
Abstract
The main advantages of magnesium alloys are that they are lightweight, easy to recycle, and have high vibration absorption. These unique characteristics make magnesium alloys important green metal materials for manufacturing, especially for the automotive and 3C products industries. The developing trends of these related industries can be recognized by forecasting the demand for magnesium alloys. This study develops grey prediction power models to forecast the demand for such a promising green metal material. Grey prediction is an appropriate technique because available data regarding the demand for magnesium alloys are not in line with any statistical assumptions. In particular, because outliers might cause a deterioration of forecasting performance, a robust nonlinear interval regression analysis with neural networks is applied to detect outliers by estimating data intervals. Then, a power model is applied to the newly generated non-equidistant data sequence without outliers. Residual modification is further considered here to improve the forecasting performance of the power model. The forecasting abilities of the proposed grey residual modification models are verified using actual magnesium alloy demand data. The experimental results for ex-post testing show that the mean absolute percentage errors of the proposed models that can work on non-equidistant data were minimal among all considered models.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Magnesium is a lightweight engineering material, and magnesium alloys are regarded as a twenty-first century green metal material. Compared with other metal materials, magnesium alloys have a few advantages: they are lightweight, have high impact resistance, high corrosion resistance, and are easy to recycle. These advantages are the reason why magnesium alloys have been widely used for the development and manufacture of various products, including the components of automobiles, aircraft, bicycles, sports equipment, and the metal cases of computer, consumer electronic, and computer (3C) products (Hong, 2016; Lu, 2014). In 2016, as a result of major demand from the automotive industry, 32% of the worldwide magnesium was consumed in the die casting of magnesium alloys (Lee et al., 2017). Next, as the main determinant of fuel consumption is vehicle weight, lightweight components are essential for the automotive and aerospace industries. As national authorities make efforts to significantly mitigate the effects of CO2 emissions and promote waste recycling, using magnesium materials in the manufacture of products, such as vehicles and 3C products, can have a very positive influence on environmental protection and energy conservation. Therefore, magnesium alloy demand forecasting can help these industries understand developing trends to quickly recognize market configurations and set up investment strategies.
In contrast to artificial intelligence techniques and time series models, grey system theory has been applied to many real-world problems (Gao et al., 2021; Rajesh, 2020). Grey prediction has drawn attention because of the need to use limited samples to characterize an unknown system without complying to any statistical assumptions (Liu & Lin, 2010). This characteristic motivated us to apply a power model of a first-order grey model with one variable (GM(1,1)), abbreviated to GM(1,1)-P, to predict the demand trends for magnesium alloys. Indeed, the GM(1,1)-P model has been widely applied to real-world problems. The literature on the applications of GM(1,1)-P is briefly described in Table 1.
In light of the applicability of the GM(1,1)-P model to real-world problems, it is interesting to apply the GM(1,1)-P and its variants to forecast the magnesium alloy demand. Two issues are particularly addressed in this paper. First, GM(1,1)-P often works well on annual or equidistant data; however, there is always the possibility that outliers might worsen the performance of the prediction model (Huang et al., 1998). To avoid outliers adversely affecting forecasting performance, robust interval regression analysis can be used to detect outliers by gauging the intervals consisting of upper and lower bounds (Hladík & Černý, 2014; Wang et al., 2015). Thus, it is interesting to develop the GM(1,1)-P that can work on a newly generated non-equidistant data sequence after removing those outliers to better forecast magnesium alloy demand.
Next, it has been demonstrated that residual modification is available to promote forecasting accuracy of an original prediction model (Liu et al., 2017). Therefore, it is reasonable to incorporate the mechanism of residual modification into GM(1,1)-P. Based on these features, this study aims to develop GM(1,1)-P and its residual version that works on non-equidistant data sequences, generated using robust nonlinear interval models to remove outliers.
To deal with the first aforementioned issue, we use two neural networks (NNs) to build a nonlinear interval model that is robust against outliers. This approach is adopted here because several studies have demonstrated the effectiveness of using two NNs on the construction of nonlinear interval models. The related literature is summarized in Table 2. As for the second issue with respect to residual modification, the functional-link net (FLN) is considered because Hu (2017) and Hu et al. (2019) indicate the effectiveness of the FLN on the combination of a grey prediction model with its residual version. The main advantage of FLNs is relieving the restrictions arising from commonly used sign estimation methods, such as Markov-chain estimation (Hsu, 2003) and genetic programming (Lee & Tong, 2011).
The remainder of this paper is organized as follows. The robust nonlinear interval regression analysis using NNs and grey prediction are introduced in Sects. 2 and 3, respectively. The proposed GM(1,1)-P along with its residual model that work on non-equidistant sequences are presented in Sect. 3. For forecasting magnesium alloy demand, we investigate the forecasting accuracy of the different grey prediction models in Sect. 4. Finally, the conclusions are presented in Sect. 5.
