
Abstract
In this work we study binary two-stage robust optimization problems with objective uncertainty. We present an algorithm to calculate efficiently lower bounds for the binary two-stage robust problem by solving alternately the underlying deterministic problem and an adversarial problem. For the deterministic problem any oracle can be used which returns an optimal solution for every possible scenario. We show that the latter lower bound can be implemented in a branch and bound procedure, where the branching is performed only over the first-stage decision variables. All results even hold for non-linear objective functions which are concave in the uncertain parameters. As an alternative solution method we apply a column-and-constraint generation algorithm to the binary two-stage robust problem with objective uncertainty. We test both algorithms on benchmark instances of the uncapacitated single-allocation hub-location problem and of the capital budgeting problem. Our results show that the branch and bound procedure outperforms the column-and-constraint generation algorithm.
Similar content being viewed by others

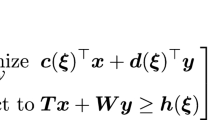
Avoid common mistakes on your manuscript.
1 Introduction
The concept of robust optimization was created to tackle optimization problems with uncertain parameters. The basic idea behind this concept is to use uncertainty sets instead of probability distributions to model uncertainty. More precisely it is assumed that all realizations of the uncertain parameters, called scenarios, are contained in a known uncertainty set. Instead of optimizing the expected objective value or a given risk-measure as common in the field of stochastic optimization, in the robust optimization framework we calculate solutions which are optimal in the worst case and which are feasible for all scenarios in the uncertainty set.
The concept was first introduced in [67]. Later it was studied for combinatorial optimization problems with discrete uncertainty sets in [53], for conic and ellipsoidal uncertainty in [13, 14], for semi-definite and least-square problems in [39, 40] and for budgeted uncertainty in [26, 27]. An overview of the robust optimization literature can be found in [2, 10, 15, 32].
The so called robust counterpart is known to be NP-hard for most of the classical combinatorial problems, although most of them can be solved in polynomial time in its deterministic version; see [53]. Furthermore it is a well-known drawback of this approach that the optimal solutions are often too conservative for practical issues [27]. To obtain better and less-conservative solutions several new ideas have been developed to improve the concept of robustness; see e.g. [1, 43, 53, 55, 63].
Inspired by the concept of two-stage stochastic programming a further extension of the classical robust approach which attained increasing attention in the last decade is the concept of two-stage robustness, or sometimes called adjustable robustness, first introduced in [12]. The idea behind this approach is tailored for problems which have two different kinds of decision variables, first-stage decisions which have to be made here-and-now and second-stage decisions which can be determined after the uncertain parameters are known, sometimes called wait-and-see decisions. As in the classical robust framework it is assumed that all uncertain scenarios are contained in a known uncertainty set and the worst-case objective value is optimized. The main difference to the classical approach is that the second-stage decisions do not have to be made in advance but can be chosen as the best reaction to a scenario after it occured. This approach can be modeled by min–max–min problems in general. Famous applications occur in the field of network design problems where in the first stage a capacity on an edge must be bought such that, after the real costs on each edge are known, a minimum cost flow is sent from a source to a sink which can only use the bought capacities [21]. An overview of recent results for two-stage robustness can be found in [72]. Several concepts closely related to the two-stage robust concept were introduced in [1, 30, 55].
In this work we study binary two-stage robust optimization problems. We consider underlying deterministic problems of the form
where \(f:Z\times \mathbb {R}^m \rightarrow \mathbb {R}\), the set \(Z\subseteq \{ 0,1 \}^{n_1+n_2}\) contains all incidence vectors of the feasible solutions and is assumed to be non-empty, \(c\in \mathbb {R}^{m}\) is a given parameter vector and \(f(x,y,\cdot )\) is concave for each given \((x,y)\in Z\). The variables x are called first-stage solutions and the variables y are called second-stage solutions. We assume that the vector c is uncertain and all possible realizations c are contained in a convex uncertainty set \(U\subset \mathbb {R}^{m}\). The binary two-stage robust problem is then defined by
where \(X\subset \{ 0,1 \}^{n_1}\) is the projection of Z onto the x-variables, i.e.
and \(Y(x):=\left\{ y\in \{ 0,1 \}^{n_2} \ | \ (x,y)\in Z\right\} \). Note that all results presented in this paper are still valid, if the recourse variables are non-integer. We do not consider uncertainty affecting the constraints of the problem which is a situation often occuring in practice for most of the classical combinatorial optimization problems. Problem (2RP) can be interpretated as follows: In the first stage, before knowing the precise uncertain vector c, the decisions \(x\in X\) have to be made. Afterwards, when the cost-vectors are known, we can choose the best feasible second-stage solution \(y\in Y(x)\) for the given costs. As usual in robust optimization we measure the worst-case over all possible scenarios in U. Note that by our definition of the set Y(x) and since the uncertainty only affects the objective function, there always exists a feasible second-stage solution \(y\in Y(x)\) for each first-stage solution \(x\in X\).
Problem (2RP) has been already studied in the literature and several exact algorithms as well as approximation algorithms have been proposed; see Sect. 1.1. While several of the existing methods are able to handle uncertainty in the constraints it is often assumed that a polyhedral description of the sets X and Y(x) is given. Besides the latter limitation most of the methods are based on dualizations or reformulations which destroy the structure of the original problem (CP). Often the uncertainty set is even restricted to be a polyhedron. In this work we derive the first oracle-based exact algorithm which solves Problem (2RP) for any deterministic problem by solving alternately the deterministic Problem (CP) and an adversarial problem presented later. For the deterministic problem any oracle can be used which returns an optimal solution of (CP) for every possible scenario in U. The advantage of the latter method is that the structure of the underlying problem is preserved and any preliminary algorithms which were derived for the underlying problem can be used. Furthermore our algorithm works for most of the common convex uncertainty sets. Additionally we apply the column-and-constraint generation algorithm (CCG) presented in [73] to Problem (2RP) and compare it to our new method.
In Sect. 1.1 we will give an overview of the literature related to two-stage robust optimization problems. In Sect. 2 we derive an oracle-based branch and bound procedure to solve Problem (2RP). Furthermore we apply the results in [73] to Problem (2RP). Finally in Sect. 3.1 we apply both methods to the uncapacitated singe-allocation hub-location problem and the capital budgeting problem and test it on classical benchmark instances from the literature.
Our main contributions:
-
We adapt the oracle-based algorithm derived in [29] and show that it can be used to calculate a lower bound for Problem (2RP) which can be implemented in a branch and bound procedure where the branching is performed over the first-stage solutions. The calculation of the lower bound can be applied to the common convex uncertainty sets and is done by alternately calling an adversarial problem over U and an oracle which returns an optimal solution of Problem (CP) for a given scenario \(c\in U\). Therefore any solution algorithm of the deterministic problem can be used to calculate this lower bound.
-
We apply the CCG algorithm presented in [73] to Problem (2RP) and show that calculating the upper bound can also be done by the same oracle-based algorithm as above.
-
We apply the branch and bound procedure and the CCG algorithm to the uncapacitated single-allocation hub-location problem and the capital budgeting problem and show that the branch and bound procedure outperforms the CCG algorithm.
1.1 Related literature
Linear two-stage robust optimization or sometimes called adjustable robust optimization was first introduced in [12]. The authors show that the problem is NP-hard even if X and Y are given by linear uncertain constraints and all variables are real; see also [57]. In [12] the authors propose to approximate the problem by assuming that the optimal values of the wait and see variables y are affine functions of the uncertain parameters. These so called affine decision rules were studied in the robust context in several articles for the case of real recourse; see e.g. [6, 11, 34, 37, 47, 54, 64, 71]. Furthermore in several works special cases are derived for which a decision rule structure is known which is optimal; see [20, 22, 48]. Further non-linear decision rules are studied in [72].
Lower bounds for two-stage robust problems can be derived by considering a finite subset of scenarios in U. Then for each selected scenario c a duplication of the second-stage solution \(y^c\) is added to the problem, see [7, 36, 45]. The authors in [24] first dualize the inner minimization and maximization problem and then apply the latter finite scenario approach to the dual problem to obtain stronger lower bounds. Note that while the finite scenario approach can also be applied to the case when the second-stage solutions are integers, for the dualization approach the second-stage variables have to be relaxed to real variables. Unfortunately both lower bounds can not be used in a branch and bound scheme since for a complete fixation of the first-stage variables the bounds are not necessarily exact.
