
Abstract
Screen printing has been adopted for fabricating a wide variety of electronic devices. However, the printing defects and reliability have been an obstacle for industrialization of printed electronics. In this research, the artificial intelligence (AI) model was developed and integrated with the in-house roll-to-roll screen printing system to detect smearing defect, which is one of the main defects of screen printing. The U-Net architecture was adopted, and a total of 19 models were designed with model sizes ranging from 8E + 3 to 3E + 7 number of parameters. Their performances as validation mean Intersection over Union (IoU) were analyzed, and the optimal model was chosen with a validation mean IoU of 95.1% and a number of parameters of 8E + 6. The printed line images were evaluated by the AI model for various printing conditions, such as printed line widths, printing paste premixing, printing speeds, and printed line directions, which showed that the model could effectively detect the smearing defects. Also, the AI model capabilities were investigated for repeated printing, which demonstrated that it can be used for the reliability assessment of the screen printing process.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The growing demand for green manufacturing technologies for electronics has fueled interest in printing technologies. While photolithography is a conventional manufacturing technology that generates a lot of waste and has many process steps, printing processes [1] are eco-friendly methods for manufacturing electronics because they simplify the production steps, reduce material waste, and are carried out in the ambient atmosphere rather than in vacuums or inert gases. Additional, new functional requirements for electronics have favored roll-to-roll manufacturing using flexible film substrates, reducing the weight and thickness of the devices while adding flexibility that gives new perspectives for its applications [2] and satisfying a mass-production demand.
Screen printing has been the most common technique for flexible and printed electronics and was adopted for fabricating green energy devices such as photovoltaics [3,4,5], energy storage devices [6], printed circuit boards (PCBs) [7, 8], front grid electrodes [9, 10], tactile sensors [11], thin-film transistors [12, 13], and display color filters [14]. Screen printing has become widely used with the roll-to-roll technique, which upscales production yield to the mass production level crucial for areas such as the internet of things (IoT) [15], smart packaging [16], and solar cells [17, 18].
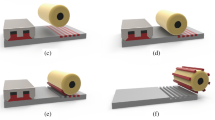
The screen printing process consists of the following steps: ink spreading, squeegee printing, screen mask snap off, and sintering. Initially, the screen mask is set up with the gap for the substrate, and the scrapper spreads the ink uniformly along the printing screen mask. Then, the squeegee pushes the screen mask toward the substrate and, while moving laterally, forces the ink through the screen mesh. In the area behind the moving squeegee, the screen mask snaps off from the substrate due to mesh tension, and the ink is left on the substrate and ready for sintering. The principal scheme of the screen printing process is shown in Fig. 1a.

a The roll-to-roll (R2R) screen printing process, and b R2R screen printing equipment quality control cameras position
Defect-free and reliable printing result is critical for the mass production and industrialization of screen printing in the field of printed electronics. These may be enhanced by controlling the screen printing process [19] and printing paste [20]. The repeated printing can be analyzed by the reliability assessment, which may help to reveal the faulty regimes with poor printing quality [21, 22]. During screen printing, printing defects may happen, in particular, the smearing of the printed lines, which may cause the exaggeration of line width. The printing paste with lower viscosity has a higher risk of smearing defects because it can contaminate the backside of the screen mask more easily than the more viscous printing paste. Also, the phase separation effect in the printing paste due to storage can be effectively mitigated by printing paste premixing leading to a reduced probability of the smearing defect occurrence.
