
Abstract
Healthcare tends to be one of the most complicated sectors, and hospitals exist at the core of healthcare activities. One of the most significant elements in hospitals is service quality level. Moreover, the dependency between factors, dynamic features, as well as objective and subjective uncertainties involved endure challenges to modern decision-making problems. Thus, in this paper, a decision-making approach is developed for hospital service quality assessment, using a Bayesian copula network based on a fuzzy rough set within neighborhood operators as a basis of that to deal with dynamic features as well as objective uncertainties. In the copula Bayesian network model, the Bayesian Network is utilized to illustrate the interrelationships between different factors graphically, while Copula is engaged in obtaining the joint probability distribution. Fuzzy rough set theory within neighborhood operators is employed for the subjective treatment of evidence from decision makers. The efficiency and practicality of the designed method are validated by an analysis of real hospital service quality in Iran. A novel framework for ranking a group of alternatives with consideration of different criteria is proposed by the combination of the Copula Bayesian Network and the extended fuzzy rough set technique. The subjective uncertainty of decision makers’ opinions is dealt with in a novel extension of fuzzy Rough set theory. The results highlighted that the proposed method has merits in reducing uncertainty and assessing the dependency between factors of complicated decision-making problems.
Similar content being viewed by others

Introduction
Hospital quality service assessment is critical for hospital management. The modern lifestyle of society requires extensive satisfaction with the quality and efficiency of hospital services. During the past year of the pandemic, healthcare and hospitals have proved to be one of the world's most highly complicated and significant sectors. The main aspects of hospital service quality include (not limited to) equipment, staff behavior, admitting, and several more directly related to patients, for instance, payment and treatment time [1]. Patient satisfaction is a degree of matching between the services that patients receive from the hospital and their expectations [2]. Therefore, improving the service quality and efficiency of hospitals’ services is a demanding task for decision makers and managers.
To assess the quality of hospital services, health care systems, and similar application domains, multi-criteria decision-making (MCDM) is typically utilized; see in [3] and [4]. In MCDM tools, a set of alternatives are examined simultaneously with consideration of different criteria. Techniques to address MCDM methods can be classified into four categories: (i) measurement tools (i.e., allocating a score for all the alternatives such as analytical hierarchy process (AHP) [5], and Evidence theory [6]); (ii) reference level methods (i.e., using an aggregation function such as TOPSIS (Technique for Order Preference by Similarity to an Ideal Solution) [7, 8], and VIKOR (Multicriteria Optimization and Compromise Solution) [9, 10]; (iii) outranking methods (i.e., comparing the pairwise comparisons for all single criterion such as PROMETHEE (king Organization Method for Enrichment Evaluation) [11], ELECTRE I, II, III, IV (Elimination and Choice Expressing Reality) [12], and QUALIFLEX (qualitative flexible multiple criteria method) [13]); (iv) other methods. MCDM tools are capable of handling complicated decision-making problems and are applicable in many application domains, including, but not limited to, business [14], process [15, 16], safety [17, 18], and supply chain [19]. More relevant, the BWM [20] has been maturely utilized in hospital service quality assessment [21].
In this study, the Copula Bayesian Network is employed to evaluate the service quality of a hospital. The decision makers' subjective uncertainty is dealt with in a novel extension of fuzzy rough set theory, and an integrated ranking system is presented to prioritize the alternatives. The study aims to design a structure to evaluate the service quality of hospitals. The outcomes could help the managers and decision makers to systematically prioritize the factors and spend the budget in a way that effectively improves the service quality of hospitals.
The rest of the paper is organized as the following. Related literature is presented in “Methodology”. Methodologies for analyzing hospital service quality, including the Bayesian Network, Copula functions, and the extended fuzzy rough set theory, are provided in “Application of study”. “Conclusion” demonstrates the application of the study provided to assess and evaluate a hospital service quality. Finally, conclusions and future discussions are listed in the last section.
Related literature
Researchers applied various MCDM methods and different integrations of techniques to evaluate the healthcare service quality in recent years due to its significance and the presence of too many qualitative and quantitative factors. However, service quality is vital for the survival of any service-based company; hospitals and healthcare institutes are at the core of the concentration. In the first study [1], the authors used MCDM methods to evaluate the service quality of B-class hospitals in Istanbul. They used AHP to find the importance weight of criteria, then TOPSIS and Yager’s min–max approach were applied to rank the crisp performance values, and finally, OWA and Compensatory AND operators were employed to aggregate the result. In another study [2], a group of scholars used MCDM tools to identify and evaluate criteria influencing public hospitals in Iran. They used four hybrid methods and integrated the results by the Copeland method to achieve the main criteria of environment, responsiveness, equipment, facilities, and professional capability. Another study [3] employed a belief function theory to improve the BWM method as a framework to assess the hospital service quality problem. They tried to tackle the vagueness of decision makers in qualitative judgment through these integrations. The evaluation based on the patient's view is also investigated by [4] in a real case study in Istanbul. They used the Interval Valued Intuitionistic Fuzzy concept to improve TOPSIS to cope with the vagueness and complexity of evaluation. Another study integrated the fuzzy sets theory and the VIKOR method to evaluate hospital service quality in Taiwan [5]. They addressed vagueness, subjectivity, and uncertainty with linguistic variables in triangular fuzzy number format.
In Croatia [6], AHP is used to measure the quality of public hospitals. They ranked the top-performing hospitals in the country. According to the study of [7], an integrated distance-based Pythagorean Fuzzy method, TOPSIS, and Fuzzy Inference System design a framework that could evaluate the healthcare service quality of hospitals. Their approach is applied to a real case study for prioritizing the ten clinics in a private hospital. Pythagorean Fuzzy TOPSIS is used to determine the inputs of the fuzzy system, and the fuzzy inference system is applied to evaluate the clinic's service quality level. A study of [9] investigated the service performance evaluation of hospitals in the recent COVID-19 situations not only for health services but also for the elimination of hesitations in the treatment and vaccination processes. They integrated CRITIC-TOPSIS with fuzzy sets and designed a framework to evaluate the hospitals, and they suggested the required policies and strategies for hospitals under pandemic situations. Interested readers could also refer to [4] for more comprehensive information about MCDM and healthcare service quality evaluation. However, MCDM methods still suffer from a couple of shortages [22, 23]: (i) subjective input information causes subjective uncertainty of results; (ii) insufficient consideration of correlations between factors; (iii) disability in diagnosis analysis; (iv) insufficient in dealing with stochastic-based decision-making problems. Bayesian Network is an asset for model and analyzing the dependence of systems and is proved to be a helpful tool in several fields, such as safety and risk analysis [24,25,26], human reliability analysis [27, 28], resilience analysis [29], marine engineering [30, 31], and others. Bayesian Network is constructed according to the Bayesian inference process that can update the Bayesian Network with both predictive and diagnostic analysis once new evidence(s) are obtained. Table 1 shows the related publications that mostly applied Fuzzy-AHP and Fuzzy-TOPSIS integrations, and Bayesian network was somehow neglected in hospital service evaluation problem studies.
Moreover, the probability distributions can be engaged to tackle the objective uncertainties by describing the continuous variables in Bayesian Network. Bayesian Network also has considerable capability to inconsistent aggregate information, quantify different uncertainties, measure dependency between the factors, and have high flexibility and efficiency to make optimum decision-making [32, 33]. Accordingly, Bayesian Network and its extensions can be utilized to address the drawbacks of MCDM tools by constructing the Bayesian Network according to the prior knowledge that comes up from decision-makers' opinions or learning the Network using conditional probability based on the considerable input data.
Bayesian Network can be utilized to make a marginal decision to evaluate hospital service quality with consideration of confidence level. However, until now, no similar study to assess hospital service quality using Bayesian Network has been published. The typical Bayesian Network is still suffering from a couple of shortages when it is implemented in hospital quality service assessment, to be specific, including modeling marginal distributions and considering the dependency of interrelationships between factors based on the stochastic nature of the problem [34,35,36]. Another lack is that in the typical Bayesian Network, the conditional probability tables will be larger and larger by increasing the number of variables, making the problem too complex to solve. Copula Bayesian Network is developed to address the complicated dependencies of continuous variables using marginal distributions and dependency functions to deal with this issue. In addition, the Copula Bayesian Network can adequately model the dependence and causalities between variables, which further addresses the stochastic nature of decision-making problems [37, 38].