Exact methods for real recourse are based on the idea of Benders’ decomposition, see [23, 44, 51, 70] or column-and-constraint generation [25, 73]. Note that for the Benders’ decomposition approaches the second-stage solutions have to be real since dualizations of the second-stage problem are used. In contrast to this the CCG algorithm even works for integer recourse, see [74]. We will apply the latter method to our problem in Sect. 2.2.
For the case of integer recourse, i.e. the second-stage variables y are modeled as integer variables, decision rules have been applied to Problem (2RP) in [18, 19] to approximate the problem. Another approximation approach is called k-adaptability and was introduced in [16]. The idea is to calculate k second-stage solutions in the first-stage and allow to choose the best out of these solutions in the second-stage. Clearly since the set of possible second-stage solutions is restricted compared to the original problem, this idea leads to an approximation of the problem. Solution methods and the quality of this approximation were studied in [22, 46, 68]. In [46] it is shown that the k-adaptability problem is exact if k is chosen larger than the dimension of the problem. The authors in [30, 31, 42] apply the k-adaptability concept to one-stage combinatorial problems to calculate a set of solutions which is worst-case optimal if for each scenario the best of these solutions can be chosen. They furthermore show that solving this problem can be done in polynomial time if an oracle for the deterministic problem exists and if the number of calculated solutions is larger or equal to the dimension of the problem. To solve the problem in the latter case they present an oracle-based algorithm which we will use in Sect. 2. The k-adaptability concept was also applied to the case that the uncertain parameters follow a discrete probability distibution [33].
Besides the exact algorithm in [73, 74] approximation methods based on uncertainty set splitting were derived in the literature to approximate two-stage robust problems with integer recourse; see [17, 61].
For two-stage robust problems with non-linear robust constraints decision rules have been applied in [58, 69]. The two-stage problem is studied for second order conic optimization problems in [28]. In [9, 56] the authors derive robust counterparts of uncertain non-linear constraints. Note that all the latter results were developed for real second-stage solutions.
While this work was under peer review a similar approach to solve two-stage robust optimization problems with uncertainty only affecting the objective function was published; see [5]. The authors study Problem (2RP) with linear objective functions and mixed-integer recourse variables, while the set Y(x) is modeled by linear constraints. They study a relaxation of the lower bound presented in Sect. 2 which is implemented in a branch and bound procedure. In contrast to the algorithm described in this work, the method in [5] is not based on the use of oracles for the deterministic problem. Therefore it can not make use of fast solution methods for (CP) as combinatorial algorithms or compact formulations with uncertain parameters appearing in the constraints; see Sect. 3.1.
2 Binary two-stage robustness
In this section we analyze the binary two-stage robust problem (2RP) with convex uncertainty sets U and derive general lower bounds which can be calculated by an oracle-based algorithm and which can be implemented in a branch and bound procedure. The branching will be done over the first-stage solutions.
The classical approach to derive lower bounds in a branch and bound procedure is relaxing the integrality and solving the relaxed problem. Applying this approach to the second-stage decisions of problem (2RP) is not useful, since for a given \(x\in X\) and \(c\in U\) an optimal solution of the relaxed second-stage problem may not be contained in \({{\,\mathrm{conv}\,}}\left( Y(x)\right) \), e.g. if the relaxation of Y(x) is a polytope which is not integral. It may be even the case that a linear description of \({{\,\mathrm{conv}\,}}\left( Y(x)\right) \) is not known. Therefore, even if all first-stage variables are fixed, the lower bound obtained by relaxing the second-stage solution variables would not necessarily be exact and an optimal solution can not be guaranteed using a branch and bound scheme. In the following lemma we derive a lower bound for Problem (2RP) which is exact if all first-stage solutions are fixed.
Lemma 1
Given \(U\subset \mathbb {R}^{m}\), then
is a lower bound for Problem (2RP).
Proof
By changing the order of the outer minimum and the inner maximum in Problem (2RP) we obtain the inequality
Merging the two minimum expressions and using \(Z\subseteq {{\,\mathrm{conv}\,}}\left( Z\right) \) yields
which proves the result. \(\square \)
Note that, since f is concave in c and since the pointwise minimum of concave functions is always concave, we have to maximize a concave objective function in Problem (LB). In [30] the authors analyze Problem (LB) for the case that f is a linear function in (x, y) and c. They prove that it can be solved in oracle-polynomial time, i.e. by a polynomial time algorithm if solving the deterministic problem (CP) is done by an oracle in constant time. Furthermore if we fix a solution \(x\in X\), then the bound (LB) is exact, which we prove in the following.
Proposition 1
If all first-stage variables are fixed then (LB) is equal to the exact objective value of the fixed first-stage solution.
Proof
Let \({\bar{x}}\in X\) be the fixed first-stage solution, then it holds
Clearly problem
is equivalent to
which proves the result. \(\square \)
The result of Proposition 1 indicates that the lower bound (LB) can be integrated in a branch and bound procedure.
In [30] it was proved that, given an oracle to solve the deterministic problem over \(Y({\bar{x}})\) for each given \({\bar{x}}\), if f is linear in (x, y) and c and under further mild assumptions, Problem (1) can be solved in oracle-polynomial time. Together with Proposition 1 a direct consequence is that, if the dimension \(n_1\) of the first-stage solutions is fixed, then we can enumerate over all possible first-stage solutions and compare the objective values in oracle-polynomial time. Hence, Problem (2RP) can be solved in polynomial time given an oracle for the optimization problem over Y(x) for each \(x\in X\).
The authors in [30] present a practical algorithm, based on the idea of column-generation for the case that f is a linear function. Applied to the more general Problem (LB) the algorithm can be derived as follows: The algorithm starts with a subset of solutions \(Z'\subset Z\), leading to problem
and then iteratively adds new solutions to \(Z'\) until optimality can be ensured. The solution which is added in each iteration is the one which has the largest impact on the optimal value. To find this solution Problem (2) can be reformulated by applying a level set transformation. The reformulation is given by
For an optimal solution \((\mu ^*,c^*)\) of the latter problem, we search for the solution \(z\in Z\) which most violates the constraint \(f(z,c^*)\ge \mu ^*\), i.e. the solution with the largest improvement on the optimal value of Problem (2). The latter task can be done by minimizing the objective function \(f(z,c^*)\) over all \(z\in Z\), i.e. solving the deterministic problem (CP) under scenario \(c^*\) by using any exact algorithm. If we can find a \(z^*\in Z\) such that \(f(z^*,c^*) < \mu ^*\), then we add \(z^*\) to \(Z'\) and repeat the procedure. If no such solution can be found, then \(f(z,c^*)\ge \mu ^*\) holds for all \(z\in Z\) and therefore \(\mu ^*\) is the optimal value of (LB). The procedure described above is presented in Algorithm 1.

Note that the Problem in Step 3 depends on the uncertainty set U and on the properties of f. If f is a linear function in c, for polyhedral or ellipsoidal uncertainty sets this is a continuous linear or quadratic problem, respectively. Both problems can be solved by the latest versions of optimization software like CPLEX [49]. Therefore the algorithm can be implemented for each deterministic problem by using any exact algorithm to solve the deterministic problem in Step 4. The main advantage of this feature is that we do not have to restrict to deterministic problems which can be modeled by a linear compact formulation as it is the case in [5]. Instead we can use any combinatorial algorithm or even mixed-integer formulations where the uncertain parameters appear in the constraints; see Sect. 3.1. We only require an arbitrary procedure which returns an optimal solution for the given scenario. In [42] the authors applied the latter algorithm to the min–max–min robust capacitated vehicle routing problem and showed that on classical benchmark instances the number of iterations of Algorithm 1 is significantly smaller than the dimension of Z in general.
