
Abstract
In this paper, we propose a regularized alternating direction method of multipliers (RADMM) for a class of nonconvex optimization problems. The algorithm does not require the regular term to be strictly convex. Firstly, we prove the global convergence of the algorithm. Secondly, under the condition that the augmented Lagrangian function satisfies the Kurdyka–Łojasiewicz property, the strong convergence of the algorithm is established. Finally, some preliminary numerical results are reported to support the efficiency of the proposed algorithm.
Similar content being viewed by others
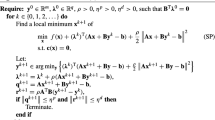

1 Introduction
In this paper, we consider the following nonconvex optimization problem
where \(f:R^{n}\rightarrow R\cup \{+\infty \}\) is a proper lower semicontinuous function, \(g:R^{m}\rightarrow R\) is a continuous differentiable function with ∇g Lipschitz continuous and modulus \(L>0\), while \(A\in R^{m\times n}\) is a given matrix. When the functions f and g are convex, the problem (1) can be transformed into the split feasibility problem [1, 2]. Problem (1) is equivalent to the following constraint optimization problem:
The augmented Lagrangian function of (2) is defined as follows:
where \(\lambda \in R^{m}\) is the Lagrangian parameter and \(\beta >0\) is the penalty parameter.
The alternating direction method of multipliers (ADMM) was first proposed by Gabay and Mercier in 1970s, which is an effective algorithm for solving the two-block convex problems [3]. The iterative scheme of the classic ADMM for problem (2) is as follows:
If f, g are convex functions, then the convergence of ADMM is well-understood and there are some recent convergence rate analysis results [4,5,6,7,8]. However, when the objective function is nonconvex, ADMM does not necessarily converge. Recently, some scholars have proposed various improved ADMM for nonconvex problems, and analyzed their convergence [9,10,11,12,13,14,15]. In particular, Guo et al. [16, 17] analyzed the strong convergence of classical ADMM for the nonconvex optimization problem of (2). Wang et al. [12, 14] studied the convergence of the Bregman ADMM for the nonconvex optimization problems, where they need the augmented Lagrangian function with respect to x or the Bregman distance in the x-subproblem to be strongly convex.
The first formula of (4) has the following structure:
When A is not the identity matrix, the above problem may not be easy. Regularization is a popular technique to simplify the optimization problems [12, 14, 18]. For example, the regular term \(\frac{1}{2}\|x-x^{k}\|^{2}_{G}\) could be added to the above problem (5), where G is a symmetric semidefinite matrix. Specifically, when \(G=\alpha I-\beta A^{\top }A\), problem (5) is converted into the following form:
with a certain known \(b^{k}\in R^{n}\). Since the first formula of (4) has the form of (6) with \(\alpha =1\), this paper considers the following regularized ADMM (in short, RADMM) for problem (2):
where G is a symmetric semidefinite matrix, \(\|x\|^{2}_{G}:=x^{ \top }Gx\).
The framework of this paper is as follows. In Sect. 2, we present some preliminary materials that will be used in this paper. In Sect. 3, we prove the convergence of algorithm (7). In Sect. 4, we report some numerical results. In Sect. 5, we draw some conclusions.
2 Preliminaries
For a vector \(x=(x_{1},x_{2},\dots ,x_{n})^{\top }\in R^{n}\), we let \(\|x\|=(\sum_{i=1}^{n} x_{i}^{2})^{\frac{1}{2}}\), \(\|x\|_{1}= \sum_{i=1}^{n} |x_{i}|\), and \(\|x\|_{\frac{1}{2}}=(\sum_{i=1}^{n} |x_{i}|^{\frac{1}{2}})^{2}\). Also \(G\succeq 0\) \((\succ 0)\) denotes that G is a positive semidefinite (positive definite) matrix. For a subset \(S\subseteq R^{n}\) and a point \(x\in R^{n}\), if S is nonempty, let \(d(x,S)=\inf_{y\in S}\|y-x \|\). When \(S=\emptyset \), we set \(d(x,S) = +\infty \) for all x. A function \(f:R^{n}\rightarrow (-\infty ,+\infty ]\) is said to be proper, if there exists at least one \(x\in R^{n}\) such that \(f(x)< +\infty \). The effective domain of f is defined through \(\operatorname{dom}f=\{x\in R ^{n}|f(x)< +\infty \}\).
