
Abstract
The SN1987A detection through neutrinos was an event of great importance in neutrino physics, being the first detection of neutrinos created outside our solar system, and then inaugurating the era of experimental neutrino astronomy. The data have been largely studied in many different analysis, and has presented several challenges in different aspects, since both supernova explosion dynamics and neutrino flavour conversion in such extreme environment still have many unknowns. In addition, the low statistics also invoke the need of unbinned statistical methods to compare any model proposal with data. In this paper we focus on a discussion about the most used statistical analysis interpretation, presenting a pedagogical way to understand and visualize this comparison.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Particle physics provides a fertile ground to a vast number of methods to statistically compare theory and data, giving a quantitative filling in order to guide the prospects of a theory, or even revealing important accomplishments or tensions in experimental efforts.
In general, when a measurement provides a large number of data points, a particular theory can visually (and intuitively) be compared to data by a superposition of measured and theoretically expected number of events, together with the associated uncertainties. However, when the number of data points is low, although there are a number of efficient methods from which is possible to draw rigorous quantitative conclusions from data, an intuitive method of comparing theory and experimental results is less direct.
One interesting phenomena, the neutrino burst detected from the supernova SN1987A, is particularly affected by low statistics, evidencing the above mentioned difficulties.
In this paper we review a particular statistical method to interpret and extract scientific conclusions from experiments with low number of data points, using the SN1987A data as an example, and propose a procedure to handle this difficulty through animations.
2 Statistical analysis
The quantitative comparison between theoretical predictions and experimental results is a major part of any scientific endeavour. When comparing theory and experimental data some important features of the theory that can be tested quantitatively are: (i) how good is the agreement between theoretical predictions and experimental data – the goodness of fit, gof, (ii) which set of theoretical parameter values provides the best agreement between theory and observations – the parameters best fit point, bfp and (iii) what is the region in the theoretical parameter phase space in which such agreement is valid for some confidence level. These features can be usually presented graphically, in ways that drive our intuition to better visually comprehend the key concepts of the statistical method used. An interested reader can follow, among many good textbooks on statistics, Ref. [1] for basic concepts of statistical data analysis.
As in many other areas, in particle physics an important quantity around such analysis is made is the detection rate of a specific event. As an example, theoretical models of solar neutrino production provide us with a steady theoretical neutrino flux, and solar neutrino experiments provide us with a detected event rate of solar neutrinos. The comparison between these two quantities can be done by translating the theoretical flux in an expected event rate, or inversely, translating the detected event rate in a compatible expected flux.
Besides, a lot of information can be extracted from the dependence of neutrino flux with its energy or time of detection. The most straightforward way to include this information on statistical analysis would be to split the total data into bins of specific energy or time intervals. Maybe the most spread statistical tool to implement these kind of analysis would be to calculate the following \(\chi ^2\):
where the indices i and j track the binning of the data, \(R^{th}_k\) is the theoretical prediction, \(R^{ex}_k\) is the experimental data and \(\sigma \) is the covariance matrix, that holds uncertainties and correlations (and then \(\sigma ^{-2}_{ij}\) is the ij element of the inverse of \(\sigma ^2\)). This analysis has one great advantage: it allows to visually grasp how good is the accordance between theory and experiment in a figure where experimental data points, uncertainties and theoretical predictions can be plotted together. If theoretical predictions are contained inside the region around the experimental data points delimited by the uncertainties, than we expect a good fit.
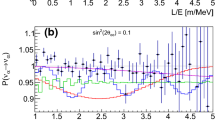
Several examples in neutrino physics can illustrate such procedure. Again taking solar neutrinos as an example, the data presented by the neutrino detector Super-Kamiokande is divided both in energy and the zenith angle that gives the Sun’s position in the time of detection. In Fig. 1 the data of 1496 days of running experiment are presented, and the binning on energy and angle can be seen. The continuous line represent the prediction for the best fit point of the statistical analysis when flavour conversion is considered in two scenarios, the large mixing angle with large \(\Delta m^2\) (LMA) and lower \(\Delta m^2\) (LOW).Footnote 1

Data from the 1496 days of Super-Kamiokande. Each day/night plot gives a binning in energy, LOW (light gray) and LMA (black) proposed solutions to be visually compared to data points. Taken from [2]
As discussed, it is possible to visually get a feeling about how good the accordance between experimental data and theoretical predictions by how the theoretical curves cross the region around the experimental data within the error bars. For this particular example, two solutions to the solar neutrino problem are presented. We can expect by visually inspecting the figure that both solutions would fit the data quite well, fact that is confirmed by a more careful statistical analysis.
