
Abstract
A dynamic model called SqEAIIR for the COVID-19 epidemic is investigated with the effects of vaccination, quarantine and precaution promotion when the traveling and immigrating individuals are considered as unknown disturbances. By utilizing only daily sampling data of isolated symptomatic individuals collected by Mexican government agents, an equivalent model is established by an adaptive fuzzy-rules network with the proposed learning law to guarantee the convergence of the model’s error. Thereafter, the optimal controller is developed to determine the adequate intervention policy. The main theorem is conducted to demonstrate the setting of all designed parameters regarding the closed-loop performance. The numerical systems validate the efficiency of the proposed scheme to control the epidemic and prevent the overflow of requiring healthcare facilities. Moreover, the sufficient performance of the proposed scheme is achieved with the effect of traveling and immigrating individuals.
Similar content being viewed by others


1 Introduction
At the end of 2019, a new disease caused by the virus severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) or COVID-19 has been discovered in Wuhan, China. Thereafter, an outbreak of COVID-19 continued to spread around the world and affected economic, education, food security and health issues (Worldometers 2022). Several preventive measures such as social distancing, locking down, vaccination and so on have been recommended and utilized to counteract the epidemic (Giordano et al. 2020). Therefore, the negative effects have been notified such that businesses shunting down, unemploying, the ineffectiveness of online education and limited vaccination and healthcare facilities (Wei et al. 2020; Ourworldindata 2022). To minimize those effects, the development of a sufficient intervention policy with model dynamics for forecasting the epidemic is imperative (Deka et al. 2020; Aghdaoui et al. 2021).

Infected cases of Mexico’s COVID-19 epidemic: Data from CONACyT (Government of Mexico 2021a) (Color figure online)
Moreover, the epidemic of COVID-19 has already spread to Mexico in four waves from January 2020 until 23 February 2022. Figure 1 shows the record of daily infected cases recorded by COVID-19 DataLab CONACyT, Mexico (Government of Mexico 2021a). Causing by the omicron variant, the fourth wave has been detected since November 2021 and the peak has been observed as 70,000 cases approximately. Obviously, this peak is very higher than the previous three waves. As a result, the healthcare facilities have been over demanded (Government of Mexico 2021b, c). Thus, an effective intervention policy is rigidly required to control the epidemic according to the limited resources.
By the formulations of nonlinear ODEs (ordinary differential equations), the dynamics of epidemics have been utilized by mathematic models for sufficient information to design the adequate intervention strategies (Leonardo and Xavier 2021; Giordano et al. 2021; Sun and Wang 2020; Liu 2021). The set of equations has been established by the developed SEIR model (Engbert et al. 2021; Jia and Chen 2021) when the individuals have been classified by the following states: Susceptible (S), Exposed (E), Infectious (I) and Recovered (R). By detailing classification, the mathematical model called SIDARTHE (Giordano et al. 2020) has been developed under the distinction between non-diagnosed and diagnosed individuals. Thereafter, the investigations to design the sufficient policy have been conducted such as the next–generation matrix optimization (Perkins and Guido 2020; Xie et al. 2020), the fuzzy fractional derivatives optimal control (Dong et al. 2020), threshold dynamics vaccination (Al-Darabsah 2020), optimal sliding mode control (Amiri-Mehra et al. 2019) and so on. Even so, the performance of those schemes is strictly related to the model’s accuracy and the intensive measurement of state variables.
As a matter of fact, all state variables can not be easy to be obtained or monitored at all times under the concept of continuous-time ODEs (Auger and Moussaoui 2021). Thus, from the practical point of view, only some states are available at a daily interval (Zhan et al. 2021; Sooknanan and Mays 2021). Furthermore, immigration and traveling can be considered as a factor that causes the spread of COVID-19 according to the advanced air-traveling business (Government of Mexico 2021d; Abbasi et al. 2020). Thus, the impulsive disturbances caused by traveling people can lead the epidemic dynamics to be a class of impulsive control systems (ICS) when the disturbances are considered occurring on the impulsive axis (Villa-Tamayo and Rivadeneira 2020; Bachar et al. 2016; Ren et al. 2020).