Note that besides the optimal value of Problem (2RP) the algorithm returns a set of feasible solutions \(Z'\subseteq Z\) and not a solution in \({{\,\mathrm{conv}\,}}\left( Z\right) \). By the correctness of the algorithm the optimal solution in \({{\,\mathrm{conv}\,}}\left( Z\right) \) must be contained in \({{\,\mathrm{conv}\,}}\left( Z'\right) \) and could be calculated by finding the optimal convex combination of the solutions in \(Z'\) which can be done by solving the problem
for the given set \(Z'\). If f is continuous, quasi-convex in z and quasi-concave in c then the latter problem is equivalent to
by Sion’s theorem [65]. Dualizing the inner maximization problem over U (e.g. by using the convex conjugate [9]) this is a continuous minimization problem. If f is a linear function this problem is a linear or a quadratic problem for polyhedral or ellipsoidal uncertainty, respectively. Nevertheless in our branch and bound procedure for non-linear functions f the set \(Z'\) is sufficient as we will see in Sect. 2.1. A practical advantage of the set \(Z'\) is that it contains a set of second-stage policies which can be used in practical applications. Instead of solving the second-stage problem each time after a scenario occured, which may be a computationally hard problem, we can choose the best of the pre-calculated second-stage policies in \(Z'\) for the actual scenario. The latter task can be done by just comparing the objective values of all solutions in \(Z'\) for the given scenario. Note that the returned set of solutions need not contain the optimal solution for each scenario. Nevertheless we will show in Sect. 3.2.1 that the calculated solutions perform very well in average over random scenarios in U.
2.1 Oracle-based branch and bound algorithm
Using the results of the previous section we can easily derive a classical branch and bound procedure to solve Problem (2RP). The idea is to branch over the first-stage solutions \(x\in X\) and to calculate the lower bound (LB) in each node of the branch and bound tree to possibly prune the actual branch of nodes. All necessary details needed to implement a branch and bound procedure are presented in the following.
Handling fixations In each node of the branch and bound tree we have a given set of fixations for the x-variables, i.e. a set of indices \(I_0\subset [n_1]\) such that \(x_i=0\) for each \(i\in I_0\) and a given set of indices \(I_1\subset [n_1]\setminus I_0\) such that \(x_i=1\) for each \(i\in I_1\). All indices in \([n_1]\setminus \left( I_0\cup I_1\right) \) are free. Therefore in each node for the given fixations we have to solve the problem
or to decide if the latter problem is infeasible. It is easy to see that the latter problem, if it is feasible, can be solved by Algorithm 1 by including the given fixations into the set Z. Note that here the oracle for the deterministic problem must be able to handle variable-fixations. Nevertheless for most of the classical problems fixations can easily be implemented in most algorithms.
Warm starts In each node of the branch and bound tree Algorithm 1 returns a set \(Z'\subset Z\) of feasible solutions satisfying the given fixations. For each possible child-node we can select the set \(Z''\subset Z'\) of solutions which satisfy the new fixations and warm-start Algorithm 1 with the set \(Z''\) in the child node.
Branching strategy An easy branching strategy can be established as follows: For the calculated set of solutions \(Z'\) returned by Algorithm 1 we define the vector \({\bar{x}}\in [0,1]^{n_1}\) by
for all \(i\in [n_1]\), i.e. the value \({\bar{x}}_i\) is the fraction of solutions in \(Z'\) for which \(x_i=1\) holds. We can then use any of the classical branching rules, e.g. we can decide to branch on the index i for which the value \({\bar{x}}_i\) is the closest to 0.5.
Another computationally more expensive approach is to calculate the optimal convex combination of the solutions in \(Z'\), i.e. after calculating the optimal \(Z'\) by Algorithm 1 we calculate an optimal solution \(\lambda ^*\) of Problem (4) and define
Now we can again use any classical branching-strategy on \({\bar{x}}\). Note that if a first-stage variable has the same value in each of the solutions in \(Z'\) then also the corresponding entry of \({\bar{x}}\) has this value.
When going over to the next open branch and bound node to be processed, we choose the one with the smallest lower-bound.
Calculating feasible solutions In each node of the branch and bound tree we want to find a feasible solution to update the upper bound on our optimal value. We do this as follows: In each branch and bound node Algorithm 1 calculates a set \(Z'\subseteq Z\) of feasible solutions. If all of the generated solutions in \(Z'\) have the same first-stage solution x, then the optimal solution of (5) has binary first-stage variables and we obtain a feasible solution \(x\in X\) which has the objective value \(\mu ^*\) returned by the algorithm. If the first-stage variables are not the same for all \(z\in Z'\) then we can either choose an arbitrary first-stage solution given by any \(z\in Z'\) or we can calculate the objective value of all first-stage solutions in \(Z'\) and choose the one with the best objective value. To this end we have to solve
for any first-stage solution \({\tilde{x}}\) given in \(Z'\). Note that the latter problem again can be solved by Algorithm 1 replacing the deterministic problem in Step 4 by
If \(X=\{ 0,1 \}^{n_1}\), as it is the case for the hub-location problem (see Sect. 3.2.1), then calculating all objective values as above can be avoided and finding a good feasible solution can be done by rounding each component of the vector \({\bar{x}}\) calculated in the latter paragraph.
2.2 Oracle-based column-and-constraint algorithm
In [73] a column-and-constraint generation method (CCG) was introduced to solve two-stage robust problems with real recourse variables. In [74] the authors show how the algorithm can be applied to two-stage robust problems with mixed-integer recourse variables. In both cases the algorithm is studied for problems with uncertain constraints. In this section we will apply the algorithm to Problem (2RP), i.e. to the special case of objective uncertainty, and show that we can again use Algorithm 1 to solve one crucial step in the CCG. In the following we derive the CCG algorithm for Problem (2RP). For more details see [73, 74].
Using a level set transformation Problem (2RP) can be reformulated by
If we choose any finite subset of scenarios \(\left\{ c^1,\ldots ,c^l\right\} \in U\) we obtain the lower bound
which is equivalent to problem
The algorithm in [73] now iteratively calculates an optimal solution \((x^*,\mu ^*)\) of the latter problem (8), which is a lower bound for Problem (2RP), and afterwards calculates a worst-case scenario \(c^{l+1}\in U\) by
The optimal value of Problem (9) is the objective value of solution \(x^*\in X\) and therefore an upper bound for Problem (2RP). Afterwards new variables \(y^{l+1}\) and the constraint
are added to Problem (8) and we iterate the latter procedure until
Clearly a solution \((x^*,\mu ^*)\) fulfilling the latter condition is optimal for Problem (2RP). Following the proof of Proposition 1 the worst-case scenario in (9) can be calculated by Algorithm 1. This can be done since we do not consider uncertainty in the constraints, while in the more general framework in [73] this is not possible.
The main difference of the latter procedure to our branch and bound algorithm is that in a branch and bound node only a subset of first-stage variables are fixed while the rest are relaxed. Then we use Algorithm 1 to calculate a lower bound for the given fixations. In the CCG procedure in each iteration a first-stage solution is calculated by Problem (8) and therefore all variables are fixed when Algorithm 1 is applied to calculate the worst-case scenario. Nevertheless the number of constraints and the number of variables of Problem (8) increase iteratively, since each second-stage variable has to be duplicated in each iteration, while in the branch and bound procedure we always iterate over the same number of first-stage variables. In Sect. 3.2.1 we will compare both algorithms on benchmark instances of the uncapacitated single-allocation hub location problem and the capital budgeting problem.
3 Applications
3.1 The uncapacitated single-allocation hub location problem with uncertain demands
In this section the oracle-based branch and bound algorithm is exemplarily applied to the single-allocation hub location problem which can be naturally defined as a two-stage problem. Furthermore due to its quadratic objective function it perfectly fits into the non-linear framework.
Hub-location problems address the strategic planning of a transportation network with many sources and sinks. In many applications sending all commodities over direct connections would be too expensive in operation. Instead, some locations are considered to serve as transshipment points and are then called hubs. Thus, strongly consolidated transportation links are established. The bundling of shipments usually outweighs the additional costs of hubs and detours. Important applications of this problem arise in air freight [50], postal and parcel transport services [41], telecommunication networks [52] and public transport networks [59]. The recent surveys of [3, 35] provide a comprehensive overview of the various variations and solution approaches of the hub location problem.
