
Abstract
The exponential growth of the Internet of Things (IoT) has led to an increased demand for secure and efficient data transmission methods. However, there is a tradeoff in the image quality and hiding capacity in the data hiding methods. Therefore, the maximum amount of data that could be stored in the image media is a difficult challenge while maintaining the image quality. Thus, to make the balance between the quality of the images and the embedding capacity, a novel interpolation-based revisable data hiding (RDH) approach is developed for IoT applications. The proposed interpolation technique takes the average of the root value for the product of two neighboring original pixel values and the third original pixel value. And for the central pixel, it takes an average of two interpolated pixels. By doing so, most of the original pixels are considered and the calculated interpolated pixel is much enhanced as its average value. Furthermore, the data hiding is performed in two stages. In the first stage, RSA is performed on the secret message, and then embedding is done based on which intensity range group. The experimental results indicate that the proposed technique enhanced the embedding capacity by 17.58% and produced 7.80% higher PSNR values for the test images as compared to the baseline methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Presently, the internet has evolved into one of the most important aspects of our everyday lives. However, it becomes difficult to maintain the confidentiality of the data as it is sent via a public network [1]. In the domain of information encryption and information concealing, various strategies have been suggested as potential solutions to the problem of ensuring the confidentiality of sensitive data. The process of encrypting information, also known as cryptography which works by jumbling the confidential communication in such a manner that it is unintelligible to anybody monitoring the conversation [2,3,4,5]. However, there is no way that this can ever be encrypted to protect the hidden message; instead, it invites the attention of attackers. As a result, under some circumstances, there is a need for covert communication that takes place in the absence of anyone’s knowledge that the communication is taking place. Because of this, some kind of method for concealing information is required [6]. The art of concealing information may be broken down into two distinct subfields: steganography and watermarking. Although steganography and watermarking are closely connected to one another and both are used to disguise secret information, the focus of each technique is different. The primary goals of steganography are to disguise the fact that communication is taking place and to safeguard confidential material [4, 7]. On the other hand, the purpose of watermarking is to ensure that confidential data is preserved and to safeguard the intellectual property of the contents.
Steganography has six mediums for communication: text, audio, video, and image. However, our study focuses on image steganography where an image is used as a carrier that helps in hiding secret information. Data hiding is a mechanism of masking/concealing any data into multimedia formats like audio, video, or text and protects their integrity over the internet. The two main categories are irreversible data concealing, in which only the secret data can be obtained, and reversible data hiding, in which both the hidden data and the cover picture may be retrieved [8,9,10,11]. More often, reversible data concealing is used. The method of calculating or computing a value that is unknown based on a value that is already known is referred to as interpolation. The input picture is expanded by adding a row and column, and then new interpolated pixel values are computed using the input picture’s pixels as references. Thus, getting the cover picture. Our research is centered on interpolation-based reversible data schemes.
In this modern era, data hiding techniques have been playing an important role in information security to protect the sensitive data over open medium. There are two main parameters that judge the effectiveness of hiding techniques, one is stego- medium quality and second one is the hiding capacity of cover-media. There exists a trade-off between stego-medium quality and hiding capacity [14,15,16,17,18,19]. In other words, higher hiding capacity often causes greater distortion, and vice versa. In the thesis, the focus of the work is to study and analyse the existing techniques to find their advantages and limitations. Additionally, new techniques are proposed to enhance the stego-medium quality and hiding capacity together. Moreover, the effectiveness of proposed system on given parameters and their comparison with existing methods are also presented. Applications of the reversible data hiding techniques are as medical imaging, forensic analysis, military and defense, confidential document transmission, secure communication in IoT, privacy preservation, biometric data security, data embedding in satellite imagery, digital health records, smart cities and surveillance, academic and research data integrity, and secure image sharing platforms.