2 Robust nonlinear interval regression analysis using NNs
Imprecise observations can be represented by estimated data intervals (Xie et al., 2014; Zeng et al., 2014). Nonetheless, an unsatisfactory interval can be obtained when a data sequence contain outliers. In Sect. 2.1, Eqs. (1), (2), (3), (4), (5), and (6) describe nonlinear interval regression analysis using NNs, and Eqs. (7), (8), (9), (10), and (11) in Sect. 2.2 describe the development of the robust nonlinear interval models against outliers.
2.1 Nonlinear interval regression analysis
In practice, a nonlinear interval model can be determined using two NNs, denoted by NNu and NNl, from a given original data sequence x = (x1, x2,…, xm). As a result, (t1, x1), (t2, x2),…, and (tm, xm) comprise a data set for the two NNs (NNu and NNl) where (tp, xp) denotes the p-th input–output pattern at time tp. Also, let \(g_{u} (t_{p} )\) and \(g_{l} (t_{p} )\) be the upper and lower limits obtained from NNu and NNl, respectively, such that the difference between \(g_{u} (t_{p}^{{}} )\) and \(g_{l} (t_{p}^{{}} )\) denotes the width of the gauged interval. A nonlinear optimization problem is formulated as.
subject to
To approximately satisfy the constraint condition, Ishibuchi and Tanaka (1992) proposed an NN-based approach in which two MLPs are used to set up the nonlinear interval model, and each MLP has a single output, a single input, and one hidden layer with five hidden units. Note that what the NN this study addresses is MLP. With a weighting parameter \(\omega_{p}\), a cost function Eu is formulated to discover the upper limit:
in which
where ω ∈ (0, 1). To determine the lower limit, cost function El is formulated as
in which
2.2 Robust nonlinear interval models
A robust nonlinear interval model can be built on the basis of the aforementioned NN-based approach, where the quality index, \(\psi_{p}\), with respect to (tp, \(x_{p}^{(0)}\)) at time tp beyond the estimated interval should be considered to help the MLP training resist outliers. The quality index is given as follows:
where c is a cutoff point, and \(\psi\) is a very small positive real value. During the model construction, rp > c means that (tp, xp) falls in the rejection region. To determine the upper limit against outliers, the absolute residual, rp, with respect to (tp, xp) is defined as follows (Chen & Jain, 1994; Huang et al., 1998):
In this approach, data in the rejection region impose little effect on the construction of NNu.
To determine c, we renumber the data by sorting rp in descending order, such that (tp, \(x_{p}^{(0)}\)) is renumbered as one as it has min{r1, r2,…, rm}. \(r_{{(1 - q_{u} )m}}\) is assigned to c, where qu (0 ≤ qu ≤ 1) indicates the tolerable limit on the rate of outliers beyond the true interval. With \(\psi_{p}\), cost function Eu is defined as (Hu, 2009, 2014)
To determine the lower limit, rp is defined as
In a similar manner, with ql being the tolerable limit on the rate of outliers beneath the true interval, c is given by \(r_{{(1 - q_{l} )m}}\) as well. With \(\psi_{p}\), cost function El is defined as
The data in the rejection region also impose little effect on the construction of NNl.
By defining the fitness function as Eu (El), the connection weights of NNu (NNl) can be determined using the toolbox in MATLAB to implement a real-valued genetic algorithm (GA). The estimated data intervals can be obtained from the best chromosome whose fitness value is a minimum among the straight generations. As a result, any data outside the data intervals can be treated as outliers. The details of applying MLPs to robust nonlinear interval regression analysis using GAs are omitted here for simplicity, but the reader is referred to Hu (2014) for further information.
3 Grey prediction
3.1 Equidistant grey prediction
GM(1,1)-P and its residual model, both of which use equidistant data sequences are described here prior to the introduction of the grey prediction models that use non-equidistant data sequences. Section 3.1 including Eqs. (12)-(20) introduces the traditional GM(1,1)-P first. Then, the residual modification model, NGM(1,1)-P, consisting of GM(1,1)-P and its residual version, is described in Sect. 3.2 including Eqs. (21)-(25).
3.1.1 GM(1,1)-P model
Given an equidistant data sequence \({\mathbf{x}}_{{}}^{(0)}\) = (\(x_{1}^{(0)}\),\(x_{2}^{(0)}\),…,\(x_{n}^{(0)}\)) composed of n data samples, a new sequence \({\mathbf{x}}_{{}}^{(1)}\) = (\(x_{1}^{(1)}\),\(x_{2}^{(1)}\),…,\(x_{n}^{(1)}\)) is generated from \({\mathbf{x}}_{{}}^{(0)}\) by a one-order accumulated generating operation (1-AGO) as (Liu & Lin, 2010)
Since \({\mathbf{x}}_{{}}^{(1)}\) monotonically increases, the following first-order Bernoulli equation can be used as the mathematical form of the GM(1,1)-P as
where a denotes the developing coefficient, b represents the control variable, and r represents the power exponent.
The time response function with respect to Eq. (13) is (Chen, 2008; Chen et al., 2008)
where r ≠ 1. Then, a and b can be estimated by a linear regression model consisting of n–1 grey difference equations with the following form:
where the background value \(z_{k}^{(1)}\) is given by
in which 0 ≤ \(\alpha\) ≤ 1. The interpolation coefficient \(\alpha\) is usually set to 0.5 for convenience, although such a setting may not be optimal.