To effectively assess the reliability of the screen printing process, the captured image of the printed line should be analyzed for detecting defects. Conventional approaches [23] involve comparison methods such as template matching and other image processing techniques to extract relevant information for assigning defective areas. These methods are fast but require a reference image, template alignment and may have recognition errors if image capturing conditions change. In this regard, AI approaches [24] became an attractive field in machine vision, and deep neural networks (DNN), including the image classification, object detection, and image segmentation, can solve complex tasks in defect detection. Depending on the size of the inspected area and the type of the defect, the assessment may be a defect classification using the whole image or image patches [25], a local defect detection or localization [26, 27], and a continuous or irregular shape defect image segmentation [28]. These DNN methods mainly require supervised training using a custom-built data set with the images of the defects and corresponding labels. The image classification models are suitable for predicting whether the defects are presented in the captured image. However, if a quantitative assessment is required, the object detection AI models, which output defects count and position, are preferable. If the defects are non-separable, object detection use is inappropriate, and the whole image should be segmented pixel-wise. One of the most popular DNN segmentation models is U-net [29], initially used in the bio-medical field, known for requirements of larger image sizes with highly detailed images for segmentation and precise segmentation accuracy. In this model, the problem of the spatial information loss is addressed by utilizing encoder-decoder architecture. Encoder, with help of pooling, gradually compresses the original image into lower resolution but with higher channel depth, and the decoder is trying to reconstruct the original image by up-sampling it to the original size.
This study aims the development of AI model for detecting smearing defect during screen printing, integrated with the in-house roll-to-roll screen printing system as green manufacturing technology. The U-net architecture for segmenting printed line images was adopted and optimized, and the performance of the AI model was analyzed for various printing conditions.
2 Experimental Setup
2.1 R2R Screen Printing Equipment
The printing experiments were done using the in-house roll-to-roll screen printing system capable of precise tension and registration control. It consists of the following units: a web transportation unit, including unwinder, web guiders, in-feeder, out-feeder, rewinder, idle rollers, load cells to measure tension, and web cleaner and deionizer; screen printing unit, including substrate stage, alignment camera stage, X–Y–Θ stage, screen mask stage; and drying and sintering unit, including heat sintering chambers with a heat plate and hot air generator. The design process of the roll-to-roll web transportation unit and the alignment process during screen printing were described in previously published papers [30, 31]. Additionally, this system was equipped with two charge-coupled device (CCD) cameras placed right after the screen printing unit with a resolution of 1280 × 1024 (width × height), one-pixel size of 2.725 µm/pixel, and field of view 3.5 × 2.8 mm (width × height) as shown in Fig. 1b. After each printing session, the two images were captured and processed for printed line smearing area measuring.
2.2 Screen Printing Mask Design
The screen mask for printing was designed as shown in Fig. 2a. It contains lines with widths from 50 to 200 µm with 500 µm pitch and various angles to the squeegeeing direction. The design was produced on the screen mask with 325 lpi stainless steel mesh with a thickness of 58 µm and an emulsion layer with a thickness of 14 µm mounted onto a 650 × 650 mm aluminum frame.

a Screen printing mask design and printed line images of 100 µm width captured for machine direction and cross direction by the b rear camera and c front camera, respectively
2.3 Screen Printing Paste
The FTL-6010S (FP Co. Ltd.) silver printing paste for fine pattern screen printing was used. It contains 0.3–3 µm silver flake particles with polyester binder, and ethyl cyanoacrylate (ECA) solvent. The declared printing paste viscosity η is 47.87 Pa s (at 50 1/s shear strain rate) and the thixotropy is 2.35 (at 5 1/s and 50 1/s shear strain rate ration). The rheology of the printing paste was measured by the Thermo Scientific HAAKE MARS III (Rheology Solutions Pty Ltd.) rheometer equipped with a parallel plates measuring geometry tool. The lower plate was 35 mm in diameter (TMP35) and the upper plate 35 mm in diameter with a shaft (P35 Ti L) and a 1 mm gap in between them. The measurements of the viscosity η and shear stress τ were done under a constant temperature of 20 °C, shear strain rate γ̇ from 0.0001 to 500 1/s, and an ascending and descending time of 90 s each (Fig. 3).

The screen printing paste’s rheological properties: dynamic viscosity
2.4 Screen Printing Process
To investigate the smearing effect at various printing conditions, the printing sessions were performed, which consisted of 200 consecutive prints with a tact time of 60 s.
