
Abstract
Circular RNAs (circRNAs) are a subclass of non-coding RNAs which have demonstrated potential as biomarkers for Alzheimer’s disease (AD). In this study, we conducted a comprehensive exploration of the circRNA transcriptome within AD brain tissues. Specifically, we assessed circRNA expression patterns in the dorsolateral prefrontal cortex collected from nine AD-afflicted individuals and eight healthy controls. Utilising two circRNA detection tools, CIRI2 and CIRCexplorer2, we detected thousands of circRNAs and performed a differential expression analysis. CircRNAs which exhibited statistically significantly differential expression were identified as AD-specific differentially expressed circRNAs. Notably, our investigation revealed 120 circRNAs with significant upregulation and 1325 circRNAs displaying significant downregulation in AD brains when compared to healthy brain tissue. Additionally, we explored the expression profiles of the linear RNA counterparts corresponding to differentially expressed circRNAs in AD-afflicted brains and discovered that the linear RNA counterparts exhibited no significant changes in the levels of expression. We used CRAFT tool to predict that circUBE4B had potential to target miRNA named as hsa-miR-325-5p, ultimately regulated CD44 gene. This study provides a comprehensive overview of differentially expressed circRNAs in the context of AD brains, underscoring their potential as molecular biomarkers for AD. These findings significantly enhance our comprehension of AD’s underlying pathophysiological mechanisms, offering promising avenues for future diagnostic and therapeutic developments.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Alzheimer’s disease (AD) is a neurodegenerative disease, classified based on its progressive decline and loss of neurons (Tom SE et al. 2015). As one of the main causes of dementia, AD has two categories, namely early-onset or sporadic AD that occurs after the age of 65, and familial AD that contains autosomal dominant missense mutations (Bhole RP et al. 2024). In particular, dysfunction of the dorsolateral prefrontal cortex is associated with impaired executive control function and working memory (Hertrich I et al. 2021; Kumar S et al. 2017) The AD pathology primarily involves misfolded, oligomerised amyloid β (Aβ) plaques (Grundke-Iqbal I et al. 1986) and accumulated neurofibrillary tangles (NFTs) (Glenner GG and Wong CW 1984), which are assessed for in AD pathology progression (Braak CD, E. Braak and F. Piette 1992). Despite ongoing research, the knowledge of AD-associated transcripts and the relationship between their dysfunction and the pathological mechanism is still elusive. Hence, a transcriptomic study on that investigates the effect of related genes and transcripts in AD has become crucial (Annese A et al. 2018; Bagyinszky E et al. 2020). Neurofilament light (NfL) and glial fibrillary acidic protein (GFAP) are proteins that have also been disclosed as imperative biomarker candidates in AD pathology (Benedet AL et al. 2021; Mantellatto G M et al. 2024; Pereira JB et al. 2021; Zhao Y et al. 2019). Remarkably, NfL is associated with the apolipoprotein E (APOE ε4) allele which is a significant biomarker in the identification of familial AD (Hawley NA et al. 2023). GFAP correlates with Aβ plaques and acts as a marker of astrogliosis in AD brain (O'Connor A et al. 2023). Moreover, advanced technology has unveiled that mutations of heterogenous nuclear ribonucleoproteins (hnRNPs) might play a crucial role as a regulatory factor in AD (Bartolomé-Nafría A et al. 2024). For instance, mutations on the prion-like domains of low complexity of hnRNPs were identified to exhibit association of amyloid fibril with neurodegenerative disease through accumulating toxicity to disorder (Lim L et al. 2016). TDP-43, a protein released in neuronal cells, was observed with features of hyperphosphorylation and ubiquitination in the progression of AD during synaptic and cognitive deterioration (Gao F et al. 2022; Lim L et al. 2016; Mantellatto G M et al. 2024) Transcriptome profiling can unravel pathogenesis mechanisms including neuronal transports, amyloid precursor protein (APP) synthesis and protein interaction during different onset stages of AD.
Circular RNAs (circRNAs) are non-coding RNAs (ncRNAs) and comprise of a covalently closed loop structure derived from the back-splicing of the pre-mRNA. Back-splicing is a spliceosome-dependent activity responsible for the upstream 5′-donor site ligating to the downstream 3′-acceptor site of the target exons (Jeck WR and Sharpless NE 2014; Wilusz JE and Sharp PA 2013). The ligated part is classified as back-splice junction (BSJ). The distinctive and intrinsic feature of circRNAs is the lack of a 5′ cap and 3′ poly (A) tail which is subsequent for their high stability and longer half-life compared to linear RNAs (Jeck WR and Sharpless NE 2014).
CircRNAs have multiple functions such as gene expression regulatory potential, translational capacity, microRNA (miRNA) sponging (Hansen TB et al. 2013), protein interaction (Goodrich JA and Kugel JF 2006) and competition with linear RNAs production (Ashwal-Fluss R et al. 2014). A significant number of circRNAs enriched in the human brain has been observed in past studies (Jeck WR and Sharpless NE 2014; Rybak-Wolf A et al. 2015; Zimmerman AJ et al. 2020). These features preposition circRNAs as disease biomarkers for detection and monitoring pathogenesis of AD (Huang J-L et al. 2020; Meng S et al. 2017). Previous studies (Lukiw W et al. 2016; Lukiw WJ et al. 2015; Shi Z et al. 2017) have demonstrated that the expression of brain tissue-specific circRNAs promotes multiple downstream responses including amyloid β (Aβ) generation and clearance, neuroinflammation, neuronal oxidative stress and autophagy. A study by Lukiw WJ et al. (2015) revealed that deficient levels ciRS-7 is ensued with failure to compete with miRNA-7 as a sponging effect, which can lead to higher expression of miRNA-7 and subsequent downregulation of the ubiquitin-conjugating enzyme UBE2A responsible for Aβ clearance. ciRS-7 also plays a role in neuroprotection through promoting proteasome and lysosome for degradation of APP and beta-site APP cleaving enzyme-1 (BACE1) levels (Shi Z et al. 2017). Neuroinflammation can be induced via the interaction of circPTK2 and miR-29b by activating microglial cells (González-Scarano F and Baltuch G, 1999; Shi Z et al. 2017). Dysregulation of circCwc27 regulates the binding affinity of purine-rich element-binding protein A (Pur-⍺) to the promoter of APP, which further control the level of cognitive decline in AD (Song C et al. 2022). To discriminate autosomal-dominant AD from sporadic AD, circPSEN1 was detected from in silico analysis which suggests its regulatory potentials in AD pathogenesis pathway and neuroinflammation (Chen HH et al. 2022). CircHomer1a, expressed in the dorsolateral prefrontal cortex, was found to play a role in synaptic expression and AD-related cognitive dysfunction (Dube U et al., 2019; Zimmerman AJ et al. 2020).
Despite these advances, what is understood about circRNAs’ role in the pathology of neurodegeneration is limited and entails further research. Here, we investigate the circular transcriptome in the AD brain, aiming towards the identification of AD-specific circRNAs.
Materials and Methods
Accession and Quality Check of RNA Sequence Data and Library Preparation of circRNAs
For this study, total RNA sequencing (RNA-seq) data in FASTQ format, derived from dorsolateral prefrontal cortex, were downloaded from the NCBI database (accession number GSE53697). The full details of sequencing data generation steps can be found in Scheckel C et al. (2016)’s study. In summary, the control cohort was selected based on the individual’s exhibition of AD pathology in the form of neurofibrillary tangles and plaques. The AD samples were selected based on a clinical dementia rating (CDR) between four and five, with short post-mortem intervals (PMI) (Scheckel C et al. 2016). The sample tissues were subjected to Trizol (Invitrogen) extraction and the RNA templates were prepared following the Illumina high-throughput TruSeq RNA sample preparation guidelines. There have been no enriched circRNAs at the performance of ribosomal RNA (rRNA) depletion. As described in the source paper (Scheckel C et al. 2016), following rRNA depletion and DNase treatment on the brain samples and neuroblastoma cell lines, AD samples 7–9 and control samples 6–8 in this study were sequenced using Illumina HiSeq 2500 at the New York Genome Centre which yielded 125-bp paired end reads, while the remaining subjects were sequenced on an Illumina HiSeq 2000 system at the Rockefeller University Genomics Resource Centre, which produced 100-bp paired end reads. A quality check on the raw sequence data files was performed using FastQC v0.11.9 (Andrews S, 2010) to ensure that the FASTQ files generated reads of sufficient quality. Adaptors were removed using Trimmomatic v0.39 (Bolger AM et al. 2014) and the quality of the trimmed data files was also evaluated with FastQC prior to the circRNA detection pipeline (Andrews S, 2010).
circRNAs Alignment and Identification
Read alignment and detection of circRNAs were performed using two different workflows with different tools and parameters. Both methods required an alignment to the UCSC hg38 reference genome obtained from the GENCODE v43 (GRCh38.p13) annotation file. The CIRI2 pathway utilises the Burrows-Wheeler alignment (BWA)-MEM v0.7.17 algorithm to align the query data (Li H and Durbin R, 2009) and produce Sequence Alignment Map (SAM) files. The SAM files containing the mapped sequences were processed through CIRI2 v2.0.6 (circRNA identifier) (Gao Y et al. 2015; Gao Y et al. 2018) for circRNA identification and annotation. The CIRCexplorer2 pathway began with Spliced Transcripts Alignment to a Reference (STAR) v2.7.6a (Dobin A et al. 2012) to generate Chimeric.out.junction files, followed by the CIRCexplorer2 pipeline (Zhang XO et al. 2016) for circRNA identification and annotation. These files were initially parsed using the CIRCexplorer2 parse module to analyse and pack the back-splice junction (BSJ) information into Browser Extensible Data (BED) files that were previously annotated by CIRCexplorer2’s annotate function. The output circRNA data from both CIRI2 and CIRCexplorer2 were selected using the margin of BSJ reads greater or equal to two, to reduce the likelihood of false positives. The common circRNAs detected by both circRNA detection tools were merged into a single file to remove redundant circRNAs, which would further reduce the likelihood of false positives.
