
Abstract
The work considers the methods and techniques, allowing the assignment of the kinetic mechanisms to the chemical reactions evaluated from signals of thermoanalytical measurements. It describes which information about the kinetic mechanisms can be found from either model-free or model-based methods. The work considers the applicability of both methods and compares their results. The multiple-step reactions with well-separated peaks can be equally analyzed by both methods, but for overlapping peaks or for simultaneously running parallel reactions the model-free methods provide irrelevant results.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Methods of kinetic analysis for thermoanalytical measurements depend on the application goal. The purpose of a kinetic analysis can have two directions:
-
1.
Find the degree of conversion for given temperature conditions, if the chemical mechanism of reaction is unknown and not really important,
-
2.
Determine and describe the kinetic mechanism if the chemical mechanism of reaction is unknown or partially unknown.
The first task is a more technical task and usually could be solved experimentally if the measurement equipment allows to follow the desired temperature conditions. If the measurements cannot be done exactly according to the temperature conditions, then extrapolation is done by kinetic methods without of the detailed description of the chemical mechanisms of the process. This study deals only with the second task, where the kinetic mechanism must be detected.
The thermoanalytical measurements for kinetic analysis must have the measured signal as the function of the time and temperature and must include signal changes caused by the chemical processes in the sample. The common signals are DSC and TG, but other signal types also could be analyzed by kinetic methods.
There are two approaches to kinetic analysis of thermoanalytical data: model-free analysis and model-based analysis. Both approaches need several thermoanalytical measurements with different temperature conditions. Usually this is a set of measurements with different heating rates or a set of isothermal measurements with different temperatures. We will consider here the set of different heating rates, because it can be analyzed by all model-free methods.
Model-free analysis allows to find activation energy of the reaction process without the assumption of a kinetic model for the process. Usually the knowledge of the reaction type is also not necessary to find the activation energy by model-free methods.
The first assumption for model-free analysis: the reaction can be always described by only one kinetic equation for the degree of reaction α:
where α is the degree of reaction, E(α) is the activation energy depending on the conversion α, and A(α) is the pre-exponential factor.
The second assumption for model-free analysis: the reaction rate at a constant value of conversion is only a function of temperature [1, 2].
It should be noted that pre-exponential factor A can be found by model-free analysis only with assumption of known function f(α), which very often is used in the view of reactions of n th order:
In model-free analysis the thermoanalytical signal is equal to the reaction rate (1), multiplied by the total effect of reaction: total enthalpy for DSC or total mass loss for TG.
There are several different model-free methods including Friedman analysis [2], Ozawa–Flynn–Wall analysis. They are wide-used for various applications [3–8], but all of them are based on the above described assumptions.
The approach of the model-based kinetic analysis is based on other assumptions.
The first assumption for the model-based method: the reaction consists of several elementary reaction steps, and the reaction rate of each step can be described by an own kinetic equation for this step, depending on the concentration of the initial reactant e j , the concentration of product p j , the pre-exponential factor A j and the activation energy E j , specific only for this step with number j [9]
Each step has an own reaction type described by the function \( f_{j} \left( {e_{j} ,p_{j} } \right) \). Some examples of such functions are: second-order reaction f = e 2, Prout–Thompkins reaction with acceleration f = e m p n, reaction with one-dimensional diffusion 0.5/p.
The number of kinetic equations is equal to the number of the reaction steps, the concentration for each reactant increases by the reaction steps where this reactant is a product, and decreases by reaction steps, where this reactant is a starting substance. For example, in the model of two consecutive steps the rate of the concentration for the intermediate product c int is calculated as the difference between the reaction rate of the first step and reaction rate of the second step:
The second assumption for model-based analysis: all kinetic parameters like activation energy, pre-exponential factor, order of reaction, and reaction type are assumed constant during the reaction progress for every individual reaction step.
The third assumption for model-based analysis: the thermoanalytical signal is the sum of the signals of the single reaction steps. The effect of each step is calculated as the reaction rate, multiplied by the effect of this step like enthalpy change or mass loss.
