
Abstract
Symmetric noise is the prevailing assumption in production analysis, but it is often violated in practice. Not only does asymmetric noise cause least-squares models to be inefficient, it can hide important features of the data which may be useful to the firm/policymaker. Here, we outline how to introduce asymmetric noise into a production or cost framework as well as develop a model to introduce inefficiency into said models. We derive closed-form solutions for the convolution of the noise and inefficiency distributions, the log-likelihood function, and inefficiency, as well as show how to introduce determinants of heteroskedasticity, efficiency and skewness to allow for heterogenous results. We perform a Monte Carlo study and profile analysis to examine the finite sample performance of the proposed estimators. We outline R and Stata packages that we have developed and apply to three empirical applications to show how our methods lead to improved fit, explain features of the data hidden by assuming symmetry, and how our approach is still able to estimate efficiency scores when the least-squares model exhibits the well-known “wrong skewness” problem in production analysis. The proposed models are useful for modeling risk linked to the outcome variable by allowing error asymmetry with or without inefficiency.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The usage of symmetric noise in econometric models engraves the assumption that a circumstance, choice, or behavior of an economic agent is ruled by the normal law where positive and negative deviations from the “trend” have the same effect on the outcome variable of an individual firm. There is substantial evidence across a wide array of fields to suggest that in practice, symmetry is not always a reasonable assumption (e.g., Genton 2004).
Asset Pricing: The probability distribution of asset returns is often skewed (Adcock 2007). When the distribution is asymmetric, the mean and variance are not sufficient statistics for investors to make optimal asset allocation decisions and ordinary least-squares (OLS) estimation is inefficient. Hence, authors have looked to methods that exploit the asymmetric nature of the data. For example, Adcock (20052010) employ multivariate skewed distributions to study the sensitivity of asset returns to return on the market portfolio. These methods extend the mean-variance methods for portfolio selection to mean-variance-skewness which can lead to improvements in performance.
Risk Management: A popular measure of an investment prospect is Value at Risk (VaR), which measures the risk of loss for investments. It is obtained by focusing on the the bottom tail of the returns distribution. For simplicity and convenience, it is often naively assumed that the distribution is symmetric. Assuming symmetry can vastly understestimate the risk being taken on by the investor. Exploiting the asymmetric nature of the data can lead to gains. For example, Goh et al. (2012) are able to outperform mean-variance approaches using half-space statistical information when asset returns are asymmetric.
Banking: Asymmetric shocks can severely impact banks. For example, managers may take on excess risk as a consequence of a principal agent problem. These low probability events emerge as large negative shocks. On the other side, deposits across large banks and savings institutions or within a single bank are highly positively skewed (Aubuchon and Wheelock 2010). In practice, the direction of the asymmetry may not be clear a priori.
Supply Shocks: Ball and Mankiw (1995) study the effects of supply shocks on inflation (i.e., shifts in the short-run Philips curve) based on relative price changes and frictions in nominal price adjustments. Price rigidities typically occur because of a sluggish price adjustment and costs associated with adjusting nominal prices. Firms typically adjust to large shocks, but not to small shocks and thus these large shocks have a disproportional impact on prices. The authors argue in favor of disproportionate effects of supply shocks on inflation and find that the inflation-skewness relationship is stronger than the inflation-variance relationship.
Interest Rate Parity: Louis et al. (1999) account for transaction costs in testing interest rate parity (IRP). They consider the relevant no-arbitrage conditions that in equilibrium are bounded in one direction. They argue that the assumption of symmetric noise in an IRP equation would result in inconsistency and therefore consider skewed composite errors (convolution of symmetric noise and one-sided error term) using stochastic frontier analysis. With this approach, they find that arbitrage margins are sometimes violated and hence there are possible arbitrage opportunities.
Educational Outcomes: There is a large literature estimating production functions using educational data (e.g., de Witte and López-Torres 2017, de Witte et al. 2010, Johnes et al. 2017, Ruggiero 1996, Thanassoulis et al. 201620172018, Thanssoulis 1999). Random shocks occur in education and some of these can be unpleasant or terrible events such as bullying, bereavement, unfair treatment, or an external event such as a school shooting. In practice, it is common to model these “shocks” as inputs in an educational production function (Ponzo 2013). Alternatively, we can allow for these large negative impacts on educational outcomes (Gershenson and Tekin 2018) to be treated as shocks. We no longer need to attribute such observations as outliers, because asymmetric noise distributions can potentially account for these unfortunate events.
Weather: Asymmetry in weather shocks also plays a role in production. Floodings, droughts, tornadoes and earthquakes are thought of as low probability events, but can result in huge damages. In agriculture, adverse events play an important role as they jeopardize the harvest. For example, Qi et al. (2015) use climactic variables as inputs in a stochastic production frontier of Wisconsin dairy farms. Modeling these events via asymmetric shocks may help determine potential losses which may prove useful for crop insurance premiums (Shaik 2013).
Measurement Error: Finally, one source of asymmetry could be measurement error. Consider the case where the output variable is measured with a one-sided error in a production function (or in a stochastic production frontier). This would produce the same type of behavior that we are attempting to model. For example, Millimet and Parmeter (2022) argue that one-sided measurement error is common for outcome variables used in political science as variables such as casualities are reported via governments which may have an incentive to skew their values.
1.1 Modeling asymmetry in production
If such asymmetries in preferences and behavior are not accounted for, we may estimate the wrong model that eventually leads to incorrect policy prescriptions. For example, the normality of the crop yield has long been rejected and was shown to be skewed, and ignoring this lead to overprediction of field crop yields (Day 1965). Profits can be driven by asymmetric capacities (Mao et al. 2019).
The main goal of this paper is to model production uncertainty by allowing for asymmetric noise in production analysis. The modeling of asymmetric noise is extremely rare in production economics.Footnote 1 We propose a set of models that introduce asymmetric noise in estimation of a production relationship in situations where a researcher believes that the production units may operate with or without efficiency.
1.2 Inefficiency
In empirical applications, firms or individuals are often assumed to operate with 100% efficiency. In neoclassical economics, firms and economic agents can exhibit inefficiency by being below their production possibilities. The conceptualization and formulation of inefficiency in production can be traced back to Koopmans (1951) and Afriat (1972).
