
Abstract
Speech signal enhancement is a subject of study in which a large number of researchers are working to improve the quality and perceptibility of speech signals. In the existing Kalman Filter method, the short-time magnitude or power spectrum due to random variations of noise was a serious problem and the signal-to-noise ratio was very low. This issue severely reduced the perceived qualityand intelligibility of enhanced speech. Thus, this paper intent to develop an improved speech enhancement model and it includes“training phase and testing phase”. In the training phase, the input noise corrupted signal is initially fed as input to both STFT-based noise estimation and NMF-based spectrum estimation forestimating the noise spectrum and signal spectrum, respectively. The obtained noise spectrum and the signal spectrum are fed as input to the Wiener filter and these filtered signals are subjected to Empirical Mean Decomposition (EMD).Since, tuning factor η plays a key role in Wiener filter, it has to be determined for each signal and from the denoised signal the bark frequency is evaluated. The computed bark frequency is fed as input to the learning algorithm referred as Fuzzy Wavelet Neural Network (FW-NN)for detecting the suited tuning factor η for the entire input signal in Wiener filter.An Adaptive Randomized Grey Wolf Optimization (AR-GWO) is proposed for proper tuning of the tuning factor η referred as tuned tuning factor (ηtuned). The proposed AR-GWO is the improved version of standard Grey wolf optimization (GWO). In the testing phase, the training is accomplished initially and from which the tuning factor is gathered for each of the relevant input signal. Then, the properly tuned tuning factor (ηtuned) from FW-NN is fed as input to EMD via adaptive wiener filter for decomposing the spectral signal and the output of EMD is denoised enhanced speech signal. At last, the performance of the adopted approach is evaluated to the existing approaches in terms of various metrics. In particular, the computation time of the adopted AR-GWO model is 34.07%, 43.57%, 28.86%, 38.88%, and 16.03% better than the existing GA, ABC, PSO, FF, and GWO approaches respectively.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the present era, speech enhancement plays a major role in the field of speech processing as it is related to the speaking as well as listening skills. In general, speech enhancement is employed with a desire of processing the noisy speech signals, thereby enhancing human perception [3, 38, 41]. Generally, the quality of the speech is related to the attributes of the speaker, like the naturalness and speaker recognizability, whereas the intelligibility of the speech is related to the meaning or information content that is hidden behind the words [45] [27]. Speech signals are utilized in many purposes and in recent times, COVID-19 [28, 36] has been detected from speech signals. Hence, it is vivid that, the ability to communicate (speak and listen) diminishes in the noisy environment.
The speech enhancement is performed with the intention of reducing the impact of the communication problem [22]. Most of the research proved that, it is a complex task to reduce the noise of the signal without distorting speech and this is the major reason behind the non-availability of an ideal enhancement systems [4, 30]. Beyond this, efforts to enhance the “higher quality and/or intelligibility of noisy speech” will definitely end up with a mass increment in the performance of the speech signal and hence it can be employed in the fields of “speech coding/compression and speech recognition, hearing aids, voice communication systems and so on” [21, 35]. Further, the goal behind each of the speech recognition might be different and they are application based, such as diminishing the listener fatigue, boosting the overall speech quality, enhancing the intelligibility and improving the performance of the voice communication device, etc. But, the major benchmark behind all the research is to diminish the noise level and to enhance the quality as well asthe intelligibility of the signal. Hence,“speech enhancement is necessary to avoid the degradation of speech quality and to overcome the limitations of human auditory systems” [2, 43].
A vast amount of automatic speech processing systems are playing a major role in human life, like the “mobile communication, speech and speaker recognition, hearing impaired and numerous other applications”. Moreover, the quality and intelligibility of speech areof utmost importance with the intention of enhancing the accuracy of information exchange [31]. Beyond this, in the controlled environment, human as well as automatic speech communications are found to be much more effective [5, 47]. The Spectral Subtraction algorithm suffers from the problem of restoration in the basis parameters of the speech like the power spectrum or the magnitude spectrum and here only the additive noise available in the signal can be removed [1]. Then, in the Sub-space analysis algorithm, there was a difficulty in enhancing the noise spectrum and updating the noise spectrum from period to period was a complex task. [46]. Thus, in order to override these entire problems, there is a necessity to have an optimal speech enhancement method.
Nowadays, literature works have come up with several techniques for speech enhancement as relates to speaking as well as listening skills. Tantibundhit et al. [44] proposed JT-FS with the desire of decomposing the speech signal into “transient” as well as “non-transient components” only the basis of the wavelet packets. Lee et al. [30] proffered P-SJL with the intention of enhancing single-channel speech. The phase-related information of the speech signal was represented using PSM which was similar to the T-F mask. Furthermore, the P-ASEalgorithm [48] was formulated on the basis of DNN. Shao and Chang [40] developed a framework of wavelet-based techniques with the intention of enhancing the performance of automatic speech recognition by eliminating the background noise. AKCF algorithm was introduced in [13]with the aim of enhancing speech. The noise as well as the speech parameters was estimated using the Estimate-Maximize (EM) method. Mohammadiha et al. [34] proposed SSD algorithms on the basis of NMF. In addition to this, the Bayesian Formulation of NMF (BNMF) was used for generating the novel speech enhancement method. Additionally, Chazan et al. [6] proposed the S-MSE algorithm in order to enhance the speech signal. Samuiet al. [39] proposed time-frequency masking in the basis of DNN with the intention of enhancing the speech signal and here the pre-training of the signal was accomplished using FRBM. Moreover, the advantages and challenges of the few works are listed in Table 1. These challenges have kept the main stand for motivating and accomplishing the new speech enhancement model.