For single-step reactions, where the reaction mechanism does not change during the reaction [10], both, model-free and model-based approaches result in the same kinetic equation with the same kinetic parameters, which are constant or nearly constant during the reaction progress. Single-step reactions are well studied in the literature, and therefore are omitted here.
For complex reactions, where the kinetic mechanism changes during the reaction, there is big difference in interpretation of kinetic results, obtained by different approaches. For model-free approaches, the change of the kinetic mechanism is described by the continuous changing of the activation energy and the pre-exponential factor with the progress of the reaction. For model-based approaches, the change of the kinetic mechanism is described by appearing of several reaction steps with own activation energy and with own reaction type.
The highest interest and complexity lies in the analysis of multi-step processes, because of the ambiguity of applying different approaches and interpretation of results.
Multiple-step reactions
Usually for reactions with unknown reaction mechanism the number of reaction steps is also unknown. Sometimes several chemical reactions could be proposed from the chemical point of view, but the kinetic parameters of the reaction steps are unknown.
There are first questions which must be answered before a kinetic analysis: how many reaction steps are present in the measured process? How many steps can be analyzed? The answers to the first and second question can be quite different. Processes can chemically have several reaction steps, but corresponding to the thermoanalytical curve, can show only a single peak. In this case only one step, responsible for this peak, can be analyzed, and only for this peak kinetic parameters can be found correctly.
Example: in the chemical process with two consecutive steps (A → B → C) the first reaction step is slow enough to produce the peak on the thermoanalytical curve. If the second process is fast and the intermediate product B reacts immediately to form product C, then the concentration of B is always near to zero, and from a thermoanalytical point of view, the process looks like a single-step process A → C. The analysis of these data provides the kinetic parameters like activation energy, pre-exponential factor and reaction order only for the first step, but the area of the DSC peak will have the meaning of the sum of enthalpies of both steps. The kinetic parameters for the first step can be found by both model-free and model-based methods. But it is impossible to find parameters for the second step from such measured data by any method, because the experimental data do not contain any kinetic information about the second step.
The kinetic parameters can be found only for those reaction steps, which are visible on the thermoanalytical curve as peaks or shoulders in DSC curves, or as steps in TG curves. Kinetic parameters cannot be found from thermoanalytical data for individual steps taking place during a reaction, without showing the corresponding peaks or part of peaks on the thermoanalytical curve.
Independent reactions
The kinetic model for this process includes several-independent reaction parameters. The most common example is the process in the mixture of several materials, which react independently of each other. Let us consider the simplest situation, the mixture of two materials, where Peak1 (on DSC or DTG curve) means the reaction in material1, and Peak2—reaction in material2.
There could be found three possible situations for a given heating rate:
-
(a)
The temperature of the Peak1 is lower than the temperature of the Peak2;
-
(b)
Peak1 and Peak2 overlap at the same temperature range;
-
(c)
the temperature of the Peak1 is higher than the temperature of the Peak2.
By the increasing of the heating rate the peaks are shifted to the higher temperatures, and the shift value is higher for lower activation energy. If the activation energies of two processes are not exactly the same, then by changing of heating rate, the distance between peaks is also changed. Therefore in one set of measurements with different heating rates one (a, b, or c), two (a + b or b + c) or all three possible situations could be present. We apply here the model-free and model-based analyses to the different data sets for the same process of two independent reactions and compare the results.
Two independent single-step decompositions for the first and second substances for the set of the same heating rates are represented in Fig. 1a, b, let us give them names “Step1” and “Step2”. It is seen that for lower heating rates the decomposition of the first substance takes place at much lower temperatures than the decomposition of the second substance. But for high heating rates there is another order: decomposition of the second substance happens earlier than that of the first one. Figure 2a shows the sum of these two TG signals, where the total effect of reaction is independent of heating rate. Again, for lower heating rates we have first step before the second step, and for high heating rates the second step is before the first step. For the middle heating rates the steps overlap and the overall curve looks like a one-step decomposition (curves 1 and 2 K/min). In Fig. 2b the Friedman energy plot is represented. The values of activation energy for the first part of reaction (α = 0.2) and its last part (α = 0.8) have no big difference.