In their seminal econometric papers, Aigner et al. (1977) and Meeusen and van den Broeck (1977) formulated stochastic frontier (SF) models, where inefficiency followed a half-normal and exponential distribution, respectively. Many extensions of these models exist and include other distributions for the unobserved inefficiency component. These include assuming the distribution of inefficiency to be truncated normal (Stevenson 1980), truncated normal with determinants (Kumbhakar et al. 1991), jointly estimated technical and allocative efficiency (Kumbhakar and Tsionas 2005), generalized exponential distribution of inefficiency (Papadopoulos 2021), semiparametric smooth coefficient framework (Yao et al. 2019), dealing with endogeneity (Amsler et al. 2016, Lai and Kumbhakar 2018, Lien et al. 2018) and modeled where noise can follow any (symmetric) law (Florens et al. 2020). Greene (2008) and Stead et al. (2019) discuss methodological advances in stochastic frontier modeling and especially distributional specifications. While in academic papers the convolution of the noise and inefficiency distributions are overwhelming skewed (Li 1996), each of these models assumes that the noise is term is symmetrically (overwhelmingly normally) distributed (Horrace and Parmeter 2018, Wheat et al. 2019).Footnote 2
Here we will propose a SF model whereby the skewness of the composite error (convolution of noise and inefficiency) may have either sign. We formulate a composite error that is skew-normal for the noise and has a one-sided distribution for the inefficiency component. We are able to derive closed-form solutions for the convolution of the two distributions as well as the log-likelihood function and its gradients. Further, we derive closed-form solutions for the inefficiency estimates as well as discuss how to incorporate determinants of heteroskedasticity, efficiency and skewness to allow for heterogenous effects.
It turns out, with our approach, if we take the stance that “wrong skewness” is an empirical issue (e.g., Simar and Wilson 2009), we are still able to estimate efficiency scores when least-squares residuals are of the “wrong skewness” (Cho and Schmidt 2020, Olson et al. 1980).Footnote 3 In this case, the SF model is inconsistent with the data and it is assumed that there is no inefficiency.
1.3 Finite sample performance
Obviously, all of our parameters are identified by the parametric assumptions on the model and the maximum likelihood principle, however, in practice, it can sometimes be difficult to estimate parameters via standard maximum likelihood techniques. This seems especially true when we have two forms of asymmetry and the sign of one of those is potentially unknown. To understand how our estimators perform in various scenarios and with various sample sizes, we conduct a Monte Carlo study and profile analysis. We obtain reliable estimates of the variance parameters in all scenarios and reliable estimates of our skewness parameter for sample sizes at or above above 200. In short, our study suggests that our estimators possess desirable finite sample properties.
1.4 Empirical performance
In order to see how asymmetric noise distributions perform in practice, we provide three empirical applications. The first application looks at risk behavior of U.S. Banks. We re-examine the cost function in Restrepo-Tobón and Kumbhakar (2014) both with and without assuming symmetric noise. Our metrics suggest that the SF model with skewed noise best fits the data. We further discover that the most risky banks (as determined by the standard deviation of return on assets) are more likely to be hit by negative shocks that have large negative effects on total costs.
In our second example, we look at an educational production function. Here we take the data collected by Gershenson and Tekin (2018) to see the impact the “Beltway Sniper” had on public school student math test scores in Virginia. As in the previous example, our SF model with asymmetric noise best fits the data. Here we find that skewness of the noise distribution is negative and is getting closer to 0 as a school is further away from a sniper attack. In other words, for those schools that are close to at least one sniper attack scene, they have a larger probability to exhibit poor academic performance.
In these first two examples, we demonstrate the performance of the proposed models applied to cost and production functions, respectively. We conclude that the model that takes the skewness of the noise distribution into account is superior to the model with symmetric noise. In both applications, we find that the most flexible model that allows (i) skewed noise where (ii) the parameters of its distribution vary across observations as well as (iii) inefficiency with observation-specific determinants performs best and provides the richest scope for interpretation. We expect that these methods will prove fruitful in uncovering previously ignored/misplaced information.
In our final example, we take data from the NBER-CES Manufacturing Industry Database (Bartelsman and Gray 1996) and examine the efficiency scores of 4-digit textile industries. For each year (1958–2011), we run separate cross-sectional regressions and report both the estimated skewness parameter and average efficiency score for each year. While most skewness estimates are near zero, many estimates are significantly above or below zero. In those years where the model has the “wrong skewness”, the conventional SF model predicts no inefficiency. This is found to be the case in about half of the cases. For our SF model, for those years, the average estimated efficiency scores are below unity.
1.5 Roadmap
The remainder of the paper is organized as follows: Section 2 summarizes the skew-normal distribution. Section 3 proposes to allow for skew-normal noise in a production or cost function as well as extends the model to allow for inefficiency. This section further examines the finite sample performance of our estimators and how to implement the procedures in both R and Stata with packages that we have created. Section 4 provides our empirical examples and the fifth section concludes. The appendices include our full set of derivations (Appendix A), extensions to truncated normal inefficiency (Appendix B), the results of the simulation study and profiling analysis (Appendix C) as well as R code to help replicate our empirical and simulation results (Appendix E).
2 Skew-normal distribution
In what follows, we employ a skew-normal (SN) noise distribution. While other distributions may be feasible or more general, we chose this skewed distribution for at least five reasons. First, it is a well studied skewed distribution with known properties and inferential aspects. Second, the standard model with normally distributed noise is a special case of the SN. Third, we are able to derive closed form solutions for many objects of interest. Fourth, it can be skewed in either direction and only requires one additional parameter to estimate.Footnote 4 Finally, our analysis can be the basis for extensions to more complicated skew-elliptical distributions (Azzalini and Capitanio 2013, Genton 2004).
Formally, the SN distribution generalizes the normal distribution by allowing for non-zero skewness. The probability density function of the extended SN distribution with the skewness parameters α0 and α1, the location parameter \(\xi \in {\mathbb{R}}\), and the variance \({\sigma }_{\omega }^{2}\, >\, 0\) is given by
where ϕ(⋅) and Φ(⋅) are the density and distribution functions of a standard normal distribution, respectively. We say that ω is skew-normally distributed: ω ~ SN(ξ, σ2, α0, α1).
Azzalini (1985) proposes to set α0 = 0 so the skewness is determined by a single parameter (α ≡ α1).Footnote 5 The density becomes
where the expected value of ω ~ SN(ξ, σ2, α) is
For the case where \(E\left(\omega \right)=0\), the density in (1) can be concentrated in terms of ξ and can be written as
where the rescaled and shifted ω is given by
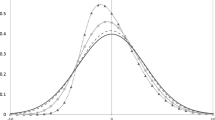
The shape of the density is determined by the parameter α. The upper and lower panels of Fig. 1 show densities of a SN random variable for σω = 0.1 and σω = 5. The two plots differ only by the scale of the axes. Here we choose only to show negative values of the skewness parameter (α < 0). For positive values of α, the density is flipped symmetrically around 0. As the absolute value of α increases, the skewness of the distribution is increasing. For α = ∞, the skew normal distribution becomes the truncated normal (Horrace 2005a, b). Figure 1 suggests that the distribution is very skewed (i.e., approaches the truncated normal distribution) for an absolute value of α around 10.Footnote 6

pdf of the skew-normal random variable
3 Production model
In this section, we describe how to introduce an asymmetric noise distribution into a production framework. We then derive the results for this noise distribution in a stochastic frontier framework. More specifically, we derive closed form solutions for the convolution of the noise and inefficiency distributions, the log-likelihood function, and inefficiency, as well show how to introduce determinants of heteroskedasticity, efficiency and skewness to allow for heterogenous results. Finally, we discuss finite sample performance via a Monte Carlo and profile analysis as well as mention R and Stata packages that we have developed and will distribute so that our results may be replicated and for authors to use for their own studies.
