfamiliar with the literature, they are sketched in “Appendix B”. Let us now make the relevant definitions.
Definition 4.1
In the notation of (2.5), for \(s \in [0,1]\) as above, let
and for \(z\in \mathbb {C}{\setminus }(-\infty ,1]\), let
where the branch of the logarithm is the principal one. We also define
where \(\ell _V\) is the constant from (2.3) and (2.4). Finally, for \(z\in \mathbb {C}{\setminus } \mathbb {R}\), let
where
Before describing the jump structure and normalization of T near infinity, we first point out some simple facts about the boundary values of \(g_s\) on \(\mathbb {R}\) which follow from its definition and (2.3) (details may be found in “Appendix B”).
Lemma 4.2
For \(\lambda \in \mathbb {R}\), let \(g_{s,\pm }(\lambda )=\lim _{\epsilon \rightarrow 0^+}g_s(\lambda \pm i \epsilon )\). Then for \(\lambda \in (-1,1)\) and \(s\in [0,1]\)
There exist \(M,C>0\) (independent of s) so that for \(\lambda \in \mathbb {R}{\setminus }[-1,1]\),
For \(\lambda \in \mathbb {R}\)
The function \(g_{s,+}-g_{s,-}\) along with an analytic continuation of it will play a significant role in our analysis of the Riemann–Hilbert problem, so we give it a name.
Definition 4.3
Let \(U\subset \mathbb {C}\) be an open neighborhood of \(\mathbb {R}\) into which d has an analytic continuation. For \(z\in U{\setminus } ((-\infty ,-1]\cup [1,\infty ))\) and \(s\in [0,1]\), let
where the square root is according to the principal branch (i.e. \(\sqrt{1-w^2}=e^{\frac{1}{2}\log (1-w^2)}\) and the branch of the logarithm is the principal one), and the contour of integration is such that it stays in U and does not cross \((-\infty ,-1]\cup [1,\infty )\).
The function \(h_s\) will often appear in the form \(e^{\pm Nh_s}\) and to estimate the size of such an exponential, we will need to know the sign of \(\mathrm {Re}(h_s)\). For this, we use the following elementary fact.
Lemma 4.4
In a small enough open neighborhood of \((-1,1)\) (independent of s) in the complex plane,
and
for all \(s\in [0,1]\), and if we restrict to a fixed set in the upper half plane such that the set is bounded away from the real axis, but inside this neighborhood of \((-1,1)\), we have e.g. \(\mathrm {Re}(h_s(z))\ge \epsilon >0\) for some \(\epsilon >0\) independent of s. A similar result holds in the lower half plane.
Again, see “Appendix B” for details on the proof of this and the next result, which describes the Riemann–Hilbert problem T solves.
Lemma 4.5
The function \(T:\mathbb {C}{\setminus } \mathbb {R}\rightarrow \mathbb {C}^{2\times 2}\) defined by (4.5) is the unique solution to the following Riemann–Hilbert problem.
-
1.
\(T:\mathbb {C}{\setminus } \mathbb {R}\rightarrow \mathbb {C}^{2\times 2}\) is analytic.
-
2.
On \(\mathbb {R}, T\) has continuous boundary values \(T_\pm \) and these are related by the jump conditions
$$\begin{aligned} T_+(\lambda )=T_-(\lambda )\begin{pmatrix} e^{-Nh_s(\lambda )} &{} f_t(\lambda )\\ 0 &{} e^{Nh_s(\lambda )} \end{pmatrix}, \qquad \lambda \in (-1,1) \end{aligned}$$(4.10)and
$$\begin{aligned} T_+(\lambda )=T_-(\lambda )\begin{pmatrix} 1 &{} f_t(\lambda )e^{N(g_{s,+}(\lambda )+g_{s,-}(\lambda )-\ell _s-V_s(\lambda ))}\\ 0 &{} 1 \end{pmatrix}, \qquad \lambda \in \mathbb {R}{\setminus }[-1,1].\nonumber \\ \end{aligned}$$(4.11) -
3.
As \(z\rightarrow \infty \),
$$\begin{aligned} T(z)=I+\mathcal {O}(|z|^{-1}). \end{aligned}$$(4.12)
The jump matrix given by (4.10) and (4.11) already looks good for \(\lambda \notin [-1,1]\), in the sense that it is exponentially close to the identity, (compare (4.11) with (4.7)). However, the issue is that across \((-1,1)\), the jump matrix is not close to the identity in any way. We will next address this issue by performing a second transformation.
4.1.2 The second transformation
As customary in this type of problems, the next step is to “open lenses”. That is, we will add further jumps to the problem off of the real line. Due to a nice factorization property of the jump matrix for T, the new jump matrix will be close to the identity on the new jump contours when we are not too close to the points ± 1 or \(x_j\).
Before going into the details of this, we will define an analytic continuation of \(f_t\) into a subset of \(\mathbb {C}\). Recall from our assumptions in Proposition 2.10 that on \((-1-\epsilon ,1+\epsilon ), \mathcal {T}(x)\) is real analytic. Thus \(\mathcal {T}\) certainly has an analytic continuation to some neighborhood of \([-1,1]\). Moreover as it is real on \([-1,1]\), we see that in some small enough complex neighborhood of \([-1,1]\) (which is independent of t), \(1-t+te^{\mathcal {T}(z)}\) has no zeroes for any \(t\in [0,1]\). Thus \(\mathcal {T}_t\) (see (4.1)) has an analytic continuation to this neighborhood for all \(t\in [0,1]\). We use this to define the analytic continuation of \(f_t\).
Definition 4.6
Let \(U_{[-1,1]}\) be some neighborhood of \([-1,1]\) which is independent of t and in which \(\mathcal {T}_t\) is analytic for \(t\in [0,1]\). In this domain, and for \(1\le l\le k-1\), let
where the powers are according to the principal branch.
We will now impose some conditions on our new jump contours. Later on, we will be more precise about what we exactly want from them, but for now, we will ignore the details.
Definition 4.7
For \(j=1,{\ldots },k+1\), let \(\Sigma _{j}^+\) \((\Sigma _{j}^-)\), be a smooth curve in the upper (lower) half plane from \(x_{j-1}\) to \(x_j\), where we understand \(x_0\) as \(-1\) and \(x_{k+1}\) as 1. The curves are oriented from \(x_{j-1}\) to \(x_j\) and independent of t, s, and N. Moreover, they are contained in \(U_{[-1,1]}\).
The domain between \(\Sigma _j^+\) and \(\Sigma _j^{-}\) is called a lens. The domain between \(\Sigma _j^+\) and \(\mathbb {R}\) is called the top part of the lens, and that between \(\Sigma _j^-\) and \(\mathbb {R}\) the bottom part of the lens. See Fig. 1 for an illustration.
Remark 4.8
Our definition here and our coming construction implicitly assume that \(\beta _j\ne 0\) for all j. If one (or more) \(\beta _j=0\), one simply ignores the corresponding \(x_j\) (so e.g. one connects \(x_{j-1}\) to \(x_{j+1}\) with a curve in the upper half plane etc).

Opening of lenses, \(k = 1\). The signs indicate the orientation of the curves: the \(+\) side is the left side of the curve and − the right
We use these contours in our next transformation.
Definition 4.9
For \(z\notin \Sigma :=\cup _{j=1}^{k+1}(\Sigma _j^+\cup \Sigma _j^-)\cup \mathbb {R}\), let
Remark 4.10
Note that S depends on our choice of the contours \(\Sigma \) (as well as s, t, and N), but we suppress this in our notation. We also point out that as \(f_t\) has zeroes at the singularities, the entries in the first column of S(z) blow up when z approaches a singularity from within the lens. Moreover, we see that we have discontinuities at the points ± 1. Thus the boundary values are no longer continuous on \(\mathbb {R}\), but on \(\mathbb {R}{\setminus } \lbrace x_j: j=0,{\ldots },k+1\rbrace \), where again \(x_0=-1\) and \(x_{k+1}=1\).
Using the definition of S, the RHP for T, and the fact that
it is simple to check what the Riemann–Hilbert problem for S should be; we omit the proof.
Lemma 4.11
S is the unique solution to the following Riemann–Hilbert problem:
-
1.
\(S:\mathbb {C}{\setminus } \Sigma \rightarrow \mathbb {C}^{2\times 2}\) is analytic.
-
2.
S has continuous boundary values on \(\Sigma {\setminus } \lbrace x_j\rbrace _{j=0}^{k+1}\) and they are related by the jump conditions
$$\begin{aligned} S_+(\lambda )= & {} S_-(\lambda )\begin{pmatrix} 1 &{}\quad 0\\ f_t(\lambda )^{-1}e^{\mp N h_s(\lambda )} &{}\quad 1 \end{pmatrix}, \quad \lambda \in \cup _{j=1}^{k+1}\Sigma _j^{\pm }{\setminus } \lbrace x_l\rbrace _{l=0}^{k+1}, \qquad \end{aligned}$$(4.15)$$\begin{aligned} S_+(\lambda )= & {} S_-(\lambda )\begin{pmatrix} 0 &{}\quad f_t(\lambda )\\ -f_t(\lambda )^{-1} &{}\quad 0 \end{pmatrix}, \quad \lambda \in (-1,1){\setminus } \lbrace x_j\rbrace _{j=1}^{k}, \end{aligned}$$(4.16)and
$$\begin{aligned} S_+(\lambda )=S_-(\lambda )\begin{pmatrix} 1 &{}\quad f_t(\lambda )e^{N(g_{s,+}(\lambda )+g_{s,-}(\lambda )-\ell _s-V_s(\lambda ))}\\ 0 &{}\quad 1 \end{pmatrix}, \quad \lambda \in \mathbb {R}{\setminus }[-1,1]. \end{aligned}$$(4.17)In (4.15) the \(\mp \) and ± notation means that we have \(e^{-Nh_s}\) in the jump matrix when we cross \(\Sigma _j^+\) and \(e^{Nh_s}\) when we cross \(\Sigma _j^-\).
-
3.
\(S(z)=I+\mathcal {O}(|z|^{-1})\) as \(z\rightarrow \infty \).
-
4.
For \(j=1,{\ldots },k, S(z)\) is bounded as \(z\rightarrow x_j\) from outside of the lenses, but when \(z\rightarrow x_j\) from inside of the lenses,
$$\begin{aligned} S(z)=\begin{pmatrix} \mathcal {O}\big (|z-x_j|^{-\beta _j}\big ) &{}\quad \mathcal {O}(1)\\ \mathcal {O}\big (|z-x_j|^{-\beta _j}\big ) &{}\quad \mathcal {O}(1) \end{pmatrix}. \end{aligned}$$(4.18)Moreover, S is bounded at ± 1.
We are now in a situation where if we are on one of the \(\Sigma _j^\pm \) or on \(\mathbb {R}{\setminus }[-1,1]\) and not close to one of the points ± 1 or \(x_j\), then the distance of the jump matrix from the identity matrix is exponentially small in N. We thus need to do something close to the points ± 1 and \(x_j\) as well as on the interval \((-1,1)\) to get a small norm problem, i.e. one that can be solved in terms of a Neumann series.
The way to proceed here is to construct functions which are solutions to approximations of the Riemann–Hilbert problem where we expect the approximations to be good if we are close to one of the points ± 1 or \(x_j\), or then alternatively when we are far away from them and we expect the approximate problem related to the behavior on \((-1,1)\) to determine the behavior of S. We then construct an ansatz to the original problem in terms of these approximations. This will lead to a small norm problem.
These approximations are often called parametrices, and we will start with the solution far away from the points ± 1 and \(x_j\). This case is often called the global parametrix.
4.2 The global parametrix
Our goal is to find a function \(P^{(\infty )}(z)\) such that it has the same jumps as S(z) across \((-1,1)\), is analytic elsewhere, and has the correct behavior at infinity. We won’t go into great detail about how such problems are solved, but we will build on similar problems solved in [42, Section 4.2] (see also for example [44, Section 5]). We will simply state the result here and sketch a proof in “Appendix C”. Later on we will need some regularity properties of the solution considered here so we will state and prove the relevant facts here.
We now define our global parametrix.
Definition 4.12
Let us write for \(z\notin (-\infty ,1]\)
and
where the powers are taken according to the principal branch. Then for \(t\in [0,1]\) and \(z\notin (-\infty ,1]\), let
where \(\mathcal {A}=\sum _{j=1}^k \beta _j/2\) and the powers are according to the principal branch. Finally, for \(z\notin (-\infty ,1]\) and \(t\in [0,1]\), define the global parametrix
where \(\mathcal {D}_t(\infty )=\lim _{z\rightarrow \infty }\mathcal {D}_t(z)=2^{-\mathcal {A}}e^{\frac{1}{2\pi }\int _{-1}^1 \frac{\mathcal {T}_t(\lambda )}{\sqrt{1-\lambda ^2}}d\lambda }\).
Remark 4.13
It’s simple to check that r and a are continuous across \((-\infty ,-1)\) so they can be analytically continued to \(\mathbb {C}{\setminus }[-1,1]\). Using the fact that \(r(\lambda )\) is negative for \(\lambda <-1\), one can check that also \(\mathcal {D}_t\) is continuous across \((-\infty ,-1)\), so in fact \(P^{(\infty )}\) is analytic in \(\mathbb {C}{\setminus }[-1,1]\).
We also point out that as \(\mathcal {T}_0(\lambda )=0\) (recall (4.1)) we can also write
The relevance of this parametrix stems from the following lemma.
Lemma 4.14
For each \(t\in [0,1], P^{(\infty )}(\cdot ) = P^{(\infty )}(\cdot , t)\) satisfies the following Riemann–Hilbert problem.
-
1.
\(P^{(\infty )}:\mathbb {C}{\setminus } [-1,1]\rightarrow \mathbb {C}^{2\times 2}\) is analytic.
-
2.
\(P^{(\infty )}\) has continuous boundary values on \((-1,1){\setminus } \lbrace x_j\rbrace _{j=1}^k\), and satisfies the jump condition
$$\begin{aligned} P^{(\infty )}_+(\lambda )=P^{(\infty )}_-(\lambda )\begin{pmatrix} 0 &{}\quad f_t(\lambda )\\ -f_t(\lambda )^{-1} &{}\quad 0 \end{pmatrix}, \qquad \lambda \in (-1,1){\setminus }\lbrace x_j\rbrace _{j=1}^k. \end{aligned}$$(4.24) -
3.
As \(z\rightarrow \infty \),
$$\begin{aligned} P^{(\infty )}(z)=I+\mathcal {O}(|z|^{-1}). \end{aligned}$$(4.25)
See “Appendix C” for a proof. Later on, we will need some estimates on the regularity of the Cauchy transform appearing in (4.21) near the interval \([-1,1]\). The fact we need is the following one.
Lemma 4.15
The function
is bounded uniformly in \(t\in [0,1]\) and z in a small enough neighborhood of \([-1,1]\). Moreover, if in a neighborhood of \([-1,1], \mathcal {T}\) is a real polynomial of fixed degree, and if we restrict its coefficients to be in some bounded set, then we have uniform boundedness of the above function in the coefficients of \(\mathcal {T}\) as well.
Proof
Let us fix a neighborhood of \([-1,1]\) such that for all \(t\in [0,1], \mathcal {T}_t\) is analytic in the closure of this neighborhood (this exists by similar reasoning as in the beginning of Sect. 4.1.2). Now write
As \(\mathcal {T}_t\) is analytic, the first term is of order \(\mathcal {O}(\sup _{t\in [0,1]}||\mathcal {T}_t'||_\infty )\) (the prime referring to the z-variable and the sup-norm is over z in the neighborhood we are considering) which is a finite constant depending on our neighborhood of \([-1,1]\) and the function \(\mathcal {T}\). In the polynomial case, one can easily check that it is bounded uniformly in the coefficients when they are restricted to a compact set. The second integral can be calculated exactly:
This can be seen for example by expanding the Cauchy kernel for large |z| as a geometric series. The integrals resulting from this are simple to calculate and one can then also calculate the remaining sum exactly. The resulting quantity agrees with \(\pi /r(z)\) on \((1,\infty )\) so by analyticity, the statement holds. The claim now follows from the uniform boundedness of \(\mathcal {T}_t\) (for which the uniform boundedness in the polynomial case is again easy to check). \(\square \)
4.3 Local parametrices near the singularities
We now wish to find functions approximating S(z) well near the points \(x_j\). We will thus look for functions that satisfy the same jump conditions as S(z) in some fixed neighborhoods of the points \(x_j\) for \(j=1,{\ldots },k\), but we will also want these approximations to be consistent with the global approximation, so we will replace a normalization at infinity with a matching condition, where we demand that the two approximations are close to each other on the boundary of the neighborhood we are looking at at. Our argument is built on [42, Section 4.3], which in turn relies on [65, Section 4]. Again, we state the relevant facts here and give some further details in “Appendix D”.