Linear RNA Analytical Pipeline
HISAT2 v2.2.0 (Kim D et al. 2019) was used to align the trimmed data to the genome index built on the reference genome UCSC hg38 using the HISAT build module. In order to assemble and quantify the linear transcripts, SAMtools v1.15.1 (Danecek P et al. 2021) was utilised to convert the HISAT2 output file format from SAM files to Binary Alignment Map (BAM) files, followed by converting the assembled transcripts into Gene Transfer Format (GTF) files from the StringTie v1.3.4d algorithm (Pertea M et al. 2015). A non-redundant set of transcripts was generated regarding the GTF files using the StringTie merge module.
Differential Expression Analysis
Circular RNAs. The annotated circRNA information was analysed in R environment v4.2.2 (http://www.R-project.org/) using edgeR v3.40.2 (Robinson MD et al. 2010), limma v3.54.2 (Phipson B et al. 2016), dplyr v1.1.2 (Wickham H FR, Henry L, Müller K, Vaughan D 2023) and tidyverse v2.0.0 (Wickham H VD, Girlich M, 2023). Average expression values in the merged data files were calculated using the counts per million (CPM) mapped reads as the unit. The library size from common circRNA read counts was normalised from a calculated normalised factor using trimmed mean of M-values (TMM). In addition to differential expression analysis on circRNAs, library size-normalised data were fit into linear model for series of arrays, followed by applying empirical Bayes statistics for differential expression onto circRNAs which ranked the order of circRNAs by evidence of arbitrary number of contrasts. All differentially expressed circRNAs that exhibited statistical significance (false discovery rate unadjusted p-value < 0.05) were selected. The p-value was later adjusted to a more stringent threshold of less than 0.1 using Banjamini-Hochberg procedure via limma (Phipson B et al. 2016) to acquire a larger number of differentially expressed circRNAs for a more comprehensive coverage. In order to visualise the differential expression of circRNAs through a robust volcano plot, the ggplot2 v3.4.2 package (H W, 2016) in R was used to display the up- and downregulated, as well as stable circRNAs.
Linear RNAs. In preparation for generating a linear transcript count matrix used for differential expression analysis, the abundance of gene read counts output from StringTie—eB arguments were supplied to the developer’s Python v3 script (Shumate A et al. 2022). The gene count matrix was then imported into the R environment for differential expression analysis on linear transcripts. Average expression values for linear RNAs were also calculated using CPM as the unit. The same packages and procedures used in the differentially expressed circRNAs analysis were also used for linear differential expression analysis (i.e. unadjusted p < 0.05) and volcano plots visualisation.
Data Visualisation
To visualise and compare the data, boxplots exhibiting CPM values from control and AD were constructed using Prism 9 v9.4.1 (https://www.graphpad.com/). The CPM values of the top ten upregulated circRNAs and their linear counterparts in AD samples were compared with control samples. The selection of upregulated circRNAs were then visualised on CircView (Feng J et al. 2017) to show contributing exons and genomic loci coordinates.
Gene Ontology Enrichment and KEGG Enrichment Analysis
The R package, clusterProfiler (Wu T et al. 2021; Yu G et al. 2012) was used for the analysis of Gene Ontology (GO) enrichment from biological processes and cellular component aspects. The input gene dataset included the top 500 differentially expressed linear RNAs and downregulated circRNAs for consistency and more comprehensive enrichment analysis, and 120 differentially expressed upregulated circRNAs. The GO over-representation test utilised the Benjamini and Hochberg (BH) p-value adjustment method to reduce false discovery rate for multiple comparison (Benjamini Y and Hochberg Y, 1995). Kyoto Encycopedia of Gene and Genomes (KEGG) enrichment analysis was performed for upregulated and top 500 downregulated circRNAs using DAVID (https://david.ncifcrf.gov/tools.jsp) (Huang da W et al. 2009; Sherman BT et al. 2022). The results of the enriched KEGG terms from DAVID were used to construct an enrichment bubble through SRplot (https://www.bioinformatics.com.cn/srplot) with a p-value cut-off of 0.5 (Tang D et al. 2023).
CircRNA-miRNA-mRNA Network
The BSJ coordinates of the selected circRNAs between CIRI2, CIRCexplorer2 and CircView outputs were validated against each other. Ten of these selected significantly upregulated circRNAs in AD samples were subjected to explore the potential miRNA-binding sites using the CRAFT v1.0 software and pipeline (Dal Molin A et al., 2022). Default parameters were used for functional analysis, table generation and graphical output. Information regarding the circRNA host gene, miRNA and target gene were retrieved from the CRAFT results. The circRNA-miRNA-mRNA network was established for selected circRNAs that exhibited several miRNA-binding sites greater or equal to seven.
Results
Circular Transcriptome Sequencing Metrics
The fastQC output revealed an average GC content of 43.39% for the nine AD samples and 44.25% for the eight control samples (Table S1). Across all trimmed samples, an average of 47,334,570 reads and 44,769,873 was detected with > 80% alignment rate for the nine AD samples and eight control samples, respectively. The output files from CIRI2 and CIRCexplorer2 were merged to identify the common circRNAs, with the average number of circRNAs detected in AD and control samples being 4676 and 5132, respectively (Table S1).
Differential circRNA Expression
A comparative analysis of circRNA expression between AD and healthy brain tissue revealed nine downregulated circRNAs using an adjusted p-value < 0.1 (FigA). There were 120 upregulated and 1325 downregulated circRNAs (p-value < 0.05) in the AD brain as depicted in FigB and listed in Table S2. The result of differential expression analysis for their linear counterparts is shown in Fig. S2.
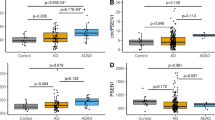
The top ten upregulated circRNAs by the smallest p-value were selected for further analysis (Table 1). The BSJ coordinates of these circRNAs matched between CIRI2, CIRCexplorer2 and CircView tools, confirming their proper genomic annotation. The log-fold change (FC) values for the selected upregulated circRNAs were all greater than 1.5. Boxplots were generated according to the CPM values for each selected circRNAs and their corresponding linear transcripts (Fig. 1). In comparison, the linear counterparts had no significantly differential expression between AD and control samples (Fig. 1 and Table S3). Of note, circATP13A3, circFANCB and circFASTKD1 presented an average CPM value of zero in the healthy control brain samples (Fig. 1). These circRNAs were considered uniquely expressed in AD brains.

Top 10 differentially expressed circRNAs (p-value < 0.05) and their linear counterparts. The number of asterisks represents the level of significance of the CPM value in AD comparing to control samples (***p-value < 0.001, **p-value < 0.01). None of the linear counterparts were statistically significant. The control and AD samples were presented in grey and pink colours, respectively. The relative linear counterparts include a grey background. The plots were created using Prism v9.4.1
Visualisation of circRNAs
Individual circRNAs were visualised using CircView, with detailed information about the expressed gene locus (Fig. 2). Exons are shown as coloured bars and labelled with increments of five. Introns are shown as black lines. The arrow on the gene locus indicates the direction of the transcript to be from 5′- to 3′- end. Coloured arrows correspond to the colour of exons, indicating the position of the exons within the gene locus. On the circular graph, the black bar represents the position of BSJ (5′-donor site and 3′-acceptor site), and the curved arrows represent the direction of exon involvement. On each coloured exon, the sequential exon number from the gene locus is shown and the exon lengths are displayed in brackets.

Visualisation of differentially expressed circTFDP2 and circATP13A3. The top two upregulated circRNAs listed in Table 1 are shown; the remaining eight circRNAs can be seen in Fig. S2. Gene transcript information was shown on top of each graph: (a) gene name. (b) Gene transcript ID. (c) Chromosome (chr) number of the circRNA. (d) The number of exons consisted of the gene. (e) Coding sequence (Cds) nucleotides coordinates. Exons are shown as coloured bars and labelled with increments of five. Introns are shown as black lines. The arrow on the gene locus indicates the direction of the transcript to be from 5′- to 3′- end. Coloured arrows correspond to the colour of exons, indicating the position of the exons within the gene locus. On the circular graph, the black bar represents the position of BSJ (5′-donor site and 3′-acceptor site), and the curved arrows represent the direction of exon involvement. On each coloured exon, the sequential exon number from the gene locus is shown and the exon lengths are displayed in brackets
Gene Ontology Terms Enrichment Analysis
As a part of this study, a more comprehensive understanding of the implications of circRNA expression on biological processes and cellular components was completed using clusterProfiler (Fig. 3 and Table 2). Among the 120 upregulated differentially expressed circRNAs, no significant enrichment of Gene Ontology (GO) terms emerged with the cut-off p-value of 0.05.

Gene ontology enrichment map for the selected circRNAs matched between CIRI2, CIRCexplorer2 and CircView outputs. A Biological process. B Cellular component. The enriched terms in the enrichment map were organised into networks. The nodes represent enriched GO terms and the node colour represents the significance of the adjust p-value. Similar terms were grouped into clusters. Groups were named using the abbreviation of terms names. The size of the node denotes the number of genes attributing to the enrichment
In contrast, to achieve higher specificity of GO enrichment, the top 500 genes expressing downregulated circRNAs were analysed, with the result demonstrating an association with seven annotated biological processes, grouped into two distinct clusters (Fig. 3 and Table 2). The enriched genes expressing the down-regulated circRNAs were involved in several biological pathways represented in a network configuration (Fig. 3A). From Fig. 3B, the cellular component analysis for the downregulated circRNAs revealed 18 annotated terms grouped into four clusters. This suggests the downregulated circRNAs in AD brain might play a role in influencing the structural organisation of cells.
There was no significant GO terms enrichment for the selected top 500 downregulated linear transcripts. However, genes expressing upregulated linear RNAs were enriched and linked significantly to one biological process: “one-carbon compound transport”.