Our production function can be written as
where the outcome variable y is the logarithm of output for a stochastic production function (or the logarithm of cost for a stochastic cost function). \(f\left({{{\boldsymbol{x}}}};{{{\boldsymbol{\beta }}}}\right)\) is a log-linear (in parameters) production or cost function with input row vector x (a constant, logarithms of the input variables and possibly other observed covariates that include environment variables that are not primary inputs, but nonetheless affect the outcome variable) and the finite parameter vector β (Sun et al. 2011).
We assume that the noise v is SN distributed with zero expectation, E(v) = 0,
with a probability density function (pdf) adopted from equation (2)
The log-likelihood function for a log-linear (in parameters) conditional expectation production (or cost) function with SN noise is given as
and the parameters can be estimated via maximum-likelihood (ML). Note that while least-squares estimation here is unbiased as it is equivalent to the quasi-maximum likelihood estimator under the assumption of normally distributed errors, it is no longer efficient (Yao and Zhao 2013).
Here we note the relationship of what we have just presented to the model originally proposed by Aigner et al. (1977), where the error term v in (3) is composed of a symmetric component that is normally distributed with a variance ς2 and a non-negative technical inefficiency component that is half-normally distributed with variance τ2. Replacing α in (4) by τ/ς and σv by \(\sqrt{{\tau }^{2}+{\varsigma }^{2}}\) yields the likelihood function for the model proposed by Aigner et al. (1977) (see equation (13.2) in Domínguez-Molina et al. 2004 as well as the discussion in Badunenko and Kumbhakar 2016). In other words, the popular SF model can be seen as a special case of the model considered in (3). The inferential aspects of this special case were studied in Badunenko et al. (2012).
With the exception of Li (1996), SF models employ asymmetric compound noise. However, those models assume that the asymmetry that is present in the composite error term is due to existing technical inefficiencies. We propose a set of models where we split the asymmetry/skewness into components attributable to uncertainty (skewed noise) and technical inefficiency (non-negative error part). We show that they can be separated. In what follows, we present a more general model, where inefficiency exists and the noise can be skewed.
3.1 Production model with inefficiency
In the presence of inefficiency, (3) becomes
where, analogous to before, the outcome variable y is the logarithm of output for a stochastic production frontier model or the logarithm of cost for a stochastic cost frontier model, x is the row vector of a constant, logarithms of the input variables and possibly other observed covariates that include environment variables that are not primary inputs but nonetheless affect the outcome variable. To present this in a general setting, we introduce the known value p, which signifies either a production or cost function:
We assume that the noise v is SN distributed with a zero expectation, E(v) = 0,
with a pdf adopted from equation (2)
We assume that the inefficiency term is exponentially distributed (Jradi et al. 2021), so its density is given by
where \(\lambda =\frac{1}{{\sigma }_{u}}\).Footnote 7 Denoting \({\xi }_{v}=-{\sigma }_{v}\sqrt{\frac{2}{\pi }}\frac{\alpha }{\sqrt{1+{\alpha }^{2}}}\) and noting from equation (5) that ϵ = v − pu, and v − ξv = ϵ + pu − ξv = ϵr + pu, where ϵr = ϵ − ξv, the joint density of u and ϵ is given by
3.1.1 Convolution of the skew normal and exponential distributions
The marginal density of ϵ is obtained by integrating u out of f(ϵ, u), noting that u ≥ 0 (i.e., \(f(\epsilon )=\int\nolimits_{0}^{\infty }f(\epsilon ,u)du\)). To do so, we first rewrite equation (6) as
Then,
The integral
can be obtained in a closed form using Owen’s T-function (see Owen 19561980). The details of the derivation are given in Appendix A. Denote the solution to (7) as \({{{\mathcal{A}}}}\):
where a = − αpλσv, b = αp, \({a}_{2}=a/\sqrt{1+{b}^{2}},{u}_{1}={\mathrm{p}}{\epsilon }_{r}/{\sigma }_{v}+\lambda {\sigma }_{v}\) and
Then the marginal density can be given in closed form as
where examples of this probability density function for a few choices of the three parameters σv, α and σu are shown in Fig. 2.

pdf of the convolution of skew-normal and exponential random variables, ϵ = v − pu, where p = −1
Given the above information, the log-likelihood based on (9) is
The full derivation, as well as the gradients of this log-likelihood function, which are useful for programming purposes, can be found in Appendix A.
3.1.2 Efficiency estimation
To obtain observation-specific estimates of inefficiency (u), we follow Jondrow et al. (1982) and first obtain the conditional distribution of u given ϵ:
We then obtain the point estimator for u (observation-specific) by finding the mean value of the conditional distribution in (11),
It can be shown (see Appendix A) that the integral in (12) has a closed form solution,
where \({\mathcal{A}}\) is defined in (8) and a, b, and u1 are defined immediately after. The estimates of efficiency can be obtained by exponentiating the negation of the quantity in (13).
3.1.3 Comparison to existing approaches
There are at least three differences between existing models and those proposed here. First, we consider a skew-normal exponential model. Wei et al. (2021a) use a half-normal distribution instead of an exponential distribution. Our own simulations along with the discussion in Papadopoulos and Parmeter (2021) and Papadopoulos (2022) suggest possible major identification issues in the skew-normal half-normal setting (and no issue with a skew-normal exponential setting). An identification problem can occur because a skew-normal distribution can be obtained via the convolution of a half-normal and a normal distribution and we apriori do not know the sign of the noise skewness. Papadopoulos (2022) shows a similar result when looking at combining an asymmetric Laplace with exponential inefficiency (even with a correctly specified model). His solution, assuming availability, is to include determinants of inefficiency. We will discuss this possibility in the next section.
Second, we derive the results in closed form, this precludes non-convergence due to approximations and adds precision to the estimates of the frontier and efficiencies. Speed of estimation is also gained which is helpful for the multistart procedure we discuss later.
Third, we introduce determinants of all error components along with skewness. While this has been studied for both variance and inefficiency, none of the aforementioned papers do so with respect to the skewness parameter.
There has also been some work on incorporating copulas into efficiency analysis (Bonanno et al. 2017 and Wei et al. 2021b). From a statistical point of view, this appears to be a generalization of our approach. Conceptually, however, we are not quite sure why we would want to introduce this dependence between the error term and inefficiency. That being said, if it did exist, these estimators would be preferable. However, if it does not exist (our prior) our model would exploit this effect and would be more efficient. We leave the comparison of these methods to future research.
