
Abstract
Purpose
The social vulnerability index (SVI), developed by the Centers for Disease Control and Prevention, is a novel composite measure encompassing multiple variables that correspond to key social determinants of health. The objective of this review was to investigate innovative applications of the SVI to oncology research and to employ the framework of the cancer care continuum to elucidate further research opportunities.
Methods
A systematic search for relevant articles was performed in five databases from inception to 13 May 2022. Included studies applied the SVI to analyze outcomes in cancer patients. Study characteristics, patent populations, data sources, and outcomes were extracted from each article. This review followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines.
Results
In total, 31 studies were included. Along the cancer care continuum, five applied the SVI to examine geographic disparities in potentially cancer-causing exposures; seven in cancer diagnosis; fourteen in cancer treatment; nine in treatment recovery; one in survivorship care; and two in end-of-life care. Fifteen examined disparities in mortality.
Conclusion
In highlighting place-based disparities in patient outcomes, the SVI represents a promising tool for future oncology research. As a reliable geocoded dataset, the SVI may inform the development and implementation of targeted interventions to prevent cancer morbidity and mortality at the neighborhood level.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The incidence of cancer in the U.S. is projected to rise in part due to increased diagnosis in aging populations and minority groups [1]. With this rise in incidence, the annual national costs for cancer-related medical services and treatments is projected to swell from $185 billion in 2015 to $246 billion by 2030 [2]. Social determinants of health (SDOH), which are non-medical factors such as socioeconomic status (SES), race, and ethnicity that influence health outcomes, are known to contribute to disparities in cancer incidence and mortality [3,4,5,6,7]. Identifying and understanding health disparities in cancer patients can inform initiatives designed to prevent excess cancer morbidity and mortality, decrease economic costs to society, and promote health equity.
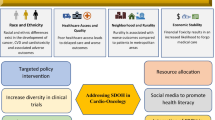
Intensive effort has been devoted to the collection of objective data measuring important social variables that impact health and quality of life. Examples of publicly accessible metrics include the Community Need Index [8], the Area Deprivation Index [9], the Distressed Communities Index [10], and the novel Social Vulnerability Index (SVI) [11]. Examples of SES-based metrics developed specifically for cancer registry data analyses include the Yost index [12] and the Yang index [13]. The SVI generally differs from these other indices in that it contains 15 different social variables and offers granular data for U.S. administrative units at the county and census tract-level (Fig. 1). Its multiple dimensions offer rich potential for comprehensive assessment of how SDOH may impact cancer care across broad geographic areas.

Social variables captured by the CDC/ATSDR SVI, categorized into four subthemes
Developed by the Centers for Disease Control and Prevention (CDC), the SVI was originally created to guide the allocation of government resources to vulnerable communities in the event of a natural or man-made disaster or a disease outbreak [11]. Vulnerable populations are defined as those who have special needs, and in the context of healthcare, these may include persons with a low SES, without a vehicle for transportation, and/or with limited English proficiency [11]. As a validated tool for disaster preparedness, recovery, and adaptation decisions [14], the SVI does not capture all SDOH such as insurance status, but it offers rich insight into many SDOH that are relevant to patient outcomes. It organizes data from the ACS into the subthemes of SES, household composition, minority status, and housing. Recently, the SVI was utilized in the assessment of SDOH on morbidity and mortality from the SARS-CoV-2 virus (COVID-19) and COVID-19 vaccine coverage [15, 16].
Previous studies have examined how various SDOH impact patients along the cancer care continuum, revealing greater cancer burden in vulnerable populations [17]. This longitudinal framework outlines cancer control areas beginning with primary prevention (e.g., exposures to risk factors) and secondary prevention (e.g., early detection, screening) and continuing onto diagnosis, treatment, survivorship care, and end-of-life care [18]. Health disparities due to social factors and neighborhood characteristics seem to impact nearly every aspect of this continuum from incidence to end-of-life [19,20,21,22]. The objective of this study was to explore innovative applications of the SVI to current oncology research through a literature review and to identify further research opportunities using the cancer care continuum framework.
Methods
This review was conducted in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines [23].
Eligibility criteria
The inclusion and exclusion criteria for study eligibility are listed in Supplementary Table S1. Studies deemed eligible for inclusion used the CDC SVI to measure any primary or secondary outcomes in the population of interest. No limiters were implemented in terms of specific data sources or outcome measures. The population of interest comprised patients identified as at risk for cancer, diagnosed with cancer, undergoing a therapeutic intervention for a cancer diagnosis, or under longitudinal surveillance for cancer recurrence.
