
Abstract
We propose a flexible nonparametric Bayesian modelling framework for multivariate time series of count data based on tensor factorisations. Our models can be viewed as infinite state space Markov chains of known maximal order with non-linear serial dependence through the introduction of appropriate latent variables. Alternatively, our models can be viewed as Bayesian hierarchical models with conditionally independent Poisson distributed observations. Inference about the important lags and their complex interactions is achieved via MCMC. When the observed counts are large, we deal with the resulting computational complexity of Bayesian inference via a two-step inferential strategy based on an initial analysis of a training set of the data. Our methodology is illustrated using simulation experiments and analysis of real-world data.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
We consider a time-index sequence of multivariate random variables of size T, \(\{y_t\}_{t=1}^T\), taking values in \(\{0,1,\ldots \}\). We build a non-parametric model by (i) assuming that the transition probability law of the sequence \(\{ y_{t} \}\) conditional on the filtration up to time \(t-1\), \(\mathbf{F}_{t-1}\), is that of a Markov chain of maximal order q, (ii) allowing non-linear dependence of the values at the previous q time points and (iii) incorporating complex interactions between lags.
We propose a Bayesian model for multivariate time series of counts based on tensor factorisations. Our development is inspired by Yang and Dunson (2016) and (Sarkar & Dunson, 2016). Yang and Dunson (2016) introduced conditional tensor factorisation models that lead to parsimonious representations of transition probability vectors together with a simple, powerful Bayesian hierarchical formulation based on latent allocation variables. This framework has been exploited in Sarkar and Dunson (2016) to build a nonparametric Bayesian model for categorical data together with an efficient MCMC inferential framework. We adopt the ideas and methods of these papers to build flexible models for time series of counts. The major difference that distinguishes our work to Sarkar and Dunson (2016) is that, unlike categorical data, we deal with time series that are infinite, rather than finite, state space Markov chains. The resulting computational complexity of our proposed model is grown as the observed counts become larger, so we propose a two-step inferential strategy in which an initial, training part of the time series data, is utilized to facilitate the inference and prediction of the rest of the data.
A common way to analyse univariate time series of counts is by assuming that the conditional probability distribution of \(y_t \mid y_{t-1}, \dots , y_{t-q}\) can be expressed as a Poisson density with rate \(\lambda _{t}\) that depends either on previous counts \(y_{t-1}, \dots , y_{t-q}\) or previous intensities \(\lambda _{t-1}, \dots , \lambda _{t-q}\). For example, one such popular model is the Poisson autoregressive model (without covariates) of order q, PAR(q):
where \(\beta _0, \beta _1, \dots , \beta _q\) are unknown parameters; see (Cameron & Trivedi, 2001). Grunwald et al. (2000), Grunwald et al. (1997) and (Fokianos, 2011) discuss the modelling and properties of a PAR(1) process. Brandt and Williams (2001) generalise PAR(1) to a PAR(q) process and apply it to the modelling of presidential vetoes in the United States. Kuhn et al. (1994) adopt such processes to model the counts of child injury in Washington Heights. When we deal with M distinct time series of counts, the PAR(q) model is written, for \(m=1,\ldots ,M\), as
see, for example, Liboschik et al. (2015). In the above equation, q is fixed for each \(m=1,\ldots ,M\). We will use this model formulation as a benchmark for comparison against our proposed methodology. Other approaches to modelling time series of counts include the integer-valued generalised autoregression conditional heteroscedastic models (Heinen, 2003; Weiß 2014) and the integer-valued autoregression processes (Al-Osh & Alzaid, 1987). We have not dealt with these models here because a proper Bayesian evaluation of their predictive performance requires a challenging Bayesian inference task which is beyond the scope of our work.
The rest of the paper is organised as follows. We specify our model in Section 2, followed by estimation and inference details in Section 3. Simulation experiments and applications are provided in Section 4 and 5, respectively.
2 Model specification
2.1 The Bayesian tensor factorisation model
2.1.1 Univariate time series
We build a probabilistic model by assuming that the transition probability law of \(y_{t}\) conditional on \(\mathbf{F}_{t-1}\) is that of a Markov chain of maximal order q:
for \(t \in {[q+1, T]}\) where the set containing all integers from i to j is denoted as [i, j]. This formulation includes the possibility that only a subset of the previous q values affects \(y_t\). We follow (Sarkar & Dunson, 2016) and introduce a series of latent variables as follows. First, let \(k_j\) denote the maximal number of clusters that the values of \(y_{t-j}\) can be separated into for predicting \(y_t\). To demonstrate the use of \(k_j\) we present a simple example. Assume that \(y_t\) depends only on \(y_{t-1}\) and the relationship in which the observed values of \(y_{t-1}\) affect the density of \(y_t\) is based on the following stochastic rule: if \(y_{t-1} > 1\) then \(y_t \sim \text {Poisson}(1)\) and if \(y_{t-1} \le 1\) then \(y_t\sim \text {Poisson}(2)\). Then \(k_1 = 2\) since the values of \(y_{t-1}\) are separated into two clusters that determine the distribution of \(y_t\). Note that if \(k_j = 1\) the value of \(y_{t-j}\) does not affect the density of \(y_t\). The collection of all these latent variables \(K:= \{k_{j}\}_{j \in {[1, q]}}\) determines how past values of the time series affect the distribution of \(y_t\).
