
Abstract
Introduction
The LIGHTNING study applied conventional and advanced analytic approaches to model, predict, and compare hypoglycemia rates of people with type 2 diabetes (T2DM) on insulin glargine 300 U/ml (Gla-300) with those on first-generation (insulin glargine 100 U/ml [Gla-100]; insulin detemir [IDet]) or second-generation (insulin degludec [IDeg]) basal-insulin (BI) analogs, utilizing a large real-world database.
Methods
Data were collected between 1 January 2007 and 31 March 2017 from the Optum Humedica US electronic health records [EHR] database. Patient-treatments, the period during which a patient used a specific BI, were analyzed for patients who switched from a prior BI or those who newly initiated BI therapy. Data were analyzed using two approaches: propensity score matching (PSM) and a predictive modeling approach using machine learning.
Results
A total of 831,456 patients with T2DM receiving BI were included from the EHR data set. Following selection, 198,198 patient-treatments were available for predictive modeling. The analysis showed that rates of severe hypoglycemia (using a modified definition) were approximately 50% lower with Gla-300 than with Gla-100 or IDet in insulin-naïve individuals, and 30% lower versus IDet in BI switchers (all p < 0.05). Similar rates of severe hypoglycemia were predicted for Gla-300 and IDeg, regardless of prior insulin experience. Similar results to those observed in the overall cohorts were seen in analyses across subgroups at a particularly high risk of hypoglycemia.
PSM (performed on 157,573 patient-treatments) revealed comparable reductions in HbA1c with Gla-300 versus first- and second-generation BI analogs, alongside lower rates of severe hypoglycemia with Gla-300 versus first-generation BI analogs (p < 0.05) and similar rates versus IDeg in insulin-naïve and BI-switcher cohorts.
Conclusions
Based on real-world data, predicted rates of severe hypoglycemia with Gla-300 tended to be lower versus first-generation BI analogs and similar versus IDeg in a wide spectrum of patients with T2DM.
Funding
Sanofi, Paris, France.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Many patients with type 2 diabetes (T2DM) will eventually require insulin therapy [1]. Current American Diabetes Association (ADA) guidelines recommend a HbA1c target of < 7.0% [1]; however, many patients do not achieve this goal due to several factors such as hypoglycemia, which remains a significant barrier to achieving glycemic control [2]. Experiencing hypoglycemia may contribute to reduced treatment adherence [3] as well as increased healthcare resource utilization and costs [4], and may also have clinical consequences such as increased risks of morbidity and mortality [5] and poorer health-related quality of life [5, 6].
First-generation basal insulin (BI) analogs, such as insulin glargine 100 U/ml (Gla-100) and insulin detemir (IDet), provide more prolonged and stable activity than neutral protamine Hagedorn (NPH) insulin, with a lower risk of hypoglycemia [7]. Further improvements in pharmacokinetic (PK)/pharmacodynamic (PD) properties have been made with the second-generation BI analogs insulin glargine 300 U/ml (Gla-300) and insulin degludec (IDeg) [8,9,10].
The EDITION randomized controlled trial (RCT) program demonstrated that Gla-300 provided similar reductions in HbA1c compared with Gla-100, but with less hypoglycemia in people with type 1 diabetes (T1DM) [11] and T2DM [12, 13]. BRIGHT, the first RCT to directly compare the efficacy and safety of Gla-300 and IDeg in insulin-naïve patients with T2DM, demonstrated that both second-generation BI analogs provided similar robust improvements in glycemic control with a low risk of hypoglycemia. Benefits were observed with Gla-300 in terms of lower hypoglycemia rates during the active titration period (week 0–12) compared with IDeg [14].
It is important to determine whether the clinical benefits of hypoglycemia reduction observed with Gla-300 in RCTs translate into a real-life clinical practice setting. Evidence from sources such as electronic health records (EHRs), claims data, and disease registries can help in this regard; however, there is a need to account for any biases reflecting the lack of randomization and potential confounders [15]. Propensity score matching (PSM) is an established method to address potential confounders by comparing cohorts that are matched according to their baseline characteristics [16]. More sophisticated predictive modeling approaches to account for potential confounders can utilize machine learning, whereby computers self-optimize predictive models based on training data or previously inputted data [17]; in this way, the computer ‘learns’ complex data interactions.
The LIGHTNING study captures information relating to hypoglycemic events using a rich EHR data source and utilizes traditional PSM techniques in addition to novel predictive modeling with machine learning to predict/compare hypoglycemia rates in people with T2DM treated with Gla-300, Gla-100, IDet, and IDeg.
Methods
The Optum Humedica EHR database was selected as the data source for the LIGHTNING study, as it combines data from more than 50 US healthcare plans involving more than 700 hospitals and 7000 clinics, and comprises EHRs from more than 80 million patients. The data were derived from inpatient, outpatient, and ambulatory patient EHRs and included details on demographic and socioeconomic categories, coded diagnoses and procedures, prescribed medications, laboratory results, and clinical administrative data.
