
Abstract
A landslide event is characterized by the distribution of landslides caused by a single triggering event. The severity of earthquake-induced landslide events can be quantified by the landslide-event magnitude, a metric derived from the frequency-size distribution of landslide inventories. However, reliable landslide inventories are not available for all earthquakes, because the preparation of a suitable inventory requires data, time, and expertise. Prediction of landslide-event magnitude immediately following an earthquake provides an estimate of the total landslide area and volume based on empirical relations. It allows to make an assessment of the severity of a landslide event in near-real time and to estimate the frequency-size distribution curve of the landslides. In this study, we used 23 earthquake-induced landslide inventories and propose a method to predict landslide-event magnitude. We selected five predictors, both morphometric and seismogenic, which are globally and readily available. We used the predictors within a stepwise linear regression and validated using the leave-one-out technique. We show that our approach successfully predicts landslide-event magnitude values and provides results along with their statistical significance and confidence levels. However, to test the validity of the approach globally, it should be calibrated using a larger and more representative dataset. A global, near real-time assessments regarding landslide-event magnitude scale can then be achieved by retrieving the readily available ShakeMaps, along with topographic and thematic information, and applying the calibrated model. The results may provide valuable information regarding landscape evolution processes, landslide hazard assessments, and contribute to the rapid emergency response after earthquakes in mountainous terrain.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
An earthquake-induced landslide event refers to landslides triggered by a particular earthquake. Such landslides are one of the most destructive secondary hazards associated with earthquakes in mountainous environments (e.g., Jibson et al. 2000). Therefore, the estimation of earthquake-induced landslide hazard is an important risk mitigation component in seismically active mountainous areas (Wasowski et al. 2011).
Earthquake-induced landslide (EQIL) inventories are the primary data source to extend our knowledge of the relationship between earthquakes and the landslides they can trigger (e.g., Tanyaş et al. 2017). Using an EQIL inventory, we can assess the distribution of landslides and better evaluate the total earthquake impacts considering this secondary seismic hazard (e.g., Robinson et al. 2017). An EQIL event is characterized by the distribution of landslides caused by a single earthquake.
The impact of EQIL events can be quantified using landslide inventories (e.g., Malamud et al. 2004). Keefer (1984) used the number of triggered landslides (NLT) to define an EQIL-event magnitude scale (mLS), which quantifies the severity of the event, and it is defined as follows:
According to the method proposed by Keefer (1984), the magnitude scale of an EQIL-event triggering 102–103 landslides is classified as “class 2”; 103–104 landslides is classified as” class 3″, etc. This is an important concept because we could better evaluate the relation between landslide causes and impacts as a quantitative approach simplifies a complex phenomenon into a single, or a few, standard values (i.e., landslide-event magnitudes) which can be compared between triggering events (Tanyaş et al. 2018a).
Malamud et al. (2004) used Keefer’s (1984) method to define mLS (Eq. 1) and improved this method using the size statistics of the landslides associated with various triggers such as earthquakes, rapid snowmelt, or large storms. Malamud et al. (2004) established that the frequency-area distribution of landslides follows an inverse power law for medium- to large-sized landslides, while the distribution shows a rollover at smaller landslide sizes. They modeled the frequency-area distribution of three well-documented event inventories and defined empirical curves to identify mLS. Tanyaş et al. (2018b) examined the frequency-area distributions of 45 earthquake-induced landslide inventories and showed that the form of the rollover does not follow the modeled empirical distribution curves. They noted that the power-law tail is the most important part of the frequency-area distribution because it gives insight in characteristics of landslide size distribution and contains the greatest volume of material (e.g., Bennett et al. 2012).
Many studies make use of the empirical distribution of landslide sizes, independently on the trigger of the landslide event (Malamud et al. 2004). For example, Guzzetti et al. (2005) extracted the probability of landslide size from frequency-size statistics of landslides and used this information for quantitative analysis of landslide hazard. The power-law region of the distribution can also be reproduced by different physically based models (Alvioli et al. 2014, 2018b; Hergarten 2012).
A magnitude scale for the landslide events can be defined by identifying the power-law fits for medium and large landslides. Thus, the examined landslide inventory may be partial (i.e., some small landslides may be missing), but the assigned mLS is equivalent to the one associated to complete landslide event based on a frequency-area distribution, obtained by properly rescaling a frequency density curve to the measured distribution in the power-law region as in Malamud et al. (2004). Malamud et al. (2004) also proposed equations to estimate the maximum landslide area (ALmax) (Eq. 2) and total landslide area (AT) (Eq. 3) triggered by one event (e.g., earthquake, rainstorm) in relation with mLS, defined as follows:
Regarding the estimation of mLS, Tanyaş et al. (2018a) introduced an updated method that better fits the observations. They determined a slope (power-law exponent) of the power-law fit for each specific landslide inventory and used this value instead of the average value (2.4) used by Malamud et al. (2004) to define the empirical frequency-area distribution curves. To construct the empirical curves, Tanyaş et al. (2018a) rotated the power-law fits around a reference point identified considering the most reliable EQIL inventories. They then determined the mLS using the constructed empirical frequency-area distribution curves. They also checked the variation in mLS in their proposed method based on different reference points and identified 95% confidence limits for various mLS intervals (Table 1). The mLS values determined by Tanyaş et al. (2018a) are presented in Table 2.
Tanyaş et al. (2018a) also proposed an updated equation to estimate total landslide area (AT) triggered by an earthquake in relation with mLS (Eq. 4):
However, calculation of mLS requires a landslide inventory which is not available for most of the landslide triggering earthquakes. The preparation of a landslide inventory is a tedious process (e.g., Wasowski et al. 2011), despite advances in mapping techniques, and it may take months to complete when based on visual image interpretation, or weeks when based on (semi-) automated image classification (Martha et al. 2010). In any case, the time required to create an EQIL inventory is too long to provide information for rapid emergency response phase after an earthquake (Robinson et al. 2017).
To capture the effect of an EQIL-event without having an inventory, some statistical relations were proposed, using a global dataset, between earthquake magnitude and the area affected by landslides or the maximum landslide distance, either from the epicenter or the rupture zone (Keefer 1984; Rodriguez et al. 1999). However, Jibson and Harp (2012) found that the proposed landslide distance buffers differ between plate-boundary earthquakes and intraplate earthquakes, where seismic wave attenuation is generally much lower and thus the proposed relation could not be used for accurate estimation of any of these landslide distance limits.
Marc et al. (2016) proposed an expression to estimate the total volume and area of EQIL. Their expression is based on seismogenic characteristics (e.g., seismic moment and asperity depth), landscape steepness, and material sensitivity (rock strength and pore pressure). However, the required inputs such as the parameters describing rock strength, earthquake asperity depth, and ground motion attenuation are often not precisely known (Li et al. 2017).
Given these circumstances, rapid prediction of mLS of EQIL events could provide us valuable information not only for studies regarding landscape evolution (e.g., Malamud et al. 2004) and hazard assessments (Guzzetti et al. 2005) but also for applications in emergency response. We could evaluate the severity of an EQIL event in near-real time, providing a rapid prediction of mLS.
In this study, we used 23 EQIL inventories and their mLS values calculated by Tanyaş et al. (2018a). We propose a method to predict mLS that can lead to estimates of the total triggered landslide area, total landslide volume, and frequency-area distribution of landslides. We construct a stepwise linear regression model using both seismogenic and morphologic predictors. We predict the mLS of EQIL events and validate our method using the leave-one-out technique.
Materials
Available data
An EQIL inventory database including 66 inventories from around the world was presented by Tanyaş et al. (2017), which included detailed information regarding their mapping methodologies. From this database, Tanyaş et al. (2018a) examined the inventories for which landslide area information is available and calculated the mLS values for 45 EQIL inventories from 32 earthquakes (Fig. 1). We examined those 45 EQIL inventories which were analyzed by Tanyaş et al. (2018a) in terms of their mLS values and excluded some of them following the inventory selection criteria presented below. The list of EQIL inventories, their main characteristics, and references are presented in Table 2.