Using the ARE-310 (THINKY U.S.A., Inc) planetary mixer, the printing paste was premixed, which includes the mixing step of 30 s at 2000 rpm and degassing step of 30 s at 2200 rpm. The nonpremixed paste was used as-is from the storage container. Besides various printing speeds, the other printing conditions were fixed as follows: the printing gap was set to 3 mm, the printing load was 13.2 kgf. The squeegee (Unitex® Ulon HP 500/9) with D-cut with Land profile (1 mm Land width) made of NDI (Naphthalene Diisocyanate) and hardness 80°–85° (Shore A°) was 300 mm in width. As a substrate, clear polyester (PET) film XG7AH7 (Toray Advanced Materials Korea, Inc.) with a thickness of 125 µm and width of 300 mm was used with a tension of 3 kgf. Web feeding was performed at a length of 200 mm. Sintering was secured by the drying and sintering unit at temperatures of 150 °C for the heat plate and 220 °C for the hot air blower. The screen printing parameters are summarized in Table 1.
3 Line Smearing Assessment Using AI Semantic Segmentation Model
To investigate the printed line smearing effect, the deep convolutional neural network was built and trained using a custom data set.
3.1 Data set
The data set was composed of printed line images with and without smearing (Fig. 4a) and a corresponding label image with areas labeled as smearing, printed line, and background, shown as black, gray, and white areas (Fig. 4b). In total, 20 original printed line images were labeled and split into training and validation data sets, with 15 images (75%) for training and 5 images (25%) for validation. Before training, the label images were one-hot encoded so the vectors [1, 0, 0], [0, 1, 0], [0, 0, 1] correspond to smearing, printed lines, and background areas respectively.

Image segmentation data set, learning process, and model optimization: a original printed line image with the smearing defect from the validation data set, b labeled data for training the model, where smearing, printed line, and background are shown as black, gray, and white areas respectively, c segmentation result predicted by the model, d training process of the segmentation model, and e the segmentation model architecture optimization
To prevent overfitting during training, the images and label images were augmented using the following effects: horizontal and vertical flip, rotation, brightness and contrast adjustments, and Gaussian blur [32].
3.2 Model Architecture and Learning Process
The DNN model concept of the U-Net model was adopted, and the model architecture is shown in Fig. 5. It contains encoder and decoder parts that are linked by skip connections to prevent the loss of spatial information during upscaling. Initially, the model was set up to input the original image from the camera with the dimensions 1024 × 1280 × 3, which was then scaled to a range of [0,1] and fed to the encoder and decoder. The encoder consisted of sequentially alternated convolutional blocks with convolutional 2D layers (Conv2D), rectified linear unit (ReLU) activation functions, and downsampling blocks with max pooling and dropout layers. The decoder consisted of the same structure of sequentially alternated convolutional blocks and upsampling blocks. The upsampling blocks consisted of transposed convolution layers (Conv2DTranspose) [33] to improve feature reconstruction when upsampling and a concatenation layer and dropout layer. The concatenation layer connected the output of each downsampling level of the encoder with the corresponding feature level of the decoder by concatenating ReLU activation outputs with Conv2DTranspose outputs to preserve spatial information, which would degrade with the model’s depth. The output layer consisted of a Conv2D layer with three filters and the softmax activation function, which is commonly used for multiclass classification, where each pixel should be classified as belonging to a single class. The output of the model has the shape 1024 × 1280 × 3, composed of a 1024 × 1280 pixel grid and 3 one-hot encoded predicted labels.

U-Net-like printed line image segmentation model architecture
Initially, the categorical cross entropy was used as a loss function, and it was modified with precalculated weights based on the class imbalance of the training data set. However, focal loss [34] showed better convergence and did not require the explicit calculation of weighting coefficients. It handled misclassified examples by down-weighting easy-to-classify examples so that the gradient was generated mainly by hard-to-classify examples.