3.1.4 Determinants of heteroskedasticity, efficiency, and skewness
It is feasible to modify our approach to allow for determinants of all parameters of error components (Kumbhakar et al. 1991, Lien et al. 2018). In other words, assuming data are available, we can model each component (variance, inefficiency and skewness) with both a deterministic and a stochastic component. We can attempt to explain the performance of firms based on exogenous variables within the firm’s production environment.Footnote 8 Examples of naturally occurring environment variables include, but are not limited to, human capital levels of managers, input and output quality measures, market share and/or climactic variables.
The noise term can be made heteroskedastic by allowing the variance to depend upon a set of exogenous environment variables (zv). To ensure that the variance is positive, we adopt the following specification
where the parameter vector γv may include an intercept term. Since noise in a production relationship can be viewed as production risk, the typically employed determinant of noise variance is the size of the unit of observation (e.g., total assets in banking).
Similarly, the variance of inefficiency, and hence the inefficiency itself, can be modeled to depend upon a set of exogenous environment variables (zu). Again, to ensure that the variance is positive, we adopt the specification
where the parameter vector γu may include an intercept term.
The first two approaches exist in the literature (Caudill et al. 1995), and here we suggest they analogously be extended for the skewness parameter to allow for heterogenous effects. Our skewness parameter can be made observation specific via
where again, the parameter vector γs may include an intercept term. Allowing for heterogeneity in skewness may be particularly useful as we may be able to determine that some firms are more susceptible to negative shocks than others. Note that this formulation allows for the skewness to take either sign and heterogeneity (as we will see later in our empirical applications) allows for both signs within a given dataset.
3.2 Finite sample performance
The parameters of (3) and (5) are obtained using maximum likelihood estimation (MLE) based on (4) and (10), respectively. The theoretical properties of MLE are well-known and all our parameters are identified by the parametric assumptions on the model. However, it can sometimes be difficult to obtain reliable estimates for some datasets in practice. The finite sample properties of the MLE estimator for (4) for different parameter constellations has been studied by Azzalini and Capitanio (1999) and Badunenko et al. (2012). If one considers (5) to be a generic statistical model with two skewed distributions, Badunenko and Kumbhakar (2016) studied the finite sample properties of a special case of this model.
For completeness, we have performed a small Monte Carlo study and profile analysis (Ritter and Bates 1996). Tables with estimated bias and MSE as well as likelihood profiles are available in Appendix C. The plots of the medians of the likelihood ratio statistics show the effect the sample size has on the finite sample performance of the estimator. As expected, the parameters are more precisely estimated with larger samples. We find some evidence that α may be difficult to estimate precisely for sample sizes below 200. Further, some profiles suggest the possibility of local maxima for α (Azzalini and Capitanio 2013, Chapter 3). To avoid this issue in practice, we suggest using a multistart procedure for optimization when using Broyden-Fletcher-Goldfarb-Shanno (BFGS) or Newton-Raphson (NR) methods.Footnote 9 The variance parameters in both (3) and (5) are precisely estimated in all scenarios.
Out of curiosity, we also wanted to see how estimates fared versus those which assume symmetry. To study this, for each production function, we generate the noise from either a Skew Normal (Appendix D.1) or a Normal distribution (Appendix D.2). The results are primarily as expected. This holds true for the parameters of the model and the efficiency scores (Appendix D). The traditional model wins out when the true distribution is symmetric and our approach tends to dominate when the noise is asymmetric. The R code for this can be found in Appendix E.5.
Overall, our Monte Carlo studies suggests that our estimators possess desirable finite sample properties.
3.3 Stata and R packages
All the analysis above can be performed using packages we have created in R (the snreg R package) and Stata statistical softwares. The R package and the Stata command can be obtained from the authors’ websites. Both softwares are accompanied by help and example files. In both softwares the names of the commands are snreg and snsf. Different from the selm command from the R package sn, the snreg command allows for determinants of heteroskedasticity as in (14) and skewness as in (16). Appendix E presents R code to help replicate our empirical results, which we discuss next.
4 Empirical illustration
In this section, we demonstrate the usefulness of our proposed methodology in three separate applications. We will look at both cost and production functions with symmetric and asymmetric noise. We will further introduce inefficiency of production units into our models. Finally, we will highlight our most flexible model that allows asymmetric noise and inefficiency, as well as determinants of (i) heteroskedasticity, (ii) inefficiency, and (iii) skewness.
We will showcase such comparisons by modeling risk in the U.S. banking industry, the effect of extreme adverse events on educational outcomes, and finally, annual data from the U.S. textile sector.
4.1 U.S. Banks
For our first application, we use a random subset of the firms employed in Restrepo-Tobón and Kumbhakar (2014). We chose a random sample of 500 banks observed in 2007 and whose total assets were between the 10th and 90th percentiles of the total assets distribution, and whose total costs were between the 10th and 90th percentiles of the total costs distribution. The code to obtain our random sample is shown in Appendix E.2.1.Footnote 10
Our goal is to estimate and compare the following models: (N0) symmetric noise with no inefficiency, (SN0) asymmetric noise with no inefficiency, (SF0) symmetric noise with inefficiency, (SF1) asymmetric noise with inefficiency and (SF2) asymmetric noise with inefficiency and determinants. These models go from the most restrictive to the most general. If the noise is asymmetric, inefficiency exists and our determinants are significant, we expect SF2 to perform best. However, if none of those events are true, N0 represents the most efficient model.
4.1.1 Translog cost function
We assume a full translog specification of the technology where 2 outputs are produced by 3 inputs. To ensure the necessary condition that the cost function is homogeneous of degree 1, we divide the total costs and prices of the first two inputs by the price of the third input.Footnote 11 More formally, our translog cost function is given as
where TC represents total costs of the bank, Y1 and Y2 are their outputs (total securities of the bank and total loans, respectively) and W1, W2 and W3 are their inputs (cost of fixed assets, cost of labor and cost of borrowed funds, respectively).Footnote 12 Each of the β represent parameters to be estimated and the form of ϵ will depend upon the model chosen.
Table 1 presents the results of our translog cost function for each of the above specifications. Recall that Model N0 is the traditional cost function where the noise is homoskedastic and symmetric, i.e., vi ~ N(0, σv) in (3).Footnote 13 Model SN0 allows the noise to be SN, where the skewness parameter α is the same for all observations. Model SF0 is the standard SF model where noise is normally distributed with a constant variance and inefficiency is exponentially distributed. Model SF1 extends model SF0 by allowing noise to be SN.
Following the above discussion, we suggest a model where risk influences total costs of production through the noise. More specifically, for each bank, the shape/skewness of the distribution of the noiseFootnote 14 depends upon the risk level of that bank. Thus, risk affects the total costs of a bank, not directly, but rather through the expected shock that a bank experiences due to being risky. Therefore, model SF2 allows the skewness parameter to be bank-specific as in (16). Here we employ a commonly used risk measure in the banking literature (Koetter et al. 2012), standard deviation of return on assets (sdroa).Footnote 15 It can be viewed as the variability in returns.