1.1 Motivation and contribution
The motivation for this work stems from the rapid expansion of the Internet of Things (IoT), which has generated an escalating demand for secure and efficient data transmission methods. In the context of IoT, the challenge arises in striking a delicate balance between preserving image quality and maximizing hiding capacity in data-hiding methods. The conventional tradeoff between these two aspects presents a significant hurdle, particularly when aiming to store the maximum amount of data within image media while ensuring image quality remains uncompromised. To address this challenge, a novel interpolation-based reversible data hiding (RDH) approach is conceived, specifically tailored for IoT applications. The key innovation lies in the proposed interpolation technique, which calculates the interpolated pixel by taking the average of the root value for the product of two neighboring original pixel values and the third original pixel value. Additionally, for the central pixel, an average of two interpolated pixels is considered. This meticulous interpolation method is designed to significantly enhance the calculated interpolated pixel by incorporating the majority of original pixels and optimizing its average value.
The contribution of the paper is given as follows:
-
This study introduces an interpolation-based reversible data hiding (RDH) method designed for IoT applications. This approach aims to strike a delicate balance between image quality and embedding capacity.
-
The research contributes an innovative interpolation technique that calculates the interpolated pixel by taking the average of the root value for the product of two neighboring original pixel values and the third original pixel value. For the central pixel, it considers an average of two interpolated pixels. This method significantly enhances the calculated interpolated pixel by incorporating the majority of original pixels.
-
Recognizing the need for security and efficiency, the proposed RDH approach conducts data hiding in two stages. In the first stage, RSA encryption is applied to the secret message, followed by embedding based on intensity range groups.
-
Through extensive experimentation, the study empirically demonstrates the efficacy of the proposed technique. It achieves a substantial 17.58% increase in embedding capacity and produces images with a 7.80% higher peak signal-to-noise ratio (PSNR) compared to baseline methods.
The rest of the paper is organized as follows: the literature review is discussed in Sects. 2 and 3 discusses the proposed method. Section 4 discusses the illustrative example of the proposed technique. The results and discussions are given in Sects. 5 and 6 concludes the paper.
2 Literature review
The literature survey part begins with an explanation of image steganography and the many types it encompasses. In the next paragraphs, this section will talk about interpolation and several interpolation-based strategies that were widely implemented.
2.1 Image steganography
The method of concealing any kind of hidden data, message, or information inside a picture by employing various embedding techniques is known as image steganography. The “cover image” is the picture that serves as a mask for the “hidden message” or “payload” of data. The “embedding method” is essentially the process or algorithm that is used to conceal the "secret message" within the “cover picture,” specifically the “stego-image,” with the “stego-key” being optional. This is what is meant by the term “embedding technique.” The “stego-key,” which is optional, must be distributed equally to both ends. The term “stego-image” refers to the finished output picture that successfully hides secret information. In a similar manner, the opposite of embedding is known as extraction, and “extraction method” refers to the procedure that is used to decipher “secret message” from “stego-image” using an optional “stego-key” [14, 22, 24]
Image steganography can be broadly classified into two domains namely spatial and transform, however, the compressed domain is also one of the domains. The cover image is directly modified where data is concealed in the spatial domain. Before the embedding process can begin, the data that is found in the cover picture will first go through the process of transformation in the transform domain, where it will be converted into a variety of signals. This research is focused on spatial domain work only [26, 27].
2.2 Interpolation and interpolation-based data hiding techniques
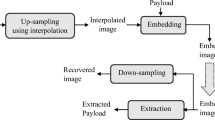
We will begin by defining “interpolation” in Sect. 2.2, and then go on to the various interpolation-based strategies that will be covered in the subsequent parts. The practice of guessing a value that does not exist directly by extrapolating from other values that are previously known is referred to as interpolation. During the process of interpolation, the original picture is enlarged, and then new interpolated pixels are formed by utilizing the pixels from the original image as references to construct the new interpolated pixels. When performing an operation that involves upscaling, a new row and column are added to the pixel matrix table that was generated from the image between rows and columns that are next to one another. Following this step, a particular interpolation approach is utilized in order to derive the cover picture from the cover image. Afterward, the cover picture is ready to be used as shown in Fig. 1.

