
Abstract
Explainability, which is the degree to which an interested stakeholder can understand the key factors that led to a data-driven model’s decision, has been considered an essential consideration in the financial domain. Accordingly, lexicons that can achieve reasonable performance and provide clear explanations to users have been among the most popular resources in sentiment-based financial forecasting. Since deep learning-based techniques have limitations in that the basis for interpreting the results is unclear, lexicons have consistently attracted the community’s attention as a crucial tool in studies that demand explanations for the sentiment estimation process. One of the challenges in the construction of a financial sentiment lexicon is the domain-specific feature that the sentiment orientation of a word can change depending on the application of directional expressions. For instance, the word “cost” typically conveys a negative sentiment; however, when the word is juxtaposed with “decrease” to form the phrase “cost decrease,” the associated sentiment is positive. Several studies have manually built lexicons containing directional expressions. However, they have been hindered because manual inspection inevitably requires intensive human labor and time. In this study, we propose to automatically construct the “sentiment lexicon composed of direction-dependent words,” which expresses each term as a pair consisting of a directional word and a direction-dependent word. Experimental results show that the proposed sentiment lexicon yields enhanced classification performance, proving the effectiveness of our method for the automated construction of a direction-aware sentiment lexicon.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The goal of sentiment analysis is the detection of the sentiment polarities of sentences, paragraphs, or documents based on textual content (Malo et al., 2014). Beyond academia, sentiment analysis has attracted significant attention in a number of industries owing to its applicability to a wide range of target populations including consumers, companies, banks, and the general public (Feng et al., 2022; Ruiz-Martínez et al., 2012; Vidanagama et al., 2022). Especially, numerous researchers have conducted sentiment analysis of news articles to estimate market sentiment, which refers to investors’ overall attitude toward the financial market (Li et al., 2020). In literature, news media has been described as the fundamental propagator of speculative price movements (Shiller, 2016), and extensive studies have suggested that the media would affect market sentiment (Campbell et al., 2012; Dougal et al., 2012; Engelberg & Parsons, 2011; Garcia, 2013; Hanna et al., 2020; Tetlock, 2007).
Explainability-the degree to which an interested stakeholder can understand the key factors that led to a data-driven model’s decision (Bracke et al., 2019; Bussmann et al., 2021)-has been considered an essential consideration in the financial domain (Mashrur et al., 2020). Hence, knowledge graphs (Cambria & Hussain, 2015; Picasso et al., 2019; Xing et al., 2018, 2019) and lexicons, which are regarded as explainable text analysis tools that can provide evidence for the model’s decision, have been widely used for sentiment analysis in the financial domain.
A sentiment lexicon is a list of words or phrases mapped to positive or negative sentiment labels. Lexicons are intuitive to interpret and easy to implement (Bandhakavi et al., 2017; Razova et al., 2022). Once a lexicon is compiled, a researcher can easily measure the text’s sentiment value without additional training data and a long learning process. Additionally, the constructed lexicon can be used as a resource to train deep learning models (Choi et al., 2020) or conduct other tasks. Thus, lexicons that can achieve reasonable performance have constantly drawn the attention of the community (Cheng et al., 2022). While recent years have witnessed remarkable advancements in sentiment analysis tasks through supervised deep learning-based approaches (Mishev et al., 2020), these methods exhibit certain limitations in that they necessitate a substantial volume of annotated data and a long learning process to train a model. Most of all, the lack of clarity regarding the rationale behind interpreting the outcomes of supervised models poses an additional constraint on the widespread adoption of supervised deep learning-based techniques within the financial domain (Mashrur et al., 2020). Accordingly, lexicons have become one of the most crucial resources in sentiment analysis studies requiring explanations for the sentiment estimation process.
The construction of a domain-specific sentiment lexicon is particularly important because the sentiment orientations of words can vary by domain (Abdaoui et al., 2017; Dehkharghani et al., 2016; Wu et al., 2018, 2019). For instance, “liability,” a term with a generally negative connotation, is neutral when used in the financial domain (Cortis et al., 2017). One of the most widely used financial domain-specific sentiment lexicons is the Loughran–McDonald Word List (Loughran & McDonald, 2011). It comprises unigrams, which are words containing a single token. A unigram lexicon works well with words having relatively straightforward associated sentiments (e.g., “profitable,” which implies a positive sentiment, or “unprofitable,” which implies a negative sentiment).
However, even the Loughran–McDonald Word List might not be sufficient to capture the financial domain-specific feature that the true sentiment of a given word can change significantly depending on the presence of directional expressions. For instance, the word “cost” is typically associated with a negative sentiment; when it is juxtaposed with “decrease” to form the phrase “cost decrease,” however, a positive sentiment is conveyed. The fact that even the Hugging Face pipeline (Jain, 2022) contextual representation-based method, one of the most powerful sentiment analysis tools, misclassifies the phrase “cost decrease” as strong negative starkly illustrates the importance of directional expressions. Given their significance, the presence of directional expressions should be carefully considered when conducting sentiment analysis on financial documents. To overcome such limitations, several attempts have been made to incorporate contextual information associated with directional expressions into lexicons. In particular, Oliveira et al. (2016) considered directional words in building a sentiment lexicon using microblog messages from StockTwits. However, their consideration of the relationships between given and directional words was still indirect because it relied on the aggregated estimates of the degree of association.
In this study, a sentiment lexicon named “sentiment lexicon composed of direction-dependent words” (Senti-DD) is proposed. Each element in Senti-DD is a pair comprising a directional word and a direction-dependent word. Throughout this study, a word is defined as direction-dependent if its sentiment orientation changes when used in combination with directional words. Direction-dependent words-such as “profit,” “cost,” or “operating loss,” which are widely used in corporate memorandums, analyst reports, and news articles analyzing the financial market-are important contextual words that affect sentiment analysis. Thus, the direct extraction of direction-dependent words are anticipated to contribute to broadening our understanding of market sentiment. The proposed sentiment lexicon is applied to benchmark datasets comprising economic news headlines, demonstrating its ability to achieve both explainability and reasonable performance.
Our work contributes to the existing literature as follows.
-
We propose a data-driven method for automatically extracting direction-dependent words that affect the sentiment of a given sentence.
-
The proposed Senti-DD, which expresses each term as a pair comprising a directional word and a direction-dependent word, is released to the research community for public usage: https://github.com/sophia-jihye/Senti-DD.
-
We develop a framework that integrates Senti-DD as a plug-in lexicon to the Loughran–McDonald Word List to achieve enhanced sentiment classification performance.