We also define a collection of time-dependent latent allocation random variables \(Z_t:= \{z_{j,t}\}_{j\in {[1,q]}}\) where \(z_{j,t}\) specifies which of the \(k_j\) clusters of \(y_{t-j}\) affects \(y_t\). We will write \(Z_t=H\) meaning that all latent variables in \(Z_t\) equal to another collection of latent variables \(H:= \{h_{j}\}_{j\in {[1,q]}}\) that do not depend on t. Finally, denote the collection \({\mathbf {H}}:= \{h_{j} \in {[1, k_{j}]}, j \in {[1,q]}\}\) that depends on K. The connection among \(Z_t\), H and \({\mathbf {H}}\) is that for any \(t \in {[q+1, T]}\), \(Z_t\) is sampled with value \(H \in {\bf {H}}\).
We are now in a position to define our model. Let \(\lambda _{Z_t}\) be the Poisson rate for generating \(y_t\) given the random variable \(Z_t\). The conditional transition probability law (3) can be written as a Bayesian hierarchical model, for \(j\in {[1,q]}\), \(H \in {\mathbf {H}}\) and \(t \in {[q+1, T]}\), as
Expressions (4) and (5) imply that
with constraints \(\lambda _{H} \ge 0\) for any \(H \in {\mathbf {H}}\) and \(\sum _{h_{j} = 1}^{k_{j}}\pi ^{(j)}_{h_{j}}(y_{t-j}) = 1\) for each combination of \((j, y_{t-j})\). Multinomial(\({[1,k]}, \pi\)) is a multinomial distribution selecting a value from [1, k] with a probability vector \(\pi\). The formulation (6) is referred to as a conditional tensor factorisation with the Poisson density PD(\(y_t; \lambda _{H}\)) being the core tensor; see (Harshman, 1970; Harshman & Lundy, 1994; Tucker, 1966; De Lathauwer et al., 2000) for a description of tensor factorisations. It can also be interpreted as a Poisson mixture model with \(\prod _{j \in {[1,q]}} \pi _{h_{j}}^{(j)}(y_{t-j})\) being the mixture weights that depend on previous values of \(y_t\).
A more parsimonious representation for our tensor factorisation model is obtained by adopting a Dirichlet process for Poisson rates \(\lambda _{H}\). Independently, for each \(H \in {\mathbf {H}}\), we use the stick-breaking construction introduced by Sethuraman (1994) in which
where \(\delta (.)\) is a Dirac delta function and independently, for \(l \in {[1,\infty )}\),
where \(\lambda _l^{*}\) represents a label-clustered Poisson rate. By letting \({\mathbf {Z}}_{Z_t}^{*}\) denote the label of the cluster that \(Z_t\) belongs to at time \(t \in {[q+1, T]}\), we complete the model formulation as
2.1.2 Multivariate time series
The model of the previous section can be readily extended to deal with multivariate responses \(\{ Y_t\}_{t=1}^T\), where \(Y_t = ( y_{1,t}, \dots , y_{M,t} )^\top\) taking values in \({\mathbb {N}}_0\). The idea is similar to the way the univariate PAR model (1) is generalised to its multivariate counterpart (2). We assume that the transition probability for any \(\tau \in {[1, M]}\) and \(t \in {[q+1, T]}\) is
The idea is that each univariate time series may depend on all or some of the q previous values of all, or some, univariate time series. Model (9) assumes that conditional on past q values of all time series before time t, the M univariate random variables at time t are independent. The formulation requires M different latent variables for each dimension but, other than that, its specific details have no essential difference from those in the univariate case.
2.1.3 Two-step inference for large counts
Imagine that based on observed data \(\{y_t\}_{t=1}^T\), one has to recursively forecast future observations \(y_{T+1}, y_{T+2}, \ldots\). Clearly, the observed values of \(\{y_t\}_{t=1}^T\) determine the form of our models in Sections 2.1.1 and 2.1.2 and as a result of this construction we may face the unfortunate situation in which a count that has been unobserved up to time T appears in the future observations. This problem can be solved by re-estimating the model but in cases where this is not desirable, we propose the following solution. We separate \(\{y_t\}_{t=1}^T\) into two segments of size \(T_1\) and \(T_2\), representing the size of pre-training dataset and training dataset, respectively, so \(\{y_t\}_{t \in {[1, T_1]}}\) and \(\{y_t\}_{t\in {[T_1+1, T_1+T_2]}}\) are the corresponding observations in these sets. We aim to use the pre-training dataset to cluster all the counts in time series and the training dataset to model the time series with labelled counts.