In addition, many optimization algorithms have been introduced recently [8,9,10, 25] and utilized in many fields for better outcomes [7]. In this research work, a modified version of a popular meta-heuristic algorithm is employed. The major contributions of this research are listed below:
-
In this research work, STFT-based noise estimation and NMF-based spectrum estimation are utilized for the estimation of the noise spectrum and signal spectrum of the noisy signal.
-
To minimize the error, a Wiener filter is employed and the tuning factor ηof Wiener filter is obtained for different signals.
-
Introducing a Fuzzy Wavelet Neural Network (FW-NN) for detecting the suited tuning factor η for the entire input signal in Wiener filter.
-
Proposed an Adaptive Randomized Grey Wolf Optimization (AR-GWO) for proper tuning of the tuning factorηreferred as tuned tuning factor(ηtuned). The proposed AR-GWO algorithm is an improved version of the traditional GWO algorithm.
The rest of the paper is organized as below: Section 2 portrays the proposed architecture of the speech enhancement model. Section 3 depicts the processed steps for enhanced speech enhancement. The results and discussions are exhibited in Section 4, and Section 5 concludes the paper.
2 Proposed architecture of speech enhancement model
2.1 Architectural representation
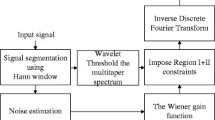
Figure 1 demonstrates the architecture of the proposed speech enhancement model in which the overall process takes place in “two major phases (i) training phase (ii) testing phase”. In the training phase, initially, the noise corrupted signal is fed as input to STFT-based noise estimation as well as NMF-based spectrum estimation, for estimating the noise spectrum and signal spectrum, respectively. The obtained spectrum (noise and signal) are given as input to the Wiener filter. These, filtered signals are subjected to EMD, from which the denoised signal can be obtained. Since, tuning factor η plays a key role in Wiener filter, it has to be determined for each signals, and is trained in FW-NN. Then, from the denoised signal the bark frequency is evaluated. The computed bark frequency is fed as input to the learning algorithm referred as FW-NNfor detecting the suited tuning factorη for the entire input signal in Weiner filter. The AR-GWO is employed for proper tuning of the tuning factorη. Moreover, in the testing phase of a signal, the training is accomplished initially, from which the tuning factorηis gathered for the corresponding input signal. Then, the properly tuned ηfrom FW-NNis fed as input to EMD via adaptive Wiener filter for decomposing the spectral signal and the output of EMD is denoised signal.

Proposed intelligence architecture for speech enhancement model
Consider the clear signal as T(n), when the noise Wgets corrupted into it, and the signal becomes noisy signal \( \overline{T}(n) \). This noisy signal is fed as input to the STFT-based noise estimation and NMF-based spectrum estimation, from which the noise spectrum WT and signal spectrum \( {\overline{W}}^T \)are obtained. The obtained noise and signal spectrum are subjected to filtration using Wiener filtering process; at the end of filtration the filtered signal \( {\overline{T}}_u(n) \) is generated. Then, \( {\overline{T}}_u(n) \) is decomposed using EMD as a result of this, the bark frequency c′(u′) is obtained. This bark frequency is utilized to train FW-NN classifier. From the spectrum WT and \( {\overline{W}}^T \) as well as from FW-NN, ‘tuned η’ referred as ηtuned is acquired for all the inputs signals with AR-GWO. In the testing process, the tuned ηtuned is acquired for the corresponding signal with the aid of the AR-GWO; this ηopt is fed as input to the adaptive Wiener filtering process with the intention of tuning the input signal \( \overline{T}(n) \). The outcomes of the adaptive Wiener filter are the filtered signal \( \overline{\overline{T_u(n)}} \). Again, \( \overline{\overline{T_u(n)}} \) is decomposed using EMD and the result is the enhanced denoised signal \( \overline{\overline{T_o(n)}} \).
3 Processed steps for enhanced speech enhancement
3.1 STFT-based noise estimation
The noise power spectral density estimatorisbased onminimum statistics to track the minima from the noisy signal [26]. The STFT coefficient of the frame γ is depicted as T(γ, p) and their mathematical formula is exhibited in Eq. (1) [14].
Here, the frequency bin is manifested as p. The frequency and time-dependent smoothing parameters is portrayed as τ(γ, p). With the intention of observing the mean power, the bias compensation factor is employed. The variance estimator of the smoothened PSD is represented as var{T(γ, p)} and the function corresponding to the length of minimum search interval is defined by the bias compensation factor Kmin. The variance estimator relating the smoothened PSD is indicated asvar{T(γ, p)} and this assist in evaluating the variance of T(γ, p) by fixing the length of the search interval in the algorithm. Eq. (2) depicts the mathematical formula for evaluating the variance estimator at the frame γ relating the frequency bin p. In Eq. (2), the mean smoothened periodograms is represented as \( \overline{T}\left(\gamma, p\right) \), and \( \overline{T^2}\left(\alpha, b\right) \) indicates the first-order recursive average of smoothened periodograms [14].
This paper deal with STFT-based noise estimation and the graphical representation of the power spectrum corresponding to the noise estimated by FFT as well as STFT is exhibited in Fig. 2. The power spectrum varies by the magnitude of the frequency component. Moreover, in determining the phase content of the signal and varying sine wave frequency that alter over time are predicted using STFT. In general, the time signals which are larger in size are sub-divided into smaller equal size signals and to each of the segments the Fourier transform is employed. In addition, in the filtering process, STFT can also be interpreted. The estimation strategy is satisfied by two major properties viz. magnitude based shift invariance property and LT-FD properties. The noise spectrum WT is obtained as the resultant.

Noise power spectrum (a) estimated by FFT (b) estimated by STFT - minimum statistics
3.2 NMF-based Spectrum estimation
In the time-frequency (γ, p) domain, the voicing of the noisy signal \( \overline{T}(n) \) takes place via STFT as per Eq. (3), to enhance the speech signal [42]. In Eq. (3), the STFT of the clear speech T(p, γ), the STFT of the noisy speech \( \overline{T}\left(p,\gamma \right) \) and the STFT of the noise signal W(p, γ) are used in pth frequency bin of γ frame. The mathematical formula for “noisy speech’s magnitude spectrum” approximation, which is most commonly, utilized assumption for NMF-based processing of speech and audio signal, is show in Eq. (4) [14].
