
Abstract
The presence of an economical solution to predict soil behaviour is essential for new construction areas. This paper aims to investigate the ultimate interpolation method for predicting the soil bearing capacity of An-Najaf city-Iraq based on field investigation information. Firstly, the engineering bearing capacity was calculated based on the in-site N-SPT values using dynamic loading for 464 boreholes with depths of 0–2 m, using the Meyerhof formula. The data then were classified and imported to the GIS program to apply the interpolation methods. Four deterministic and two geostatistical interpolation methods were applied to produce six bearing capacity maps. The statistical analyses were performed using two methods: the common cross-validation method by the coefficient of determination (R2) and root mean square error (RMSE), where the results showed that ordinary kriging (OK) is the ultimate method with the least RMSE and highest R2. These results were confusing so, the backward elimination regression (BER) procedure was applied to gain the definite result. The results of BER show that among all the deterministic methods, the IDW is the optimal and most significant interpolation method. The result of geostatistical methods shows that EBK is the best method in our case than the OK method. BER also applied to all six methods and shows that IDW is the ultimate significant method. The results indicate no general ultimate interpolation method for all cases and datasets type; therefore, the statistical analyses must be performed for each case and dataset.
Similar content being viewed by others

Introduction
The Allowable bearing capacity is an influential geotechnical parameter used to decide the most convenient foundation for a particular structure. Bearing capacity is essential for the type and depth of foundations to prevent damages, especially those resulting from loads and earthquakes (Al-Maliki et al. 2018). A Geodatabase for soil geotechnical properties can help save a high portion of the total project cost. Generally, it is a complicated, time-consuming, and expensive process to create a Geodatabase for a specific area because it requires considerable data. Instead, using interpolation methods to predict the non-spatial points from the existing ones can be very helpful.
Different methods for spatial interpolation have been developed. Many factors affect the predictions and the results of spatial interpolation of the methods. This reason increases the difficulty in selecting the optimal input data method (Li and Heap 2014). Spatial interpolation methods are increasingly used in many disciplines, such as botany, geology, agriculture, hydrology, and climatology (Bernardi et al. 2017; Xu et al. 2015; Emadi and Baghernejad 2014; Hadi and Tombul 2018; Eldrandaly and Abu-Zaid 2011; Hernandez-Stefanoni and Ponce-Hernandez 2006).
Multiple approaches and methodologies were used to estimate soil engineering properties using GIS interpolation tools. Kravchenko and Bullock (1999) evaluated three interpolation methods (i.e., inverse distance weighting IDW, ordinary kriging OK, and lognormal ordinary kriging LOK) to determine the best interpolation method for mapping soil properties (Kravchenko and Bullock 1999). El May et al. (2010) study the urban area using the environmental geologic map using the GIS program to map the geotechnical zoning for safe construction (El May et al. 2010). Orhan and Tosun (2010) used the GIS program to prepare geotechnical maps for several soil properties that fully visualize the study area’s whole sub-surface. The zones maps are implemented to specify the appropriate foundation soils in the residential (Orhan and Tosun 2010). Ali and Fakhraldin (2016) investigate the soil's physical and chemical properties to give base data, which can be used for future construction design (Ali and Fakhraldin 2016). Sohaib K. et al. conducted many studies to interpolate soil properties in developing a geotechnical database for An-Najaf city in (Al-Mamoori 2017; Al-Mamoori et al. 2018, 2019a, b, 2020a, b).
Selecting the convenient interpolation technique is the most important factor to gain the most accurate results as different interpolation methods will give different results. Among diverse interpolation methods, none is unequivocally optimal; thus, the best method for a particular case will only be obtained by applying the possible interpolation methods and comparing them. There were many studies regarding this aspect. For example, Luo et al. (2008) carried out a study to compare seven interpolation methods to choose the best method for mean daily wind speed grids; the data used were from 190 points across England and Wales. Among the seven methods technique (TSA, IDW, LPI, TPS, UK, Cokriging, and OK), the results indicated that OK and UK are the optimal interpolation methods for this particular case (Luo et al. 2008). Another study compares three interpolation methods (i.e. IDW, radial basis function (RBF), and Kriging (including OK, simple kriging SK, and UK) to interpolate groundwater depth. These methods were applied to data belong to 22 years from forty-eight wells in the Minqin oasis area. The results showed that SK is the best method for interpolating groundwater depths (Sun et al. 2009). Robinson and Metternicht (2006) implement and compare four interpolation methods (i.e., OK, LOK, IDW, and Splines) to interpolate some soil properties. The results have shown no single interpolation method that can produce the most accurate results to generate continuous maps of soil properties (Robinson and Metternicht 2006).
