
Abstract
It is quite common that the structure of a time series changes abruptly. Identifying these change points and describing the model structure in the segments between these change points is of interest. In this paper, time series data is modelled assuming each segment is an autoregressive time series with possibly different autoregressive parameters. This is achieved using two main steps. The first step is to use a likelihood ratio scan based estimation technique to identify these potential change points to segment the time series. Once these potential change points are identified, modified parametric spectral discrimination tests are used to validate the proposed segments. A numerical study is conducted to demonstrate the performance of the proposed method across various scenarios and compared against other contemporary techniques.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The statistical properties of time series data, such as mean and variance or the coefficients of the regression model, may change abruptly at unknown time points. Identifying those unknown time points is referred to as change point detection or time series segmentation. The change point problem was first considered by Page (1954) and Page (1955) for quality control. Since then, the topic has been explored theoretically and computationally in the field of statistics and computer science, and has been applied to economics (Bai and Perron 2003; Bai 2010), finance (Aue and Horváth 2013; Andreou and Ghysels 2009), and biology (Olshen et al. 2004; Niu and Zhang 2012). Furthermore, see the recent survey papers by Jandhyala et al. (2013), Aminikhanghahi and Cook (2017) and Truong et al. (2020) for the development of univariate or multivariate time series segmentation methods.
There are essentially two types of approaches for detecting unknown change points under a parametric design: the model selection method and the traditional hypothesis testing method. Model selection or exact segmentation methods generally include two elements, a cost function and an optimization algorithm. The computational complexity depends on the complexity of data and the number of change points. In contrast, the approximate segmentation methods have significantly less computational cost when there are more change points. Here, we follow in the direction of the approximate segmentation methods.
One popular representation of the approximate segmentation methods is the binary segmentation (BS) family of methods. The core idea is that BS tests if there is a change point in the process at each step or iteration (see Fryzlewicz 2014 for a detailed description). BS has gained huge popularity due to the minor computational cost and its user-friendliness. However, the method may ignore change points if the length of the segment is relatively short. Hence, Olshen et al. (2004) further improved the BS algorithm, and proposed the circular BS (CBS) method. Fryzlewicz (2014) proposed the wild BS (WBS) approach to detect the number and locations of changes in a piecewise stationary model when the values of the parameters change. Another representation of the approximate segmentation methods is bottom-up segmentation, which is less explored than the BS algorithm (we recommend the paper by Keogh et al. 2001 for further details). Bottom-up segmentation is also easy to apply: the first step is to obtain a sequence of overestimated change points; the second step is to eliminate the falsely-detected ones.
However, both the BS algorithm and the bottom-up method may suffer from the multiple testing problem. Eichinger et al. (2018) mentions in regards to the BS algorithm that “it can be difficult to interpret the results in terms of significance due to the multiple testing involved”. Thus, Fryzlewicz (2014) added a randomized segment selection step to the BS method. Li et al. (2016) proposed multiscale change point segmentation with controlled false discovery rate (FDR) based on multiscale statistics considered by Frick et al. (2014) for inferring the changes in the mean of an independent sequence of random variables. Cao and Wu (2015) developed a large scale multiple testing procedure for data with clustered signals. The earlier references that introduced FDR for multiple change point detection include Niu and Zhang (2012) and Hao et al. (2013), which are motivated by genome data. Hitherto, only a small amount of literature attempts to address this issue. When the observations are dependent, detecting multiple change points is quite a difficult task, especially in the case of autoregressive processes. Davis et al. (1995) studied the asymptotic behavior of the likelihood ratio statistic in testing if a change point has occurred in the mean, the autocovariance structure or the order of an autoregressive process. Later on, Davis et al. (2006) estimated all the parameters of a piecewise stationary autoregressive process by using a genetic algorithm to optimize an information criterion as objective function. Hušková et al. (2007) firstly derived the limiting behavior of various max-type test statistics under the hypothesis of whether there is an autocorrelation coefficient change in an autoregressive time series, then compares the asymptotic results of these test statistics with corresponding resampling procedures in the paper of Hušková et al. (2008). Peštová and Pešta (2017) developed a method based on the ratio type statistic to test at most one possible regression parameter change in an AR(1) series. Chakar et al. (2017) proposed a robust approach for estimating change points in the mean of an AR(1) process. Korkas and Fryzlewicz (2017) upgraded the WBS algorithm by applying a locally stationary wavelet process for estimating change points in the second-order structure of a piecewise stationary time series model. Yau and Zhao (2016) proposed a likelihood ratio scan method (LRSM) to estimate change points in piecewise stationary processes.