In this case, we will have to introduce a bit more notation before defining our actual object. We first introduce a change of coordinates that will blow up in a neighborhood of a singularity in a good way.
Definition 4.16
Fix some \(\delta >0\) (independent of N, s, and t). Let us write \(U_{x_j}\) for the open \(\delta \)-disk surrounding \(x_j\). We assume that \(\delta \) is small enough that the following conditions are satisfied:
-
(i)
\(|x_i-x_j|>3\delta \) for \(i\ne j\).
-
(ii)
\(|x_j\pm 1|>3\delta \) for all \(j\in \lbrace 1,{\ldots },k\rbrace \).
-
(iii)
For all \(j, U_{x_j}'\)—the open \(3\delta /2\)-disk around \(x_j\)—is contained in U, which is some neighborhood of \(\mathbb {R}\) into which d has an analytic continuation (see e.g. Definition 4.3).
For \(z\in U_{x_j}'\), let
where the root is according to the principal branch, and the integration contour does not leave \(U_{x_j}'\).
Remark 4.17
The reason for introducing the two neighborhoods \(U_{x_j}\) and \(U_{x_j}'\), is that we will want the local parametrices to be analytic functions approximately agreeing with \(P^{(\infty )}\) on the boundary of \(U_{x_j}\), but to ensure that they behave nicely near the boundary, we will construct them such that they are analytic in \(U_{x_j}'\).
We also point out that by taking \(\delta \) smaller if needed, \(\zeta _s\) can be seen to be injective as d is positive on \([-1,1]\). More precisely, we see that \(\zeta _s'(x_j)>c N\) for some constant c which is independent of s (but not necessarily of \(\delta )\) and \(|\zeta _s''(z)|\le C N\) uniformly in \(z\in U_{x_j}'\) for some \(C>0\) independent of s (but not necessarily of \(\delta )\). From this one sees that \(\zeta _s\) is injective in a small enough (N- and s-independent) neighborhood of \(x_j\).
In addition to this change of coordinates, we will need to add further jumps to make our jump contour more symmetric, in order to obtain an approximate problem with a known solution.
Definition 4.18
For \(z\in U_{x_j}'\), let
where the roots are principal branch roots. Moreover, let
The precise form of \(\zeta _s\) will be important for us to be able to see that the local parametrices indeed approximately agree with \(P^{(\infty )}\) on the boundary of \(U_{x_j}\). We also point out that for small enough \(\delta , \zeta _s\) is one-to-one, and it preserves the real axis (along with the orientation of the plane as it’s conformal).
We also point out that \(W_j\) is almost identical to \(f_t^{1/2}\), apart from the fact that it introduces some further branch cuts to it: along the imaginary axis in the \(\zeta _s\)-plane, as well as on the real axis (recall that \(f_t\) has no branch cut along the real axis). These further branch cuts are useful in transforming the Riemann–Hilbert problem for the parametrix into one with certain constant jump matrices along a very special contour. This problem has been studied in [65].
We are now able to clarify our choice of the contours \(\Sigma _j^{\pm }\) apart from the behavior near the end points ± 1.
Definition 4.19
Let \((\Sigma _l^{\pm })_l\) be such that
and
Outside of \(U_{x_j}'\) (apart from close to \(\pm 1)\), we take \((\Sigma _l^{\pm })_l\) to be smooth, without self-intersections and the distance between them and the real axis to be bounded away from zero and of order \(\delta \), and such that the contours are contained in U—the neighborhood of \(\mathbb {R}\) into which d has an analytic continuation. For an illustration, see Fig. 2.

Choice of the jump contours near the singularities
Using the injectivity of \(\zeta _s\) we argued in Remark 4.17 and the Koebe quarter theorem, it is immediate that \(\Sigma _j^\pm \) and \(\Sigma _{j-1}^\pm \) are well defined for large enough N and small enough \(\delta \) (large and small enough being independent of s).
We still need one further ingredient before defining our local parametrix. This is a solution to a model Riemann–Hilbert problem—a problem where the jump contours and matrices are particularly simple and a solution can be given explicitly in terms of suitable special functions. We will give a rather compact definition here with a more detailed description in “Appendix D”.
Definition 4.20
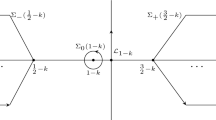
Let us denote by Roman numerals the octants of the complex plane—so we write \(\mathrm {I}=\lbrace r e^{i\theta }: r>0,\theta \in (0,\pi /4)\rbrace \) and so on. Denote by \(\Gamma _l\) the boundary rays of these octants: for \( 1\le l \le 8, \Gamma _l=\{ re^{i\frac{\pi }{4}(l-1)}, r >0\}\), oriented as in Fig. 3.
For \(\zeta \in \mathrm {I}\), let
where \(H_\nu ^{(i)}\) are Hankel functions and the root is according to the principal branch. In other octants, \(\Psi \) satisfies the following Riemann–Hilbert problem:
-
1.
\(\Psi : \mathbb {C}{\setminus } \cup _{l=1}^8 \overline{\Gamma _l}\rightarrow \mathbb {C}^{2\times 2}\) is analytic.
-
2.
\(\Psi \) has continuous boundary values on each \(\Gamma _l\) and satisfies the following jump condition (again for the orientation, see Fig. 3) \(\Psi _+(\zeta )=\Psi _-(\zeta )K(\zeta )\) for \(\zeta \in \cup _{l=1}^8 \Gamma _l\), where
$$\begin{aligned} K(\zeta )={\left\{ \begin{array}{ll} \begin{pmatrix} 0 &{}\quad 1\\ -1 &{}\quad 0 \end{pmatrix}, &{}\zeta \in \Gamma _1\cup \Gamma _5\\ \begin{pmatrix} 1&{}\quad 0\\ e^{-\pi i \beta _j} &{}\quad 1 \end{pmatrix}, &{} \zeta \in \Gamma _2\cup \Gamma _6\\ e^{\pi i \frac{\beta _j}{2}\sigma _3}, &{} \zeta \in \Gamma _3\cup \Gamma _7\\ \begin{pmatrix} 1&{}\quad 0\\ e^{\pi i \beta _j} &{}\quad 1 \end{pmatrix},&\zeta \in \Gamma _4\cup \Gamma _8 \end{array}\right. } \end{aligned}$$(4.32)

Jump contour of the model RHP
Uniqueness of such a \(\Psi \) can be argued in a similar manner as usual. First of all, one can check that for \(\zeta \in \mathrm {I}, \det \Psi (\zeta )=1\). As the jump matrices all have unit determinant, \(\det \Psi \) is analytic in \(\mathbb {C}{\setminus } \lbrace 0\rbrace \), so \(\det \Psi (\zeta )=1\) for \(\zeta \in \mathbb {C}\) (one can check that \(\zeta =0\) is a removable singularity). Consider then some other solution to the problem, say \({\widetilde{\Psi }}\). As \(\det \Psi =\det {\widetilde{\Psi }}=1\), \(\Psi (\zeta ) {\widetilde{\Psi }}(\zeta )^{-1}\) is analytic in \(\mathbb {C}{\setminus } \cup _{l=1}\overline{\Gamma _l}\) and equals I for \(\zeta \in \mathrm {I}\). Again it follows from the jump structure that \(\Psi (\zeta ) {\widetilde{\Psi }}(\zeta )^{-1}\) continues analytically to \(\mathbb {C}{\setminus } \lbrace 0\rbrace \) so it must equal I everywhere. For an explicit description of the solution, see “Appendix D”.
The local parametrices will then be formulated in terms of this function \(\Psi \), a coordinate change given by \(\zeta _s\), the function \(W_j\), and an analytic (\(\mathbb {C}^{2\times 2}\)-valued) “compatibility matrix” E, which is needed for the matching condition to be satisfied. We now make the relevant definitions.
Definition 4.21
For \(z\in U_{x_j}'\cap \lbrace \mathrm {Im}(z)>0\rbrace \), write
where the − sign is in the domain \(\lbrace z\in \mathbb {C}: \mathrm {arg}(\zeta _s(z))\in (0,\pi /2)\rbrace \) and the \(+\) sign is in the domain \(\lbrace z\in \mathbb {C}: \mathrm {arg}(\zeta _s(z))\in (\pi /2,\pi )\rbrace \). For \(z\in U_{x_j}'\cap \lbrace \mathrm {Im}(z)<0\rbrace \), write
where − sign is in the domain \(\lbrace z\in \mathbb {C}: \mathrm {arg}(\zeta _s(z))\in (-\pi /2,0)\rbrace \) and the \(+\) sign is in the domain \(\lbrace z\in \mathbb {C}: \mathrm {arg}(\zeta _s(z))\in (-\pi ,-\pi /2)\rbrace \).
Finally, for \(z\in U_{x_j}'{\setminus } \Sigma \), let
Remark 4.22
Using (4.27)—the definition of \(W_j\)—as well as (4.24)—the jump conditions of \(P^{(\infty )}\), one can check that E has no jumps in \(U_{x_j}'\). Moreover, using the behavior of both functions near \(x_j\), one can check that E does not have an isolated singularity at \(x_j\), so E is analytic in \(U_{x_j}'\).
We also point out that it follows directly from the definitions, i.e. (4.27), (4.33), (4.34), and (4.35), that for \(z\in U_{x_j}'{\setminus } \Sigma \)
The main claim about \(P^{(x_j)}\) is the following, whose proof we sketch in “Appendix D”.
Lemma 4.23
The function \(P^{(x_j)}\) satisfies the following Riemann–Hilbert problem.
-
1.
\(P^{(x_j)}:U_{x_j}'{\setminus } \Sigma \rightarrow \mathbb {C}^{2\times 2}\) is analytic.
-
2.
\(P^{(x_j)}\) has continuous boundary values on \(\Sigma \cap U_{x_j}'{\setminus } \lbrace x_j\rbrace \) and these satisfy the following jump conditions (with the same orientation as for S and same convention for the sign in \(e^{\mp Nh_s(\lambda )})\): for \(\lambda \in (U_{x_j}'{\setminus } \lbrace x_j\rbrace )\cap (\Sigma _{j-1}^+\cup \Sigma _{j-1}^-\cup \Sigma _j^+\cup \Sigma _j^{-1})\)
$$\begin{aligned} P^{(x_j)}_+(\lambda )=P^{(x_j)}_-(\lambda )\begin{pmatrix} 1 &{}\quad 0\\ f_t(\lambda )^{-1} e^{\mp Nh_s(\lambda )} &{}\quad 1 \end{pmatrix}, \end{aligned}$$(4.37)and for \(\lambda \in \mathbb {R}\cap U_{x_j}'{\setminus } \lbrace x_j\rbrace \)
$$\begin{aligned} P^{(x_j)}_+(\lambda )=P^{(x_j)}_-(\lambda )\begin{pmatrix} 0 &{}\quad f_t(\lambda )\\ -f_t(\lambda )^{-1} &{}\quad 0 \end{pmatrix}. \end{aligned}$$(4.38) -
3.
\(P^{(x_j)}(z)\) is bounded as \(z\rightarrow x_j\) from outside of the lenses, but when \(z\rightarrow x_j\) from inside of the lenses
$$\begin{aligned} P^{(x_j)}(z)=\begin{pmatrix} \mathcal {O}(|z-x_j|^{-\beta _j}) &{}\quad \mathcal {O}(1)\\ \mathcal {O}(|z-x_j|^{-\beta _j}) &{}\quad \mathcal {O}(1)\\ \end{pmatrix}. \end{aligned}$$(4.39) -
4.
For \(z\in \partial U_{x_j}\)
$$\begin{aligned} P^{(x_j)}(z)\left[ P^{(\infty )}(z)\right] ^{-1}=I+\mathcal {O}(N^{-1}), \end{aligned}$$(4.40)where the \(\mathcal {O}(N^{-1})\)-term is a \(2\times 2\) matrix whose entries are \(\mathcal {O}(N^{-1})\) uniformly in z, s, t, \(\lbrace |x_i-x_j|\ge 3\delta \ \mathrm {for \ } i\ne j\rbrace \), and \(\lbrace |1\pm x_j|\ge 3\delta \ \mathrm {for all } j\in \lbrace 1,{\ldots },k\rbrace \rbrace \). If in a neighborhood of \([-1,1], \mathcal {T}\) is a real polynomial of fixed degree, the error is also uniform in the coefficients once they are restricted to some bounded set.
For our second differential identity, we will actually need more precise information about \(P^{(x_j)}\) on \(\partial U_{x_j}\). While we will only use it in the \(\mathcal {T}=0\) case, it is not more difficult to formulate the result in the general case.
Lemma 4.24
For \(z\in \partial U_{x_j}\)
where the \(\mathcal {O}(N^{-2})\)-term is a \(2\times 2\) matrix whose entries are \(\mathcal {O}(N^{-2})\) uniformly in z, s, and \(\lbrace |x_i-x_j|\ge 3\delta \ \mathrm {for \ } i\ne j\rbrace \) and \(\lbrace |1\pm x_j|\ge 3\delta \ \mathrm {for \ all \ } j\in \lbrace 1,{\ldots },k\rbrace \rbrace \).
The \(t=0, s=0\) case of these results has been proven in [42, Section 4.3], though without focus on the uniformity relevant to us. Due to this, we will again sketch a proof in “Appendix D”.
4.4 Local parametrices at the edge of the spectrum
The reasoning here is similar to the previous section—we wish to find a function approximating S near the points ± 1. We will do this by approximating the Riemann–Hilbert problem and imposing a matching condition. Our argument will follow [42, Section 4.4], which in turn relies on [22]. We will focus on the approximation at 1, as the one at \(-1\) is analogous. Again we will provide a sketch of the relevant proofs in “Appendix E”. We will begin by introducing the relevant coordinate change in this case (analogous to \(\zeta _s\) in the previous section).
Definition 4.25
Let \(\delta >0\) satisfy the conditions of Definition 4.16. Denote by \(U_{1}\) a \(\delta \)-disk around 1 and \(U_{1}'\) denote a \(3\delta /2\)-disk around 1. We assume that \(\delta \) is small enough that d has an analytic extension to \(U_{1}'\). Moreover, we assume \(\delta \) is small enough—though independent of s—so that with a suitable choice of the branch, the function
is analytic and injective in \(U_1'\), for all \(s\in [0,1]\).
We will justify that this is indeed possible in “Appendix E”. This conformal coordinate change allows us to define what \(\Sigma _{k+1}^\pm \) looks like near 1. Let \(\delta >0\) be small enough to satisfy the conditions of Definition 4.25 and so that \(\mathcal {T}_t\) is analytic in \(U_1'\) for all \(t\in [0,1]\). We will define the local parametrix in \(U_1'\) and impose the matching condition on \(\partial U_1\). Let us thus define \(\Sigma _{k+1}^\pm \) in \(U_1'\) (Fig. 4).
Definition 4.26
Inside \(U_1'\), let \(\Sigma _{k+1}^\pm \) be such that

Choice of the jump contours near the edge of the spectrum
Remark 4.27
The angle \(2\pi /3\) is slightly arbitrary here. In [22] the model Riemann–Hilbert problem relevant to us is constructed for a family of angle parameters \(\sigma \in (\pi /3,\pi )\), and any angle here would work just as well for us, but we choose this for concreteness.
Also we point out that the above definition is fine as we know that \(\xi _s\) is injective and we can apply the Koebe quarter theorem to ensure that the preimage of the rays is non-empty.
We are now also in a position to define our local parametrix. As in the previous section, we need for this a solution to a certain model RHP considered in [22] as well as a function which is analytic in \(U_{x_j}'\) which is required for the matching condition to hold.
Definition 4.28
Let us write \(\mathrm {I}=\lbrace re^{i\theta }: r>0,\theta \in (0,2\pi /3)\rbrace , \mathrm {II}=\lbrace re^{i\theta }: r>0,\theta \in (2\pi /3,\pi )\rbrace , \mathrm {III}=\lbrace re^{i\theta }: r>0,\theta \in (-\pi ,-2\pi /3)\rbrace \), and \(\mathrm {IV}=\lbrace re^{i\theta }: r>0,\theta \in (-2\pi /3,0)\rbrace \). Then define
where \(\mathrm {Ai}\) is the Airy function (see Fig. 5)
Morover, define another “compatibility matrix”
where the roots are principal branch roots, and
Remark 4.29
Note that we can write
Again the relevant fact about this function is that it satisfies a suitable Riemann–Hilbert problem. Part of this is the fact that F in (4.45) is an analytic function in \(U_1'\). As before, we sketch the proof in “Appendix E”.