We first define a collection of latent variables \(\{w_{1:c-1}, \mu _{1:c}, c\}\) that models the pre-training data \(\{y_t\}_{t \in {[1, T_1]}}\) as
for any \(t \in {[1, T_1]}\), \(0< w_{i} < 1\), \(\sum _{i=1}^{c}w_{i} = 1\), \(\mu _{i} \ge 0\). Thus, (10) assumes that any \(y_{t}\) in the pre-training dataset is distributed as a finite mixture of Poisson distributions with c components, weights \(w_{i}\) and intensities \(\mu _{i}\). The usual latent structure for such mixture models assumes indicator variables \(d_{t}\) representing the estimated label of the mixture component that \(y_{t}\) belongs to, so \(p(d_{t} = i) = w_i\) for all \(i \in {[1,c]}\).
We exploit this finite mixture clustering of the pre-training dataset to build our model for the training dataset. We define another collection of latent variables as \(D_t = \{ d_{j,t} \}_{j\in {[1, q]}}\) and by setting \(d_{j,t} = d_{t-j}\) for all \(j\in {[1, q]}\) and \(t\in {[T_1+1+q, T_1+T_2]}\). We then build a probabilistic model for the training dataset by assuming that the transition probability law of the sequence \(\{ y_{t} \}_{t \in {[T_1+1+q, T_1+T_2]}}\) conditional on \({\mathbf {F}}_{t-1}\) is that of a probabilistic model of this target sequence conditional on \(D_t\). That is, we have
The conditional transition probability law (11) can then be written as a Bayesian hierarchical model, for \(j \in {[1, q]}\) and \(t \in {[T_1+1+q, T_1+T_2]}\), as
(12) and (13) immediately imply that
with constraints \(\lambda _{H} \ge 0\) for any \(H \in {\mathbf {H}}\) and \(\sum _{h_{j} = 1}^{k_{j}}\pi ^{(j)}_{h_{j}}(d_{j,t}) = 1\) for each combination of \((j, d_{j,t})\). It is clear that (14) is equivalent to (12) and (13). From (14) the expectation of \(y_{t}\) conditional on \(D_t\) is
The rest of the model which utilises the stick-breaking process for \(\lambda _H\) is similar to the one used in Sect. 2.1.1.
2.1.4 Priors
We assign independent priors on \(\pi ^{(j)}(d_{j,t})\) as
with \(\gamma _{j} = 0.1\). Also, we follow (Sarkar & Dunson, 2016) and set priors
where \(j \in {[1, q]}\), \(\kappa \in {[1,c]}\). Notice that \(\varphi\) controls \(p(k_{j} = \kappa )\) and the number of important lags for the proposed conditional tensor factorisation; for all our experiments throughout this paper, we set \(\varphi = 0.5\). Following (Viallefont et al., 2002), we place for the Gamma density of \(\lambda _l^{*}\) parameters a as the mid-range of \(y_{t}\) in the training dataset \(a = \frac{1}{2} [\max (\{y_t\}_{t \in {[T_1+1+q, T_1+T_2]} }) - \min (\{y_t\}_{t \in {[T_1+1+q, T_1+T_2]} })]\) and \(b = 1\). We set \(\alpha _0 = 1\) for the Beta prior to \(V_l\). Finally, we truncate the series (7), by assuming
and we set \(L=100\).
3 Estimation and inference
The joint density of the general model of Section 2.2.3 can be expressed as \(p(y, Z, {\mathbf {Z}}^{*}, D, \lambda ^{*}, \pi ^{*}, \pi _K)\), where \(D = \{D_t\}_{t\in {[T_1+1, T_1+T_2]}}\) and \(K = \{k_j\}_{j \in {[1,q]}}\). The Poisson mixture model in the pre-training set is estimated with the MCMC algorithm of Marin et al. (2005). For any \(t>T_1\) we then estimate \(d_{t} = \arg _i \max \text {PD}(y_{t}, \mu _i)\), \(i \in {[1,c]}\). Our BTF model has a finite number of mixture components with an unknown number of components due to the randomness of the random variable matrix K. We follow (Yang & Dunson, 2016) and estimate K separately through a stochastic search variable selection (George & McCulloch, 1997) based on approximated marginal likelihood. As (Yang & Dunson, 2016) point out, such an approach is helpful since it fixes the numbers of inclusions of the tensor and the sampling process of K can indicate whether a predictor is important. The rest of the inference proceeds by sampling all other random variables conditional on K and D through MCMC.