Definition 2.1
([19])
The function \(f:R^{n}\rightarrow R\cup \{+\infty \}\) is lower semicontinuous at x̄, if \(f(\bar{x})\leq \liminf_{x\rightarrow \bar{x}}f(x)\). If f is lower semicontinuous at every point \(x\in R^{n}\), then f is called a lower semicontinuous function.
Definition 2.2
([19])
Let \(f:R^{n}\rightarrow R \cup \{+\infty \}\) be a proper lower semicontinuous function.
-
(i)
The Fréchet subdifferential, or regular subdifferential, of f at \(x\in \operatorname{dom} f\), denoted by \(\hat{\partial }{f(x)}\), is the set of all elements \(u\in R^{n}\) which satisfy
$$\hat{\partial } {f(x)}=\biggl\{ u\in R^{n}\Bigm| \lim _{y\neq x}\inf_{y\rightarrow x}\frac{f(y)-f(x)-\langle u, y-x\rangle }{ \Vert y-x \Vert }\geq 0\biggr\} , $$when \(x \notin \operatorname{dom} f\), let \(\hat{\partial } f(x)=\emptyset \);
-
(ii)
The limiting-subdifferential, or simply the subdifferential, of f at \(x\in \operatorname{dom} f\), denoted by \(\partial f(x)\), is defined as
$$\partial f(x)=\bigl\{ u\in R^{n}\mid \exists x^{k} \rightarrow x, f\bigl(x^{k}\bigr) \rightarrow f(x), u^{k} \in \hat{\partial }f\bigl(x^{k}\bigr)\rightarrow u, k \rightarrow \infty \bigr\} . $$
Proposition 2.1
([20])
Let \(f:R^{n}\rightarrow R \cup \{+\infty \}\) be a proper lower semicontinuous function, then
-
(i)
\(\hat{\partial }f(x)\subseteq \partial f(x)\) for each \(x\in R^{n}\), where the first set is closed and convex while the second one is only closed;
-
(ii)
Let \(u^{k}\in \partial f(x^{k})\) and \(\lim_{k\rightarrow \infty }(x^{k},u^{k})=(x,u)\), then \(u\in \partial f(x)\);
-
(iii)
A necessary condition for \(x\in R^{n}\) to be a minimizer of f is
$$\begin{aligned} 0\in \partial f(x); \end{aligned}$$(8) -
(iv)
If \(g:R^{n}\rightarrow R\) is continuously differentiable, then \(\partial (f+g)(x)=\partial f(x)+\nabla g(x)\) for any \(x\in \operatorname{dom} f\).
A point that satisfies (8) is called a critical point or a stationary point. The set of critical points of f is denoted by crit f.
Lemma 2.1
([21])
Suppose that \(H(x,y)=f(x)+g(y)\), where \(f:R^{n}\rightarrow R\cup \{+\infty \}\) and \(g:R^{m}\rightarrow R\) are proper lower semicontinuous functions, then
The following lemma is very important for the convergence analysis.
Lemma 2.2
([22])
Let function \(h:R^{n}\rightarrow R\) be continuously differentiable and its gradient ∇h be Lipschitz continuous with modulus \(L>0\), then
Definition 2.3
We say that \((x^{*},y^{*},\lambda ^{*})\) is a critical point of the augmented Lagrangian function \(\mathcal{L_{\beta }(\cdot )}\) of (2) if it satisfies
Obviously, (2) is equivalent to \(0\in \partial \mathcal{L _{\beta }}(x^{*},y^{*},\lambda ^{*})\).
