
Abstract
In this paper, we have proposed an approach for parameter identification of random field for rigid viscoplastic material. It is assumed that the random field is stationary and Gaussian with known autocovariance function. Karhunen–Loève decomposition has been used to quantify the effects of random inputs. A method is presented that takes into account only the first two statistical moments of the analyzed displacement field, and only two values of searched process are identified—mean value and coefficient of variation in autocovariation function. It has been shown that this approach is desirable when complicated systems are analyzed. The discretization of the governing equations has been described by the finite element method. The sparse grid stochastic collocation method has been used to solve the stochastic direct problem. It is shown that for the described nonlinear equations, the response function due to searched parameters with wide bounds and with reduced number of measurement points has many local extrema and global optimization technique is required. Genetic algorithm has been adopted to compute the functional cost. Numerical example shows the identification problem for compressed cylindrical sample. It is revealed that the key factor determining the convergence of the method is the degree of reduction in the height of the tested sample.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Deterministic metal-forming problems have been considered in many publications [3, 18, 23, 34, 36]. In these problems, the parameters characterizing the material properties or boundary conditions are assumed to be known (achieved as the approximation of experimental studies). This is a good approach for a theoretical study of the problem, but it fails when the real object is analyzed. Experiments show that random fluctuations of geometrical and material parameters, or load values, significantly affect the behavior of the test object. For this reason, in metal-forming processes, a stochastic approach has been used. Due to the considerable progress in computer technology and an associated significant increase in computing power, this approach, in recent years, has been widely used [1, 2, 17, 33].
The most common method of solving the above-posed problem is the Monte Carlo method and the perturbation method [21, 22, 40]. Monte Carlo method is easy to implement and does not require changes in the existing code. Despite these advantages, it often requires a huge amount of sampling that the complex nonlinear problems can lead to many hours of calculations. Perturbation method is based on the extension of a classical deterministic finite element method or the finite difference method [16]. This method based on the Taylor series of expansion allows the calculation of second-order statistics and is suitable for a small level of uncertainty, typically less than 10% for first-order technique and less than 15% for second-order [21].
In recent years, the stochastic spectral finite element method (SSFEM) and the stochastic collocation method (SCM) [5, 46] have gained a growing popularity. First one was proposed by Ghanem and Spanos [13]; subsequently, it was developed by other researchers [25, 26, 45] and applied to the problem of finite deformations [2]. Despite its high effectiveness and the possibility of its application to a number of problems, the use of the SSFEM may cause problems if governing equations are complicated and complex. In this case, it may be difficult to derive explicit forms of coefficients in the equations (large number of integration is needed). The equations in this method are coupled, but the domain decomposition method can be used to reduce the computation time [14, 41]. The idea behind the second method resembles the Monte Carlo method. The main difference is the definition of the sampling points defined as a tensor product of a set of one-dimensional quadrature points associated with probability distribution function. This method was initially applied to the numerical integration problems with the large number of dimensions [12]. It gained its significance after the introduction of the sparse grid technique [6, 39], which contributed to the considerable reduction in the sampling points in the multidimensional random space. Due to the possibility of using the already-existing source code of the deterministic program (used as the so-called black box), it has been used in the following paper. A similar approach to the analysis of the hyperelastic–viscoplastic large deformation problem has been proposed in paper [1].
Inverse problems, as ill posed, may be the cause of huge problems connected with the identification of the specified parameter in the deterministic approach, especially in cases of large sensitivity to small changes. The above-mentioned reasons may cause significant errors in solving stochastic problems, by overlapping variety of errors: measurement errors, approach errors and a random perturbation of a searched parameter [11]. Classical methods of solving inverse problems, usually based on the sensitivity analysis, may be found in the numerous works [4, 8, 28, 30, 31, 42]. Solutions of stochastic inverse problems usually associated with heat conduction can be found in the work of Zabaras and co-workers [25, 47, 48] as well as associated with current flow [37]. In these works, to solve the inverse problem, the authors have used gradient methods. Problems of parameter identification in plastic forming of porous materials can be found in [38]. The above-mentioned works assume the existence of a global minimum of response function. In general, except the global minimum, there can exist local minima that disqualify local search methods. Therefore, a non-deterministic method of the minimization of a functional achieved by the use of recently popular genetic algorithms [15, 19, 20, 24] has been proposed. This method is used to optimize problems for the deterministic plastic forming in works [9, 32].
2 Brief Description of the Direct Deterministic Problem
This chapter will first present basic equations governing the problem. These equations can be found in a number of publications on the plastic metal-forming problem [18, 34].
2.1 Rigid Viscoplasticity
The mechanism of plastic deformation of the rigid viscoplastic material is described by the following equations [23]:
where \(\sigma_{ij}\) is a Cauchy stress tensor, \(\bar{\sigma }\)—effective stress, \(\dot{\varepsilon }\)—strain rate, \(\dot{\bar{\varepsilon }}\)—effective strain rate, \(u\)—velocity. To the above equations, boundary conditions should be attached in the form of the initial velocity and the friction at the interface between the sample and a tool.
2.2 Finite Element Approximation Footnote 1
The starting point to formulate the rigid viscoplastic finite element method is to describe the appropriate functional. Rate form of virtual work equations (matrix notation) is as follows [7, 49]:
