
Abstract
Remote sensing is now a valued solution for more accurately budgeting water supply by identifying spectral and spatial information. A study was put in place in a Vitis vinifera L. cv. Cabernet-Sauvignon vineyard in the San Joaquin Valley, CA, USA, where a variable rate automated irrigation system was installed to irrigate vines with twelve different water regimes in four randomized replicates, totaling 48 experimental zones. The purpose of this experimental design was to create variability in grapevine water status, in order to produce a robust dataset for modeling purposes. Throughout the growing season, spectral data within these zones was gathered using a Near InfraRed (NIR) - Short Wavelength Infrared (SWIR) hyperspectral camera (900 to 1700 nm) mounted on an Unmanned Aircraft Vehicle (UAV). Given the high water-absorption in this spectral domain, this sensor was deployed to assess grapevine stem water potential, Ψstem, a standard reference for water status assessment in plants, from pure grapevine pixels in hyperspectral images. The Ψstem was acquired simultaneously in the field from bunch closure to harvest and modeled via machine-learning methods using the remotely sensed NIR-SWIR data as predictors in regression and classification modes (classes consisted of physiologically different water stress levels). Hyperspectral images were converted to bottom of atmosphere reflectance using standard panels on the ground and through the Quick Atmospheric Correction Method (QUAC) and the results were compared. The best models used data obtained with standard panels on the ground and allowed predicting Ψstem values with an R2 of 0.54 and an RMSE of 0.11 MPa as estimated in cross-validation, and the best classification reached an accuracy of 74%. This project aims to develop new methods for precisely monitoring and managing irrigation in vineyards while providing useful information about plant physiology response to deficit irrigation.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
In semi-arid climates, exemplified by the San Joaquin Valley, CA, USA, the discernible depletion of water resources accentuates the exigency for data-centric water management and the widespread adoption of sustainable practices (Alida et al., 2018). The significance of water management in grapevine production cannot be overstated. For decades, tools like the pressure chamber have played a crucial role in facilitating plant-oriented irrigation decisions (Levin et al., 2021). However, recent years have witnessed a surge in sensing methodologies (Bellvert et al., 2015; Brillante et al., 2015) and modeling approaches (Brillante et al., 2016a). The quality of grapes is influenced by their water status across both spatial and temporal dimensions (Brillante et al., 2017; Yu et al., 2021). Furthermore, production outcomes can be modulated through deficit irrigation strategies (Martinez-Luscher et al., 2017; Brillante et al., 2018a). Among the most prevalent deficit irrigation approaches in grapevine cultivation are regulated and sustained deficit irrigation. Regulated deficit irrigation involves scheduling water deficits based on the assumption that the grapevine’s response to stress conditions varies with the growth stage, particularly during pre- and post-veraison (Castellarin et al., 2007; Hardie & Considine, 1976; Matthews et al., 1987). In contrast, sustained deficit irrigation maintains a consistent water deficit regardless of the phenological stage. When implemented optimally, deficit irrigation has the potential to enhance fruit quality and sustainability without compromising yield (Edwards et al., 2013). Emerging systems can implement variable irrigation at a localized scale to tailor the conditions of each row according to a predetermined water schedule, thereby enhancing the efficiency of water utilization. The implementation of such systems necessitates innovative solutions to accurately determine the water requirements of plants with increased spatial resolution.
While grapevines exhibit drought tolerance, prolonged or intense irrigation deficiency can induce physiological changes, impacting both physical and chemical composition (Maimaitiyiming et al., 2020). Remote sensing imagery has the capacity to identify these changes, with structural alterations in cells observable in the NIR domain (De Bei et al., 2011), and water content variations influencing the SWIR signature (Kandylakis et al., 2020). Hyperspectral imaging, combining spectral and spatial information, proves valuable in assessing vine water status. Previous research, such as that by Kandylakis et al. (2020), indicates the utility of UAV-based SWIR (900–1700 nm) reflectance in measuring grapevine stomatal conductance. Nevertheless, for irrigation scheduling purposes, water potential measurements remain the gold standard adopted by growers (Santesteban et al., 2019). Additionally, Laroche-Pinel et al. (2021a), demonstrated that satellite-based NIR (780–875 nm) and SWIR (1565–2280 nm) reflectance at 10–20 m resolution can predict grapevine stem water potential. However, enhanced pixel resolution that is achievable through UAV acquisition, particularly for removing inter-row signatures, is imperative.
While agricultural remote sensing continues to drive economic and environmental advancements through enhanced resource management decisions, apprehensions persist regarding the interpretation, cost, and accuracy linked to UAVs and their associated sensors (Khanal et al., 2020). The objective of this study was to assess the ability of UAV-mounted hyperspectral imagery in the SWIR to predict grapevine water potentials or to classify the water stress levels. We focused on the SWIR as water has specific absorption regions in this domain, and we used UAV as a platform as the proximity of the camera would reduce the interference with the humidity in the atmosphere. This research seeks to present preliminary yet novel data to fill a gap in the existing literature, as no prior studies have investigated the application of such technology and methodology in predicting plant water status.