The magnitude spectrum matrices of the varied signal are indicated as per Eq. (5) and magnitude spectral value corresponding to γ frame for the pth bin is depicted as jp, γ. The count of the frequency bins is represented as H and the time frames are indicated as I.
For the training data \( {J}_T\in {N}_{+}^{H\times {I}_T} \)as well as \( {J}_W\in {N}_{+}^{H\times {I}_W} \), the Eq. (5) is employed separately in the training stage and the outcome of these data is the basis matrices in terms of clear speech \( {F}_T=\left[{r}_{Hl}^T\right]\in {N}_{+}^{H\times {L}_T} \)and noise \( {F}_W=\left[{r}_{Hl}^W\right]\in {N}_{+}^{H\times {L}_W} \), respectively. The count of base vectors is indicated as L. In Eq. (6) ζ represents a H × I matrix, whose entities is equal to one and the transpose of the matrix, is represented as T′. In addition, the basis matrices are fixed in the enhancement stage as \( {F}_T=\left[{F}_T{F}_W\right]\in {N}_{+}^{H\times \left({L}_T+{L}_W\right)} \).The activation matrix \( {E}_{\hat{T}}={\left[{E}_T^{T\prime }{E}_W^{T\prime}\right]}^{T\prime}\in {N}_{+}^{\left({L}_T+{L}_W\right)\times {I}_{\hat{T}}} \) corresponding to the noisy speech is estimated from \( {J}_{\hat{T}}\in {N}_{+}^{H\times {I}_{\hat{T}}} \) by means of employing the NMF activation update. Further, with the assistance got from the Wiener Filter (WF), the clear speech spectrum is evaluated from the speech signal only after obtaining the activation matrix as per Eq. (7). The estimated PSD matrices corresponding of the clear speech is manifested as V′T = [V′T(p, γ)] and the evaluated PSD matrices corresponding to the noisy signal is represented as \( V{\prime}_W=\left[V{\prime}_W\left(p,\gamma \right)\right]\in {N}_{+}^{H\times {I}_{\hat{T}}} \) in Eq. (7). Further, as per Eqs. (8) and (9) the next solution is obtained via the temporal smoothing of the period grams. The temporal smoothing factor of speech ωT and noise ωW is shown in Eqs. (8) and (9), respectively.
The signal spectrum \( {\overline{W}}^T \)is obtained as the outcomes.
The obtained noise spectrum WT and signal spectrum \( {\overline{W}}^T \)are subjected to filtration using Wiener filtering process.
3.3 WienerFilter
In the signal enhancement technique, the Wiener filter has been employed in large scale [15]. The Wiener filter works on the principle of producing an estimate of the clean signal from the corrupted noise signal. The estimation is accomplished by minimizing MSE in between the desired signal and additive noise corrupted signal. The filter transfer functionis shown in Eq. (10) and it gives the solution to this optimization problem in the frequency domain. This equation is generated by considering the signal spectrum \( {\overline{W}}^T \)and the noise spectrum WT as uncorrelated and stationary signals. The power spectral density of \( {\overline{W}}^T \)is represented as GT(ω) and the power spectral density of WT is depicted as GW(ω). The mathematical formula for SNR is exhibited in Eq. (11) and the SNR formula can be incorporated in the filter transfer function as per Eq. (12). The estimated signal magnitude spectrum is indicated as \( {\hat{G}}_W\left(\omega \right) \).
At the end of filtration the filtered signal \( {\overline{T}}_u(n) \) is generated.
The Wiener filteroften fails at all the frequencies due to the drawback of fixed frequency response and requirement of estimating the clean signal and noise signal’s power spectral density prior to filtering.
3.4 Empirical model decomposition
EMD [16] was introduced by Huang as an adaptive technique in which small number of orthogonal empirical modes referred as IMF were added to represent the complex data. The symmetric envelope is present in each of the mode in terms of local maximums and minimums. Thus at all locations of the envelope, mean is zero and in the underlying signal, there is no requirement of linearity or time invariance. Further, by the process of shifting, the riding waves are eliminated. The shifting process of EMD algorithm can be depicted as shown below. Two main properties are obeyed by EMD during the splitting of \( {\overline{T}}_u(n) \) into its IMF components. They are (a) In between two subsequent zero crossing, the IMF has only one extremum and (b) Mean value of IMF is zero.
The data set \( {\overline{T}}_u(n) \) is decomposed into IMFs ye(n) and residue q(n). The mathematical formula corresponding to this decomposition is described in Eq. (13).
Furthermore, the detailed steps of EMD are given below.
-
At first, initialization is processed i.e., d ≔ 1,q0(n) = y(n)
-
As per the following steps, dth IMF is extracted
Set k0(n) ≔ qd − 1(n),m ≔ 1 and local maxima and minima of whole km − 1(n) are identified. Then the envelope UBm − 1(n) for km − 1(n) defined by the maxima and LBm − 1(n) by the minima using the cubic splines interpolation.For both the envelopes belonging to km − 1(n), the mean zm − 1(n) is determined as \( {z}_{m-1}(n)=\frac{1}{2}\left({UB}_{m-1}(n)-{LB}_{m-1}(n)\right) \). This running mean is referred as low frequency local trend. Further, via the process of shifting, the evaluation of high- frequency local detail takes place.
Further, the mth component is formed as km(n) ≔ km − 1(n) − zm − 1(n). In case if km(n) is not found to be accordance with whole IMF criteria, then the process of shifting is continued by increasing mm + 1. In case, if all IMF criteria is satisfied by km(n), then set yd(n) ≔ km(n) and qd(n) ≔ qd − 1(n) − yd(n).