where \(\varvec{F}^{\text{T}} = [\begin{array}{*{20}c} {F_{r} } & {F_{z} } \\ \end{array} ]\) represent surface tractions associated with surface \(S_{F}\).
Using decomposition of Cauchy stress tensor to hydrostatic and deviatoric part \({\varvec{\upsigma}} = {\mathbf{I}}\sigma_{m} + {\mathbf{s}}\), where \(\sigma_{m} = \frac{1}{3}tr\left( {\varvec{\upsigma}} \right)\), \({\mathbf{I}}\) is a second-order unit tensor, and Levy–Mises equation
following functional can be written as:
Obtaining the solution of Eq. (5) should be determined by the form of Eq. (2), which can be a source of random uncertainty
where \(\omega\) denotes random event. Using definition of strain rate \(\dot{\varepsilon }_{v} = tr\left( {{\dot{\mathbf{\varepsilon }}}} \right)\) and assuming that \(\sigma_{m} = K\dot{\varepsilon }_{v}\), Eq. (7) can be written as a variation of the functional in the form:
where \(\delta {\dot{\varvec{\upvarepsilon }}}\) is the variation in strain rate, \(\delta \dot{\varepsilon }_{v}\) is variation in volumetric strain rate and \(K\) is a penalty constant (very large positive constant) used to remove the incompressibility constraint on admissible velocity field.
Boundary tractions in metal-forming problems are mainly frictional forces. The modeling of these forces is traditionally made in two ways: by means of a friction coefficient and by means of a friction factor [33, 34]. A directly applied friction coefficient leads to non-symmetric matrices and is not commonly used in bulk deformation metal forming. A friction factor is defined by the equation:
where \(\tau\) is the shear friction stress, \(k_{\text{y}}\) is the shear yield stress of the material and \(m\) is the friction factor.
In considering the boundary conditions, a major problem is faced when a point of reverse relative velocity between workpiece and die exists, and its position is not known a priori. This happens, for instance, in ring compression with high friction. The orientation of the friction force changes at that point, so an abrupt jump in its value shows up. In such a case, we can use the equation for the friction force:
where \(u_{\text{R}}\) is the magnitude of relative velocity between die and workpiece, \(a\) is a constant several orders of magnitude less than the die velocity and \(\left| {u_{\text{D}} } \right|\) is the magnitude of die velocity. Above-mentioned boundary conditions have been modeled similar to the works [23, 34].
3 Stochastic Direct Problem
In the stochastic collocation method, the output stochastic process is formed on the basis of the solution of the deterministic problem. The input random process in a form of coefficients in governing equations or in boundary conditions is discretized. This method will be discussed in detail further in this article.
3.1 Method of Random Field Discretization
In this work, it is assumed that the considered random fields are Gaussian processes, or such processes, for which the random variable at each point \({\varvec{x}}\) has normal distribution, as for the material parameters is the most common. It is also assumed that the random fields are stationary in a wide sense [43] by which they satisfy the following assumptions: \(E\left( {\alpha ({\varvec{x}},\omega )^{2} } \right) < \infty\), \(E\left( {\alpha ({\varvec{x}},\omega )} \right) = {\text{const}}\), \({\text{Cov}}(\varvec{x}_{1} ,\varvec{x}_{2} ) = \left. {{\text{Cov}}({\varvec{\uptau}})} \right|_{{{\varvec{\uptau}} = \varvec{x}_{1} - \varvec{x}_{2} }}\).
For the description of the random field \(\alpha ({\varvec{x}},\omega )\), expected value is most commonly used:
and covariance function:
where
is a Gaussian measure of the probability space, \(\Omega \in \left( { - \infty ,\infty } \right)\) and function \(\varphi \left( \xi \right)\) has normal distribution:
wherein \(\mu\) is the expected value and \(\sigma\) is the standard deviation.
A stochastic process \(Y(\varvec{x},\omega ),\) [43] where (\(\varvec{x} \in A \subset R\), \(\omega \in \Omega\)) we call a function, in which each number x assigns a random variable \(Y(\omega )\) defined in a fixed probability space \((\Omega ,{\rm Z},P)\). Here, \(\Omega\) is the set of elementary events, \({\rm Z}\) and \(\sigma\)-algebra and \(P\) is a probability measure. To obtain a computationally useful representation of the process \(Y(\varvec{x},\omega )\), it will be presented in the canonical form. Among the various forms of such a representation, a spectral representation—Karhunen–Loève expansion—will be adopted for further considerations [13, 26, 47]. This expansion may be presented in the following form:
In Eq. (16), \(\varvec{\xi}(\omega )\) is a set of random variables. Constants \(\lambda\) and functions \(f(\varvec{x})\) are the eigenvalues and eigenvectors of the covariance kernel:
Let us assume that the random field is two dimensional.
Hence [13]:
and
After substituting Eqs. (18) and (19) to (16), the following equation can be obtained:
Such Karhunen–Loève expansion is usually truncated to M terms:
To solve the integral Eq. (17), it is necessary to define the kernel \(C(\varvec{x}_{1} ,\varvec{x}_{2} )\). Following the work of Ghanem and Spanos [13], to expand the process \(Y(\varvec{x},\omega )\) the following function is adopted:
where \(b_{x}\) is a correlation length in x direction, \(b_{x}\) in y direction, and \({\text{Var}}_{Y}\) is a coefficient of variation.
3.2 Sparse Grid Stochastic Collocation method (SG-SCM)
In order to discuss in detail, the SG-SCM method in the first place will present definitions necessary for the interpolation problems.
Let \({\varvec{\upxi}}\) represent a point in random space \(\Gamma \subset {\mathbb{R}}^{N}\), \(\Pi_{N}\) is a N-dimensional space of polynomials and \(\Pi_{N}^{p}\)—subspace of polynomials of degree p. Interpolation problem, as in [46], can be formulated as follows: For a set of nodes \(\Theta_{N} = \left\{ {{\varvec{\upxi}}_{i} } \right\}_{i = 1}^{N}\) in N-dimensional random space \(\Gamma\) and for a smooth function \(f:{\mathbb{R}}^{N} \to {\mathbb{R}}\), polynomial \(\mathcal{I}f\) is to be identified such that \(\mathcal{I}f\left( {{\varvec{\upxi}}_{i} } \right) = f\left( {{\varvec{\upxi}}_{i} } \right)\), \(\forall i = 1, \ldots ,M\).
In the case of the use of the Lagrange interpolation, interpolation polynomial can be summarized as follows:
wherein
and
To formulate the stochastic direct problem, let Eq. (5) be rewritten in the form of:
To solve the above stochastic Eq. (26) in the first step, the infinite probabilistic space is reduced to finite-dimensional one. For this purpose, we have used the assumption of finite-dimensional noise [5, 46], which says that the stochastic process can be represented by a finite number N of independent random variables \(\left[ {\xi^{1} (\omega ) ,\ldots ,\xi^{N} (\omega )} \right]\). To obtain this representation, Karhunen–Loève expansion can be used, and then, Eq. (26) with boundary conditions can be written in the following form:
Let us assume that \(\left\{ {\xi^{i} } \right\}_{i}^{N}\) are random variables with probability density functions \(\rho_{i} {:\Gamma }^{i} \to {\mathbb{R}}\), with limited domains and
Then, using Doob–Dynkin lemma [27] the solution of the boundary problem (29) can be represented by the same random variables \(\left\{ {\xi^{i} } \right\}_{i}^{N}\), that is \(\varvec{u} = \varvec{u}\left( {\varvec{x},\xi^{1} (\omega ), \ldots ,\xi^{N} (\omega )} \right)\). Using the formula (23), we can write for each component of the vector \(\varvec{u}\):
The procedure of stochastic collocation for Eq. (29) is as follows:
For each collocation point \(\varvec{\xi}\), equation written in variational form:
is solved.
Using the property:
M sets of uncoupled equations are obtained relative to the k.
In order to determine the rth central statistical moment, the following formula is used:
where \({\varvec{v}}_{\text{node}}\) is a vector of solution at a specified finite element grid point.
To perform the procedure of stochastic collocation, a set of collocation points must be defined. If we use the cubatures to determine numerically the integral in Eq. (34), that is:
where \(w_{k}\) are weights, natural choice of points will be the same set as in the cubatures. Under this assumption, computation of rth moment will be reduced to
In the case of a multidimensional random space, the set of collocation points is built on the basis of one-dimensional quadratures \(\Theta\) by the use of the tensor product. If for each of the directions \(i = 1,2, \ldots ,N\) there is:
where \(m_{i}\) is the number of points in the direction i, then for the multidimensional space interpolation function takes the form [10, 46]:
in which \(\otimes\) denotes tensor product.
The above formula requires \(M = m_{1} \ldots m_{N}\) points. In the case of using the same number of points in each space, the total number will be \(M = m^{N}\). This number rapidly increases with the number of the random spaces which leads to the need of re-running the program solving the deterministic problem. To reduce the number of points, the so-called sparse grid method can be used.
One of the selection methods for the minimum number of points, from the full tensor product set is Smolyak method [39], in which a set of points is determined on the basis of
where \(\varvec{i} = \left( {m_{1} ,m_{2} ,\ldots ,m_{N} } \right)\) is the so-called multi-index and \(\mu\) is the interpolation level.
Smolyak interpolation formula is as follows
4 The Inverse Problem
The accuracy of computer simulations of processes depends on the quality of mathematical models which describe those processes. The quality of models depends, in turn, on many different parameters, that need to be determined on an experimental way. If some values are determined through an experiment, and those values are then used to make a computer simulation of the same experiment, it may turn out that the result varies from the ones obtained during an experiment. Those differences result from the heterogeneity of stress fields, as well as deformations within a sample, which is a common element of the majority of metal deformation processes. To eliminate the described divergences, one needs to solve the inverse problem.
The idea of the inverse method comes down to minimizing the differences between the results of experiments \(Y\left( {t,\varvec{x}} \right)\) and the results of simulations \(v\left( {t,\varvec{x},\varvec{P}} \right)\). In case of the stochastic problem, the task can be reduced to the minimization of a functional which is dependent on the statistical moments of the specified order n:
where
is the operator of nth statistical central moment with Gaussian measure and \(\varvec{P}\) is the vector of searched parameters. Obviously for \(n = 1\)\(E\left( \cdot \right) = \mu_{1} \left( \cdot \right)\) can be written.
In practice, an approach is used that is based on the criterion of least squares:
Similar approach is considered in [48]. Some parameters need to impose an additional limiting condition (e.g., to preserve the physical meaning of the law) in the form of:
where \(\varvec{P}^{L}\) are lower boundary constraints and \(\varvec{P}^{U}\) are upper boundary constraints.
4.1 Optimization Algorithm
The genetic algorithms are a group of optimization methods based on random factor. They are grouped with artificial intelligence tools. The inventor of these algorithms, which are based on the rules that are also used in genetics, is John Holland [20].
The base of genetic algorithms is a well-known fact of the evolution theory, which states that the organisms that are the most adjustable have the greatest chances of survival, and that their offspring greatly influences the subsequent generations of the species. This assumption is directly used in the genetic algorithms. Consecutively, the strategy used by the algorithm is similar to the natural selection; and that is the reason why the terminology is similar to the one used in genetics.
The procedure can be described as follows:
-
A.
Generation of initial population \({\mathbf{P}}_{i}\) for \(i = 1, \ldots ,n_{\text{pop}}\) of individuals with random values is initialized. These initial individual values are chosen within user-defined bound \(\left[ {P_{j}^{L} ,P_{j}^{U} } \right]\), where \(P_{j}^{L}\) are lower boundary constraints and \(P_{j}^{U}\) are upper boundary constraints for \(j = 1, \ldots ,n\), where \(n\) is the dimension of problem space. Hence,
$$P_{i,j} = rnd_{i,j} \left( {P_{j}^{U} - P_{j}^{L} } \right) + P_{j}^{L} ;\;i = 1, \ldots ,n_{\text{pop}} ;\;j = 1, \ldots ,n$$ -
B.
Evaluation of fitness function subject to boundary constrains (44) for each individual,
-
C.
Selection The reproduction operation is carried out by choosing individuals according to their relative fitness. There are different methods to perform this operation. A method that lays out a line in which each parent corresponding to a section of the line of length proportional to its scaled value is used. The algorithm moves along the line in steps of equal size. At each step, the algorithm allocates a parent from the section it lands on. The first step is a uniform random number less than the step size,
-
D.
Reproduction Genetic algorithm creating children for the next generation specifies the number of individuals that are guaranteed to survive to the next generation and specifies the fraction of the next generation that are produced by crossover,
-
E.
Mutation Genetic algorithm makes small random changes in the individuals in the population to create mutation children. Mutation provides genetic diversity and enables the genetic algorithm to search a broader space,
-
F.
Steps B to E are repeated until the specified convergence of fitness function or specified number of generations is satisfied.
5 Numerical Examples
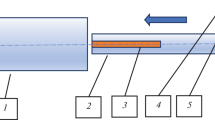
As an example, we have considered the simulation of axisymmetric compression of steel cylinder by flat dies (Fig. 1).