Distribution of examined earthquakes with a landslide inventory listed in Table 2
We used both seismogenic and morphologic independent variables in a linear regression analysis. As seismogenic variables, we collected earthquake magnitudes and the estimated values of peak ground acceleration (PGA), peak ground velocity (PGV), and Modified Mercalli Intensity (MMI) from the US Geological Survey (USGS) ShakeMap system (Allen et al. 2008; Garcia et al. 2012). The ShakeMap system provides the deterministic estimates of ground-motion parameters in near-real time. Additionally, we used Global Centroid-Moment Tensor (CMT) half duration (the duration of the rupture process) (Dziewonski et al. 1981; Ekström et al. 2012) as another seismogenic variable.
We used the Shuttle Radar Topography Mission (SRTM) digital elevation model (about 30-m resolution) (NASA Jet Propulsion Laboratory (JPL) 2013) to create morphologic variables.
Selection of inventories
Each of the available EQIL inventories has a varying level of quality and completeness, which are difficult to assess both quantitatively and qualitatively due to lack of metadata regarding mapping preferences and the subjectivity of mapping procedure. We checked the mapping techniques of selected landslide inventories to get a general idea about the quality of mapping. In each inventory, the landslide-affected area was analyzed systematically by visual interpretation of satellite images and/or aerial photography. In addition, Tanyaş et al. (2017) introduced an evaluation system to help users assess the suitability of the available inventories for different types of studies. They listed four essential criteria to check whether the inventory suitable for a landslide susceptibility or hazard assessment, or to investigate the distribution, types, and patterns of landslides in relation to morphological and geological characteristics (Table 3). Based on this approach, Tanyaş et al. (2017) assigned scores to each inventory. We indicated those scores in Table 2 to have a general idea about the quality of mapping in the examined inventories. Scores show that each inventory meets at least half of the criteria and we decided to use these in this study.
Considering other available information about inventories provided by Tanyaş et al. (2017), we discarded several of them to increase the reliability of the applied method. The list of selected EQIL inventories and the exclusion criteria are presented in Table 2.
We excluded incomplete EQIL inventories for which we know that only part of the landslide-affected area was mapped. For example, the 1989 Loma Prieta EQIL inventory is such a partial inventory where McCrink (2001) only mapped part of triggered landslides to test a dynamic slope stability method. Similarly, part of the landslide-affected area associated with the 2006 Kiholo Bay earthquake was mapped in detail by Harp et al. (2014) to check if the landslide-distribution pattern is predictable using a high-resolution ground-motion simulation model. EQIL inventories that can be attributed to more than one earthquake were also excluded, such as the 1980 Mammoth Lakes (Harp et al. 1984), the 1993 Finisterre (Meunier et al. 2008), the 1997 Umbria-Marche (Marzorati et al. 2002), and the 2004 Mid-Niigata (GSI of Japan 2005; Sekiguchi and Sato 2006; Yagi et al. 2007). In each of these inventories, the earthquake associated with the triggered landslides is not clear, and thus this can cause a problem in the representation of seismogenic variables regarding these inventories. Also, we excluded the 2007 Niigata Chuetsu-Oki inventory (Kokusai Kogyo 2007) because pre-earthquake landslides were not eliminated in this inventory (Collins et al. 2012). If we have more than one inventory for the same earthquake, we only included the one that has the largest number of landslides and covers the largest area (Table 2). We also excluded the earthquakes without ShakeMap data, such as the 1998 Jueili and 2007 Aysen Fjord earthquakes. For the rest of the inventories, we checked the uncertainties of the ShakeMaps data. The relative uncertainty level of each ShakeMap output is described by a quality grading developed by Wald et al. (2008). The grades of the selected ShakeMaps data (Table 2) show that none of them belongs to the poorest grades, which are D and F.
Methods
Delineation of the geographical boundary of a landslide event is usually no trivial task. For example, in the case of inventories prepared by field campaigns, a crucial step is to determine the area that was actually surveyed by the researchers (Bornaetxea et al. 2018; Guzzetti et al. 2012). Inventories prepared by visual interpretation of aerial or satellite imagery (Alvioli et al. 2018c; Casagli et al. 2017; Guzzetti et al. 2012), as is the case for many of the inventories considered in this work, should indicate the boundary of the available images, or the actual area mapped. However, in many cases, this information is not available.
The peak ground acceleration (PGA) contours, which show a correlation with landslide density (e.g., Meunier et al. 2007), was used to identify the landslide-affected area. Wilson and Keefer (1985) are the first who proposed a minimum threshold of 0.05 g to such a boundary. They used the data gathered by Keefer (1984) regarding the 40 EQIL inventories. However, EQIL inventory maps were only available for a few of the 40 reported earthquakes (Tanyaş et al. 2017), and the general relations and conclusions reported were pieced together from various resources, listed in Keefer and Tannaci (1981). Similar minimum PGA thresholds that covers all triggered landslides were also reported for individual EQIL inventories as 0.01 g for the 1980 Irpinia earthquake (Del Gaudio and Wasowski 2004) and 0.02–0.04 g for the Mineral, Virginia earthquake (Jibson and Harp 2012). Recently, Jibson and Harp (2016) analyzed six EQIL events and explored the absolute minimum PGA value considering the very smallest failures (< 1 m3) triggered by the corresponding earthquakes. They examined four of those inventories by field studies and showed that PGA contour covering all landslides ranges from 0.02 to 0.08 g. They investigated two other inventories using aerial-photographic interpretations and pointed out the PGA range of 0.05–0.11 g as an absolute outermost limit of triggered landslides.
Jibson and Harp (2016) also stated that the proposed outermost limits of triggered landslides can only be valid where susceptible slopes are extensive. Yet, the actual area that is affected by landslides depends on the local topographic, lithologic, climatic, and land cover conditions, which are different for each earthquake-affected area, and the interaction between these features and ground shaking causes the specific landslide distribution pattern. Thus, for some of the inventories such a common PGA limit could be larger or smaller than the real landslide-affected area. In this study, we also assumed that the susceptible slopes are extensive in our examined sites to estimate the boundary of a landslide-affected area.
Note that in the case of EQIL, there can be a significant difference between the area that includes the entire landslide population, and one that includes the vast majority (e.g., 90%) of them. Hancox et al. (2002) use the term “main area affected by landslides.” Despite the lack of explanation regarding the parameter in the referred paper, we adapted that term here, modifying it slightly to the main landslide-affected area, and defined it to include the area containing 90% of the mapped landslides. To define the term main landslide-affected area, we examined the inventories and we systematically calculated the percentage of the total number of landslides contained within various PGA contours. We began examining from the highest to lowest PGA contours provided by the USGS ShakeMap system and keep examining until we find the PGA contour covering 90% of the mapped landslides. All other analyses were conducted for the identified main landslide-affected areas.
Eliminating the flat regions as non-susceptible zones to landsliding is a generally accepted approach in landslide modeling studies (e.g., Kritikos et al. 2015). Thus, we defined those regions and subtracted them from the main landslide-affected areas. To identify the flat areas, we used the GRASS GIS module r.geomorphon by Jasiewicz and Stepinski (2013) to extract the “flat” landform class, and an algorithm that gets rid of the sparse pixel result developed by Alvioli et al. (2018a). The algorithm starts from the pixels classified as “flat” by r.geomorphons and shrinks the borders of the flat raster map by a few pixels and then grows it again; the procedure is repeated until sparse pixels disappear.