Materials and methods
Study site and experiment scheme
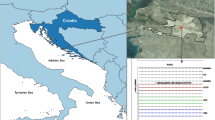
The study was conducted on a commercial vineyard in Cantua Creek, California (36.50745° N, 120.29715° W, WGS84). The vineyard was planted with Vitis vinifera L. cv. Cabernet Sauvignon grafted on rootstock Vitis berlandieri Planch x Vitis Rupestris Scheele cv. 1103 Paulsen and spaced at a distance of 3.3 m between the rows and 2.1 m between the plants. The vines were spur-pruned and trained in a double cordon in a California sprawl trellis. The experimental site was spread across 144 vineyard rows; twelve treatments were replicated four times in a randomized complete block design (Fig. 1). Each block contained three rows, separated by three buffer rows. Within each row, four treatments were established, each consisting of ten vines (21 m long). Measurements were taken from the four central vines, and the results were averaged. The irrigation schedule was assigned following an incomplete factorial design with treatments corresponding to water allocation rates before and after veraison as a percentage of the grower allocation, as presented in Fig. 1. This resulted in four sustained deficit irrigation schedules all over the season, receiving water at rates of 100%, 80%, 60%, and 40% of the control corresponding to the grower allocation (water amounts per plant ranged from 16 L/plant-week (40%) to 40 L/plant-week (100%), and eight regulated deficit irrigation treatments, with varying water amounts “pre” and “post” veraison. Variable deficit irrigation was implemented in weekly intervals (Fig. 1). Vines were tagged and geolocated with a centimeter precision GNSS (Global Navigation Satellite System) receiver.

Schematic representing the trial design showing the geographical location of the experiment, the 48 experimental units in 12 rows where ground data were acquired, and the incomplete factorial design used
Plant water status measurements
Plant water status was measured five times starting on June 15, 2022, around bunch closure, until August 3, 2022, right before the commercial harvest. As in Brillante et al. (2016b), one mature leaf from a primary shoot per vine was bagged in Mylar® 30 min prior to being removed from the plant to allow equilibration with the stem water potential. The stem water potential (Ψstem) was then measured using a pressure chamber (Scholander et al., 1965). The Ψstem values can be used to categorize grapevines as belonging to different levels of water stress, from mild to severe. There is not a universal consensus to translate plant measurements in water stress classes, as it also depends on the variety and environmental conditions (Brillante et al., 2016a; Suter et al., 2019; Dayer et al., 2022), and a few different scales can be found in the literature (Lovisolo et al., 2010, Van Leeuwen et al., 2023). Here, we used this approach: there is a generalized consensus that at about − 1.5 MPa, grapevine starts to enter a severe water stress zone characterized by cavitation and turgor loss (Gambetta et al., 2020). Starting from this threshold of -1.5 MPa, we divided the data into two more classes with − 0.2 MPa increments, as this value corresponds to a change of 1‰ in δ13C (Brillante et al., 2018b) and therefore can be deemed physiologically meaningful. These generated three classes: 1- Moderate stress with Ψstem superior to -1.30 MPa, 2- High stress with Ψstem between − 1.30 MPa and − 1.5 MPa, and 3- Severe stress with Ψstem inferior to − 1.5 MPa. Our translation of Ψstem values to water stress classes is meant to have blurred boundaries and was developed to test a classification approach in this study.
Image acquisition and processing
Data from both aerial and ground sources were gathered simultaneously. The drone employed for all flights was the Matrice 600 Pro (DJI, Shenzhen, China). The hyperspectral camera utilized was the Specim AFX-17 (Specim, Oulu, Finland). This push-broom camera captures images across 112 bands spanning from 900 to 1700 nm. Image collection occurred at an altitude of 30 m. Pixel resolution was adjusted during the post-processing to 3 cm x 3 cm. Each experimental row was imaged individually, and twelve nadir image strips were acquired. As described in Fig. 2, images were first corrected and georeferenced (Step 1), using CaliGeo Pro (Specim, Spectral Imaging Ltd. Oulu, Finland.) then the different flights were merged into one mosaic image, and the region of interest was extracted using ENVI (L3Harris Geospatial, Boulder, Colorado, United States) (Step 2). For the third step, the images were segmented into three classes based on their spectral signature: (1) canopy (2) shadow, and (3) inter-row using perClass Mira (perClass BV, NL). The classification model was trained using manually labeled pixels chosen randomly in the images (~ 500 pixels for each class). The segmentation reached 99.7% overall accuracy on the training set and 90.5% overall accuracy on the test set (100 pixels for each class). A classification mask was exported, and the “canopy” class was extracted from the image. The mean radiance was extracted from each zone for each date (Step 4) and converted to reflectance using a white standard panel positioned in the field during the drone flight, and analysis was performed on reflectance values. Prior to analysis, reflectance spectra were smoothed using a Savitzky–Golay (Savitzky & Golay, 1964) with a moving window of five and a polynomial function of the first order.

Images pre-process steps. 1- The images were corrected and georeferenced. 2- The images were merged to create a mosaic and the region of interest was extracted (corresponding to the portion of the field under variable rate irrigation). 3- The images were segmented based on the spectral signature of the canopy, the soil, and the shadow, and the canopy signature was extracted. 4- Band values were extracted for each experimental unit where ground data were collected
Images captured above the vegetation canopy may undergo alterations due to the atmospheric absorption and scattering mechanisms (Dave, 1980; Kaufman, 1984). In satellite imagery, it is imperative to implement appropriate atmospheric correction procedures to transform the initial top of the atmosphere (TOA) spectral values into spectra at the bottom of the atmosphere (BOA), free from atmospheric influences. These issues are limited when acquiring images closer to the target, as when using UAVs, although correction models have also been proposed for these scenarios (Schläpfer et al., 2020; Suomalainen et al., 2021). Alternatively, a standard panel on the ground can be used. In this study, we tested the use of a standard panel on the ground, and also compared results obtained with the application, prior to canopy extraction, of an atmospheric correction method called Quick Atmospheric Correction (QUAC), which is a module implemented in ENVI. The use of this last method results in the removal of the water absorption bands around 1400 nm.
Machine-learning analysis
To explore the possibility to use hyperspectral SWIR images to predict vine water status, two different types of models were tested in this study: 1- Regression models to predict Ψstem values and 2- classification models to predict water stress category from moderate to severe water stress as described in Section “Plant water status measurements”.
