
Abstract
This paper proposes a new speech enhancement (SE) algorithm utilizing constraints to the Wiener gain function which is capable of working at 10 dB and lower signal-to-noise ratios (SNRs). The wavelet thresholded multitaper spectrum was taken as the clean spectrum for the constraints. The proposed algorithm was evaluated under eight types of noises and seven SNR levels in NOIZEUS database and was predicted by the composite measures and the SNRLOSS measure to improve subjective quality and speech intelligibility in various noisy environments. Comparisons with two other algorithms (KLT and wavelet thresholding (WT)) demonstrate that in terms of signal distortion, overall quality, and the SNRLOSS measure, our proposed constrained SE algorithm outperforms the KLT and WT schemes for most conditions considered.
Similar content being viewed by others


1 Introduction
The objective of speech enhancement (SE, also called noise reduction) algorithms is to improve one or more perceptual aspects of the noisy speech by decreasing the background noise without affecting the intelligibility of the speech [1]. Research on SE can be traced back to 40 years ago with two patents by Schroeder [2], where an analog implementation of the spectral magnitude subtraction method was described. Since then, the problem of enhancing speech degraded by uncorrelated additive noise, when only the noisy speech is available, has become an area of active research [3]. Researchers and engineers have approached this challenging problem by exploiting different properties of speech and noise signals to achieve better performance [4].
SE techniques have a broad range of applications, from hearing aids to mobile communication, voice-controlled systems, multiparty teleconferencing, and automatic speech recognition (ASR) systems [4]. The algorithms can be summarized into four classes: spectral subtractive [5]–[8], sub-space [9],[10], statistical model-based [11]–[13], and Wiener-type [3],[14]–[16] algorithms.
Much progress has been made in the development of SE algorithms capable of improving speech quality [17],[18] which was evaluated mainly by the objective performance criteria such as signal-to-noise ratio (SNR) [19]. However, SE algorithm that improves speech quality may not perform well in real-world listening situations where background noise level and characteristics are constantly changing [20]. The first intelligibility study done by Lim [21] in the late 1970s found no intelligibility improvement with the spectral subtraction algorithm for speech corrupted in white noise at −5 to 5 dB SNR. Thirty years later, a study conducted by Hu and Loizou [1] found that none of the examined eight different algorithms improved speech intelligibility relative to unprocessed (corrupted) speech. Moreover, according to [1], the algorithms with the highest overall speech quality may not perform the best in terms of speech intelligibility (e.g., logMMSE [12]). And the algorithm which performs the worst in terms of overall quality may perform well in terms of preserving speech intelligibility (e.g., KLT [9]). To our knowledge, very few speech enhancement algorithms [22]–[25] claimed to improve speech intelligibility by subjective tests for either normal-hearing listeners or hearing-impaired listeners. Hence, we focused in this paper on improving performance on speech intelligibility of the SE algorithm.
From [19], we know that the perceptual effects of attenuation and amplification distortion on speech intelligibility are not equal. Amplification distortion in excess of 6.02 dB (region III) bears the most detrimental effect on speech intelligibility, while the attenuation distortion (region I) was found to yield the least effect on intelligibility. Region I+II constraints are the most robust in terms of yielding consistently large benefits in intelligibility independent of the SE algorithm used. However, in order to divide those three regions [19], the estimated magnitude spectrum needs to be compared with the clean spectrum which we usually do not have in real circumstances.
In this paper, we explored the multitaper spectrum which was shown in [26] to have good bias and variance properties. The spectral estimate was further refined by wavelet thresholding the log multitaper spectrum in [16]. The refined spectrum was proposed in this paper to be used as an alternative of the clean spectrum. Then, the region I+II constraints were imposed and incorporated in the derivation of the gain function of the Wiener algorithm based on a priori SNR [3]. We have experimentally evaluated its performance under a variety of noise types and SNR conditions.
The structure of the rest of this paper is organized as follows. Section 2 provides the background information on wavelet thresholding the multitaper spectrum, and Section 3 presents the proposed approach which imposes constraints on the Wiener filtering gain function. Section 4 contains the speech and noise database and metrics used in the evaluation. The simulation results are given in Section 5. Finally, a conclusion of this work and the discussion are given in Section 6.