Model SF2 also adds explanatory variables for heteroskedasticity and inefficiency (Equations (14) and (15), respectively). For the variance, we look at the total assets (TA) of the bank and for inefficiency, we use a scope variable, which is the Hirschman-Herfindahl index across five loan categories (i.e., how focused a bank is in terms of loans).Footnote 16
4.1.2 Results
Our most basic comparison is between the first two models: N0 and SN0 (symmetric and asymmetric noise without inefficiency, respectively). The estimated skewness coefficient is 1.38, which is significant at conventional levels. The noise distribution is close to the pink density shown in Fig. 1, mirrored around 0. The N0 model is rejected by the LR test in favor of the SN0 model (p-value of the LR test is 0.0036). Although OLS is unbiased, it is no longer efficient in the presence of asymmetric noise.
We now move to introducing inefficiency into our cost function.Footnote 17 Table 1 shows that the symmetric SF model SF0 exhibits better fit than SN0 with the same number of parameters. We should be careful here however as SF0 and SN0 are non-nested and hence the LR-test is not necessarily informative. When we allow both skewed noise and inefficiency (model SF1), the LR test clearly rejects SN0 in favor of SF1 (p-value of the LR test is 6.13e-05)Footnote 18 and also for SF1 in favor of SF0 (p-value of the LR test is 0.0078). However, note that SF1 restricts the shapes of the noise and inefficiency distributions to be the same for all banks. The most flexible model, SF2, best fits the data among all those considered in Table 1. The LR test gives preference to SF2 over SF1 (the p-value of the LR test is 7.57e-05).Footnote 19
Figure 3 shows the kernel estimated density of the predicted skewness (\(\hat{\alpha }(z)\)) for our preferred model, SF2. The probability mass of a negatively skewed distribution with a zero mean implies that the majority of banks are expected to have a slight negative shock to their operations. Another property of this distribution is that the left tail is thicker than the right. In other words, large positive shocks are more frequent than large negative shocks.

Kernel estimated densities of skewness (Model SF2). The vertical dash-dotted line is 0. The solid vertical line is the mean
Figure 4 plots the predicted skewness against a skewness determinant. There are only a few very risky banks (i.e., sdroa is very large). At low risk levels, the skewness is quite low (approximately − 4 for sdroa). A shock of a low risk bank comes from a very skewed distribution and therefore such a bank is likely to be hit by a negative shock that has a detrimental effect on total costs. At the mean level of sdroa (0.32), the estimated skewness is − 2.5, the value of the estimated skewness in SF1 (where skewness is assumed constant). The skewness remains negative until sdroa reaches 0.95, which is the 96th percentile of the sdroa distribution. For the 4 percent (of the most) risky banks in our sample, the skewness is positive, implying a thicker right tail of the noise distribution.

The estimate of skewness (fitted values) plotted against the determinant (Model SF2). The rug plot on each axis essentially shows a one-dimensional heatmap
It is worth noting that in SF2, the inefficiency determinant scope, is statistically significant. The negative coefficient means that as scope increases, bank inefficiency is decreasing. Further, the determinant of heteroskedasticity (total assets) is also statistically significant. The negative coefficient here suggests that the variance decreases with the size of total assets. Finally, Fig. 5 shows estimated densities of efficiency scores from all of our SF models. There are no marked differences in the distributions.

Kernel estimated densities of efficiencies. Vertical lines are respective means
4.2 Beltway sniper
Here we investigate the effects of the 2002 “Beltway Sniper” mass shootings on student achievement in Virginia’s public elementary schools (Gershenson and Tekin 2018). Traumatic events, especially those which are ‘close to home’, can have serious impacts on student outcomes. However, different from past research (Ponzo 2013), we attempt to model these low probability events in the noise distribution.Footnote 20
We follow Levin (1974) and Hanushek (1979) and consider an educational production function as a process of converting inputs (i.e., school resources) into outputs (i.e., student achievement). We go a step further and account for inefficiency in educational production as it has been argued that estimating educational production functions accounting for inefficiency is a proper approach for examining educational outcomes (Ruggiero 20062019, Thanassoulis et al. 20162018).
4.2.1 Educational production function
Our (school level) educational production function is given as
where the βs represent parameters to be estimated and the composition of ϵ follows the same models in the previous sub-section. math is our output variable measured in logs (school-level proficiency in the Standards of Learning standardized test given each spring in Virginia public schools). Our input variables are student-teacher ratios (ratio), full-time equivalent teachers (fte), percent Black (black), and percent Hispanic (hispanic).
Similar to before, we estimate five different models (N0, SN0, SF0, SF1, and SF2). In this context, “production inefficiency” represents student underachievement. We will use total enrollment (enroll) as a measure of size, percent free lunch (frp), and closeness (closeness) to a sniper attack as determinants of our noise components.Footnote 21closeness is the primary determinant of interest and measures the distance (in miles) the school is from the closest sniper attack.
4.2.2 Results
Table 2 provides the regression results for our familiar set of models. Note that in the previous sub-section we analyzed a cost function (i.e., p = −1) and the smaller outcome variable was preferable. Here, we analyzing a production function (i.e., p = 1) and larger outcome values are preferable (i.e., higher levels of proficiency). The results here represent 5th grade students in the year 2003 (same academic year as the attacks).
It is clear that the SN0 model fits the data far better than N0 (the LR statistic is 136.53 while the critical value of the \({\chi }_{1}^{2}\) at the 1% level of significance is 6.63), and thus there is a good reason to believe the skewness of the noise term is not 0. Based on the LR test, including inefficiency (SF0) provides a better fit than simply allowing for asymmetric noise (the LR statistic is 40.97). When we consider the model that contains both inefficiency and skewness, restricting the shape of the noise distribution for all schools to be the same (model SF1), the constant skewness parameter is not statistically insignificant. The likelihood increased by only 0.4, which is not enough to conclude that SF1 is preferred to SF0. Note that when we do not account for possible skewness in the noise, we overestimate the effect of the proportion of Black or Hispanic students on educational outcome.
The most flexible model (SF2) allows the skewness parameter to vary depending on how close the school is from a shooting scene. We find a significant increase in the log-likelihood (the LR statistic of the LR test between SF2 and SF1 is 118.4 whereas the critical value of the \({\chi }_{3}^{2}\) at the 1% level of significance is 11.34). As for the determinants of the error components, we find that as the proportion of pupils who are eligible for free or reduced-price lunch is increasing, underachievement is increasing. The skewness of the noise distribution is increasing as a school is further away from a sniper attack (as shown in Fig. 6).Footnote 22 The noise for those schools that are close to at least one sniper attack scene, have large negative skewness, implying that the left tail is much thicker than the right tail. In other words, as risk is increasing, schools have a larger probability to exhibit poor, rather than good test results. Figure 7 shows that negative skewness is a feature of the noise distribution for all public schools in our sample.

