
Abstract
This article presents a new strategy for reviewing large, multidisciplinary academic literatures: a multi-method comprehensive review (MCR). We present this approach and demonstrate its use by the NGO Knowledge Collective, which aims to aggregate knowledge on NGOs in international development. We explain the process by which scholars can identify, analyze, and synthesize a population of hundreds or thousands of articles. MCRs facilitate cross-disciplinary synthesis, systematically identify gaps in a literature, and can create data for further scholarly use. The main drawback is the significant resources needed to manage the volume of text to review, although such obstacles may be mitigated through advances in “big data” methodologies over time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
In 2014, our research team concluded that the abundance of research on nongovernmental organizations (NGOs) focused on international development had reached a point of diminishing returns. Spanning methods and disciplines, positivist, critical, and theoretical conversations about the roles and effects of NGOs had fractured. Research appeared in a virtual cornucopia of journals representing nonprofit studies, international development, public health, public administration, public policy, political science, sociology, urban planning, economics, education, and anthropology, among other academic and practitioner-oriented fields. This decentralized literature made it difficult for scholars to learn from others outside their immediate field, and harder still to draw big conclusions about whether or how NGOs could be most useful in development.
The typical method for evaluating a large number of studies is the systematic review, but we found such a review insufficient for our goal. As described below, most systematic reviews address a narrow question with a close reading of a limited number of articles in an attempt to synthesize findings and isolate things like effect sizes. The NGO Knowledge Collective (NKC) aimed to be more comprehensive, answering the big question, “What have we studied and what have we learned about NGOs after 35 years of scholarship?” The present article concedes that a single study cannot fully answer that question, even with four primary investigators (PIs), three years, and dozens of research assistants (RAs). But the approach we created in trying does make a complex literature tractable and counteracts intellectual siloes. For the case of NGOs and international development, our method allowed us a bird’s-eye perspective on the state of an extremely large field. By combining big data techniques of topic modeling and keyword counts with qualitative efforts to systematically code samples of articles, we revealed the six questions that broadly structure the study of NGOs in development; systematic biases in what has or has not been studied and who has done the studying; methodological trends and deficiencies in how NGOs have been studied; and that authors tend to report positive effects of NGOs on development outcomes. Such comprehensive findings would not have been possible with a traditional systematic review. This method is not specific to nonprofit studies. As scholarship in interdisciplinary or large fields proliferates, comprehensive “state of the field” research will become increasingly necessary. Indeed, the increasing number of systematic reviews published in recent years indicates the demand for such research is already present. Scholarship on topics such as race and gender, climate change, political polarization, and migration is similarly international, interdisciplinary, and immense, suggesting other fields ripe for attention.
In addition to this review method, we also created a tool to facilitate better research going forward: a public data portal that allows users to search for bibliographic and other information about articles on NGOs using geographies, sectors, and topics.Footnote 1 The search feature makes it faster and easier to identify relevant articles than is possible with a traditional article search process. Like other recent efforts to expand access to nonprofit data more broadly,Footnote 2 we hope that this portal will make the abundance of NGO research more accessible to all scholars. Most importantly, in identifying systematic gaps in knowledge and whose research is published, we hope to improve benefits for those whom NGOs seek to help.
A New Review Method: The Multi-method Comprehensive Review (MCR)
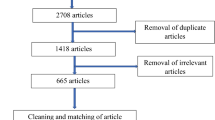
Like a traditional systematic review, the MCR strives to identify relevant literature, aggregate results, and synthesize evidence-based scholarship. Both methods accomplish this outcome using a structured, formal, and replicable process that includes multiple phases (Petticrew & Roberts, 2006). For example, Moher et al. (2009) direct systematic reviewers to progress methodically through three steps—identification, screening, and analysis—also used by the MCR (see Fig. 1). And both review methods act as funnels that intake many articles, exclude some based on preset criteria, and finally synthesize those relevant to the research question. Systematic reviews typically identify a large number of articles, but rarely analyze more than a portion of them (cf. Gazley and Guo (2020)). For example, among seven systematic reviews published by this journal, the initial identification ranged between 229 and 110,893 articles (averaging 18,547), yet authors analyzed only 33 to 133 articles (averaging 78).Footnote 3 A systematic review requires such sharp culling to maintain adherence to a precise question, such as “what are [people’s] motives for episodic volunteering?” (Dunn et al., 2016, p. 425).