KEGG Pathway Analysis
To further analyse and interpretate the functional meaning of the dysregulated circRNAs, genes of the significantly differentially expressed circRNAs were subjected to KEGG analysis. Among the top 500 downregulated circRNAs, sphingolipid signalling pathway, lysine degradation and T-cell receptor signalling pathways were most related to the target genes (p-value < 0.01) (Fig. 4). KEGG pathway analysis revealed that only one pathway named as Apelin signalling pathway (p-value < 0.05) was associated with genes expressing the top 120 upregulated circRNAs.

KEGG pathway analysis of down-regulated circRNAs (p-value < 0.05). y-axis represents the enriched KEGG pathway. The size of the nodes represents the number of genes involved for each enrichment. The colour of the nodes represents the significance of the p-value
circRNA-miRNA-mRNA Network
The CRAFT tool interlinks with multiple types of databases (miRbase, GeneCards, NCBI Entrez, Ensembl, Uniprot and NCBI Pubmed) in to order to generate functional prediction result. It delivers several predicted miRNA-binding sites and miRNAs for the input circRNA IDs and sequences (Table 3). From the ten selected upregulated circRNAs (Table 1), four circRNAs were identified to express miRNA-binding sites.
The CRAFT software predicted a number of miRNAs-binding sites for each of the ten circRNAs (Table S4). A previous study assumed that the number of specific miRNA-binding sites is greater than seven (Hall IF et al., 2019). Hence, of those which are selected for the miRNA sponges’ prediction, circUBE4B contained the highest number of miRNA-binding sites, and it was the only circRNA acting as potential miRNA sponges (Table 4). Among the list of predicted miRNAs, hsa-miR-4739 comprised of the highest frequency of miRNA-binding sites and highest density value of 0.1.
Circular plots on miRNA section generated for circUBE4B and circFASTKD1 (Fig. 5) using CRAFT software were selected for comparison of visualisation. Each plot displays all predicted miRNAs and their respective MREs for the designated circRNA. The name of the predicted miRNAs’ and their MREs’ positions on the specific circRNAs were retrieved from miRBase, which is a miRNA database integrated within the CRAFT software. Circular plots for circFANCB and circPICALM are in Fig. S3.

Graphical visualisation of miRNA-binding sites along sequences of circUBE4B (A) and circFASTKD1 (B). The small grey circle at the centre represents the respective circRNA. Each extended blue bar represents predicted miRNAs. The sequential numbers positioned vertically at the middle of the circle represent the number of miRNAs sharing identical MRE start position. The outermost layer of the circle, delineated by sequential numbers in a clockwise direction represents the circRNA sequence length
To investigate the circRNA-associated competing endogenous RNA (ceRNA) regulatory network, CRAFT tool revealed that circUBE4B, through predicting mRNA target associated with hsa-miR-328-5p (Table 4), potentially regulates the expression of the CD44 gene (Fig. 6 and Table S3). None of the other target genes expressing mRNAs predicted by CRAFT tool for miRNAs listed in Table 4 were significantly differentially expressed in this analysis.

CircUBE4B and CD44 mRNA expression in AD and control samples. The number of asterisks represent the level of significance of the CPM value in AD comparing to control samples (**p-value < 0.01, *p-value < 0.5). For circUBE4B, the control and AD samples were presented in grey and pink colours, respectively. For the CD44 mRNA, the control and AD samples were presented in green and blue colours, respectively
Discussion
CircRNAs are a class of non-coding RNAs that have yet to be extensively explored in the context of neurodegenerative diseases. According to the pathogenesis of neurodegenerative disease, neuronal loss directly leads to less proficient neuronal maintenance and synaptic transmission (Tom SE et al. 2015). This study aims to deepen the understanding of the circRNA transcriptome within the Alzheimer’s disease (AD) landscape and subsequently expand on the initial discovery of circRNA expression in AD. By conducting a differential expression analysis of circRNAs in nine AD samples and eight control samples followed by the visualisation of selected circRNAs, and investigation on the circRNAs functions.
Transcriptome Sequencing Metrics
Lower Measurement of circRNAs Recovered than Linear RNAs
An intriguing finding centres around the distribution of low counts per million (CPM) values (CPM < 1) among the top ten selected circRNAs in both AD and control samples (Table 1). In contrast, their linear counterparts showcase notably higher CPM values. This pattern of lower circRNA abundance aligns with prior findings and echoes established trends in circRNA expression levels (Aquilina-Reid C et al. 2022; Cheng Y et al. 2023; Takenaka K et al. 2023). A study by Guo et al. (Guo JU et al. 2014) suggested that low abundance of circRNAs in mammalian tissues was a result of imperfect pre-mRNA splicing. Back-splicing of circRNAs is regulated by multiple elements, which modulates the back-splicing event to be less efficient.
It is worth noting that the identification of circRNAs is restricted to the detection of back-splice junction (BSJ) sequences within aligned reads (Feng J et al. 2017; Gao Y et al. 2015; Zhang XO et al. 2016), while linear RNAs are identified based on the short reads that match the reference gene loci (Pertea M et al. 2015). CircRNA detection algorithms aim to produce comparatively reliable results through minimising the false positive rates, which involves the use of gene annotations or canonical splice signals. However, these strategies were found to impact the algorithms sensitivity (Szabo L and Salzman J, 2016). To increase the accuracy of this study, common circRNAs detected by CIRI2, CIRCexplorer2 and CircView were filtered as considering the algorithm-specific criteria for BSJ-aligned reads.
A Higher Number of Downregulate circRNAs in AD Samples
A differential expression analysis for circRNAs and their linear counterparts (Fig. 7) in between AD samples and control samples was completed. In this study, a higher number of downregulated circRNAs and genes were identified, which is reflective in other neurodegenerative diseases such as Parkinson’s disease and Huntington’s disease (Kong F et al. 2021; Li MD et al. 2014). A higher number of downregulation of circRNAs might indicate the disruption of relevant interactions and downstream pathways such as gene regulatory abilities as well as interactions with miRNAs and RNA-binding proteins (Ashwal-Fluss R et al. 2014; Goodrich JA and Kugel JF 2006; Hansen TB et al. 2013; Pamudurti NR et al. 2017). For instance, dysregulated expression of circRNAs in the brain impacts multiple downstream responses. Previous studies AD have demonstrated circRNAs in the brain which are involved in Aβ generation and clearance, neuroinflammation, neuronal oxidative stress and autophagy in (González-Scarano F and Baltuch G, 1999; Huang J-L et al. 2020; Lukiw WJ et al. 2015; Wang H et al. 2019; Zhou Z-b et al. 2018). Therefore, the discovery of dysregulation of AD-associated circRNAs indicates neuronal and synaptic dysfunction in AD brains.

Volcano plots of differentially expressed circRNAs in AD compared to control subjects. Differentially expressed circRNAs are based on an adjusted p-value < 0.1 (A), and unadjusted p-value < 0.05 (B). Downregulated circRNAs are presented in blue and upregulated circRNAs are presented in red. The plot was generated with − log10 of the p-values and fold change (FC) on the axis
Significance of the Differentially Expressed circRNAs
Uniquely Differentially Expressed circRNAs
This study revealed uniquely differentially expressed circRNAs that have not yet been mentioned in AD including circATP13A3, circFANCB and circFASTKD1 (Table 1). As these uniquely circRNAs are only observed in the AD samples, it implies the potential unknown pathways or interactions of the molecules that are involved in circRNAs regulations and potentially AD-specific pathogenic mechanisms. Notably, this pattern of dysregulation is not mirrored in the linear counterparts of these circRNAs, which exhibit no significantly differential expression between AD and control samples (Fig) (Rybak-Wolf A et al. 2015). A study using poly(A) + RNA samples obtained from AD brains also displayed no correlation in expression levels between the most abundant circRNAs and their mRNA counterparts through ranking (Arizaca Maquera KA et al. 2023). The heightened expression of dysregulated circRNAs could potentially serve as indicative markers of their involvement in AD pathology.
Selected Upregulated circRNAs in This Study and Their Associated Linear Products Found in Previous Studies
Among the group of top ten upregulated circRNAs (Table 1), none have previously been identified as differentially expressed in AD brains. However, their linear RNA counterparts or the resultant protein products have been linked to AD pathogenesis. For instance, the upregulated Septin7 protein has been implicated in molecular reactions within AD mice, implying its potential significance in disease processes of AD in humans (Wang X et al. 2018). Similarly, the ubiquitin conjugation E4B (UBE4B) protein’s ability to target the miR-9 gene contributes to tau tangle degradation in AD patients, further reinforcing its role in disease modulation (Subramanian M et al. 2021). Previous studies have demonstrated implications of downregulated circFASTKD1 and circGF2I (Gao WQ et al. 2020; Yuan C et al. 2022) associated with myocardial infarction. Similarly, these circRNAs have also been observed in an intersection between cardiovascular and neurodegenerative disease pathways (Huang L-Y et al. 2023). Furthermore, the linear counterpart of the PICALM’s dysregulation influences the risk of AD development by impacting APP processing, Aβ transcytosis and tau progression, highlighting its multifaceted influence on AD pathogenesis (Ando K et al. 2022).
Statistically Significantly Upregulated circRNAs in AD and Relevant Studies
Amongst the 120 statistically significantly upregulated circRNAs (Table S2), three were previously described as being upregulated in AD in literature (Li Y et al. 2020; Ma N et al. 2020; Song C et al. 2022). For instance, the upregulation of circPCCA was validated through microarray analysis (p-value < 0.001) and exhibited increased expression in AD, hinting its potential as a robust marker for the diagnosis of AD (Li Y et al. 2020). Similarly, circCwc27, which is abundantly expressed and significantly upregulated in AD, may be promising as a therapeutic target for cognitive dysfunction in AD patients (Song C et al. 2022). Another example is circPTK2, which warrants further investigation into its potential involvement in AD processes (Ma N et al. 2020). The identification of these circRNAs in AD samples validates the analytical pipeline and findings in this project and provides an understanding to the other upregulated circRNAs in AD pathology.