Considering the merits of the Copula Bayesian Network to solve a decision-making problem, subjective decision makers opinions still play vital roles in acquiring an important weight of criteria in hospital quality service. Therefore, in this study, an extension of fuzzy Rough set theory is used to cope with the ambiguities and uncertainty of subjective knowledge collected from decision makers which require no prior knowledge of decision makers and can also objectively handle the decision-making problems [39].
The contributions of this study are:
-
The Copula Bayesian Network is used to analyze the hospital service quality.
-
A novel extension of fuzzy Rough set theory based on neighborhood operators is engaged to deal with the subjective uncertainty of decision-makers' opinions.
-
A framework for ranking a group of alternatives considering different criteria is proposed by combining the Copula Bayesian Network and the extended fuzzy Rough set technique.
Methodology
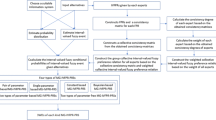
In this section, a five-step-based methodology is proposed to solve a decision-making problem by finding the optimum solutions, see Fig. 1.

The proposed framework to obtain the optimum solutions
Step one: defining the decision-making problem
Decision-making problems in an ordinary way fall into a problem to solve or a decision to make. The initial schedule of solving the mentioned task is to define the problem (i.e., finding the highest priority for an alternative among a set of alternatives). In this study, the decision-making problem is designed to rank the alternatives in descending order by considering the importance weight of the criteria. Accordingly, first, all potential alternatives, together with criteria, should be recognized.
Step two: translating the decision-making problem into a Bayesian Network model
Bayesian Network is a well-known probabilistic tool for constructing conditional dependency among a set of variables. The translation of the decision-making problem into a Bayesian Network model is to structure, in detail, the decisive goal and criteria (see Step 1). To be specific, Bayesian Network is a well-known probabilistic tool to construct conditional dependency among a set of variables consisting of two parts: directed acyclic graph and Conditional Probability Tables (CPTs). In the directed acyclic graph, nodes are variables, and edges are causalities between nodes. Nodes can be categorized into root nodes (no edge points to), intermediate nodes (with both starts-with and point-to edges), and leaf nodes (without start-with edges).
Bayesian Network propagates probabilistic information by the conditional probability function [40], as:
where \(P{(}A{|}B)\) represents the probability of node A given the state of node B, \(P\left( A \right)\) and \(P\left( B \right)\) denote prior probabilities of nodes \(A\) and \(B\)
Assume that in a typical BN, \(n\) variables as \(A_{ 1} , A_{ 2} , A_{ 3} , \ldots , A_{ n}\), are included. In this accordance, the joint probability distribution of variables is decomposed as:
Equation (2) can be simplified into Eq. (3) according to the D-separation rule [20], as:
Assume that a typical BN is structured having a set of limited variables as \(M = \left\{ {A_{ 1} ,A_{ 2} ,A_{ 3} ,A_{ 4} } \right\}\), and consists of a set of arcs that illustrates the interdependency and relationships between the existing variables. Bayesian Network is a robust and powerful decision-making tool compared to the other existing analysis method. The reason for utilizing BN in this paper are highlighted as the following: (i) graphical representation as a network helps decision makers that could track the process and have a better undersetting of the problem, (ii) BN could engage both objective and subjective data as an input, (iii) it also could handle the uncertainty as well as updating the information.
Up to this point, Bayesian Network is briefly explained. Next, Decision-makers should identify all factors and subfactors related to the alternative selection. Afterwards, the importance weight of all factors and corresponding subfactors should be computed, which will further be explained in step three. Finally, the causality between the factors and subfactors will be determined to better understand the cause-and-effect relationship within the factors.
Step three: collecting experts’ opinions for factor weighting
This step gathers a heterogeneous group of decision makers (e.g., four to six individuals). It should be added that all of the called decision makers must have a relevant background, expertise, or education regarding the application of study and have a proper understanding of the proposed methodology, the idea behind the work, and how their contributions are essential and can considerably value to the scientific communities. In addition, the group of decision makers should declare that there is not any conflict of interest as well as any kind of relationship that might impact the outcome of the elicitation process and the outcome of the investigations. A group of experts as decision makers should be employed to provide a proper significant weight for the factors involved. In this study, an extension of the fuzzy Rough set theory is improved to collect and aggregate decision-makers’ opinions. The aggregation of experts' opinions into BN is extensively discussed in previous authors' published work. To avoid repetition and duplication, an interested reader can refer to the following references [41, 42].
Dubios and Prade [37] propose the fuzzy Rough set theory[43]. Afterwards, several extensions have been proposed to meet actual engineering requirements, and the most popular ones are fuzzy Rough set models [44, 45]. Such studies extended the technique by replacing the fuzzy binary relations with a fuzzy covering or replacing the fuzzy binary relations with fuzzy neighborhood operators. However, the fuzzy covering is strict, which raises difficulties in common decision-making problems.
To deal with this situation, the concept of \(\beta \)-coverings is proposed in [46], in which two different fuzzy Rough sets are presented by defining a fuzzy \(\beta \)-neighborhood. Accordingly, Yang and Hu [47] worked to expand the theoretical knowledge related to fuzzy \(\beta \)-coverings estimation space underlying the idea of fuzzy Rough set theory and fuzz \(\beta \)-neighborhood operators. It should be noted that the four types of fuzzy \(\beta \)-neighborhood operators proposed in [47] can be further extended to the four categories of fuzzy \(\beta \)-neighborhood operators [48]. However, the fuzzy \(\beta \)-neighborhood operators cannot satisfy the relexification feature, which is also a considerable shortage of the fuzzy Rough set theory. Therefore, in this study, we unutilized a novel type of reflex \(\beta \)-neighborhood operators in fuzzy \(\beta \)-coverings [49].
The proposed \(\beta \)-neighborhood operators are defined in the following subsection.
Theories and definitions
Some of the main fuzzy operators can be summarized as the following [39]:
-
(I)
There are three types of \(t\)-norms (showing as\(\tau \)) for all \(c ,d\in \left[0 ,1\right] ,\)
-
•
The standard minimum operator:\({\tau }_{ M }\left(c ,d\right)=\mathrm{min}(c ,d)\),
-
•
The algebraic product: \({\tau }_{P }\left(c ,d\right)=c*d\),
-
•
The Lukasiewics \({\tau }_{ L }\left(c,d\right)=\mathrm{max}( 0 ,c+d-1)\),
-
(II)
There are three types of R-implicators (showing as \(\Lambda )\) for all \(c ,d\in \left[\mathrm{0,1}\right] ,\)
-
•
It is Godel implicator according to the \(\tau_{ M}\)
$$ {\Lambda }_{{ \tau_{ L } }} \left( {c ,d} \right) = \left\{ {\begin{array}{*{20}c} {1 c \le d} \\ {d d > c} \\ \end{array} ,} \right. $$where R-implicators for all\(c ,d \in \left[ { 0, 1} \right] , \tau_{ L } \left( {c ,d} \right) = {\text{sup}}\{ c \in \left[ {0 , 1} \right)| \tau_{ } \left( {c,d} \right) \le d\)].
It is Godel implicator according to the \(\tau_{ P}\)
$$ {\Lambda }_{{ \tau_{ L } }} \left( { c ,d} \right) = \left\{ {\begin{array}{*{20}c} {1 c \le d} \\ {d/c d > c} \\ \end{array} } \right. $$ -
•
It is Lukasiewics implicatory according to the \({\tau }_{ L }:{\Lambda }_{{ \tau }_{ L }}\left( c ,d\right)=\mathrm{min}(c ,c-c+d)\)
According to the fuzzy neighborhood operators, some of the fuzzy covering can be summarized as follows.