In turn, with the ordinary least squares (OLS) method, a and b can be derived as
in which
Finally, the predicted value of \(x_{k}^{(0)}\) can be obtained by the inverse 1-AGO (1-IAGO):
To optimally construct GM(1,1)-P, we apply the well-known optimization modeling software, Linear Interactive and General Optimizer (LINGO), to solve the optimization problem by minimizing the mean absolute percentage error (MAPE) as
subject to r ≠ 1, \(\hat{x}_{1}^{(1)}\) = \(x_{1}^{(1)}\), Eq. (3), and Eqs. (5), (6), (7) and (8).
That is, MAPE is the sum of the APE of xk (k = 1, 2,…, n) divided by the sample size. The computational steps of setting up the optimized GM(1,1)-P model are as follows.
Step 1 Generate accumulated generating sequence from the equidistant data sequence.
Step 2 Construct GM(1,1)-P with LINGO to obtain the optimal parameters, including the developing coefficient (a), control variable (b), interpolation coefficient (\(\alpha\)), and power exponent (r).
Step 3 Obtain the predicted sequence with 1-IAGO.
It should be noted that GM(1,1)-P, also called the nonlinear grey Bernoulli model, is identical to GM(1,1) when r = 0. In particular, the power exponent makes GM(1,1)-P much more useful than GM(1,1) (Dang et al., 2016; Lu et al., 2016).
3.1.2 Residual modification of GM(1,1)-P model
After constructing the GM(1,1)-P model, a sequence of absolute residual values, \({{\varvec{\upvarepsilon}}}_{{}}^{(0)}\) = (\(\varepsilon_{2}^{(0)}\), \(\varepsilon_{3}^{(0)}\),…, \(\varepsilon_{n}^{(0)}\)), is generated where
A residual model is established with respect to \({{\varvec{\upvarepsilon}}}_{{}}^{(0)}\) as GM(1,1)-P using \({\mathbf{x}}_{{}}^{(0)}\) such that the corresponding time response function is
In common with GM(1,1)-P, aε and bε can be derived by the OLS method. A new predicted value can be obtained by modifying the predicted value produced by GM(1,1)-P as
The resultant prediction model consisting of GM(1,1)-P and its residual version is called RGM(1,1)-P.
Traditionally, sk is 1 or − 1 (Liu & Lin, 2010). Even so, to optimally determine sk, since it has been indicated that an FLN without hidden layers is effective for building a residual modification model (Hu et al., 2019), we set up an FLN to better integrate GM(1,1)-P and its residual version. Let tk denote the time k with respect to \(\hat{x}_{k}^{(0)}\). The input pattern for the FLN is an enhanced pattern, vk = (tk, sin(πtk), cos(πtk), sin(2πtk), cos(2πtk)). Let w = (w1, w2, w3, w4, w5) be a vector of connection weights. Then, the actual output of vk can be obtained as:
where θ is the bias and ˗1 ≤ yk ≤ 1. As a result, a new predicted value generated from the proposed model can be computed as follows:
in which \(\eta\) > 0 and sk = \(\eta\) yk. Thus, the new value of \(\hat{x}_{k}^{(0)}\) ranges from \(\hat{x}_{k}^{(0)} - \eta y_{k} \hat{\varepsilon }_{k}^{(0)}\) to \(\hat{x}_{k}^{(0)} + \eta \hat{\varepsilon }_{k}^{(0)}\).
To set up the RGM(1,1)-P, we use the toolbox in MATLAB to develop a real-valued GA, using MAPE as the fitness function, by which the connection weights of the FLN can be optimally determined. The relevant parameters can be obtained from the best chromosome whose fitness value is a minimum among all the straight generations. As a result, the computational steps to construct the RGM(1,1)-P are briefly summarized as follows.
Step 1 Build the optimized GM(1,1)-P using the equidistant data sequence with LINGO.
Step 2 In common with the construction of the optimized GM(1,1)-P model, use the equidistant residual sequence to establish the optimized residual GM(1,1)-P model with LINGO.
Step 3 Obtain the predicted sequence using an FLN to optimally combine the predicted values obtained from the optimized GM(1,1)-P and its optimized residual model. The optimized FLN is derived with the GA toolbox in MATLAB.
3.2 Non-equidistant grey prediction
After removing outliers with the robust nonlinear interval model, the original equidistant data sequence becomes non-equidistant (Li et al., 2012). We use NGM(1,1)-P to denote a GM(1,1)-P model that can work on non-equidistant data. In our design, we first construct NGM(1,1)-P and then the residual NGM(1,1)-P. Therefore, NGM(1,1)-P is first introduced in Sect. 4.1 including Eqs. (26), Eq. (27) and Eq. (28). Generation of the proposed residual combination model, called RNGM(1,1)-P, consisting of NGM(1,1)-P and its residual version, is then described in Sect. 4.2 including Eqs. (29), (30), (31), and (32).