Dysregulation of circRNAs Comparing to Their Linear Host Transcripts
In this study, the circRNA abundance and levels of dysregulation are independent to their linear transcripts (Fig. 1). It is known that back-splicing requires spliceosome and canonical splice sites to produce circRNAs (Ashwal-Fluss R et al. 2014). A recent study (Liang D et al. 2017) has revealed that the depletion of components of the U2 small nuclear ribonucleoprotein (snRNP) spliceosome could promote higher expression of circRNAs whilst reducing mRNA production. Liang et al. (Liang D et al. 2017) proposed that canonical splicing necessitates the transition promoted by U1/U2 snRNP from cross-exon interaction to cross-intron interaction, compared to canonical back-splicing. On the other hand, the U4/U5/U6-tri-snRNP components’ spliceosome directly promotes circularisation (Schneider M et al. 2010; Starke S et al. 2015). Hence, inhibition of some subunits of spliceosome might improve circRNAs expression, while not significantly affect levels of canonical splicing. This supports the findings in this study where only competent circRNAs were statistically significantly upregulated in this project, but their linear host mRNAs exhibit no significantly differential expression.
Gene Ontology Enrichment and KEGG Pathway Analysis for Differentially Expressed circRNAs
The preliminary GO enrichment analysis for downregulated circRNAs included numerous terms related to the nervous system including synapse, neurons and dendrites, which are related to the affected AD tissues (Griffiths J and Grant SGN 2023) (Table 2; Fig. 3). Disruptions of synapse formation and maintenance directly contribute to cognitive decline, a characteristic symptom of AD (Dorostkar MM et al. 2015). Among the biological process GO terms, processes related to synapse organisation and activity were prominent, constituting five out of the seven processes. This implicates strong correlation between the downregulation of the host genes expressing these circRNA and the symptoms of AD. Although the GO analysis is based on protein products derived from linear RNAs, the association between circRNAs and linear transcripts should not be ignored. It has been noted that circRNAs are able to influence the expression of linear transcripts by competing for mRNA splicing machinery (Ashwal-Fluss R et al. 2014). It insinuates a possibility for them to indirectly contribute to the onset of AD symptoms through this mechanism. Further evidence of downregulated circRNAs contributing to the pathogenesis of AD is observed from the cell component GO terms results, with 11 out of 18 terms related to the nervous system (Fig. 3A). The most significant cell component term was glutamatergic synapse, where its disruption has been observed to be one of the most important pathological indicators of cognitive decline for AD (Coleman PD and Yao PJ 2003). The dysregulation of one-carbon compound transport has been reported to result in increased homocysteine levels in circulation, which was accompanied by AD progression and cognitive decline (Smith AD and Refsum H, 2016). Other enriched terms such as neuron to neuron synapse, dendritic spine and postsynaptic density have been reported and are consistent with the current literature on AD progression (Dorostkar MM et al. 2015; Griffiths J and Grant SGN 2023; Vyas Y and Montgomery JM 2016). The corroboration from other studies reinforces the notion that downregulated circRNAs contribute to AD’s pathophysiological development and progression.
According to the Kyoto Encyclopedia of Genes and Genomes (KEGG) enrichment, the downregulated circRNAs enriched several signalling pathways (Fig. 4) which have been reported previously to be significant for AD pathogenesis. Sphingolipids, a highly enriched pathway in this KEGG analysis, were able to contribute to the biogenesis regulation of Aβ, tau, ⍺-Syn, and APOE that are biomarkers of AD pathogenesis (Wang X et al. 2024). For example, sphingolipids interact with Aβ oligomers to form endogenous GAβ seeds which urge the aggregation of extracellular Aβ plaques, leading to cell apoptosis and neurotoxicity in AD brain (Matsuzaki K, 2020). Decrease of lysine metabolism was observed in hippocampus region of AD brain tissue (Xu J et al. 2016). CircPSEN1 is involved in lysine degradation in autosomal-dominant AD patients (Chen HH et al. 2022). Evidence indicates that the dysfunction of T-cell receptor signalling pathway in immunological and pathological regulation could potentially modulates the cell homeostasis and neuroinflammatory response in AD (Browne TC et al. 2013; Dai L and Shen Y, 2021). Genes expressing the downregulated circRNAs are enriched in nucleocytoplasmic transport, which are responsible for the damage of the nuclear pore complex or other impairment of factors in AD (Nag N and Tripathi T, 2023). Notch signalling pathway is a conserved cell signalling control involved in vascular and cerebrovascular development and function (Knopman DS et al. 2003). Mutation of the PSEN1 identified in this study was demonstrated to induce Aβ and neuronal activity at the stage of human-induced pluripotent stem cell-derived cortical spheroids modification. It was also found to increase Notch signalling in familial AD (Hurley EM et al. 2023). More than 40% of neuronal synapses are glutamatergic synapses; therefore, the accumulation of neurotoxicity is recognised as a result of the abnormality of glutamatergic synapses and dysregulation of glutamate (Bukke VN et al. 2020; Cassano T et al. 2012). Efferocytosis in AD brain tissue denotes for the clearance of apoptotic neurons and Aβ by phagocytosis (Tajbakhsh A et al. 2021), which brings over a positive effect for AD brain. The “bacterial invasion of epithelial cells” from the reported KEGG pathway can be explained when AD-related pathological activity contributes to and the entry of the noxious microbiomes into the circulation through the leaky blood–brain barrier dysbiosis in AD patients (Bulgart HR et al. 2020). Moreoever, reducing dopaminergic neurons correlates with memory impairment and reward dysfunction at pre-plaque stage (Nobili A et al. 2017). Polycomb repressive complex from the KEGG pathway was known to prevent and downregulate the expression of harmful genes via methylation process in AD (Cholewa-Waclaw J et al. 2016; Kouznetsova VL et al. 2019). By implementing the top 120 upregulated circRNAs to KEGG pathway analysis, RYR2I and PIK3C3 were reported to have involvement in the apelin signalling pathway. Upregulation of RYR2 leads to higher probability deteriorates neuronal dysfunction in familial AD via processing modification on neuronal hyperactivity (Yao J and Chen SRW 2024). Study from Yang C et al. (2017) uncovered that the PIK3C3 protein is associated with a complex that is able to disrupt APP metabolism and Aβ homeostasis. Of note, the annotation of GO or KEGG enrichment analysis is still based on protein coding gene, which results in less interpretation on intrinsic functions of the circRNAs (Cheng Y et al. 2023).
CircRNA-miRNA-mRNA Network
Several studies have revealed the regulatory potential for circRNAs during the circRNA-miRNA-mRNA network in development of AD (Li Y et al. 2022; Lu Y et al. 2019; Ma N et al. 2019; Zhang Q et al. 2022). The competitive endogenous network suggests the noncoding RNAs competes with other RNAs to bind to miRNAs for regulatory function (Gao L et al. 2021; Salmena L et al. 2011). The investigation of miRNA-binding sites for the selected circRNAs revealed circRNAs’ unique ability to bind to their target miRNAs (Table 3). It is predicted that the upregulated circUBE4B has the capacity to act as a potent miRNA sponge to multiple miRNAs (Table 4). Of note, the functional role of gene expression regulation for circUBE4B is manifested through its targeting of gene CD44 via hsa-miR-328-5p, whose linear transcript from gene CD44 was also observed to be upregulated in AD samples. This corroborates with the statement that circRNAs as a miRNA sponge leads to inhibition of miRNA from binding to its target gene, consequently leading to the expression of linear RNA of the target gene. Tan et al.’s study in 2021 illustrated the correlation of miR-328-3p with multiple target genes expressing mRNAs in AD pathogenesis. Notably, miRNA strand denoted with − 3p or − 5p suffix represent the mature miRNA derived in either 3′ – 5′ prime end direction or 5′ – 3′ prime end direction, respectively (Kozomara A and Griffiths-Jones S, 2014). Referring to the miRBase database (https://mirbase.org/), both hsa-miR-328-3p/5p strands are functional but might involve distinct regulatory potentials in neurons due to their structural difference (Kim J et al. 2004). From previous studies, CD44 serves as a marker for microglial and astrocytic activation in AD brain (Akiyama H et al. 1993; Pesämaa I et al. 2023). It was known that CD44 correlates with a neuroinflammatory marker called chitinase-3-like protein 1 (also known as YKL-40), which is involved in Aβ and neurofibrillary tangles development in AD pathogenesis (Craig-Schapiro R et al. 2010). Based on previous finding about roles of YKL-40 in repair and remodelling (Zhao T et al. 2020), it was hypothesised that CD44 and YKL-40 are responsible for neuroprotection during cognitive impairment (Kognole AA and Payne CM 2017; Moreno-Rodriguez M et al. 2020; Toole BP 2009). Overall, circUBE4B targets the trafficking of hsa-miR-328-5p and promotes expression of CD44 in brain region of dorsolateral prefrontal cortex of AD patients, thereby implicated in the pathology of AD. From a clinical perspective, circUBE4B might serve as a potential biomarker for AD diagnosis and treatment, referring to its regulatory role in the circRNA-miRNA-mRNA competitive endogenous network (Memczak S et al. 2013). This finding supports the understanding that circRNAs is pivotal for complex molecular interaction and expression regulatory.
Concluding Remarks
As the roles of AD-specific circRNAs remain relatively unexplored, the profiles of circRNAs uncovered in this study hold the potential to serve as biomarkers for early AD diagnosis and disease progression monitoring. Furthermore, although the functions of circRNAs within biological processes are not fully elucidated, the insights derived from this study underscore their potential significance, warranting further investigation.
