
Abstract
This study assesses the potential of using multispectral images collected by an unmanned aerial system (UAS) on machine learning (ML) frameworks to estimate cereal rye (Secale cereal L.) biomass. Multispectral images and ground-truth cereal rye biomass data were collected from 15 farmers’ fields up to three times between March and May in northwest Ohio. Images were processed to derive 13 vegetation indices (VIs). Out of 13 VIs, six optimal sets of VIs, including excess green (ExG), normalized green red difference index (NGRDI), soil adjusted vegetation index (SAVI), blue green ratio (B_G_ratio), red-edge triangular vegetation index (RTVI), and normalized difference red-edge (NDRE) were selected using the variance inflation factor (VIF) based feature selection approach. Six regression models including a multiple linear regression (MLR), elastic net (ENET), multivariate adaptive regression splines (MARS), support vector machine (SVM), random forest (RF), and extreme gradient boosting (XGB) were investigated for estimation of cereal rye biomass based on the VIs. For most of the models, the six selected VIs performed better than or similar to the full set of 13 VIs with R2 ranging from 0.24 to 0.59 and RMSE ranging from 83.13 to 91.89 g/m2 during 10-fold cross-validation. During independent accuracy assessment with the selected set of VIs, XGB exhibited the highest R2 (0.67) and lowest RMSE (83.13 g/m2) and MAE (48.13 g/m2) followed by RF and ENET. For all the models, the agreement between observed and predicted biomass was high for biomass less than or equal to 200 g/m2 but decreased for biomass greater than 200 g/m2. When field-collected structural features were integrated with the selected VIs, the models showed improved performance, with R2 and RMSE of the models reaching up to 0.82 and 61.67 g/m2 respectively. Among the six VIs, SAVI showed the strongest impact on the model prediction for the best-performing RF and XGB regression models. The findings of this study demonstrate the potential of precisely estimating and mapping cereal rye biomass based on UAS-captured multispectral images. Timely information on cover crop growth can facilitate numerous decision-making processes, including planning the planting operations, and management of nutrients, weeds, and soil moisture to improve agronomic and environmental outcomes.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Cover cropping, a widely advocated conservation practice in agriculture for improving soil and water quality, offers numerous benefits, including increased nitrogen (N) retention, soil erosion control, weed suppression, enhancement of soil microbiology, and an increase in overall soil organic matter (Adetunji et al., 2020; Daryanto et al., 2018; Finney et al., 2016). Timely information on cover crop growth is crucial for managing nutrient and water balances within a field (Abdalla et al., 2019; Meyer et al., 2022), helping farmers to make timely agronomic decisions to enhance both the profitability and sustainability of crop production. Traditional methods for assessing the growth and biomass of cover crops, such as on-field surveys involving destructive sampling of living biomass followed by measuring dry weight, are costly, time-consuming, and labor-intensive processes (Kaspar & Bakker, 2015). This limits data collection to fewer locations, potentially failing to accurately represent within-field variabilities and differences across larger geographic regions. In contrast, remote sensing (RS) technology provides a non-destructive, cost-effective, rapid, and scalable approach to estimating cover crop biomass by assessing spectral signatures of crops within a field and/or region.
Unmanned aerial system (UAS) based RS for crop monitoring has gained significant interest in recent years due to its operational ease, affordability, and capacity to capture high-resolution data. Specifically, UASs have been used to study various aspects of crop growth, including canopy characteristics, crop growth rate, plant density, growth stage detection, disease detection, biomass estimation, and yield estimation (Awais et al., 2021; Holman et al., 2016; Koh et al., 2019; Rosle et al., 2019; Ye et al., 2020; Yue et al., 2021; Zhu et al., 2022). Vegetation indices (VIs) based on multispectral images have been commonly used to estimate biomass among various cover crops including cereal rye (Secale cereal L.), triticale (Yuan et al., 2019), barley (Prabhakara et al., 2015), wheat (Jennewein et al., 2022), legumes (Roth & Streit, 2018), oats (Sharma et al., 2022), and alfalfa (Tang et al., 2021). For instance, Yuan et al. (2019) compared the linear relationships between four VIs, including the normalized difference vegetation index (NDVI), green ratio egetation index (GRVI), green NDVI (GNDVI), and triangular vegetation index (TVI), derived from a series of images and ground truth biomass of cereal rye and triticale before termination. Relationships between VIs and cover crop biomass varied among VIs and across different fields, with R2 ranging from 0.42 to 0.93 and RMSE from 9.4 to 27.2%. Similarly, the NDVI, red edge infection point (REIP), and green red vegetation index (GRVI) showed correlations with the biomass of legumes and dicots in Switzerland, with R2 ranging from 0.03 to 0.37 (Roth & Streit, 2018). The significance of VIs in capturing variabilities in biomass and crop growth can vary among different crops. This variation is attributed to factors such as photosynthetic pigments, water content, nutrient status, and several other physiological aspects. Furthermore, VIs can be sensitive to external environmental factors and crop growth stages (Vélez et al., 2023), as well as the spectral region utilized in deriving them. The latter often depends on the quality of sensors (Alckmin et al., 2019). Hence, the selection of an optimal set of VIs specific to crops and growth stages is crucial for establishing meaningful relationships between the spectral and biophysical properties of crops.
Application of VIs in estimating biomass however can present limitations mainly due to saturation of VIs at a higher biomass range (Jennewein et al., 2022; Prabhakara et al., 2015). In contrast, structural features, such as crop height and canopy cover, are less sensitive to higher biomass and thus can effectively capture variability in crop growth compared to VIs (Tang et al., 2021). Galán et al. (2020) combined agronomic traits such as grain yield and plant height with VIs in a linear regression model and obtained an R2 of 0.77 when predicting 274 different cereal rye hybrids.
A majority of the prior works focused on cereal rye biomass estimation using VIs have extensively relied upon linear models. While linear models are valuable in understanding the interaction and making inferences, they are limited when it comes to learning complex non-linear relationships between variables. Therefore, there remains untapped potential in harnessing non-linear machine learning (ML) models for estimating cereal rye biomass using VIs.
In recent years, ML models have received increased interest in effectively modeling crop biophysical properties using RS variables. Sharma et al. (2022) developed four ML models, including partial least squares (PLS), support vector machine (SVM), random forest (RF), and artificial neural network (ANN), that integrated UAS collected multispectral data with 315 ground-truth observations from three oat fields in South Dakota, USA. The best model for oat biomass estimation varied across different sites and growth stages, suggesting the importance of careful examination of multiple ML algorithms. Bai et al. (2023) evaluated four ML models- RF, SVM, partial least squares (PLS), and ANN, to estimate above-ground biomass of multiple cover crop species based on a single-site experiment in Nebraska. In the study, the linear model, specifically PLS, demonstrated superior performance compared to non-linear models, underscoring the importance of linear models in some instances. In a similar study utilizing Planetscope satellite imagery and hyperspectral data collected via spectroradiometer, biomass estimation of mixed cover crop species was performed using an RF model. The model’s performance varied across different periods, with R2 ranging from 0.36 to 0.61 (Kharel et al., 2023).
To the best of our knowledge, there is a noticeable lack of studies, specifically addressing cereal rye biomass estimation in on-farm fields across multiple growth stages using UAS images, while employing a variety of both linear and non-linear ML models. Therefore, the objective of this study is to develop and evaluate cereal rye biomass estimation models by integrating ground truth data collected from 15 on-farm fields representing various field conditions and growth stages using multitemporal UAS data in linear and non-linear ML frameworks. The specific objectives of this study are to (i) determine the optimal set of VIs for cereal rye biomass estimation, (ii) compare the performance of different ML models for cereal rye biomass estimation, and (iii) evaluate the potential application of structural features for cereal rye biomass estimation. We hypothesize that (i) selection of optimal VIs minimizes multicollinearity issues while also resulting in better model performance, (ii) ML models will outperform linear regression models in cereal rye biomass estimation, and (iii) structural features will outperform spectral features and their integration will improve model stability.
Methods
Study sites and experimental design
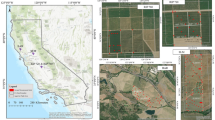
This study was conducted in Ohio’s portion of the Western Lake Erie basin (WLEB). WLEB is one of the most impaired watersheds in the Great Lakes region, where water quality issues driven by nutrient and sediment loading from agricultural lands are a major concern (Berry et al., 2017; Michalak et al., 2013). Fifteen fields, planted with cereal rye between late September and mid-November in the fall of 2020, were selected across 10 counties in the study area (Fig. 1). Of 15 fields, two were planted in corn and 13 in soybean, representing varying management practices (Table 1). Cereal rye was planted using a drilling technique in 13 of the 15 fields, and aerial seeding and broadcasting were implemented in two other fields. The weather conditions varied across the cover crop growing season, with differences in average temperature ranging from 6.2 to 19 ℃ and monthly total precipitation ranging from 19 to 151 mm among sites.