The estimate of skewness (fitted values) plotted against the respective determinant. The rug plot on each axis essentially shows a one-dimensional heatmap

Kernel estimated density of skewness. The vertical dashed-dotted line is 0. The solid vertical line is the mean
4.3 NBER data: textile industries
Our final application uses data from the well studied (Bonanno et al. 2017) NBER-CES Manufacturing Industry Database (Bartelsman and Gray 1996). For each available year (1958–2011), we focus on the textile industry (SIC 4-digit industry: 2200–2399) because these particular samples are known to exhibit the “wrong skewness” of OLS residuals (Hafner et al. 2018).
We estimate SF models where noise is either assumed to normal or SN and the distribution of the inefficiency term is assumed to be exponentially distributed. In the case of a SN distribution, we omit determinants and therefore have a constant skewness parameter for each year. In each setting, we use a translog production function where the output (total value added) is produced by capital (total real capital stock), labor (total employment) and materials (total cost of materials).
Figure 8 plots the estimated skewness parameter for each year. The blue circles represent coefficients that are statistically insignificant, while the red triangles represent statistically significant estimates of α. We do not observe uniformity of coefficient magnitudes; they range from roughly −2.5 to approximately 6. Although we see both signs for skewness, most estimates are close to 0. With regards to the magnitude, there is no clustering, trend, or situation where the estimates appear to be persistent over time. The skewness coefficient can be negative in 1 year and positive the year after. Finally, there appears to be no clustering or trend with respect to significance of the estimated coefficients.

The estimated skewness coefficient by year
Figure 9 dissects Fig. 8 to differentiate between years where the skewness of the OLS residuals are negative (‘correct’ skewness) or positive (‘wrong’ skewness). In years where the SN-Exp model results in a large positive significant skewness parameter, the skewness of OLS residuals is ‘wrong’. Where the skewness of OLS residuals is ‘correct’, the skewness parameter is only rarely significant.

The estimated skewness coefficient by year
Finally, Fig. 10 shows average efficiency scores by year for both the asymmetric and symmetric noise models. In years where the OLS residuals are of the ‘wrong skewness’, the conventional SF model predicts no inefficiency (i.e., the average efficiency score is 1). We observe this in about half of the cases. In each of those years, our model estimates inefficiency (the average efficiency score is around 0.975). In about 10% of the years, the average efficiencies from both models are the same. This happens in years when the skewness of the OLS residuals is ‘correct’ and the estimated skewness coefficient in our model is indistinguishable from 0 and is statistically insignificant (red circles in Fig. 9). Considering both what we have seen here and our simulations, there is evidence that our approach can identify inefficiency in each year of our sample.

The average of the efficiency score estimated by N-Exp and SN-Exp models by year
5 Conclusions
In this paper, we propose to model asymmetric noise in production analysis. We discussed how to estimate a production or cost function with asymmetric noise and extended this model for a skew-normal noise distribution for stochastic frontier analysis. Our methods result in closed form solutions for the log-likelihood function and inefficiency. We are able to incorporate determinants of these components (heteroskedasticity, inefficiency and skewness) in an estimation procedure that jointly estimates all parameters of interest. The set of the proposed models will be instrumental to researchers who wish, for example, to model risk associated with the outcome variable by allowing for asymmetry in the error term with or without inefficiency.
We showcased these methods in simulations as well as in three separate empirical applications, including one that showed that our approach is able to estimate efficiency scores when OLS residuals are of the “wrong skewness”. Given that we have produced user-friendly R and Stata packages, we believe that these techniques can easily be applied across a wide range of fields within production analysis.
Notes
Bonanno et al. (2017) consider a generalized logistic distribution for noise, Wei et al. (2021a) consider a skew-normal distribution, while Wei et al. (2021b) consider a skew normal copula-based stochastic frontier model. Horrace et al. (2022) look at asymmetry in production models using quantile methods. The set of models that we introduce in this article go a step further by deriving closed-form solutions and introducing determinants into each of the components. Models that introduce technical inefficiency into a production process (Domínguez-Molina et al. 2004), which we discuss next, are also exceptions. However, as we show below, the latter models are special cases of a model with a general asymmetric noise.
"Wrong skewness” is an empirical artifact that occurs when least-squares residuals have a positive skew in a production function or negative skew in a cost function.
This convenience and simplicity comes at a price as the “SN family does not provide an adequate stochastic model for cases with high skewness or kurtosis” (Azzalini and Capitanio 2013). That being said, the SN distribution offers a statistical model that regulates the skewness, is tractable (closed form solutions) and is easily interpretable.
See Azzalini and Capitanio (2013, Chapter 2) for details on the extended skew-normal distribution.
See DiCiccio and Monti (2004) for inferential aspects of the parameters of the SN distribution.
We also considered the case of truncated normally distributed inefficiency (u) and these results are provided in Appendix B.
Both BFGS and NR optimization methods are available as options in our R and Stata procedures. The starting values for the vector of parameters to maximize (10) are chosen as follows. We use the method of moments values for the normal-exponential model to define starting values of all parameters except the skewness part. If zs in (16) contains only a constant, the multistart procedure goes over values from − 2 to 2 with an interval of 0.1 as starting values for α; ± 0.01 are used instead of 0. If zs contains also variables, the starting values for the slopes in (16) are set to 0. Using multistarts proved to work well both in our simulations and empirical examples.
We repeated this experiment several times to ensure that the general conclusions were not dependent upon this particular sample of banks.
The choice of which input price is a numeraire does not affect the estimation.
For a more detailed description of the data, see Koetter et al. (2012).
Model N0 is essentially OLS, however it is fit by the ML estimator under the assumption that the noise is normally distributed.
We also tried Z-score of a bank. These results are similar and are available upon request.
The five categories of loans are listed as agricultural, commercial and industrial, individual, real estate, and other.
Recall that with a symmetric noise such as in SF0, ϵ in (5) is negatively skewed for a production function and positively skewed for a cost function.
The careful reader will have noticed that the signs of the skewness parameters in SN0 and SF1 are flipped. Note that they are not expected to have the same sign, as the noise in SF1 is only a part of the compound error term. The cumulant of noise in an SN model is
$${K}_{{v}_{SN0}}(t)=\ln 2-{\sigma }_{{v}_{SN0}}\sqrt{\frac{2}{\pi }}\frac{{\alpha }_{SN0}}{\sqrt{1+{\alpha }_{SN0}^{2}}}t+\frac{{\sigma }_{{v}_{SN0}}^{2}{t}^{2}}{2}+\ln \left[\Phi \left({\sigma }_{{v}_{SN0}}\frac{{\alpha }_{SN0}}{\sqrt{1+{\alpha }_{SN0}^{2}}}t\right)\right],$$while the cumulant of noise in an SN-Exp model is
$$\begin{array}{rcl}{K}_{{\epsilon }_{SF1}}(t)&=&\ln 2-{\sigma }_{{v}_{SF1}}\sqrt{\frac{2}{\pi }}\frac{{\alpha }_{SF1}}{\sqrt{1+{\alpha }_{SF1}^{2}}}t+\frac{{\sigma }_{{v}_{SF1}}^{2}{t}^{2}}{2}\\ &&+\ln \left[\Phi \left({\sigma }_{{v}_{SF1}}\frac{{\alpha }_{SF1}}{\sqrt{1+{\alpha }_{SF1}^{2}}}t\right)\right]+{\mathsf{p}}\ln \left(1-{\sigma }_{u}t\right),\forall {\sigma }_{u} < 1/t.\end{array}$$(17)Even if the noise in both SN0 and SF1 have (roughly) the same third moment (t = 3), the α parameters are likely to be different due to presence of σu.