2 Wavelet thresholding the multitaper spectrum
In real-world scenarios, the background noise level and characteristics are constantly changing [20]. Better estimation of the spectrum is required to alleviate the distortion caused by SE algorithms. For speech enhancement, the most frequently used power spectrum estimator is direct spectrum estimation based on Hann windowing. However, windowing reduces only the bias not the variance of the spectral estimate [27]. The multitaper spectrum estimator [26], on the other hand, can reduce this variance by computing a small number (L) of direct spectrum estimators (eigenspectra) each with a different taper (window) and then averaging the L spectral estimates. The underlying philosophy is similar to Welch’s method of modified periodogram [27].The multitaper spectrum estimator is given by
with
where N is the data length, and a k is the k th sine taper used for the spectral estimate , which is proposed by Riedel and Sidorenko [28] and defined by
The sine tapers were proved in [28] to produce smaller local bias than the Slepian tapers, with roughly the same spectral concentration.
The multitaper estimated spectrum can be further refined by wavelet thresholding techniques [29]–[31]. Improved periodogram estimates were proposed in [29], and improved multitaper spectrum estimates were proposed in [30],[31]. The underlying idea behind those techniques is to represent the log periodogram as ‘signal’ plus the ‘noise’, where the signal is the true spectrum and the noise is the estimation error [32]. It was shown in [33] that if the eigenspectra defined in Equation 2 are assumed to be uncorrelated, the ratio of the estimated multitaper spectrum and the true power spectrum S(ω) conforms to a chi-square distribution with 2L degrees of freedom, i.e.,
Taking the log of both sides, we get
From Equation 5, we know that the log of the multitaper spectrum can be represented as the sum of the true log spectrum plus a logχ2 distributed noise term. It follows from Bartlett and Kendall [34] that the distribution of logυ(ω) is with mean ϕ(L)−log(L) and variance ϕ′(L), where ϕ(·) and ϕ′(·) denote, respectively, the digamma and trigamma functions. For L≥5, the distribution of logυ(ω) will be close to a normal distribution [35]. Hence, provided L is at least 5, the random variable η(ω)
will be approximately Gaussian with zero mean and variance . If Z(ω) is defined as
then we have
i.e., the log multitaper power spectrum plus a known constant (log(L)−ϕ(L)) can be written as the true log power spectrum plus approximately Gaussian noise η(ω) with zero mean and known variance [30].
The model in Equation 8 is well suited for wavelet denoising techniques [36]–[39] for eliminating the noise η(ω) and obtaining a better estimate of the log spectrum. The idea behind refining the multitaper spectrum by wavelet thresholding can be summarized into four steps [16].
-
Obtain the multitaper spectrum using Equations 1 to 3 and calculate Z(w) using Equation 7.
-
Apply a standard periodic discrete wavelet transform (DWT) out to level q0 to Z(w) to get the empirical DWT coefficients zj,k at each level j, where q0 is specified in advance [40].
-
Apply a thresholding procedure to zj,k.
-
The inverse DWT is applied to the thresholded wavelet coefficients to obtain the refined log spectrum.
3 Speech enhancement based on constrained Wiener filtering algorithm
Among the numerous techniques that were developed, the Wiener filter can be considered as one of the most fundamental SE approaches, which has been delineated in different forms and adopted in various applications [4]. The Wiener gain function is the least aggressive, in terms of suppression, providing small attenuation even at extremely low SNR levels.
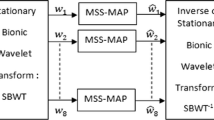
A block diagram of the proposed SE algorithm is shown in Figure 1. The initial four frames are assumed to be noise only. The algorithm can be described as follows. The input noisy speech signal is decomposed into frames of 20-ms length with an overlap of 10 ms by the Hann window. Each segment was transformed using a 160-point discrete Fourier transform (DFT). The spectrum of the segmented noisy and noise signal are estimated by the multitaper method and then further refined by wavelet thresholding technique. The estimated ‘clean’ spectrum was gotten from the refined multitaper estimated noisy and noise spectrum. On the other hand, the noise-corrupted sentences were enhanced by the Wiener algorithm based on a priori SNR estimation [3]. The region I+II constraints were then imposed on the enhanced spectrum. Finally, the inverse fast Fourier transform (FFT) was applied to obtain the enhanced speech signal.

