
Abstract
Fuzzy knowledge-based systems (FKBS) are significantly applicable in the area of control, classification, and modeling, having knowledge in the form of fuzzy if-then rules. Type-2 fuzzy theory is used to make these systems more capable of dealing with inherent uncertainties in real-world problems. In this paper, the authors have proposed a genetic tuning approach named lateral displacement and expansion/compression (LDEC) in which α and β parameters are calculated to adjust the parameters of interval type-2 membership functions. α tuning deals with lateral displacement, whereas β tuning carries out compression/expansion operation. The interpretability and accuracy features are considered during the development of this approach. The experimental results show the performance of the proposed approach.
Similar content being viewed by others


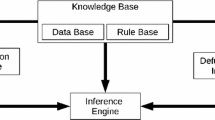
Introduction
Fuzzy systems, more specifically fuzzy knowledge-based systems (FKBS) or fuzzy rule-based systems (FRBS), are significantly applicable in areas like control [1], classification [2], and modeling [3]. The essential feature of FKBS is the incorporation of human expert knowledge which is in the form of fuzzy [4] extended if-then rules. The major components of FKBS are fuzzification interface, inference engine, knowledge base, and defuzzification interface [5]. Knowledge base (KB) is composed of two components: data base (DB) and rule base (RB). DB is the repository of membership functions (MFs) and scaling functions (SFs) representing linguistic values, whereas RB is the collection of knowledge related to problems in terms of fuzzy if-then rules.
The design and implementation of KB can be assumed as an optimization task. Hence, genetic algorithms (GAs) are used for learning and tuning of various parameters of KB due to their strong capacity of searching in a complicated and poorly defined search space. Such an application of GAs in developing FKBS is specifically named as genetic fuzzy systems (GFS) [5–8]. GFS have been used for handling various types of applications like predicting surface finish in ultraprecision diamond [9], bioaerosol detector [10], classification of intrusion attacks from a network traffic data [11], tool wear monitoring [12], smart base isolation system [13], etc.
Fuzzy systems for applications like in economics, medicine, etc. are to be developed such that the users may understand how they work by inspecting their KB and functioning. Technically, this feature is called ‘interpretability’ [14] which is the subjective feature of a fuzzy system showing how much the system is readable/understandable to the users by observing its functionality. Accuracy [15] is another feature showing the closeness between the real model and the developed model. Interpretability and accuracy are contradictory with each other, i.e., one can be improved at the cost of the other, denoted by ‘interpretability-accuracy trade-off’ (I-A Trade-Off) [16–19]. For the above applications, interpretability as well as accuracy is required to be maintained at the higher level by maintaining a good I-A Trade-Off.
Interpretability and accuracy features are directly related to the approaches of developing FKBS which are domain expert method and experimental data method. In the first method, domain experts of the problem are contributing their knowledge to develop the RB of the FKBS. Such FKBS are much more interpretable. In the second method, RB is generated by using some machine learning method applied on the data set of the particular problem. The FKBS developed by the second method are less interpretable but are more generic. An idea of generating FKBS with the experimental data method guided by the domain expert method is good enough toward achieving an I-A Trade-Off with higher levels of interpretability as well as accuracy.
The special interest of this paper is the use of interval type-2 fuzzy systems (IT2FS) [20]. The membership functions are tuned using GAs, which leads toward a new system, the ‘type-2 genetic fuzzy system’ (T2GFS).
The paper continues with the ‘Interpretability issues in FKBS’ section in which the interpretability issues of FKBS are discussed. The ‘Tuning and learning operations in FKBS’ section introduces the basics of tuning and learning approaches. The fundamentals of type-2 fuzzy systems are discussed in the ‘Type-2 fuzzy systems’ section. A new lateral displacement and expansion/compression (LDEC) tuning approach is discussed in the ‘Proposed LDEC tuning approach’ section. The genetic representation of KB and the proposed tuning approach is discussed in the ‘Genetic representation of knowledge base’ section. Experimental results are discussed in the ‘Experiments and results’ section.
Interpretability issues in FKBS
Interpretability [14, 21–23] and accuracy [15] are the two important features considered during the design of fuzzy systems. Basically, interpretability is identified as a feature to understand the significance of something [21], and it is also known with other names like comprehensibility, intelligibility, transparency, readability, understandability, etc. Also, the quantification of interpretability is a highly subjective task depending on various parameters like experience, preference, and the knowledge of the person who interprets the system functionality.
Linguistic fuzzy modeling (LFM) and precise fuzzy modeling (PFM) [24] are two modeling approaches of fuzzy systems. In LFM, fuzzy models are developed by means of linguistic FRBS which are called Mamdani-type FKBS [25] mainly focusing on interpretability. On the other hand, PFM is developed considering the accuracy parameter and called Takagi-Sugeno FKBS [26]. Accuracy improvement in LFM [15] and interpretability improvement in PFM [14] are carried out to achieve the desired I-A Trade-Off.
Various approaches have been developed to deal with different issues of the interpretability of fuzzy systems. These are discussed in Table 1.
Many other indexes and methodologies have been developed for assessing the interpretability, which are considered in this paper. These are (1) number of rules (NOR), (2) total rule length (TRL) - the sum of the number of premises in all the rules, and (3) average rule length (ARL) - calculated by TRL/NOR.
Nauck's index (NI) [35] has been proposed to assess the interpretability of fuzzy rule-based classifiers. It is given by
where (it measures the complexity), (it is the average normalized partition index), and cov is the average normalized coverage degree of the fuzzy partition. For strong fuzzy partition (SFP), it is equal to 1.
Similarly, a new global fuzzy index has been proposed in [36]. In this approach, the index has been computed as the outcomes of the inference of hierarchical fuzzy system.
Tuning and learning operations in FKBS
During the design of genetic FKBS, tuning and learning operations (Figure 1) are carried out to improve the performance of FKBS [5, 6]. In the tuning operation, the parameters of DB constituents, MFs and SFs, are adjusted, maintaining no change in the previously defined RB, whereas in the learning operation, the parameters of RB are changed simultaneously with the DB. There are three main approaches for carrying out learning operations: the Pittsburgh approach [37], Michigan approach [38], and iterative rule learning approach [39].