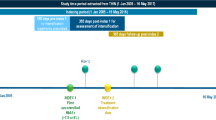
The data set used for the LIGHTNING study was collected from 1 January 2007 to 31 March 2017 from 831,456 people with T2DM receiving BI treatment (Fig. 1). The study window for analysis was constrained to 1 April 2015 through 31 March 2017, a time window when all four BI analogs (Gla-300, Gla-100 [Sanofi, Paris, France], IDet, and IDeg [Novo Nordisk, Bagsvaerd, Denmark]) were available in clinical practice. Full details of the methodology used in the LIGHTNING study have been described separately [18].

LIGHTNING study population: patient selection. aMultiple BI was defined as patient-treatments that have another BI start within 1 week (before or after) of the specified BI start. bInactivity was defined as the lack of any time-stamped data. cPopulation included in PSM analysis. BI basal insulin, PSM propensity score matching
Study Population
The study involved patients with a confirmed diagnosis of T2DM (presence of one or more International Classification of Diseases [ICD] 9 or 10 codes [ICD-9: 250.×0; 250.×2; ICD-10: E11]), with one or more prescriptions for an antidiabetic drug at any time during the study window, and who were aged ≥ 18 years at the time of their first known prescription of a BI in the EHR database. Patients who were likely to have a predominant diagnosis of T1DM [19] were excluded. Within the insulin-naïve population, individuals with prior use of any insulin in the baseline period were excluded. Individuals who switched between BIs >10 times within the study window were also excluded, as they were deemed likely to represent unusual clinical behavior.
Study Design
The unit of analysis for LIGHTNING was defined as a ‘patient-treatment,’ which was the period that a patient was treated with a specific BI. In this way, the use of the available data was maximized, as individual patients may have had multiple patient-treatments with different BIs (Fig. S1 in the Electronic supplementary material, ESM). Additional inclusion criteria were applied to patient-treatments, including no prescription of a different BI treatment within 7 days of the index date and no treatment inactivity in the year prior to the index date. A further inclusion criterion was applied to the PSM analysis cohort, whereby at least one HbA1c measurement at baseline was required (Table S1 in the ESM) to allow for the assessment of glycemic control.
The treatment index date was defined as the date of the first prescription of BI (insulin-naïve cohort), or the change of prescription from one BI to another (BI-switcher cohort). Treatment end was defined as either the end of the follow-up period in the data set (March 2017), the change of prescription from the index BI to another BI, or 1 year after the treatment index date (whichever occurred earliest). Hypoglycemic events (as defined in Fig. 2) were captured within the patient-treatment period. The duration considered when determining hypoglycemia rates was the duration of the patient-treatment period minus that of all inpatient stays during this period (since patients are often switched to a different BI upon hospital admission).

Comprehensive definitions of hypoglycemia and severe hypoglycemia used in the LIGHTNING study. aMaximum of one hypoglycemic event in a calendar day. In the case of same-day hypoglycemic events, the severe event is counted; secondary inpatient hypoglycemic events are excluded. bCodes used to identify hypoglycemia: ICD-9: 249.30; 249.80; 250.30; 250.31; 250.80; 250.81; 251.0; 251.1; 251.2; 270.3 (inclusion of 249.80, 250.80, and 250.81 only in the absence of other contributing diagnoses (ICD-9, 259.8, 272.7, 681.xx, 682.xx, 686.9x, 707.1–707.9, 709.3, 730.0–730.2, or 731.8)); ICD-10: E08.64; E08.641; E08.649; E09.64; E09.641; E09.649; E10.64; E10.641; E10.649; E11.64; E11.641; E11.649; E13.64; E13.641; E13.649; E15; E16.0; E16.1; E16.2. cCodes regarded as severe by default: ICD-9: 249.30; 250.30; 250.31; 251.0; ICD-10: E08.641; E09.641; E10.641; E11.641; E13.641; E15. dADA, EASD Joint Statement on Hypoglycemia 2016. ED emergency department, IM intramuscular, ICD International Classification of Diseases
Target Outcome: Hypoglycemic Event Rates
Hypoglycemic events were defined as severe and nonsevere. The definition of ‘severe’ hypoglycemia is provided in Fig. 2, including ICD-9/10 codes, plasma glucose measurement < 54 mg/dL (< 3.0 mmol/L; indicative of serious, clinically relevant hypoglycemia [1]), and natural language processing (NLP) that identified hypoglycemia from clinical notes (as described previously [20]); any event not defined as ‘severe’ was classed as a ‘nonsevere’ event.
Statistical analyses were stratified by insulin-naïve and BI-switcher subgroups. Further stratification was performed on each subgroup to investigate populations that were particularly susceptible to experiencing hypoglycemia, defined as those at an increased hypoglycemia risk (due to experiencing ≥ 1 severe episode within the last year), having moderate renal impairment, > 5 years of insulin exposure, and a hypoglycemic episode [≤ 70 mg/dL (≤ 3.9 mmol/L)] within the last 12 weeks; those with moderate/severe renal impairment (defined as any one of the following: estimated glomerular filtration rate [eGFR] < 60 mL/min/1.73 m2, nephropathy, proteinuria, or requirement for dialysis); those on a basal-bolus regimen; and those over 65 or over 75 years of age.