3.1 MCMC for finite Poisson mixtures
We follow the procedure in Marin et al. (2005). \(\{y_{t}\}_{t\in {\mathbb {Z}}_{[1, T_1]}}\) is a mixture of c univariate Poisson distributions with density \(\sum _{i=1}^{c} w_i \text {PD}(y_t;\mu _i)\), \(\{w_i\}_{i \in {\mathbb {Z}}_{[1,c]}}\) are weights with \(\sum _{i=1}^c w_i = 1\) and \(\{\mu _i\}_{i \in {\mathbb {Z}}_{[1,c]}}\) are the corresponding Poisson rates. By setting the priors as \(\mu _i \sim \text {Gamma}(1, 1)\), \(\hspace{5.0pt}\{w_i\}_{i \in {\mathbb {Z}}_{[1,c]}} \sim \text {Dirichlet}(1, \dots , 1),\) the corresponding Gibbs sampler is as follows: (i) Generate the label of \(y_t\), \(\iota _{t}\), for \(t \in {\mathbb {Z}}_{[1, T_1]}\), \(i \in {\mathbb {Z}}_{[1,c]}\) as \(p(\iota _{t} = i) \propto w_i \left( \mu _i \right) ^{y_{t}} \exp \left( -\mu _i \right)\) and set \(n_i = \sum _{t \in {\mathbb {Z}}_{[1, T_1]}} \mathbb {1}_{\iota _{t} = i}\) and \({\mathbf {I}}_i = \sum _{t \in {\mathbb {Z}}_{[1, T_1]}}\mathbb {1}_{\iota _{t} = i} y_{t}\) (ii) Generate \(\{w_i\}_{i \in {\mathbb {Z}}_{[1,c]}} \sim \text {Dirichlet}(1 + n_1, \dots , 1 + n_{c})\) and (iii) for \(i \in {\mathbb {Z}}_{[1,c]}\), generate \(\mu _i \sim \text {Gamma}(1 + {\mathbf {I}}_i, 1 + n_i).\)
3.2 Important lags selection
Important lags are inferred by the variable \(K = \{k_{j}\}_{ j\in {\mathbb {Z}}_{[1, q]}}\). The basic calculations are as follows. Following (Sarkar & Dunson, 2016), the posterior of \(K = \{k_{j}\}_{ j\in {\mathbb {Z}}_{[1, q]}}\) can be sampled as
with \(k_{j} = \max \left( \{z_{j,t}\}_{t\in {\mathbb {Z}}_{[T_1+1+q, T_1+T_2]}}\right) , \dots , c\) and \(n_{j,\omega } = \sum _{t \in {\mathbb {Z}}_{[T_1+1+q, T_1+T_2]}} \mathbb {1} \{d_{j,t} = \omega . \}\) The levels of \(d_{j,t}\) are partitioned into \(k_{j}\) clusters \(\{ C_{j,r}: r = 1, \dots , k_{j} \}\) with each cluster \(C_{j,r}\) assumed to correspond to its own latent class \(h_{j} = r\). With independent Dirichlet priors on the mixture kernels \(\lambda _H \sim \text {Gamma}(a, b)\) marginalised out, the likelihood of our targeted response \(\{y_{t}\}_{t\in {\mathbf {T}}_2^{*}}\) conditional on the cluster configuration \(C = \{C_{j,r}: j \in {\mathbb {Z}}_{[1,q]}, r \in {\mathbb {Z}}_{[1, k_j]}\}\) is given by
where \(\xi = \mathbb {1}\{ d_{1,t} \in C_{1, h_{1}}, \dots , d_{q,t} \in C_{q, h_{q}} \}\). Then the MCMC steps for \(j \in {\mathbb {Z}}_{[1, q]}\) are: (i) If \(1 \le k_{j} \le c\), we propose to either increase \(k_{j}\) to \((k_{j}+1)\) or decrease \(k_{j}\) to \((k_{j}-1)\). (ii) If an increasing move is proposed, we randomly split a cluster of \(d_{j,t}\) into two clusters. We accept this move with an acceptance rate based on the approximated marginal likelihood. (iii) If a decrease move is proposed, we randomly merge two clusters of \(d_{j,t}\) into a single cluster. We accept this move with an acceptance rate based on the approximated marginal likelihood. If \(K^{*}\) and \(C^{*}\) are the updated model index and cluster, \(\alpha (\cdot ; \cdot )\) is the Metropolis-Hastings acceptance rate, \(L(\cdot )\) is the likelihood function and \(q(\cdot \rightarrow \cdot )\) is the proposal function, we obtain
3.3 Full conditional densities
For given D and K, denote by \(\zeta\) a generic variable that collects the variables that are not explicitly mentioned, including y. Then the corresponding Gibbs sampling steps are
-
Sample \({\mathbf {Z}}^{*}_H\) for each \(H \in {\mathbf {H}}\) from \(p({\mathbf {Z}}^{*}_H = l \mid \zeta ) \propto \pi ^{*}_l (\lambda _l^{*})^{n_H^{*}} \exp \left( -n_H\lambda _l^{*}\right)\) where \(n_H^{*} = \sum _{t\in {\mathbb {Z}}_{[T_1+1+q, T_1+T_2]}}\mathbb {1} \{ Z_t = H \} y_{t}\) and \(n_H = \sum _{t \in {\mathbb {Z}}_{[T_1+1+q, T_1+T_2]}} \mathbb {1} \{ Z_t = H \}.\)
-
Sample \(V_l\) for \(l \in {\mathbb {Z}}_{[1, L]}\) from \(V_l \mid \zeta \sim \text {Beta}\left( 1 + {\mathbf {N}}^{*}_l, \alpha _0 + \sum _{l' > l} {\mathbf {N}}^{*}_{l'} \right)\) where \({\mathbf {N}}^{*}_l = \sum _{H \in {\mathbf {H}}} \mathbb {1} \{ {\mathbf {Z}}^{*}_H = l \}\), and update \(\pi ^{*}_l\) accordingly.