a Broader study area indicating the distribution of fields in cereal rye cover crops in northwest Ohio and b Six sampling locations per field where ground-truth data were collected c Monthly variation in temperature and precipitation across the study sites, determined based on the PRISM daily climate dataset
Data collection
Field data collection
Ground-truth data on soil properties, biomass weight, canopy cover, and crop height were collected from six locations per field for all fields by considering variability in soil properties present within a field. The approximate sampling locations were mapped and stored before heading out for data collection. After locating their positions on the field, sampling locations were marked and bounded using a 0.25 m2 quadrat (Fig. 2b). At first, canopy cover was measured using the Canopeo mobile application while crop height was manually measured by using a measuring tape (Fig. 2c, d). Following that, all the cereal rye plants within the quadrat were cut up to the root and collected in a paper bag. To capture variability in cereal rye biomass growth, samples were collected up to three times in the spring of 2020—T1 (March 2 to March 9), T2 (March 29 to April 6), and T3 (April 26 to May 12). It is important to note that three fields were sampled only twice due to logistical issues while the remaining 12 fields were sampled three times. This resulted in a total of 252 ground-truth observations containing biomass information. Since samples were collected through destructive sampling, the locations across three times were kept apart but close enough to represent the same portion of the field. The biomass samples were then oven-dried at 55 ℃ and weighed to determine dry weight. The term cereal rye biomass hereafter refers to the total dry weight biomass obtained after drying the sampled biomass.

Field data collection a UAS surveys involving multispectral image collection b 0.25 m2 quadrat for biomass data collection c Tape measurement of plant height and d Measurement of canopy cover using Canopeo
Biomass samples collected over three times—T1, T2, and T3 from 15 fields, were grouped into two categories—early and late planting, for the ANOVA test to understand variabilities in biomass based on the timing of cereal rye planting. Fields planted in late September to early October were grouped in early planting, and the fields planted in late October to early November were grouped in late planting.
Image acquisition and processing
Before every UAS flight, markers were placed around six sampling locations, with one marker at each sampling location, at every field site. These markers were later used in the georeferencing of Orthomosaic images, which helped in precisely locating sampling locations on the image and facilitating the subsequent extraction of spectral values corresponding to ground truth data (Fig. 3a). UAS flights were conducted using a DJI Phantom 4 multispectral (DJI Innovations, Shenzhen, China) to capture images in the visible and near-infrared regions (Blue [450 ± 16 nm], Green [560 ± 16 nm], Red [650 ± 16 nm], Red Edge [730 ± 16 nm], and Near-infrared [840 ± 26 nm]). Notably, this UAS differs from the standard DJI Phantom 4, featuring an RGB camera and a multispectral camera array comprising five cameras. UAS surveys were conducted at a speed of approximately 5 m/s at about 90 m above-ground surface, maintaining mostly 80% front and 70% side overlap in a lawnmower pattern, which resulted in a Ground Sampling Distance (GSD) of 4.8 cm in images. These images were then processed, stitched together, and rectified using an image processing software, Pix4Dmapper (Pix4D SA, Switzerland), at a spatial resolution of 6 cm/pixel.

a Quadrats used for biomass sampling along with red cones next to them and b delineation of the corresponding quadrat area on the image for extraction of spectral values
Data extraction
Data extraction at six sampling locations within each field was completed using geopandas and rasterio packages in the Python platform. At first, a 0.5 m × 0.5 m region of interest (ROI) around each sampling location was created, which was then used to compute average spectral values within the ROI based on zonal statistics (Fig. 3b). Of 252 locations containing biomass data, 13 observations were removed from the analyses due to gaps in data, resulting from missing cover crop height and canopy cover data and stitching issues of multispectral images (Table 1). The extracted spectral values of five multispectral bands from images were then used for computing 13 commonly used VIs (Table 2), representing crop growth and biomass (Kross et al., 2015; Meng et al., 2013; Santin-Janin et al., 2009). For instance, NDVI has been found to better estimate low to medium crop biomass, while EVI and TVI are good predictors of biomass at a higher range (Alexandridis et al., 2020; Prabhakara et al., 2015). Green band-based indices such as GNDVI and NGRDI are more sensitive to N content and growth than the red band-based indices (Gitelson & Merzlyak, 1998; Hunt et al., 2005). SAVI is recognized for minimizing spectral responses influenced by background soil reflectance, especially in scenarios where biomass is sparse, resulting in minimal crop reflectance. It has demonstrated effective performance in accurately estimating crop biomass (Xu et al., 2018). Unlike NDVI, red edge-based indices were found to be more strongly correlated with biomass at a higher range due to their higher sensitivity to leaf chlorophyll content (Jennewein et al., 2022).
Data preprocessing and model development
Feature selection
To develop a model for cereal rye biomass estimation, the derived VIs (Table 2) were used as independent variables and observed dry cereal rye biomass weight as a response variable. The 239 observations were initially split into 70% training (n = 151) and 30% testing (n = 88) datasets, with careful stratification by field, to avoid potential correlations between observations within a specific field. This approach resulted in 10 fields randomly assigned for training and 5 for testing. Feature scaling was performed on both training and test data by applying the min–max normalization technique as a part of the initial steps in model training and testing.
Before training and tuning of models, multicollinearity among VIs in the training dataset was assessed. The VIs, derived from various combinations of spectral bands in multispectral images, contained somewhat redundant information about crop growth, as evidenced by cross-correlation (Fig. 4). To enhance model stability and interpretation, a subset of VIs was selected using variance inflation factor (VIF) statistics. VIF measures the inflation of variance due to correlations among predictor variables and can be calculated for each predictor by regressing it with every other variable (Salmerón et al., 2020) (Eq. 1).
where R2 represents the coefficient of determination of the model. VIF < 10 indicates no multicollinearity while VIF ≥ 10 indicates serious multicollinearity between predictor variables. The calculation of VIF began with all 13 VIs, and iteratively, the VI with the highest VIF was removed until the best combination of VIs yielded scores below 10.

Correlation matrix among VIs extracted from UAS captured multispectral images
Machine learning models
A suite of regression algorithms, including multiple linear regression (MLR), elastic net (ENET), multivariate adaptive regression splines (MARS), SVM, RF, and extreme gradient boosting (XGB) was used to fit interactions among predictor and response variables. The entire modeling pipeline was conducted in Rstudio (Posit Software, Boston).
Linear regression is the simplest model which can be used as a starting point or as a base model for other advanced models. It uses the least squares method to estimate the best-fitting line. Meanwhile, ENET is a regularized form of linear regression that takes advantage of both ridge regression and LASSO regression for accurate prediction (Zou & Hastie, 2005). The ENET algorithm uses a weighted combination of both regularization techniques. While ENET aims to improve the linear regression model using regularization techniques, models such as MARS, SVM, RF, and XGB can be used to learn non-linear relationships.
MARS is an algorithm for automatically creating a piecewise linear model that provides an intuitive way of capturing nonlinearity in a dataset using polynomial and step functions, unlike linear regression (Friedman, 1991). The MARS model is tuned using two tuning parameters: the maximum degree of interactions (degree) and the number of terms (nprune) retained in the final model. The degree was set from 1 to 3 while nprune was started with 10 values between 1 and 100.
SVM minimizes the error by using a hyperplane and maximizing the margin between predicted and actual values (Smola & Schölkopf, 2004). SVM requires tuning of hyperparameters including the loss function (ε), penalty (c), and the kernel function (linear, polynomial, and radial kernel functions). During the tuning process, a sigma between 0.01 and 1 and cost between 0.1 and 2 were considered.
RF is one of the widely used ensemble models, which is expressed as an average of simple individual decision trees dn(x) which are built using different sets of subsamples from the data (Breiman, 2001) (Eq. 2). Since the model is created from random bootstrap samples, it is considered to be robust in handling noise and minimizing overfitting issues (Fawagreh et al., 2014). Three different hyperparameters were considered for tuning: ntree (number of decision trees: between 100 and 1000), mtry (number of features at each split: between 1 to number of features present), and nodesize (minimum node size: 1 to 10).
XGB is an optimized version of a gradient-boosting algorithm that aims to improve the speed and accuracy of the algorithm (Chen & Guestrin, 2016). In this algorithm, unlike in RF, boosting is done to combine weak tree models with low accuracy to build strong models with better performance and accuracy. Four hyperparameters were tuned: ntrees (number of trees: between 100 and 1000), max_depth (complexity of the model: 3, 6, 8, 10, 15, 20, 30), eta (learning rate: 0.001, 0.01, 0.1), and gamma (pseudo-regularization: 0, 0.1, 0.5).
