
Abstract
In Lewisean signaling games with common interests, perfect signaling strategies have been shown to be optimal in terms of communicative success and evolutionary fitness. However, in signaling game models that involve contextual cues, ambiguous signaling strategies can match up to or even outperform perfect signaling. For a minimalist example of such a context signaling game, I will show that three strategy types are expected to emerge under evolutionary dynamics: perfect signaling, partial ambiguity and full ambiguity. Moreover, I will show that partial ambiguity strategies are the most expected outcome and have the greatest basin of attraction among these three types when sender and receiver costs are arbitrarily small or similar. I will demonstrate that the evolutionary success of partial ambiguity is due to being risk dominant, which points to a better compatibility with other strategy types.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In his introduction to an essay about pragmatic principles, Horn (1984) reformulates an idea by Zipf (1949) as follows:
[...]George Kingsley Zipf set out to explain all of natural language [...] in terms of an overarching Principle of Least Effort. In the linguistic realm, however, Zipf (1949:20ff.) acknowledged two basic and competing forces. The Force of Unification, or Speaker’s Economy, is a direct least effort correlate, a drive towards simplification which, operating unchecked, would result in the evolution of exactly one totally unmarked infinitely ambiguous vocable (presumably uhhhh). The antithetical Force of Diversification, or Auditor’s Economy, is an anti-ambiguity principle leading toward the establishment of as many different expressions as there are meanings to communicate. Given m meanings, the speaker’s economy will tend toward ‘a vocabulary of one word which will refer to all the m distinct meanings’, while the hearer’s economy will tend toward ‘a vocabulary of m different words with one distinct meaning for each word.’ As Zipf (1949:21) (under)states, ‘The two opposing economies are in extreme conflict.
The idea that speaker and hearer economy operates as a driving force in language evolution and change goes back to Paul (1888) and was, among others, adopted and refined by Martinet (1962). Importantly, the thought experiment by Horn stresses the point that (i) when language evolution and change are exclusively driven by speaker economy, natural language would be maximally ambiguous, whereas (ii) when language evolution and change are exclusively driven by hearer economy, natural language would be completely unambiguous.Footnote 1 Since both forces operate on natural language, the result is a partially ambiguous communication system.Footnote 2 And indeed, different forms of ambiguity are essential parts of natural language, including lexical ambiguity, semantic and syntactic ambiguity, or the related concept of vagueness.Footnote 3
Moreover, there is no reason to disregard the idea that the principles of speaker and hearer economy affect the emergence of communication systems in general, instead of human natural language exclusively. In a common interestFootnote 4 signaling scenario, the overarching goal is to transfer information successfully between a sender and a receiver. However, the sender as well as the receiver might certainly have an evolutionary benefit from minimizing the effort, as long as communication remains successful. The assumption that speaker/hearer economy operates beyond natural language would predict that communication systems of non-human species also develop (partial) ambiguity. And indeed, plenty of examples exist.Footnote 5 For example, putty-nosed monkeys display signaling behavior where they use particular series of ‘hack’ calls to inform others about a range of different states, such as ‘presence of an eagle’, ‘baboons fighting nearby’, ‘a tree fell nearby’, and more (Arnold and Zuberbühler 2006).
David Lewis (1969) developed a game-theoretical model that helps to delineate how a meaningful communication system can evolve through emerging regularities of communicative behavior: the (common interest) signaling game. In the most basic variant of such a signaling game (Lewis 1969) the expected utilities for sender and receiver are optimal if and only if their strategies form a one-to-one mapping between states and actions. The reason is quite obvious: only such a mapping guarantees perfect information transfer, and players’ utilities are defined in terms of communicative success. In subsequent research it has been shown for most variants of the Lewis signaling game that perfect signaling systems (i) are the most expected outcome under evolutionary dynamics, as well as imitation and learning dynamics (cf. Barrett 2006; Skyrms 2010; Huttegger and Zollman 2011), and (ii) display the highest level of evolutionary stability in comparison to non-perfect signaling (cf. Wärneryd 1993; Huttegger 2007).
Yet if the thought experiment of Horn can be extended to the emergence of communication systems in general, then a perfect signaling system should not be the most expected outcome in signaling game strategies. Then, perfect signaling describes the endpoint of the scenario in which hearer economy operates unchecked and without an opposing force: a completely unambiguous communication system. A more expected outcome should be a partially ambiguous communication system that nevertheless guarantees successful communication due to some hearer effort to disambiguate by other means. And this is the crucial point: the standard signaling game does not involve any mechanism that gives the hearer an option for disambiguation by other means. Only by altering or extending the standard game in particular ways can ambiguous signaling match up to or even outperform perfect signaling, as shown in recent research (cf. Santana 2014; O’Connor 2015).
In this article I will show that in a signaling game model that involves contextual cues and optionally sender/receiver costs, strategies of ambiguous signaling can be evolutionarily stable and match up to perfect signaling. In a minimalist example, I will show that three strategy types are an expected outcome under evolutionary dynamics and evolutionarily stable strategies: perfect signaling (PS), full ambiguity (FA), and partial ambiguity (PA). The latter is a strategy type that involves one-to-one mappings for some signals, and one-to-many mappings for others. Furthermore, it turns out that (i) PA strategies are the most expected outcome under imitation dynamics, and (ii) they have the greatest basin of attraction under evolutionary dynamics in a scenario that involves only PA, PS and FA strategies, under the assumption that the sender and receiver costs are very similar.
The article is structured as follows: In Sect. 2, I will introduce the Lewis signaling game and outline previous work on ambiguous signaling. In Sect. 3, I will give a definition for the context signaling game and introduce a minimalist example, similar to the one given by Santana (2014). I will use Santana’s analysis of PS and FA strategies as a starting point and will complement it by pointing out the circumstances under which his result does or does not hold. In Sect. 4, I will apply a computational model of imitation dynamics to conduct a holistic exploration of the logical strategy space. The result shows that the most expected outcome is the PA strategy type. In Sect. 5, I will conduct an evolutionary analysis of a scenario that includes only these three strategy types. I will show that when sender and receiver costs are very similar in absolute terms, PA strategies have the greatest basin of attraction due to risk dominance, which points to a better compatibility to other strategies. In Sect. 6, I will discuss the results particularly with respect to speaker and hearer economy.
2 Signaling games and ambiguity
A signaling game (Lewis 1969) is a game-theoretic model that outlines the information transfer between a sender and a receiver. It involves i) a set T of states each of which represents the private information of the sender, ii) a set S that contains signals that the sender transfers to the receiver, and iii) a set R that contains response actions that the receiver can choose. Furthermore, \(U: T \times R \rightarrow \mathbb {R}\) is a utility function that determines how well a state matches a response action. In the original game there is exactly one optimal action for any state. The utility function is defined as \(U(t,r) = 1\) if r is an optimal response action to t, else 0.
The simplest non-trivial variant of the signaling game has two states, two signals and two actions: \(T = \{t_1, t_2\}\), \(S = \{a, b\}\), \(R = \{r_1, r_2\}\). The utility function of the original game can be defined as an action being optimal to a state when both share the same index. Therefore: \(U(t_{i},r_{j}) = 1\) iff \(i = j\), else 0. Figure 1 shows the extensive form game, which depicts the way this game is played: a state \(t \in T\) is randomly chosen by nature N. Then the sender (\(P_1\)) wants to communicate the given state by choosing a signal of S. Afterwards the receiver (\(P_2\)) chooses a response \(r \in R\). Communication is successful if and only if the state matches the response action, which results in an optimal utility of 1 for both players, else 0, as indicated by the utility values at the end of each branch. The dashed lines connect situations that the receiver cannot distinguish.

Extensive form game of the simple variant of a signaling game
The game determines the relationship between states and response actions through its utility function, but it does not determine any relationship between signals and states or signals and actions. Thus, due to the model definition itself, signals are meaningless. But signals can become meaningful due to regularities in sender and receiver behavior. Such behavior can be described in terms of strategies. A sender strategy is defined by a function \(\sigma : T \rightarrow S\), and a receiver strategy is defined by a function \(\rho : S \rightarrow R\). For the introduced variant of the game there are two combinations of sender strategy and receiver strategy that attribute meaning to both signals. In one combination the sender uses the strategy \(t_1 \rightarrow a\), \(t_2 \rightarrow b\), and the receiver uses the strategy \(a \rightarrow r_1\), \(b \rightarrow r_2\), in the other combination the sender uses the strategy \(t_1 \rightarrow b\), \(t_2 \rightarrow a\), and the receiver uses the strategy \(b \rightarrow r_1\), \(a \rightarrow r_2\). Both strategy combinations are depicted in Fig. 2.

The two signaling systems of the simple variant of a signaling game
Lewis (1969) called such strategy profiles signaling systems, which have interesting properties. First of all, they attribute a distinct meaning to each signal. For example, the strategy pair of Fig. 2 (left) attributes the meaning \(t_1/r_1\) to signal a and \(t_2/r_2\) to signal b. Furthermore, signaling systems guarantee perfect information transfer and result in maximal expected utility (EU).Footnote 6 Signaling systems are also the only strict Nash equilibria (cf. Myerson 1997) and evolutionarily stable strategies (Maynard Smith and Price 1973) of the EU table (cf. Wärneryd 1993; Huttegger 2007).
Concepts such as the Nash equilibrium or evolutionary stability can explain why signaling systems are superior to other strategy combinations once a population of interacting agents has reached such a state, but they cannot explain how they reach such a state in the first place, by assuming that signals are initially meaningless. To explore the paths that might lead from a meaningless to a meaningful signal, it is necessary to explore the process that leads from participants’ arbitrary signaling behavior to a behavior that constitutes a stable state. Such a process can be studied through update dynamics, such as replicator dynamics (Taylor and Jonker 1978), or imitation and learning rules (cf. Barrett 2009; Skyrms 2010; Huttegger and Zollman 2011). Here, different analyses of the introduced simple variant of the signaling game reveal that a signaling system is the most expected outcome. First of all, they are the only stable attractors under replicator dynamics (cf. Wärneryd 1993; Huttegger 2007). Furthermore, simulation studies of agents that are playing the simple version of the signaling game repeatedly and update via reinforcement learning (cf. Bush and Mosteller 1955; Roth and Erev 1995) revealed that signaling systems are the unique destination (cf. Barrett 2006).