Jump contour of \(Q(\xi )\)
Lemma 4.30
The function F from (4.45) is analytic in \(U_1'\) and the function \(P^{(1)}(z)\) satisfies the following Riemann–Hilbert problem.
-
1.
\(P^{(1)}(z)\) is analytic in \(U_1'{\setminus } (\Sigma _{k+1}^+\cup \Sigma _{k+1}^-\cup \mathbb {R})\).
-
2.
For \(\lambda \in (-1,1)\cap U_1', P^{(1)}\) satisfies
$$\begin{aligned} P^{(1)}_+(\lambda )=P^{(1)}_-(\lambda )\begin{pmatrix} 0 &{}\quad f_t(\lambda )\\ -f_t(\lambda )^{-1} &{}\quad 0 \end{pmatrix}. \end{aligned}$$(4.48)For \(\lambda \in (1,\infty )\cap U_1', P^{(1)}\) satisfies
$$\begin{aligned} P^{(1)}_+(\lambda )=P^{(1)}_-(\lambda )\begin{pmatrix} 1 &{}\quad f_t(\lambda ) e^{N(g_{+,s}(\lambda )+g_{s,-}(\lambda )-V_s(\lambda )-\ell _s)}\\ 0 &{}\quad 1 \end{pmatrix}. \end{aligned}$$(4.49)For \(\lambda \in \Sigma _{k+1}^{\pm }, P^{(1)}\) satisfies
$$\begin{aligned} P^{(1)}_+(\lambda )=P^{(1)}_-(\lambda )\begin{pmatrix} 1 &{}\quad 0\\ f_t(\lambda )^{-1} e^{\mp Nh_s(\lambda )} &{}\quad 1 \end{pmatrix}. \end{aligned}$$(4.50) -
3.
For \(z\in \partial U_1, P^{(1)}\) satisfies the following matching condition,
$$\begin{aligned} P^{(1)}(z)\left[ P^{(\infty )}(z)\right] ^{-1}=I+\mathcal {O}(N^{-1}),\qquad \end{aligned}$$(4.51)where the entries of the \(\mathcal {O}(N^{-1})\) matrix are \(\mathcal {O}(N^{-1})\) uniformly in \(z\in \partial U_1\), uniformly in \(\lbrace x_i\rbrace \) for \(|x_i-x_j|\ge 3\delta \) for \(i\ne j\) and \(|x_i\pm 1|\ge 3\delta \) for \(j\in \lbrace 1,{\ldots },k\rbrace \), uniformly in \(t\in [0,1]\), and uniformly in \(s\in [0,1]\). If in a neighborhood of \([-1,1], \mathcal {T}\) is a real polynomial with fixed degree, the error is also uniform in the coefficients once they are restricted to some bounded set.
Again we will need finer asymptotics for our second differential identity and we will formulate them in the \(\mathcal {T}=0\) case.
Lemma 4.31
For \(z\in \partial U_{1}\)
where the \(\mathcal {O}(N^{-2})\)-term is a \(2\times 2\) matrix whose entries are \(\mathcal {O}(N^{-2})\) uniformly in z, s, and \(\lbrace |x_i-x_j|\ge 3\delta \ \mathrm {for \ } i\ne j\rbrace \) and \(\lbrace |1\pm x_j|\ge 3\delta \ \mathrm {for \ all \ } j\in \lbrace 1,{\ldots },k\rbrace \rbrace \).
Remark 4.32
Using the definition of F, one can check that this can be written also as
From the previous representation of the matching condition matrix, one can easily see that the subleading term is indeed of order N. The benefit of this representation is that as F and \(F^{-1}\) are analytic in \(U_1\), the subleading term is analytic in \(U_1{\setminus } \lbrace 1\rbrace \) and has (at most) a second order pole at \(z=1\).
4.5 The final transformation and asymptotic analysis of the problem
We now perform the final transformation of the problem, and solve it asymptotically. The proofs of these statements are essentially standard in the RHP literature, but we don’t know of a reference where the exact calculations we need exist and also issues such as uniformity in our relevant parameters are essential for us, but not usually stressed in the literature. Thus we provide proofs in “Appendix F”.
Definition 4.33
Let us fix some small \(\delta >0\) (“small” being independent of t and s and detailed in Sects. 4.3 and 4.4), and write \(U_{\pm 1}\) for a \(\delta \)-disk around ± 1 and \(U_{x_j}\) for a \(\delta \)-disk around \(x_j\). We also assume that for \(i\ne j, |x_i-x_j|\ge 3\delta \) and for all \(i\ne 0,k+1, |x_i\pm 1|\ge 3\delta \). We then define
We now state what is the Riemann–Hilbert solved by R—for details, see “Appendix F”.
Lemma 4.34
For the \(\delta \) in Definition 4.33, define
where \(\mathbb {R}\) and the lenses are oriented as before. \(\partial U_{x_j}\) and \(\partial U_{\pm 1}\) are oriented in a clockwise manner—see Fig. 6. Then R is the unique solution to the following Riemann–Hilbert problem:
-
1.
\(R:\mathbb {C}{\setminus } \Gamma _\delta \rightarrow \mathbb {C}^{2\times 2}\) is analytic.
-
2.
R satisfies the jump conditions \(R_+(\lambda ) = R_-(\lambda ) J_R(\lambda )\) (with lenses and \(\mathbb {R}\) oriented as before, and the circles are oriented clockwise), where the jump matrix \(J_R\) take the following form:
-
(i)
For \(\lambda \in \mathbb {R}{\setminus } [-1-\delta ,1+\delta ]\),
$$\begin{aligned} J_R(\lambda )&= P^{(\infty )}(\lambda )\begin{pmatrix} 1 &{}\quad f_t(\lambda ) e^{N(g_{s,+}(\lambda )+g_{s,-}(\lambda )-V_s(\lambda )-\ell _s)}\\ 0 &{}\quad 1 \end{pmatrix}\left[ P^{(\infty )}(\lambda )\right] ^{-1}. \end{aligned}$$(4.54) -
(ii)
For \(\lambda \in \cup _{j=1}^{k+1}\Sigma _j^\pm {\setminus }\overline{U_{-1}\cup \cup _{j=1}^k U_{x_j}\cup U_1}\),
$$\begin{aligned} J_R(\lambda )=P^{(\infty )}(\lambda )\begin{pmatrix} 1 &{}\quad 0\\ f_t(\lambda )^{-1}e^{\mp Nh_s(\lambda )} &{}\quad 1 \end{pmatrix}\left[ P^{(\infty )}(\lambda )\right] ^{-1}. \end{aligned}$$(4.55) -
(iii)
For \(\lambda \in \partial U_{x_j}{\setminus } \cup _{j=1}^{k+1}(\Sigma _j^+\cup \Sigma _j^-)\),
$$\begin{aligned} J_R(\lambda )=P^{(x_j)}(\lambda )\left[ P^{(\infty )}(\lambda )\right] ^{-1}. \end{aligned}$$(4.56) -
(iv)
For \(\lambda \in \partial U_{\pm 1}{\setminus } (\mathbb {R}\cup \cup _{j=1}^{k+1}(\Sigma _j^+\cup \Sigma _j^-)\),
$$\begin{aligned} J_R(\lambda )=P^{(\pm 1)}(\lambda )\left[ P^{(\infty )}(\lambda )\right] ^{-1}. \end{aligned}$$(4.57)
-
(i)
-
3.
As \(z\rightarrow \infty \),
$$\begin{aligned} R(z)=I+\mathcal {O}(|z|^{-1}). \end{aligned}$$(4.58)

The jump contour of the Riemann–Hilbert problem for R, in the case \(k = 1\)
The first ingredient to solving this Riemann–Hilbert problem is to show that the jump matrix of R(z) is close to the identity matrix in a suitable sense.
Lemma 4.35
For \(z \in \Gamma _\delta \), write \(J_R(z)=I+\Delta _R(z)=I+\Delta \) for the jump matrix of R as described in Lemma 4.34. Then for any \(p\ge 1\), and large enough N (“large enough” depending only on V)
where the norm is any matrix norm, the \(L^p\)-spaces are with respect to the Lebesgue measure on the jump contour, and the \(\mathcal {O}(N^{-1})\) term is uniform in everything relevant (i.e., \((x_i)\) for \(|x_i-x_j|\ge 3\delta \), for \(i\ne 0,k+1\): \(|x_i\pm 1|\ge 3\delta \), in \(s,t\in [0,1]\), and if \(\mathcal {T}\) is a real polynomial in a neighborhood of \([-1,1]\), then in its coefficients when restricted to a bounded set; but may depend on \(\delta )\).
See “Appendix F” for a proof. We will want to show that R is close to the identity, and the tool which allows us to do this is the following representation of R as a solution to a suitable integral equation involving its jump matrix.
Proposition 4.36
Let \(\delta >0\) be small enough (“small enough” being independent of s and t). For N sufficiently large (again independent of s and t), the unique solution of the Riemann–Hilbert problem for R (see Lemma 4.34) is given by
where
is the Cauchy operator on \(\Gamma _\delta \), and \(C_\Delta (f) = C_-(f \Delta )\) where \(C_-(f) = \lim _{z \rightarrow s} C(f)\) as z approaches a point \(s \in \Gamma _\delta \backslash \{ \mathrm {intersection\ points}\}\) from the −side of \(\Gamma _\delta \) (for the orientation, see Lemma 4.34).
Finally, what we want to show is that \(R(z)=I+\mathcal {O}(N^{-1})\) uniformly in everything relevant and use this as well as the explicit form of our parametrices to analyze our differential identities. The precise statement we need is the following one.
Theorem 4.37
For small enough \(\delta >0\) (again small enough being independent of relevant quantities) and large enough N (large enough being independent of everything relevant) with respect to any matrix norm \(|\cdot |\), there exists a \(c>0\) such that
uniformly in \((x_i)\) for \(|x_i-x_j|\ge 3\delta , |x_i\pm 1|\ge 3\delta \) for \(i\ne 0,k+1, t,s \in [0,1], z \in \mathbb {C} \backslash \Gamma _\delta \), and if \(\mathcal {T}\) is a real polynomial in a neighborhood of \([-1,1]\), then the error is uniform in its coefficients when these are restricted to a bounded set.
Moreover, for \(\mathcal {T}=0\), we have
uniformly in \((x_i)\) for \(|x_i-x_j|\ge 3\delta , |x_i\pm 1|\ge 3\delta \) for \(i\ne 0,k+1, s \in [0,1]\), and \(z \in \mathbb {C} \backslash (\Gamma _\delta \cup \cup _{j=0}^{k+1} U_{x_j})\). Here \(R_1(z) = \sum _{j=0}^{k+1} R_1^{(x_j)}(z)\) with
where E and F are the “compatibility matrices” from Definitions 4.21 and 4.28. In particular, we have
where
Remark 4.38
As discussed in [42], using the asymptotic expansions of the Airy function and Bessel functions, the matching conditions of the local parametrices can be extended into asymptotic expansions in inverse powers of N. These then can be used to prove a full asymptotic expansion for R and \(R'\). We don’t have use for this, so we won’t discuss it further.
5 Integrating the differential identities
In this section we will use our asymptotic solution and precise form of the parametrices to analyze the asymptotics of the differential identities (3.11) and (3.13), and finally integrate them. We will start with (3.11).
5.1 The differential identity (3.11)
Here we will give a (slightly simplified) variant of the argument in [20, Section 5.3] to integrate the differential identity (3.11). As there are minor modifications due to the differences in the models and the argument being relevant for (3.13), we present a full proof here. The main goal we wish to prove is the following.
Proposition 5.1
Let V be one-cut regular, \(\mathcal {T}\) as in Proposition 2.10, and \(\delta >0\) small enough, but independent of N. Then as \(N\rightarrow \infty \),
where o(1) is uniform in \(\lbrace (x_j)_{j=1}^k: |x_i-x_j|\ge 3\delta , i\ne j \ and \ |x_i\pm 1|\ge 3\delta \ \forall i\rbrace \), and if in a neighborhood of \([-1,1], \mathcal {T}\) is a real polynomial of fixed degree, then the error is also uniform in the coefficients of \(\mathcal {T}\) when these are restricted to a bounded set.
The way we will do this is we’ll express the integrand in (3.11) in a slightly different way which will allow deforming our integration contour in such a way that we can express Y in terms of R and the global parametrix \(P^{(\infty )}\). The expression will be such that to leading order, we can treat R as the identity, and using the global parametrix, we can perform the relevant integrals explicitly.
Let us begin with expressing our integral in terms of the global parametrix. We first remind the reader that we denoted by \(U_{[-1,1]}\) a fixed (independent of N and t) complex neighborhood of \([-1,1]\) into which \(\mathcal {T}_t\) had an analytic continuation for all \(t\in [0,1]\). We also assumed that the lenses and neighborhoods \((U_{x_j})_{j=0}^{k+1}\) were inside \(U_{[-1,1]}\).
Lemma 5.2
Let \(\tau _+:[0,1]\rightarrow \lbrace z\in \mathbb {C}: \mathrm {Im}(z)\ge 0\rbrace \cap U_{[-1,1]}\) be a smooth simple curve independent of N. We also assume that \(\tau _+(0)<-1, \tau _+(1)>1\), and that \(\tau (s)\) is outside of the lenses and neighborhoods \((U_{x_j})_{j=0}^{k+1}\) for all s. We also define \(\tau _-\) in a similar way but in the lower half plane and with the assumption that \(\tau _-(0)=\tau _+(0)\) as well as \(\tau _-(1)=\tau _+(1)\). See Fig. 7 for an illustration.
Then for \(t\in [0,1]\)
where o(1) is uniform in \(t\in [0,1], \lbrace (x_j)_{j=1}^k: |x_i-x_j|\ge 3\delta , i\ne j \ and \ |x_i\pm 1|\ge 3\delta \ \forall i\rbrace \), and if in a neighborhood of \([-1,1], \mathcal {T}\) is a real polynomial of fixed degree, then the error is also uniform in the coefficients of \(\mathcal {T}\) when these are restricted to a bounded set.

Deforming the integration contour, \(k = 1\)
Proof
Let us write \(Y'=\partial _x Y\). We first note that an elementary calculation using (3.8) and the fact that the first column of Y consists of polynomials which have no jump across \(\mathbb {R}\), show that for \(\lambda \in \mathbb {R}\),
Now recall that \(Y_{12,\pm }\) and \(Y_{22,\pm }\) have continuous boundary values on \(\mathbb {R}\) so we see that the terms \(Y_{22}Y_{11}'-Y_{12}Y_{21}'\) are analytic in \(\mathbb {C}{\setminus } \mathbb {R}\) and are continuous up to the boundary. Moreover, by our construction, \(f_t(z)^{-1}\partial _t f_t(z)\) is analytic in \(U_{[-1,1]}\). We can thus argue by Cauchy’s integral theorem to deform the integration contour. In particular, plugging (5.2) into (3.11), we find
Notice that
Unravelling our transformations, we note as we are not inside the lenses or the neighborhoods, we have on \(\mathbb {R}{\setminus } [\tau _+(0),\tau _+(1)]\) and on \(\tau _\pm \)
where we have used the global parametrix in the last equality. Since the \(P^{(\infty )}\)-RHP implies that \(P^{(\infty )}(z)\) is complex analytic when \(z \not \in [-1,1], I+\mathcal {O}(|z|^{-1})\) as \(z \rightarrow \infty \), and \(\det P^{(\infty )} \equiv 1\), we see that both \(\left( P^{(\infty )}\right) ^{-1}\) and \(\left( P^{(\infty )}\right) '\) are bounded when we are away from a (complex) neighbourhood of \([-1, 1]\). One can easily check that they are in fact uniformly bounded in all our relevant parameters. Combined with the estimates
in Theorem 4.37, we have \(S^{-1}S' = \left( P^{(\infty )}\right) ^{-1}\left( P^{(\infty )}\right) ' + \mathcal {O}(N^{-1})\).