These six ML models were trained using a 10-fold cross-validation (CV) approach across 10 random seeds to better understand the sensitivity and variance of the models due to the randomness in selecting different seed values. During the 10-fold CV, hyperparameters associated with each model were tuned using a random grid search method (Table S1). A model instance with minimum RMSE across 10 runs for each ML model was selected for further analyses. To understand the significance of feature selection in improving model performance, models were compared for both full and selected set of VIs.
Model evaluation
After training the models, they were evaluated using the test dataset not used in model tuning. This was conducted based on three metrics, including R2 (Eq. 3), root mean square error (RMSE) (Eq. 4), and mean absolute error (MAE) (Eq. 5). RMSE is the standard deviation of the prediction errors while MAE is the average of absolute differences between observed values and predicted values. They are expressed as:
where, n is the total number of samples, yi and ŷi are the observed and predicted values of sample i, ȳ represents the mean of observed values. The higher value of R2 and lower value of RMSE and MAE represent the higher accuracy and precision of a model.
Spectral and structural features
To develop models of various combinations of VIs and crop structural properties in cereal rye biomass estimation, three approaches (M): M1 (based only on VIs), M2 (based only on structural features), and M3 (based on a combination of VIs and structural features) were used. These models were then compared to identify the ones that offer the best overall performance in estimating cereal rye biomass, along with determining the most effective independent variables.
Shapely Additive Explanations (SHAP) analysis (Lundberg & Lee, 2017) was used to investigate model behavior and explore the impact that each feature has on the model prediction of the target output (response variable). The impact of features on model behavior was investigated using bar and summary plots. These SHAP values were computed in R utilizing the kernelshap function available in the kernelshap package. It is however important to emphasize that SHAP values do not imply causation but rather aid in explaining the behavior of the model concerning prediction values of the output variable.
Results/findings
Cover crop biomass over time
The cereal rye biomass varied across the sampling period from early to late spring of 2021. The average biomass of 15 fields changed from 17.92 g/m2 in March to 189.57 g/m2 in May. Along with an increase in biomass, the variability in biomass growth increased significantly, with a standard deviation of 22.12 g/m2 in early March (T1) to 42.41 g/m2 in later March and early April (T2) to 187 g/m2 in late April and early May (T3) (Fig. 5). The increase in cereal rye biomass in early spring compared to winter can be attributed to the warming of the weather, with an average monthly temperature that ranged between 6.5 ℃ in March to 10.7 ℃ in April to 15 ℃ in May. Fields that were planted early had significantly higher biomass than fields that were planted late at p < 0.05 based on the ANOVA test.

Variation in overall cereal rye biomass by a time of sampling and b time of sampling and planting date. “Early planted” indicates cereal rye planted in late September to early October and “late planted” indicates cereal rye planted in late October to early November. The numbers on top of each box in the figure represent mean biomass and different superscripts in the same period represent whether the biomass values are significantly different across planting dates
Feature selection
During the screening of thirteen VIs to address multicollinearity issues using the VIF approach, NDVI was removed in step 1, followed by SR_RE in step 2, TVI in step 3, R_G_ratio in step 4, GNDVI in step 5, EVI in step 6, and SR in step 7, due to their higher VIF scores (Fig. 6). Throughout these steps, SAVI, B_G_ratio, and ExG consistently exhibited lower VIF scores, indicating their reduced correlation with the remaining VIs. Ultimately, in the final iteration, six VIs including ExG, NGRDI, SAVI, B_G_ratio, RTVI, and NDRE, with a VIF score below 10, were selected for further model comparisons.

VIF score of VIs at multiple iterations. At each iteration, the VI with the highest VIF score was systematically removed, and the VIF was recalculated for the updated set of VIs in the subsequent step. The process was repeated for a total of eight iterations to identify the optimal set of VIs without multicollinearity
Cereal rye biomass estimation models
Models based on VIs
For the RF model utilizing the full set of VIs, the average values of R2, RMSE, and MAE were 0.52, 94.07 g/m2, and 56.13 g/m2, respectively. Conversely, when trained on the selected VIs, RF achieved slightly improved performance, with average values of 0.55 for R2, 90.48 g/m2 for RMSE, and 54.11 g/m2 for MAE. Similarly, for XGB, the corresponding average values were 0.49, 97.09 g/m2, and 59.58 g/m2 for the full set, and 0.52, 94.77 g/m2, and 57.36 g/m2 for the selected VIs showing improvement with the selected subset (Fig. 7).

Model performance for cereal rye biomass estimation based on a full and selected set of six VIs. Values for each metric considered are based on a 10-fold CV with the training dataset. Note: the boxplots illustrate the variation in each of the metrics, reflecting the diverse performance observed during training
Meanwhile, MLR and ENET demonstrated comparable performance across both the full set and selected VIs. MLR achieved average R2 of 0.46 and 0.47, average RMSE of 98.62 g/m2 and 96.89 g/m2, and average MAE of 65.43 g/m2 and 65.04 g/m2 for the full set and selected VIs, respectively. Similarly, ENET yielded average R2 values of 0.47 and 0.50, average RMSE of 95.49 g/m2 and 95.78 g/m2, and average MAE of 61.78 g/m2 and 63.41 g/m2 for the full set and selected VIs, respectively. While R2 seemed to be better for the selected subset, RMSE was in a similar range and MAE was even higher. Therefore, there was no clear evidence for a stronger performance for either the full set or selected subset in the case of ENET.
Conversely, MARS and SVM models exhibited stronger performance when trained on the full set of VIs compared to the selected VIs. MARS achieved average R2 values of 0.50 and 0.38, average RMSE of 93.72 g/m2 and 98.97 g/m2, and average MAE of 57.65 g/m2 and 63.74 g/m2 for the full set and selected VIs, respectively. Similarly, SVM achieved R2 values of 0.52 and 0.44, average RMSE of 95.05 g/m2 and 97.24 g/m2, and average MAE of 61.80 g/m2 and 52.03 g/m2 for the full set and selected VIs, respectively. While R2 of the SVM model based on the full set of features was higher than that of the selected VIs, MAE did not decrease. For further analyses, the best-performing models based on six selected VIs were considered.
During the assessment of models using an independent test dataset on six selected VIs, ENET, RF, and XGB outperformed the MLR. XGB exhibited the highest R2 (0.67) and lowest RMSE (83.13 g/m2) and MAE (48.13 g/m2), followed by RF (R2 = 0.59, RMSE = 91.89 g/m2, MAE = 53.93 g/m2) and ENET (R2 = 0.55, RMSE = 96.77 g/m2, MAE = 61.50 g/m2) (Fig. 8). MLR showed an R2 of 0.54, RMSE of 97.63 g/m2 and MAE of 64.40 g/m2. Conversely, MARS and SVM exhibited poor performance compared to the MLR model, with the lowest R2 (0.24), RMSE (126.33 g/m2), and MAE (72.83 g/m2) associated with MARS and R2 (0.49), RMSE (102.97 g/m2), and MAE (59.99 g/m2) associated with SVM. Figure S.1 in the supporting document shows a comparison between the ground truth and predicted cereal rye biomass across 88 observations in five test fields organized three times representing trends in cereal rye biomass growth.

Performance of six models, trained with selected VIs, during an independent accuracy assessment. Models exhibit poor performance for biomass > 200 g/m2, particularly evident in data collected in late spring (T3)
While all models demonstrated strong performance for biomass ranges below 200 g/m2, the prediction error notably increased at higher biomass values greater than 200 g/m2 as the growing season progressed (Figs. 8, 9). RF (RMSE = 185 g/m2) and XGB (RMSE = 156.91 g/m2) had lower prediction errors at higher biomass ranges, in contrast to MLR (RMSE = 196.60 g/m2), ENET (RMSE = 201.92 g/m2), MARS (RMSE = 282.75 g/m2), and SVM (RMSE = 223.44 g/m2) (Table 3). Nonetheless, the prediction error remained relatively high, particularly in comparison to lower cereal rye biomass values (59.72 g/m2 for RF and 59.67 g/m2 for XGB). This discrepancy highlights the limitations of relying solely on spectral VIs for predicting cereal rye biomass, especially at higher biomass ranges. Notably, RF and XGB showcased superior performance when utilizing the selected group of VIs compared to all the other models. Consequently, we exclusively employed these two best-performing models with the selected subset of six VIs for further analyses.