TGA data set for the mixture of two substances decomposing independently. TGA set for substance1 (a) and substance2 (b)

TGA set for a mixture, calculated as the sum of two independent sets (a), model-free analysis for this set of data (b). Activation energies for α = 0.2 and for α = 0.8 are the same
The steps are well-separated for the low and for the high heating rates. Let us analyze separately the set of three curves at low heating rates, the set of three curves at high heating rates, and the total set of curves by the both model-free and model-based methods and then compare the results.
In Fig. 3 the data set and the results for the low heating rates are represented. Here the steps are well separated. Figure 3a shows the formal concentrations of each substance for the lowest heating rate, where the Step1 is earlier than the Step2. From model-free analysis, the activation energy for first part of reaction (e.g., α = 0.2) is lower than the second part of reaction (e.g., α = 0.8).

Formal concentration of reactants for decomposition of independent substances at the lowest heating rate (a); TGA signal (b), and activation energy as the function of conversion from Friedman analysis (c) for the set of three low heating rates
The predictions based on model-free results can be done only for much lower heating rates, where the steps remain well separated. For heating rates higher than the ones presented in this figure, the steps are overlapped and model-free prediction cannot be used because it cannot show the independent character of the steps. It is impossible to get the curves shown in Fig. 4b by the predictions based on activation energies from Fig. 3c.

Formal concentration of reactants for decomposition of independent substances at the highest heating rate (a); TGA signal (b), and activation energy as the function of conversion from Friedman analysis (c) for the set of three high heating rates
In Fig. 4 the data set and results for high heating rates are represented. Figure 4a with the formal concentrations of substances shows that now the Step2 is earlier than the Step1. The steps are still slightly overlapping, but for very high heating rates the overlapping disappears and peaks will be well separated. The model-based analysis of the two independent steps provides the same results as for the set of low heating rates. The results of model-free analysis are now not the same as the results for the set of low heating rates. The first part of reaction with α = 0.2 has the higher activation energy than the second part of reaction with α = 0.8. Now the predictions based on model-free results can be done only for very high heating rates, where the steps are well separated. But for lower heating rates there is the overlapping of steps and model-free predictions cannot get a result showing the independent character of steps. It is impossible to get the curves shown in Fig. 3b by the predictions based on activation energies from Fig. 4c.
Figure 2b shows the model-free analysis for complete set of data for independent steps. The steps are separated only for low and high heating rates, but overlapped for the middle heating rates. Model-free analysis produces very high error bars, now the activation energies for α = 0.2 and for α = 0.8 are the same. But the model-based analysis based on two independent steps provides here the same results as for the two previous sets of data.
The comparison of the model-free results for the process with independent steps indicates different dependencies of the activation energy on the degree of conversion for the set of high heating rates, for the set of low heating rates and for the complete set of data. It means that the model-free result for overlapping independent steps depends on the heating rate and on the number of measured curves. But this fact is in conflict with the above mentioned second assumption of the model-free analysis, where the reaction rate at a constant conversion must be only a function of temperature. If this assumption of the model-free analysis cannot be fulfilled, then the model-free analysis may not be used for the situation with overlapping independent steps.
The reason for the different model-free results for the range of overlapping peaks can be found by the detailed consideration of applying this analysis to the total data set.
Three sets of data, a set with low heating rates, a set with high heating rates and a complete set of data were analyzed by model-free and by model-based analysis. The model-based results are the same for all three sets. The model-free results are different for all three sets.