Finite element model of ring compression test
The investigated material is assumed to follow nonlinear isotropic hardening behavior (Voce hardening law [44]) and the Perzyna flow stress model [29] is considered, which is described by the expression:
where \(k({\mathbf{x}})\) is the initial yield stress, \(R_{0} ({\mathbf{x}})\), \(R_{\inf } ({\mathbf{x}})\), \(b({\mathbf{x}})\) are the material parameters characterizing the isotropic hardening behavior, \(n(\omega ,{\mathbf{x}}) = \frac{1}{{\delta (\omega ,{\mathbf{x}})}}\) is the strain-rate hardening parameter and \(\gamma (\omega ,{\mathbf{x}})\) is material viscosity parameter.
As the first example, two parameters of Eq. (45) are chosen, \(\delta (\omega ,{\mathbf{x}})\) and \(\gamma (\omega ,{\mathbf{x}})\). Displacement measurements in the vector \({\mathbf{Y}}\) are adopted directly from numerical simulation. It is assumed that the searched parameters are the stationary two-dimensional random fields with the characteristics \(E\left( {\delta (x,y)} \right) = \delta_{0}\), \(E\left( {\gamma (x,y)} \right) = \gamma_{0}\) and with the known covariance functions, namely:
where the correlation length \(b_{x} = 1.0\), \(b_{y} = 1.0\). The parameters \(\delta_{0}\), \(\gamma_{0}\) and \({\text{Var}}_{\delta }\), \({\text{Var}}_{\gamma }\) are unknown. Let us assume that other functions of the model are known, deterministic and constant (Table 1). Therefore, the searched vector is of the form \({\mathbf{P}} = \left[ {\delta_{0} ,\gamma_{0} ,{\text{Var}}_{\delta } ,{\text{Var}}_{\gamma } } \right]\). In order to perform identification of selected parameters, a set of experimental data \({\mathbf{Y}}\) should be defined. The ideal and desirable solution will be to use a displacement field at any point defined by a grid of nodes in the finite element method. In reality, measurements at the deforming sample are only possible on the outer surface [38]. In the analyzed example, it has been decided to choose to analyze the horizontal displacement of the outermost points (Fig. 2). Using the square root of the objective function (43) for the above-described set of data points and a combination of the two parameters \(\delta_{0} \in \left\langle {0.3,0.6} \right\rangle\), \(\gamma_{0} \in \left\langle {0.3,0.7} \right\rangle\) s−1 with constant \({\text{Var}}_{\delta } = 0.01\), \({\text{Var}}_{\gamma } = 0.01\) s−1, the response function is obtained. This function has local minima (Fig. 3); therefore, it decides to use the stochastic optimization method to determine the global minimum.

