
Abstract
Background
Recent researches have found a strong correlation between the triglyceride-glucose (TyG) index or the atherogenic index of plasma (AIP) and cardiovascular disease (CVD) risk. However, there is a lack of research on non-invasive and rapid prediction of cardiovascular risk. We aimed to develop and validate a machine-learning model for predicting cardiovascular risk based on variables encompassing clinical questionnaires and oculomics.
Methods
We collected data from the Korean National Health and Nutrition Examination Survey (KNHANES). The training dataset (80% from the year 2008 to 2011 KNHANES) was used for machine learning model development, with internal validation using the remaining 20%. An external validation dataset from the year 2012 assessed the model’s predictive capacity for TyG-index or AIP in new cases. We included 32122 participants in the final dataset. Machine learning models used 25 algorithms were trained on oculomics measurements and clinical questionnaires to predict the range of TyG-index and AIP. The area under the receiver operating characteristic curve (AUC), accuracy, precision, recall, and F1 score were used to evaluate the performance of our machine learning models.
Results
Based on large-scale cohort studies, we determined TyG-index cut-off points at 8.0, 8.75 (upper one-third values), 8.93 (upper one-fourth values), and AIP cut-offs at 0.318, 0.34. Values surpassing these thresholds indicated elevated cardiovascular risk. The best-performing algorithm revealed TyG-index cut-offs at 8.0, 8.75, and 8.93 with internal validation AUCs of 0.812, 0.873, and 0.911, respectively. External validation AUCs were 0.809, 0.863, and 0.901. For AIP at 0.34, internal and external validation achieved similar AUCs of 0.849 and 0.842. Slightly lower performance was seen for the 0.318 cut-off, with AUCs of 0.844 and 0.836. Significant gender-based variations were noted for TyG-index at 8 (male AUC=0.832, female AUC=0.790) and 8.75 (male AUC=0.874, female AUC=0.862) and AIP at 0.318 (male AUC=0.853, female AUC=0.825) and 0.34 (male AUC=0.858, female AUC=0.831). Gender similarity in AUC (male AUC=0.907 versus female AUC=0.906) was observed only when the TyG-index cut-off point equals 8.93.
Conclusion
We have established a simple and effective non-invasive machine learning model that has good clinical value for predicting cardiovascular risk in the general population.
Similar content being viewed by others


Introduction
Cardiovascular disease and oculomics
Cardiovascular disease (CVD) is a profound global public health challenge and ranks among the primary contributors to the worldwide disease burden [1, 2]. CVD remains a leading cause of both mortality and morbidity on a global scale, taking an estimated 17.9 million lives each year, even with advancements in preventive strategies and therapeutic techniques. The assessment of cardiovascular risk assumes paramount importance in global public health.
Patients with CVD are more easily found to have metabolic abnormalities, such as insulin resistance, hyperglycemia, and dyslipidemia [3, 4]. Recently, some new indicators calculated through blood glucose and serum lipids, such as the triglyceride-glucose index (TyG-index) and the atherogenic index of plasma (AIP) demonstrated to be a higher correlation with CVD [5]. Furthermore, TyG-index and AIP are good indicators for cardiovascular risk [5, 6]. Different cut-off point values for TyG-index and AIP can reflect the cardiovascular risks of different groups of people.
Previous studies have confirmed that ophthalmology diseases are closely related to CVD. Eye is an organ that can directly reflect microvascular changes [7]. The pathogenesis of many CVDs also leads to ocular changes [8]. Therefore, it is feasible to use the pathology of eyes to predict CVD. Oculomics is a newly proposed concept in recent years [9]. It refers to the blending of big data, artificial intelligence (AI), and ocular imaging to identify retinal biomarkers of systemic disease [10, 11]. AI has been extensively employed in the medical field for several years, automatically uncovering intrinsic patterns and connections between data variables and related diseases [12,13,14,15]. In the present study, we leveraged data from the Korean National Health and Nutrition Examination Survey (KNHANES) to develop and validate a machine-learning model for predicting cardiovascular risk based on variables encompassing clinical questionnaires and oculomics, as shown in Fig. 1. This model effectively anticipates the range of TyG-index and AIP, which reflect the level of cardiovascular risks.

Central illusion. Machine-learning-based cardiovascular risk prediction using data extracted from oculomics and clinic variables in Korean National Health and Nutrition Examination Survey (KNHANES)
Materials and methods
Dataset
This study used a comprehensive health examination dataset based on the Korean National Health and Nutrition Examination Survey (KNHANES IV and V; available online at https://knhanes.kdca.go.kr/knhanes/eng) conducted from the year 2008 to 2012. The KNHANES surveyed both comprehensive ophthalmologic examinations and DEXA only during this period. The study protocol was approved by the Institutional Review Board of the Korean Center for Disease Control and Prevention (No. 2008-04EXP-01-C, 2009-01CON-03-C, 2010-02CON-21-C, 2011-02CON-06-C, and 2012-01EXP-01-2C), and data collection was approved by the Institutional Review Board of the Korean National Institute for Bioethics Policy. All participants signed consent forms for the use of their health information for data collection of the KNHANES. The KNHANES is a nationwide, population-based, cross-sectional survey conducted by the Division of Chronic Disease Surveillance of the Korea Centers for Disease Control and Prevention [16]. This project randomly selected all participants from 200 (2008-2009) and 192 (2010-2011) enumeration districts using stratified sampling in which the following factors were considered: population, sex, age, regional area, and type of residential area. The KNHANES comprises health records based on health interviews, health examinations, and nutrition surveys. Each participant completed a questionnaire containing information such as age, household income, alcohol use, smoking status, hypertension, and diabetes [17].