-
The shifting process can be stopped, if qd(n) represents a residuum and if not, then continue the shifting process by increasing d, d + 1 and again begin the process.
Further, EMD algorithm achieves the completeness of the decomposition process automatically as \( y(n)=\sum \limits_{d=1}^v{y}_d+q \) and this represents an identity. The locally orthogonal IMFs are generated by EMD algorithm and lacks to guarantee the global orthogonality, since identical frequencies might be utilized by neighboring IMFs at different time points. As a result of this, the bark frequency c′(u′) is obtained. This bark frequency is utilized to train FW-NN classifier.
3.5 Fuzzy wavelet neural network (FW-NN) classifier
Classification is the most frequently used prediction type [37]. Generally, the wavelet functions are combined with neural nets to provide better results [17,18,19]. In this work, a FW-NN model is employed and it is combination of fuzzy logic concepts and wavelet neural network. In FW-NN, each fuzzy rule corresponds to a WNN comprised of numerous wavelets with changeable translation and dilation parameters. The fuzzy rules are being the consequent part of theFW-NN architecture and it is described only by wavelet functions. The output of WNN is expressed as per Eq. (14).
In which κj is jth layers wavelet activation function corresponding to the hidden layer. In addition, δj is the weight between the hidden (hid) and output layer.
The FWNN combines the wavelet functions and the TSK fuzzy system. A MF is shown by each of the region in the TSK fuzzy model. The FWNN has the properties of high precision and fast convergence. The FW-NN has six layers and they are discussed in the below section.
Layer 1 (input layer)
The input signal vector In = (In1, In2, …, Inn) is fed as input to the next layer and the whole FW-NN model is trained with the bark frequency c′(u′).
Layer 2 (fuzzification layer)
The fuzzy MFs are shown by each of the neuron in IF part of the rules. The MFs values are the outcomes’ from this layer. In the first layer there is l1 count of MFs and in the second layer there is l2 count of MFs. For the ith input variable, the Gaussian membership function is shown as per Eq. (15).
Layer 3 Grey wolf (fuzzy rule layer)
In this layer, each neurons show fuzzy rule. The lth nodes outcome is denoted as per Eq. (2). Here, each of the input MFs based possible combinations describes a fuzzy rule.
Layer 4 Grey wolf (normalization layer)
Normalization factor is computed for each of the neurons in this layer. The lth nodesnormalization factor is expressed as per Eq. (17).
Layer 5
The weighted output value is computed in this layer as per Eq. (18).
Layer 6
The overall output is calculated in this layer by summing the previous layers outputs. This is mathematically shown in Eq. (19).
During the training phase, the MSE is selected as the performance index and this MSE minimization is being the major objective of the current research work. The mathematical formula for MSE based training is shown in Eq. (20). Here, the actual FWNN outcome is Act and the desired outcome is Pre.
4 Adaptive randomizatized grey wolf algorithm: solution encoding and objective function
4.1 Objective function and solution encoding
The major objective of the current research work is to minimize the error Er of the FW-NN. This is expressed mathematically in Eq. (21).
The AR-GWO is employed for properly tuning the tuning factor η, which is accomplished by means of optimizing the hidden neurons (hid) of FW-NN. The solution fed as input to AR-GWO is exhibited in Fig. 3.

Solution encoding
4.2 Standard GWO
GWO [11, 32] was introduced by Mirjalili on the basis of the natural behavior of the grey wolves and it belongs to the category of swarm intelligence algorithm. Three are four types of grey wolves and these wolves stay in groups. The highest authority among them is the α (alpha) and it has the responsibility of taking decision. The supporter of α in taking decisions is β (beta), the lowest among these wolves is ω (omega) and it has to bow other wolves. The leftovers are referred as δ (delta). The main phases of GWO are “hunting, chasing and approaching the prey, encircling the prey and attacking the prey”. The upcoming section portrays the mathematical model of GWO.
Mathematical model of GWO
-
(i)
Search for prey (exploitation): In the search process, the 1st, 2nd and 3rd best solutions are obtained during the search process of unique α, β and δ
-
(ii)
Encircling prey: The mathematical formula for prey encircling during the hunting process is represented in Eqs. (22) and (23). In Eq. (24) the current iteration and the localization of the prey is represented as x&Cg(x). The coefficient vectors are indicated as Y and D. In addition, C(x) represents the position of the grey wolf and the random values are manifested as b1 & b2. In addition Eqs. (24) and (25) are the mathematical formula for calculating the coefficient vectors Y and D, here there is a gradual decrease in the value of c from 2 to 0 over the course of iterations.
-
(iii)
Hunting the prey: There lacks no information on the location of the prey in the search space. An assumption is made here that a better knowledge on the potential location of prey can be acquired from α, β and δ. This is the reason behind the storage first three results by discarding the others. The mathematical formula for hunting of prey is depicted in Eqs. (26) to (32) [32].
-
(iv)
(iv) Attacking the prey (exploitation): This is the end process of hunting behaviour of grey wolf and this process take place, when the prey is stationary.
4.3 AR-GWO
The conventional GWO suffers from the drawbacks of “bad local searching ability, low solving precision and slow convergence”. So, the AR-GWO is formulated. In the conventional GWO, the random values b1and b2 are within the range [0, 1] and they are utilized to find the coefficient vectors Y and D in Eqs. (24) and (25). But, in the proposed model, instead of random numbers the proposed algorithm determines the random values bi1 and bi2 on the basis the fitness functions. The coefficient vectors are presented as Yi and Di are computed by utilizing Eqs. (33) and (34). Here i denote α, β and δ wolves. Further, the random values bi1 and bi2 are determined by using Eqs. (35) and (36), in which fitness of the best wolves either α, β or δ is represented as Fi,
The resultant from AR-GWO is the properly tuned tuning factor ηtuned, which is fed as input to adaptive Wiener filtering.