-
We carry out in-depth experiments to compare the proposed lexicon with other conventional lexicons. We also show that the proposed lexicon can perform reasonably well even when compared to pretrained models.
In this study, our objective is to directly ascertain the association between directional and direction-dependent words. We automatically extract 56 direction-dependent wordsFootnote 1 and construct a lexicon comprising 1767 pairs.Footnote 2 Given the widespread use of directional and direction-dependent words in financial texts, the sentiment pairs within Senti-DD are anticipated to play a pivotal role in determining the overall sentiment polarity of a sentence. To gauge the effectiveness of the automatically constructed lexicon proposed in this study, we conducted sentiment classification tasks, wherein Senti-DD consistently outperformed other baseline lexicons, achieving higher F1 scores. This suggests that the inclusion of directional and direction-dependent words in our lexicon contributes significantly to its effectiveness in capturing sentiment nuances in financial text.
2 Related works
There are two general approaches for constructing financial lexicons: (1) manual approaches, in which sentiment words are determined purely by experts’ manual inspection; and (2) corpus-based approaches, in which sentiment words are extracted from a given corpus.
The most popular manually constructed financial sentiment lexicon is the Loughran–McDonald Word List. Loughran and McDonald (2011) claimed that approximately three-quarters of the negative words found in the Harvard General Inquirer (HGI) word lists (Stone et al., 1962) were associated with non-negative sentiments when viewed from the perspective of business applications. To appropriately determine sentiment words in the financial domain, Loughran and McDonald (2011) created an accurate and reliable lexicon by examining 2.5 billion words in the Form 10-K filings, which comprehensively summarize individual companies’ financial performance. However, manually constructed lexicons face limitations in terms of time, human labor, and background knowledge (Li et al., 2014).
To address the issues associated with the manual construction of sentiment lexicons and satisfy the growing demand for the sentiment analysis of financial textual data, corpus-based approaches using statistical features have been proposed to automate the construction process. Yekrangi and Abdolvand (2021) used pointwise mutual information (PMI) to estimate the polarities of individual words. The authors first analyzed 554,915 textual documents published on Bloomberg and Reuters between 2006 and 2013 to identify the words frequently used in the financial domain, and then investigated the sentiment orientation of each word. Brazdil et al. (2022) proposed scoring methods that use word frequencies to estimate the distribution of word occurrence probabilities. The authors developed a manually labeled dataset comprising sentences from Portuguese news articles and analyzed the distribution of word occurrences across various sentiment scores.
However, these studies did not consider the domain-specific feature required to analyze texts used in the financial domain. As indicated in Sect. 1, one of the most important characteristics of financial text is that the sentiment orientation of certain terms can change significantly depending on the presence of directional expressions.
A few studies have attempted to manually build lexicons containing directional expressions. Malo et al. (2014) extracted a list of terms from the Investopedia website and found 177 financial entities that could affect the sentiment of a sentence when used with motion verbs. Krishnamoorthy (2018) manually defined words that indicated the results of firm activities-such as improvement or decline in sales, market share, operating profit, operating cost, orders, and inventory turns—as lagging indicators and defined words that indicated future events—such as the number of new stores and employees—as leading indicators. Moreno-Ortiz et al. (2020) carefully analyzed business news articles to identify financial terms that conveyed a sentiment when combined with directional lexical elements. Defining the pairing of a term and a directional element as a multi-word expression, they constructed a lexicon containing 6470 entries, including both single- and multi-word expressions. These studies on manual curation demonstrated improvement in terms of sentiment analysis, proving the importance of directionality in the financial domain. However, further improvements can be achieved by automatically extracting direction-dependent sentiment words.
Oliveira et al. (2016) attempted to automatically construct a lexicon containing directional expressions by measuring the relationship between words and modifiers. A modifier is an optional element that modifies the meaning of another element in a phrase or clause structure. For each word, the authors measured the degrees of association with sentiment labels and modifiers, respectively. Two types of modifiers were used in their experiment: intensifiers (e.g., “more” and “increase”) and diminishers (e.g., “less” and “decrease”). However, as the study relied on the aggregated estimates of the degree of word association, the given words and modifiers still had indirect relationships, resulting in a number of expressions that are ambiguous to be considered sentiment words.
Table 1 provides a summary of lexicons proposed in previous studies. The HGI word lists, serving as a lexicon for general domains, comprise 11,788 phrases, including 1915 positive phrases and 2291 negative phrases. The Loughran–McDonald Word List, a manually constructed financial domain-specific lexicon without consideration of directional words, consists of 86,486 phrases, encompassing 354 positive phrases and 2355 negative phrases. Malo et al. (2014)’s lexicon, also manually constructed but with consideration of directional words, consists of 177 entities that have a discernible effect on sentiment when combined with a verb representing movement up or down. Oliveira et al. (2016)’s lexicon, an automatically constructed lexicon with indirect consideration of directional words, contains 20,550 phrases, each assigned continuous sentiment scores.
In this study, direction-dependent words were directly extracted based on the measure of association between given words and their direction-dependency types to overcome these limitations. PMI, a popular lexical statistic that computes the intensity of coexistence between two variables, was used as a measure of association. Previous studies have used PMI to generate sentiment words by calculating the degree of association between words and sentiments (Oliveira et al., 2016) or expand seed words by calculating the degree of association between given words (Yekrangi & Abdolvand, 2021; Yu et al., 2013). The proposed lexicon was then built by adding pairs comprising directional and direction-dependent words.
3 Proposed approach
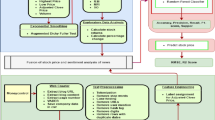
In this section, we introduce a data-driven sentiment lexicon construction framework. The proposed lexicon, Senti-DD, is constructed by computing the PMI score as an estimate of a given word’s direction-dependency type. An overview of the proposed framework is shown in Fig. 1.

Overview of the proposed sentiment lexicon construction framework
3.1 Direction-dependency type tagging for each sentence
As a first step in constructing Senti-DD, polar sentences representing either positive or negative sentiment are gathered from a finance-related labeled corpus. Given a set of polar sentences and a word list with each word assigned the directional label “up” or “down,” the UpScore and DownScore of a subject sentence are defined as the number of “up” and “down” words, respectively, found in the sentence. In the experiment, the verbs in a given sentence and the directional words were stemmed using the Porter Stemmer in the NLTK library (Bird et al., 2009) and then compared for matches. Following the findings of Pramana et al. (2022), which suggested that stemming demonstrates reasonably high performance for shorter queries, we employed the stemming method for word comparison in this study, which specifically deals with one-sentence-long financial news headlines. Finally, each sentence, s, is given a direction score, \(DirectionScore(s) = UpScore(s) - DownScore(s),\) that reflects the degree of direction conveyed by s.