Image Steganography
Interpolation-based data concealing was initially suggested by Jung and Yoo [5] in the form of a process in which the input picture is first down-scaled, and then the cover image is created by interpolating the original picture, referred as the original image. The neighbor mean interpolation (NMI) is being used by this scheme. The secret data bits have been encoded in each pixel of the cover picture, with the exception of the pixel in the top left corner, which serves as the reference pixel. The cover image has been split up into blocks of size 2 × 2 that are non-intersecting and are ordered zigzag-style as shown in Fig. 2.

Cover picture partitioned into four non-intersecting 2 × 2 blocks
The decision of the amount of bits that are supposed to be included within each pixel is done by comparing the relevant pixel to the reference pixel and finding the difference between the two. After the hidden data bits have been added up, the corresponding pixel will have a higher integer value, which then can be used to conceal the information.
RDH, which is based on parabolic interpolation and was established by Zhang et al. [3], is used for various medical applications. To begin, the original cover picture \(Q = (q(i,j))mn\) was rescaled by a factor of two to create the interpolated image \(P = (p(i,j))2m2n\). Suppose \(i\) and \(j\) as even numbers, then \(p(i,j) = q(i/2,j/2)\) in the interpolated picture P. In any other case, the value of \(p(i,j)\) would be found by solving the parabolic equation \(y = ax2 + bx + c\). Secret information was then inserted by taking advantage of the interpolated pixels, and the pixels where \(p(i,j) = q(i/2,j/2)\) are left unaltered by the procedure.
In the embedding approach developed by P. Tsai et al. [20], a cover picture was cut up into non-overlapping image blocks of 5 by 5 pixels. A basis pixel for the linear prediction process is used which is actually the pixel in the middle of each block. The linear prediction algorithm is then applied to the other pixels in the block, which results in the generation of residual values. The technique known as “histogram shifting” was used to store confidential data by changing the histogram of residual. Additionally, the embedding payload was increased by using several pairings of the zero and peak points via the application of the histogram shifting.
Malik et al. [8] introduced an even–odd embedding technique with a weighted NMI interpolation method on the basis of the recovery strategy. This is a Two-Phase technique, in which the cover photograph is scanned in the first pass to generate a location map 1. The location map 1 keeps track of odd value pixels. The location map 1 is compressed to generate compressed location map 1 and transformed into a base 3 bitstream representation. The odd value pixels are embedded with secret data. In second pass, the same process is repeated, but for even pixel values. The location map 2 is created for even pixels, and then compressed location map 2 is created. These values are converted to base 3 bitstream and these even value pixels are embedded with secret data. At the end of both location maps special bit sequence is marked to enable the extraction. The value 255 in 1st pass and 0 in 2nd pass is ignored to avoid overflow/underflow issues.
According to Lu et al. [21]'s research, one of the embedding techniques that is used most often in the spatial sector is the edge-based approach. Image interpolation using Neighboring Pixels (INP) was the method that was employed for this method's interpolation. The embedding process typically occurs directly on pixels, resulting in visual distortion. Hence, edge-based methods are involved to minimize these distortions. This is a Two-Phase technique, in which construction of location map 1 is done after the cover image is scanned in the first pass. Location map 1 keeps track of odd value pixels. The location map 1 is compressed to generate compressed location map 1 and transformed into a base 3 bitstream representation. The odd value pixels are embedded with secret data. In the second pass, the same process is repeated, but for even pixel values. Location map 2 is created for even pixels and then compressed location map 2 is created. These values are converted to base 3 bitstream and secret data is embedded into these even value pixels. A special bit sequence is marked at the end of both location maps to enable the extraction. The value 255 in 1st pass and 0 in 2nd pass is ignored to avoid overflow/underflow issues. So, Lu’s method typically mixed data hiding algorithms and existing interpolation for enhancing image visual quality and capacity of embedding.