Measurement points chosen for analysis (10 points along the vertical surface)

Contour plot of response function for parameters \(\delta_{0} \in \left\langle {0.3,0.6} \right\rangle\), \(\gamma_{0} \in \left\langle {0.3,0.7} \right\rangle\) s−1, \({\text{Var}}_{\delta } = 0.1\), \({\text{Var}}_{\gamma } = 0.1\) s−1. 30% of reduction in height, first example
Using the Karhunen–Loève expansion for two-dimensional random fields, the following equations can be obtained:
In further analysis, the proposed SG-SCM is compared to Monte Carlo method. As the relevant point, only one node (Fig. 4) is chosen. As shown (Fig. 5), there is a good correlation between the results obtained from MC method and the probability density of the normal distribution. To choose the appropriate level of interpolation \(\mu\) (Smolyak sparse grid), standard deviation for order 1–3 (second moment) at chosen node is computed (Fig. 6). In order to select the appropriate values of the parameters (Karhunen–Loève expansion order, SG interpolation level), direct stochastic method (SG-SCM) analysis is performed for several configurations of these parameters (Table 2). As the basic selection criteria, minimum value of the difference between the solution of SG-SCM and the MC method and the lowest number of collocation points is chosen. Performed analysis (Figs. 6, 7) has shown that the lowest sufficient order of interpolation level can be adopted as \(\mu = 1\) and order of Karhunen–Loève expansion can be adopted as \(M = 3\).