The purpose of this paper is to statistically determine the optimal GIS-based interpolation method for soil Bearing Capacity data collected from 464 sites. Six GIS-based spatial interpolation methods have been implemented.
Data and methods
Study area
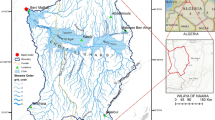
31.933 latitudes and 44.2833 longitudes bound An-Najaf city (including Kufa). It covers an area of about 105.1 km2 An-Najaf city has 81 neighbourhoods Fig. 1.

Study area location
Arid and semi-arid are the main characteristics of An-Najaf's climate where the summer is hot and dry (Sabreen et al. 2020; Farhan et al. 2019), with an average temperature of 45 °C. The winter is short, cold, and wet, with an average temperature of 24 °C. The average annual rainfall is 100 mm in the wet period and 30 mm in the dry (Jasim et. al. 2020; Kareem et al. 2021).
Data
The study is dependent on data from soil samples collected from 464 sites in the study area. The utilized data were taken from the “National Center for Construction Laboratories and Researches (NCCLR)-Babylon” based on a cooperation memo. NCCLR- Babylon is a division of the “Iraqi National Center for Construction Laboratories and Research (NCCLR)”. The data were collected for 464 sites, as shown in Fig. 2 (Governorate of Babylon 2016).

Soil bearing capacity samples’ location
Methods
Bearing capacity data were performed by ArcGIS 10.7 using Geostatistical Analyst Wizard GAW. GAW has two types of interpolation techniques: deterministic and geostatistical. Each type has a group of interpolation methods. Most of the methods depend on point data to produce a surface or grid (Bolstad 2016; Ogryzek et al. 2020; Peng et al. 2017, Abbass Jasim et al. 2017).
In this paper, both interpolation techniques were used for mapping soil engineering bearing capacity point data. The deterministic interpolation techniques, including four methods (IDW), local polynomial interpolation (LPI), radial basis functions (RBF) and global polynomial interpolation (GPI). The geostatistical interpolation technique has two methods ordinary kriging (OK) and empirical bayes kriging (EBK).
Interpolation methods
Two groups of interpolation methods have been used in this study which are as the followings:
Deterministic methods
These methods produce surfaces depending on either the resemblance or the degree of homogeneity of the examined points. These methods can be divided into global and local. Global methods utilize all the data to predict the unknown values, while Local methods use only the data within neighbourhoods to predict the unknown values from the observation points. GAW provides four deterministic interpolation techniques. One of them is a global interpolator (i.e., GPI), and the other three are local interpolators (i.e., IDW, LPI, and RBF). Deterministic methods are precise interpolators and can produce a surface that goes along the control points. Furthermore, imprecise interpolators can produce a value that differs from its value at the point’s location (i.e. GPI and LPI) (Eldrandaly and Abu-Zaid 2011). In this paper, all four methods were used (IDW, LPI, RBF, and GPI), and below is some information about each method:
Inverse distance weighted (IDW)
It presumes that the connection and resemblance rate among contiguous points is commensurate to the distance between them. Each interpolated point has a weight equal to the inverse of its distance from the point (i.e. the closest place to the known point has more weight than the far ones) (Robinson and Metternicht 2006; Setianto et al. 2013; Bhunia et al. 2018). In the IDW method, the unknown points value is estimated using the following equation (Eq. 1). The optimal power in the IDW surface in our study is (1.427).
where:z(x0): the interpolated value, n: the values of total sample data, xi: the ith data value, hij: the separation distance between interpolated value and the sample data value, ß: the weighting power.
Local polynomial interpolation (LPI)
LPI can generate a grid surface that picks up the short-range variance (Johnston et al. 2001). It is suitable for interpolating points only within the area of a specific neighbourhood rather than the whole dataset (Hani and Abari 2011). Thus, the overlapping among neighbourhoods may occur, while the cell's value at the centre of any neighbourhood is estimated as predicted. The optimal Goodness of Fit in the study area is (2.39).