The superiority of signaling systems as the result of learning and evolution is mitigated when the game is altered or extended. For example, it can be shown that when changing state frequencies and adding signal costs, then pooling strategiesFootnote 7—although not evolutionarily stable—have a reasonable basin of attraction under diverse update dynamics (cf. Mühlenbernd and Franke 2014). Furthermore, by increasing the number of states, signals and responses, so-called partial pooling strategies have a non-zero potential to emerge under learning and evolution dynamics (cf. Barrett 2006; Mühlenbernd and Nick 2014) and are neutrally stable strategies (cf. Pawlowitsch 2008).Footnote 8 Anyhow, in all these scenarios, perfect signaling is generally still superior in terms of expected utility and evolutionary stability. In the following I will discuss a number of conditions under which pooling strategies are equivalent or even superior to perfect signaling with respect to these aspects. But first I will introduce the term ambiguity in the context of signaling game strategies.
In the definition of ambiguity I follow Santana (2014) in that I call a sender strategy ambiguous when two conditions are met: i) it maps a signal to multiple states, and ii) distinguishing these states or not can make a difference in utility. The second condition implies that a pooling strategy is not necessarily ambiguous: Fig. 3 (left)

A partial pooling sender strategy (left) and a partial pooling receiver strategy (right)
depicts a partial pooling strategy. It allows for partial information transmission: in combination with the receiver strategy in Fig. 3 (right), it differentiates two of three states. Due to our definition, this strategy is not ambiguous when it does not make a difference in utility, e.g. when the utility function is defined so that \(U(t_2,r_2) = U(t_3,r_2)\).Footnote 9 However, under the standard utility function (\(U(t_i,r_j) = 1\) if \(i=j\), else 0) the strategy pair of Fig. 3 is ambiguous since it makes a difference in utility if the sender differentiates between \(t_1\) or \(t_2\), or not.
We can now turn to the question of what circumstances make ambiguity equal or superior to perfect signaling. One important aspect is the alignment of interests between sender and receiver. In the game introduced, the interests are completely aligned: sender and receiver score both the same in every interaction, either 1 or 0 (see Fig. 1). But under the assumption of (partial) conflict, pooling appears to be advantageous. For example, Crawford and Sobel (1982) can prove that the level of pooling in signaling increases when the alignment of interests between sender and receiver decreases. The intuition behind this is as follows: in situations of partial conflict the sender has an interest to not (completely) share his information state, and ambiguous signaling is a strategic means to accomplish this. Strategic components of ambiguous signaling are studied in diverse disciplines, ranging from the research of animals signaling in evolutionary biology (Zahavi 1975; Johnstone 1997) to the study of job market signaling in economics (Spence 1973; Farrell and Rabin 1996).
But in the following I will focus on the standard assumption in Lewisean signaling games, namely that the interests of sender and receiver are totally aligned in that both have an interest in perfect information transfer. What circumstances can make ambiguity advantageous in such cases? Of course, when there are more states than signals, ambiguity is then inevitable and perfect signaling is simply not possible (cf. Skyrms 2010). An extreme form of this situation is given when the state space is infinite, e.g. as is given for models with continuous state spaces, such as the sim-max game (Jäger 2007b). O’Connor (2015) studied a version of the sim-max game where the sender is allowed to choose the number of signals she wants to use for communication. In this model the number of signals can be infinite, thus perfect signaling is theoretically possible. O’Connor (2015) can prove that ambiguous signaling is optimal if each additional signal involves a constant additional cost value for the sender, even when this cost value is arbitrarily small.
Santana (2014) introduces a model that also involves sender costs, but the state space is not very large or infinite. His model involves an additional set of contextual cues. These cues are revealed to the receiver during the play and give a hint at which states are possible and which not. Santana (2014) proves that, in such a game, ambiguous signaling can outperform perfect signaling in terms of expected utility and evolutionary stability. In the next section I will use Santana’s model as a starting point to study the conditions that are advantageous to ambiguity or to perfect signaling, thereby refining his analysis in diverse ways.
3 The context signaling game and a preliminary analysis
The context signaling game is an extension of the signaling game as introduced by Lewis (1969). Its additional features are contextual cues, and, optionally, sender and receiver costs. In the following I will introduce a minimalist variant of a context signaling game. This variant involves four states, four signals and four response actions: \(T = \{t_1, t_2, t_3, t_4 \}\), \(S = \{a, b, c, d \}\), \(R = \{r_1, r_2, r_3, r_4 \}\). Furthermore, there is a set of contextual cues \(\Gamma = \{\gamma _1, \gamma _2\}\) which indicate what kind of states are possible. Here, \(\gamma _1\) tells the receiver that \(t_1\) or \(t_2\) is the case, whereby \(\gamma _2\) indicated that either \(t_3\) or \(t_4\) is the case.
The game is played between a sender and a receiver. It is assumed that both players act according to pure strategies. A sender strategy \(\sigma \in \mathcal {S}\) is defined as function \(T \rightarrow S\) and determines for every state what kind of signal is used by the sender. A receiver strategy \(\rho \in \mathcal {R}\) is defined as function \(S \times \Gamma \rightarrow R\) and determines for every possible combination of contextual cue and signal what kind of response action the receiver chooses.
Moreover, different strategies can come with different costs. The sender might pay for the precision (Santana 2014) or complexity (Rubinstein 2000; Deo 2015) of her strategy. The receiver might pay for the case that he has to process additional contextual cues. Consider the following example of animal alarm calls: If a call means ‘attack by a bird of prey’ OR ‘attack by a snake’, the receiver is aware of danger, but still has to scan the environment to choose the right response action, whereby an unambiguous alarm call does not require such a scan.Footnote 10 I will assume sender and receiver costs to be minute with respect to the value of communicative success, and I will also allow each to be zero. The sender costs are defined by a sender cost function \(c_s: \mathcal {S} \rightarrow \mathbb {R}_0^+\), and the receiver costs are defined by a receiver cost function \(c_r: \mathcal {R} \rightarrow \mathbb {R}_0^+\). Concrete costs for different strategies will be determined further down, where I will explore various values.
The utilities for sender and receiver can be defined for every state and with respect to strategy pairs, assuming the standard utility function, which yields 1 when the state corresponds to the response action (else 0). Note that such a match is given when the response action \(r_j\) (as result of the receiver strategy \(\rho \)) and the state \(t_i\) of the sender (who uses strategy \(\sigma \)) have the same index, thus when \(i=j\) in \(r_j = \rho (\sigma (t_i))\). By integrating sender and receiver costs, the sender utility function for playing \(\sigma \) against \(\rho \) in state \(t_i\) is given as:

The receiver utility function for playing \(\rho \) against \(\sigma \) in state \(t_i\) is given as:
Given these definitions, one round of the game looks as follows:
-
1.
A state \(t\in T\) is chosen with probability \(\nicefrac {1}{4}\) and revealed to the sender.
-
2.
The sender chooses a signal s according to her strategy \(\sigma \)
-
3.
The receiver receives a context strategy pair \((\gamma , s)\), whereby \(\gamma \in \Gamma \) is the contextual cue, thus either \(\gamma _1\) or \(\gamma _2\) , depending on state t
-
4.
The receiver chooses a response action r according to his strategy \(\rho \)
-
5.
Both players receive payoffs according to utility functions \(U_s\) and \(U_r\)
As already mentioned, the utility functions define how well a sender and a receiver strategy work for a particular state t. In the evolutionary analysis I will study the expected utility, namely the average utility of a sender and a receiver strategy over all states \(t \in T\). These expected utilities are defined by the following two EU functions for sender (\(EU_s\)) and receiver (\(EU_r\)):
Santana (2014) studied the version of the context signaling game introduced in this paper with respect to two particular strategy types. Each type can be exemplified by a strategy pair, of which one forms a signaling system (Fig. 4a), and the other forms an ambiguous system (Fig. 4b).

a Sender strategy \(\sigma _1\) and receiver strategy \(\rho _1\) form a perfect signaling (PS) strategy pair. b Sender strategy \(\sigma _2\) and receiver strategy \(\rho _2\) form a full ambiguity (FA) strategy pair. The cycles around \(t_1\), \(t_2\) and around \(t_3\), \(t_4\) represent context scenarios, either \(\gamma _1\) or \(\gamma _2\). The dashed lines of receiver strategies represent links unused for the given strategy pair
In the following I will call the first strategy type perfect signaling (PS), and the second one full ambiguity (FA).Footnote 11 Now lets assume that strategy \(\sigma _1\) might be more costly than strategy \(\sigma _2\) due to precision and/or complexity: \(c_s(\sigma _1) = \epsilon _s \ge 0\) and \(c_s(\sigma _2) = 0\). Furthermore, let’s assume that strategy \(\rho _1\) is cost-free, since the receiver does not need to access contextual cues, whereby strategy \(\rho _2\) might involve some costs: \(c_r(\rho _1) = 0\) and \(c_r(\rho _2) = \epsilon _r \ge 0\). For this scenario Table 1 shows the expected utility (EU) table for all combinations of sender and receiver strategies.
An important concept in evolutionary game theory is evolutionary stability (Maynard Smith and Price 1973), since an evolutionarily stable strategy (ESS) has an invasion barrier and is e.g. resistant to drift. Note that for an asymmetric game, such as the EU table of Table 1, the concepts of an ESS and of a strict Nash equilibrium coincide (Selten 1980). In other words, to detect evolutionarily stable strategy pairs in Table 1, one has to find those whose sender utility is the unique maximum in the column, and whose receiver utility is the unique maximum in the row at the same time. Note that the PS strategy pair \(\langle \sigma _1, \rho _1 \rangle \) fulfills this condition and is evolutionarily stable, if \(\epsilon _r > 0\). For the same reason, the FA strategy pair \(\langle \sigma _2, \rho _2 \rangle \) is evolutionarily stable, if \(\epsilon _s > 0\).Footnote 12
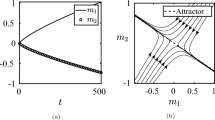
Santana (2014) studied the case where \(\epsilon _s > 0\) and \(\epsilon _r = 0\). In such a scenario, the FA strategy is an ESS, but the PS strategy is not. Figure 5a shows the changes in population states under the replicator dynamics (Taylor and Jonker 1978) for \(\epsilon _s = 0.03\) and \(\epsilon _r = 0\). As the figure shows, the strategy pair \(\langle \sigma _1, \rho _1 \rangle \) (bottom left corner) is not evolutionarily stable, since the receiver population can drift between \(\rho _1\) and \(\rho _2\). Once the receiver population uses (almost) entirely \(\rho _2\), the sender population is attracted by \(\sigma _2\), reaching the ESS \(\langle \sigma _2, \rho _2 \rangle \) (top right corner). This completes the potential drift from PS \(\langle \sigma _1, \rho _1 \rangle \) to FA \(\langle \sigma _2, \rho _2 \rangle \).