Equivalent plastic strain plot for 30% of reduction in height

Probability density function of equivalent plastic strain for relevant node used in analysis. Dots: Monte Carlo method for 2000 samples; solid line: normal distribution mean 0.273 and standard deviation 0.0159

Expected value of equivalent plastic strain for relevant node obtained with different kinds of configuration of KL expansion order versus SG interpolation level (according to Table 2.)

Standard deviation of equivalent plastic strain for relevant node obtained with different kinds of configuration of KL expansion order versus SG interpolation level (according to Table 2.)
Besides the choice of the appropriate measurement points, the degree of reduction in height of the sample is important. In the first step of analysis, 30% of reduction (Fig. 4) has been taken. On the graph of response function (Fig. 3), there are local extrema. Clearly visible is the global extreme (\(\delta_{0} = 0.357\), \(\gamma_{0} = 0.55\;{\text{s}}^{ - 1}\)).
With the above assumption, the identification problem is performed. The analysis shows high efficiency and stability of the method (Figs. 8, 9, Table 3).

A graph of fitness function (best value) convergence of genetic algorithm (30% of reduction in height, 3 runs, first example)

A graph of fitness function (mean value) convergence of genetic algorithm (30% of reduction in height, 3 runs, first example)
In the second step of the analysis, 50% of reduction in height is chosen (Fig. 10). Similar to the first step of analysis in the bottom of response function graph (Fig. 11), area with global extreme appears. There are also a number of local extremes, but the difference between the values of the response function is small and it is impossible to clearly define the global extreme. Occurring phenomenon can be explained by the combined effect of a small number of measurement points and a small sensitivity of the response function to changes in the parameters \(\delta_{0}\) and \(\gamma_{0}\) [35].

Equivalent plastic strain plot for 50% of reduction

Contour plot of response function for parameters \(\delta_{0} \in \left\langle {0.3,0.6} \right\rangle\), \(\gamma_{0} \in \left\langle {0.3,0.7} \right\rangle\) s−1, \({\text{Var}}_{\delta } = 0.1\), \({\text{Var}}_{\gamma } = 0.1\) s−1. 30% of reduction in height, first example
In addition, the response function for 40% reduction in height is determined. In the graph of the response function (Fig. 12), a transition state between 30 and 50% of reduction can be observed. At the bottom of the figure can be noticed clearly visible global extremes and many local extremes in the rest of the analyzed area.

Contour plot of response function for parameters \(\delta_{0} \in \left\langle {0.3,0.6} \right\rangle\), \(\gamma_{0} \in \left\langle {0.3,0.7} \right\rangle\) s−1, \({\text{Var}}_{\delta } = 0.1\), \({\text{Var}}_{\gamma } = 0.1\) s−1. 40% of reduction in height, first example
As shown in the graphs (Figs. 13, 14), the identification method allows obtaining similar parameters as the simulated ones. In the third-run, the convergence is achieved but the dispersion of the values indicates the instability of the solution (Table 4).

A graph of fitness function (best value) convergence of genetic algorithm (50% of reduction in height, 3 runs, first example)

A graph of fitness function (mean value) convergence of genetic algorithm (50% of reduction in height, 3 runs, first example)
As the second example, two parameters characterizing the isotropic hardening behavior of Eq. (46) (Voce hardening law) are chosen, \(R_{\inf } (\omega ,{\mathbf{x}})\) and \(b(\omega ,{\mathbf{x}})\). Similar to the analysis in the first example, two cases of reduction in height are chosen, 30% and 50%. In both cases, the same stochastic (interpolation level \(\mu = 1\), order of Karhunen–Loève expansion \(M = 3\)) and parameters have been adopted as in the first example (Table 1). Using the Karhunen–Loève expansion for two-dimensional random fields, the following equations can be obtained:
where \(E\left( {R_{\inf } (x,y)} \right) = R_{\inf ,0}\), \(E\left( {b(x,y)} \right) = b_{0}\) and with the known covariance functions (similar to the first example). Therefore, the searched vector is of the form \({\mathbf{P}} = \left[ {R_{\inf ,0} ,b_{0} ,{\text{Var}}_{{R_{\inf } }} ,{\text{Var}}_{b} } \right]\). The assumed reduction in sample height is also important in identifying parameters related to Voce hardening law. For the 30% reduction in height in the response function graph, the global extreme is clearly visible (Fig. 15). The identification process is stable and converges with the solution (Figs. 16, 17). Table 5 shows the results of the analysis for three runs.