Definition 1
[46]. Let us assume that \(U\) is a universal set where \(F\left( U \right)\) denotes a fuzzy family set of \(U\). Assume that \(\tilde{\delta } = \left( {\delta_{ 1} ,\delta_{ 2} , \ldots ,\delta_{ m} } \right)\) with \(\delta_{ j} \in F\left( U \right)\) and \(C = \left( {1,2, \ldots m} \right)\) would be an index for all \(k \in C\). For each \(\beta \in \left[ { 0,1} \right]\), \(\tilde{\delta }\) is named a fuzzy \(\beta\)-covering of \(U\) satisfying \(\left( {\bigcup\nolimits_{j = 1}^{m} {\delta_{m} } } \right)\left( {a \ge \beta } \right)\) for all \(a \in U\). Then, the pair of \(\left( {U,\tilde{\delta }} \right)\) is named a fuzzy \(\beta\)-covering estimation space and illustrated as F \(\beta CAS\)
Definition 2
Let us assume that \(\left( {U,\tilde{\delta }} \right)\) is a F \(\beta CAS\) for some \(\beta \in \left( {0 ,1} \right]\) and\(\tilde{\delta } = \left( {\delta_{ 1} ,\delta_{ 2} , \ldots ,\delta_{ m} } \right)\). Then for every\(a \in U\), the \(\beta\)-neighborhood system can be written as:
In addition, the fuzzy \(\beta\)-neighborhood operator can be defined as the following:
Where \({\Delta }_{ \beta , Ma }^{{ \tilde{\delta }}} \left( a \right)\left( a \right) \ge \beta\) for each \(a \in U\).
The operators \({\Delta }_{ \beta , Ma }^{{ \tilde{\delta }}}\) is somehow \(\beta\)-reflexive, and therefore this operator cannot satisfy the reflexivity when \(\beta \ne 1\).
Definition 3
[47]. Let us assume that \(\left( {U,\tilde{\delta }} \right)\) is a F \(\beta CAS\) for some value of \(\beta \in \left( {0 ,1} \right]\) and\(a \in U\), the fuzzy \(\beta\)-minimal description \(\widetilde{Md}_{{\beta , \tilde{\delta }}}^{{{\text{ Yang }}\& {\text{ Hu}} }} \left( a \right)\) and fuzzy \(\beta\)-maximal description \(\widetilde{Md}_{{ \beta , \tilde{\delta }}}^{{{\text{ Yang }}\& {\text{ Hu}} }} \left( a \right)\) can be defined as the following:
Definition 4
Let us assume that \(\psi \left( {\delta ,a} \right)\) denotes a fuzzy neighborhood system of \(a\) when\(a \in U\), in which \(\psi \left( {\delta ,a} \right) = \left\{ {\delta_{ j} \in \delta \left| { \delta_{ j} \left( a \right)} \right\rangle 0} \right\}\). Accordingly, the fuzzy minimal and maximal descriptions of \(a\) as \(\widetilde{Md}\left( {\delta ,a} \right)\) and\(\widetilde{MD}\left( {\delta ,a} \right)\), respectively, can be presented as the following:
According to the mentioned equations, four fuzzy neighborhood operators were proposed by D’eer et al. [50]. Let us assume that \(\left( {U,\tilde{\delta }} \right)\) is a finite fuzzy covering estimation space (FCAS), \(\tau\) a \(t\)-norm and \(L\) an implication. Therefore, for \(\forall a,b \in U\), the following operators can be defined:
where the fuzzy covering \(\delta\) is a crisp covering, and the four mentioned fuzzy neighborhood operators are fully reflexive. The first and third operators are properly transitive, and the last operator is symmetric.
Remark 1
Intuitionistic fuzzy numbers are one of the main essential types of fuzzy numbers and are widely used in fuzzy operators. To obtain more information related to the intuitionistic fuzzy number, one can refer to [51, 52].
Recently, four novel types of fuzzy \(\beta\)-neighborhood operators have been proposed by Ye et al. [49] to deal with the shortcoming of existing neighborhood operators such as [47]. In the following, these three novel operators in a finite F \(\beta\) CAS are explained.
Definition 5
Let us assume that \(\left( {U,\tilde{\delta }} \right)\) is a finite F \(\beta\) CAS, \(\tau\) is a \(t\)-norm and \(L\) is an implicator, for \(a ,b \in U\), the operators \({\Delta }_{{ \widetilde{\delta },s }}^{ \beta }\) (\(s = 1, 2, 3, {\text{and}} \, 4):U = \acute{F} \left( U \right):a \to {\Delta }_{{\tilde{\delta },s }}^{ \beta } \left( a \right)\) are redefined the four types mentioned above of fuzzy \(\beta\)-neighborhood operators. \({\Delta }_{ \delta ,s }^{ \beta }\) (\(s = 1,2,3,{\text{ and }}4)\) can be therefore defined as the following order:
According to Eqs. (14)–(17), the following results can be concluded:
-
If \(\tilde{\delta }\) is a fuzzy covering, Eqs. (14)–(17) can degenerate into Eqs. (6)–(9), respectively. They would be called as \({\Delta }_{{\widetilde{ \delta },1 }}^{ 1} = {\Delta }_{1}^{{\tilde{\delta }}} ,{\Delta }_{{ \tilde{\delta },2 }}^{ 2} = {\Delta }_{2 }^{{\widetilde{ \delta }}}\),\({\Delta }_{{\widetilde{\delta }, 3 }}^{ 3} = {\Delta }_{3 }^{{\tilde{\delta }}}\), and\({\Delta }_{{ \tilde{\delta }, 4 }}^{ 4} = {\Delta }_{ 4 }^{{\widetilde{ \delta }}}\).
-
If \(\tilde{\delta }\) is a fuzzy covering, then \({\Delta }_{{\widetilde{ \delta }, 1 }}^{ 1} \left( a \right) \subseteq {\Delta }_{{\widetilde{ \delta }, 1 }}^{ 1,Ma}\)(a),\({\Delta }_{{\widetilde{ \delta }, 2 }}^{ 2, Ma } \left( a \right) \subseteq {\Delta }_{{\widetilde{ \delta }, 2 }}^{ 1} \left( a \right)\), \(\Delta_{{\widetilde{\delta },3}}^{ 1} \left( a \right) \subseteq \Delta_{{\widetilde{\delta },3}}^{3,Ma}\)(a), and\({\Delta }_{{\widetilde{ \delta }, 1 }}^{{ 4, {\text{Ma}} }} \left( a \right) \subseteq {\Delta }_{{\widetilde{ \delta }, 4 }}^{ 1} \left( a \right)\).
If \(\tilde{\delta }\) is a crisp covering, the operators \({\Delta }_{{\widetilde{ \delta }, s }}^{ \beta }\) (\(s = 1, 2, 3, {\text{and}} \, 4)\) overlap with four conventional kinds of neighborhood operators, which are defined by Yao et al. [49].
It should be highlighted that the computation of operators \({\Delta }_{{\widetilde{ \delta }, 4 }}^{ \beta }\) and \({\Delta }_{{\widetilde{ \delta }, 1 }}^{ \beta }\) are independent of the factor\(\beta\). Once all opinions are collected from decision makers in any form of fuzzy numbers, all the fuzzy numbers can be aggregated into a crisp number by implementing the above methodology.
Step four: performing Copula learning
A Copula is a function to create a joint multivariate distribution in which one dimension of marginal distribution would be combined. Copula has enough capability, such as having considerable flexibility in structural characterizing. Moreover, it is a robust and powerful tool for selecting a probability distribution, even in mistaken selection [53]. Besides, the \(n\)-dimensional continues multivariate random numbers as vector \(x = \left( {x_{ 1} ,x_{ 2} , \ldots x_{ n} } \right)\) has this chance to be reformed based on \(n\) univariate marginal distributions \(F_{ 1} \left( {x_{ 1} } \right),F_{ 2} (x_{ 2} ), \ldots ,F_{ n} (x_{ n} )\) and \(n\)-dimensional Copula function \(\tilde{C}\), which is defined in the following equations. The Copula function \(\tilde{C}\left[ {0,1} \right]^{ d} \to \left[ {0,1} \right]\) maps univariate the marginal joint cumulative distributions \(F_{ 1} \left( { x_{ 1} } \right),F_{ 2} ( x_{ 2} ), \ldots ,F_{ n} ( x_{ n} )\) into the joint distribution \(F\) [54].