Tuning and learning approaches for the FKBS.
In the literature, two types of approaches are found for tuning operations: one is related to applying SFs for handling linguistic hedges and the other is the tuning of the MF parameters. In this paper, the second approach of MF tuning is considered.
The scaling functions are responsible for adjusting the universe of discourse of input and output variables to the domain. The parameters used for tuning the scaling functions are scaling factor, upper and lower bounds (linear scaling functions), and contraction/dilation parameters (non-linear scaling function). The linguistic hedges are used and applied on the tuned MFs as discussed in [40–42]. The main linguistic hedges are as follows: very, more-or-less, extremely, very-very, positively, and negatively. Linguistic hedges are playing the role of adjectives and adverbs in the languages responsible for changing the qualitative linguistic statements.
Apart from tuning, learning, and interpretability issues in the design of FKBS, several other burning issues are like dealing with the high dimensionality of the data along with handling imbalanced data sets (Figure 2).

Issues and challenges in fuzzy knowledge-based system design.
Type-2 fuzzy systems
To implement FKBS, type-2 fuzzy sets (T2FS) [43, 44] are used having more capacity to deal with inherent uncertainties in the system to be developed. General type-2 fuzzy sets require high computational cost and type reduction complexity; hence, interval type 2 fuzzy sets [45–48] are preferred to model and implement various problems.
T2FS which is denoted by A* is characterized by MF , where x ∈ X and u ∈ J x ⊆ [0, 1]:
Here, ; when all , then A* is an interval type-2 fuzzy set.
A type-2 fuzzy system [49] is identified as a FLS with if-then rules in which at least one linguistic term is a T2FS. Normally, a type-2 fuzzy system differs from a type-1 fuzzy system by having one extra component at the output processing, which is called type reducer (Figure 3). Also, in the type 2 fuzzy system, the antecedent and consequent parts of the rule must have at least one T2FS.

Block diagram of type 2 fuzzy systems[49].
Proposed LDEC tuning approach
In this section, the authors have proposed a LDEC tuning approach for adjusting the parameters of interval type-2 fuzzy MFs. The two-phase procedure of the tuning approach is given in Figure 4. The first phase includes α tuning operation, and in the second phase, β tuning operation is performed.