Contour plot of response function for parameters \(R_{\inf ,0} \in \left\langle {44.0,60.0} \right\rangle \;{\text{MPa}}\), \(b_{0} \in \left\langle {14.2,20.2} \right\rangle\), \({\text{Var}}_{{R_{\inf } }} = 16.0\;{\text{MPa}}\), \({\text{Var}}_{b} = 2.0\). 30% of reduction in height, second example

A graph of fitness function (best value) convergence of genetic algorithm (30% of reduction in height, 3 runs, second example)

A graph of fitness function (mean value) convergence of genetic algorithm (30% of reduction in height, 3 runs, second example)
In the second case (50% reduction in height) for assumed range of values of the parameters: \(R_{\inf ,0} \in \left\langle {44.0,60.0} \right\rangle \;{\text{MPa}}\), \(b_{0} \in \left\langle {14.2,20.2} \right\rangle\), \({\text{Var}}_{{R_{\inf } }} = 16.0\;{\text{MPa}}\), \({\text{Var}}_{b} = 2.0\), the response function graph has many maxima and minima (Fig. 18). In the surroundings of the global minimum (the searched solution), local maxima and minima are visible. Even the case of using a hybrid method combining the random method with the gradient optimization method will be much more difficult or even impossible. Using only gradient optimization will also be impossible in this case.

Contour plot of response function for parameters \(R_{\inf ,0} \in \left\langle {44.0,60.0} \right\rangle \;{\text{MPa}}\), \(b_{0} \in \left\langle {14.2,20.2} \right\rangle\)\({\text{Var}}_{{R_{\inf } }} = 16.0\;{\text{MPa}}\), \({\text{Var}}_{b} = 2.0\). 50% of reduction in height, second example
The identification process is shown in the graphs (Figs. 19, 20). Solution has been found, and the values of the parameters are similar to the simulated ones. In the third-run, the convergence is achieved but the dispersion of the values indicate the instability of the solution (Table 6).

A graph of fitness function (best value) convergence of genetic algorithm (50% of reduction in height, 3 runs, second example)

