
Abstract
A fuzzy regression function approach is a fuzzy inference system method whose rules cannot be determined based on expert opinion, unlike a classical fuzzy inference system. In a fuzzy regression function approach, an input matrix consists of memberships obtained by the fuzzy clustering method and lagged variables of the time series. In the fuzzy regression function approach, the output vector corresponding to this input matrix is also created and the parameter estimation for the method is carried out with the ordinary least square method. As it is known, the ordinary least square method assumes that the data are linear. In addition, although it is very useful to include a priori information describing the formation of the data in the model, in most cases this information is not available. It is also inappropriate to use a model that does not accurately characterize the data. However, it is not appropriate to estimate parameters for nonlinear data using the ordinary least square method. One of the methods to be used in such a situation is the Gaussian process regression method. While the parameters of a selected basis function are fitted in the ordinary least squares regression method, how all measured data are related is determined in the Gaussian process regression. Besides, Gaussian process regression is a Bayesian approach, it can provide uncertainty measurements on forecasts. In this study, a fuzzy Gaussian process regression function is proposed. The contribution of this paper is to propose a new fuzzy inference system that can be used to solve nonlinear data by proposing a fuzzy Gaussian process regression function. The performance of the newly proposed method is evaluated based on the closing values of the Bitcoin and Crude oil time series. The performance comparison of the proposed method is evaluated with many different forecasting methods and it is concluded that the proposed method has superior forecasting performance.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Fuzzy inference systems methods (FISs) are a framework for computation based on the fundamental concepts of fuzzy set theory proposed by Zadeh (1965), fuzzy rules, and fuzzy reasoning. Fuzzy sets were originally suggested by Zadeh (1965). Fuzzy sets have been used and are beneficial in several important papers in the literature such as Chen (1996), Chen and Chen (2002), Lin et al. (2006), Chen and Hsu (2008) and Chen and Lee (2010), Boltürk (2022), Nguyen-Huynh and Vo-Van (2023), Qian et al. (2023), Sobhi and Dick (2023), Nishad and Aggarwal (2023) and Minaev et al. (2023). FISs methods use fuzzy set theory to match the inputs to the outputs. FISs are composed of three elements: fuzzification, knowledge base (rule base or database), and defuzzification. In the fuzzification stage, a real-valued input is mapped to a fuzzy set through membership functions. At this stage, the input can also be a fuzzy set. The rule base phase is a database of language rules in if–then format. Using these If–Then rules, a judgment is performed by producing a fuzzy output according to the fuzzy input from the fuzzification phase. In the defuzzification phase, this fuzzy output is transformed to produce a crisp (real-valued) output. Among these factors, the fact that the knowledge base is based on expert knowledge and the number of inputs in the system increases makes the determination of rules very difficult and complex.
The fuzzy regression functions approach suggested by Türkşen (2008) utilizes fuzzy functions instead of complex relationships in the rule base. In the FRF method, the inputs and outputs of the system are first clustered with the fuzzy clustering method proposed by Bezdek et al. (1984), and membership values are obtained. These membership values are combined with the system inputs to form an independent variable matrix and an target vector corresponding to these inputs. Then, using ordinary least squares (OLS) based multiple regression analysis, the number of fuzzy functions is obtained as the number of fuzzy sets. There are several studies in the literature on FRF methods.
Beyhan and Alci (2010) developed the concept of fuzzy regression functions with exogenous input autoregressive modeling. Aladag et al. (2014) used fuzzy regression functions for forecasting of Australian beer consumption time series. Gasir and Crockett (2016) proposed a fuzzy regression tree to forecast complex datasets. Başkir (2016) used a fuzzy regression function with least square estimates for modeling Dupont analysis on the Turkish insurance sector. Aladag et al. (2016) proposed a fuzzy time series forecasting method based on a fuzzy regression function approach. Baser and Demirhan (2017) forecasted the horizontal global solar radiation by using a hybrid method based on fuzzy regression functions with a support vector machine. Tak (2018) proposed a meta-fuzzy regression functions approach that aggregates methods for the same purpose into functions. Tak et al. (2018) combined the autoregressive moving average model ARMA with the fuzzy regression functions approach. Bas et al. (2019) suggested a novel fuzzy regression function approach using ridge regression as a replacement for multiple linear regression.