Propensity Score Matching
PSM was performed as a preliminary analysis of hypoglycemic event rates. This was intended to complement results from two studies that utilized PSM to compare rates of hypoglycemia between BIs in the Predictive Health Intelligence Environment EHR database: the DELIVER 2 study (investigating switching to either Gla-300 or other BIs) [21] and the DELIVER D+ study (investigating switching to Gla-300 or IDeg from Gla-100 or IDet) [22]. PSM reduces the potentially confounding effects of key baseline clinical variables by matching individuals or samples based on these variables (Fig. S2 in the ESM). In LIGHTNING, patient treatment periods were matched one-to-one (based on propensity score) to provide cohorts of patient-treatments with similar baseline characteristics. Differences in 17 distinct independent variables for baseline characteristics were identified between the different BI cohorts and used for PSM (Table S1 in the ESM); these included age, time from diabetes diagnosis, and most recent HbA1c measurement in the baseline period. Matching was implemented using the R package Matchit and stratified by prior insulin use (insulin-naïve or BI switchers). For consistency with the DELIVER 2 and DELIVER D+ studies [21, 22], the PSM analysis in LIGHTNING was performed on severe hypoglycemia and any hypoglycemia (it should be noted that the definition of severe hypoglycemia reported in the present analysis differed from that used in the DELIVER studies [21, 22]). To establish whether PSM cohorts were comparable in terms of glycemic control, a further validation was performed on the change in HbA1c from the baseline period of each patient-treatment to between 76 and 180 days post index date. Analyses of the change in HbA1c from baseline also required at least one HbA1c measurement within the patient treatment period. As hypoglycemia within the 12 months prior to the index date was one of the 17 distinct independent variables identified, PSM was performed separately for severe hypoglycemia and any hypoglycemia.
Independent-sample t tests (two-sided) were performed on the matched groups to test for statistically significant differences between drug cohorts in target variables. Confidence intervals (CIs) for point estimates of the differences between drug cohorts were calculated from the standard errors of the mean.
Insulin-Specific Hypoglycemia Prediction: Predictive Modeling
In addition to the PSM analysis, a separate analysis using a predictive modeling approach was used to predict hypoglycemia rates for Gla-300 versus each comparator (full details shown in Fig. S3 in the ESM). Firstly, two different types of covariates were determined from the full patient-treatment data set. The first type were clinical covariates selected from baseline characteristics that are well-established factors which affect hypoglycemia risk; the other type were data-driven covariates determined using a machine-learning algorithm. Baseline characteristics were determined using a ‘look-back’ period of 1–8 years, depending on the characteristic. Missing baseline HbA1c values were imputed as part of the modeling process.
The predictive modeling approach used in LIGHTNING was an iterative process which employed bootstrapping [23]. Bootstrapping is a method by which data are repeatedly resampled to allow the generation of summary statistics (e.g., medians and confidence intervals). In LIGHTNING, the bootstrapping process used random sampling with replacement. During this process, a sample data set is created by randomly selecting patient-treatments from the original data set; importantly, the patient-treatment is replaced in the original data set, so it is possible for the sample data set to contain duplicate patient-treatments. Because of this, the sample data set can contain the same number of patient-treatments as the original data set without being identical to it. Repeating this random process can, therefore, generate multiple different sample data sets across which summary statistics can be calculated.
In LIGHTNING, random sampling with replacement was applied to each BI-specific cohort to generate random data sets which were then each used to develop BI-specific predictive Poisson generalized linear models. The random data sets were split to create a training data set (80%, used to train each BI-specific predictive model) and a test data set (20%, used to evaluate each model’s performance; Fig. 2).
During the ‘training’ process, covariates were selected that best predicted hypoglycemia rates (i.e., those that minimized the prediction error of the model) using least absolute shrinkage and selection operator (LASSO) regression [24] performed on the training data set. LASSO regression selects variables which enhance the prediction accuracy of the predictive model. The trained model was then applied to the ‘test’ data set to test the accuracy of the model [using metrics such as the area under the curve (AUC)].
Next, each BI-specific model was applied to the full data set of all patient-treatments (i.e., patient-treatments using Gla-300, IDeg, Gla-100, or IDet) to obtain a prediction of the insulin-specific mean hypoglycemia rate that would be observed assuming all patients were using a specific BI.
At this point, the initial random sampling with replacement step was performed again, along with all subsequent steps, and the entire modeling process was repeated; this ‘bootstrapping’ was performed until the median and CI values stabilized (630 times for rates of severe hypoglycemia, and 1134 times for rates of nonsevere hypoglycemia), with separate BI-specific predictive models being generated during each ‘bootstrap’. After these multiple iterations (bootstraps), a median point estimate of the hypoglycemia rate was derived, and the 95% CI was determined from the spread of the individual estimated mean hypoglycemia rates.
Statistical analyses were performed on the insulin-naïve and BI-switcher (previously treated with BI) populations. The null hypothesis was that comparators were equal to Gla-300. The statistical significance (p value) of the between-treatment difference in hypoglycemia rates was calculated as the proportion of bootstraps in which the estimated rate difference (comparator minus Gla-300) was opposite in sign to the overall estimated rate difference. Therefore, if the overall point estimate rate difference was negative (i.e., Gla-300 had a lower rate versus the comparator), a p value of 0.05 would mean that the estimated rate difference was positive (i.e., Gla-300 had a higher rate versus the comparator in 5% of tests). This proportion was then multiplied by two to account for the lack of assumption of directionality of effect, because the overall estimated rate difference could have been either negative or positive. This is similar to the p value of the two-sided variant of a classical statistics test, such as Student’s t test.