Enhancing the approach introduced by Jung and Yoo led to the development of enhanced neighbor mean interpolation (ENMI), which was suggested by Chang et al. [23]. The values of non-diagonal pixels are determined in this method by taking an average of the values of the pixels that are immediately adjacent to them, while the values of diagonal pixels are determined by taking an average of all the four neighboring pixel values that are right next to them. Following the phase of interpolation, the data embedding process is carried out in two steps. The LSB approach is used in the first step of the process, whereas histogram modification is utilized in the subsequent stage. Stego image S’ is obtained after using LSB substitution and later on final stego image S is obtained after histogram modification.
Another method for hiding data using interpolation was offered by Malik et al. [9], who suggested dividing the cover picture into blocks of size 2 × 2 which are non-overlapping, after that using the Eq. (1) to determine the absolute difference between the two block sizes as \(D(i,1)=|Ci(\mathrm{1,1})- Ci(\mathrm{0,1})|\) and \(D(i,2)=|Ci(\mathrm{1,1})- Ci(\mathrm{0,1})|\). Now, by taking the log value of upper and lower limits of the difference values \(D\), the amount of the bits to be hidden is decided by the count of embedding bits is denoted by \(n(i,1)\) and \(n(i,2)\), whereas the new pixel values are determined by \(m(i,1)\) and \(m(i,2).\) This scheme has less computation cost as it hides more amount of bits in complex regions than in smooth regions and hence increasing both visual quality and hiding capacity.
Malik et al. [13] proposed a novel interpolation technique and also an RDH method which is based on pixel intensity range groups. Here, an 8-bit secret key is chosen and XORed with each byte of the secret message. It categorizes the intensity levels into three groups G1, G2, and G3, and now based on which group the identified interpolated pixel belongs to, it replaces 4, 3, and 2 secret message bits respectively into corresponding LSB bits of the identified interpolated pixel. Hence, both visual quality and payload are maintained, hence improved performance is seen. Table 1 shows the systematic analysis of interpolation-based reversible data hiding scheme.
3 Proposed algorithm
This section provides an illustration the techniques that are used for image interpolation and the embedding method. Firstly, the cover image that is formed after applying the interpolation method to the initial image. Secondly, data hiding method is applied and an image of Stego-image \(S\) is generated as the output from an original picture O of size \(N\times N\) being utilized as an input. The proposed technique whose algorithms will be discussed in Sects. 3.1 and 3.2.
3.1 Image interpolation and data hiding technique
An original image of size \(N\times N\) is upscaled by adding empty rows and columns between two adjacent rows and columns. Now, by using an interpolation technique these empty row and column values are calculated based on known original pixel values. Our proposed interpolation technique takes the average of the root value for the product of two nearby/neighboring original pixel values and the third original pixel value. And for the central pixel, it takes an average of two interpolated pixels. By doing so, most of the original pixels are taken into account and the calculated interpolated pixel is much enhanced as its average value. After calculating all the unknown values by using formula, we obtain a cover image. The next step is to perform data hiding.