For a class of discrete-time systems, ICS schemes have been proposed by some works such that (Gao et al. 2011; Liguang and Shuzhi 2016). It is worth mentioning that those controllers for ICS have focused on linear systems with well-defined models (He and Xu 2015; Nieto et al. 2011). By considering optimal-control approaches with ICS, only limited schemes have been recently proposed such as a linear-quadratic (LQ) controller (Cacace et al. 2020), an adaptive dynamic programming (ADP) (Wei et al. 2020) and Pontryagin’s maximum principle (Abbasi et al. 2020). The performance of those schemes is promptly related to the model’s accuracy and data-fitting to select the model’s parameters. Furthermore, for the model-free approach, the neural optimal controller (Hernandez-Mejia et al. 2018) and the optimal control based on passivity (Hernandez-Mejia et al. 2020) have been developed but the full state observer has been strongly required.
The focus of this work is to derive the intervention policy including vaccination, quarantine and precaution promotion with the optimal control aspect by utilizing only the daily data of isolated symptomatic infectious. Firstly, the conventional SEIR is redesigned as the SqEAIIR epidemic model which includes quarantined individuals and subgroups of infected individuals. By considering SqEAIIR as a class of discrete-time controlled plants, the control effort \(u \in {\mathbb {R}}_{\ge 0}^3\) denotes the intervention policy and the output is the number of daily isolated infected individuals. Therefore, the parameters of SqEAIIR are determined by data-fitting with the fourth wave of the Mexico COVID-19 epidemic. Secondly, the affine equivalent model is established by an adaptive fuzzy-rules emulated network (FREN) (Treesatayapun and Uatrongjit 2005; Treesatayapun 2020) to represent the discrete-time manner of the epidemic by using only the daily data (Government of Mexico 2021a). The learning law is developed to improve the equivalent model’s performance with the convergence analysis. The proposed optimal controller is derived by the affine equivalent model which is linear with respect to the observed individual. Finally, the intervention policy is determined when the impulsive immigrating and traveling issues are considered as the unknown disturbances. Moreover, the limitations of resources such that vaccines, promotion budget and healthcare facilities are deliberated.
The structure of this paper is organized as follows. The problem formulation and SqEAIIR epidemic model are given in Sect. 2 with a general class of non-affine discrete-time systems. In Sect. 3, an adaptive network FREN is utilized to establish the affine equivalent model by using only the daily data of isolated symptomatic individuals. The optimal intervention policy is formulated in Sect. 4 with the closed-loop analysis. In Sect. 5, numerical systems are provided to validate the proposed scheme altogether with the impulsive immigrating and traveling. In Sect. 6, the work is concluded and summarized.

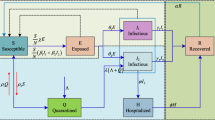
SqEAIIR flow diagram and controlled plant concept (Color figure online)
2 Problem Formulation
2.1 Mathematical Model of SqEAIIR Epidemic
In this section, a formulation of the extended SEIAR model called SqEAIIR is derived by integrating state variables of quarantined people and vaccinated individuals. The total population is categorized into seven groups as follows: susceptible S(t), exposed E(t), symptomatic infectious \(I_\mathrm{s}(t)\), asymptomatic infectious A(t), symptomatic infectious who isolated in hospitals and health-care facilities \(I_\mathrm{i}\), recovered R(t) and quarantined Q(t) individuals.
The flow diagram between individual groups of SqEAIIR is depicted in Fig. 2. Therefore, the dynamic model is mathematically governed as the following:
and the infection force is defined as
All SqEAIIR’s parameters are described by Table 1 and \(\varLambda _\mathrm{o}\) denotes the recruitment rate.