Block diagram of the proposed speech enhancement algorithm.
The implementation details of the proposed method can be described in the following four steps. For each speech frame,
-
compute the multitaper power spectrum of the noisy speech y using Equation 1 and estimate the multitaper power spectrum of the clean speech signal by , where is the multitaper power spectrum of the noise. can be obtained using noise samples collected during speech absent frames. Here, L is set to 16. Any negative elements of are floored as follows:
(9)where β is the spectral floor set to β=0.002.
-
compute and then apply the DWT of Z(ω) out to level q0 to obtain the empirical DWT coefficients zj,k for each level j, where q0 is specified to be 5 [40]. Threshold the wavelet coefficients zj,k and apply the inverse DWT to the thresholded wavelet coefficients to obtain the refined log spectrum, , of the noisy singal. Repeat the above procedure to obtain the refined log spectrum, , of the noise signal. The estimated power spectrum of the clean speech signal can be estimated using
(10) -
let Y(ω,t) denote the magnitude of the noisy spectrum at time frame t and frequency bin ω estimated by the method in [41]. Then, the estimate of the signal spectrum magnitude is obtained by multiplying Y(ω,t) with a gain function G(ω,t) as . The Wiener gain function is based on the a priori SNR and is given by
(11)where SNRprio is the a priori SNR estimated using the decision-directed approach [3],[19] as follows:
(12)where is the estimate of the power spectral density of background noise, and α is a smoothing constant (typically set to α=0.98).
-
to maximize speech intelligibility, the final enhanced spectrum, X M (ω,t), can be obtained by utilizing the region I+II constraints to the enhanced spectrum as follows:
(13)Finally, the enhanced speech signal can be obtained by apply the inverse FFT of X M (ω,t).
The above estimator was applied to 20-ms duration frames of the noisy signal with 50% overlap between frames. The enhanced speech signal was combined using the overlap and add method.
4 Evaluation setup
The proposed SE algorithm was tested using a speech database that was corrupted by eight different real-world noises at different SNRs. The system was evaluated using both the composite evaluation measures proposed in [42] and the SNRLOSS measure proposed in [43].
4.1 Database description
For the evaluation of SE algorithms, NOIZEUS [44] is preferred since it is a noisy speech corpus recorded by [18] to facilitate comparison of SE algorithms among different research groups [20]. The noisy database contains thirty IEEE sentences [45] which were recorded in a sound-proof booth using Tucker Davis Technologies (TDT; Alachua, FL, USA) recording equipment. The sentences were produced by three male and three female speakers (five sentences/speaker). The IEEE database was used as it contains phonetically balanced sentences with relatively low word-context predictability. The 30 sentences were selected from the IEEE database so as to include all phonemes in the American English language. The sentences were originally sampled at 25 kHz and downsampled to 8 kHz.
To simulate the receiving frequency characteristics of the telephone handsets, the intermediate reference system (IRS) filter used in ITU-T P.862 [46] for evaluation of the perceptual evaluation of speech quality (PESQ) measures was independently applied to the clean and noise signal [17]. Then, noise segment of the same length as the speech signal was randomly cut out of the noise recordings, appropriately scaled to reach the desired SNR levels (−8,−5,−2,0,5,10, and 15 dB) and finally added to the filtered clean speech signal. Noise signals were taken from the AURORA database [47] and included the following recordings from different places: train, babble (crowd of people), car, exhibition hall, restaurant, street, airport, and train station. Therefore, in total, there are 1,680 (30 sentences × 8 noises × 7 SNRs) noisy speech segments in the test set.