Based on the relationship between its direction score and sentiment label, each sentence is assigned a tag representing a direction-dependency type. Two direction-dependency tags are used: “proportional” and “inversely proportional.” A sentence is tagged “proportional” if its sentiment is either positive with a direction score greater than zero or negative with a direction score less than zero. Similarly, a sentence is tagged “inversely proportional” if its sentiment is either positive with a direction score less than zero or negative with a direction score greater than zero. The proposed framework uses only “proportional” and “inversely proportional”-type sentences.
3.2 Estimation of the degree of association Between a word and a direction-dependency type
Prior to estimating statistical correlations, each sentence is transformed into a list of nouns via tokenization and part-of-speech tagging using the Natural Language Toolkit (NLTK) library (Bird et al., 2009). All extracted nouns are lemmatized using the NLTK. Nouns that occur in fewer than one percent of the sentences are disregarded.
The association between each word, w, and its direction-dependency type, which is either “proportional,” \(t_p,\) or “inversely proportional,” \(t_i,\) is measured using the following definition of the PMI score, \(PMI(w,t)=\log_2{\frac{p(w,t)}{p(w)p(t)}},\) where p(w, t) is the probability that a sentence of direction-dependency type t containing the word w is found in the subject corpus, p(w) is the probability that w is found in the subject corpus, and p(t) is the probability that a sentence of direction-dependency type t is found in the subject corpus.
To simplify the calculation, the dependency score of a given word w is defined as follows:
where \(\delta \ge 0\) is a parameter that adjusts the number of direction-dependent entities; setting a larger value of \(\delta\) decreases the number of entities, and vice versa. In this study, to obtain as many direction-dependent entities as possible, the value of \(\delta\) in Eq. 1 was set to 0.
Table 2 demonstrates the calculation of the dependency score for the word “profit.” A word with a positive dependency score is regarded as a candidate word of the “proportional” type, which represents a positive sentiment when used with “up” words and a negative sentiment when used with “down” words. Similarly, a word with a negative dependency score is regarded as a candidate word of the “inversely proportional” type, which represents a positive sentiment when used with “down” words and a negative sentiment when used with “up” words.
3.3 Extraction of direction-dependent words
Based on the relationship between the direction-dependency tag of a sentence and the dependency score of a word, a single representative word from each sentence is extracted according to the following rules: if a sentence is “proportional,” the word with the highest dependency score among the candidate “proportional” words is extracted as a “proportional” type direction-dependent word. Conversely, if a sentence is “inversely proportional,” the word with the lowest dependency score among the candidate “inversely proportional” words is extracted as an “inversely proportional” type direction-dependent word. For post-processing, words containing non-alphabet characters and words with less than k letters, where k is a parameter adjusting the number of direction-dependent words, are treated as noise and filtered out. A small value of k leads to treating unimportant words as direction-dependent words, while a large value of k causes important words to be excluded from the set of direction-dependent words. Based on manual checking, it was concluded that words with less than 3 letters had no significant meaning for the data used in this study; consequently, the value of k was set to 3.
3.4 Senti-DD construction based on the directional and direction-dependent word lists
To construct Senti-DD, pairs of words are created from the lists of directional and direction-dependent words, respectively. A pair comprising an “up” and a “proportional” word or a pair comprising a “down” and an “inversely proportional” word is labeled as a positive-context pair. Similarly, a pair comprising an “up” and an “inversely proportional” word or a pair comprising a “down” and a “proportional” word is labeled as a negative-context pair.
4 Experiment
4.1 Details on building Senti-DD
Directional words were defined following the experimental settings used in previous works (Krishnamoorthy, 2018; Malo et al., 2014). “Up” and “down” terms were formed by using the HGI word lists (Stone et al., 1962) as seed lists, with words defined under the “increase” and “rise” categories classified as “up” terms and those under the “decrease” and “fall” categories classified as “down” terms. Following manual review, 20 terms were classified under the “up” category and 11 were classified under the “down” category. Table 3 presents the full list of carefully selected directional words.
It would be noteworthy to mention that the predetermined terms labeled as “up” and “down” (considered as directional words) in this study constitute a cost-effective resource easily accessible online. Our proposed method strategically employs these readily available directional words to construct a resource comprising direction-dependent words, which are inherently difficult to obtain. This strategy enables us to harness easily accessible linguistic cues for developing a more sophisticated and specialized lexicon aligned with our research goals.
From the 4835 sentences in the DS50 dataset, 691 sentences were tagged as “proportional” and 28 were tagged as “inversely proportional.” Table 4 lists examples of sentences with tags.
4.2 Evaluation framework
Evaluating the quality of the sentiment lexicon becomes very difficult without several inter-annotator agreement metrics (Takala et al., 2014), which require a significant time and labor expense. Thus, we propose assessing the performance of the proposed lexicon by performing sentiment classification as a downstream task. Figure 2 presents an overview of the proposed evaluation framework.

Overview of the proposed evaluation framework
Sentiment classification is performed based on an augmented lexicon combining the Loughran–McDonald Word List and Senti-DD. Using the Loughran–McDonald Word List, the overall polarity of a sentence is determined; then, the score is refined using Senti-DD to capture the co-occurrence of directional and direction-dependent words. Finally, based on the refined score, the sentence is classified as positive, negative, or neutral.
4.2.1 Loughran–McDonald Word List-based sentiment score
For a given sentence, s, its PosScore and NegScore are defined as the number of positive and negative words in the Loughran–McDonald Word List, respectively, that it contains. The sentiment score of s is then computed as follows:
4.2.2 Senti-DD-based refined score
Using Senti-DD, ContPosScore and ContNegScore are defined as the number of positive- and negative-context pairs found, respectively, in the subject sentence. Then, the context score is computed as follows:
The sentiment score is refined based on the ContextScore to capture the additional positivity or negativity influenced by the context of the sentence. This refinement process involves the summation of SentimentScore and ContextScore as follows:
Table 5 demonstrates the calculation of a refined score.
Finally, sentences with refined scores greater than, equal to, or less than zero are classified as positive, neutral, or negative, respectively.