Two-tier tuning approach.
α tuning operation
In the α tuning operation, all the coordinates of IT2MF are shifted by parameter α and the new coordinates would be as follows: a' = a ± α, b' = b ± α, c' = c ± α, d' = d ± α, e' = e ± α, depending on the positive and negative values of α. When the value of parameter α is positive, it leads to a tuned MF with forward lateral displacement (Figure 5a), and the negative value of α leads to backward lateral displacement (Figure 5b). The value of α is calculated as given below.

α tuning approach. (a) Forward lateral displacement. (b) Backward lateral displacement.
β tuning operation
In the β tuning approach, parameter β is applicable on parameters a, b, d, and e. After the tuning operation, the coordinates would be as follows:
The position of c is assumed to be fixed. The value of β is calculated as follows:
A positive value of β leads to compression (Figure 6a), whereas a negative value performs the expansion operation (Figure 6b).

β tuning approach. (a) Compression. (b) Expansion.
Genetic representation of knowledge base
GAs [50, 51] are popular search techniques for ill-defined and complex search spaces. They are based on natural evolution. The initial population G(0) is generated with chromosomes representing DB and RB information and subsequently goes under evolution. During evolution, the next generation G(n + 1) is generated by applying crossover and mutation operators on the generation G(n). On each generation, each individual is evaluated by a fitness function. A termination condition is set to stop the evolution process.
In [52], inter-valued fuzzy sets (IVFS) have been used to implement a linguistic fuzzy rule-based classification system based on a new interval fuzzy reasoning method along with a new fuzzy rule learning process, called IVTURS-FARC.
In [53], the performance of a fuzzy rule-based classification system is improved using an interval-valued fuzzy set and a tuning approach using genetic algorithm. The uncertainty is modeled by the function ‘weak ignorance.’
Various parameters of type-2 fuzzy systems are optimized using GAs and other bio-inspired optimization algorithms. Few of these works are summarized in Table 2.
New proposed KB representation using GA
Encoding scheme
A two-folded encoding scheme has been presented here to represent the DB information:
where CRM encodes the membership function and CRT encodes the tuning information for the membership function.
Each MF would be represented by a five-tuple representation scheme (Figure 7). The i th MF of the j th input will be represented by MF i (x j ) and mathematically would be expressed as shown in Figure 7.

Chromosome encoding for the MF representation.
The following rule is encoded as shown in Figure 8: IF x1 is MFi 1(x1) … and x n is MF in (x n ), THEN y is MFin+1(y). It is represented by CRR.

Chromosome encoding in the RB.
The real coded chromosomes are used to encode the DB tuning information (CRT) (Figure 9). For the i th input variable, the chromosome will be represented as shown in Figure 9 if there are n MFs for one variable.

Chromosome representation for DB tuning information.
Figure 10 gives the description of the tuning operation on MFs using α and β parameters.

α - β (LDEC) tuning shown with MFs.
Fitness function
The chromosomes are evaluated with the fitness function that considers the minimization of mean squared error (MSE):
where the size of the data set is M. F(ai) is the output obtained from FRBS for the i th example. The desired output is bi.
GA operators
To perform GA operations, the following GA operators are used:
-
Selection: Tournament selection has been used for the selection operation.
-
Crossover: Crossover is the operator that generates new offspring by integrating multiple parents. A simple two-point crossover has been applied to all the chromosomes.
-
Mutation: This operator is used to maintain the diversity in the solutions from one generation to another generation. This operator changes the values of one or more bits in the chromosomes. In this proposed approach, a uniform mutation operator has been used in which the bits of chromosomes are altered within uniform random values at user-specified ranges.
Experiments and results
The RB generation methods used in the experiments are the decision tree (DT) method, Wang-Mendel method [64], and fast prototyping algorithms. The experiments are supported by the open-access free software tool ‘Guaje’ [29, 65] for type-1 fuzzy system implementation.
The proposed approach has been tested on Haberman's Survival Data Set. This data set is available at the UCI Machine Learning Repository [66]. The data set is prepared on behalf of the test cases of survivals of patients who have undergone breast cancer surgery. The major characteristics of the data set are tabulated in Table 3.
The IT2MF for the data set input and output are given in Figure 11a,b,c,d.