We conducted data curation based on the KNHANES dataset. Initially, individuals lacking either clinical variables or oculomics variables (N=13136), as well as those with missing TyG-index or AIP values (N=553), were excluded. Following this filtration process, a cohort of 32122 participants was included in this study. Then we utilized the KNHANES data from year 2008 to 2011 for model development and internal validation, exploring and verifying the associations between input variables and TyG-index as well as AIP. The model construction employed a five-fold cross-validation method. The training set, comprising 80% of randomly selected data from the year 2008 to 2011, was employed for machine learning model development, as the internal validation set encompassed the last 20% of randomly chosen data from this database. And the external validation set, sourced from the year 2012, was used to evaluate the model’s ability to predict AIP and TyG-index for previously unseen cases (Fig. 2). The code of this research is open source and can be accessed at “https://github.com/RickyZhang901/ML-Based-AIP_TYG”.
Key variables definition
The TyG-index was calculated as ln [TG (triglycerides) (mg/dL) \(\times\) FBG (fasting blood glucose) (mg/dL)/2], derived from previous studies [18, 19]. The AIP is a logarithmically transformed ratio of TG to HDL-C (High density lipoprotein cholesterol) in molar concentration (mmol/L), and it is mathematically derived from log (TG/HDL-C) [20]. Regarding the outcomes, we selected different cut-off points for TyG-index and AIP. Their different tangent values can reflect the cardiovascular risk of different groups of people. For the TyG-index endpoint, we chose 8.0 [21], the upper one-third value of TyG values (8.75) [22], and the upper one-fourth value of TyG values (8.93) [23]. As for the AIP endpoint, 0.318 [20] and 0.34 [24] were chosen as the cut-off points. Endpoint values beyond these numerical cut-off points were deemed to indicate high cardiovascular risk, while values below were considered low risk.
Ophthalmic examination
In this study, we analyzed oculomics measurements graded by ophthalmologists. A comprehensive eye examination was conducted by the Korean Ophthalmological Society (KOS) using a vehicle equipped with ophthalmic devices. Trained ophthalmologists measured the eyelid positions of all participants. Marginal reflex distance 1 (MRD1) was defined as the distance from the upper eyelid margin to the corneal light reflex in the primary position (Supplementary Table S1). MRD1 values were obtained, and blepharoptosis was defined as an MRD1 of less than 2mm for either eye [25]. Ophthalmologists made a differential diagnosis of blepharoptosis with particular attention to avoiding misdiagnosis of pseudoptosis and dermatochalasis. The levator muscle function test was also performed by measuring the upper eyelid excursion from downgaze to upgaze (Supplementary Table S1), excluding any influence of frontalis muscle function, and sorted into normal (\(\ge\)12mm) and decreased levator function (\(\le\)11mm). Standardized slit-lamp examinations were performed to diagnose pterygium and cataracts. Fundus photographs were obtained using a digital fundus camera (TRC-NW6S; Topcon, Tokyo, Japan). For each eye of each participant, a 45\(^{\circ }\) digital retinal fundus image centered on the macula and fovea was obtained. All fundus photographs were subjected to preliminary and detailed grading. Preliminary grades for retinal diseases and optic discs were assigned to the retinal images by trained ophthalmologists, and multiple retinal specialists performed detailed grading. After grading the fundus photographs, glaucoma was defined according to a previous study [26]. When the conditions of the two eyes from one participant differed, the worse eye was chosen for the analysis. The KOS National Epidemiologic Survey Committee periodically trained ophthalmologists to control the quality of the survey.
Statistical analysis
Population baseline table
Statistical analyses were performed with SPSS version 24.0 (IBM Corp, Armonk, NY, USA), Python 3, and R version 4.2.2 (www.R-project.org). Continuous variables were described as mean ± standard deviation (SD) and compared by independent T-test or ANOVA. Categorical variables were described as numbers (percentages) and compared using chi-square tests.
Processing missing value
In this study, we employed polynomial interpolation to handle missing values in the dataset. Polynomial interpolation, a commonly utilized technique, fills in the missing values by constructing curves between known data points, preserving the overall trend of the data more effectively without introducing excessive noise. Thus, this method maintains the relative smoothness and continuity of the data. We deleted those variables with more than 30% missing and processed the remaining variables with missing value filling only in the internal dataset, which from the year 2008 to 2011 KNHANES.
Spearman correlation analysis
Within this research, we utilized Spearman correlation analysis to identify variables strongly correlated with the target variable. Spearman correlation analysis, a nonparametric statistical method, measures the monotonic relationship between two variables, which is particularly suitable for data that does not adhere to the assumption of a linear relationship. And the p<0.001 is considered as a statistically significant difference. Through Spearman correlation analysis, we effectively reduced the dimensions of the dataset, thereby enhancing modeling efficiency.
Features construction
In addition to the selected features, we employed AutoFeat [27] for feature construction. This automated feature engineering tool facilitates extracting more insightful features from the raw data through a sequence of feature engineering steps, encompassing both directly derived features and interaction features. This augmentation would furnish our model with a more extensive wellspring of information, contributing to enhancing the model’s generalizability and predictive accuracy. From the processing missing value step to the feature construction step, we only used the data set from 2008 to 2011 of KNHANES to avoid going against established data science best practices. Supplementary Fig. S3 details the process of building our model and the different uses of data sets from different years.