The problem of this visualization is when there is no efficient way to collect the data to form bins, for instance, due to the low event rate. In particular, when the event rate is very low it is necessary to take the experimental data event by event.
In this context, what we propose here is to recover a way to visually access how good the accordance between experimental data and theoretical prediction in a particular scenario when the statistical analysis is done event by event: the neutrino data from Supernova 1987A.
3 Supernova 1987A
The Core Collapse Supernova is a remarkable end of life of a star and one of the most peculiar astrophysical phenomena. Despite being a prominent optical event, its most outstanding property is the powerful release of \(\sim 99\%\) of gravitational binding energy, generally in the order of \(\sim 10^{53}\) erg, from a \(m \gtrsim 10 M_\odot \) progenitor star in (anti)neutrinos of all flavors in MeV scale.
Nevertheless the high neutrino luminosity, a limitation in the neutrino observation on Earth is related to the high distance D from the source, with decreasing flux proportional to \(D^{-2}\), restricting the possible region for neutrino burst detection to a galactic or nearby the Milky Way, that possesses a low supernova rate of \(\sim 1\) per century [3].
Even though, in 1987, three detectors, Kamiokande II [4, 5], IMB [6, 7] and Baksan [8], were capable to observe a neutrino signal associated to a SN in the Large Magellanic Cloud (\(\sim 50\) kpc). These data are presented in Fig. 2. In contrast with Super-Kamiokande data in Fig. 1, these are individual events, and there is no obvious way to overlap a theoretical curve to them. Since the theoretical models provide a flux density and any kind of binning to convert this density into an event probability would be quite arbitrary, the approach through an unbinned maximum likelihood estimation is a robust alternative to confront the theoretical hypothesis with these individual events. In next section we describe such procedure.

Positron energy and relative time from the IMB, Kamiokande II and Baksan detectors, with a total of 29 events
4 Modelling SN1987A event-by-event likelihood
Frequently the likelihood treatment in particle physics involves the usage of Poisson distribution \(P(\mu , n)\), that fits well to phenomena that has small probability to occur, but a large number of tries. Given a measured variable set \(\mathbf{x}\), the Poisson likelihood is given by:
where \(n_i\) can be a particular number of events that occurs in a \(x_i + \delta x_i\) interval of our variable, in a number N of intervals, or bins, and \(\mu (x_i)\) is the expected value in the same interval. It is convenient to write \(\mu (x_i)\) as a distribution function on the variable \(x_i\), or \(\mu (x_i) = R(x_i)\delta x_i\), with a given events rate \(R(x_i) = \frac{dN}{dx_i}\) in an equally spaced bin of variable \(\delta x_i\) and number of counts \(n_i\). Including it in Eq. (2):
However, binning the data to use a single expected value of a set of points requires to assume a given statistical distribution of such a bin, that generally is assumed to be Gaussian for higher number of entries. The low statistics scenario does not allow this assumption, then it is possible to model the likelihood (3) to account for each event apart. This can be made by taking the bin to an infinitesimal width \(\delta x \rightarrow dx\) and number of counts \(n_i \rightarrow 1\), so we consider only infinitesimal bins with one event and drop the others, then (3) becomes
that also has the change from total number of bins \(N_{bins}\) to total number of observed events \(N_{obs}\) and the index i accounts for each individual event. The idea behind maximum likelihood is to maximize the quantity in (4), or given the correspondence \({\mathscr {L}} = e^{-\chi ^2/2}\), minimize the \(\chi ^2(\mathbf{x})= -2 \log {\mathscr {L}}(\mathbf{x})\) to respect to a free set of parameters \(\mathbf{x}\). If we have a single event at \(x=\bar{x}\), this expressions reduces to \(e^{- \int R(x) dx} R(\bar{x}) \). For different models with a normalized expected event rate \(\int R(x)dx\), the likelihood is maximized for the model with the highest value of \(R(x_i)\). And letting the normalization runs freely, it is maximized for \(\int R(x) dx=1\). It is straightforward to note that if we consider more than one single event this maximum occurs on the total number of events.
In a supernova detection, such as SN1987A, the variables x are the neutrino energy, the detection time and events scattering angle, i.e. \(R=R(E, t, \cos \theta )\) [9]:
with \(n_p\) being the number of free protons of each detector, \(\sigma (E_\nu , \cos {\theta })\) is the inverse beta decay cross section [10], \(\phi _{\bar{\nu }_e}(E_\nu , t)\) represents the electron antineutrino flux on Earth, \(\xi (\cos {\theta })\) is an angular bias of IMB detector and \(\eta (E_e)\) is an efficiency function taken from [8], that fits the reported efficiency points from each collaboration.