Data hiding is performed in two stages. In the first stage, RSA is performed on the secret message as follows:
Input: Original message in blocks \({M}_{1}, {M}_{2}, \dots {M}_{n}\) Output: Encrypted data in blocks \({CT}_{1}, {CT}_{2}, \dots {CT}_{n}\) | |
|---|---|
1 | Initialize two random prime numbers \({Pr}_{1}\) and \({Pr}_{2}\) |
2 | Calculate \(T = {Pr}_{1} * {Pr}_{2}\) // This is the first part of the public key |
3 | Calculate \(\upphi (T) = ({Pr}_{1}-1) * ({Pr}_{2}-1)\) |
4 | Choose a random integer \({R}_{e}\) //This is the second part of the public key ∴ \(1 < {R}_{e} < \phi \left(T\right)\) And greatest common divisor of (\({R}_{e}\), \(\phi \left(T\right)\)) should be \(1\) |
5 | Calculate \({R}_{d}\) ∴ \({R}_{d} \equiv {{R}_{e}}^{-1} mod \phi (T)\) // which is the private key |
6 | Calculate \({CT}_{i}= \left({{M}_{i}}^{{R}_{e}}\right)mod T\) ∴ \(i=1 \mathrm{To }n\)// Encryption function |
7 | Repeat step 6 for all blocks \({M}_{1}, {M}_{2}, \dots {M}_{n}\) |
8 | Store and combine the encrypted data \({CT}_{1}, {CT}_{2}, \dots {CT}_{n}\) |
9 | End |
And then in the next stage, the cipher text is embedded inside the cover image which is obtained after the interpolation step based on which intensity range group, the identified pixel belongs to, respective LSB bits are embedded inside it and hence, finally resulting in a stego-image.
The pixel intensity ranges, along with the number of bits hidden in the least significant bits (LSBs) of the defined pixel, are outlined as follows: In G1, the pixel range [0,15] is considered, and secret data is embedded into the 4 LSBs of the specified pixel. Similarly, in G2, the pixel range [14, 28] is considered, and secret data is embedded into the 3 LSBs of the specified pixel. In G1, the pixel range [32,191] is considered, and secret data is embedded into the 2 LSBs of the specified pixel. In G1, the pixel range [192,255] is considered, and secret data is embedded into the 1 LSBs of the specified pixel.
3.2 Data extraction
Data extraction helps to retrieve both the secret message as well as the cover image. It firsts identifies all the interpolated pixels and then based on which group it lies, corresponding LSB bits are taken out and added to the cipher text stream. Now, again RSA is performed in order to decipher the cipher text and hence resulting in obtaining the secret message. At the receiving end the user can convert the encrypted data using the following decryption function \({M}_{i}= \left({{CT}_{i}}^{{R}_{d}}\right)mod T\). Finally, after discarding all the interpolated pixels, the original picture is retrieved.
4 Illustrative example of proposed technique
In this section, the embedding process for the image interpolation and data hiding is discussed in Sect. 4.1 and the data extraction process is discussed in Sect. 4.2.
4.1 Embedding process for the image interpolation and data hiding
Consider a \(2 \times 2\) block of an original image. For interpolation, we add a row and a column between adjacent rows and columns. Our interpolation technique is then applied to calculate new pixel values. Let’s say we need to calculate \(C(\mathrm{0,1})\) value. Firstly, the root value of product of 2 and 4 is obtained and then the average of this value with 6 is done. By repeating the same process, we obtain cover image C. Now, the RSA algorithm is applied for encryption on the secret message so that the security of the message is increased and then let say the cipher stream obtained is 00110101010001110110 as shown in Fig. 3.

An example of image interpolation and data hiding on a block of an image
The values (4, 4, 4, 5, 6) are interpolated pixels into which secret bits will be concealed. Consider first identified interpolated pixel,4, convert it into its binary form i.e.,00000100 and according to our intensity ranges 4 falls under G1 category, that means four bits of secret message i.e.,0011 will be concealed by simple LSB substitution and hence new interpolated pixel will be 3. The next identified pixel is 4(00000100) which again falls G1 group and hence replacing four of its LSB bits with next four bits of secret message (0101) which results in new pixel, 5(00000101). Similar embedding process is followed for the rest of the interpolated pixels 4, 5, 6 and at the end we get stego-image S.
