
Abstract
The uniaxial compressive strength (UCS) and tensile strength (T0) are crucial parameters in field development and excavation projects. Traditional lab-based methods for directly measuring these properties face practical challenges. Therefore, non-destructive techniques like machine learning have gained traction as innovative tools for predicting these parameters. This study leverages machine learning methods, specifically random forest (RF) and decision tree (DT), to forecast UCS and T0 using real well-logging data sourced from a Middle East reservoir. The dataset comprises 2600 data points for model development and over 600 points for validation. Sensitivity analysis identified gamma-ray, compressional time (DTC), and bulk density (ROHB) as key factors influencing the prediction. Model accuracy was assessed using the correlation coefficient (R) and the absolute average percentage error (AAPE) against actual parameter profiles. For UCS prediction, both RF and DT achieved R values of 0.97, with AAPE values at 0.65% for RF and 0.78% for DT. In T0 prediction, RF yielded R values of 0.99, outperforming DT's 0.93, while AAPE stood at 0.28% for RF and 1.4% for DT. These outcomes underscore the effectiveness of both models in predicting strength parameters from well-logging data, with RF demonstrating superior performance. These models offer the industry an economical and rapid tool for accurately and reliably estimating strength parameters from well-logging data.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The investigation of rock mechanical parameters holds paramount importance throughout various stages in the life cycle of oil and gas wells. These applications encompass predicting pore pressure, assessing wellbore stability, ensuring well integrity, optimizing drilling operations, and enhancing hydraulic fracturing (Moose et al. 2003; Klimentos 2005; Fjaer et al. 2008; Kholsravantain et al. 2016; Germay et al. 2017; Hussain et al. 2020). Among these parameters, rock strength emerges as a fundamental characteristic. As defined by Fjaer et al. (2008), rock strength signifies the stress level at which rocks undergo failure. Rock failure poses a prevalent challenge in the oil and gas industry, leading to complications like sand production and reservoir compaction, detrimentally impacting well productivity. These repercussions encompass reduced formation permeability, diminished reservoir pressure, and decreased production rates (Settari and Walters 2001; Boutt et al. 2011; Najibi et al. 2017).
Uniaxial/unconfined compressive strength (UCS) and tensile strength (T0) stand out as primary indicators of rock mechanical properties, gaining widespread utilization in fields such as mining and petroleum industries (Parsajoo et al. 2021; He et al. 2020). The determination of UCS can be executed directly through standardized procedures outlined by the International Society of Rock Mechanics (Ulusay and Hudson 2007) and the American Society for Testing and Materials (Standard ASTM 2010). Meanwhile, Tensile Strength is often identified as the highest stress–strain curve point, typically around 0.1 of the UCS value, especially in proximity to excavation areas, where it tends to be notably lower than compressive strength (Perras and Diederichs 2014). Both UCS and tensile strength testing, however, necessitate meticulously prepared samples, incurring expenses, consuming time, and inducing destruction (Kalantari et al. 2018). Consequently, alternative techniques have emerged for assessing rock UCS, including block punch, scratch, point load strength (PLS), and Schmidt hammer tests (SHT) (Palassi and Emami 2014; He et al. 2019, 2020). Additionally, the Brazilian tensile strength (BTS) test is a commonly employed method for evaluating tensile strength (Heidari et al. 2012; Mahdiyar et al. 2019).
Numerous empirical relationships have been established to infer UCS and tensile strength from these indirect methodologies, predominantly employing straightforward multiple regression and statistical approaches, as highlighted by A. Mahmoodzadeh et al. (2021a, b). For instance, Kahraman et al. (2005) unveiled a direct connection between UCS and PLS, while Madhubabu et al. (2016) employed linear correlations involving compressive strength, porosity, PLS, and Poisson's ratio, especially concerning carbonate rocks. In addition, several research investigations have explored the correlation between UCS and compressional wave velocity. These correlations have been modeled both exponentially (Moradian and Behnia 2009a, b; Nefeslioglu 2013; Mishra and Basu 2013) and linearly (Yilmaz and Yuksek 2009; Dehghan et al. 2010; Armaghani et al. 2016; Heidari et al. 2018a, b; Celik 2019). Furthermore, a multitude of empirical relationships have been devised to relate tensile strength to BTS, incorporating various rock index tests such as block punch and point load testing (Nazir et al. 2013; Haung et al. 2019; Harandizadeh et al. 2020; Parsajoo et al. 2021). Additionally, diverse studies have endeavored to establish connections between UCS and BTS for different rock types (Altındağ and Güney 2010; Comakli and Cayirli 2019). Nevertheless, these investigations have indicated that the precision of these empirical correlations is constrained, typically yielding average coefficients of determination (R2) in the range of 0.4–0.7. This underscores the demand for a high degree of precision when predicting BTS during the initial formulation of these equations. Moreover, the scarcity of data or limited laboratory measurements might lead scientists to employ these correlations without scrutinizing their underlying assumptions (Azimian et al. 2014; Hassanvand et al. 2018).
