
Abstract
Background
Missing data in costs and/or health outcomes and in confounding variables can create bias in the inference of health economics and outcomes research studies, which in turn can lead to inappropriate policies. Most of the literature focuses on handling missing data in randomized controlled trials, which are not necessarily always the data used in health economics and outcomes research.
Objectives
We aimed to provide an overview on missing data issues and how to address incomplete data and report the findings of a systematic literature review of methods used to deal with missing data in health economics and outcomes research studies that focused on cost, utility, and patient-reported outcomes.
Methods
A systematic search of papers published in English language until the end of the year 2020 was carried out in PubMed. Studies using statistical methods to handle missing data for analyses of cost, utility, or patient-reported outcome data were included, as were reviews and guidance papers on handling missing data for those outcomes. The data extraction was conducted with a focus on the context of the study, the type of missing data, and the methods used to tackle missing data.
Results
From 1433 identified records, 40 papers were included. Thirteen studies were economic evaluations. Thirty studies used multiple imputation with 17 studies using multiple imputation by chained equation, while 15 studies used a complete-case analysis. Seventeen studies addressed missing cost data and 23 studies dealt with missing outcome data. Eleven studies reported a single method while 20 studies used multiple methods to address missing data.
Conclusions
Several health economics and outcomes research studies did not offer a justification of their approach of handling missing data and some used only a single method without a sensitivity analysis. This systematic literature review highlights the importance of considering the missingness mechanism and including sensitivity analyses when planning, analyzing, and reporting health economics and outcomes research studies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
There is a large amount of literature on methods to handle missing data in randomized controlled trials, which are not necessarily always the only data source used in health economics and outcomes research. |
Researchers should report the presence of missing data and consider the mechanism of missingness. |
Researchers should conduct sensitivity analyses and report those results in the study. |
1 Introduction
Missing data are defined as “values that are not available and that would be meaningful for analysis if they were observed” [1]. Unfortunately, some study protocols and/or statistical analysis plans used in the health economics and outcomes research (HEOR) studies place little emphasis on the approach to assess missing data. Data can be missing because of various reasons, which can include patient attrition during the study follow-up, unavailability of clinical information and/or patient-reported outcomes (PROs) [2]. Observations with missing information about costs or other outcomes may be systematically different from those with complete information. Missing data can bias the inference in HEOR studies because of incomplete information for costs and/or health outcomes and in confounding variables, which in turn can lead to inappropriate policies [3]. The HEOR studies considered in the context of the present article are real-world evidence studies that conducted a secondary/post-hoc analysis using randomized controlled trial (RCT) data, and a within-trial cost-utility analysis in which the outcome of interest was costs or PROs including preference-based utilities (e.g., EQ-5D). The study also had to be observational by design using specific analytical approaches to address missing utility, costs, or scores. However, this article did not include those studies, which addressed other healthcare resource utilizations such as hospitalizations, physician visits, or telemedicine costs.
There is a large amount of literature on handling missing data in RCTs that are not necessarily always the data used in HEOR [1, 4]. A review of issues of the Health Technology Assessment from 2013 to 2015 found that the most common approach for the RCT-based cost-effectiveness analysis was to restrict analysis to those observations with complete data [5]. A previous study provided a structured approach and practical guidance on managing missing data in the context of a cost-effectiveness analysis based on RCT data to address the uncertainty associated with missing data, and quantify its impact on results [3]. However, in HEOR studies, which are based on large, observational, often longitudinal and/or multi-country data sources, missing data may cause substantially more bias as more data on outcomes, exposure and/or other confounding variables may be missing [6]. The causes and patterns of missing data in observational data sources considered in HEOR studies tend to be different from what can be observed in RCTs. For example, many HEOR studies use data sources where patients were not randomized in treatment groups, and the presence of missing data may further confound relationships between treatment and outcomes, which complicates the ability to determine the effect of missingness on outcomes. It becomes more challenging to disentangle potential bias because of missing data from other types of bias in observational studies. Though the presence of missing data can produce considerable bias in HEOR studies, it is often not given adequate attention.
Methods that are specifically developed to account for missing data generated from RCTs might not be immediately applicable to studies based on observational data. Efficacy and safety are important endpoints for RCTs, whereas HEOR studies based on observational data sources jointly model costs and outcomes, which might make it more challenging to apply modern analytical techniques to handle missing data. Moreover, in a RCT, one might have access to individual patient-level data, whereas in a HEOR study based on observational data one might have access to only summary statistics, which does not enable the assessment of the potential mechanisms and individual patterns of missingness. Nonetheless, few studies have attempted to address the issues of handling missing data in HEOR based on different data sources [7]. This study bridges that gap by focusing on handling missing data within the context of HEOR.
The objectives of the present study are to provide an overview of different types of missing data mechanisms used in HEOR studies and report the findings of a systematic literature review (SLR) of specific methods used to deal with missing data derived from trials (a post-hoc or secondary analysis using RCT data, and a within-trial cost-utility analysis), observational studies, reviews, and previously published guidance. This review specifically focused on handling missing data within the HEOR field emphasizing cost, and PRO measures including preference-based utilities (e.g., EQ-5D). It needs to be mentioned here that the objective was not to quantify how often all of the different methods to handle missing data were used or how often researchers ignore the issue of missing data in the HEOR studies considered in the specific context of this article.