Definition 2.4
([21] (Kurdyka–Łojasiewicz property))
Let \(f:{R}^{n}\rightarrow {R}\cup \{+\infty \}\) be a proper lower semicontinuous function. If there exist \(\eta \in (0,+\infty ]\), a neighborhood U of x̂, and a concave function \(\varphi :[0, \eta )\rightarrow R_{+}\) satisfying the following conditions:
-
(i)
\(\varphi (0)=0\);
-
(ii)
φ is continuously differentiable on \((0,\eta )\) and continuous at 0;
-
(iii)
\(\varphi '(s)>0\) for all \(s\in (0,\eta )\);
-
(iv)
\(\varphi '(f(x)-f(\hat{x}))d(0,\partial f(x))\geq 1\), for all \(x \in U\cap [f(\hat{x})< f(x)< f(\hat{x})+\eta ]\),
then f is said to have the Kurdyka–Łojasiewicz (KL) property at x̂.
Lemma 2.3
([23] (Uniform KL property))
Let \(\varPhi _{\eta }\) be the set of concave functions which satisfy (i), (ii) and (iii) in Definition 2.4. Suppose that \(f:R^{n}\rightarrow {R}\cup \{+\infty \}\) is a proper lower semicontinuous function and Ω is a compact set. If \(f(x)\equiv a\) for all \(x\in \varOmega \) and f satisfies the KL property at each point of Ω, then there exist \(\varepsilon >0\), \(\eta >0\), and \(\varphi \in \varPhi _{\eta }\) such that
for all \(x\in \{x\in {R}^{n}|d(x,\varOmega )<\varepsilon \}\cap [x:a<f(x)<a+ \eta ]\).
3 Convergence analysis
In this section, we prove the convergence of algorithm (7). Throughout this section, we assume that the sequence \(\{z^{k}:=(x^{k},y ^{k},\lambda ^{k})\}\) is generated by RADMM (7). Firstly, the global convergence of the algorithm is established by the monotonically nonincreasing sequence \(\{\mathcal{L}_{\beta }(z^{k})\}\). Secondly, the strong convergence of the algorithm is proved under the condition that \(\mathcal{L}_{\beta }(\cdot )\) satisfies the KL property. From optimality conditions of each subproblem in (7), we have
That is,
We need the following basic assumptions on problem (2).
Assumption 3.1
-
(i)
\(f: R^{n}\rightarrow R\cup \{+\infty \}\) is proper lower semicontinuous;
-
(ii)
\(g:R^{m}\rightarrow R\) is continuously differentiable, with \(\|\nabla g(u)-\nabla g(v)\|\leq L\|u-v\|\), \(\forall u,v\in R^{n}\);
-
(iii)
\(\beta >2L\) and \(\delta :=\frac{\beta -L}{2}-\frac{L^{2}}{ \beta }>0\);
-
(iv)
\(G\succeq 0\) and \(G+A^{\top }A \succ 0\).
The following lemma implies that sequence \(\{\mathcal{L_{\beta }}(z ^{k})\}\) is monotonically nonincreasing.
Lemma 3.1
Proof
From the definition of the augmented Lagrangian function \(\mathcal{L_{\beta }(\cdot )}\) and the third formula of (11), we have
and
From Assumption 3.1(ii), Lemma 2.2 and (11), we have
Inserting (15) into (14) yields
Since \(\lambda ^{k+1}=\lambda ^{k}-\beta (Ax^{k+1}-y^{k+1})\), we have
and
It follows that
Combining (16), (17) and (18), we have
From \(-\lambda ^{k+1}=\nabla g(y^{k+1})\) and Assumption 3.1(ii), we have
Adding (13), (19) and (20), one has
Since \(x^{x+1}\) is the optimal solution of the first subproblem of (7), one has
Thus
□
Lemma 3.2
If the sequence \(\{z^{k}\}\) is bounded, then
Proof
Since \(\{z^{k}\}\) is bounded, \(\{z^{k}\}\) has at least one cluster point. Let \(z^{*}=(x^{*},y^{*},\lambda ^{*})\) be a cluster point of \(\{z^{k}\}\) and let a subsequence \(\{z^{k_{j}}\}\) converge to \(z^{*}\). Since f is lower semicontinuous and g is continuously differentiable, then \(\mathcal{L}_{\beta }(\cdot )\) is lower semicontinuous, and hence
Thus \(\{\mathcal{L}_{\beta }(z^{k_{j}})\}\) is bounded from below. Furthermore, by Lemma 3.1, sequence \(\{\mathcal{L}_{ \beta }(z^{k})\}\) is nonincreasing, and so \(\{\mathcal{L}_{\beta }(z ^{k})\}\) is convergent. Moreover, \(\mathcal{L}_{\beta }(z^{*})\leq \mathcal{L}_{\beta }(z^{k})\), for all k.