Notably, one of the limitations of this study is the relatively small AD sample size (Scheckel C et al. 2016). The small sample size potentially contributes to no differentially expressed linear transcripts with adjusted p-value < 0.1 (Fig. S1). The tool used for Gene Ontology enrichment analysis requires enriched genes and gene clusters to calculate and generate enriched pathways (Yu G et al. 2012). This implies that less genes from a smaller sample size might not show relevant pathways due to the lack of enriched genes. The lack of GO enrichment in this study for the upregulated circRNAs indicated a controversial statement in terms of circRNAs function in AD and Gene Ontology annotation. A previous study by Tomczak et al. (Tomczak A et al. 2018) on the evolution of GO and its annotation suggested a continuous upgrade of GO annotations might deliver different interpretation of the 120 upregulated circRNAs and AD pathology. Additionally, the annotation of GO terms is still based on the discovered function of the proteins encoded by genes, which results in insufficient interpretation of the intrinsic functions of the circRNAs (Cheng Y et al. 2023). Hence, larger sample sizes and diverse brain regions could provide a more comprehensive picture of circRNA dysregulation in AD.
Regarding the circRNA detection tools used in this study, there is a sense of ambiguity in detecting the BSJs for circRNA identification as other biological molecules also naturally exhibit BSJs (Jeck WR and Sharpless NE 2014). From the evaluation of circRNAs detection methods on the RNA-seq datasets (Nguyen MH et al. 2022), CIRI2 and CIRCexplorer2 both revealed a comparatively satisfactory performance on circRNAs detection. It has been reported that the true discovery rates for these two tools remain below 80%, which is an acceptable value due to their aim of detecting as many circRNAs as possible (Nguyen MH et al. 2022). In this project, to minimize the number of false positives, common circRNAs detected by both CIRI2 and CIRCexplorer2 were merged and demonstrated that some AD-associated circRNAs detected by single algorithm were discarded from downstream analysis. Consequently, the potential loss of these circRNAs might compromise the accuracy, sensitivity and reliability of the subsequent results. The advent of long-read sequencing such as Oxford nanopore technology, which allows construction of full length circRNA sequence, eventually facilitates large-scale detection of circRNAs independent of BSJs detection (Rahimi K et al. 2021).
As the author (Dal Molin A et al., 2022) mentioned in their paper about CRAFT assessment and parameters optimisation, the sensitivity of this tool combining both miRanda and PITA databases for MREs detection remained ranging from 0.36 to 0.71 depending on the threshold setup. Although the integration of experimentally determined AGO2-binding sites might improve sensitivity for CRAFT, the number of predictions declined to 6%. Hence, CRAFT tool was built with low stringency in order to generate the targets for circRNA-miRNA-mRNA as complete as possible. In this project, the input parameters were set as default for prediction, which compromises the accurate filtering and interactions between the ceRNAs.
Additionally, exploring the potential of circRNAs as therapeutic targets or diagnostic biomarkers requires validation in independent cohorts and longitudinal studies. The advent of long-read sequencing like nanopore, which allows construction of full-length circRNA sequence, eventually facilitates large-scale detection of circRNAs independent of BSJs detection. In prediction of circRNAs-miRNAs-mRNAs targets and interactions, Circr (Dori M et al. 2022), a newly developed computational tool that also works on detecting these interactions can be used for validation. To validate the predicted circUBE4B-hsa-miR-328-5p-CD44 network, laboratory experiment is required. For example, RNA immunoprecipitation and fluorescent in situ hybridisation can be used to identify visualise circRNA-miRNA bindings and localisation. Additionally, reverse transcription quantitative polymerase chain reaction (RT-qPCR) and dual luciferase assay can help verify the targeting relationship in context of expression between the miRNA with the target gene (Li Y et al. 2022; Luo Q et al. 2023).
Despite these constraints, the identification of differentially expressed circRNAs and circRNA-miRNA-mRNA network within the dorsolateral prefrontal cortex of AD brains presents new avenues for future experimental exploration. In conclusion, the complex landscape of circRNAs in the context of neurodegenerative diseases, particularly Alzheimer’s disease, remains an area of great complexity including the pathogenesis and interactive pathways. As our understanding of the roles of circRNAs deepens, it opens doors to novel diagnostic and potential therapeutic avenues for neurodegenerative diseases that urgently need effective interventions.
Data Availability
Data is provided within the manuscript or supplementary information files.
References
Akiyama H, Tooyama I, Kawamata T, Ikeda K, McGeer PL (1993) Morphological diversities of CD44 positive astrocytes in the cerebral cortex of normal subjects and patients with Alzheimer’s disease. Brain Res 632:249–259. https://doi.org/10.1016/0006-8993(93)91160-t
Ando K, Nagaraj S, Kucukali F, de Fisenne MA, Kosa AC, Doeraene E, Lopez Gutierrez L, Brion JP et al (2022) PICALM and Alzheimer’s disease: an update and perspectives. Cell 11:3994. https://doi.org/10.3390/cells11243994
Andrews S (2010) FastQC: a quality control tool for high throughput sequence data, Cambridge, UK. Available online at: http://www.bioinformatics.babraham.ac.uk/projects/fastqc
Annese A, Manzari C, Lionetti C, Picardi E, Horner DS, Chiara M, Caratozzolo MF, Tullo A et al (2018) Whole transcriptome profiling of late-onset Alzheimer’s disease patients provides insights into the molecular changes involved in the disease. Sci Rep 8:4282. https://doi.org/10.1038/s41598-018-22701-2
Aquilina-Reid C, Brennan S, Curry-Hyde A, Teunisse GM, The Nygc Als C, Janitz M (2022) Circular RNA expression and interaction patterns are perturbed in amyotrophic lateral sclerosis. Int J Mol Sci 23:14665. https://doi.org/10.3390/ijms232314665
Arizaca Maquera KA, Welden JR, Margvelani G, Miranda Sardón SC, Hart S, Robil N, Hernandez AG, de la Grange P et al (2023) Alzheimer’s disease pathogenetic progression is associated with changes in regulated retained introns and editing of circular RNAs. Front Mol Neurosci 16:1141079. https://doi.org/10.3389/fnmol.2023.1141079
Ashwal-Fluss R, Meyer M, Pamudurti NR, Ivanov A, Bartok O, Hanan M, Evantal N, Memczak S et al (2014) circRNA biogenesis competes with pre-mRNA splicing. Mol Cell 56:55–66. https://doi.org/10.1016/j.molcel.2014.08.019
Bagyinszky E, Giau VV, An SA (2020) Transcriptomics in Alzheimer’s disease: aspects and challenges. Int J Mol Sci 21:3517. https://doi.org/10.3390/ijms21103517
Bartolomé-Nafría A, García-Pardo J, Ventura S (2024) Mutations in human prion-like domains: pathogenic but not always amyloidogenic. Prion 18:28–39. https://doi.org/10.1080/19336896.2024.2329186
Benedet AL, Milà-Alomà M, Vrillon A, Ashton NJ, Pascoal TA, Lussier F, Karikari TK, Hourregue C et al (2021) Differences between plasma and cerebrospinal fluid glial fibrillary acidic protein levels across the Alzheimer disease continuum. JAMA Neurol 78:1471–1483. https://doi.org/10.1001/jamaneurol.2021.3671
Benjamini Y, Hochberg Y (1995) Controlling the false discovery rate: a practical and powerful approach to multiple testing. JRStatSoc, b: Stat 57:289–300. https://doi.org/10.1111/j.2517-6161.1995.tb02031.x
Bhole RP, Chikhale RV, Rathi KM (2024) Current biomarkers and treatment strategies in Alzheimer disease: an overview and future perspectives. IBRO Neurosci Rep 16:8–42. https://doi.org/10.1016/j.ibneur.2023.11.003
Bolger AM, Lohse M, Usadel B (2014) Trimmomatic: a flexible trimmer for Illumina sequence data. J Bioinform 30:2114–2120. https://doi.org/10.1093/bioinformatics/btu170
Braak CD, Braak E, Piette F (1992) Neuropathological stageing of Alzheimer related changes correlates with psychometrically assessed intellectual status. Neurobiol Aging 13:S43–S44. https://doi.org/10.1016/0197-4580(92)90298-C
Browne TC, McQuillan K, McManus RM, O’Reilly JA, Mills KH, Lynch MA (2013) IFN-γ Production by amyloid β-specific Th1 cells promotes microglial activation and increases plaque burden in a mouse model of Alzheimer’s disease. J Immunol 190:2241–2251. https://doi.org/10.4049/jimmunol.1200947