Compliance with Ethics Guidelines
The OPTUM databases used in the LIGHTNING study were compliant with the Health Insurance Portability and Accountability Act. Fully anonymized retrospective data were obtained from OPTUM via a license agreement, and the LIGHTNING study did not involve primary data collection by the authors. The LIGHTNING study was therefore deemed exempt from ethical approval.
Results
Baseline Characteristics
Propensity Score Matching Population
The PSM analysis population comprised 157,573 BI patient-treatments eligible for analysis across the drug cohorts (Fig. 1). The cohort sizes prior to and post PSM are shown in Table S2 of the ESM. There were a proportion of patient-treatments (38%) within the PSM population (after matching) for which the insulin status was not well captured in the databases, so those patient-treatments were not included in the present analysis by previous insulin status.
Prior to PSM, there were differences between the insulin-specific populations in 17 baseline characteristic variables (shown in Table S1 of the ESM). After PSM, these variables were similar across the BI treatment groups, with the exception of the ‘line of BI treatment’ variable in the insulin-naïve subgroup, which was slightly higher in the Gla-300 group (mean of 1.20) versus the Gla-100 group (mean of 1.15; p = 0.0015).
Predictive Modeling Population
After the selection process, patient-treatments for Gla-300 (n = 10,253), Gla-100 (n = 109,119), IDet (n = 63,502), and IDeg (n = 15,324) were available for BI-specific model development (Fig. 1). After development, each model was then applied to the full data set of patient-treatments in LIGHTNING (the ‘scoring data set’), including those on Gla-300, IDeg, Gla-100, and IDet (n = 198,198). The results for insulin-naïve and BI switcher cohorts are discussed in the present analysis. Prior insulin use was not well captured in 43.2% of patient-treatments within the population available for predictive modeling; these patient-treatments are not included in the presented analyses.
Descriptive baseline characteristics are presented in Table 1. The mean age was approximately 60 years across the insulin-naïve and BI-switcher groups for both Gla-300 and IDeg cohorts, with an equal distribution of male and female patients in each group. In the BI-switcher population, baseline HbA1c levels were approximately 9.0% in all BI treatment groups, while in the insulin-naïve population, baseline levels were between 9.4% and 9.6%. During the 12 months prior to the index date, the rate of any hypoglycemia or severe hypoglycemia was higher in the BI-switcher populations compared with the insulin-naïve populations for all four BI treatment groups. The mean duration of treatment was significantly shorter with IDeg (188 days) and significantly longer with Gla-100 (279 days) and IDet (264 days) compared with Gla-300 (237 days, p < 0.0001 for all).
Hypoglycemia and HbA1c Change: Propensity Score Matching Analysis
Following PSM analysis, rates of severe hypoglycemia were significantly lower with Gla-300 versus both Gla-100 and IDet (p < 0.05) in the matched insulin-naïve and BI-switcher cohorts (Fig. 3a). Rates of any hypoglycemia were lower with Gla-300 versus IDet (p < 0.05) in the insulin-naïve cohort, but were similar with Gla-300 and both first-generation BI analogs in the BI-switcher cohort. Severe hypoglycemia rates were not statistically different with IDeg and Gla-300 in either the BI-switcher or insulin-naïve groups (p > 0.05, Fig. 3a), whereas rates of any hypoglycemia were significantly lower with Gla-300 versus IDeg in the BI-switcher and insulin-naïve groups (p < 0.05, Fig. 3c). HbA1c reductions were comparable between BIs within both subgroups (both p > 0.05; Fig. 3b, d).

a Severe hypoglycemic event rate following PSM; b HbA1c change following PSM on severe hypoglycemia; c all hypoglycemic event rates following PSM; d HbA1c change following PSM on any hypoglycemia. *p < 0.05, Gla-300 vs BI comparator; SD shown as text in b and d. BI basal insulin, PPY per patient-year, PSM propensity score matching, SD standard deviation, SE standard error
Hypoglycemia Prediction: Predictive Modeling Analysis
Following the predictive modeling analysis, predicted severe hypoglycemic event rates with Gla-300 were significantly lower than with Gla-100 or IDet (both p < 0.01) and no different from those with IDeg in the insulin-naïve cohort, and lower than with IDet (p < 0.01) but no different from those with Gla-100 or IDeg in the BI-switcher cohort (Fig. 4a). Predicted rates of nonsevere hypoglycemia were significantly lower with Gla-300 versus all comparator BIs in the insulin-naïve cohort (p < 0.001) but were similar with all BIs in the BI-switcher cohort (Fig. 4b).

Predicted rates of a severe and b nonsevere hypoglycemic events by basal insulin and prior insulin experience. *p < 0.05. Numbers within the insulin-naïve and BI-switcher groups refer to the number of patient-treatments. BI basal insulin, CI confidence interval, PPY per patient-year
In the BI-switcher cohort, statistically significantly lower rates of severe hypoglycemia with Gla-300 versus IDet were predicted for clinically relevant subgroups of patients: those with moderate to severe renal impairment; basal-bolus insulin regimens; and those ≥ 65 years of age (Fig. 5b). For a similar subanalysis performed in the insulin-naïve group, a significantly lower rate of severe hypoglycemia was predicted with Gla-300 versus both first-generation BI analogs across all clinically relevant subgroups included in this analysis (Fig. 5a). Predicted rates of severe hypoglycemia were similar with Gla-300 and IDeg across all clinically relevant subgroups in the insulin-naïve and BI-switcher cohorts (Fig. 5a, b).