Within-field variability in observed and predicted cereal rye biomass for one of the test fields, overlaid on the visual image. Observed biomass represented data collected on April 26, 2021 (T3) for field 10, while predicted cereal rye biomass was based on the best-performing XGB model applied with spectral VIs for the same time. While some differences exist between observed and predicted cereal rye biomass, predicted biomass captured overall trend in observed biomass values for most of the observed locations. Note: the predicted maps of cereal rye biomass could not be generated for other models that incorporated structural properties. This limitation is due to the absence of spatially explicit crop height and canopy cover information, unlike VIs
Integration of structural features
Models based on canopy cover and crop height
The best-performing RF and XGB models with field-collected canopy cover and crop height were observed to perform significantly better than their VI-based versions. In an independent accuracy assessment, RMSE decreased from 91.89 to 57.49 g/m2 and R2 values increased from 0.59 to 0.84 for RF whereas RMSE decreased from 83.13 to 59.94 g/m2 and R2 values increased from 0.67 to 0.83 for XGB (Figs. 8, 10) when compared with the performance of models based exclusively on VIs. Notably, with structural features, the models show a better fit for a higher biomass range. RF and XGB showed RMSE of 114.15 and 110.10 g/m2 respectively for data points with observed biomass greater than 200 g/m2. This is a 38.3% and 27.3% decrease compared to the RMSE observed with RF and XGB models with only VIs at biomass greater than 200 g/m2.

Performance of RF (left) and XGB (right) models based on only canopy cover and crop height variable in the test data
Models based on VI, canopy cover, and crop height
When field-collected canopy cover and crop height variables were combined with the selected VIs, the models performed better than VIs-based models but not compared to the models that relied only on canopy cover and crop height (M2). During the testing phase, the RF model had an R2 of 0.82, with corresponding RMSE and MAE values of 61.67 and 33.18 g/m2 respectively, while for the XGB model, the R2 was 0.78, and the RMSE and MAE were 67.19 and 39.37 g/m2, respectively (Fig. 11). These results signify a notable improvement, with a 39% and 16% increase in R2, a 32% and 19% decrease in RMSE, and a 38% and 18% decrease in MAE for RF and XGB, respectively, compared to their VIs-based counterparts (i.e. M1). Notably, the improvement was more pronounced for the RF model than the XGB. Similarly, the error went down for both models at a higher biomass range compared to the VIs-based models. For biomass higher than 200 g/m2, RMSE decreased by 26% and 22% for RF and XGB, respectively. This shows significant improvement in model fit in resolving issues encountered with the VIs with the inclusion of canopy cover and crop height. The performance of these models however was slightly lower than the same models when trained solely on structural features, such as canopy cover and crop height. This emphasizes the significance of considering the potential concerns associated with the use of VIs and underscores the importance of incorporating structural features in biomass estimation. One thing to note here is that structural features were derived from field measurements while spectral VIs were based on multispectral RS images. Further elaboration on this topic has been provided in the discussion section.

Performance of RF (left) and XGB (right) models based on selected VIs, canopy cover, and crop height variables in the test data
Feature importance
Based on the SHAP analyses of the best-performing RF and XGB regression models for cereal rye biomass prediction using only VIs, the variable that had the overall strongest impact on model prediction was SAVI. While the ranking of the three next important variables—NDRE, NGRDI, and B_G_ratio- varied between the two models, they consistently appeared in the list of top four variables (Fig. 12). Across both models, higher values of SAVI, NDRE, and NGRDI are in light orange (dots in the figure) and indicate a positive impact on cereal rye biomass, while higher values of B_G_ratio (purple dots) have a negative impact on cereal rye biomass prediction. The importance of features according to Shapley values as global feature contribution by the mean SHAP value across samples in the training set is provided in the supporting document (Figure S.2).

SHAP analyses for RF (left) and XGB (right) models for cereal rye biomass estimation. The models include six selected subsets of VIs. Important features are ranked from top to bottom. Low SHAP values (purple) have a negative impact while high values (orange) have a positive impact on prediction value
Based on the SHAP analyses of both RF and XGB models consisting of VIs and structural features, crop height had the overall strongest impact on model prediction behavior followed by canopy cover (Fig. 13; Figure S.3). This outcome is consistent with the enhanced performance of models considering only these two structural variables. An increase in both crop height and canopy cover increased cereal rye biomass. After the inclusion of these two variables, the impact of the four VIs that were ranked high in the VIs-based models diminished, with SAVI consistently emerging as the strongest VI. The ranking of other VIs, such as NDRE, B_G_ratio, and NGRDI, were inconsistent and varied between models compared to the rankings observed in VI-based models.

SHAP analyses for RF (left) and XGB (right) models consisting of six VIs and two structural features as the predictor variables for cereal rye biomass prediction
Discussion
Importance of feature selection
In this study, we took multiple modeling approaches to predict cereal rye biomass. Given our objective to find the optimal set of VIs for cereal rye biomass prediction, our focus was on comparing models that incorporated all available VIs with those utilizing a limited set of VIs. The models built using only the six selected VIs performed better than or similar to the models with a full set of 13 VIs most of the time (Fig. 7). This supports our hypothesis that the selection of optimal VIs minimizes multicollinearity issues while also resulting in better model performance. While non-linear models like RF and XGB can handle multi-collinearity, prior studies focused on above-ground biomass prediction (Adame-Campos et al., 2019; Bai et al., 2023Kuhn & Johnson, 2013) have reported findings similar to ours, emphasizing that the feature selection is crucial in improving model interpretability, reducing overfitting, reducing computation efficiency, improving generalization, and reducing the noise in the dataset.
In the study, we used the VIF approach to identify and remove highly correlated variables to address multicollinearity. However, it is important to recognize that there exist various other common approaches for feature selection, including stepwise regression, ranking- and wrapper-based selection, which can yield different outcomes compared to the VIF approach. This discrepancy arises due to the distinct criteria and algorithms employed by each method, along with their varying assumptions about the data. For instance, stepwise regression iteratively adds or removes variables based on statistical significance and thus can be sensitive to the order of variable inclusion or exclusion. Wrapper-based methods evaluate subsets of features using predictive performance and thus can perform well on the training data but may not generalize well to unseen data. Ranking-based methods, on the other hand, prioritize features based on individual importance measures but can include variables with redundant information when considered together in the model. In comparison, the VIF approach explicitly addresses multicollinearity by quantifying the correlation between predictors. Being aware of these differences is crucial during modeling workflow, ultimately leading to more robust and reliable model outcomes.
Spectral vs structural features in biomass prediction
In our study, we observed a notable improvement in model performance when structural features such as crop height and canopy cover were included. Consistent with our hypothesis, models with structural features outperformed the models based solely on VIs. Due to the greater sensitivity of canopy cover and crop height to higher biomass compared to VIs, VI-based features did not provide much additional information. This could explain the inflated standard errors and lower R2 values observed in models that considered both VIs and structural properties (Figs. 10 and 11) compared to models based solely on structural properties.
Based on the SHAP analysis of the best-performing RF and XGB models for biomass estimation in our study, SAVI consistently emerged as the most influential feature, followed by B_G_ratio, NGRDI, and NDRE. This finding aligns well with the findings of prior studies where SAVI performed superior in estimating various crop biophysical characteristics compared to other VIs (Venancio et al., 2020; Xu et al., 2018). For instance, Venancio et al. (2020) evaluated spectral VIs for estimating corn green biomass (i.e. total amount of above-ground vegetative part excluding corn grain) and identified SAVI as one of the best-performing among nine VIs. Similarly, Xu et al. (2018) demonstrated a robust linear relationship (i.e. R2 = 0.77) between SAVI and cover crop biomass including cereal rye.
This distinctive robustness of SAVI could be attributed to its ability to minimize data noise arising from soil reflectance, achieved through its incorporation of a soil correction factor. This enhances its suitability for providing reliable estimates, particularly under conditions of sparse vegetation. Notably, our original data consists of all pixels within a sampling region, further supporting the robustness of the SAVI-based model. In addition to SAVI, NDRE emerged as a noteworthy contributor in both RF and XGB models, a finding consistent with previous studies (Amaral et al., 2015; Kanke et al., 2016; Wang et al., 2016). NDRE has been found to exhibit greater sensitivity than NDVI as a biomass predictor (Amaral et al., 2015; Wang et al., 2016). Such phenomena can be attributed to the stronger relationships of red-edge-based VIs compared to red-based VIs with agronomic attributes (Kanke et al., 2016; Peng & Gitelson, 2012) due to the higher sensitivity of the red-edge spectrum to change in chlorophyll than the red portion (Filella & Penuelas, 1994; Lichtenthaler et al., 1996).
In the study, we observed reduced sensitivity of models in the prediction of cereal rye biomass, particularly those above 200 g/m2. Models that used VIs consistently underestimated biomass exceeding 200 g/m2. These findings align with prior studies that estimated crop biomass using RS-derived VIs (Chen et al., 2009; Jennewein et al., 2022; Mutanga & Skidmore, 2004; Nguy-Robertson et al., 2012; Prabhakara et al., 2015; Thenkabail et al., 2000; Thieme et al., 2020) and associated the poor performance of models with the saturation of VIs. The reduced sensitivity of VIs to higher biomass is predominantly linked to saturation in light reflectance within specific bands such as blue, green, red, and NIR (Chen et al., 2009; Thenkabail et al., 2000). Specifically, in a healthy crop canopy, there is high reflectance of light in the NIR and green regions, coupled with strong absorption in the red and blue regions. As the canopy cover increases, light absorption in the red and blue regions peaks, while reflectance in the NIR and green regions continues to rise. Consequently, this disparity in reflectance changes results in a minimal or no increase in overall VIs value, even with a further increase in biomass.