The remainder of this article is structured as follows. We first provide a brief summary on the types of missing data and the most common approaches used in HEOR studies. Then, we describe the methods of the SLR and its main findings. In the final section, we discuss handling missing data in HEOR studies based on the findings of the review.
1.1 Background on Missing Data Classifications and Mechanism for Data Missingness
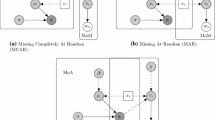
This section uses the classification of missing data problems as proposed by Rubin according to the following types of mechanism for missing data: missing completely at random (MCAR), missing at random (MAR), and missing not at random (MNAR) [8,9,10]. An example of each of those mechanisms is available in Sections 1.1 and 1.2 of the Electronic Supplementary Material (ESM).
1.1.1 Missing Completely at Random (MCAR)
In this case, the observed or unobserved values of all variables in a study do not have any influence on the probability of an observation being missing [11].
1.1.2 Missing at Random (MAR)
In this case, the probability of missing data for a particular variable is associated with the observed values of variables (either observed values of other variables in the dataset or observed values for the same variable at previous timepoints) in the dataset, but not upon the missing data [11]. When a researcher had no control over missingness, and the distribution of missingness is unknown, MAR is the assumption. Generally speaking, it is not possible to test whether MAR holds in any dataset [12].
1.1.3 Missing Not at Random (MNAR)
In this case, the probability of missing data for a particular variable is related to the underlying value of that specific variable, even within the strata of observed variables, as well as other unobserved values within the dataset [11]. An alternative approach to classify the mechanism of missingness is to place it in two categories: (1) ignorable and (2) non-ignorable (informative) [8, 9, 13, 14]. In the case of ignorable missingness, missing values occur independently of the data collection process; the MCAR and MAR mechanisms belong to this category. If MAR holds, then the missing data model is considered “ignorable” for all practical purposes. To make valid inferences, one needs to consider the factors, which might influence the missing data rate [9]. In the case of non-ignorable missingness, there is a structural cause to the missingness mechanism that depends on unobserved variables or the missing value itself and should be addressed when dealing with the missing data. The MNAR mechanism falls under the non-ignorable missingness category. In the case of non-ignorable missingness, it is important to consider and justify the process that created the missing data [9]. There are situations in real-world HEOR studies, in which the missingness mechanism cannot be classified distinctly under MAR/MCAR/MNAR classes and therefore MAR/MNAR do not always coincide with the clear distinction between ignorable and non-ignorable. The assumption of ignorable or non-ignorable is important for real-world HEOR studies involving missing data.
It is important to highlight that all methods for handling missing data imply some assumptions (implicitly or explicitly) on the mechanisms. In the next section, we provide a summary of the most commonly used approaches to missing data.
1.2 Background on Methods to Deal with Missing Data
The methods to deal with missing data include the following: complete-case analysis (CCA), available-case (AC) analysis, multiple imputation (MI), multiple imputation by chained equation (MICE), and predictive mean matching. The MICE is a type of MI technique, which can tackle both continuous and categorical variables and uses a series of regression to model variables with missing data conditional upon other variables in the dataset [15]. A detailed description of these methods is provided in Sections 1.1 and 1.2 of the ESM.
2 Methods
2.1 Literature Search Strategy
PubMed was searched for relevant peer-reviewed journal articles in English published until December 2020. The inclusion criteria focused on those studies for which the analysis of interest focused on estimation of health-state utility values, health state-related costs, or quantification of PROs in relation to health states. We excluded primary RCT studies from this review and studies where the outcome of interest pertained to safety or efficacy only. Studies were excluded if they did not discuss or review methodologies to account for missing data or if they conducted only a CCA as a method to address missing data and did not employ any other techniques, and did not deal with cost, utility, or PRO data. No minimum sample size was considered as an inclusion criterion in this SLR. The inclusion and exclusion criteria are listed in Table 1. The full search strategy and the keywords used in the search are listed in Table 1 of the ESM.
It is worthwhile to mention in this context that at the design phase of this review, the feasibility of conducting separate reviews for guidance papers and analytical studies was explored. After running several search strings and identifying initial studies, we found that it was not clear how to distinguish between these two types of article. Indeed, most methodological guidance documents include an analysis using actual data and can therefore be considered as both a guidance and analytical study. Conversely, generic guideline documents around the topic of missing data seldom include detailed technical guidance. We therefore decided to conduct a single search to cover all of our studies of interest.
2.2 Selection and Extraction of Studies
Identified records were reviewed independently by two reviewers in accordance with the pre-defined search strategy. All disagreements were resolved with the help of a third reviewer to reach a consensus. The data extraction was performed with specific attention to the type of the study, the presence and type of missing data in costs and health outcomes, and the methods used to tackle missing data.
To make the extraction process homogeneous across volunteers, a pre-designed rubric to identify the type of study, data source, and methods explored to handle missing data was provided to each volunteer. A sample extraction was also provided by one of the reviewers to guide the volunteers in the extraction process.