Changes in population states under replicator dynamics of the game of EU-table Table 1 for a cost values \(\epsilon _s = 0.03\), \(\epsilon _r = 0\), and b for cost values \(\epsilon _s = \epsilon _r = 0.03\)
Santana adduced this scenario for his argument, namely that ambiguity has an evolutionary advantage over perfect signaling. But his conclusion should be taken with a grain of salt. He argues that \(\epsilon _s\) can be expected to be arbitrarily small. But note that when \(\epsilon _s\) approaches 0, the basin of attraction of the FA strategy approaches 0. Thus, although the FA strategy is still evolutionarily stable, its basin of attraction is minute. Therefore, its stability advantage over PS can be expected to be minute when it comes to evolutionary dynamics with noise, such as mutation. I will underpin this point in the next section.
Moreover, Santana considered only one of four possible scenarios. And only in this scenario does FA have an evolutionary advantage over PS. For example, when \(\epsilon _s = 0\) and \(\epsilon _r = 0\), then none of both strategy types is an ESS, and a drift can happen in both directions. Moreover, when \(\epsilon _s = 0\) and \(\epsilon _r > 0\), Santana’s scenario is reversed and PS is the only ESS of the given EU table. Finally, when \(\epsilon _s > 0\) and \(\epsilon _r > 0\), both strategies are ESS and have an invasion barrier. Figure 5b shows the respective changes of population states under replicator dynamics for \(\epsilon _s = 0.03\) and \(\epsilon _r = 0.03\). As the figure shows, a drift from \(\rho _1\) to \(\rho _2\) is not possible anymore.
When sender and receiver costs are non-zero, PS and FA are both ESS. In such a scenario a more refined selection criterion for evolutionary stability can help to point out which of both strategies has an evolutionary advantage over the other: stochastic stability (cf. Foster and Young 1990). The idea is as follows. We assume that the evolutionary dynamics is non-deterministic due to noisy mutation: the mutation rate changes randomly. If we wait long enough, every ESS will eventually be invaded, no matter how high its invasion barrier is. Thus, given two ESS \(s_i\) and \(s_j\), there is a non-zero probability \(p_{ij}\) that the system switches from \(s_i\) and \(s_j\), as well as a non-zero probability \(p_{ji}\) for the reverse switch. Now, if and only if \(p_{ij} > p_{ji}\), then \(s_j\) is the only stochastically stable strategy (and \(s_i\), if and only if \(p_{ij} < p_{ji}\)), and the probability to stay with \(s_j\) approaches 1 when the mutation rate approaches 0.
To study the stochastic stability of strategy pairs, I will first introduce the pairwise expected utility \(EU_p\), which represents the expected utility for playing a strategy pair \(\langle \sigma ,\rho \rangle \) against \(\langle \sigma ',\rho ' \rangle \). \(EU_p\) is based on the idea that an agent is sender and receiver each with probability \(\frac{1}{2}\). Here, an agent plays her sender strategy \(\sigma \) against another agent’s receiver strategy \(\rho '\) with frequency \(\frac{1}{2}\), and her receiver strategy \(\rho \) against another agent’s receiver strategy \(\sigma '\) with frequency \(\frac{1}{2}\). Therefore, \(EU_p\) is defined as follows:
\(EU_p\) produces symmetric EU tables. The EU table for all possible strategy combinations of \(\sigma _1\), \(\sigma _2\), \(\rho _1\) and \(\rho _2\) is depicted in Table 2.Footnote 13
Note that for non-zero sender and receiver costs, both strategy pairs \(\langle \sigma _1,\rho _1 \rangle \) and \(\langle \sigma _2,\rho _2 \rangle \) are evolutionarily stable, whereas \(\langle \sigma _1,\rho _2 \rangle \) and \(\langle \sigma _2,\rho _1 \rangle \) are not (proof in Appendix A.1). But which strategy pair it stochastically stable? The PS type \(\langle \sigma _1,\rho _1 \rangle \) or the FA type \(\langle \sigma _2,\rho _2 \rangle \)? The answer: it depends on the relationship between sender and receiver costs. More concretely, it can be shown that the following proposition holds (proof in “Appendix A.2”)Footnote 14:
Proposition 1
Given the EU table of Table 2. If \(\epsilon _s > \epsilon _r\) then strategy pair \(\langle \sigma _2,\rho _2 \rangle \) is stochastically stable, whereas if \(\epsilon _s < \epsilon _r\) then strategy pair \(\langle \sigma _1,\rho _1 \rangle \) is stochastically stable.
To conclude, my analysis completes the one by Santana (2014) in that it indicates all the reasonable scenarios of sender and receiver cost combinations and the impact on evolutionary stability aspects. Santana pointed to a scenario where FA has an evolutionary advantage over PS, and I argue that this advantage is minute when the proposed sender costs are minute. Furthermore, I presented a scenario where it can be exactly the other way around. Moreover, I showed that when non-zero sender and receiver costs are involved, then FA and PS both are evolutionarily stable. I proved that in such a scenario one or the other strategy type is stochastically stable if and only if it involves less costs than its counterpart. However, this analysis is still preliminary, since it considers only two strategy types. Note that there might be further strategy types—next to FA and PS—that ensure perfect communication and are evolutionarily relevant. Therefore, it is a straightforward next step to explore the whole strategy space of the context signaling game.
4 Exploring the whole strategy space
The goal of this section is twofold. First of all, I want to set up an infrastructure that enables players to adopt any logically possible strategy of the context signaling game, with the goal to work out the spectrum of all evolutionarily successful strategies. Secondly, I want to study the four scenarios discussed in the last section (no costs, only sender costs, only receiver costs, sender and receiver costs) under noisy dynamics to investigate each scenario’s effect on the success of FA, PS or any other strategy.
Note that the defined version of the context signaling game allows for \(4^4 = 256\) different sender strategies and \(4^8 = 65536\) different receiver strategies. These numbers indicate that an integral analysis of the whole game space exceeds feasibility. Instead, I will investigate the game space by conducting simulation experiments of an agent-based model that approximates replicator dynamics, whereby agents are initially assigned with randomly selected sender and receiver strategies.
The implementation of this algorithm is represented as (Python similar) Pseudo-CodeFootnote 15 in Fig. 6.

Pseudo Python code of the ‘pairwise difference’ imitation algorithm
This algorithm accomplishes an imitation dynamics with the decision method ‘pairwise difference’ (PD). It can be shown that PD imitation is one of multiple agent-based protocols that approximate replicator dynamics (cf. Izquierdoy et al. 2018). Moreover, the dynamics are more realistic for real agency, since it considers a finite population, and its members don’t need to have global knowledge, such as the average utility of the population (as necessary for an agent-based interpretation of the replicator dynamics), but only about one interlocutor’s accumulated utility.
The algorithm works as follows: The input parameters are a set of agents, a signaling game G, a set S of sender strategies and a set R of receiver strategies, a mutation rate q, an imitation mode M and a breaking condition B (lines 1–6). First, all agents are initialized with a random sender and receiver strategy (lines 7–9). Then a number of simulation steps is accomplished until the breaking condition is reached (line 10). In each simulation step every agent interacts with every other agent by playing game G, one as sender, the other as receiver. After each interaction, the sender agent’s accumulated sender utility (ASU) and the receiver agent’s accumulated receiver utility (ARU) are incremented by the utility they scored in the game (interaction part, lines 11–15).
Afterwards each agent \(a_i\) is attributed to another random agent \(a_j\) (lines 16–17). In dependence of the imitation mode M the agent \(a_i\) either checks for imitating the whole strategy pair of the other agent, or for imitating sender or receiver strategy separately. Case \(M=1\): if agent \(a_i\) has a lower sum of ASU and ARU value than \(a_j\), then \(a_i\) adopts the strategy pair of the other agent with probability that equals the difference of both agents’ sum of ASU and ARU values (lines 18–21). Case \(M=2\): If agent \(a_i\) has a lower ASU value than \(a_j\), she adopts the sender strategy of the other agent with a probability that equals the difference of both agents’ ASU values (lines 23–25); the same happens independently for the ARU values (lines 26–28). Finally, all agents’ ASU and ARU values will be reset for starting a new round and their strategies might be altered with respect to the mutation rate q (lines 29–33)Footnote 16.
Note that the imitation mode allows for a replication of a one-population or two-population analysis. Consider that my initial analysis of Table 1 considers a two-population model where a population of senders interacts with a population of receivers. On the other hand, my extended analysis of Table 2 and all further analyses of this article consider a one-population model where one population of agents interacts by alternating roles. To cover both scenarios, I will conduct experiments of the PD imitation algorithm for a one-population analysis (by setting \(M=1\)) and a two-population analysis (by setting \(M=2\)).
For the exploration of the whole game space it is necessary to assign a cost value to every logically possible strategy. First, I define the sender strategy costs with respect to the number of signals involved in the strategy. In more detail, let \(\phi _s: \mathcal {S} \rightarrow \mathbb {N}\) be the function that yields the number of different signals that a sender strategy \(\sigma \in \mathcal {S}\) uses, then the cost function \(c_s(\sigma )\) is defined as \(c_s(\sigma ) = \phi _s(\sigma ) \cdot \epsilon _s\), whereby \(\epsilon _s \in \mathbb {R}_0^+\) is the precision weight parameter. Secondly, I define the receiver strategy costs with respect to the number of times the contextual cues need to be accessed. In more detail, let \(\phi _r: \mathcal {R} \rightarrow \mathbb {N}\) be the function that yields the number of times that a receiver strategy \(\rho \in \mathcal {R}\) construes a signal in different ways in both contexts, then the cost function \(c_r(\rho )\) is defined as \(c_r(\rho ) = \phi _r(\rho ) \cdot \epsilon _r\), whereby \(\epsilon _r \in \mathbb {R}_0^+\) is the context access weight parameter.
I conducted \(2 \times 4 = 8\) experiments that pay attention to the two imitation modes and the four cost scenarios. For Experiments 1 to 4, I consider a one-population model by setting \(M=1\). In Experiment 1, I did not consider any costs by setting \(\epsilon _s = 0\) and \(\epsilon _r = 0\). In Experiment 2, I only considered sender costs (\(\epsilon _s = 0.01\), \(\epsilon _r = 0\)), in Experiment 3, only receiver costs (\(\epsilon _s = 0\), \(\epsilon _r = 0.01\)), and in Experiment 4, sender and receiver costs (\(\epsilon _s = 0.01\), \(\epsilon _r = 0.01\)). For Experiments 5–8, I considered a two-population model by setting \(M=2\) and used the same costs settings such as for Experiments 1–4.