-
Sample each \(\lambda ^{*}_l\) with \(l \in {\mathbf {L}}\) from \(\lambda ^{*}_l \mid \zeta \sim \text {Gamma}\left( a + N_H^{*}(l), b + N_H(l)\right) ,\) where \(N_H^{*}(l) = \sum _{H \in {\mathbf {H}}} \mathbb {1} \{ {\mathbf {Z}}^{*}_H = l \} n_H^{*}\) and \(N_H(l) = \sum _{H \in {\mathbf {H}}} \mathbb {1} \{ {\mathbf {Z}}^{*}_H = l \} n_H.\)
-
For \(j \in {\mathbb {Z}}_{[1,q]}\) and \(\omega \in {\mathbb {Z}}_{[1,c]}\), sample
$$\begin{aligned} \left\{ \pi ^{(j)}_{1}(\omega ), \dots , \pi ^{(j)}_{k_{j}}(\omega ) \right\} | \zeta \sim \text {Dirichlet}\{ \gamma _{j} + n_{j,\omega }(1), \dots , \gamma _{j} + n_{j,\omega }(k_{j})\} \end{aligned}$$where \(n_{j,\omega }(h_{j}) = \sum _{t \in {\mathbb {Z}}_{[T_1+1+q, T_1+T_2]}} \mathbb {1} \{ z_{j,t} = h_{j}, d_{j,t} = \omega \}\).
-
Sample \(z_{j,t}\) for \(j \in {\mathbb {Z}}_{[1,q]}\) and \(t \in {\mathbb {Z}}_{[T_1+1+q, T_1+T_2]}\) from
$$\begin{aligned} p(z_{j,t} = h | z_{j',t} = h_{j'}, j' \ne j, \zeta ) \propto \pi _{h}^{(j)}(d_{j,t})\left( \lambda ^{*}_{{\mathbf {Z}}^{*}_{H_{\dots / j = h}}}\right) ^{y_{t}} \exp \left( -\lambda ^{*}_{Z^{*}_{H_{\dots / j = h}}}\right) , \end{aligned}$$where \(H_{\dots / j = h}\) is equal to H at all position except the j-th position taking the value h.
4 Simulation experiments
We tested our methodology with simulated data from designed experiments against the Poisson autoregressive model (1) through the log predictive score calculated in an out-of-sample (test) dataset \({\mathfrak {T}}\) of size \({{\tilde{T}}}\). For each model the log predictive score is estimated by
where \(\hat{p}^{(i)}(y_t)\) denotes the one-step ahead estimated transition probability of observing \(y_{t \in {\mathfrak {T}}}\) calculated using the parameter values at the i-th iteration of MCMC with total N iterations. It measures the predictive accuracy of the model by assessing the quality of the uncertainty quantification. A model predicts better when the log predictive score is smaller; see, for example, Czado et al. (2009). For each designed scenario, we generated 10 datasets with 5, 000 data points and out-of-sample predictive performance for all models was tested by using either the first 4, 000 or 4, 500 data points as training datasets and calculating the log predictive scores approximated via the MCMC output at the rest 1, 000 or 500 test data points respectively. The resulting mean log predictive score that is reported in Tables 1, 2, 3 is the average log predictive score across the 10 generated datasets. The pre-training dataset for the BTF model has been chosen to be the first 3, 000 points. All MCMC runs were based on the following burn-in and posterior samples respectively: 2, 000 and 5, 000 for fitting the Poisson mixtures on the pre-training dataset; 1, 000 and 2, 000 for selecting the important lags and their corresponding number of inclusions; and 2, 000 and 5, 000 for sampling the rest of the parameters. Bayesian inference for Poisson autoregressive model was obtained by ’rjags’ (Plummer et al., 2016) package based on 5,000 burn-in and 10,000 MCMC samples respectively. We first chose the order q of the model by choosing among all models with maximum order up to \(q+2\) using the AIC and BIC criteria. We set the priors for parameters as \(\beta _0 \sim N(0, 10^{-6})\) and \(\beta _i \sim N(0, 10^{-4})\) for any \(i \in {[1,q]}\).