Then Eq. (4) becomes:
where R is a triply differential equation, \(R=\frac{d^3N}{dE\,dt\,d\cos \theta }\) and N is the expected number of events at the detector. For simplicity we did not include the scattering angle dependence on the animations presented in the following, although they were used in the likelihood calculation. A complete analysis, including other details such as background and energy resolution can be seen in [9, 11,12,13,14,15].

Theoretical events rate cumulative integrated over time (Eq. 8) (blue) and normally distributed data as proposed in (9) (red) changing along relative detection time since the first measured neutrino from SN1987A. The time scale runs logarithmically in the first second and linearly afterwards to better show the data structure for early time events (see the animation here: https://github.com/santosmv/Animations-visualizing-SN1987A-data-analysis/blob/main/events_rate.png)
5 Single event distribution
The main ingredient to construct the likelihood is the theoretical triply differential expected rate. However, since there is no way to convert the theoretical predictions into some quantity to be compared with individual events, we can instead modify the events to match the theoretical probability distribution. For instance, all SN1987A events are published with an uncertainty in energy, so the true information we can take from each event is a probability distribution around some most probable result. Assuming such distribution to be Gaussian, a specific event with measured energy \(\bar{E}_\nu \pm \sigma _E\), where \(\sigma _E\) is the energy uncertainty, measured on time \(\bar{t}\pm \sigma _t\), with \(\sigma _t\) being the uncertainty in time, is related to the following probability distribution:
where \(P(E_\nu ,t)\) is the probability that the event had a true energy between \(E_\nu \) and \(E_\nu +dE_\nu \), and was measured in the true time between t and \(t+dt\).
This can be compared with the theoretical probability of inducing an event on the detector:
where A is a normalization constant that takes into account the number of targets in the detector and its efficiency. The neutrino interaction cross section is given by \(\sigma (E_\nu )\), and \(\phi (E_\nu ,t)\) is the neutrino flux. The specific parameterization of these two last functions will be presented in the sequence.
To proper visualize the data points being collected, we can create an animation with the detected event probability integrated on time. Since the uncertainty on time is very small, the distribution converges to a \(\delta \)-function, and such animation would advance in steps while the data gets collected:
Such animation is presented in Fig. 3 (red curve). Since what is presented is the cumulative result after integrating on time, the final moment of this animation, when integrated also on energy, provides all the 29 events detected by the three experiments. The comparison with theoretical predictions can be made visually if we produce a similar animation for the expected number of events, integrating Eq. (8) on time, also presented in Fig. 3 (dashed curve). This method of a model independent curve representing the spectrum has already been fully discussed in [16,17,18], where Refs. [17, 18] also bring a comparative analysis to neutrino emission models.Footnote 2
Our parameterization of the electron antineutrinoFootnote 3 flux \(\phi (E_\nu , t)\) in Eq. (8) follows the model of Ref. [9] and consists in a two-component emission (accretion + cooling) with nine free parameters, that come from the proposed flux \(\phi = \phi (t, E, \cos \theta , \mathbf{y})\), with \(\mathbf{y} = (T_c, R_c, \tau _c, T_a, M_a, \tau _a)\), where \(T_c\) (\(T_a\)) is the initial antineutrino (positron) temperature from the cooling (accretion) phase, \(R_c\) is the radius of the neutrinosphere, \(\tau _c\) (\(\tau _a\)) is the characteristic time from the cooling (accretion) phase and \(M_a\) is the initial accreting mass. The remaining three free parameters are a time offset \(t_{\mathrm{off}}\) to be adjusted independently for each detector. It was assumed that the neutrino flux was affected by mixing exclusively through MSW effect, in the normal hierarchy scenario [19, 20], with mixing parameters taken from [21]. A more detailed discussion of fitting SN1987A data in a similar way can be seen in the widely cited [22]. A complete comparison of distinct parameterizations is also discussed in [18].
These parameters are estimated from an event-by-event maximum likelihood, and the best fit values of our analysis, used in Fig. 3, are:
As described before, the maximization on the likelihood depends on two terms. The term in the exponential factor is related to the number of events, and drives the theoretical parameters to those who provides the right expected number of events, i.e., the area under the curves at the end of the animation in Fig. 3. It is quite easy to grasp if our theoretical model fits well the data by this aspect.
The second term access how close the theoretical curve is to the experimental one at the data central points, both in energy and in time. Since the uncertainty in time is negligible, we can visually compare the curves at the moments a new data is collected, providing us with a visual tool to this second ingredient of the statistical analysis. By performing these two analysis on Fig. 3, we can expect that, although not perfect, the theoretical prediction would provide a reasonably good fit to the data.