Chakravarty et al. (2020) proposed a robust fuzzy regression functions approach against the outliers. Tak (2020) suggested a forecasting method based on fuzzy regression functions using a possibilistic fuzzy clustering method alternative to the fuzzy clustering method using maximum likelihood estimates for the parameters. Tak (2021a) proposed a forecast combination with meta-possibilistic fuzzy functions. Pehlivan and Turksen (2021) used a multiplicative fuzzy clustering algorithm instead of the fuzzy clustering method and proposed a multiplicative fuzzy regression function method. Tak (2021b) proposed meta-fuzzy functions based on feed-forward neural networks with a single hidden layer for forecasting. Bas (2022) proposed an approach to robust fuzzy regression functions that can be used even in the presence of outliers in the data set. Bas and Egrioglu (2022) replaced the fuzzy clustering algorithm with the Gustafson-Kessel clustering algorithm in their FRF approach. Chakravarty et al. (2022a) proposed a fuzzy regression functions approach by the use of a noise cluster within fuzzy clustering algorithms. Chakravarty et al. (2022b) proposed a modified fuzzy regression functions framework using a noise cluster for robust wind forecasting. Tak and İnan (2022) proposed a fuzzy regression method to employ an elastic net in fuzzy functions to overcome the multicollinearity problem. Cevik et al. (2023) proposed a forecast combination approach with meta-fuzzy functions for forecasting the number of immigrants within the maritime line security project in Turkey. In addition to these studies, there are numerous studies in the literature where both fuzzy methods and artificial neural network methods are used in the forecasting problem.
Chen and Phuong (2017) proposed a new fuzzy time series forecasting method based on optimal partitions of intervals in the universe of discourse and optimal weighting vectors of two-factor second-order fuzzy-trend logical relationship groups. Cheng et al. (2016) proposed a new fuzzy time series forecasting method for forecasting the Taiwan stock exchange capitalization-weighted stock index. Chen and Jian (2017) proposed a new fuzzy forecasting method based on two-factors second-order fuzzy-trend logical relationship groups, particle swarm optimization techniques, and similarity measures between the subscripts of fuzzy sets. Singh et al. (2018) proposed a firefly algorithm-based neural network for nonlinear discrete-time systems. Zeng et al. (2019) proposed a new clustering-based fuzzy time series forecasting method based on linear combinations of independent variables, the subtractive clustering algorithm, and the artificial bee colony algorithm. Chen et al. (2019) proposed a fuzzy time series forecasting model based on proportions of intervals and particle swarm optimization techniques. Gupta and Kumar (2019) proposed a novel high-order probabilistic fuzzy set-based forecasting method in the environment of both non-probabilistic and probabilistic uncertainties.
Chen et al. (2020) used fuzzy information granulation and deep neural networks combined to solve traffic-flow forecasting. Fan et al. (2021) suggested a deep-learning approach for financial market prediction. Pant and Kumar (2022a) proposed a fuzzy time series forecasting method based on hesitant fuzzy sets, particle swarm optimization, and support vector machines. Pant and Kumar (2022b) proposed a novel method for fuzzy time series forecasting based on particle swarm optimization and intuitionistic fuzzy set. Goyal and Bisht (2023) proposed an adaptive hybrid fuzzy time series forecasting technique based on particle swarm optimization. Samal and Dash (2023) developed a novel stock index trend predictor model by integrating multiple criteria decision-making with an optimized online sequential extreme learning machine. Song et al. (2024) proposed a hybrid time series forecasting model by developing linear and nonlinear series separately. Pant and Kumar (2024) proposed a hesitant fuzzy sets-based computational method for weighted fuzzy time series.