In contemporary times, artificial intelligence (AI) has emerged as a superior alternative to human reasoning when it comes to establishing connections between strength parameters and the available field or laboratory measurements. As pointed out by Fjaer et al. (2008), machine learning (ML) techniques offer a way to surmount several challenges and uncertainties associated with imprecisions, data deficiencies, and the intricacies of drilling operations, as emphasized in studies by Al-Abduljabbar et al. (2020), Mahmoud et al. (2020), Ahmed et al. (2019), and others. The integration of machine learning into the processing of logging data has brought about a transformative impact in the realm of petroleum engineering and reservoir characterization.
Machine learning methodologies, including neural networks, decision trees, and support vector machines, have clearly demonstrated their effectiveness in gleaning valuable insights from extensive and intricate logging datasets. These algorithms exhibit the capability to swiftly discern patterns, anomalies, and correlations within the data, thereby empowering geoscientists and engineers to make well-informed decisions concerning reservoir properties, fluid compositions, and lithology classifications. Furthermore, machine learning models exhibit proficiency in managing substantial volumes of historical and real-time logging data, rendering them indispensable tools for the optimization of well drilling, production strategies, and reservoir management, as highlighted in studies conducted by Ali et al. (2020, 2021, 2023) and Ashraf et al. (2021).
Numerous studies in the existing body of literature have undertaken the task of predicting unconfined compressive strength (UCS) using a variety of artificial intelligence techniques, often drawing on core data as their foundation (Rabbani et al. 2012). Take, for instance, the work of Heidari et al. (2018a, b), which leveraged a dataset comprising 109 data points encompassing parameters like p-wave velocity, Is50, and block punch index BPI. In their study, they employed the fuzzy inference system (FIS) to estimate UCS, and the precision of their model was meticulously evaluated using the R2 statistic, yielding an impressive score of 0.91. Additionally, artificial neural network (ANN) methodologies have gained significant traction among researchers as a powerful tool for UCS prediction, consistently achieving accuracy levels exceeding 0.9 in various studies (Mohamed et al. 2015; Torabi-Kaveh et al. 2015; Madhubabu et al. 2016; Ferentinou and Fakir 2017; Sharma et al. 2017; Mahmoodzadeh et al. 2021a, b). Furthermore, the prognosis of Brazilian Tensile Strength (BTS) has been successfully carried out using ANN approaches, incorporating diverse rock parameters such as grain size, rock type, and mineral ratios, as exemplified by the work of Singh et al. (2001). Notably, several studies have embraced alternative input variables including density, Schmidt hammer readings, and Is50 (Mahdiyar et al. 2019; Haung et al. 2019; Parsajoo et al. 2021), consistently delivering superior predictive accuracy when compared to traditional multiple regression techniques. For a comprehensive overview of the latest advancements in machine learning (ML) applications for the prediction of UCS and tensile strength (T0) across diverse lithologies, please refer to Table 1.
Despite the advancements in this area of research, most of the existing studies used a relatively small number of data points, limiting the model’s accuracy. In addition, most of the inputs used for the training and testing of the AI models were collected from core logs and lab measurements. The objective of this work is to utilize a large set of logging data, approximately 2600 data points, acquired from an actual field in the middle east for UCS and T0 Prediction using two ML techniques, decision tree (DT) and random forest (RF) and compare them to find the most accurate technique. The data is comprised of gamma-ray (GR), Sonic time compressional (DTC) and Shear (DTS) times, rock bulk density (RHOB), and neutron porosity. According to the literature RF and DT have been used in the oil and gas industry, with little work for tensile strength and UCS prediction from Well Logs. This will overcome the difficulties associated with lab measurements as well as provide a fast tool for measuring these parameters during the early stage of well development using well-logging data.
Methodology
In this study, we employed a comprehensive methodology that harnessed the power of decision trees (DT) and random forest (RF) algorithms to predict two critical parameters, uniaxial compressive strength (UCS) and tensile strength (T), crucial for characterizing reservoir rock types. Our approach commenced with rigorous data preprocessing, including feature selection and normalization, to ensure the quality and consistency of the dataset. Subsequently, we utilized decision trees to create individual predictive models for UCS and T. These models were further integrated into a random forest ensemble, leveraging the strengths of multiple decision trees to enhance predictive accuracy. The following sections discuss the data description and preprocessing, details about the used ML methods and their advantage, and the input parameters importance and selection.