In our regression model, we did not use the variables such as lithology, land cover or climate that we could not evaluate their contribution to landsliding. For example, we did not include lithologic units because without knowing their geotechnical properties, the description of a lithologic unit is not enough to evaluate its role in landslide initiation process. Instead, we used morphologic variables which were used in statistical landslide probability assessments (e.g., Budimir et al. 2015; Reichenbach et al. 2018). For example, Budimir et al. (2015) examined EQIL causal factors in their review papers. They investigated nine studies and presented the percentages at which covariates were found to be significant. Budimir et al. (2015) stated that in all those studies slope was found as a significant variable. On the other hand, distance to streams was found significant in at least 20% of those studies, while profile curvature, topographic wetness index (TWI), and surface roughness were found significant in at least 10% of those studies. Tanyaş et al. (2017) analyzed about 554,000 landslide initiation points from 46 EQIL events and examined the frequency values of earthquake-induced landslides in intervals of slope, surface roughness, local relief, and distance to streams. They stated that the highest landslide frequencies are concentrated in particular intervals for all of these parameters. This implies that these variables may be good candidates to check their significance in our regression analysis as well.
Slope is a factor controlling the normal and shear stresses, which take a role in slope stability. Local relief is the maximum difference in height in a local neighborhood of each pixel and can be related to slope instability caused by tectonic uplift. It partially correlates with slope. Both slope and local relief are related to the magnitude of static stress loading in hillslopes (Parker et al. 2015). TWI (Moore et al. 1991) is a proxy for potential soil wetness used to estimate the spatial variability of wetness within a landscape (e.g., Nowicki Jessee et al. 2018). It can take a role in slope stability by changing the pore water pressure. We used vector ruggedness measure (VRM) to consider surface roughness. It quantifies local variation in terrain more independently of slope than other methods such as land surface ruggedness index or terrain ruggedness index (Sappington et al. 2007). Tanyaş et al. (2017) showed that the majority of EQIL are initiated at low VRM values, and the number of observed EQIL decreases while VRM increases. Distance to stream is proxy related to fluvial undercutting (e.g., Kritikos et al. 2015) that cause high rates of shear stress as a result of loss of lateral support (Korup 2004). Tanyaş et al. (2017) showed that the majority of EQIL are initiated close to river channels and the frequency of observed landslides gradually decreases while going far away from channels. Profile curvature is a measure describing the concavity/convexity of slope along the vertical direction. Having a concave surface can increase slope instability by increasing the subsurface drainage that can cause high water pressure (Pierson 1980).
To create our morphologic variables used as covariates in our regression model, we worked with a few of the modules of GRASS GIS (Neteler and Mitasova 2013) and SAGA GIS (Conrad et al. 2015). In total, we derived six DEM derivatives (Table 4) using the module given within parentheses; slope (r.slope.aspect) (Hofierka et al. 2009), topographic wetness index (r.topidx) (Cho 2000), vector ruggedness measure (r.vector.ruggedness) (Sappington et al. 2007), distance to stream (r.watershed and r.grow) (Ehlschlaeger 1989), local relief (r.geomorphon) (Jasiewicz and Stepinski 2013), and profile curvatures (r.param.scale) (Wood 1996).
We also tested five seismogenic variables (PGA, PGV, MMI, earthquake magnitude, and half duration) in linear regression analysis (Table 4). MMI is a scale classifying the shaking strength observed at a site. PGA is the largest peak acceleration recorded in a strong-motion accelerogram of an earthquake, while PGV is the largest increase in velocity experienced by a particle on the ground during an earthquake (Bormann et al. 2013). If the variables such as fault-rupture mechanism and fault geometry are known, they are also taken into account, and a ShakeMap is created accordingly (e.g., Wald 2013). Therefore, we can assume that fault-rupture mechanism and fault geometry is represented by the resultant ground-motion parameters provided by ShakeMap. One of these ground-motion parameters is used in almost all statistical based EQIL prediction models (e.g., Nowicki Jessee et al. 2018; Nowicki et al. 2014; Robinson et al. 2017; Tanyas et al. 2019). PGA, PGV, and MMI are collinear variables and thus we considered three of them to identify the most significant ground motion parameter for this study. The other two-seismogenic variables, earthquake magnitude, and half duration are proxies for energy released by rupturing and duration of rupturing, respectively.
Apart from two independent variables (earthquake magnitude and half duration) which do not have any variation within a landslide-affected area, we calculated both mean value and its standard deviation for each independent variable to represent the characteristics of main landslide-affected areas.
We evaluated the significance level of each variable used in the linear regression model based on p values. We selected a significance level of 5%, which refers to a p value of 0.05 as a confidence level, below which the relation between the examined independent and dependent variables were considered significant (Moore et al. 2012). To decide on the best predictor subset, we run the stepwise linear regression algorithm provided by Matlab (Version R2017b). We applied a forward feature selection method which searches for covariates to add to the model based on p value. The algorithm tests the model with and without a potential covariate at each step considering p value. The algorithm tests not only the individual terms but also their interactions (e.g., multiplication of variables). If any of the available covariates in the model has a p value less than 0.05, the one with the smallest p value is added into a model and this procedure is repeated until the significant covariates are included into the model. This procedure provided us the set of covariates giving the best model performance. We then checked the collinearity between those variables using the variance inflation factor (VIF) (Chatterjee and Hadi 2012); a VIF larger than 10 is assumed as an indication of a collinearity.
Because we have limited observations, to validate our model, we used the leave-one-out methodology and predicted mLS values for each earthquake using the described stepwise linear regression algorithm. Considering p values, we selected the best predictor subset and the corresponding best model.
Results
To define the term main landslide-affected area, we compared the differences in PGA values covering the various landslide populations. For example for the Haiti inventory (Harp et al. 2016), PGA contours of 0.23 g, 0.36 g, 0.41 g, and 0.48 g contain 100%, 90%, 80%, and 70% of the entire mapped landslide population, respectively. We calculated these values for all inventories. Table 5 shows the PGA values and the percentage of the total number of landslides falling within these limiting PGA contours for each inventory. Table 5 shows that except for the 2007 Pisco, Peru earthquake (Mw 8.0), the 0.12 g is the minimum PGA contour covering at least 90% of the mapped landslides in each inventory. The 2007 Pisco earthquake is an offshore event where significant part of the area covered by large peak ground acceleration (PGA) locates at sea. Therefore, for this earthquake, the 0.12-g PGA contour covers about 80% of the mapped landslides (Table 5). Given these observations, we took the 0.12-g PGA contour as an estimate for the boundary of main landslide-affected area. This PGA value is slightly larger than the PGA range (0.05–0.11 g) indicated in the literature (e.g., Jibson and Harp 2016) as the outmost limit of EQIL, and thus consistent with the literature.
We calculated our predictors for the area bounded by the 0.12-g PGA contour in each landslide-affected area. The stepwise regression algorithm identified five predictors as the best subset explaining our dependent variable: Earthquake magnitude (EqM), profile curvature (mean), profile curvature (std), TWI (mean), and EqM × TWI (mean) (Table 6). The regression equation is as follows:
The regression model run using these predictors show that each predictor has a p value less than 0.05 and thus, they all have high significance in our model. We checked the collinearity between predictors using VIF. We excluded our interaction term (EqM × TWI (mean)) from the collinearity evaluation (Friedrich 1982). The results show that VIF values for all other variables are less than two and thus, the collinearity is not an issue for the selected variables. Among the selected variables, earthquake magnitude (EqM), profile curvature (mean), and TWI (mean) have explicit physical meaning in our regression equation in addition to their statistical significance. On the other hand, profile curvature (std) and the interaction term (EqM × TWI (mean)) have only statistical significance.
We presented the adjusted R2, root-mean-square error (RMSE), and mean absolute error (MAE) values for the best-fit line (Fig. 2). The adjusted R2 value shows that the model explains 86% of the variability of the response data around its mean. On the other hand, the average magnitude of the error is 0.39 (RMSE) and the absolute differences between predicted and calculated mLS value is 0.30 (MAE).