On the other hand, summing up of (12) for \(k=0,1,2,\dots ,p\), it follows that
Since \(\delta >0\), \(G\succeq 0\), and p is chosen arbitrarily,
From (20) we have
Next we prove \(\sum_{k=0}^{+\infty }\|x^{k+1}-x^{k}\|^{2}< + \infty \). From \(\lambda ^{k+1}=\lambda ^{k}-\beta (Ax^{k+1}-y^{k+1})\), we have
Then
Therefore, we have \(\sum_{k=0}^{+\infty }\|x^{k+1}-x^{k}\|^{2} _{A^{\top }A}< +\infty \). Taking into account (22), we have
Since \(A^{\top }A+G\succ 0\) (see Assumption 3.1(iv)), one has \(\sum_{k=0}^{+\infty }\|x^{k+1}-x^{k}\|^{2}< +\infty \).
Therefore, \(\sum_{k=0}^{+\infty }\|z^{k+1}-z^{k}\|^{2}< + \infty \). □
Lemma 3.3
Define
Then \((\varepsilon ^{k+1}_{x}, \varepsilon ^{k+1}_{y}, \varepsilon ^{k+1}_{\lambda })^{\top }\in \partial \mathcal{L_{\beta }}(z^{k+1})\). Furthermore, if \(A^{\top }A\succ 0\), then there exists \(\tau >0\) such that
Proof
By the definition of \(\mathcal{L}_{\beta }(\cdot )\), one has
Combining (24) and (11), we get
From Lemma 2.1, one has \((\varepsilon ^{k+1}_{x}, \varepsilon ^{k+1}_{y}, \varepsilon ^{k+1}_{\lambda })^{\top }\in \partial \mathcal{L_{\beta }}(z^{k+1})\).
On the other hand, it is easy to see that there exists \(\tau _{1}>0\) such that
Due to \(A^{\top }A\succ 0\) and (23), there exists \(\tau _{2}>0\) such that
Since \((\varepsilon ^{k+1}_{x}, \varepsilon ^{k+1}_{y}, \varepsilon ^{k+1} _{\lambda })^{\top }\in \partial \mathcal{L_{\beta }}(z^{k+1})\), from (26), (20) and (27), there exists \(\tau >0\) such that
□
Theorem 3.1
(Global convergence)
Let Ω denote the cluster point set of the sequence \(\{z^{k}\}\). If \(\{z^{k}\}\) is bounded, then
-
(i)
Ω is a nonempty compact set, and \(d(z^{k},\varOmega ) \rightarrow 0\), as \(k\rightarrow +\infty \),
-
(ii)
\(\varOmega \subseteq \operatorname{crit}\mathcal{L_{\beta }}\),
-
(iii)
\(\mathcal{L_{\beta }}(\cdot )\) is constant on Ω, and \(\lim_{k\rightarrow +\infty }\mathcal{L_{\beta }}(z^{k})=\mathcal{L _{\beta }}(z^{*})\) for all \(z^{*}\in \varOmega \).
Proof
(i) From the definitions of Ω and \(d(z^{k}, \varOmega )\), the claim follows trivially.
(ii) Let \(z^{*}=(x^{*},y^{*},\lambda ^{*})\in \varOmega \), then there is a subsequence \(\{z^{k_{j}}\}\) of \(\{z^{k}\}\), such that \(\lim_{k_{j}\rightarrow +\infty }z^{k_{j}}=z^{*}\). Since \(x^{k+1}\) is a minimizer of function \(\mathcal{L}_{\beta }(x,y^{k},\lambda ^{k})+ \frac{1}{2}\|x-x^{k}\|^{2}_{G}\) for the variable x, one has
that is,
Lemma 3.1 implies that \(\lim_{k\rightarrow \infty }\|x^{k+1}-x^{k}\|^{2}_{G}=0\). Since \(\mathcal{L}_{\beta }(\cdot )\) is continuous with respect to y and λ, we have
On the other hand, since \(\mathcal{L}(\cdot )\) is lower semicontinuous,
Combining (29) and (30), we get \(\lim_{k_{j}\rightarrow +\infty }\mathcal{L}_{\beta }(z^{k_{j}})= \mathcal{L}_{\beta }(z^{*})\). Then \(\lim_{k_{j}\rightarrow +\infty }f(x^{k_{j}})=f(x^{*})\). By taking the limit \(k_{j}\rightarrow +\infty \) in (11), we have
that is, \(z^{*}\in \rm {crit}\mathcal{L}_{\beta }\).