Predicted rates of severe hypoglycemia in clinically relevant subgroups of the insulin-naïve (a) and BI-switcher (b) groups. *p < 0.05. a≥ 1 severe hypoglycemic episode within the last year, moderate renal impairment, >5 years of insulin exposure, hypoglycemic episode within last 12 weeks. bCompromised estimated glomerular filtration rate, nephropathy, proteinuria, dialysis. BI basal insulin, CI confidence interval, PPY per patient-year
AUC measures for the predicted models (representing how well the models discriminated patients according to their likelihood of experiencing hypoglycemic events [0 = no discrimination; 1 = complete discrimination]) were 0.756 (Gla-300), 0.783 (Gla-100), 0.787 (IDet), and 0.779 (IDeg) for severe events, and 0.844 (Gla-300), 0.784 (Gla-100), 0.782 (IDet), and 0.843 (IDeg) for nonsevere events, indicating that the models accurately predicted hypoglycemic events.
Discussion
The LIGHTNING study compared hypoglycemia rates between Gla-300 and first- and second-generation BI analogs in a real-life setting using PSM and predictive modeling.
Predictive modeling indicated that Gla-300 is associated with ~ 50% lower rates of severe hypoglycemia compared with either of the first-generation BI analogs (Gla-100 or IDet; p < 0.05) in insulin-naïve individuals and a 30% reduction in rates versus IDet in BI switchers (p < 0.05). Predicted rates of severe hypoglycemia were numerically lower with Gla-300 versus Gla-100 (21% lower) in the BI-switcher group, although this was not significant (p = 0.076). When comparing the two second-generation BI analogs, predicted rates of severe hypoglycemia were numerically lower with Gla-300 versus IDeg in insulin-naïve individuals (25% lower; p = 0.096, not significant), and were similar with both second-generation BI analogs in BI switchers. An overview of the hypoglycemia rate results is shown in Fig. S4 of the ESM.
The PSM analysis demonstrated that Gla-100, IDet, and IDeg provided similar HbA1c reductions to Gla-300, but that Gla-300 was associated with lower rates of severe hypoglycemia versus both first-generation BI analogs, irrespective of prior insulin status (all p < 0.05). Gla-300 also provided significantly lower rates of any hypoglycemia versus IDet and IDeg in the insulin-naïve group and versus IDeg in the BI-switcher groups (all p < 0.05) (Fig. S4 in the ESM).
LIGHTNING benefited from the use of NLP, which allowed the capture of more hypoglycemic events than previous observational studies, with approximately half of all events being captured through NLP [21]. A sensitivity analysis that assessed the impact of both NLP and the < 54 mg/dL (< 3.0 mmol/L) definition of severe hypoglycemia on hypoglycemic event rates following PSM produced comparable results to those reported here (Fig. S5 in the ESM).
Real-world data are not explicitly intended for research purposes, and often lack important elements and/or completeness. In addition, there is a need to account for the lack of randomization and potential confounders that could otherwise introduce bias [15]. To address these potential limitations, the LIGHTNING study utilized a variety of methods, including NLP, to more comprehensively capture hypoglycemic events within a real-world evidence data source (Optum Humedica EHR). In addition, we applied conventional PSM and novel predictive modeling approaches to account for potential biases which can occur when analyzing complex real-world data. Compared with the more traditional methodology of the PSM analysis, the predictive modeling was more exhaustive, allowing for broader control of confounders in a larger and more generalizable BI-treated population.
A number of findings from the LIGHTNING real-world data are consistent with reported results from several RCTs that have demonstrated similar reductions in HbA1c but lower rates of hypoglycemia (primarily nonsevere) with second-generation versus first-generation BI analogs in individuals with T2DM [12, 13, 25]. Similarities can also be seen between results from LIGHTNING and the BRIGHT RCT, where lower rates of hypoglycemia confirmed by a blood glucose measurement of ≤ 70 mg/dL (< 3.9 mmol/L) with Gla-300 versus IDeg were observed in the 12-week titration period [14]. Some differences were also observed between the results of previous RCTs and LIGHTNING, which could be due to the highly selected conditions of the RCTs. For example, EDITION 1 and 2 showed significantly lower rates of nonsevere hypoglycemia in BI switchers, a finding not observed in LIGHTNING. Additionally, 60% of nonsevere hypoglycemic events in LIGHTNING were identified by NLP; as such, this definition may encompass a much broader spectrum of hypoglycemic events compared with RCTs that require an accompanying blood glucose measurement for nonsevere hypoglycemia.
The hypoglycemic event rates indicated by PSM and the predictive modeling results of LIGHTNING also demonstrated consistency with other real-world studies, such as the DELIVER D+ and DELIVER 2 retrospective observational studies [21, 22]. DELIVER D+ demonstrated similar improvements in glycemic control and rates of hypoglycemia when switching from Gla-100 or IDet to Gla-300 or IDeg [22], and DELIVER 2 showed significantly lower rates of hypoglycemia associated with hospitalization or an emergency department visit (as a proxy for severe hypoglycemia) in adults with T2DM switching from either Gla-100, IDet, Gla-300, or IDeg to Gla-300 versus other (mainly first-generation) BI analogs [21].