4.3 Dataset description
Three datasets containing labeled economic news headlines were used: the Financial Phrase Bank (FPB) (Malo et al., 2014), the dataset created for subtask 2 of Task 5 in SemEval 2017 (SemEval) (Cortis et al., 2017), and the dataset created for Task 1 of the financial opinion mining and question answering (FiQA) challenge (Maia et al., 2018). The FPB comprises 4835 English sentences annotated by 16 experts in finance and business. The annotators were instructed to give a positive, negative, or neutral label according to how they thought the information in a sentence might affect the stock price of the mentioned company. Based on the level of agreement (50, 66, 75, and 100%) among the annotators, the FPB was divided into four subsets: DS50, DS66, DS75, and DS100, respectively. Each of the 960 messages in the SemEval database was annotated with a floating-point value between − 1 (negative) and 1 (positive) denoting the sentiment expressed towards the mentioned company; a value of 0 denoted neutral sentiment. Each of the 436 publicly available FiQA sentences was annotated with a target aspect sentiment score ranging from − 1 (negative) to 1 (positive). In the experiment, the sentiment score of the aspect in a given sentence was treated as the sentiment score of the sentence; for sentences with multiple aspects, one aspect was randomly selected and the other aspects were removed. As the original labels of the sentences in SemEval and FiQA had continuous sentiment scores, we categorized these sentences into positive, neutral, and negative classes if their scores were greater than, equal to, or less than zero, respectively. The characteristics of each dataset are listed in Table 6.
To ensure the robustness of the results, a stratified five-fold cross-validation was conducted. The process was repeated five times, with each of the five folds used exactly once as test data, and the average score was obtained.
4.4 Baselines
Sentiment140 (Mohammad et al., 2013), SentiWordNet (SWN) (Baccianella et al., 2010), semantic orientation calculator (SO-CAL) (Taboada et al., 2011), multi-perspective question answering opinion corpus (MPQA) (Wilson et al., 2005), TextBlob,Footnote 3 valence aware dictionary for sentiment reasoning (VADER) (Hutto & Gilbert, 2014), SentiStrength (Thelwall et al., 2010), a lexicon developed by Finn Arup Nielsen (AFINN) (Nielsen, 2011), and Loughran–McDonald Word List (Loughran & McDonald, 2011) were used as baseline lexicons for comparison.
The terms used in Sentiment140 and VADER have sentiment scores with floating-point values. Sentiment140 uses 43,431 terms with scores ranging from − 5 to 5 and returns the sum of the scores for the words in a given sentence. VADER uses a curated lexicon of 7517 words and returns a normalized score ranging from − 1 to 1. In an experiment using Sentiment140 and VADER, scores greater than or equal to 0.05, less than or equal to − 0.05, and between − 0.05 and 0.05 were classified as positive, negative, and neutral, respectively. SWN uses 117,659 terms with scores for positivity, negativity, and objectivity ranging from − 1 to 1. SO-CAL uses 6395 terms with discrete sentiment-scores ranging from − 5 to 5. AFINN uses a lexicon containing 2477 words with scores between − 5 and 5. SWN, SO-CAL, and AFINN return sentiment scores for individual sentences by subtracting the sums of negative scores from the positive scores of the words. TextBlob and SentiStrength are rule-based sentiment analyzers using lexicons of 2918 and over 2800 terms, respectively. Both analyzers return a sentiment score ranging from − 1 to 1. Loughran–McDonald Word List contains 354 positive words and 2355 negative words. MPQA contains 2718 positive words and 4911 negative words. For Loughran–McDonald Word List and MPQA, the sentiment score was obtained by subtracting the number of negative words from the number of positive words, as defined in Eq. 2. In our experiment using SWN, SO-CAL, AFINN, TextBlob, SentiStrength, Loughran–McDonald Word List, and MPQA, we classified a sentence as positive, negative, or neutral if its sentiment score was greater than, less than, or equal to zero, respectively.
We also compared the proposed method, which achieves reasonable performance using lexicon-based intuitive inference, with several pretrained models— Word2Vec model with logistic regression (Word2Vec) (Mikolov et al., 2013), Bidirectional Encoder Representations from Transformers (BERT) (Devlin et al., 2019), and a robustly optimized BERT (RoBERTa) (Liu et al., 2019)— that achieve high performance but are treated as black boxes. Word2Vec obtained sentence embedding by averaging the embeddings of words within a sentence; using these sentence embeddings as feature vectors, logistic regression was then conducted. BERT and RoBERTa adopted fine-tuning approaches. For fine-tuning, an embedding layer was added on top of the existing hidden layers; subsequently, classification was conducted using the embedding vectors obtained for the sentences as feature vectors.
In this experiment, we used the word2vec-google-news-300,Footnote 4bert-base-uncased,Footnote 5 and roberta-baseFootnote 6. for Word2Vec, BERT, and RoBERTa models, respectively. For BERT and RoBERTa, model parameters were optimized using the Adam optimizer (Kingma & Ba, 2015) with a weight decay of 0.01. The batch size was set to eight; the learning rates were based on the warm-up schedule strategy proposed by Vaswani et al. (2017), with warm-up occurring over the first 500 steps; and the maximum number of training epochs was set to three. The primary focus of this study was to demonstrate the feasibility of automatically constructing a financial domain-specific sentiment lexicon using directional words, rather than pursuing an optimal sentiment lexicon that enables state-of-the-art sentiment analysis performance. In line with this research objective, hyperparameter values, such as the number of epochs, were determined heuristically. However, exploring the potential of incorporating a hyperparameter tuning process would be a valuable direction for future investigations.
5 Results and discussion
Table 7 shows the classification performance of the respective methods on the sentiment classification task. LM indicates Loughran–McDonald Word List. All values are weighted average values, with the best value among lexicon-based methods per measure marked in bold. The results on the four subsets of the FPB indicate that the proposed LM + Senti-DD consistently outperforms other baseline lexicons by achieving higher F1 scores. Considering that low levels of agreement imply low-quality labels, the results prove the robustness of the proposed method against variations in labeling quality. This indicates that the Senti-DD score refinement process, which reflects context by capturing the co-occurrence of directional and direction-dependent words, is effective when applied to documents with both high and low levels of consent for sentiment (high- and low-quality labels, respectively).
As previously discussed in Sect. 1, lexicon-based approaches offer notable advantages due to their inherent explainability and transparency. These characteristics enable a comprehensive analysis of the internal mechanisms involved in calculating the sentiment score for each case. The performance improvement achieved by LM + Senti-DD can be attributed to its ability to reflect context by incorporating the effects of directional words when classifying sentences. For example, LM misclassifies the sentence “Profit for the period was EUR 10.9 million, down from EUR 14.3 million in 2009” (Malo et al., 2014) as neutral because the sentence contains neither positive nor negative words in the LM. The proposed method, however, correctly classifies the sentence as negative because it contains both “down” and “profit” as “down-” and “proportional-” type words. Figure 3 illustrates this example of sentiment analysis using Senti-DD.