4.4 Adaptive WienerFiltering
The role of tuning ratio ηtuned is highly substantiated. The estimated tuning ratio by the FW-NN, on the basis of the c′(u′) (bark frequency) of the NMF-based filtered EMD signal \( {\overline{T}}_o(n) \) is fine-tuned by AR-GWO. Mathematically, c′(u′) can be expressed as per Eq. (37)
The properly tuned tuning ratio ηtuned acquired from AR- GWO is fed as input to the wiener filter, instead of the constant η. The outcomes of the Adaptive Wiener filter are the filtered signal \( \overline{\overline{T_u(n)}} \). Again, \( \overline{\overline{T_u(n)}} \) is decomposed using EMD and the result is the enhanced denoised signal \( \overline{\overline{T_o(n)}} \).
In the training process, the training library is constructed by giving the known c′(u′) (bark frequency) and tuning ratio ηtuned as inputs. The testing process is said to be the online process, while the training process is an offline process. The appropriate tuning factor for diverse noises are identified in the offline process and with this, the FW-NN is trained. The actual enhancement process takes place in the online mechanism, where the tuning factor is identified with the trained network.
5 Results and discussion
5.1 Experimental setup
The proposed speech enhancement model using GWO with FW-NN was implemented in MATLAB and the resultant of each of the analysis is observed. The data set for the research work is gathered from [23]. In this database, the five noise types, namely, “airport noise, exhibition noise, restaurant noise, station noise and street noise” are added to the speech signals. The performance of the proposed model (AR-GWO) is compared with the extant modelslike GA [29], PSO [20], ABC [24], FF [12] and GWO [14] in terms of “SDR, PESQ, SNR, RMSE, Correlation, ESTOI and CSED”. Also, statistical analysis and computational time analysis are performed. Figure 4 exhibits the noisy and denoised signal for different approaches like GA, PSO, ABC, FF and GWO.

The noisy and denoised signal of various approaches (a) GA (b) ABC (c) PSO (d) FF(e) GWO and (f) AR-GWO
5.2 Performce analysis of airport noise
The performance evaluation of the proposed model over the existing model for airport noise at varying SNR levels is shown in Table 2. whenSNR = 0 dB, the SDR of the proposed model is 2.13%, 1.04%, 0.67%, 0.56% and 2.4% superior to the extant models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively.PESQ of the proposed model at SNR = 0 dB exhibits an improvement of 3.7%, 2.6%, 4.5%, 1.3% and 1% over the extant models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively.In airport noise at SNR = 5 dB, RMSE of the proposed model is 3.4%, 2.7%, 1.6%, 3.44% and 0.9% superior to the traditional models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. At SNR = 10 dB, ESTOI of the proposed model is 1.11% better than GA based η tuning, 1.6% better than ABC based η tuning, 2% better than PSO based η tuning, 1.7% better than FF based η tuning and 0.9% better than GWO based η tuning. Further, at SNR = 10 dB, STOI of the proposed model shows an improvement of 0.9%, 1%, 1.2%, 1.1% and 0.7% better than classical model like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively.
5.3 Performce analysis of exhibition noise
Table 3 exhibits the performance analysis of the proposed model over exiting for exhibition noise at different SNR levels. At SNR = 0 dB, the proposed model shows an improvement of 10.3%, 3.6% 10.2%, 3.1% and 1.6% over the classical models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectivelyin terms of SNR. Further, RMSE of the proposed model is 5.4%, 2.4%, 6.5%, 2% and 0.9% better than the extant models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively at SNR = 0 dB. For the exhibition noise at SNR = 5 dB, the SDR of the proposed model is improvedover the existing model as 15.7%, 2.16%, 1.2%, 0.86%, and 6.83% by GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. Then, in terms of Correlation at SNR = 10 dB, the proposed model is found to be better than the existing approaches GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. ESTOI of the proposed model is 0.6% better than GA based η tuning, 0.05% better than ABC based η tuning, 0.06% better than PSO based η tuning, 0.3% better than FF based η tuningand 0.15% better than GWO based η tuningat SNR = 10 dB.
5.4 Performce analysis of restaurant noise
Table 4 portrays the performance evaluation of the proposed model over the existing for restaurant noise at different SNR levels. From, which SDR of the signal at SNR = 0 dB is 8.5%, 5.7%, 9.7%, 5.7% and 4.3% superior to the classical models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning. PESQ of the proposed modelis found to be 1.2%, 0.4% better than GA and ABC, 0.2%, 0.9% and0.7% better than PSO, FF and GWO, respectively at SNR = 0 dB. Then, for SNR = 5 dB, RMSE of the proposed model exhibits superiority to the traditional models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning by 1.54%, 0.04%, 1.2%, 0.7% and 0.09%, respectively. Further, in terms of SNR, there is an improvement of 1.8%, 0.19%, 1.6%, 0.9% and 0.7% in the proposed model over the existing model like GA, ABC, PSO, FF and GWO, respectively at SNR = 5 dB. Moreover, from SNR = 10 dB, STOI of the proposed model is 0.8%, 0.5%, 0.7%, 0.6% and 0.76% better than state-of-art models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning. CSED at SNR = 10 dB is 6.9%, 2%, 6.7%, 5.9% and 5.13% superior to the extant modelsGA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively.