Graph showing the model result. The confidence intervals which are shown by vertical error bars are calculated for each prediction separately. Uncertainties in calculated mLS values are given by using ± 2σ error bars. Calculated mLS values are obtained from Tanyaş et al. (2018a)
To validate this model, for each predictor subset, we followed the leave-one-out technique and predicted the entire mLS array. Results show that adjusted R2 is 0.79, RMSE is 0.50, and MAE is 0.40 (Fig. 3a). The residuals show a random distribution around a constant value without a distinct pattern and the average residual value is 0.0004 (Fig. 3b). This supports our assumption that a linear dependence exists between mLS and the variables. The average uncertainty for the calculated mLS values, which were shown by horizontal error bars in Fig. 3a and vertical error bars in Fig. 3b, is 0.15. In a few cases (e.g., EQIL Inventory ID of 2, 10, 12, 20, and 21), the residuals are lower than uncertainties in calculated mLS values. These are the cases that our predictions are successful. In all cases, our predictions stay within the 95% confidence limits for the best-fit line passing from the origin (Fig. 3a).

Graphs showing the results of validation using the leave-one-out methodology: a the distribution of calculated versus predicted mLS values and the best-fit line passing from the origin and b the residuals for predicted mLS values. The confidence intervals which are shown by vertical error bars are calculated for each prediction separately in (a). The uncertainties in calculated mLS values (± 2σ) are given by horizontal error bars in (a) and vertical error bars in (b). Calculated mLS values are obtained from Tanyaş et al. (2018a). The number in the lower graph refers to the EQIL inventory IDs listed in Table 5
We can predict mLS and other measures that we can estimate using mLS, soon after an earthquake, in four steps (Fig. 4): (i) the PGA map of an investigated earthquake is obtained from USGS ShakeMap system and the SRTM DEM is obtained for the areas bounded by minimum PGA value of 0.12 g; (ii) the independent variables listed in Table 6 are collected/derived for non-flat areas; (iii) the proposed regression equation (Eq. 5) is run using the coefficients listed in Table 6 and mLS is predicted for the examined earthquake; and (iv) the maximum landslide area (Eq. 2) and the total landslide area (Eq. 4) are estimated using existing methodologies (Malamud et al. 2004; Tanyaş et al. 2018a). Further, the variation ranges for the estimated mLS are calculated using the confidence intervals given in Table 1. Frequency-size distribution of the examined landslide event can be estimated using the empirical curves proposed by Malamud et al. (2004).

Flowchart for the proposed method
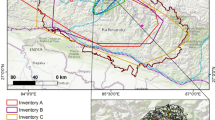
We used the 2004 Mid-Niigata earthquake as an example to show the application of the proposed method (Fig. 5), which is presented in Fig. 4. We have three landslide inventories (GSI of Japan 2005; Sekiguchi and Sato 2006; Yagi et al. 2007) for this earthquake but all of them include landslides triggered by a sequence of earthquakes rather than a single main shock. Therefore, we discarded these inventories in the modeling stage (see Table 2) because they may include more landslides and thus the predicted mLS using a single earthquake may be lower than the calculated mLS.

Illustration of the four-step procedure (Fig. 4) to predict mLS and related parameters for the 2004 Mid-Niigata earthquake. In STEP-1, the 0.12-g PGA contour as an estimate for the boundary of main landslide-affected area is identified. In STEP-2, the independent variables are determined for non-flat regions located within the main landslide-affected area. In STEP-3, the regression equation (Eq. 5) is run to predict mLS. In STEP-4, the number of triggered landslides (NLT) is estimated (Eq. 1) to predict the maximum landslide area (ALmax) (Eq. 2), and the total landslide area (AT) (Eq. 4). The empirical frequency-size distribution curve corresponding to estimated mLS is also identified in STEP-4. The empirical frequency-size distribution curves presented in STEP-4 are taken from Malamud et al. (2004)
We predicted mLS using our proposed regression equation (Eq. 5). Also, we predicted the maximum landslide area (ALmax in Fig. 5) and the total landslide area (AT in Fig. 5) based on existing methodologies (Malamud et al. 2004; Tanyaş et al. 2018a). The predicted mLS (3.06 ± 0.33), the maximum landslide area (ALmax) (0.16 km2 (− 0.07, + 0.11)), and the total landslide area (AT) (2.82 km2 (− 1.24, + 2.12)) are close to the values calculated from the 2004 Mid-Niigata inventory map created by Yagi et al. (2007) (mLS = 3.11 ± 0.04; ALmax = 0.17 km2 and AT = 3.80 km2). As we expected, our predictions are lower than the values calculated from three of the inventories (see Table 2) due to the overprinting of landslides from different earthquakes. We did not predict total landslide volume using the equation suggested by Malamud et al. (2004) because the examined inventories do not have volume information to validate our prediction. We estimated the frequency-area distribution of landslides (Fig. 5) which can be useful for quantitative analysis of landslide hazard assessment. Note that the form of the frequency-area distribution curve may not be representative for small landslides (Tanyaş et al. 2018b) and thus we suggest to focus on the power-law tail in this estimate.
Discussion
The most relevant advantage of our method is that we use both static and dynamic parameters, which are publicly available. The static predictors are DEM derivatives and thus they can be easily derived for any location on the globe. Earthquake magnitude and ShakeMap data can be obtained using USGS ShakeMap system in near-real time.
The proposed method has also some limitations. Our approach gives poor prediction results in a few cases as was shown in Fig. 3, due to several reasons. First, offshore events may not be well characterized using the proposed approach. In offshore earthquakes, most of the areas bounded by the 0.12-g PGA contour are not located on land, and thus our morphological predictors may not represent the landslide-affected area well. Figure 3 shows that for two offshore earthquakes, we have residuals, which are larger than MAE (0.40). The 1978 Izu Oshima Kinkai (3) and the 2010 Eastern Honshu (18) earthquakes give residual values of 0.57 and 0.50, respectively. Second, the quality of the ShakeMap data may also affect our model performance since we identify the main landslide-affected area using the PGA values from the raster files provided by USGS ShakeMap system. The relatively poor quality of ShakeMap regarding the 2010 Yushu earthquake may be the reason for having a larger residual (0.69) than the average value for this earthquake. Third, the inventories used for the calculation of mLS values may be incomplete or may contain landslides which were not triggered by the specific earthquake. If these landslides are medium or large in size, this may affect the calculated mLS value. Landslide mapping is a subjective procedure (e.g., Tanyaş et al. 2017), and each landslide inventory can be exposed to various levels of amalgamation and the delineated landslide polygons may show minor/major differences comparing to the actual landslide boundaries based on the quality of an inventory. However, evaluating the quality and completeness of the inventories is not possible without examining the landslides from the original imagery from which the inventories were made, which is very time-consuming. This implies an uncertainty in mLS that we could not assess quantitatively. Further studies need to assess this uncertainty. Fourth, the simplicity of the proposed method may be the main reason for poor prediction in some cases. We used earthquake magnitude (EqM), profile curvature (mean and standard deviation), topographic wetness index (TWI) (mean), and EqM × TWI (mean) (Table 6) to derive our regression equation. We used mean values and standard deviations for these variables which may not represent the landslide-affected areas in a few cases, affecting the prediction performance. Moreover, we could not consider some variables that may play an important role in landslide initiation and thus affect the resulting landslide-event magnitude. For example, shear strength parameters of slope material are not available globally. Although a global lithologic map is available (e.g., Hartmann and Moosdorf 2012), the evaluation of the strength parameters only based on lithologic descriptions is not a reliable method. Similarly, we could not account for the effect of previous earthquakes (Parker et al. 2015), or previously occurred landslides (Samia et al. 2017) because we do not have globally available datasets to quantify the effect of such variables.