(iii) Let \(z^{*}\in \varOmega \). There exists \(\{z^{k_{j}}\}\) such that \(\lim_{k_{j}\rightarrow +\infty }z^{k_{j}}= z^{*}\). Combining \(\lim_{k_{j}\rightarrow +\infty }\mathcal{L}_{\beta }(z^{k_{j}})= \mathcal{L}_{\beta }(z^{*})\) and the fact that \(\{\mathcal{L}_{\beta }(z^{k})\}\) is monotonically nonincreasing, for all \(z^{*}\in \varOmega \), we have
and so \(\mathcal{L}_{\beta }(\cdot )\) is constant on Ω. □
Theorem 3.2
(Strong convergence)
If \(\{z^{k}\}\) is bounded, \(A^{\top }A\succ 0\), and \(\mathcal{L}_{\beta }(z)\) satisfies the KL property at each point of Ω, then
-
(i)
\(\sum_{k=0}^{+\infty }\|z^{k+1}-z^{k}\|< +\infty \),
-
(ii)
The sequence \(\{z^{k}\}\) converges to a stationary point of \(\mathcal{L}_{\beta }(\cdot )\).
Proof
(i) Let \(z^{*}\in \varOmega \). From Theorem 3.1, we have \(\lim_{k\rightarrow +\infty }\mathcal{L}_{\beta }(z ^{k}) =\mathcal{L}_{\beta }(z^{*})\). We consider two cases:
(a) There exists an integer \(k_{0}\), such that \(\mathcal{L}_{\beta }(z ^{k_{0}})=\mathcal{L}_{\beta }(z^{*})\). From Lemma 3.1, we have
Then, one has \(\|x^{k+1}-x^{k}\|^{2}_{G}=0\), \(y^{k+1}=y^{k}\), \(k\geq k_{0}\). From (20), one has \(\lambda ^{k+1}=\lambda ^{k}\), \(k>k_{0}\). Furthermore, from (23) and \(A^{\top }A\succ 0\), we have \(x^{k+1}=x^{k}\), \(k>k_{0}+1\). Thus \(z^{k+1}=z^{k}\), \(k>k_{0}+1\). Therefore, the conclusions hold.
(b) Suppose that \(\mathcal{L}_{\beta }(z^{k})>\mathcal{L}_{\beta }(z ^{*})\), \(k\geq 1\). From Theorem 3.1(i), it follows that for \(\varepsilon >0\), there exists \(k_{1}>0\), such that \(d(z^{k},\varOmega )< \varepsilon \), for all \(k>k_{1}\). Since \(\lim_{k\rightarrow +\infty }\mathcal{L}_{\beta }(z^{k})= \mathcal{L}_{\beta }(z^{*})\), for given \(\eta >0\), there exists \(k_{2}>0\), such that \(\mathcal{L}_{\beta }(z^{k})<\mathcal{L}_{\beta }(z^{*})+\eta \), for all \(k>k_{2}\). Consequently, one has
It follows from the KL property, that
By the concavity of φ and since \(\mathcal{L}_{\beta }(z^{k})- \mathcal{L}_{\beta }(z^{k+1})=(\mathcal{L}_{\beta }(z^{k})- \mathcal{L}_{\beta }(z^{*})) -(\mathcal{L}_{\beta }(z^{k+1})- \mathcal{L}_{\beta }(z^{*})) \), we have
Let \(\bigtriangleup _{p,q}=\varphi (\mathcal{L}_{\beta }(z^{p})- \mathcal{L}_{\beta }(z^{*}))- \varphi (\mathcal{L}_{\beta }(z^{q})- \mathcal{L}_{\beta }(z^{*}))\). Combining \(\varphi '(\mathcal{L}_{ \beta }(z^{k})-\mathcal{L}_{\beta }(z^{*}))>0\), (31) and (32), we have
From Lemma 3.3, we obtain
From Lemma 3.1 and the above inequality, we have
Thus
Furthermore,
Using the fact that \(2ab\leq a^{2}+b^{2}\), we obtain
Summing up the above inequality for \(k=\tilde{k}+1,\dots ,s\), yields
Thus
Notice that \(\varphi (\mathcal{L}_{\beta }(z^{s+1})-\mathcal{L}_{ \beta }(z^{*}))>0\), so taking the limit \(s\rightarrow +\infty \), we have
Thus
It follows from (20) that
From \(A^{\top }A\succ 0\), (23) and the above two formulas, we obtain
Since
we know
(ii) From (i), we known that \(\{z^{k}\}\) is a Cauchy sequence and so is convergent. Theorem 3.2(ii) follows immediately from Theorem 3.1(ii). □
In the above results, we have assumed the boundedness of the sequence \(\{z^{k}\}\). Next, we present two sufficient conditions ensuring this requirement.