Six supervised models were used in this study for regression and classification purposes using the scikit-learn package in Python (Pedregosa et al., 2011). All of them were tested using a five-fold cross-validation. The “balanced class weight” parameter of scikit-learn was used for the classifications to automatically adjust weights inversely proportional to class frequencies in the input data. Hyperparameter optimization was used to improve model performances. When no improvement was observed, the values were set to scikit-learn default, and when the parameters were optimized, the specific values are indicated below for each model.
The first approach tested was a K-neighbors model, KNN (Guo et al., 2003), the idea behind KNN is that to predict the class or value of a new data point, it looks at the k-closest data points from the training set and use their known classes or values to make a prediction. The “k” in KNN represents the number of nearest neighbors considered when making a prediction (for this study k = 10 for the classifier and k = 5 for the regressor). KNN is known for its simplicity and intuitive approach, but it may not perform well in high-dimensional or large datasets. It’s also sensitive to irrelevant features and noise in the data (Zhang, 2016).
The second approach tested was Random Forest, RF, (Breinmann, 2001), it is an ensemble learning method that operates by constructing a multitude of decision trees during training and outputs the class (classification) or mean prediction (regression) of the individual trees. Each decision tree is trained on a random subset of the training data, and at each node of the tree, a random subset of features is considered for splitting. It has proven to be a versatile and powerful tool in machine learning, widely used for both classification and regression tasks in agriculture (Belgiu and Dragut, 2016). The parameters that were optimized in this work are the number of trees and the maximum depth of the tree; in this study, the number of trees was set to 80 and the maximum depth to 5 for the regression and 10 for the classification.
The third approach tested was the Extra Tree algorithm, short for Extremely Randomized Trees, is an ensemble learning method that shares similarities with Random Forest. It builds a collection of decision trees, each trained on a bootstrap sample of the training data and incorporates an additional layer of randomness in the tree-building process (Geurts et al., 2006). The number of trees was set to 20 for this study.
The fourth approach tested was Gradient Boosting Machine, GBM, a machine learning ensemble technique that aims to create a strong predictive model by combining the outputs of multiple weak learners, usually decision trees, in a sequential manner (Friedman, 2001). Unlike bagging approaches such as Random Forest, where trees are built independently, gradient boosting builds trees sequentially. The learning rate was set to 0.1, and the number of boosting stages to perform to 100.
The fifth approach tested was Partial Least Square, PLS, (Höskuldsson, 1988). It is particularly useful when dealing with datasets where the number of predictor variables (features) is high, like hyperspectral data, and when there may be multicollinearity among these variables (Wold et al., 2001). The number of components was set to 15 after optimization.
Finally, a Support Vector Machine, SVM, was tested (Chapelle et al., 1999). The fundamental principle behind SVM is to find the optimal hyperplane that separates data points of different classes in a feature space. This hyperplane is chosen such that it maximizes the margin, which is the distance between the hyperplane and the nearest data points of each class, also known as support vectors. For the classification, the kernel used was a polynomial function of degree 2 and a regularization parameter (C) of 10. For the regression, the kernel was a linear function with C = 10.
Regression model results were compared using the coefficient of determination (R2) and root mean square error (RMSE), and classification results were compared using the mean overall accuracy.
The best two models for regression and for classification were then explored to investigate the distribution of the predicted values or classes compared to the observed ones using a plot of the measured and predicted values for the regression and using confusion matrices for the classification. The importance of each spectral band was also analyzed for the best models to understand better what part of the spectra was the most useful to reduce the error in predicting Ψstem.
Results
Grapevine water status
The Ψstem, assessed throughout the 2022 season, exhibited a range between − 1.2 MPa and − 1.8 MPa. There was a gradual decline from June to early August, indicating a transition from moderate water stress to severe water stress, as illustrated in Fig. 3. Notably, the decline intensified after mid-July, reaching a point where all plants experienced severe water stress. For classification purposes, 17 data points belong to the first category, “Moderate Water Stress,” 70 measurements to the second category, “High Water Stress,” and 100 measurements to the last one, “Severe Water Stress.”

Evolution of Ψstem measured during the 2022 season. The trend line represents the average of all experimental units; error bars represent the standard deviations of the mean values
Models’ comparison
Table 1 displays the outcomes of the machine learning models used for predicting Ψstem values (regression) or classes (classification) with the different corrections of the data to BOA reflectance for the testing sets. The most effective models are highlighted in bold. In terms of regression, both Random Forest (RF) and Support Vector Machine (SVM) demonstrated superior performance, achieving the highest R2 (0.54) and the lowest RMSE (0.11 MPa) in cross-validation results. As for classification, the Partial Least Squares (PLS) model exhibited the highest accuracy at 74.17%, while Random Forest (RF) reached the second-highest accuracy at 72.77%.
Applying atmospheric correction using QUAC and not the standard panel lowers the precision and accuracy of all the models, with the best R2 being only 0.24 and RMSE 0.14 MPa for the regression and the best accuracy of 61.25% for the classification, both achieved with the SVM model.
Best regression models exploration
Figure 4 shows the distribution of measured and predicted Ψstem values of the two best regression models RF (2a) and SVM (2b). Both distribution clouds showcase a generally acceptable fit, but there is a slight dispersion observed. While the models capture the overall trend, the scattered points suggest some variability in the predictions, indicating that certain data points deviate from the model’s expected values.

Scatterplot of measured vs. predicted Ψstem values with RF (left) and SVM (right) models for testing set (n = 187, R2 = 0.54, RMSE = 0.11 MPa for both models)
Figure 5 shows the importance of the spectral bands used by the two best regression models in Ψstem prediction, using reflectance data obtained using the standard panel on the ground. The RF model used mostly the bands located around 1420 nm and 1460 nm (Fig. 5a). Concerning the SVM, the most important bands are located around 1050 nm and 1200 nm (Fig. 5b).

