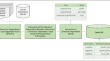
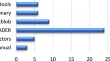
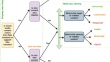
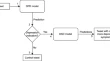
A comparative evaluation for question answering over Greek texts by using machine translation and BERT Michalis MountantonakisLoukas MertzanisYannis Tzitzikas Original Paper 19 June 2024
Which words are important?: an empirical study of Assamese sentiment analysis Ringki DasThoudam Doren Singh Original Paper 19 June 2024
Umigon-lexicon: rule-based model for interpretable sentiment analysis and factuality categorization Clément Levallois Original Paper 17 June 2024
A survey on geocoding: algorithms and datasets for toponym resolution Zeyu ZhangSteven Bethard Survey 10 June 2024
The link between translation difficulty and the quality of machine translation: a literature review and empirical investigation Sahar AraghiAlfons Palangkaraya Original Paper Open access 10 June 2024
Cantonese natural language processing in the transformers era: a survey and current challenges Rong XiangEmmanuele ChersoniYushi Li Survey Open access 08 June 2024
Slovenian parliamentary corpus siParl Katja MedenTomaž ErjavecAndrej Pančur Original Paper Open access 02 June 2024
A sentiment corpus for the cryptocurrency financial domain: the CryptoLin corpus Manoel Fernando Alonso GadiMiguel Ángel Sicilia Original Paper Open access 25 May 2024
Automatic construction of direction-aware sentiment lexicon using direction-dependent words Jihye ParkHye Jin LeeSungzoon Cho Original Paper Open access 25 May 2024
Dataset on sentiment-based cryptocurrency-related news and tweets in English and Malay language Nur Azmina Mohamad ZamaniNorhaslinda KamaruddinAhmad Muhyiddin B. Yusof Original Paper 20 May 2024
Preservation of sentiment in machine translation of low-resource languages: a case study on Slovak movie subtitles Jaroslav ReichelĽubomír Benko Original Paper Open access 15 May 2024
Analyzing learner language: the case of the Hebrew Learner Essay Corpus Chen GafniLivnat Herzig SheinfuxShuly Wintner Original Paper Open access 15 May 2024
Cross-linguistically consistent semantic and syntactic annotation of child-directed speech Ida SzubertOmri AbendMark Steedman Original Paper Open access 15 May 2024
Data augmentation and transfer learning for cross-lingual Named Entity Recognition in the biomedical domain Brayan Stiven LancherosGloria Corpas PastorRuslan Mitkov Original Paper Open access 10 May 2024
Features in extractive supervised single-document summarization: case of Persian news Hosein RezaeiSeyed Amid Moeinzadeh MirhosseiniMohamad Saraee Original Paper Open access 08 May 2024
Mismatching-aware unsupervised translation quality estimation for low-resource languages Fatemeh AzadiHeshaam FailiMohammad Javad Dousti Original Paper 05 May 2024
Improving Arabic sentiment analysis across context-aware attention deep model based on natural language processing Abubakr H. OmbabiWael OuardaAdel M. Alimi Originl Paper 27 April 2024
ArEntail: manually-curated Arabic natural language inference dataset from news headlines Rasha ObeidatYara Al-HarahshehMaram Gharaibeh Original Paper 22 April 2024
Faux Hate: unravelling the web of fake narratives in spreading hateful stories: a multi-label and multi-class dataset in cross-lingual Hindi-English code-mixed text Shankar BiradarSunil SaumyaArun Chauhan Original Paper 16 April 2024
Depression symptoms modelling from social media text: an LLM driven semi-supervised learning approach Nawshad FarruqueRandy GoebelOsmar R. Zaïane Original Paper Open access 04 April 2024
A morphologically annotated longitudinal corpus of spoken Czech child–adult interactions Anna ChromáJakub SlámaJolana Treichelová OriginalPaper 30 March 2024
TCMeta: a multilingual dataset of COVID tweets for relation-level metaphor analysis Mojca BrglezOmnia ZayedPaul Buitelaar Original Paper Open access 30 March 2024
A longitudinal multi-modal dataset for dementia monitoring and diagnosis Dimitris GkoumasBo WangMaria Liakata Original Paper Open access 30 March 2024
DILLo: an Italian lexical database for speech-language pathologists Federica BeccariaAngela CristianoGloria Gagliardi Original Paper Open access 23 March 2024