Lemma 3.4
Suppose that \(A^{\top }A\succ 0\) and
If one of the following statements is true:
-
(i)
f is coercive, i.e., \(\lim_{\|x\|\rightarrow + \infty }f(x)=+\infty \),
-
(ii)
f is bounded from below and g is coercive, i.e., \(\inf_{x\in R^{n}}f(x)>-\infty \) and \(\lim_{\|x\|\rightarrow +\infty }g(x)=+\infty \),
then \(\{z^{k}\}\) is bounded.
Proof
(i) Suppose that f is coercive. From Lemma 3.1, we know that \(\mathcal{L}_{\beta }(z^{k})\leq \mathcal{L}_{\beta }(z^{1})<+\infty \), for all \(k\geq 1 \). Combining with \(\nabla g(x^{k})=-\lambda ^{k}\), one has
Since \(\beta >2L\) and f is coercive, it is easy to see that \(\{x^{k}\}\), \(\{\lambda ^{k}\}\), and \(\{\frac{\beta }{2}\|Ax^{k}-y^{k}-\frac{1}{ \beta }\lambda ^{k}\|^{2}\}\) are bounded. Furthermore, \(\{y^{k}\}\) is bounded. Thus \(\{z^{k}\}\) is bounded.
(ii) Similar as with (i), we have
Notice that \(\beta >2L\), function f is bounded from below, g is coercive and Assumption 3.1(ii) holds, thus \(\{y^{k}\}\), \(\{\lambda ^{k}\}\), and \(\{\frac{\beta }{2}\|Ax^{k}-y^{k}-\frac{1}{ \beta }\lambda ^{k}\|^{2}\}\) are bounded. Since \(A^{\top }A\succ 0\), \(\{x^{k}\}\) is bounded. Thus \(\{z^{k}\}\) is bounded. □
4 Numerical examples
In compressed sensing, one needs to find the sparsest solution of a linear system, which can be modeled as
where \(D\in R^{m\times n}\) is the measuring matrix, \(b\in R^{m}\) is observed data, \(\|x\|_{0}\) denotes the number of nonzero elements of x, which is called the \(l_{0}\) norm.
Problem (36) is NP-hard. In practical applications, one may relax the \(l_{0}\) norm to the \(l_{1}\) norm or \(l_{\frac{1}{2}}\) norm, and consider their regularized versions, which lead to the following convex problem (37) and nonconvex problem (38):
and
In this section, we will apply RADMM (7) to solve the above two problems. For simplicity, we set \(b=0\) throughout this section. Applying RADMM (7) to problem (37) with \(G=\alpha I-\beta D^{ \top }D\) yields
where \(S(\cdot ;\mu )=\{s_{\mu }(x_{1}),s_{\mu }(x_{2}),\dots ,s_{ \mu }(x_{n})\}^{\top }\) is the soft shrinkage operator [24] defined as follows:
Applying RADMM (7) to problem (38) with \(G=\alpha I- \beta D^{\top }D\) yields
where \(H(\cdot ;\mu )=\{h_{\mu }(x_{1}),h_{\mu }(x_{2}),\dots ,h_{ \mu }(x_{n})\}^{\top }\) is the half-shrinkage operator [25] defined as follows:
with \(\varphi (x)=\arccos (\frac{\mu }{8}(\frac{x_{i}}{3})^{- \frac{3}{2}})\).