Radial basis function (RBF)
RBF creates a surface grid to go through all measured points. Consequently, it is considered a precise technique. It generates similar values to those measured at the same point, and the predicted values may fluctuate above and below the maximum and minimum of the observed values (Pham et al. 2020) (Li et al. 2011). RBF is an inappropriate method if there is a great value change in short distances (Johnston et al. 2001). This method is similar to IDW, but the fluctuation of predicated value. There is also a smoothening parameter to control the smoothness of the resulting surface (Biancolini et al. 2018), and the optimal kernel parameter in the study area is (0.41).
Global polynomial interpolation (GPI)
GPI is a fast and imprecise method that applies multiple regression to the whole dataset (Johnston et al. 2001; İmamoğlu and Sertel 2016). It is more suitable for slightly and gradually changing data (İmamoğlu and Sertel 2016). In this interpolation technique, the points at the border and edge can significantly influence the resulted surface. The orders allowed in the GPI are ten, and each order suits a specific characteristic in the data (Johnston et al. 2001).
A first-order (linear) is used in this study because it suits one plane among the data as equation discerned:
where.\(z\left({x}_{i}, {y}_{i}\right)\): the datum at location. (xi, yi), βi: the parameters. ε (xi, yi): the random error.
Geostatistical interpolation methods
Geostatistical methods are known as the Kriging family. It is a statistically powerful interpolation method that depends on the spatial correlation that controls the distance or direction among sample points and can be used to explain surface spatial variation. Specify the number of the points or all points within a certain radius to determine each location’s result value. This method is widely used in soil science and geology (Belkhiri and Narany 2015; Elumalai et al. 2017; Gharechelou et al. 2016; Reza et al. 2016). There are three types of kriging available in geostatistical analyst; ordinary kriging (OK), empirical Bayesian, and areal interpolation. In this study, only two methods (i.e. OK and EBK) were applied (Gómez-Hernández 2016). The Areal Interpolation (AI) was excluded because it is suitable for polygons, not for points.
Ordinary kriging (OK)
The OK method combines the measured statistical properties of the data. The measuring of the strength of statistical correlation in this method is a function of distance where spatial correlation fades, and the partial sill corresponds to the maximum variability in the absence of spatial dependence. In our case study, the optimal partial sill is (10.145). The semivariogram is used by the kriging approach to express the spatial autocorrelation. OK estimates Z*(x0) and error estimation Variance \({\sigma }_{k}^{2}\) (x0) at any individual point x0 were, respectively, calculated as follows:
where:ki: The weights. l is the lag range constant; and (× 0 _ xi) is the semivariogram value of the distance between × 0 and xi (Gia Pham et al. 2019; Mohammadi et al. 2019; Zeng et al. 2020). A semivariogram is expressed as follows:
where c(h) is semivariance, h is the lag distance, Z is the parameter of the points values, N(h) is the number of pairs of points separated by a lag distance h, Z(xi), and Z (xi + h) are values of Z at positions xi and xi + h (Liu et al. 2013).
Empirical Bayesian kriging (EBK)
EBK is the most complex method because it implies that the supposed semivariogram is the right one for linear interpolation (Javari 2017; Samsonova et al. 2017; Krivoruchko and Butler 2013; Krivoruchko 2012). The parameters in the newly developed EBK are automatically optimized using several semivariogram models rather than a single semivariogram. Therefore, it differs from other methods of classical Kriging. The steps used in the EBK method are an estimation and simulation of the semivariogram model using available data and simulated data (Li and Heap 2014).
Assessment of interpolation results
Two approaches were used to evaluate the optimal and best performance interpolation method: cross-validation and backward elimination regression BER method. For each approach, the interpolation methods were separated into Deterministic and Geostatistical. Comparative analysis was then applied to all methods. Separating the interpolation methods into Deterministic and Geostatistical will help researchers use one of the two techniques (i.e., deterministic or geostatistical).
Cross-validation
The six interpolation methods were verified individually by using cross-validation with predicted soil bearing capacity values. The comparison analysis among six interpolation methods was done depending on the (root mean square error (RMSE), mean absolute error (Dungca et al. 2017), and the coefficient of determination (R2)) (Adhikary and Dash 2017; Meng et al. 2018) (Amini et al. 2019).
where:N: number of data points. \({x}_{i}^{\mathrm{intp}}\): the studied variable’s ith interpolated value. \({x}_{i}^{\mathrm{meas}}\): the studied variable’s ith measured value. \(\overline{{x }^{\mathrm{intp}}}\): the studied variable’s average interpolated value. \(\overline{{\mathrm{x} }^{\mathrm{meas}}}\): the studied variable’s average measured value.