Consider first the integral along \(\mathbb {R}{\setminus } [\tau _+(0),\tau _+(1)]\). Using the specific form (4.22) of \(P^{(\infty )}\), (5.3), and the fact that terms containing R give something o(1), a direct calculation shows that
Thus
and one finds from (4.7) that as \(N\rightarrow \infty \), the integral along \(\mathbb {R}{\setminus } [\tau _+(0),\tau _+(1)]\) is o(1) uniformly in everything relevant.
Consider then the integrals along \(\tau _\pm \). A similar direct calculation shows that
and hence
where again o(1) is uniform in everything relevant. This yields the claim once we notice that by contour deformation and (4.8)
\(\square \)
Our next task is to calculate the \(\tau _\pm \) integrals. To do this, we introduce some notation.
Definition 5.3
For \(z\in \mathbb {C}{\setminus }(-\infty ,1]\), let
where the logarithm is with the principal branch, \(\mathcal {A}=\sum _{j=1}^k \beta _j/2\), and FH refers to Fisher–Hartwig. We also define for \(z\in \mathbb {C}{\setminus } [-1,1]\)
where r(z) is as in (4.19) and Sz refers to Szegő.
Note that we have \(\mathcal {D}_t'/\mathcal {D}_t=q_{FH}'+q_{Sz}'\). We will need the following fact before proving Proposition 5.1. The following is an analogue of a result in [17] in the case of the circle.
Lemma 5.4
Write \(\tau _\pm \) be as in Lemma 5.2. We have
Proof
Let us recall that we saw in the proof of Lemma 4.15 that off of \([-1,1]\) we can write
which implies that \(q_{Sz}\) is bounded in a neighborhood of \([-1,1]\) and \(q_{Sz}(\pm 1,t)=\frac{1}{2}\mathcal {T}_t(\pm 1)\). Moreover, we see from this that
This in turn implies that \(q_{Sz}'\) is bounded except at \(z=\pm 1\) where it has singularities of order \(|z\mp 1|^{-1/2}\); in particular these are integrable ones. Due to the singularities being integrable, we can perform contour deformation and integrate by parts in the z-integral in the left hand side of (5.6). Noting that \(f_t^{-1}\partial _t f_t=\partial _t\mathcal {T}_t=:{\dot{\mathcal {T}}}_t\) (we will use a dot here and below to indicate time derivatives below when there is no risk of confusion), we see that
Let us write for \(x\in (-1,1), s(x)=\sqrt{1-x^2}\). As for \(x\in (-1,1), r_\pm (x)=\pm is(x)\), we see by Sokhotski–Plemelj that
where \(\mathbf {1}_{(-1,1)}\) is the indicator function of the interval \((-1,1)\), and \(\mathcal {H}\) denotes the Hilbert transform (note that the Hilbert transform is well defined as \(\mathbf {1}_{(-1,1)}\mathcal {T}_t/s\in L^p(\mathbb {R})\) for \(p\in [1,2)\)).
To simplify notation slightly, let us write \(\langle f,g\rangle :=\int _\mathbb {R}f(x)g(x)dx\). Integrating by parts in the t integral in (5.7) we see that
Our aim is now to show that actually \(\frac{1}{2\pi }\int _0^1\langle \mathcal {T}_t',\mathbf {1}_{(-1,1)}s \mathcal {H}(\mathbf {1}_{(-1,1)}{\dot{\mathcal {T}}}_t/s)\rangle dt=-I\) so we would have \(I=-\langle \mathcal {T}',\mathbf {1}_{(-1,1)}s \mathcal {H}(\mathbf {1}_{(-1,1)}\mathcal {T}/s)\rangle /4\pi \), which we will see to be equivalent to our claim. To see that indeed \(\frac{1}{2\pi }\int _0^1\langle \mathcal {T}_t',\mathbf {1}_{(-1,1)}s \mathcal {H}(\mathbf {1}_{(-1,1)}{\dot{\mathcal {T}}}_t/s)\rangle dt=-I\), we note first that
implying that for say a continuous \(f:[-1,1]\rightarrow \mathbb {R}\) and \(x\in (-1,1)\)
Using the definition of the Cauchy principal value integral, one can also check easily that for a smooth \(f:[-1,1]\rightarrow \mathbb {R}\) and \(x\in (-1,1)\)
Thus integrating by parts in the x integral, using the fact that \(q_+(\pm 1,t)=q_-(\pm 1,t)\), and (5.10), we see that
We then note that
and
Plugging these into (5.11), using the fact that \(s'(x)=-x/s(x)\) along with the anti-self adjointness of \(\mathcal {H}\) we see that
Note that \(1/s\notin L^2(-1,1)\) so we can’t use the anti-self adjointness of the Hilbert transform on the space \(L^2\), but we use the fact that if \(f\in L^p(\mathbb {R})\) and \(g\in L^{p'}(\mathbb {R})\), where \(p'\) is the Hölder conjugate of p, then \(\int g\mathcal {H}f=-\int f\mathcal {H}g\)—see e.g. [64, Theorem 102].
Plugging (5.12) into (5.8), we find our previous claim that
Making use of the anti-self adjointness of \(\mathcal {H}\) again, this translates into
which is our claim. \(\square \)
We are now in a position to finish the proof.
Proof of Proposition 5.1
We start with the result of Lemma 5.2. Consider first the integral along \([-1,1]\). Here we note that by the definition of \(f_t, \int _0^1 f_t(x)^{-1}\partial _t f_t(x)dt=\log f_1(x)-\log f_0(x)=\mathcal {T}(x)\). This yields the \(\mathcal {O}(N)\)-term in (5.1).
Let us now consider the \(\mathcal {D}_t'/\mathcal {D}_t\)-terms. The contribution from \(q_{Sz}\) is calculated in Lemma 5.4, so we need to understand the contribution of \(q_{FH}\). As \(q_{FH}\) is independent of t, we find that
Now as
we see by Cauchy’s integral theorem, the fact that \(r_\pm (x)={\pm }i\sqrt{1-x^2}\) for \(x\in (-1,1)\), and Sokhotski-Plemelj that
Thus combining (5.14), (5.6), our reasoning about the \(\mathcal {O}(N)\) term, and Lemma 5.2, yields
where o(1) is uniform in everything relevant. This is precisely the claim. \(\square \)
5.2 The differential identity (3.13)
The main goal of this section is to prove the following identity.
Proposition 5.5
Let V be one-cut regular, \(\mathcal {T}\) as in Proposition 2.10, \(\delta >0\) small enough but independent of N. Then as \(N\rightarrow \infty \),
where o(1) is uniform in \(\lbrace (x_j)_{j=1}^k: |x_i-x_j|\ge 3\delta , i\ne j \ \mathrm {and} \ |x_i\pm 1|\ge 3\delta \ \forall i\rbrace \).
The arguments are largely similar to those related to the differential identity (3.11) so we will be less detailed here. The arguments in the proof of Lemma 5.2 can be repeated in this case with the only difference being that we replace \(\partial _t f_t\) by \(- Nf\partial _s V_s\) and d with \(d_s\) etc, apart from approximating R by the identity—we’ll need the \(\mathcal {O}(N^{-1})\) contribution from R here as well. We will also need to assume that our lenses and neighborhoods of the singularities are chosen so that V is analytic in some neighborhood of them, but as we assumed V to be real analytic, we can of course do this. We will also assume that \(\tau _\pm \) are inside this domain where V can be analytically continued to. Repeating the arguments from the previous section in such a setting leads to the following lemma.
Lemma 5.6
Let \(\tau _\pm \) be as in Lemma 5.2 with the difference that we assume that the contours are within the domain where V is analytic in.
Then for \(s\in [0,1]\)
where o(1) is uniform in \(s\in [0,1], \lbrace (x_j)_{j=1}^k: |x_i-x_j|\ge 3\delta , i\ne j \ and \ |x_i\pm 1|\ge 3\delta \ \forall i\rbrace \) and
The proof is essentially identical to that of Lemma 5.2 and we omit it. We now consider the asymptotics of the integral of this from \(s=0\) to \(s=1\). Let us first consider the order \(N^2\) term.
Lemma 5.7
We have
Proof
This follows immediately from the definitions: \(\partial _s V_s(x)=V(x)-2x^2\) and \(d_s(x)=(1-s)\frac{2}{\pi }+sd(x)\). \(\square \)
For \(\mathcal {J}\)-terms, we note that we now need to take into account \(\mathcal {O}(N^{-1})\) terms in the expansion of R—these will result in \(\mathcal {O}(1)\) terms in the differential identity. We first focus on the \(\mathcal {O}(N)\) terms which come from the \(\mathcal {O}(1)\) terms in the expansion of R. For this, repeating our argument from the previous section results in the \(\mathcal {O}(N)\) term being
where \(\gamma \) is a nice curve enclosing \([-1,1]\) inside which everything relevant is analytic. We again have \(\mathcal {D}'(z)/\mathcal {D}(z)=q_{Sz}'(z,0)+q_{FH}'(z,0)=q_{FH}'(z,0)\) (as \(q_{Sz}(z,0)=0\)). Recalling that
an application of Sokhotski-Plemelj shows that the order N terms combine into the following quantity
Finally, let us consider the \(\mathcal {O}(1)\) terms. We will make use of the following lemma (whose variants are surely well known in the literature, but as we don’t know of a reference exactly in our setting we will sketch a proof of it).
Lemma 5.8
For \(x\in (-1,1)\) and one-cut regular potential V,
and
Proof
For (5.16), define the function \(H:(\mathbb {C}{\setminus }[-1,1])\rightarrow \mathbb {C}\)
Using Sokhotksi-Plemelj and (2.3), one can check that this function is continuous across \((-1,1)\). One also sees easily that H is bounded at ± 1 so we conclude that it is entire. Finally as \(H(\infty )=-2\pi \), Liouville implies that \(H(z)=-2\pi \). An application of Sokhotski-Plemelj then implies (5.16).
We note that as a consequence of (5.16), one can check that what’s required for (5.17) is to prove the identity
One can easily check that these are both smooth functions of x and satisfy \(p(1)=q(1)=0\), so it’s enough for us to check that \(p'(x)=q'(x)\). For this, let us first write
We again make use of the fact that differentiation commutes with the Hilbert transform so one can check that
We conclude that \(p=q\) and (5.17) is true. \(\square \)
Now to get a hold of the \(\mathcal {O}(1)\)-terms we are interested in, we need the \(\mathcal {O}(N^{-1})\) term in the expansion of \(\mathcal {J}_s\) for the \(\tau _\pm \)-integrals. Again by Theorem 4.37, we know that
where the claim about \(R^{-1}\) follows by Neumann series expansion. Inspecting (5.3), one realizes that the extra \(\mathcal {O}(N^{-1})\) correction is indeed given by
Let us consider first the contributions from the \(R_1^{(x_j)}\) terms with \(j\in \lbrace 1,{\ldots },k\rbrace \) (recall Theorem 4.37 for the definition of this and \(\mathcal {J}^{(x_j)}\) below).
Lemma 5.9
Let \(\tau _\pm \) be as in Lemma 5.4 and \(j\in \lbrace 1,{\ldots },k\rbrace \). Then
uniformly in \(x_j\in (-1+\epsilon ,1-\epsilon )\).
Proof
Recall first of all from Theorem 4.37 that for \(j\in \lbrace 1,{\ldots }k\rbrace \)
where
Let us first focus on the z-integral in the statement of the lemma. Note first that
and
Using (5.20) and (5.21) one can check with direct calculations that
and
Recalling that \(\partial _s V_s(z)=V(z)-2z^2\), we thus see by integration by parts, contour deformation, and Sokhotski-Plemelj that
and simply by Sokhotski-Plemelj that
Let us first focus on the integral of the first term. We have from (5.22) and (5.16)
Let us now turn to the second term. We have from (5.23) and (5.17) that
Let us note that we can write \(c_{x_j,s}^2=e^{i\theta _N(x_j)} e^{2\pi i N s\int _{x_j}^1\left( d(\lambda )-\frac{2}{\pi }\right) \sqrt{1-\lambda ^2}}d\lambda \), where \(e^{i\theta _N(x_j)}\) is a complex number of unit length and independent of s. Thus
Integrating this by parts, noting that \(\frac{d}{ds}d_s(x)=d(x)-\frac{2}{\pi }\) is bounded and \(1/d_s(x)^2\) is bounded in x and s, we see that
uniformly in \(x_j\in (-1+\epsilon ,1-\epsilon )\). Combining (5.24) and (5.25), yields the claim (5.19). \(\square \)
Let us now treat the integrals associated to \(\mathcal {J}^{(\pm 1)}\).
Lemma 5.10
We have
Proof
We only prove the first equality. From Theorem 4.37 we have
where \(G_s^{(1)}\) is defined in (E.2) and we have \(G_s^{(1)}(1) = \pi \sqrt{2} d_s(1)\). Note that
Thus integrating by parts, contour deformation, and a simple application of Lemma 5.8 imply that
and
In a similar manner and with an application of Lemma 5.8,
which implies
Consider finally the \(a(z)^{-2}\) term. One can easily check that
We can safely ignore the second term on the RHS, as we saw that it will integrate to zero. Moreover, we essentially calculated the integral related to the first term already:
and we find
Putting together (5.27), (5.28), and (5.29) a direct calculation leads to
\(\square \)
Proof of Proposition 5.5
This is simply a combination of Lemmas 5.6, 5.7, (5.15), Lemmas 5.9, and 5.10. \(\square \)
We are now in a position to apply these results.
6 Proof of Theorem 1.1
As discussed earlier, we do this through Proposition 2.9. Before proving this, we will need to recall Krasovsky’s result for the GUE from [42] and a result of Claeys and Fahs [14] which we need to control the situation when the singularities are close to each other. Let us begin with Krasovsky’s result [42, Theorem 1].
Theorem 6.1
(Krasovsky) Let \((x_j)_{j=1}^k\) be distinct points in \((-1,1)\), let \(\beta _j>-1\), and let \(H_N\) be a GUE matrix (i.e. \(V(x)=2x^2)\). Then as \(N\rightarrow \infty \)
uniformly in compact subsets of \(\lbrace (x_1,{\ldots },x_k)\in (-1,1)^k: x_i\ne x_j \ \mathrm {for} \ i\ne j\rbrace \). Here \(C(\beta )=2^{\frac{\beta ^2}{2}}\frac{G(1+\beta /2)^2}{G(1+\beta )}\), and G is the Barnes G function.
We mention that Krasovsky’s result is actually valid for complex \(\beta _j\) with real part greater than \(-1\), and he used a slightly different normalization, but obtaining this formulation follows after trivial scaling. Also his formulation of the result does not stress the uniformity, but it can easily be checked through uniform bounds on the jump matrices which are similar to the ones we have considered.
Combining this with Proposition 5.5 yields the following result.
Proposition 6.2
Let \(H_N\) be drawn from a one-cut regular ensemble with potential V and support of the equilibrium measure normalized to \([-1,1]\). If \((x_j)_{j=1}^k\) are distinct points in \((-1,1)\) and \(\beta _j\ge 0\) for all j, then
uniformly in compact subsets of \(\lbrace (x_1,{\ldots },x_k)\in (-1,1)^k:x_i\ne x_j \ \mathrm {for} \ i\ne j\rbrace \).
Proof
Let us write \(\mathbb {E}_V\) for the expectation with respect to an ensemble with potential V. Note that from (3.1) setting \(f=1\), we have
so we see from Proposition 5.5 that for \(f(\lambda )=\prod _{j=1}^k |\lambda -x_j|^{\beta _j}\) and \(V_0(x)=2x^2\)
where we have the desired uniformity.
Let us now recall the logarithmic potential of the arcsine law (see e.g. [61, Section 1.3: Example 3.5]): \(\frac{1}{\pi }\int _{-1}^1\log |x-y|/\sqrt{1-x^2}dx=-\log 2\) for all \(y\in (-1,1)\). This along with (2.3) imply that
This in turn implies that
Combining this with Theorem 6.1 and (6.1) yields the claim. \(\square \)
We now recall the result of Claeys and Fahs that we will need, namely [14, Theorem 1.1].
Theorem 6.3
(Claeys and Fahs) Let V be one-cut regular and let the support of the associated equilibrium measure be [a, b] with \(a<0<b\). Let \(\beta>0, u>0\), and \(f_u(x)=|x^2-u|^\beta \). Then
uniformly as \(u\rightarrow 0\) and \(N\rightarrow \infty \). Here
and \(\sigma _\beta (s)\) is analytic on \(-i\mathbb {R}_+\), independent of V, N, and u and satisfies:
Moreover, the integral involving \(\sigma _\beta \) is taken along \(-i\mathbb {R}_+\).