For each experiment I conducted 1000 simulation runs. In each simulation run a population of 100 agents played the context signaling game as defined in the last section. The breaking condition was reached when (i) either the whole population adopted the same strategy type which has at least \(75\%\) communicative success, or (ii) 10,000 simulation steps were reached. The mutation rate was set to 0.0001.
The basic results of all four experiments were as follows: for the one-population analysis (Experiments 1–4), the whole population agreed on a particular strategy type in around \(45.5\%\) of all 4000 simulation runs, whereas in the remaining runs the population did not establish a convention that enabled sufficient communicative success (within the first 10,000 simulation steps, see breaking condition). For the two-population analysis (Experiments 5–8), the whole population agreed on a particular strategy type in around \(86.5\%\) of all 4000 simulation runs.Footnote 17 Moreover, when the whole population adopted a convention, it was always one of the three following strategy types: (i) an FA strategy type as exemplarily represented by the strategy pair \(\sigma _2\) and \(\rho _2\) (Fig. 4b), (ii) a PS strategy type as exemplarily represented by the strategy pair \(\sigma _1\) and \(\rho _1\) (Fig. 4a), and (iii) a third strategy type that can be described as a hybrid version of FA and PS. In the following I will label this strategy type as partially ambiguous (PA). An exemplary PA strategy pair is depicted in Fig. 7.

Sender strategy \(\sigma _3\) and receiver strategy \(\rho _3\) form a partial ambiguity (PA) strategy pair. Dashed lines of the receiver strategy represent unused links for the given strategy pair
PA sender strategies use 3 signals, of which one is ambiguous and resolved by the context, whereas the other two signals are unambiguous.

Results of the simulation experiment of the PD imitation dynamics
The detailed results are presented in Fig. 8a for Experiments 1–4 (one-population update) and Fig. 8b for Experiments 5–8 (two-population update). The results show two important aspects. First of all, with respect to the comparison between PS and FA, it is evident that FA emerges more often across all cost settings in the one-population analysis. Furthermore, in the two-population analysis, sender costs turn out to have an impact by enabling the emergence of FA more often than of PS. A more detailed analysis of these effects would go beyond the scope of this paper. However, it shows that the impact of receiver costs is not evident, and the impact of sender costs is only evident in the two-population model. Moreover, this effect is expected to be even less by reducing the cost value more.
Note that a second aspect of the results is much more prominent, namely that the PA strategy type emerged clearly more frequently than PS and FA across all eight settings. In the next section I will conduct a formal analysis of a scenario with exclusively these three strategy types to detect the evolutionary advantage of the PA strategy type.
5 An evolutionary analysis of three strategy types in competition
In this section I will study a scenario that involves exclusively the three exemplary strategy pairs \(\langle \sigma _1,\rho _1 \rangle \), \(\langle \sigma _2,\rho _2 \rangle \) (Fig. 4) and \(\langle \sigma _3,\rho _3 \rangle \) (Fig. 7). Table 3
shows the corresponding \(EU_p\) table for the minimalist model of the context signaling game with cost values as defined in the last section. It can be shown that all three strategy pairs are evolutionarily stable (proof in “Appendix A.3”)Footnote 18. Furthermore, it can be shown that when \(\epsilon _s = \epsilon _r\), none of the three strategy pairs has an advantage with respect to stochastic stability (proof in “Appendix A.5”): all three strategies are expected to emerge with the same probability in the long run. Moreover, it can be shown that the following proposition holds (proof in “Appendix A.4”):
Proposition 2
Given the EU table of Table 3. If \(\epsilon _s > \epsilon _r\) then strategy pair \(\langle \sigma _2,\rho _2 \rangle \) is stochastically stable, whereas if \(\epsilon _s < \epsilon _r\) then strategy pair \(\langle \sigma _1,\rho _1 \rangle \) is stochastically stable.

Changes of population states under the replicator dynamics of the symmetric game of Table 3, projected on a simplex
Note that according to Proposition 2, stochastic stability cannot explain the evolutionary advantage of PA types, but, to the contrary, rather indicates that PS types or FA types possess an advantage. But what can explain the success of PA types? We might get a better understanding by taking a look at the changes of population states under replicator dynamics the of the EU-table of Table 3, which is given in Fig. 9 for \(\epsilon _s = 0.01\) and \(\epsilon _r = 0.01\).Footnote 19 As can be observed, strategy pair \(\langle \sigma _3,\rho _3 \rangle \) has a considerable greater basin of attractionFootnote 20. A computational analysis confirmed the impression, namely that \(\langle \sigma _3,\rho _3 \rangle \) has a basin of attraction of \(39.2\%\) of all population states, whereas \(\langle \sigma _1,\rho _1 \rangle \) and \(\langle \sigma _2,\rho _2 \rangle \) both have one of \(30.4\%\) each.Footnote 21
Why is the PA strategy more successful under evolutionary dynamics than its competitors? An answer can be found in the following fact. The PA strategy is risk dominant Harsanyi and Selten 1988. In general, risk dominance plays an important role in evolutionary settings. For example, in \(2\times 2\) games with multiple equilibria, it has been shown that the risk-dominant equilibrium (i) is the only stochastically stable strategy Young 1993, (ii) has generally the largest basin of attraction under replicator dynamics (Zhang and Hofbauer 2015), and (iii) is most likely selected under ongoing mutation (Kandori et al. 1993).
A strategy is risk dominant when it has the highest average utility for a neutral population state. With respect to the scenario in Table 3 this is the case when each strategy has a frequency of \(\frac{1}{3}\). Moreover, let us for the sake of simplicity assume \(\epsilon _s = \epsilon _r = \epsilon \). Then it can be shown that the PS strategy \(\langle \sigma _1, \rho _1\rangle \) has an average utility of \(\frac{7}{8} - 6\epsilon \), the FA strategy \(\langle \sigma _2, \rho _2\rangle \) has an average utility of \(\frac{7}{8} - 6\epsilon \) as well, and the PA strategy \(\langle \sigma _3, \rho _3 \rangle \) has an average utility of \(\frac{11}{12} - 6\epsilon \). In other words, the PA type’s average utility over a neutral population state is by \(\frac{1}{24} \gtrsim 4\%\) greater than that of the PS and FA strategy type. Note that the reason for PA being risk dominant can be found in the fact that PS and FA are less compatible with each other, since they only have an expected communicative success of \(\frac{3}{4}\), whereas the PA type has an expected communicative success of \(\frac{7}{8}\) to both of them. Hence, the secret of PA’s success can be nicely described with the phrase: “When two (people) quarrel, a third rejoices.”
But note that the PA strategy has the greatest basin of attraction only when sender and receiver costs are minute and/or very similar. By increasing the difference between sender and receiver cost weights, the PA type’s basin of attraction decreases (Fig. 10).

The basins of attraction of the three strategy types under replicator dynamics for EU-table Table 3 over a range of cost values with \(0 \le \epsilon _s \le 0.1\) and \(\epsilon _r = 0.1-\epsilon _s\)
shows a computational calculation of the basins of attraction of all three strategy types in dependence of the different cost values \(0 \le \epsilon _s \le 0.1\) and \(\epsilon _r = 0.1- \epsilon _s\). As can be observed, the PS strategy type has the greatest basin of attraction when \(\epsilon _r - \epsilon _s \gtrsim 0.03\), and the FA strategy type has the greatest basin of attraction when \(\epsilon _s - \epsilon _r \gtrsim 0.03\). However, for the range of costs where \(|\epsilon _s-\epsilon _r| \lesssim 0.03\), PA has the greatest basin of attraction. Therefore, by assuming sender and receiver costs to be arbitrarily low, we can generally suppose that the cost difference is less than 0.03 and then PA is the most expected outcome under evolutionary dynamics.
6 Discussion and conclusion
The mainstream of work that studies Lewisean signaling games (i) is based on the underlying assumption that a perfect signaling strategy is the only optimal type of communication, and (ii) is looking for ways to demonstrate the superiority of perfect signaling to non-perfect signaling, both in the form of a static description (e.g Nash equilibria, ESS) or a dynamic interpretation (outcome of learning and evolutionary dynamics). In recent studies it has been considered that not perfect signaling, but ambiguous signaling is in many cases more advantageous (cf. Santana 2014; O’Connor 2015). With this work I want to direct the reader’s attention to the fact that to be an advantageous and evolutionarily successful communication system, a signaling strategy does not have to be the one nor the other extreme configuration, but can be partially ambiguous by combining precision with context-dependency.
This study considers a particular minimalist example that produces only three strategy types that guarantee perfect information transfer, types which I labeled perfect signaling, partial ambiguity, and full ambiguity. However, communication systems are most often more complex, especially when it comes to natural language. How can the result of this study be transferred to more general cases? Let’s assume a context signaling game with \(n \in \mathbb {N}_{>2}\) states, signals and response actions. Moreover, depending on the arrangement of the contextual space, we obtain a set of strategy types that allows for perfect communication. This set of strategy types must involve a minimal number \(l \in \mathbb {N}\) of signals that have to be used to guarantee perfect communication, and a maximal number \(h \in \mathbb {N}\) of signals that are sufficient to guarantee perfect communication, whereby \(1 \le l \le h \le n\). In this scenario, a strategy type that uses l signals is the most ambiguous one, and a strategy type that uses h signals is the least ambiguous one. In general, a strategy type that uses i signals, \(l \le i \le h\), has a level of ambiguity that is inversely proportional to i.
In the generalized scenario we would probably expect an intermediate value of ambiguity to be mostly successful under evolutionary dynamics, for example an i value close to \(\frac{l+h}{2}\). However, as the basin of attraction calculation in the last section revealed (cf. Fig. 10), the particular level depends on the speaker and hearer costs. When \(\epsilon _s \gg \epsilon _r\), then a higher level of ambiguity (low i) is expected to be mostly successful, whereas when \(\epsilon _s \ll \epsilon _r\), it is exactly the other way around. Note that the relationship of both cost values determines the strength of following speaker or hearer economy, since a low-i strategy type prefers speaker economy over hearer economy, whereas a high-i strategy type prefers hearer economy over speaker economy. In other words, it is the value of precision (speaker costs) and the costs of disambiguation (hearer costs) that determine the strength of following speaker and hearer economy.