Also, when the marginals are continuous, \(\tilde{C}\) can be explained by:
where \(F_{ i} \left( {x_{ i} } \right)\) \(\forall i \in \left\{ {1, 2, \ldots n} \right\}\) is the marginal distribution of \(x_{ i}\), and \(\tilde{C}\) is based on the Copula function, and \(u_{i} = F_{ i} \left( { x_{ i} } \right)\) for \(i \in \left\{ {1, 2, \ldots n} \right\}\). Moreover, for the bivariate distribution, \(F\left( {x_{ 1} ,x_{ 2} } \right)\) can be shown in terms of the Copula function and two different marginal joint cumulative distributions as:
In which, \(\theta\) is signified by the Copula parameter to calculate the dependency of two different variables \(x_{ 1}\) and \(x_{ 2}\), defined by the Pearson correlation coefficient and denoted as \(\rho\). The parameter \(\rho\), therefore, be obtained as:
In which, \(\mu_{{x_{1} }}\) and \(\mu_{{x_{2} }}\) are the mean values of \(x_{ 1}\) and \(x_{ 2}\), \(\sigma_{{ x_{ 1} }}\) and \(\sigma_{{ x_{ 2} }}\) reflect the standard deviation of \(x_{ 1}\) and \(x_{ 2}\), and \(f_{ 1} \left( {x_{ 1} } \right)\) and \(f_{ 2} \left( {x_{ 2} } \right)\) represent the marginal probability density function of \(x_{1}\) and \(x_{2}\), respectively.
Integrating Copula into Bayesian Network to create Copula Bayesian Network models supports the handling of complex decision-making problems, as it can fully consider the dependency within the variables in the Network based on an existing database. Considering data availability from objective data or elicitation process from decision makers, Copula can be appropriately determined by two different aspects: marginal distributions to fit the variables’ properties and Copula functions to model dependency structure. The way of determining marginal distributions and Copula functions is provided as follows:
(i) Determining marginal distributions
The most significant task to evaluate the best-fitted marginal distribution for the variables is properly describing a probability distribution. Three types of marginal distributions are typically used Normal distribution, Beta distribution, and lognormal distribution, see Table 2. To evaluate the precision of marginal distributions, the comparison tools like the Akaike Information Criterion (AIC), see Eq. (18) is applicable. The AIC with minimum value shows that the best marginal distribution is fitted.
where the likelihood is the maximum value for the model.
(ii) Determining the Copula function
Copula functions have unique characteristics such as tail dependency, symmetry, etc. Therefore, these Copula functions can be utilized to fit the various models and make an appropriate effect on the output’s viability. Besides, the Gaussian normal Copula, which is one of the most important and common Copula based on elliptical Copula, is presented as:
The Gaussian normal Copula is an \(n\)-dimensional generalization, easy to structure dependencies with uncertainty, and efficient in modeling bivariate distribution with a lack of data [45]. Therefore, Gaussian normal Copula among existing ones is selected in this study. The density function of Gaussian normal Copula is presented as:
Thus, the main difference between the Gaussian normal Copula and joint cumulative distribution function is that the variables in the Gaussian normal Copula follow different types of the marginal cumulative distribution function, which provide a better firing with a complex system.
In Eqs. (19) and (20), the \(\rho\) is the \(n\)-order symmetric positive definite with the \({\text{diag}}\left( \rho \right) = 1\), \(\phi_{ \rho }\) is a standard multivariate normal distribution with correlation matrix \(\rho\), \(\phi^{ - 1}\) denotes the inverse function standard univariate normal cumulative distribution function \(\xi = (\phi^{ - 1} (x_{ 1} ),\phi^{ - 1} (x_{ 2 } ), \ldots \phi^{ - 1} (x_{ n } ))\), and \(I\) represent the unit matrix. Assume that the dimension of \(n\) is equal to 2, the following Equation can determine the bivariate normal Copula, as:
where \(\rho_{ 12}\) represents the correlation coefficient of the bivariate standard normal distributions.
Step five: Bayesian network analysis
In this section, four types of analysis are introduced to show the proposed model can be effectively used in decision-making problems, including (i) model validation, (ii) correlation analysis, (iii) forward propagation analysis, and (iv) backward propagation analysis.
Model validation
The Kolmogorov–Smirnov test is performed to estimate the goodness of the obtained best-fitting marginal. The Kolmogorov–Smirnov test calculates the distance within the empirical distribution and approximates the distribution’s function, see Eq. (26). In the null hypothesis at a significant level of 0.5%, the data shape a unique distribution when \(h = 0\) and \(p\)-value \(> 0.05\).
Which \(F_{abs}\) follows the empirical distributions according to the collected data. \(F_{ exp} \left( x \right)\) follows the approximated distribution, and the supremum of the measurement distance is \({\varvec{Sup}}\).
Similarly, the empirical Copula depends on the given data engaged in examining if the Gaussian Copula makes for the best fitting of the data. Assume that \(\left( {x_{ i} ,y_{ i} } \right)\) \(\left( {i = 1,2, \ldots n} \right)\) are a sample from \(\left( {X,Y} \right)\). The empirical distribution functions of \(X {\text{and}} Y\) can be presented by \(F_{ n} \left( x \right)\) and \(G_{ n} \left( x \right)\), respectively. Accordingly, the empirical bivariate Copula is defined as:
where \(I_{\left[ , \right]}\) denotes the indicative function, and \(F_{ n} \left( {x_{ i} } \right) \le u,I_{{\left[ {F_{ n} \left( {x_{ i} } \right) \le u} \right]}} = 1\); otherwise, \(I_{{\left[ {F_{n } \left( {x_{i } } \right) \le u} \right]}} = 0\).
In addition, the empirical Copula can be compared with other types of Copulas according to the computation of Euclidean distance as the following Equation:
where \(u_{ i} = F_{ n } \left( {x_{i} } \right),\nu_{i} = G_{n} \left( {x_{i} } \right)\) \(\left( {i = 1,2, \ldots n} \right)\), \(\widehat{{Co_{ n} }}\left( {u_{ i} ,\nu_{ i} } \right)\) stands for the empirical Copula, and \(\widehat{Co}\left( {u_{ i} ,\nu_{ i} } \right)\) is the best-fitted Copula.
The correlation analysis
The Correlation analysis is to quantify the correlation degree between two variables or nodes. The standard correlation coefficient measures the linear relation between two variables and does not consider the impact of other variables. However, it may be the effect of the un-controlled variable on these two variables, which causes misleading outputs. To deal with this challenge, one can use the partial correlation coefficient to evaluate relationships between the two variables under the influence of other variables in the Network. For instance, variable \(z\) is related to two variables of \(x\) and \(y\), and the partial correlation analysis of the \(x\) and \(y\) can be computed according to standard correlation as presented in Eq. (29), in which the output is between zero and 1, meaning that zero shows that there is no linear relationship and 1 or − 1 denotes the highest or lowest linear relationships:
where \(\gamma_{ xz}\) denotes the correlation between two variables \(x\) and \(z\), \(\gamma_{ yz}\) is the correlation between the variables \(y\) and \(z\), \(\gamma_{ xy, z}\) is the correlation between \(x\) and \(y\); both are un-correlated with variable \(z\).
In addition, the Spearman ranking correlation has similarities with the partial correlation coefficient. If the result is closer to 1 or − 1, the relationships would be more robust. In addition, Spearman’s ranking correlation is significantly dependent on the ranking of each variable rather than the existing data, see Eq. (30):
where \(d_{i} = {\text{rank}}\left( {x_{i} } \right) - {\text{rank}}\left( {y_{i} } \right)\) is the gap in the ranks according to the element \(i\) is somehow the paired set of data \(x\) and \(y\), and \(n\) denotes the amount of data from the two variables \(x\) and \(y\).