Considering the saturation effect of VIs in biomass assessment biomass during peak growing seasons, it becomes imperative to consider other proxies such as canopy cover and height that provide greater sensitivity in high biomass situations, ensuring more reliable biomass estimation. This aspect was demonstrated in our study, where canopy cover and height consistently outperformed VIs. This finding was evident in the SHAP analyses of both RF and XGB models, which included VIs and structural features (Fig. 13). Between canopy height and cover, crop height contributed more to the model performance, possibly due to saturation issues associated with canopy cover. Some of the challenges of considering canopy cover in biomass estimation were discussed by Prabhakara et al. (2015) that was focused on estimating the biomass of various cover crop species including cereal rye. The study observed that canopy cover saturated at a biomass of around 150 g/m2. Their findings suggested that estimating biomass with canopy cover as a predictor becomes challenging once it reaches 75% or more.
Recognizing the importance of these structural properties, studies in recent years have included these factors in biomass estimation. Roth and Streit (2018) employed spectral and structural features derived from visual and NIR images collected using UAS to assess legumes and dicots’ biomass in Switzerland. They observed that crop height exhibited the highest correlation (R2 = 0.58 to 0.74) with biomass compared to VIs (R2 = 0.03 to 0.37). However, even with the inclusion of structural features, most studies demonstrated limited predictive accuracy. Tang et al. (2021) used crop height, canopy area, NDRE, and NGRDI in a linear regression model for alfalfa biomass estimation and achieved R2 values ranging from 0.51 to 0.71. Similarly, Galán et al. (2020) utilized crop height, grain yield, and six selected VIs (GNDVI, Lichtenthaler index 3 (LI3), green leaf index (GLI), SR, Photochemical reflectance index (PhoRI), and pigment-specific simple ratio chlorophyll a (PSSRa)) in a linear regression model for cereal rye prediction and observed an R2 of 0.77.
While our study showcased improved model performance by integrating spectral VIs and structural features compared to previous research, it's worth noting that the features such as canopy cover and crop height included in the model were field-based, meaning they were manually collected, in contrast to these studies (Dhakal et al., 2023; Liu et al., 2023; Xu et al., 2022) that considered crop height information derived using visual or multispectral images collected via UAS.
It is also worth noting that previous studies have primarily focused on extracting crop height information using the structure from motion (SFM) in two ways: (i) process images collected at two-time stamps: one during bare soil conditions (digital terrain model (DTM)) and another during leaf-on conditions (digital surface model (DSM)) (Liu et al., 2023) (ii) identify the bare soil surface present within a field to interpolate ground surface (Dhakal et al., 2023; Xu et al., 2022). However, this process may not always be feasible, especially in areas with dense vegetation cover or when there is a lack of bare soil images for reference DTM. Additionally, the quality of DTM and DSMs generated through SFM reconstruction is often influenced by environmental conditions, such as lighting (sunny vs. cloudy days) during image acquisition, and sensor characteristics (Feng et al., 2021; Tmušić et al., 2020). Although we lacked images of fields in bare soil conditions to utilize image-derived height information in our study, we believe that the SFM reconstruction process can serve as an effective alternative in situations where sensors capable of capturing accurate crop height information, such as LIDAR, are unavailable.
Performance of biomass estimation model
Among the six ML regression models, RF and XGB were found to estimate cereal rye biomass with low error and better explain variance in low and high ranges than MLR, ENET, MARS, and SVM. This is consistent with prior studies that have consistently shown that RF and XGB models fitted with RS-derived features outperform other regression models, including MLR, SVM, artificial neural network (ANN), and partial least squares regression (PLSR) in estimating crop yield and biomass (Geng et al., 2021; Han et al., 2019; Meng et al., 2013; Tian et al., 2021; Wang et al., 2022a, 2022b; Zhang et al., 2021). For instance, Han et al. (2019) found RF to be the most stable model in estimating maize biomass in a plot scale study, while Tian et al. (2021) reported RF and XGB as superior in estimating above-ground mangrove biomass. Additionally, Zhang et al. (2021) demonstrated that XGB surpassed stepwise and RF regression in predicting maize biomass. Despite traditional parametric models offering better interpretability and ease of implementation, non-parametric models like RF and XGB tend to outperform them due to their ability to capture non-linear interactions among variables (Meng et al., 2020).
The accuracy of the models based on spectral VIs in our study aligns well with previous research that focused on utilizing solely RS variables to estimate cover crop biomass, particularly, cereal rye. Our best-performing models, RF (R2 = 0.59, RMSE = 91.89 g/m2, MAE = 53.93 g/m2) and XGB (R2 = 0.67, RMSE = 83.13 g/m2, MAE = 48.13 g/m2), demonstrated robust outcomes across both lower (0 to 200 g/m2) and higher biomass ranges (> 200 g/m2) across the cereal rye growing season. In a similar study aimed at estimating cover crop biomass, Prabhakara et al. (2015) reported R2 values ranging from 0.26 to 0.40 and 0.40 to 0.63 using linear regression and log-linear regression model, respectively, with 10 VIs for five cover crop species including cereal rye, based on field samples collected throughout the cover crop growing season. Similar to results in our study, when the data were limited to early sampling dates, the regression between the VIs and the biomass improved significantly with R2 values ranging from 0.59 to 0.84 and 0.63 to 0.86 for linear and log-linear regression models, respectively. This could be due to reduction in VI saturation occuring in high biomass at later growing stages. Another study employed a simple linear regression approach using four VIs and estimated cereal rye and triticale biomass with validation R2 ranging from 0.47 to 0.93 (Yuan et al., 2019). However, the overall performance of this method was constrained by a limited biomass range, reaching only up to 140 g/m2, which likely did not encounter issues related to VI saturation unlike in our study with biomass ranging up to 634 g/m2.
To improve the estimation of springtime cereal rye biomass, Jennewein et al. (2022) integrated VIs with synthetic aperture radar (SAR) imagery-derived features in a log-linear model but achieved limited success with R2 of 0.38 and RMSE of 77.2 g/m2. In a two-year field experiment involving the estimation of five cover crop species conducted in Nebraska, Bai et al. (2023) evaluated the performance of four ML models (RF, SVM, PLS, and ANN) using only spectral VIs. They reported R2 values ranging from 0.62 to 0.77, with higher RMSE values ranging from 106.3 to 136.5 g/m2. Similarly, Kharel et al. (2023) reported biomass predictions for mixed species using RF models on individual spectral bands present in Planetscope image and the derived VIs within a similar range (R2 = 0.25 to 0.61). By integrating a large set of datasets coming from multiple on-farm fields and multiple growth stage data, as well as employing various ML models coupled with a variable selection process, the VI-based models in our study achieved relatively superior performance compared to prior studies. This underscores the robustness of our approach in the context of cereal rye biomass estimation and supports our hypotheses regarding the superior performance of ML models. These models, combined with RS observations, can be utilized to comprehend the spatial variability of cereal rye growth within a field (e.g. Fig. 9) for precision management of planting, weeds, nutrients, and moisture.
Limitations and future work
In this study, our focus was on identifying VIs and developing models leveraging VIs and/or structural properties suitable to predict cereal rye biomass. We utilized a total of 239 ground-truth data collected from 15 farmers' fields ranging in size from 9 to 78 acres, spread across the northwestern part of Ohio. While our analyses provided useful insights into the importance of VIs and structural properties in cereal rye biomass prediction under diverse field conditions compared to prior studies that mostly relied on plot-based or limited on-farm data, we think data from more fields and multiple years could further enhance the model's generalizability and robustness.
Saturation of VIs as we have observed in the study can pose a known limitation for the application of VIs in biomass estimation. Therefore, it is necessary to assess such saturation effects of VIs to avoid the underestimation of biomass. Since structural properties such as crop height are less sensitive to saturation, efforts need to be directed toward inclusion of them whenever feasible.
Our ability to create DTM which is essential for computing crop height based on the SFM technique was limited by the lack of images representing bare soil conditions and the absence of bare soil surface present within cereal rye fields at later stages of data collection (T2 to T3). Future efforts should be directed towards developing new and/or employing existing methods that leverage RGB and/or multispectral images to accurately derive crop height information, which can then be integrated into the model for robust estimation of crop biomass. Furthermore, special consideration should be given to ensure quality aerial multispectral images for remote sensing applications in agricultural fields. This will make certain that the orthomosaic stitching process goes smoothly and the data gap does not persist.