5.5 Performce analysis of station noise
From 5 represents the performance analysis of the proposed model over exiting for station noise at different SNR values as (Table 5 shows the performance evaluation of the proposed model over existing model for station noise at varying SNR).. From the table, at SNR = 0 dB, the proposed model overtakes the extant modelsGA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning by 2.6%, 4.5%, 1.2%, 2.7% and 1%, respectively in terms of SDR. Moreover, SEQ of the proposed model at SNR = 0 dB is 3.7%, 1.14%, 2.2%, 1.7% and 1% better than the extant models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. Then, for SNR = 5 dB, the proposed model is better than extant models, 5.4% by GA, 2.4% by ABC, 1.2% by PSO, 3.1% by FF and 1.6% by GWO. SEI of the proposed model at SNR = 10 dB, an improvement of 0.3%, 0.2%, 0.1%, 0.5% and 0.02% over the state-of-art models. Then, atSNR = 15 dB, the proposed model is 0,6%, 0.02%, 0.9%, 0.3% and 0.4% better than extant modelsGA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning in terms of STOI. In terms of CSED at SNR = 15 dB, the proposed model is 9.5%, 4.5%, 10.9%, 9.8% and 7.7% better than the traditional models GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively.
5.6 Performce analysis of street noise
The performance evaluation of the proposed model over the existing model for the street noise is shown in Table 6. For SNR = 0db, the proposed model exhibits an improvement of 1.7%, 0.5%, 1.3%, 1.72% and 1.7% over the classical models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively in terms of CSED. Then, for the same SNR, the STOI of the projected model is 0.4%, 0.3%, 0.9%, 0.7% and 0.3% superior to the state-of-art models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. For SNR = 5 dB, ESTOI of the proposed model is 1.3%, 0.9%, 1.4%, 0.5% and 0.4% superior to the conventional models GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. The correlation of the signal for the same SNR is 0.35%, 0.017%, 0.13%, 0.2% and 0.29% superior to the existing approaches GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. Then, in case of SNR = 15 dB, the PESQ of the proposed model is 1.8%, 0.27%, 0.8%, 0.9% and 0.89% better than GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively. Then, for the same SNR, the proposed model is 2.2%, 0.3%, 2.7%, 1.7% and 2.12% better than the traditional models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively in terms of SDR at 15 dB.
5.7 Statistical analysis
The evaluation of statistical analysis of the adopted and existing approaches is depicted in Fig. 5. The outcomes are provided based on the error and thus the proposed model value is lower than the existing works. On considering the results, the best value of the adopted AR-GWO scheme is 9.41%, 3.51%, 8.99%, 3.84%, and 4.53% superior to the existing GA, ABC, PSO, FF, and GWO approaches. Furthermore, in mean case scenario, the suggested approach value is 5.21%, 2.57%, 3.37%, 2.81%, and 2.33% superior to the existing GA, ABC, PSO, FF, and GWO approaches. Moreover, the median value of the AE-GWO approach is 0.013641 and it is 5.22%, 2.99%, 3.77%, 3.92%, and 2.41% better than the existing GA, ABC, PSO, FF, and GWO methods. Therefore, the effectiveness of the proposed speech enhancement model is proved.

Statistical analysis of the proposed and existing approaches
5.8 Computational time analysis
In this section, the computational time of the proposed and existing methods is evaluated and it is depicted in Fig. 6. From the graph, the computation time of the proposed AR-GWO method is 227.86 and it is 34.07%, 43.57%, 28.86%, 38.88%, and 16.03% better than the existing GA, ABC, PSO, FF, and GWO approaches respectively. Thus, the effectiveness of the adopted AR-GWO based speech enhancement method is validated.

Computational time analysis of the proposed and existing approaches
5.9 Practical implications
The major aim of the proposed speech enhancement is to suppress the noise in a noisy speech signal and improve the quality and intelligibility of speech. The proposed speech enhancement approach utilizes in real-time applications such as speech recognition, mobile phones, VoIP, teleconferencing systems and hearing aids.
6 Conclusion
In this paper, an optimized fuzzy wavelet neural network based speech enhancement model is proposed. In the training phase, the input noise corrupted signal was initially provided as input to both STFT-based noise estimation and NMF-based spectrum estimation for estimating the noise spectrum and signal spectrum, respectively. The obtained noise spectrum and the signal spectrum are fed as input to the wiener filter and these filtered signals are subjected to EMD.Since, tuning factorη plays a key role in wiener filter, it has to be determined for each signals, and is trained in FW-NN. Then, from the denoised signal the bark frequency is evaluated. The computed bark frequency is fed as input to the learning algorithm referred as FW-NN for detecting the suited tuning factorη for the entire input signal in Weiner filter. The AR-GWO is employed for proper tuning of the tuning factor η referred as tuned tuning factor (ηtuned). In the testing phase, the training is accomplished initially and from which the tuning factor is gathered for each of the relevant input signal. Then, the properly tuned tuning factor (ηtuned) from FW-NN is fed as input to EMD via adaptive wiener filter for decomposing the spectral signal and the output of EMD is denoised enhanced speech signal.Theresultant acquired is compared over the existing models in terms of various measures. In case of street noise, at SNR = 0db, the proposed model exhibits an improvement of 1.7%, 0.5%, 1.3%, 1.72% and 1.7% over the classical models like GA based η tuning, ABC based η tuning, PSO based η tuning, FF based η tuning and GWO based η tuning, respectively in terms of CSED. Thus, the effectiveness of the work is validated via the result analysis. However, in statistical analysis, the standard deviation metric value is not better than the existing ones. Hence, in the future work, we enhanced our proposed work by utilizing the recent optimization algorithms and validate the work in real-time applications.
Data availability
The data that support the findings of this study is “NOIZEUS” openly available in https://ecs.utdallas.edu/loizou/speech/noizeus/.