In this paper, we develop a new Multiple Comparisons Procedure for a Multiple Change Point Problem (MCP-MCP, or MCP2 for short), to estimate the number and locations of change points in a piecewise stationary autoregressive model. The procedure includes three simple steps: the first step is to apply the likelihood ratio scan statistics by Yau and Zhao (2016) to obtain a set of potentially overestimated change points; the second step is to use the spectral discrimination procedure developed by Grant and Quinn (2017) to eliminate possibly falsely discovered change points; the third step is to use a classic controlling FDR procedure and an adjusted p-value Bonferroni procedure to address the multiple testing issue. Our work is mainly inspired by Yau and Zhao (2016) and Korkas and Fryzlewicz (2017) and, to the best of our knowledge, is the first paper to address the multiple testing issue taking the dependency into account as a bottom-up segmentation method.
As indicated by Mercurio and Spokoiny (2004), it is highly risky to treat non-stationary data as though they are from a stationary process when making predictions and forecasting. Therefore, the estimation accuracy tends to be very important and the exact properties of estimates need careful attention. In our simulation study, we focus on the correct estimated number and locations of change points. The structure of the paper is as follows. In Sect. 2, we provide the details of the MCP2 method. In Sect. 3, through extensive simulation experiments and in Sect. 4, through two real data examples, we evaluate the performance of the MCP2, LRSM and WBS methods. Lastly, we conclude the paper in Sect. 5 with discussion and comments on future research.
2 A multiple comparisons procedure for change point detection
2.1 Non-stationary time series segmentation as a multiple testing problem
We start this section by demonstrating the autoregression process segmentation problem, and how it can be viewed as a multiple hypothesis testing problem. Let \(x_{1}, x_{2},\ldots ,x_{T}\) be a sequence of an autoregression process, with q the unknown number of change points and \(k_{1}, k_{2},\ldots , k_{q}\) their respective unknown positions, where \(1< k_{1}< k_{2}< \cdots< k_{q} < T\). The autoregression process with multiple change points is illustrated as below
where \(\varepsilon _{t} \sim i.i.d.N(0,\sigma ^2_{t})\) and each segment is a stationary autoregression of order p (AR(p)) and independent of each other. This problem can be expressed as a classical single hypothesis testing problem, as follows. Letting \(\theta _{t}\) be the parameters that generate the data at each time point, \(t = 1, \ldots , k_{q}, \ldots ,T\),
If \(H_{1}\) is supported, the data are split into \( q+1 \) segments, (\(x_{1}, x_{2}, \ldots , x_{k_{1}}\)), (\( x_{k_{1}+1}, x_{k_{1}+2}, \ldots , x_{k_{2}} \)), \(\ldots \), (\( x_{k_{q}+1}, x_{k_{q}+2}, \ldots , x_{T} \)), with different generating parameters for each segment denoted by \(\theta _{i} : = (p_{i},\beta _{p_{i}}^{(i)},{\sigma ^2}^{(i)})\), \(i = 1, \ldots , q+1\).
The ambitious objective is to estimate the number of change points q, the location vector \( k = (k_{1}, k_{2}, \cdots , k_{q}) \) and the parameters for each segment \(\theta _{i}\). It is not practical to achieve this objective through the aforementioned single hypothesis testing framework, hence we decompose (1) to multiple hypothesis tests
for \(i = 1, \ldots , q\). Since we assume that each segment is an independent time series, (2) can be viewed as a multiple testing problem by determining whether two adjacent segments (\( x_{k_{i-1}+1} , x_{k_{i-1}+2}, \ldots , x_{k_{i}} \)) and (\( x_{k_{i}+1}, x_{k_{i}+2}, \ldots , x_{k_{i+1}} \)) have been generated by the same underlying stochastic process. We use a parametric spectral discrimination approach to solve this problem.
2.2 Change points exploration by using scan statistics
In Sect. 2.1, we did not define the range of q, which could be any value between 0 and T. Therefore, as the first step, a possibly overestimated set of change points will be estimated by using the likelihood ratio scan statistics proposed by Yau and Zhao (2016). A brief introduction is given in this section.