Example of sentiment analysis using Senti-DD
By contrast, for SemEval and FiQA, most of the lexicons produce low F1 scores of less than 0.5. This is because lexicon-based methods can degrade sentiment analysis performance if sentiment words are not explicitly expressed within a sentence. On the other hand, pretrained models demonstrate an improved performance relative to lexicon-based methods on nearly all measures. It appears that pretrained models trained on various sources such as Wikipedia can detect contexts that are not expressed in direction-dependent words. For instance, the sentence “Cuts equivalent to the costs of about 35–45 employees are the target, the company said” (Malo et al., 2014), which is labeled as a negative class in DS50, is incorrectly classified as neutral by LM + Senti-DD but correctly classified as negative by pretrained models such as BERT and RoBERTa. We presume that these pretrained models might detect that the sentence refers to layoffs; then, they might classify the sentence as negative based on Wikipedia-driven knowledge that layoffs occur in crises. However, it is important to highlight that the inference mechanism of pretrained models that employ neural network-based operations is generally regarded as a black box; the preceding statements pertaining to the internal mechanisms of pretrained models are based solely on speculative reasoning from our perspective. Thus, in this study, we focused on building a lexicon that provides an intuitive reasoning basis, albeit with a performance worse than that of pretrained models.
Table 8 and Fig. 4 show the experimental results on the DS100 dataset in detail. Interestingly, the F1 score for the negative class achieved by LM + Senti-DD is nearly twice the score achieved by LM. This indicates that LM + Senti-DD generally outperforms other lexicons, particularly in classifying sentences into positive and negative classes. Although VADER achieves a high recall for the positive class, its precision is significantly lower than that of LM + Senti-DD; consequently, LM + Senti-DD achieves a higher F1 score. It appears that the rules for calculating sentiment scores in VADER tend to be biased toward predicting a large number of positive sentiments. Similarly, Sentiment140 records a high recall and relatively lower precision for the negative class, which can be attributed to Sentiment140’s bias toward predicting a substantial number of negative sentiments.

Graphical comparison of the results for the DS100 dataset. LM indicates Loughran–McDonald Word List
Table 9 lists all of the direction-dependent words extracted from the DS50 dataset. The table lists 49 “proportional” and 7 “inversely proportional”-type words in alphabetical order. As described in Sect. 3, “proportional”-type words can lead to a positive or negative sentiment when combined with an “up” or a “down” type word, respectively, and the opposite applies to “inversely proportional”-type words. A majority of the words appear to be appropriately identified. Intuitively, the words “capital,” “demand,” “investment,” “profit,” and “revenue” are correctly listed as “proportional” words; and the term “cost” is correctly listed as an “inversely proportional” word.
As indicated in Sect. 4.1, the number of sentences in the DS50 dataset tagged as “inversely proportional” is relatively small, leading to a small number of “inversely proportional”-type words. Furthermore, the imbalance between the number of “proportional” and “inversely proportional”-type sentences appears to produce noisy words such as “beer” and “day” that are not intuitively interpreted as direction-dependent words. This is due to the possibility that some words that should be frequently used regardless of direction-dependency types might appear only in certain types of sentences and not in other types of sentences. Notwithstanding these limitations, these preliminary results demonstrate the possibility of automatically acquiring direction-dependent words using the proposed PMI-based method.
To provide evidence for the interpretable sentiment classification process using the proposed Senti-DD lexicon, we conducted an additional experiment on the entire DS100 dataset consisting of 2259 sentences. The experiment utilized all direction-dependent words from Table 9 to construct the Senti-DD lexicon. The complete list of positive/negative pairs detected in each sentence is accessible at https://github.com/sophia-jihye/Senti-DD/blob/main/results/senti_dd_interpretability_evidence_for_appendix.csv, with 20 samples of experimental results listed in Appendix 1. The results presented in Appendix 1 demonstrate that directional and direction-dependent words are highly prevalent in financial texts, supporting the evidence that these words influence the overall sentiment polarity of a sentence. Among the 20 cases in Appendix 1, 10 are correctly classified, while the remaining 10 are misclassified using Senti-DD. Each case is explained through detected positive and negative pairs. For instance, the sentence “Excluding non-recurring items, pre-tax profit surged 45% to EUR 80 million” was correctly classified as positive, with Senti-DD identifying positive pairs such as (profit, surge) and (item, surge). Conversely, the sentence “At the same time, profit of the company increased by 10% in H1 and reached EUR 79,000” originally labeled as positive, was misclassified as neutral due to the detected pairs (profit, increase) and (company, increase) being considered a positive and negative context in Senti-DD, respectively. If users consider (company, increase) as a non-negative context and decide to remove it from the lexicon, this would modify the sentiment classification process, leading to the correct classification of the sentence as positive.
6 Conclusion
With the growing demand for sentiment analysis in financial and economic applications, it is essential to build domain-specific sentiment lexicons that can achieve both high performance and explainability. In this study, we proposed a financial domain-specific sentiment lexicon, Senti-DD, whose elements comprise pairs of directional and direction-dependent words. Extensive experimental results demonstrate that an augmented lexicon obtained using Senti-DD outperformed existing sentiment lexicons in solving sentiment classification tasks. In particular, Senti-DD identified “communication” and “value” as “proportional” type words that create a positive/negative sentiment when they are combined with an up/down-type word. Considering that these direction-dependent words can have either a positive or negative effect on the stock price of the companies, they can serve as lexical items for corporate performance indicators. Future research can examine the impact of each of the automatically extracted corporate performance indicators on the company’s stock price. While the inference mechanism of pretrained models relies solely on speculative reasoning, the proposed sentiment lexicon allows for transparent explainability of the sentiment analysis process. Conducting a future study to investigate the integration of the proposed lexicon into transformer-based approaches to enhance their explainability would be worthwhile.
Analyzing the statements and minutes of the Federal Open Market Committee can also be considered a future work. The Federal Open Market Committee meets eight times each year to decide on monetary policy; during these meetings, the participants formulate their views on economic conditions and determine their stance on monetary policy (Cannon, 2015). Thus, automatic analysis of statements and minutes released at these meetings will broaden the understanding of current financial conditions and future monetary policy directions. It would be possible to automatically extract terms that frequently appear in documents that affect interest rate increases/decreases by treating the interest rate increase/decrease figures that are reported immediately after the announcement of the document as labels, instead of sentence labels expressed as “positive” or “negative.” We anticipate that more comprehensive analysis of various modes of central bank communications would help to capture the intricacies of sentiment in financial language.