4.2 Performance evaluation
The performance of an SE algorithm can be evaluated both subjectively and objectively. In general, subjective listening test is the most accurate and preferable method for evaluating speech quality and intelligibility. However, it is time consuming and cost expensive. Recently, many researchers have placed much effort on developing objective measures that would predict subjective quality and intelligibility with high correlation [42],[43],[48],[49] with subjective listening test. Among them, the composite objective measures [42] were proved to have high correlation with subjective ratings and, at the same time, capture different characteristics of the distortions present in the enhanced signals [35], while the SNRLOSS measure [43] was found appropriate in predicting speech intelligibility in fluctuating noisy conditions by yielding a high correlation for predicting sentence recognition. Therefore, the composite objective measures and the SNRLOSS measure were adopted to predict the performance of the proposed SE algorithm on subjective quality and speech intelligibility, respectively.
4.2.1 The composite measures to predict subjective speech quality
The composite objective measures are obtained by linearly combining existing objective measures that highly correlate with subjective ratings. The objective measures include segmental SNR (segSNR) [18], weighted-slope spectral (WSS) [50], PESQ[51], and log likelihood ration (LLR) [18].
The three new composite measures obtained from multiple linear regression analysis are given below:
-
Csig: A five-point scale of signal distortion (SIG) formed by linearly combining the LLR, PESQ, and WSS measures (Table 1).
-
Cbak: A five-point scale of noise intrusiveness (BAK) formed by linearly combining the segSNR, PESQ, and WSS measures (Table 1).
-
Covl: The mean opinion score of overall quality (OVRL) formed by linearly combining the PESQ, LLR, and WSS measures.
The three new composite measures obtained from multiple linear regression analysis are given below:
The correlation coefficients between the three composite measures and real subjective measures are given in Table 2[42]. All three parameters should be maximized in order to get the best performance.
4.2.2 The SNRLOSS measure to predict speech intelligibility
The SNR loss in band j and frame m is defined as follows [43]:
where SNR X (j,m) is the input SNR in band j, is the SNR of the enhanced signal in the j th frequency band at the m th frame.
Assuming the SNR range is restricted to [−SNRLim,SNRLim] dB (SNRLim=3 in this paper), the S L(j,m) term is then limited as follows:
and subsequently mapped to the range of [0, 1] using the following equation:
where C− and C+ are parameters (fixed to be 1 in this paper) controlling the slopes of the mapping function which was defined in the range of [0, 1]; therefore, the frame SNRLOSS is normalized to the range of 0≤SNRLOSS(j,m)≤1. The average SNRLOSS is finally computed by averaging SNRLOSS(j,m) over all frames in the signal as follows:
where M is the total number of data segments in the signal, and f SNRLOSS(m) is the average (across bands) SNR loss computed as follows:
where W(j) is the weight (i.e., band importance function [52]) placed on the j th frequency band and was taken from Table B.1 in the ANSI standard [52].
The implementation of the SNRLOSS measure was supplied in the website of the authors in [43]. The smaller the value of the SNRLOSS measure is, the better performance of the SE algorithm is achieved.
5 Simulation results
The evaluation of the subjective quality and intelligibility of the speech enhanced by our proposed SE algorithm are reported in this section. Three other SE schemes, namely, wavelet thresholding (WT) [16], KLT [9], and Wiener algorithm with clean signal present (Wiener_Clean) [19], were also evaluated in order to gain a comparative analysis of the proposed SE algorithm. The KLT algorithm was proved in [1] and [22] by subjective tests to perform well in terms of preserving speech intelligibility for normal hearing listeners and improving speech intelligibility significantly for cochlear implant users in regard to recognition of sentences corrupted by stationary noises, respectively. The Wiener_Clean algorithm was taken as the ground truth in this paper because there is clean signal used in the algorithm. The unprocessed noisy signal (UP) was also evaluated by the SNRLOSS measure for comparison purposes. The implementations of these three schemes were taken from the implementations in [18].
