
Abstract
Landslide as one of the natural hazards has always caused huge financial losses and fatalities. Hence the goal of the present article is improvement in the prediction results of landslide occurrence in Tutkabon region in Gilan Province (Iran). For this purpose the Dempster–Shafer theory of evidence together with analyses and techniques of geospatial information systems (GIS) have been implemented for modeling and considering the uncertainties inherent in data selection. Also the parameters of slope, height, morphological conditions, earth curvature and distance to river and proximity to faults are taken as effective factors in landslide occurrence. Using the Dempster–Shafer theory, the belief, unbelief and uncertainty values for sub classes of each parameter are calculated separately and in continuation, utilizing the spatial information system, the landslide occurrence risk maps for each of these values are prepared at the study area. Finally for assessment of the results, the locations of landslide occurrence at the study area and the risk belief map are compared to each other. The results indicate that 65% of the landslides occur at the very high hazard class. Also assessing the results a value of AUC = 0.74 was obtained for the area under the prediction rate curve of the belief map.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Landslide is one of the most important natural hazards which occurs all around the world and causes huge economic damages in the infrastructure like roads, buildings etc. Hence identifying susceptible areas for occurrence of this phenomenon could be effective in risk prediction and planning and consequently reducing losses (Guzzetti et al. 2006). There are many parameters involved in landslide and as whole include the two internal and external groups. The internal components indicate constant characteristics of the area including the slope, direction of slope, soil type, height, earth curvature etc. On the other hand occurrence of the earthquake and precipitation and as whole the factors which are not constant and predictable are those which are among the external parameters. The studies have shown that landslide occurrence depends upon two factors and among them the external parameters are time-dependent and their examination requires complete information on their temporal and spatial distribution. For this reason in assessing the possibility of landslide occurrence and ultimately preparing the corresponding risk map, only the internal parameters are utilized (Bui et al. 2016).
With respect to the impact of various parameters in occurrence of this phenomenon and need for preparation of the spatial distribution maps per each of these parameters and combining them, use of the spatial information system as a powerful tool in processing spatial data is indispensable. In the past decades various models have been presented for combining the spatial layers including the fuzzy sets theory, probability theory, artificial neural networks. For example Ermini et al. (2005), Gomez and Kavzoglu (2005), Caniani et al. (2008), Pradhan (2010), Wu et al. (2013), Aghdam et al. (2016), and Bui et al. (2016) incorporating the artificial neural networks and fuzzy deduction system combined the spatial layers for prediction of the landslide. Also Dahal et al. (2008) utilized the probability theory for weighing the effective parameters and preparation of the risk map. Likewise Ozdemir (2011) has implemented the Bayesian method.
Sharma et al. (2012) used the entropy model for hazard classification of a region in India. Also Pourghasemi et al. (2012) investigated occurrence of landslide in the region of Safarood and implemented the conditional probability and entropy models for this purpose. Among other methods one could refer to the logistic regression model which has been utilized by Bui et al. (2011), Chauhan et al. (2010), and Devkota et al. (2013) the precision of this model is compared to other methods like Shannon’s entropy and conditional probability theory methods. Albeit a similar comparison is made by Felicísimo et al. (2013), but here they have also implemented classification methods in their comparison. Generally, in all models first the spatial maps corresponding to each of the effective layers are prepared and then by combining them using the mentioned methods, the landslide occurrence risk maps are produced.
In many research works the multi-criteria assessment methods have been implemented, among them one could refer to the research conducted by Yilmaz (2009), Pradhan (2010), Akgun (2012), Quan and Lee (2012), Kayastha et al. (2013), Lallianthanga et al. (2013), Wu et al. (2014), Najafabadi et al. (2016), Pourghasemi and Rossi (2016), and Karlsson et al. (2016). In all of these studies the integration of Analytic Hierarchy Process and spatial information systems is used for preparation of the landslide occurrence risk map. In other research works Yao et al. (2008) and Ballabio and Sterlacchini (2012) have utilized the support vector machine for this purpose. Among other methods we could refer to the research conducted by Althuwaynee et al. (2012) in which the evidence theory is used for classification of hazard susceptible areas.