Importance of each spectral band in the RF model (a) and the SVM model (b) for the regression model. Models developed on reflectance data obtained using a standard reflectance panel on the ground
Best classification models exploration
Confusion matrices of the two best classification models are described in Fig. 6, these are the PLS and RF models using reflectance data obtained by using the panel on the ground. In both cases, the third category, “Severe water stress,” is very well predicted, with more than 80% of severely stressed vines well predicted by the models (85% with RF and 83% with PLS). The second category, “high stress,” is better predicted by PLS with 71% than RF with 67%. The accuracy of the first category, “moderate stress,” is lower, with 33% for RF and 45% for PLS, with the most confusion with the second category, where around half of the moderately stressed vines are predicted as highly stressed (49% with RF and 55% with PLS).

Confusion Matrices for RF (a) and PLS (b) model predictions. Classification models assessing water stress levels in grapevine. Models developed on reflectance data obtained using a standard reflectance panel on the ground
The band importance for these two classification models is shown in Fig. 7. The RF model used the bands located around the same wavelength as the regression model completed by the wavelengths around 1150 nm and 1200 nm. Concerning the PLS, the highest-important wavelength is 1450 nm.

Importance of each spectral band in the RF model (a) and the PLS model (b) for the two best classification models, assessing water stress levels in grapevine. Models developed on reflectance data obtained using a standard reflectance panel on the ground
Discussion
Comparison with previous attempts using spectroscopy to predict Ψstem
Previous research works based on hand-hold spectrometers demonstrated the potential of spectroscopy in estimating grapevine water status with high accuracy (De Bei et al., 2011; Tardaguila et al., 2017; Laroche-Pinel et al., 2021b), however using spectrometer in the field is not the optimal approach for efficiently covering a large area and swiftly measuring the spatial variability within a vineyard. This research marks the pioneering utilization of a SWIR hyperspectral camera affixed to a UAV for the monitoring of grapevine Ψstem, over an unsurpassed range of irrigation regimes within the same experiment. In regression, the most effective model of this study achieved an R2 of 0.54, accompanied by an RMSE of 0.11 MPa; and a 74% overall accuracy in classification. The advantage of the UAV platform is that it eliminates inter-row interference and captures pure canopy pixels, therefore improving the accuracy achieved with SWIR from satellite imagery (Laroche-Pinel et al., 2021a).
Previous investigations employing UAVs with multispectral cameras and machine learning have demonstrated similar predictive capabilities for Ψstem using datasets of reduced sizes (Poblete et al., 2017; Baluja et al., 2012). For instance, Poblete et al. (2017), achieved R2 values ranging from 0.56 to 0.87 with an error of 0.12 MPa on twenty sample points, and Baluja et al. (2012), reported a training R2 of 0.68 on ten sample points. A more consistent dataset was collected by Tang et al. (2022), which achieved an RMSE in cross-validation of 0.12 MPa, although the model presented was not only based on reflectance data but also included weather data as predictors, and these had the highest importance in the model. Vine water status can be highly correlated with weather data as it is one of the parameters influencing it, and this relationship can be used in machine-learning models (Brillante et al., 2016a). As weather data can vary less than other parameters, such as soil, at a short distance, a strong reliance on weather data must not be to the detriment of other variables to avoid the risk of underestimating prediction performance in space, particularly in fields with strong environmental variability. In this work, we choose not to include predictors other than reflectance data as we aimed to evaluate the potential of SWIR hyperspectral imagery. Also, the inclusion of date-specific information, such as weather data in machine-learning models must be done with attention as it can appear to improve performances but ultimately make it harder for the model to generalize because of overfitting problems. For example, including weather data as predictors would have generated a leakage because only five measurement dates are in our dataset. It would have been possible for the model to use a unique combination of weather data as a specific indicator of the measurement dates. In these conditions, when the variability in weather data or the number of measurement dates is not large, the learning process will generally favor the association between measurement dates and response data, using the weather data as a proxy of the measurement dates. It will not learn to fit the true relationships between weather data and response data, for example between water status and temperature, because it will likely reduce the error less than learning the measurement date. It is common sense, but also evident in Fig. 3 for example, that plant physiology data measured on the same date is more likely to be similar with respect to the plant physiology measured on different days. Looking at these figures, it is easy to realize that a model that uses measurement dates as predictors can accurately classify the stress levels (as data from each measurement date are contained almost exclusively in one single class). In regression mode, because the standard deviation of Ψstem measurements is ~ 0.2 MPa in a single day, a model that accurately assesses the average Ψstem in each measurement date would have an RMSE of ~ 0.1 MPa. When including date-specific information as a predictor in machine-learning models, it is important to use a validation system that takes that into account, thus date-out cross-validation (Laroche-Pinel et al., 2024a); this would have demanded a larger dataset than what we had available.
Model performances and future steps for improvement
The Ψstem shows variability both in time and space (Fig. 3), with a decrease from June to August but also different levels of stress at one date as a result of different irrigation regimes. The fact that Ψstem measurements represent a good variability of plant water stress is a positive starting point for the project. Variability in data is crucial for developing robust models, as it allows for a more comprehensive understanding of the underlying patterns and relationships. However, there is still potential for improvement in the next step of the project to include more data points in the low water stress (high Ψstem values). By expanding the range of values to predict, it will expose the model to a more extensive set of scenarios. This can help the model generalize better to different conditions and make more accurate predictions encompassing a wider range of water stress levels. It will then help to improve the distribution of the predicted and observed values plots (Fig. 4).