The main source of uncertainty in single-allocation hub location problems are demand fluctuations. Thus, it is important to include this uncertainty when deciding hub locations and allocations of the nodes to the hubs. Installing a hub is a long-term decision which lasts for many years or even for several decades. Nonetheless, the allocation to the hub nodes are mid-to-short-term decisions as they can be changed over time. In [62] the variable allocation variant for single-allocation hub location problems under stochastic demand uncertainty is proposed.
We consider a directed graph \(G=(N,A)\), where \(N = \{1,2, \ldots , n\}\) corresponds to the set of nodes that denote the origins, destinations, and possible hub locations, and A is a set of arcs that indicate possible direct links between the different nodes. Let \(w_{ij}\ge 0\) be the amount of flow to be transported from node i to node j and \(d_{ij}\) the distance between two nodes i and j. We denote by \(O_i=\sum _{j\in N}w_{ij}\) and \(D_i=\sum _{j\in N}w_{ji}\) the total outgoing flow from node i and the total incoming flow to node i, respectively. For each \(k\in N\), the value \(f_{k}\) represents the fixed set-up cost for locating a hub at node k. The cost per unit of flow for each path \(i-k-m-j\) from an origin node i to a destination node j passing through hubs k and m respectively, is \(\chi d_{ik}+\alpha d_{km}+\delta d_{m j}\), where \(\chi \), \(\alpha \), and \(\delta \) are the nonnegative collection, transfer, and distribution costs respectively and \(d_{ik}\), \(d_{km}\), and \(d_{m j}\) are the distances between the given pairs of nodes. Typically \(\alpha \le \min \left\{ \chi , \delta \right\} \) since otherwise using a hub would not be beneficial. Note that if hub nodes are fully interconnected, every path between an origin and a destination node will contain at least one and at most two hubs. The SAHLP consists of selecting a subset of nodes as hubs and assigning the remaining nodes to these hubs such that each spoke node is assigned to exactly one hub with the objective of minimizing the overall costs of the network.
To formulate the SAHLP, we follow the first formulation of this problem introduced by O’Kelly [60]. Two types of decision variables are introduced. First, the
variables indicate whether a node is used as a hub in the transportation network. Second, the
variables show how the nodes are allocated to the hub nodes. SAHLP can then be formulated as the following binary quadratic program:
The objective is to minimize the total costs of the network which includes the costs of setting up the hubs, the costs of collection and distribution of items between the spoke nodes and the hubs, and the costs of transfer between the hubs. Constraints (11) indicate that each node i is allocated to precisely one hub (i.e. single allocation) while Constraints (12) enforce that node i is allocated to a node k only if k is selected as a hub node. The binary conditions are enforced by Constraints (13).
In order to solve SAHLP, many solution methods have been proposed in the literature. The classical approach to obtain an exact solution is to linearize the quadratic objective function. In [41, 66] two mixed-integer linear programming (MILP) formulations for the problem have been proposed which are based on a path and a flow representation, respectively. The path-based formulation in [66] has \(O(|N|^4)\) variables and \(O(|N|^3)\) constraints and its linear programming (LP) relaxation was shown to provide tight lower bounds. However, due to the large number of variables and constraints, the path-based formulation can only be solved for instances of relatively small sizes. Alternatively, the flow-based formulation of [41] uses only \(O(|N|^3)\) variables and \(O(|N|^2)\) constraints to linearize the problem. To formulate the flow-based SAHLP model (SAHLP-flow), new variables \(z_{ikm}\) are defined as the total amount of flow originating at node i and routed via hubs located at nodes k then m, respectively. SAHLP-flow is formulated as
Similar to SAHLP, the objective function minimizes the hub setup costs, the costs of collection and distribution, and the inter-hub transfer costs. Besides Constraints (11), (12), (13) which are also used in SAHLP, Constraints (14) are flow balance constraints while Constraints (15) ensure that a flow is possible from spoke i to hub k only if node i is allocated to hub k; see [38]. Finally, Constraints (16) indicate the non-negativity restriction on the variables z.
The presented flow-based formulation is typically regarded to be the most effective linearized formulation in order to obtain exact solutions for the single-allocation hub location problem. In our computations we use this simple solution method to solve Step 4 in Algorithm 1. Note that although in the flow-based formulation the uncertain parameters \(w_{ij}\) appear in the constraints, we can use this formulation as an oracle in our algorithm while other methods which require linear programming formulations without uncertainty in the constraints can not make use of it.
The SAHLP splits up naturally in first- and second-stage problems as the decision variables in the SAHLP are subject to different planning horizons as discussed above. Therefore, the two-stage robust SAHLP can be modeled as follows:
where
We assume that \(U\subset \mathbb {R}_+^{n^2}\) is a convex uncertainty set. Note that this classical formulation is a quadratic two-stage robust problem. To solve Problem (SAHLP-2RP) we use the branch and bound procedure described in Sect. 2. To this end lower bounds can be calculated by Algorithm 1 implementing the flow linearization SAHLP-flow in CPLEX [49] to solve the oracle in Step 4. The variable fixations in each node of the branch and bound tree can be added as constraints to the SAHLP-flow formulation.
3.1.1 Computational results
In this section we apply the branch and bound method derived in Sect. 2.1 and the CCG method presented in Sect. 2.2 to the SAHLP. Both algorithms were implemented in C++. For the branch and bound procedure we calculate the lower and upper bounds by Algorithm 1 as discussed in the previous sections. The dual solution \({\bar{x}}\) is calculated as presented in (6). The branching is performed on the variable \({\bar{x}}_i\) which is the closest to 0.5. A feasible solution is calculated by rounding the entries of \({\bar{x}}\) to the closest integer value. Note that by this rounding procedure we always obtain a feasible first-stage solution for the SAHLP since we do not have restrictions on the first-stage variables. For the selection of the next branch and bound node to be processed we use the best-first strategy, i.e. the node with the smallest dual bound is processed next.
For the CCG algorithm we implemented Problem (8) in CPLEX 12.8 while Problem (9) is solved by Algorithm 1. In Algorithm 1 the dual problem in Step 3 is solved by CPLEX 12.8 [49]. As deterministic oracle in Step 4 we use the flow linearization SAHLP-flow presented in Sect. 3.1 which was also implemented in CPLEX 12.8. After termination of Algorithm 1 we delete all solutions z from the calculated set \(Z'\) which have a non-zero slack in the dual problem in Step 3, i.e. for which \(f(z,c^*) > \mu ^*\) in the last iteration of Algorithm 1. By dualizing the dual problem in Step 3 it can be shown that the optimal value does not change by throwing out all calculated solutions with non-zero slack.
Generation of random instances We generated random instances as follows: As basis for our instances we use a selection of instances of the AP and the CAB datasets which were intensively studied in the hub location literature. The AP instances are based on the mail flows of Australia Post and were introduced in [41]. The CAB instances contain airline passenger interactions between 25 major cities in the United States of America and were first studied in [60]. Both datasets can be found in [8]. Since there is only one CAB instance available, we introduce three additional instances (cab1 to cab3) by varying the demand values as follows: For each node pair \(i,j\in N\), the demand values are drawn randomly from the interval \([0.01 {\bar{w}}_{ij}, 10 {\bar{w}}_{ij}]\), where \({\bar{w}}_{ij}\) is the demand value of the original cab instance. The number of locations n together with its pairwise distances \(d_{ij}\) are given by the instance data. The set-up costs for hub locations are also given by the instance data in case of the AP instances. According to [4], the set-up cost at node k are set to \(15 \log (O_k)\) for the CAB instances. The collection, transfer and distribution costs are set to \(\chi =3\), \(\alpha =0.75\) and \(\delta = 2\) for the AP instances while for the CAB instances \(\chi =1\), \(\delta =1\) and \(\alpha \) is varied in \(\left\{ 0.2,1\right\} \). For each instance and each \(\varGamma \in \left\{ 0.02n^2, 0.1n^2\right\} \), rounded down if fractional, we generate 10 random budgeted uncertainty sets which are defined by
Here \({\bar{w}}\) are the flows given by the AP or CAB instances, respectively, while \({\hat{w}}_{ij}\) is chosen randomly in \([0,\bar{w}_{ij}]\) for each \(i,j\in N\), i.e. the change in demand can be at most \(100\%\) of the given mean \({\bar{w}}_{ij}\).