Backward elimination regression BER
This method starts with a model containing all the K candidate regressors or variables. One by one excludes the regressor with the smallest partial F-statistic if its F-statistic is insignificant, e.g., if the variable has an insignificant F value. This variable is excluded from the model, and then a new regression model will be repeated on the remaining variables to exclude to insignificant one and so on till reaching the most significant variable (Landau 2019; Zhang and Li 2015; Matloff 2017; Montgomery and Runger 2014; Acevedo 2012; Montgomery et al. 2012). The BER procedure using SPSS has been applied three times to determine the best interpolation among all of them. The second time among the deterministic methods and the third time among geostatistical methods.
Results and discussion
GIS Interpolation maps
Six different interpolation methods' maps for 464 soil Bearing Capacity samples with class interval (1 Ton/m2) have been carried out using ArcGIS 10.7 (Geostatistical Wizard) Fig. 3. The Bearing Capacity range is between (4–15 Ton/m2). The deterministic methods show a spatial distribution similarity between (IDW and RBF) maps from the first visual impression. At the same time, the (LPI and GPI) straight and continuous zones are more similar to spline. Geostatistical methods show differences in smoothing because the OK map seems rougher class borders than EBK. Visual interpretation can approximate the best interpolation method suitable for the case study and dataset but is not definite. Thus, Statistical analysis is required. Two Statistical analyses have been implemented on the measured bearing capacity value and the predicted value obtained from cross-validation.

Six interpolation methods’ maps of the spatial distribution of bearing capacity
Statistical analysis
Comparison of interpolation methods using Cross-validity procedure
The cross-validation method was applied to obtain the predicted values for 464 soil samples’ points to assess the more accurate interpolation methods. Coefficient of determination (R2), mean relative error (MRE), root mean square error (RMSE), and summation Error (SUM) have been computed for six methods Table 1. The results showed that the IDW shows a stronger R2 (0.63) but a higher value in the other parameters in the deterministic methods. In contrast, the results were confusing in the geostatistical methods because EBK shows very slight strong in R2 while OK has low better values in the errors parameters Table 1. This confusion could happen, in our case, due to the small differences in the tests’ values and human error compared to more than one parameter. For more accurate and non-human errors, the BER model has been applied. It is worth mentioning that R2 is considered an important indication for good spatial sampling. In our case, the best R2 is around 0.6 because the spatial distribution is not good because the sampling was according to the construction projects, and the distance among points is irregular. Therefore, R2 is very useful for sampling location quality, and in engineering must be at least 0.7 or more.
Backward elimination regression analysis
BER using SPSS software was used to specify in a definite and straightforward way the best interpolation methods. BER, as mentioned, is the best and simple statistical way to examine and determine the optimal method because it removes the least significant variable in the model each time. Then repeats the model again and again for the remaining variables until it reduces them to one most significant variable. BER has been applied to the two interpolation group methods (deterministic, geostatistical) separately and combined.
The BER test results show that the IDW is the optimal and most significant interpolation method among all the deterministic methods. GPI is considered the most inappropriate and insignificant method because it is removed in the first model, followed by LPI removed in the second model. The third model is between the remaining two methods IDW and RBF Table 2. At the same time. The result of geostatistical methods shows that EBK is the best method in our case than the OK method, which is eliminated in the first model Table 3.
BER also applied on all six methods and shows that IDW is the ultimate significant method among them by using GAW. The fifth model is between the two deterministic methods IDW and RBF. The most interesting is that EBK was removed in the first model due to the impact and significance of IDW Table 4.
The results indicate that the researcher should choose one type of method in each case study, whether deterministic or geostatistical, according to the case study and dataset and make analysis and comparison to determine the best method among them.