The best models to predict Ψstem values reached an R2 of 0.54 and an RMSE of 0.11 MPa (Table 1). This is similar to what Kandylakis et al. (2020) found for the relationship between SWIR images and stomatal conductance. In their study, R2 started from 0.60 when using an average of nine pixels per vine depending on the variety studied (Cabernet Sauvignon was not present in their study). To our knowledge, it is the only study to directly compare our results with, both in terms of material and methodology (SWIR drone images to predict vine water status). As highlighted by Kandylakis et al. (2020), the model reached better accuracy (R2 > 0.80) when fewer pixels were selected from each vine. In future works, it will be interesting to avoid averaging spectral data over the whole experimental unit and instead analyze values on a plant-by-plant basis.
The best classification reached an overall accuracy of 74.17% (Table 1) with good accuracies for the second class “high stress” with 67% for the RF (Fig. 6a), and 71% for the PLS (Fig. 6b) and even higher for the third class, “severe water stress” with an accuracy of 85% for the RF and 83% for the PLS. More confusion appeared for the first class, “moderate water stress”, predicted as highly stressed at 49% using RF and 55% using PLS. This low accuracy can come from the unbalanced dataset in this study with only 17 measurements belonging to this class. Improving the range of the measurements in the next step of the study will improve the classification’s performance.
Further improvements in future work could include the prediction of stomatal conductance data and exploration of other machine learning models, such as Convolutional Neural Networks, which have been shown to improve prediction accuracy in hyperspectral data by Sawyer et al. (2023).
Comparison of reflectance correction methods
In this study, a white panel was used on the ground to convert the data from radiance to reflectance, but a test was also performed applying atmospheric correction using the QUAC module in ENVI. This last method resulted in a significant reduction in the accuracy of all models (Table 1). This raises doubts about the relevance of employing such a preprocessing module for drone applications, given that data acquired from UAVs is considerably less susceptible to atmospheric effects. Other recent studies have already demonstrated that specific methods need to be developed for UAV correction purposes when no standard panels are used during the acquisition (Schläpfer et al., 2020; Suomalainen et al., 2021).
Comparison of modeling approaches
Among all the models tested here to predict Ψstem measurements, RF performed the best along with SVM for the regression part with an R2 of 0.54 and an RMSE of 0.11 MPa and is the second-best model behind PLS for the classification with an accuracy of 72.77% (Table 1). Other recent studies also found RF to be relevant to analyzing ground-based hyperspectral data to predict vine water stress (Loggenberg et al., 2018; Pôças et al., 2020; Thapa et al., 2022). That can be explained by different reasons. The first one is that RF is an ensemble learning method combining predictions of multiple models (decision trees), this can be beneficial when dealing with complex and high-dimensional data such as hyperspectral data. It is also a very flexible model able to capture non-linear and more complex relationships. Moreover, hyperspectral data may contain noise or irrelevant features and RF tends to be robust to noisy data, as it averages over multiple trees, reducing the impact of outliers or irrelevant information. However, RF, as every empirical model, can be limited in terms of extrapolation to new data that are not representation of the data training population as shown by Vetrivel et al. (2015) and Chan et al., (2008).
SVM has the same R2 and RMSE as RF, is also robust in handling non-linear relationships, and is particularly effective in high-dimension spaces. It has also been proven to be effective in predicting Ψstem using hyperspectral data from a hand-held spectrometer by Laroche-Pinel et al. in 2021. PLS reached the best overall classification accuracy with 74.17%, this method excels in dimensional reduction to capture latent variables and performs feature extraction to effectively reduce the dimension of the input data while capturing the most relevant information (Geladi & Kowalski, 1986). It has also been used to predict vine water status using VIS-SWIR hyperspectral data from a spectrometer (Rapaport et al., 2015).
Spectral band importance
The most informative wavelengths for predicting Ψstem as used by the most performant models (Fig. 5 for the regressions models and Fig. 7 for the classification models) are located around 1200 nm and 1400 nmwhich was expected, as already shown in previous studies to predict plant water status (Kandylakis et al., 2020; De Bei et al., 2011; Laroche-Pinel et al., 2021a, b). Bands depths of water absorption features centered around 1200 nm and 1440 nm (Palmer & Williams, 1974; Curcio & Petty, 1951) and those wavelengths are often related to water content (Tian & Philpot, 2015). This result confirms the relevance of this method to predicting plant water status based on their spectral signature in the SWIR domain. This can also explain why the correction using QUAC reaches suboptimal results, as these wavelengths are automatically removed during the correction.
Further research will explore the use of a limited number of bands (the most relevant/important) in order to increase model performance by removing noise that can be present in hyperspectral data (Pal & Foody, 2010, Kumar et al., 2001; Laroche-Pinel et al., 2024b).
Conclusion
In conclusion, this pioneering study marks a significant advancement in the application of drone-mounted hyperspectral cameras for the prediction of Ψstem in plants. Although more data is necessary to derive broader implications and conclude on the reliability of the technique, and further investigation is warranted, the promising results obtained through both regression and classification analyses underscore the potential of this technology in monitoring plant water status, a crucial parameter for assessing vine health and optimizing water management strategies.
The R2 value of 0.54 achieved by the best regression model, coupled with a low root mean square error (RMSE) of 0.11, demonstrates promising preliminary results of the proposed approach in estimating Ψstem. Additionally, the accuracy of the best classification model reaching 74% further supports the utility of drone-based hyperspectral imagery for categorizing plants based on their water status and identifying problematic areas in agriculture fields.
However, it is essential to acknowledge that there are avenues for improvement in future research endeavors. One notable area for enhancement involves addressing the variability in field measurements with lower water stress levels, which may impact the precision and generalization of the models. Furthermore, shifting the focus from a unit scale to a plant basis could yield more nuanced insights, allowing for a more comprehensive understanding of individual plant responses to water stress.
While this study marks a groundbreaking step in leveraging drone-based hyperspectral imagery for predicting Ψstem, the findings indicate that there is still room for refinement and expansion. Continued efforts are crucial for advancing the accuracy and applicability of such models in precision viticulture and water resource management.