In this study, for the first time in the literature, the Gaussian Process Regression (GPR) method is used instead of OLS regression in the FRF method. The motivation for this paper is that the FRF method is based on OLS regression and OLS regression is not a suitable method for parameter estimation for nonlinear data. Based on this motivation, this study proposes a fuzzy inference system that can be used for nonlinear data. The contribution of this paper is to adapt the GPR method, which can provide uncertainty measures on forecasts and can work with both small data and nonlinear data, to the FRF method using the OLS method. Another contribution of the study is to propose a new FRF method based on the GPR method instead of the OLS regression-based FRF method, which is not suitable for parameter estimation using the ordinary least squares method for nonlinear data. The performance of the proposed fuzzy regression functions approach based on Gaussian process regression (FRF-GPR) is examined by analyzing randomly selected Bitcoin and crude oil time series.
The other sections of the paper are as follows. Section 2 briefly introduces the GPR method. Section 3 presents the step-by-step algorithm of the proposed FRF-GPR method. Section 4 reports the analysis results obtained by comparing the proposed method with alternative methods. Section 5 summarizes the discussion and conclusions of the study.
2 Gaussian process regression
GPR is a strong and versatile nonparametric regression technique. It is especially helpful where the association between input variables and output is not known explicitly or may be ambiguous. GPR is a Bayesian approximation that can model the uncertainty in forecasts.
Let a linear regression model be as given in Eq. (1).
where \(\varepsilon \sim N\left(0,{\sigma }^{2}\right).\)
A GPR model describes the response by introducing latent variables, \(f({x}_{i})\), \(i=\mathrm{1,2},...,n\) and overt basis functions, \(h\), from a Gaussian process (GP). A GP is a collection of random variables with any finite number of common Gaussian distributions.
Let's consider the model given in Eq. (2).
where \(f\left(x\right) \sim GP\left(0,k\left(x,{x}{\prime}\right)\right).\) So, \(f\left(x\right)\) has a zero mean with covariance function, \(k\left(x,{x}^{\mathrm{^{\prime}}}\right)\). The covariance function \(k\left(x,{x}^{\mathrm{^{\prime}}}\right)\) is typically characterized by a sequence of kernel parameters or hyperparameters. Different kernel functions can be used in GPR. In this study, the following squared exponential kernel function given by Eq. (3) is used.
The response \(y\) can be modeled as in Eq. (4).
where \(X=\left(\begin{array}{c}{x}_{1}^{T}\\ {x}_{2}^{T}\\ \vdots \\ {x}_{n}^{T}\end{array}\right) , y=\left(\begin{array}{c}{y}_{1}\\ {y}_{2}\\ \vdots \\ {y}_{n}\end{array}\right) , H=\left(\begin{array}{c}1, h\left({x}_{1}^{T}\right)\\ 1,h\left({x}_{2}^{T}\right)\\ \vdots \\ 1,h\left({x}_{n}^{T}\right)\end{array}\right)\) and \(f=\left(\begin{array}{c}f\left({x}_{1}\right)\\ f\left({x}_{2}\right)\\ \vdots \\ f\left({x}_{n}\right)\end{array}\right).h(x)\) is a sequence of elementary functions that transform the original feature vector x into a new feature vector\(h(x)\). To make the GPR model nonparametric, \(f\left({x}_{i}\right)\) is a latent variable for each observation\(x\). Parameter estimation in GPR is based on Eqs. (5) and (6).
The predictions or forecasts of the model can be obtained by using Eq. (7).
The alphas in this equation are calculated by Eq. (8).
3 The proposed method
In this study, a fuzzy inference system method based on Gaussian process regression is proposed for the first time in the literature. In this new fuzzy inference system, the GPR method is used instead of OLS regression which was used for parameter estimation in the classical FRF method.
Thus, a fuzzy inference system that can be used for nonlinear data sets is proposed by using the GPR method, that does not require the linearity assumption that is valid in the OLS method. This new proposed fuzzy inference system method, FRF-GPR method, is presented step by step with the following algorithm.
Algorithm:
FRF-GPR.
Step 1. Setting the parameters of the FRF-GPR algorithm.
In this first step, the algorithm parameters are first determined.
\(c:\) The number of fuzzy clusters.
\(p:\) The number of lagged variables.
Step 2. The data set is separated into training and test set.
In this step, the test set length \((ntest)\) is first determined and the time series is divided into training \((ntrain)\) and test sets according to the determined test set length. Once this distinction is made, the proposed method starts to be applied to the training set.
Step 3. Creating the inputs and target of the FRF-GPR method.