Spatial variation of soil bearing capacity
The allowable bearing capacity final map produced using the IDW and EBK interpolation method is the best one for preliminary engineering designs in An-Najaf city Figs. 4, 5. The maps show a similar spatial distribution of bearing capacity values. The allowable bearing between (10.1 to 15 Ton\m2) is spatially distributed in the north, east, and west of the study area. This spatial distribution may be due to the impact of well compacted geological silty sand of Injana formation (Upper Fars) and Dibdibba formation. Bearing capacity below (10.1 Ton\m2) is spatially distributed in the middle neighbourhoods with direction NW–SE, and this could be because of an ancient fluvial deposit and anthropogenic canals.

IDW bearing capacity maps

EBK bearing capacity maps
Conclusions
With economic development and population growth in An-Najaf city, the need for many new buildings is arises, most of which are constructed in new areas where there is a lack of information about the soil layers’ properties. Therefore, the presence of an economical solution to predict soil behaviour is essential. In this research, six different methods have interpolated the bearing capacity to determine the ultimate one using two statistical methods: the cross-validation and BER methods.
By comparing the results of the two statistical methods, it is concluded that the BER method gives strong and more confident results than the cross-validation method as it eliminates the weakest variable at each run until the strongest variable remained. Also, dividing the interpolation methods into deterministic and geostatistical will give more accurate results. Based on this conclusion, researchers recommend using BER to compare the interpolation methods for any studied feature after dividing the interpolation methods into deterministic and statistical. The best Deterministic Interpolation Method for the Bearing Capacity of our case and dataset is the IDW. While the best geostatistical interpolation method is the EBK and the best overall interpolation method is the IDW.
The produced map of bearing capacity by the IDW interpolation method indicates that the allowable Bearing Capacity ranges between 4 and 15 Ton\m2. This kind of map proposes a robust database for the study area; also, they ease understanding the data visually. As well, using these maps will help saving expenses along with time and effort. Another advantage of producing geotechnical maps for soil bearing capacity is to guide engineers and decision-makers to decide the best choice for any construction design, the most suitable foundation design, and the appropriate treatment needed. Finally, the results of this paper might be used for laying the foundations of smart cities.
Data availability
Not available.
Code availability
Not available.
References
Abbass Jasim I, Lafta Farhan S, Kareem Al-Mamoori S (2017) Smart government: analysis of shift methods in municipal services delivery: the study area: Al-Kut – Iraq. J Kerbala Univ 13(3):1–15
Acevedo MF (2012) Data analysis and statistics for geography, environmental science, and engineering. CRC Press (Book: ISBN 9781466592216)
Adhikary PP, Dash CJ (2017) Comparison of deterministic and stochastic methods to predict spatial variation of groundwater depth. Appl Water Sci 7(1):339–348. https://doi.org/10.1007/s13201-014-0249-8
Ali TS, Fakhraldin MK (2016) Soil parameters analysis of Al-Najaf City in Iraq: case study. J Geotech Eng 3(1):56–62
Al-Maliki LAJ, Al-Mamoori SK, El-Tawel K, Hussain HM, Al-Ansari N, Al Ali MJ (2018) Bearing Capacity Map for An-Najaf and Kufa Cities Using GIS. Engineering 10(5):262–269. https://doi.org/10.4236/eng.2018.105018
Al-Mamoori SK (2017) Gypsum content horizontal and vertical distribution of An-Najaf and Al-Kufa Cities’ soil by using GIS. Basrah J Eng Sci 17(1):48–60
Al-Mamoori SK, Al-Maliki LA, Hussain HM, Al-Ali MJ (2018) Distribution of sulfate content and organic matter In An-Najaf and Al-Kufa Cities’ soil using GIS. Kufa J Eng 9(3):92–111