Conclusion
This study explores the potential of using UAS multispectral imagery for the estimation of cereal rye biomass using data collected over three growth stages of cereal rye at 15 on-farm fields in northwest Ohio, USA. It also investigates the significance of different combinations of VIs and crop structural properties for predicting cereal rye biomass using six regression algorithms- MLR, ENET, MARS, SVM, RF, and XGB. The performance of these models was evaluated to gauge their effectiveness in biomass prediction. The main findings of this study include:
-
Feature selection based on VIF scoring resulted in the selection of six VIs out of a total of 13 VIs. The selected VIs included ExG, NGRDI, SAVI, B_G_ratio, RTVI, and NDRE.
-
The models built using only the six selected VIs performed better than or similar to the models with a full set of 13 VIs most of the time with R2 ranging from 0.24 to 0.59 and RMSE ranging from 83.13 to 91.89 g/m2 during cross-fold validation.
-
During the independent assessment of VI-based models using the test dataset, XGB exhibited the highest R2 (0.67) and lowest RMSE (83.13 g/m2) and MAE (48.13 g/m2), followed by RF and ENET.
-
All ML models provided reasonable estimates for biomass at a range less than or equal to 200 g/m2 but were underestimated when predicting biomass greater than 200 g/m2.
-
When field-collected structural features such as canopy cover and crop height were combined with the selected VIs, the models performed better than VIs-based models but not compared to the models that relied only on canopy cover and crop height.
-
Based on the SHAP analyses of the best-performing RF and XGB regression models for cereal rye biomass prediction using only VIs, the variable that had the overall strongest impact on model prediction was SAVI. While the ranking of the three next important variables—NDRE, NGRDI, and B_G_ratio- varied between the two models, they consistently appeared in the list of top four variables.
The methodology developed in this study demonstrates the potential for the development of a tool for farmers that may facilitate precise estimation and mapping of cereal rye biomass. Timely information on cover crop growth is crucial for the production of cash crops following cover crops for numerous decision-making purposes, including planning the planting operations, and management of nutrients, weeds, and soil moisture to improve agronomic and environmental outcomes.
Data availability
Data will be made available on request.
References
Abdalla, M., Hastings, A., Cheng, K., Yue, Q., Chadwick, D., Espenberg, M., Truu, J., Rees, R. M., & Smith, P. (2019). A critical review of the impacts of cover crops on nitrogen leaching, net greenhouse gas balance and crop productivity. Global Change Biology, 25(8), 2530–2543. https://doi.org/10.1111/gcb.14644
Adame-Campos, R. L., Ghilardi, A., Gao, Y., Paneque-Gálvez, J., & Mas, J.-F. (2019). Variables selection for aboveground biomass estimations using satellite data: A comparison between relative importance approach and stepwise Akaike’s information criterion. ISPRS International Journal of Geo-Information. https://doi.org/10.3390/ijgi8060245
Adetunji, A. T., Ncube, B., Mulidzi, R., & Lewu, F. B. (2020). Management impact and benefit of cover crops on soil quality: A review. Soil and Tillage Research, 204, 104717. https://doi.org/10.1016/j.still.2020.104717
Alckmin, G., Kooistra, L., Lucieer, A., & Rawnsley, R. (2019). Feature filtering and selection for dry matter estimation on perennial ryegrass: A case study of vegetation indices. International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 42, 1827–1831.
Alexandridis, T. K., Ovakoglou, G., & Clevers, J. G. P. W. (2020). Relationship between MODIS EVI and LAI across time and space. Geocarto International, 35(13), 1385–1399. https://doi.org/10.1080/10106049.2019.1573928
Amaral, L. R., Molin, J. P., Portz, G., Finazzi, F. B., & Cortinove, L. (2015). Comparison of crop canopy reflectance sensors used to identify sugarcane biomass and nitrogen status. Precision Agriculture, 16(1), 15–28. https://doi.org/10.1007/s11119-014-9377-2
Awais, M., Li, W., Cheema, M. J. M., Hussain, S., AlGarni, T. S., Liu, C., & Ali, A. (2021). Remotely sensed identification of canopy characteristics using UAV-based imagery under unstable environmental conditions. Environmental Technology & Innovation, 22, 101465. https://doi.org/10.1016/j.eti.2021.101465
Bai, G., Koehler-Cole, K., Scoby, D., Thapa, V. R., Basche, A., & Ge, Y. (2023). Enhancing estimation of cover crop biomass using field-based high-throughput phenotyping and machine learning models. Frontiers in Plant Science, 14, 1277672. https://doi.org/10.3389/fpls.2023.1277672
Berry, M. A., Davis, T. W., Cory, R. M., Duhaime, M. B., Johengen, T. H., Kling, G. W., Marino, J. A., Den Uyl, P. A., Gossiaux, D., Dick, G. J., & Denef, V. J. (2017). Cyanobacterial harmful algal blooms are a biological disturbance to Western Lake Erie bacterial communities. Environmental Microbiology, 19(3), 1149–1162. https://doi.org/10.1111/1462-2920.13640
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324
Broge, N. H., & Leblanc, E. (2001). Comparing prediction power and stability of broadband and hyperspectral vegetation indices for estimation of green leaf area index and canopy chlorophyll density. Remote Sensing of Environment, 76(2), 156–172. https://doi.org/10.1016/S0034-4257(00)00197-8
Cao, Q., Miao, Y., Shen, J., Yu, W., Yuan, F., Cheng, S., Huang, S., Wang, H., Yang, W., & Liu, F. (2016). Improving in-season estimation of rice yield potential and responsiveness to topdressing nitrogen application with Crop Circle active crop canopy sensor. Precision Agriculture, 17(2), 136–154. https://doi.org/10.1007/s11119-015-9412-y
Chen, J., Gu, S., Shen, M., Tang, Y., & Matsushita, B. (2009). Estimating aboveground biomass of grassland having a high canopy cover: An exploratory analysis of in situ hyperspectral data. International Journal of Remote Sensing, 30(24), 6497–6517. https://doi.org/10.1080/01431160902882496
Chen, P., Tremblay, N., Wang, J., Philippe, V., Huang, W., & Li, B. (2010). New index for crop canopy fresh biomass estimation. Spectroscopy and Spectral Analysis. https://doi.org/10.3964/j.issn.1000-0593(2010)02-0512-06
Chen, T., & Guestrin, C. (2016). Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. https://doi.org/10.1145/2939672.2939785
Daryanto, S., Fu, B., Wang, L., Jacinthe, P. A., & Zhao, W. (2018). Quantitative synthesis on the ecosystem services of cover crops. Earth-Science Reviews, 185(June), 357–373. https://doi.org/10.1016/j.earscirev.2018.06.013
Dhakal, R., Maimaitijiang, M., Chang, J., & Caffe, M. (2023). Utilizing spectral, structural and textural features for estimating oat above-ground biomass using UAV-based multispectral data and machine learning. Sensors. https://doi.org/10.3390/s23249708
Fawagreh, K., Gaber, M. M., & Elyan, E. (2014). Random forests: From early developments to recent advancements. Systems Science & Control Engineering, 2(1), 602–609.
Feng, L., Chen, S., Zhang, C., Zhang, Y., & He, Y. (2021). A comprehensive review on recent applications of unmanned aerial vehicle remote sensing with various sensors for high-throughput plant phenotyping. Computers and Electronics in Agriculture, 182, 106033. https://doi.org/10.1016/j.compag.2021.106033
Filella, I., & Penuelas, J. (1994). The red edge position and shape as indicators of plant chlorophyll content, biomass and hydric status. International Journal of Remote Sensing, 15(7), 1459–1470. https://doi.org/10.1080/01431169408954177
Finney, D. M., White, C. M., & Kaye, J. P. (2016). Biomass production and carbon/nitrogen ratio influence ecosystem services from cover crop mixtures. Agronomy Journal, 108(1), 39–52. https://doi.org/10.2134/agronj15.0182
Friedman, J. H. (1991). Multivariate adaptive regression splines. The Annals of Statistics, 19(1), 1–67. https://doi.org/10.1214/aos/1176347963
Galán, R. J., Bernal-Vasquez, A.-M., Jebsen, C., Piepho, H.-P., Thorwarth, P., Steffan, P., Gordillo, A., & Miedaner, T. (2020). Hyperspectral reflectance data and agronomic traits can predict biomass yield in winter rye hybrids. BioEnergy Research, 13(1), 168–182. https://doi.org/10.1007/s12155-019-10080-z
Gamon, J., & Surfus, J. (1999). Assessing leaf pigment content and activity with a reflectometer. The New Phytologist, 143(1), 105–117.