The parameters \(u_\mathrm{v}(t)\), \(u_\mathrm{q}(t)\) and \(u_\mathrm{m}(t)\) are non-negative control efforts \(\in [0,1]\) or the interventional policy including vaccination, quarantine and precaution promotion such as social distancing and the use of face masks, respectively. It’s worth remarking that the main objective of SqEAIIR in (1) is used to validate the proposed interventional policy within the per-unit such that the works in Xie et al. (2020), Dong et al. (2020), Amiri-Mehra et al. (2019). Therefore, the controlled plant is considered as the unknown dynamics described by the block diagram in Fig. 2. Unlike the previous works such as Dong et al. (2020), Abbasi et al. (2020), Perkins and Guido (2020), in this work, the policy is determined by a model-free adaptive control without any requirement of the dynamics in (1).
2.2 Discrete-Time Equivalent Model and Immigrating Disturbance
The aim of this work is to determine the optimal intervention policy including vaccination: \(u_\mathrm{v}\), quarantine: \(u_\mathrm{q}\) and precaution promotion: \(u_\mathrm{m}\). In this work, the dynamics of SqEAIIR are considered as a class of non-affine discrete-time systems depicted in Fig. 3 when the control inputs are \(u_\mathrm{v}(k)\), \(u_\mathrm{q}(k)\) and \(u_\mathrm{m}(k)\) and the observed output is \(I_\mathrm{i}(k+1)\). k denotes the sampling time index with the interval 1-day. It’s worth emphasizing that from the practical point of view, \(I_\mathrm{i}(k)\) can be daily obtained from the official databases such as CONACYT (Government of Mexico 2021a) and the immigrant population can be considered as the disturbance \(d(k=\kappa _j)\) when \(\kappa _j\) indicates the date of immigration occurring.

SqEAIIR as a class of unknown discrete-time systems and immigrating disturbance (Color figure online)
To simplify, the equivalent model for the discrete-time system in Fig. 3 can be established as
where \(F_\mathrm{d}(-)\) is the unknown nonlinear function and
By generalizing the problem formulation mentioned above, the discrete-time system in (3) is reformulated as
\(\varSigma _1\): \(k\ne \kappa _j\)
where \(U(k)=[u_\mathrm{v}(k) \, u_\mathrm{q}(k)\, u_\mathrm{m}(k)]^\mathrm{T}\) and
\(\varSigma _2\): \(k =\kappa _j\)
In this work, the disturbance \(d(\kappa _j)\) is considered as the unknown signal but its effect can be monitored through \(I_\mathrm{i}(k+1)\) at \({\varSigma _2}\) which can be obtained by the database. By this motivation, the data-driven equivalent model will be established by using only the daily data of \(I_\mathrm{i}(k)\). Thereafter, the approximated optimal controller will be designed by using the data-driven equivalent model.
3 Adaptive Data-Driven Affine Equivalent Model
3.1 Equivalent Model and Learning Laws
By utilizing the compact form dynamic-linearization (Hou et al. 2017; Treesatayapun 2017), it exists functions \(f_\mathrm{o}(I_\mathrm{i}(k)) \in {\mathbb {R}}_{\ge 0}\) and \(g_\mathrm{o}(I_\mathrm{i}(k)) \in {\mathbb {R}}_{\ge 0}^3\) for the affine dynamics which are equivalent with the system in (6) such that
According to the universal function approximation of FREN (Treesatayapun and Uatrongjit 2005; Treesatayapun 2020), it exists the affine model based on the analytic functions \(f_\mathrm{m}(I_\mathrm{i}(k)) \in {\mathbb {R}}_{\ge 0}\) and \(g_\mathrm{m}(I_\mathrm{i}(k)) \in {\mathbb {R}}_{\ge 0}^3\) such that
where \(\hat{I}_\mathrm{i}(k+1)\) denotes the estimated \(I_\mathrm{i}(k+1)\). Without loss of generality, \(g_\mathrm{m}(k)\) can be expressed as
Thus, the equivalent model in (8) is rearranged as
Therefore, functions \(f_\mathrm{m}(k)\) and \(g_{\mathrm{m}i}(k)\) for \(i=1, 2, 3\) are utilized by FRENs as the following:
and
respectively, where \(\phi (k) \in {\mathbb {R}}^{N_\mathrm{f}}\) is the basis vector of x(k) membership functions and \(\beta _\mathrm{f}(k) \in {\mathbb {R}}^{N_\mathrm{f}}\) and \(\beta _{\mathrm{g}i}(k) \in {\mathbb {R}}^{N_\mathrm{f}}\) are adjustable weights. \(N_\mathrm{f}\) is the number of membership functions of FREN when the network architecture is illustrated in Fig. 4.