Bukke VN, Archana M, Villani R, Romano AD, Wawrzyniak A, Balawender K, Orkisz S, Beggiato S et al (2020) The dual role of glutamatergic neurotransmission in Alzheimer’s disease: from pathophysiology to pharmacotherapy. Int J Mol Sci. https://doi.org/10.3390/ijms21207452
Bulgart HR, Neczypor EW, Wold LE, Mackos AR (2020) Microbial involvement in Alzheimer disease development and progression. Mol Neurodegener 15:42. https://doi.org/10.1186/s13024-020-00378-4
Cassano T, Serviddio G, Gaetani S, Romano A, Dipasquale P, Cianci S, Bellanti F, Laconca L et al (2012) Glutamatergic alterations and mitochondrial impairment in a murine model of Alzheimer disease. Neurobiol Aging 33:1121.e1121–1112. https://doi.org/10.1016/j.neurobiolaging.2011.09.021
Chen HH, Eteleeb A, Wang C, Fernandez MV, Budde JP, Bergmann K, Norton J, Wang F et al (2022) Circular RNA detection identifies circPSEN1 alterations in brain specific to autosomal dominant Alzheimer’s disease. Acta Neuropathol Commun 10:29. https://doi.org/10.1186/s40478-022-01328-5
Cheng Y, Xu S-M, Takenaka K, Lindner G, Curry-Hyde A, Janitz M (2023) A unique circular RNA expression pattern in the peripheral blood of myalgic encephalomyelitis/chronic fatigue syndrome patients. Gene 877:147568. https://doi.org/10.1016/j.gene.2023.147568
Cholewa-Waclaw J, Bird A, von Schimmelmann M, Schaefer A, Yu H, Song H, Madabhushi R, Tsai LH (2016) The role of epigenetic mechanisms in the regulation of gene expression in the nervous system. J Neurosci 36:11427–11434. https://doi.org/10.1523/jneurosci.2492-16.2016
Coleman PD, Yao PJ (2003) Synaptic slaughter in Alzheimer’s disease. Neurobiol Aging 24:1023–1027. https://doi.org/10.1016/j.neurobiolaging.2003.09.001
Craig-Schapiro R, Perrin RJ, Roe CM, Xiong C, Carter D, Cairns NJ, Mintun MA, Peskind ER et al (2010) YKL-40: a novel prognostic fluid biomarker for preclinical Alzheimer’s disease. Biol Psychiatry 68:903–912. https://doi.org/10.1016/j.biopsych.2010.08.025
da Huang W, Sherman BT, Lempicki RA (2009) Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nat Protoc 4:44–57. https://doi.org/10.1038/nprot.2008.211
Dai L, Shen Y (2021) Insights into T-cell dysfunction in Alzheimer’s disease. Aging Cell 20:e13511. https://doi.org/10.1111/acel.13511
Dal Molin A, Gaffo E, Difilippo V, Buratin A, Tretti Parenzan C, Bresolin S, Bortoluzzi S (2022) CRAFT: a bioinformatics software for custom prediction of circular RNA functions. Brief Bioinform 23:bbab601. https://doi.org/10.1093/bib/bbab601
Danecek P, Bonfield JK, Liddle J, Marshall J, Ohan V, Pollard MO, Whitwham A, Keane T et al (2021) Twelve years of SAMtools and BCFtools. Gigascience 10:gia008. https://doi.org/10.1093/gigascience/giab008
Dobin A, Davis CA, Schlesinger F, Drenkow J, Zaleski C, Jha S, Batut P, Chaisson M et al (2012) STAR: ultrafast universal RNA-seq aligner. J Bioinform 29:15–21. https://doi.org/10.1093/bioinformatics/bts635
Dori M, Caroli J, Forcato M (2022) Circr, a computational tool to identify miRNA:circRNA associations. Front Bioinform 2:852834. https://doi.org/10.3389/fbinf.2022.852834
Dorostkar MM, Zou C, Blazquez-Llorca L, Herms J (2015) Analyzing dendritic spine pathology in Alzheimer’s disease: problems and opportunities. Acta Neuropathol 130:1–19. https://doi.org/10.1007/s00401-015-1449-5
Dube U, Del-Aguila JL, Li Z, Budde JP, Jiang S, Hsu S, Ibanez L, Fernandez MV et al (2019) An atlas of cortical circular RNA expression in Alzheimer disease brains demonstrates clinical and pathological associations. Nat Neurosci 22:1903–1912. https://doi.org/10.1038/s41593-019-0501-5
Feng J, Xiang Y, Xia S, Liu H, Wang J, Ozguc FM, Lei L, Kong R et al (2017) CircView: a visualization and exploration tool for circular RNAs. Brief Bioinform 20:745–751. https://doi.org/10.1093/bib/bbx070
Gao Y, Wang J, Zhao F (2015) CIRI: an efficient and unbiased algorithm for de novo circular RNA identification. Genome Biol 16:4. https://doi.org/10.1186/s13059-014-0571-3
Gao Y, Zhang J, Zhao F (2018) Circular RNA identification based on multiple seed matching. Brief Bioinform 19:803–810. https://doi.org/10.1093/bib/bbx014
Gao WQ, Hu XM, Zhang Q, Yang L, Lv XZ, Chen S, Wu P, Duan DW et al (2020) Downregulation of circFASTKD1 ameliorates myocardial infarction by promoting angiogenesis. Aging 13:3588–3604. https://doi.org/10.18632/aging.202305
Gao L, Zhao Y, Ma X, Zhang L (2021) Integrated analysis of lncRNA–miRNA–mRNA ceRNA network and the potential prognosis indicators in sarcomas. BMC Med Genomics 14:67. https://doi.org/10.1186/s12920-021-00918-x
Gao F, Hu M, Zhang J, Hashem J, Chen C (2022) TDP-43 drives synaptic and cognitive deterioration following traumatic brain injury. Acta Neuropathol 144:187–210. https://doi.org/10.1007/s00401-022-02449-w
Glenner GG, Wong CW (1984) Alzheimer’s disease: Initial report of the purification and characterization of a novel cerebrovascular amyloid protein. Biochem Biophys Res Commun 120:885–890. https://doi.org/10.1016/S0006-291X(84)80190-4
González-Scarano F, Baltuch G (1999) Microglia as mediators of inflammatory and degenerative diseases. Annu Rev Neurosci 22:219–240. https://doi.org/10.1146/annurev.neuro.22.1.219
Goodrich JA, Kugel JF (2006) Non-coding-RNA regulators of RNA polymerase II transcription. Nat Rev Mol Cell Biol 7:612–616. https://doi.org/10.1038/nrm1946
Griffiths J, Grant SGN (2023) Synapse pathology in Alzheimer’s disease. Semin Cell Dev Biol 139:13–23. https://doi.org/10.1016/j.semcdb.2022.05.028
Grundke-Iqbal I, Iqbal K, Tung YC, Quinlan M, Wisniewski HM, Binder LI (1986) Abnormal phosphorylation of the microtubule-associated protein tau (tau) in Alzheimer cytoskeletal pathology. Proc Natl Acad Sci USA 83:4913–4917. https://doi.org/10.1073/pnas.83.13.4913
Guo JU, Agarwal V, Guo H, Bartel DP (2014) Expanded identification and characterization of mammalian circular RNAs. Genome Biol 15:409. https://doi.org/10.1186/s13059-014-0409-z
H W, (2016) ggplot2: elegant graphics for data analysis. Springer-Verlag, New York, USA. https://ggplot2.tidyverse.org
Hall IF, Climent M, Quintavalle M, Farina FM, Schorn T, Zani S, Carullo P, Kunderfranco P et al (2019) Circ_Lrp6, a circular RNA enriched in vascular smooth muscle cells, acts as a sponge regulating miRNA-145 function. Circ Res 124:498–510. https://doi.org/10.1161/CIRCRESAHA.118.314240
Hansen TB, Jensen TI, Clausen BH, Bramsen JB, Finsen B, Damgaard CK, Kjems J (2013) Natural RNA circles function as efficient microRNA sponges. Nature 495:384–388. https://doi.org/10.1038/nature11993
Hawley NA, Myers MA, Pizer JH, Ikonomou VC, Wagaman B, Campbell I, O’Bryant S, Hill BD (2023) A - 50 Examining NfL as a moderator for APOE status and cognitive dispersion. Arch Clin Neuropsychol 38:1213–1213. https://doi.org/10.1093/arclin/acad067.067
Hertrich I, Dietrich S, Blum C, Ackermann H (2021) The role of the dorsolateral prefrontal cortex for speech and language processing. Front Hum Neurosci 15:645209. https://doi.org/10.3389/fnhum.2021.645209
Huang J-L, Su M, Wu D-P (2020) Functional roles of circular RNAs in Alzheimer’s disease. Ageing Res Rev 60:101058. https://doi.org/10.1016/j.arr.2020.101058
Huang L-Y, Ou Y-N, Yang Y-X, Wang Z-T, Tan L, Yu J-T (2023) Associations of cardiovascular risk factors and lifestyle behaviors with neurodegenerative disease: a Mendelian randomization study. Transl Psychiatry 13:267. https://doi.org/10.1038/s41398-023-02553-9
Hurley EM, Mozolewski P, Dobrowolski R, Hsieh J (2023) Familial Alzheimer’s disease-associated PSEN1 mutations affect neurodevelopment through increased Notch signaling. Stem Cell Reports 18:1516–1533. https://doi.org/10.1016/j.stemcr.2023.05.018
Jeck WR, Sharpless NE (2014) Detecting and characterizing circular RNAs. Nat Biotechnol 32:453–461. https://doi.org/10.1038/nbt.2890
Kim J, Krichevsky A, Grad Y, Hayes GD, Kosik KS, Church GM, Ruvkun G (2004) Identification of many microRNAs that copurify with polyribosomes in mammalian neurons. Proc Natl Acad Sci USA 101:360–365. https://doi.org/10.1073/pnas.2333854100
Kim D, Paggi JM, Park C, Bennett C, Salzberg SL (2019) Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat Biotechnol 37:907–915. https://doi.org/10.1038/s41587-019-0201-4
Knopman DS, Parisi JE, Boeve BF, Cha RH, Apaydin H, Salviati A, Edland SD, Rocca WA (2003) Vascular dementia in a population-based autopsy study. Arch Neurol 60:569–575. https://doi.org/10.1001/archneur.60.4.569