3.2.1 NGM(1,1)-P model
A non-equidistant sequence, (x(0)(t1), x(0)(t2),…, x(0)(tn)) (n ≤ m), is obtained by removing outliers from the original sequence, where x(0)(ti) denotes the actual value at time ti (i ≤ n). Let \(\Delta {t_i} = {t_i} - {t_i}_{ - 1}\), where i = 2, 3,…, n. Of course, \(\Delta t_{i}\) is not a constant. Let \({\mathbf{x}}_{{}}^{(0)}\) = (\(x_{1}^{(0)}\),\(x_{2}^{(0)}\),…,\(x_{n}^{(0)}\)) = (x(0)(t1), x(0)(t2),…, x(0)(tn)). There are four main differences between GM(1,1)-P and NGM(1,1)-P.
First, GM(1,1)-P and NGM(1,1)-P are set up by equidistant and non-equidistant sequences, respectively. Next, instead of 1-AGO, \({\mathbf{x}}_{{}}^{(1)}\) = (x(1)(t1), x(1)(t2),…, x(1)(tn)) = (\(x_{1}^{(1)}\),\(x_{2}^{(1)}\),…,\(x_{n}^{(1)}\)) for NGM(1,1)-P can be generated by the following AGO as (Dang et al., 2016; Liu et al., 2017)
Then, the time response function obtained by solving the following whitening equation is
where r ≠ 1 and k = 2, 3,…, n. Finally, with the following IAGO, the predicted value for NGM(1,1)-P with respect to \(x_{k}^{(0)}\) is given by
Being analogous with the construction of GM(1,1)-P, the computational steps of setting up the optimized NGM(1,1)-P model are as follows.
Step 1 Remove outliers from the equidistant data sequence using the robust nonlinear interval model to detect outliers.
Step 2 Generate the accumulated generating sequence from the non-equidistant data sequence.
Step 3 Construct NGM(1,1)-P with LINGO to obtain the optimal parameters, including the developing coefficient, control variable, and interpolation coefficient.
Step 4 Obtain the predicted sequence with IAGO.
3.2.2 Residual modification of NGM(1,1)-P model
We set up the residual model of NGM(1,1)-P using the absolute residual value, \(\varepsilon_{k}^{(0)}\), which is defined as
The prediction model consisting of NGM(1,1)-P and its residual version is called RNGM(1,1)-P. There are four main differences between RGM(1,1)-P and RNGM(1,1)-P as well. First, RGM(1,1)-P and RNGM(1,1)-P are set up using equidistant and non-equidistant residual sequences, respectively. Next, RNGM(1,1)-P follows the specific AGO where
Then, the corresponding time response function is
where r ≠ 1. In common with NGM(1,1)-P, aε and bε can be derived by the OLS method. Lastly, with the specific IAGO, the predicted value for RNGM(1,1)-P can be generated by
Figure 1 depicts a flowchart of the construction the proposed RNGM(1,1)-P model. The computational steps to set up the RNGM(1,1)-P are briefly summarized as follows.

Flowchart for constructing the RNGM (1,1)-P model
Step 1 Build the optimized NGM(1,1)-P using the non-equidistant data sequence with LINGO.
Step 2 In common with the construction of an optimized NGM(1,1)-P model, use the non-equidistant residual sequence to establish the optimized residual NGM(1,1)-P model with LINGO.
Step 3 Obtain the predicted sequence with an FLN to optimally combine the predicted values obtained from the optimized NGM(1,1)-P and its optimized residual model. The GA toolbox in MATLAB is applied to optimize the connection weights of the FLN.
4 Experiments
Experiments were conducted for magnesium alloy demand forecasting to make comparisons between the different grey prediction models using the equidistant sequences and those using the non-equidistant sequences. The former include the optimized GM(1,1) and optimized GM(1,1)-P, and the latter includes the proposed NGM(1,1), NGM(1,1)-P, and RNGM(1,1)-P. It is reasonable to include GM(1,1) with equidistant sequences and NGM(1,1) with non-equidistant sequences because GM(1,1) is the most commonly used grey prediction model (Liu et al., 2017). Several distinctive prediction models, the adaptive NGM(1,1) (ANGM(1,1)) (Chang et al., 2014) and FLNGM(1,1) (Hu (2017)), were included as well. It should be noted that, when a grey prediction model is developed on the basis of GM(1,1), “GM(1,1)” can be incorporated into the corresponding acronym by convention. The considered prediction models include:
-
(1)
NGM(1,1): A non-equidistant version of GM(1,1);
-
(2)
GM(1,1)-P: A power model of the GM(1,1);
-
(3)
NGM(1,1)-P: A non-equidistant version of GM(1,1)-P;
-
(4)
RGM(1,1)-P: A power model that integrates GM(1,1)-P with residual modification;
-
(5)
RNGM(1,1)-P: A power model that integrates NGM(1,1)-P with residual modification;
-
(6)
ANGM(1,1): Adaptive NGM(1,1) proposed by Chang et al. (2014) has shown its superiority over some prediction models for non-equidistant data sequences on some real cases including synthetic control charts and color filter manufacturing.