Data-driven affine equivalent model (Color figure online)
To improve the model performance by tuning all adjustable weights, the learning laws are established with the estimation error \(\hat{e}(k+1)\) given as
In order to establish the learning laws, the cost function \(\hat{E}(k+1)\) over the k-iteration is defined as
Firstly, by applying the gradient search, the learning law of \(\beta _\mathrm{f}(k)\) is obtained as
where \(\eta _\mathrm{f}\) denotes as the learning rate. Therefore, let’s apply the chain rule along (8) to (14), it leads to
Thus, the learning law in (15) becomes
Secondly, let’s repeat the same procedure as (15) to (17) with \(\beta _{\mathrm{g}i}(-)\) for \(i=1,2,3\), we obtain
where \(\eta _{\mathrm{g}i}\) is the ith learning rate. Thereafter, by applying the chain rule, we have
Thus, the learning law in (18) is rewritten as
It’s worth denoting that the learning rates \(\eta _\mathrm{f}\) and \(\eta _{\mathrm{g}i}\) can play an important role in the model performance. Therefore, the selection of the proper learning rates will be discussed next.
3.2 Performance Analysis
The performance of the learning laws can be guaranteed by setting \(\eta _\mathrm{f}\) and \(\eta _{\mathrm{g}i}\) according to the following theorem.
Theorem 1
For the equivalent model proposed by (8) with the learning laws (17) and (20), the estimation error (13) is a convergent sequence when the learning rates \(\eta _\mathrm{f}\) and \(\eta _{\mathrm{g}i}\) are designed by the following conditions:
and
where \(0<\gamma _\mathrm{f}<2\), \(0<\gamma _\mathrm{g}<2\), \(U_{\mathrm{i}M}=\max {|U_\mathrm{i}(k)|}, \forall k=1,2, \ldots \) and
Proof
Let’s define the Lyapunov function \(L_\mathrm{m}(k)\) as
Therefore, the change of \(L_\mathrm{m}(k)\) is derived as
For the proof thereafter, the analysis is conducted by two parts for \(\eta _\mathrm{f}\) and \(\eta _{\mathrm{g}i}\) as the following:
Part I (\(\eta _\mathrm{f}\)): According to the weight parameter \(\beta _\mathrm{f}(k)\), \(\Delta \hat{e}(k)\) is estimated as \(\Delta \hat{e}_\mathrm{f}(k)\) such that
By recalling (8), (11) and (17) with one step backward, we obtain
Substitute (27) into (25), it yields
For the convergence of the sequence \(\hat{e}(k)\) or \(\Delta L_\mathrm{m}(k)\le 0\), it requires that
or
It’s clear that the condition in (30) is fulfilled as
Thus, the proof of (21) is completed.
Part II (\(\eta _{\mathrm{g}i}\)): For the weight parameters \(\beta _{\mathrm{g}i}(k)\), the change of Lyapunov function \(\Delta \hat{e}(k)\) is approximated as \(\Delta \hat{e}_{\mathrm{g}i}(k)\) as
Let’s recall (8), (12) and (20) with one step backward, we have
Substitute (33) into (32), we obtain
With negative semi-define \(\Delta L_\mathrm{m}(k)\), it leads to
Considering (22) with (35), it’s clear that
for \(i=1,2,3\). Thus, the proof is completed here. \(\square \)
4 Model-Free Optimal Preventative Policy
To prevent the inundation of \(I_\mathrm{i}\) individuals according to the limited resources of hospitals or medical institutions, the optimal interventional policy including vaccination, quarantine and precaution promotion is derived by the optimal control scheme. It’s worth emphasizing that the daily data of \(I_\mathrm{i}(k)\) is only required and utilized in this approach.