Metrics for evaluation
To evaluate the performance of the machine learning models, we computed the Area Under the Curve (AUC), accuracy, precision, recall, and F1 score for predicting the TyG-index and AIP separately. The AUC, which reflects the comprehensive performance of the model across a spectrum of classification thresholds, serves as a pivotal metric in evaluating the model’s efficacy. A substantial AUC denotes an exceptional discernment capacity of the model in distinguishing between positive and negative samples. Accuracy, as the cornerstone metric for assessing classification prowess, represents the ratio of correctly predicted samples to the total samples. An increase in accuracy can somewhat indicate enhanced model performance, but accuracy is not a comprehensive metric when the sample distribution is not balanced. Precision, on the other hand, delineates the ratio of true positive samples to the model’s predicted positives within the entirety of predicted positive samples. Amplified precision signals a heightened precision in the identification of positive samples. Recall embodies the ratio of model-predicted positive samples to true positive samples, thus showcasing the model’s resilience in detecting all positive samples. The F1 score, embodying the harmonious fusion of precision and recall, acts as a comprehensive metric for gauging the holistic performance of the model. A higher F1 score corresponds to a superior overall model performance. The formulas for computing these metrics can be found in the supplementary materials (Supplementary Fig. S1).
Machine learning algorithms
Regarding the machine learning algorithms, we adopted various models to conduct predictive analysis, aiming to explore the effectiveness of different models in addressing cardiovascular prediction problems. These models encompass Random Forest [28], Extra Trees [29], Bagging [30], Decision Tree [31], Extra Tree [29], XGBoost [32], LGBM [33], Gradient Boosting [34], Support Vector Machine (SVM) [35], AdaBoost [36], Label Propagation [37], Label Spreading [37], Linear SVM [35], Logistic Regression [38], Ridge Regression [39], Ridge CV [39], Multi-Layer Perceptron (MLP) [40], K Neighbors [41], Stochastic Gradient Descent Classifier (SGD) [42], Bernoulli NB [43], Perceptron [40], Passive Aggressive [44], Quadratic Discriminant Analysis [45], Gaussian NB [43], and Dummy. Through the utilization of these diverse machine learning models, we aim to evaluate their performance on the dataset comprehensively. This endeavor will aid in understanding which models exhibit optimal performance in handling our specific problem and what their strengths and weaknesses are. We conducted experiments using a five-fold cross-validation approach and employed multiple evaluation metrics to compare these models, including accuracy, precision, recall, and F1 score. These evaluation metrics will assist us in selecting the most suitable machine learning model for addressing our specific problem and provide guidance for future improvements and optimizations.
Results
Correlation analysis of data exploration
Initial processing of the raw dataset was conducted, as illustrated in Fig. 2 and Supplementary Fig. S3. After excluding variables with no significant statistical differences (P>0.001), we removed variables without clinical value and those directly calculable to yield outcome indicators. The remaining variables were used as input for our model. To illustrate the associations between the variables incorporated in the model, we generated a heatmap of Spearman coefficients (Fig. 3). Detailed descriptions of the input variables for the machine learning models are shown in Supplementary Table S1.

Heatmap of Spearman correlation ship in oculomics and clinic variables with TyG-index and AIP. Detailed descriptions of the input variables are shown in Supplementary Table S1. The standard names in the dictionary corresponding to different codes in the heatmap are shown in Supplementary Table S2. TyG-index, Triglyceride-glucose index. AIP, Atherogenic index of plasma
The findings are displayed in the form of a heatmap, where the color gradient from dark to light indicates the correlation from high to low. Due to space constraints, the variables in Fig. 3 are represented in the form of codes. Each code or character has a specific meaning, which can be found in the dictionaries of KNHANES for the years 2007-2009 and 2010-2012.
Demographic analysis
In this study, a total of 32,122 participants (14,254 males and 17,868 females) from KNHANES were included in the final dataset. We gathered 36 input features comprising 11 demographic variables, 4 anthropometric parameters, and 21 ophthalmological measurements. These data were utilized to identify potential factors that may affect TyG-index or AIP, and the authentic calculated values of TyG-index or AIP were used as the outcome for constructing the machine learning model. Demographic characteristics of the participants are shown in Table 1. Baseline oculomics measurement specifics are detailed in Supplementary Tables S3 and S4 (Fig. 3).

ROC and AUC of models use both oculomics and clinic variables as input variables. a-c The performance of our model using TyG-index=8.0, 8.75, or 8.93 as the cut-off point in the internal validation dataset is demonstrated. d-f The performance of our model using TyG-index=8.0, 8.75, or 8.93 as the cut-off point in the external validation dataset is demonstrated. AUC, Area under curve. TyG, Triglyceride-glucose index.ROC, Receiver operating characteristic
Our findings revealed that there were significant differences in the outcome values of TyG-index or AIP across all age and gender subgroups (p<0.001). Additionally, over 50% of the participants in the survey were either non-smokers (n=20223, 62.96%) or within the normal weight range (n=20110, 62.61%).
Model performance and verification
We employed 25 machine learning algorithms for model establishment. After screening the correlation coefficient, the input variables consist of 36 variables, including 15 clinical indicators and 21 ophthalmic indicators.