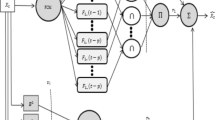
The training set is first lagged by the number of lagged variables. Then, the target vector corresponding to this lagged time series are created. These lagged variables of the training set and the target vector corresponding to these lagged variables are put together in a matrix and clustered with FCM. Thus, membership values \(({\mu }_{ik},i=\mathrm{1,2},\cdots ,c;k=\mathrm{1,2},\cdots ,ntrain)\) are obtained. Where \(ntrain\) is the length of the training set.
For each fuzzy set, an input matrix is created with these membership values and some non-linear transformations of these membership values and the lagged variables of the training set. This input matrix and the target vector corresponding to this input matrix are given by Eqs. (9)–(13) respectively.
The input matrix given by Eq. (9) is a combination of the unit matrix given by Eq. (10), the membership matrix consisting of membership values and various non-linear transformations of membership values given by Eq. (11), and the matrix of lagged variables of the time series given by Eq. (12).
Step 4. The fuzzy Gaussian regression functions for each fuzzy set are estimated by Gaussian process regression using Eqs. (9)–(13).
Step 5. The final outputs of the training set are derived by assigning weights to the membership values corresponding to the outputs obtained by Gaussian process regression as given in Eq. (9).
Step 6. The input matrix and the target vector for the test set are reconfigured by Eqs. (14)–(18) respectively. The final outputs of the test set are derived by assigning weights to the membership values corresponding to the outputs.
The input matrix given by Eq. (14) is a combination of the unit matrix given by Eq. (15), the membership matrix consisting of membership values and various non-linear transformations of membership values given by Eq. (16), and the matrix of lagged variables of the time series given by Eq. (17) for the test set.
4 Applications
The performance of the proposed FRF-GPR method is evaluated on Bitcoin and daily observed 1-year Crude Oil time series. In the analysis of these time series, different time series are created from each Bitcoin and Crude Oil time series. The information about these time series is given in Table 1.
These time series are downloaded from the Yahoo Finance website (https://finance.yahoo.com/).
In the assessment of the analysis performance of the proposed FRF-GPR method, the FRF proposed by Türkşen (2008), the multilayer perceptron artificial neural network (MLP-ANN) proposed by Rumelhart et al. (1986), the multiplicative neuron model artificial neural network (SMNM-ANN) proposed by Yadav et al. (2007), Pi-sigma artificial neural network (PS-ANN) proposed by Shin and Ghosh (1991), long short term memory artificial neural network (LSTM-ANN) proposed by Hochreiter and Schmidhuber (1997) and fuzzy time series network (FTS-N) proposed by Bas et al. (2015) are utilized.
To determine the optimal number of inputs and the number of hidden layers \((m)\) for the MLP-ANN method, each parameter is increased one by one between one and five for different combinations. To determine the optimal number of inputs for the SMNM-ANN method, the number of inputs is increased by one between one and five. To determine the optimal number of inputs and the degree for the PS-ANN method, each parameter is increased one by one between one and five for different combinations. To determine the optimal number of inputs and the number of fuzzy clusters \((c)\) for the FRF-GPR, FRF, and FTS-N methods, the number of inputs is tried between one and ten, and the number of fuzzy clusters is tried between three and ten. To determine the optimal number of inputs, hidden layer unit \((h),\) and the number of hidden layers for the LSTM-ANN method \((m)\), each parameter is increased one by one between one and five for different combinations. The test set length is taken as 14 for each analyzed series.
The analysis results obtained from all methods are evaluated on the test set of each time series using the root mean square error criterion given by Eq. (19).
Here \({ntest,x}_{t}\) and \({\widehat{x}}_{t}\) shows the number of test samples, the observed values, and the forecasts, respectively. Considering that each method will be affected by the initial solutions, thirty different solutions are realized using the optimal parameter values for each method. Each method is run 30 times with its optimal parameters and thus 30 different RMSE values are obtained for each method. Finally, the mean, median, standard deviation, interquartile range, and minimum and maximum statistics of these RMSE values are calculated.
The analysis results obtained for Series 1–5, which are different sub-time series derived from the Bitcoin time series, are given in Tables 2, 3, 4, 5, 6.