Geng, L., Che, T., Ma, M., Tan, J., & Wang, H. (2021). Corn biomass estimation by integrating remote sensing and long-term observation data based on machine learning techniques. Remote Sensing. https://doi.org/10.3390/rs13122352
Gitelson, A., & Merzlyak, M. (1998). Remote sensing of chlorophyll concentration in higher plant leaves. Advances in Space Research, 22(5), 689–692. https://doi.org/10.1016/S0273-1177(97)01133-2
Gitelson, A., & Merzlyak, M. N. (1994). Quantitative estimation of chlorophyll-a using reflectance spectra: Experiments with autumn chestnut and maple leaves. Journal of Photochemistry and Photobiology b: Biology, 22(3), 247–252. https://doi.org/10.1016/1011-1344(93)06963-4
Han, L., Yang, G., Dai, H., Xu, B., Yang, H., Feng, H., Li, Z., & Yang, X. (2019). Modeling maize above-ground biomass based on machine learning approaches using UAV remote-sensing data. Plant Methods, 15(1), 1–19. https://doi.org/10.1186/s13007-019-0394-z
Holman, F. H., Riche, A. B., Michalski, A., Castle, M., Wooster, M. J., & Hawkesford, M. J. (2016). High throughput field phenotyping of wheat plant height and growth rate in field plot trials using UAV based remote sensing. Remote Sensing. https://doi.org/10.3390/rs8121031
Huete, A. (1988). A soil-adjusted vegetation index (SAVI). Remote Sensing of Environment, 25(3), 295–309. https://doi.org/10.1016/0034-4257(88)90106-X
Huete, A., Didan, K., Miura, T., Rodriguez, E. P., Gao, X., & Ferreira, L. G. (2002). Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sensing of Environment, 83(1), 195–213. https://doi.org/10.1016/S0034-4257(02)00096-2
Hunt, E. R., Cavigelli, M., Daughtry, C. S. T., Mcmurtrey, J. E., & Walthall, C. L. (2005). Evaluation of digital photography from model aircraft for remote sensing of crop biomass and nitrogen status. Precision Agriculture, 6(4), 359–378. https://doi.org/10.1007/s11119-005-2324-5
Jennewein, J. S., Lamb, B. T., Hively, W. D., Thieme, A., Thapa, R., Goldsmith, A., & Mirsky, S. B. (2022). Integration of satellite-based optical and synthetic aperture radar imagery to estimate winter cover crop performance in cereal grasses. Remote Sensing. https://doi.org/10.3390/rs14092077
Jordan, C. F. (1969). Derivation of leaf-area index from quality of light on the forest floor. Ecology, 50(4), 663–666. https://doi.org/10.2307/1936256
Kanke, Y., Tubaña, B., Dalen, M., & Harrell, D. (2016). Evaluation of red and red-edge reflectance-based vegetation indices for rice biomass and grain yield prediction models in paddy fields. Precision Agriculture, 17(5), 507–530. https://doi.org/10.1007/s11119-016-9433-1
Kaspar, T. C., & Bakker, M. G. (2015). Biomass production of 12 winter cereal cover crop cultivars and their effect on subsequent no-till corn yield. Journal of Soil and Water Conservation, 70(6), 353–364. https://doi.org/10.2489/jswc.70.6.353
Kharel, T. P., Bhandari, A. B., Mubvumba, P., Tyler, H. L., Fletcher, R. S., & Reddy, K. N. (2023). Mixed-species cover crop biomass estimation using planet imagery. Sensors. https://doi.org/10.3390/s23031541
Koh, J. C. O., Hayden, M., Daetwyler, H., & Kant, S. (2019). Estimation of crop plant density at early mixed growth stages using UAV imagery. Plant Methods, 15(1), 64. https://doi.org/10.1186/s13007-019-0449-1
Kross, A., McNairn, H., Lapen, D., Sunohara, M., & Champagne, C. (2015). Assessment of RapidEye vegetation indices for estimation of leaf area index and biomass in corn and soybean crops. International Journal of Applied Earth Observation and Geoinformation, 34, 235–248. https://doi.org/10.1016/j.jag.2014.08.002
Lichtenthaler, H. K., Gitelson, A., & Lang, M. (1996). Non-destructive determination of chlorophyll content of leaves of a green and an aurea mutant of tobacco by reflectance measurements. Journal of Plant Physiology, 148(3), 483–493. https://doi.org/10.1016/S0176-1617(96)80283-5
Liu, Y., Feng, H., Yue, J., Fan, Y., Bian, M., Ma, Y., Jin, X., Song, X., & Yang, G. (2023). Estimating potato above-ground biomass by using integrated unmanned aerial system-based optical, structural, and textural canopy measurements. Computers and Electronics in Agriculture, 213, 108229. https://doi.org/10.1016/j.compag.2023.108229
Lundberg, S., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems, 30. https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html
Meng, B., Liang, T., Yi, S., Yin, J., Cui, X., Ge, J., Hou, M., Lv, Y., & Sun, Y. (2020). Modeling alpine grassland above ground biomass based on remote sensing data and machine learning algorithm: A case study in East of the Tibetan Plateau, China. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 13, 2986–2995. https://doi.org/10.1109/JSTARS.2020.2999348
Meng, J., Du, X., & Wu, B. (2013). Generation of high spatial and temporal resolution NDVI and its application in crop biomass estimation. International Journal of Digital Earth, 6(3), 203–218. https://doi.org/10.1080/17538947.2011.623189
Meyer, N., Bergez, J.-E., Justes, E., & Constantin, J. (2022). Influence of cover crop on water and nitrogen balances and cash crop yield in a temperate climate: A modelling approach using the STICS soil-crop model. European Journal of Agronomy, 132, 126416. https://doi.org/10.1016/j.eja.2021.126416
Michalak, A. M., Anderson, E. J., Beletsky, D., Boland, S., Bosch, N. S., Bridgeman, T. B., Chaffin, J. D., Cho, K., Confesor, R., Daloğlu, I., DePinto, J. V., Evans, M. A., Fahnenstiel, G. L., He, L., Ho, J. C., Jenkins, L., Johengen, T. H., Kuo, K. C., LaPorte, E., & Zagorski, M. A. (2013). Record-setting algal bloom in Lake Erie caused by agricultural and meteorological trends consistent with expected future conditions. Proceedings of the National Academy of Sciences, 110(16), 6448–6452. https://doi.org/10.1073/pnas.1216006110
Moges, S. M., Raun, W. R., Mullen, R. W., Freeman, K. W., Johnson, G. V., & Solie, J. B. (2005). Evaluation of green, red, and near infrared bands for predicting winter wheat biomass, nitrogen uptake, and final grain yield. Journal of Plant Nutrition, 27(8), 1431–1441. https://doi.org/10.1081/PLN-200025858
Mutanga, O., & Skidmore, A. K. (2004). Narrow band vegetation indices overcome the saturation problem in biomass estimation. International Journal of Remote Sensing, 25(19), 3999–4014. https://doi.org/10.1080/01431160310001654923
Nguy-Robertson, A., Gitelson, A., Peng, Y., Viña, A., Arkebauer, T., & Rundquist, D. (2012). Green leaf area index estimation in maize and soybean: Combining vegetation indices to achieve maximal sensitivity. Agronomy Journal, 104(5), 1336–1347. https://doi.org/10.2134/agronj2012.0065
Peng, Y., & Gitelson, A. A. (2012). Remote estimation of gross primary productivity in soybean and maize based on total crop chlorophyll content. Remote Sensing of Environment, 117, 440–448. https://doi.org/10.1016/j.rse.2011.10.021
Peroni Venancio, L., Chartuni Mantovani, E., & do Amaral, C. H., Usher Neale, C. M., Zution Gonçalves, I., Filgueiras, R., & Coelho Eugenio, F. (2020). Potential of using spectral vegetation indices for corn green biomass estimation based on their relationship with the photosynthetic vegetation sub-pixel fraction. Agricultural Water Management, 236, 106155. https://doi.org/10.1016/j.agwat.2020.106155
Prabhakara, K., Dean Hively, W., & McCarty, G. W. (2015). Evaluating the relationship between biomass, percent groundcover and remote sensing indices across six winter cover crop fields in Maryland, United States. International Journal of Applied Earth Observation and Geoinformation, 39, 88–102. https://doi.org/10.1016/j.jag.2015.03.002
Rosle, R., & Che’Ya, N. N., Roslin, N. A., Halip, R. M., & Ismail, M. R. (2019). Monitoring early stage of rice crops growth using normalized difference vegetation index generated from UAV. IOP Conference Series: Earth and Environmental Science, 355(1), 12066. https://doi.org/10.1088/1755-1315/355/1/012066
Roth, L., & Streit, B. (2018). Predicting cover crop biomass by lightweight UAS-based RGB and NIR photography: An applied photogrammetric approach. Precision Agriculture, 19(1), 93–114. https://doi.org/10.1007/s11119-017-9501-1
Rouse, J. W., Haas, R. H., Deering, D. W., Schell, J. A., & Harlan, J. C. (1974). Monitoring the vernal advancement and retrogradation (greenwave effect) of natural vegetation. E75-10354
Salmerón, R., García, C., & García, J. (2020). Overcoming the inconsistences of the variance inflation factor: A redefined VIF and a test to detect statistical troubling multicollinearity. arXiv:2005.02245
Santin-Janin, H., Garel, M., Chapuis, J.-L., & Pontier, D. (2009). Assessing the performance of NDVI as a proxy for plant biomass using non-linear models: A case study on the Kerguelen archipelago. Polar Biology, 32(6), 861–871. https://doi.org/10.1007/s00300-009-0586-5
Sellaro, R., Crepy, M., Trupkin, S. A., Karayekov, E., Buchovsky, A. S., Rossi, C., & Casal, J. J. (2010). Cryptochrome as a sensor of the blue/green ratio of natural radiation in Arabidopsis. Plant Physiology, 154(1), 401–409. https://doi.org/10.1104/pp.110.160820
Sharma, P., Leigh, L., Chang, J., & Maimaitijiang, M. (2022). Above-ground biomass estimation in oats using UAV remote sensing and machine learning. Sensors, 22(2), 601.