For a window radius h we define a corresponding scanning window \(R_{t}(h)\) and observations as
The likelihood ratio scan statistics is then
By scanning the observed time series data, a sequence of \(LS_{h}(t)\) will be obtained at \(t=\)h, \(h+1\), ..., \(T-h\). If h meets certain criteria, at most one change point outputs in \(R_{t}(h)\), and if there is a change at t, then \(LS_{h}(t)\) tends to be large. Hence, a set of potential change points \( {\hat{k}} = (k_{1}, k_{2}, \ldots , k_{q}) \) will be obtained after the scanning process.
2.3 A likelihood ratio test for comparing time series
Given a set of estimated change points, we then apply a modified version of the parametric spectral discrimination test proposed by Grant and Quinn (2017) to test if the adjacent segments are from the same autoregressive process. We fit the autoregressive models
to two adjacent segments of lengths \(T_{1}\) and \(T_{2}\), respectively, where \(\left\{ \varepsilon _{t}\right\} \) and \(\left\{ u_{t}\right\} \) are independent processes with zero mean and variances \(\sigma _{\varepsilon }^{2}\) and \(\sigma _{u}^{2}\), respectively. Although the test is developed as though \(\left\{ \varepsilon _{t}\right\} \) and \(\left\{ u_{t}\right\} \) are i.i.d and Gaussian, the asymptotic distribution of the test statistic holds under much weaker conditions (Grant 2018). Note that we are also assuming that the processes have zero mean, and in practice the time series are mean-corrected before analysis. That is, we do not consider a shift in mean between segments to constitute a change point, but rather consider only changes in the second-order properties. The hypothesis test is
Under the null hypothesis, the underlying processes share the same autocovariance structure, or, in other words, have the same spectral density (hence the term spectral discrimination tests). In order to compute the likelihood ratio statistic, we need the maximum likelihood estimators of the parameters under both \(H_{0}\) and \(H_{A}\). Under \(H_{A}\), the processes are independent and the parameters can be estimated separately using, for example, the Levinson–Durbin algorithm (Levinson 1947; Durbin 1960). For a given order p, the algorithm computes the estimators
where
T is the sample size and \({\widehat{\varGamma }}_{p}\) is the \(p\times p\) matrix with \(\left( i,j\right) \)th entry given by \({\widehat{\gamma }}\left( \left| i-j\right| \right) \). These estimators are the solutions to the Yule–Walker equations, and represent method of moment estimators of the model parameters. Asymptotically, they are equivalent to the maximum likelihood estimators under Gaussianity. Under \(H_{0}\), for \(j=0,\ldots ,p\), we define
Replacing \({\widehat{\gamma }}\left( j\right) \) by \(c\left( j\right) \) in the Levinson–Durbin algorithm gives estimators for the common parameters. The test statistic is
where \({\widehat{\sigma }}_{\varepsilon ;A}^{2}\) and \({\widehat{\sigma }}_{u;A}^{2}\) are the estimators of \(\sigma _{\varepsilon }^{2}\) and \(\sigma _{u}^{2}\) under \(H_{A}\), and \({\widehat{\sigma }}_{0}^{2}\) is the estimator of the common residual variance under \(H_{0}\). We reject \(H_{0}\) when \(\varLambda \) is greater than the \(100\left( 1-\alpha \right) \)th percentile of the \(\chi ^{2}\) distribution with \(p_{x}+p_{y}-p+1\) degrees of freedom.
Since the orders are unknown in practice, they can be estimated using, for example, an information criterion such as BIC. This is easily incorporated into the Levinson–Durbin algorithm. However, it was shown in Grant and Quinn (2017) that the test performs poorly when the underlying time series are not truly autoregressive. The proposed solution was to use autoregressive approximation by fixing the orders, under both \(H_{0}\) and \(H_{A}\), as \(p_{x}=p_{y}=p=\left\lfloor \left( \log T_{\min }\right) ^{v}\right\rfloor \), where \(v>1\), \(T_{\min }=\min \left( T_{1},T_{2}\right) \) and \(\left\lfloor \left( \log T_{\min }\right) ^{v} \right\rfloor \) is the integer component of \(\left( \log T_{\min }\right) ^{v} \). The null hypothesis is then rejected when \(\varLambda \) is greater than the \(100\left( 1-\alpha \right) \)th percentile of the \(\chi ^{2}\) distribution with \(p+1\) degrees of freedom. The test then performs well even when the time series are not autoregressive, with the cost being some loss in power in the autoregressive case.