In terms of performance evaluation, based on the clinical questionnaire and oculomics measurement variables, we tested the overall model performance for five endpoints, yielding promising results (Tables 2 and 3). Moreover, due to the independent nature of the KNHANES database across different years, utilizing data from different years as internal and external validation sets is a common practice [46, 47]. In the predictive model employing all input factors, when the TyG-index cut-off values were 8.0, 8.75, and 8.93, the model’s AUC in the internal validation set was 0.812, 0.873, and 0.911, respectively, while in the external validation set, the AUC was 0.809, 0.863, and 0.901. We plot the model performance in the internal and external validation datasets with different TyG-index cut-off points as predicted outcomes in Fig. 4. As for the AIP endpoint, when set at 0.34, the internal and external validation sets are 0.849 and 0.842, respectively. Slightly poorer performance was observed for the 0.318 cut-off value, with AUCs of 0.844 and 0.836, but it remained reliable and compelling. The results of AIP endpoints are presented in Fig. 5.

ROC and AUC of models use both oculomics and clinics as input variables. a-b The performance of our model using AIP=0.318 or 0.34 as the cut-off point in the internal validation dataset is demonstrated. c-d The performance of our model using AIP=0.318 or 0.34 as the cut-off point in the external validation dataset is demonstrated. AIP, Atherogenic index of plasma. AUC, Area under curve. ROC, Receiver operating characteristic

ROC and AUC in the internal validation models used both oculomics and clinic as input variables. a-c, g-h Five cut-off points of AIP and TyG-index in the male subgroup. d-f, i-j Five cut-off points of AIP and TyG-index in the female subgroup. AIP, Atherogenic index of plasma. AUC, Area under curve. ROC, Receiver operating characteristic. TyG-index, Triglyceride-glucose index
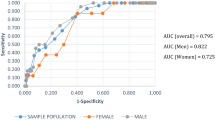
In addition, as gender is an independent risk factor for CVD [48], to eliminate the overfitting caused by gender bias in the overall predictive model, we conducted subgroup analyses for males and females separately. Results between gender subgroups are shown in Fig. 6. The AUC of models in male and female subgroups are most close only when the cut-off point of TyG-index is 8.93 (AUC=0.907 versus 0.906). The differences were observed when the cut-off point of TyG-index was set at 8, 8.9, and the cut-off point of AIP was set at 0.318, 0.34. The AUC values in males and females are corresponding with 0.832 and 0.790, 0.874 and 0.862, 0.853 and 0.825, 0.858 and 0.831.
Regarding specific models, the Gradient Boosting method demonstrated the best performance across most experiments (Tables 2 and 3). The AUC of the LGBM method was only stronger than Gradient Boosting method with a slight advantage of 0.001 in the external validation set of 0.318 and 0.34. In the other three cut-off points, the LGBM method was slightly inferior to Gradient Boosting, although the results were similar. It is worth noting that out of the 25 methods employed, the top 7 methods were selected for illustration purposes (Tables 2 and 3, Supplementary Tables S5, S6, S7, and S8).
Discussion
In this study, we realized the use of oculomics and clinic variables to predict the range of TyG-index and AIP by machine learning algorithms. The model demonstrated outstanding prediction efficiency with both internal and external datasets.
CVD is one of the most critical and dangerous chronic diseases in the world [49]. Early prevention and risk assessment of CVD are vital to patients or healthy adults. In order to achieve early prevention and risk assessment of CVD, many studies have been conducted on the risk factors of CVD. TyG-index and AIP combine traditional risk factors such as blood lipids and/or blood glucose that can reflect cardiovascular risk in different aspects. It has also been pointed out that TyG-index and AIP are better indicators of CVD than single biomarkers like TG and HDL-C [50, 51]. Recently, a systematic review documented that a greater TyG index might be individualistically linked to a greater incidence of atherosclerotic CVD among asymptomatic individuals. Several studies have confirmed the cross-sectional correlation between AIP and cardiovascular risk [52, 53]. Therefore, in primary screening of the population, especially in clinical practice, the TyG index and AIP can be considered to identify patients with high risk of CVD.
As previously reported, the eye provides a unique and transparent medium through which we can observe and measure various biological markers without any invasive procedures. Since oculomics was proposed in 2020, it has been widely discussed as a concept that combines AI, big data, and eye images [9]. Oculomics can be used for the prediction of many diseases, including sarcopenia and schizophrenia [46, 54, 55]. As for CVD, a review discussed the possibility of cardiovascular risk assessment based on oculomics [56, 57]. There are also studies combining oculomics and genomics to reveal aneurysm-related biomarkers [58]. In our study, we used oculomics and clinical features to predict cardiovascular risk. As for the cardiovascular risk, we selected different thresholds for TyG-index and AIP. The TyG-index cut-off point equals 8, and it is from a study involving 150,000 Koreans [21]. A graded positive association was observed between the TyG-index and CVD hospitalization. Per 1-unit increase in the TyG-index, a 16% increase in CVD hospitalization was demonstrated. When the cut-off point is the upper one-third of TyG values, we calculated 8.75 in our study population [22]. Compared with the lowest tertile of the TyG index, the highest tertile (tertile 3) was associated with a greater incidence of the composite outcome, myocardial infarction, stroke, and incident type 2 diabetes. When the cut-off point is the upper one-fourth of TyG values, we calculated 8.93 in our study population [23]. During 8.2 years of mean follow-up, the highest TyG index quartile demonstrated that these patients were at higher risk for stroke (HR=1.259; 95% CI 1.233-1.286), for MI (HR=1.313; 95% CI 1.28-1.346), and for both (HR=1.282; 95% CI 1.261-1.303) compared with participants in the lowest TyG index quartile.