Analysis of results The results for the branch and bound procedure are presented in Tables 1 and 2. Each row shows the average over all 10 random instances of the following values from left to right: The instance name; the number of locations n for the AP instances; the value \(\varGamma \) of the budgeted uncertainty set \(U_\varGamma \); the value of \(\alpha \) for the CAB instances; the gap \(\varDelta _{\text {det}}\) in %, i.e. the percental difference between the optimal value of Problem (2RP) and the deterministic problem with weights \({\bar{w}}\); the total solution time t in seconds; the number of nodes solved in the branch and bound tree; the percental difference \(\varDelta _{\text {root}}\) of the upper bound and the lower bound calculated for the root problem of the branch and bound tree; the total number of oracle calls; the average number of iterations \(i_{\text {lb}}\) of Algorithm 1 to calculate the lower bounds; the average number of iterations \(i_{\text {ub}}\) of Algorithm 1 to calculate the upper bounds; the number of solutions returned by the branch and bound method or the number of iterations of the CCG, respectively; the average percental difference \({{\bar{\varDelta }}}\) (over 10 random scenarios in \(U_\varGamma \)) between the best solution in \(Z'\) and the deterministic optimal solution in each scenario. To be more precicely, to obtain the value \({{\bar{\varDelta }}}\) we generate 10 random scenarios in \(U_\varGamma \) by the following procedure: We first create \(n^2\) equally distributed random numbers \(s_{i}\) in \([0,\varGamma ]\) and define \(s_0:=0\). Assume the numbers are given in increasing order. We then define \(\delta _i:= s_i-s_{i-1}\). If \(\delta \le {\mathbf 1}\) is not true we start the procedure again. The random scenario is then given by w with
After generating 10 random scenarios \(w^1,\ldots w^{10}\), in each scenario we compare the costs of the best solution in \(Z'\) to the costs of the optimal solution in the scenario, i.e. for the optimal first-stage solution \({\bar{x}}\) we define
and set \({{\bar{\varDelta }}}\) to the average of all \(\varDelta _l\). For the CCG algorithm we define \(Z'\) as the set of solutions calculated in the last iteration by Problem (8). Note that since the set of optimal second-stage solutions in \(Z'\) is not unique and especially may not be the same for both algorithms, the value of \({{\bar{\varDelta }}}\) can be different for the branch and bound procedure and for the CCG.
The results for the AP instances are shown in Table 1. The gap \(\varDelta _{\text {det}}\) increases with \(\varGamma \) and with the dimension. The number of calculated nodes in the branch and bound tree is in most cases close to 1 and seems to remain constant with increasing dimension. Nevertheless the run-time increases with the dimension and with \(\varGamma \) which is mainly due to the increasing run-time of Algorithm 1. Here with higher dimension the calculation time of the deterministic problem increases, while with increasing \(\varGamma \) the number of iterations of Algorithm 1 increases which was already observed in [30, 42]. Another positive observation is that the root gap is very small in general, mostly 0 and never larger than \(34\%\). The number of iterations of Algorithm 1 is larger for the calculations of the lower bound than for the upper bound, which is because not all hub variables are fixed in the former case. Nevertheless the number of iterations is very low and never larger than 2.2 for the lower bound and 1.2 for the upper bound. This leads to a very small number of policies calculated by Algorithm 1 and to a very small number of oracle calls in total. Finally the values of \({{\bar{\varDelta }}}\) indicate that the returned second-stage solutions are optimal in most of the scenarios, as \({{\bar{\varDelta }}}\) is 0 for most of the instances. Note that for larger dimensions due to the time consuming computations we did not determine the \({{\bar{\varDelta }}}\) values.
The computations for the CAB instances are presented in Table 2. The results look similar to the results related to the AP instances. The gap \(\varDelta _{\text {det}}\) is larger for larger values of \(\alpha \) and \(\varGamma \). The root gap is again very small for most of the instances and never larger than \(30\%\). The number of nodes in the branch and bound tree is very low, but in general higher than that for the AP instances. Nevertheless it is never larger than \(8\%\) in average. In contrast to the AP instances the total run-time does not increase much with increasing \(\varGamma \). Instead the run-time increases significantly with increasing \(\alpha \). The reason for this is the larger number of iterations performed by Algorithm 1 to calculate the lower and the upper bounds. Comparing the calculated solutions to the optimal values on random scenarios, the percental difference \({{\bar{\varDelta }}}\) is again very close to 0 for all of the instances.

Development of the runtime in seconds of both algorithms
All results for the CCG algorithm are presented in Tables 3 and 4. Each row shows the average over all 10 random instances of the following values from left to right: The instance name; the number of locations n for the AP instances; the value \(\varGamma \) of the budgeted uncertainty set \(U_\varGamma \); the value of \(\alpha \) for the CAB instances; the total solution time t in seconds; the average time \(t_{\text {lb}}\) in seconds to solve the lower bound Problem (8); the average time \(t_{\text {ub}}\) in seconds to solve the upper bound Problem (9); the number of solutions l calculated by Problem (8) which is equal to the number of iterations of the CCG algorithm; the average percental difference \({{\bar{\varDelta }}}\) (over 10 random scenarios \({\tilde{w}}\in U_\varGamma \)) between the best of the solutions calculated in the last iteration by Problem (8) and the deterministic optimal solution in each scenario w; see the definition of \({{\bar{\varDelta }}}\) above.
The results of the CCG algorithm are less convincing. We could solve AP instances up to 50 locations in reasonable time, while for the branch and bound procedure we managed to solve instances with 90 locations. Furthermore the runtime is at least three times as large as for the branch and bound method for most of the instances and even larger for growing dimension. The same effect holds for the CAB instances. Here the runtime is much higher for the instances with \(\alpha =1\). The large runtime of the CCG is mainly caused by the lower bound problem (8). The calculations of the upper bound, solved by Algorithm 1, are less time consuming, at most 6 s in average. The number of calculated solutions, i.e., the number of iterations, is slightly larger than that for the branch and bound procedure but still very small, never larger than 5. A positive effect is that the performance \({{\bar{\varDelta }}}\) of the calculated solutions on random scenarios is very close to 0 for all instances.
In Fig. 1 we compare the runtimes in seconds of both algorithms. The results show that the runtime of the CCG method increases rapidly for more than 25 locations and is always much larger than the runtime of the branch and bound method. For the larger value of \(\varGamma \) the run-time of the CCG method explodes if n is larger than 40.
Analysis of results for hard instances For the realistic instances calculated above the number of nodes in the branch and bound tree, the number of iterations of the CCG as well as the number of iterations of Algorithm 1 is very low. The same effect occurs for most of the randomly generated instances we tested. To test the boundaries of our algorithm we generated further instances which are generated as the instances above with the only difference that the values \({\hat{w}}_{ij}\) are randomly drawn in \([0,10 w_{ij}]\), i.e. the uncertainty sets are much larger. Furthermore for the AP instances we varied \(\alpha \in \left\{ 0.75, 1.5\right\} \). The results for the branch and bound procedure are presented in Table 5. For the CCG algorithm we could not even solve instances with 25 locations in reasonable time.
The results in Table 5 show that the number of nodes in the branch and bound tree and the number of iterations of Algorithm 1 are larger than those for the realistic instances above but still never get larger than 33 and 12 respectively. Both values are larger for the CAB instances. The number of nodes decreases with increasing dimension and with increasing \(\alpha \). The same holds for the root gap which is lower than that for the realistic instances for most of the instances. Clearly the gap \(\varDelta _{\text {det}}\) is much larger than for the smaller uncertainty sets. Similar to the results above the number of iterations for the calculations of the lower and the upper bounds and therefore the number of total oracle calls seem to be independent of the dimension. The same holds for the number of calculated second-stage solutions. The performance of these solutions over random scenarios is worse than for the realistic instances above, but still very small and never larger than \(0.3\%\). For the CAB instances it is larger for \(\alpha =1\). For the CCG algorithm the results are not very convincing. Even for instances with 20 locations finding an optimal solution took more than 16 hours in average for \(\alpha =0.75\). Interestingly here the instances with smaller \(\alpha \) were harder to solve (Table 6).