Input (a, b, c) and output (d) variables. (a) Age. (b) Year of operation. (c) Number of positive auxiliary nodes detected. (d) Survival.
Type-1 fuzzy system implementation
The values of accuracy and interpretability measures calculated in the following experiments are given in Table 4 and Figure 12:

Interpretability and accuracy parameters.
-
Experiment 1 (E1)
-
Fuzzy partition method: hierarchical fuzzy partition (HFP) and rule generation method: Wang-Mendel method
-
Experiment 2 (E2)
-
Fuzzy partition method: strong fuzzy partition (SFP) and rule generation method: Wang-Mendel method
-
Experiment 3 (E3)
-
Fuzzy partition method: HFP and rule generation method: fuzzy decision trees
-
Experiment 4 (E4)
-
Fuzzy partition method: SFP and rule generation method: Wang-Mendel method
Type 2 fuzzy system implementation
The values of tuning parameters α and β calculated in the experiment are given in Table 5.
-
Experiment 5 (E5)
-
In this experiment (Table 6), the parameters of the genetic algorithm are as follows:
-
Number of generations = 2,000
-
Size of population = 70
-
Tournament size = 2
-
Size of population = 70
-
Mutation probability = 0.1
-
Crossover probability =0.5
-
Initial rules are generated by using the Wang-Mendel method.
-
Experiment 6 (E6)
-
In this experiment (Table 7), the initial rules are generated by a fuzzy decision tree with the following parameter settings:
-
Minimum cardinality of leaf = 1
-
Coverage threshold = 0.9
-
Minimum deviance gain = 0.001
-
Minimum significant level = 0.2
-
Pruning condition = yes
The genetic algorithm parameters are the same as those in experiment 5.
The result comparisons of the proposed approach are outlined in Table 8.
Conclusions
Type-2 fuzzy systems are strongly capable of modeling uncertainties in FKBS than type1 fuzzy systems using three-dimensional membership function representation. General type-2 fuzzy systems are deteriorating the interpretability of the systems, so IT2FS have been preferred to implement the proposed model with good interpretability.
The tuning and learning operations in the development of fuzzy systems playa vital role in improving their performance. This is considered as an optimization task and dealt properly with the application of evolutionary approaches, like GAs. The proposed tuning approach LDEC adjusts the parameters of interval type-2 fuzzy membership functions. This approach is based on the lateral displacement, expansion, and compression operations on the MFs. The proposed tuning approach is interpretable and the experimental results are found satisfactory.
Abbreviations
- DB:
-
data base
- FKBS:
-
fuzzy knowledge-based system
- GAs:
-
genetic algorithms
- GFS:
-
genetic fuzzy systems
- KB:
-
knowledge base
- MFs:
-
membership functions
- RB:
-
rule base
- SFs:
-
scaling functions.
References
Palm R, Drainkov D, Hellendorn H: Model Based Fuzzy Control. Springer, Berlin; 1997.
Kuncheva LI: Fuzzy Classifier Design. Studies in Fuzziness and Soft Computing. Springer, Berlin; 2000.
Pedrycz W: Fuzzy Modelling: Paradigms and Practices. Kluwer, Boston; 1996.
Ross TJ: Fuzzy Logic with Engineering Applications. Wiley, Chichester; 2009.
Cordon O, Herrera F, Hoffmann F, Magdalena L: Genetic Fuzzy Systems: Evolutionary Tuning and Learning of Fuzzy Knowledge Bases. World Scientific, Singapore; 2001.
Herrera F: Genetic fuzzy systems: taxonomy, current research trends and prospects. Evol. Intel. 2008, 1: 27–46. 10.1007/s12065-007-0001-5
Herrera F: Genetic fuzzy systems: status, critical considerations and future directions. Int. J. Comput. Intell. Res. 2005, 1(1):59–67.
Cordon O, Gomide F, Herrera F, Hoffmann F, Magdalena L: Ten years of genetic fuzzy systems: current framework and new trends. Fuzzy Set. Syst. 2005, 141: 5–31.