Although the performance of the proposed lexicon is promising, there is room for improvement. The proposed approach necessitates the meticulous selection of directional words by the researchers in order to construct a financial domain-specific sentiment lexicon. However, the creation of a predefined set of directional words is a time-consuming and subjective process. Additionally, the directional words may evolve over time with the emergence of new jargon. To mitigate the need for researchers’ manual intervention in defining directional words and to capture the most current vocabulary, the exploration of automatic identification of directional words should be regarded as a future study. Meanwhile, the proposed method classifies sentences as neutral when it contains equal numbers of positive and negative words; this is a passive approach to detecting neutrality. Valdivia et al. (2018) demonstrated that detecting neutrality first before classifying sentences as positive or negative can improve sentiment analysis performance; thus, pre-detection of neutrality in financial documents can be considered in future work. Fine-grained sentiment analysis, which classifies sentiments into multi-classes (Van de Kauter et al., 2015) rather than binary classes, can also be explored. In general, classes can be subdivided into anxiety, sadness, anger, excitement, and happiness (Wang et al., 2020); in the case of financial documents, classes can be further segmented by identifying whether positivity/negativity is directed toward the entire market or a particular company. In addition, acquiring a larger number of financial documents such as analyst reports containing many directional words will help improve the quality of Senti-DD.
The proposed approach, which automatically extracts words dependent on certain types of words, can easily be applied to other domains. For example, it would be interesting to extend the approach to sentiment analysis of online reviews on electronics, in which the sentiment orientation of the term “definition” changes depending on the presence of the terms “high” and “low.” The phrase “high-definition” leads to a positive sentiment, while “low-definition” leads to a negative sentiment. In this context, the proposed lexicon would assist in accurate sentiment analysis by treating the term “definition” as a “proportional”-type word that represents a positive sentiment when used with “high” and a negative sentiment when used with “low.” In future studies, different characteristics of direction-dependent words in various domains would be investigated.
Data availability
The codes and the proposed sentiment lexicon, Senti-DD, are available at https://github.com/sophia-jihye/Senti-DD. The original datasets used in the experiments— the Financial Phrase Bank (Malo et al., 2014), the dataset created for subtask 2 of Task 5 in SemEval 2017 (Cortis et al., 2017), and the dataset created for Task 1 of the financial opinion mining and question answering (Maia et al., 2018)— are available in the following repositories, respectively: https://www.researchgate.net/publication/251231364_FinancialPhraseBank-v10, https://alt.qcri.org/semeval2017/task5/index.php, and https://sites.google.com/view/fiqa/home.
Notes
https://github.com/sloria/TextBlob [Accessed: January 6, 2024].
https://huggingface.co/fse/word2vec-google-news-300 [Accessed: January 6, 2024].
https://huggingface.co/bert-base-uncased [Accessed: January 6, 2024].
https://huggingface.co/roberta-base [Accessed: January 6, 2024].
References
Abdaoui, A., Azé, J., Bringay, S., & Poncelet, P. (2017). Feel: A French expanded emotion lexicon. Language Resources and Evaluation, 51(3), 833–855.
Baccianella, S., Esuli, A., & Sebastiani, F. (2010). SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the 7th conference on international language resources and evaluation (pp. 2200–2204).
Bandhakavi, A., Wiratunga, N., Massie, S., & Padmanabhan, D. (2017). Lexicon generation for emotion detection from text. IEEE Intelligent Systems, 32(1), 102–108.
Bird, S., Klein, E., & Loper, E. (2009). Natural language processing with python: Analyzing text with the natural language toolkit. O’Reilly.
Bracke, P., Datta, A., Jung, C., & Sen, S. (2019). Machine learning explainability in finance: An application to default risk analysis. Bank of England Working Paper. Retrieved January 6, 2024, from https://www.bankofengland.co.uk/working-paper/2019/machine-learning-explainability-in-finance-an-application-to-default-risk-analysis
Brazdil, P., Silvano, P., Silva, F., Muhammad, S., Oliveira, F., Cordeiro, J., & Leal, A. (2022). Extending general sentiment lexicon to specific domains in (semi-) automatic manner. In 1st Workshop on sentiment analysis & linguistic linked data: Proceedings of the workshops and tutorials held at LDK 2021 co-located with the 3rd language, data and knowledge conference.
Bussmann, N., Giudici, P., Marinelli, D., & Papenbrock, J. (2021). Explainable machine learning in credit risk management. Computational Economics, 57(1), 203–216.
Cambria, E., & Hussain, A. (2015). Sentic computing. Cognitive Computation, 7(2), 183–185.
Campbell, G., Turner, J. D., & Walker, C. B. (2012). The role of the media in a bubble. Explorations in Economic History, 49(4), 461–481.
Cannon, S. (2015). Sentiment of the FOMC: Unscripted. Economic Review - Federal Reserve Bank of Kansas City, 100(4), 5–31.
Cheng, W. K., Bea, K. T., Leow, S. M. H., Chan, J. Y.-L., Hong, Z.-W., & Chen, Y.-L. (2022). A review of sentiment, semantic and event-extraction-based approaches in stock forecasting. Mathematics, 10(14), 2437.
Choi, S., Park, H., Yeo, J., & Hwang, S.-W. (2020). Less is more: Attention supervision with counterfactuals for text classification. In Proceedings of the 2020 conference on empirical methods in natural language processing (pp. 6695–6704).
Cortis, K., Freitas, A., Daudert, T., Huerlimann, M., Zarrouk, M., Handschuh, S., & Davis, B. (2017). Semeval-2017 task 5: Fine-grained sentiment analysis on financial microblogs and news (pp. 519–535). Association for Computational Linguistics (ACL). Retrieved January 6, 2024, from https://alt.qcri.org/semeval2017/task5/index.php
Dehkharghani, R., Saygin, Y., Yanikoglu, B., & Oflazer, K. (2016). SentiTurkNet: A Turkish polarity lexicon for sentiment analysis. Language Resources and Evaluation, 50(3), 667–685.
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pretraining of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American Chapter of the Association for Computational Linguistics: Human language technologies (pp. 4171–4186).
Dougal, C., Engelberg, J., Garcia, D., & Parsons, C. A. (2012). Journalists and the stock market. The Review of Financial Studies, 25(3), 639–679.
Engelberg, J. E., & Parsons, C. A. (2011). The causal impact of media in financial markets. The Journal of Finance, 66(1), 67–97.
Feng, Z., Zhou, H., Zhu, Z., & Mao, K. (2022). Tailored text augmentation for sentiment analysis. Expert Systems with Applications, 205, 117605.