As for the threshold of AIP, we chose 0.318 and 0.34. In type 2 diabetic subjects undergoing percutaneous coronary intervention, AIP plays an important role in predicting the prognosis. A recent study approved that when the value of AIP is higher than 0.318, the prognosis of the high AIP group was significantly worse than that of the low AIP group [20]. Another threshold for AIP was determined to be 0.34 in the study population [24]. High AIP (\(\ge\)0.34)presented the highest risk of cardiovascular deaths in patients with type 2 diabetes mellitus. Remarkably, in our study, the predictive efficacy was most conspicuous when TyG-index equated to 8.93, or AIP reached 0.318, suggesting that individuals demonstrating these particular indicators should be classified as the cohort at heightened risk for subsequent cardiovascular disease.
Gender differences in CVD have been discussed in recent studies [59]. A recent study showed that the absolute incidence of CVD in men was significantly higher than in women across all age groups [60]. Some researchers have observed that diabetes is more likely to be associated with ischemic heart disease in women than in men. And women are more likely to present with ischemia with no obstructive coronary arteries (INOCA) [61, 62]. On the treatment side, new treatments that are useful in men have not led to significant reductions in CVD mortality in women [63, 64]. So it is necessary to assess the gender-specific cardiovascular risks. In the subgroup analysis of this study, we found that the predictive efficacy of women was only stronger than that of men in both external validation sets when TyG=8.75 (AUC=0.849 and 0.867) and TyG=8.93 (0.881 and 0.908). Among all the remaining cut-off values of TyG and AIP, the AUC of the male subgroup was higher than that of the female subgroup. Our model has good predictive value for both men and women. Furthermore, this result suggests that the role of the TyG-index in predicting cardiovascular risk in women may be worthy of further exploration.
In this study, we used oculomics and non-invasive clinical data to predict the TyG index and AIP which are good indicators for CVD. Our research proposed that machine learning-based models successfully enhance the predictive performance for detecting abnormal ranges of AIP and TyG-index by using clinical questionnaires and oculomics. This conclusion holds promise for early identification of heightened cardiovascular risk by forecasting atypical TyG-index and AIP values in patients.
Therefore, our study has several strengths. First, we achieved good prediction of TYG and AIP by using variables from oculomics and clinical questionnaires. Both oculomics and clinical variables in the questionnaire were obtained non-invasively. These data are well recorded in the KNHANES database. We achieved the acquisition of these data and the construction of models at low cost. Low cost and non-invasiveness are important advantages for widespread application in clinical real-life scenarios [65]. Furthermore, although in its early stages, artificial intelligence (AI)-based oculomics methods may be a valuable non-invasive tool in primary care settings, enabling accurate diagnosis more cost-effectively and providing immediate results [66, 67]. Thus, our study has the advantage of enabling early detection and early intervention to prevent the progression of CVD in individuals at a low cost. In addition, due to the easy availability of ocular biomarkers, our study may also help eliminate barriers to uneven medical resources among regions with different economic levels.
Limitation
Nevertheless, this study still bears several limitations. Firstly, whether the results of this study can be applied to populations of other races that differ significantly from Asians remains to be further validated. The KNHANES dataset is primarily composed of the East Asian population. Previous studies have indicated differences in upper eyelid anatomy between Asians and Caucasians [68]. Secondly, we only included a limited number of oculomics measurement variables due to data limitations. The original fundus photographs in the KNHANES database were inaccessible, preventing us from establishing an image-based predictive model. Incorporating imaging data such as oculomics photographs and retinal images could yield more high-throughput information and potentially improve the prediction of cardiovascular risk [10].
Conclusion
In this study, we integrated two classifications of prognostic determinants, encompassing both clinical and oculomics textual parameters, in the formulation of the subject selection and model establishment. Throughout the experiment, we independently predicted the TyG-index and the AIP, yielding encouraging findings. These two variables collectively portray the metabolic status and may have an influence on the risk prediction of cardiovascular risks.
Availability of data and materials
No datasets were generated or analysed during the current study.
Abbreviations
- AIP:
-
Atherogenic index of plasma
- AUC:
-
Area under the curve
- BMI:
-
Body mass index
- CVD:
-
Cardiovascular disease
- DBP:
-
Diastolic blood pressure
- HDL-C:
-
High density lipoprotein cholesterol
- KNHANES:
-
Korean National Health and Nutrition Examination Survey
- MI:
-
Myocardial infarction
- SBP:
-
Systolic blood pressure
- TyG-index:
-
Triglyceride-glucose index
References
Tsao CW, Aday AW, Almarzooq ZI, Anderson CA, Arora P, Avery CL, et al. Heart disease and stroke statistics–2023 update: a report from the American Heart Association. Circulation. 2023;147(8):e93–621.
Lopez AD, Mathers CD, Ezzati M, Jamison DT, Murray CJ. Global and regional burden of disease and risk factors, 2001: systematic analysis of population health data. Lancet. 2006;367(9524):1747–57.
Tsai SF, Yang CT, Liu WJ, Lee CL. Development and validation of an insulin resistance model for a population without diabetes mellitus and its clinical implication: a prospective cohort study. Eclinicalmedicine. 2023;58:101934.
Meigs JB, Rutter MK, Sullivan LM, Fox CS, D’Agostino RB Sr, Wilson PW. Impact of insulin resistance on risk of type 2 diabetes and cardiovascular disease in people with metabolic syndrome. Diabetes Care. 2007;30(5):1219–25.