The mean IoU metric, which better shows the performance of the segmentation with a class-imbalanced data set, was used to evaluate the model. The learning process is shown in Fig. 4d, and the result is shown in Fig. 4c. Table 2 contains the model hyperparameters summary.
The model architecture utilizes padding in convolutional layers to keep the dimensions of the output predictions the same as input images. Network sizes with various depths and number of filters in convolutional layers were trained, and their performances as validation data set mean IoU were summarized in Fig. 4e. Totally 19 models were analyzed with model depths from 5 to 11 convolutional blocks and with 4–5 model sizes for each model depth by doubling the number of filters in each convolutional layer (Table 3). For example, the basic architecture for a five-block network was set to 4–8–16–8–4 combination of filters for convolutional layers in corresponding blocks. And to increase the size of the basic model, the number of filters was iteratively doubled (8–16–32–16–8 combination of filters for the next size model). So this allowed to generate a wide range of model sizes starting from 8E + 3 up to 3E + 7 number of parameters. For the five-block model depth, the models with sizes 8E + 3, 3E + 4, 1E + 5, 5E + 5, and 2E + 6 number of parameters demonstrated 82.1%, 90.9%, 92.0%, 94.3%, and 94.1% performances correspondingly. As the total number of parameters increases, the validation mean IoU of the trained model improves without sights of overfitting, suppressed by heavy augmentation and dropout performed. The models with seven, nine, and eleven-block depths have a similar trend to the five-block models but with a smaller gap in validation mean IoU among the model sizes. While there is a slight fluctuation in the performances of the similar size networks, it is negligible due to the randomness of the weights initialization, which affects the convergence of the model at every training attempt. The further increase of the model depth does not contribute to the model performance, however may become a bottleneck due to exponentially increased computational burden and thus the time required during inference and dedicated GPU memory. Even shallower networks have reached sufficient performances comparable to the models with deeper architectures, so the optimal size of the DNN network for printed defect segmentation lies in the range of 2E + 6 to 8E + 6 parameters. While training smaller models, the initial dropout rate of 0.5 implemented for deeper models was too high, which affected their performance or even prevented the smaller models from convergence during training, and should have been reduced. Also, some larger models with the initial convolutional block with 64 filters required the batch size to be reduced from 5 to 2 images per batch due to the GPU memory exhaustion. Based on the discussion above, the nine-depth model with 32–64–128–256–512–256–128–64–32 filters combination was chosen, which has a competitively high performance and a reasonable number of parameters, 95.1% and 8E + 6 respectively.
3.3 Model Integration with the Screen Printing System
The screen printing smearing detection model was deployed on a computer integrated with the roll-to-roll screen printing system through an Ethernet connection, as shown in Fig. 6a, b. While obtained images of printed lines were saved onto the network drive in the computer with the AI model, the python script was segmenting the images and calculating the relative area for each label: background, printed line, and smearing. This data is then sent to the roll-to-roll screen printing system.

The printed lines smearing detection model integration: a the in-house roll-to-roll screen printing system, and b the integration scheme of the AI model
4 Results
4.1 Smearing Area Measuring
The nine-block DNN model with the 32–64–128–256–512–256–128–64–32 numbers of filters per block architecture, as described in Sect. 3.2, was applied and the segmentation results at the 100th time print under various conditions are shown in Fig. 7. The AI model was capable of recognizing the printed lines with various sizes of the smearing defect depending on the line widths (Fig. 7a), printing paste premixing conditions (Fig. 7b), printing speeds (Fig. 7c), and printed lines directions (Fig. 7d). For the various line widths (Fig. 7a), the smearing was estimated as 11.6%, 19.9%, and 19.7% for 50 µm, 75 µm, and 100 µm, respectively. For the paste premixing conditions (Fig. 7b), the smearing defects for nonpremixed and premixed paste conditions were 19.9% and 3.6%, correspondingly. For the various printing speeds (Fig. 7c), 19.9%, 0.0%, and 0.0% were calculated for the 10 mm/s, 50 mm/s, and 100 mm/s printing speeds. The smearing defect for the cross-directional and machine-directional printed lines (Fig. 7d) was measured at 20.5% and 3.2%, respectively. The smearing defect occurs more for wider printed lines, and the smearing for the premixed paste is reduced compared to the nonpremixed paste. The smearing for the machine-directional printed lines is lower than the cross-directional printed lines. With the printing speed increase, Even though the smearing defect was almost zero at the 100th time print for 50 mm/s and 100 mm/s printing speeds, a different kind of defect, the bulge defect [27], occurred.