The real-world nature of the LIGHTNING source data ensures that individuals with T2DM with varied baseline characteristics, including those with potential risk factors for hypoglycemia, are included. Previous clinical trials have demonstrated that both Gla-300 and IDeg provide reduced hypoglycemia versus Gla-100 in both insulin-naïve and pretreated patients who are at a higher risk of experiencing hypoglycemia [26, 27]. Consistent with these observations, the LIGHTNING predictive modeling demonstrated comparable rates of severe hypoglycemia with Gla-300 and IDeg in subgroups that were particularly at risk of hypoglycemia.
As with all retrospective observational studies, the accuracy and validity of the LIGHTNING results are limited by the quality of the data and the robustness of the study design and methodology. Importantly, EHR data are often less complete than those from RCTs. For example, 38% of patient-treatments in LIGHTNING did not have prior insulin use data (possibly due to patient interactions with healthcare systems not captured by the EHR database). Data were also unavailable on patients’ insulin doses; as such, it is not possible to determine if any observed hypoglycemia rate differences were due to differences in insulin dose. It was also not possible to assess the reasons why patients were initiated on each insulin (e.g., owing to suboptimal control with their previous treatment, the availability of each BI, the previous experience of the prescribing healthcare professional). In future studies, it may be of interest to assess whether NLP approaches could be used to investigate factors influencing switch behavior. HbA1c measurements were not available for all patients, and although missing values were imputed, the missing data may have affected the model’s ability to fully account for glycemic control when assessing hypoglycemia. However, results from the PSM analysis demonstrated that, where these HbA1c values were available, Gla-300 was associated with lower rates of severe hypoglycemia and similar HbA1c reductions compared with either Gla-100 or IDet.
Further limitations include the fact that the beginning of the treatment period was defined by BI prescription, which may not be indicative of the actual dispensing and use of this product.
Although baseline glucagon-like peptide 1 receptor agonist (GLP-1RA) was controlled in PSM, no other glucose-lowering medications (e.g., sulfonylureas) were controlled for. However, this is because there were no differences identified in concomitant medication use at baseline other than for GLP-1 RA use.
The predictive modeling results rely on the models being generalizable (i.e., they provide results similar to those experienced in real-life); however, these models are simplifications of the complexities of interacting factors that affect hypoglycemia risk. Further validation may still be required, as is often the case for novel methodologies. However, it is reassuring that, while some differences were observed between results of the predictive modeling and PSM (which could be due to the different methodologies used), results were predominantly consistent.
Gla-300 was available approximately 9 months before IDeg in the US (Gla-300: Mar/Apr 2015; IDeg: Dec 2015); this difference in availability may explain the significantly shorter treatment duration in the IDeg versus Gla-300 population. A shorter treatment duration would result in a higher proportion of the patient-treatment period comprising time when patients were actively titrating a new BI, making them more susceptible to hypoglycemia. As hypoglycemic events were measured for each patient-treatment period as a whole, and data on the distribution of these events are not available, it is not possible to determine the hypoglycemic event rates for the ‘titration phase’ versus the ‘maintenance phase’ for the different BI analogs, as has been done in RCTs. However, treatment duration was included as a covariate for modeling in an effort to control for this potential bias.
Of note, the definition of severe hypoglycemia in LIGHTNING included a plasma glucose measurement of < 54 mg/dL (< 3.0 mmol/L). While this definition is not typically defined as severe, ADA guidelines denote this threshold as being indicative of serious, clinically significant hypoglycemia [1]. As such, the definitions of severe hypoglycemia in LIGHTNING were designed to capture these important hypoglycemic events, and may allow the predictions of hypoglycemia rates to be more generalizable to real-world practice, although further validation is required.
Conclusions
In summary, the LIGHTNING study compared hypoglycemia rates with Gla-300 versus first- and second-generation BI analogs in a real-life setting using traditional PSM techniques, in addition to a novel predictive modeling approach. The results of LIGHTNING provide additional support that hypoglycemia rates, particularly severe hypoglycemic events, are lower with Gla-300 than with first-generation BI analogs and are comparable to those with IDeg in real-world practice. Predicted rates of severe hypoglycemia were approximately 50% lower with Gla-300 versus Gla-100 or IDet (1 event every 14 years with Gla-300 versus 1 event every 7 years with Gla-100 or IDet) in previously insulin-naïve individuals, and 30% lower with Gla-300 versus IDet (1 event every 5 years with Gla-300 versus 1 event every 3 years with IDet) in the BI-switcher population. Comparable rates of severe hypoglycemia were predicted when comparing the two second-generation BI analogs. Given the large burden hypoglycemia poses to individuals with hypoglycemia and on healthcare providers, these reductions in clinically relevant hypoglycemia observed with the real-life use of Gla-300 versus first-generation BIs may facilitate real-world decision making.
References
American Diabetes Association. Improving care and promoting health in populations: standards of medical care in diabetes—2018. Diabetes Care. 2018;41(Suppl 1):S7–S12.
Cryer PE. Hypoglycemia: still the limiting factor in the glycemic management of diabetes. Endocr Pract. 2008;14(6):750–6.