The analysis results obtained for Series 1 indicate that the proposed FRF-GPR method is the most effective analysis method in terms of mean, standard deviation, median, interquartile range and maximum statistics compared to other methods.
In the analysis results obtained for Series 2, it is seen that the proposed FRF-GPR method is the best method for the standard deviation statistic and the third-best method for the mean statistic.
Based on the analysis results obtained for Series 3, the proposed FRF-GPR method is again the best analysis method in terms of mean, standard deviation, median and maximum statistics.
The proposed FRF-GPR method is the most efficient analysis technique for the mean, standard deviation, median, interquartile range and maximum statistics as a result of the analysis results obtained for Series 4.
The analysis results obtained for Series 5 show that the proposed FRF-GPR method is better than the other analysis methods in terms of mean, standard deviation and maximum statistics. The results of the analysis obtained for different sub-series derived from the crude oil time series, Series 6–Series 10, are given in Tables 78, 9, 10, 11.
The results of the analysis of Series 6 reveal that the proposed FRF-GPR method stands out in the mean, median, standard deviation and maximum statistics.
In line with the analysis results of Series 7 given in Table 8, it can be said that the proposed FRF-GPR method is the second most successful method among all analysis methods in general when all statistics are considered.
In the analysis results of Series 8 given in Table 9, it is seen that the proposed FRF-GPR method ranks first again in the mean, median, and maximum statistics.
The analysis results for Series 9 in Table 10 show that the proposed FRF-GPR method is first in the maximum statistic and generally second in the other statistics. The results of the analysis given in Table 11 for Series 10 confirm that the proposed FRF-GPR method ranks first in all statistics.
The optimal parameters obtained from each method for the analyzed series are given in Tables 12 and 13. In addition, these optimal parameter values are obtained from the validation sets. Also, (–) indicates that the method does not have a corresponding value for a cell of the Tables 12 and 13.
5 Conclusions
In this study, for the first time in the literature, the GPR method is used for the parameter estimation phase of the FRF method instead of OLS regression. In this way, it is investigated whether GPR regression, which can also work with nonlinear data, is an advantage over the FRF method using OLS regression. The contribution of this paper to the literature is to propose a new approach of fuzzy regression functions using the GRP method instead of the OLS method, which is not suitable for parameter estimation of nonlinear data.
When the analysis results obtained from all methods are evaluated together, it can be said that the proposed FRF-GPR method obtains better forecasting results than the OLS-based FRF method. In addition, the proposed FRF-GPR method produced better forecasting results than many well-known shallow and deep artificial neural network methods in the literature. In future studies, the GPR method can also be used for parameter estimation of intuitionistic and picture fuzzy regression function methods.
Data availability
Data will be made available on request.
References
Abhishekh GSS, Singh SR (2018) A new method of time series forecasting using intuitionistic fuzzy set based on average-length. J Ind Prod Eng 37(4):175–185
Aladag CH, Turksen IB, Dalar AZ, Egrioglu E, Yolcu U (2014) Application of type-1 fuzzy functions approach for time series forecasting. Turkish Journal of Fuzzy Systems 5(1):1–9