Last but not least, a considerable drawback of this study is that there are only a limited number of digital landslide inventories available. Although we worked with the largest EQIL dataset available (Tanyaş et al. 2017), the number of selected inventories is still limited given the variation in seismogenic or environmental characteristics of the examined landslide events. With a larger EQIL inventory database, landslide events can be better categorized based on common features and different regression coefficients can be calculated for each of those categories. For example, offshore earthquakes can be analyzed separately to address the possible drawback mentioned above. Similarly, categorizing the earthquakes having different faulting mechanism would be possible with a larger database. Although the ground motion estimates provided by ShakeMap take into account the characteristics of faulting mechanism such as fault type and geometry (e.g., Wald 2013), categorization of inventories considering these features may help us to improve our mLS predictions as well. Now, we have only 10 landslide events associated with strike-slip faulting and 13 events with thrust faulting, while no EQIL inventory is available that is associated with normal faulting (Table 2), which is not sufficient to make separate categories.
Conclusions
We analyzed 23 EQIL inventories to develop an approach for the near-real-time prediction of the landslide-event magnitude scale. We restricted our analyses within non-flat regions located within the main landslide-affected areas, which were identified using the PGA contour containing 90% of the landslides and largest PGA values. For each of the main landslide-affected areas, we calculated mean values of three independent seismogenic and six morphologic variables and their standard deviations (Table 4). Additionally, we gathered earthquake magnitude and half duration for each earthquake and examined 20 variables in total. We assumed a linear dependence for mLS over the variables and identified five variables as the best subset of the independent parameters using a stepwise linear regression algorithm. Using the selected subset of variables, we identified the coefficients of the regression model and validated this model using the leave-one-out approach, since we have limited observations.
Validation results show that our proposed approach provides a relatively good prediction (adjusted R2 = 0.79, RMSE = 0.50, and MAE = 0.40) for mLS. Although this has not been tested in practice, it is possible to make near-real-time predictions as the required predictors can be derived rapidly after an earthquake.
Rapid prediction of mLS can improve our ability to estimate the intensity of landslide events within a day after an earthquake and, thus, it can provide useful information in the emergency response phase. Using the predicted mLS, we can also estimate maximum landslide area, total landslide area, and volume, which can help us better understand the balance between crustal advection and seismically induced mass wasting and thus the landscape evolution process (e.g., Hovius et al. 2011). We can also estimate the frequency-size distribution of landslide-event using the empirical curves of Malamud et al. (2004). Tanyaş et al. (2018a) emphasized the variation in the slope of frequency-size distribution curves and argue that modeling the frequency-size distribution of landslides may not be accurate using an average slope as Malamud et al. (2004) did. However, in the absence of landslide-event inventory, to provide estimates regarding the size distribution of landslides, the empirical curves of Malamud et al. (2004) can be quite useful. Our method needs further calibration using a larger dataset to ensure its validity globally. With a larger EQIL database, this model can be improved addressing some of the drawbacks mentioned above and predict mLS with smaller uncertainties.
References
Allen TI, Wald DJ, Hotovec AJ, Lin K-W, Earle P, Marano KD (2008) An atlas of ShakeMaps for selected global earthquakes. U.S Geological Survey Open-File Report 2008–1236, 35 p. https://pubs.usgs.gov/of/2008/1236. Accessed 1 March 2018
Alvioli M, Guzzetti F, Rossi M (2014) Scaling properties of rainfall induced landslides predicted by a physically based model. Geomorphology 213:38–47. https://doi.org/10.1016/j.geomorph.2013.12.039
Alvioli M, Guzetti F, Marchesini I (2018a) Nation-wide, general-purpose delineation of geomorphological slope units in Italy. In: Geomorphometry 2018, 12–17 August 2018, Boulder, CO, USA. https://doi.org/10.7287/peerj.preprints.27066v1
Alvioli M, Melillo M, Guzzetti F, Rossi M, Palazzi E, von Hardenberg J, Brunetti MT, Peruccacci S (2018b) Implications of climate change on landslide hazard in Central Italy. Sci Total Environ 630:1528–1543. https://doi.org/10.1016/j.scitotenv.2018.02.315
Alvioli M, Mondini AC, Fiorucci F, Cardinali M, Marchesini I (2018c) Topography-driven satellite imagery analysis for landslide mapping. Geomat Nat Haz Risk 9:544–567. https://doi.org/10.1080/19475705.2018.1458050
Barlow J, Barisin I, Rosser N, Petley D, Densmore A, Wright T (2015) Seismically-induced mass movements and volumetric fluxes resulting from the 2010 Mw=7.2 earthquake in the Sierra Cucapah, Mexico. Geomorphology 230:138–145. https://doi.org/10.1016/j.geomorph.2014.11.012
Basharat M, Rohn J, Baig MS, Khan MR (2014) Spatial distribution analysis of mass movements triggered by the 2005 Kashmir earthquake in the Northeast Himalayas of Pakistan. Geomorphology 206:203–214. https://doi.org/10.1016/j.geomorph.2013.09.025
Basharat M, Ali A, Jadoon IA, Rohn J (2016) Using PCA in evaluating event-controlling attributes of landsliding in the 2005 Kashmir earthquake region, NW Himalayas, Pakistan. Nat Hazards 81:1999–2017. https://doi.org/10.1007/s11069-016-2172-9
Bennett G, Molnar P, Eisenbeiss H, McArdell B (2012) Erosional power in the Swiss Alps: characterization of slope failure in the Illgraben. Earth Surf Process Landf 37:1627–1640. https://doi.org/10.1002/esp.3263
Bormann P, Aki K, Lee WHK, Schweitzer J (2013) Glossary. - In: Bormann, P. (Ed.), New manual of seismological observatory practice 2 (NMSOP 2), Potsdam : Deutsches GeoForschungsZentrum GFZ, pp. 1—200. https://doi.org/10.2312/GFZ.NMSOP-2_Glossary
Bornaetxea T, Rossi M, Marchesini I, Alvioli M (2018, 2018) Effective surveyed area and its role in statistical landslide susceptibility assessments. Nat Hazards Earth Syst Sci discuss:1–22. https://doi.org/10.5194/nhess-2018-88
Budimir MEA, Atkinson PM, Lewis HG (2015) A systematic review of landslide probability mapping using logistic regression. Landslides 12:419–436. https://doi.org/10.1007/s10346-014-0550-5
Casagli N, Frodella W, Morelli S, Tofani V, Ciampalini A, Intrieri E, Raspini F, Rossi G, Tanteri L, Lu P (2017) Spaceborne, UAV and ground-based remote sensing techniques for landslide mapping, monitoring and early warning. Geoenviron Disasters 4(9). https://doi.org/10.1186/s40677-017-0073-1
Chatterjee S, Hadi AS (2012) Regression analysis by example, 5th edn. Wiley, New York
Cho H (2000) GIS hydrological modeling system by using programming interface of GRASS. Master’s thesis. Kyungpook National University
Collins BD, Kayen R, Tanaka Y (2012) Spatial distribution of landslides triggered from the 2007 Niigata Chuetsu–Oki Japan earthquake. Eng Geol 127:14–26. https://doi.org/10.1016/j.enggeo.2011.12.010
Conrad O, Bechtel B, Bock M, Dietrich H, Fischer E, Gerlitz L, Wehberg J, Wichmann V, Böhner J (2015) System for automated geoscientific analyses (SAGA) v. 2.1. 4. Geosci Model Dev 8:1991–2007. https://doi.org/10.5194/gmd-8-1991-2015