A graph of fitness function (mean value) convergence of genetic algorithm (50% of reduction in height, 3 runs, second example)
Computations are performed on computer made of 32 physical cores, 2.53 GHz clock speed each. In the case of parameter’s identification in Perzyna model (example 1), computational time is 439.217 min for 30% reduction in height and 603.078 min for 50% reduction in height. In the second example, computational time in both cases is close to the first example.
6 Concluding Remarks
The paper proposes a method of parameter’s identification of two-dimensional random field in rigid viscoplasticity. The investigated material is assumed to follow nonlinear isotropic hardening behavior (Voce hardening law), and the Perzyna flow stress model is adopted.
The analysis allows for the following conclusions:
-
The degree of reduction in height significantly affects instability of solution, which is the cause of local extremes compaction in the surrounding of global extreme. This behavior can be explained by the significant plasticizing of the sample.
-
SG-SCM method works well with viscoplastic forming problems, even with a small number of collocation points for multidimensional random space.
-
GA works well with stochastic inverse problems assuming the use of multithreading to which the method is well adapted.
-
The system response to the random disturbances modeled as a stationary Gaussian random field is also Gaussian random field.
The comparison shows that the proposed method works well with nonlinear problems and it is convergent to Monte Carlo method due to first and second statistical moments. The analysis of inverse problem has revealed that the proposed identification method is appropriate when the stochastic process with use of the first two statistical moments only and the knowledge of measurement only at external surfaces are considered.
Notes
Equations are presented for axially symmetric case.
References
Acharjee S, and Zabaras N, Comput Struct 85 (2007) 244.
Acharjee S, and Zabaras N, Comput Methods Appl Mech Eng 195 (2006) 2289.
Adamus J, and Lacki P, Comput Mater Sci, 50 (2011) 1305.
Alifanov O M, Inverse Heat Transfer Problems, Springer, Berlin (1994).
Babuška I, Nobile F, and Tempone R, SIAM J Numer Anal 45 (2007), 1005.
Barthelmann V, Novak E, and Ritter K, Adv Comput Math 12 (2000), 273.
Bathe J, Finite Element Procedures in Engineering Analysis, Prentice-Hall, Englewood Cliffs (1982).
Beck J V, and Arnold K J, Parameter Estimation in Engineering and Science, James Beck (1977).
Castro C F, António C A C, and Sousa L C, J Mater Process Technol 146 (2004) 356.
Eiermann M, Ernst O G, and Ullmann E, Comput Vis Sci 10 (2007) 3.
Gelin J C, and Ghouati O. CIRP Ann Manuf Technol 44 (1995) 189.
Gerstner T, and Griebel M, Numer Algorithm 18 (1998) 209.
Ghanem R, and Spanos P D, Stochastic Finite Elements: A Spectral Approach (revised edition), Dover Publications, New York (2003).
Ghosh, D, Avery P, and Farhat C, Int J Numer Methods Eng, 80 (2009) 914.
Golberg D E, Genetic Algorithms in Search, Optimization and Machine Learning, Addison-Wesley Longman Publishing Co., Inc, Boston, MA (1989).
Grzywiński M, and Sluzalec A, Int J Heat Mass Trans, 43 (2000) 4003.
Grzywiński M, and Sluzalec A, Int J Eng Sci 40 (2002) 367.
Hartley P, Pillinger I, and Sturgess C E, Numerical Modelling of Material Deformation Processes: Research, Development and Applications, Springer, Berlin (2012).
Haupt R L, and Haupt S E, Practical Genetic Algorithms, Wiley, Hoboken (2004).
Holland J H, Adaptation in Natural and Artificial Systems. An Introductory Analysis with Application to Biology, Control, and Artificial Intelligence, University of Michigan Press, Ann Arbor (1975).
Kaminski M, The Stochastic Perturbation Method for Computational Mechanics, Wiley, Hoboken (2013).
Kleiber M, and Hien T D, The Stochastic Finite Element Method: Basic Perturbation Technique and Computer Implementation. Wiley, Hoboken (1992).
Kobayashi S, Oh S I, and Altan T, Metal Forming and the Finite-Element Method (Vol. 4). Oxford University Press, Oxford (1989).
Michalewicz Z, Genetic Algorithms Data Structures = Evolution Programs, Springer, Berlin (1999).
Narayanan V A B, and Zabaras N, Int J Numer Methods Eng 60 (2004) 1569.
Nouy A, and Le Maître O P, J Comput Phys 228 (2009) 202.
Oksendal B, Stochastic Differential Equations: An Introduction with Applications, Springer, Berlin (2013).
Ozisik M N, Inverse Heat Transfer: Fundamentals and Applications, CRC Press, Boca Raton (2000).
Perzyna P, Theory of Viscoplasticity, PWN, Warsaw (1966).
Pokorska I, Int J Numer Methods Eng 73 (2008) 1077.
Pokorska I, and Sluzalec A, ICCES: Int Conf Comput Exp Eng Sci 4 (2007) 171.
Roy S, Ghosh S, and Shivpuri R, Int J Mach T Manuf 37 (1997) 29.
Sluzalec A, Int J Mech Sci 42 (2000) 1935.
Sluzalec A, Theory of Metal Forming Plasticity: Classical and Advanced Topics, Springer, Berlin (2004).
Sluzalec A, Str Mult Opt 45 (2012) 139.
Sluzalec A, Introduction to Nonlinear Thermomechanics: Theory and Finite-Element Solutions, Springer, Berlin (2012).
Sluzalec A, Adv Electr Comput Eng 14 (2014) 25.
Sluzalec A, Int J Nonlinear Sci Numer Simul 15 (2014), 135-147.
Smolyak S A, Dokl Akad Nauk SSSR 4 (1963) 123.
Stefanou G, Comput Methods Appl Mech Eng 198 (2009), 1031.
Subber W, and Sarkar A, J Comput Phys 257 (2014) 298.
Tikhonov A N, and Arsenin V I, Solutions of Ill-Posed Problems (Vol. 14), Winston, Washington, DC (1977).
Vanmarcke E, Random Fields: Analysis and Synthesis, World Scientific Publishing Co Inc., Singapore (2010).
Voce E, J Inst Met 74 (1948) 537.
Xiu D, Numerical Methods for Stochastic Computations: A Spectral Method Approach, Princeton University Press, Princeton (2010).
Xiu D, and Hesthaven J S, SIAM J Sci Comput 27 (2005), 1118.
Zabaras N, Handbook of Numerical Heat Transfer, chapter 17, Wiley, Hoboken (2004).
Zabaras N, and Ganapathysubramanian B, J Comput Phys, 227 (2008) 4697.
Zienkiewicz O C, and Taylor R L, The Finite Element Method, Butterworth-Heinemann, Oxford (2000).
Acknowledgements
The authors are grateful for granting access to the computing infrastructure built in the projects No. POIG.02.03.00-00-028/08 “PLATON - Science Services Platform” and No. POIG.02.03.00-00-110/13 “Deploying high-availability, critical services in Metropolitan Area Networks (MAN-HA).”
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ponski, M., Sluzalec, A. Modeling and Simulation of Stochastic Inverse Problems in Viscoplasticity. Trans Indian Inst Met 72, 2803–2817 (2019). https://doi.org/10.1007/s12666-019-01757-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12666-019-01757-2