It is possible to adjust the test to consider a change in mean as a change point. In this case, the models we fit (using the fixed autoregressive order approach outlined above) are
and the null hypothesis is
Letting
we replace \({\widehat{\gamma }} \left( j \right) \) and \(c \left( j \right) \) by
and
respectively. The test statistic is then computed in the same way using parameter estimates from the Levinson–Durbin algorithm. The null hypothesis is rejected when \(\varLambda \) is greater than the \(100\left( 1-\alpha \right) \)th percentile of the \(\chi ^{2}\) distribution with \(p+2\) degrees of freedom.
2.4 Approaches for multiple hypothesis tests
Generally, for a single hypothesis test, we specify a Type I error, say 0.05, and make a conclusion based on the test statistic which meets this specification while giving the highest power. When multiple hypotheses are tested simultaneously, the probability of at least one incorrect “statistically significant” outcome is increased with as the number of independent tests increases, which may result in incorrect conclusions. Thus, it is necessary to evaluate the tests as a whole. Numerous procedures have been proposed for this multiple comparison problem. In this paper, we implement two classical procedures: Controlling the false discovery rate, proposed by Benjamini and Hochberg (1995) (BH); and the adjusted p-values approach of Wright (1992).
As per the previous subsection, we can obtain unadjusted p-values \(p_{(1)},p_{(2)}\), \(\ldots ,\)\(p_{(q)}\) corresponding to the multiple hypotheses considered in (2). Let \(P_{(1)} \le P_{(2)}\le \cdots \le P_{(q)}\) be the ordered \(p_{(1)},p_{(2)}, \ldots ,p_{(q)}\) from smallest to largest. The BH multiple-testing procedure is as follows.
Next, we adopt the adjusted p-values method by Bonferroni procedure as follows.
3 Simulation study
3.1 Choice of scanning window
In this section, we use nine classic examples to compare the performance of the MCP2 method with methods from recent literature including the likelihood ratio scan method (LRSM) by Yau and Zhao (2016) and the wild binary segmentation method (WBS) by Korkas and Fryzlewicz (2017). Except for model G, the models used in the simulation study also were considered by Yau and Zhao (2016). For each model, we simulated 100 sequences. The first step of both the LRSM and MCP2 method is to obtain the possible change points by using likelihood ratio scan statistics, which involves the tuning parameter — scanning radius h. Theoretically, the LRSM requires \(r\log (T)^2 \le h \le ml_k/2\), where \(ml_k\) denotes the minimum length between the adjacent change points, T is the length of the time series, and r is specified by the user. The scanning radius \(h = \max \{50, 2\log (T)^2\}\) is suggested by Yau and Zhao (2016) as a rule-of-thumb. However, the LRSM may not be applicable when the \(h \le ml_k/2\) is violated, additionally, \(h \le ml_k/2\) criterion is not practical as the minimum distance of neighboring change points is unknown.
Hence, we implement a sensitivity analysis to study the optimal choice of h in the MCP2 method for each model, displayed by Table 1. In the table, \(\%:{\hat{N}}=N\) denotes the the percentage that the estimated number of change points is the actual number. We also investigate average degrees of freedom of \(\chi ^{2}\) distribution, as \(p=\left\lfloor \left( \log T_{\min }\right) ^{v}\right\rfloor \), the length of segment may be affected by the scanning window h.
We have tested multiple values of h, it is shown that the choice of h has an impact on the detection rate (\(\%:{\hat{N}}=N\)). Optimal scanning window h can be selected based on two criteria. We first consider choosing the minimum value of h which gives the maximum detection rate (\(\%:{\hat{N}}=N\)). Second, we select the value of h which is less than the first segment’s length. For example, the exact change point of Model D is located at 50, although the detection rate increased as h increased, the optimal value of h should be less than 50; otherwise, the actual change point is dismissed at the beginning. The optimal scanning window for each model is summarised in Table 2.
3.2 Comparison between methods
To measure the detection accuracy of the methods, we consider evaluating the estimated number of change points and the estimated locations separately. In this paper, we define the exact detection rate as the proportion that the estimated number of change points equals to the correct number of change points among 100 sequences, shown by \(\%:{\hat{N}}=N\) in Table 1. Table 3 summarises the performance in terms of estimated number of change-points for each model. In addition, we designed novel plots to display the distance between the actual and estimated locations of change points, which could help evaluate the detection accuracy on estimated locations.
In order to compare with LRSM, we used the same setting for both the LRSM and MCP2 method: \(h = 2\log (T)^2\), \(ml_k=50\) is set for Model A, B, C, G, and H; \(h = \log (T)^2\), \(ml_k=25\) is set for Model I; \(h = \log (T)^2\), \(ml_k=50\) is set for Model D, E and F.