3 Results
A total of 1433 records were identified. After the exclusion of books (n = 7) and duplicate records (n = 2), abstracts from 1424 records were screened for eligibility. Following abstract screening, 57 articles were assessed for eligibility based on full-text articles of which 40 studies met the eligibility criteria for the study (Fig. 1). Included studies are summarized in Table 2 of the ESM.

Preferred reporting items for systematic reviews and meta-analyses (PRISMA) diagram
3.1 Characteristics of Included Studies
There was considerable heterogeneity in the design of the studies, and some of these were based on a combination of designs (Table 2). Thirteen (32.5%) studies were pharmacoeconomic analyses [16,17,18,19,20,21,22,23,24,25,26,27,28], eight studies (20%) addressed guidelines [3, 29,30,31,32,33,34,35], seven (17.5%) studies used simulation [16, 18, 19, 32, 33, 36, 37], and seven (17.5%) studies were methodological [7, 37,38,39,40,41,42] in nature. Other types of studies included two systematic reviews and two survey research articles [43,44,45,46]. Two studies involving survey research were designed to gather health-related quality-of-life information from participants. One of the systematic reviews addressed handling missing data in within-trial cost effectiveness, while the other was an educational review of using cost data in a pharmacoeconomic analysis that addressed various methods of handling of missing cost data [43, 44].
Twenty-one (52.5%) studies used RCTs [3, 16,17,18,19,20,21,22,23,24,25,26,27,28, 30,31,32,33, 39, 47, 48] and six (15%) studies [7, 36, 41, 46, 51, 52] used retrospective or prospective cohorts as the only source of data. Two review studies [43, 44], one study describing guidelines [35], and one methodological paper [38] did not use any data source (Table 2).
3.2 Methods Used to Handle Missing Data
Thirty (75%) studies used MI for addressing missing data [3, 7, 16, 17, 19,20,21,22,23, 25,26,27,28,29,30,31,32,33,34, 36, 37, 39,40,41, 43,44,45,46, 49, 50]. Among these thirty studies, seven studies used MI with predictive mean matching [16, 19, 23, 27, 28, 31, 32] and 17 studies used MICE [3, 16, 19, 21,22,23, 25,26,27,28, 31, 32, 37, 39, 43, 45, 49], one study used MI based on data augmentation [17], and one study implemented MI by using a fully conditional specification [36]. Fifteen (37.5%) studies used a CCA [3, 7, 16, 17, 19, 20, 30, 32, 34, 35, 40, 43, 44, 46, 51] while three studies used pattern-mixture models [3, 31, 47], three studies used last value carried forward [20, 35, 44] and two studies used an AC analysis [43, 46] (Table 2; Fig. 2).

Frequency of different methods and techniques used to handle missing data. CCA complete-case analysis, LVCF last value carried forward, MI multiple imputation, MICE multiple imputation by chained equation, PMM predictive mean matching
Several other methods were used that included item and aggregate imputation and inverse probability weighting [25, 33, 43]. Seventeen out of 21 studies that utilized the RCT as the only source of data used MI [3, 16, 17, 19,20,21,22,23, 25,26,27,28, 30,31,32,33, 39]. The remaining four studies used a range of methods including the semiparametric model with propensity score method, Bayesian approach with Markov Chain Monte Carlo, and mean value of available response [18, 24, 47, 48]. Six studies based on retrospective or prospective cohorts also used MI, CCA, or Bayesian robust two-stage causal modeling with an instrumental variable approach.
Twenty studies addressed missing data issues by incorporating multiple methods [3, 7, 16,17,18,19,20, 24, 25, 31,32,33,34, 36, 37, 40, 42, 46,47,48], while 11 studies used one single method [21,22,23, 26,27,28, 39, 41, 45, 49, 50]. Nine studies lacked any empirical illustration or were theoretical in nature [29, 30, 35, 38, 43, 44, 51,52,53].
Seventeen studies addressed dealing with missing cost data [3, 16,17,18,19,20,21,22,23, 25,26,27,28, 30, 31, 43, 47], 23 studies dealt with missing health outcomes data [3, 7, 16, 19,20,21,22,23,24,25,26, 28,29,30,31,32,33, 35, 39, 40, 46, 47, 50], which included PROs, and only nine studies addressed dealing with missing covariates [26, 28, 34, 36, 37, 45, 46, 49, 50]. Among those 17 studies dealing with missing cost data, 15 used MI [3, 16, 17, 19,20,21,22,23, 25,26,27,28, 30, 31, 43], 11 used MICE [3, 16, 19, 21, 22, 25,26,27,28, 31, 43], seven used CCA [3, 16, 17, 19, 20, 30, 43], four used predictive mean matching [16, 19, 27, 31], one study used last value carried forward [20], and one study used a pattern-mixture model [31].