-
(7)
FLNGM(1,1): FLNGM(1,1) was originally developed for equidistant data, which uses an FLN to optimally integrate the optimized GM(1,1) and its residual model. For simplicity, the details of FLNGM(1,1) are omitted here, but the study of Hu (2017) can be consulted for more information.
-
(8)
NFLNGM(1,1): NFLNGM(1,1) denotes a non-equidistant FLNGM(1,1);
-
(9)
NN: The NN we use is a multi-layer perceptron (MLP) that has a single output, a single input, and one hidden layer with five hidden units.
As for parameter specifications involving the construction of the proposed model, when using the GA to set up the MLPs introduced in Sect. 2.2, we assigned values of 1000, 50, 0.8, and 0.01 to the total generations, population size, crossover, and mutation probabilities, respectively. In addition, ω in Eq. (4) and \(\psi\) in Eq. (7) are equal to 0.2 and 10–5, respectively. To construct the proposed model, \(\eta\) in Eq. (25) was specified as 20. Although several factors could affect the performance of the GA, there are no optimal values that can be assigned to its parameter specifications (Osyczka, 2003).
4.1 Case I: Magnesium die castings demand of China
China has consumed most of the magnesium in the world since 1999, and it has provided at least 80% of all magnesium materials used worldwide since 2008. With a demand of 70% from the automotive industry and 20% from the 3C products industry, about 35% of the magnesium has been consumed in die casting production with magnesium alloys (Lee et al., 2017). Magnesium die casting demand forecasting can thus reflect magnesium alloy demand and can indicate the developing trends of the automotive and 3C products industries in China.
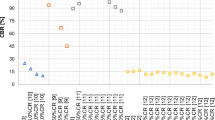
We used the historical data of the demand for magnesium die casting that was reported and analyzed by Hsu (2012), Hong (2015a, 2015b), and Lee et al. (2017). Data from 2002 to 2012 were used for model fitting, and data from 2013 and 2014 were used for ex-post testing. The upper and lower limits are shown in Fig. 2 after performing the robust nonlinear interval regression analysis with qu = ql = 0.1. There are two outliers outside of the identified data intervals. The optimized NGM(1,1), NFLNGM(1,1), AGM(1,1), optimized NGM(1,1)-P, and RNGM(1,1)-P were constructed using the non-equidistant sequence by removing data in 2007 and 2009. The forecasting results are described in Table 3. Table 4 shows the forecasting accuracy obtained by the NN, GM(1,1), FLNGM(1,1), GM(1,1)-P, and RGM(1,1)-P that worked on the equidistant data sequence.

Outlier detection of training data for Case I
Table 5 summarizes forecasting accuracy for model fitting and ex-post testing. In terms of MAPE, we can see that the proposed RNGM(1,1)-P outperformed all the other models considered for model fitting and ex-post testing. In addition to MAPE, Table 5 also includes two commonly used measures mean absolute deviation (MAD) and root mean square error (RMSE) defined as (Xiao et al., 2021):
In terms of MAD and RMSE, we can see that the RNGM(1,1)-P outperformed most of the other considered prediction models for ex-post testing, despite that the RNGM(1,1)-P was slightly inferior to RGM(1,1)-P for ex-post testing.
4.2 Case II: Magnesium alloy ingot and powder demand of Taiwan
In Taiwan, all magnesium materials are imported from abroad. Magnesium alloy ingots and scrap are the main materials imported for the magnesium alloy industry. Most of the magnesium alloys are used to manufacture the cases of 3C products, such as smart phones, tablet computers, and notebooks, by die casting and thixomolding. Taiwan is the global leader in the die casting of magnesium alloys for 3C products (Hong, 2016). To maintain this competitive advantage, magnesium alloy forecasting can be important in enabling 3C product manufacturers to recognize developing trends in related markets. Accordingly, the imported quantity of magnesium alloy ingots and scrap can be used to indirectly reflect the trends of the magnesium alloy demand of Taiwan.
We used the historical data of the import quantity of magnesium alloy ingots and scrap that was reported and analyzed by Lu (2014) and Hong (2016). Data from 2002 to 2012 were used for model fitting, and data from 2013 and 2015 were used for ex-post testing. In Fig. 3, Two circles indicate outliers outside of the data intervals that were identified after performing the robust nonlinear interval regression analysis with qu = ql = 0.1. The optimized NGM(1,1), NFLNGM(1,1), AGM(1,1), optimized NGM(1,1)-P, and RNGM(1,1)-P were constructed using the non-equidistant sequence by removing data in 2004 and 2010. Table 6 shows the prediction results. The prediction results obtained by NN, GM(1,1), FLNGM(1,1), GM(1,1)-P, and RGM(1,1)-P that worked on the original equidistant sequence are described in Table 7.