Al-Mamoori SK, Al-Maliki LAJ, El-Tawel K, Hussain HM, Al-Ansari N, Al Ali MJ (2019a) Chloride, calcium carbonate and total soluble salts contents distribution for An-Najaf and Al-Kufa Cities’ soil by using GIS. Geotech Geol Eng 37(3):2207–2225. https://doi.org/10.1007/s10706-018-0754-x
Al-Mamoori SK, Al-Maliki LAJ, Al-Sulttani AH, El-Tawil K, Hussain HM, Al-Ansari N (2019b) Horizontal and vertical geotechnical variations of soils according to USCS classification for the City of An-Najaf Iraq using GIS. Geotech Geol Eng. https://doi.org/10.1007/s10706-019-01139-x
Al-Mamoori SK, Kareem SL, Al-Maliki LA, El-Tawil K (2020a) Geotechnical maps for angle of internal friction of An-Najaf Soil-Iraq using GIS. Wasit J Eng Sci. https://doi.org/10.31185/ejuow.Vol8.Iss2.166
Al-Mamoori SK, Attiyah AN, Al-Maliki LA, Al-Sulttani AH, El-Tawil K, Hussain HM (2020b) seismic risk assessment of reinforced concrete frames at Al-Najaf City-Iraq using geotechnical parameters. In: Mahdi OK, Deepankar C (eds) Modern applications of geotechnical engineering and construction. Springer, pp 329–348
Amini MA, Torkan G, Eslamian S, Zareian MJ, Adamowski JF (2019) Analysis of deterministic and geostatistical interpolation techniques for mapping meteorological variables at large watershed scales. Acta Geophys 67(1):191–203. https://doi.org/10.1007/s11600-018-0226-y
Belkhiri L, Narany TS (2015) Using multivariate statistical analysis, geostatistical techniques and structural equation modeling to identify spatial variability of groundwater quality. Water Resour Manage 29(6):2073–2089. https://doi.org/10.1007/s11269-015-0929-7
Bernardi ADC, Bettiol G, Mazzuco G, Esteves S, Oliveira P, Pezzopane J (2017) Spatial variability of soil fertility in an integrated crop livestock forest system. Adv Animal Biosci 8(2):590–593. https://doi.org/10.1017/S2040470017001145
Bhunia GS, Shit PK, Maiti R (2018) Comparison of GIS-based interpolation methods for spatial distribution of soil organic carbon (SOC). J Saudi Soc Agric Sci 17(2):114–126. https://doi.org/10.1016/j.jssas.2016.02.001
Biancolini M, Chiappa A, Giorgetti F, Groth C, Cella U, Salvini P (2018) A balanced load mapping method based on radial basis functions and fuzzy sets. Int J Numer Meth Eng 115(12):1411–1429. https://doi.org/10.1002/nme.5850
Bolstad P (2016) GIS fundamentals: a first text on geographic information systems. Eider Press, Minnesota (ISBN: 9781506695877)
Dungca JR, Concepcion I Jr, Limyuen MCM, To See, Vicencio MR (2017) Soil bearing capacity reference for Metro Manila, Philippines. Int J Geomate 12(32):5–11. https://doi.org/10.21660/2017.32.6556
El May M, Dlala M, Chenini I (2010) Urban geological mapping: geotechnical data analysis for rational development planning. Eng Geol 116(1–2):129–138. https://doi.org/10.1016/j.enggeo.2010.08.002
Eldrandaly K, Abu-Zaid M (2011) Comparison of six GIS-based spatial interpolation methods for estimating air temperature in western Saudi Arabia. J Environ Inform 18(1):38–45. https://doi.org/10.3808/jei.201100197
Elumalai V, Brindha K, Sithole B, Lakshmanan E (2017) Spatial interpolation methods and geostatistics for mapping groundwater contamination in a coastal area. Environ Sci Pollut Res 24(12):11601–11617. https://doi.org/10.1007/s11356-017-8681-6
Emadi M, Baghernejad M (2014) Comparison of spatial interpolation techniques for mapping soil pH and salinity in agricultural coastal areas, northern Iran. Arch Agron Soil Sci 60(9):1315–1327. https://doi.org/10.1080/03650340.2014.880837
Farhan SL, Jasim IA, Al-Mamoori SK (2019) The transformation of the city of Najaf, Iraq: analysis, reality and future prospects. J Urban Regen Renew 13(2):160–171
Gharechelou S, Tateishi R, Sharma RC, Johnson BA (2016) Soil moisture mapping in an arid area using a land unit area (LUA) sampling approach and geostatistical interpolation techniques. ISPRS Int J Geo-Inf. https://doi.org/10.3390/ijgi5030035