The long term cost function V(k) is firstly defined as
where \(0<\gamma \le 1\) is a discount parameter, q is a positive constant and \(H\in {\mathbb {R}}^{3\times 3}\) is a positive diagonal matrix such that \(H_i>0\) for \(i=1,2,3\).
By rearranging the cost function (37), it yields
Considering the cost function in (38) in the quadratic form, the following Lemma is conducted.
Lemma 1
If the general formulation of the control law U(k) in (38) can be rearranged by the vector K(k) as
then the cost function V(k) in (38) can be reformulated as a quadratic form such that
where P is a positive time-varying parameter.
Proof
Let’s recall (37), thus, we have
Using (39) with (41), it yields
Substituting (39) into (7), we obtain
where
and
By utilizing the dynamics in (43), it leads to
where \(a_{\prod _\mathrm{o}}(k+i-1)=a_\mathrm{o}(k+i-1)a_\mathrm{o}(k+i-2)\cdots a_\mathrm{o}(k)\). Substituting (43) into (42), we have
where \(P=\sum _{i=0}^{\infty }\gamma ^{i}[qa^2_{\prod _\mathrm{o}} (k+i-1)+K^\mathrm{T}(i+k)HK(i+k)]\). Thus, the proof is completed. \(\square \)
Remark 1
It’s worth to emphasize that the parameter P is a time-varying one comparing with the other quadratic value functions and optimization schemes (Abbasi et al. 2020).
According to the result of Lemma 1, it’s clear that the relation in (38) can be rearranged with the parameter P such that
Thus, Hamiltonian equation \(H_\mathrm{m}(I_\mathrm{i},U)\) can be obtained as
By utilizing (49) and the equivalent model (7), it leads to
Considering \(\frac{\partial {H(k)}}{\partial {U_k}}=0\), the control law can be derived as
where
Therefore, the performance analysis of the closed loop system under the proposed control law (51) is conducted by the following theorem.
Theorem 2
For a class of discrete-time systems satisfied the equivalent model (7), thus, the convergence of closed-loop systems under the control law (51) is guaranteed when \(I_\mathrm{i}(k)\ge 0\) and
Proof
By recalling (48) with the control law (51) and the equivalent model (7), we have
For the case of infected individual \(I_\mathrm{i}(k)>0\), it leads to
where
By considering
it requires that
or
Therefore, we have
Next, let’s recall the closed-loop system in (43). It’s clear that I(k) is a convergence sequence when
That leads to
or
By the setting of \(\gamma \) mentioned in (37), it yields
and
By utilizing (63–65) with (60), it leads to (53). Thus, the proof is completed. \(\square \)
For the practical point of view here, \(\acute{f}_\mathrm{o}(k)\) and \(g_\mathrm{o}(k)\) are unknown. Therefore, the affine equivalent model proposed in Sect. 3 is utilized. Thus, the gain vector K(k) in (52) can be employed as
Remark 2
For the conclusion, in this work, the equivalent model (8) is firstly established by utilizing the actual data. Secondly, the interventional policy is appointed by the optimal controller in Lemma 1: (39) when the gain vector K(k) is determined by (66).
5 Numerical Results
5.1 Parameters Setting and Model Accuracy
To validate the accuracy of SqEAIIR, the raw data from the Mexican government CONACyT (Government of Mexico 2021a) is utilized for the fourth wave of epidemic according to the omicron variant from November 2021 to 23 February 2022. By using the initial values given by Table 2 and the parameters represented by Table 3, Fig. 5 illustrates the plots of raw data and model’s results including \(I_\mathrm{i}\), \(I_\mathrm{s}\) and A individuals. As a result, SqEAIIR’s dynamics (1) can predict and mimic the epidemic behavior. Furthermore, according to the data from healthcare institutes in Mexico such as IMSS (Government of Mexico 2021b) and ISSSTE (Government of Mexico 2021c), the maximum capacity of COVID-19 cases who need hospital facilities is displayed by the red dashed line in Fig. 5. The over-demand has occurred for the fourth wave of the epidemic caused by the omicron variant.