Among the 23 studies dealing with missing health outcome data, 19 used MI [3, 7, 16, 19,20,21,22,23, 25, 26, 28,29,30,31,32,33, 39, 40, 50], 11 studies used MICE [3, 16, 19, 21, 22, 25, 26, 28, 31, 32, 39], ten studies used CCA [3, 7, 16, 19, 20, 30, 32, 35, 40, 46], six studies used predictive mean matching [16, 19, 23, 28, 31, 32], one study used last value carried forward [20], and one study mentioned a pattern-mixture model [31]. All of the nine studies dealing with missing data of covariates used MI [26, 28, 34, 36, 37, 45, 46, 49, 50], seven studies used MICE [26, 28, 37, 45, 46, 49, 50], and one study used a CCA [46].
Eleven studies [21,22,23, 26,27,28, 39, 41, 45, 49, 50] used only a single method without considering a sensitivity analysis to evaluate any potential impact of the selected method on the result of the analysis. We also observed that only three studies have attempted to use non-imputation based methods, such as propensity score matching, inverse probability weighting, or an instrumental variable [33, 41, 48].
3.3 Findings from Three Guidance Documents
Table 3 presents a list of recommendations from three guidance papers [3, 5, 32], which address missing data in a context within the scope of this review. They emphasized efforts to be undertaken to minimize missing data in the design and data collection phase of the study. For instance, in surveys, questionnaires should be designed in a user-friendly manner with appropriate modes of administration and follow-up necessary to improve participants’ engagement and subsequently minimize missing data [5]. Researchers should provide a thorough description of missing data magnitude and patterns and identify the associations between outcomes, baseline variables, and missingness [3]. Though a CCA may be an appropriate choice in some cases, it has major limitations in the context of studies using repeated measures. Use of a CCA approach can also cause a loss of statistical power [5]. If MI is used, it is recommended that the imputation model includes all available variables, even those that are not included in the analysis model. There is also a need to validate the method chosen to handle missing data by comparing the results with a different method under the same assumption on the missing data mechanism [3]. Another guidance paper addressing missing PRO data in RCTs [32] suggested that if the sample size is small and there is a large amount of missing data, imputation at the composite score level might be more useful. If there are many item nonresponses, imputation at the item or subscale level becomes more beneficial. However, imputation at the item level might give rise to a non-convergence issue. This paper suggested the use of treatment as an explanatory variable in a MI model to resolve the non-convergence issue after considering the distributional assumptions of the outcomes in the study [32]. If ordinal logit models were used for imputation purposes, one should be cautious about the low count in the levels of the items to be imputed [32]. Each statistical model to be used in the imputation should be pretested before implementation to ensure that appropriate estimates can be produced.
These three guidance papers highlighted the importance of conducting a sensitivity analysis to identify a possible departure from the MAR assumption by using alternate approaches, for example, a selection model or pattern-mixture model [3, 5, 32]. However, the choice between two approaches depends on the importance of expressing the difference between observed and unobserved data in a specific research context [3]. In the context of a sensitivity analysis, a selection model considers alternative missing data mechanisms (e.g., MNAR), while a pattern-mixture model recognizes the differences in the distribution of the observed and unobserved data [3].
4 Discussions and Practical Considerations
The studies included in this review were very heterogeneous in terms of design. We found that most studies used MI. Although many studies included multiple methods for missing data, several studies did not. The results of the review emphasized the importance of sensitivity analyses. We also found that MI is preferred as a technique when the missing data mechanism was considered as MAR in economic evaluations based on registry studies [29]. In a previous review with recommendations, it was further emphasized that the information collection process, assumptions, and limitations of the choice of methods should be reported and a sensitivity analysis should be conducted in cost-effectiveness analysis studies [30].
In the context of using an imputation model for handling missing data in PRO studies, recommendations included considering the prevalence of missing data in the study, the sample size, the number of items, and the number of levels within individual items in the measurement instrument. The recommendation also suggested inclusion of the above factors in the analysis plan [32].
All data analyses rely on assumptions and their assessment, including those underlying the approach used to handle (or not handle) missing data, is important when making methodological decisions. This requires a thorough assessment of the missingness mechanism when choosing a method to address missing data. Although we did find that MI was one of the most common approaches used for handling missing data, likely because of its flexibility, there was variability in the approach used to impute data. In some cases, other approaches relying on the MAR assumption, such as propensity score methods (either matching or inverse probability weighting) were used in included studies and this approach may be more or less helpful depending on the context of the data [43, 48]. If incomplete cases provide little information, then inverse probability weighting may be a preferred approach over MI, as inverse probability weighting models the probability that an individual is a complete case, whereas the MI models the distribution of missing values given observed data [43]. Researchers should be cognizant that the MI technique does not recover the missing values but replaces them with plausible values of the specific variables in order to subsequently analyze complete datasets, which allow the incorporation of the uncertainty in the imputed values of the variable. The literature review also suggests that using as many predictors as possible is important for making the MAR assumption more plausible [9]. This has implications for study planning and underscores the importance of having sufficient auxiliary variables: these are covariates that are used in the imputation models but commonly not of particular interest in the final analytical model; inclusion of these variables can improve the missing data handling procedure by better resembling the MAR assumption or by increasing power by recapturing some of the missing information [11]. Furthermore, our findings suggest that evaluation of the plausibility of underlying analytic assumptions is important. This implies that researchers should include sensitivity analyses that assess the robustness of the results to violation of MAR. Researchers should also pay attention to the skewness of cost distribution and the boundness of utility measures when regression models are used for the purpose of imputation [3].