Aladag CH, Yolcu U, Egrioglu E, Turksen IB (2016) Type-1 fuzzy time series function method based on binary particle swarm optimisation. International Journal of Data Analysis Techniques and Strategies 8(1):2–13
Bas E (2022) Robust fuzzy regression functions approaches. Inf Sci 613:419–434
Bas E, Egrioglu E (2022) A fuzzy regression functions approach based on Gustafson-Kessel clustering algorithm. Inf Sci 592:206–214
Bas E, Egrioglu E, Aladag CH, Yolcu U (2015) Fuzzy-time-series network used to forecast linear and nonlinear time series. Appl Intell 43:343–355
Bas E, Egrioglu E, Yolcu U, Grosan C (2019) Type 1 fuzzy function approach based on ridge regression for forecasting. Granular Computing 4:629–637
Baser F, Demirhan H (2017) A fuzzy regression with support vector machine approach to the estimation of horizontal global solar radiation. Energy 123:229–240
Başkir MB (2016) Type-1 fuzzy modeling for DuPont analysis on Turkish insurance sector. Turkish Journal of Fuzzy Systems (TJFS) 7(1):29–40
Beyhan S, Alci M (2010) Fuzzy functions based ARX model and new fuzzy basis function models for nonlinear system identification. Appl Soft Comput 10(2):439–444
Bezdek JC, Ehrlich R, Full W (1984) FCM: The fuzzy c-means clustering algorithm. Comput Geosci 10(2–3):191–203
Boltürk E (2022) Fuzzy sets theory and applications in engineering economy. Journal of Intelligent & Fuzzy Systems 42(1):37–46
Cevik FC, Gever B, Tak N, Khaniyev T (2023) Forecast combination approach with meta-fuzzy functions for forecasting the number of immigrants within the maritime line security project in Turkey. Soft Comput 27(5):2509–2535
Chakravarty S, Demirhan H, Baser F (2020) Fuzzy regression functions with a noise cluster and the impact of outliers on mainstream machine learning methods in the regression setting. Appl Soft Comput 96:106535
Chakravarty S, Demirhan H, Baser F (2022a) Modified fuzzy regression functions with a noise cluster against outlier contamination. Expert Syst Appl 205:117717
Chakravarty S, Demirhan H, Baser F (2022b) Robust wind speed estimation with modified fuzzy regression functions with a noise cluster. Energy Convers Manag 266:115815
Chen SM, Chen YC (2002) Automatically constructing membership functions and generating fuzzy rules using genetic algorithms. Cybern Syst 33(8):841–862
Chen SM, Hsu CC (2008) A new approach for handling forecasting problems using high-order fuzzy time series. Intelligent Automation & Soft Computing 14(1):29–43
Chen SM, Jian WS (2017) Fuzzy forecasting based on two-factors second-order fuzzy-trend logical relationship groups, similarity measures and PSO techniques. Inf Sci 391:65–79
Chen SM, Lee LW (2010) Fuzzy decision-making based on likelihood-based comparison relations. IEEE Trans Fuzzy Syst 18(3):613–628
Chen SM, Phuong BDH (2017) Fuzzy time series forecasting based on optimal partitions of intervals and optimal weighting vectors. Knowl-Based Syst 118:204–216
Chen SM, Zou XY, Gunawan GC (2019) Fuzzy time series forecasting based on proportions of intervals and particle swarm optimization techniques. Inf Sci 500:127–139
Chen J, Yuan W, Cao J, Lv H (2020) Traffic-flow prediction via granular computing and stacked autoencoder. Granular Comput 5:449–459
Chen SM (1996) A fuzzy reasoning approach for rule-based systems based on fuzzy logics. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) 26(5): 769–778.
Cheng SH, Chen SM, Jian WS (2016) Fuzzy time series forecasting based on fuzzy logical relationships and similarity measures. Inf Sci 327:272–287
Fan MH, Chen MY, Liao EC (2021) A deep learning approach for financial market prediction: Utilization of Google trends and keywords. Granular Computing 6:207–216
Gasir F, Crockett K (2016) On the suitability of type-1 Fuzzy regression tree forests for complex datasets. In: Information Processing and Management of Uncertainty in Knowledge-Based Systems: 16th International Conference. Springer, pp 656–663.