4.2 Data extraction
Now we have a \(3\times 3\) stego-image sub-block. For data extraction, firstly, the interpolated pixels 3, 5, 4, 7, 6 are identified from the stego-image S. The first interpolated pixel that is known to be in G1 is number 3. Thus, in accordance with our algorithm's rule, four LSB are removed and then added to the data stream, because the binary representation of 3 is 00000011. The next interpolated pixel is 5(00000101), which is likewise under G1. Four LSB 0101 are thus extracted and appended to the data stream. The whole procedure is done in a similar manner for each interpolated pixel. Finally, the data stream is obtained as (00110101010001110110). Now, decryption is done by applying RSA decryption algorithm to this obtained data stream. Hence, we can obtain a secret message. The secret message was obtained along with the original image after eradicating all the interpolated pixels.
5 Results and discussions
This section discusses the results of the proposed interpolation-based reversible data hiding scheme and existing methods. Five images namely airplane, peppers, boat, Elaine, and baboon are considered which are of \(256\times 256\) pixels size for analysis of the proposed and existing work as shown in Fig. 4. Later a detailed analysis is also given by considering 40 images. We have implemented the proposed method using Python running on the system having 12th Gen Intel(R) Core (TM) i7-1255 U 1.7 GHz with 16 GB of RAM and × 64- based processor. For performance analysis, two important metrics which include visual image quality using PSNR and embedding capacity in bits have been used. Figure 4 shows the stego images after hiding the data using the proposed technique.

Cover and Stego test images
Bits-per-pixel is a measurement used to represent the total number of embedded bits (bpp). This amount will be anything from 0 to 8 bits per pixel for a picture in which each pixel is stored with 256 different shades of grey. In addition, we differentiate between embedding capacity and payload in our evaluations. To be more specific, the embedding capacity is defined as the total amount of bits that may be included into a picture by using the RDHEI approach. The term “payload” refers to the entire amount of bits that make up the message that may be encapsulated inside an image. In image steganography, having higher embedding capacity is always better. Peak Signal to Noise Ratio (PSNR) is used to measure the quality of the image in decibels (dB). In image steganography, higher the PSNR value, higher the image visual quality.
The mean squared error (MSE) is a measure of the average squared difference between corresponding elements of two images, typically the original image and a reconstructed image called stego-image. The formula for MSE is as follows:
where \(n\) is the total number of pixels in the image, \({X}_{i}\) is the ith element of the original image, \({Y}_{i}\) is the i-th element of the reconstructed image.
The outcome of the proposed scheme is compared with schemes proposed by authors namely Jung et al. [5], Lu et al. [21], Chang et al. [23], Malik et al. [8, 9, 12], and their image quality is shown in Fig. 4. Table 2 shows the PSNR values for all the test images used along with PSNR values of the existing schemes Jung et al. method [5], Zhang et al. method [3], Shaik et al. method [25], and Malik et al. method [13]. It can be clearly observed from Table 2 that the PSNR value has increased when compared to other existing schemes. Thus, it can be clearly stated that our interpolation technique is superior than the existing aforementioned interpolation methods. Additionally, this scheme is characterized as a reversible data hiding method, as it solely alters the interpolated pixels for concealing the secret data, which can subsequently be recovered at the recipient’s end through the designated interpolation method.
It is also evident from Fig. 5 that the PSNR value of the proposed method has increased when compared to other existing schemes Jung et al. method [5], Zhang et al. method [3], Shaik et al. method [25], and Malik et al. method [13]. Figure 6 shows the embedding capacity for the test images used where proposed scheme results are compared with existing schemes Jung et al. method [5], Zhang et al. method [3], Shaik et al. method [25], and Malik et al. method [13]. The results obtained are much higher.

PSNR values graph for the test images


Embedding capacity comparison graphs for existing schemes and proposed scheme
Over this, it is evident from the graphs that the embedding capacity has been greatly improved by at least 40 percent for the majority of the test case images. As a result, the performance of our proposed method for interpolation and embedding is superior to that of existing methods Jung et al. method [5], Zhang et al. method [3], Shaik et al. method [25], and Malik et al. method [13]. These presented results also confirm the superiority of the proposed method in comparison to the existing ones. The primary factor contributing to the excellent performance of the suggested approach lies in its simplicity. Unlike other techniques that involve intricate calculations, our method achieves its effectiveness by straightforwardly replacing the least significant bits (LSBs) of the pixels with the corresponding secret data bits.