I argued that a context signaling model is a refinement of the signaling game that describes a more realistic scenario, since pure coding is the exception in natural communication systems, whereas contextual cues are frequently exploited whenever accessible. Particularly natural language is on many levels shaped by a confrontation of clarity and context-dependency. Therefore, it is not surprising that the context signaling model has already found its application in the study of natural language features. As an early example, Jäger (2007a) studied the evolutionary stability of case marking systems of transitive sentences by using a context signaling model. In his model, the information states are transitive sentences, the signals are grammatical case markers, and the contextual cues reveal the animacy or prominence of the sentences’ nominal phrases. Jäger (2007a) showed that the stochastically stable strategies of the model represent with high fidelity the (more or less ambiguously marked) case systems of the world’s languages.
In a more recent example, Deo (2015) uses a context signaling model to study the change in the aspectual systems of languages of the world: typological data show that some languages have an explicit progressive aspect, such as the ‘be + -ing’-construction in English, whereas other languages do not differentiate between progressive and non-progressive. For example, the German sentence ‘Ich arbeite’ can have the meaning ‘I am working’ or ‘I (use to) work.’ This ambiguity must be resolved from the context. In Deo’s model, the information states are different readings of verbal constructions, the signals are aspect markers, and the contextual cues indicate the probability of different readings. Deo (2015) showed that a historically attested progress of aspectual systems can be reconstructed under replicator dynamics with mutation.
These examples are supposed to stress the relevance of context signaling models when it comes to more concrete phenomena in natural languages. But note that explaining language change and evolution solely through usage-based principles should be taken with a grain of salt. Many other factors can also play an important role, particularly the factor of learnability, as e.g. illustrated through the Iterated Learning Model (cf. Kirby 2002; Kirby et al. 2014, 2015). In this respect, Brochhagen et al. (2018) introduces a model that analyses signaling games with respect to functional pressure toward successful communication and effects of transmission perturbations on (iterated) language learning. Moreover, next to functional factors, social factors, too, are known to be driving forces in language change (cf. Croft 2000; Labov 2001). Last but not least, a number of studies argue that many aspects of language change might be neutral and do not require any intrinsic driving force (cf. Blythe 2012; Stadler et al. 2016; Newberry et al. 2017; Kauhanen 2017).
It should be taken into consideration that contextual cues are not always as accessible or veridical as given in my model. For example, in the study by Mühlenbernd and Enke (2017)—which examines the model of the study discussed by Deo (2015) by addressing an agent-based learning model—it was shown that a reduction in the access to contextual cues has a tremendous effect on the simulation results and enables one to better reconstruct the phenomenon under investigation. Moreover, in the model discussed by Jäger (2007a), contextual cues are not \(100\%\) veridical and only represent a probability for which a particular state is given, which reflects empirical data of usage frequencies of grammatical forms. Moreover, Brochhagen (2017) shows that the advantage of ambiguous communication depends on the reliability of contextual cues, which is expected to be high when e.g. priors among interlocutors are sufficiently aligned relative to the truth-conditions of a language.
Apart from these points that must surely be considered for a more complete picture, the model shows an important aspect of many communication systems: their level of ambiguity is to a large extent a result of a negotiation process between sender and receiver by following speaker economy and hearer economy to particular degrees. As Horn indicated in his thought experiment that was presented in the introduction section, and as my formal analysis of the minimalist example showed, when both economies interact with each other to a similar degree (similar sender and receiver costs), the most expected result is a partially ambiguous communication system that distributes the effort among sender and receiver to roughly the same amount.
Notes
There are certainly more factors that drive the language use of speaker and hearer. First of all, both participants have (in many situations) a common interest, namely to communicate successfully. Note that in the model I present in this study I consider common interest for successful communication as an overarching goal of both participants, and optimizing speaker/hearer economy as a secondary though important motive.
Note that this study considers a usage-based approach by describing general mechanisms in language change and evolution through communicative acts (horizontal transmission). I do not consider the effect of language learning/acquisition (vertical transmission), but I will discuss it shortly in the final Sect. 6. Note that from a learning point of view, the receiver has motives to receive less words, e.g. for memorizing a smaller vocabulary.
I refer to Brochhagen (2017) for a more thorough discussion.
The term ‘common interests’ points to a scenario where both sender and receiver have aligned interests for faithful and exact information transfer. One example of an alternative scenarios is a ‘partial conflict’ situation, where parties may have an interest in deceiving for their own benefit.
See e.g. Santana (2014), Sect. 4 for more details and examples.
The expected utility function \(EU(\sigma ,\rho )\) returns the average utility for a sender strategy \(\sigma \) against a receiver strategy \(\rho \). It will be formally introduced in Sect. 3.
Pooling strategies map multiple states to one signal. A discussion about the relationship between pooling and ambiguous signaling will follow in this section.
Neutral stability is a mitigation of evolutionary stability. It can be shown that a population can be trapped in a neutrally stable state (Pawlowitsch 2008).
As Santana (2014) illustrated, in such a case one could invent a state \(t_2^* = (t_2\) or \(t_3)\) which joins \(t_2\) and \(t_3\) and makes the sender strategy \(t_1\rightarrow a\) and \(t_2^*\rightarrow b\) a signaling strategy.
As this scenario exemplifies, the receiver costs are supposed to represent the receiver’s effort for disambiguation. In general, I intend to describe sender and receiver costs in the most usage-based way, in that sender costs represent the effort for being precise, and receiver costs present the effort for disambiguation. Note that there might also be production costs (sender) and processing costs (receiver), but I consider them as neglectable. Moreover, there might also be learning costs for a smaller or larger inventory, but I also disregard them due to the focus on usage-based economies, not on learning-based aspects (see also Footnote 2).
The reason for the label ‘full’ is to clearly distinguish this strategy type from another strategy type of ‘partial’ ambiguity, which I will study in subsequent sections.
A second condition for the PS (FA) strategy type to be an ESS is \(\epsilon _r\) (\(\epsilon _s\)) to be less than \(\frac{1}{2}\). Since costs are assumed to be minute in comparison to communicative success (utility of 1), this requirement is considered to be generally satisfied.
For symmetric utility tables it is sufficient to display the row players utility.
The actual Python implementation can be found in an OSF repository under the following link: https://osf.io/w3jt5/?view_only=030ef8ac10bc4c4ba5a70bea853b994a.
The mutation rate determines how likely an agent changes her sender and receiver strategy due to error or drive for exploration. The mutation step changes a random link (a connection from an information state to a signal for a sender strategy; a connection from a context-signal pair to a response action for a receiver strategy) of a strategy.
This difference is most certainly caused by the fact that the two-population model allows for a greater number of strategy pair combinations and therefore enables more easily the emergence of strategy pairs that are sufficiently successful. In the one-population model agents start with 100 different strategy pairs, for which it is quite likely that one with sufficient communicative success is not among them. On the other hand, in the two-population model agents start with 100 sender and 100 receiver strategies that allow for 10,000 different strategy pairs due to imitating them separately.
Note that the proof in “Appendix A.3” requires \(\epsilon _s\) and \(\epsilon _r\) both to be lower than \(\frac{1}{4}\). Since costs are assumed to be minute in comparison to communicative success (utility of 1), this requirement is considered to be generally satisfied.
Note that the population states of \(3 \times 3\) symmetric games can be projected on a 2-dimensional simplex, where each corner represents a homogeneous population state.
The basin of attraction of a strategy \(\sigma \) under a dynamics D is defined by the proportion of all population states that are attracted by \(\sigma \) under D.
For the computation of the basins of attraction I analyzed the EU table of Table 3 (for particular \(\epsilon _s\) and \(\epsilon _s\) values) with the discrete time one-population replicator dynamics for ca. 20,000 uniformly distributed initial population states.
References
Arnold, K., & Zuberbühler, K. (2006). The alarm-calling system of adult male putty-nosed monkeys, cercopithecus nictitans martini. Animal Behaviour, 72(3), 643–653.
Barrett, J. A. (2006). Numerical simulations of the lewis signaling game: Learning strategies, pooling equilibria, and the evolution of grammar (Technical Report). Institute for Mathematical Behavioral Sciences, University of California, Irvine.
Barrett, J. A. (2009). The evolution of coding in signaling games. Theory and Decision, 67, 223–237.
Blythe, R. A. (2012). Neutral evolution: A null model for language dynamics. Advances in Complex Systems, 15, 1150015.
Brochhagen, T. (2017). Signaling under uncertainty: Interpretative alignment without a common prior. The British Journal for the Philosophy of Science, 71(2), 471–496.
Brochhagen, T., Franke, M., & van Rooij, R. (2018). Coevolution of lexical meaning and pragmatic use. Cognitive Science, 42, 2757–2789.
Bush, R., & Mosteller, F. (1955). Stochastic models of learning. New York: Wiley.
Crawford, V. P., & Sobel, J. (1982). Strategic information transmission. Econometrica, 50, 1431–1451.
Croft, W. (2000). Explaining language change. London: Longman.
Deo, A. (2015). The semantic and pragmatic underpinnings of grammaticalization paths: The progressive to imperfective shift. Semantics and Pragmatics, 8(14), 1–52.
Farrell, J., & Rabin, M. (1996). Cheap talk. The Journal of Economic Perspectives, 10(3), 103–118.
Foster, D., & Young, P. (1990). Stochastic evolutionary game dynamics. Theoretical Population Biology, 38(2), 219–232.
Harsanyi, J. C., & Selten, R. (1988). A general theory of equilibrium selections in games. Cambridge: MIT Press.
Horn, L. (1984). Towards a new taxonomy of pragmatic inference: Q-based and R-based implicature. In D. Schiffrin (Ed.), Meaning, form, and use in context: Linguistic applications (pp. 11–42). Washington: Georgetown University Press.
Huttegger, S. M. (2007). Evolution and the explanation of meaning. Philosophy of Science, 74(1), 1–27.
Huttegger, S. M., & Zollman, K. J. S. (2011). Signaling games: Dynamics of evolution and learning. In A. Benz, C. Ebert, G. Jäger, & R. van Rooij (Eds.), Language, games, and evolution Language, games, and evolution (pp. 160–176). Berlin: Springer.
Izquierdoy, L. R., Izquierdoz, S. S., & Sandholm, W. H. (2018). An introduction to ABED: Agent-based simulation of evolutionary game dynamics (Technical Report). Unpublished manuscript.
Jäger, G. (2007a). Evolutionary game theory and typology: A case study. Language, 83(1), 74–109.
Jäger, G. (2007b). The evolution of convex categories. Linguistics and Philosophy, 30, 551–564.
Johnstone, R. A. (1997). The evolution of animal signals. In J. R. Krebs & N. B. Davies (Eds.), Behavioural ecology: An evolutionary approach (pp. 155–178). Blackwell: Oxford.