Dai F, Xu C, Yao X, Xu L, Tu X, Gong Q (2011) Spatial distribution of landslides triggered by the 2008 Ms 8.0 Wenchuan earthquake, China. J Asian Earth Sci 40:883–895. https://doi.org/10.1016/j.jseaes.2010.04.010
Del Gaudio V, Wasowski J (2004) Time probabilistic evaluation of seismically induced landslide hazard in Irpinia (southern Italy). Soil Dyn Earthq Eng 24:915–928. https://doi.org/10.1016/j.soildyn.2004.06.019
DSPR-KU (2016) Slope movement condition by 2016 Kumaoto earthquake in Minami-Aso village (as of 19:00 JST on 18 Apr 2016), edited, disaster prevention research institute, Kyoto University. http://www.slope.dpri.kyoto-u.ac.jp/disaster_reports/2016KumamotoEq/2016KumamotoEq2.html. Accessed 15 Sept 2016
Dziewonski AM, Chou T-A, Woodhouse JH (1981) Determination of earthquake source parameters from waveform data for studies of global and regional seismicity. J Geophys Res Solid Earth 86:2825–2852. https://doi.org/10.1029/JB086iB04p02825
Ehlschlaeger CR (1989) Using the AT search algorithm to develop hydrologic models from digital elevation data. In: Proceedings of the international geographic information system (IGIS) symposium, Baltimore, MD, 1989. Baltimore, MD, pp 275–281
Ekström G, Nettles M, Dziewoński AM (2012) The global CMT project 2004–2010: centroid-moment tensors for 13,017 earthquakes. Phys Earth Planet Inter 200-201:1–9. https://doi.org/10.1016/j.pepi.2012.04.002
Friedrich RJ (1982) In defense of multiplicative terms in multiple regression equations. Am J Polit Sci 26:797–833. https://doi.org/10.2307/2110973
Garcia D, Mah R, Johnson K, Hearne M, Marano K, Lin K, Wald D, Worden C, So E (2012) ShakeMap atlas 2.0: an improved suite of recent historical earthquake ShakeMaps for global hazard analyses and loss model calibration. In: World Conference on Earthquake Engineering, 2012. https://pubs.er.usgs.gov/publication/70046678. Accessed 1 Dec 2017
Gorum T, van Westen CJ, Korup O, van der Meijde M, Fan X, van der Meer FD (2013) Complex rupture mechanism and topography control symmetry of mass-wasting pattern, 2010 Haiti earthquake. Geomorphology 184:127–138. https://doi.org/10.1016/j.geomorph.2012.11.027
Gorum T, Korup O, van Westen CJ, van der Meijde M, Xu C, van der Meer FD (2014) Why so few? Landslides triggered by the 2002 Denali earthquake, Alaska. Quat Sci Rev 95:80–94. https://doi.org/10.1016/j.quascirev.2014.04.032
Govi M (1977) Photo-interpretation and mapping of the landslides triggered by the Friuli earthquake (1976). Bull Int Assoc Eng Geol 15:67–72. https://doi.org/10.1007/BF02592650
GSI of Japan (Geospatial Information Authority of Japan) (2005) 1:25,000 Damage map of the Mid Niigata Prefecture earthquake in 2004: 3sheets
Guzzetti F, Reichenbach P, Cardinali M, Galli M, Ardizzone F (2005) Probabilistic landslide hazard assessment at the basin scale. Geomorphology 72:272–299. https://doi.org/10.1016/j.geomorph.2005.06.002
Guzzetti F, Mondini AC, Cardinali M, Fiorucci F, Santangelo M, Chang K-T (2012) Landslide inventory maps: new tools for an old problem. Earth Sci Rev 112:42–66. https://doi.org/10.1016/j.earscirev.2012.02.001
Hancox GT, Perrin ND, Dellow GD (2002) Recent studies of historical earthquake-induced landsliding, ground damage, and MM intensity in New Zealand. Bull N Z Soc Earthq Eng 35:59–95
Harp EL, Jibson RW. (1995) Inventory of landslides triggered by the 1994 Northridge, California earthquake: U.S. Geological Survey Open-File Report. 95–213. https://pubs.usgs.gov/of/1995/ofr-95-0213/
Harp EL, Jibson RW. (1996) Landslides triggered by the 1994 Northridge, California earthquake. Bull Seismol Soc Am 86(1B):319–332
Harp EL, Keefer DK (1990) Landslides triggered by the earthquake. In: Rymer MJ and Ellsworth WL (eds.) “the Coalinga, California, earthquake of May 2, 1983” US Geological Survey Professional Paper 1487:335–347. https://pubs.usgs.gov/pp/1487/report.pdf. Accessed 1 Sept 2017
Harp EL, Wilson RC, Wieczorek GF (1981) Landslides from the February 4, 1976, Guatemala earthquake, U.S. Geological Survey Professional Paper 1204-A, 35 p, 2 plates. https://pubs.er.usgs.gov/publication/pp1204A. Accessed 1 Sept 2017
Harp EL, Tanaka K, Sarmiento J, Keefer DK (1984) Landslides from the May 25–27, 1980, Mammoth Lakes, California, earthquake sequence. U.S. Geological Survey Miscellaneous Investigations Series Map vol I-1612. https://pubs.er.usgs.gov/publication/i1612. Accessed 1 Sept 2017
Harp EL, Hartzell SH, Jibson RW, Ramirez-Guzman L, Schmitt RG (2014) Relation of landslides triggered by the Kiholo Bay earthquake to modeled ground motion. Bull Seismol Soc Am 104:2529–2540. https://doi.org/10.1785/0120140047
Harp EL, Jibson RW, Schmitt RG (2016) Map of landslides triggered by the January 12, 2010, Haiti earthquake: U.S. Geological Survey Scientific Investigations Map 3353, 15 p., 1 sheet, scale 1:150,000. https://doi.org/10.3133/sim3353
Hartmann J, Moosdorf N (2012) The new global lithological map database GLiM: a representation of rock properties at the earth surface geochemistry. Geophys Geosyst 13:Q12004. https://doi.org/10.1029/2012gc004370
Hergarten S (2012) Topography-based modeling of large rockfalls and application to hazard assessment. Geophys Res Lett 39:L13402. https://doi.org/10.1029/2012GL052090
Hofierka J, Mitasova H, Neteler M (2009) Geomorphometry in GRASS GIS. In: Hengl T, Reuter HI (eds) Geomorphometry: concepts, software, applications. Developments in soil science, vol 33. Elsevier, pp 387–410. https://doi.org/10.1016/S0166-2481(08)00017-2
Hovius N, Meunier P, Lin CW, Chen H, Chen YG, Dadson S, Horng MJ, Lines M (2011) Prolonged seismically induced erosion and the mass balance of a large earthquake. Earth Planet Sci Lett 304:347–355. https://doi.org/10.1016/j.epsl.2011.02.005
Huang TF, Lee CT (1999) Landslides triggered by the Jueili earthquake. Paper presented at the Proceedings of the 1999 Annual Meeting of the Geological Society of China, Taipei
Jasiewicz J, Stepinski TF (2013) Geomorphons — a pattern recognition approach to classification and mapping of landforms. Geomorphology 182:147–156. https://doi.org/10.1016/j.geomorph.2012.11.005
Jibson RW, Harp EL (2012) Extraordinary distance limits of landslides triggered by the 2011 mineral, Virginia, earthquake. Bull Seismol Soc Am 102:2368–2377. https://doi.org/10.1785/0120120055
Jibson RW, Harp EL (2016) Ground motions at the outermost limits of seismically triggered landslides. Bull Seismol Soc Am 106:708–719. https://doi.org/10.1785/0120150141
Jibson RW, Harp EL, Michael JA (2000) A method for producing digital probabilistic seismic landslide hazard maps. Eng Geol 58:271–289. https://doi.org/10.1016/S0013-7952(00)00039-9
Keefer DK (1984) Landslides caused by earthquakes. Geol Soc Am Bull 95:406–421 https://pubs.er.usgs.gov/publication/70014049. Accessed 1 Sept 2017
Keefer DK, Tannaci NE (1981) Bibliography of landslides, soil liquefaction, and related ground failures in selected historic earthquakes, - edn. https://doi.org/10.3133/ofr81572
Kokusai Kogyo (2007) Aerial photo interpretation of earthquake damage from the 2007 Niigata Chuetsu–oki Earthquake. Kokusai Kogyo Co., Ltd, Japan
Korup O (2004) Geomorphic implications of fault zone weakening: slope instability along the Alpine Fault, South Westland to Fiordland. N Z J Geol Geophys 47:257–267. https://doi.org/10.1080/00288306.2004.9515052
Kritikos T, Robinson TR, Davies TR (2015) Regional coseismic landslide hazard assessment without historical landslide inventories: a new approach. J Geophys Res Earth Surf 120:711–729. https://doi.org/10.1002/2014JF003224