Forward propagation
Forward propagation analysis is adding new evidence into the nodes with the exaptation of leaf nodes, in this case, Bayesian Network could be renovated by forwarding propagation. The goals provided in the leaf nodes evaluate how appropriate locations would exist for lift installation. This can be predicated in Eq. (31) following an assumption, which causes are mutually independent:
where (\(x_{ 1} ,x_{ 2} , \ldots .,x_{ n}\)) is a group of random variables denoted the causes, and \(z\) is the main goal in the Bayesian Network.
According to the Equation above, the marginal distribution with the leaf node’s mean and variance will be altered. Therefore, the best location can be evaluated compared to the effect in the Bayesian Network according to the different forward reasonings.
Backward propagation analysis
Backward propagation analysis is to diagnose the goal’s causes in complicated system dependency. Bayes' theorem is used to compute the posterior probability distribution of causes \(x _{i}\). The distribution variation shows how much a cause can contribute to the consequence, see Eq. (32). In general, the greater is the change, the more significant the cause is in the location determination of the system:
where \(P\left( {x_{ i} {|}z} \right)\) is the conditional probability for variable \(x_{ i}\) given evidence \(z\).
Application of study
Hospital service quality in a Metropolitan city is estimated by the proposed fuzzy Rough Copula Bayesian Network based on neighborhood operators’ decision-making approach. The health care service system has 200 beds capacity and 11 operation rooms. This hospital is allocated to the affected patients with COVID, with a high number of confirmed cases per 1 million people and considerable loss of medical service staff in the early stage of the SARS-CoV-2 outbreak. In addition, heavy daily patient circulation and an increasing number of confirmed severe cases requiring hospitalization are causing the hospital to face a lack of bed capacity. Increasing the workload of medical staff in a short period maximizes the need to sterilize the equipment and medical tools. Thus, this extensive workload is supposed to raise the number of confirmed cases and occupational accidents. As can be seen From Fig. 2, the alternatives and criteria of the present study to evaluate hospital service quality are obtained from [3, 5, 55].

The structural criteria and sub-criteria to assess hospital service quality
The evaluation of hospital service quality includes 6 criteria (C1–C6) and 33 sub-criteria (F1–F33). Decision-makers knowledge and technical information are employed to establish the Bayesian Network model. The criteria and sub-criteria will cause the center of attention, which is called the service quality index (QI). The QI explains as a probabilistic service quality index, which indicates how much the understudy hospital good is in service quality in a range of zero and one. The QI can quantitively show the service quality of hospitals. Besides, for a single hospital, QI ranks the subfactors from the best to worth, and subsequently, corrective actions can be presented to improve the worth subfactors. To create the influence diagram (cause and effect), in the Bayesian Network of all 33 subfactors, 6 criteria and QI are named root nodes, intermediate nodes, and leaf nodes, respectively.
Using the input data obtained from 800 patients in a private hospital in Tehran Metropolitan, the size of the decision-making problem would be \(33 \times 800\), which directly influences hospital service quality. In this problem, each problem has 800 data points to construct the marginal distribution that has been modeled in the Bayesian Network structure. The determined 33 variables obtained from the patients’ opinions act as evaluation indicators to evaluate the influence on the service quality index. It is also clear that the higher numerical value is showing much more promising with specific variables. Respecting the consistency of input data, all \(33 \times 800\) collected from patients' and decision makers' opinions are normalized in intervals zero and one.
Concerning the different input data, #\(C_{ 1} - \# C_{ 6}\) play the intermediates nodes in the influence diagram. Root cause analysis shows that the reason for intermediates nodes is based on the nodes #\(F_{ 1} - \# F_{ 33}\). As a hierarchical structure, the nodes at different levels contribute to the node QI, which is located at the highest level. Obtaining the value of QI is the first task that can be defined as a functional node. QI describes the hospital quality index qualitatively. Using qualitative decision makers opinions based on a fuzzy Rough set, the functional node of QI is defined as the weighted sum of six criteria or intermediate nodes #\(C_{ 1} - \# C_{ 6}\) following the Equation as \(QI = 0.1C_{ 1} + 0.1C_{ 2} + 0.25C_{ 3} + 0.1C_{ 4} + 0.15C_{ 5} + 0.3C_{ 6}\).
An extension of fuzzy Rough set theory based on fuzzy \(\beta \)-neighborhood operators using Eq. (14) is utilized to illustrate the way of obtaining importance weight set, that is, {0.1, 0.1, 0.25, 0.1, 0.15, 0.3}. The type of data in the is most of the fuzzy Rough theory-based applications is IFNs (intuitionistic fuzzy numbers), obtained from the language terms’ translation. However, it is rare to derive IFNs from the current data for numerical data with ambiguity and uncertainty in practice. Therefore, it asked 800 patients to express their opinions on the more important criteria as an extra task. The 62 patients out of 800 share their judgment in qualitative terms. The collected qualitative terms. There are a couple of approaches such as that use proposed Pythagorean fuzzy numbers (PFNs) as a proper alternative for IFNs, such as in [56, 57]. Therefore, all collected input qualitative terms are transferred into the PFNs and then aggregated into a single PFN. Since all PFNs are obtained from every single criterion, using Eq. (14), the crisp importance weight for all criteria is then computed.
According to the QI function, criteria \(C_{6}\) has a more significant impact on the result. Also, the linear function of QI shows the normalized evaluation of six intermediate nodes. As much as the #\(C_{ 1} - \# C_{ 6}\) is close to the 1, which means they have better performance in Bayesian Network. However, the main important task is ranking the subfactors to find out that with the lowest rank and further corrective actions to be improved. Therefore, a group of decision makers identified the variables which they will thoroughly evaluate by Copula Bayesian Network. To model QI uncertainty in Bayesian Network, the main task is finding the proper marginal distribution for the continuous variables #\(C_{ 1} - \# C_{ 6}\) and #\(F_{ 1} - \# F_{ 33}\), indicating the corresponding probability distribution data learning. The marginal distributions can properly fit the extreme values compared to the empirical distributions. As listed in Table 2, three marginal distributions are engaged to model the empirical distributions of continuous variables #\(C_{ 1} - \# C_{ 6}\) and #\(F_{ 1} - \# F_{ 33}\) from learning data. Mainly, the six intermediate nodes #\(C_{ 1} - \# C_{ 6}\) are somehow input variables, and the best marginal distributions would be fitted to their input data. The process of fitting marginal distribution for all 33 input variables. For every single variable, the AIC value of all three candidate distributions is compared to obtain the best-fitted marginal distributions considering the lowest AIC value. One of the main ways to obtain the marginal distributions is using the maximum likelihood approach. Table 3 provides the best-fitted marginal distribution for all input variables. These obtained marginal distributions should then be validated using Eq. (26). It is concluded that both marginal distributions and empirical data have compact shapes, which means that the marginal distributions have a high capability to be fitted to the empirical distributions. All marginal distributions are acceptable as they have a significant level of 0.5%, with \(h = 0\) and \(p\) value \(> 0.05\). Accordingly, the bivariate Copula with consideration of interpretability and symmetry is integrated into the structured Bayesian Network model to characterize dependency between the variables-based Eq. (28), and therefore by computing the Euclidean distance between the empirical distributions (Eq. (27)) and another type of Copula function including t-Copula Gumbel Copula, and Frank Copula, the effectiveness of normal Copula can be verified. To show the dependency of the variables to reach the hospital service quality index (QI) with consideration of multivariate Copula relevant criteria and subfactors, the Gaussian Copula is used (Eqs. 23, 24). The corresponding Copula Bayesian Network is depicted in Fig. 3.

The Copula Bayesian Network evaluates the hospital's quality index
To make a proper decision in assessing and evaluating the hospital quality service, correlation analysis, standard statistical analysis, and regression analysis is performed, in which the influence of each factor in the constructability of QI is assessed. Therefore, the factor with the highest correlation should be the lowest rank to receive corrective actions to improve the hospital service quality in the next assessment. The result of the studies above is provided in Table 4.