Flow diagram for NKC
The MCR, by contrast, aggregates and synthesizes the received wisdom on broader topics. Broader topics, fittingly, allow broader lines of inquiry in the literature to be studied and summarized. In our previous work, we identified six overarching questions asked by NGO scholars about “the nature of NGOs; their emergence and development; how they conduct their work; their impacts; how they relate to other actors; and how they contribute to the (re)production of cultural dynamics” (Brass et al., 2018b, p. 136). These broader topics and bigger questions draw on more extensive literatures produced by inter- and multidisciplinary scholarly communities. We demonstrated how to answer one of these questions using the existing literature through an analysis of NGO impacts in the health and governance fields; others could do the same with other fields, or the other questions. Here, we describe the MCR and explain how scholars can identify, screen, and analyze a population of hundreds or even thousands of articles (see Fig. 1).
Step #1: Identification
An MCR begins by identifying potentially relevant articles by establishing the parameters of the evidence base. For example, researchers may set bounds on the type of publication (only peer-reviewed journals, or also dissertations, books and book chapters, practitioner reports, etc.), publication timeframe, or language included in the review. Researchers also decide whether to search in publication titles, abstracts, keywords, tables of contents, full text, or some subset of these.
Second, researchers identify precise search terms. As an example, the NKC project included many terms loosely synonymous with the NGO organizational form, including “non-governmental development organization,” “third sector,” “civil society organization,” and 15 other search terms. It is also crucial to consider spelling variants and pluralized terms—e.g., “organization/organization”—and acronyms—e.g., “NGO,” “NPO,” and “FBO.” In our case, such variations quickly expanded the list to 100 organization terms. We required that a publication contain at least one of these terms in its title, abstract, or keywords. And given we were primarily interested in NGO activities in the context of international development, we required that the article be about such organizations operating in one or more developing countries or have a clear focus on international development activities broadly conceived, such as aid or humanitarian action. This meant that a publication needed at least one location term (211 terms and their variants—e.g., “Haiti” or “Global South”) or development terms (30 terms and their variants—e.g., “least developed countries” or “micro-credit”) in either its title, abstract, or keywords. This led to a final Boolean phrase that was 3,068 words long but logically simple. In practice, the NKC corpus tends to include all NGOs active in non-OECD countries, but generally excludes research on NGO activities happening solely in developed countries. Of course, the MCR method itself can be replicated with different selection criteria, and we welcome efforts to conduct a similar review on NGOs in developed countries.
Third, having defined the review's scope, researchers choose the article repository, or database, to query. Researchers with strong limiting parameters or who want to leverage robust search features may be constrained in their options. For the NKC’s purposes, EBSCO Academic Search Premier had the most desirable qualities. EBSCO Academic Search Premier includes nearly 2000 peer-reviewed academic journals in its database and thus provided more extensive coverage than other specialized journal repositories. (If our search criteria were different, such as working papers or news articles, then other repositories would be more desirable.) It also provided a good interface with EndNote, as well as automatic download of some article PDFs. We used EBSCO's Export Manager to bulk-transfer records into a central EndNote repository. The initial search produced more than 11,000 records.
Step #2: Screening
The MCR and systematic review diverge in the second step. In systematic reviews, researchers apply an exclusion standard that dramatically narrows the research corpus. Usually a precise research topic, method (e.g., randomized controlled trials), or assessment of research quality defines this standard. In contrast, the MCR screening process rejects publications only if they clearly do not relate to the topic or some other broad parameter. Such screening requires multiple people to read each title, abstract, and keyword to remove “false positives.” For example, in the NKC project, the search query returned chemistry research on nano graphene oxide (NGO), but a human RA quickly identified such research as irrelevant. Likewise, the NKC only included academic articles that self-identified as a research article. Screening by RAs filtered out book notes and speeches by the heads of professional associations. For the NKC, carefully vetted Master’s and undergraduate RAs double-coded all articles. The PIs adjudicated discrepancies and articles about which the RAs were uncertain.