Abbreviations
- ABC:
-
Artificial Bee Colony optimization
- CSED:
-
Cumulative Squared Euclidean Distance
- DNN:
-
Deep Neural Network
- ESTOI:
-
Extended STOI
- FF:
-
Firefly optimization
- FRBM:
-
Fuzzy Restricted Boltzmann Machines
- GA:
-
Genetic Algorithm
- GWO:
-
Grey Wolf optimization
- HMM:
-
Hidden Markov Model
- IFD:
-
Instantaneous Frequency Deviation
- IMF:
-
Intrinsic Mode Functions
- IRM:
-
Ideal Ratio Mask
- JT-FS:
-
Joint Time-Frequency Segmentation Algorithm
- KCF:
-
Kalman Filter-Based
- LT-FD:
-
linear time-frequency distribution
- MMSE:
-
Minimum Mean Square Error
- MSE:
-
Mean Square Error
- NMF:
-
Nonnegative Matrix Factorization
- P-ASE:
-
Phase-Aware Speech Enhancement
- PDF:
-
Power Spectral Density
- PESQ:
-
Perceptual Evaluation Of Speech Quality
- P-SJL:
-
Phase-Sensitive Joint Learning Algorithm
- PSD:
-
Power Spectral Density
- PSM:
-
Phase-Sensitive Mask
- PSO:
-
Particle Swarm Optimization
- PWFT:
-
perceptual wavelet filter bank
- RMSE:
-
Root-Mean-Square Error
- SDR:
-
Source To- Distortion Ratio
- S-MSE:
-
Single-Microphone Speech Enhancement
- SNR:
-
Signal-To-Noise Ratio
- SSD:
-
Supervised Speech Denoising
- STFT:
-
Short-Time Fourier Transform
- STOI:
-
Extended STOI
- T-F:
-
Time-Frequency
- VoIP:
-
Voice over Internet Protocol
References
Abel J, Fingscheidt T (2018) Artificial speech bandwidth extension using deep neural networks for wideband spectral envelope estimation. IEEE/ACM Trans Audio, Speech, Lang Process 26(1):71–83
Arcos CD, Vellasco M, Alcaim A (2018) Ideal neighbourhood mask for speech enhancement. Electron Lett 54(5):317–318
Bai H, Ge F, Yan Y (2018) DNN-based speech enhancement using soft audible noise masking for wind noise reduction. China Commun 15(9):235–243
Bando Y, Itoyama K, Konyo M, Tadokoro S, Nakadai K, Yoshii K, Kawahara T, Okuno HG (2018) Speech enhancement based on Bayesian low-rank and sparse decomposition of multichannel magnitude spectrograms. IEEE/ACM Trans Audio, Speech, Lang Process 26(2):215–230
Bao F, Abdulla WH (2019) A new ratio mask representation for CASA-based speech enhancement. IEEE/ACM Trans Audio, Speech Lang Process 27(1):7–19
Chazan SE, Goldberger J, Gannot S (2016) A hybrid approach for speech enhancement using MoG model and neural network phoneme classifier. IEEE/ACM Trans Audio, Speech, Lang Process 24(12):2516–2530
Dehghani M, Montazeri Z, Dhiman G, Malik OP, Morales-Menendez R, Ramirez-Mendoza RA, Dehghani A, Guerrero JM, Parra-Arroyo L (2020) A spring search algorithm applied to engineering optimization problems. Appl Sci 10(18):6173
Dhiman G, Kaur A (2019) STOA: a bio-inspired based optimization algorithm for industrial engineering problems. Eng Appl Artif Intell 82:148–174
Dhiman G, Kumar V (2017) Spotted hyena optimizer: a novel bio-inspired based metaheuristic technique for engineering applications. Adv Eng Softw 114:48–70
Dhiman G, Kumar V (2018) Emperor penguin optimizer: a bio-inspired algorithm for engineering problems. Knowl-Based Syst 159:20–50
Fahad M, Aadil F, Rehman Z, Khana S, Shah PA, Muhammad K, Lloret J, Wang H, Lee JW, Mehmoode I (2018) Grey wolf optimization based clustering algorithm for vehicular ad-hoc networks. Comput Electric Eng 70:853–870
Fister I, Iztok Fister X-SY Jr, Brest J (2013) A comprehensive review of firefly algorithms. Swarm Evol Comput 13:34–46
Gannot S, Burshtein D, Weinstein E (2008) Iterative and sequential Kalman filter-based speech enhancement algorithms. IEEE Trans Speech Audio Process 6(4):373–385
Garg A, Sahu OP (2020) Enhancement of speech signal using diminished empirical mean curve decomposition-based adaptive Wiener filtering. Pattern Anal Appl 23(1):179–198
Grimble M (1984) Weiner and Kalman filters for systems with random parameters. IEEE Trans Autom Control 29(6):552–554
Grispino AS, Petracca GO, Dominguez AE (2013) Comparative analysis of wavelet and EMD in the filtering of radar signal affected by Brown noise. IEEE Latin Am Trans 11(1):81–85
Guido RC (2011) A note on a practical relationship between filter coefficients and scaling and wavelet functions of discrete wavelet transforms. Appl Math Lett 24(7):1257–1259
Guido RC (2017) Effectively interpreting discrete wavelet transformed signals [lecture notes]. IEEE Signal Process Mag 34(3):89–100
Guido RC, Vieira LS, Junior SB, Sanchez FL, Maciel CD, Fonseca ES, Pereira JC (2007) A neural-wavelet architecture for voice conversion. Neurocomputing 71(1–3):174–180
Hamza D, Tashan T (2021) Dual channel speech enhancement using particle swarm optimization. Indonesian J Electric Eng Comput Sci 23(2):821–828
He Q, Bao F, Bao C (2017) Multiplicative update of auto-regressive gains for codebook-based speech enhancement. IEEE/ACM Trans Audio, Speech, Lang Process 25(3):457–468
Hou J, Wang S, Lai Y, Tsao Y, Chang H, Wang H (2018) Audio-visual speech enhancement using multimodal deep convolutional neural networks. IEEE Trans Emerg Topics Comput Intell 2(2):117–128
https://ecs.utdallas.edu/loizou/speech/noizeus/ (n.d.) (Access Date: 01-03-2019)
Karaboga D, Basturk B (2008) On the performance of artificial bee colony (ABC) algorithm. Appl Soft Comput 8(1):687–697