Table 1 presents the results of out-of-sample comparative predictive ability based on six generated Poisson autoregressive models based on (1). Notice that when the order q is high and there are only a few true coefficients, as in cases C, E and F, the maximal order Markov structure of the BTF model achieves a comparative, satisfactory predictive performance. Given that the data generating process is based on Poisson autoregressive models these results are very promising.
Next, we generated data in which past values affect current random variables in a non-linear fashion as follows. There are \({\mathbf {K}}\) important lag(s) \(\{ y_{t-i_{1}}, \dots , y_{t-i_{{\mathbf {K}}}} \}\) and, for given \(\nu _+\), \(\nu _-\), if \(\sum ^{{\mathbf {K}}}_{j = 1} y_{t-i_{j}} \ge {\mathbf {K}} \nu _+\), then \(y_{t} \sim \text {Poisson}(\nu _+)\); else \(y_{t} \sim \text {Poisson}(\nu _-)\). We designed 6 scenarios and the results are shown in Table 2. Our proposed modelling formulation outperforms the Bayesian Poisson autoregressive model in all but one scenario.
Finally, we replicated the last exercise by testing the models in a more challenging data generation mechanism in which the response is multivariate. We designed 6 different scenarios by generating an M-dimensional time series \(\{y_{m,t}\}_{m \in {[1, M]}}\) and assuming that we are interested in predicting \(y_{1, t}\). For \(t \le 10\), we generated \(y_{m,t}\) from Pois(\(\nu _{-}\)) for each m; for \(t > 10\), if \(\sum ^{{\mathbf {K}}}_{i = 1} y_{m_i, t-j_i} \ge \nu _{-}\) we generate \(y_{1, t} \sim \text {Poisson}(\nu _{+})\), else \(y_{1, t} \sim \text {Poisson}(\nu _{-})\). We fitted an M-dimensional multivariate Poisson autoregressive model of order q that predicts \(y_{\ell ,t}\) with covariates \(\{y_{m,t-1}\}_{m \in {M},m\ne \ell }\) as
where \(\beta _{\ell ,0},\beta _{\ell ,i}\) and \(\zeta _{\ell ,m}\) are unknown parameters. Table 3 shows that for all 6 Scenarios, the Bayesian tensor factorisation model achieves impressively better predictive performance than the Bayesian Poisson autoregressive model.
The times needed to run the MCMC algorithms for Bayesian Poisson autoregressive and BTF models are comparable. For 1000 iterations we needed, on average, 20 s for the BTF model implemented with our matlab code and 25 s for the Bayesian Poisson autoregressive models implemented with rjags.
5 Applications
5.1 Univariate flu data
We compared our Bayesian tensor factorisation model to Bayesian Poisson autoregressive model with two datasets from Google Flu Trends that refer to 514 Norway, Switzerland and Castilla-La Mancha weekly flu counts in Spain, see Fig. 1. We chose the maximum lag q to be 10 for all models we applied to the data. We examined the sensitivity to the size of the pre-training data by considering three scenarios. We used 103(20%), 154(30%) and 206(40%) pre-training sizes and compared their predictive ability against the best models for Bayesian Poisson autoregression formulations based on AIC and BIC criteria. The last 103 and 52 data points were chosen for out-of-sample test comparison for each dataset. To demonstrate how our methodology works, we will present MCMC results for the Norway dataset based on 154 training points; results for both datasets and for all training sizes are given at the end of the Section.

Trace plot of 514 time-series data points counting flu cases in Norway, Aargau as well as Bern in Switzerland and five regions in eastern Spain including Andalusia, Castilla-La Mancha, Illes Balears, Region de Murcia and Valencian Community counted by each week from 09-Oct-2005 to 09-Aug-2015
The pre-training results are illustrated in Fig. 2. There are barely significant differences among 6 of the 10 clusters in the left panel so we fix the number of clusters to be 5, see Fig. 2. Figure 3 shows some MCMC results for the rest of our Bayesian tensor factorisation model. With 411 training data points, Panels (a),(b) and (c) provide strong evidence that there are two important predictors, 6 possible combinations of \((h_1,...,h_q)\) and 6 unique \(\lambda _{h_1, \dots , h_q}\). Similarly, when the length of the training dataset is 462 panels (d),(e) and (f) indicate that there is evidence for only one important predictor, the total number of possible combinations of \((h_1,...,h_q)\) is either 3 or 4, and that there are 3 unique \(\lambda _{h_1, \dots , h_q}\).

Fitting of a mixture of Poisson distributions. The dataset used is the pre-training data from flu cases in Norway counted by each week from 09-Oct-2005 to 09-Aug-2015. Panels a and b indicate that the outcome for a total number of clusters c are 10 and 5 respectively. The top panels illustrate the Poisson rates of their corresponding label of clusters, whilst the bottom panels show their corresponding log weights

MCMC frequency results. In all panels, the x-axis represents the number and the y-axis does the relative frequency.Top three panels: 411 training data points; bottom three panels: 462 training data points. a, d: The relative frequency distributions for the number of important predictor(s). b, e: The relative frequency distributions of \(\prod _{j=1}^q k_j\), or the total number of possible combinations of \((h_1, \dots , h_q)\). c, f: The relative frequency distributions of the number of unique \(\lambda _{h_1, \dots , h_q}\)
Model selection results for the Poisson autoregression models are illustrated in Fig. 4. MCMC was based on 5,000 burn-in and 10,000 runs by using ’rjags’, see (Plummer et al., 2016). For the resulting parameter estimates see Table 4.