Polonsky WH, Henry RR. Poor medication adherence in type 2 diabetes: recognizing the scope of the problem and its key contributors. Patient Prefer Adherence. 2016;10:1299–307.
Meneghini LF, Lee LK, Gupta S, Preblick R. Association of hypoglycaemia severity with clinical, patient-reported and economic outcomes in US patients with type 2 diabetes using basal insulin. Diabetes Obes Metab. 2018;20(5):1156–65.
Frier BM. Hypoglycaemia in diabetes mellitus: epidemiology and clinical implications. Nat Rev Endocrinol. 2014;10(12):711–22.
Evans M, Khunti K, Mamdani M, et al. Health-related quality of life associated with daytime and nocturnal hypoglycaemic events: a time trade-off survey in five countries. Health Qual Life Outcomes. 2013;11:90.
Heise T, Mathieu C. Impact of the mode of protraction of basal insulin therapies on their pharmacokinetic and pharmacodynamic properties and resulting clinical outcomes. Diabetes Obes Metab. 2017;19(1):3–12.
Becker RH, Dahmen R, Bergmann K, Lehmann A, Jax T, Heise T. New insulin glargine 300 Units mL-1 provides a more even activity profile and prolonged glycemic control at steady state compared with insulin glargine 100 Units mL-1. Diabetes Care. 2015;38(4):637–43.
Heise T, Hermanski L, Nosek L, Feldman A, Rasmussen S, Haahr H. Insulin degludec: four times lower pharmacodynamic variability than insulin glargine under steady-state conditions in type 1 diabetes. Diabetes Obes Metab. 2012;14(9):859–64.
Heise T, Nosek L, Bottcher SG, Hastrup H, Haahr H. Ultra-long-acting insulin degludec has a flat and stable glucose-lowering effect in type 2 diabetes. Diabetes Obes Metab. 2012;14(10):944–50.
Matsuhisa M, Koyama M, Cheng X, et al. New insulin glargine 300 U/ml versus glargine 100 U/ml in Japanese adults with type 1 diabetes using basal and mealtime insulin: glucose control and hypoglycaemia in a randomized controlled trial (EDITION JP 1). Diabetes Obes Metab. 2016;18(4):375–83.
Ritzel R, Roussel R, Bolli GB, et al. Patient-level meta-analysis of the EDITION 1, 2 and 3 studies: glycaemic control and hypoglycaemia with new insulin glargine 300 U/ml versus glargine 100 U/ml in people with type 2 diabetes. Diabetes Obes Metab. 2015;17(9):859–67.
Terauchi Y, Koyama M, Cheng X, et al. New insulin glargine 300 U/ml versus glargine 100 U/ml in Japanese people with type 2 diabetes using basal insulin and oral antihyperglycaemic drugs: glucose control and hypoglycaemia in a randomized controlled trial (EDITION JP 2). Diabetes Obes Metab. 2016;18(4):366–74.
Rosenstock J, Cheng A, Ritzel R, et al. More similarities than differences testing insulin glargine 300 units/mL versus insulin degludec 100 units/mL in insulin-naive type 2 diabetes: the randomized head-to-head BRIGHT trial. Diabetes Care. 2018;41(10):2147–54.
Sherman RE, Anderson SA, Dal Pan GJ, et al. Real-world evidence—what is it and what can it tell us? N Engl J Med. 2016;375(23):2293–7.
Kosiborod M, Cavender MA, Fu AZ, et al. Lower risk of heart failure and death in patients initiated on sodium-glucose cotransporter-2 inhibitors versus other glucose-lowering drugs: the CVD-REAL study (comparative effectiveness of cardiovascular outcomes in new users of sodium-glucose cotransporter-2 inhibitors). Circulation. 2017;136(3):249–59.
Larranaga P, Calvo B, Santana R, et al. Machine learning in bioinformatics. Brief Bioinform. 2006;7(1):86–112.
Bosnyak Z, Zhou FL, Jimenez J, Berria R. Predictive modeling of hypoglycemia risk with basal insulin use in type 2 diabetes: use of machine learning in the LIGHTNING study. Diabetes Therapy. 2018. https://doi.org/10.1007/s13300-019-0567-9.
Klompas M, Eggleston E, McVetta J, Lazarus R, Li L, Platt R. Automated detection and classification of type 1 versus type 2 diabetes using electronic health record data. Diabetes Care. 2013;36(4):914–21.
Nunes AP, Yang J, Radican L, et al. Assessing occurrence of hypoglycemia and its severity from electronic health records of patients with type 2 diabetes mellitus. Diabetes Res Clin Pract. 2016;121:192–203.
Zhou FL, Ye F, Berhanu P, et al. Real-world evidence concerning clinical and economic outcomes of switching to insulin glargine 300 units/mL vs other basal insulins in patients with type 2 diabetes using basal insulin. Diabetes Obes Metab. 2018;20(5):1293–7.
Sullivan SD, Bailey TS, Roussel R, et al. Clinical outcomes in real-world patients with type 2 diabetes switching from first- to second-generation basal insulin analogues: Comparative effectiveness of insulin glargine 300 units/mL and insulin degludec in the DELIVER D+ cohort study. Diabetes Obes Metab. 2018;20(9):2148–58.