Kaur S, Awasthi LK, Sangal AL, Dhiman G (2020) Tunicate Swarm Algorithm: A new bio-inspired based metaheuristic paradigm for global optimization. Eng Appl Artif Intell 90:103541
Krawczyk M, Gerkmann T (2014) STFT phase reconstruction in voiced speech for an improved Single-Channel speech enhancement. IEEE/ACM Trans Audio, Speech Lang Process 22(12):1931–1940
Krawczyk-Becker M, Gerkmann T (2018) On speech enhancement under PSD uncertainty. IEEE/ACM Trans Audio, Speech, Lang Process 26(6):1144–1153
Kuqi, B, Elezaj E, Millaku B, Dreshaj A, Hung NT (2021) "The impact of COVID-19 (SARS-CoV-2) in tourism industry: evidence of Kosovo during Q1, Q2 and Q3 period of 2020." J Sustain Finance Invest 1–12
LeBlanc, R, Selouani SA (2019) "Self-adaptive tuning for speech enhancement algorithm based on evolutionary approach." In 2019 IEEE First International Conference on Cognitive Machine Intelligence (CogMI), pp. 16–22. IEEE
Lee J, Skoglund J, Shabestary T, Kang H (2018) Phase-sensitive joint learning algorithms for deep learning-based speech enhancement. IEEE Signal Process Lett 25(8):1276–1280
Martín-Doñas JM, Gomez AM, Gonzalez JA, Peinado AM (2018) A deep learning loss function based on the perceptual evaluation of the speech quality. IEEE Signal Process Lett 25(11):1680–1684
Ming J, Crookes D (2017) Speech enhancement based on full-sentence correlation and clean speech recognition. IEEE/ACM Trans Audio, Speech, Lang Process 25(3):531–543
Mirjalili S (2014) Seyed Mohammad Mirjalili, Andrew Lewis, "Grey wolf optimizer". Adv Eng Softw 69:46–61
Mohammadiha N, Smaragdis P, Leijon A (2013) Supervised and unsupervised speech enhancement using nonnegative matrix factorization. IEEE Trans Audio Speech Lang Process 21(10):2140–2151
Ou S, Song P, Gao Y (2018) Soft Decision Based Gaussian-Laplacian Combination Model for Noisy Speech Enhancement. Chin J Electron 27(4):827–834
Parente G, Gargano T, Di Mitri M, Cravano S, Thomas E, Vastano M, Maffi M, Libri M, Lima M (2021) Consequences of COVID-19 lockdown on children and their pets: dangerous increase of dog bites among the paediatric population. Children 8(8):620
Prasanalakshmi B, Farouk A (2019) Classification and prediction of student academic performance in king khalid university-a machine learning approach. Indian J Sci Technol 12:14
Rehr R, Gerkmann T (2018) On the importance of super-Gaussian speech priors for machine-learning based speech enhancement. IEEE/ACM Trans Audio, Speech, Lang Process 26(2):357–366
Samui S, Chakrabarti I, Ghosh SK (2019) Time–frequency masking based supervised speech enhancement framework using fuzzy deep belief network. Appl Soft Comput 74:583–602
Shao Y, Chang C (2011) Bayesian separation with sparsity promotion in perceptual wavelet domain for speech enhancement and hybrid speech recognition. IEEE Trans Syst Man Cybern Syst Hum 41(2):284–293
Stahl J, Mowlaee P (2018) A pitch-synchronous simultaneous detection-estimation framework for speech enhancement. IEEE/ACM Trans Audio, Speech, Lang Process 26(2):436–450
Sun M, Li Y, Gemmeke JF, Zhang X (2015) Speech enhancement under low SNR conditions via noise estimation using sparse and low-rank NMF with Kullback–Leibler divergence. IEEE/ACM Trans Audio, Speech Lang Process 23(7):1233–1242
Tan K, Chen J, Wang D (2019) Gated residual networks with dilated convolutions for monaural speech enhancement. IEEE/ACM Trans Audio, Speech Lang Process 27(1):189–198
Tantibundhit C, Pernkopf F, Kubin G (2010) Joint time–frequency segmentation algorithm for transient speech decomposition and speech enhancement. IEEE Trans Audio Speech Lang Process 18(6):1417–1428
Wang Y, Brookes M (2018) Model-based speech enhancement in the modulation domain. IEEE/ACM Trans Audio, Speech, Lang Process 26(3):580–594
Wang J, Xie X, Kuang J (2018) Microphone array speech enhancement based on tensor filtering methods. China Commun 15(4):141–152
Yilmaz S, Oysal Y (2010) Fuzzy wavelet neural network models for prediction and identification of dynamical systems. IEEE Trans Neural Netw 21(10):1599–1609
Zheng N, Zhang X (2019) Phase-aware speech enhancement based on deep neural networks. IEEE/ACM Trans Audio, Speech, Lang Process 27(1):63–76
Acknowledgements
I would like to express my very great appreciation to the co-authors of this manuscript for their valuable and constructive suggestions during the planning and development of this research work.
Author information
Authors and Affiliations
Contributions
All authors have made substantial contributions to conception and design, revising the manuscript, and the final approval of the version to be published. Also, all authors agreed to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Corresponding author
Ethics declarations
Ethical approval
This paper does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
Not Applicable.
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Jadda, A., Prabha, I.S. Adaptive Weiner filtering with AR-GWO based optimized fuzzy wavelet neural network for enhanced speech enhancement. Multimed Tools Appl 82, 24101–24125 (2023). https://doi.org/10.1007/s11042-022-14180-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-14180-5