Model-free analysis (Friedman analysis) for the process of two independent steps is represented in Fig. 5, where the logarithm of the reaction rate is plotted as a function of the reciprocal absolute temperature. The method calculates the activation energy as the slope of the straight line drawn through the points with the same conversion value. In the plot, the curves with high heating rates are higher than the curves with the low heating rates. Each of two peaks on each curve corresponds to a reaction step.

Friedman graphic for the reaction with independent steps with marked points of conversion = 0.95 and dashed line through them. Iso-conversional lines are drawn separately for each step
In Fig. 5 the iso-conversional lines are drawn separately for each independent step. It is seen that the independent steps go through each other. For low heating rates Step1 appears before Step2 (graphic must be read from right to left because of the reciprocal temperature), and for high heating rate Step1 appears after Step2. Stars mark the points with the same conversion value of 0.95, dashed line is drawn through them. It is clearly seen that the stars with low heating rates belong to the Step2, and are placed on the straight line with slope, corresponding to Step2. The stars with high heating rates belong to Step1 and are placed on the straight line with slope corresponding to Step1. Here the peaks go independently through each other. This fact could be used as the indicator of independent reaction steps.
The dashed line represents the attempt to use the standard model-free analysis for the complete data set, where iso-conversion line must be drawn through all points with the same conversion value (marked with stars). But the points belong to different reactions and therefore are not placed on one line. By using linear regression, a straight dashed line results, which is far from the marked points (stars), especially for the highest and for the lowest heating rates. This fact produces very high error bars in the energy plot. The found activation energy is not the activation energy of the first step, and not the activation energy of the second step, but some value between them. The extrapolation of this data set to the much higher or to the much lower additional heating rates will give more deviation from the drawn straight line and real iso-conversional points. In other words, the model-free predictions for such a situation of independent steps for both very low and very high heating rates will be even more far from the real process.
The order of peaks depends on the heating conditions. The sequential order of peak for dynamic measurements cannot be the same as the order of peaks for isothermal conditions. Therefore an erroneous simulation could happen if the model-free analysis is done for the set of dynamic data with different heating rates, and then the prediction is done for isothermal conditions. Data for analysis must contain wide range of heating rates, even better including also isothermal measurements to have complete information about independent processes.
Model-free methods cannot provide the correct values of activation energy for each of simultaneously running-independent processes. It can be used with reasonable results only for processes, where peaks are well separated, show no overlapping for any heating rate, and where the order of peaks never changes.
Short summary for the processes with independent steps:
-
1.
Model-based kinetic analysis:
(+) can be used for the processes with independent steps. It ensures the stable kinetic results independent on heating rates and overlapping of peaks;
(+) provides correct kinetic results for both well-separated and overlapping peaks;
(+) ensures correct predictions for both well separated and overlapping cases.
-
2.
Model-free kinetic analysis:
(−) provides contradictory kinetic results for the data of the same process with different sets of heating rates;
(+) provides correct kinetic results for separated peaks;
(−) provides incorrect kinetic results for data sets containing overlapping peaks;
(+) provides correct predictions for the temperature conditions, where no overlapping happens;
(−) provides incorrect predictions for the temperature conditions with overlapping;
-
3.
If the steps go through each other by changing of heating rate then the steps are independent.
Here the advantages of methods are marked with (+), and disadvantages—with (−).
Consecutive reactions
Let us consider the consecutive reactions, where each reaction step has the corresponding peak on the thermoanalytical curve.
The general kinetic model has the following view: A → B → C → D → …
Sometimes the steps are separated, and the curve has several separated steps connected with horizontal part of measured curve, like TG curve for two-steps decomposition of Lanthanum hydroxide [11]:
But the steps in consecutive reactions are not always well separates like in this sample. Very often the activation energy of the second step is higher than the activation energy for the first step. Let us consider the set of data where the decomposition goes according to schema A → B → C. The kinetic parameters for simulation are the same as for the process with independent steps. The simulated data are presented in Fig. 6a. Here the total reaction effect is always the same and independent of the heating rate. For the low heating rates (Fig. 7) the steps are well separates, the Step1 is earlier than the Step2, and TG curves are very similar to the data for the process with independent steps. Model-free analysis for this data set with consecutive steps produces the same results (Fig. 7c) like model-free analysis for the independent steps (Fig. 3c). Predictions based on model-free results for these data can be done only for much lower heating rates, where the steps remain well separated and there is no difference between the situation with independent steps and the situation with consecutive steps.