Lacroix P, Zavala B, Berthier E, Audin L (2013) Supervised method of landslide inventory using panchromatic SPOT5 images and application to the earthquake-triggered landslides of Pisco (Peru, 2007, Mw8. 0). Remote Sens 5:2590–2616. https://doi.org/10.3390/rs5062590
Li W-l, R-q H, Xu Q, Tang C (2013) Rapid susceptibility mapping of co-seismic landslides triggered by the 2013 Lushan earthquake using the regression model developed for the 2008 Wenchuan earthquake. J Mt Sci 10:699–715. https://doi.org/10.1007/s11629-013-2786-2
Li G, West AJ, Densmore AL, Jin Z, Parker RN, Hilton RG (2014) Seismic mountain building: landslides associated with the 2008 Wenchuan earthquake in the context of a generalized model for earthquake volume balance. Geochem Geophys Geosyst 15:833–844. https://doi.org/10.1002/2013GC005067
Li G, West AJ, Densmore AL, Jin Z, Zhang F, Wang J, Clark M, Hilton RG (2017) Earthquakes drive focused denudation along a tectonically active mountain front. Earth Planet Sci Lett 472:253–265. https://doi.org/10.1016/j.epsl.2017.04.040
Liao H-W, Lee C-T (2000) Landslides triggered by the Chi-Chi earthquake. In: Proceedings of the 21st Asian conference on remote sensing pp 383–388. ftp://140.115.123.47/download/!Chi_Chi%20Landslide%20Inventory%202000/ACRS2000.pdf. Accessed 1 Sept 2017
Malamud BD, Turcotte DL, Guzzetti F, Reichenbach P (2004) Landslide inventories and their statistical properties. Earth Surf Process Landf 29:687–711. https://doi.org/10.1002/esp.1064
Marc O, Hovius N, Meunier P, Gorum T, Uchida T (2016) A seismologically consistent expression for the total area and volume of earthquake-triggered landsliding. J Geophys Res Earth Surf 121:640–663. https://doi.org/10.1002/2015JF00373
Martha TR, Kerle N, Jetten V, van Westen CJ, Kumar KV (2010) Characterising spectral, spatial and morphometric properties of landslides for semi-automatic detection using object-oriented methods. Geomorphology 116:24–36. https://doi.org/10.1016/j.geomorph.2009.10.004
Marzorati S, Luzi L, De Amicis M (2002) Rock falls induced by earthquakes: a statistical approach. Soil Dyn Earthq Eng 22:565–577. https://doi.org/10.1016/S0267-7261(02)00036-2
McCrink PT (2001) Regional earthquake-induced landslide mapping using Newmark displacement criteria, Santa Cruz County, California. In: Ferriz H and Anderson, ed. Engineering geology practice in Northern California, Association of Engineering Geologists Special Publication 12, California Geological Survey Bulletin 210:77–93. https://eurekamag.com/research/019/877/019877815.php. Accessed 1 Sept 2017
Meunier P, Hovius N, Haines AJ (2007) Regional patterns of earthquake-triggered landslides and their relation to ground motion. Geophys Res Lett 34:L20408. https://doi.org/10.1029/2007GL031337
Meunier P, Hovius N, Haines JA (2008) Topographic site effects and the location of earthquake induced landslides. Earth Planet Sci Lett 275:221–232. https://doi.org/10.1016/j.epsl.2008.07.020
Moore ID, Grayson RB, Ladson AR (1991) Digital terrain modelling: a review of hydrological, geomorphological, and biological applications. Hydrol Process 5:3–30. https://doi.org/10.1002/hyp.3360050103
Moore DS, Craig BA, McCabe GP (2012) Introduction to the practice of statistics, Sixth edn. WH Freeman, New York
NASA Jet Propulsion Laboratory (JPL) (2013) NASA Shuttle Radar Topography Mission United States 1 arc second. NASA EOSDIS Land Processes DAAC, USGS Earth Resources Observation and Science (EROS) Center, Sioux Falls, South Dakota (https://lpdaacusgsgov), accessed January 1, 2015. https://doi.org/10.5067/MEaSUREs/SRTM/SRTMUS1.003
Neteler M, Mitasova H (2013) Open source GIS: a GRASS GIS approach, vol 689. Springer, Boston. https://doi.org/10.1007/978-0-387-68574-8
NIED (2016) Distribution map of mass movement by the 2016 Kumamoto earthquake, edited by National Research Institute for Earth Science and Disaster of Japan. http://www.bosai.go.jp/mizu/dosha.html. Accessed 1 Sept 2017
Nowicki Jessee MA, Hamburger MW, Allstadt KE, Wald DJ, Robeson SM, Tanyas H, Thomas EM (2018) A global empirical model for near real-time assessment of seismically induced landslides. J Geophys Res Earth Surf. https://doi.org/10.1029/2017JF004494
Nowicki MA, Wald DJ, Hamburger MW, Hearne M, Thompson EM (2014) Development of a globally applicable model for near real-time prediction of seismically induced landslides. Eng Geol 173:54–65. https://doi.org/10.1016/j.enggeo.2014.02.002
Papathanassiou G, Valkaniotis S, Ganas A, Pavlides S (2013) GIS-based statistical analysis of the spatial distribution of earthquake-induced landslides in the island of Lefkada, Ionian Islands, Greece. Landslides 10:771–783. https://doi.org/10.1007/s10346-012-0357-1
Parker R, Hancox G, Petley D, Massey C, Densmore A, Rosser N (2015) Spatial distributions of earthquake-induced landslides and hillslope preconditioning in the northwest South Island, New Zealand. Earth Surf Dyn 3:501–525. https://doi.org/10.5194/esurf-3-501-2015
Pierson TC (1980) Piezometric response to rainstorms in forested hillslope drainage depressions. J Hydrol N Z 19:1–10 https://www.jstor.org/stable/43944461. Accessed 1 March 2018
Reichenbach P, Rossi M, Malamud BD, Mihir M, Guzzetti F (2018) A review of statistically-based landslide susceptibility models. Earth Sci Rev 180:60–91. https://doi.org/10.1016/j.earscirev.2018.03.001
Roback K et al. (2017) Map data of landslides triggered by the 25 April 2015 Mw 7.8 Gorkha, Nepal earthquake: U.S. Geological Survey data release. https://doi.org/10.5066/F7DZ06F9
Robinson TR, Rosser NJ, Densmore AL, Williams JG, Kincey ME, Benjamin J, Bell HJA (2017) Rapid post-earthquake modelling of coseismic landslide magnitude and distribution for emergency response decision support. Nat Hazards Earth Syst Sci Discuss 2017:1–29. https://doi.org/10.5194/nhess-2017-83
Rodriguez C, Bommer J, Chandler R (1999) Earthquake-induced landslides: 1980–1997. Soil Dyn Earthq Eng 18:325–346. https://doi.org/10.1016/S0267-7261(99)00012-3
Samia J, Temme A, Bregt A, Wallinga J, Guzzetti F, Ardizzone F, Rossi M (2017) Do landslides follow landslides? Insights in path dependency from a multi-temporal landslide inventory. Landslides 14:547–558. https://doi.org/10.1007/s10346-016-0739-x
Sappington J, Longshore KM, Thompson DB (2007) Quantifying landscape ruggedness for animal habitat analysis: a case study using bighorn sheep in the Mojave Desert. J Wildl Manag 71:1419–1426. https://doi.org/10.2193/2005-723
Sato HP, Hasegawa H, Fujiwara S, Tobita M, Koarai M, Une H, Iwahashi J (2007) Interpretation of landslide distribution triggered by the 2005 Northern Pakistan earthquake using SPOT 5 imagery. Landslides 4:113–122. https://doi.org/10.1007/s10346-006-0069-5
Sekiguchi T, Sato HP (2006) Feature and distribution of landslides induced by the Mid Niigata Prefecture earthquake in 2004, Japan. J Jpn Landslide Soc 43:142–154. https://doi.org/10.3313/jls.43.142
Sepúlveda S, Serey A, Lara M, Pavez A, Rebolledo S (2010) Landslides induced by the April 2007 Aysén Fjord earthquake, Chilean Patagonia. Landslides 7:483–492. https://doi.org/10.1007/s10346-010-0203-2
Suzuki K (1979) On the disaster situation/land condition map of the Izu-Oshima Kinkai earthquake, 1978 map. J Jpn Cartograph Assoc 17:16–22. https://doi.org/10.11212/jjca1963.17.2_16
Tang C, Westen CJV, Tanyaş H, Jetten VG. (2016) Analyzing post-earthquake landslide activity using multi-temporal landslide inventories near the epicentral area of the 2008 Wenchuan earthquake. Nat Hazards Earth Syst Sci 16(12):2641. https://doi.org/10.5194/nhess-16-2641-2016.