As it can be seen from Table 4, subfactor #\({F}_{ 24}\) (Hospital health caregivers and medical staff care for patients) has the lowest rank and needs to be improved by corrective actions. It is followed by #\({F}_{ 9}\) (Hospital has patient catering services), #\({F}_{ 13}\) (Hospital with professional medical staff), #\({F}_{ 26}\) (Medical staff for individual requirements of the patient), and #\({F}_{ 3}\)(Good ventilation in hospital wards). A comparison of the results reached by the proposed approach and a novel BWM-based method with an extension of belief theory [3] is performed, see Fig. 4. It can be concluded that the two approaches present different results. However, this study has merits in consideration of multiple types of distributions, Log-Normal, Normal, and Beta, rather than only the Normal distribution considered in [3], and distributing weights to experts to avoid bias of experts’ opinions applied. Hence, the results computed by the proposed method tend to be more reliable and credible than those of other methods, such as in [3], and others that are disabled to consider the aforementioned aspects. The correlation analysis between the strongest variables is presented in Fig. 5 ((QI-#\(F_{ 4}\)(E(QI|#\(F_{ 4} = 3.324 + 0.044{ }\# F_{ 4} - 0.137{ }\# F_{ 4}^{2} + 0.478{ }\# F_{ 4}^{3}\)), QI-#\(F_{ 21} ({\text{QI }}|{ }\# F_{ 21} = 3.317 + 0.008{ }\# F_{ 21} - 0.015{ }\# F_{ 21}^{2} + 0.001{ }\# F_{ 21}^{3} )\), and QI-#\(F_{ 27} ({\text{QI }}|{ }\# F_{ 27} = - 456.007 + 1897.006 \# F_{ 27} - 2571.050{ }\# F_{ 27}^{2} + 1160.961{ }\# F_{ 27}^{3} )\)), the sample is equal to 10,000).

A comparison study based on the present study and in [3]

The correlation analysis between the most robust variables
Another analysis is backward propagation using Eq. (32) is performed to obtain the optimal hospital quality index. As can be seen from Table 5, the results of the posterior probability of criteria and subfactors are provided. The correlation analysis between the most substantial variables is presented in Fig. 6. It can be understood that the optimal value of #\(C_{ 1} - \# C_{ 6}\) and #\(F_{ 1} - \# F_{ 33}\) to reach \(QI = 1\) will change the priority of receiving corrective actions for the sub-actors to improve the hospital service quality for the next assessment turn.

A comparison study before and after backward propagation
The last analysis is forward propagation or Copula Bayesian inference, which adds new evidence to the prior probability of variables. More specifically, the current version of the Network can continuously modify the newly added evidence(s). Therefore, the hospital quality index could be updated, subsequently, in the forward propagation using Eq. (27). It merely denotes that forward propagation is a supportive tool to update decision-making over time in different types of scenarios. In this study, we defined a scenario by changing the distributions of variables \(\#{F}_{11},\#{F}_{18}\), and #\({F}_{31}\) from lognormal into Beta distribution within parameters of \(\alpha =8.5, 11.5, a=0, \mathrm{and} \, b=1\). The result of the forward propagation analysis is provided in Table 6. The correlation analysis between the strongest variables is presented in Fig. 7.

A comparison study before and after forward propagation based on the defined scenario
According to the analysis that has been performed, decision makers can obtain which factors have the lowest rank and need corrective actions to be received. Moreover, it can be understood what the outstanding value of each factor is to reach the optimum service quality index and how the model can be updated and be dynamic over time. Besides, in the case of a couple of hospitals, they can be compared together based on the value obtained from the service quality index for every single hospital. This may also affect receiving the budget, award, and system reputation.
Comparison analysis
This subsection aims to determine the proposed methodology's feasibility and practicality via comparison analysis with initially two standard MCDM methods, and then with regular BN. In this subsection, the result of the proposed approach is compared with three different methods, including BWM [58], TOPSIS [59], and regular BN. The comparison outcomes among the proposed approach, BWM, and TOPSIS are presented in Table 7, illustrated in Fig. 8. This reflects that the priority of all solutions is entirely consistent with the first highest of the solutions. It simply means that the first solution in all methods is the same. This shows that the decision makers, based on some realistic restrictions such as time and complexity, can also rely on other types of methods. However, as reflected by the results of the two selected other models, this deduction is not valid for selecting the optimal solution.

The comparison of the proposed approach with BWM, and TOPSIS
In addition, the Spearman rank correlation coefficient is computed between each pair of methods, displayed in Table 8 to accurately reflect the conformity of the importance ranking of methods. Clearly, the greater Spearman correlation coefficient simply means higher conformity between the ranking techniques. As presented in Table 8, the ranking conformity of the proposed approach with other methods, BWM and TOPSIS, is greater than the ranking conformity with the rest of the pairwise comparisons. The conformity of failure modes priorities in comparison to the proposed approach with three other methods proves that the developed approach works correctly in the same direction as the other three methods, while the slight differences affirm the excellence proposed approach method due to its more robust mathematical structure versus the other methods. As mentioned in the methodology section, a physical explanation for this is that the proposed approach considers the different types of uncertainty, including process, model, subjective and objective input data.
According to the Spearman correlation coefficient, the importance weighting in descending order is provided, and the total ranking of the proposed approach with BWM and TOPSIS is depicted in Fig. 9. Thus, compared with BWM and TOPSIS, the proposed approach in this study is much more reliable and applicable in identifying the inter-relationship between different factors.

The importance ranking of among each pair of the proposed approach with BWM, and TOPSIS
In the next comparison analysis, we developed regular BN considering the same input data and compared the outcomes with the proposed Fuzzy Rough Copula Bayesian Network model. As it can be seen from Fig. 10, an illustration of regular BN is developed using the GeNIe Modeler software package (https://www.bayesfusion.com/genie/). It should be added that, in the previous study conducted by authors [60], the regular BN is applied to assess the assess the quality index of a medical service. The input information for relevant alternatives (child nodes in Bayesian Network) is obtained from objective and subjective data. As an example, for the node alternative “Hospital staff are neat and tidy”, the percentage of how much this sentence is correct is obtained. Subsequently, the best-fitted distraction derived is the normal distribution. This process is continued for all nodes to obtain the best-fitted disruptions based on objective data or subjective opinions from decision makers. For the node obtained objectively, “Hospital has a professional medical staff”. It should be added that more than 90% of the data points are less than 80%, and the data focus on average values. The criticality analysis is carried out in the regular BN model to show the priority of failure modes and their contributions to the quality index. As it can be seen from Table 9, the failure mode priority in the proposed approach and regular BN is different, and the fact is that the proposed approach considers both objective and subjective uncertainty while the regular BN does not. The Spearman rank correlation coefficient is derived as 0.804489, which is less than the Spearman rank correlation coefficient of BWM and TOPSIS. However, regular BN, due to its capability to be updated over time, has much more advantages compared to the common MCDM tools.

An illustration of regular BN is developed using GeNIe Modeler software
Conclusion
This study proposes integrating the Copula Bayesian Network and fuzzy Rough set theory to assess, evaluate, and manage hospital service quality under an uncertain environment. The hospital service quality evaluation problem has been investigated by different researchers and several integrated methods. The current study used the Copula Bayesian Network to analyze the service quality, where a novel extension of fuzzy Rough set theory based on neighborhood operators is employed to tackle the subjective uncertainty of the problem. The designed framework integrates the Copula Bayesian Network and extends fuzzy rough set theory could rank a group of alternatives considering different criteria. In the present work, it is derived that the \({F}_{ 24}\) (Hospital health caregivers and medical staff care for patients) have the lowest rank and need to be improved by corrective actions. It is followed by #\({F}_{ 9}\) (Hospital has patient catering services), #\({F}_{ 13}\) (Hospital with professional medical staff), #\({F}_{ 26}\) (Medical staff for individual requirements of the patient), and #\({F}_{ 3}\)(Good ventilation in hospital wards).
Based on the results obtained from the proposed approach, the following merits and advantages compared to MCDM tools can be highlighted:
-
Copula Bayesian Network model can provide a better understanding of the causalities and the features in a complex system like hospital quality service, which many factors play a role in this regard.
-
Copula Bayesian Network can also serve as a more convicting decision-making tool under objective uncertainty using different distributions and performing inference analysis over time.