Outlier detection of training data for Case II
In terms of MAPE, Table 7 indicates that, among the prediction models considered here, the proposed RNGM(1,1)-P model demonstrated its superiority in the ex-post testing, despite that the RNGM(1,1)-P was slightly inferior to FLNGM(1,1) and NFLNGM(1,1) for model fitting. Indeed, one should place more emphasis on the results with respect to generalization (Luo et al, 2013). Table 8 summarizes forecasting accuracy for model fitting and ex-post testing. In addition to MAPE, we can see that the RNGM(1,1)-P outperformed most of the other considered prediction models in terms of MAD and RMSE for ex-post testing. The RNGM(1,1)-P outperformed all the other models by RMSE, but it was slightly inferior to NFLNGM(1,1) and ANGM(1,1) by MAD.
4.3 Statistical analysis
To demonstrate the superiority of the proposed RNGM(1,1)-P, statistical analysis was conducted by using the Wilcoxon signed-rank test. The forecasting accuracy of the RNGM(1,1)-P was compared with that each of the other prediction models considered for ex-post testing. Let the statistic \(R^{ - }\) denote the sum of ranks for the last four and three years of Cases I and II, respectively, in which the accuracy of the proposed RNGM(1,1)-P was inferior to that of one prediction model. For instance, compared to NGM(1,1), \(R^{ - }\) was equal to the sum of ranks for the seven years in which the accuracy of the RNGM(1,1)-P was inferior to that of the NGM(1,1). As \(R^{ - }\) = 4 which was less than the critical value of 6 at a significance level of 0.1 with respect to a right-tailed test, the RNGM(1,1)-P was significantly superior to the NGM(1,1). It was found that \(R^{ - }\) = 7 which was slightly greater than the critical value at a significance level of 0.1 when comparing with the NFLNGM(1,1), the RNGM(1,1)-P seems to be superior to the NFLNGM(1,1) as well. As a result, the RNGM(1,1)-P significantly outperformed most of the considered prediction models except for the GM(1,1)-P and NN. Even so, the RNGM(1,1)-P performed better than the GM(1,1)-P and NN from the viewpoint of the MAPE for ex-post testing.
5 Discussion
The prediction accuracy of the proposed RNGM(1,1)-P was examined using real magnesium alloy demand data from China and Taiwan. The experimental results for ex-post testing show that the MAPEs of the proposed model were minimal among all considered models. Statistical analysis further indicated that the RNGM(1,1)-P significantly outperformed the most of the considered prediction models as well. In terms of MAPEs, since the RNGM(1,1)-P outperformed the RGM(1,1)-P that can only deal with the original equidistant sequence, this indicated that the forecasting performance of the RGM(1,1)-P can be improved by removing outliers from data sequences. Altogether, the above results demonstrated the high applicability of the proposed RNGM(1,1)-P in the forecast of magnesium alloy demand.
As mentioned above, MAPE is the primary measure to examine forecasting accuracy of the considered prediction models here. From Tables 5 and 8, we can see that the RNGM(1,1)-P outperformed the other considered models in terms of MAPE for ex-post testing. However, it cannot beat the other considered models in terms of MAD and RMSE. The reason is that all considered grey prediction models were constructed by minimizing MAPE rather than MAD and RMSE. Even so, with MAD and RMSE, the proposed RNGM(1,1)-P is comparable to the other considered models. It should be noted that, for magnesium material demand forecasting, Hu (2020) applied grey relational analysis to access the relative importance of each sample for GM(1,1), and a residual modification without constructing residual models was then provided. Indeed, the contributions of this study are quite different from those of Hu (2020).
6 Conclusions
Many countries have established high standards for lowering CO2 emissions and energy consumption for automobiles, and constructing lightweight products has become an effective way to achieve these standards. Undoubtedly, magnesium alloys are important metal materials for the automotive industry, as well as for 3C products, aircraft, and medical appliances. As manufacturers need to invest in research and development in the use of magnesium alloys, the development of well-performed demand forecasting models is important and can help manufacturers understand the developing trends of related markets.
The main contribution of this study is to develop the grey residual modification model, namely RNGM(1,1)-P, to forecast the demand of magnesium alloy demand. To remove outliers that might give rise to a deterioration of forecasting accuracy, the robust nonlinear interval models were particularly employed to generate non-equidistant data sequences. It turns out that the proposed RNGM(1,1)-P can work on the resultant non-equidistant data sequences, and it is not necessary for the available data to comply with any statistical assumption.
The findings of this study also highlight several directions for our future work. First, this study did not consider exogenous variables such as the price of magnesium and business indicators in the context of the demand for magnesium alloy. As multivariate models may yield better predictions than single-variable models (Hu, 2020; Ma et al., 2019; Wu et al., 2019), we will investigate the applicability of several models, such as the multivariable models of Moonchai and Chutsagulprom (2020), the cumulative sum operator in grey prediction using integral transformations of Wei et al. (2020), and the background value optimization nonlinear model of Wu et al. (2020), to forecast the demand for magnesium alloy. Next, since there are shortcomings of MAPE outlined by Vandeput (2021), we will investigate how to incorporate the other measures such as MAD and RMSE into the construction of the proposed models to improve forecasting accuracy.
References
Chang, C. J., Li, D. C., Chen, C. C., & Chen, C. S. (2014). A forecasting model for small non-equigap data sets considering data weights and occurrence possibilities. Computers and Industrial Engineering, 67, 139–145.