SqEAIIR fitting with raw data according to 4th wave of omicron variant (Color figure online)
5.2 Optimal Control and Intervention
By utilizing SqEAIIR and its parameters in Sect. 5.1, the proposed equivalent model (8) and the controller (39) and (66) are constructed and validated. Thereafter, the parameters of the equivalent model and the upper bound of control efforts are designed by using the following information: \(\phi _M=9\), \(U_{1M}=0.07\), \(U_{2M}=0.2\) and \(U_{3M}=0.5\) according to Auger and Moussaoui (2021), Abbasi et al. (2020), Government of Mexico (2021b, 2021c). According Theorem 1, let’s select \(\gamma _\mathrm{f}=\gamma _\mathrm{g}=1\), thus, the learning rates are determined as
and
Secondly, all controller’s parameters are given according to Theorem 2 as followings: \(\gamma =\), \(P(1)=10\), \(H_1=0.04\), \(H_2=0.07\) and \(H_3=0.1\).


Controlled \(I_\mathrm{i}(k)\) and \(\hat{I}_\mathrm{i}(k)\) (Color figure online)

Control efforts or policy intervention (Color figure online)
The control effort \(U(k)=[u_\mathrm{m}(k) \; u_\mathrm{q}(k) \; u_\mathrm{v}(k)]^\mathrm{T}\) is determined by (39) and (66). Thus, the response is depicted by the plot in Fig. 6 as the black line when the policy is initiated at Day 1st. For a case of delay, the blue line in Fig. 6 represents the response when the policy is initiated at Day 7th. As a result, the infected patients who require healthcare facilities are still under capacity. Figure 7 illustrates the equivalent model performance with the plots of \(I_\mathrm{i}(k)\) and its estimated \(\hat{I}_\mathrm{i}(k)\). Thereafter, the policy intervention is displayed in Fig. 8.

Immigrating pattern (Color figure online)
5.3 Immigrating Disturbance
Next, the immigrating disturbance is considered for individuals. In this test, let’s define the immigrating pattern by the plots in Fig. 9 according to the data from Government of Mexico (2021a, 2021d). That leads to the immigration of four individual groups as \(d_\mathrm{S}(\kappa _j)\), \(d_\mathrm{E}(\kappa _j)\), \(d_\mathrm{A}(\kappa _j)\) and \(d_\mathrm{R}(\kappa _j)\) for disturbances of susceptible, exposed, asymptomatic infectious and recovered individuals, respectively. It’s worth to remark that the impulsive index is denoted as \(\kappa _j\) for \(j=1, 2, \ldots 9\) such that \(\kappa _1=10: [@k=10]\).

Policy intervention response without and with applying controller with populations immigration (Color figure online)

Control efforts or policy intervention with populations immigration (Color figure online)
The uncontrolled response of SqEAIIR with the immigration effect is plotted by the solid-blue line in Fig. 10 when the response without immigrating is shown by the dash-dotted line in Fig. 10. Therefore, by applying the proposed policy intervention, the response is depicted by the black line in Fig. 10. Figure 11 shows the plots of the optimal intervention policy.
It’s worth emphasizing that only \(I_\mathrm{i}(k)\) is utilized for the controller and all impulsive disturbances are considered as unknown signals. Thus, the proposed controller can respond to the impulsive disturbances or immigration of individual groups
6 Conclusions
The dynamic model called SqEAIIR has been proposed to mimic the dynamics of the COVID-19 epidemic. The accuracy of SqEAIIR has been validated by the raw data collected by CONACyT, Mexico for the fourth wave caused by the omicron variant from Nov. 2022 until 23 Feb. 2022. From the practical point of view, only the daily data of patients who require the medication and hospital facilities are appropriately recorded and collected. For that reason, the discrete-time equivalent model has been established by an adaptive network FREN by utilizing only the daily data of symptomatic infectious who isolated in hospitals and healthcare facilities \(I_\mathrm{i}(k)\). Thereafter, the intervention policy including vaccination, quarantine and precaution promotion has been developed by the aspect of model-free optimal control. The proposed policy has reduced the number of infected individuals to prevent the overrun of healthcare’s capacity. Moreover, the effect of traveling on migrating has been studied by considering the immigration of each individual as an unknown disturbance. As a result, the proposed scheme has presented a sufficient policy to control the number of infected individuals.