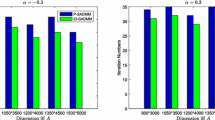
For simplicity, we denote algorithms (39) and (40) by SRADMM and HRADMM, respectively. The selection of relevant parameters in numerical experiments is given below. We now conduct an experiment to verify convergence of the nonconvex RADMM, and reveal its advantages in sparsity-inducing and efficiency through comparing the performance of HRADMM and SRADMM. In the experiment, \(m=511\), \(n=512\), the matrix \(D\in R^{511\times 512}\) is obtained by unitizing the matrix with randomly generated entries obeying the normal distribution \(\mathcal{N}(0,1)\), the noise vector \(\varepsilon \sim \mathcal{N}(0,1)\), the recovery vector \(r=Dx^{0}+\varepsilon \), and the regularization parameters are \(\gamma =0.0015\), \(\beta =0.8\), \(\alpha =2.5\).
The experimental results are shown in Fig. 1, where the restoration accuracy is measured by means of the mean squared error:
where \((x^{*},y^{*})=(0,0)\) is the optimal solution for the problems (37) and (38), respectively.

Comparison the performance of HRADMM and SRADMM
Programming is performed on Matlab R2014a, a computer running the program is configured as follows: Windows 7 system, Inter(R) Core(TM) i7-4790 CPU 3.60 GHz, 4 GB memory. Numerical results show that algorithm (7) is efficient and stable. As shown in Fig. 1, both sequences \(x^{k}\) and \(y^{k}\) were fairly near the true solution. i.e., the convergence is justified. It is readily seen that HRADMM converges faster than SRADMM.
5 Conclusion and outlook
In this paper, a regularized alternating direction method of multipliers is proposed for a class of nonconvex problems. Firstly, the global convergence of the algorithm is analyzed. Secondly, under the condition that the augmented Lagrangian function \(\mathcal{L}_{\beta }(\cdot )\) satisfies the Kurdyka–Łojasiewicz property, the strong convergence of the algorithm is analyzed. Finally, the effectiveness of the algorithm is verified by numerical experiments.
References
Yao, Y.H., Liou, Y.C., Yao, J.C.: Iterative algorithms for the split variational inequality and fixed point problems under nonlinear transformations. J. Nonlinear Sci. Appl. 10, 843–854 (2017)
Yao, Y.H., Yao, J.C., Liou, Y.C., Postolache, M.: Iterative algorithms for split common fixed points of demicontractive operators without prior knowledge of operator norms. Carpath. J. Math. 34, 459–466 (2018)
Gabay, D., Mercier, B.: A dual algorithm for the solution of nonlinear variational problems via finite element approximations. Comput. Math. Appl. 2(1), 17–40 (1976)
He, B.S., Yuan, X.M.: On the \(O(1/n)\) convergence rate of the Douglas–Rachford alternating direction method. SIAM J. Numer. Anal. 50(2), 700–709 (2012)
Monteiro, R.D.C., Svaite, B.F.: Iteration-complexity of block-decomposition algorithms and the alternating direction method of multipliers. SIAM J. Optim. 23(1), 475–507 (2013)
He, B.S., Yuan, X.M.: On non-ergodic convergence rate of Douglas–Rachford alternating direction method of multipliers. Numer. Math. 130(3), 567–577 (2015)
Han, D.R., Sun, D.F., Zhang, L.W.: Linear rate convergence of the alternating direction method of multipliers for convex composite quadratic and semi-definite programming. IEEE Trans. Autom. Control 60(3), 644–658 (2015)
Hong, M.Y.: A distributed, asynchronous, and incremental algorithm for nonconvex optimization: an ADMM approach. IEEE Trans. Control Netw. Syst. 5(3), 935–945 (2018)
Li, G.Y., Pong, T.K.: Global convergence of splitting methods for nonconvex composite optimization. SIAM J. Optim. 25(4), 2434–2460 (2015)