Data availability
Data are available upon reasonable request. Please contact the corresponding author.
References
Alida, C., Kiparsky, M., Kennedy, R., Hubbard, S., Bales, R., Pecharroman, L. C., Kamyar Guivetchi, K., McCready, C., & Darling, G. (2018). Data for water decision making: Informing the implementation of California’s open and transparent water data act through research and engagement (p. 56). Center for Law, Energy & the Environment, UC Berkeley School of Law. https://doi.org/10.15779/J28H01.
Baluja, J., Diago, M. P., Balda, P., Zorer, R., Meggio, F., Morales, F., & Tardaguila, J. (2012). Assessment of vineyard water status variability by thermal and multispectral imagery using an unmanned aerial vehicle (UAV). Irrigation Science, 30, 511–522.
Belgiu, M., & Drăguţ, L. (2016). Random forest in remote sensing: A review of applications and future directions. ISPRS Journal of Photogrammetry and Remote Sensing, 114, 24–31.
Bellvert, J., Marsal, J., Girona, J., & Zarco-Tejada, P. J. (2015). Seasonal evolution of crop water stress index in grapevine varieties determined with high-resolution remote sensing thermal imagery. Irrigation Science, 33, 81–93.
Breinman, L. (2001). Random forests. Machine Learning, 45, 5–32.
Brillante, L., Mathieu, O., Bois, B., van Leeuwen, C., & Lévêque, J. (2015). The use of soil electrical resistivity to monitor plant and soil water relationships in vineyards. Soil, 1, 273–286. https://doi.org/10.5194/soil-1-273-201.
Brillante, L., Mathieu, O., Lévêque, J., & Bois, B. (2016a). Ecophysiological modeling of grapevine water stress in Burgundy terroirs by a machine-learning approach. Frontiers in Plant Science, 7, 796. https://doi.org/10.3389/fpls.2016.00796.
Brillante, L., Bois, B., Lévêque, J., & Mathieu, O. (2016b). Variations in soil-water use by grapevine according to plant water status and soil physical-chemical characteristics—A 3D spatio-temporal analysis. European Journal of Agronomy, 77, 122–135. https://doi.org/10.1016/j.eja.2016.04.004.
Brillante, L., Martínez-Luscher, J., Yu, R., Plank, C. M., Sanchez, L., Bates, T. L., Brenneman, C., Oberholster, A., & Kurtural, S. K. (2017). Assessing spatial variability of grape skin flavonoids at the vineyard scale based on plant water status mapping. Journal of Agricultural and Food Chemistry, 65(26), 5255–5265. https://doi.org/10.1021/acs.jafc.7b01749.
Brillante, L., Martínez-Lüscher, J., & Kurtural, S. K. (2018a). Applied water and mechanical canopy management affect berry and wine phenolic and aroma composition of grapevine (Vitis vinifera L., Cv. Syrah) in Central California. Scientia Horticulturae, 227, 261–271. https://doi.org/10.1016/j.scienta.2017.09.048.
Brillante, L., Mathieu, O., Lévêque, J., Van Leeuwen, C., & Bois, B. (2018b). Water status and must composition in grapevine cv. Chardonnay with different soils and topography and a mini meta-analysis of the δ13C/water potentials correlation. Journal of the Science of Food and Agriculture, 98(2), 691–697.
Castellarin, S. D., Matthews, M. A., Di Gaspero, G., & Gambetta, G. A. (2007). Water deficits accelerate ripening and induce changes in gene expression regulating flavonoid biosynthesis in grape berries. Planta, 227, 101–112.
Chan, J. C. W., & Paelinckx, D. (2008). Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sensing of Environment, 112(6), 2999–3011.
Chapelle, O., Haffner, P., & Vapnik, V. N. (1999). Support vector machines for histogram-based image classification. IEEE Transactions on Neural Networks, 10(5), 1055–1064.
Curcio, J. A., & Petty, C. C. (1951). The near infrared absorption spectrum of liquid water. JOSA, 41(5), 302–304.
Dave, J. V. (1980). Effect of atmospheric conditions on remote sensing of vegetation parameters. Remote Sensing of Environment, 10(2), 87–99.
Dayer, S., Lamarque, L. J., Burlett, R., Bortolami, G., Delzon, S., Herrera, J. C., Cochard, H., & Gambetta, G. A. (2022). Model-assisted ideotyping reveals trait syndromes to adapt viticulture to a drier climate. Plant Physiology, 190(3), 1673–1686.
De Bei, R., Cozzolino, D., Sullivan, W., Cynkar, W., Fuentes, S., Dambergs, R., Pech, J., & Tyerman, S. (2011). Non-destructive measurement of grapevine water potential using near infrared spectroscopy. Australian Journal of Grape and Wine Research, 17(1), 62–71. https://doi.org/10.1111/j.1755-0238.2010.00117.
Edwards, E. J., & Clingeleffer, P. R. (2013). Interseasonal effects of regulated deficit irrigation on growth, yield, water use, berry composition and wine attributes of Cabernet Sauvignon grapevines. Australian Journal of Grape and Wine Research, 19(2), 261–276. https://doi.org/10.1111/ajgw.12027.
Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 1189–1232.
Gambetta, G. A., Herrera, J. C., Dayer, S., Feng, Q., Hochberg, U., & Castellarin, S. D. (2020). The physiology of drought stress in grapevine: Towards an integrative definition of drought tolerance. Journal of Experimental Botany, 71(16), 4658–4676.
Geladi, P., & Kowalski, B. R. (1986). Partial least-squares regression: A tutorial. Analytica Chimica Acta, 185, 1–17.
Geurts, P., Ernst, D., & Wehenkel, L. (2006). Extremely randomized trees. Machine Learning, 63, 3–42.