Step #3: Data Preparation
In a systematic review, trained experts iteratively read and/or code publications to synthesize findings. As we explain in the next section, the MCR uses two forms of computerized text analysis alongside human coding to analyze the research corpus. To prepare the selected articles for text analysis software, all articles must be text-readable. Machine-encoded text is nearly universal for recent publications. However, optical character recognition (OCR) may be required to convert older or scanned publications.
Most text analysis software cannot distinguish between an article's main text and its superfluous content such as journal names, running headers, and bibliographies. This superfluous text may introduce noise into automated text analysis and should be removed. For the NKC’s MCR, we used Python to eliminate running titles, which appeared as repeated phrases on each page. We relied on the brute force of five RAs to open and delete the bibliographies of 3336 .txt files, either at the end or in footnotes. We did not delete in-text citations because it was impractical and we determined author names and publication dates would not bias our analysis. It took our team 115.25 h (roughly two minutes per article) to delete the bibliographies. The remaining corpus was cleaner and 15% leaner (as measured by file size) than the original downloaded files.
Step #4: Multi-Method Analysis
Once files have been cleaned, the MCR combines quantitative text analysis, topic modeling, and an in-depth qualitative content analysis of a random sample of articles. By triangulating these methods, researchers comprehensively review a large research corpus and validate findings with multiple techniques. While the MCR need not include these three particular methods, we believe it is best practice to triangulate more than two methods. The three that we discuss offer valuable synergies.
Computer-assisted text analysis calculates frequencies of a predetermined dictionary of key terms. Depending on the research question, these terms may include country and region names (e.g., Haiti, sub-Saharan Africa), development sectors (e.g., microfinance, sustainability), analytic topics (e.g., service provision, civil society), method (e.g., regression, field experiment, in-depth interview), or research topic (e.g., volunteering, regulation). Computer software, such as PowerGREP in SAS or NVivo, can calculate keyword frequencies within each publication. Normalizing these frequencies by a common denominator—e.g., article length—produces a comparable value. Establishing an appropriate cut-point—e.g., frequencies one standard deviation over the corpus mean—allows researchers to make descriptive claims about each article, which can then be aggregated to the corpus level.
Frequency analyses are generally easy; they are most valuable if the predetermined dictionary of terms is exhaustive. To account for the possibility of an incomplete dictionary, the NKC MCR complements frequency counts with an inductive and unconstrained method: topic modeling. This machine learning technique uses the corpus as its sample and identifies words that disproportionately occur together within documents. Topic modeling outputs lists of words—known as “topics”—that appear in publications together at rates greater than expected by chance. The process does not name or label the topics, so researchers must generalize and interpret the list of words. But topic modeling reports the percentage of each document that is associated with each topic. This technique both identifies new terms associated with a known topic and reveals new topics within a broader literature. For example, the NKC used topic modeling to identify 450 keywords that comprise 45 research topics. We found the Structural Topic Models package in R (Roberts et al., 2019) to be especially useful for this task. We use these topics as one way to categorize the article information on the NKC portal. However, because the NKC topics are derived from the literature in our corpus on NGOs and development, topic-based searches on the portal will only identify articles that also have a clear development focus. The portal does not contain all possible articles on the topics listed, only those within our final corpus of 3336 articles.
The MCR’s final method validates and builds on the two forms of computerized text analysis. In it, researchers randomly sample 10–20% of their corpus and conduct two separate analyses. First, they use the random sample to validate the findings from both computerized analyses. Researchers should quickly verify that the key term frequencies and topics from the full corpus roughly match those of the random sample. They should not, however, be too quick to abandon prior findings if human coding refutes the quantitative results. Instead, researchers should treat discrepancies as part of an iterative process and use the human element to refine or reinterpret the quantitative analysis.