Gia Pham T, Kappas M, Van Huynh C, Nguyen HKL (2019) Application of ordinary kriging and regression kriging method for soil properties mapping in hilly region of Central Vietnam. ISPRS Int J Geo Inf 8(3):147. https://doi.org/10.3390/ijgi8030147
Gómez-Hernández JJ (2016) Geostatistics for environmental applications. Math Geosci 48(1):1–2. https://doi.org/10.1007/s11004-015-9627-5
Investigation Reports from National Center for Construction Laboratories & Research (NCCLR) (2016) Governorate of Babylon, Iraq
Hadi SJ, Tombul M (2018) Comparison of spatial interpolation methods of precipitation and temperature using multiple integration periods. J Indian Soc Remote 46(7):1187–1199. https://doi.org/10.1007/s12524-018-0783-1
Hani A, Abari SAH (2011) Determination of Cd, Zn, K, pH, TNV, organic material and electrical conductivity (EC) distribution in agricultural soils using geostatistics and GIS (case study: South-Western of Natanz-Iran). World Acad Sci Eng Technol 5:852–855. https://doi.org/10.5281/zenodo.1328007
Hernandez-Stefanoni JL, Ponce-Hernandez R (2006) Mapping the spatial variability of plant diversity in a tropical forest: comparison of spatial interpolation methods. Environ Monit Assess 117(1–3):307–334. https://doi.org/10.1007/s10661-006-0885-z
İmamoğlu MZ, Sertel E (2016) Analysis of different interpolation methods for soil moisture mapping using field measurements and remotely sensed data. IJEGEO 3(3):11–25. https://doi.org/10.30897/ijegeo.306477
Jasim IA, Farhan SL, Al-Maliki LA, Al-Mamoori SK (2020) Climatic treatments for housing in the traditional holy cities: a comparison between najaf and yazd cities. IOP Conf Ser Earth Environ Sci 754(1):012017. https://doi.org/10.1088/1755-1315/754/1/012017
Javari M (2017) Comparison of interpolation methods for modeling spatial variations of Precipitation in Iran. Int J Environ Sci Edu. 12(5):1037–1054. https://doi.org/10.12973/ijese.2016.322a
Johnston K, Ver Hoef JM, Krivoruchko K, Lucas N (2001) Using ArcGIS geostatistical analyst, vol 380. Esri Redlands
Kareem SL, Jaber WS, Al-Maliki LA, Al-husseiny RA, Al-Mamoori SK, Alansari N (2021) Water quality assessment and phosphorus effect using water quality indices: Euphrates River- Iraq as a case study. Groundw Sustain Dev 14:100630. https://doi.org/10.1016/j.gsd.2021.100630
Kravchenko A, Bullock DG (1999) A comparative study of interpolation methods for mapping soil properties. Agron J 91(3):393–400. https://doi.org/10.2134/agronj1999.00021962009100030007x
Krivoruchko KJER, CA.(2012) Available at https://www.esri.com/news/arcuser/1012/empirical-byesian-kriging.html
Krivoruchko K, Butler K (2013) Unequal probability-based spatial mapping. Redlands: Esri https://www.esri.com/about/newsroom/arcuser/unequal-probability-based-spatial-sampling/
Landau S (2019) A handbook of statistical analyses using SPSS. Chapman & Hall
Li J, Heap AD (2014) Spatial interpolation methods applied in the environmental sciences: a review. Enviro Modell Softw 53:173–189
Li X, Chen Z, Chen H, Chen Z (2011) Spatial distribution of soil nutrients and their response to land use in eroded area of South China. Procedia Environ Sci 10:14–19. https://doi.org/10.1016/j.proenv.2011.09.004
Liu ZP, Shao MA, Wang YQ (2013) Large-scale spatial interpolation of soil pH across the Loess Plateau. China Environ Earth Sci 69(8):2731–2741. https://doi.org/10.1007/s12665-012-2095-z
Luo W, Taylor M, Parker S (2008) A comparison of spatial interpolation methods to estimate continuous wind speed surfaces using irregularly distributed data from England and Wales. Int J Climatol A J Royal Meteorol Soc 28(7):947–959. https://doi.org/10.1002/joc.1583
Matloff N (2017) Statistical regression and classification: from linear models to machine learning. Chapman and Hall/CRC
Meng Q, Zhang L, Sun Z, Meng F, Wang L, Sun Y (2018) Characterizing spatial and temporal trends of surface urban heat island effect in an urban main built-up area: a 12-year case study in Beijing, China. Remote Sens Environ 204:826–837. https://doi.org/10.1016/j.rse.2017.09.019