We did find that a substantial minority of 15 studies used the CCA as one of the methods to deal with missing data. The previous literature review of handling missing data in the context of an RCT found that the most common method of handling was the CCA, followed by simple imputation [4]. In contrast to this, this SLR found that among real-world evidence studies and within-trial cost-utility analyses that used specific methods in conjunction with a CCA or alone to handle missing data, MI was the most common approach. It is important to note that though a CCA is a straightforward method to implement, it is generally only valid (i.e., lead to unbiased estimates) under the MCAR assumption, which is a very strong assumption that is unlikely to be met in many HEOR applications. Recently, there is some suggestion that a CCA may be preferable to MI when exposure and confounding variables in a main analysis are MNAR because many applications of MI assume data are MAR [54]. However, even in the circumstances where CCA would lead to unbiased results, it is an inefficient approach as it does not include all the information available from the incomplete records [54].
Researchers should report the presence and patterns of missing data in outcomes, confounders, and auxiliary variables. For instance, the fraction of missing information measured also should be considered as it can give precious information on choosing auxiliary variables to be used in imputation models to handle missing data [55].
Consistent with the guideline documents reviewed, we also recommend that researchers should assess the proportion and patterns of missingness of all variables and use alternative missing data handling methods in a sensitivity analysis [6]. Note that there is no general consensus on a specific threshold for the proportion of missingness above which a CCA is not warranted, it can vary from 2% to 10%. One of the limitations of this SLR is it was restricted to studies published in the English language only. Another limitation is that because the primary objective of this study was to identify specific analytical methods beyond the default approach of the CCA to handle missing data, this SLR excluded those studies that used the CCA as the only method to handle missing data, as those studies did not make an explicit acknowledgment of the presence of missing data. Finally, we acknowledge that the SLR included articles published until December 2020; this is because the main findings of the review served as the foundation for a series of discussions, which informed the development of the guidance presented in this paper.
5 Conclusions
There was a large amount of HEOR literature on handling missing data in a RCT context; however, there were very few studies that have attempted to address missing data. This is the first SLR that attempts to bridge this gap in the HEOR literature by identifying all of the different specific analytical methods that are used to handle missing data in HEOR studies based on different data sources. Based on the literature review, this study further delineates recommendations for researchers to handle missing data in the context of observational or real-world evidence studies.
All of our recommendations are based on current practices that were reported in the HEOR literature, as found within the scope of this review, and serve as an important stepping stone to advance the field on the topic. We found that most studies used MI as an analytic approach relying on the MAR assumption. Based on our review of what is currently reported in the literature including existing recommendations, we suggest that HEOR researchers consider the missingness mechanism and include sensitivity analyses when devising analysis plans.
References
Little RJ, D’Agostino R, Cohen ML, Dickersin K, Emerson SS, Farrar JT, et al. The prevention and treatment of missing data in clinical trials. New Engl J Med. 2012;367:1355–60.
Panel on Handling Missing Data in Clinical Trials. National Research Council. The prevention and treatment of missing data in clinical trials. Washington, DC: National Academic Press; 2010.
Faria R, Gomes M, Epstein D, White IR. A guide to handling missing data in cost-effectiveness analysis conducted within randomized controlled trials. Pharmacoeconomics. 2014;32:1157–70.
Bell ML, Fiero M, Horton NJ, Hsu C. Handling missing data in RCTs; a review of the top medical journals. BMC Med Res Methodol. 2014;14:118. https://doi.org/10.1186/1471-2288-14-118.
Leurent B, Gomes M, Carpenter JR. Missing data in trial-based cost-effectiveness analysis: an incomplete journey. Health Econ. 2018;27:1024–40. https://doi.org/10.1002/hec.3654.
Lee KJ, Tiling KM, Cornish RP, Little RJA, Bell ML, Goetghebeur E, et al. Framework for the treatment and reporting of missing data in observational studies: the treatment and reporting of missing data in observational studies framework. J Clin Epidemiol. 2021;134:79–88. https://doi.org/10.1016/j.jclinepi.2021.01.008.
Gomes M, Gutacker N, Bojke C, Street A. Addressing missing data in patient-reported outcome measures (PROMS): implications for the use of PROMS for comparing provider performance. Health Econ. 2016;25:515–28. https://doi.org/10.1002/hec.3173.
Little RJA, Rubin DB. Statistical analysis with missing data. 3rd ed. Hoboken: Wiley; 2020.
Van Buuren S. Flexible imputation of missing data. 2nd ed. Boca Raton: Chapman and Hall/CRC; 2018.
Rubin DB. Inference and missing data. Biometrika. 1976;63:581–90.
Enders KG. Applied missing data analysis. New York: The Guilford Press; 2010.
Schafer JL, Graham JW. Missing data: our view of the state of the art. Pychol Methods. 2002;7:147–77.
Little RJ. Regression with missing X’s: a review. J Am Stat Assoc. 1992;87(420):1227–37.