Second, researchers code each article in the random sample for relevant features. These features will vary based on research question, but the process of coding should always be rigorous and systematic. For example, in the NKC, we coded for the location of authors’ institutions and whether they worked for the organization described in the article, the type of research design, the sector studied, and reported effects of the organizations. We suggest creating a coding protocol in Qualtrics, NVivo, or similar software and assigning coders the task of completing coding using that software for each publication they review from the random sample. Some coding protocol elements may gather quantitative data—e.g., the sample size of survey or field experiments, the duration of ethnographic research—while other elements may be open-ended to facilitate qualitative analysis, such as identifying research questions and summarizing findings. Any of the elements coded can then be aggregated for later quantitative analyses.
Benefits of the MCR with Examples from the NGO Knowledge Collective
The comprehensive nature of an MCR provides benefits difficult to otherwise achieve. First, because it is such a broad and deep multidisciplinary aggregation of information, an MCR allows questions, data, and analysis from vastly different disciplines to “speak” to one another in a way that rarely happens otherwise. For example, in the NKC project’s manuscript on reported effects of NGOs on service provision outcomes, we pull data from articles written by quantitative public health scholars, legal scholars, education experts, and ethnographic anthropologists (Brass et al., 2018b). All of this scholarship touched on ways that NGOs have provided health and education services, and many reported whether or not such services were beneficial to the communities they aimed to serve, as well as how NGOs interacted with the government. But in many cases, the NKC was able to aggregate information from articles that went beyond the article’s main contribution. Specifically, in many cases, reporting on whether an NGO had beneficial, deleterious, mixed, or no effect on the community was not an author’s primary contribution. But using the MCR allowed us to include authors’ reports of NGO effects in service provision and governance in our analysis. More generally, the majority of articles include descriptions of organizations, their activities, or the communities studied, regardless of their ultimate findings. This sort of information is easily lost over time, because any one study of an organization’s activities is not generalizable. In another article, we examined trends in articles’ word and topic use over several decades to understand the origins and use of international development buzzwords (Schnable et al., 2021). And in our most comprehensive article, the MCR allowed us to identify the overarching questions that together characterize nearly all of the published articles on NGOs (Brass et al., 2018a).Footnote 4
A second benefit is that the sheer volume of material collected in an MCR allows identification of gaps in the literature in a more rigorous and complete manner than otherwise possible. Most scholars identify such gaps in a more intuitive manner, based on their own experience in a particular set of scholarship, and/or through their own scholarly searches. Such approaches can reveal insights, but are also prone to considerable errors of omission and oversight. Using the entire corpus of academic literature on NGOs, for example, allowed us to note geographic disparities and potential service sector favoritism in the literature. We found that 55 countries (nearly a third of the global total) did not have a single peer-reviewed article published in English that analyzed them in any depth. Including a full corpus also revealed the prevalence of authors associated with one of the organizations they write about (Brass et al., 2018a). We also found that surprisingly few research designs offered clear counterfactuals or criteria for case selection. At the same time, the MCR suffers from the biases in the articles that comprise it, just as the outcomes of any big data effort are strongly influenced by the input material.
Finally, an MCR like the NKC’s creates a dataset not only for one systematic review publication, but that other scholars can use for any sort of related literature review. The NKC data are publicly available and easily searchable, dramatically reducing search time to find the complete set of articles on a topic.Footnote 5 The data can be used for a theory section or literature review, or for countless systematic reviews of more narrow topics, such as the answers to the six research questions. As long as the dataset is updated periodically, the initial work of the MCR can become a go-to tool for large and small systematic reviews.
Practical Challenges of the MCR
Over the course of creating the NKC, we learned a great deal about undertaking massive data collection and multidisciplinary analysis. In particular, because our MCR was so large, even the smallest decisions had serious potential ramifications that exceeded those of a “normal” sized research project. Path dependency effects were also extensive, because the costs of backtracking were so high.