Dixon PM. Bootstrap resampling. In: El-Shaarawi AH, Piegorsch WW, eds. Encyclopedia of environmetrics. Chichester: Wiley; 2006.
Tibshirani R. Regression shrinkage and selection via the lasso. J R Stat Soc Ser B (Methodol). 1996;58(1):267–88.
Ratner RE, Gough SC, Mathieu C, et al. Hypoglycaemia risk with insulin degludec compared with insulin glargine in type 2 and type 1 diabetes: a pre-planned meta-analysis of phase 3 trials. Diabetes Obes Metab. 2013;15(2):175–84.
Ritzel R, Harris SB, Baron H, et al. A randomized controlled trial comparing efficacy and safety of insulin glargine 300 units/mL versus 100 units/mL in older people with type 2 diabetes: results from the SENIOR study. Diabetes Care. 2018;41(8):1672–80.
Wysham C, Bhargava A, Chaykin L, et al. Effect of insulin degludec vs insulin glargine U100 on hypoglycemia in patients with type 2 diabetes: the SWITCH 2 randomized clinical trial. JAMA. 2017;318(1):45–56.
Acknowledgements
The authors would like to thank Quantum Black (McKinsey & Company) for data collection and statistical analyses, and Emmanuelle Boëlle-Le-Corfec of Sanofi for her statistical review of our methods and results.
Funding
This work was supported by Sanofi, Paris, France. Publishing and journal processing charges were also funded by Sanofi. All authors had full access to all of the data in this study and take complete responsibility for the integrity of the data and accuracy of the data analysis.
Editorial Assistance
The authors would like to thank Arthur Holland and Hannah Brown of Fishawack Communications for editorial assistance. This work was funded by Sanofi.
Authorship
All named authors meet the International Committee of Medical Journal Editors (ICMJE) criteria for authorship for this article, take responsibility for the integrity of the work as a whole, and have given their approval for this version to be published.
Disclosures
Jeremy Pettus—consultant: Diasome, Eli Lilly, Insulet, MannKind, Novo Nordisk, Sanofi; research support: JDRF; speakers bureau: MannKind, Novo Nordisk, Sanofi. Ronan Roussel—advisory panel: Abbott, AbbVie, AstraZeneca, Eli Lilly, Janssen, Medtronic, MSD, Novo Nordisk, Physiogenex, Sanofi; consultant: Sanofi; speakers bureau: Servier; research support: Amgen, Sanofi, Novo Nordisk. Fang Liz Zhou—employee: Sanofi. Zsolt Bosnyak—employee: Sanofi. Jukka Westerbacka—employee: Sanofi. Rachele Berria—employee: Sanofi. Javier Jimenez—employee: Sanofi. Bjorn Eliasson—personal fees (advisory panels and/or consultant) from Amgen, AstraZeneca, Boehringer Ingelheim, Eli Lilly, Merck Sharp & Dohme, Mundipharma, Navamedic, Novo Nordisk, and RLS Global outside the submitted work, and grants from Sanofi outside the submitted work. Irene Hramiak—consultant: AstraZeneca, Bristol-Myers Squibb, Eli Lilly, GlaxoSmithKline, Insulet, Janssen, Merck, Novo Nordisk, Sanofi; research support: AstraZeneca, Bristol-Myers Squibb, Eli Lilly, GlaxoSmithKline, Janssen, Lexicon, Medtronic, Merck, Novo Nordisk, Sanofi; honoraria, consultation fees, or speakers bureau fees: Janssen, Merck, Novo Nordisk. Timothy Bailey—research support: Abbott, Ambra, Ascensia, BD, Boehringer Ingelheim, Calibra Medical, Companion Medical, Dance Biopharm, Dexcom, Eli Lilly, Glooko, Glysens, Kowa, Lexicon, MannKind, Medtronic, Novo Nordisk, Sanofi, Senseonics, Taidoc, Versartis, Xeris; Consulting honoraria: Abbott, Ascensia, AstraZeneca, BD, Calibra Medical, Capillary Biomedical, Eli Lilly, Intarcia, Medtronic, Novo Nordisk, Sanofi. Luigi Meneghini—advisory panel: Novo Nordisk, Sanofi, Intarcia, AstraZeneca; consultant: Novo Nordisk, Sanofi.
Compliance with Ethics Guidelines
The OPTUM databases used in the LIGHTNING study were compliant with the Health Insurance Portability and Accountability Act. Fully anonymized retrospective data were obtained from OPTUM via a license agreement, and the LIGHTNING study did not involve primary data collection by the authors. The LIGHTNING study was therefore deemed exempt from ethical approval.
Open Access
This article is distributed under the terms of the Creative Commons Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/), which permits any noncommercial use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Author information
Authors and Affiliations
Corresponding author
Additional information
Enhanced Digital Features
To view enhanced digital features for this article go to https://doi.org/10.6084/m9.figshare.7578167
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

Cite this article
Pettus, J., Roussel, R., Liz Zhou, F. et al. Rates of Hypoglycemia Predicted in Patients with Type 2 Diabetes on Insulin Glargine 300 U/ml Versus First- and Second-Generation Basal Insulin Analogs: The Real-World LIGHTNING Study. Diabetes Ther 10, 617–633 (2019). https://doi.org/10.1007/s13300-019-0568-8
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13300-019-0568-8