Analysis of the impact of uncertainty in landslide prediction is among important issues which has less been dealt with in previous studies and in these research they have generally contented with preparation of the landslide occurrence risk maps. In this article utilizing the Dempster–Shafer theory which is a recognized theory in issues of uncertainty, in addition to preparing the landslide occurrence risk map for the study area, the impact of uncertainty on the results is investigated in spatial form. Among distinguished advantages of this method, with respect to other methods, is calculation of the uncertainty in occurrence of the expected results so that it models inherent uncertainty and limitation of human cognition concerning his surrounding world. In this article the landslide occurrence map is used for modeling and assessment of the results. In the Dempster–Shafer theory method a number of points are foreseen for training and preparation of the map and the remaining points are used for assessment of the results. Finally for overall assessment of the results the prediction rate curve is utilized and the area under the aforementioned curve is considered as the overall precision parameter in prediction.
In continuation, the study area and implemented data are presented in section two and the method of research is presented in section three. Also section four includes the research results and discussion, and at the final section the conclusion is presented.
Study area and used data
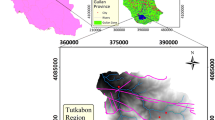
The study area in this article is Tutkabon basin which is located in Gilan Province, south of Rasht City and north east of Roodbar town in Iran. This basin is located at 49°30′22″–49°51′02″ longitude and 36°42′44″–36°54′15″ latitude. This basin covering an area of 43011 ha. is limited to Deilaman basin from the north and to Siahrood basin from the east and south and to Sefidrood River from the west. Tutkabon River is comprised of two rivers of Seidan and Amarloo which are joined near Dashtvil village and formed Tutkabon River. At Tutkabon basin there are two cities of Tutkabon and Barehsar and a few villages with 250 households. Darfak Mountain with a height of 2720 m is located at the northern side of the basin and is the largest mountain of the area. Figure 1 shows the study area.

General plan of the study area
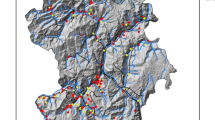
The information layers used in this article include the 7 layers of aspect, slope, geomorphology, earth curvature, distance to river, proximity to faults, and elevation. For calculating the slope and earth curvature layers use has been made of Digital Elevation Model (DEM) of the study area. Figure 2 shows the used data in this article. In this article, each layer is classified based on its importance and condition of the area (Althuwaynee et al. 2012). Also use has been made of the landslide occurrence map for assessment of the results implementing the Dempster–Shafer theory method which depicts 48 points of landslide occurrence in the study area. Figure 3 shows the location of landslide occurrence points in the study area.


Used layers

Landslide occurrence points in the study area
Research method
The goal of this article is to assess the risk associated with landslide occurrence in the study area with respect to the impact of uncertainty on the results. For this purpose the Dempster–Shafer theory has been utilized which is a widely accepted method for investigation of uncertainty. The process of performing this article is in this way that first the intended area is specified and the needed spatial layers which include 7 layers of effective parameters in occurrence of a landslide and also a layer of landslide occurrence points have been prepared using the spatial information systems. The next stage includes the process of preparing landslide risk map and assessing the impact of uncertainty on the results utilizing the above mentioned method. At this stage using the Dempster–Shafer theory, the belief, unbelief and uncertainty mass functions are defined considering the landslide occurrence points. Applying these functions on the spatial data of the used parameters and combining them, the belief, unbelief and uncertainty maps are obtained where each of these maps represents a significant level of landslide occurrence probability. At the end the obtained results are compared using the prediction rate curve.