To comprehensively validate the efficacy of the proposed method, an extensive study was conducted, involving the analysis of forty images as shown in Fig. 7. Corresponding outcomes for embedding capacity and PSNR with various images are detailed in Table 3. The analysis indicates that the highest achieved embedding capacity was 7,439,827 bits, with the lowest at 5,546,887 bits. In terms of PSNR, the recorded range was from 36.91 dB (highest) to 33.06 dB (lowest). On average, the embedding capacity settled at 5,628,377 bits, with an average PSNR of 34.66 dB. These findings provide robust evidence supporting the promising performance of our proposed method.

Forty cover images
6 Conclusion
In this work, an interpolation-based reversible data hiding scheme is designed and its performance is analyzed. In this first phase, an interpolation method is proposed and then a data hiding method using RSA is proposed. The proposed method is performing better as compared to the existing methods in terms of embedding capacity as well as PSNR. In the proposed technique, it is observed that there is at least a 4.9% increase in PSNR values and at least a 22% increase in embedding capacity. The proposed technique has close PSNR and embedding capacity values, which shows that we were successful in creating a balance between visual quality and data-hiding capacity. Therefore, it was observed that the proposed methodology provides better PSNR results and embedding capacity values. Future studies may benefit from considering these suggestions which include integrating steganography with encryption to reduce the likelihood of steganographic methods being broken through steganalysis, adopting hybrid steganographic approaches, and using less noise-distorting methods. High visual quality, a huge embedding capacity, and robust resistance to any attacks are necessary for optimum image steganography.
Data availability
All the information will be available on request to Riya Punia (puniariya850@gmail.com).
References
Lee C-F, Huang Y-L. Reversible data hiding scheme based on dual stegano-images using orientation combinations. Telecommun Syst. 2013;52(4):2237–47.
Hassan FS, Gutub A. Novel embedding secrecy within images utilizing an improved interpolation-based reversible data hiding scheme. J King Saud Univ-Comput Inform Sci. 2020;34:2017–30.
Zhang X, Sun Z, Tang Z, Chunqiang Yu, Wang X. High capacity data hiding based on interpolated image. Multimed Tools Appl. 2017;76(7):9195–218.
Wang J, Mao N, Chen X, Ni J, Wang C, Shi Y. Multiple histograms based reversible data hiding by using FCM clustering. Signal Process. 2019;159:193–203.
Jung K-H, Yoo K-Y. Data hiding method using image interpolation. Comput Stand Interfac. 2009;31(2):465–70.
Liu Y-C, Hsien-Chu Wu, Shyr-Shen Yu. Adaptive DE-based reversible steganographic technique using bilinear interpolation and simplified location map. Multimed Tools Appl. 2011;52(2):263–76.
Murthy VMMK, Rama S, Manikandan VM. Reversible data hiding using block-wise histogram shifting and run-length encoding. Int J Adv Computer Sci Appl. 2021;12(5):74.
Malik A, Sikka G, Verma HK. An image interpolation based reversible data hiding scheme using pixel value adjusting feature. Multimed Tools Appl. 2017;76(11):13025–46.
Malik A, Sikka G, Verma HK. Image interpolation based high capacity reversible data hiding scheme. Multimed Tools Appl. 2017;76(22):24107–23.
Gutub A, Al-Shaarani F. Efficient implementation of multi-image secret hiding based on LSB and DWT steganography comparisons. Arab J Sci Eng. 2020;45(4):2631–44.
Kumar R, Jung K-H. Robust reversible data hiding scheme based on two-layer embedding strategy. Inf Sci. 2020;512:96–107.
Malik A, Sikka G, Verma HK. A reversible data hiding scheme for interpolated images based on pixel intensity range. Multimed Tools Appl. 2020;79(25):18005–31.