Much more is in fact known about \(\sigma _\beta \). For example, it is known to satisfy a Painlevé V equation. A generalization of it was studied extensively in [15]. Theorem 6.3 and Proposition 6.2 let us prove the convergence of \(\mathbb {E}[\mu _N(f)^2]\)—the argument is similar to analogous ones in [14, 15].
Proposition 6.4
Let \(\varphi :(-1,1)\rightarrow [0,\infty )\) be continuous and have compact support. Moreover, let \(\beta \in (0,\sqrt{2})\). Then
Proof
This is very similar to the proof of [14, Corollary 1.11] where a more general statement was proven for the GUE. Let us fix some small \(\epsilon >0, \alpha \in (\beta ^2/2,1)\), and write the relevant moment in the following way:
It follows immediately from Proposition 6.2 that if there is some \(\epsilon >0\) such that \(|x-y|\ge \epsilon \) and \(x,y\in (-1+\epsilon ,1-\epsilon )\) then uniformly in such x, y
As \(\varphi \) has compact support in \((-1,1)\), this is precisely the situation for the integral in \(A_{N,1}(\epsilon )\). We conclude that
Let us now consider \(A_{N,3}\). Here we find by Cauchy–Schwarz and Proposition 6.2 that there exists some finite \(B(\beta )\) (uniform in the relevant x, y) such that
so we see that as \(N\rightarrow \infty \)
since we chose \(\alpha >\beta ^2/2\).
Thus to conclude the proof, it’s enough to show that
Let us begin doing this by noting that if we write \(u=\frac{(x-y)^2}{4}\) and \(V_{x,y}(\lambda )=V(\lambda +(x+y)/2)\), then in the notation of Theorem 6.3
This follows from (2.2) through the change of variables \(\lambda _i=\mu _i+\frac{x+y}{2}\). The goal is to make use of Theorem 6.3 to estimate \(D_{N-1}(f_u;V_{x,y})\). There are several issues we need to check to justify this. First of all, we need \(V_{x,y}\) to be one-cut regular and the interior of the support of its equilibrium measure to contain the point 0. This is simple to justify as one can check from the Euler–Lagrange equations that the equilibrium measure associated to \(V_{x,y}\) is simply \(d(u+\frac{x+y}{2})\sqrt{1-(u+\frac{x+y}{2})^2}du\) and its support is \([-1-\frac{x+y}{2},1-\frac{x+y}{2}]\). The remaining conditions for one-cut regularity are easy to check with this representation.
It is less obvious that we can use Theorem 6.3 to study the asymptotics of \(D_{N-1}(f_u;V_{x,y})\) as now \(V_{x,y}\) depends on x and y and we would need the errors in the theorem to be uniform in V as well. As mentioned in [14] for the GUE, for \(x,y\in (-1+\epsilon ,1-\epsilon )\), this can be checked by going through the relevant estimates in the proof. This is true also for general one-cut regular ensembles. As checking this may be non-trivial for a reader with little background in Riemann–Hilbert problems, we outline how to do this in “Appendix G”.
We may therefore use Theorem 6.3, and so we have
where the error estimates are uniform in \(|x-y|<\epsilon \) and \(x,y\in (-1+\epsilon ,1-\epsilon )\). Note that now
again uniformly in the relevant values of x and y.
Recall that we’re considering u such that \(\sqrt{u}<2\epsilon \) but \(\sqrt{u}>N^{-\alpha }\) with \(\frac{\beta ^2}{2}<\alpha <1\). We then have \(s_{N,u}\rightarrow -i\infty \) uniformly in the relevant x, y and using [15, equation (1.26)] one has
uniformly for \(x,y\in (-1+\epsilon ,1-\epsilon )\) and \(2N^{-\alpha }<|x-y|<\epsilon \).
On the other hand, reversing our mapping from V to \(V_{x,y}\), we see that
Thus we see that uniformly for \(x,y\in (-1+\epsilon ,1-\epsilon )\) and \(2N^{-\alpha }<|x-y|<\epsilon \)
where o(1) means something that tends to zero as \(N\rightarrow \infty \). Using these estimates, we can write for such x, y
uniformly in \(x,y\in (-1+\epsilon ,1-\epsilon )\) and \(2N^{-\alpha }<|x-y|<\epsilon \). Plugging in Proposition 6.2, we see that this becomes
We conclude that
which was the missing part of the proof. \(\square \)
Next we need to study the cross term \(\mathbb {E}\mu _{N,\beta }(\varphi ){\widetilde{\mu }}_{N,\beta }^{(M)}(\varphi )\) along with the fully truncated term \(\mathbb {E}[{\widetilde{\mu }}_{N,\beta }^{(M)}(\varphi )^2]\). For this, we need Proposition 2.10, so let us finish the proof of it.
Proof of Proposition 2.10
We have now
where \(f(\lambda )=f_1(\lambda )=e^{\mathcal {T}(\lambda )}\prod _{j=1}^k|\lambda -x_j|^{\beta _j}\). Since we know the asymptotics of this for \(\mathcal {T}=0\), we can apply Proposition 5.1 to get the relevant asymptotics for \(\mathcal {T}\ne 0\):
uniformly in everything relevant. Applying Proposition 6.2 to this yields the claim. \(\square \)
We now apply this to understanding the remaining terms.
Proposition 6.5
Let \(\beta \in (0,\sqrt{2})\) and \(\varphi :(-1,1)\rightarrow [0,\infty )\) be continuous with compact support. Then for fixed \(M\in \mathbb {Z}_+\)
Proof
Let us first consider the cross term. We write this as
Let us begin by calculating the numerator. Note that as we have only one singularity, Proposition 2.10 gives us asymptotics which are uniform in x throughout the whole integration region. To apply Proposition 2.10, we point out that we now have \(\mathcal {T}(\lambda )=\mathcal {T}(\lambda ;y)=-\beta \sum _{k=1}^{M}\frac{2}{k}{\widetilde{T}}_k(\lambda )T_k(y)\). We need uniformity in y, but this is ensured by the fact that in a neighborhood of \([-1,1], \mathcal {T}\) is a polynomial of fixed degree and its coefficients are uniformly bounded for fixed M. Using the facts that \(\int _{-1}^1 T_k(y)/\sqrt{1-y^2}dy=0\) for \(k\ge 1, P.V.\frac{1}{\pi }\int _{-1}^1 T_k'(y)\sqrt{1-y^2}/(x-y)dy=kT_k(x)\), and the orthogonality of the Chebyshev polynomials: \(2\int _{-1}^1 T_k(\lambda )T_l(\lambda )/(\pi \sqrt{1-\lambda ^2})d\lambda =\delta _{k,l}\) for \(k,l\ge 1\), we see that
uniformly in \(x,y\in (-1+\epsilon ,1-\epsilon )\). We see that the \(\mathbb {E}[|\det (H_N-x)|^\beta ]\)-term in the denominator will cancel, but we still need to understand the \(\mathbb {E}e^{\beta {\widetilde{X}}_{N,M}(y)}\)-term. This now has no singularity, so we get the asymptotics from Proposition 2.10 by setting \(\beta _j=0\) for all j. Thus we find with a similar argument that
uniformly in y, and we conclude that
For the fully truncated term one argues in a similar way: in this case
and only the part quadratic in \(\mathcal {T}\) affects the leading order asymptotics. Going through the calculations one finds
\(\square \)
Before proving Proposition 2.9, we need to know that \(\mu _\beta \) exists, namely we need to prove Lemma 2.5.
Proof of Lemma 2.5
As discussed earlier, this boils down to showing that \((\mu _\beta ^{(M)}(\varphi ))_{M=1}^\infty \) is bounded in \(L^2\) for continuous \(\varphi :[-1,1]\rightarrow [0,\infty )\). From the definition of \(\mu _\beta ^{(M)}\) (see (2.11)), we see that
Now from Propositions 6.4 and 6.5, we see that if \(\varphi \) had compact support in \((-1,1)\), then
so for fixed \(M\in \mathbb {Z}_+\) and continuous, compactly supported in \((-1,1)\), non-negative \(\varphi \)
as \(\beta ^2/2<1\). For continuous \(\varphi :[-1,1]\rightarrow [0,\infty )\), we get the same inequality simply by approximating \(\varphi \) by a compactly supported one. We conclude that \(\mu _\beta ^{(M)}(\varphi )\) is indeed bounded in \(L^2\) and thus (as it is a martingale as a function of M), a limit \(\mu _\beta (\varphi )\) exists in \(L^2(\mathbb {P})\). \(\square \)
We are now in a position to prove Proposition 2.9.
Proof of Proposition 2.9
As noted, Propositions 6.4 and 6.5 imply that
As this is a limit of a second moment, it is non-negative and we see that
On the other hand, Lemma 2.3 and Fatou’s lemma imply that
so we see actually that
We still need to prove that when we first let \(N\rightarrow \infty \) and then \(M\rightarrow \infty , {\widetilde{\mu }}_{N,\beta }^{(M)}(\varphi )\) converges in law to \(\mu _\beta (\varphi )\). As \(\mu _\beta (\varphi )\) is constructed as a limit of \(\mu _\beta ^{(M)}(\varphi )\), this will follow from showing that \({\widetilde{\mu }}_{N,\beta }^{(M)}(\varphi )\) converges to \(\mu _{\beta }^{(M)}(\varphi )\) in law if we let \(N\rightarrow \infty \) for fixed M. For this, consider the function \(F:\mathbb {R}^M\rightarrow [0,\infty )\)
We now have
where o(1) is deterministic. Moreover, if \((A_k)_{k=1}^M\) are the i.i.d. standard Gaussians used in the definition of \(\mu _{\beta }^{(M)}\), then \(F(A_1,{\ldots },A_M)=\mu _{\beta }^{(M)}(\varphi )\). It follows easily from the dominated convergence theorem that F is a continuous function, so if we knew that
as \(N\rightarrow \infty \), we would be done. This is of course well known and follows from more general results such as [36] for polynomial potentials or [10] for more general ones. Nevertheless, we point out that it also follows from our analysis. If one looks at the function \(\mathcal {T}(\lambda )=\sum _{j=1}^M \alpha _j \frac{2}{\sqrt{j}}({\widetilde{T}}_j(\lambda )-\int T_j(u)\mu _V(du))\), one can then check that it follows from Proposition 2.10 (setting \(\beta _j=0\) for all j) that
which implies the claim. \(\square \)
Theorem 1.1 is essentially a direct corollary of Proposition 2.9.
Proof of Theorem 1.1
It is a standard probabilistic argument that Proposition 2.9 implies that also \(\mu _{N,\beta }(\varphi )\) converges in law to \(\mu _\beta (\varphi )\) as \(N\rightarrow \infty \) (for compactly supported continuous \(\varphi :(-1,1)\rightarrow [0,\infty )\))—see e.g. [39, Theorem 4.28]. Upgrading to weak convergence is actually also very standard. One can simply approximate general continuous \(\varphi :[-1,1]\rightarrow [0,\infty )\) by ones with compact support in \((-1,1)\) and argue by Markov’s inequality. For further details, we refer to e.g. [38, Section 4]. \(\square \)
References
Anderson, G., Guionnet, A., Zeitouni, O.: An introduction to random matrices. Cambridge Studies in Advanced Mathematics, vol. 118. Cambridge University Press, Cambridge (2010)
Arguin, L.-P., Belius, D., Bourgade, P.: Maximum of the characteristic polynomial of random unitary matrices. Commun. Math. Phys. 349(2), 703–751 (2017)
Arguin, L.-P., Belius, D., Bourgade, P., Radziwiłł, M., Soundararajan, K.: Maximum of the Riemann zeta function on a short interval of the critical line. Preprint arXiv:1612.08575
Astala, K., Jones, P., Kupiainen, A., Saksman, E.: Random conformal weldings. Acta Math. 207(2), 203–254 (2011)
Bacry, E., Kozhemyak, A., Muzy, J.-F.: Log-normal continuous cascade model of asset returns: aggregation properties and estimation. Quant. Finance 13(5), 795–818 (2013)
Berestycki, N.: An elementary approach to Gaussian multiplicative chaos. Electron. Commun. Probab. 22, Paper No. 27, 12 pp (2017)
Berestycki, N.: Introduction to the Gaussian free field and Liouville quantum gravity. Available on the author’s website
Bramson, M., Ding, J., Zeitouni, O.: Convergence in law of the maximum of the two-dimensional discrete Gaussian free field. Commun. Pure Appl. Math. 69(1), 62–123 (2016)
Borodin, A., Ferrari, P.: Anisotropic growth of random surfaces in \(2+1\) dimensions. Commun. Math. Phys. 325(2), 603–684 (2014)
Borot, G., Guionnet, A.: Asymptotic expansion of \(\beta \) matrix models in the one-cut regime. Commun. Math. Phys. 317(2), 447–483 (2013)
Charlier, C.: Asymptotics of Hankel determinants with a one-cut regular potential and Fisher-Hartwig singularities. Preprint arXiv:1706.03579
Chhaibi, R., Madaule, T., Najnudel, J.: On the maximum of the C\(\beta \)E field. Preprint arXiv:1607.00243
Chhaibi, R., Najnudel, J., Nikeghbali, A.: The Circular Unitary Ensemble and the Riemann zeta function: the microscopic landscape and a new approach to ratios. Invent. Math. 207(1), 23–113 (2017)
Claeys, T., Fahs, B.: Random matrices with merging singularities and the Painlevé V equation. SIGMA Symmetry Integrability Geom. Methods Appl. 12, Paper 031, 44 pp (2016)
Claeys, T., Krasovsky, I.: Toeplitz determinants with merging singularities. Duke Math. J. 164(15), 2897–2987 (2015)
David, F., Kupiainen, A., Rhodes, R., Vargas, V.: Liouville quantum gravity on the Riemann sphere. Commun. Math. Phys. 342(3), 869–907 (2016)
Deift, P.: Integrable Operators. Differential Operators and Spectral Theory, 69–84, Amer. Math. Soc. Transl. Ser. 2, 189, Amer. Math. Soc., Providence, RI (1999)
Deift, P.: Orthogonal polynomials and random matrices: a Riemann-Hilbert approach. Courant Lecture Notes in Mathematics, 3. New York University, Courant Institute of Mathematical Sciences, New York; American Mathematical Society, Providence, RI, viii+273 pp (1999)
Deift, P., Its, A., Krasovsky, I.: Asymptotics of Toeplitz, Hankel, and Toeplitz \(+\) Hankel determinants with Fisher-Hartwig singularities. Ann. Math. (2) 174(2), 1243–1299 (2011)
Deift, P., Its, A., Krasovsky, I.: On the asymptotics of a Toeplitz determinant with singularities. Random matrix theory, interacting particle systems, and integrable systems, 93–146, Math. Sci. Res. Inst. Publ., 65, Cambridge Univ. Press, New York (2014)
Deift, P., Kriecherbauer, T., McLaughlin, K.T.-R.: New results on the equilibrium measure for logarithmic potentials in the presence of an external field. J. Approx. Theory 95, 388–475 (1998)
Deift, P., Kriecherbauer, T., McLaughlin, K.T.-R., Venakides, S., Zhou, X.: Strong asymptotics of orthogonal polynomials with respect to exponential weights. Commun. Pure Appl. Math. 52(12), 1491–1552 (1999)
Deift, P., Zhou, X.: A steepest descent method for oscillatory Riemann–Hilbert problems. Asymptotics for the MKdV equation. Ann. Math. (2) 137(2), 295–368 (1993)
Duplantier, B., Sheffield, S.: Liouville quantum gravity and KPZ. Invent. Math. 185(2), 333–393 (2011)
Ercolani, N.M., McLaughlin, K.D.T.-R.: Asymptotics of the partition function for random matrices via Riemann–Hilbert techniques and applications to graphical enumeration. Int. Math. Res. Not. 14, 755–820 (2003)
Fokas, A.S., Its, A.R., Kitaev, A.V.: The isomonodromy approach to matrix models in 2D quantum gravity. Commun. Math. Phys. 147, 395–430 (1992)
Forrester, P.J.: Log-Gases and Random Matrices London Mathematical Society Monographs Series, vol. 34. Princeton University Press, Princeton (2010)
Forrester, P.J., Frankel, N.E.: Applications and generalizations of Fisher–Hartwig asymptotics. J. Math. Phys. 45(5), 2003–20028 (2004)
Fyodorov, Y.V., Hiary, G.A., Keating, J.P.: Freezing transition, characteristic polynomials of random matrices, and the Riemann zeta function. Phys. Rev. Lett. 108, 170601 (2012). 5pp
Fyodorov, Y.V., Keating, J.: Freezing transitions and extreme values: random matrix theory, and disordered landscapes. Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 372(2007), 20120503 (2014). 32 pp