5.1 Performance of predicting subjective quality
5.1.1 Performance average over all eight kinds of noise
In Figure 2, the proposed algorithm is compared with WT and KLT algorithms in terms of the composite measures averaging over all eight noises for seven SNRs. The four objective measures (LLR, segSNR, WSS, and PESQ) that composed the composite measures were also given in the first row for reference. The Wiener_Clean algorithm, as the ground truth, performed the best for all four objective evaluation measures. According to [42], the LLR measure performed the best in terms of predicting signal distortion, while the PESQ measure gave the best prediction for both noise intrusiveness and overall speech quality. From the first row of Figure 2, we can notice that our proposed algorithm gives better performance than both WT and KLT in terms of the LLR measure for all seven SNRs tested. Moreover, when SNR is smaller than 5 dB, our proposed algorithm also performed better than both WT and KLT for the PESQ measure.

Averaged over seven SNRs. The composite measure comparisons for four SE schemes (WT, KLT, proposed, and Wiener_Clean) averaged over seven SNRs (−8,−5,−2,0,5,10, and 15 db) for eight kinds of noise.
The second row of Figure 2 shows the composite measures, which include Csig, Cbak, and Covl, estimated by the combination of all those four objective measures expressed in the first row. In terms of both signal distortion Csig and overall quality Covl, our proposed method performs the best when SNR is less than 10 dB. Specifically speaking, for overall quality measure Covl, the proposed algorithm improved 10.94%, 18.94%, 21.63%, 23.66%, and 6.67% for −8,−5,−2,0, and 5 dB, respectively, when compared with the KLT method. In general, the proposed algorithm achieved 13.88% and 6.40% improvement for Csig and Covl, respectively, when average over all seven tested SNR levels. However, for Cbak, the WT and KLT algorithms give similar and better results than our proposed one when SNR is no smaller than 0 dB. The improvement was 0.98%, 6.98%, 11.11%, and 16.55% for 0, 5, 10, and 15 dB, respectively. In average, the WT and KLT methods were 5.14% better than our proposed algorithm in terms of background intrusiveness Cbak.
5.1.2 Performance average over seven SNRs
Figure 3 shows the three different composite measures averaged over seven SNRs for eight kinds of noise computed for WT, KLT, Wiener_Clean, and proposed SE algorithms. The Wiener_Clean algorithm still works as the ground truth here. From Figure 3, it is clear that in terms of Csig, the KLT works much better than WT. Hence, the proposed algorithm is compared with only the KLT method here. We observe that on average, the proposed algorithm is better than the KLT method in terms of Csig for train (9.19%), babble (15.93%), car (14.51%), exhibition hall (7.74%), restaurant (16.74%), street (13.42%), airport (16.64%), and train station (16.23%) noises. The number in the bracket indicates the Csig by which our proposed algorithm is better than the KLT method. The mean Csig over all eight noise types of our proposed SE algorithm is 13.88% better than that of the KLT method. Furthermore, the proposed SE algorithms outperforms the KLT in terms of Covl by an average of 6.40% over all eight kinds of noise that were considered. However, in terms of background intrusiveness Cbak, the KLT algorithm gives an average of 5.14% better results than our proposed algorithm.

Averaged over eight kinds of noise. The composite measure comparisons for four SE schemes (WT, KLT, proposed, and Wiener_Clean) averaged over eight kinds of noise for seven SNRs (−8,−5,−2,0,5,10, and 15 dB).
Thus, in conclusion, the proposed SE algorithm was predicted to be able to achieve the best overall subjective quality for most SNRs and all noise types considered when comparing with WT and KLT algorithms.
5.2 Performance of predicting speech intelligibility
The SNRLOSS measure values obtained from each algorithm (include UP) were subjected to statistical analysis in order to assess their significant differences. A highly significant effect (p<0.005) was found in all SNR levels and all types of noise by analysis of variance (ANOVA). Following the ANOVA, multiple comparison statistical tests according to Tukey’s HSD test were done to assess the significance between algorithms. The difference was deemed significant if the p value was smaller than 0.05.