Garcia, D. (2013). Sentiment during recessions. The Journal of Finance, 68(3), 1267–1300.
Hanna, A. J., Turner, J. D., & Walker, C. B. (2020). News media and investor sentiment during bull and bear markets. The European Journal of Finance, 26(14), 1377–1395.
Hutto, C., & Gilbert, E. (2014). VADER: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the international AAAI conference on web and social media (pp. 216–225).
Jain, S. M. (2022). Introduction to transformers for NLP. Apress. https://doi.org/10.1007/978-1-4842-88443
Kingma, D. P., & Ba, J. (2015). Adam: A method for stochastic optimization. In 3rd International conference on learning representations.
Krishnamoorthy, S. (2018). Sentiment analysis of financial news articles using performance indicators. Knowledge and Information Systems, 56(2), 373–394.
Li, J.-H., You, C.-F., Huang, & C.-S. (2020). Do mutual fund managers time market sentiment? International Journal of Financial Research, 11(5), 527–537.
Li, X., Xie, H., Chen, L., Wang, J., & Deng, X. (2014). News impact on stock price return via sentiment analysis. Knowledge-Based Systems, 69, 14–23.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). Roberta: A robustly optimized bert pretraining approach. arXiv preprint. arXiv:1907.11692
Loughran, T., & McDonald, B. (2011). When is a liability not a liability? textual analysis, dictionaries, and 10-ks. The Journal of Finance, 66(1), 35–65.
Maia, M., Handschuh, S., Freitas, A., Davis, B., McDermott, R., Zarrouk, M., & Balahur, A. (2018). WWW’18 Open Challenge: Financial Opinion Mining and Question Answering. In Companion proceedings of the the web conference 2018 (pp. 1941–1942). Retrieved January 6, 2024, from https://sites.google.com/view/fiqa/home
Malo, P., Sinha, A., Korhonen, P., Wallenius, J., & Takala, P. (2014). Good debt or bad debt: Detecting semantic orientations in economic texts. Journal of the Association for Information Science and Technology, 65(4), 782–796.
Mashrur, A., Luo, W., Zaidi, N. A., & Robles-Kelly, A. (2020). Machine learning for financial risk management: A survey. IEEE Access, 8(203203), 203223.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (Vol. 26, pp. 3111–3119). Curran Associates.
Mishev, K., Gjorgjevikj, A., Vodenska, I., Chitkushev, L. T., & Trajanov, D. (2020). Evaluation of sentiment analysis in finance: From lexicons to transformers. IEEE Access, 8(131662), 131682.
Mohammad, S., Kiritchenko, S., & Zhu, X. (2013). NRC-Canada: Building the state-of-the-art in sentiment analysis of tweets. In Proceedings of the 7th international workshop on semantic evaluation (pp. 321–327).
Moreno-Ortiz, A., Fernández-Cruz, J., & Hernández, C. P. C. (2020). Design and evaluation of SentiEcon: A fine-grained economic/financial sentiment lexicon from a corpus of business news. In Proceedings of the 12th language resources and evaluation conference (pp. 5065–5072).
Nielsen, F. Å. (2011). A new ANEW: Evaluation of a word list for sentiment analysis in microblogs. In Proceedings of the ESWC2011 workshop on “Making Sense of Microposts”: Big things come in small packages (Vol. 718, pp. 93–98).
Oliveira, N., Cortez, P., & Areal, N. (2016). Stock market sentiment lexicon acquisition using microblogging data and statistical measures. Decision Support Systems, 85(62), 73.
Picasso, A., Merello, S., Ma, Y., Oneto, L., & Cambria, E. (2019). Technical analysis and sentiment embeddings for market trend prediction. Expert Systems with Applications, 135, 60–70.
Pramana, R., Subroto, J. J., Gunawan, A. A. S., & Anderies. (2022). Systematic literature review of stemming and lemmatization performance for sentence similarity. In 2022 IEEE 7th international conference on information technology and digital applications (ICITDA) (pp. 1–6).
Razova, E., Vychegzhanin, S., & Kotelnikov, E. (2022). Does BERT look at sentiment lexicon? In International conference on analysis of images, social networks and texts (pp. 55–67).
Ruiz-Martínez, J. M., Valencia-García, R., & García-Sánchez, F. (2012). Semantic-based sentiment analysis in financial news. In Proceedings of the 1st international workshop on finance and economics on the semantic web (pp. 38–51).
Shiller, R. J. (2016). Irrational exuberance. Princeton University Press. https://doi.org/10.1515/9781400865536
Stone, P. J., Bales, R. F., Namenwirth, J. Z., & Ogilvie, D. M. (1962). The general inquirer: A computer system for content analysis and retrieval based on the sentence as a unit of information. Behavioral Science, 7(4), 484.
Taboada, M., Brooke, J., Tofiloski, M., Voll, K., & Stede, M. (2011). Lexicon-based methods for sentiment analysis. Computational Linguistics, 37(2), 267–307.
Takala, P., Malo, P., Sinha, A., & Ahlgren, O. (2014). Gold-standard for topic-specific sentiment analysis of economic texts. In N. Calzolari (Ed.), Proceedings of the 9th international conference on language resources and evaluation (LREC’14) (pp. 2152–2157). European Language Resources Association (ELRA).
Tetlock, P. C. (2007). Giving content to investor sentiment: The role of media in the stock market. The Journal of Finance, 62(3), 1139–1168.
Thelwall, M., Buckley, K., Paltoglou, G., Cai, D., & Kappas, A. (2010). Sentiment strength detection in short informal text. Journal of the Association for Information Science and Technology, 61(12), 2544–2558.
Valdivia, A., Luzón, M. V., Cambria, E., & Herrera, F. (2018). Consensus vote models for detecting and filtering neutrality in sentiment analysis. Information Fusion, 44, 126–135.
Van de Kauter, M., Breesch, D., & Hoste, V. (2015). Fine-grained analysis of explicit and implicit sentiment in financial news articles. Expert Systems with Applications, 42(11), 4999–5010.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (Vol. 30). Curran Associates.
Vidanagama, D., Silva, A., & Karunananda, A. (2022). Ontology based sentiment analysis for fake review detection. Expert Systems with Applications, 206, 117869.
Wang, Z., Ho, S.-B., & Cambria, E. (2020). Multi-level fine-scaled sentiment sensing with ambivalence handling. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 28(04), 683–697.
Wilson, T., Wiebe, J., & Hoffmann, P. (2005). Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of human language technology conference and conference on empirical methods in natural language processing (pp. 347–354).