Simulated data (a) and model-free analysis (b) for two consecutive steps

Formal concentration of reactants for decomposition process with two consecutive steps at low heating rate (a); corresponding TGA signal (b), and activation energy as the function of conversion from Friedman analysis (c)
Increasing the heating rates, the Step1 is shifted to the higher temperatures much more than the Step2, and the overlapping of steps happens. By the further increasing of heating rates, the Step1 is shifted more to the right, but Step2 cannot be shifted less than Step1 (like for independent steps), because in the consecutive process the Step2 must be always after Step1, and the situation similar to Fig. 4b will never happen. In Fig. 8 the data for high heating rates are presented. The steps are extremely overlapped, and they will be always overlapped for any higher heating rate. For the high heating rates the reaction step B → C runs only if the intermediate product B exists. Therefore the reaction rate for the second step cannot exceed the reaction rate of the first step, and the first step is the limiting step for the second step. For very high heating rates the reaction rates of Step1 and Step2 are equal, the concentration of the intermediate product B is always about zero (Fig. 8a), and two-step process looks like single-step process A → C, which produces one-step TG curve and contains no information about the kinetics of the second step. If the consecutive peaks highly overlap, then one of these steps is the limiting step and the same activation energy for this limiting step can be found by both model-free and model-based analysis. But the information about the non-limiting step is missing or very poorly presented, and cannot be found accurately by any method. If the overlapping of steps changes by changing of the heating rate, then the additional measurements with better separation of steps can give additional kinetic information about the non-limiting step.

Formal concentration of reactants for decomposition process with two consecutive steps at high heating rate (a); corresponding TGA signal (b), and activation energy as function of conversion from Friedman analysis (c)
In Fig. 6a the complete data set and analysis results for the process with consecutive steps are represented. The steps are separated only for low heating rates, but overlapping for low and high heating rates. Model-free analysis in Fig. 6b produces very high error bars for activation energy values. But for this set of data the model-based analysis with the kinetic model of two consecutive steps provides again the same results like for the set of data with well-separated peaks for low heating rates.
For the three sets of data of the same process the model-free analysis provides three different dependencies E a(α). Let us find the reason for the different model-free results in the Friedman plot.
If the peaks for consecutive reactions show overlapping, but are still well-visible, then in the overlapping ranges of α two reaction steps take place simultaneously: previous step is still not finished, and the next step is already started. It corresponds to the state, where simultaneously two reactions take place. But by model-free analysis only one value of activation energy can be found. For the state where peaks overlap the model-free analysis provides only one intermediate value, which already does not correspond to the activation energy of the first step, and yet does not correspond to the activation energy of the second step. If really only one reaction runs at any time point in the states where no overlapping occurs, then model-free analysis can provide a correct result (Fig. 7c).
The model-based analysis provides the correct kinetic parameters for each reaction step for the data set containing both well-separated and overlapping steps. If the overlapping is wide, then the parameters of non-limiting step could not be found or could be found with less accuracy. For the consecutive reactions the order of steps is always the same and independent from heating rate.
The model-free plot is represented in Fig. 9. Two groups of iso-conversional lines are shown, each for the own reaction step. Peak for Step1 exists as well for low as for high heating rates. Peak for Step2 exists only for low heating rates and slightly for middle heating rates. It disappears completely for very high heating rates, where Step1 becomes to be a limiting step.