Chen, C. I. (2008). Application of the novel nonlinear grey Bernoulli model for forecasting unemployment rate. Chaos, Solitons & Fractals, 37, 278–287.
Chen, C. I., Chen, H. L., & Chen, S. P. (2008). Forecasting of foreign exchange rates of Taiwan’s major trading partners by novel nonlinear Grey Bernoulli model NGBM(1, 1). Communications in Nonlinear Science and Numerical Simulation, 13, 1194–1204.
Chen, D. S., & Jain, R. C. (1994). A robust back propagation learning algorithm for function approximation. IEEE Transactions on Neural Networks, 5, 467–478.
Chen, Y. Y., Liu, H. T., & Hsieh, H. L. (2019). Time series interval forecast using GM(1,1) and NGBM(1, 1) models. Soft Computing, 23, 1541–1555.
Cheng, C. B., & Lee, E. S. (2001). Fuzzy regression with radial basis function network. Fuzzy Sets and Systems, 119, 291–301.
Dang, Y. G., Wang, Z. X., Qian, W. Y., & Xiong, P. P. (2016). Grey Prediction Techniques and Methods. Science Press.
Gao, M., Yang, H., Xiao, Q., & Goh, M. (2021). A novel fractional grey Riccati model for carbon emission prediction. Journal of Cleaner Production. https://doi.org/10.1016/j.jclepro.2020.124471
Hao, P. Y. (2009). Interval regression analysis using support vector networks. Fuzzy Sets and Systems, 160, 2466–2485.
Hladík, M., & Černý, M. (2014). Tolerance approach to possibilistic nonlinear regression with interval data. IEEE Transactions on Cybernetics, 44, 2509–2520.
Hong, D. L. (2015). Comments on Demand and Supply for the Magnesium Industry in China, IT IS Industrial Commentary, Industry and Technology Intelligence Services Project Office, Ministry of Economic Affairs (Taiwan).
Hong, D.L. (2015). Analysis of Demand and Supply for The Magnesium Industry in China, IT IS Industrial Commentary, Industry and Technology Intelligence Services Project Office, Ministry of Economic Affairs (Taiwan).
Hong, D. L. (2016). 2016 Special of Non-Ferrous Metals in Emerging Markets on Magnesium, Technical Report No. MIRDC-105-A20H, Industry and Technology Intelligence Services Project Office, Ministry of Economic Affairs (Taiwan).
Hsu, Y. R. (2012). 2012 Special of Non-Ferrous Metals in China on Magnesium, Technical Report No. MIRDC-101-A32G, Industry and Technology Intelligence Services Project Office, Ministry of Economic Affairs (Taiwan).
Hsu, L. C. (2003). Applying the grey prediction model to the global integrated circuit industry. Technology Forecasting and Social Change, 70, 563–574.
Hu, Y. C. (2009). Functional-link nets with genetic-algorithm-based learning for robust nonlinear interval regression analysis. Neurocomputing, 72, 1808–1816.
Hu, Y. C. (2014). Multilayer perceptron for robust nonlinear interval regression analysis using genetic algorithms. The Scientific World Journal. https://doi.org/10.1155/2014/970931
Hu, Y. C. (2017). Grey prediction with residual modification using functional-link net and its application to energy demand forecasting. Kybernetes, 46(2), 349–363.
Hu, Y. C. (2020). Constructing grey prediction models using grey relational analysis and neural networks for magnesium material demand forecasting. Applied Soft Computing. https://doi.org/10.1016/j.asoc.2020.106398
Hu, Y. C., Jiang, P., & Lee, P. C. (2019). Forecasting tourism demand by incorporating neural networks into Grey-Markov models. Journal of the Operational Research Society, 70, 12–20.
Huang, L., Zhang, B. L., & Huang, Q. (1998). Robust interval regression analysis using neural networks. Fuzzy Sets and Systems, 97, 337–347.
Ishibuchi, H., & Nii, M. (2001). Fuzzy regression using asymmetric fuzzy coefficients and fuzzified neural networks. Fuzzy Sets and Systems, 119, 273–290.
Ishibuchi, H., & Tanaka, H. (1992). Fuzzy regression analysis using neural networks. Fuzzy Sets and Systems, 50, 257–265.
Ishibuchi, H., Tanaka, H., & Okada, H. (1993). An architecture of neural networks with interval weights and its application to fuzzy regression analysis. Fuzzy Sets and Systems, 57, 27–39.
Lee, L. P., Grandfield, J., Sun, S. J., & Wang, C. Y. (2017). (2017), 2016 global supply and demand on magnesium. Singapore: Annual Meeting of International Magnesium Association.
Lee, Y. S., & Tong, L. I. (2011). Forecasting energy consumption using a grey model improved by incorporating genetic programming. Energy Conversion and Management, 52, 147–152.
Li, Q. F., Dang, Y. G., & Wang, Z. X. (2012). An extended GM(1,1) power Model for non-equidistant series. Journal of Grey System, 24, 269–274.