Kandori, M., Mailath, G. J., & Rob, R. (1993). Learning, mutation and long-run equilibrium in games. Econometrica, 61, 29–56.
Kauhanen, H. (2017). Neutral change. Journal of Linguistics, 53, 327–358.
Kirby, S. (2002). Learning, bottleneck and the evolution of recursive syntax. In T. Briscoe (Ed.), Linguistic evolution through language acquisition: Formal and computational models (pp. 173–204). Cambridge: Cambridge University Press.
Kirby, S., Griffiths, T., & Smith, K. (2014). terated learning and the evolution of language. Current Opinion in Neurobiology, 28, 108–114.
Kirby, S., Tamariz, M., Cornish, H., & Smith, K. (2015). Compression and communication in the cultural evolution of linguistic structure. Cognition, 141, 87–102.
Labov, W. (2001). Principles of linguistic change: Social factors. New York: Blackwell.
Lewis, D. (1969). Convention. A philosophical study. Cambridge: Havard University Press.
Martinet, A. (1962). A functional view of language. Oxford: Clarendon Press.
Maruta, T. (1997). On the relationship between risk-dominance and stochastic stability. Games and Economic Behavior, 19(2), 221–234.
Maynard Smith, J., & Price, G. (1973). The logic of animal conflict. Nature, 146, 15–18.
Morris, S., Rob, R., & Shin, H. S. (1995). P-dominance and belief potential. Econometrica, 63(1), 145–157.
Mühlenbernd, R., & Enke, D. (2017). The grammaticalization cycle of the progressive—A game-theoretic analysis. Morphology, 27(4), 497–526.
Mühlenbernd, R., & Franke, M. (2014). Proceedings of the European conference on social intelligence. In A. Herzig & E. Lorini (Eds.), Meaning, evolution and the structure of society (Vol. 1283, pp. 28–39). Toulouse: Toulouse University.
Mühlenbernd, R., & Nick, J. (2014). Language change and the force of innovation. In S. Katrenko & K. Rendsvig (Eds.), Pristine perspectives on logic, language, and computation (Vol. 8607, pp. 194–213). Heidelberg: Springer.
Myerson, R. B. (1997). Game theory: Analysis of conflict. Cambridge: Harvard University Press.
Newberry, M. G., Ahern, C. A., Clark, R., & Plotkin, J. B. (2017). Detecting evolutionary forces in language change. Nature, 551, 223–226.
O’Connor, C. (2015). Ambiguity is kinda good sometimes. Philosophy of Science, 82(1), 110–121.
Paul, H. (1888). Principles of the history of language (translated by h.a. strong). London, Swan Sonnenschein, Lowrey & Co.
Pawlowitsch, C. (2008). Why evolution does not always lead to an optimal signaling system. Games and Economic Behavior, 63, 203–226.
Roth, A. E., & Erev, I. (1995). Learning in extensive-form games: Experimental data and simple dynamic models in the intermediate term. Games and Economic Behaviour, 8, 164–212.
Rubinstein, A. (2000). Economics and language. Cambridge: Cambridge University Press.
Santana, C. (2014). Ambiguity in cooperative signaling. Philosophy of Science, 81(3), 398–422.
Selten, R. (1980). A note on evolutionarily stable strategies in asymmetric animal conflicts. Journal of Theoretical Biology, 84, 93–101.
Skyrms, B. (2010). Signals: Evolution, learning and information. Oxford: Oxford University Press.
Spence, M. (1973). Job market signaling. Quarterly Journal of Economics, 87(3), 355–374.
Stadler, K., Blythe, R. A., Smith, K., & Kirby, S. (2016). Momentum in language change. Language Dynamics and Change, 6, 171–198.
Taylor, P. D., & Jonker, L. B. (1978). Evolutionarily stable strategies and game dynamics. Mathematical Biosciences, 40, 145–156.
Wärneryd, K. (1993). Cheap talk, coordination, and evolutionary stability. Games and Economic Behavior, 5(4), 532–546.
Young, P. (1993). The evolution of conventions. Econometrica, 61, 57–84.
Zahavi, A. (1975). Mate selection—A selection for a handicap. Journal of Theoretical Biology, 1(53), 205–214.
Zhang, B., & Hofbauer, J. (2015). Equilibrium selection via replicator dynamics in \(2\times 2\) coordination games. International Journal of Game Theory, 44, 433–448.
Zipf, G. K. (1949). Human behavior and the principle of least effort. Pearson: Addison-Wesley.
Funding
Funding was provided by Narodowa Agencja Wymiany Akademickiej (NAWA, Polish National Agency for Academic Exchange) (Grant No. PPN/ULM/2019/1/00222).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Evolutionary stability of \(\langle \sigma _1,\rho _1 \rangle \) and \(\langle \sigma _2,\rho _2 \rangle \) in Table 2
To show: Given EU table Table 2 with \(0<\epsilon _s < \frac{1}{2}\) and \(0< \epsilon _r < \frac{1}{2}\). The strategy pairs \(\langle \sigma _1,\rho _1 \rangle \) and \(\langle \sigma _2,\rho _2 \rangle \) are evolutionarily stable, whereas \(\langle \sigma _1,\rho _2 \rangle \) and \(\langle \sigma _2,\rho _1 \rangle \) are not evolutionarily stable.
-
1.
\(\langle \sigma _1,\rho _1 \rangle \) is a strict Nash equilibrium and therefore an ESS. Proof: \(EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle )\) is a unique maximum in the first row.
-
(a)
$$\begin{aligned} {\begin{aligned}&EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \text { }&> EU_p(\langle \sigma _1,\rho _2 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \\&\Rightarrow \text { }&1 - \frac{\epsilon _s}{2} \text { }&> \text { } 1 - \frac{\epsilon _s+\epsilon _r}{2}\\&\Rightarrow \text { }&\epsilon _r \text { }&> \text { } 0 \surd \\ \end{aligned} } \end{aligned}$$
-
(b)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \text { }&> EU_p(\langle \sigma _2,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \\&\Rightarrow \text { }&1 - \frac{\epsilon _s}{2} \text { }&> \text { } \frac{3}{4}\\&\Rightarrow \text { }&\frac{1}{2} \text { }&> \text { } \epsilon _s \surd \\ \end{aligned} } \end{aligned}$$
-
(c)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \text { }&> EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \\&\Rightarrow \text { }&1 - \frac{\epsilon _s}{2} \text { }&> \text { } \frac{3}{4} - \frac{\epsilon _r}{2}\\&\Rightarrow \text { }&\frac{1}{2} \text { }&> \text { } \epsilon _s - \epsilon _r \surd \\ \end{aligned} } \end{aligned}$$
\(\square \)
-
(a)
-
2.
\(\langle \sigma _2,\rho _2 \rangle \) is a strict Nash equilibrium and therefore an ESS. Proof: \(EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle )\) is a unique maximum in the fourth row.
-
(a)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \text { }&> EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \\&\Rightarrow \text { }&1 - \frac{\epsilon _r}{2} \text { }&> \text { } \frac{3}{4} - \frac{\epsilon _s}{2}\\&\Rightarrow \text { }&\frac{1}{2} \text { }&> \text { } \epsilon _r - \epsilon _s \surd \\ \end{aligned} } \end{aligned}$$
-
(b)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \text { }&> EU_p(\langle \sigma _1,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \\&\Rightarrow \text { }&1 - \frac{\epsilon _r}{2} \text { }&> \text { } 1 - \frac{\epsilon _s+\epsilon _r}{2}\\&\Rightarrow \text { }&\epsilon _s \text { }&> \text { } 0 \surd \\ \end{aligned} } \end{aligned}$$
-
(c)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \text { }&> EU_p(\langle \sigma _2,\rho _1 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \\&\Rightarrow \text { }&1 - \frac{\epsilon _r}{2} \text { }&> \text { } \frac{3}{4}\\&\Rightarrow \text { }&\frac{1}{2} \text { }&> \text { } \epsilon _r \surd \\ \end{aligned} } \end{aligned}$$
\(\square \)
-
(a)
-
3.
\(\langle \sigma _1,\rho _2 \rangle \) is not a Nash equilibrium and therefore not an ESS. Proof: \(EU_p(\langle \sigma _1,\rho _2 \rangle ,\langle \sigma _1,\rho _2 \rangle )\) is not a maximum in the second row.
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _1,\rho _2 \rangle ,\langle \sigma _1,\rho _2 \rangle ) \text { }&< EU_p(\langle \sigma _2,\rho _1 \rangle ,\langle \sigma _1,\rho _2 \rangle ) \\&\Rightarrow \text { }&1 - \frac{\epsilon _r+\epsilon _s}{2} \text { }&< \text { } 1\\&\Rightarrow \text { }&0 \text { }&< \text { } \epsilon _r+\epsilon _s \\ \end{aligned} } \end{aligned}$$\(\square \)
-
4.
\(\langle \sigma _2,\rho _1 \rangle \) is not a Nash equilibrium and therefore not an ESS. Proof: \(EU_p(\langle \sigma _2,\rho _1 \rangle ,\langle \sigma _2,\rho _1 \rangle )\) is not a maximum in the third row.
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _2,\rho _1 \rangle ,\langle \sigma _2,\rho _1 \rangle ) \text { }&< EU_p(\langle \sigma _1,\rho _2 \rangle ,\langle \sigma _2,\rho _1 \rangle ) \\&\Rightarrow \text { }&\frac{1}{2} \text { }&< \text { } 1 - \frac{\epsilon _r+\epsilon _s}{2}\\&\Rightarrow \text { }&\epsilon _r+\epsilon _s \text { }&< \text { } 1 \\ \end{aligned} } \end{aligned}$$\(\square \)
1.2 Stochastic stability of \(\langle \sigma _1,\rho _1 \rangle \) and \(\langle \sigma _2,\rho _2 \rangle \) in Table 2
To show: Given EU table Table 2 with \(0<\epsilon _s < \frac{1}{2}\) and \(0< \epsilon _r < \frac{1}{2}\). The strategy pair \(\langle \sigma _1,\rho _1 \rangle \) is stochastically stable iff \(\epsilon _s < \epsilon _r\), and the strategy pair \(\langle \sigma _2,\rho _2 \rangle \) is stochastically stable iff \(\epsilon _s > \epsilon _r\).