Mohammadi M, Shabanpour M, Mohammadi MH, Davatgar N (2019) Characterizing spatial variability of soil textural fractions and fractal parameters derived from particle size distributions. Pedosphere 29(2):224–234. https://doi.org/10.1016/S1002-0160(17)60425-9
Montgomery DC, Runger GC (2014) Applied statistics and probability for engineers. Wiley (ISBN: 978-1-118-74395-9)
Montgomery DC, Peck EA, Vining GG (2012) Introduction to linear regression analysis, vol 821. Wiley (Book: ISBN 0-471-41540-5)
Ogryzek M, Krypiak-Gregorczyk A, Wielgosz P (2020) Optimal geostatistical methods for interpolation of the ionosphere: a case study on the St Patrick’s day storm of 2015. Sensors 20(10):2840. https://doi.org/10.3390/s20102840
Orhan A, Tosun H (2010) Visualization of geotechnical data by means of geographic information system: a case study in Eskisehir city (NW Turkey). Enviro Earth Sci 61(3):455–465. https://doi.org/10.1007/s12665-009-0357-1
Peng J, Loew A, Merlin O, Verhoest NE (2017) A review of spatial downscaling of satellite remotely sensed soil moisture. Rev Geophys 55(2):341–366. https://doi.org/10.1002/2016RG000543
Pham BT, Phong TV, Nguyen HD, Qi C, Al-Ansari N, Amini A, Ly H-B (2020) A comparative study of kernel logistic regression, radial basis function classifier, multinomial naïve bayes, and logistic model tree for flash flood susceptibility mapping. Water 12(1):239. https://doi.org/10.3390/w12010239
Reza SK, Nayak DC, Chattopadhyay T, Mukhopadhyay S, Singh SK, Srinivasan R (2016) Spatial distribution of soil physical properties of alluvial soils: a geostatistical approach. Arch Agron Soil Sci 62(7):972–981. https://doi.org/10.1080/03650340.2015.1107678
Robinson T, Metternicht G (2006) Testing the performance of spatial interpolation techniques for mapping soil properties. Comput Electron Agr 50(2):97–108. https://doi.org/10.1016/j.compag.2005.07.003
Sabreen LK, Sohaib KA-M, Laheab AA-M, Mohammed QA-D, AL-ANSARI N (2020) Optimum location for landfills landfill site selection using GIS technique: Al-Naja City as a case study. Cogent Eng. https://doi.org/10.1080/23311916.2020.1863171
Samsonova VP, Blagoveshchenskii YN, Meshalkina YL (2017) Use of empirical Bayesian Kriging for revealing heterogeneities in the distribution of organic carbon on agricultural lands. Eurasian Soil Sci 50(3):305–311. https://doi.org/10.1134/S1064229317030103
Setianto A, Setianto A, Triandini T, Triandini T (2013) Comparison of kriging and inverse distance weighted (IDW) interpolation methods in lineament extraction and analysis. J SE Asian Appl Geol 5(1):21–29. URL: https://repository.ugm.ac.id/id/eprint/136178
Sun Y, Kang S, Li F, Zhang L (2009) Comparison of interpolation methods for depth to groundwater and its temporal and spatial variations in the Minqin oasis of northwest China. Environ Modell Softw 24(10):1163–1170. https://doi.org/10.1016/j.envsoft.2009.03.009
Xu W, Zou Y, Zhang G, Linderman M (2015) A comparison among spatial interpolation techniques for daily rainfall data in Sichuan Province, China. Int J Climatol 35(10):2898–2907. https://doi.org/10.1002/joc.4180
Zeng L, Shi Q, Guo K, Xie S, Herrin JS (2020) A three-variables cokriging method to estimate bare-surface soil moisture using multi-temporal VV-polarization synthetic-aperture radar data. Hydrogeol J 28(6):2129–2139. https://doi.org/10.1007/s10040-020-02177-z
Zhang L, Li K (2015) Forward and backward least angle regression for nonlinear system identification. Automatica 53:94–102. https://doi.org/10.1016/j.automatica.2014.12.010
Funding
Open access funding provided by Lulea University of Technology.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors stated that there are no conflicts of interest of any kind.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Al-Mamoori, S.K., Al-Maliki, L.A., Al-Sulttani, A.H. et al. Statistical analysis of the best GIS interpolation method for bearing capacity estimation in An-Najaf City, Iraq. Environ Earth Sci 80, 683 (2021). https://doi.org/10.1007/s12665-021-09971-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-021-09971-2