Wu, L., Morstatter, F., & Liu, H. (2018). SlangSD: Building, expanding and using a sentiment dictionary of slang words for short-text sentiment classification. Language Resources and Evaluation, 52(3), 839–852.
Wu, S., Wu, F., Chang, Y., Wu, C., & Huang, Y. (2019). Automatic construction of target-specific sentiment lexicon. Expert Systems with Applications, 116, 285–298.
Xing, F. Z., Cambria, E., & Welsch, R. E. (2018). Intelligent asset allocation via market sentiment views. IEEE Computational Intelligence Magazine, 13(4), 25–34.
Xing, F. Z., Cambria, E., & Zhang, Y. (2019). Sentiment-aware volatility forecasting. Knowledge-Based Systems, 176, 68–76.
Yekrangi, M., & Abdolvand, N. (2021). Financial markets sentiment analysis: Developing a specialized lexicon. Journal of Intelligent Information Systems, 57(1), 127–146.
Yu, L.-C., Wu, J.-L., Chang, P.-C., & Chu, H.-S. (2013). Using a contextual entropy model to expand emotion words and their intensity for the sentiment classification of stock market news. Knowledge-Based Systems, 41, 89–97.
Acknowledgements
This work was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (No. 2021R1A2C2093785 and 2018R1D1A1A02045842).
Funding
Open Access funding enabled and organized by Seoul National University.
Author information
Authors and Affiliations
Contributions
Conceptualization: Jihye Park; Methodology: Jihye Park; Investigation: Jihye Park; Validation: Jihye Park, Hye Jin Lee; Writing - original draft preparation: Jihye Park, Hye Jin Lee; Supervision: Sungzoon Cho.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interest to declare that are relevant to the content of this article.
Ethical approval
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix 1: A sample of 20 sentiment classification results from the entire DS100 dataset consisting of 2259 sentences
Appendix 1: A sample of 20 sentiment classification results from the entire DS100 dataset consisting of 2259 sentences
Headline | Label | Senti-DD prediction | Positive pairs detected using Senti-DD | Negative pairs detected using Senti-DD |
|---|---|---|---|---|
m real s sales are expected to have increased by 4 year on year to eur 609 m in the second quarter of 2010 | Positive | Positive | [‘sale_increas’, ‘quarter_increas’, ‘year_increas’] | [] |
finnish metal industry solutions supplier outotec oyj net profit rose to 50 4 mln euro $ 72 5 mln for the first nine months of 2007 from 20 1 mln euro $ 28 9 mln for the same period of 2006 | Positive | Positive | [‘solution_rose’, ‘mln_rose’, ‘profit_rose’, ‘oyj_rose’, ‘month_rose’, ‘net_rose’, ‘metal_rose’, ‘period_rose’] | [] |
adp news feb 12 2009 finnish construction company lemminkainen oyj hel : lem1s said today its net profit decreased to eur 63 5 million usd 81 1 m for 2008 from eur 80 6 million for 2007 | Negative | Negative | ‘[construction_decreas’, ‘company_decreas’] | [‘profit_decreas’, ‘net_decreas’, ‘eur_decreas’, ‘oyj_decreas’, ‘news_decreas’] |
in the fourth quarter of 2008 net sales increased by 2 to eur 1 050 7 mn from eur 1 027 0 mn in the fourth quarter of 2007 | Positive | Positive | [‘quarter_increas’, ‘mn_increas’, ‘net_increas’, ‘sale_increas’, ‘eur_increas’] | [] |
excluding non recurring items pre tax profit surged 45 to eur 80 m | Positive | Positive | [‘profit_surg’, ‘item_surg’] | [] |
net sales of finnish food industry company l+ñnnen tehtaat s continuing operations increased by 13 in 2008 to eur 349 1 mn from eur 309 6 mn in 2007 | Positive | Positive | [‘sale_increas’, ‘eur_increas’, ‘mn_increas’, ‘net_increas’] | [‘company_increas’] |
eps from continuing operations came in at 0 30 eur up from 0 17 | Positive | Positive | [‘eur_up’] | [] |
eps for the quarter came in at 0 36 eur up from 0 33 eur a year ago and ahead of forecast of 0 33 eur | Positive | Positive | [‘eur_up’, ‘year_up’, ‘quarter_up’] | [] |
the chain posted sales of 298 million euros for full 2005 a rise of 19 5 percent year on year | Positive | Positive | [‘sale_rise’, ‘year_rise’, ‘percent_rise’] | [] |
international sales rose by 59 8 to eur 1 244 4 mn | Positive | Positive | [‘eur_rose’, ‘sale_rose’, ‘mn_rose’] | [] |
teleste was set up in 1954 and is divided into broadband cable networks and video networks business areas | Neutral | Positive | [‘business_up’, ‘area_up’] | [] |
the company can not give up palm oil altogether however | Neutral | Negative | [] | [‘company_up’] |
savon koulutuskuntayhtyma finland based company has awarded contract for specialist agricultural or forestry machinery | Positive | Neutral | [‘contract_award’] | [‘company_award’] |
the stock rose for a second day on wednesday bringing its two day rise to gbx12 0 or 2 0 | Positive | Negative | [] | [‘day_rose’, ‘day_rise’] |
finnish it consultancy satama interactive oyj said on november 13 2006 that jarmo lonnfors took up the position of ceo | Neutral | Positive | [‘oyj_up’] | [] |
stock exchange announcement 20 july 2006 1 1 basware share subscriptions with warrants and increase in share capital a total of 119 850 shares have been subscribed with basware warrant program | Neutral | Positive | [‘share_increas’, ‘capital_increas’] | [] |
elcoteq se is europe s largest contract electronics maker and has set up a unit in bangalore in association with avista advisory of mumbai | Neutral | Positive | [‘contract_up’, ‘maker_up’] | [] |
following this increase huhtamaki s registered share capital is eur 360 62 m and the number of shares outstanding is 106 063 320 | Neutral | Positive | [‘share_increas’, ‘capital_increas’] | [] |
at the same time profit of the company increased by 10 in h1 and reached ls 79 000 | Positive | Neutral | [‘profit_increas’] | [‘company_increas’] |
repeats sees 2008 operating profit down y y reporting by helsinki newsroom keywords : tecnomen results | Negative | Neutral | [‘result_down’] | [‘profit_down’] |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Park, J., Lee, H.J. & Cho, S. Automatic construction of direction-aware sentiment lexicon using direction-dependent words. Lang Resources & Evaluation (2024). https://doi.org/10.1007/s10579-024-09737-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s10579-024-09737-9