Guo, G., Wang, H., Bell, D., Bi, Y., & Greer, K. (2003). KNN model-based approach in classification. In On The Move to Meaningful Internet Systems 2003: CoopIS, DOA, and ODBASE: OTM Confederated International Conferences, CoopIS, DOA, and ODBASE 2003, Catania, Sicily, Italy, November 3–7, 2003. Proceedings (pp. 986–996). Springer Berlin Heidelberg.
Hardie, W., & Considine, J. (1976). Response of grapes to water-deficit stress in particular stages of development. American Journal of Enology and Viticulture, 27(2), 55–61. https://doi.org/10.5344/ajev.1974.27.2.55.
Höskuldsson, A. (1988). PLS regression methods. Journal of Chemometrics, 2(3), 211–228.
Kandylakis, Z., Falagas, A., Karakizi, C., & Karantzalos, K. (2020). Water stress estimation in vineyards from aerial SWIR and multispectral UAV data. Remote Sensing, 12(15), 2499. https://doi.org/10.3390/rs12152499.
Kaufman, Y. J. (1984). Atmospheric effects on remote sensing of surface reflectance. Remote Sensing: Critical Review of Technology, 475, 20–33.
Khanal, S., Kc, K., Fulton, J. P., Shearer, S., & Ozkan, E. (2020). Remote sensing in Agriculture —accomplishments, limitations, and opportunities. Remote Sensing, 12(22), 3783. https://doi.org/10.3390/rs12223783.
Kumar, S., Ghosh, J., & Crawford, M. M. (2001). Best-bases feature extraction algorithms for classification of hyperspectral data. IEEE Transactions on Geoscience and Remote Sensing, 39(7), 1368–1379.
Laroche-Pinel, E., Duthoit, S., Albughdadi, M., Costard, A. D., Rousseau, J., Chéret, V., & Clenet, H. (2021a). Towards vine water status monitoring on a large-scale using Sentinel-2 images. Remote Sensing, 13(9), 1837.
Laroche-Pinel, E., Albughdadi, M., Duthoit, S., Chéret, V., Rousseau, J., & Clenet, H. (2021b). Understanding vine hyperspectral signature through different irrigation plans: A first step to monitor vineyard water status. Remote Sensing, 13(3), 536. https://doi.org/10.3390/rs13030536.
Laroche-Pinel, E., Cianciola, V., Singh, K., Vivaldi, A. G., & Brillante, L. (2024a). Assessing the Spatial-Temporal Performance of Machine Learning in Predicting Grapevine Water Status from Landsat 8 Imagery via Block-Out and date-out Cross-validation. (In review).
Laroche-Pinel, E., Singh, K., Flasco, M., Cooper, M. L., Fuchs, M., & Brillante, L. (2024b). Grapevine Red Blotch Virus Detection in the Vineyard. Leveraging Machine Learning with VIS/NIR Hyperspectral Images. (In review).
Levin, A., & Nackley, L. (2021). Principles and practices of plant-based irrigation management. HortTechnology, 31(6), 650–660. https://doi.org/10.21273/HORTTECH04862-21.
Loggenberg, K., Strever, A., Greyling, B., & Poona, N. (2018). Modelling water stress in a Shiraz vineyard using hyperspectral imaging and machine learning. Remote Sensing, 10(2), 202.
Lovisolo, C., Perrone, I., Carra, A., Ferrandino, A., Flexas, J., Medrano, H., & Schubert, A. (2010). Drought-induced changes in development and function of grapevine (Vitis spp.) organs and in their hydraulic and non-hydraulic interactions at the whole-plant level: A physiological and molecular update. Functional Plant Biology, 37(2), 98–116.
Maimaitiyiming, M., Sagan, P., Sidike., Maimaitijiang, M., Miller, A. J., & Kwasniewski, M. (2020). Leveraging very-high spatial resolution hyperspectral and thermal UAV imageries for characterizing diurnal indicators of grapevine physiology. Remote Sensing, 12(19), 3216. https://doi.org/10.3390/rs12193216.
Martínez-Lüscher, J., Brillante, L., Nelson, C. C., Al-Kereamy, A. M., Zhuang, S., & Kurtural, S. K. (2017). Precipitation before bud break and irrigation affect the response of grapevine ‘Zinfandel’ yields and berry skin phenolic composition to training systems. Scientia Horticulturae, 222, 153–161. https://doi.org/10.1016/j.scienta.2017.05.011.
Matthews, M. A., Anderson, M. M., & Schultz, H. R. (1987). Phenology and growth responses to early and late season water deficits in Cabernet franc. Vitis, 26, 147–160.
Pal, M., & Foody, G. M. (2010). Feature selection for classification of hyperspectral data by SVM. IEEE Transactions on Geoscience and Remote Sensing, 48(5), 2297–2307.
Palmer, K. F., & Williams, D. (1974). Optical properties of water in the near infrared. JOSA, 64(8), 1107–1110.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, et al. (2011). Scikit-learn: Machine learning in Python. The Journal of Machine Learning Research, 12, 2825–2830.
Poblete, T., Ortega-Farías, S., Moreno, M. A., & Bardeen, M. (2017). Artificial neural network to predict vine water status spatial variability using multispectral information obtained from an unmanned aerial vehicle (UAV). Sensors (Basel, Switzerland), 17(11), 2488.
Pôças, I., Tosin, R., Gonçalves, I., & Cunha, M. (2020). Toward a generalized predictive model of grapevine water status in Douro region from hyperspectral data. Agricultural and Forest Meteorology, 280, 107793.
Rapaport, T., Hochberg, U., Shoshany, M., Karnieli, A., & Rachmilevitch, S. (2015). Combining leaf physiology, hyperspectral imaging and partial least squares-regression (PLS-R) for grapevine water status assessment. ISPRS Journal of Photogrammetry and Remote Sensing, 109, 88–97.