Wu D-C, Tsai W-H. A steganographic method for images by pixel-value differencing. Pattern Recogn Lett. 2003;24(9–10):1613–26.
Hu J, Li T. Reversible steganography using extended image interpolation technique. Comput Electr Eng. 2015;46:447–55.
Yang C-H, Wang S-J, Weng C-Y. Capacity-raising steganography using multi-pixel differencing and pixel-value shifting operations. Fund Inform. 2010;98(2–3):321–36.
Shen S, Huang L, Tian Q. A novel data hiding for color images based on pixel value difference and modulus function. Multimed Tools Appl. 2015;74(3):707–28.
Swain G. Adaptive pixel value differencing steganography using both vertical and horizontal edges. Multimed Tools Appl. 2016;75(21):13541–56.
Khodaei M, Bigham BS, Faez K. Adaptive data hiding, using pixel-value-differencing and LSB substitution. Cybern Syst. 2016;47(8):617–28.
Tsai P, Yu-Chen Hu, Yeh H-L. Reversible image hiding scheme using predictive coding and histogram shifting. Signal Process. 2009;89(6):1129–43.
Lu T-C, Chang C-C, Huang Y-H. High capacity reversible hiding scheme based on interpolation, difference expansion, and histogram shifting. Multimed Tools Appl. 2014;72(1):417–35.
Rukundo O, Cao H. Nearest neighbor value interpolation. arxiv preprint arXiv:12111768. 2012. https://doi.org/10.14569/IJACSA.2012.030405.
Chang Y-T, Huang C-T, Lee C-F, Wang S-J. Image interpolating based data hiding in conjunction with pixel-shifting of histogram. J Supercomput. 2013;66(2):1093–110.
Chan C-K, Cheng L-M. Hiding data in images by simple LSB substitution. Pattern Recogn. 2004;37(3):469–74.
Hussain M, Wahab AWA, Idris YIB, Ho ATS, Jung K-H. Image steganography in spatial domain: a survey. Signal Process Image Commun. 2018;65:46–66.
Al-Dmour H, Al-Ani A. A steganography embedding method based on edge identification and XOR coding. Expert Syst Appl. 2016;46:293–306.
Cox I, Miller M, Bloom J, Fridrich J, Kalker T. Digital watermarking and steganography. Cambridge: Morgan kaufmann; 2007.
Singh S. Adaptive PVD and LSB based high capacity data hiding scheme. Multimed Tools Appl. 2020;79(25):18815–37.
Mandal PC, Mukherjee I, Chatterji BN. High capacity reversible and secured data hiding in images using interpolation and difference expansion technique. Multimed Tools Appl. 2021;80:3623–44.
Benseddik ML, Zebbiche K, Azzaz MS, et al. Interpolation-based reversible data hiding in the transform domain for fingerprint images. Multimed Tools Appl. 2022;81:20329–56.
Mohammad AA. A high quality interpolation-based reversible data hiding technique using dual images. Multimed Tools Appl. 2023. https://doi.org/10.1007/s11042-023-15092-8.
Shastri S, Thanikaiselvan V. Interpolation based dual image reversible data hiding using trinary encoding. Multimed Tools Appl. 2023. https://doi.org/10.1007/s11042-023-15574-9.
Roselinkiruba R. Reversible data hiding using optimization, interpolation and binary image encryption techniques. Multimed Tools Appl. 2023;82:35757–80.
Author information
Authors and Affiliations
Contributions
RP: methodology, software, investigation, writing original draft. AM: conceptualization, methodology, writing—review & editing, Validation. SS: Methodology, writing—review & editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Punia, R., Malik, A. & Singh, S. An interpolation-based reversible data hiding scheme for internet of things applications. Discov Internet Things 3, 18 (2023). https://doi.org/10.1007/s43926-023-00048-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s43926-023-00048-z