Dempster–Shafer theory
The Dempster–Shafer theory of evidence was first presented by Shafer in the year 1976 and has been used as a mathematical model for spatial integration and preparation of mineral potential maps. The most important advantage of the Dempster–Shafer theory of evidence is its capability of being used for investigation of the uncertainty concept and discusses over the existing beliefs about a situation or a set of situations. Beliefs over the events are not identical but implementing this theory one could investigate and combine the existing evidences of the situations in a similar method. The output results of this theory include the belief, unbelief, uncertainty and plausibility sets (Olteanu-Raimond et al. 2015; Shi 2009). The primary concepts needed for the Dempster–Shafer theory are the recognition framework, power set and mass function. Assume that \(\theta\) is a finite set of elements. An element could be a proposition or a goal, \(\theta\) is called the recognition framework. The power set of \(\theta\) which is represented by \(\varOmega (\theta )\), indicates sets of different combinations of the \(\theta\) elements and also the empty set \(\left( \emptyset \right)\). The mass function which is denoted by \({\text{m}}\) is defined by Eq. (1) (Shi 2009).
The mass function, \({\text{m}}\), is called the basic probability assignment function. If set \({\text{A}}\) is a sub-set of the power set \(\theta\), then \({\text{m}}\left( {\text{A}} \right)\) indicates the share of set \({\text{A}}\) from all the corresponding and available evidences and supports the claim about a specific element of \(\theta\) which belongs to set \({\text{A}}\). In this theory the belief function is defined according to Eq. (2).
Also the plausibility function is defined by Eq. (3) where \(\overline{\text{A}}\) is the complement of set \({\text{A}}\).
In Eq. (2), the criterion \({\text{Bel}}\left( {\text{A}} \right)\) measures the probability which should be among the elements in \({\text{A}}\) and means the combination of all beliefs which precisely belong to the elements in sub set \({\text{A}}\). Also in Eq. (3), the criterion \({\text{Pl}}\left( {\text{A}} \right)\) measures the maximum probability which could be distributed among the elements of \({\text{A}}\) and represents the combined beliefs which are in union with the elements of sub set \({\text{A}}\). For this purpose the power sets and recognition sets are defined according to Eq. (4).
where parameter \({\bar{\text{s}}}_{\text{p}}\) indicates the probability of non-occurrence of landslide in pixel \({\text{p}}\). Also parameter \({\text{s}}_{\text{p}}\) indicates the probability of landslide occurrence in pixel \({\text{p}}\). In most spatial studies which have utilized the Dempster–Shafer theory, weighing of the effective layers is done by the specialists and for their combination the Dempster’s orthogonal rule is implemented and the partial effects of sub classes are not included in the risk analysis. To deal with this issue in the present research the opinions of specialists have not been implemented but the existing data corresponding to the cases of landslide occurrence were considered in determination of the mass function and this is the advantage of the current research. Thus modeling and definition of the mass function would not be dependent upon the specialists’ opinions, which themselves possess uncertainties and are related to their experiences.
Obviously the most important part in utilizing the Dempster–Shafer theory is the way of determining the mass function for calculation of the belief, unbelief and uncertainty values. For this purpose in the present research the likelihood ratio function was used for determination of mass function. Thus implementing the landslide occurrence map, two functions were defined for stating the probability of occurrence (belief) and probability of non-occurrence (unbelief) in the future. Assume that in the present research \({\text{L}}\) layers are selected for investigation of landslide occurrence probability where each layer includes j sub-classes. Each of these layers is taken as instance and the likelihood ratio function for landslide occurrence is defined by Eqs. (5) and (6).
In this relationship \({\text{N}}\left( {\text{L}} \right)\) denotes the total number of land slide occurrences in the study area, \({\text{N}}\left( {{\text{L}}\mathop \cap \nolimits {\text{E}}_{\text{ij}} } \right)\) denotes the number of landslide occurrence in sub-class j of layer i, \({\text{N}}\left( {\text{A}} \right)\) denotes the total number of pixels in the area and \({\text{N}}\left( {{\text{E}}_{\text{ij}} } \right)\) denotes the number of pixels in sub-class j of layer i. In this relationship the numerator indicates the ratio of landslides occurred in sub-class j of layer i and the denominator also indicates the ratio of the areas of this sub-class in which no landslide has occurred to the total area of this sub-class. Finally this relationship is used for producing the belief values. Likewise for obtaining the unbelief values, the likelihood function is defined for probability of non-occurrence of landslide according to Eq. (6).