Roy SS: Design of genetic fuzzy expert system for predicting surface finish in ultra-precision diamond tuning of metal matrix composite. J. Mater. Process. Technol. 2006, 173: 337–344. 10.1016/j.jmatprotec.2005.12.003
Pulkkinen P, Hytonen J, Koivisto H: Developing a bioaerosol detector using hybrid genetic fuzzy systems. Eng. Appl. Artif. Intel. 2008, 21: 1330–1346. 10.1016/j.engappai.2008.01.006
Tseng CH, Kwong S, Wang H: Genetic fuzzy rule mining approach and evaluation of feature selection techniques for anomaly intrusion detection. Pattern Recogn. 2007, 40: 2373–2391. 10.1016/j.patcog.2006.12.009
Achiche S, Balazinski M, Baron L, Jemielniak K: Tool wear monitoring using genetically-generated fuzzy knowledge bases. Eng. Appl. Artif. Intel. 2002, 15: 303–314. 10.1016/S0952-1976(02)00071-4
Kim HS, Roschke PN: Design of fuzzy logic controller for smart base isolation system using genetic algorithms. Eng. Struct. 2006, 28: 84–96. 10.1016/j.engstruct.2005.07.006
Cassilas J, Cordon O, Herrera F, Magdalena L: Interpretability Issues in Fuzzy Modeling. Studies in Fuzziness and Soft Computing. Springer, Berlin; 2003.
Cassilas J, Cordon O, Herrera F, Magdalena L: Accuracy Improvements in Linguistic Fuzzy Modeling. Studies in Fuzziness and Soft Computing. Springer, Berlin; 2003.
Alcala R, A-Fdez J, Cassilas J, Cordon O, Herrera F: Hybrid learning models to get the interpretability-accuracy trade-off in fuzzy modeling. Soft. Comput. 2006, 10: 717–734. 10.1007/s00500-005-0002-1
Shukla PK, Tripathi SP: A survey on interpretability-accuracy (I-A) trade-off in evolutionary fuzzy systems. Proceedings of 5th International Conference on Genetic and Evolutionary Computing (ICGEC 2011), Kitakyushu, 29 Aug–1 Sept 2011
Shukla PK, Tripathi SP: A review on the interpretability-accuracy trade-off in evolutionary multi-objective fuzzy systems (EMOFS). Information 2012, 3(3):256–277.
Shukla PK, Tripathi SP: Interpretability issues in evolutionary multi-objective fuzzy knowledge base systems. In Proceedings of 7th International Conference on Bio-inspired Computing: Theories and Applications (BIC-TA 2012) Advances in Intelligent Systems and Computing, vol. 201. Edited by: Bansal JC. Springer, New Delhi; 2012:473–484.
Liang Q, Mendel JM: Interval type-2 fuzzy logic systems: theory and design. IEEE Trans. Fuzzy Syst. 2000, 8(5):535–550. 10.1109/91.873577
Alonso JM, Magdalena L: Special issue on interpretable fuzzy systems. Inform. Sci. 2011, 181: 4331–4339. 10.1016/j.ins.2011.07.001
Alonso JM, Magdalena L, Gonzalez-Rodriguez G: Looking for a good fuzzy system interpretability index: an experimental approach. Int. J. Approx. Reason. 2009, 51: 115–134. 10.1016/j.ijar.2009.09.004
Jin Y: Fuzzy modeling of high dimensional systems: complexity reduction and interpretability improvement. IEEE Trans. Fuzzy Syst. 2000, 8(2):212–221. 10.1109/91.842154
Cassilas J, Cordon O, Herrera F, Magdalena L: Interpretability improvements to find the balance interpretability-accuracy in fuzzy modeling: an overview. In Interpretability Issues in Fuzzy Modeling, Studies in Fuzziness and Soft Computing. Edited by: Cassilas J, Cordon O, Herrera F, Magdalena L. Springer, Heidelberg; 2003:3–22.
Mamdani EH: Applications of fuzzy algorithms for controlling a simple dynamic plant. Proceedings of Institution of Electrical Engineers 1974, 121(12):1585–1588. 10.1049/piee.1974.0328
Takagi T, Sugeno M: Fuzzy identification of systems and its application to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, 15: 116–132.
Guillaume S: Designing fuzzy inference system from data: an interpretability oriented review. IEEE Trans. Fuzzy Syst. 2001, 9(3):426–443. 10.1109/91.928739