"Approaches to sentiment analysis of Hungarian political news at the sentence level" Orsolya RingMartina Katalin SzabóIstván Üveges Original Paper Open access 23 March 2024
Introducing the 3MT_French dataset to investigate the timing of public speaking judgements Beatrice BiancardiMathieu CholletChloé Clavel OriginalPaper Open access 23 March 2024
VeLeRo: an inflected verbal lexicon of standard Romanian and a quantitative analysis of morphological predictability Borja HerceBogdan Pricop Project Notes Open access 23 March 2024
An aligned corpus of Spanish bibles Gerardo SierraGemma Bel-EnguixNúria Bel Original Paper Open access 15 March 2024
Computational approaches to Portuguese: introduction to the special issue Diana SantosThiago Alexandre Salgueiro Pardo Editorial 06 March 2024 Pages: 1 - 6
SOLD: Sinhala offensive language dataset Tharindu RanasingheIsuri AnuradhaMarcos Zampieri Original Paper Open access 06 March 2024
Infectious risk events and their novelty in event-based surveillance: new definitions and annotated corpus François DelonGabriel BédubourgMarc Tanti Original Paper 05 March 2024
Semantic search as extractive paraphrase span detection Jenna KanervaHanna KittiFilip Ginter Original Paper Open access 01 February 2024
A new methodology for automatic creation of concept maps of Turkish texts Merve BayrakDeniz Dal Original Paper 28 January 2024
Large scale annotated dataset for code-mix abusive short noisy text Paras TiwariSawan RaiC. Ravindranath Chowdary OriginalPaper 25 January 2024
A flexible tool for a qualia-enriched FrameNet: the FrameNet Brasil WebTool Tiago Timponi TorrentEly Edison da Silva MatosVanessa Maria Ramos Lopes Paiva Original Paper 22 January 2024
NewsCom-TOX: a corpus of comments on news articles annotated for toxicity in Spanish Mariona TauléMontserrat NofreXavier Bonet Original Paper Open access 17 January 2024
Toxic comment classification and rationale extraction in code-mixed text leveraging co-attentive multi-task learning Kiran Babu NelatooriHima Bindu Kommanti Original Paper 13 January 2024
Multi-layered semantic annotation and the formalisation of annotation schemas for the investigation of modality in a Latin corpus Helena Bermúdez-SabelFrancesca Dell’OroPaola Marongiu Project Notes 06 January 2024
AC-IQuAD: Automatically Constructed Indonesian Question Answering Dataset by Leveraging Wikidata Kerenza DoxolodeoAdila Alfa Krisnadhi OriginalPaper Open access 03 January 2024
KurdiSent: a corpus for kurdish sentiment analysis Soran BadawiArefeh KazemiVali Rezaie Original Paper 02 January 2024
Syntactic annotation for Portuguese corpora: standards, parsers, and search interfaces Pablo FariaCharlotte GalvesCatarina Magro Original Paper 26 December 2023 Pages: 301 - 346
Democratizing neural machine translation with OPUS-MT Jörg TiedemannMikko AulamoSami Virpioja Original Paper Open access 13 December 2023 Pages: 713 - 755
Linguistic annotation of Byzantine book epigrams Colin SwaelensIlse De VosEls Lefever Original Paper 13 December 2023
When MIPVU goes to no man’s land: a new language resource for hybrid, morpheme-based metaphor identification in Hungarian Gábor SimonTímea BajzátEszter Szlávich Original Paper Open access 09 December 2023
EmoTwiCS: a corpus for modelling emotion trajectories in Dutch customer service dialogues on Twitter Sofie LabatThomas DemeesterVéronique Hoste Original Paper Open access 08 December 2023 Pages: 505 - 546
Resources building for sentiment analysis of content disseminated by Tunisian medias in social networks Emna FsihRahma BoujelbaneLamia Hadrich Belguith OriginalPaper 02 December 2023
A corpus of Persian literary text Shahab RajiMalihe AlikhaniMatthew Stone Original Paper Open access 23 November 2023 Pages: 409 - 425
A corpus of English learners with Arabic and Hebrew backgrounds Omaima AbboudBatia LauferShuly Wintner Project Notes 20 November 2023
The Reading Everyday Emotion Database (REED): a set of audio-visual recordings of emotions in music and language Jia Hoong OngFlorence Yik Nam LeungFang Liu OriginalPaper Open access 20 November 2023