For the proof of stochastic stability, I will use the notion of p-dominance (Morris et al. 1995) which addresses the so-called p-value of strategies. The p-value of a strategy for a symmetric game with strategy set S and utility function U is defined in the following way:
Definition 1
(p-value). Given a symmetric \(n \times n\) game with a set of n strategies S and a utility function over strategies \(u: S^2\rightarrow \mathbb {R}\). Let \(\sigma _{NE} \subseteq S\) be the set of all strategies that are Nash equilibria. Furthermore, let’s define the gain of strategy s against itself versus another strategy \(s'\) against it by the function \(g(s,s') = u(s,s) - u(s',s)\), and let’s define the bypass gain of a strategy s against a strategy \(s'\) by the function \(b(s,s') = \max _{s''}(u(s,s'')-u(s',s''))\). Then the direct p-potential between two strategies s and \(s'\) can be defined as \(d(s,s') = \frac{b(s',s)}{b(s',s)+g(s,s')}\). The p-value of a strategy is defined by its maximal p-potential over all strategies that are Nash equilibria:
The strategy with the minimal p-value is called the p-dominant strategy of the game (Morris et al. 1995). Moreover, Maruta (1997) was able to show that a p-dominant strategy s with \(p(s) < \frac{1}{2}\) is the only stochastically stable strategy of the game. With access to the notion of p-dominance and its relationship to stochastic stability, I will show the following:
-
1.
If \(\epsilon _s < \epsilon _r\) then \(p(\langle \sigma _1,\rho _1 \rangle ) < \frac{1}{2}\) and is therefore the only stochastically stable strategy. Proof: Note that since only \(\langle \sigma _1,\rho _1 \rangle \) and \(\langle \sigma _2,\rho _2 \rangle \) are Nash Equilibria, only these two strategy pairs have to be considered. Furthermore, in the following I abbreviate \(\langle \sigma _1,\rho _1 \rangle \) with \(\pi _1\) and \(\langle \sigma _2,\rho _2 \rangle \) with \(\pi _2\). Then the p-value of \(\pi _1\) can be computed by the following steps (cf. Definition ):
-
\(g(\pi _1, \pi _2) = EU_p(\pi _1,\pi _1)- EU_p(\pi _2,\pi _1) = 1- \frac{\epsilon _s}{2} - \frac{3}{4} + \frac{\epsilon _r}{2} = \frac{1}{4} - \frac{\epsilon _s}{2} + \frac{\epsilon _r}{2}\)
-
\(b(\pi _2,\pi _1) = EU_p(\pi _2,\pi _2)- EU_p(\pi _1,\pi _2) = 1- \frac{\epsilon _r}{2} - \frac{3}{4} + \frac{\epsilon _s}{2} = \frac{1}{4} - \frac{\epsilon _r}{2} + \frac{\epsilon _s}{2}\)
-
\(d(\pi _1,\pi _2) = \frac{b(\pi _2,\pi _1)}{b(\pi _2,\pi _1)+g(\pi _1, \pi _2)} = \frac{1}{2} - \epsilon _r + \epsilon _s\)
-
\(p(\pi _1) = d(\pi _1,\pi _2) = \frac{1}{2} - \epsilon _r + \epsilon _s\)
It is easy to see that if \(\epsilon _s < \epsilon _r\) the \(p(\langle \sigma _1,\rho _1 \rangle ) = p(\pi _1) < \frac{1}{2}\). \(\square \)
-
-
2.
If \(\epsilon _s > \epsilon _r\) then \(p(\langle \sigma _2,\rho _2 \rangle ) < \frac{1}{2}\) and is therefore the only stochastically stable strategy. Proof: With the same premises and notation as before, the p-value of \(\pi _2\) can be computed by the following steps (cf. Definition ):
-
\(g(\pi _2, \pi _1) = EU_p(\pi _2,\pi _2)- EU_p(\pi _1,\pi _2) = 1- \frac{\epsilon _r}{2} - \frac{3}{4} + \frac{\epsilon _s}{2} = \frac{1}{4} - \frac{\epsilon _r}{2} + \frac{\epsilon _s}{2}\)
-
\(b(\pi _1,\pi _2) = EU_p(\pi _1,\pi _1)- EU_p(\pi _2,\pi _1) = 1- \frac{\epsilon _s}{2} - \frac{3}{4} + \frac{\epsilon _r}{2} = \frac{1}{4} - \frac{\epsilon _s}{2} + \frac{\epsilon _r}{2}\)
-
\(d(\pi _2,\pi _1) = \frac{b(\pi _1,\pi _2)}{b(\pi _1,\pi _2)+g(\pi _2, \pi _1)} = \frac{1}{2} - \epsilon _s + \epsilon _r\)
-
\(p(\pi _2) = d(\pi _2,\pi _1) = \frac{1}{2} - \epsilon _s + \epsilon _r\)
It is easy to see that if \(\epsilon _s > \epsilon _r\) the \(p(\langle \sigma _2,\rho _2 \rangle ) = p(\pi _2) < \frac{1}{2}\). \(\square \)
-
1.3 Evolutionary stability of \(\langle \sigma _1,\rho _1 \rangle \), \(\langle \sigma _2,\rho _2 \rangle \) and \(\langle \sigma _3,\rho _3 \rangle \) in Table 3
To show: Given EU table Table 3 with \(0<\epsilon _s < \frac{1}{4}\) and \(0< \epsilon _r < \frac{1}{4}\). The strategy pairs \(\langle \sigma _1,\rho _1 \rangle \), \(\langle \sigma _2,\rho _2 \rangle \) and \(\langle \sigma _3,\rho _3 \rangle \) are evolutionarily stable.
-
1.
\(\langle \sigma _1,\rho _1 \rangle \) is a strict Nash equilibrium and therefore an ESS. Proof: \(EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle )\) is a unique maximum in the first row.
-
(a)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \text { }&> EU_p(\langle \sigma _1,\rho _2 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \\&\Rightarrow \text { }&1 - 2\epsilon _s \text { }&> \text { } \frac{3}{4}-\epsilon _s-\epsilon _r\\&\Rightarrow \text { }&\frac{1}{4} \text { }&> \epsilon _s-\epsilon _r \surd \\ \end{aligned} } \end{aligned}$$
-
(b)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \text { }&> EU_p(\langle \sigma _3,\rho _3 \rangle ,\langle \sigma _1,\rho _1 \rangle ) \\&\Rightarrow \text { }&1 - 2\epsilon _s \text { }&> \text { } \frac{7}{8}-\frac{3\epsilon _s+\epsilon _r}{2}\\&\Rightarrow \text { }&\frac{1}{4} \text { }&> \epsilon _s-\epsilon _r \surd \\ \end{aligned} } \end{aligned}$$
\(\square \)
-
(a)
-
2.
\(\langle \sigma _2,\rho _2 \rangle \) is a strict Nash equilibrium and therefore an ESS. Proof: \(EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle )\) is a unique maximum in the second row.
-
(a)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \text { }&> EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \\&\Rightarrow \text { }&1 - (\epsilon _s + \epsilon _r) \text { }&> \text { } \frac{3}{4} - 2\epsilon _s\\&\Rightarrow \text { }&\frac{1}{4} \text { }&> \text { } \epsilon _r - \epsilon _s \surd \\ \end{aligned} } \end{aligned}$$
-
(b)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \text { }&> EU_p(\langle \sigma _3,\rho _3 \rangle ,\langle \sigma _2,\rho _2 \rangle ) \\&\Rightarrow \text { }&1 - (\epsilon _r+\epsilon _r) \text { }&> \text { } \frac{7}{8} - \frac{3\epsilon _s+\epsilon _r}{2}\\&\Rightarrow \text { }&\frac{1}{4} \text { }&> \text { } \epsilon _r - \epsilon _s \surd \\ \end{aligned} } \end{aligned}$$
\(\square \)
-
(a)
-
3.
\(\langle \sigma _3,\rho _3 \rangle \) is a strict Nash equilibrium and therefore an ESS. Proof: \(EU_p(\langle \sigma _3,\rho _3 \rangle ,\langle \sigma _3,\rho _3 \rangle )\) is a unique maximum in the third row.
-
(a)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _3,\rho _3 \rangle ,\langle \sigma _3,\rho _3 \rangle ) \text { }&> EU_p(\langle \sigma _1,\rho _1 \rangle ,\langle \sigma _3,\rho _3 \rangle ) \\&\Rightarrow \text { }&1 - \frac{3\epsilon _s + \epsilon _r}{2} \text { }&> \text { } \frac{7}{8} - 2\epsilon _s\\&\Rightarrow \text { }&\frac{1}{4} \text { }&> \text { } \epsilon _r - \epsilon _s \surd \\ \end{aligned} } \end{aligned}$$
-
(b)
$$\begin{aligned} { \begin{aligned}&EU_p(\langle \sigma _3,\rho _3 \rangle ,\langle \sigma _3,\rho _3 \rangle ) \text { }&> EU_p(\langle \sigma _2,\rho _2 \rangle ,\langle \sigma _3,\rho _3 \rangle ) \\&\Rightarrow \text { }&1 - \frac{3\epsilon _s + \epsilon _r}{2} \text { }&> \text { } \frac{7}{8} - (\epsilon _s+\epsilon _r)\\&\Rightarrow \text { }&\frac{1}{4} \text { }&> \text { } \epsilon _s - \epsilon _r \surd \\ \end{aligned} } \end{aligned}$$
\(\square \)
-
(a)
1.4 Conditions for stochastic stability of \(\langle \sigma _1,\rho _1 \rangle \), \(\langle \sigma _2,\rho _2 \rangle \), \(\langle \sigma _3,\rho _3 \rangle \) in Table 3
To show: Given EU table Table 3 with \(0<\epsilon _s < \frac{1}{4}\) and \(0< \epsilon _r < \frac{1}{4}\). The strategy pair \(\langle \sigma _1,\rho _1 \rangle \) is stochastically stable iff \(\epsilon _s < \epsilon _r\), the strategy pair \(\langle \sigma _2,\rho _2 \rangle \) is stochastically stable iff \(\epsilon _s > \epsilon _r\), and the strategy pair \(\langle \sigma _3,\rho _3 \rangle \) is not stochastically stable for any parameter combination.
For the proof I will address the notion of p-dominance (Morris et al. 1995) as already used in “Appendix A.2”. With access to the notion of p-dominance and its relationship to stochastic stability, I will show the following:
-
1.
If \(\epsilon _s < \epsilon _r\) then \(p(\langle \sigma _1,\rho _1 \rangle ) < \frac{1}{2}\) and is therefore the only stochastically stable strategy.