Table 3 gives the statistical comparisons of the SNRLOSS measure between unprocessed noisy sentences (UP) and enhanced sentences by four SE algorithms (WT, KLT, Wiener_Clean, and proposed). At the same time, the comparisons between our proposed SE algorithm and the other three algorithms were also given. From Table 3, we know that when compared with the UP, our proposed algorithm was predicted by the SNRLOSS measure to be able to improve the intelligibility in low SNRs for most noises tested (italicized). The R in the table gives the percentage by which our algorithm is better than others; the value is negative because better performance gave smaller SNRLOSS measure. Furthermore, our proposed SE algorithm was also compared with the WT and KLT algorithms and was proved to supply better performance for most conditions tested.
6 Conclusions
The main contribution of this paper was the introduction of a new SE algorithm based on imposing constraint on Wiener gain function. Experiments were done on NOIZEUS database for eight kinds of noise (AURORA database) across seven different SNRs ranging from −8 to 15 dB. The Wiener_Clean algorithm was taken as the ground truth. The performance of our proposed algorithm was compared with WT and KLT methods. The results were analyzed mainly by three composite measures and the SNRLOSS measure to predict the performance on subjective quality and speech intelligibility, respectively. Through extensive experiments, we showed that when averaged over all eight kinds of noises, our proposed SE algorithm achieved the best results in terms of predicting signal distortion Csig and overall quality Covl when SNR is no more than 10 dB. Furthermore, we investigated the individual performance on each noise type. Our proposed SE algorithm outperformed the KLT algorithm for all noise types tested in terms of both Csig and Covl. On the other hand, the SNRLOSS measure comparisons with both the UP and other SE algorithms predicted that our proposed algorithm was able to improve speech intelligibility for low SNR levels and outperform WT and KLT algorithms for most conditions examined.
It is important to point out that the three composite measures and the SNRLOSS measure used in this paper are adopted for predicting the subjective quality and intelligibility of noisy speech enhanced by noise suppression algorithms because of their high correlation with real subjective tests [42],[43]. Further subjective tests on both normal-hearing listeners and hearing-impaired listeners are needed to verify the effectiveness of the proposed algorithm on improving both subjective quality and speech intelligibility. It is also worth mentioning that depending on the nature of the application, some practical SE systems may require very high quality speech but can tolerate a certain amount of noise, while other systems may want speech as clean as possible even with some degree of speech distortion. Therefore, it should be noted that according to different applications, different SE algorithms should be chosen to meet the variant requirement.
References
Hu Y, Loizou PC: A comparative intelligibility study of single-microphone noise reduction algorithms. J. Acous. Soc. Am 2007, 122(3):1777-1786. 10.1121/1.2766778
MR Schroeder, Apparatus for suppressing noise and distortion in communication signals. U.S Patent 3180936 (April27, 1965).
Scalart P, Vieira-Filho J: Speech enhancement based on a priori signal to noise estimation. In Proceedings of the 21st IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP-96). Atlanta, Georgia; 1996:629-632.
Chen J, Benesty J, Huang Y: New insights into the noise reduction wiener filter. IEEE Trans. Audio Speech Lang. Process 2006, 14(4):1218-1234. 10.1109/TSA.2005.860851
Boll S: Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Proces 1979, 27(2):113-120. 10.1109/TASSP.1979.1163209
M Berouti, R Schwartz, J Makhoul, in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 4. Enhancement of speech corrupted by acoustic noise, (1979), pp. 208–211.
Gustafsson H, Nordholm SE, Claesson I: Spectral subtraction using reduced delay convolution and adaptive averaging. IEEE Trans. Speech Audio Proces 2001, 9(8):799-807. 10.1109/89.966083
S Kamath, PC Loizou, in Student Research Abstracts of Proc. IEEE International Conference On Acoustics, Speech, and Signal Processing (ICASSP), 4. A multi-band spectral subtraction method for enhancing speech corrupted by colored noise (Orlando, FL, USA, 2002), pp. IV-4164.