Liu D, Yeung EH, McLain AC, Xie Y, Buck Louis GM, Sundaram R. A two-step approach for analysis of nonignorable missing outcomes in longitudinal regression: an application to Upstate KIDS study. Paediatr Perinat Epidemiol. 2017;31:468–78. https://doi.org/10.1111/ppe.12382.
Azur MJ, Stuart EA, Frangakis C, Leaf PJ. Multiple imputation by chained equations: what is it and how does it work? Int J Methods Psychiatr Res. 2011;20(1):40–9. https://doi.org/10.1002/mpr.329.
Brand J, van Buuren S, le Cessie S, van den Hout W. Combining multiple imputation and bootstrap in the analysis of cost-effectiveness trial data. Stat Med. 2019;30:210–20. https://doi.org/10.1002/sim.7956.
Burton A, Billingham LJ, Bryan S. Cost-effectiveness in clinical trials: using multiple imputation to deal with incomplete cost data. Clin Trials. 2007;4:154–61. https://doi.org/10.1177/1740774507076914.
Lambert PC, Billingham LJ, Cooper NJ, Sutton AJ, Abrams KR. Estimating the cost-effectiveness of an intervention in a clinical trial when partial cost information is available: a Bayesian approach. Health Econ. 2008;17:67–81. https://doi.org/10.1002/hec.1243.
Vroomen JM, Eekhout I, Dijkgraaf MG, van Hout H, de Rooij SE, Heymans MW, et al. Multiple imputation strategies for zero-inflated cost data in economic evaluations: which method works best? Eur J Health Econ. 2016;17:939–50. https://doi.org/10.1007/s10198-015-0734-5.
Manca A, Palmer S. Handling missing data in patient-level cost-effectiveness analysis alongside randomized clinical trials. Appl Health Econ Health Policy. 2005;4:65–75. https://doi.org/10.2165/00148365-200504020-00001.
Finch AP, Velzen PV, Riet GT, Sterk PJ, Prins JM, Bosmans JE. Doxycycline added to prednisolone in outpatient-treated acute exacerbations of COPD: a cost-effectiveness analysis alongside a randomized controlled trial. Pharmacoeconomics. 2019;37:689–99. https://doi.org/10.1007/s40273-018-0756-9.
Canaway A, Frew E, Lancashire E, Pallan M, Hemming K, Adab P. Economic evaluation of a childhood obesity prevention programme for children: results from the WAVES cluster randomized controlled trial conducted in schools. PLoS One. 2019;14:e0219500. https://doi.org/10.1371/journal.pone.0219500.
Alili ME, Schuurhuizen CSEW, Braamse AMJ, Beekman ATF, van der Linden MH, Konings IR, et al. Economic evaluation of a combined screening and stepped-care treatment program targeting psychological distress in patients with metastatic colorectal cancer: a cluster randomized controlled trial. Palliat Med. 2020;34:934–45. https://doi.org/10.1177/0269216320913463.
Lobban F, Akers N, Appelbe D, Capuccinello RI, Chapman L, Collinge L, et al. A web-based, peer-supported self-management intervention to reduce distress in relatives of people with psychosis or bipolar disorder: the REACT RCT. Health Technol Assess. 2020;24:1–142. https://doi.org/10.3310/hta24320.
Michalowsky B, Hoffmann W, Kennedy K, Xie F. Is the whole larger than the sum of its parts? Impact of missing data imputation in economic evaluation conducted alongside randomized controlled trials. Eur J Health Econ. 2020;21:717–28.
Pazmino S, Boonen A, Stouten V, De Cock D, Joly J, Van der Elst K, et al. Two-year cost-effectiveness of different COBRA-like intensive remission induction schemes in early rheumatoid arthritis: a piggyback study on the pragmatic randomised controlled CareRA trial. Ann Rheum Dis. 2020;79:556–65. https://doi.org/10.1136/annrheumdis-2019-216874.
Pennington M, Ring H, Howlett J, Smith C, Redley M, Murphy C, et al. The impact of an epilepsy nurse competency framework on the costs of supporting adults with epilepsy and intellectual disability: findings from the EpAID study. J Intellect Disabil Res. 2019;63:1391–400. https://doi.org/10.1111/jir.12679.
van Dongen JM, Persoon S, Jongeneel G, Bosmans JE, Kersten MJ, Brug J, et al. Long-term effectiveness and cost-effectiveness of an 18-week supervised exercise program in patients treated with autologous stem cell transplantation: results from the EXIST study. J Cancer Surviv. 2019;13:558–69. https://doi.org/10.1007/s11764-019-00775-9.
Blommestein HM, Franken MG, Uyl-de Groot CA. A practical guide for using registry data to inform decisions about the cost effectiveness of new cancer drugs: lessons learned from the PHAROS registry. Pharmacoeconomics. 2015;33(6):551–60. https://doi.org/10.1007/s40273-015-0260-4.
Gabrio A, Mason AJ, Baio G. Handling missing data in within-trial cost-effectiveness analysis: a review with future recommendations. Pharmacoecon Open. 2017;1:79–97. https://doi.org/10.1007/s41669-017-0015-6.