Fyodorov, Y.V., Khoruzhenko, B.A., Simm, N.: Fractional Brownian motion with Hurst index \(H=0\) and the Gaussian Unitary Ensemble. Ann. Probab. 44(4), 2980–3031 (2016)
Fyodorov, Y.V., Simm, N.: On the distribution of maximum value of the characteristic polynomial of GUE random matrices. Nonlinearity 29, 2837–2855 (2016)
Garoufalidis, S., Popescu, I.: Analyticity of the planar limit of a matrix model. Ann. Henri Poincaré 14(3), 499–565 (2013)
Hughes, C.P., Keating, J., O’Connell, N.: On the characteristic polynomial of a random unitary matrix. Commun. Math. Phys. 220(2), 429–451 (2001)
Ivanov, V., Olshanski, G.: Kerov’s central limit theorem for the Plancherel measure on Young diagrams. Symmetric functions 2001: surveys of developments and perspectives, pp. 93–151. Kluwer Acad. Publ, Dordrecht (2002)
Johansson, K.: On fluctuations of eigenvalues of random Hermitian matrices. Duke Math. J. 91(1), 151–204 (1998)
Kahane, J.-P.: Sur le chaos multiplicatif. Ann. Sci. Math. Québec 9(2), 105–150 (1985)
Kallenberg, O.: Random measures. Fourth edition. Akademie, Berlin; Academic Press, Inc., London, 187 pp (1986)
Kallenberg, O.: Foundations of Modern Probability, 2nd edition. Probability and its Applications (New York). Springer, New York, xx+638 pp (2002)
Keating, J.P., Snaith, N.C.: Random matrix theory and \(\zeta (\frac{1}{2}+it)\). Commun. Math. Phys. 214(1), 57–89 (2000)
Kenyon, R.: Dominos and the Gaussian free field. Ann. Probab. 29(3), 1128–1137 (2001)
Krasovsky, I.: Correlations of the characteristic polynomials in the Gaussian unitary ensemble or a singular Hankel determinant. Duke Math. J. 139(3), 581–619 (2007)
Kuijlaars, A.B.J., McLaughlin, K.T.-R.: Generic behavior of the density of states in random matrix theory and equilibrium problems in the presence of real analytic external fields. Commun. Pure Appl. Math. 53, 736–785 (2000)
Kuijlaars, A.B.J., McLaughlin, K.T.-R., Van Assche, W., Vanlessen, M.: The Riemann-Hilbert approach to strong asymptotics for orthogonal polynomials on \([-1,1]\). Adv. Math. 188(2), 337–398 (2004)
Lacoin, H., Rhodes, R., Vargas, V.: Complex Gaussian multiplicative chaos. Commun. Math. Phys. 337(2), 569–632 (2015)
Lambert, G., Ostrovsky, D., Simm, N.: Subcritical multiplicative chaos for regularized counting statistics from random matrix theory. Preprint arXiv:1612.02367
Lambert, G., Paquette, E.: The law of large numbers for the maximum of almost Gaussian log-correlated fields coming from random matrices. Preprint arXiv:1611.08885
Le Gall, J.-F.: Uniqueness and universality of the Brownian map. Ann. Probab. 41(4), 2880–2960 (2013)
Madaule, T., Rhodes, R., Vargas, V.: Glassy phase and freezing of log-correlated Gaussian potentials. Ann. Appl. Probab. 26(2), 643–690 (2016)
Miermont, G.: The Brownian map is the scaling limit of uniform random plane quadrangulations. Acta Math. 210(2), 319–401 (2013)
Miller, J., Sheffield, S.: Quantum loewner evolution. Duke Math. J. 165(17), 3241–3378 (2016)
Miller, J., Sheffield, S.: Liouville quantum gravity and the Brownian map I: the QLE(8/3,0) metric. Preprint arXiv:1507.00719
Miller, J., Sheffield, S.: Liouville quantum gravity and the Brownian map II: geodesics and continuity of the embedding. Preprint arXiv:1605.03563
Miller, J., Sheffield, S.: Liouville quantum gravity and the Brownian map III: the conformal structure is determined. Preprint arXiv:1608.05391
Najnudel, J.: On the extreme values of the Riemann zeta function on random intervals of the critical line. Preprint arXiv:1611.05562
Porter, D., Stirling, D.S.G.: Integral equations. A practical treatment, from spectral theory to applications. Cambridge Texts in Applied Mathematics. Cambridge University Press, Cambridge, xii+372 pp (1990)
Paquette, E., Zeitouni, O.: The maximum of the CUE field. Int. Math. Res. Not. 1–92 (2017)
Rhodes, R., Vargas, V.: Gaussian multiplicative chaos and applications: a review. Probab. Surv. 11, 315–392 (2014)
Rhodes, R., Vargas, V.: Lecture notes on Gaussian multiplicative chaos and Liouville Quantum Gravity. Preprint arXiv:1602.07323
Rider, B., Virág, B.: The noise in the circular law and the Gaussian free field. Int. Math. Res. Not. IMRN, no. 2, Art. ID rnm006, 33 pp (2007)
Saff, E.B., Totik, V.: Logarithmic potentials with external fields, Grundlehren der Mathematischen Wissenschaften, vol. 316. Springer, Berlin (1997)
Saksman, E., Webb, C.: The Riemann zeta function and Gaussian multiplicative chaos: statistics on the critical line. Preprint arXiv:1609.00027
Sheffield, S.: Conformal weldings of random surfaces: SLE and the quantum gravity zipper. Ann. Probab. 44(5), 3474–3545 (2016)
Titchmarsh, E.C.: Introduction to the Theory of Fourier Integrals, 3rd edn. Chelsea Publishing Co., New York (1986). x+394 pp
Vanlessen, M.: Strong asymptotics of the recurrence coefficients of orthogonal polynomials associated to the generalized Jacobi weight. J. Approx. Theory 125(2), 198–237 (2003)
Watson, G.N.: A treatise on the theory of Bessel functions. Cambridge University Press, Cambridge, England; The Macmillan Company, New York, vi+804 pp (1944)
Webb, C.: The characteristic polynomial of a random unitary matrix and Gaussian multiplicative chaos–the \(L^2\)-phase. Electron. J. Probab. 20(104), 21 (2015)
Acknowledgements
First of all, we wish to thank the three anonymous reviewers of this article for their careful reading, helpful comments, and pointing out errors in a previous version of this article. We also wish to thank Igor Krasovsky for pointing out to us how to extend our main result from the GUE to general one-cut regular ensembles, Benjamin Fahs for helpful discussions about [14], and Christophe Charlier for pointing out some errors in a previous version of this article. Further, we wish to thank the Heilbronn Institute for Mathematical Research for support during the workshop Extrema of Logarithmically Correlated Processes, Characteristic Polynomials, and the Riemann Zeta Function, during which part of this work was carried out. N. Berestycki’s work is supported by EPSRC Grants EP/L018896/1 and EP/I03372X/1. M. D. Wong is a PhD student at the Cambridge Centre for Analysis, supported by EPSRC Grant EP/L016516/1. Some of this work was carried out while the first and third authors visited the University of Helsinki, funded in part by EPSRC Grant EP/L018896/1. They also wish to thank the University of Helsinki for its hospitality during this visit. C. Webb wishes to thank the Isaac Newton Institute for Mathematical Sciences for its hospitality during the Random Geometry program, during which this project was initiated. C. Webb was supported by the Eemil Aaltonen Foundation grant Stochastic dynamics on large random graphs and Academy of Finland Grants 288318 and 308123.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Proof of differential identities
In this appendix we prove Lemmas 3.6 and 3.7.
Proof of Lemma 3.6
First of all, note that all of the appearing objects are differentiable functions of t as can be seen from the determinantal representation of the polynomials (3.5).
Recall from (3.4) that \(\log D_{j}(f_t)=-2\sum _{k=0}^j \log \chi _k(f_t)\). Also from (3.3), we see that all polynomials of degree less than j are orthogonal to \(p_j\), so
and
Thus we see that
The Christoffel–Darboux identity (see e.g. [18, page 55]) states that
Here \('\) denotes differentiation with respect to x. Plugging this into (A.1), we see that
Using (3.3), one finds that the first integral equals \(j+1\) (note that the term corresponding to \(p'_j p_{j+1}\) integrates to zero by orthogonality) so its derivative equals zero. Recalling that for \(Y(z,t)=Y_{j+1}(z,t)\), we have
where we ignore the second column of the matrix as it’s not relevant right now. Thus we see the claim by replacing \(p_j\) and \(p_{j+1}\) by the entries of Y and setting \(j{=}N-1\). \(\square \)
We now prove our second differential identity.
Proof of Lemma 3.7
The beginning of the proof is identical to the proof of Lemma 3.6. Indeed, we can repeat everything up to (A.1) to get
Again making use of Christoffel–Darboux and orthogonality, we find
which yields the claim when we set \(j=N-1\). \(\square \)
Appendix B: Proofs for the first transformation
In this appendix we prove Lemmas 4.2, 4.4, and 4.5. Variants of Lemma 4.2 are certainly well known in Riemann–Hilbert literature (see e.g. [22, Proposition 5.4]), but to have it in precisely the form we need it, we sketch a proof.
Proof of Lemma 4.2
The first statement—(4.6)—is simply linearity and making use of the fact that for the GUE, one has \(\ell _\textit{GUE}=-1-2\log 2\) in our normalization. This amounts to simply calculating the logarithmic potential (or noncommutative entropy) of the semi-circle law. This is a standard calculation and we omit the proof, see e.g. Theorem 4.1 in [33] or alternatively one can integrate (2.3) against the arcsine law and use the logarithmic potential of the arcsine law [61, Section 1.3: Example 3.5].
For (4.7) consider first the case where \(|\lambda |-1>M\). Here we note that \(g_{s,+}(\lambda )+g_{s,-}(\lambda )=2\log |\lambda |+\mathcal {O}(1)\) as \(|\lambda |\rightarrow \infty \) (uniformly in s), but we know that \(V(\lambda )/\log |\lambda |\rightarrow \infty \) as \(|\lambda |\rightarrow \infty \), so we see that by choosing M large enough (independent of s), \(g_{s,+}(\lambda )+g_{s,-}(\lambda )-V_s(\lambda )-\ell _s\le -\log |\lambda |\).
For the \(|\lambda |-1<M\)-case, note that the left side of (4.7) is a continuous function, and if we take \(M'<M\), then our function is a continuous function which is (uniformly in s) negative on \([M',M]\). Thus it’s enough to consider the situation where M is small. In particular, we can assume it’s so small, that d is positive in \(|\lambda |-1\in (0,M)\). Let us focus on the \(\lambda >1\) case. The \(\lambda <-1\) case is similar.
Let us suppress the dependence on s and write \(F(\lambda )=g_+(\lambda )+g_-(\lambda )-V(\lambda )-\ell \). As \(F(1)=0\), we have by using the Euler–Lagrange equation (2.3) at the point \(x=1\)
In the x-integral, let us make the change of variables, \(1-x=(u-1)y\). We find
We conclude that \(F(\lambda )=-\int _1^\lambda \mathcal {O}(\sqrt{u-1})du+\mathcal {O}((\lambda -1)^2)\) which implies the claim in (4.7).
For (4.8), we note that for \(\lambda \in \mathbb {R}\) and \(x\in (-1,1)\)
Thus for \(\lambda \in \mathbb {R}\)
which is (4.8). \(\square \)
We now move on to prove Lemma 4.4.
Proof of Lemma 4.4
Let \(\lambda \in (-1,1)\) and \(\epsilon >0\) be small. We have
The first term is purely imaginary. The second term is an analytic function of \(\epsilon \) (in a small enough \(\lambda \)-dependent neighborhood of the origin), it vanishes at \(\epsilon =0\), its derivative at \(\epsilon =0\) is positive, and second derivative in a neighborhood of zero is bounded. From this one can conclude that for small enough \(\epsilon >0\), the real part of \(h_s(\lambda +i\epsilon )>0\). A similar argument works for the claim about the real part of \(h_s(\lambda -i\epsilon )\). Such an argument is easily extended into a uniform one in this case. \(\square \)
Finally we prove Lemma 4.5.
Proof of Lemma 4.5
Uniqueness can be argued as for Y. The analyticity condition comes from analyticity of Y and \(g_s\), so let us look at the jump conditions. Consider first \(\lambda \in (-1,1)\). Then from (4.5), (3.8), (4.8), (4.6), and some elementary matrix calculations one finds
For \(|\lambda |>1\), we note that by (4.8), \(g_{s,+}(\lambda )-g_{s,-}(\lambda )\in \lbrace 0,2\pi i\rbrace \), and a similar argument results in
which is precisely (4.11).
For the behavior at infinity, we note that as \(z\rightarrow \infty \) (uniformly for z not on the negative real axis) \(g_s(z)=\log z+\mathcal {O}(|z|^{-1})\). Thus we see from (3.9) and (4.5) that indeed (4.12) is satisfied (with behavior on the negative real axis coming from continuity up to the boundary). \(\square \)
Appendix C: The RHP for the global parametrix
In this appendix we will sketch a proof of Lemma 4.14. We will make use of the fact that the result is proven for \(t=0\), i.e. the case when \(\mathcal {T}=0\), in [42, Section 4.2] (which relies on a similar result in [44, Section 5], which again makes use of results in e.g. [18]).
Sketch of a proof of Lemma 4.14
The analyticity condition was already argued in Remark 4.13. The normalization at infinity is easy to see from the fact that the a-matrix (in right hand side of (4.22)) is \(2I+\mathcal {O}(|z|^{-1})\) and \(\mathcal {D}_t(z)=\mathcal {D}_t(\infty )+\mathcal {O}(|z|^{-1})\) as \(z\rightarrow \infty \). Thus the jump condition is the main one to check.
This would be a fairly short calculation to check directly, but we make use of it being known for \(t=0\) and the representation (4.23). We start by noting that by the Sokhotski-Plemelj formula and (4.23), for \(\lambda \in (-1,1){\setminus } \lbrace x_j\rbrace _{j=1}^k\)
where P.V. denotes the Cauchy principal value integral. Thus from the jump condition of \(P^{(\infty )}(z,0)\) (note that \(\det P^{(\infty )}(z,t)=1\) so everything makes sense)
Noting that (from the definition of r; see (4.19)) \(r_+(\lambda )=i\sqrt{1-\lambda ^2}\) and \(r_-(\lambda )=-i\sqrt{1-\lambda ^2}\) so with a simple calculation
which is precisely the claim as \(f_0e^{\mathcal {T}_t}=f_t\). \(\square \)
Appendix D: The RHP for the local parametrix near a singularity
Here we give further details about the local parametrix near a singularity. First of all, we give a full description of the solution to the model RHP—the function \(\Psi \).
Definition D.1
Recall that we use Roman numerals for the octants of the plane: \(\mathrm {I}=\lbrace r e^{i\theta }: r>0,\theta \in (0,\pi /4)\rbrace \) and so on. We also write \(I_\nu \) and \(K_\nu \) for the modified Bessel functions of the first and second kind, as well as \(H_\nu ^{(1)}\) and \(H_\nu ^{(2)}\) for the Hankel functions of the first and second kind. We then define (again roots are principal branch roots)
In [65, Theorem 4.2] it is shown that this function indeed satisfies the problem we used in Definition 4.20. An important fact about the function \(\Psi \) is its behavior near the origin. The following was also part of [65, Theorem 4.2]: as \(\zeta \rightarrow 0\)
We also mention that the function \(\Psi \) could be expressed in terms of the confluent hypergeometric function of the second kind as in [19, 20]. Let us now sketch the proof of Lemma 4.23.
Sketch of a proof of Lemma 4.23
Consider first the analyticity condition. As we mentioned in Remark 4.22, one can check that E is analytic in \(U_{x_j}'\), so the jumps of \(P^{(x_j)}\) come from those of \(\Psi (\zeta _s(z)), W_j(z)^{-\sigma _3}\) and \(e^{-N\phi _s(z)\sigma _3}\).