Kognole AA, Payne CM (2017) Inhibition of mammalian glycoprotein YKL-40: identification of the physiological ligand. J Biol Chem 292:2624–2636. https://doi.org/10.1074/jbc.M116.764985
Kong F, Lv Z, Wang L, Zhang K, Cai Y, Ding Q, Sun Z, Zhen H et al (2021) RNA-sequencing of peripheral blood circular RNAs in Parkinson disease. Medicine (baltimore) 100:e25888. https://doi.org/10.1097/md.0000000000025888
Kouznetsova VL, Tchekanov A, Li X, Yan X, Tsigelny IF (2019) Polycomb repressive 2 complex-molecular mechanisms of function. Protein Sci 28:1387–1399. https://doi.org/10.1002/pro.3647
Kozomara A, Griffiths-Jones S (2014) miRBase: annotating high confidence microRNAs using deep sequencing data. Nucleic Acids Res 42:D68-73. https://doi.org/10.1093/nar/gkt1181
Kumar S, Zomorrodi R, Ghazala Z, Goodman MS, Blumberger DM, Cheam A, Fischer C, Daskalakis ZJ et al (2017) Extent of dorsolateral prefrontal cortex plasticity and its association with working memory in patients with Alzheimer disease. JAMA Psychiat 74:1266–1274. https://doi.org/10.1001/jamapsychiatry.2017.3292
Li H, Durbin R (2009) Fast and accurate short read alignment with Burrows-Wheeler transform. J Bioinform 25:1754–1760. https://doi.org/10.1093/bioinformatics/btp324
Li MD, Burns TC, Morgan AA, Khatri P (2014) Integrated multi-cohort transcriptional meta-analysis of neurodegenerative diseases. Acta Neuropathol Commun 2:93. https://doi.org/10.1186/s40478-014-0093-y
Li Y, Fan H, Sun J, Ni M, Zhang L, Chen C, Hong X, Fang F et al (2020) Circular RNA expression profile of Alzheimer’s disease and its clinical significance as biomarkers for the disease risk and progression. Int J Biochem Cell Biol 123:105747. https://doi.org/10.1016/j.biocel.2020.105747
Li Y, Han X, Fan H, Sun J, Ni M, Zhang L, Fang F, Zhang W et al (2022) Circular RNA AXL increases neuron injury and inflammation through targeting microRNA-328 mediated BACE1 in Alzheimer’s disease. Neurosci Lett 776:136531. https://doi.org/10.1016/j.neulet.2022.136531
Liang D, Tatomer DC, Luo Z, Wu H, Yang L, Chen L-L, Cherry S, Wilusz JE (2017) The output of protein-coding genes shifts to circular RNAs when the pre-mRNA processing machinery is limiting. Mol Cell 68:940-954.e943. https://doi.org/10.1016/j.molcel.2017.10.034
Lim L, Wei Y, Lu Y, Song J (2016) ALS-causing mutations significantly perturb the self-assembly and interaction with nucleic acid of the intrinsically disordered prion-like domain of TDP-43. PLoS Biol 14:e1002338. https://doi.org/10.1371/journal.pbio.1002338
Lu Y, Tan L, Wang X (2019) Circular HDAC9/microRNA-138/sirtuin-1 pathway mediates synaptic and amyloid precursor protein processing deficits in Alzheimer’s disease. Neurosci Bull 35:877–888. https://doi.org/10.1007/s12264-019-00361-0
Lukiw WJ, Zhao Y, Pogue AI, Bhattacharjee S, Dua P (2015) P3–012: circular RNA (circRNA-7; ciRS-7) impacts microrna-7 trafficking and downregulates the ubiquitin-conjugating enzyme E2A (UBE2A) in sporadic Alzheimer’s disease (AD) brain. J Alzheimer’s Dis 11:624–624. https://doi.org/10.1016/j.jalz.2015.06.878
Lukiw W, Zhao Y, Rogaev E, Bhattacharjee S (2016) A Circular RNA (circRNA) ciRS-7 in Alzheimer’s disease (AD) targets miRNA-7 trafficking and promotes deficits in the expression of the ubiquitin conjugase (UBE2A) and the epidermal growth factor receptor (EGFR). FASEB J 30(587):581. https://doi.org/10.1096/fasebj.30.1_supplement.587.1
Luo Q, Li J, Miao H, Su S, Chen Y, Xu C, Zhao C, Huang J et al (2023) circSSPO boosts growth of esophageal squamous cell carcinoma through upregulation of micrRNA-6820–5p-mediated KLK8 and PKD1 expression. Cell Biol Toxicol 39:3219–3234. https://doi.org/10.1007/s10565-023-09828-3
Ma N, Pan J, Ye X, Yu B, Zhang W, Wan J (2019) Whole-transcriptome analysis of APP/PS1 mouse brain and identification of circRNA-miRNA-mRNA networks to investigate AD pathogenesis. Mol Ther Nucleic Acids 18:1049–1062. https://doi.org/10.1016/j.omtn.2019.10.030
Ma N, Tie C, Yu B, Zhang W, Wan J (2020) Circular RNAs regulate its parental genes transcription in the AD mouse model using two methods of library construction. FASEB J 34:10342–10356. https://doi.org/10.1096/fj.201903157R
Mantellatto GM, Pelegrini LNC, Whelan R, Cominetti MR (2024) Present and future of blood-based biomarkers of Alzheimer’s disease: beyond the classics. Brain Res J 1830:148812. https://doi.org/10.1016/j.brainres.2024.148812
Matsuzaki K (2020) Aβ–ganglioside interactions in the pathogenesis of Alzheimer’s disease. Biochim Biophys Acta (BBA) 1862:183233. https://doi.org/10.1016/j.bbamem.2020.183233
Memczak S, Jens M, Elefsinioti A, Torti F, Krueger J, Rybak A, Maier L, Mackowiak SD et al (2013) Circular RNAs are a large class of animal RNAs with regulatory potency. Nature 495:333–338. https://doi.org/10.1038/nature11928
Meng S, Zhou H, Feng Z, Xu Z, Tang Y, Li P, Wu M (2017) CircRNA: functions and properties of a novel potential biomarker for cancer. Mol Cancer 16:94. https://doi.org/10.1186/s12943-017-0663-2
Moreno-Rodriguez M, Perez SE, Nadeem M, Malek-Ahmadi M, Mufson EJ (2020) Frontal cortex chitinase and pentraxin neuroinflammatory alterations during the progression of Alzheimer’s disease. J Neuroinflammation 17:58. https://doi.org/10.1186/s12974-020-1723-x
Nag N, Tripathi T (2023) Tau-FG-nucleoporin98 interaction and impaired nucleocytoplasmic transport in Alzheimer’s disease. Brief Funct Genomics 22:161–167. https://doi.org/10.1093/bfgp/elac022
Nguyen MH, Nguyen H-N, Vu TN (2022) Evaluation of methods to detect circular RNAs from single-end RNA-sequencing data. BMC Genomics 23:106. https://doi.org/10.1186/s12864-022-08329-7
Nobili A, Latagliata EC, Viscomi MT, Cavallucci V, Cutuli D, Giacovazzo G, Krashia P, Rizzo FR et al (2017) Dopamine neuronal loss contributes to memory and reward dysfunction in a model of Alzheimer’s disease. Nat Commun 8:14727. https://doi.org/10.1038/ncomms14727
O’Connor A, Abel E, Benedet AL, Poole T, Ashton N, Weston PSJ, Heslegrave AJ, Ryan N et al (2023) Plasma GFAP in presymptomatic and symptomatic familial Alzheimer’s disease: a longitudinal cohort study. J Neurol Neurosurg Psychiatry 94:90–92. https://doi.org/10.1136/jnnp-2022-329663
Pamudurti NR, Bartok O, Jens M, Ashwal-Fluss R, Stottmeister C, Ruhe L, Hanan M, Wyler E et al (2017) Translation of CircRNAs. Mol Cell 66:9-21.e27. https://doi.org/10.1016/j.molcel.2017.02.021
Pereira JB, Janelidze S, Smith R, Mattsson-Carlgren N, Palmqvist S, Teunissen CE, Zetterberg H, Stomrud E et al (2021) Plasma GFAP is an early marker of amyloid-β but not tau pathology in Alzheimer’s disease. Brain 144:3505–3516. https://doi.org/10.1093/brain/awab223
Pertea M, Pertea GM, Antonescu CM, Chang TC, Mendell JT, Salzberg SL (2015) StringTie enables improved reconstruction of a transcriptome from RNA-seq reads. Nat Biotechnol 33:290–295. https://doi.org/10.1038/nbt.3122
Pesämaa I, Müller SA, Robinson S, Darcher A, Paquet D, Zetterberg H, Lichtenthaler SF, Haass C (2023) A microglial activity state biomarker panel differentiates FTD-granulin and Alzheimer’s disease patients from controls. Mol Neurodegener 18:70. https://doi.org/10.1186/s13024-023-00657-w
Phipson B, Lee S, Majewski IJ, Alexander WS, Smyth GK (2016) Robust hyperparameter estimation protects against hypervariable genes and improves power to detect differential expression. Ann App Stat 10(946–963):918. https://doi.org/10.1214/16-AOAS920
Rahimi K, Venø MT, Dupont DM, Kjems J (2021) Nanopore sequencing of brain-derived full-length circRNAs reveals circRNA-specific exon usage, intron retention and microexons. Nat Commun 12:4825. https://doi.org/10.1038/s41467-021-24975-z
Robinson MD, McCarthy DJ, Smyth GK (2010) edgeR: a bioconductor package for differential expression analysis of digital gene expression data. J Bioinform 26:139–140. https://doi.org/10.1093/bioinformatics/btp616
Rybak-Wolf A, Stottmeister C, Glažar P, Jens M, Pino N, Giusti S, Hanan M, Behm M et al (2015) Circular RNAs in the mammalian brain are highly abundant, conserved, and dynamically expressed. Mol Cell 58:870–885. https://doi.org/10.1016/j.molcel.2015.03.027
Salmena L, Poliseno L, Tay Y, Kats L, Pandolfi Pier P (2011) A ceRNA hypothesis: the Rosetta stone of a hidden RNA language? Cell 146:353–358. https://doi.org/10.1016/j.cell.2011.07.014
Scheckel C, Drapeau E, Frias MA, Park CY, Fak J, Zucker-Scharff I, Kou Y, Haroutunian V et al (2016) Regulatory consequences of neuronal ELAV-like protein binding to coding and non-coding RNAs in human brain. Elife 5:e10421. https://doi.org/10.7554/eLife.10421