Leurent B, Gomes M, Faria R, Morris S, Grieve R, Carpenter JR. Sensitivity analysis for not-at-random missing data in trial-based cost-effectiveness analysis: a tutorial. Pharmacoeconomics. 2018;36:889–901. https://doi.org/10.1007/s40273-018-0650-5.
Rombach I, Gray AM, Jenkinson C, Murray DW, Rivero-Arias O. Multiple imputation for patient reported outcome measures in randomised controlled trials: advantages and disadvantages of imputing at the item, subscale or composite score level. BMC Med Res Methodol. 2018;18:87. https://doi.org/10.1186/s12874-018-0542-6.
Rombach I, Jenkinson C, Gray AM, Murray DW, Rivero-Arias O. Comparison of statistical approaches for analyzing incomplete longitudinal patient-reported outcome data in randomized controlled trials. Patient Relat Outcome Meas. 2018;9:197–209. https://doi.org/10.2147/prom.s147790.
Blake HA, Leyrat C, Mansfield KE, et al. Propensity scores using missingness pattern information: a practical guide. Stat Med. 2020;39(11):1641–57. https://doi.org/10.1002/sim.8503.
Coens C, Pe M, Dueck AC, Sloan J, Basch E, Calvert M, International Standards in Analyzing Patient-Reported Outcomes and Quality of Life Endpoints Data Consortium, et al. International standards for the analysis of quality-of-life and patient-reported outcome endpoints in cancer randomised controlled trials: recommendations of the SISAQOL Consortium. Lancet Oncol. 2020;21:e83-96. https://doi.org/10.1016/s1470-2045(19)30790-9.
Nevalainen J, Kenward MG, Virtanen SM. Missing values in longitudinal dietary data: a multiple imputation approach based on a fully conditional specification. Stat Med. 2009;28(29):3657–69. https://doi.org/10.1002/sim.3731.
Coffman DL, Zhou J, Cai X. Comparison of methods for handling covariate missingness in propensity score estimation with a binary exposure. BMC Med Res Methodol. 2020;20(1):168. https://doi.org/10.1186/s12874-020-01053-4.
Kharroubi SA, Brennan A, Strong M. Estimating expected value of sample information for incomplete data models using Bayesian approximation. Med Decis Mak. 2011;31(6):839–52. https://doi.org/10.1177/0272989x11399920.
Simons CL, Rivero-Arias O, Yu LM, Simon J. Multiple imputation to deal with missing EQ-5D-3L data: should we impute individual domains or the actual index? Qual Life Res. 2015;24(4):805–15. https://doi.org/10.1007/s11136-014-0837-y.
Hartwell ML, Khojasteh J, Wetherill MS, Croff JM, Wheeler D. Using structural equation modeling to examine the influence of social, behavioral, and nutritional variables on health outcomes based on NHANES data: addressing complex design, nonnormally distributed variables, and missing information. Curr Dev Nutr. 2019;3(5):nzz010. https://doi.org/10.1093/cdn/nzz010.
Shi D, Tong X, Meyer MJ. A Bayesian approach to the analysis of local average treatment effect for missing and non-normal data in causal modeling: a tutorial with the ALMOND Package in R. Front Psychol. 2020;11:169. https://doi.org/10.3389/fpsyg.2020.00169.
Wang G, Lu J, Choi KS, Zhang G. A transfer-based additive LS-SVM classifier for handling missing data. IEEE Trans Cybern. 2020;50:739–52. https://doi.org/10.1109/tcyb.2018.2872800.
Franklin M, Lomas J, Walker S, Young T. An educational review about using cost data for the purpose of cost-effectiveness analysis. Pharmacoeconomics. 2019;37:631–43. https://doi.org/10.1007/s40273-019-00771-y.
van Dongen JM, El Alili M, Varga AN, Guevara Morel AE, Jornada Ben A, Khorrami M, et al. What do national pharmacoeconomic guidelines recommend regarding the statistical analysis of trial-based economic evaluations? Expert Rev Pharmacoecon Outcomes Res. 2020;20:27–37. https://doi.org/10.1080/14737167.2020.1694410.
Adam S, Martin-Diener E, Camey B, Egger Hayoz C, Konzelmann I, et al. Health-related quality of life in long-term prostate cancer survivors after nerve-sparing and non-nerve-sparing radical prostatectomy: results from the multiregional PROCAS study. Cancer Med. 2020;9:5416–24. https://doi.org/10.1002/cam4.3197.
Beletsioti C, Niakas D. Health-related quality of life in adult population before and after the onset of financial crisis: the case of Athens, Greece. Qual Life Res. 2019;28:3237–47. https://doi.org/10.1007/s11136-019-02281-y.
Mason AJ, Gomes M, Grieve R, Carpenter JR. A Bayesian framework for health economic evaluation in studies with missing data. Health Econ. 2018;27:1670–83. https://doi.org/10.1002/hec.3793.
Chen C, Shen B, Liu A, Wu R, Wang M. A multiple robust propensity score method for longitudinal analysis with intermittent missing data. Biometrics. 2021;77:519–32. https://doi.org/10.1111/biom.13330.
Badawi O, Breslow MJ. Readmissions and death after ICU discharge: development and validation of two predictive models. PLoS One. 2012;7(11):e48758. https://doi.org/10.1371/journal.pone.0048758.