Hu Y, Loizou PC: A generalized subspace approach for enhancing speech corrupted by colored noise. IEEE Trans. Speech Audio Proces 2003, 11(4):334-341. 10.1109/TSA.2003.814458
Jabloun F, Champagne B: Incorporating the human hearing properties in the signal subspace approach for speech enhancement. IEEE Trans. Speech Audio Proces 2003, 11(6):700-708. 10.1109/TSA.2003.818031
Ephraim Y, Malah D: Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Proces 1984, 32(6):1109-1121. 10.1109/TASSP.1984.1164453
Ephraim Y, Malah D: Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Proces 1985, 33(2):443-445. 10.1109/TASSP.1985.1164550
Loizou PC: Speech enhancement based on perceptually motivated Bayesian estimators of the magnitude spectrum. IEEE Trans. Speech Audio Proces 2005, 13(5):857-869. 10.1109/TSA.2005.851929
Lim JS, Oppenheim AV: Enhancement and bandwidth compression of noisy speech. Proc. IEEE 1979, 67(12):1586-1604. 10.1109/PROC.1979.11540
Lim JS, Oppenheim AV: All-pole modeling of degraded speech. IEEE Trans. Acoust. Speech Signal Proces 1978, 26(3):197-210. 10.1109/TASSP.1978.1163086
Hu Y, Loizou PC: Speech enhancement based on wavelet thresholding the multitaper spectrum. IEEE Trans. Speech Audio Proces 2004, 12(1):59-67. 10.1109/TSA.2003.819949
Hu Y, Loizou PC: Subjective comparison and evaluation of speech enhancement algorithms. Speech Commun. 2007, 49(7):588-601. 10.1016/j.specom.2006.12.006
Loizou PC: Speech Enhancement: Theory and Practice. CRC, Boca Raton; 2007.
Loizou PC, Kim G: Reasons why current speech-enhancement algorithms do not improve speech intelligibility and suggested solutions. IEEE Trans. Audio Speech Lang. Process 2011, 19(1):47-56. 10.1109/TASL.2010.2045180
Y Hu, PC Loizou, in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 1. Subjective comparison of speech enhancement algorithms, (2006), pp. 153–156.
Lim JS: Evaluation of a correlation subtraction method for enhancing speech degraded by additive white noise. IEEE Trans. Acoust. Speech Signal Proces 1978, 26(5):471-472. 10.1109/TASSP.1978.1163129
Loizou PC, Lobo A, Hu Y: Subspace algorithms for noise reduction in cochlear implants. J. Acoust. Soc. Am 2005, 118(5):2791-2793. 10.1121/1.2065847
Kim G, Lu Y, Hu Y, Loizou PC: An algorithm that improves speech intelligibility in noise for normal-hearing listeners. J. Acoust. Soc. Am 2009, 126(3):1486-1494. 10.1121/1.3184603
Healy EW, Yoho SE, Wang Y, Wang DL: An algorithm to improve speech recognition in noise for hearing-impaired listeners. J. Acoust. Soc. Am 2013, 134(4):3029-3038. 10.1121/1.4820893
K Hu, P Divenyi, D Ellis, Z Jin, BG Shinn-Cunningham, DL Wang, in ISCA Tutorial and Research Workshop on Statistical and Perceptual Audition (SAPA). Preliminary intelligibility tests of a monaural speech segregation system, (2008), pp. 11–16.
Thomson DJ: Spectrum estimation and harmonic analysis. Proc. IEEE 1982, 70(9):1055-1096. 10.1109/PROC.1982.12433
Kay SM: Modern Spectral Estimation. Prentice-Hall, Englewood Cliffs; 1988.
Riedel KS, Sidorenko A: Minimum bias multiple taper spectral estimation. IEEE Trans. Signal Process 1995, 43(1):188-195. 10.1109/78.365298
Moulin P: Wavelet thresholding techniques for power spectrum estimation. IEEE Trans. Signal Process 1994, 42(11):3126-3136. 10.1109/78.330372
Walden AT, Percival DB, McCoy EJ: Spectrum estimation by wavelet thresholding of multitaper estimators. IEEE Trans. Signal Process 1998, 46(12):3153-3165. 10.1109/78.735293
Cristan AC, Walden AT: Multitaper power spectrum estimation and thresholding: wavelet packets versus wavelets. IEEE Trans. Signal Process 2002, 50(12):2976-2986. 10.1109/TSP.2002.805503
Wahba G: Automatic smoothing of the log periodogram. J. Am. Stat. Assoc 1980, 75(369):122-132. 10.1080/01621459.1980.10477441
Percival DB: Spectral Analysis for Physical Applications: Multitaper and Conventional Univariate Techniques. Cambridge University Press, Cambridge; 1993.