For the note of this work, the proposed intervention policy may be used as a guideline for the authority to control the epidemic.
References
Abbasi Z, Zamani I, Amiri-Mehra AH, Shafieirad M, Ibeas A (2020) Optimal control design of impulsive SQEIAR epidemic models with application to COVID-19. Chaos Solitons Fract 139:110054
Aghdaoui H, Alaoui AL, Nisar KS, Tilioua M (2021) On analysis and optimal control of a SEIRI epidemic model with general incidence rate. Results Phys 20:103681
Al-Darabsah I (2020) Threshold dynamics of a time-delayed epidemic model for continuous imperfect-vaccine with a generalized nonmonotone incidence rate. Nonlinear Dyn 101:1281–1300
Amiri-Mehra AH, Zamani I, Abbasi Z, Ibeas A (2019) Observer-based adaptive PI sliding mode control of developed uncertain SEIAR influenza epidemic model considering dynamic population. J Theor Biol 482:109984
Auger P, Moussaoui A (2021) On the threshold of release of confinement in an epidemic SEIR model taking into account the protective effect of mask. Bull Math Biol 83:25
Bachar M, Raimann JG, Kotanko P (2016) Impulsive mathematical modeling of ascorbic acid metabolism in healthy subjects. J Theor Biol 392:35–47
Cacace F, Cusimano V, Palumbo P (2020) Optimal impulsive control with application to antiangiogenic tumor therapy. IEEE Trans Control Syst Technol 28(1):106–117
Deka A, Pantha B, Bhattacharyya S (2020) Optimal management of public perceptions during a flu outbreak: a game-theoretic perspective. Bull Math Biol 82:139
Dong NP, Long HV, Khastan A (2020) Optimal control of a fractional order model for granular SEIR epidemic with uncertainty. Commun Nonlinear Sci Numer Simul 88:105312
Engbert R, Rabe MM, Kliegl R, Reich S (2021) Sequential data assimilation of the stochastic SEIR epidemic model for regional COVID-19 dynamics. Bull Math Biol 83:1
Gao Y, Zhang X, Lu G, Zheng Y (2011) Impulsive synchronization of discrete-time chaotic systems under communication constraints. Commun Nonlinear Sci Numer Simul 16:1580–1588
Giordano G, Blanchini F, Bruno R, Colaneri P, Filippo AD, Matteo AD, Colaneri M (2020) Modelling the COVID-19 epidemic and implementation of population-wide interventions in Italy. Nat Med 26:855–860
Giordano G, Colaneri M, Filippo AD, Blanchini F, Bolzern P, Nicolao GD, Sacchi P, Colaneri P, Bruno R (2021) Modeling vaccination rollouts, SARS-CoV-2 variants and the requirement for non-pharmaceutical interventions in Italy. Nat Med 27:993–998
Giordano G, Blanchini F, Bruno R, Colaneri P, Filippo AD, Matteo AD, Colaneri M (2020) A SIDARTHE model of COVID-19 epidemic in Italy. arXiv:2003.09861v1, pp. 1-17
Government of Mexico (2021a) CONACyT (COVID-19 DataLab). https://datos.covid-19.conacyt.mx/. Accessed 24 Mar 2021
Government of Mexico (2021b) IMSS. http://www.imss.gob.mx/covid-19. Accessed 03 Mar 2021
Government of Mexico (2021c) The Mexican Institute for Social Security and services for state workers or civil service social security. https://www.gob.mx/issste. Accessed 03 Mar 2021
Government of Mexico (2021d) INM: the National Institute of Migration. https://www.inm.gob.mx. Accessed 03 Mar 2021
He D, Xu L (2015) Ultimate boundedness of non-autonomous dynamical complex networks under impulsive control. IEEE Trans Circuits Syst II(62):997–1001
Hernandez-Mejia G, Alanis AY, Hernandez-Vargas EA (2018) Neural inverse optimal control for discrete-time impulsive systems. Neurocomputing 314:101–108