AI smearing defect detection under various conditions: for 100th printing results and its’ corresponding predictions by the AI model for a various line widths, b various printing paste premixing conditions, c various printing speeds, and d various printed lines directions
The smearing data were obtained for sequential printing using the chosen AI segmentation model, as shown in Figs. 8 and 9, for cross-directional and machine-directional printed lines correspondingly. Figure 8 shows that the smearing region occurs at the beginning of the printing and builds up until the saturation point. The saturation point was estimated using an exponentially weighted moving average with averaging window of 10 prints, which corresponds to the parameter \(\mathrm{\alpha }=0.\left(18\right)\). The maximum values were taken and shown in Fig. 10. The highest saturation of smearing defect for 100 µm cross-directional lines reached 21.4% and 22.8% for nonpremixed and premixed printing pastes correspondingly (Fig. 10a). The saturation points for 50 µm and 75 µm cross-directional lines were reduced from 13.3% and 21.4% to 3.2% and 8.6%, correspondingly, by printing paste premixing. As for machine-directional lines, the maximum saturation point of 5.6% was reached for 100 µm line width, which is comparably lower than for 100 µm width cross-directional lines, and after premixing, it was reduced to 0.6%, while for 50 µm and 75 µm line widths, the smearing was almost eliminated. The smearing area build-up for premixed paste is slowed down and took 50 prints to saturate, while for nonpremixed paste, it reached the upper level after several prints. Figure 11 shows that premixing significantly improved smearing for 50 µm and 75 µm line widths, while for a 100 µm line width, the improvement was reduced and based mainly on the smearing build-up rates decrease. The smearing area criterion can be used for adjusting the printing process to keep the printing conditions in the safe operating window, which can be selected based on the layout design or other factors. Alternatively, it can optimize the number of screen mask cleaning operations which can reduce a burden on the environment.

Segmentation results: labeled area percentage at 10 mm/s printing speed for a, b 50 µm, c, d 75 µm, e, f 100 µm cross-directional (CD) line widths when the paste is nonpremixed and premixed, respectively

Segmentation results: labeled area percentage at 10 mm/s printing speed for a, b 50 µm, c, d 75 µm, e, f 100 µm machine-directional (MD) line widths when the paste is nonpremixed and premixed, respectively

Segmentation results: maximum smearing area calculated using weighted exponential moving average with window size = 10 (α = 0.(18) correspondingly) in percentage at 10 mm/s printing speed for a cross-directional printed lines, and b machine-directional printed lines

Segmentation results: total average smearing area in percentage at 10 mm/s printing speed for a cross-directional printed lines, and b machine-directional printed lines
5 Conclusion
As one of the green manufacturing technologies for flexible and printed electronics, the roll to roll screen printing process has drawn attention. In this study, the AI model was developed to detect smearing defects during the screen printing process. The U-Net architecture was adopted for segmenting the printed line images into three classes: smearing, printed line, and background. Totally 19 models were analyzed with model depths from 5 to 11 convolutional blocks and 4–5 model sizes ranging from 8E + 3 to 3E + 7 number of parameters. The semantic segmentation DNN models were trained during 2000 epochs using a labeled data set of printed line images with the smearing defect, and their performances were evaluated by validation mean IoU. The DNN model with nine-block architecture and the 32–64–128–256–512–256–128–64–32 numbers of filters per block was chosen with the validation mean IoU and number of parameters 95.1% and 8E + 6, respectively. The DNN model was tested on the printed line images under various printing conditions, such as printed line widths, printing paste premixing, printing speeds, and printed line directions, which showed that it could detect the smearing defects effectively. The smearing area was determined using the segmentation results by the summation of the corresponding pixels. The AI model was also tested for repeated printing and can be used for reliability assessment of the screen printing process. We expect that the research on the AI model for roll to roll screen printing would have a strong impact on the mass production of electronics having fine-line screen printed patterns and further accelerate the market commercialization of this eco-friendly manufacturing process.