-
(a)
Model A: stationary AR(1) process with various \(\beta = -\,0.7, -\,0.1, 0.4, 0.7\)
$$\begin{aligned} x_{t}= \beta x_{t-1} + \varepsilon _{t}, 1 \le t \le 1024 \end{aligned}$$(4)We evaluate the performance of the methods via Model A that there is no change point. LRSM is overall perfect under model A, WBS is nearly perfect except the poor performance when \(\beta = -\,0.7\). MCP2 method performs well and almost uniformly with various \(\beta \), while tends to have over-segmentation problem, regardless of the value of h.
-
(b)
Model B: piecewise stationary auto-regressive process
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} 0.9x_{t-1} + \varepsilon _{t} &{}1 \le t \le 512\\ 1.69x_{t-1} - 0.81x_{t-2} + \varepsilon _{t}, &{}513 \le t \le 768\\ 1.32x_{t-1} - 0.81x_{t-2} + \varepsilon _{t}, &{}769 \le t \le 1024\\ \end{array}\right. } \end{aligned}$$(5)From Table 3, it is clear that LRSM is outstanding over the others, WBS has the lowest accuracy rate and tends to overestimate the number of change points, and MCP2BH suffers from overestimation as well. Moreover, LRSM gives the most accurate estimated locations which can be seen by looking at Fig. 1. Estimated location of WBS spaced out around the true location 768, compared with the estimates at 512, it seems to lose the power to detect the second change-point, which may be the reason for overestimation. If we look at the setting of Model B, at the second location, the coefficients of the adjacent AR(2) segments are very close, which make it difficult to detect. Similarly, the estimated locations of MCP2 methods show mild variation at 512 and 768.
-
(c)
Model C: piecewise stationary AR(1) process
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} 0.4x_{t-1} + \varepsilon _{t} &{}1 \le t \le 400\\ -0.6x_{t-1} + \varepsilon _{t}, &{}401 \le t \le 612\\ 0.5x_{t-1} + \varepsilon _{t}, &{}613 \le t \le 1024\\ \end{array}\right. } \end{aligned}$$(6)Comparing with model B, the performance of all methods improved for estimates of both the number and locations of change points. It can be seen from Fig. 2, in the WBS method, there is a mild spread at the first location 400. MCP2 methods perform well under this model.
-
(d)
Model D: piecewise stationary AR(1) process with a short segment
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} 0.75x_{t-1} + \varepsilon _{t} &{}1 \le t \le 50\\ -0.5x_{t-1} + \varepsilon _{t}, &{}51 \le t \le 1024\\ \end{array}\right. } \end{aligned}$$(7)LRSM remains the outstanding method in estimating the number of change points compared with the others. However, there is a large distance between estimated locations and true location in WBS and LRSM comparing with MCP2 methods, as shown in Fig. 3. MCP2 method is superior in estimating the location under this model.
-
(e)
Model E: piecewise stationary near-unit-root process with changing variance
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} 0.999x_{t-1} + \varepsilon _{t} &{}\varepsilon _{t}\sim N(0,1), 1 \le t \le 400\\ 0.999x_{t-1} + \varepsilon _{t}, &{}\varepsilon _{t}\sim N(0,1.5^2),401 \le t \le 750\\ 0.999x_{t-1} + \varepsilon _{t}, &{}\varepsilon _{t}\sim N(0,1),751 \le t \le 1024\\ \end{array}\right. } \end{aligned}$$(8)Since the autocorrelation coefficients of this series remain unchanged for each segment and close to 1, all methods do not perform well.
-
(f)
Model F: piecewise stationary AR process with high autocorrelation
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} 1.399x_{t-1} - 0.4x_{t-2} + \varepsilon _{t} &{}\varepsilon _{t}\sim N(0,1), 1 \le t \le 400\\ 0.999x_{t-1} + \varepsilon _{t}, &{}\varepsilon _{t}\sim N(0,1.5^2),401 \le t \le 750\\ 0.699x_{t-1} + 0.3x_{t-2} + \varepsilon _{t}, &{}\varepsilon _{t}\sim N(0,1),751 \le t \le 1024\\ \end{array}\right. } \end{aligned}$$(9)Simulations from models E and F are challenging data sets. From Table 3, the detection rate for all methods is quite low at around 0.3. Hence, it is not useful to plot the corresponding locations. MCP2 performs slightly better than the other two methods when the optimal scanning window is applied.