Data description
The dataset employed in this investigation comprises well logging data sourced from carbonate reservoirs situated in the Middle East. This logging dataset encompasses 2670 records, encompassing critical parameters, such as gamma-ray (GR), compressional time (DTC), shear time (DTS), bulk density (ROHB), and neutron porosity (NPHI). According to pertinent literature sources, these parameters hold significant relevance in predicting the rock's strength properties (Madhubabu et al. 2016; Matin et al. 2018; Mahmoodzadeh et al. 2021a, b). The tensile strength of the rock is contingent upon various factors, including mineralogical composition, texture, and porosity. For instance, gamma-ray (GR) logs can be leveraged to estimate mineralogical composition and clay content, critical in gauging rock strength. Additionally, compressional time (DTC) and shear time (DTS) logs facilitate the estimation of P-wave and S-wave velocities, pivotal for determining Young's modulus and Poisson's ratio. Furthermore, bulk density (ROHB) and neutron porosity (NPHI) logs prove invaluable in assessing porosity density, thereby aiding in the prediction of mechanical properties, such as Young's modulus, Poisson's ratio, and UCS.
To ensure the robustness of the predictive models, a validation dataset comprising 638 data points from an alternate well was incorporated. The collected data was subjected to random division into training and testing sets, with varying ratios ranging from 60:40 to 85:15. Remarkably, the optimal model performance was achieved when employing a 70:30 ratio. Figure 1 provides a representative depiction of the dataset employed in this study, showcasing well logging tracks for various logging parameters alongside their associated UCS and T values.

example of logging track for the different well logs
Table 2 shows the statistical parameters of the training data, including the minimum and maximum value, the range of the data, the mean, and the standard deviation. The GR values range from 3.338 API to 85.799 API, DTC ranges from 44.899 us/ft to 66.124 us/ft, while the bulk density ranges from 2.325 g/cc to 3.045 g/cc.
Decision trees (DT)
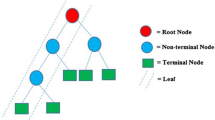
Decision trees are a concept drawn from the structure of ordinary trees, featuring nodes, a root, branches, and leaves (Ali et al. 2012). As elucidated by Zhao and Zhang (2008), decision trees manifest as a manifestation of supervised classification. The typical orientation for a Decision Tree, as noted by Ali et al. (2012), involves its construction from left to right, commencing at the root node and progressing downward. The initial node of the tree, where this journey commences, is aptly referred to as the root node, while the terminal point of the tree's branches is termed a leaf. Furthermore, each node within the tree represents distinct characteristics, with the range of values being depicted through branches extending from internal nodes, functioning as partition points for the respective sets of values associated with the given characteristic (Ali et al. 2012). A visual representation of this Decision Tree architecture can be observed in Fig. 2.

Decision tree structure
Random forest (RF)
Random Forest, originally conceived by Breiman (2001), comprises an ensemble of unpruned regression or classification trees, as outlined in Breiman's work in 2001. According to insights from Ali et al. (2012), Random Forest leverages a set of L tree-structured base classifiers {h(Xɵn), n = 1, 2, 3…L}, with X representing the input and {ɵn} denoting a family of dependent, identically distributed random vectors. Importantly, the data undergoes random selection for each Decision Tree, allowing the creation of a Random Forest through the randomized sampling of either a feature subset and/or a training data subset for every Decision Tree. Furthermore, features are subject to random selection at each decision split, thereby enhancing prediction accuracy by mitigating correlations between trees, achieved through the randomized feature selection. Thus, as elucidated by Ali et al. (2012), the growth of each tree follows these steps:
-
N is subject to random sampling. This sample serves as a training dataset, drawn with replacement from the original data when the training dataset contains N cases.
-
M signifies the total number of inputs. At each node, a variable m is chosen, exceeding M. Additionally, m variables are randomly selected from the pool of M variables, with the optimal split based on these m variables used for node division. Moreover, the value of m remains constant throughout the forest's growth.
-
Pruning is not applied during the expansion of each tree, allowing them to reach their maximal extent.
Input parameters importance
In this investigation, it was imperative to explore the connection between the input and output parameters in order to identify the significant factors affecting the prediction process. This analysis also illustrates how sensitive the output parameters are to variations in the input parameters. To accomplish this, we employed the Pearson correlation coefficient (R), as calculated by Eq. 1, which spans from − 1, indicating a strong negative relationship, to 1, indicating a strong positive relationship.
where, R is the correlation coefficient, yi is the dependent parameter, xi is the independent parameter,\({\sigma }_{x}\mathrm{ and }{\sigma }_{y}\), are the standard deviations of independent and dependent parameters, \({\mu }_{x}\) and \({\mu }_{y}\), are the mean of the independent and dependent parameters. The correlation coefficient between the UCS and the input parameters were found to be 0.54, − 0.93, − 0.92, 0.15, − 0.95 for GR, DTC, DTS, RHOB, NPHI, respectively. In addition, by studying the effect of each parameter, it was found that the highest relation observed between the output and the input parameter was when the gamma-ray and DTC, and ROHB were used for the analysis as shown in Table 3. Although other parameters were tested, their significance was minuscule as the reduction in the R-value was inconsequential.