As \(\zeta _s\) preserves the real axis, and \(\Sigma \) was chosen so that under \(\zeta _s, \Sigma \cap U_{x_j}'\) is mapped to the real axis and lines intersecting origin at angles \(\pm \pi /4\). Thus from Definition 4.20, \(\Psi (\zeta _s(z))\) has jumps on \(\Sigma \) and \(\lbrace z:\mathrm {Re}(\zeta _s(z))=0\rbrace \).
From (4.27)—the definition of \(W_j\)—we see that \(W_j\) has jumps only across \(\mathbb {R}\) and \(\lbrace z:\mathrm {Re}(\zeta _s(z))=0\rbrace \). Also from (4.28) and (4.9) we see that \(\phi \) only has a jump across \(\mathbb {R}\).
Thus to see that \(P^{(x_j)}(z,t,s)\) is analytic in \(U_{x_j}'{\setminus } \Sigma \), we need to check that the jump of \(W_j(z)^{-\sigma _3}\) cancels that of \(\Psi (\zeta _s(z))\) along \(\lbrace z:\mathrm {Re}(\zeta _s(z))=0\rbrace \). Let us look at for example the jump across \(\lbrace z: \mathrm {Re}(\zeta _s(z))=0, \mathrm {Im}(\zeta _s(z))>0\rbrace =\zeta _s^{-1}(\Gamma _3)\). From (4.27) we find that for \(\lambda \in \zeta _s^{-1}(\Gamma _3)\) (where the orientation is as for \(\Gamma _3\))
Combining this with (4.32)
so we see that \(P^{(x_j)}(z)\) is continuous across \(\zeta _s^{-1}(\Gamma _3)\). The argument is similar for the jump across \(\zeta _s^{-1}(\Gamma _7)\). We conclude that \(P^{(x_j)}\) is analytic in \(U_{x_j}'{\setminus } \Sigma \).
Consider now the jump structure. The existence of continuous boundary values is inherited from the corresponding properties of \(\Psi , W_j\) and \(\phi _s\). As \(W_j\) and \(\phi _s\) have no jumps across \(\Sigma _{j-1}^\pm \) or \(\Sigma _j^\pm \), the jumps here come from the jumps of \(\Psi \). Let us consider for example \(\lambda \in \zeta _s^{-1}(\Gamma _2)\). Here using the jump condition of \(\Psi \), an elementary matrix calculation shows that
Calculating the jump matrix across \(\Sigma _{j-1}^\pm \) and \(\Sigma _j^-\) is similar. For the jump across \(\mathbb {R}\), we have for example for \(\lambda \in U_{x_j}'\cap (x_j,\infty )\), from (4.27), (4.28), the analyticity of \(h_s\) across \(U_{x_j}'\cap \mathbb {R}\), along with Definition 4.20:
The calculation for the jump across \(U_{x_j}'\cap (-\infty ,x_j)\) is similar.
To see (4.39), note first that as \(z\rightarrow x_j, \zeta _s(x)=\mathcal {O}(|z-x_j|)\) (the implicit constant depending on \(x_j, N\), and s, but this doesn’t matter now) and \(W_j(z)=\mathcal {O}(|z-x_j|^{\beta _j/2})\). So we have from (D.9) that for \(z\in \zeta _s^{-1}(\mathrm {I})\) and \(z\rightarrow x_j\)
As E is analytic in \(U_{x_j}'\), it is in particular bounded at \(x_j\), so as multiplying from the left doesn’t mix the columns, we have the same behavior for \(E(z)\Psi (\zeta _s(z))W_j(z)^{-\sigma _3}\). Now also \(\phi _s\) is bounded at \(x_j\) and again multiplying by a diagonal matrix doesn’t mix the columns so we have the claimed asymptotics for \(P^{(x_j)}(z)\) as \(z\rightarrow x_j\) from \(\zeta _s^{-1}(\mathrm {I})\). The other regions are similar.
Let us now focus on the matching condition (4.40). We note that as d is positive on \([-1,1]\), we see that for \(z\in \partial U_{x_j}\) (and for \(\delta \) small enough), \(|\zeta _s(z)|\asymp N\) where the implied constants are uniform in \(x_j\in (-1+3\delta ,1-3\delta ), s\in [0,1]\), and \(z\in \partial U_{x_j}\). Thus to study \(\Psi (\zeta _s(z))\), we can make use of the large argument expansion of Bessel functions. We won’t go into great detail here, but simply refer the reader to [65, Section 4.3] and references therein.
For simplicity, we focus on the domain \(\lbrace z: \mathrm {arg}\ \zeta _s(z)\in (0,\pi /2)\rbrace \). In the other domains, one has different asymptotics for \(\Psi \), but the argument is similar. The relevant asymptotics here are
where the implied constant in \(\mathcal {O}(|\zeta |^{-1})\) is uniform in the first quadrant. Here and below, the \(\mathcal {O}\)-notation will refer to a \(2\times 2\) matrix whose entries satisfy the relevant bound. Noting from (4.26), (4.9), and (4.28), that for \(z\in U_{x_j}'\cap \lbrace \mathrm {Im}(z)>0\rbrace \)
It then follows from this and (D.10) that for \(z\in \zeta _s^{-1}(\mathrm {I}\cup \mathrm {II})\cap \partial U_{x_j}\)
where the \(\mathcal {O}(N^{-1})\) term is uniform in everything relevant. Using (4.33) and (4.35), we see that for \(z\in \zeta _s^{-1}(\mathrm {I}\cup \mathrm {II})\cap \partial U_{x_j}\)
where the \(\mathcal {O}(N^{-1})\) term is uniform in everything relevant and
The claim (in this sector of the boundary) will then follow if we show that A is uniformly bounded in everything relevant. As \(\phi _{s,+}(x_j)\) is purely imaginary (see (4.9)), we see that the relevant question is the boundedness of \(P^{(\infty )}(z)W_j(z)^{\sigma _3}\) and its inverse. Looking at (4.22), we see that this is equivalent to \(\mathcal {D}_t(z)^{-1}W_j(z)\) being uniformly bounded and uniformly bounded away from zero. Let us write this quantity out. From (4.21) and (4.27) we have
\(z+r(z)\) is obviously bounded for z in a compact set, the integral term is uniformly bounded in everything relevant by Lemma 4.15, and the last term is bounded as \(\mathcal {T}_t\) is uniformly bounded in everything relevant. Similarly we see uniform boundedness away from zero. This concludes the proof for \(z\in \zeta _s^{-1}(\mathrm {I}\cup \mathrm {II})\cap \partial U_{x_j}\). The proof in the remaining parts of the boundary are similar. \(\square \)
We now move on to considering the proof of Lemma 4.24.
Proof of Lemma 4.24
Here we simply need to take into account the next term in the asymptotic expansion of \(\Psi \). The argument is otherwise as in the proof of Lemma 4.23. For simplicity, we will focus on the case where \(\zeta \) is in the first quadrant. Other quadrants are handled in a similar manner. We refer to the discussion around [65, equation (5.9)] for the following asymptotics:
where the error \(\mathcal {O}(|\zeta |^{-2})\) is uniform for \(\zeta \) in the first quadrant. Then arguing as in the previous proof, we see that
where we used the uniform boundedness of A and \(A^{-1}\). Noting that
making use of \(\zeta _s(z)\asymp N\) uniformly in everything relevant for \(z\in \partial U_{x_j}\) and the fact that the asymptotic expansion of \(\Psi \) is uniform, we see the claim. Again, the argument in the other regions is similar. \(\square \)
Appendix E: The RHP for the local parametrix near the edge of the spectrum
In this section we will give some further details about the parametrices near the edge of the spectrum. First we will justify the definition of the function \(\xi _s\) from (4.42).
Justification of the definition of \(\xi _s\). The argument is essentially as in [22, Section 7]. Let us first recall some properties of \(\phi _s\). From (4.28) and (4.9), we note that \(\phi _s\) has a jump across \(U_1'\cap (-1,1)\) but is continuous across \(U_1'\cap (1,\infty )\), so it is analytic in \(U_1'{\setminus }[-1,1]\). Moreover, in \(U_1'{\setminus }[-1,1]\) we can write
where \({\widetilde{G}}^{(1)}_s\) is analytic in \(U_1'\). Expanding \({\widetilde{G}}^{(1)}_s\) as a series, integrating, and taking into account the branch structure of \(\phi _s\), we can write
where the power is according to the principal branch and \(G^{(1)}_s\) is analytic in \(U_{1}'\). If we expand \(G^{(1)}_s(z)=\sum _{k=0}^\infty G^{(1)}_{s,k}(z-1)^k\) and \({\widetilde{G}}^{(1)}_s(w)=\sum _{k=0}^\infty {\widetilde{G}}^{(1)}_{s,k}(w-1)^k\), then
Now as \({\widetilde{G}}^{(1)}_{s,0}=\frac{3\pi }{\sqrt{2}}d_s(1)\) is uniformly bounded away from zero, we see from the above display that the same holds for \(G^{(1)}_{s,0}\). By Cauchy’s integral formula (for derivatives),
for some constant \(C_\delta \) independent of s, so we again get a similar bound for \(G^{(1)}_{s,k}\). From this type of estimate, one can easily argue that by possibly decreasing \(\delta \) by some s-independent factor, \(G^{(1)}_s\) is zero free in \(U_1'\). Thus with a suitable convention for the branch of the power, the function
is analytic in \(U_1'\).
For injectivity, note that the derivative of the function \(z\mapsto (z-1)G^{(1)}_s(z)^{2/3}\) at \(z=1\) is uniformly (in s) bounded away from zero and its second derivative is uniformly bounded in s and in a small enough (s independent) neighborhood of 1. Thus by decreasing \(\delta \) if needed (in an s independent manner), we have univalence of \(\xi _s\). \(\square \)
We now sketch the proof of Lemma 4.30.
Sketch of a proof of Lemma 4.30
Let us first of all consider the analyticity of F. \(P^{(\infty )}\) is analytic in \(U_1'{\setminus } [-1,1], f^{1/2}\) is analytic in \(U_1'\), and as \(\zeta _s(1)=0, \zeta _s^{1/4}\) has a branch cut in \(U_1\). We note from (E.2) that as one can check (from (4.9)) that \(-\phi _s(\lambda )>0\) for \(\lambda>1, G_s(\lambda )>0\) for \(\lambda >1\). Thus \(G_s\) is real on \(\mathbb {R}\cap U_1'\). As we argued above that it’s zero free, it must be positive on \(\mathbb {R}\cap U_1'\), so we see that \(\xi _s(\lambda )<0\) for \(\lambda <1\). As we are dealing with the principal branch, the cut of \(\xi _s^{1/4}\) is along \(U_1'\cap (-1,1)\). It’s thus enough to check that F is continuous across \((-1,1)\cap U_1'\) and does not have an isolated singularity at \(z=1\).
For the continuity across \((-1,1)\), let \(\lambda \in (-1,1)\cap U_1'\). We have from (4.24) and the jump for \(\xi _s^{1/4}\): for \(\lambda \in (-1,1)\cap U_1'\)
so that
Thus F is continuous across \((-1,1)\cap U_1'\).
For the absence of an isolated singularity, we note that the entries of \(\xi _s(z)^{\sigma _3/4}\) behave at worst like \(|z-1|^{-1/4}\) as \(z\rightarrow 1\). From (4.22) and Lemma 4.15, we see that the entries of \(P^{(\infty )}(z)\) behave at worst like \(|z-1|^{-1/4}\) as well. As \(f^{1/2}(z)\) is bounded at \(z=1\), the entries of F(z) behave at worst like \(|z-1|^{-1/2}\). This is not strong enough to be a pole, so there can be no isolated singularity at \(z=1\) and F is analytic.
Towards checking the analyticity of \(P^{(1)}\) on \(U_1'{\setminus } \Sigma \), we refer to [22, Section 7] on the following matter (in their notation \(Q=\Psi ^\sigma \)): \(Q(\xi _s(z))\) is analytic on \(U_1'{\setminus } \Sigma \) and it satisfies the following jump conditions:
and
As \(f_t^{\pm 1/2}\) is analytic in \(U_1'\) as if F, and \(\phi _s\) has a jump along \((-1,1)\cap U_1'\), we see that \(P^{(1)}\) indeed is analytic in \(U_1'\).
The jump conditions come from those of Q. Let us check for example the one across \((-1,1)\cap U_1'\)—(4.48). For \(\lambda \in (-1,1)\cap U_1'\), we have
The other jump conditions are similar.
Let us then check the matching condition. Let \(z\in \partial U_1\). For small enough \(\delta \) (independent of s), it is clear from (4.9) and (4.28) that \(|\phi _s(z)|\) is bounded away from zero uniformly in s and uniformly in \(z\in \partial U_1\). Thus \(|\xi _s(z)|\asymp N^{2/3}\) where the implied constants are uniform in z and s. We can thus make use of the large \(|\xi |\) asymptotics of \(\mathrm {Ai}(\xi )\) and \(\mathrm {Ai}'(\xi )\) to obtain asymptotics for \(Q(\xi _s(z))\). For this, we will again refer to [22]—in particular [22, (7.30)]: for \(z\in \partial U_1\)
where the error is uniform in z and s. Recalling that the construction of \(\xi _s\) was precisely so that \(\frac{2}{3}\xi _s(z)^{3/2}=-N\phi _s(z)\), we see that
with the \(\mathcal {O}(N^{-1})\)-term being uniform in everything relevant. Thus
As \(f_t(z)^{\pm 1}\) as well as the entries of \([P^{(\infty )}]^{\pm 1}\) are uniformly (in everything relevant) bounded on \(\partial U_1\), the claim follows. \(\square \)
We will also give a proof of Lemma 4.31.
Proof of Lemma 4.31
This is again proven as the matching condition, but using finer asymptotics of the Airy function. In particular, one has (see [22, (7.30)])
where the constant implied by the \(\mathcal {O}\) notation is uniform in everything relevant. Thus arguing as in the previous proof, we see that for \(z\in \partial U_1\)
uniformly in everything relevant. \(\square \)
Appendix F: Proofs concerning the final transformation and solving the R-RHP
In this section we sketch proofs concerning the final transformation and the solution of the R-RHP. We start with checking that R indeed solves the RHP of Lemma 4.34.
Proof of Lemma 4.34
Uniqueness follows from S being the unique solution to its problem. The last condition is immediate to check as for large \(|z|, R(z)=S(z)[P^{(\infty )}(z)]^{-1}\) and both of these terms are asymptotically \(I+\mathcal {O}(|z|^{-1})\). The jump conditions simply make use of the definition of R and the jump conditions of S—these are direct to check and we skip this.
For the analyticity condition we begin with the domain \(U_{\pm 1}\). Here the construction of \(P^{(\pm 1)}\) was such that it would have the same jumps as S so R has no branch cuts inside of \(U_{\pm 1}\). We are left with the possibility that R would have an isolated singularity at \(z=\pm 1\). Recall that S(z) is bounded as \(z\rightarrow \pm 1\), while Lemma 4.15 implies that the entries of \([P^{(\infty )}(z)]^{-1}\) can blow up at most like \(|z\mp 1|^{-1/4}\) as \(z\rightarrow \pm 1\). Thus the possible isolated singularity of R is not strong enough to be a pole (or essential), so it is removable, and R is analytic in \(U_{\pm 1}\).
Consider now a neighborhood \(U_{x_j}\). Again, by the construction of the parametrix, there are no jumps here, and the only possible singularity is an isolated singularity at \(x_j\). Recall now that as \(z\rightarrow x_j\) from outside of the lenses, \(S(z)=\mathcal {O}(1)\), and as \(z\rightarrow x_j\) from inside of the lenses,
\(P^{(x_j)}(z)\) has similar behavior near \(x_j\). To estimate it’s inverse, we note that \(\det P^{(x_j)}(z)=1\) for all \(z\in U_{x_j}\) - which follows directly from the definitions once one knows that \(\det \Psi =1\) (which we argued following Definition 4.20, or one could check directly using the explicit representation of \(\Psi \) from “Appendix D”).
We thus see that as \(z\rightarrow x_j\) from outside of the lenses, \([P^{(x_j)}(z)]^{-1}\) remains bounded, and as \(z\rightarrow x_j\) from inside the lenses, we have
so we conclude that from the inside of the lens, the entries of the matrix \(S(z)[P^{(x_j)}(z)]^{-1}\) have singularities of order \(\mathcal {O}(|z-x_j|^{-\beta _j})\) at worst. Now we see that as \(S(z)[P^{(x_j)}(z)]^{-1}\) remains bounded as \(z\rightarrow x_j\) from outside of the lenses, it can’t have a pole at \(x_j\). But as the degree of the singularity is bounded (we can find an integer k such that \((z-x_j)^kS(z)[P^{(x_j)}(z)]^{-1}\) tends to zero as \(z\rightarrow x_j\)), the singularity can’t be essential either. Thus the only possibility is that the singularity is removable, and R(z) is analytic in \(U_{x_j}\). Thus we see that R indeed solves the Riemann–Hilbert problem. \(\square \)
We next prove the relevant estimate for the jump matrix.