In this relationship the numerator indicates the ratio of class \({\text{E}}_{\text{ij}}\) where no landslide has occurred to the total number of landslides and the denominator also indicates the areas outside of sub-class \({\text{E}}_{\text{ij}}\) where landslide has not occurred. The second stage is normalization of output values from the two mass functions. For this purpose the output values per each pixel are divided by the values obtained from pixels of sub-class j of layer i. Finally the mass function \({\text{m}}\left( \theta \right)_{{{\text{E}}_{\text{ij}} }}\) is calculated to determine the uncertainty from Eq. (7).
where the \({\text{m}}\left( \theta \right)_{{{\text{E}}_{\text{ij}} }}\) value represents the mass function to calculate the uncertainty.
Results and discussion
Investigation and analysis of uncertainty in landslide occurrence in spatial terms needs preparation of the uncertainty map for the study area. For this purpose and for preparation of landslide occurrence risk map, the Dempster–Shafer theory was implemented in this article and with respect to the relationships given in Sect. 3.1, the belief, unbelief and uncertainty values are calculated for each of these classes and the results are given in Table 1.
After calculation of the belief, unbelief and uncertainty values using the presented mass functions and implementing the Dempster–Shafer combination rule for each pixel, ultimately the three belief, unbelief and uncertainty maps were produced. These maps are presented in Figs. 4, 5 and 6.

The belief map for landslide occurrence

The disbelief map for landslide occurrence

The uncertainty map for landslide occurrence
As is seen in these figures, the produced maps are classified in 5 categories. In the belief map (Fig. 4) the maximum hazard of landslide occurrence belongs to the north western and central parts of the study area which include the medium and sharp slopes (10°–25°) and also medium to low height regions and the minimum hazard values belong to the higher heights and also plain regions. In the unbelief map (Fig. 5) the minimum values belong to areas where they have high belief values. In this map, dispersion of the hazard classes is greater with respect to the belief map and this issue is in direct relation with the location of landslide occurrence points which are selected randomly for educational purpose. But the largest values are observed in higher heights and also around the rivers. Due to the direct relationship between the landslide and distance to the faults, it is expected that the near fault areas fall in the higher hazard class. But examination of the presented hazard classes together with the fault lines shows that this has not fully occurred. So that in the central and western parts, nearly the areas near the faults belong to the higher hazard classes. But the southern and eastern faults of the area belong to the medium to the low hazard class and also the areas near the northern fault are located in the very low hazard class. This issue is due to non-occurrence of landslide in these areas. In this respect the geological map of the study area is effective and could not be overlooked. Because these regions are located in the high heights and according to the geomorphologic map, the area has rocky and stable layers.
Likewise in the uncertainty map (Fig. 6); those areas have the maximum values which belong to the low and very low classes in the belief and unbelief maps. These areas are those which are located at high heights and also around the rivers. Among these regions one could refer to the northern and southern parts of the area which are colored in black in Fig. 6. These areas had the lowest values in the belief and unbelief maps and are specified in white color. This map is among the important and unique outcomes of the Dempster–Shafer method and it could be implemented in determining the priorities for planning of landslide occurrence hazard.
When investigating the landslide hazard, the main goal is to find areas with maximum probability of occurrence. But notwithstanding what kind of method is implemented for this purpose, assessment of the results is of vital importance. Finally for assessment of the utilized method, 23 points which were not used in the training process were implemented as assessment points. Among these, 18 points belonged to the very high and high risk classes which indicate that about 65% of the estimated landslides belong to these two classes. Also the 5 remained points belonged to other classes. Figure 7 presents the landslide occurrence points together with the belief map and the faults of the area.

The belief map together with the landslide occurrence places and fault lines
Examining the output map for the belief values, the ratio of pixels corresponding to each class were extracted and the results are given in Fig. 8. Thus the highest percentage of the study area was located in the low class and after that the medium, very low, high and very high classes are ranked, respectively.