-
(g)
Model G: piecewise stationary AR(1) process with three change points
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} 0.7x_{t-1} + \varepsilon _{t} &{}1 \le t \le 125\\ 0.3x_{t-1} + \varepsilon _{t} &{}126 \le t \le 532\\ 0.9x_{t-1} + \varepsilon _{t} &{}533 \le t \le 704\\ 0.1x_{t-1} + \varepsilon _{t} &{}705 \le t \le 1024\\ \end{array}\right. } \end{aligned}$$(10)It can be indicated from Table 3 that MCP2 outperformed the other methods under this model in terms of estimating the number of change points. Both WBS and LRSM methods suffer from the underestimation. For location estimates, there is an outlier—(\({\hat{k}}_1=518\), \({\hat{k}}_2=704\), \({\hat{k}}_3=909\)) in Fig. 4 of MCP2BH. WBS and LRSM had similar performance. Overall, MCP2WRI is recommended for this model.
-
(h)
Model H: piecewise stationary ARMA(1,1) process with three change points
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} 0.7x_{t-1} + \varepsilon _{t} + 0.6\varepsilon _{t-1} &{}1 \le t \le 125\\ 0.3x_{t-1} + \varepsilon _{t} + 0.3\varepsilon _{t-1} &{}126 \le t \le 532\\ 0.9x_{t-1} + \varepsilon _{t} &{}533 \le t \le 704\\ 0.1x_{t-1} + \varepsilon _{t} - 0.5\varepsilon _{t-1} &{}705 \le t \le 1024\\ \end{array}\right. } \end{aligned}$$(11)Similar to the previous model, MCP2 has the best performance when estimating the number of change points, while the LRSM and WBS method has the tendency to underestimate the number of change points, as shown in Table 3. Furthermore, it is interesting to see that WBS and MCP2 have a mild variation at the second change-point from Fig. 5. A location estimate vector—(\({\hat{k}}_1=429\), \({\hat{k}}_2=646\), \({\hat{k}}_3=705\)) is an outlier in WBS plot. Comparing WBS with LRSM, LRSM remains robust when estimating the locations.
-
(i)
Model I: piecewise stationary moving average process
$$\begin{aligned} x_{t}= {\left\{ \begin{array}{ll} \varepsilon _{t} + 0.8\varepsilon _{t-1} &{}1 \le t \le 128\\ \varepsilon _{t} + 1.68\varepsilon _{t-1} - 0.81\varepsilon _{t-2} &{}129 \le t \le 256\\ \end{array}\right. } \end{aligned}$$(12)Tables 1 and 3 show that all methods performed well when estimating the number of change points. In terms of estimating the locations, all methods performed poorly. Fig. 5 indicates that the estimates of LRSM and WBS method have large spread around the true change-point, while the estimates of MCP2 method tend to cluster below 128.

Plots of estimated locations of change points from different methods under model B. Horizontal line stands for the sequence of estimated changes only when the estimated number of change points equals to 2. The dashed black lines represent the true locations of change points, 512 and 768

Plots of estimated locations of change points from different methods under model C. Horizontal line stands for the sequence of estimated changes only when the estimated number of change points equals to 2. The dashed black line represents the true locations of change points, 400 and 612

Plots of estimated locations of change points from different methods under model D. Horizontal line stands for the sequence of estimated changes only when the estimated number of change points equals to 1. The dashed black line represents the true location of change points at 50

Plots of estimated locations of change points from different methods under model G. Horizontal line stands for the sequence of estimated changes only when the estimated number of change points equals to 3. The dashed black line represents the true locations of change points, 125, 532 and 704

Plots of estimated locations of change points from different methods under model H. Horizontal line stands for the sequence of estimated changes only when the estimated number of change points equals to 3. The dashed black line represents the true locations of change points, 125, 532 and 704

Plots of estimated locations of change points from different methods under model I. Horizontal line stands for the sequence of estimated changes only when the estimated number of change points equals to 1. The dashed black line represents the true location of change point at 128
3.3 Discussion of simulation results
In the simulation study, we have used nine settings to evaluate the performance of the MCP2, LRSM and WBS methods. We firstly had a discussion on the choice of scanning window. Comparing with LRSM, the implementation of MCP2 is not limited to the value of h. The optimal value of h has been provided in Table 2. Then, we evaluated the methods from two perspectives: the accuracy in detecting the number of change points and the accuracy in detecting the locations. Searching for the number of change points is the first challenge since it may be overestimated or underestimated, as shown in Table 3. We produce Figs. 1, 2, 3, 4, 5 and 6 to show that fitting between estimated change points and true change points conditioned on that the estimated number of change points is correct. Overall, the MCP2 performs well and shows its superiority under Model G. Model H and I demonstrate that detecting change-points in a piecewise stationary moving average process remains a challenge. As shown in Fig. 6, the estimates from all methods display a large spread.