Proof of Lemma 4.35
Let us first consider the jump matrix on \(\mathbb {R}{\setminus } [-1-\delta ,1+\delta ]\). Here we have
First of all, we note that the entries of \(P^{(\infty )}(\lambda )\) and \([P^{(\infty )}(\lambda )]^{-1}\) are bounded (uniformly in everything relevant) in this area, and \(f_t(\lambda )\) grows like \(|\lambda |^{\sum _{j=1}^k \beta _j}\) as \(|\lambda |\rightarrow \infty \). From (4.7), we see that there exist constants \(C,M>0\) depending only on V such that for \(|\lambda |>1+M, e^{N(g_{s,+}(\lambda )+g_{s,-}(\lambda )-V_s(\lambda )-\ell _s)}\le |\lambda |^{-N}\) and for \(|\lambda |-1\in (0,M), e^{N(g_{s,+}(\lambda )+g_{s,-}(\lambda )-V_s(\lambda )-\ell _s)}\le e^{-NC(|\lambda |-1)^{3/2}}\). From these estimates, it’s easy to see that any \(L^p\) norm on \(\mathbb {R}{\setminus }[-1-\delta ,1+\delta ]\) is exponentially small in N.
Consider next the part of the contour lying on the boundaries of the lenses. More precisely, we have for \(\lambda \in \cup _{j=1}^{k+1}\Sigma _j^\pm {\setminus }\overline{U_{-1}\cup \cup _{j=1}^k U_{x_j}\cup U_1}\),
We now refer to Lemma 4.4, which states that for example for \(\lambda \in \Sigma _j^+{\setminus }\overline{U_{-1}\cup \cup _{l=1}^k U_{x_l}\cup U_1}\), there exists an \(\epsilon >0\) independent of s and \(\lambda \) such that \(\mathrm {Re}(h_s(\lambda ))>\epsilon \) (we assume that the distance between this part of the contour and the real axis is bounded away from zero uniformly in everything relevant). Moreover, \(f_t(\lambda )^{-1}\) is uniformly bounded here so we again get exponential smallness for any \(L^p\) norm uniformly in everything relevant for this part of the contour (as the contour has finite length). The \(\Sigma _j^{-}\)-case is identical.
For \(\partial U_{x_j}\) and \(\partial U_{\pm 1}\) the bounds come from the matching conditions in Lemmas 4.23 and 4.30. Combining the estimates from the different parts of the contour is elementary and we find the claim. \(\square \)
The next proof we consider is the representation of R in terms of a certain Neumann-series. The proof follows [22, Theorem 7.8], and while it is a standard fact, we record it here for completeness.
Proof of Proposition 4.36
By the Sokhotski-Plemelj theorem, we see that the function \({\widehat{R}}=I+ C(R_+ - R_-)\) satisfies \({\widehat{R}}_+-{\widehat{R}}_-=R_+-R_-\) across \(\Gamma _\delta {\setminus } \lbrace \mathrm {intersection points}\rbrace \) (note that from our proof of Lemma 4.35, we see that \(R_+-R_-=R_-\Delta \) has nice enough decay at infinity for \({\widehat{R}}\) to be well defined). Thus the function \({\widehat{R}}-R\) has no jump across \(\Gamma _\delta {\setminus } \lbrace \mathrm {intersection points}\rbrace \). By construction, both functions are bounded at the intersection points of the different parts of the contour, and behave like \(I+\mathcal {O}(|z|^{-1})\) as \(z\rightarrow \infty \), so by Liouville’s theorem
In particular, taking the limit from the − side, we obtain
It is well known that \(C_-\) is a bounded operator from \(L^2(\Gamma _\delta )\) to \(L^2(\Gamma _\delta )\)—see e.g. the discussion and references in [22, Appendix A]. Given the estimate in Lemma 4.35 the operator norm of \(C_\Delta \) is of order \(\mathcal {O}(1/N), I - C_\Delta \) is invertible (and the inverse can be expanded as a Neumann series) for N sufficiently large and the result follows. \(\square \)
Finally we prove the main result concerning R. Our proof is a minor modification of that in [42].
Proof of Theorem 4.37
Note that since \((I - C_\Delta )(R_- - I) = C_\Delta (I)\) and since the \(L^2\)-boundedness of \(C_-\) implies that \(||C_\Delta (I)||_{L^2(\Gamma _\delta )}=\mathcal {O}(N^{-1})\) (uniformly in everything relevant), we have
for some \(c_1 > 0\) (independent of the relevant quantities).
Now fix some small \(\epsilon > 0\), and suppose z is at least \(\epsilon \) away from the jump contour \(\Gamma _\delta \). Recall that in the proof of (4.59), we saw that \((I-C_\Delta )^{-1}C_\Delta (I)=R_--I\), so we have (for \(c_2,c_3,c_4\) depending on \(\epsilon \) but not on \(t,s,{\ldots }\))
where we used Cauchy–Schwarz in the second step and the facts that \(R_-\) is bounded on \(\Gamma _\delta \) and behaves like \(I+\mathcal {O}(|\lambda |^{-1})\), as \(\lambda \rightarrow \infty \).
For \(z \in \mathbb {C} \backslash \Gamma _\delta \) that is within a distance of \(\epsilon \) from \(\Gamma _\delta \) but not close to any intersection points, we use the usual trick of contour deformation. First note that we can analytically continue the jump matrix \(J_R\) to, without loss of generality, a \((2\epsilon )\)-neighbourhood of \(\Gamma _\delta \), with the estimates in Lemma 4.35 remaining true (up to a change of constants).
We may assume that z lies on the \(+\) side of \(\Gamma _\delta \). Let \({\widetilde{\Gamma }}_{\delta }\) be the contour in Fig. 8, obtained from \(\Gamma _\delta \) with the dotted part replaced by a half circle of radius \(\epsilon \), and \({\widetilde{R}}\) be defined as shown, where J is the analytic continuation of \(J_R\). Then \({\widetilde{R}}(z)\) satisfies the same Riemann–Hilbert problem as R(z) except on the new contour \({\widetilde{\Gamma }}_\delta \). Repeating our argument for the case where z is at distance at least \(\epsilon \) from the contour, we see that
for a \(c_5\) which is uniform in the relevant quantities. Now note that all estimates established so far are also uniform in \(\delta \in K \subset (0, \delta _0]\) for some compact set K and \(\delta _0 > 0\), see [22, Section 7.2]. If z is close to any intersection points we may then deform our contour by varying \(\delta \).
For the derivative, let us consider the case where the distance between z and the jump contour is greater than \(\epsilon \). Then by Cauchy’s integral formula we have
where the last equality follows from the uniform estimates for \(R(w)-I\). For z close to the contour we argue by contour deformation again.

Deforming the R-RHP
We now want to extract the second order asymptotics when \(\mathcal {T}= 0\). Since
repeating our argument with minor modifications we see that
uniformly off of \(\Gamma _\delta \) and uniformly in everything relevant. Now by definition, we have
With similar arguments as in the proof of Lemma 4.35, one can easily see (e.g. using Cauchy–Schwarz and a \(L^2\)-norm bound on the jump matrix on the unbounded part of the contour and a \(L^\infty \)-norm bound on the part of the contour on the boundary of the lenses) that the contribution from the part of the contour on \(\mathbb {R}\) and on the boundary of the lenses has uniformly (in everything relevant) exponentially small contribution to \(C(\Delta )\). Thus we have for z not on the jump contour
where the orientation of the contours is in the clockwise direction and the \(\mathcal {O}(N^{-2})\) is uniform in everything relevant. From Lemmas 4.24, 4.31, and Remark 4.32, we can then write (again for z off of the jump contour)
where the superscripts have been added to underline that the functions depend on the singularity we are considering.
Consider now \(z\notin U_{x_j}\) with \(j\in \lbrace 1,{\ldots },k\rbrace \). Then as \(E,E^{-1}\) are analytic in \(U_{x_j}\) and \(1/\zeta ^{(x_j)}_s(w)\) has a simple pole at \(w=x_j\) (and no other singularities in \(U_{x_j}\)), we see that
where, by writing \(b_{x_j} = a_+(x_j)^2 + a_+(x_j)^{-2}\) and \({\bar{b}}_{x_j} = a_+(x_j)^2 - a_+(x_j)^{-2}\), one finds (after an elementary calculation)
Here we made use of the fact that \(E^{(x_j)}\) is analytic at \(x_j\) so we can evaluate \(E^{(x_j)}(x_j)\) using the formula (4.33).
For \(R_1^{(\pm 1)}(z)\) with \(z \notin U_{\pm 1}\) the residue calculations are more involved (but still straightforward) because of the presence of a second order pole. We just summarize here that
where the functions \(G_s^{(\pm 1)}(z)\) come from
(see “Appendix E”). \(\mathcal {J}^{(x_j)}(z)\) may now be obtained by direct calculation. \(\square \)
Appendix G: Uniformity of the asymptotics in Theorem 6.3
In this appendix we will give a brief outline of how to check that the asymptotics in Theorem 6.3 are still uniform when we replace V by \(V_{x,y}\) when \(x,y\in (-1+\epsilon ,1-\epsilon )\) (in the notation of Sect. 6). We will not try to be self contained here and we will use notations both from [14] and ones we’ve adopted earlier in this article. We won’t provide all of the relevant definitions from [14]. We will simply try to provide a map of how to go over the argument.
Let us write \(u=(x-y)^2/4\ge 0\) (which in the notation of [14] is t) and \(v=(x+y)/2\in (-1+\epsilon ,1-\epsilon )\), where \(\epsilon \) is determined by the support of our non-negative test function. We also write \(V_v(z)=V(z+v)\). In the notation of Sect. 6, we are interested in the asymptotics of \(D_{N-1}(f_u;V_v)\), which in the notation of [14] would be \({\widehat{Z}}_N(u,\beta ,V_v)/N!\). Note that in the notation of [14], \(\beta \) is replaced by \(\alpha \).
Let us write Y for the solution of the RHP related to \(D_{N-1}(f_u;V_v)\). Y depends on u and v, but as usual, we suppress this dependence in our notation. Then as the “center of mass” and “relative motion” coordinates decouple, or \(\partial _u V_v=0\) for all u and v, the proof of [14, Proposition 4.1] carries through word to word and one finds
The goal will be to integrate this from zero to some positive u. Even though \(\pm \sqrt{u}\) lie on the jump contour of Y, this quantity in fact does not have a jump so the notation is justified. Moreover one can calculate the relevant quantities at a point z and then let \(z\rightarrow \pm \sqrt{u}\)—in particular the point z can be taken to be outside of the relevant lenses and for simplicity in the lower half plane (see [14, Figure 8]). In [14, Section 6], using results of [15], it is argued that near the points \(\pm \sqrt{u}\), but outside of the lenses, one can write
where \(\ell _v\) and \(g_v\) refer to the \(\ell \)- and g-quantities constructed from the potential \(V_v\). If we restrict to points z outside of the lenses and in the lower half plane, then one has
where (see the discussion around [14, equation (4.13)] for details about the branch and integration contour—note that in the notation of [14], d is h and the support of the equilibrium measure is [a, b] instead of our \([-1-v,1-v]\))
\(\lambda _v\) is a coordinate change which for z in the lower half plane is defined by (see [14, equation (6.2)])
The main reason the uniformity of the asymptotics holds is that varying \(v\in (-1+\epsilon ,1-\epsilon )\) does not change the qualitative behavior of the asymptotics of \(\lambda _v(z)\). If one were to allow \(v=\pm 1\), then the situation would be different.
For the definition of \(\Psi ^{(2)}(\lambda ,s)\), we refer to [14, Section 3], but point out here that while it depends on \(\beta \), it does not depend on x, y, or V. The function \(E_v\) is analytic in a neighborhood of zero (containing the points \(\pm \sqrt{u}\)) and for the values of z we are interested in, it can be written as (see [14, Section 6.4])
where \(\mathcal {N}_v(z)\) is the global parametrix which is of similar form as the one we consider in Sect. 4.2 apart from the support of the equilibrium measure now being \([-1-v,1-v]\) which changes the formulas slightly. See also around [14, equations (5.5) and (6.1)] for details. In particular, as \(z\rightarrow \pm \sqrt{u}\) for a fixed \(N, \mathcal {N}_v(z)\sim (z\mp \sqrt{u})^{-\frac{\beta }{2}\sigma _3}\) uniformly in v. This combined with the fact that \(\phi _{v,+}(\pm \sqrt{u})\) is purely imaginary implies that in a neighborhood of the origin, \(E_v, E_v^{-1}\), and \(E_v'\) are bounded uniformly in \(v\in (-1+\epsilon ,1-\epsilon )\).
Finally \(R_v\) is a solution to a small norm RHP. As pointed out in [14], the analysis of \(R_v\) and its RHP is essentially carried out in [15]. While verifying in full detail the asymptotic behavior of \(R_v\) is not something we will do, we will briefly sketch part of the argument, namely uniform asymptotics for the jump matrix across part of the boundary of a neighborhood of the origin. Analyzing the jump matrix of R in the remaining part of the contour is similar and with a standard argument one finds that R is uniformly close to the identity and its derivative is uniformly small.
From the definition of \(R_v\) in [14, Section 6.5] we see for z on the boundary of some neighborhood of the origin containing the points \(\pm \sqrt{u}\)
Following the notation in [14, Section 3], we note that we can write
where \(\Psi _{CK}\) is the solution to the RHP in [15, Section 3] and \(\chi (\lambda )\) is defined in [14, (3.12)]. We note that as u is always small for us, \(|\lambda _v(z)/|s||\sim u^{-1/2}\) is large if z is at a fixed distance from \(\pm \sqrt{u}\). We thus want to know the \(\lambda \rightarrow \infty \) asymptotics of \(\Psi _{CK}(\lambda ,s)\) for all values of s. This was studied in [15]. For the relevant asymptotics for \(\Psi _{CK}(\zeta ;s)\), we refer to the discussion relevant to [15, equations (3.6), (5.25), and (6.32)]. For \(\Psi ^{(2)}(\lambda ;s)\) these asymptotics translate into the following: for large \(|\lambda |\)
Using (G.6) and fact that \(E_v\) and \(E_v^{-1}\) are uniformly bounded, we thus see that for all u and uniformly in v, the jump matrix along this part of the jump contour is
Going over such an argument in full detail would then imply that \(R_v\) can be solved through the general small-norm approach and one has uniform asymptotics for \(R_v\), e.g. \(R_v(z)=I+\mathcal {O}(N^{-1})\) and \(R_v'(z)=\mathcal {O}(N^{-1})\) uniformly in z and \(v\in (-1+\epsilon ,1-\epsilon )\).
Let us now return to the differential identity (G.1). With a basic matrix algebra argument, one finds from (G.2) as in [14, Section 5]
where
For the asymptotics of the \(\frac{d}{dz}\Psi ^{(2)}\)-term, one can argue exactly like in [14, Section 6.4] (see also [14, equations (5.27) and (5.28); Lemma 5.3]) to find that as \(z\rightarrow \pm \sqrt{u}\),
where \(\mathcal {O}(1)\) is uniform in v.
Thus what remains is the B-term. For this, by what we’ve argued about R and E, we see that \((RE)^{-1}(RE)'=\mathcal {O}(1)\) uniformly in v in a neighborhood of zero. Thus it is enough to show that as \(z\rightarrow \pm \sqrt{u}, ((\Psi ^{(2)})^{-1}\mathcal {O}(1)\Psi ^{(2)})_{22}=\mathcal {O}(1)\) uniformly in v. Here again the asymptotics of \(\Psi ^{(2)}\) come from [15], and in fact the uniformity in v follows from the argument for a fixed v as in [14, Section 5.6 and Section 6.6] and the uniform behavior of \(\lambda _v\).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Berestycki, N., Webb, C. & Wong, M.D. Random Hermitian matrices and Gaussian multiplicative chaos. Probab. Theory Relat. Fields 172, 103–189 (2018). https://doi.org/10.1007/s00440-017-0806-9
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-017-0806-9