Schneider M, Will CL, Anokhina M, Tazi J, Urlaub H, Lührmann R (2010) Exon definition complexes contain the Tri-snRNP and can be directly converted into B-like precatalytic splicing complexes. Mol Cell 38:223–235. https://doi.org/10.1016/j.molcel.2010.02.027
Sherman BT, Hao M, Qiu J, Jiao X, Baseler MW, Lane HC, Imamichi T, Chang W (2022) DAVID: a web server for functional enrichment analysis and functional annotation of gene lists (2021 update). Nucleic Acids Res 50:W216-w221. https://doi.org/10.1093/nar/gkac194
Shi Z, Chen T, Yao Q, Zheng L, Zhang Z, Wang J, Hu Z, Cui H et al (2017) The circular RNA ciRS-7 promotes APP and BACE1 degradation in an NF-κB-dependent manner. FEBS J 284:1096–1109. https://doi.org/10.1111/febs.14045
Shumate A, Wong B, Pertea G, Pertea M (2022) Improved transcriptome assembly using a hybrid of long and short reads with StringTie. PLoS Comput Biol 18:e1009730. https://doi.org/10.1371/journal.pcbi.1009730
Smith AD, Refsum H (2016) Homocysteine, B vitamins, and cognitive impairment. Annu Rev Nutr 36:211–239. https://doi.org/10.1146/annurev-nutr-071715-050947
Song C, Zhang Y, Huang W, Shi J, Huang Q, Jiang M, Qiu Y, Wang T et al (2022) Circular RNA Cwc27 contributes to Alzheimer’s disease pathogenesis by repressing Pur-α activity. Cell Death Differ 29:393–406. https://doi.org/10.1038/s41418-021-00865-1
Starke S, Jost I, Rossbach O, Schneider T, Schreiner S, Hung L-H, Bindereif A (2015) Exon circularization requires canonical splice signals. Cell Rep 10:103–111. https://doi.org/10.1016/j.celrep.2014.12.002
Subramanian M, Hyeon SJ, Das T, Suh YS, Kim YK, Lee J-S, Song EJ, Ryu H et al (2021) UBE4B, a microRNA-9 target gene, promotes autophagy-mediated Tau degradation. Nat Commun 12:3291. https://doi.org/10.1038/s41467-021-23597-9
Szabo L, Salzman J (2016) Detecting circular RNAs: bioinformatic and experimental challenges. Nat Rev Genet 17:679–692. https://doi.org/10.1038/nrg.2016.114
Tajbakhsh A, Read M, Barreto GE, Ávila-Rodriguez M, Gheibi-Hayat SM, Sahebkar A (2021) Apoptotic neurons and amyloid-beta clearance by phagocytosis in Alzheimer’s disease: pathological mechanisms and therapeutic outlooks. Eur J Pharmacol 895:173873. https://doi.org/10.1016/j.ejphar.2021.173873
Takenaka K, Olzomer EM, Hoehn KL, Curry-Hyde A, Jun Chen B, Farrell R, Byrne FL, Janitz M (2023) Investigation of circular RNA transcriptome in obesity-related endometrial cancer. Gene 855:147125. https://doi.org/10.1016/j.gene.2022.147125
Tang D, Chen M, Huang X, Zhang G, Zeng L, Zhang G, Wu S, Wang Y (2023) SRplot: a free online platform for data visualization and graphing. PLoS ONE 18:e0294236. https://doi.org/10.1371/journal.pone.0294236
Tom SE, Hubbard RA, Crane PK, Haneuse SJ, Bowen J, McCormick WC, McCurry S, Larson EB (2015) Characterization of dementia and Alzheimer’s disease in an older population: updated incidence and life expectancy with and without dementia. Am J Public Health 105:408–413. https://doi.org/10.2105/ajph.2014.301935
Tomczak A, Mortensen JM, Winnenburg R, Liu C, Alessi DT, Swamy V, Vallania F, Lofgren S et al (2018) Interpretation of biological experiments changes with evolution of the Gene Ontology and its annotations. Sci Rep 8:5115. https://doi.org/10.1038/s41598-018-23395-2
Toole BP (2009) Hyaluronan-CD44 interactions in cancer: paradoxes and possibilities. Clin Cancer Res 15:7462–7468. https://doi.org/10.1158/1078-0432.Ccr-09-0479
Vyas Y, Montgomery JM (2016) The role of postsynaptic density proteins in neural degeneration and regeneration. Neural Regen Res 11:906–907. https://doi.org/10.4103/1673-5374.184481
Wang X, Fei F, Qu J, Li C, Li Y, Zhang S (2018) The role of septin 7 in physiology and pathological disease: a systematic review of current status. J Cell Mol Med 22:3298–3307. https://doi.org/10.1111/jcmm.13623
Wang H, Li Z, Gao J, Liao Q (2019) Circular RNA circPTK2 regulates oxygen-glucose deprivation-activated microglia-induced hippocampal neuronal apoptosis via miR-29b-SOCS-1-JAK2/STAT3-IL-1β signaling. Int J Biol Macromol 129:488–496. https://doi.org/10.1016/j.ijbiomac.2019.02.041
Wang X, Li H, Sheng Y, He B, Liu Z, Li W, Yu S, Wang J et al (2024) The function of sphingolipids in different pathogenesis of Alzheimer’s disease: a comprehensive review. Biomed Pharmacother 171:116071. https://doi.org/10.1016/j.biopha.2023.116071
Wickham H VD, Girlich M (2023) tidyr: Tidy Messy, USA. R package version 2.0.0. https://github.com/tidyverse/tidyr, https://tidyr.tidyverse.org
Wickham H FR, Henry L, Müller K, Vaughan D (2023) dplyr: a grammar of data manipulation, USA. R package version 1.1.2. https://github.com/tidyverse/dplyr, https://dplyr.tidyverse.org
Wilusz JE, Sharp PA (2013) A circuitous route to noncoding RNA. Science 340:440–441. https://doi.org/10.1126/science.1238522
Wu T, Hu E, Xu S, Chen M, Guo P, Dai Z, Feng T, Zhou L et al (2021) clusterProfiler 4.0: A universal enrichment tool for interpreting omics data. Innovation (Camb) 2:100141. https://doi.org/10.1016/j.xinn.2021.100141
Xu J, Begley P, Church SJ, Patassini S, Hollywood KA, Jüllig M, Curtis MA, Waldvogel HJ et al (2016) Graded perturbations of metabolism in multiple regions of human brain in Alzheimer’s disease: snapshot of a pervasive metabolic disorder. Biochim Biophys Acta 1862:1084–1092. https://doi.org/10.1016/j.bbadis.2016.03.001
Yang C, Cai CZ, Song JX, Tan JQ, Durairajan SSK, Iyaswamy A, Wu MY, Chen LL et al (2017) NRBF2 is involved in the autophagic degradation process of APP-CTFs in Alzheimer disease models. Autophagy 13:2028–2040. https://doi.org/10.1080/15548627.2017.1379633
Yao J, Chen SRW (2024) RyR2-dependent modulation of neuronal hyperactivity: a potential therapeutic target for treating Alzheimer’s disease. J Physiol 602:1509–1518. https://doi.org/10.1113/JP283824
Yu G, Wang LG, Han Y, QY. H, (2012) clusterProfiler: an R package for comparing biological themes among gene clusters. OMICS 16:284–287. https://doi.org/10.1089/omi.2011.0118
Yuan C, Lu J, Chen Z, Zhou Q (2022) Circ-GTF2I/miR-590-5p axis aggravates myocardial ischemia-reperfusion injury by regulating kelch repeat and BTB domain-containing protein 7. Evid Based Complement Alternat Med 2022:2327669. https://doi.org/10.1155/2022/2327669
Zhang XO, Dong R, Zhang Y, Zhang JL, Luo Z, Zhang J, Chen LL, Yang L (2016) Diverse alternative back-splicing and alternative splicing landscape of circular RNAs. Genome Res 26:1277–1287. https://doi.org/10.1101/gr.202895.115
Zhang Q, Chen B, Yang P, Wu J, Pang X, Pang C (2022) Bioinformatics-based study reveals that AP2M1 is regulated by the circRNA-miRNA-mRNA interaction network and affects Alzheimer’s disease. Front Genet 13:1049786. https://doi.org/10.3389/fgene.2022.1049786
Zhao Y, Xin Y, Meng S, He Z, Hu W (2019) Neurofilament light chain protein in neurodegenerative dementia: a systematic review and network meta-analysis. Neurosci Biobehav Rev 102:123–138. https://doi.org/10.1016/j.neubiorev.2019.04.014
Zhao T, Su Z, Li Y, Zhang X, You Q (2020) Chitinase-3 like-protein-1 function and its role in diseases. Signal Transduct Target Ther 5:201. https://doi.org/10.1038/s41392-020-00303-7
Zhou Z-b, Niu Y-l, Huang G-x, Lu J-j, Chen A, Zhu L (2018) Silencing of circRNA.2837 plays a protective role in sciatic nerve injury by sponging the miR-34 family via regulating neuronal autophagy. Mol Ther Nucleic Acids 12:718–729. https://doi.org/10.1016/j.omtn.2018.07.011
Zimmerman AJ, Hafez AK, Amoah SK, Rodriguez BA, Dell’Orco M, Lozano E, Hartley BJ, Alural B et al (2020) A psychiatric disease-related circular RNA controls synaptic gene expression and cognition. Mol Psychiatry 25:2712–2727. https://doi.org/10.1038/s41380-020-0653-4
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. Y.G., Y.C. and S-.M.X. were supported by Australian Government Research Training Program Scholarship.
Author information
Authors and Affiliations
Contributions
Y.G.: formal analysis, writing—original draft. S-.M.X., Y.C., K.T. and G.L.: methodology, writing—review and editing. M.J.: conceptualization, writing—review and editing, supervision.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Cite this article
Gao, Y., Xu, SM., Cheng, Y. et al. Investigation of the Circular Transcriptome in Alzheimer’s Disease Brain. J Mol Neurosci 74, 64 (2024). https://doi.org/10.1007/s12031-024-02236-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12031-024-02236-0