4 Real data analysis
4.1 Example 1: physiological data time series
In this section, we use two linked medical time series, BabyECG and BabySS, which are available in the R package wavethresh, containing 2048 observations of an infant’s heart rate and sleep state sampled every 16 s recorded from 21:17:59 to 06:27:18. Both of them were recorded from the same 66 day old infant. The dashed line represents a change in sleep state. Korkas and Fryzlewicz (2017) has analysed the BabyECG time series as a real data example of a piecewise stationary time series by using the WBS method. Here we compare MCP2 with WBS, since LRSM is not applicable for this situation. From Fig. 7, it can be seen that all methods tend to be in agreement at most estimated change points. MCP2 is able to identify the short segment if we use the smallest scanning window whereas WBS may ignore the shorter segments. In addition, the BH procedure is more conservative than Wright’s. We remark that the selection of a scanning window exerts a control on the final estimates. In this situation, the scanning window we use is \(h = \max \left\{ 50,\log (2048)^2 \right\} \).

Performance of MCP2 with WBS, the top and bottom dotted line represents MCP2-BH and MCP2-Wright, the middle dotted line represents WBS method with default setting. The right hand axis represents 1 = quiet sleep, 2 = between quiet and active sleep, 3 = active sleep, 4 = awake
4.2 Example 2: monthly IBM stock returns
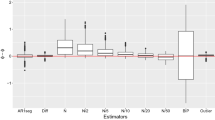
The experiment we perform here is used for comparing MCP2 with the LRSM method by analysing monthly stock returns of IBM from January 1962 to October 2014, which is an example tested by Yau and Zhao (2016) using LRSM. The scanning window used in MCP2 is the same as LRSM, which is \(h=41\). LRSM gives two changes at 307 (July 1987) and 491 (November 2002), whereas MCP2-BH gives two estimations at 390 (June 1994) and 492 (December 2002). MCP2-Wright gives only one detection at 492. It seems that there is a clear agreement on the second change point (Fig. 8).

Performance of MCP2 with LRSM, the blue line represents LRSM, the orange dotted line represents MCP2-BH method
5 Conclusion
In this paper, we proposed the MCP2 method which shows the flexibility and superior performance over the LRSM and WBS methods in piecewise stationary autoregressive process with more than two change points. In terms of measuring the locations of change points, we used novel statistical plots instead of the Hausdorff distance, one advantage being that we can get insights from the plots as to what caused the over-segmentation. In addition, the plots clearly demonstrated the performance of each method when estimating the locations of change points.
Although the MCP2 method worked particularly well in simulations in identifying change points when there were some, the Type I error rates were above the significance level under the null models (Model A). This may be due to the fact that, although the method accounts for multiple testing in the second (validation) stage, there is still uncertainty not accounted for from the first (detection) stage. A way of accounting for this would be to use the Bonferroni procedure with a p-value correction which reflects the number of scan statistics examined. A conservative approach is to set the p-value threshold to \(\alpha / T\), which will reduce the Type I error rate with the trade-off that the power to detect true change points is also reduced. Future work will refine this approach, but preliminary simulation results suggest that good power is retained compared with the other methods.
Other future research will involve a theoretical investigation of our method as well as work to further improve the estimation accuracy.