-
Utilizing a novel extension of fuzzy Rough set theory as a powerful tool can properly deal with inaccuracy. The advantage is that this does not necessarily require any prior knowledge beyond the data set, and in some studies with a lack of data could be a reliable choice.
-
Using a new neighborhood operator in the proposed extension of fuzzy rough set theory can adequately satisfy reflexivity.
However, during the study, a couple of challenges have arisen in this study, which need to be considered as a direction for future work. First, in this study, the Clayton Copula is not evaluated as a tool; therefore, this should be considered with the three other types of Copula functions. Secondly, in this study, a method is proposed based on dealing with a combination of subjective and objective uncertainties, that is, while a combination of them is under discussion in literature; thus, it would be better to propose a method much more objectively or subjectively. Finally, using a hybrid methodology has extensive advantages in dealing with a complex decision-making problem; however, in practice, as a limitation, it makes time-consuming and cannot be a proper tool in an emergency decision-making problem. Therefore, such hybrid approaches need to be coded as an application. As the future direction, the probability theory can be integrated into MCDM methods alongside fuzzy concepts. Moreover, evaluating the service quality of different departments in a hospital is a potential topic for further studies.
Data availability
All data generated or analysed during this study are included in this published article.
References:
Akdag H, Kalaycı T, Karagöz S, Zülfikar H, Giz D (2014) The evaluation of hospital service quality by fuzzy MCDM. Appl Soft Comput 23:239–248. https://doi.org/10.1016/j.asoc.2014.06.033
Torkzad A, Beheshtinia MA (2019) Evaluating and prioritizing hospital service quality. Int J Health Care Qual Assur 32:332–346. https://doi.org/10.1108/IJHCQA-03-2018-0082
Fei L, Lu J, Feng Y (2020) An extended best-worst multi-criteria decision-making method by belief functions and its applications in hospital service evaluation. Comput Ind Eng 142:106355. https://doi.org/10.1016/j.cie.2020.106355
Mutlu M, Tuzkaya G, Sennaroğlu B (2017) Multi-criteria decision making techniques for healthcare service quality evaluation: a literature review. Sigma J Eng Nat Sci 35:501–512
Chang TH (2014) Fuzzy VIKOR method: a case study of the hospital service evaluation in Taiwan. Inf Sci (NY) 271:196–212. https://doi.org/10.1016/j.ins.2014.02.118
Kadoić N, Šimić D, Mesarić J, Ređep NB (2021) Measuring quality of public hospitals in Croatia using a multi-criteria approach. Int J Environ Res Public Health. https://doi.org/10.3390/ijerph18199984
Karasan A, Erdogan M, Cinar M (2022) Healthcare service quality evaluation: an integrated decision-making methodology and a case study. Socioecon Plan Sci. https://doi.org/10.1016/j.seps.2022.101234
Li H, Yazdi M, Huang C-G, Peng W (2022) A reliable probabilistic risk-based decision-making method: Bayesian technique for order of preference by similarity to ideal solution (B-TOPSIS). Soft Comput 26:12137–12153. https://doi.org/10.1007/s00500-022-07462-5
Erdogan M, Ayyildiz E (2022) Comparison of hospital service performances under COVID-19 pandemics for pilot regions with low vaccination rates. Expert Syst Appl. https://doi.org/10.1016/j.eswa.2022.117773
Li X, Han Z, Yazdi M, Chen G (2022) A CRITIC-VIKOR based robust approach to support risk management of subsea pipelines. Appl Ocean Res 124:103187. https://doi.org/10.1016/j.apor.2022.103187
Baki B, Peker I (2015) An integrated evaluation model for service quality of hospitals: a case study from Turkey, undefined
Lupo T (2016) A fuzzy framework to evaluate service quality in the healthcare industry: an empirical case of public hospital service evaluation in Sicily. Appl Soft Comput J 40:468–478. https://doi.org/10.1016/j.asoc.2015.12.010
Chen CT, Hung WZ (2018) Evaluating the service quality of hospital by using TOPSIS with interval type-2 fuzzy sets. In: 2017 international conference fuzzy theory its applications IFUZZY 2017, Institute of Electrical and Electronics Engineers Inc., pp 1–5. https://doi.org/10.1109/iFUZZY.2017.8311786
Perçin S (2019) A combined fuzzy multicriteria decision-making approach for evaluating hospital website quality. J Multi-Criteria Decis Anal 26:129–144. https://doi.org/10.1002/mcda.1671
Yucesan M, Gul M (2020) Hospital service quality evaluation: an integrated model based on Pythagorean fuzzy AHP and fuzzy TOPSIS. Soft Comput 24:3237–3255. https://doi.org/10.1007/s00500-019-04084-2
Yazdi M, Mohammadpour J, Li H, Huang H-Z, Zarei E, Pirbalouti RG, Adumene S (2023) Fault tree analysis improvements: a bibliometric analysis and literature review. Qual Reliab Eng Int. https://doi.org/10.1002/qre.3271
Watson SI, Lilford RJ, Sun J, Bion J (2021) Estimating the effect of health service delivery interventions on patient length of stay: a Bayesian survival analysis approach. J R Stat Soc Ser C Appl Stat 70:1164–1186. https://doi.org/10.1111/rssc.12501
Li H, Yazdi M (2022) Dynamic decision-making trial and evaluation laboratory (DEMATEL): improving safety management system BT—advanced decision-making methods and applications in system safety and reliability problems: approaches, case studies, multi-criteria decision-maki. In: Li H, Yazdi M (eds) Springer International Publishing, Cham, pp 1–14. https://doi.org/10.1007/978-3-031-07430-1_1
dos Santos BM, Godoy LP, Campos LMS (2019) Performance evaluation of green suppliers using entropy-TOPSIS-F. J Clean Prod 207:498–509. https://doi.org/10.1016/j.jclepro.2018.09.235
Chauhan A, Golestani N, Yazdi M, Njue JCW, Abbassi R, Salehi F (2023) A novel integrated methodology for human reliability assessment in hydrogen fuelling stations. Int J Hydrog Energy. https://doi.org/10.1016/j.ijhydene.2022.12.181
Mou Q, Xu Z, Liao H (2016) An intuitionistic fuzzy multiplicative best-worst method for multi-criteria group decision making. Inf Sci (NY) 374:224–239. https://doi.org/10.1016/j.ins.2016.08.074
Pan Y, Zhang L, Koh J, Deng Y (2021) An adaptive decision making method with copula Bayesian network for location selection. Inf Sci (NY) 544:56–77. https://doi.org/10.1016/j.ins.2020.07.063
Yazdi M (2019) Improving failure mode and effect analysis (FMEA) with consideration of uncertainty handling as an interactive approach. Int J Interact Des Manuf 13:441–458. https://doi.org/10.1007/s12008-018-0496-2
Yazdi M, Kabir S (2017) A fuzzy Bayesian network approach for risk analysis in process industries. Process Saf Environ Prot 111:507–519. https://doi.org/10.1016/j.psep.2017.08.015
Adedigba SA, Khan F, Yang M (2017) Dynamic failure analysis of process systems using principal component analysis and Bayesian network. Ind Eng Chem Res 56:2094–2106. https://doi.org/10.1021/acs.iecr.6b03356
Yazdi M, Golilarz NA, Nedjati A, Adesina KA (2022) Intelligent fuzzy Pythagorean Bayesian decision making of maintenance strategy selection in offshore sectors BT—intelligent and fuzzy techniques for emerging conditions and digital transformation. In: Kahraman C, Cebi S, Cevik Onar S, Oztaysi B, Tolga AC, Sari IU (eds) Springer International Publishing, Cham, pp 598–604