Tanyaş H, van Westen CJ, Allstadt KE, Anna Nowicki Jessee M, Görüm T, Jibson RW, Godt JW, Sato HP, Schmitt RG, Marc O, Hovius N (2017) Presentation and analysis of a worldwide database of earthquake-induced landslide inventories. J Geophys Res Earth Surf 122:1991–2015. https://doi.org/10.1002/2017JF004236
Tanyaş H, Allstadt KE, van Westen CJ (2018a) An updated method for estimating landslide-event magnitude. Earth Surf Process Landf 43:1836–1847. https://doi.org/10.1002/esp.4359
Tanyaş H, Westen CJ, Allstadt KE, Jibson RW (2018b) Factors controlling landslide frequency-area distributions. Earth Surf Process Landf. https://doi.org/10.1002/esp.4543
Tanyas H, Rossi M, Alvioli M, van Westen CJ, Marchesini I (2019) A global slope unit-based method for the near real-time prediction of earthquake-induced landslides. Geomorphology 327:126–146. https://doi.org/10.1016/j.geomorph.2018.10.022
Tian YY, Xu C, Xu XW, Wu SE, Chen J (2015) Spatial distribution analysis of coseismic and pre-earthquake landslides triggered by the 2014 Ludian MS6.5 earthquake. Dizhen Dizhi 37:291–306. https://doi.org/10.3969/j.issn.0253-4967.2015.01.023
Uchida T et al. (2004) A study on methodology for assessing the potential of slope failures during earthquakes technical note of National Institute for Land and Infrastructure Management, No204, 91p. http://www.nilim.go.jp/lab/bcg/siryou/tnn/tnn0204.htm. Accessed 1 March 2018
Wald DJ (2013) Adding secondary hazard and ground-truth observations to PAGER’s loss modeling. In: Comes T, Fiedrich F, Fortier S, Geldermann J, Müller T (eds) Proceedings of the 10th international ISCRAM conference, Baden-Baden, 2013. https://pdfs.semanticscholar.org/a5ec/24064191678254a6d24e79224e6b756b29eb.pdf?_ga=2.45165485.824836976.1543839668-2090541343.1542724036
Wald DJ, Lin K-w, Quitoriano V (2008) Quantifying and qualifying USGS ShakeMap uncertainty, U.S. Geological Survey Open File Report 2008–1238, 26 pp. https://pubs.usgs.gov/of/2008/1238/pdf/OF08-1238_508.pdf. Accessed 1 Sept 2017
Wartman J, Dunham L, Tiwari B, Pradel D (2013) Landslides in eastern Honshu induced by the 2011 Tohoku earthquake. Bull Seismol Soc Am 103:1503–1521. https://doi.org/10.1785/0120120128. Accessed 1 Sept 2017
Wasowski J, Keefer DK, Lee C-T (2011) Toward the next generation of research on earthquake-induced landslides: current issues and future challenges. Eng Geol 122:1–8. https://doi.org/10.1016/j.enggeo.2011.06.001
Wilson R, Keefer D (1985) Predicting areal limits of earthquake-induced landsliding. In: Earthquake hazards in the Los Angeles Region—an earth science perspective. Ziony J (ed), U.S. Geological Survey Professional Paper 1360:317–345
Wood J (1996) The geomorphological characterisation of digital elevation models, doctoral dissertation. University of Leicester, U.K.
Xu C, Xu X, Yu G (2013) Landslides triggered by slipping-fault-generated earthquake on a plateau: an example of the 14 April 2010, Ms 7.1, Yushu, China earthquake. Landslides 10:421–431. https://doi.org/10.1007/s10346-012-0340-x
Xu C, Xu X, Shyu JBH, Zheng W, Min W (2014a) Landslides triggered by the 22 July 2013 Minxian–Zhangxian, China, Mw 5.9 earthquake: inventory compiling and spatial distribution analysis. J Asian Earth Sci 92:125–142. https://doi.org/10.1016/j.jseaes.2014.06.014
Xu C, Xu X, Yao X, Dai F (2014b) Three (nearly) complete inventories of landslides triggered by the May 12, 2008 Wenchuan Mw 7.9 earthquake of China and their spatial distribution statistical analysis. Landslides 11:441–461. https://doi.org/10.1007/s10346-013-0404-6
Xu C, Xu X, Shyu JBH (2015) Database and spatial distribution of landslides triggered by the Lushan, China Mw 6.6 earthquake of 20 April 2013. Geomorphology 248:77–92. https://doi.org/10.1016/j.geomorph.2015.07.002
Yagi H, Yamasaki T, Atsumi M (2007) GIS analysis on geomorphological features and soil mechanical implication of landslides caused by 2004 Niigata Chuetsu earthquake. J Jpn Landslide Soc 43:294–306. https://doi.org/10.3313/jls.43.294
Yagi H, Sato G, Higaki D, Yamamoto M, Yamasaki T (2009) Distribution and characteristics of landslides induced by the Iwate–Miyagi Nairiku earthquake in 2008 in Tohoku District, Northeast Japan. Landslides 6:335–344. https://doi.org/10.1007/s10346-009-0182-3
Zhang J, Liu R, Deng W, Khanal NR, Gurung DR, Murthy MSR, Wahid S (2016) Characteristics of landslide in Koshi River Basin, Central Himalaya. J Mt Sci 13(10):1711–1722. https://doi.org/10.1007/s11629-016-4017-0
Acknowledgements
The authors thank two anonymous reviewers for their constructive suggestions. For the sharing of their EQIL inventories, the authors are also thankful to the following researchers: Chenxiao Tang, Chong Xu, Chyi-Tyi Lee, Edwin L. Harp, F.C. Dai, Gen Li, George Papathanassiou, Geospatial Information Authority of Japan, Hiroshi Yagi, Hiroshi P. Sato, Jianqiang Zhang, John Barlow, Joseph Wartman, LI Wei-le, Masahiro Chigira, Mattia De Amicis, Muhammad Basharat, Pascal Lacroix, Sergio A. Sepúlveda, Tai-Phoon Huang, Taro Uchida, Timothy P. McCrink, and Tsuyoshi Wakatsuki. Thanks to Yoko Tamura (PASCO) for the assistance with obtaining the dataset provided by PASCO Corporation and Kokusai Kogyo Company Ltd. of Japan and Tokyo Takayama (Asia Air Survey Co., Ltd. of Japan) for assistance with obtaining the datasets provided by National Institute for Land and Infrastructure Management of Japan.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Tanyaş, H., van Westen, C.J., Persello, C. et al. Rapid prediction of the magnitude scale of landslide events triggered by an earthquake. Landslides 16, 661–676 (2019). https://doi.org/10.1007/s10346-019-01136-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10346-019-01136-4