Comparison of the pixels in the belief map
In addition to the above assessment, in this section also use has been made of the prediction rate curve for assessment of the results e. As is seen in Fig. 9, more than 30 cases of landslides are located at the 40% of the study area and dispersion of the landslide points in the higher hazard classes confirms this issue. In this diagram the horizontal axis represents the area ratio in percentage form of the study area, where the lower values correspond to the classes with higher rates of hazard and with increase in the percentage value of the area, the classes with lower rates of hazard are added cumulatively to this value so that ultimately the value equal to unity would represent the entire area. Also the value obtained in this article for AUC (area under the curve) using the belief map is 0.74 which with respect to the limited number of landslide occurrences is a high precision value and indicates good efficiency of the Dempster–Shafer theory of evidence in prediction of the landslide occurrence.

The prediction rate curve using the belief map
Conclusion
With respect to concerns over the issue of landslide occurrence and its devastating consequences, identifying areas susceptible to this event is of vital importance. On the other hand the impact of uncertainty in the information layers being used and the expected results could not be overlooked. In this article to prepare the landslide occurrence risk map and also precise investigation of the impact of spatial uncertainty on the results, the Dempster–Shafer theory is implemented. That is while in the previous studies various methods were incorporated for producing maps without taking into account the uncertainty. So in this article through definition of a unique mass function first the belief, unbelief and uncertainty values for each of the sub-classes were calculated separately. Then implementing the Dempster–Shafer’s rule of combination of evidences, the corresponding values of different parameters for preparation of the belief, unbelief and uncertainty maps are combined separately and the corresponding maps are prepared. To validate the results, a comparison was made between the landslide occurrence points and the hazard classes in the belief map. Also the prediction rate curve and the area under this curve was utilized as the precision parameter. Assessment of the results indicates the high accuracy and precision of this method in predicting landslide occurrence. The results of this article could be implemented in decision making and management of the land use and urban planning. Considering that the results of this article indicate the direct impact of uncertainty on the results, it would result in reduced error in decision making.
References
Aghdam IN, Varzandeh MHM, Pradhan B (2016) Landslide susceptibility mapping using an ensemble statistical index (Wi) and adaptive neuro-fuzzy inference system (ANFIS) model at Alborz Mountains (Iran). Environ Earth Sci 75:1–20
Akgun A (2012) A comparison of landslide susceptibility maps produced by logistic regression, multi-criteria decision, and likelihood ratio methods: a case study at İzmir, Turkey. Landslides 9:93–106
Althuwaynee OF, Pradhan B, Lee S (2012) Application of an evidential belief function model in landslide susceptibility mapping. Comput Geosci 44:120–135
Ballabio C, Sterlacchini S (2012) Support vector machines for landslide susceptibility mapping: the Staffora River Basin case study, Italy. Math Geosci 44:47–70
Bui DT, Lofman O, Revhaug I, Dick O (2011) Landslide susceptibility analysis in the Hoa Binh province of Vietnam using statistical index and logistic regression. Nat Haz 59:1413–1444
Bui DT, Tuan TA, Klempe H, Pradhan B, Revhaug I (2016) Spatial prediction models for shallow landslide hazards: a comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 13:361–378
Caniani D, Pascale S, Sdao F, Sole A (2008) Neural networks and landslide susceptibility: a case study of the urban area of Potenza. Nat Haz 45:55–72
Chauhan S, Sharma M, Arora MK (2010) Landslide susceptibility zonation of the Chamoli region, Garhwal Himalayas, using logistic regression model. Landslides 7:411–423
Dahal RK, Hasegawa S, Nonomura A, Yamanaka M, Masuda T, Nishino K (2008) GIS-based weights-of-evidence modelling of rainfall-induced landslides in small catchments for landslide susceptibility mapping. Environ Geol 54:311–324