A key challenge was posed by the judgment needed in the screening and analysis steps at the scale of thousands of articles. Managing RAs to screen 11,000 articles turned out to be a significant task, requiring distributing spreadsheets with assigned articles to 10+ RAs across three institutions, ensuring that they then uploaded their coding to the cloud, and then reconciling the double-coding system. Not unsurprisingly, some RAs disappeared and some spreadsheets were lost. All PIs had to adjudicate hundreds of articles where RAs had disagreed or been unsure about a decision. Training of new RAs also took time, but was greatly facilitated by RAs (mainly PhD students) who had worked on the project for a long time.
We faced larger decisions that determined the course of the project, though we did not always anticipate their spillover or long-term effects. Decisions in the first phase about scope especially impacted the contours of the database: These included leaving out non-English publications, the gray literature, and non-journal literature. The first exclusion probably would be the easiest to remedy given that the same steps we followed for the MCR could be followed using comparable databases to EBSCO that index articles in other languages. Incorporating the gray literature would be a completely different challenge, as much of it is not publicly available, and finding that which is accessible requires systematic Google searches or searching through databases unique to specific funders (such as USAID’s Development Experience Clearinghouse). But given that the actors who produce gray literature—donors and the organizations they fund—often produce valuable research on third sector organizations, it would be ideal to find a way to include such work. Finally, we know that books and edited volumes contain excellent research on third sector organizations, but finding a way to analyze such publications is much more complicated as they do not always have abstracts and take much longer to review than a standard journal article.
The choice not to include screening criteria for article quality in the corpus was also fateful. Although systematic reviews typically impose such criteria, we could not identify any unbiased way to do so across so many fields, time periods, and research methodologies. An attempt at asking RAs to assess the quality of articles produced wildly varying results. So the NKC database includes articles of varying quality, but we feel this is not a major weakness as even those of lower quality can still contribute knowledge about nonprofit organizations. Relatedly, the overwhelmingly positive findings about the effects of NGOs on development outcomes (Brass et al., 2018a, 2018b) made it impossible to use the MCR techniques to assess the shortcomings of NGOs. We are unable to determine why positive findings abound in the literature, but several possibilities exist. Perhaps authors are unlikely to write papers about null or negative results, or there is a publishing bias against such papers, or it could be due to the experiences and positions of the authors. Or, perhaps it could just be that NGOs are largely successful in doing what they purport to do.
While the diversity of theories and methods covered is a strength of the MCR, it presents one of the greatest challenges in the analysis phase. While all of the articles we included were research articles, not all were empirical. The corpus included both theoretical and interpretivist pieces, as well as pieces we deemed “merely descriptive.” There are no “findings” to aggregate with pieces like these. Similarly, our MCR excluded studies that we know involved NGOs intimately, because authors didn’t think of themselves as writing about NGOs—for example, they saw themselves as writing about “education interventions” that happened to be managed by NGOs. This exclusion particularly affects randomized controlled trials implemented by NGOs outside the field of public health.
A final set of challenges was imposed by the logistics of dealing with a complex search and analysis process parceled out across multiple universities. Some examples illustrate this point. The 11,000 records produced by the initial search of EBSCO had to be stored in the cloud and accessible to all project team members across three academic institutions.Footnote 6 After researching multiple citation management software options, we chose EndNote because of its compatibility with EBSCO’s PDF exports. As an EndNote library cannot sit in the cloud, we designated the EndNote library of one of the PIs as the shared “home” for all 11,000 records. RAs were then granted access to the library so that they could easily read the title, keywords, and abstract while screening articles for inclusion in the analysis. We were also then left with a convenient way to manage the bibliographies for our papers.
In our first publication, we ultimately also had to scale back our initial goal of being able to answer “what do we know about NGOs?” in favor of identifying the questions authors have asked about NGOs as well as the likely biases in the literature based on the topics and regions (not) studied. Although we had aimed to describe the answers to the six key questions we found authors have asked about NGOs, we realized that doing so required extensive qualitative analysis of the subset of articles asking such questions. Moving forward, we plan to use the MCR to facilitate smaller, more traditional systematic reviews that answer these key questions.