Development of the parameters of the branch and bound procedure over \(\alpha \) for the 20LL instance with random deviations \({\hat{w}}_{ij}\in [0,10 {\bar{w}}_{ij}]\), \(\chi =3\) and \(\delta = 2\). The graphs in the right plot are presented in logarithmic scale

The optimal solution of the nominal scenario \(\bar{w}\) (top left) and the optimal two-stage robust solution presented by all 3 solutions in \(Z'\) returned by Algorithm 1 in the optimal branch and bound node for a 20LL instance with \(\alpha =1.5\) and \(\varGamma =40\)
In Fig. 2 we present the development of several problem parameters over \(\alpha \) for the 20LL instance. All values are the average over 10 random uncertainty sets with random deviations \({\hat{w}}_{ij}\in [0,10 {\bar{w}}_{ij}]\). Cost parameters are defined as above by \(\chi =3\) and \(\delta = 2\). Figure 2 shows that the number of nodes in the branch and bound tree rapidly decreases with increasing \(\alpha \). Furthermore the number of iterations performed by Algorithm 1 to calculate the upper bounds and the number of returned policies in \(Z'\) increases until \(\alpha = 2\) and afterwards slowly decreases. The number of iterations performed by Algorithm 1 to calculate the lower bounds is nearly constant and slightly decreases. The root gap of the branch and bound procedure decreases with increasing \(\alpha \) and tends to 0. In contrast to this the performance of the returned policies in \(Z'\), indicated by \({{\bar{\varDelta }}}\), seems to get worse with increasing \(\alpha \), and seems to be constant for \(\alpha \ge 2\). Nevertheless all \({{\bar{\varDelta }}}\) values are very small and remain close to \(0.2\%\) for \(\alpha \ge 2\).
In summary the results show that the number of nodes of the branch and bound procedure and the number of iterations of Algorithm 1 are very low for the realistic instances of the SAHLP. Hence we could solve instances with up to 90 locations in less than 4 h. Furthermore the number of calculated policies \(|Z'|\) is very low for the hub location problem but they perform very well on random scenarios. For the larger uncertainty sets, the number of nodes of the branch and bound procedure and the number of iterations of Algorithm 1 is larger but is still very low compared to the dimension of the problem. Furthermore the latter values seem to be nearly constant with increasing dimension. The runtime and the number of iterations of Algorithm 1 increase with increasing \(\alpha \) while the number of nodes of the branch and bound tree decreases.
An example of an optimal solution of a random instance with 20 locations and \({\hat{w}}_{ij}\) randomly drawn in \([0,10 {\bar{w}}_{ij}]\) is shown in Fig. 3. The figure shows the optimal solution of the nominal scenario \({\bar{w}}\) and the three returned solutions in \(Z'\). The number of hubs is larger in the two-stage robust solution than in the deterministic solution since for flexible re-allocation after a scenario occured it can be beneficial to build further hubs in advance. Furthermore the figure indicates that a hub which is used by many locations in the deterministic solution may not be used by the second-stage reactions of the two-stage solution.
3.2 The capital budgeting problem
In this section the oracle-based branch and bound algorithm and the CCG algorithm are exemplarily applied to the two-stage robust capital budgeting problem studied in [5] which can be naturally defined as a two-stage problem.
The capital budgeting problem (CB) is an investment planning problem, where a subset of n projects has to be selected. Each project \(i\in [n]\) has costs \(c_i\) and an uncertain profit \(\tilde{p}_i\) which depends on a set of m risk factors \(\xi \in U\subset \mathbb {R}^m\). The profits are given by \({\tilde{p}}_i(\xi ) = (1+\frac{1}{2}Q_i^\top \xi ){\bar{p}}_i\), where \({\bar{p}}_i\) are the nominal profits and \(Q_i\) is the i-th row of the factor loading matrix. For each project the company can decide if it wants to invest in the project here-and-now or if it wants to wait until the risk factors are known. If an investment is postponed to the second stage the profit generated by the project is \(f{\tilde{p}}_i\) where \(0\le f<1\). The costs of a project are the same in the first and the second stage. The company has a given budget B for investing in projects and can additionally take out a loan of volume \(C_1\) with costs \(\lambda \) in the first stage and a loan of volume \(C_2\) with costs \(\lambda \mu \) in the second stage where \(\mu > 1\). The aim is to maximize the worst-case profit. This problem can be formulated as
where \(X=\left\{ (x,x_0)\in \{ 0,1 \}^{n+1} \ | \ c^\top x \le B + C_1x_0\right\} \) is the set of feasible first-stage solutions and
is the set of feasible second-stage solutions. For more details see [5].
3.2.1 Computational results
In this section we apply the branch and bound method derived in Sect. 2 and the CCG method presented in Sect. 2.2 to the capital budgeting problem. The implementation of both algorithms is the same as in Sect. 3.1. As deterministic oracle in Step 4 of Algorithm 1 we implemented the deterministic version of the integer programming formulation of Problem (17) in CPLEX 12.8. Note that since we consider a maximization problem here the terms upper bound and lower bound are swapped.
We compare both variants of calculating a dual solution \({\bar{x}}\) presented in (6) and (7) which we denote by DualSol-Avg and DualSol-Opt, respectively. The branching is performed on the variable which is the closest to 0.5. A feasible first-stage solution is obtained by rounding the entries of \({\bar{x}}\) to the closest integer value. If this solution is not feasible we choose the first solution which was returned by Algorithm 1 after the calculation of the upper bound.
For our tests we use the original instances studied in [5]. The authors generate random instances with \(n\in \left\{ 10,20,30,40,50,100\right\} \) projects and \(m\in \left\{ 4,6,8\right\} \) risk factors. For each combination 20 instances are generated. The uncertainty set is given by the box \(U=[-1,1]^m\). For more details see [5].
Analysis of results The results for the branch and bound procedure are presented in Tables 7 and 8. Each row in Table 7 shows the average over all 20 instances of the following values from left to right: The number of projects n; the number of risk factors m; the total number of nodes solved in the branch and bound tree; the total number of oracle calls; the total time t in seconds to solve the instance to optimality; the percentage of instances which could be solved to optimality during the timelimit of 7200 s.
Each row in Table 8 shows the average over all 20 instances of the following values from left to right: The number of projects n; the number of risk factors m; the gap \(\varDelta _{\text {det}}\) in %; the root-gap \(\varDelta _{\text {root}}\) in %; the average number of iterations \(i_{\text {ub}}\) of Algorithm 1 to calculate the upper bounds; the average number of iterations \(i_{\text {lb}}\) of Algorithm 1 to calculate the lower bounds; the number of solutions \(|Z'|\) Algorithm 1 returned for the optimal first-stage solution x; the average percental difference \({{\bar{\varDelta }}}\) (over 10 random scenarios in U) between the best solution in \(Z'\) and the deterministic optimal solution in each scenario; see Sect. 3.1 for a precise definition. All values are presented for both variants, DualSol-Avg and DualSol-Opt. The bold-faced values indicate which of the two variants is better.
The results in Table 7 indicate that the DualSol-Opt variant performs much better on most of the instances. The larger computational effort which is made to calculate the optimal dual solution does not have an impact on the total run-time since the number of processed nodes in the branch and bound tree is much smaller. For both variants the number of nodes processed in the branch and bound tree and the number of oracle calls are significantly larger than for the SAHLP; compare to Sect. 3.1. Both values and therefore the run-time increase with increasing m. Interestingly the instances with dimension \(n=30\) and \(n=40\) seem to be the hardest to solve. The total run-time for the instances with \(m=8\) is very large. Nevertheless for most of the configurations all instances could be solved during the timelimit.