In all LR tests, we consider a standard χ2 distribution for the LR statistic as the tested parameters are not bounded.
It would be interesting to see our estimator applied to studies about the effect of bullying on educational outcomes (e.g., Lacey and Cornell 2013).
Estimating different specifications of an educational production function and noise components led to the same conclusions.
As in the previous application, we find a positive relationship between the determinant and skewness parameter. However, in this application, a larger determinant implies a lower risk.
References
Adcock CJ (2005) Exploiting skewness to build an optimal hedge fund with a currency overlay. Eur J Finance 11:445–462
Adcock CJ (2007) Extensions of Stein’s lemma for the skew-normal distribution. Commun Stat Theory Methods 36:1661–1671
Adcock CJ (2010) Asset pricing and portfolio selection based on the multivariate extended skew-Student-t distribution. Ann Oper Res 176:221–234
Afriat SN (1972) Efficiency estimation of production functions. Int Econ Rev 13:5–23
Aigner D, Lovell CAK, Schmidt P (1977) Formulation and estimation of stochastic frontier production function models. J Econ 6:21–37
Amsler C, Prokhorov A, Schmidt P (2016) Endogeneity in stochastic frontier models. J Econ 190:280–288
Aubuchon CP, Wheelock DC (2010) The geographic distribution and characteristics of U.S. bank failures, 2007–2010: do bank failures still reflect local economic conditions? Fed Bank St. Louis Rev 92:395–415
Azzalini A (1985) A class of distributions which includes the normal ones. Scand J Stat 12:171–178
Azzalini A, Capitanio A (1999) Statistical applications of the multivariate skew normal distribution. J R Stat Soc 61:579–602
Azzalini A, Capitanio A (2013) The Skew-Normal and Related Families. Institute of Mathematical Statistics Monographs Cambridge University Press
Badunenko O, Henderson DJ, Kumbhakar SC (2012) When, where and how to perform efficiency estimation. J R Stat Soc Ser A175:863–892
Badunenko O, Kumbhakar SC (2016) When, where and how to estimate persistent and transient efficiency in stochastic frontier panel data models. Eur J Oper Res 255:272–287
Ball L, Mankiw NG (1995) Relative-price changes as aggregate supply shocks. Quart J Econ 110:161–193
Bartelsman EJ, Gray W (1996) The NBER Manufacturing Productivity Database. Working Paper 205, National Bureau of Economic Research
Bonanno G, De Giovanni D, Domma F (2017) The ‘wrong skewness’ problem: a respecification of stochastic frontiers. J Prod Anal 47:49–64
Caudill SB, Ford JM, Gropper DM (1995) Frontier estimation and firm-specific inefficiency measures in the presence of heteroscedasticity. J Bus Econ Stat 13:105–11
Chavas J-P, Chambers RG, Pope RD (2010) Production economics and farm management: a century of contributions. Am J Agric Econ 92:356–375
Cho C-K, Schmidt P (2020) The wrong skew problem in stochastic frontier models when inefficiency depends on environmental variables. Empir Econ 58:2031–2047
Day RH (1965) Probability distributions of field crop yields. J Farm Econ 47:713–741
de Witte K, López-Torres L (2017) Efficiency in education: a review of literature and a way forward. J Oper Res Soc 68:339–363
de Witte K, Thanassoulis E, Simpson G, Battisti G, Charlesworth-May A (2010) Assessing pupil and school performance by non-parametric and parametric techniques. J Oper Res Soc 61:1224–1237
DiCiccio TJ, Monti AC (2004) Inferential aspects of the skew exponential power distribution. J Am Stat Assoc 99:439–450
Domínguez-Molina JA, González-Farías G, Ramos-Quiroga R (2004) Coastal flooding and the multivariate skew-t distribution. In: Genton MG (ed.) Skew-Elliptical Distributions and Their Applications, Ch 14, 1st edn. Chapman and Hall/CRC, New York, p 243–258
Florens J-P, Simar L, Van Keilegom I (2020) Estimation of the boundary of a variable observed with symmetric error. J Am Stat Assoc 115:425–441
Genton, MG (ed) (2004) Skew-elliptical distributions and their applications: a journey beyond normality, 1st edn. Chapman and Hall/CRC, New York
Gershenson S, Tekin E (2018) The effect of community traumatic events on student achievement: evidence from the beltway sniper attacks. Educ Finance Policy 13:513–544
Goh JW, Lim KG, Sim M, Zhang W (2012) Portfolio value-at-risk optimization for asymmetrically distributed asset returns. Eur J Oper Res 221:397–406
Greene WH (2008) The Econometric Approach to Efficiency Analysis. In: The Measurement of Productive Efficiency and Productivity Change Oxford University Press, New York
Hafner CM, Manner H, Simar L (2018) The “wrong skewness” problem in stochastic frontier models: a new approach. Econ Rev 37:380–400
Hanushek EA (1979) Conceptual and empirical issues in the estimation of educational production functions. J Hum Resour 14:351–388
Horrace WC (2005) On ranking and selection from independent truncated normal distributions. J Econ 126:335–354.