Devkota KC et al (2013) Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in GIS and their comparison at Mugling-Narayanghat road section in Nepal Himalaya. Nat Hazards 65:135–165
Ermini L, Catani F, Casagli N (2005) Artificial neural networks applied to landslide susceptibility assessment. Geomorphology 66:327–343
Felicísimo ÁM, Cuartero A, Remondo J, Quirós E (2013) Mapping landslide susceptibility with logistic regression, multiple adaptive regression splines, classification and regression trees, and maximum entropy methods: a comparative study. Landslides 10:175–189
Gomez H, Kavzoglu T (2005) Assessment of shallow landslide susceptibility using artificial neural networks in Jabonosa River Basin, Venezuela. Eng Geol 78:11–27
Guzzetti F, Galli M, Reichenbach P, Ardizzone F, Cardinali M (2006) Landslide hazard assessment in the Collazzone area, Umbria, Central Italy. Nat Hazards Earth Syst Sci 6:115–131
Karlsson C, Kalantari Z, Mörtberg U, Olofsson B, Lyon S (2016) The impact of expert knowledge on natural hazard susceptibility assessment using spatial multi-criteria analysis. In: EGU General Assembly Conference Abstracts, p 951
Kayastha P, Dhital M, De Smedt F (2013) Application of the analytical hierarchy process (AHP) for landslide susceptibility mapping: a case study from the Tinau watershed, west Nepal. Comput Geosci 52:398–408
Lallianthanga R, Lalbiakmawia F, Lalramchuana F (2013) Landslide hazard zonation of Mamit Town, Mizoram, India using remote sensing and GIS techniques. Int J Geol Earth Environ Sci 3:148–194
Najafabadi RM, Ramesht MH, Ghazi I, Khajedin SJ, Seif A, Nohegar A, Mahdavi A (2016) Identification of natural hazards and classification of urban areas by TOPSIS model (case study: bandar Abbas city, Iran) Geomatics. Nat Hazards Risk 7:85–100
Olteanu-Raimond A-M, Mustiere S, Ruas A (2015) Knowledge formalization for vector data matching using belief theory. J Spatial Inf Sci 2015:21–46
Ozdemir A (2011) Landslide susceptibility mapping using Bayesian approach in the Sultan Mountains (Akşehir, Turkey). Nat Hazards 59:1573–1607
Pourghasemi HR, Rossi M (2016) Landslide susceptibility modeling in a landslide prone area in Mazandarn Province, north of Iran: a comparison between GLM, GAM, MARS, and M-AHP methods Theoretical and Applied Climatology, pp 1–25
Pourghasemi HR, Mohammady M, Pradhan B (2012) Landslide susceptibility mapping using index of entropy and conditional probability models in GIS: safarood Basin, Iran. Catena 97:71–84
Pradhan B (2010) Landslide susceptibility mapping of a catchment area using frequency ratio, fuzzy logic and multivariate logistic regression approaches. J Indian Soc R Sens 38:301–320
Quan H-C, Lee B-G (2012) GIS-based landslide susceptibility mapping using analytic hierarchy process and artificial neural network in Jeju (Korea). KSCE J Civ Eng 16:1258–1266
Sharma L, Patel N, Ghose M, Debnath P (2012) Influence of Shannon’s entropy on landslide-causing parameters for vulnerability study and zonation—a case study in Sikkim, India. Arabian J Geosci 5:421–431
Shi W (2009) Principles of modeling uncertainties in spatial data and spatial analyses. CRC Press
Wu X, Niu R, Ren F, Peng L (2013) Landslide susceptibility mapping using rough sets and back-propagation neural networks in the Three Gorges, China. Env Earth Sci 70:1307–1318
Wu Y, Chen L, Cheng C, Yin K, Török Á (2014) GIS-based landslide hazard predicting system and its real-time test during a typhoon, Zhejiang Province, Southeast China. Eng Geol 175:9–21
Yao X, Tham L, Dai F (2008) Landslide susceptibility mapping based on support vector machine: a case study on natural slopes of Hong Kong, China. Geomorphology 101:572–582
Yilmaz I (2009) Landslide susceptibility mapping using frequency ratio, logistic regression, artificial neural networks and their comparison: a case study from Kat landslides (Tokat—Turkey). Comput Geosci 35:1125–1138
Author information
Authors and Affiliations
Corresponding authors
Rights and permissions
About this article

Cite this article
Milaghardan, A.H., Delavar, M. & Chehreghan, A. Uncertainty in landslide occurrence prediction using Dempster–Shafer theory. Model. Earth Syst. Environ. 2, 1–10 (2016). https://doi.org/10.1007/s40808-016-0240-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40808-016-0240-5