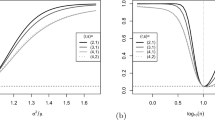
AIC and BIC scores given by PAR(q) models with q labelled in the x-axis for flu cases in Norway counted by each week from 09-Oct-2005 to 09-Aug-2015. a: The AIC scores for the scenario with 411 training data points and 103 testing data points; b: The BIC scores for the scenario with 411 training data points and 103 testing data points; c: The AIC scores for the scenario with 462 training data points and 52 testing data points; d: The BIC scores for the scenario with 462 training data points and 52 testing data points
Table 5 indicates that in all pre-training size scenarios BTF outperform, in terms of predictive ability expressed with log predictive scores, Bayesian Poisson autoregression models. There is clearly a trade-off between good mixture estimation and adequate training size that is expressed in small and large pre-training sizes respectively. In our small empirical study it seems that there is evidence for some robustness in the inference procedure when the pre-training size is small, since 103 points outperform 206 points with the 154 points being the best performing pre-training size. The predictive means and \(95\%\) credible intervals of BTF and of the PAR(5) model that had one of the best predictive performances based on 103 test data are depicted in Fig. 5.
The average run times for the MCMC algorithms for BTF and the Bayesian Poisson autoregression models are comparable. For the former, 1000 iterations take approximately 20 s with our code written in matlab, whereas the latter takes approximately 25 s for 1000 iterations in the R package ‘rjags’.
5.2 Multivariate flu data
We revisit the flu data of the previous subsection by jointly modelling flu cases in (i) the adjacent Swiss cantons of Bern and Aargau and (ii) in five neighbouring regions in south-eastern Spain, namelyAndalusia, Castilla-La Mancha, Illes Balears, Region de Murcia and Valencian Community. The data are depicted in Fig. 1 and consist of 514 weekly counts from 09-Oct-2005 to 09-Aug-2015.

Out of sample predictive means and \(95\%\) highest credible regions (HCRs) of Bayesian tensor factorisations (BTF) and Poisson autoregressive models (PAR) compared against the Castilla-La Mancha data. The sizes of training and testing data are 411 and 103 respectively
We chose the maximum lag q to be ten for all multivariate BTF models we applied to the data. The sizes of training against the testing dataset are 411 : 103 and 462 : 52 respectively. Our BTF considered the first 154 data points as the pre-training dataset.
Figures 6, 7, 8, 9 illustrate how lags were selected in each real data application. Note that a lag is considered to be important, and thus is selected, when its corresponding relative frequency distribution is higher than 0.5.
The predictive ability of the models compared to the Bayesian Poisson autoregression models are given in Tables 6 and 7. In the Swiss cantons it seems that the BTF model underperforms when Aargau flu cases are predicted from past flu cases of Aargu and Bern, whereas it outperforms when we predict Bern cases based on past data from Aargau and Bern. An informal justification of this behaviour is that from the data it seems that the two series have very high positive contempoaneous and lag-one correlations so naturally the model (16) that captures very well these linear dependencies outperforms our model. Such situations are expected when a general non-parametric model is compared to a linear model with the corresponding data generating mechanism to be primarily linear-based.
Table 7 presents the five-dimensional example of Spanish regions in which the counts of each region are predicted from past counts of all five regions. Here, in eight out of ten cases BTF outperforms the Poisson autoregression model and in particular the log-predictive scores are dramatically lower in all cases with smaller training (462) and higher test (103) sizes. This is not surprising since our model is capable of capturing the complicated five-dimensional dependencies created in these Spanish regions.

Lag selection for the Norway (left pair) and the Castilla-La Mancha (right pair) flu datasets. Each pair of figures represents (i) the inclusion proportions (y-axis) of different lags (x-axis) for the scenario with 411 training and 103 testing data points and (ii) the inclusion proportions (y-axis) of different lags (x-axis) for the scenario with 462 training data points and 52 testing data points

Important lag selection for the Swiss flu dataset. Y-axis represents the inclusion proportions of different lags in x-axis

Important lag selection for the south-eastern Spain flu dataset. Y-axis represents the inclusion proportions of different lags in x-axis for the scenario with 411 training data points and 103 testing data points. A: Andalusia; CLM: Castilla-La Mancha; IB: Illes Balears; RM: Region de Murcia; VC: Valencian Community

Important lag selection for the south-eastern Spain flu dataset. Y-axis represents the inclusion proportions of different lags in x-axis for the scenario with 462 training data points and 52 testing data points. A: Andalusia; CLM: Castilla-La Mancha; IB: Illes Balears; RM: Region de Murcia; VC: Valencian Community
6 Discussion
We have introduced a new flexible modelling framework for that extends Bayesian tensor factorisations to multivariate time series of count data. Extensive simulation studies and analysis of real data provide evidence that the flexibility of these models offers an important alternative to other multivariate time series models for counts.