Note that since \(\langle \sigma _1,\rho _1 \rangle \), \(\langle \sigma _2,\rho _2 \rangle \) and \(\langle \sigma _2,\rho _2 \rangle \) are Nash Equilibria, all three strategy pairs have to be considered. Furthermore, in the following I abbreviate \(\langle \sigma _1,\rho _1 \rangle \) with \(\pi _1\), \(\langle \sigma _2,\rho _2 \rangle \) with \(\pi _2\) and \(\langle \sigma _3,\rho _3 \rangle \) with \(\pi _3\). Then the p-value of \(\pi _1\) can be computed by the following steps:
\(\pi _1\) vs \(\pi _2\):
-
\(g(\pi _1, \pi _2) = EU_p(\pi _1,\pi _1)- EU_p(\pi _2,\pi _1) = 1- 2\epsilon _s - \frac{3}{4} + \epsilon _s + \epsilon _r = \frac{1}{4} - \epsilon _s + \epsilon _r\)
-
\(b(\pi _2,\pi _1) = EU_p(\pi _2,\pi _2)- EU_p(\pi _1,\pi _2) = 1- \epsilon _s - \epsilon _r - \frac{3}{4} + 2\epsilon _s = \frac{1}{4} + \epsilon _s - \epsilon _r\)
-
\(d(\pi _1,\pi _2) = \frac{b(\pi _2,\pi _1)}{b(\pi _2,\pi _1)+g(\pi _1, \pi _2)} = \frac{1}{2} + 2\epsilon _s - 2\epsilon _r\)
\(\pi _1\) vs \(\pi _3\):
-
\(g(\pi _1, \pi _3) = EU_p(\pi _1,\pi _1)- EU_p(\pi _3,\pi _1) = 1- 2\epsilon _s - \frac{7}{8} + \frac{3\epsilon _s+\epsilon _r}{2} = \frac{1}{8} - \frac{\epsilon _s}{2} + \frac{\epsilon _r}{2}\)
-
\(b(\pi _3,\pi _1) = EU_p(\pi _3,\pi _3)- EU_p(\pi _1,\pi _3) = 1- \frac{3\epsilon _s+\epsilon _r}{2} - \frac{7}{8} + 2\epsilon _s = \frac{1}{8} + \frac{\epsilon _s}{2} - \frac{\epsilon _r}{2}\)
-
\(d(\pi _1,\pi _3) = \frac{b(\pi _3,\pi _1)}{b(\pi _3,\pi _1)+g(\pi _1, \pi _3)} = \frac{1}{2} + 2\epsilon _s - 2\epsilon _r\)
p-value of \(\pi _{1}\):
-
\(p(\pi _1) = \max (d(\pi _1,\pi _2),d(\pi _1,\pi _3)) = \frac{1}{2} + 2\epsilon _s - 2\epsilon _r\)
It is easy to see that if \(\epsilon _s < \epsilon _r\) then \(p(\pi _1) < \frac{1}{2}\). \(\square \)
-
-
2.
If \(\epsilon _s > \epsilon _r\) then \(p(\langle \sigma _2,\rho _2 \rangle ) < \frac{1}{2}\) and is therefore the only stochastically stable strategy.
With the same premises and notation as in proof 1, the p-value of \(\pi _2\) can be computed by the following steps:
\(\pi _2\) vs \(\pi _1\):
-
\(g(\pi _2,\pi _1) = EU_p(\pi _2,\pi _2)- EU_p(\pi _1,\pi _2) = 1- \epsilon _s - \epsilon _r - \frac{3}{4} + 2\epsilon _s = \frac{1}{4} + \epsilon _s - \epsilon _r\)
-
\(b(\pi _1, \pi _2) = EU_p(\pi _1,\pi _1)- EU_p(\pi _2,\pi _1) = 1- 2\epsilon _s - \frac{3}{4} + \epsilon _s + \epsilon _r = \frac{1}{4} - \epsilon _s + \epsilon _r\)
-
\(d(\pi _2,\pi _1) = \frac{b(\pi _1,\pi _2)}{b(\pi _1,\pi _2)+g(\pi _2, \pi _1)} = \frac{1}{2} - 2\epsilon _s + 2\epsilon _r\)
\(\pi _2\) vs \(\pi _3\):
-
\(g(\pi _2, \pi _3) = EU_p(\pi _2,\pi _2)- EU_p(\pi _3,\pi _2) = 1- (\epsilon _s + \epsilon _r ) - \frac{7}{8} + \frac{3\epsilon _s+\epsilon _r}{2} = \frac{1}{8} + \frac{\epsilon _s}{2} - \frac{\epsilon _r}{2}\)
-
\(b(\pi _2,\pi _3) = EU_p(\pi _3,\pi _3)- EU_p(\pi _2,\pi _3) = 1- \frac{3\epsilon _s+\epsilon _r}{2} - \frac{7}{8} + \epsilon _s + \epsilon _r = \frac{1}{8} - \frac{\epsilon _s}{2} + \frac{\epsilon _r}{2}\)
-
\(d(\pi _2,\pi _3) = \frac{b(\pi _3,\pi _2)}{b(\pi _3,\pi _2)+g(\pi _2, \pi _3)} = \frac{1}{2} - 2\epsilon _s + 2\epsilon _r\)
p-value of \(\pi _{2}\)
-
\(p(\pi _2) = \max (d(\pi _2,\pi _1),d(\pi _2,\pi _3)) = \frac{1}{2} - 2\epsilon _s + 2\epsilon _r\)
It is easy to see that if \(\epsilon _s > \epsilon _r\) then \(p(\pi _2) < \frac{1}{2}\). \(\square \)
-
-
3.
For all \(\epsilon _s, \epsilon _r > 0\): \(p(\langle \sigma _3,\rho _3 \rangle ) \ge \frac{1}{2}\) and is therefore never the only stochastically stable strategy.
With the same premises and notation as in proof 1 and 2, the p-value of \(\pi _3\) can be computed by the following steps:
\(\pi _3\) vs \(\pi _1\):
-
\(g(\pi _3,\pi _1) = EU_p(\pi _3,\pi _3)- EU_p(\pi _1,\pi _3) = 1- \frac{3\epsilon _s+\epsilon _r}{2} - \frac{7}{8} + 2\epsilon _s = \frac{1}{8} + \frac{\epsilon _s}{2} - \frac{\epsilon _r}{2}\)
-
\(b(\pi _1, \pi _3) = EU_p(\pi _1,\pi _1)- EU_p(\pi _3,\pi _3) = 1- 2\epsilon _s - \frac{7}{8} + \frac{3\epsilon _s+\epsilon _r}{2} = \frac{1}{8} - \frac{\epsilon _s}{2} + \frac{\epsilon _r}{2}\)
-
\(d(\pi _3,\pi _1) = \frac{b(\pi _1,\pi _3)}{b(\pi _1,\pi _3)+g(\pi _3, \pi _1)} = \frac{1}{2} - 2\epsilon _s + 2\epsilon _r\)
\(\pi _3\) vs \(\pi _2\):
-
\(g(\pi _3,\pi _2) = EU_p(\pi _3,\pi _3)- EU_p(\pi _2,\pi _3) = 1- \frac{3\epsilon _s+\epsilon _r}{2} - \frac{7}{8} + \epsilon _s + \epsilon _r = \frac{1}{8} - \frac{\epsilon _s}{2} + \frac{\epsilon _r}{2}\)
-
\(b(\pi _2, \pi _3) = EU_p(\pi _2,\pi _2)- EU_p(\pi _3,\pi _2) = 1- (\epsilon _s + \epsilon _r ) - \frac{7}{8} + \frac{3\epsilon _s+\epsilon _r}{2} = \frac{1}{8} + \frac{\epsilon _s}{2} - \frac{\epsilon _r}{2}\)
-
\(d(\pi _3,\pi _2) = \frac{b(\pi _2,\pi _3)}{b(\pi _2,\pi _3)+g(\pi _3, \pi _2)} = \frac{1}{2} + 2\epsilon _s - 2\epsilon _r\)
p-value of \(\pi _{3}\):
-
\(p(\pi _3) = \max (d(\pi _3,\pi _1),d(\pi _3,\pi _2)) = \left\{ \begin{array}{ll} \frac{1}{2} + 2\epsilon _s - 2\epsilon _r &{} \text {if } \epsilon _s > \epsilon _r \\[3mm] \frac{1}{2} - 2\epsilon _s + 2\epsilon _r &{} \text {else} \end{array} \right. \)
It is easy to see that for all \(\epsilon _s, \epsilon _r > 0\): \(p(\pi _3) \ge \frac{1}{2}\). \(\square \)
-
1.5 Stochastic stability of \(\langle \sigma _1,\rho _1 \rangle \), \(\langle \sigma _2,\rho _2 \rangle \), \(\langle \sigma _3,\rho _3 \rangle \) in Table 3 when sender and receiver costs are equal
To show: Given EU table Table 3 with \(0<\epsilon _s < \frac{1}{4}\) and \(0< \epsilon _r < \frac{1}{4}\). With respect to stochastic stability, the strategy pairs \(\langle \sigma _1,\rho _1 \rangle \), \(\langle \sigma _2,\rho _2 \rangle \), and \(\langle \sigma _3,\rho _3 \rangle \) are expected to emerge with the same probability in the long run if and only if \(\epsilon _s = \epsilon _r\).
For the proof I will address the notion of p-dominance (Morris et al. 1995) as already used in “Appendix A.2”. With access to the notion of p-dominance and its relationship to stochastic stability, it can be shown that all three strategy pairs have the same p-value of \(\frac{1}{2}\). Note that the proofs in “Appendix A.4” entailed the following p-values:
-
\(p(\langle \sigma _1,\rho _1 \rangle ) = \frac{1}{2} + 2\epsilon _s - 2\epsilon _r\)
-
\(p(\langle \sigma _2,\rho _2 \rangle ) = \frac{1}{2} - 2\epsilon _s + 2\epsilon _r\)
-
\(p(\langle \sigma _3,\rho _3 \rangle ) = \left\{ \begin{array}{ll} \frac{1}{2} + 2\epsilon _s - 2\epsilon _r &{} \text {if } \epsilon _s > \epsilon _r \\[3mm] \frac{1}{2} - 2\epsilon _s + 2\epsilon _r &{} \text {else} \end{array} \right. \)
It is easy to see from these equations that \(p(\langle \sigma _1,\rho _1 \rangle ) = p(\langle \sigma _2,\rho _2 \rangle ) = p(\langle \sigma _3,\rho _3 \rangle ) = \frac{1}{2}\) if and only if \(\epsilon _s = \epsilon _r\). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mühlenbernd, R. Evolutionary stability of ambiguity in context signaling games. Synthese 198, 11725–11753 (2021). https://doi.org/10.1007/s11229-020-02826-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11229-020-02826-6