Hernandez-Mejia G, Alanis AY, Hernandez-Gonzalez M, Findeisen R, Hernandez-Vargas EA (2020) Passivity-based inverse optimal impulsive control for influenza treatment in the host. IEEE Trans Control Syst Technol 28(1):94–105
Hou Z, Chi R, Gao H (2017) An overview of dynamic-linearization-based data-driven control and applications. IEEE Trans Ind Electron 64(5):4076–4090
Jia L, Chen W (2021) Uncertain SEIAR model for COVID-19 cases in China. Fuzzy Optim Decis Mak 20:243–259
Leonardo L, Xavier R (2021) A modified SEIR model to predict the COVID-19 outbreak in Spain and Italy: simulating control scenarios and multi-scale epidemics. Results Phys 21:103746
Liguang X, Shuzhi SG (2016) Set-stabilization of discrete chaotic systems via impulsive control. Appl Math Lett 53:52–62
Liu Z (2021) Uncertain growth model for the cumulative number of COVID-19 infections in China. Fuzzy Optim Decis Mak 20:229–242
Nieto JJ, Rodriguez-Lopez R, Pesqueira MV (2011) Exact solution to the periodic boundary value problem for a first-order linear fuzzy differential equation with impulses. Fuzzy Optim Decis Mak 10:323
Ourworldindata (2022) Coronavirus (COVID-19) Vaccinations. https://ourworldindata.org/covid-vaccinations. Accessed 24 Feb 2022]
Perkins TA, Guido E (2020) Optimal control of the COVID-19 pandemic with non-pharmaceutical interventions. Bull Math Biol 82:118
Ren H, Shi P, Deng F, Peng Y (2020) Fixed-time synchronization of delayed complex dynamical systems with stochastic perturbation via impulsive pinning control. J Frankl Inst 357(17):12308–12325
Sooknanan J, Mays N (2021) Harnessing social media in the modelling of pandemics challenges and opportunities. Bull Math Biol 83:57
Sun T, Wang Y (2020) Modeling COVID-19 epidemic in Heilongjiang province, China. Chaos Solitons Fract 138:109949
Treesatayapun C (2017) Discrete-time adaptive controller based on non-switch reaching condition and compact system dynamic estimator. J Franklin I 354(5):6783–6804
Treesatayapun C (2020) Prescribed performance of discrete-time controller based on the dynamic equivalent data model. Appl Math Model 78:366–382
Treesatayapun C, Uatrongjit S (2005) Adaptive controller with Fuzzy rules emulated structure and its applications. Eng Appl Artif Intell 18:603–615
Villa-Tamayo MF, Rivadeneira PS (2020) Adaptive impulsive offset-free MPC to handle parameter variations for Type 1 diabetes treatment. Ind Eng Chem Res 59:5865–5876
Wei L, Qing K, Kezan L (2020) Dynamic stability of an SIVS epidemic model with imperfect vaccination on scale-free networks and its control strategy. J Franklin Inst 357(11):7092–7121
Wei Q, Song R, Liao Z, Li B, Lewis FL (2020) Discrete-time impulsive adaptive dynamic programming. IEEE Trans Cybern 50(10):4293–4306
Worldometers (2022) Worldometers coronavirus. https://www.worldometers.info/coronavirus/. Accessed 24 Feb 2022
Xie YK, Wang Z, Lu JW, Li YX (2020) Stability analysis and control strategies for a new SIS epidemic model in heterogeneous networks. Appl Math Comput 383:125381
Zhan C, Chen J, Zhang H (2021) An investigation of testing capacity for evaluating and modeling the spread of coronavirus disease. Inf Sci 561:211–229
Acknowledgements
Author would like to thank CONACyT, ISSSTE and IMSS.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Treesatayapun, C. Model Dynamics and Optimal Control for Intervention Policy of COVID-19 Epidemic with Quarantine and Immigrating Disturbances. Bull Math Biol 84, 122 (2022). https://doi.org/10.1007/s11538-022-01080-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11538-022-01080-w