Next steps for the MCR
We considered titling this piece, “Methods for Messy, Massive Literatures: Don’t Try This at Home.” It was intended to be a word of caution for those wishing to replicate the process we followed of combing through thousands of articles, building a sensible corpus, converting text into data to be analyzed, supplementing that data with more qualitative analyses, and then putting everything onto a portal for other scholars to use. Had we known that doing so would require years of work, hundreds of hours on Skype, and dozens of RAs to ultimately conclude that there is still so much about NGOs that we do not yet know, would we have embarked on the same messy journey? Absolutely.
Most traditional systematic reviews and related meta-analyses are remarkable for their elegance and parsimony, often precisely because of their singular focus on isolating effect sizes of concern to only a single discipline or subdiscipline. But the expansion of third sector research (and many other important topics) over the past three decades cuts across disciplines and employs myriad methodologies. Research is also increasingly global and comparative, and may have temporal dynamics of historical research. The abundance of research that cuts across disciplines, methods, time periods, and geographies, combined with the general accumulation of knowledge over time and the development of new analytical tools for handling big data, allows us to reimagine what kinds of research might be possible. And while an MCR can reveal disciplinary boundaries and hint at fragments in a field, learning from other disciplines in this flexible yet systematic manner can also reduce duplicated efforts and produce further specialization without requiring researchers to stretch the boundaries of their own disciplines too far.Footnote 7 For those wishing to embark on their own MCR, it allows us to offer a few helpful tips.
First, the MCR is intended for research that cuts across disciplines, research methodologies, and regions both within and outside of nonprofit and other organizational studies. For example, someone could conduct an MCR of third sector organizations similar to ours but within developed countries only. But the technique could also be applied to other subject areas, like policy studies or legal studies where there is an “object” of study (like the third sector organization, in our case) that appears across sectors and regions, such as climate adaptation or corporate social responsibility.
Second, there are significant coordination costs of undertaking an MCR. Our MCR required a team of four PIs with varied skills and interests, financial and technical support from three different universities, and a large support staff of RAs. We began our MCR not knowing the ultimate size of our corpus or how difficult it would be it to screen articles based on a research topic that is theoretically in our wheelhouse but is much fuzzier in practice. Colleagues, particularly from fields where systematic reviews are more common, blanched upon learning our MCR included more than 3000 articles. However, working through these challenges produced outcomes whose benefits outweigh these costs.
Third, the outcome of an MCR should be as much a tool for others as it is for the researchers who conducted it. Researchers who conduct an MCR should aim to make their corpus accessible and keep it up to date for public use. We have attempted to do this through the NKC data portal, ngoknowledgecollective.org, which we see as having a number of potential uses for scholars of third sector organizations. For anyone writing a literature review, the portal significantly reduces the time spent screening out false positives. Scholars can also easily use the portal to identify the pool of articles to consider for a traditional, systematic review. Scholars needing to identify gaps in the literature in order to propose new research to funders can also make use of the portal to ensure that the literature it includes does not address their question. In other words, the large net we cast captured a lot of research on NGOs and development—but what we did not capture because it has not yet been done is just as important.
In conclusion, the process through which we developed the MCR was a bit like building an airplane while flying it. The mechanics are relatively straightforward—identify and download relevant articles, screen out false positives, and convert the articles into text files to be analyzed using content analysis, topic modeling, or simple keyword searches. As such, the method is easily replicable. But the journey of how we produced the NGO Knowledge Collective reveals a lot of coordination, data management, and a healthy dose of frustration. Did we ultimately answer the question we set out to in the beginning—what have we learned about NGOs and international development? Perhaps not, but we certainly know all the work that is required to answer it.
Notes
While copyright restrictions and paywalls prevent us from providing full-text articles (i.e., our raw data), the portal helps researchers identify relevant articles, which can then be accessed via their personal or institutional journal subscriptions. It also contains the metadata produced by the NKC about each article, including topics, keywords, and countries.
Three recent examples include the Open Data Collective, the Nonprofit Organization Research Panel, and the Global Register of Nonprofit Data Sources (GRNDS).
See list on p. 4.
The data are available at ngoknowledgecollective.org.
Not surprisingly, clouds shifted. We started with DropBox, then migrated to Box as the home institution of two of the PIs made the shift, and have since had to move to OneDrive as that same institution switched cloud allegiances yet again.