In contrast to the latter results, the values in Table 8 are not much larger than for the SAHLP. The root-gap is better for the DualSol-Opt variant for most of the instances but is very small for both methods and at most \(8\%\). The number of iterations performed to calculate the upper and the lower bounds and the number of calculated solutions are slightly larger than for the SAHLP but still very small. All values seem to be independent of the size of the dimension and the number of risk factors. The gap \({{\bar{\varDelta }}}\) is slightly larger than for the SAHLP but still at most \(1\%\).
The results for the CCG are presented in Table 9. Each row shows the average over all 20 instances of the following values from left to right: The number of projects n; the number of risk factors m; the percentage of instances which could be solved to optimality during the timelimit of 7200 s, the optimality gap of the CCG after 7200 s; the total solution time t in seconds (exceeding the timelimit is counted as 7200 s); the average solution time \(t_{\text {ub}}\) to calculate the upper bounds; the average solution time \(t_{\text {lb}}\) to calculate the lower bounds; the total number of iterations; the average percental difference \({{\bar{\varDelta }}}\) (over 10 random scenarios in U) between the best solution in \(Z'\) and the deterministic optimal solution in each scenario. Here \(Z'\) is the set of solutions calculated by Algorithm 1 in the last iteration. Note that we stopped the calculations for each instance after 7200 s, since for several instances the memory used by CPLEX was too large. Therefore the run-times can not be compared to the run-times of the branch and bound method.
As for the SAHLP the results of the CCG algorithm are less convincing. The number of instances solved to optimality during the timelimit is much smaller than for the branch and bound method, sometimes smaller than \(55\%\). Nevertheless the optimality gap after the timelimit is very small, at most \(3.6\%\). The number of iterations is small for most of the instances and seems to be independent of the size of the dimension. It increases with increasing m. As for the SAHLP most of the run-time is used to calculate the upper bound problem. The gap \({{\bar{\varDelta }}}\) is smaller than \(1\%\) for most of the instances, as it is the case for the branch and bound method.
To summarize, for the two-stage robust capital budgeting problem the number of nodes processed in the branch and bound tree and the number of oracle calls is significantly larger than for the SAHLP. Nevertheless since the deterministic problem can be solved much faster the total run-time is not larger for the instances with small m. Although most of the instances could be solved during the timelimit by the branch and bound method, the run-time for instances with \(m=8\) can be very large. But still the branch and bound method solves significantly more instances to optimality than the CCG. Nevertheless the optimality gap of the CCG after the timelimit is very small.
4 Conclusion
In this paper we derive a branch and bound procedure to solve robust binary two-stage problems for a wide class of objective functions. We show that the oracle-based column generation algorithm presented in [30] can be adapted to calculate lower bounds which can be used in a classical branch and bound procedure. The whole procedure can be implemented for any algorithm solving the underlying deterministic problem. Furthermore we apply the column-and-constraint generation algorithm studied in [73] to our problem and show that again the oracle-based algorithm in [30] can be used to solve one step of the procedure. We test both algorithms on classical benchmark instances of the single-allocation hub location problem and on random instances of the capital budgeting problem. We show that the number of nodes in the branch and bound tree, the number of iterations of the CCG algorithm as well as the number of iterations of the column generation algorithm are very low for the SAHLP while the number of branch and bound nodes increases significantly for the capital budgeting problem. Nevertheless our branch and bound procedure is much faster than the CCG algorithm and can solve larger instances in reasonable time. Furthermore our computational results indicate that for both algorithms the precalculated second-stage solutions perform very well on random scenarios.
References
Adjiashvili, D., Stiller, S., Zenklusen, R.: Bulk-robust combinatorial optimization. Math. Program. 149(1–2), 361–390 (2015)
Aissi, H., Bazgan, C., Vanderpooten, D.: Min–max and min–max regret versions of combinatorial optimization problems: a survey. Eur. J. Oper. Res. 197(2), 427–438 (2009)
Alumur, S.A., Kara, B.Y.: Network hub location problems: the state of the art. Eur. J. Oper. Res. 190(1), 1–21 (2008)
Alumur, S.A., Nickel, S., Saldanha-da Gama, F.: Hub location under uncertainty. Transp. Res. Part B Methodol. 46(4), 529–543 (2012)
Arslan, A., Detienne, B.: Decomposition-based approaches for a class of two-stage robust binary optimization problems. Technical Report (2019)
Atamtürk, A., Zhang, M.: Two-stage robust network flow and design under demand uncertainty. Oper. Res. 55(4), 662–673 (2007)
Ayoub, J., Poss, M.: Decomposition for adjustable robust linear optimization subject to uncertainty polytope. CMS 13(2), 219–239 (2016)
Beasley, J.E.: OR library (2012)
Ben-Tal, A., Den Hertog, D., Vial, J.P.: Deriving robust counterparts of nonlinear uncertain inequalities. Math. Program. 149(1–2), 265–299 (2015)
Ben-Tal, A., El Ghaoui, L., Nemirovski, A.: Robust Optimization. Princeton University Press, Princeton (2009)
Ben-Tal, A., Golany, B., Nemirovski, A., Vial, J.P.: Retailer-supplier flexible commitments contracts: a robust optimization approach. Manuf. Serv. Oper. Manag. 7(3), 248–271 (2005)
Ben-Tal, A., Goryashko, A., Guslitzer, E., Nemirovski, A.: Adjustable robust solutions of uncertain linear programs. Math. Program. 99(2), 351–376 (2004)
Ben-Tal, A., Nemirovski, A.: Robust convex optimization. Math. Oper. Res. 23(4), 769–805 (1998)
Ben-Tal, A., Nemirovski, A.: Robust solutions of uncertain linear programs. Oper. Res. Lett. 25(1), 1–13 (1999)
Bertsimas, D., Brown, D.B., Caramanis, C.: Theory and applications of robust optimization. SIAM Rev. 53(3), 464–501 (2011)
Bertsimas, D., Caramanis, C.: Finite adaptability in multistage linear optimization. IEEE Trans. Autom. Control 55(12), 2751–2766 (2010)
Bertsimas, D., Dunning, I.: Multistage robust mixed-integer optimization with adaptive partitions. Oper. Res. 64(4), 980–998 (2016)
Bertsimas, D., Georghiou, A.: Binary decision rules for multistage adaptive mixed-integer optimization. Math. Program. 167, 1–39 (2014)
Bertsimas, D., Georghiou, A.: Design of near optimal decision rules in multistage adaptive mixed-integer optimization. Oper. Res. 63(3), 610–627 (2015)
Bertsimas, D., Goyal, V.: On the power and limitations of affine policies in two-stage adaptive optimization. Math. Program. 134(2), 491–531 (2012)
Bertsimas, D., Goyal, V.: On the approximability of adjustable robust convex optimization under uncertainty. Math. Methods Oper. Res. 77(3), 323–343 (2013)
Bertsimas, D., Iancu, D.A., Parrilo, P.A.: Optimality of affine policies in multistage robust optimization. Math. Oper. Res. 35(2), 363–394 (2010)
Bertsimas, D., Litvinov, E., Sun, X.A., Zhao, J., Zheng, T.: Adaptive robust optimization for the security constrained unit commitment problem. IEEE Trans. Power Syst. 28(1), 52–63 (2013)
Bertsimas, D., de Ruiter, F.J.: Duality in two-stage adaptive linear optimization: faster computation and stronger bounds. INFORMS J. Comput. 28(3), 500–511 (2016)
Bertsimas, D., Shtern, S.: A scalable algorithm for two-stage adaptive linear optimization. Technical Report (2018)