Mikut R, Jakel J, Groll L: Interpretability issues in data based learning of fuzzy systems. Fuzzy Set. Syst. 2005, 150: 179–197. 10.1016/j.fss.2004.06.006
Alonso JM, Magdalena L: HILK++: an interpretability guided fuzzy modeling methodology for learning readable and comprehensible fuzzy rule based classifiers. Soft. Comput. 2011, 15(10):1959–1980. 10.1007/s00500-010-0628-5
Alonso JM, Magdalena L, Guillaume S: HILK: a new methodology for designing highly interpretable linguistic knowledge bases using fuzzy logic formalism. Int. J. Intell. Syst. 2008, 23(7):761–794. 10.1002/int.20288
Zhou SM, Gan JQ: Low level interpretability and high level interpretability: a unified view of data-driven interpretable fuzzy system modeling. Fuzzy Set. Syst. 2008, 159: 3091–3131. 10.1016/j.fss.2008.05.016
Mencar C, Fanelli AM: Interpretability constraints for fuzzy information granulation. Inform. Sci. 2008, 178: 4585–4618. 10.1016/j.ins.2008.08.015
Gacto MJ, Alcala R, Herrera F: Interpretability of linguistic fuzzy rule based systems: an overview of interpretability measures. Inform. Sci. 2011, 181: 4340–4360. 10.1016/j.ins.2011.02.021
Fazzolari M, Giglio B, Alcala R, Marcelloni F, Herrera F: A study on the application of instance selection techniques in genetic fuzzy rule based classification systems: accuracy-complexity trade-off. Knowledge Based Syst 2013, 54: 32–41.
Nauck DD: Measuring interpretability in rule based classification systems. In Proceedings of FUZZ-IEEE. Missouri; 25–28 May 2003
Alonso JM, Guillaume S, Magdalena L: A hierarchical fuzzy system for assessing interpretability of linguistic knowledge bases in classification problems. Proceedings of IPMU 2006, Information Processing and Management of Uncertainty in Knowledge Based Systems, Paris, 2–7 July 2006 348–355.
Smith SF Dissertation. In A learning system based on genetic adaptive algorithms. Department of Computer Science, University of Pittsburgh; 1980.
Booker LB Dissertation. In Intelligent behavior as an adaptation to the task environment. Department of Computer and Communication Sciences, University of Michigan; 1982.
Venturini G: SIA: A supervised inductive algorithm with genetic search for learning attribute based concepts. Proceedings of European Conference on Machine Learning, Vienna 5–7 Apr 1993
Shi H, Ward R, Kharma N: Expanding the definitions of linguistic hedges. Proceedings of Joint 9th IFSA World Congress & 20th NAFIPS, Vancouver, 25–28 July 2001
Zadeh LA: A fuzzy set theoretic interpretation of linguistic hedges. J Cybernetics 1972, 2(3):4–34. 10.1080/01969727208542910
Cox E: The Fuzzy Systems Handbook. AP Professional, New York; 1998.
Mizumoto M, Tanaka K: Some properties of fuzzy sets of type 2. Inf. Control. 1976, 31: 312–340. 10.1016/S0019-9958(76)80011-3
Mendel JM, John RIB: Type-2 fuzzy sets made simple. IEEE Trans. Fuzzy Syst. 2002, 10(2):117–127. 10.1109/91.995115
Wu H, Mendel JM: Uncertainty bounds and their use in the design of interval type-2 fuzzy logic systems. IEEE Trans. Fuzzy Syst. 2002, 10(5):622–639. 10.1109/TFUZZ.2002.803496
Wu D: On the fundamental differences between interval type-2 and type-1 fuzzy logic controllers. IEEE Trans. Fuzzy Syst. 2012, 20(5):832–848.
Wu D: Approaches for reducing the computational cost of interval type-2 fuzzy logic systems: overview and comparison. IEEE Trans. Fuzzy Syst. 2013, 21(1):80–99.
Chen SM, Chang YC, Pan JS: Fuzzy rules interpolation for sparse fuzzy rule based systems based on interval type-2 Gaussian fuzzy sets and genetic algorithms. IEEE Trans. Fuzzy Syst. 2013, 21(3):412–425.
Karnik NN, Mendel JM: Type-2 fuzzy logic systems. IEEE Trans. Fuzzy Syst. 1999, 7(6):643–658. 10.1109/91.811231
Goldberg DE: Genetic Algorithms in Search, Optimization and Machine Learning. Addison-Wesley, Reading; 1989.