An important aspect of our proposed models is that direct MCMC inference cannot avoid an increased computational complexity as observed counts grow. We have dealt with this issue with a two-stage inferential procedure that successfully deals with large observed counts.
Availability of data and material
The google flu data are publically available.
Code availability
The code will be free and available from Petros Dellaportas’ web site.
References
Al-Osh, M. A., Alzaid, & Aus A. (1987). First-order integer-valued autoregressive (inar (1)) process. Journal of Time Series Analysis, 8(3), 261–275.
Brandt, P. T., & Williams, J. T. (2001). A linear poisson autoregressive model: The poisson ar (p) model. Political Analysis, pp. 164–184.
Cameron, A. C., & Trivedi, P. K. (2001). Essentials of count data regression. A companion to theoretical econometrics, 331.
Czado, C., Gneiting, T., & Held, L. (2009). Predictive model assessment for count data. Biometrics, 65(4), 1254–1261.
De Lathauwer, L., De Moor, B., & Vandewalle, J. (2000). A multilinear singular value decomposition. SIAM Journal on Matrix Analysis and Applications, 21(4), 1253–1278.
Fokianos, K. (2011). Some recent progress in count time series. Statistics, 45(1), 49–58.
George, E. I., & McCulloch, R. E. (1997). Approaches for bayesian variable selection. Statistica sinica, pp. 339–373.
Grunwald, G. K., Hamza, K., & Hyndman, R. J. (1997). Some properties and generalizations of non-negative bayesian time series models. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 59(3), 615–626.
Grunwald, G. K., Hyndman, R. J., Tedesco, L., & Tweedie, R. L. (2000). Theory & Methods: Non-Gaussian Conditional Linear AR (1) Models. Australian & New Zealand Journal of Statistics, 42(4), 479-495.
Harshman, R. (1970). Foundations of the parafac procedure: Model and conditions for an explanatory factor analysis. Technical Report UCLA Working Papers in Phonetics 16, University of California, Los Angeles, Los Angeles, CA.
Harshman, R. A., & Lundy, M. E. (1994). Parafac: Parallel factor analysis. Computational Statistics and Data Analysis, 18(1), 39–72.
Heinen, A. (2003). Modelling time series count data: an autoregressive conditional poisson model. Available at SSRN 1117187.
Kuhn, L., Davidson, L. L., & Durkin, M. S. (1994). Use of poisson regression and time series analysis for detecting changes over time in rates of child injury following a prevention program. American Journal of Epidemiology, 140(10), 943–955.
Liboschik, T., Fokianos, K., & Fried, R. (2015). tscount: An R package for analysis of count time series following generalized linear models. Germany: Universitätsbibliothek Dortmund Dortmund.
Marin, J.-M.., Mengersen, K., & Robert, C. P. (2005). Bayesian modelling and inference on mixtures of distributions. Handbook of statistics, 25, 459–507.
Plummer, M. et al. (2016). rjags: Bayesian graphical models using mcmc. R package version, 4(6)
Sarkar, A., & Dunson, D. B. (2016). Bayesian nonparametric modeling of higher order markov chains. Journal of the American Statistical Association, 111(516), 1791–1803.
Sethuraman, J. (1994). A constructive definition of dirichlet priors. Statistica sinica, pp. 639–650.
Tucker, L. R. (1966). Some mathematical notes on three-mode factor analysis. Psychometrika, 31(3), 279–311.
Viallefont, V., Richardson, S., & Green, P. J. (2002). Bayesian analysis of poisson mixtures. Journal of nonparametric statistics, 14 (1–2), 181–202.
Weiß, C. H. (2014). Ingarch and regression models for count time series. Wiley StatsRef: Statistics Reference Online, pp. 1–6.
Yang, Y., & Dunson, D. B. (2016). Bayesian conditional tensor factorizations for high-dimensional classification. Journal of the American Statistical Association, 111(514), 656–669.
Acknowledgements
We would like to thank Abhar Sarkar for kindly providing us his code for his JASA 2016 paper.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
The code has been written by ZW. ZW, PD and IK had equal contributions at the development of the theory.
Corresponding author
Ethics declarations
Conflict of interest
Not applicable.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Editor: Vu Nguyen, Dani Yogatama.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Z., Dellaportas, P. & Kosmidis, I. Bayesian tensor factorisations for time series of counts. Mach Learn 113, 3731–3750 (2024). https://doi.org/10.1007/s10994-023-06441-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-023-06441-7