Fernández-Macías JC, Ochoa-Martínez AC, Varela-Silva JA, Pérez-Maldonado IN. Atherogenic index of plasma: novel predictive biomarker for cardiovascular illnesses. Arch Med Res. 2019;50(5):285–94.
Tao LC, Xu Jn, Wang Tt, Hua F, Li JJ. Triglyceride-glucose index as a marker in cardiovascular diseases: landscape and limitations. Cardiovasc Diabetol. 2022;21(1):1–17.
Chua J, Chin CWL, Hong J, Chee ML, Le TT, Ting DSW, et al. Impact of hypertension on retinal capillary microvasculature using optical coherence tomographic angiography. J Hypertens. 2019;37(3):572.
Wong TY, Klein R, Klein BE, Tielsch JM, Hubbard L, Nieto FJ. Retinal microvascular abnormalities and their relationship with hypertension, cardiovascular disease, and mortality. Surv Ophthalmol. 2001;46(1):59–80.
Wagner SK, Fu DJ, Faes L, Liu X, Huemer J, Khalid H, et al. Insights into systemic disease through retinal imaging-based oculomics. Transl Vis Sci Technol. 2020;9(2):6.
Poplin R, Varadarajan AV, Blumer K, Liu Y, McConnell MV, Corrado GS, et al. Prediction of cardiovascular risk factors from retinal fundus photographs via deep learning. Nat Biomed Eng. 2018;2(3):158–64.
Zekavat SM, Raghu VK, Trinder M, Ye Y, Koyama S, Honigberg MC, et al. Deep learning of the retina enables phenome-and genome-wide analyses of the microvasculature. Circulation. 2022;145(2):134–50.
Johnson KW, Torres Soto J, Glicksberg BS, Shameer K, Miotto R, Ali M, et al. Artificial intelligence in cardiology. J Am Coll Cardiol. 2018;71(23):2668–79.
Chen RJ, Wang JJ, Williamson DF, Chen TY, Lipkova J, Lu MY, et al. Algorithmic fairness in artificial intelligence for medicine and healthcare. Nat Biomed Eng. 2023;7(6):719–42.
Zhang Y, Yu M, Tong C, Zhao Y, Han J. CA-UNet Segmentation Makes a Good Ischemic Stroke Risk Prediction. Interdisciplinary Sciences: Computational Life Sciences. 2023;16:58–72.
Lu MY, Chen TY, Williamson DF, Zhao M, Shady M, Lipkova J, et al. AI-based pathology predicts origins for cancers of unknown primary. Nature. 2021;594(7861):106–10.
Kweon S, Kim Y, Jang Mj, Kim Y, Kim K, Choi S, et al. Data resource profile: the Korea national health and nutrition examination survey (KNHANES). Int J Epidemiol. 2014;43(1):69–77.
Yoo TK, Oh E. Association between dry eye syndrome and osteoarthritis severity: a nationwide cross-sectional study (KNHANES V). Pain Med. 2021;22(11):2525–32.
Simental-Mendía LE, Rodríguez-Morán M, Guerrero-Romero F. The product of fasting glucose and triglycerides as surrogate for identifying insulin resistance in apparently healthy subjects. Metab Syndr Relat Disord. 2008;6(4):299–304.
Guerrero-Romero F, Simental-Mendía LE, González-Ortiz M, Martínez-Abundis E, Ramos-Zavala MG, Hernández-González SO, et al. The product of triglycerides and glucose, a simple measure of insulin sensitivity. Comparison with the euglycemic-hyperinsulinemic clamp. J Clin Endocrinol Metab. 2010;95(7):3347–51.
Qin Z, Zhou K, Li Y, Cheng W, Wang Z, Wang J, et al. The atherogenic index of plasma plays an important role in predicting the prognosis of type 2 diabetic subjects undergoing percutaneous coronary intervention: results from an observational cohort study in China. Cardiovasc Diabetol. 2020;19:1–11.
Jung MH, Yi SW, An SJ, Yi JJ, Ihm SH, Han S, et al. Associations between the triglyceride-glucose index and cardiovascular disease in over 150,000 cancer survivors: a population-based cohort study. Cardiovasc Diabetol. 2022;21(1):1–10.
Lopez-Jaramillo P, Gomez-Arbelaez D, Martinez-Bello D, Abat MEM, Alhabib KF, Avezum Á, et al. Association of the triglyceride glucose index as a measure of insulin resistance with mortality and cardiovascular disease in populations from five continents (PURE study): a prospective cohort study. Lancet Health Longev. 2023;4(1):e23–33.
Hong S, Han K, Park CY. The triglyceride glucose index is a simple and low-cost marker associated with atherosclerotic cardiovascular disease: a population-based study. BMC Med. 2020;18:1–8.
Fu L, Zhou Y, Sun J, Zhu Z, Xing Z, Zhou S, et al. Atherogenic index of plasma is associated with major adverse cardiovascular events in patients with type 2 diabetes mellitus. Cardiovasc Diabetol. 2021;20(1):1–11.
Paik JS, Han K, Yang SW, Park Y, Na K, Cho W, et al. Blepharoptosis among Korean adults: age-related prevalence and threshold age for evaluation. BMC Ophthalmol. 2020;20(1):1–8.
Yoo TK, Hong S. Artificial neural network approach for differentiating open-angle glaucoma from glaucoma suspect without a visual field test. Investig Ophthalmol Vis Sci. 2015;56(6):3957–66.