Michalewicz Z: Genetic Algorithms + Data Structures = Evolution Programs. Springer Verlag, Berlin; 1996.
Sanz JA, Fernandez A, Bustince H: IVTURS: A linguistic fuzzy rule based classification system based on a new interval valued fuzzy reasoning method with tuning and rule selection. IEEE Trans. Fuzzy Syst. 2013, 21(3):399–411.
Sanz J, Fernandez A, Bustince H, Herrera F: A genetic tuning to improve the performance of fuzzy rule based classification systems with interval valued fuzzy sets: degree of ignorance and lateral position. Int. J. Approx. Reason. 2011, 52(6):751–766. 10.1016/j.ijar.2011.01.011
Wu D, Tan WW: A simplified type-2 fuzzy logic controller for real time control. ISA Trans. 2006, 45(4):503–516. 10.1016/S0019-0578(07)60228-6
Wu D, Tan WW: Genetic learning and performance evaluation of interval type-2 fuzzy logic controllers. Eng. Appl. Artif. Intel. 2006, 19(8):829–841. 10.1016/j.engappai.2005.12.011
Sepulveda R, Castillo O, Melin P, R–Diaz A, Montiel O: Exponential study of intelligent controllers under uncertainty using type-1 and type-2 fuzzy logic. Inform. Sci. 2007, 177(10):2023–2048. 10.1016/j.ins.2006.10.004
Martinez R, Castillo O, Aguilar LT: Optimization of interval type-2 fuzzy logic controllers for a perturbed autonomous wheeled mobile robot using genetic algorithms. Inform. Sci. 2009, 179(13):2158–2174. 10.1016/j.ins.2008.12.028
Zarandi MHF, Rezaee B, Turksen IB, Neshat E: A type-2 fuzzy rule-based expert system model for stock price analysis. Expert Syst. Appl. 2009, 36(1):139–154. 10.1016/j.eswa.2007.09.034
Castillo O, Melin P, Alanis A, Montiel O, Sepulveda R: Optimization of interval type-2 fuzzy logic controllers using evolutionary algorithms. Soft. Comput. 2011, 15(6):1145–1160. 10.1007/s00500-010-0588-9
Castillo O, M-Marroquin R, Melin P, Valdez F, Soria J: Comparative study of bio-inspired algorithms applied to optimization of type-1 and type-2 fuzzy controllers for an autonomous mobile robot. Inform. Sci. 2012, 192(1):19–38.
Hidalgo D, Melin P, Castillo O: An optimization method for designing type-2 fuzzy inference systems based on the footprint of uncertainty using genetic algorithms. Expert Syst. Appl. 2012, 39(4):4590–4598. 10.1016/j.eswa.2011.10.003
Castillo O, Melin P: Optimization of type-2 fuzzy systems based on bio-inspired methods: a concise review. Inform. Sci. 2012, 205(1):1–19.
Hosseini R, Qanadli SD, Barman S, Mazinani M, Ellis T, Dehmeshki J: An automatic approach for learning and tuning Gaussian interval type-2 fuzzy membership functions applied to lung CAD classification system. IEEE Trans. Fuzzy Syst. 2012, 20(2):224–234.
Wang LX, Mendel JM: Generating fuzzy rule by learning from examples. IEEE Trans. Syst. Man Cybern. 1992, 22(6):1414–1427. 10.1109/21.199466
Alonso JM, Magdalena L: Generating understandable and accurate fuzzy rule based systems in a Java environment. In Fuzzy Logic and Applications, 9th International Workshop, WILF 2011, Trani, Italy, August 29–31, 2011. Lecture Notes in Artificial Intelligence, vol. 6857. Edited by: Fanelli AM, Pedrycz W, Petrosino A. Springer, Berlin; 2011:212–219.
Bache K, Lichman M: UCI Machine Learning Repository. School of Information and Computer Science, University of California, Irvine, CA; (2013). Accessed 15 June 2013 http://archive.ics.uci.edu/ml
Author information
Authors and Affiliations
Corresponding author
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Shukla, P.K., Tripathi, S.P. A new approach for tuning interval type-2 fuzzy knowledge bases using genetic algorithms. J. Uncertain. Anal. Appl. 2, 4 (2014). https://doi.org/10.1186/2195-5468-2-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/2195-5468-2-4