Liu, S., & Lin, Y. (2010). Grey Information: Theory and Practical Applications. Springer-Verlag.
Liu, S., Yang, Y., & Forrest, J. (2017). Grey Data Analysis: Methods. Springer, Berlin: Models and Applications.
Lu, Y. J. (2014). Special of Non-Ferrous Metals in Emerging Markets on Magnesium, Technical Report No. MIRDC-103-A10G, Industry and Technology Intelligence Services Project Office, Ministry of Economic Affairs (Taiwan).
Lu, J., Xie, W., Zhou, H., & Zhang, A. (2016). An optimized nonlinear grey Bernoulli model and its application. Neurocomputing, 177, 206–214.
Luo, D. R., Guo, K. Z., & Huang, H. R. (2013). Regional economic forecasting combination model based on RAR + SVR. In B. Y. Cao & H. Nasseri (Eds.), Fuzzy Information & Engineering and Operations Research & Management, Advances in Intelligent Systems and Computing (Vol. 211, pp. 329–338). Springer.
Ma, X., Liu, Z., & Wang, Y. (2019). Application of a novel nonlinear multivariate grey Bernoulli model to predict the tourist income of China. Journal of Computational and Applied Mathematics, 347, 84–94.
Moonchai, S., & Chutsagulprom, N. (2020). Short-term forecasting of renewable energy consumption: Augmentation of a modified grey model with a Kalman filter. Applied Soft Computing. https://doi.org/10.1016/j.asoc.2019.105994
Nasrabadi, E., & Hashemi, S. M. (2008). Robust fuzzy regression analysis using neural networks. International Journal of Uncertainty, Fuzziness and Knowlege-Based Systems, 16, 579–598.
Osyczka, A. (2003). Evolutionary Algorithms for Single and Multicriteria Design Optimization. Physica-Verlag.
Pao, H. T., Fu, H. C., & Tseng, C. L. (2012). Forecasting of CO2 emissions, energy consumption and economic growth in China using an improved grey model. Energy, 40, 400–409.
Rajesh, R. (2020). Sustainability performance predictions in supply chains: Grey and rough set theoretical approaches. Annals of Operations Research. https://doi.org/10.1007/s10479-020-03835-x
Wang, C., Li, J., & Guo, P. (2015). The normalized interval regression model with outlier detection and its real-world application to house pricing problems. Fuzzy Sets and Systems, 274, 109–123.
Wang, Z. X., Hipel, K. W., Wang, Q., & He, S. W. (2011). An optimized NGBM(1,1) model for forecasting the qualified discharge rate of industrial wastewater in China. Applied Mathematical Modelling, 35, 5524–5532.
Wei, B., Xie, N., & Yang, L. (2020). Understanding cumulative sum operator in grey prediction model with integral matching. Communications in Nonlinear Science and Numerical Simulation. https://doi.org/10.1016/j.cnsns.2019.105076
Wu, L. Z., Li, S. H., Huang, R. Q., & Xu, Q. (2020). A new grey prediction model and its application to predicting landslide displacement. Applied Soft Computing. https://doi.org/10.1016/j.asoc.2020.106543
Wu, W., Ma, X., Zeng, B., Wang, Y., & Cai, W. (2019). Forecasting short-term renewable energy consumption of China using a novel fractional nonlinear grey Bernoulli model. Renewable Energy, 140, 70–87.
Xiao, Q., Shan, M., Gao, M., Xiao, X., & Goh, M. (2020). Parameter optimization for nonlinear grey Bernoulli model on biomass energy consumption prediction. Applied Soft Computing. https://doi.org/10.1016/j.asoc.2020.106538
Xiao, Q., Shan, M., Gao, M., Xiao, X., & Guo, H. (2021). Evaluation of the coordination between China’s technology and economy using a grey multivariate coupling model. Technological and Economic Development of Economy, 27(1), 24–44.
Xie, N., Liu, S., Yuan, C., & Yang, Y. (2014). Grey number sequence forecasting approach for interval analysis: A case of China’s gross domestic product prediction. The Journal of Grey System, 26(1), 45–58.
Zeng, B., Li, C., Zhou, X. Y., & Long, X. J. (2014). Prediction model of interval grey number with a real parameter and its application. Abstract and Applied Analysis. https://doi.org/10.1155/2014/939404
Zheng, C., Wu, W. Z., Xie, W., Li, Q., & Zhang, T. (2020). Forecasting the hydroelectricity consumption of China by using a novel unbiased nonlinear grey Bernoulli model. Journal of Cleaner Production, 28, 1–15.
Acknowledgements
This research is supported by the Ministry of Science and Technology, Taiwan under Grant MOST 108-2410-H-033-038-MY2 and MOST 110-2410-H-033-013-MY2.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author declares that he has no conflict of interest. This article does not contain any studies with human participants performed by the author.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hu, YC. Demand forecasting of green metal materials using non-equidistant grey prediction with robust nonlinear interval regression analysis. Environ Dev Sustain 24, 9809–9831 (2022). https://doi.org/10.1007/s10668-021-01846-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10668-021-01846-7