Horn F, Pack R, Rieger M. The autofeat python library for automated feature engineering and selection. In: Machine Learning and Knowledge Discovery in Databases: International Workshops of ECML PKDD 2019, Würzburg, Germany, September 16–20, 2019, Proceedings, Part I. Springer; 2020. p. 111–120.
Breiman L. Random forests. Mach Learn. 2001;45:5–32.
Geurts P, Ernst D, Wehenkel L. Extremely randomized trees. Mach Learn. 2006;63:3–42.
Breiman L. Bagging predictors. Mach Learn. 1996;24:123–40.
Quinlan JR. Induction of decision trees. Mach Learn. 1986;1:81–106.
Chen T, Guestrin C. Xgboost: A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016. p. 785–794.
Ke G, Meng Q, Finley T, Wang T, Chen W, Ma W, et al. Lightgbm: A highly efficient gradient boosting decision tree. Advances in Neural Information Processing Systems. 2017;30:3149–57.
Friedman JH. Greedy function approximation: a gradient boosting machine. Ann Stat. 2001;29(5):1189–232.
Cortes C, Vapnik V. Support-vector networks. Mach Learn. 1995;20:273–97.
Freund Y, Schapire R, Abe N. A short introduction to boosting. J-Jpn Soc Artif Intell. 1999;14(771–780):1612.
Zhu X, Ghahramani Z. Learning from labeled and unlabeled data with label propagation. Technical Report. CMU-CALD-02-107, Carnegie Mellon University. 2002.
Cox DR. The regression analysis of binary sequences. J R Stat Soc Ser B Stat Methodol. 1958;20(2):215–32.
Hoerl AE, Kennard RW. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics. 1970;12(1):55–67.
Rosenblatt F. The perceptron: a probabilistic model for information storage and organization in the brain. Psychol Rev. 1958;65(6):386.
Fix E, Hodges JL. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int Stat Rev/Rev Int Stat. 1989;57(3):238–47.
Bottou L. Stochastic gradient descent tricks. In: Neural Networks: Tricks of the Trade: Second Edition. Springer. 421–436.
BAYES. An essay towards solving a problem in the doctrine of chances. Biometrika. 1958;45(3-4):296–315.
Crammer K, Dekel O, Keshet J, Shalev-Shwartz S, Singer Y. Online passive aggressive algorithms. J Mach Learn Res. 2006;7:551–85.
Gnanadesikan R, Blashfield R, Breiman L, Dunn O, Friedman J, Hartigan K, et al. Discriminant analysis and clustering. Stat Sci. 1989;4(1):34–69.
Kim BR, Yoo TK, Kim HK, Ryu IH, Kim JK, Lee IS, et al. Oculomics for sarcopenia prediction: a machine learning approach toward predictive, preventive, and personalized medicine. EPMA J. 2022;13(3):367–82.
Kim J, Mun S, Lee S, Jeong K, Baek Y. Prediction of metabolic and pre-metabolic syndromes using machine learning models with anthropometric, lifestyle, and biochemical factors from a middle-aged population in Korea. BMC Public Health. 2022;22(1):664.
Walli-Attaei M, Rosengren A, Rangarajan S, Breet Y, Abdul-Razak S, Al Sharief W, et al. Metabolic, behavioural, and psychosocial risk factors and cardiovascular disease in women compared with men in 21 high-income, middle-income, and low-income countries: an analysis of the PURE study. Lancet. 2022;400(10355):811–21.
World Health Organization: Preventing chronic disease: a vital investment. Geneva: World Health Organization; 2005.
Mirjalili SR, Soltani S, Heidari Meybodi Z, Marques-Vidal P, Kraemer A, Sarebanhassanabadi M. An innovative model for predicting coronary heart disease using triglyceride-glucose index: a machine learning-based cohort study. Cardiovasc Diabetol. 2023;22(1):200.
Kim SH, Cho YK, Kim YJ, Jung CH, Lee WJ, Park JY, et al. Association of the atherogenic index of plasma with cardiovascular risk beyond the traditional risk factors: a nationwide population-based cohort study. Cardiovasc Diabetol. 2022;21(1):81.
Dobiasova M. AIP-atherogenic index of plasma as a significant predictor of cardiovascular risk: from research to practice. Vnitr Lek. 2006;52(1):64–71.
Dobiášová M, Frohlich J, Šedová M, Cheung MC, Brown BG. Cholesterol esterification and atherogenic index of plasma correlate with lipoprotein size and findings on coronary angiography. J Lipid Res. 2011;52(3):566–71.
Wu JH, Liu TYA. Application of Deep Learning to Retinal-Image-Based Oculomics for Evaluation of Systemic Health: A Review. J Clin Med. 2022;12(1):152.
Wagner SK, Cortina-Borja M, Silverstein SM, Zhou Y, Romero-Bascones D, Struyven RR, et al. Association Between Retinal Features From Multimodal Imaging and Schizophrenia. JAMA Psychiatr. 2023;80(5):478–87.
Arnould L, Meriaudeau F, Guenancia C, Germanese C, Delcourt C, Kawasaki R, et al. Using Artificial Intelligence to Analyse the Retinal Vascular Network: The Future of Cardiovascular Risk Assessment Based on Oculomics? A Narrative Review Ophthalmol Ther. 2023;12(2):657–74.
Barriada RG, Masip D. An Overview of Deep-Learning-Based Methods for Cardiovascular Risk Assessment with Retinal Images. Diagnostics. 2022;13(1):68.