Data Availability
Image data set for this study can be found at: https://data.mendeley.com/datasets/sjrxbzwm7m.
References
Liu, Y., Shang, S., Mo, S., Wang, P., & Wang, H. (2021). Eco-friendly strategies for the material and fabrication of wearable sensors. International Journal of Precision Engineering and Manufacturing-Green Technology, 8(4), 1323–1346. https://doi.org/10.1007/s40684-020-00285-5
Wong, W. S., & Salleo, A. (2009). Flexible electronics: Materials and applications (Vol. 11). Springer Science & Business Media. https://doi.org/10.1007/978-0-387-74363-9
Erath, D., Filipović, A., Retzlaff, M., Goetz, A. K., Clement, F., Biro, D., & Preu, R. (2010). Advanced screen printing technique for high definition front side metallization of crystalline silicon solar cells. Solar Energy Materials and Solar Cells, 94(1), 57–61. https://doi.org/10.1016/j.solmat.2009.05.018
Zhang, L., Liu, T., Liu, L., Hu, M., Yang, Y., Mei, A., & Han, H. (2015). The effect of carbon counter electrodes on fully printable mesoscopic perovskite solar cells. Journal of Materials Chemistry A, 3(17), 9165–9170. https://doi.org/10.1039/C4TA04647A
Nam, J.-B., Jang, Y.-R., Hwang, Y.-T., Kim, H.-H., Jung, I.-H., & Kim, H.-S. (2021). Intense pulsed light sintering of screen-printed paste electrode on silicon solar cell for high throughput and cost-effective low temperature metallization. International Journal of Precision Engineering and Manufacturing-Green Technology. https://doi.org/10.1007/s40684-021-00346-3
Wang, Y., Kwok, H. Y. H., Pan, W., Zhang, Y., Zhang, H., Lu, X., & Leung, D. Y. C. (2020). Printing Al-air batteries on paper for powering disposable printed electronics. Journal of Power Sources, 450, 227685. https://doi.org/10.1016/j.jpowsour.2019.227685
Eshkeiti, A., Reddy, A. S. G., Emamian, S., Narakathu, B. B., Joyce, M., Joyce, M., Fleming, P. D., Bazuin, B. J., & Atashbar, M. Z. (2015). Screen printing of multilayered hybrid printed circuit boards on different substrates. IEEE Transactions on Components, Packaging and Manufacturing Technology, 5(3), 415–421. https://doi.org/10.1109/TCPMT.2015.2391012
Ersman, P. A., Zabihipour, M., Tu, D., Lassnig, R., Strandberg, J., Åhlin, J., Nilsson, M., Westerberg, D., Gustafsson, G., & Berggren, M. (2020). Monolithic integration of display driver circuits and displays manufactured by screen printing. Flexible and Printed Electronics, 5(2), 024001. https://doi.org/10.1088/2058-8585/ab7ab4
He, X., Shen, G., Xu, R., Yang, W., Zhang, C., Liu, Z., Chen, B., Liu, J., & Song, M. (2019). Hexagonal and square patterned silver nanowires/PEDOT:PSS composite grids by screen printing for uniformly transparent heaters. Polymers, 11(3), 468. https://doi.org/10.3390/polym11030468
Wang, S., Liu, N., Yang, C., Liu, W., Su, J., Li, L., Yang, C., & Gao, Y. (2015). Fully screen printed highly conductive electrodes on various flexible substrates for asymmetric supercapacitors. RSC Advances, 5(104), 85799–85805. https://doi.org/10.1039/C5RA16724H
Ra, Y., La, M., Cho, S., Park, S. J., & Choi, D. (2021). Scalable batch fabrication of flexible, transparent and self-triggered tactile sensor array based on triboelectric effect. International Journal of Precision Engineering and Manufacturing-Green Technology, 8(2), 519–531. https://doi.org/10.1007/s40684-020-00267-7