We thank a reviewer for this suggestion.
References
Alegre, I., & Moleskis, M. (2019). Beyond financial motivations in crowdfunding: A systematic literature review of donations and rewards. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations. https://doi.org/10.1007/s11266-019-00173-w
Brass, J. N., Longhofer, W., Robinson, R. S., & Schnable, A. (2018a). NGOs and international development: A review of thirty-five years of scholarship. World Development, 112, 136–149. https://doi.org/10.1016/j.worlddev.2018.07.016
Brass, J. N., Robinson, R. S., & Shermeyer, A. (2018b). Reported effects of NGOs in service provision, and the mediating effect of NGO-government relations. Paper presented at the ARNOVA Annual Meeting (November 2018), Austin, TX.
Dunn, J., Chambers, S. K., & Hyde, M. K. (2016). Systematic review of motives for episodic volunteering. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations, 27(1), 425–464. https://doi.org/10.1007/s11266-015-9548-4
Englert, B., & Helmig, B. (2018). Volunteer performance in the light of organizational success: A systematic literature review. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations, 29(1), 1–28. https://doi.org/10.1007/s11266-017-9889-2
Gazley, B., & Guo, C. (2020). What do we know about nonprofit collaboration? A systematic review of the literature. Nonprofit Management and Leadership, 31(2), 211–232. https://doi.org/10.1002/nml.21433
Igalla, M., Edelenbos, J., & van Meerkerk, I. (2019). Citizens in action, what do they accomplish? A systematic literature review of citizen initiatives, their main characteristics, outcomes, and factors. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations, 30(5), 1176–1194. https://doi.org/10.1007/s11266-019-00129-0
Laurett, R., & Ferreira, J. J. (2018). Strategy in nonprofit organisations: A systematic literature review and agenda for future research. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations, 29(5), 881–897. https://doi.org/10.1007/s11266-017-9933-2
Moher, D., Liberati, A., Tetzlaff, J., Altman, D. G., & The PRISMA Group. (2009). Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med 6(7), e1000097. https://doi.org/10.1371/journal.pmed.1000097
Petticrew, M., & Roberts, H. (2006). Systematic reviews in the social sciences: A practical guide. Blackwell.
Roberts, M. E., Stewart, B. M., & Tingley, D. (2019). stm: An R package for structural topic models. Journal of Statistical Software, 91(2), 1–40. https://doi.org/10.18637/jss.v091.i02
Salido-Andres, N., Rey-Garcia, M., Alvarez-Gonzalez, L. I., & Vazquez-Casielles, R. (2020). Mapping the field of donation-based crowdfunding for charitable causes: Systematic review and conceptual framework. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations. https://doi.org/10.1007/s11266-020-00213-w
Schnable, A., Demattee, A., Robinson, R. S., & Brass, J. N. (2021). International development buzzwords: Understanding their use among donors, NGOs, and academics. The Journal of Development Studies, 57(1), 26–44. https://doi.org/10.1080/00220388.2020.1790532
van Lunenburg, M., Geuijen, K., & Meijer, A. (2020). How and why do social and sustainable initiatives scale? A systematic review of the literature on social entrepreneurship and grassroots innovation. VOLUNTAS: International Journal of Voluntary and Nonprofit Organizations. https://doi.org/10.1007/s11266-020-00208-7
Acknowledgements
We gratefully acknowledge financial support from Indiana University (O’Neill School of Public and Environmental Affairs, Lilly Family School of Philanthropy, Tobias Center for Innovation in International Development, and Social Science Research Commons); Emory University (Goizueta Business School); and American University (Center on Health, Risk, and Society and School of International Service).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors know of no conflicts of interest associated with this research. This research did not involve human subjects.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schnable, A., DeMattee, A.J., Robinson, R.S. et al. The Multi-method Comprehensive Review: Synthesis and Analysis when Scholarship is International, Interdisciplinary, and Immense. Voluntas 33, 1219–1227 (2022). https://doi.org/10.1007/s11266-021-00388-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11266-021-00388-w