Huang Y, Li C, Shi D, Wang H, Shang X, Wang W, et al. Integrating oculomics with genomics reveals imaging biomarkers for preventive and personalized prediction of arterial aneurysms. EPMA J. 2023;14(1):73–86.
Vaccarezza M, Papa V, Milani D, Gonelli A, Secchiero P, Zauli G, et al. Sex/gender-specific imbalance in CVD: could physical activity help to improve clinical outcome targeting CVD molecular mechanisms in women? Int J Mol Sci. 2020;21(4):1477.
Ekblom-Bak E, Ekblom B, Söderling J, Börjesson M, Blom V, Kallings LV, et al. Sex-and age-specific associations between cardiorespiratory fitness, CVD morbidity and all-cause mortality in 266.109 adults. Prev Med. 2019;127:105799.
Mehta PK, Wei J, Wenger NK. Ischemic heart disease in women: a focus on risk factors. Trends Cardiovasc Med. 2015;25(2):140–51.
Bairey Merz CN, Shaw LJ, Reis SE, Bittner V, Kelsey SF, Olson M, et al. Insights from the NHLBI-Sponsored Women’s Ischemia Syndrome Evaluation (WISE) Study: Part II: gender differences in presentation, diagnosis, and outcome with regard to gender-based pathophysiology of atherosclerosis and macrovascular and microvascular coronary disease. J Am Coll Cardiol. 2006;47(3S):S21–9.
Gemmati D, Varani K, Bramanti B, Piva R, Bonaccorsi G, Trentini A, et al. “Bridging the gap” everything that could have been avoided if we had applied gender medicine, pharmacogenetics and personalized medicine in the gender-omics and sex-omics era. Int J Mol Sci. 2019;21(1):296.
Ford ES, Ajani UA, Croft JB, Critchley JA, Labarthe DR, Kottke TE, et al. Explaining the decrease in US deaths from coronary disease, 1980–2000. N Engl J Med. 2007;356(23):2388–98.
Ivanović D, Kupusinac A, Stokić E, Doroslovački R, Ivetić D. ANN prediction of metabolic syndrome: a complex puzzle that will be completed. J Med Syst. 2016;40:1–7.
DeBuc DC. AI for identification of systemic biomarkers from external eye photos: a promising field in the oculomics revolution. Lancet Digit Health. 2023;5(5):e249–50.
Babenko B, Traynis I, Chen C, Singh P, Uddin A, Cuadros J, et al. A deep learning model for novel systemic biomarkers in photographs of the external eye: a retrospective study. Lancet Digit Health. 2023;5(5):e257–64.
Jeong S, Lemke BN, Dortzbach RK, Park YG, Kang HK. The Asian upper eyelid: an anatomical study with comparison to the Caucasian eyelid. Arch Ophthalmol. 1999;117(7):907–12.
Acknowledgements
Not applicable.
Funding
This study is partially supported by National Natural Science Foundation of China (62176016, 72274127, 81600351), National Key R &D Program of China(No.2021YFB2104800), Guizhou Province Science and Technology Project: Research on Q &A Interactive Virtual Digital People for Intelligent Medical Treatment in Information Innovation Environment (supported by Qiankehe[2024] General 058), Haidian innovation and translation program from Peking University Third Hospital (HDCXZHKC2023203), Key R&D Program of Shandong Province, China (2021CXGC010504), and Capital Health Development Research Project(2022-2-2013).
Author information
Authors and Affiliations
Contributions
Chao Tong, Niansang Luo and Kun Zhang are the guarantors of the study. All authors (Yuqi Zhang, Sijin Li, Weijie Wu, Yanqing Zhao, Jintao Han, Chao Tong, Niansang Luo, Kun Zhang) were involved in the conceptualization and design of the study. Yuqi Zhang and Sijin Li were responsible for the experiment. Data cleaning was done by Sijin Li and Weijie Wu. Analysis and interpretation were done by Yanqing Zhao and Sijin Li under the supervision and withthe support of Jintao Han, Chao Tong, Niansang Luo and Kun Zhang. Drafting of the article was done by Yuqi Zhang, Sijin Li and Weijie Wu. All authors (Yuqi Zhang, Sijin Li, Weijie Wu, Yanqing Zhao, Jintao Han, Chao Tong, Niansang Luo, Kun Zhang) revised and contributed to the intellectual content of the article. All authors (Yuqi Zhang, Sijin Li, Weijie Wu, Yanqing Zhao, Jintao Han, Chao Tong, Niansang Luo, Kun Zhang) approved the final version of the article, including the authorship list.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
The study protocol was approved by the Institutional Review Board of the Korean Center for Disease Control and Prevention (No. 2008-04EXP-01-C, 2009-01CON-03-C, 2010-02CON-21-C, 2011-02CON-06-C and 2012-01EXP-01-2C). The raw data sets are publicly available through the KNHANES website, and data collection from the KNHANES dataset was approved by the Institutional Review Board of the Korean National Institute for Bioethics Policy. The study adhered to the tenets of the Declaration of Helsinki. Institutional Review Board of the Korean National Institute for Bioethics Policy waived the requirement for informed consent for this study.
Consent for publication
All the authors approved the manuscript for publication.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhang, Y., Li, S., Wu, W. et al. Machine-learning-based models to predict cardiovascular risk using oculomics and clinic variables in KNHANES. BioData Mining 17, 12 (2024). https://doi.org/10.1186/s13040-024-00363-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13040-024-00363-3