Santesteban, L. G., Miranda, C., Marín, D., Sesma, B., Intrigliolo, D. S., & Mirás-Avalos (2019). Discrimination ability of leaf and stem water potential at different times of the day through a meta-analysis in grapevine (Vitis vinifera L). Agricultural Water Management, 221, 202–210. https://doi.org/10.1016/j.agwat.2019.04.020.
Savitzky, A., & Golay, M. J. E. (1964). Smoothing and differentiation of data by simplified least squares procedures. Analytical Chemistry, 36(8), 1627–1639. https://doi.org/10.1021/ac60214a047.
Sawyer, E., Laroche-Pinel, E., Flasco, M., Cooper, M. L., Corrales, B., Fuchs, M., & Brillante, L. (2023). Phenotyping grapevine red blotch virus and grapevine leafroll associated viruses before and after symptom expression through machine-learning analysis of hyperspectral images. Frontiers in Plant Science, 14, 1117869. https://doi.org/10.3389/fpls.2023.1117869.
Schläpfer, D., Popp, C., & Richter, R. (2020). Drone data atmospheric correction concept for multi-and hyperspectral imagery–the droacor model. The International Archives of the Photogrammetry Remote Sensing and Spatial Information Sciences, 43, 473–478.
Scholander, P. F., Bradstreet, E. D., Hemmingsen, E. A., & Hammel, H. T. (1965). Sap pressure in vascular plants: Negative hydrostatic pressure can be measured in plants. Science (Vol. ,148 N.Y.), 148, pp. 339–346). New York. 366810.1126/science.148.3668.339.
Suomalainen, J., Oliveira, R. A., Hakala, T., Koivumäki, N., Markelin, L., Näsi, R., & Honkavaara, E. (2021). Direct reflectance transformation methodology for drone-based hyperspectral imaging. Remote Sensing of Environment, 266, 112691.
Suter, B., Triolo, R., Pernet, D., Dai, Z., & Van Leeuwen, C. (2019). Modeling stem water potential by separating the effects of soil water availability and climatic conditions on water status in grapevine (Vitis vinifera L). Frontiers in Plant Science, 10, 1485. https://doi.org/10.3389/fpls.2019.01485.
Tang, Z., Jin, Y., Alsina, M. M., McElrone, A. J., Bambach, N., & Kustas, W. P. (2022). Vine water status mapping with multispectral UAV imagery and machine learning. Irrigation Science, 40(4–5), 715–730.
Tardaguila, J., Fernández-Novales, J., Gutiérrez, S., & Diago, M. P. (2017). Non‐destructive assessment of grapevine water status in the field using a portable NIR spectrophotometer. Journal of the Science of Food and Agriculture, 97(11), 3772–3780.
Thapa, S., Kang, C., Diverres, G., Karkee, M., Zhang, Q., & Keller, M. (2022). Assessment of water stress in vineyards using on-the-go hyperspectral imaging and machine learning algorithms. Journal of the ASABE, 65(5), 949–962.
Tian, J., & Philpot, W. D. (2015). Relationship between surface soil water content, evaporation rate, and water absorption band depths in SWIR reflectance spectra. Remote Sensing of Environment, 169, 280–289.
van Leeuwen, C., Bois, B., Brillante, L., Destrac-Irvine, A., Gowdy, M., Martin, D. (2023). Carbon isotope discrimination (so-called δ 13C) measured on grape juice is an accessible tool to monitor vine water status in production conditions. IVES Technical Reviews, Vine and Wine.
Vetrivel, A., Gerke, M., Kerle, N., & Vosselman, G. (2015). Identification of damage in buildings based on gaps in 3D point clouds from very high resolution oblique airborne images. ISPRS Journal of Photogrammetry and Remote Sensing, 105, 61–78.
Wold, S., Sjöström, M., & Eriksson, L. (2001). PLS-regression: A basic tool of chemometrics. Chemometrics and Intelligent Laboratory Systems, 58(2), 109–130.
Yu, R., Brillante, L., Torres, N., & Kurtural, S. K. (2021). Proximal sensing of vineyard soil and canopy vegetation for determining vineyard spatial variability in plant physiology and berry chemistry. Oeno One, 55(2). https://doi.org/10.20870/oeno-one.2021.55.2.4598.
Zhang, Z. (2016). Introduction to machine learning: k-nearest neighbors. Annals of Translational Medicine, 4(11).
Acknowledgements
The authors wish to thank the generous funding of the American Vineyard Foundation, grant #2023–2718, and the CSU Agriculture Research Institute, ARI-HIS Fellowship granted to graduate student Kaylah Vasquez and ARI- Campus, grant #23-02-111. Thanks to Bronco Wine Co. for access to the vineyard and cooperation in the irrigation setting, and thanks to Verdi Ag. for support with the irrigation devices. Thanks to Vincenzo Cianciola, Khushwinder Singh, Guadalupe Partida, Anais Rico, and Mauricio Soriano for their help with the field data collection.
Author information
Authors and Affiliations
Contributions
E Laroche-Pinel: Data Curation, Formal Analysis, Funding Acquisition, Investigation, Methodology, Software, Validation, Visualization, Writing – Original Draft; KR Vasquez: Data curation, Investigation, Visualization, Writing – review & editing; L Brillante: Conceptualization, Formal Analysis, Funding Acquisition, Investigation, Methodology, Project Administration, Resources, Supervision, Writing – review & editing.
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Laroche-Pinel, E., Vasquez, K.R. & Brillante, L. Assessing grapevine water status in a variably irrigated vineyard with NIR/SWIR hyperspectral imaging from UAV. Precision Agric (2024). https://doi.org/10.1007/s11119-024-10170-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s11119-024-10170-9