Consequently, the decision was made to build the models using these three parameters, GR, DTC, and RHOB Moreover, the testing data was found to fall in the same range as the training data, which was observed from its statistical parameters shown in Table 4. This step added more confidence to the models making the data unbiasedly selected and representative of the original data set. Furthermore, in addition to Pearson correlation, the absolute average percentage error (AAPE) in Eq. 2, was used to assess the quality of the model. The lower the percentage, the better the prediction method.
where n is the number of data points
Result and discussion
Decision tree (DT)
DT model optimum parameters were adjusted to improve the accuracy of the model as shown in Table 5. It was found that the Maximum Depth of the tree is “11” and “6” for T0 and UCS respectively, while the maximum feature was “sqrt” for tensile strength prediction and “auto” for UCS predictive model. The ‘maximum feature’, represents the size of the random subsets considered while splitting a node. Thus, when ‘Max-Feature’ is “auto”, it means that the random forest is a bagged ensemble of ordinary regression trees while “sqrt” means the subset size is considered sqrt(n-features), where n_features represents the number of features in data.
Figures 3 and 4 depict a comparison between the actual and predicted strength parameters throughout both the training and testing phases. These results aptly demonstrate the DT model's impressive capacity to forecast UCS and T0 with remarkable precision based on the well logging data. Notably, during the training phase, the T0 predictions achieved an R value of 0.99 and 0.93 for testing, accompanied by AAPE scores of 0.45% and 1.4%, respectively. Additionally, the linear relationship between forecasted UCS values and actual measurements was notably strong, registering R values of 0.99 and 0.97, while the AAPE amounted to 0.56% and 0.97% during training and testing, respectively.

DT model tensile strength result. a Training, b Testing

DT model UCS prediction result. a Training, b testing
Random forest (RF)
RF optimum parameters were found through sensitivity analysis and summarized in Table 5. The maximum feature was “auto” for UCS and T0 predictive models. The Number of estimate N, which was found to greatly affects the accuracy of the model was found 100 and 150 for the T0 and UCS models respectively. The results displayed in Fig. 5 show that RF was able to predict tensile strength with R values of 0.99 for training and 0.98 for testing, while the AAPE values were less than 1% during the training and testing stage.

RF Tensile strength result. a Training, b testing
Mirroring the outcomes observed in the prediction of tensile strength, the RF model exhibited a remarkable capacity for accurately predicting UCS. This proficiency is underscored by the one-to-one correspondence between the predicted and actual UCS values, wherein R values of 0.99 and 0.98 were recorded, accompanied by AAPE scores of 0.28% and 0.59% during the training and testing phases, respectively (see Fig. 6).

RF UCS prediction results. a Training, b Testing
Validation of the DT and RF models
The validation process for both models involved a separate dataset collected from well-2, comprising approximately 600 data points, with their respective statistical characteristics outlined in Table 6. The remarkable congruity between the predicted and actual UCS and T0 values underscores the precision and reliability of these models in forecasting strength parameters based on well-logging data. The evaluation of this correspondence employed the correlation coefficient (R) to gauge the relationship between predicted and measured values, while model quality was assessed using AAPE, as illustrated in Fig. 7. For the tensile strength models, R values were determined to be 0.93 and 0.97 for DT and RF, respectively, affirming RF's superiority as a predictive model. This superiority was further substantiated by the AAPE scores of 0.65% for RF and 1.4% for DT. Figure 8 exhibits the linear correlation between measured and predicted UCS values for DT and RF, revealing an R-value of 0.97. However, the corresponding AAPE figures were 0.65% for RF and 0.78% for DT.

Tensile strength models validation. a RF, b DT

UCS models validation. a RF, b DT
Across the study's three stages—training, testing, and validation—DT and RF consistently demonstrated their capacity to deliver high-quality and accurate predictive models for both tensile strength and unconfined compressive strength, as derived from well logs. This performance, notably, surpassed existing models in the literature (as shown in Table 1). Moreover, this study's use of actual well logging profiles eliminated the uncertainties tied to lab measurements of input parameters, and the substantial dataset employed further contributed to the models' robustness and precision.