You, S., Peng, Q.Y.: A non-convex alternating direction method of multipliers heuristic for optimal power flow. In: IEEE International Conference on Smart Grid Communications, pp. 788–793. IEEE Press, New York (2014)
Hong, M.Y., Luo, Z.Q., Razaviyayn, M.: Convergence analysis of alternating direction method of multipliers for a family of nonconvex problems. SIAM J. Optim. 26(1), 3836–3840 (2014)
Wang, F.H., Xu, Z.B., Xu, H.K.: Convergence of Bregman alternating direction method with multipliers for nonconvex composite problems (2014). Preprint. Available at arXiv:1410.8625
Hong, M., Luo, Z.Q., Razaviyayn, M.: Convergence analysis of alternating direction method of multipliers for a family of nonconvex problems. SIAM J. Optim. 26(1), 337–364 (2016)
Wang, F.H., Cao, W.F., Xu, Z.B.: Convergence of multi-block Bregman ADMM for nonconvex composite problems. Sci. China Inf. Sci. 61(12), 53–64 (2018)
Yang, L., Pong, T.K., Chen, X.J.: Alternating direction method of multipliers for a class of nonconvex and nonsmooth problems with applications to background/foreground extraction. SIAM J. Imaging Sci. 10(1), 74–110 (2017)
Guo, K., Han, D.R., Wu, T.T.: Convergence of alternating direction method for minimizing sum of two nonconvex functions with linear constraints. Int. J. Comput. Math. 94(8), 1–18 (2016)
Guo, K., Han, D.R., Wang, Z.W., Wu, T.T.: Convergence of ADMM for multi-block nonconvex separable optimization models. Front. Math. China 12(5), 1139–1162 (2017)
Zhao, X.P., Ng, K.F., Li, C., Yao, J.C.: Linear regularity and linear convergence of projection-based methods for solving convex feasibility problems. Appl. Math. Optim. 78, 613–641 (2018)
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis. Springer, Berlin (1998)
Mordukhovich, B.S.: Variational Analysis and Generalized Differentiation I: Basic Theory. Springer, Berlin (2006)
Attouch, H., Bolte, J., Redont, P., Soubeyran, A.: A proximal alternating minimization and projection methods for nonconvex problems: an approach based on the Kurdyka–Łojasiewicz inequality. Math. Oper. Res. 35(2), 438–457 (2010)
Nesterov, Y.: Introduction Lectures on Convex Optimization: A Basic Course. Springer, Berlin (2013)
Frankel, P., Garrigos, G., Peypouquet, J.: Splitting methods with variable metric for Kurdyka–Lojasiewicz functions and general convergence rates. J. Optim. Theory Appl. 165(3), 874–900 (2015)
Daubechies, I., Defrise, M., De Mol, C.: An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun. Pure Appl. Math. 57(11), 1413–1457 (2003)
Xu, Z., Chang, X., Xu, F., Zhang, H.: \(l_{\frac{1}{2}}\) regularization: a thresholding representation theory and a fast solver. IEEE Trans. Neural Netw. Learn. Syst. 23(7), 1013–1027 (2012)
Availability of data and materials
The authors declare that all data and material in the paper are available and veritable.
Authors’ information
JinBao Jian, Ph.D., professor, E-mail: jianjb@gxu.edu.cn; Ye Zhang, E-mail: yezhang126@126.com; MianTao Chao, Ph.D., associate professor, E-mail: chaomiantao@126.com.
Funding
This research was supported by the National Natural Science Foundation of China (Nos. 11601095, 11771383) and by the Natural Science Foundation of Guangxi Province (Nos. 2016GXNSFBA380185, 2016GXNSFDA380019 and 2014GXNSFFA118001).
Author information
Authors and Affiliations
Contributions
All authors contributed equally and significantly in writing this article. All authors wrote, read, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Jian, J.B., Zhang, Y. & Chao, M.T. A regularized alternating direction method of multipliers for a class of nonconvex problems. J Inequal Appl 2019, 193 (2019). https://doi.org/10.1186/s13660-019-2145-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13660-019-2145-0