To visualize the effect of spectral distortion impact on events rate, we used two sets of parameters for \(T_a\) and \(M_a\) (in green and in cyan) that are excluded at \(90\%\) C.L. according to our analysis. The green curve produces a distortion for low energy events, while the cyan produces a distortion that favour high-energy events. Also on light grey we present the best-fit point of our analyses, shown in Fig. 2 (see the animation here: https://github.com/santosmv/Animations-visualizing-SN1987A-data-analysis/blob/main/events_rate_worse_fit.png)
It is useful now to analyse a set of theoretical parameters that do not fit well the data. This is done in Fig. 4, where we chosed two set of parameters that are excluded at 90% C.L. according to our analysis. These parameters were chosen in a way to not change the total number of predicted events, so we can focus on the energy spectrum information. It is clear, again using a visual comparison, that these new set of parameters produce a worse fit to the data, fact that is confirmed by a full statistical analysis.
As it was pointed out earlier, the two main neutrino observables that we are taking into consideration are the neutrino energy and the time of detection. After discussing the first on the above analysis, we will now focus on the second, and the best way to do this is the limits in neutrino mass that can be achieved using this statistical method.
6 Neutrino mass limits
An important remark is that the neutrino detection spread in time is an important source of physical information, allowing us to probe both Supernova explosion mechanisms and neutrino properties. The most important neutrino property that can be probed by such time spread is its mass.
The first difficulty in these kind of analysis is that the data itself does not allow us to correlate the time of arrival of the neutrino burst at the detectors with the unknown time at which the neutrinos left the Supernova. The solution is to use the data itself to establish, through statistical analysis, the match between the neutrino flux theoretical prediction and the data, taking the time of arrival of the first neutrino event in each detector as a marker. The time of the following events, \(t_i\) are taken as relative ones to the time of arrival of the first event, \(t_1\):
and \(t_1\) is left to vary freely to best match the theoretical prediction in a previously established time scale.
This simple picture arises when we assume massless neutrinos. In this case the relative time between events is identical to the relative time between the emission of these detected neutrinos on the production site, since the time delay due to the travel between the supernova and the detectors does not depend on the neutrino properties. In Fig. 3 it is assumed a vanishing mass neutrino, and the time showed on the animation correspond to the time since the supernova offset.

Effect of neutrino mass delay on SN1987A detected burst compared to standard flux for a \(3 \sigma \) excluded neutrino mass. The gray line corresponds to the fitted theory in Fig. 3 (see the animation here: https://github.com/santosmv/Animations-visualizing-SN1987A-data-analysis/blob/main/events_rate_mass_delay.png)
However, since the neutrinos have mass, neutrinos with different energies have different velocities, which changes the described scenario. More energetic neutrinos travels faster then less energetic neutrinos, meaning that the relative times between events does not correspond to relative times of the neutrinos emission. The correction is done by a simple kinematic analysis:
where D is the distance to the supernova, and m and E are the neutrino mass and event energy. The sub-index p (d) refers to the time at production (detection). The emission time of each event is then calculated from the relative times \(\delta _i\), and the kinematic corrections:
For more details, we refer to [22, 23].
Instead of making the correction on the time of the production, presented here to give proper credit to the authors that proposed and performed this analysis, we prefer to correct the theoretical predictions by continuous spread in time on the neutrino flux spectrum at the detector. So, instead of converting the time of the detected events to the supernova emission, we adjust the theoretical prediction to the detector site. Clearly both choices are equivalent, but with this second procedure we can use the same data animation presented in Fig. 3, and adjust the theoretical curve by making the replacement:
in Eq. (8).
An animation evidencing this model independent limit is shown in Fig. 5, where we chose an exceeding neutrino mass of 30 eV, highly beyond of astrophysical limits of \(\sim 5\) eV [22, 23] in order to effectively visualize the delay given by mass, with the same astrophysical parameters used to produce Fig. 3, and then with the same neutrino flux at the source. But due to the different time lag of neutrinos traveling to Earth with different energies, the time history of the expected number of events changes significantly, allowing us to place a limit on neutrino analysis using a proper statistical analysis.
7 Conclusion
This paper intended to present a pedagogical view of how to understand the likelihood analysis when an event-by-event treatment is necessary. The detection of SN1987A is a perfect example for that, once a lot of physics can be extracted by the few events that were collected through neutrino detection. It also has the interesting feature that different information can be extracted from the total expected number of events, its spectral distortion or its time structure. We present some animations as a visual tool to understand the statistical procedure, and produce a first impression on how different models fit the data.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: The experimental data used in the present manuscript is public and available in https://doi.org/10.1093/acprof:oso/9780198508717.001.0001. There is no public repository for the data of results, but we can provide to anyone who request to corresponding author.]