Figures 9 and 10 summarize the performance indicators for RF and DT models to predict UCS and T. RF model showed a superior performance with R values higher than 0.98 in predicting UCS and T for the different datasets with AAPE less than 0.7%. DT model showed slightly lower performance as the AAPE increased to 1.4% in predicting the T for the testing and validation datasets.

Summary of the developed models’ performance for predicting UCS in different datasets. a R values, b AAPE

Summary of the developed models’ performance for predicting T in different datasets. a R values, b AAPE
Future developments for this study encompass the exploration of advanced machine learning algorithms. More advanced machine learning algorithms beyond decision trees (DT) and Random Forests (RF) including ANN, ANFIS, GBR, and others in order to improve the prediction accuracy and robustness. In addition, future work includes continuous refinement of feature engineering, potential data augmentation, and real-world application testing. Collaborative efforts with experts from geology and materials science will refine models and their practicality.
Conclusions
The investigation harnessed the power of Random Forest (RF) and Decision Tree (DT) machine learning (ML) techniques to forecast unconfined compressive strength (UCS) and Tensile strength (T0) from a well-logging dataset encompassing gamma-ray (GR), compressional time (DTC), shear time (DTS), bulk density (ROHB), and Neutron porosity (NPHI). The key findings are summarized below.
-
Both DT and RF models exhibited remarkable proficiency in predicting strength parameters throughout the formation with exceptional precision.
-
The RF model showcased superior prediction accuracy when compared to DT.
-
The study underwent validation using data from well-2, affirming the robustness of both models, with R-values exceeding 0.93.
Leveraging these two models presents an economical and expeditious solution for the industry to anticipate mechanical parameters using well-logging data, characterized by an extraordinary degree of precision and reliability. Notably, it's crucial to acknowledge that this study's scope was confined to carbonate reservoirs, and further experimentation across diverse geological formations is imperative for the broad applicability of these findings.
Abbreviations
- DTC:
-
Compressional time (us/ft)
- DTS:
-
Shear time (us/ft)
- Is50:
-
Point load strength index
- NPHI:
-
Neutron porosity (fraction)
- PLS:
-
Point load strength (MPa)
- PSO:
-
Particle swarm optimization
- R :
-
Correlation coefficient (dimensionless)
- R 2 :
-
Coefficient of determination (dimensionless)
- RL:
-
Lithology type
- Rn:
-
Schmidt Hammer rebound number (dimensionless)
- ROHB:
-
Bulk density (g/cc)
- SFS:
-
Stochastic fractal search
- T0:
-
Tensile strength (MPa)
- UCS:
-
Unconfined compressive strength (MPa)
- V p :
-
P-wave velocity (ft/s)
- W :
-
Weathering grade
- x i :
-
Independent parameter
- y i :
-
Dependent parameter
- \({\mu }_{x}\) :
-
Mean of independent parameter
- \({\mu }_{y}\) :
-
Mean of dependent parameter
- \({\sigma }_{x}\) :
-
Standard deviation of independent parameter
- \({\sigma }_{y}\) :
-
Standard deviation of independent parameter
- AAPE:
-
Absolute average percentage error
- AI:
-
Artificial intelligence
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- ANN:
-
Artificial neural network
- ASTM:
-
American Society for Testing and Materials
- BPI:
-
Block punch index
- BTS:
-
Brazilian tensile strength
- CPI:
-
Cylinder punch index
- FIS:
-
Fuzzy inference system
- GR:
-
Gamma ray
- IWO:
-
Invasive weed optimization
- ML:
-
Machine learning
References
Ahmed A, Ali A, Elkatatny S, Abdulraheem A (2019) New artificial neural networks model for predicting rate of penetration in deep shale formation. Sustainability 11(22):6527
Al-Abduljabbar A, Gamal H, Elkatatny S (2020) Application of artificial neural network to predict the rate of penetration for S-shape well profile. Arab J Geosci 13(16):1–11
Ali J, Khan R, Ahmad N, Maqsood I (2012) Random forests and decision trees. Int J Comput Sci Issues (IJCSI) 9(5):272
Ali M, Ma H, Pan H, Ashraf U, Jiang R (2020) Building a rock physics model for the formation evaluation of the Lower Goru sand reservoir of the Southern Indus Basin in Pakistan. J Petrol Sci Eng 194:107461