Smola, A. J., & Schölkopf, B. (2004). A tutorial on support vector regression. Statistics and Computing, 14(3), 199–222. https://doi.org/10.1023/B:STCO.0000035301.49549.88
Tang, Z., Parajuli, A., Chen, C. J., Hu, Y., Revolinski, S., Medina, C. A., Lin, S., Zhang, Z., & Yu, L. X. (2021). Validation of UAV-based alfalfa biomass predictability using photogrammetry with fully automatic plot segmentation. Scientific Reports, 11(1), 1–13. https://doi.org/10.1038/s41598-021-82797-x
Thenkabail, P. S., Smith, R. B., & De Pauw, E. (2000). Hyperspectral vegetation indices and their relationships with agricultural crop characteristics. Remote Sensing of Environment, 71(99), 158–182.
Thieme, A., Yadav, S., Oddo, P. C., Fitz, J. M., McCartney, S., King, L. A., Keppler, J., McCarty, G. W., & Hively, W. D. (2020). Using NASA Earth observations and Google Earth Engine to map winter cover crop conservation performance in the Chesapeake Bay watershed. Remote Sensing of Environment, 248, 111943. https://doi.org/10.1016/j.rse.2020.111943
Tian, Y., Huang, H., Zhou, G., Zhang, Q., Tao, J., Zhang, Y., & Lin, J. (2021). Aboveground mangrove biomass estimation in Beibu Gulf using machine learning and UAV remote sensing. Science of the Total Environment, 781(12), 146816. https://doi.org/10.1016/j.scitotenv.2021.146816
Tmušić, G., Manfreda, S., Aasen, H., James, M. R., Gonçalves, G., Ben-Dor, E., Brook, A., Polinova, M., Arranz, J. J., Mészáros, J., Zhuang, R., Johansen, K., Malbeteau, Y., de Lima, I. P., Davids, C., Herban, S., & McCabe, M. F. (2020). Current practices in UAS-based environmental monitoring. Remote Sensing. https://doi.org/10.3390/rs12061001
Tucker, C. J., & Sellers, P. J. (1986). Satellite remote sensing of primary production. International Journal of Remote Sensing, 7(11), 1395–1416. https://doi.org/10.1080/01431168608948944
Vélez, S., Martínez-Peña, R., & Castrillo, D. (2023). Beyond vegetation: A review unveiling additional insights into agriculture and forestry through the application of vegetation indices. J, 6(3), 421–436. https://doi.org/10.3390/j6030028
Wang, F., Yang, M., Ma, L., Zhang, T., Qin, W., Li, W., Zhang, Y., Sun, Z., Wang, Z., Li, F., & Yu, K. (2022a). Estimation of above-ground biomass of winter wheat based on consumer-grade multi-spectral UAV. Remote Sensing. https://doi.org/10.3390/rs14051251
Wang, J., Liu, T., Zhang, J., Yuan, H., & Acquah, G. E. (2022b). Spectral variable selection for estimation of soil organic carbon content using mid-infrared spectroscopy. European Journal of Soil Science, 73(4), e13267. https://doi.org/10.1111/ejss.13267
Wang, X., Miao, Y., Guan, Y., Xia, T., Lu, J., & Mulla, D. J. (2016). An evaluation of two active canopy sensor systems for non-destructive estimation of spring maize biomass. In 2016 Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics). https://doi.org/10.1109/Agro-Geoinformatics.2016.7577610
Woebbecke, D., Meyer, G., Von Bargen, K., & Mortensen, D. (1995). Color indices for weed identification under various soil, residue, and lighting conditions. Transactions of the ASAE, 38(1), 259–269.
Xu, L., Zhou, L., Meng, R., Zhao, F., Lv, Z., Xu, B., Zeng, L., Yu, X., & Peng, S. (2022). An improved approach to estimate ratoon rice aboveground biomass by integrating UAV-based spectral, textural and structural features. Precision Agriculture, 23(4), 1276–1301. https://doi.org/10.1007/s11119-022-09884-5
Xu, M., Lacey, C. G., & Armstrong, S. D. (2018). The feasibility of satellite remote sensing and spatial interpolation to estimate cover crop biomass and nitrogen uptake in a small watershed. Journal of Soil and Water Conservation, 73(6), 682–692. https://doi.org/10.2489/jswc.73.6.682
Ye, H., Huang, W., Huang, S., Cui, B., Dong, Y., Guo, A., Ren, Y., & Jin, Y. (2020). Recognition of Banana Fusarium Wilt based on UAV remote sensing. Remote Sensing. https://doi.org/10.3390/rs12060938
Yuan, M., Burjel, J. C., Isermann, J., Goeser, N. J., & Pittelkow, C. M. (2019). Unmanned aerial vehicle-based assessment of cover crop biomass and nitrogen uptake variability. Journal of Soil and Water Conservation, 74(4), 350–359. https://doi.org/10.2489/jswc.74.4.350
Yue, J., Feng, H., Li, Z., Zhou, C., & Xu, K. (2021). Mapping winter-wheat biomass and grain yield based on a crop model and UAV remote sensing. International Journal of Remote Sensing, 42(5), 1577–1601. https://doi.org/10.1080/01431161.2020.1823033
Zhang, Y., Xia, C., Zhang, X., Cheng, X., Feng, G., Wang, Y., & Gao, Q. (2021). Estimating the maize biomass by crop height and narrowband vegetation indices derived from UAV-based hyperspectral images. Ecological Indicators, 129, 107985. https://doi.org/10.1016/j.ecolind.2021.107985
Zhou, Y., Zhang, L., Xiao, J., Chen, S., Kato, T., & Zhou, G. (2014). A comparison of satellite-derived vegetation indices for approximating gross primary productivity of grasslands. Rangeland Ecology & Management, 67(1), 9–18. https://doi.org/10.2111/REM-D-13-00059.1
Zhu, W., Rezaei, E. E., Nouri, H., Sun, Z., Li, J., Yu, D., & Siebert, S. (2022). UAV-based indicators of crop growth are robust for distinct water and nutrient management but vary between crop development phases. Field Crops Research, 284, 108582. https://doi.org/10.1016/j.fcr.2022.108582
Zou, H., & Hastie, T. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society: Series B (statistical Methodology), 67(2), 301–320. https://doi.org/10.1111/j.1467-9868.2005.00503.x
Acknowledgements
We want to thank Boden Fisher, Brigitte Moneymaker, Abha Bhattarai, and Gaoshoutong Si for their contribution and support during field data collection.
Funding
This work was supported by funds from OSU L&L Grant (PG107271), SI Grant (PG107338), Ohio Soybean Council (GR123740), OSU Soybean Research Center, USDA-AFRI Grant (GR130726), and Hatch Project (NC1195).
Author information
Authors and Affiliations
Contributions
Kushal KC: Conceptualization, formal analysis, methodology, software, validation, visualization, writing—original draft, writing—review and editing. Sami Khanal: Conceptualization, funding acquisition, investigation, methodology, project administration, supervision, writing—review and editing. Matthew Romanko: Data collection, writing—review and editing. Andrew Perrault: Writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing financial interests or personal relationships that could have influenced the work in the paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
KC, K., Romanko, M., Perrault, A. et al. On-farm cereal rye biomass estimation using machine learning on images from an unmanned aerial system. Precision Agric (2024). https://doi.org/10.1007/s11119-024-10162-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s11119-024-10162-9