Musharraf M, Smith J, Khan F, Veitch B, MacKinnon S (2016) Assessing offshore emergency evacuation behavior in a virtual environment using a Bayesian Network approach. Reliab Eng Syst Saf 152:28–37. https://doi.org/10.1016/j.ress.2016.02.001
Musharraf M, Hassan J, Khan F, Veitch B, MacKinnon S, Imtiaz S (2013) Human reliability assessment during offshore emergency conditions. Saf Sci 59:19–27. https://doi.org/10.1016/j.ssci.2013.04.001
Yazdi M, Khan F, Abbassi R, Quddus N (2022) Resilience assessment of a subsea pipeline using dynamic Bayesian network. J Pipeline Sci Eng 2:100053. https://doi.org/10.1016/j.jpse.2022.100053
Wu WS, Yang CF, Chang JC, Château PA, Chang YC (2015) Risk assessment by integrating interpretive structural modeling and Bayesian network, case of offshore pipeline project. Reliab Eng Syst Saf 142:515–524. https://doi.org/10.1016/j.ress.2015.06.013
Ping P, Wang K, Kong D, Chen G (2018) Estimating probability of success of escape, evacuation, and rescue (EER) on the offshore platform by integrating Bayesian Network and Fuzzy AHP. J Loss Prev Process Ind 54:57–68. https://doi.org/10.1016/j.jlp.2018.02.007
Yazdi M, Khan F, Abbassi R, Rusli R (2020) Improved DEMATEL methodology for effective safety management decision-making. Saf Sci 127:104705. https://doi.org/10.1016/j.ssci.2020.104705
Shekari E (2017) Risk-based evaluation of pitting corrosion in process facilities, Memorial University of Newfoundland, 2017. http://research.library.mun.ca/id/eprint/13051. Accessed June 2021
Hänninen M, Valdez Banda OA, Kujala P (2014) Bayesian network model of maritime safety management. Expert Syst Appl 41:7837–7846. https://doi.org/10.1016/j.eswa.2014.06.029
Khakzad N (2019) System safety assessment under epistemic uncertainty: using imprecise probabilities in Bayesian network. Saf Sci 116:149–160. https://doi.org/10.1016/j.ssci.2019.03.008
Li H, Yazdi M (2022) Integration of the Bayesian network approach and interval type-2 fuzzy sets for developing sustainable hydrogen storage technology in large metropolitan areas BT—advanced decision-making methods and applications in system safety and reliability problem. In: Li H, Yazdi M (eds). Springer International Publishing, Cham, pp 69–85. https://doi.org/10.1007/978-3-031-07430-1_5
Pan Y, Ou S, Zhang L, Zhang W, Wu X, Li H (2019) Modeling risks in dependent systems: a Copula-Bayesian approach. Reliab Eng Syst Saf 188:416–431. https://doi.org/10.1016/j.ress.2019.03.048
Zilko AA, Kurowicka D, Goverde RMP (2016) Modeling railway disruption lengths with Copula Bayesian Networks. Transp Res Part C Emerg Technol 68:350–368. https://doi.org/10.1016/j.trc.2016.04.018
Radzikowska AM, Kerre EE (2002) A comparative study of fuzzy rough sets. Fuzzy Sets Syst 126:137–155. https://doi.org/10.1016/S0165-0114(01)00032-X
Fenton NE, Martin D (2013) Risk assessment and decision analysis with Bayesian networks
Zarei E, Yazdi M, Abbassi R, Khan F (2019) A hybrid model for human factor analysis in process accidents: FBN-HFACS. J Loss Prev Process Ind. https://doi.org/10.1016/j.jlp.2018.11.015
Yazdi M (2019) Ignorance-aware safety and reliability analysis : A heuristic approach. Qual Reliab Eng Int 36:652–674. https://doi.org/10.1002/qre.2597
Dubois D, Prade H (1990) Rough fuzzy sets and fuzzy rough sets. Int J Gen Syst 17:191–209. https://doi.org/10.1080/03081079008935107
Dai J, Hu H, Wu WZ, Qian Y, Huang D (2018) Maximal-discernibility-pair-based approach to attribute reduction in fuzzy rough sets. IEEE Trans Fuzzy Syst 26:2174–2187. https://doi.org/10.1109/TFUZZ.2017.2768044
Mi JS, Zhang WX (2004) An axiomatic characterization of a fuzzy generalization of rough sets. Inf Sci (NY) 160:235–249. https://doi.org/10.1016/j.ins.2003.08.017
Ma L (2016) Two fuzzy covering rough set models and their generalizations over fuzzy lattices. Fuzzy Sets Syst 294:1–17. https://doi.org/10.1016/j.fss.2015.05.002
Yang B, Hu BQ (2019) Fuzzy neighborhood operators and derived fuzzy coverings. Fuzzy Sets Syst 370:1–33. https://doi.org/10.1016/j.fss.2018.05.017
Yao Y, Yao B (2012) Covering based rough set approximations. Inf Sci (NY) 200:91–107. https://doi.org/10.1016/j.ins.2012.02.065
Ye J, Zhan J, Ding W, Fujita H (2021) A novel fuzzy rough set model with fuzzy neighborhood operators. Inf Sci (NY) 544:266–297. https://doi.org/10.1016/j.ins.2020.07.030
D’eer L, Cornelis C, Godo L (2017) Fuzzy neighborhood operators based on fuzzy coverings. Fuzzy Sets Syst 312:17–35. https://doi.org/10.1016/j.fss.2016.04.003
Gholamizadeh K, Zarei E, Omidvar M, Yazdi M (2022) Fuzzy sets theory and human reliability: review, applications, and contributions BT—linguistic methods under fuzzy information in system safety and reliability analysis. In: Yazdi M (ed) Springer International Publishing, Cham, pp 91–137. https://doi.org/10.1007/978-3-030-93352-4_5
Yazdi M (2022) A brief review of using linguistic terms in system safety and reliability analysis BT—linguistic methods under fuzzy information in system safety and reliability analysis. In: Yazdi M (ed). Springer International Publishing, Cham, pp 1–4. https://doi.org/10.1007/978-3-030-93352-4_1
D’Angelo GM, Weissfeld LA (2013) Application of copulas to improve covariance estimation for partial least squares. Stat Med 32:685–696. https://doi.org/10.1002/sim.5533
Morales-Nápoles O, Paprotny D, Worm D, Abspoel-Bukman L, Courage W (2017) Characterization of precipitation through copulas and expert judgement for risk assessment of infrastructure. ASCE-ASME J Risk Uncertain Eng Syst Part A Civ Eng 3:04017012. https://doi.org/10.1061/ajrua6.0000914
Li L, Benton WC (2003) Hospital capacity management decisions: Emphasis on cost control and quality enhancement. Eur J Oper Res 146:596–614. https://doi.org/10.1016/S0377-2217(02)00225-4
Yazdi M (2019) Acquiring and sharing tacit knowledge in failure diagnosis analysis using intuitionistic and Pythagorean assessments. J Fail Anal Prev 19:369–386. https://doi.org/10.1007/s11668-019-00599-w
Yazdi M (2022) Linguistic methods under fuzzy information in system safety and reliability analysis. Springer, Cham. https://doi.org/10.1007/978-3-030-93352-4%0A%0A
Rezaei J (2015) Best-worst multi-criteria decision-making method. Omega (United Kingdom) 53:49–57. https://doi.org/10.1016/j.omega.2014.11.009
Li H, Yazdi M (2022) Advanced decision-making methods and applications in system safety and reliability problems. Springer, Cham. https://link.springer.com/book/9783031074295. Accessed June 2021
Yazdi M, Adumene S, Zarei E (2022) Introducing a probabilistic-based hybrid model (fuzzy-BWM-Bayesian network) to assess the quality index of a medical service BT—linguistic methods under fuzzy information in system safety and reliability analysis. In: Yazdi M (ed). Springer International Publishing, Cham, pp 171–183. https://doi.org/10.1007/978-3-030-93352-4_8
Acknowledgements
This study was sponsored by the Postdoctoral Research Foundation of China (2021M703686), Guangdong Basic and Applied Basic Research Foundation (2021A1515110306), and Fundamental Research Funds for the Central Universities, Sun Yat-sen University (22qntd1711).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Li, H., Yazdi, M., Huang, HZ. et al. A fuzzy rough copula Bayesian network model for solving complex hospital service quality assessment. Complex Intell. Syst. 9, 5527–5553 (2023). https://doi.org/10.1007/s40747-023-01002-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-023-01002-w