Friedman graphic for the reaction with two consecutive steps with marked points of conversion = 0.95 and dashed line through them. Iso-conversional lines are drawn separately for each step
The dashed line is drawn through the points with α = 0.95, marked with stars. These points belong to the different chemical reactions and to the different sets of iso-conversion lines. And again, like for independent steps, the attempt to draw straight line through stars has no big success. The activation energy, found from the slope of this line, has the meaning of an intermediate value between activation energies of Step1 and Step2, and has very high error bars on the energy plot. The extrapolation of this data set to the higher or to the lower additional heating rates, will give high deviation of real iso-conversional points from the drawn straight line. Therefore, the model-free predictions for such a situation of consecutive steps with overlapping peaks will be very far from the real process.
Short summary for the processes with consecutive steps:
-
1.
Model-based kinetic analysis:
(+) can be used for the processes with consecutive steps. It ensures the stable kinetic results independent on heating rates and overlapping of peaks;
(+) provides correct kinetic results for both well-separated and overlapping peaks;
(+) ensures correct predictions for both well-separated and overlapping cases.
-
2.
Model-free kinetic analysis:
(−) provides contradictory kinetic results for the data of the same process with different sets of heating rates;
(+) provides correct kinetic results for separated peaks;
(−) provides incorrect kinetic results for data sets containing overlapping peaks;
(+) provides correct predictions for the temperature conditions, where no overlapping happens;
-
3.
If one of steps completely disappeared by changing of heating rate then the steps are consecutive.
Competitive reactions
Let us consider the reaction with two steps with the same initial reactant A and different products B and C.
-
A → B step 1
-
A → C step 2
If the activation energies of these steps are not the same then the increasing or decreasing of heating rate changes the ratio of the products B and C in the product mixture. If the activation energy of step1 is lower than the activation energy of step 2, then the decreasing of the heating rate moves the step1 to much lower temperatures and step1 becomes to be dominant in the model. Reaction will go mainly by A → B. If the measurements with only low heating rates are analyzed then only activation energy of the first step will be found by both model-free and model-based methods. Increasing of the heating rate forces to increase the branch A → C and to increase the amount of product C in the mixture. If the measurements with only high heating rates are analyzed, then only the second reaction takes place, and the activation energy only of the second step can be found. If the measurements with low and high heating rates are analyzed together then the model-free analysis provides the intermediate value between activation energies of steps with low accuracy. Model-based analysis provides both values correctly only if the contribution of the each competitive step is known.
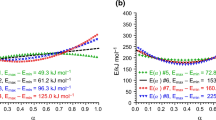
In Fig. 10b the total simulated data set is presented. For the low heating rates only Step1 with reaction A → B happens (Fig. 11). For the high heating rates mostly reaction A → C exists (Fig. 12). For intermediate heating rates we have both reactions simultaneously, and the product is the mixture of B and C (Fig 10a).

Formal concentration of reactants for a decomposition process with two competitive steps at the middle heating rate (a), simulated data (b), and model-free analysis (c) for two competitive steps

Formal concentration of reactants for a decomposition process with two competitive steps at the low heating rate

Formal concentration of reactants for a decomposition process with two competitive steps at the high heating rate
The model-free analysis for all three situations (Fig. 10c) provides non-constant dependence of activation energy from conversion with high error bars. This is the indicator of multi-step process. Moreover, the dependences E a(α) are different for all three data sets. It means that the activation energy for the given conversion value depends not only on temperature, but on the heating rate. This fact is in the contradiction with the second assumption of the model-free analysis. It means that the model-free analysis cannot be used for the competitive steps.
The Friedman graphic (Fig. 13) shows again the same problem like for independent and competitive steps: the points with the same value of conversion, marked here with stars, are not placed directly on the same line. If the straight dashed line is placed through these points by using of linear regression, then the activation energy found from its slope is the intermediate value between activation energies of Step1 and Step2.