Horrace WC (2005) Some results on the multivariate truncated normal distribution. J Multivar Anal 94:209–221
Horrace WC, Parmeter CF (2018) A laplace stochastic frontier model. Econ Rev 37:260–280
Horrace WC, Parmeter CF, Wright I (2022) On Asymmetry and Quantile Estimation of the Stochastic Frontier Model. Working Paper. University of Miami
Johnes J, Portela M, Thanassoulis E (2017) Efficiency in education. J Oper Res Soc 68:331–338
Jondrow J, Lovell CAK, Materov IS, Schmidt P (1982) On the estimation of technical inefficiency in the stochastic frontier production function model. J Econ 19:233–238
Jradi S, Parmeter CF, Ruggiero J (2021) Quantile estimation of stochastic frontiers with the normal-exponential specification. Eur J Oper Res 295:475–483
Just RE, Pope RD (1978) Stochastic specification of production functions and economic implications. J Econ 7:67–86
Kibara MJ, Kotosz B (2019) Estimation of stochastic production functions: the state of the art. Hungarian Stat Rev 2:57–89
Koetter M, Kolari JW, Spierdijk L (2012) Enjoying the quiet life under deregulation? evidence from adjusted lerner indicies for U.S. banks. Rev Econ Stat 94:462–480
Koopmans TC (1951) An Analysis of Production as an Efficient Combination of Activities. In: Koopmans TC (ed.) Activity Anlaysis of Production and Allocation, chap. 13 Cowles Commission for Research in Economics, New York: Wiley
Kumbhakar SC, Ghosh S, McGuckin JT (1991) A generalized production frontier approach for estimating determinants of inefficiency in U.S. dairy farms. J Bus Econ Stat 9:279–286
Kumbhakar SC, Parmeter CF, Zelenyuk V (2020) Stochastic frontier analysis: Foundations and advances i. Handbook of production economics, 1–40
Kumbhakar SC, Tsionas EG (2005) The joint measurement of technical and allocative inefficiencies. J Am Stat Association 100:736–747
Lacey A, Cornell D (2013) The impact of teasing and bullying on schoolwide academic performance. J Appl Sch Psychol 29:262–283
Lai H-p, Kumbhakar SC (2018) Endogeneity in panel data stochastic frontier model with determinants of persistent and transient inefficiency. Econ Lett 162:5–9
Levin HM (1974) Measuring efficiency in educational production. Pub Financ Q 2:3–24
Li Q (1996) Estimating a stochastic production frontier when the adjusted error is symmetric. Econ Lett 52:221–228
Lien G, Kumbhakar SC, Alem H (2018) Endogeneity, heterogeneity, and determinants of inefficiency in Norwegian crop-producing farms. Int J Prod Econ 201:53–61
Louis H, Blenman LP, Thatcher JS (1999) Interest rate parity and the behavior of the bid-ask spread. J Financ Res 22:189–206
Mao Z, Liu W, Feng B (2019) Opaque distribution channels for service providers with asymmetric capacities: Posted-price mechanisms. Int J Prod Econ 215:112–120
Meeusen W, van den Broeck J (1977) Efficiency estimation from Cobb-Douglas production functions with composed error. Int Econ Rev 18:435–444
Millimet DL, Parmeter CF (2022) Accounting for skewed or one-sided measurement error in the dependent variable. Political Anal 30:66–88
Olson JA, Schmidt P, Waldman DM (1980) A monte carlo study of estimators of stochastic frontier production functions. J Econ 13:67–82
Owen DB (1956) Tables for computing bivariate normal probabilities. Ann Math Stat 27:1075–1090
Owen DB (1980) A table of normal integrals. Commun Stat Simul Comput 9:389–419
Papadopoulos A (2021) Stochastic frontier models using the Generalized Exponential distribution. J Prod Anal 55:15–29
Papadopoulos A (2022) The noise error component in stochastic frontier analysis. Empir Econ 1–35. https://doi.org/10.1007/s00181-022-02339-w
Papadopoulos A, Parmeter CF (2021) Type ii failure and specification testing in the stochastic frontier model. Eur J Oper Res 293:990–1001
Ponzo M (2013) Does bullying reduce educational achievement? an evaluation using matching estimators. J Pol Model 35:1057–1078
Qi L, Bravo-Ureta BE, Cabrera VE (2015) From cold to hot: climatic effects and productivity in Wisconsin dairy farms. J Dairy Sci 98:8664–8677
Restrepo-Tobón D, Kumbhakar SC (2014) Enjoying the quiet life under deregulation? Not quite. J Appl Econ 29:333–343
Ritter C, Bates DM (1996) Profile methods. In Prat A (ed) COMPSTAT Physica-Verlag HD, Heidelberg, p 123–134
Ruggiero J (1996) Efficiency of educational production: an analysis of new york school districts. Rev Econ Stat 78:499–509
Ruggiero J (2006) Measurement error, education production and data envelopment analysis. Econ Educ Rev 25:327–333. Special Issue: In Honor of W. Pierce Liles
Ruggiero J (2019) The Choice of Comparable DMUs and Environmental Variables, Springer International Publishing, Cham, p 123–144
Schmidt P (2011) One-step and two-step estimation in SFA models. J Prod Anal 36:201–203
Shaik S (2013) Crop insurance adjusted panel data envelopment analysis efficiency measures. Am J Agric Econ 95:1155–1177
Simar L, Wilson PW (2009) Inferences from cross-sectional, stochastic frontier models. Econ Rev 29:62–98
Stead AD, Wheat P, Greene WH (2019) Distributional forms in stochastic frontier analysis, Springer International Publishing, Cham, p 225–274
Stevenson RE (1980) Likelihood functions for generalized stochastic frontier estimation. J Econ 13:57–66
Sun K, Henderson DJ, Kumbhakar SC (2011) Biases in approximating log production. J Appl Econ 26:708–714
Thanassoulis E et al. (2016) Applications of data envelopment analysis in education, Springer, Boston, MA, p 367–438
Thanassoulis E, Dey PK, Petridis K, Goniadis I, Georgiou AC (2017) Evaluating higher education teaching performance using combined analytic hierarchy process and data envelopment analysis. J Oper Res Soc 68:431–445
Thanassoulis E, Sotiros D, Koronakos G, Despotis D (2018) Assessing the cost-effectiveness of university academic recruitment and promotion policies. Eur J Oper Res 264:742–755
Thanssoulis E (1999) Setting achievement targets for school children. Educ Econ 7:101–119
Wang H-j, Schmidt P (2002) One-step and two-step estimation of the effects of exogenous variables on technical efficiency levels. J Prod Anal 18:129–144
Wei Z, Conlon EM, Wang T (2021a) Asymmetric dependence in the stochastic frontier model using skew normal copula. Int J Approx Reason 128:56–68
Wei Z, Zhu X, Wang T (2021b) The extended skew-normal-based stochastic frontier model with a solution to ‘wrong skewness’ problem. Statistics 55:1387–1406
Wheat P, Stead AD, Greene WH (2019) Robust stochastic frontier analysis: a Student’s t-half normal model with application to highway maintenance costs in England. J Prod Anal 51:21–38
Yao F, Zhang F, Kumbhakar SC (2019) Semiparametric smooth coefficient stochastic frontier model with panel data. J Bus Econ Stat 37:556–572
Yao W, Zhao Z (2013) Kernel density-based linear regression estimate. Commun Stat Theory Methods 42:4499–4512
Acknowledgements
This paper benefited from feedback provided by colleagues and participants of conferences. We specifically wish to thank Taras Bodnar, William Horrace, Subal Kumbhakar, Pavlo Mozharovskyi, Alecos Papadopoulos, Christopher Parmeter, and Léopold Simar. We wish to thank Seth Gershenson for providing data.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Badunenko, O., Henderson, D.J. Production analysis with asymmetric noise. J Prod Anal 61, 1–18 (2024). https://doi.org/10.1007/s11123-023-00680-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-023-00680-5