Bartlett MS, Kendall DG: The statistical analysis of variance-heterogeneity and the logarithmic transformation. Suppl. J. R. Stat. Soc 1946, 8(1):128-138. 10.2307/2983618
Quackenbush SR, Barnwell TP, Clements MA: Objective Measures of Speech Quality. Prentice-Hall, Englewood Cliffs; 1988.
Donoho DL, Johnstone IM: Ideal spatial adaptation by wavelet shrinkage. Biometrika 1994, 81(3):425-455. 10.1093/biomet/81.3.425
Donoho DL: De-noising by soft-thresholding. IEEE Trans. Inform. Theory 1995, 41(3):613-627. 10.1109/18.382009
Donoho DL, Johnstone IM: Adapting to unknown smoothness via wavelet shrinkage. J. Am. Stat. Assoc 1995, 90(432):1200-1224. 10.1080/01621459.1995.10476626
Johnstone IM, Silverman BW: Wavelet threshold estimators for data with correlated noise. J. Roy. Stat. Soc. B 1997, 59(2):319-351. 10.1111/1467-9868.00071
Mallat SG: A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans. Pattern Anal. Mach. Intell 1989, 11(7):674-693. 10.1109/34.192463
Rangachari S, Loizou PC: A noise-estimation algorithm for highly non-stationary environments. Speech Commun. 2006, 48(2):220-231. 10.1016/j.specom.2005.08.005
Y Hu, PC Loizou, in Proceedings of INTERSPEECH. Evaluation of objective measures for speech enhancement, (2006), pp. 1447–1450.
Ma J, Loizou PC: SNR loss: a new objective measure for predicting the intelligibility of noise-suppressed speech. Speech Commun 2011, 53(3):340-354. 10.1016/j.specom.2010.10.005
Hu Y, Loizou PC: Subjective comparison and evaluation of speech enhancement algorithms. Speech Commun 2007, 49(7):588-601. 10.1016/j.specom.2006.12.006
Rothauser EH, Chapman WD, Guttman N, Hecker MHL, Nordby KS, Silbiger HR, Urbanek GE, Weinstock M: IEEE recommended practice for speech quality measurements. IEEE Trans. Audio Electroacoust 1969, 17(3):225-246. 10.1109/TAU.1969.1162058
International Telecommunication Union, P.862: Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrow-Band Telephone Networks and Speech Codecs. (ITU-T Recommendation P. 862, 2000).
H Hirsch, D Pearce, in ASR-2000. The AURORA experimental framework for the performance evaluation of speech recognition systems under noisy conditions (Paris, France, 2000), pp. 181–188.
Hu Y, Loizou PC: Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process 2008, 16(1):229-238. 10.1109/TASL.2007.911054
Hu Y, Ma J, Loizou PC: Objective measures for predicting speech intelligibility in noisy conditions based on new band-importance functions. J. Acoust. Soc. Am 2009, 125(5):3387-3405. 10.1121/1.3097493
D Klatt, in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 7. Prediction of perceived phonetic distance from critical-band spectra: a first step, (1982), pp. 1278–1281.
International Telecommunication Union, ITU-T Recommendation P.835: Subjective Test Methodology for Evaluating Speech Communication Systems that Include Noise Suppression Algorithms. (ITU-T Recommendation P.835, 2003).
ANSI, Methods for Calculation of the Speech Intelligibility Index. Technical Report S3.5-1997, American National Standards Institute (1997).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

{kind=link}
{kind=link}
{kind=link}
Cite this article
Ma, Y., Nishihara, A. A modified Wiener filtering method combined with wavelet thresholding multitaper spectrum for speech enhancement. J AUDIO SPEECH MUSIC PROC. 2014, 32 (2014). https://doi.org/10.1186/s13636-014-0032-7
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13636-014-0032-7