Friedman graphic for the reaction with two competitive steps with marked points of conversion = 0.5 and dashed line through them
The indicator of the presence of the competitive steps is the dependence of the total effect on the heating rate like in Fig. 10b. This dependence cannot be explained by the independent steps like in Fig. 1, because for independent steps the total effect of reaction is independent of heating rates and always the same. The dependence of the total effect on the heating rate also cannot be explained by the consecutive steps like in Fig. 6a, because for consecutive steps the total effect of reaction is always the same for any heating rate. The only explanation for such dependence is the presence of competitive steps with a mixture of final products where the contribution of each component depends on the heating rate. It could be formulated with other words: The dependence of the total effect of reaction on heating rates is the indicator of competitive steps.
Short summary for the processes with competitive steps:
-
1.
Model-based kinetic analysis:
(+) can be used for the processes with competitive steps. It can explain, describe and predict the dependence of total reaction effect on the heating rate;
(+) provides correct kinetic results for both well-separated and overlapping peaks;
(+) ensures correct predictions for both well-separated and overlapping cases.
-
2.
Model-free kinetic analysis:
(−) provides contradictory kinetic results for the data sets of the same process with different heating rates;
(−) provides incorrect kinetic results for overlapped peaks;
(−) does not take into account the dependence of total reaction effect on the heating rate and therefore cannot provide correct predictions
Selection of the best model
Very often the several different solutions can be found for the same data set. And then the following questions come: What solution is correct? What solution could be used for the predictions?
Typical example: the data for parallel and consecutive steps looks similar in the range of heating rate, where the steps are well-separated or show very slight overlapping. If the data look like in Fig. 14 (similar to Figs. 3b, 7b), then three results could be possible:

Example of data for kinetic analysis
-
1.
Model-free analysis provides the two plateaus in the plot of activation energy: E = 110 for α < 0.6 and E = 500 for α > 0.6.
-
2.
Model-based analysis provides model of two independent steps with E = 110 and E = 500 kJ/mol.
-
3.
Model-based analysis provides model of two consecutive steps with E = 110 and E = 500 kJ/mol.
Question: What solution could be used for the predictions?
If the predictions must be done from here for the much lower heating rates, then the reaction steps will remain well-separated and Step1 will be always earlier than the Step2. All three solutions give the same predicted signal for well-separated peaks, and each of them can be used.
Let us see, what happens if the predictions must be done to the much higher heating rates, where the big overlapping of steps happens. The dependence E a. vs. α for three low heating rates is the same for both set with two independent steps and set with two consecutive steps. Predictions by model-free analysis do not take into account the interaction of the steps, and produce the same predictions for both cases. This fact must be considered as the disadvantage of the model-free method. The prediction according to model-free analysis is very far from the predictions for the model with independent steps. It is clear that model-free analysis may not be used for the predictions of process with even only two independent processes. It may also not be used for reactions with three or more parallel steps. But some authors [1] still believe that “obtaining E vs. alpha dependence is enough for kinetic predictions … further computations may not be necessary”.
Additionally they say, that “if there is no significant difference between two different mechanisms, then it means that both mechanisms provide the same goodness of fit”. Does it mean that any of suggested models can be taken for predictions? But the predictions for these models are not the same. The model-based predictions for model with independent steps (Fig. 3b) differ dramatically from the predictions according to model with consecutive steps (Fig. 8b).
If the real mechanism consists of independent reactions, then the model with independent steps can describe the correct behavior of system for high heating rates. And only this model must be used for predictions. If the real mechanism has two consecutive steps, then the model with consecutive steps must be used. But how to recognize which of these two models is correct? If the steps are well-separated then the data are the same (Figs 3b, 7b). If the data are the same then these data contain no information about the interaction of steps. The difference between data from these two models can be seen in the range of the overlapping of peaks and in the range of high heating rates. Therefore, we can say that these data contain no information about the mechanism of the process. The set of three low heating rates contains only information of the presence of two steps, but not any information about the interaction between them. It has no sense to select the most appropriate model here according to any mathematical criteria like F test or correlation coefficient, because the information about the interaction of steps is not present in the experimental data.