Ali M, Jiang R, Ma H, Pan H, Abbas K, Ashraf U, Ullah J (2021) Machine learning-A novel approach of well logs similarity based on synchronization measures to predict shear sonic logs. J Petrol Sci Eng 203:108602
Ali M, Zhu P, Huolin M, Pan H, Abbas K, Ashraf U, Zhang H (2023) A novel machine learning approach for detecting outliers, rebuilding well logs, and enhancing reservoir characterization. Nat Resour Res 32(3):1047–1066
Altındağ R, Güney A (2010) Predicting the relationships between brittleness and mechanical properties (UCS, TS and SH) of rocks. https://hdl.handle.net/20.500.12809/4536
Armaghani D, Tonnizam Mohamad E, Momeni E et al (2016) Prediction of the strength and elasticity modulus of granite through an expert artificial neural network. Arab J Geosci 9:48. https://doi.org/10.1007/s12517-015-2057-3
Ashraf U, Zhang H, Anees A, Mangi HN, Ali M, Zhang X, Tan S (2021) A core logging, machine learning and geostatistical modeling interactive approach for subsurface imaging of lenticular geobodies in a clastic depositional system, SE Pakistan. Nat Resour Res 30:2807–2830
Azimian A, Ajalloeian R, Fatehi L (2014) an empirical correlation of uniaxial compressive strength with P-wave velocity and point load strength index on Marly rocks using statistical method. Geotech Geol Eng 32:205–214. https://doi.org/10.1007/s10706-013-9703-x
Boutt DF, Cook BK, Williams JR (2011) A coupled fluid–solid model for problems in geomechanics: application to sand production. Int J Numer Anal Meth Geomech 35(9):997–1018. https://doi.org/10.1002/nag.938
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Çelik SB (2019) Prediction of uniaxial compressive strength of carbonate rocks from nondestructive tests using multivariate regression and LS-SVM methods. Arab J Geosci 12(6): 1–17. https://doi.org/10.1007/s12517-019-4307-2.
Comakli R, Cayirli S (2019) A correlative study on textural properties and crushability of rocks. Bull Eng Geol Environ 78:3541–3557. https://doi.org/10.1007/s10064-018-1357-8
Dehghan S, Sattari GH, Chelgani SC, Aliabadi MA (2010) Prediction of uniaxial compressive strength and modulus of elasticity for Travertine samples using regression and artificial neural networks. Min Sci Technol (China) 20(1):41–46. https://doi.org/10.1016/S1674-5264(09)60158-7
Ebdali M, Khorasani E, Salehin S (2020) A comparative study of various hybrid neural networks and regression analysis to predict unconfined compressive strength of travertine. Innov Infrastruct Solut 5(3):1–14. https://doi.org/10.1007/s41062-020-00346-3
Ferentinou M, Fakir M (2017) An ANN approach for the prediction of uniaxial compressive strength, of some sedimentary and igneous rocks in eastern KwaZulu-Natal. Proced Eng 191:1117–1125. https://doi.org/10.1016/j.proeng.2017.05.286
Fjaer E, Holt RM, Horsrud P, Raaen AM, Risne A (2008) Petroleum related rock mechanics. Elsevier, Amsterdam
Germay C, Lhomme T, Richard T (2017) Using high resolution, continuous profiles of core properties for the upscaling of rock mechanical tests results and the accurate calibration of geomechanical models. In: 51st US Rock Mechanics/Geomechanics Symposium. OnePetro.
Harandizadeh H, Armaghani DJ, Mohamad ET (2020) Development of fuzzy-GMDH model optimized by GSA to predict rock tensile strength based on experimental datasets. Neural Comput Appl 32:14047–14067. https://doi.org/10.1007/s00521-020-04803-z
Hassanvand M, Moradi S, Fattahi M, Zargar G, Kamari M (2018) Estimation of rock uniaxial compressive strength for an Iranian carbonate oil reservoir: modeling vs. artificial neural network application. Pet Res 3(4):336–345. https://doi.org/10.1016/j.ptlrs.2018.08.004
He M, Zhang Z, Ren J, Huan J, Li G, Chen Y, Li N (2019) Deep convolutional neural network for fast determination of the rock strength parameters using drilling data. Int J Rock Mech Min Sci 123:104084
He M, Li N, Zhu J, Chen Y (2020) Advanced prediction for field strength parameters of rock using drilling operational data from impregnated diamond bit. J Pet Sci Eng 187(2019):106847. https://doi.org/10.1016/j.petrol.2019.106847
Heidari M, Khanlari GR, Kaveh MT, Kargarian S (2012) Predicting the uniaxial compressive and tensile strengths of gypsum rock by point load testing. Rock Mech Rock Eng 45(2):265–273. https://doi.org/10.1007/s00603-011-0196-8