Kim, J.-H., Kim, J., Lee, G. J., Jeong, J., & Choi, B. (2013). Screen-printed Cu source/drain electrodes for a-InGaZnO thin-film transistors. Molecular Crystals and Liquid Crystals, 586(1), 161–167. https://doi.org/10.1080/15421406.2013.853531
Cao, X., Chen, H., Gu, X., Liu, B., Wang, W., Cao, Y., Wu, F., & Zhou, C. (2014). Screen printing as a scalable and low-cost approach for rigid and flexible thin-film transistors using separated carbon nanotubes. ACS Nano, 8(12), 12769–12776. https://doi.org/10.1021/nn505979j
Lee, T.-M., Choi, Y.-J., Nam, S.-Y., You, C.-W., Na, D.-Y., Choi, H.-C., Shin, D.-Y., Kim, K.-Y., & Jung, K.-I. (2008). Color filter patterned by screen printing. Thin Solid Films, 516(21), 7875–7880. https://doi.org/10.1016/j.tsf.2008.05.044
Phung, T. H., Gafurov, A. N., Kim, I., Kim, S. Y., Kim, K. M., & Lee, T.-M. (2021). IoT device fabrication using roll-to-roll printing process. Scientific Reports, 11(1), 1–11. https://doi.org/10.1038/s41598-021-99436-0
Hakola, L., Jansson, E., Futsch, R., Happonen, T., Thenot, V., Depres, G., Rougier, A., & Smolander, M. (2021). Sustainable roll-to-roll manufactured multi-layer smart label. The International Journal of Advanced Manufacturing Technology. https://doi.org/10.1007/s00170-021-07640-z
Krebs, F. C., Tromholt, T., & Jørgensen, M. (2010). Upscaling of polymer solar cell fabrication using full roll-to-roll processing. Nanoscale, 2(6), 873–886. https://doi.org/10.1039/B9NR00430K
Välimäki, M., Apilo, P., Po, R., Jansson, E., Bernardi, A., Ylikunnari, M., Vilkman, M., Corso, G., Puustinen, J., Tuominen, J., & Hast, J. (2015). R2R-printed inverted OPV modules—Towards arbitrary patterned designs. Nanoscale, 7(21), 9570–9580. https://doi.org/10.1039/C5NR00204D
Pan, J., Tonkay, G. L., & Quintero, A. (1999). Screen printing process design of experiments for fine line printing of thick film ceramic substrates. Journal of Electronics Manufacturing, 09(03), 203–213. https://doi.org/10.1142/s096031319900012x
Lin, H.-W., Chang, C.-P., Hwu, W.-H., & Ger, M.-D. (2008). The rheological behaviors of screen-printing pastes. Journal of Materials Processing Technology, 197(1), 284–291. https://doi.org/10.1016/j.jmatprotec.2007.06.067
Lee, T.-M., Noh, J.-H., Kim, I., Kim, D.-S., & Chun, S. (2010). Reliability of gravure offset printing under various printing conditions. Journal of Applied Physics, 108(10), 102802. https://doi.org/10.1063/1.3510466
Kim, G. E., Woo, K., Kang, D., Jang, Y., Choi, Y.-M., Lee, M. G., Lee, T.-M., & Kwon, S. (2016). A study on the enhancement of the reliability in gravure offset roll printing with blanket swelling control. Journal of Micromechanics and Microengineering, 26(10), 105014. https://doi.org/10.1088/0960-1317/26/10/105014
Malge, P. S., & Nadaf, R. S. (2014). PCB defect detection, classification and localization using mathematical morphology and image processing tools. International Journal of Computer Applications. https://doi.org/10.5120/15240-3782