Simms V, Downing J, Namisango E, Powell RA, et al. Change in multidimensional problems and quality of life over three months after HIV diagnosis: a multicentre longitudinal study in Kenya and Uganda. BMC Infect Dis. 2019;19(1):248. https://doi.org/10.1186/s12879-019-3855-0.
Lin FC, Cai J, Fine JP, Lai HJ. Nonparametric estimation of the mean function for recurrent event data with missing event category. Biometrika. 2013. https://doi.org/10.1093/biomet/ast016.
Bayley KB, Belnap T, Savitz L, et al. Challenges in using electronic health record data for CER: experience of 4 learning organizations and solutions applied. Med Care. 2013;51(8 Suppl. 3):S80–6. https://doi.org/10.1097/mlr.0b013e31829b1d48.
Li J, Yu Y. A nonparametric test of missing completely at random for incomplete multivariate data. Psychometrika. 2015;80:707–26. https://doi.org/10.1007/s11336-014-9410-4.
Hughes RA, Heron J, Sterne JAC, Tilling K. Accounting for missing data in statistical analyses: multiple imputation is not always the answer. Int J Epidemiol. 2019;48(4):1294–304. https://doi.org/10.1093/ije/dyz032.
Madley-Dowd P, Hughes R, Tilling K, Heron J. The proportion of missing data should not be used to guide decisions on multiple imputation. J Clin Epidemiol. 2019;110:63–73. https://doi.org/10.1016/j.jclinepi.2019.02.016.
Acknowledgments
We thank all the reviewers who commented during presentations and open meetings at various conferences. We especially thank the following people who submitted written comments on drafts of our manuscript, as this feedback significantly improved the quality of the report and contributed to the consensus nature of this manuscript: Manuel Gomes, Naohiro Yonemoto, Aikaterini Bilitou, Muhammed Rashid, and Ravi K. Goyal. We also thank the following individuals for their support with reviewing abstracts and preliminary data: Gianluca Baio, Juan-David Rueda, and Christoph Gerlinger. We extend special thanks to Clarissa Cooblall, MPH, CHES for project management support.
Funding
Open access funding provided by SUPSI - University of Applied Sciences and Arts of Southern Switzerland.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
None of the authors received support for their participation and contribution in this article. All authors volunteered their time for the discussion, research, and writing of this article. None of the authors had any financial or non-financial interests that are directly or indirectly related to this article. However, the following authors disclose the following: Kumar Mukherjee has received two research grants during the previous 3 years from the Harvey L. Neiman Health Policy Institute and Emory University and Organic Remedies outside the submitted work. Necdet Gunsoy has received personal fees from GlaxoSmith Kline previously. He is an employee and shareholder of AbbVie, which has no financial or non-financial interests that are directly or indirectly related to this article. Rita Kristy is an employee of Astellas Pharma, which has no financial or non-financial interests that are directly or indirectly related to this article. Joseph C. Cappelleri is an employee and stockholder of Pfizer Inc, which has no financial or non-financial interests that are directly or indirectly related to this article. Jessica Roydhouse has received personal fees from Amgen and grants from Royal Hobart Hospital Research Foundation and U Birmingham Enterprise through her employer, outside the submitted work. Helene Karcher is an employee and shareholder of Novartis, which has no financial or non-financial interests that are directly or indirectly related to this article. She is also the Editor-in-Chief of the journal Epidemiologic Methods, from where she receives an annual honorarium outside of the submitted work. Gian Luca Di Tanna has received fees paid by Amgen and Gilead Sciences, Inc. to his previous employer for methodological support on many projects outside the submitted work.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Availability of data and material
All data analyzed as part of this study are included in this published article (and its supplementary information files).
Code availability
Not applicable.
Authors’ contributions
KM: literature selection, reviewed the data, statistical analysis and interpretation of data, drafted the manuscript. NG: conceptualization and design, literature search and selection, quality assessment of included studies, data extraction, reviewed and revised the manuscript. RK: conceptualization and design, literature search and selection, reviewed the data, reviewed and revised the manuscript. JC: conceptualization and design, reviewed the data, reviewed and revised the manuscript. JR: reviewed the data generated, reviewed and revised the manuscript. JS: reviewed the data generated, reviewed and revised the manuscript. DV: conceptualization and design, reviewed the data, reviewed and revised the manuscript. SR: reviewed the data generated, reviewed and revised the manuscript. NO: reviewed the data generated, reviewed and revised the manuscript. SRP: reviewed the data generated, reviewed and revised the manuscript. HK: conceptualization and design, literature search and selection, quality assessment of included studies, data extraction, reviewed the data generated, reviewed and revised the manuscript. GLDT: conceptualization and design, literature selection, quality assessment of included studies, drafted the manuscript, supervision of the manuscript.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Mukherjee, K., Gunsoy, N.B., Kristy, R.M. et al. Handling Missing Data in Health Economics and Outcomes Research (HEOR): A Systematic Review and Practical Recommendations. PharmacoEconomics 41, 1589–1601 (2023). https://doi.org/10.1007/s40273-023-01297-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40273-023-01297-0