Heidari M, Mohseni H, Jalali SH (2018a) Prediction of uniaxial compressive strength of some sedimentary rocks by fuzzy and regression models. Geotech Geol Eng 36:401–412. https://doi.org/10.1007/s10706-017-0334-5
Heidari M, Mohseni H, Jalali SH (2018) Prediction of uniaxial compressive strength of some sedimentary rocks by fuzzy and regression models. Geotech Geol Eng 36(1):401–412. https://doi.org/10.1007/s10706-017-0334-5
Huang L, Asteris PG, Koopialipoor M, Armaghani DJ, Tahir MM (2019) Invasive weed optimization technique-based ANN to the prediction of rock tensile strength. Appl Sci 9(24):5372. https://doi.org/10.3390/app9245372
Hussain M, Amao AO, Al-Ramadan K, Negara A, Saleh TA (2020) Non-destructive techniques for linking methodology of geochemical and mechanical properties of rock samples. J Petrol Sci Eng 195:107804. https://doi.org/10.1016/j.petrol.2020.107804
Jing H, Nikafshan Rad H, Hasanipanah M, Jahed Armaghani D, Qasem SN (2021) Design and implementation of a new tuned hybrid intelligent model to predict the uniaxial compressive strength of the rock using SFS-ANFIS. Eng Comput 37(4):2717–2734. https://doi.org/10.1007/s00366-020-00977-1
Kahraman S, Gunaydin O, Fener M (2005) The effect of porosity on the relation between uniaxial compressive strength and point load index. Int J Rock Mech Min Sci 42(4):584–589. https://doi.org/10.1016/j.ijrmms.2005.02.004
Kalantari S, Hashemolhosseini H, Baghbanan A (2018) Estimating rock strength parameters using drilling data. Int J Rock Mech Min Sci 104:45–52. https://doi.org/10.1016/j.ijrmms.2018.02.013
Khosravanian R, Aadnoy BS (2016) Optimization of casing string placement in the presence of geological uncertainty in oil wells: offshore oilfield case studies. J Petrol Sci Eng 142:141–151. https://doi.org/10.1016/j.petrol.2016.01.033
Klimentos T (2005) Optimizing drilling performance by wellbore stability and pore-pressure evaluation in deepwater exploration. In: International Petroleum technology conference. OnePetro.
Madhubabu N, Singh PK, Kainthola A, Mahanta B, Tripathy A, Singh TN (2016) Prediction of compressive strength and elastic modulus of carbonate rocks. Measurement 88:202–213. https://doi.org/10.1016/j.measurement.2016.03.050
Mahdiabadi N, Khanlari G (2019) Prediction of uniaxial compressive strength and modulus of elasticity in calcareous mudstones using neural networks, fuzzy systems, and regression analysis. Period Polytech Civ Eng 63(1):104–114. https://doi.org/10.3311/PPci.13035
Mahdiyar A, Armaghani DJ, Marto A et al (2019) Rock tensile strength prediction using empirical and soft computing approaches. Bull Eng Geol Environ 78:4519–4531. https://doi.org/10.1007/s10064-018-1405-4
Mahmoodzadeh A, Mohammadi M, Hashim Ibrahim H, Nariman Abdulhamid S, Ghafoor Salim S, Farid Hama Ali H, Kamal Majeed M (2021) Artificial intelligence forecasting models of uniaxial compressive strength. Transp Geotech 27(2020):100499. https://doi.org/10.1016/j.trgeo.2020.100499
Mahmoodzadeh A, Mohammadi M, Ibrahim HH, Abdulhamid SN, Salim SG, Ali HFH, Majeed MK (2021b) Artificial intelligence forecasting models of uniaxial compressive strength. Transp Geotech 27:100499. https://doi.org/10.1016/j.trgeo.2020.100499
Mahmoud AA, Elkatatny S, Al-AbdulJabbar A, Moussa T, Gamal H, Al Shehri D (2020) Artificial neural networks model for prediction of the rate of penetration while horizontally drilling carbonate formations. In: 54th U.S. rock mechanics/geomechanics symposium, Golden
Matin SS, Farahzadi L, Makaremi S, Chelgani SC, Sattari G (2018) Variable selection and prediction of uniaxial compressive strength and modulus of elasticity by random forest. Appl Soft Comput 70:980–987. https://doi.org/10.1016/j.asoc.2017.06.030
Mishra DA, Basu A (2013) Estimation of uniaxial compressive strength of rock materials by index tests using regression analysis and fuzzy inference system. Eng Geol 160:54–68. https://doi.org/10.1016/j.enggeo.2013.04.004
Mohamad ET, Armaghani DJ, Momeni E, Abad SVANK (2015) Prediction of the unconfined compressive strength of soft rocks: a PSO-based ANN approach. Bull Eng Geol Env 74(3):745–757. https://doi.org/10.1007/s10064-014-0638-0
Moos D, Peska P, Finkbeiner T, Zoback M (2003) Comprehensive wellbore stability analysis utilizing quantitative risk assessment. J Petrol Sci Eng 38(3–4):97–109. https://doi.org/10.1016/S0920-4105(03)00024-X