Ren, Z., Fang, F., Yan, N., & Wu, Y. (2021). State of the art in defect detection based on machine vision. International Journal of Precision Engineering and Manufacturing-Green Technology. https://doi.org/10.1007/s40684-021-00343-6
Wei, P., Liu, C., Liu, M., Gao, Y., & Liu, H. (2018). CNN-based reference comparison method for classifying bare PCB defects. The Journal of Engineering, 2018(16), 1528–1533. https://doi.org/10.1049/joe.2018.8271
Adibhatla, V. A., Chih, H.-C., Hsu, C.-C., Cheng, J., Abbod, M. F., & Shieh, J.-S. (2020). Defect detection in printed circuit boards using you-only-look-once convolutional neural networks. Electronics, 9(9), 1547. https://doi.org/10.3390/electronics9091547
Gafurov, A. N., Phung, T. H., Kim, I., & Lee, T.-M. (2022). AI-assisted reliability assessment for gravure offset printing system. Scientific Reports, 12(1), 2954. https://doi.org/10.1038/s41598-022-07048-z
Jiang, J., Cao, P., Lu, Z., Lou, W., & Yang, Y. (2020). Surface defect detection for mobile phone back glass based on symmetric convolutional neural network deep learning. Applied Sciences, 10(10), 3621. https://doi.org/10.3390/app10103621
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional networks for biomedical image segmentation. In N. Navab, J. Hornegger, W. M. Wells, & A. F. Frangi (Eds.), Medical image computing and computer-assisted intervention—MICCAI 2015 (pp. 234–241). https://doi.org/10.1007/978-3-319-24574-4_28
Jeong, J., Gafurov, A. N., Park, P., Kim, I., Kim, H.-C., Kang, D., Oh, D., & Lee, T.-M. (2021). Tension modeling and precise tension control of roll-to-roll system for flexible electronics. Flexible and Printed Electronics, 6(1), 015005. https://doi.org/10.1088/2058-8585/abdf39
Gafurov, A. N., Jeong, J., Park, P., Kim, I., Phung, T. H., Kim, H.-C., Kang, D., Oh, D., & Lee, T.-M. (2021). Registration error analysis and compensation of roll-to-roll screen printing system for flexible electronics. Flexible and Printed Electronics, 6(2), 024003. https://doi.org/10.1088/2058-8585/abf987
Buslaev, A., Iglovikov, V. I., Khvedchenya, E., Parinov, A., Druzhinin, M., & Kalinin, A. A. (2020). Albumentations: Fast and flexible image augmentations. Information, 11(2), 125. https://www.mdpi.com/2078-2489/11/2/125
Zeiler, M. D., Krishnan, D., Taylor, G. W., & Fergus, R. (2010). Deconvolutional networks. IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2010, 2528–2535. https://doi.org/10.1109/CVPR.2010.5539957
Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980–2988). https://arxiv.org/abs/1708.02002
Acknowledgements
This study was supported by the National Research Foundation of Korea (NRF) grant funded by the Korean government (MSIT) (No. 2020R1A5A1019649), and the principle research R&D program of the Korea Institute of Machinery and Materials (NK230E).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gafurov, A.N., Phung, T.H., Ryu, BH. et al. AI-Aided Printed Line Smearing Analysis of the Roll-to-Roll Screen Printing Process for Printed Electronics. Int. J. of Precis. Eng. and Manuf.-Green Tech. 10, 339–352 (2023). https://doi.org/10.1007/s40684-022-00461-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40684-022-00461-9