There are several ways to solve this problem:
-
Get the information about mechanism from the chemical knowledge about the system. For example, if decomposition of one substance happens (like Calcium oxalate monohydrate), then it is most probably a reaction with consecutive steps. If originally it was the mixture of non-interacting materials, then probably it is the model with independent steps.
-
Add the set of experimental data with additional measurements containing information about the interaction of the steps. The good set of data must contain the measurements with well-separated steps as well as the measurements with the big overlapping of steps. The measurements with well-separated steps allow estimating accurately the kinetic parameter for each step, but have no information about the step interaction. The measurements with big overlapping of steps contain information about activation energy of each step with very low accuracy, but they allow to find the type of interaction between steps.
The present example of three curves shows not any problem for low heating rate predictions, but has not enough information for predictions for high heating rates. The inverse situation is mostly dangerous, where there is not enough data available for predictions at the low heating rates. Practically, it comes to such situations when only dynamic measurements are done, and not correct isothermal predictions are performed based on them.
Conclusions
-
If the steps go through each other independently by changing of heating rate then the steps are independent.
-
If one step completely disappears by changing of heating rates and not coming again by further changing heating rates then this step connected consequently to other steps.
-
If the value of total effect (mass loss or area) changes by changing of heating rates then the steps are competitive.
-
For all three situations the model-based analysis can be used for both searching of kinetic parameters and predictions.
-
The model-free analysis can be used for estimation E a(α) only for the data sets with well-separated steps.
-
Model-free results of the previous item can be used only for the conditions where no overlapping happens.
-
All simulations and both modelfree and model based analysis in this work are performed by the software NETZSCH Thermokinetics 3.1.
References
Vyazovkin S, et al. ICTAC kinetics committee recommendations for performing kinetic computations on thermal analysis data. Thermochim Acta. 2011;520:1–19.
Friedman HL. Kinetics of thermal degradation of char-forming plastics from thermogravimetry. Application to a phenolic plastic. J Polym Sci Part C. 1964;6:183–95.
Albu P, Bolcu C, Vlase G, Doca N, Vlase T. Kinetics of degradation under non-isothermal conditions of a thermooxidative stabilized polyurethane. J Therm Anal Calorim. 2011;105(2):685–9.
Tiţa D, Fuliaş A, Tiţa B. Thermal stability of ketoprofen Part 2. Kinetic study of the active substance under isothermal conditions. J Therm Anal Calorim. 2012. doi:10.1007/s10973-011-2147-8.
Bhattacharjya D, Selvamani T, Mukhopadhyay I. Thermal decomposition of hydromagnesite. Effect of morphology on the kinetic parameters. J Therm Anal Calorim. 2012;107(2):439–45.
Bodescu A-M, Sîrghie C, Vlase T, Doca N. Kinetics of thermal decomposition of natrium oxalato-oxo-diperoxo molibdate. J Therm Anal Calorim. 2011. doi:10.1007/s10973-011-1993-8.
Mothé MG, Leite LFM, Mothé CG. Kinetic parameters of different asphalt binders by thermal analysis. J Therm Anal Calorim. 2011;106(3):679–84.
Klimova I, Kaljuvee T, Mikli V, Trikkel A. Influence of some lime-containing additives on the thermal behavior of urea. J Therm Anal Calorim. 2012. doi:10.1007/s10973-012-2244-3.
Opfermann J. Kinetic analysis using multivariate non-linear regression. Therm Anal Calorim. 2000;60:641–58.
Opfermann JR, Flammersheim H-J. Some comments to the paper of J.D. Sewry and M.E. Brown: “Model-free” kinetic analysis? Thermochim Acta. 2003;397:1–3.
Neumann A, Walter D. The thermal transformation from lanthanum hydroxide to lanthanum hydroxide oxide. Thermochim Acta. 2006;445(2):200.
Open Access
This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Moukhina, E. Determination of kinetic mechanisms for reactions measured with thermoanalytical instruments. J Therm Anal Calorim 109, 1203–1214 (2012). https://doi.org/10.1007/s10973-012-2406-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10973-012-2406-3