Moradian OZ, Behnia M (2009a) Predicting the uniaxial compressive strength and static Young’s modulus of intact sedimentary rocks using the ultrasonic test. Int J Geomech. https://doi.org/10.1061/(ASCE)1532-3641(2009)9
Moradian ZA, Behnia M (2009b) Predicting the uniaxial compressive strength and static Young’s modulus of intact sedimentary rocks using the ultrasonic test. Int J Geomech 9(1):14–19. https://doi.org/10.1061/(ASCE)1532-3641(2009)9:1(14)
Najibi AR, Ghafoori M, Lashkaripour GR, Asef MR (2017) Reservoir geomechanical modeling: in-situ stress, pore pressure, and mud design. J Pet Sci Eng 151:31–39. https://doi.org/10.1016/j.petrol.2017.01.045
Nazir R, Momeni E, Armaghani DJ, Amin MM (2013) Correlation between unconfined compressive strength and indirect tensile strength of limestone rock samples. Electron J Geotech Eng 18(1):1737–1746
Nefeslioglu HA (2013) Evaluation of geo-mechanical properties of very weak and weak rock materials by using non-destructive techniques: ultrasonic pulse velocity measurements and reflectance spectroscopy. Eng Geol 160:8–20. https://doi.org/10.1016/j.enggeo.2013.03.023
Palassi M, Emami V (2014) A new nail penetration test for estimation of rock strength. Int J Rock Mech Min Sci 66:124–127. https://doi.org/10.1016/j.ijrmms.2013.12.016
Parsajoo M, Armaghani DJ, Mohammed AS, Khari M, Jahandari S (2021) Tensile strength prediction of rock material using non-destructive tests: a comparative intelligent study. Transp Geotech 31:100652. https://doi.org/10.1016/j.trgeo.2021.100652
Perras MA, Diederichs MS (2014) A review of the tensile strength of rock: concepts and testing. Geotech Geol Eng 32(2):525–546. https://doi.org/10.1007/s10706-014-9732-0
Rabbani E, Sharif F, Koolivand Salooki M, Moradzadeh A (2012) Application of neural network technique for prediction of uniaxial compressive strength using reservoir formation properties. Int J Rock Mech Min Sci 1997(56):100–111. https://doi.org/10.1016/j.ijrmms.2012.07.033
Settari A, Walters DA (2001) Advances in coupled geomechanical and reservoir modeling with applications to reservoir compaction. Spe J 6(03):334–342. https://doi.org/10.2118/74142-PA
Sharma LK, Vishal V, Singh TN (2017) Developing novel models using neural networks and fuzzy systems for the prediction of strength of rocks from key geomechanical properties. Meas J Int Meas Confed 102:158–169. https://doi.org/10.1016/j.measurement.2017.01.043
Singh VK, Singh D, Singh TN (2001) Prediction of strength properties of some schistose rocks from petrographic properties using artificial neural networks. Int J Rock Mech Min Sci 38(2):269–284. https://doi.org/10.1016/S1365-1609(00)00078-2
Standard ASTM (2010) D7012–10 (2010) Standard test method for compressive strength and elastic moduli of intact rock core specimens under varying states of stress and temperatures. Annual Book of ASTM Standards, American Society for Testing and Materials, West Conshohocken, pp 495–498.
Torabi-Kaveh M, Naseri F, Saneie S, Sarshari B (2015) Application of artificial neural networks and multivariate statistics to predict UCS and E using physical properties of Asmari limestones. Arab J Geosci 8(5):2889–2897. https://doi.org/10.1007/s12517-014-1331-0
Ulusay R, Hudson JA (2007) The blue book–the complete ISRM suggested methods for rock characterization, testing and monitoring: 1974–2006. ISRM and Turkish National Group of ISRM, Ankara.
Yilmaz I, Yuksek G (2009) Prediction of the strength and elasticity modulus of gypsum using multiple regression, ANN, and ANFIS models. Int J Rock Mech Min Sci 46(4):803–810. https://doi.org/10.1016/j.ijrmms.2008.09.002
Zhao Y, Zhang Y (2008) Comparison of decision tree methods for finding active objects. Adv Space Res 41(12):1955–1959. https://doi.org/10.1016/j.asr.2007.07.020
Acknowledgements
The authors would like to thank KFUPM for providing permission to publish this study.
Funding
There is no External fund for this research. The authors would like to thank Kind Fahd University of Petroleum & Minerals for giving permission to publish this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ibrahim, A.F., Hiba, M., Elkatatny, S. et al. Estimation of tensile and uniaxial compressive strength of carbonate rocks from well-logging data: artificial intelligence approach. J Petrol Explor Prod Technol 14, 317–329 (2024). https://doi.org/10.1007/s13202-023-01707-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-023-01707-1