Notes
By the time these data was released, both set of parameters provided acceptable solutions to the solar neutrino problem, as is discussed in [2].
Once the detectors in 1987 were capable to measure a single channel, the inverse beta decay (\(\bar{\nu }_e + p \rightarrow e^+ + n\)), only electron antineutrinos could be detected.
References
G. Cowan, Statistical Data Analysis, 1st edn. (Clarendon Press, Oxford, 1998), pp. 70–93
M.B. Smy, Nucl. Phys. B Proc. Suppl. 118, 25–32 (2003). https://doi.org/10.1016/S0920-5632(03)01300-8
K. Rozwadowska, F. Vissani, E. Cappellaro, New Astron. Rev. 83, 101498 (2021). https://doi.org/10.1016/j.newast.2020.101498
K. Hirata et al., Phys. Rev. Lett. 58, 1490 (1987). https://doi.org/10.1103/PhysRevLett.58.1490
K. Hirata et al., Phys. Rev. D 38, 448 (1988). https://doi.org/10.1103/PhysRevD.38.448
R.M. Bionta et al., Phys. Rev. Lett. 58, 1494 (1987). https://doi.org/10.1103/PhysRevLett.58.1494
T. Haines et al., Nucl. Instrum. Meth. A 264, 1 (1988). https://doi.org/10.1016/0168-9002(88)91097-2
E.N. Alekseev et al., Phys. Lett. B 205, 2–3 (1988). https://doi.org/10.1016/0370-2693(88)91651-6
G. Pagliaroli et al., Astropart. Phys. 31, 3 (2009). https://doi.org/10.1016/j.astropartphys.2008.12.010
P. Vogel, J.F. Beacom, Phys. Rev. D 60, 053003 (1999). https://doi.org/10.1103/PhysRevD.60.053003
A. Ianni et al., Phys. Rev. D 80, 043007 (2009). https://doi.org/10.1103/PhysRevD.80.043007
B. Jegerlehner, F. Neubig, G. Raffelt, Phys. Rev. D 54, 1194 (1996). https://doi.org/10.1103/PhysRevD.54.1194
M.L. Costantini, A. Ianni, F. Vissani, Phys. Rev. D 70, 043006 (2004). https://doi.org/10.1103/PhysRevD.70.043006
F. Vissani, G. Pagliaroli, Astron. Lett. 35, 1–6 (2009). https://doi.org/10.1134/S1063773709010010
A. Mirizzi, G.G. Raffelt, Phys. Rev. D 72, 063001 (2005). https://doi.org/10.1103/PhysRevD.72.063001
M.L. Costantini, A. Ianni, G. Pagliaroli, F. Vissani, J. Cosmol. Astropart. Phys. 05(14) (2007). https://doi.org/10.1088/1475-7516/2007/05/014
H. Yuksel, J.F. Beacom, Phys. Rev. D 76, 083007 (2007). https://doi.org/10.1103/PhysRevD.76.083007
F. Vissani, J. Phys. G Nucl. Part. Phys. 42, 013001 (2014). https://doi.org/10.1088/0954-3899/42/1/013001
A.S. Dighe, A.Y. Smirnov, Phys. Rev. D 62, 033007 (2000). https://doi.org/10.1103/PhysRevD.62.033007
C. Lunardini, A.Y. Smirnov, Astropart. Phys. 21, 703–720 (2004). https://doi.org/10.1016/j.astropartphys.2004.05.005
P.A. Zyla et al., Rev. Part. Phys. 2020, 083C01 (2020)
T.J. Loredo, T.Q. Lamb, Phys. Rev. D 65, 063002 (2002). https://doi.org/10.1103/PhysRevD.65.063002
G. Pagliaroli, F. Rossi-Torres, F. Vissani, Astropart. Phys. 33, 5–6 (2010). https://doi.org/10.1016/j.astropartphys.2010.02.007
Acknowledgements
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior – Brasil (CAPES) – Finance Code 001. The authors are also thankful for the support of FAPESP funding Grant 2014/19164-6. The authors are thankful to Pedro Dedin for useful discussions during the production of this article.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Funded by SCOAP3
About this article

{kind=link}
{kind=link}
{kind=link}
Cite this article
dos Santos, M.V., de Holanda, P.C. Understanding and visualizing the statistical analysis of SN1987A neutrino data. Eur. Phys. J. C 82, 145 (2022). https://doi.org/10.1140/epjc/s10052-022-10091-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-022-10091-9