Bertsimas, D., Sim, M.: Robust discrete optimization and network flows. Math. Program. 98(1–3), 49–71 (2003)
Bertsimas, D., Sim, M.: The price of robustness. Oper. Res. 52(1), 35–53 (2004)
Boni, O., Ben-Tal, A.: Adjustable robust counterpart of conic quadratic problems. Math. Methods Oper. Res. 68(2), 211 (2008)
Buchheim, C., Kurtz, J.: Min–max–min robustness: a new approach to combinatorial optimization under uncertainty based on multiple solutions. Electron. Notes Discrete Math. 52, 45–52 (2016)
Buchheim, C., Kurtz, J.: Min–max–min robust combinatorial optimization. Math. Program. 163(1), 1–23 (2017)
Buchheim, C., Kurtz, J.: Complexity of min–max–min robustness for combinatorial optimization under discrete uncertainty. Discrete Optim. 28, 1–15 (2018)
Buchheim, C., Kurtz, J.: Robust combinatorial optimization under convex and discrete cost uncertainty. EURO J. Comput. Optim. 6(3), 211–238 (2018)
Buchheim, C., Pruente, J.: K-adaptability in stochastic combinatorial optimization under objective uncertainty. Eur. J. Oper. Res. 277, 953–963 (2019)
Calafiore, G.C.: Multi-period portfolio optimization with linear control policies. Automatica 44(10), 2463–2473 (2008)
Campbell, J.F., O’Kelly, M.E.: Twenty-five years of hub location research. Transp. Sci. 46(2), 153–169 (2012)
Campi, M.C., Calafiore, G.: Decision making in an uncertain environment: the scenario-based optimization approach. In: Multiple Participant Decision Making, pp. 99–111. Advanced Knowledge International (2004)
Chen, X., Zhang, Y.: Uncertain linear programs: extended affinely adjustable robust counterparts. Oper. Res. 57(6), 1469–1482 (2009)
Correia, I., Nickel, S., Saldanha-da Gama, F.: Single-assignment hub location problems with multiple capacity levels. Transp. Res. Part B Methodol. 44(8), 1047–1066 (2010)
El Ghaoui, L., Lebret, H.: Robust solutions to least-squares problems with uncertain data. SIAM J. Matrix Anal. Appl. 18(4), 1035–1064 (1997)
El Ghaoui, L., Oustry, F., Lebret, H.: Robust solutions to uncertain semidefinite programs. SIAM J. Optim. 9(1), 33–52 (1998)
Ernst, A.T., Krishnamoorthy, M.: Efficient algorithms for the uncapacitated single allocation p-hub median problem. Locat. Sci. 4(3), 139–154 (1996)
Eufinger, L., Kurtz, J., Buchheim, C., Clausen, U.: A robust approach to the capacitated vehicle routing problem with uncertain costs. Technical Report (2018)
Fischetti, M., Monaci, M.: Light robustness. In: Ahuja, R.K., et al. (eds.) Robust and Online Large-Scale Optimization, pp. 61–84. Springer, Berlin (2009)
Gabrel, V., Lacroix, M., Murat, C., Remli, N.: Robust location transportation problems under uncertain demands. Discrete Appl. Math. 164, 100–111 (2014)
Hadjiyiannis, M.J., Goulart, P.J., Kuhn, D.: A scenario approach for estimating the suboptimality of linear decision rules in two-stage robust optimization. In: 2011 50th IEEE Conference on Decision and Control and European Control Conference, pp. 7386–7391. IEEE (2011)
Hanasusanto, G.A., Kuhn, D., Wiesemann, W.: K-adaptability in two-stage robust binary programming. Oper. Res. 63(4), 877–891 (2015)
Iancu, D.A.: Adaptive robust optimization with applications in inventory and revenue management. Ph.D. Thesis, Massachusetts Institute of Technology (2010)
Iancu, D.A., Sharma, M., Sviridenko, M.: Supermodularity and affine policies in dynamic robust optimization. Oper. Res. 61(4), 941–956 (2013)
IBM Corporation: IBM ILOG CPLEX Optimization Studio V12.8.0 (2017)
Jaillet, P., Song, G., Yu, G.: Airline network design and hub location problems. Locat. Sci. 4(3), 195–212 (1996)
Jiang, R., Zhang, M., Li, G., Guan, Y.: Benders’ decomposition for the two-stage security constrained robust unit commitment problem. In: IIE Annual Conference. Proceedings, p. 1. Institute of Industrial and Systems Engineers (IISE) (2012)
Klincewicz, J.G.: Hub location in backbone/tributary network design: a review. Locat. Sci. 6(1), 307–335 (1998)
Kouvelis, P., Yu, G.: Robust Discrete Optimization and Its Applications. Springer, Berlin (1996)
Kuhn, D., Wiesemann, W., Georghiou, A.: Primal and dual linear decision rules in stochastic and robust optimization. Math. Program. 130(1), 177–209 (2011)
Liebchen, C., Lübbecke, M., Möhring, R., Stiller, S.: The concept of recoverable robustness, linear programming recovery, and railway applications. In: Ahuja, R.K., et al. (eds.) Robust and Online Large-Scale Optimization, pp. 1–27. Springer, Berlin (2009)
Marandi, A., Ben-Tal, A., den Hertog, D., Melenberg, B.: Extending the scope of robust quadratic optimization. Technical Report (2017)
Minoux, M.: On 2-stage robust lp with RHS uncertainty: complexity results and applications. J. Glob. Optim. 49(3), 521–537 (2011)
Nagy, Z.K., Braatz, R.D.: Robust nonlinear model predictive control of batch processes. AIChE J. 49(7), 1776–1786 (2003)
Nickel, S., Schöbel, A., Sonneborn, T.: Hub location problems in urban traffic networks. In: Pursula, M., Niittymäki, J. (eds.) Mathematical methods on optimization in transportation systems, pp. 95–107. Springer, Boston (2001)
O’Kelly, M.E.: A quadratic integer program for the location of interacting hub facilities. Eur. J. Oper. Res. 32(3), 393–404 (1987)
Postek, K., den Hertog, D.: Multistage adjustable robust mixed-integer optimization via iterative splitting of the uncertainty set. INFORMS J. Comput. 28(3), 553–574 (2016)
Rostami, B., Kämmerling, N., Buchheim, C., Naoum-Sawaya, J., Clausen, U.: Stochastic single-allocation hub location. Technical Report (2018)
Schöbel, A.: Generalized light robustness and the trade-off between robustness and nominal quality. In: Stein, O. (ed.) Mathematical Methods of Operations Research, pp. 1–31. Springer, Berlin (2014)
Shapiro, A.: A dynamic programming approach to adjustable robust optimization. Oper. Res. Lett. 39(2), 83–87 (2011)
Sion, M., et al.: On general minimax theorems. Pac. J. Math. 8(1), 171–176 (1958)
Skorin-Kapov, D., Skorin-Kapov, J., O’Kelly, M.: Tight linear programming relaxations of uncapacitated p-hub median problems. Eur. J. Oper. Res. 94(3), 582–593 (1996)
Soyster, A.L.: Convex programming with set-inclusive constraints and applications to inexact linear programming. Oper. Res. 21(5), 1154–1157 (1973)
Subramanyam, A., Gounaris, C.E., Wiesemann, W.: K-adaptability in two-stage mixed-integer robust optimization. Technical Report (2017)
Takeda, A., Taguchi, S., Tütüncü, R.H.: Adjustable robust optimization models for a nonlinear two-period system. J. Optim. Theory Appl. 136(2), 275–295 (2008)
Thiele, A., Terry, T., Epelman, M.: Robust linear optimization with recourse. Rapport Technique, pp. 4–37 (2009)
Vayanos, P., Kuhn, D., Rustem, B.: A constraint sampling approach for multi-stage robust optimization. Automatica 48(3), 459–471 (2012)
Yanıkoğlu, İ., Gorissen, B., den Hertog, D.: Adjustable robust optimization—a survey and tutorial. Available online at ResearchGate (2017)
Zeng, B., Zhao, L.: Solving two-stage robust optimization problems using a column-and-constraint generation method. Oper. Res. Lett. 41(5), 457–461 (2013)
Zhao, L., Zeng, B.: An exact algorithm for two-stage robust optimization with mixed integer recourse problems. submitted, available on Optimization-Online.org (2012)
Acknowledgements
Open Access funding provided by Projekt DEAL. We would like to thank the referees for their valuable comments which significantly improved the paper. Furthermore we thank Ayse Nur Arslan and Boris Detienne for providing us their instances on the capital budgeting problem. This work has been supported by the German Research Foundation (DFG) under Grant No. BU 2313/2 – CL 318/14.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kämmerling, N., Kurtz, J. Oracle-based algorithms for binary two-stage robust optimization. Comput Optim Appl 77, 539–569 (2020). https://doi.org/10.1007/s10589-020-00207-w
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-020-00207-w