Goyal G, Bisht DC (2023) Adaptive hybrid fuzzy time series forecasting technique based on particle swarm optimization. Granular Computing 8(2):373–390
Gupta KK, Kumar S (2019) A novel high-order fuzzy time series forecasting method based on probabilistic fuzzy sets. Granular Computing 4:699–713
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780
Lin HC, Wang LH, Chen SM (2006) Query expansion for document retrieval based on fuzzy rules and user relevance feedback techniques. Expert Syst Appl 31(2):397–405
Minaev YM, Filimonova OY, Minaeva YI (2023) Forecasting of fuzzy time series based on the concept of the nearest fuzzy sets and tensor models of time series. Cybern Syst Anal 59(1):165–176
Nguyen-Huynh L, Vo-Van T (2023) A new fuzzy time series forecasting model based on clustering technique and normal fuzzy function. Knowl Inf Syst 65(8):3489–3509
Nishad AK, Aggarwal G (2023) Hesitant fuzzy time series forecasting model of higher order based on one and two-factor aggregate logical relationship. Eng Appl Artif Intell 126:106897
Pant M, Kumar S (2022a) Fuzzy time series forecasting based on hesitant fuzzy sets, particle swarm optimization and support vector machine-based hybrid method. Granular Computing 7:861–879
Pant M, Kumar S (2022b) Particle swarm optimization and intuitionistic fuzzy set-based novel method for fuzzy time series forecasting. Granular Computing 7(2):285–303
Pant S, Kumar S (2024) HFS-based computational method for weighted fuzzy time series forecasting model using techniques of adaptive radius clustering and grey wolf optimization. Granular Computing. https://doi.org/10.1007/s41066-023-00434-6
Pehlivan NY, Turksen IB (2021) A novel multiplicative fuzzy regression function with a multiplicative fuzzy clustering algorithm. Romanian Journal of Information Science and Technology 24(1):79–98
Qian Y, Wang J, Zhang H, Zhang L (2023) Research of a combination system based on fuzzy sets and multi-objective marine predator algorithm for point and interval prediction of wind speed. Environ Sci Pollut Res 30(13):35781–35807
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning representations by back-propagating errors. Nature 323(6088):533–536
Samal S, Dash R (2023) Developing a novel stock index trend predictor model by integrating multiple criteria decision-making with an optimized online sequential extreme learning machine. Granular Computing 8(3):411–440
Shin Y, Ghosh J (1991) The pi-sigma network: An efficient higher-order neural network for pattern classification and function approximation. In: IJCNN-91-Seattle international joint conference on neural networks. IEEE, pp 13–18
Singh UP, Jain S, Tiwari A, Singh RK (2018) Approximation of nonlinear discrete-time system using FA-based neural network. Granular Computing 3:49–59
Sobhi S, Dick S (2023) An investigation of complex fuzzy sets for large-scale learning. Fuzzy Sets Syst 471:108660
Song M, Wang R, Li Y (2024) Hybrid time series interval prediction by granular neural network and ARIMA. Granular Computing. https://doi.org/10.1007/s41066-023-00422-w
Tak N (2018) Meta fuzzy functions: Application of recurrent type-1 fuzzy functions. Appl Soft Comput 73:1–13
Tak N (2020) Type-1 possibilistic fuzzy forecasting functions. J Comput Appl Math 370:112653
Tak N (2021a) Forecast combination with meta possibilistic fuzzy functions. Inf Sci 560:168–182
Tak N (2021b) Meta fuzzy functions based feed-forward neural networks with a single hidden layer for forecasting. J Stat Comput Simul 91(13):2800–2816
Tak N, İnan D (2022) Type-1 fuzzy forecasting functions with elastic net regularization. Expert Syst Appl 199:116916
Tak N, Evren AA, Tez M, Egrioglu E (2018) Recurrent type-1 fuzzy functions approach for time series forecasting. Appl Intell 48:68–77
Türkşen IB (2008) Fuzzy functions with LSE. Appl Soft Comput 8(3):1178–1188
Yadav RN, Kalra PK, John J (2007) Time series prediction with single multiplicative neuron model. Appl Soft Comput 7(4):1157–1163
Zadeh LA (1965) Fuzzy sets. Inf Control 8(3):338–353
Zeng S, Chen SM, Teng MO (2019) Fuzzy forecasting based on linear combinations of independent variables, subtractive clustering algorithm and artificial bee colony algorithm. Inf Sci 484:350–366
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). No funding was received for this work.
Author information
Authors and Affiliations
Contributions
EE: methodology, conceptualization, writing, data analysis, software. EB: methodology, conceptualization, software, writing, editing. MYC: methodology, conceptualization.
Corresponding author
Ethics declarations
Conflict of interest
The authors do not have any competing interests.
Ethical approval and consent to participate
This article does not contain any studies with human participants or animals performed by any of the authors.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Egrioglu, E., Bas, E. & Chen, MY. A fuzzy Gaussian process regression function approach for forecasting problem. Granul. Comput. 9, 47 (2024). https://doi.org/10.1007/s41066-024-00475-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s41066-024-00475-5