References
Aminikhanghahi S, Cook DJ (2017) A survey of methods for time series change point detection. Knowl Inf Syst 51(2):339–367
Andreou E, Ghysels E (2009) Structural breaks in financial time series. In: Mikosch T, Kreiß JP, Davis RA, Andersen TG (eds) Handbook of financial time series. Springer, Berlin, pp 839–870
Aue A, Horváth L (2013) Structural breaks in time series. J Time Ser Anal 34(1):1–16
Bai J (2010) Common breaks in means and variances for panel data. J Econom 157(1):78–92
Bai J, Perron P (2003) Computation and analysis of multiple structural change models. J Appl Econom 18(1):1–22
Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing. J R Stat Soc 57(1):289–300
Cao H, Wu W (2015) Changepoint estimation: another look at multiple testing problems. Biometrika 102(4):974–980
Chakar S, Lebarbier E, Lévy-Leduc C, Robin S (2017) A robust approach for estimating change-points in the mean of an AR(1) process. Bernoulli 23(2):1408–1447
Davis RA, Huang D, Yao YC (1995) Testing for a change in the parameter values and order of an autoregressive model. Ann Stat 23:282–304
Davis RA, Lee TCM, Rodriguez-Yam GA (2006) Structural break estimation for nonstationary time series models. J Am Stat Assoc 101(473):223–239
Durbin J (1960) The fitting of time-series models. Revue de l’Inst Int Stat 28(3):233–244
Eichinger B, Kirch C et al (2018) A MOSUM procedure for the estimation of multiple random change points. Bernoulli 24(1):526–564
Frick K, Munk A, Sieling H (2014) Multiscale change point inference. J R Stat Soc 76(3):495–580
Fryzlewicz P (2014) Wild binary segmentation for multiple change-point detection. Ann Stat 42(6):2243–2281
Grant AJ (2018) Parametric methods for time series discrimination. PhD thesis, Macquarie University, Sydney, Australia
Grant AJ, Quinn BG (2017) Parametric spectral discrimination. J Time Ser Anal 38(6):838–864
Hao N, Niu YS, Zhang H (2013) Multiple change-point detection via a screening and ranking algorithm. Statistica Sinica 23(4):1553–1572
Hušková M, Prášková Z, Steinebach J (2007) On the detection of changes in autoregressive time series I. Asymptotics. J Stat Plan Inference 137(4):1243–1259
Hušková M, Kirch C, Prášková Z, Steinebach J (2008) On the detection of changes in autoregressive time series, II. Resampling procedures. J Stat Plann Inference 138(6):1697–1721
Jandhyala V, Fotopoulos S, MacNeill I, Liu P (2013) Inference for single and multiple changepoints in time series. J Time Ser Anal 34(4):423–446
Keogh E, Chu S, Hart D, Pazzani M (2001) An online algorithm for segmenting time series. In: Proceedings 2001 IEEE international conference on data mining, IEEE, pp 289–296
Korkas KK, Fryzlewicz P (2017) Multiple change-point detection for non-stationary time series using wild binary segmentation. Statistica Sinica 27:287–311
Levinson N (1947) The Wiener RMS (root mean square) error criterion in filter design and prediction. J Math Phys 25:261–278
Li H, Munk A, Sieling H (2016) FDR-control in multiscale change-point segmentation. Electron J Stat 10(1):918–959
Mercurio D, Spokoiny V (2004) Statistical inference for time-inhomogeneous volatility models. Ann Stat 32(2):577–602
Niu YS, Zhang H (2012) The screening and ranking algorithm to detect DNA copy number variations. Ann Appl Stat 6(3):1306–1326
Olshen AB, Venkatraman E, Lucito R, Wigler M (2004) Circular binary segmentation for the analysis of array-based DNA copy number data. Biostatistics 5(4):557–572
Page ES (1954) Continuous inspection schemes. Biometrika 41(1/2):100–115
Page E (1955) A test for a change in a parameter occurring at an unknown point. Biometrika 42(3/4):523–527
Peštová B, Pešta M (2017) Asymptotic and bootstrap tests for a change in autoregression omitting variability estimation. In: International work-conference on time series analysis, Springer, pp 187–202
Truong C, Oudre L, Vayatis N (2020) Selective review of offline change point detection methods. Sig Process 167:107299. https://doi.org/10.1016/j.sigpro.2019.107299
Wright SP (1992) Adjusted p-values for simultaneous inference. Biometrics 48(4):1005–1013
Yau CY, Zhao Z (2016) Inference for multiple change points in time series via likelihood ratio scan statistics. J R Stat Soc 78(4):895–916
Acknowledgements
We thank two reviewers and the Guest Editor for helpful comments which improved the paper. Andrew J. Grant is supported by a Sir Henry Dale Fellowship jointly funded by the Wellcome Trust and the Royal Society (Grant No. 204623/Z/16/Z).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, L., Grant, A.J. & Sofronov, G. Multiple change point detection and validation in autoregressive time series data. Stat Papers 61, 1507–1528 (2020). https://doi.org/10.1007/s00362-020-01198-w
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00362-020-01198-w