Data sources
A systematic search for relevant articles was performed in MEDLINE (Ovid), Embase (Ovid), Web of Science Core Collection (Clarivate), Scopus (Elsevier), and PubMed (National Library of Medicine) from database inception to 13 May 2022. A medical research librarian (D.P.F.) developed and tailored the search strategy to each database. Controlled vocabulary (MeSH and Emtree) and natural language terms were selected for the concepts of social vulnerability and cancer. The full search strategy for each database is included in Supplementary Methods S1. Searches were limited to articles published in the English language, but no other limiters or published search filters were used. Gray literature resources including conference abstracts were included as an additional source for relevant articles.
EndNote X9 (Clarivate) was used to remove duplicate results. Deduplicated results were then uploaded to Rayyan, a free web application developed to facilitate collaborative systematic reviews.
Study selection
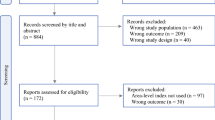
Three investigators (T.T., H.Q.D., and M.A.R.) independently screened the titles and abstracts of identified records using Rayyan. All records deemed potentially relevant by at least one investigator were retrieved for full-text review. Three investigators (T.T., H.Q.D., and M.A.R.) then independently assessed all full-text manuscripts for study eligibility and voted on their inclusion or exclusion. The classification of each article was based on a unanimous vote. For articles in disagreement, input from a fourth investigator (K.C.N.) was then solicited and incorporated into a decision-making process based on group consensus. Overlapping samples were also identified and resolved. In the circumstance that identical samples and analyses were presented in both a conference abstract and a journal article, the peer-reviewed publication was selected for inclusion. The reference lists of included articles were also examined to identify any additional relevant articles. The study selection process is summarized in the PRISMA flow diagram (Supplementary Figure S1).
Data extraction
A group of three investigators (T.T., M.A.R., and H.Q.D.) performed the data extraction process in which each included article was assigned to two of the three investigators for close review and data extraction. The following variables were extracted: study design, research question, data sources, patient population, use of the SVI, other SDOH measures, primary outcomes, secondary outcomes, and effect measures. Any discordance was resolved by group consensus with the supervision of a fourth investigator (K.C.N.).
Reporting quality assessment
Three investigators (T.T., M.A.R., and H.Q.D.) assessed the reporting quality of the included articles using a scoring worksheet adapted for the purposes of this review (Supplementary Methods S2). Developed for the appraisal of observational studies [24], the worksheet reflects the 22 items on the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) checklist [25].
For each item on the checklist, studies received one point for complete reporting, half a point for incomplete reporting, or zero points for no reporting. Based on the total average number of points, the quality of each study was classified as excellent (full 22 points), good (19–21 points), fair (14–18 points), and low (0–13 points). The reporting quality of each article was assessed and scored by two out of three investigators (T.T., M.A.R., and H.Q.D.), and the average of the individual scores determined the final quality classification. To receive a high score, studies must have had described efforts to address potential sources of bias, control for cofounding factors, and provide unadjusted and adjusted estimates [25].
Results
A total of 593 results were retrieved from the five databases (MEDLINE, n = 81; Embase, n = 160; Web of Science, n = 132; Scopus, n = 117; PubMed, n = 103). Following deduplication, 260 unique records were identified. Of the 73 full-text manuscripts assessed for study eligibility, 31 met all criteria for inclusion [26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56]. A summary of the 31 included studies is presented in Table 1, and their primary and secondary outcomes are shown in Supplementary Table S2. Of the 31 included studies, 28 (90.3%) executed a cross-sectional study design based on secondary data analyses [26,27,28,29,30, 32,33,34,35,36,37,38,39,40,41, 43,44,45, 47,48,49,50,51,52,53,54,55,56], and 3 (9.7%) studies executed a retrospective cohort study design with longitudinal follow-up of patient outcomes [31, 42, 46].
Reporting quality
We appraised the reporting quality of each study, placing emphasis on potential biases and confounding factors, and these results are summarized in Table 2. A majority (51.6%) of studies were rated as demonstrating excellent reporting quality [26,27,28,29, 34,35,36,37,38, 42, 43, 47, 49, 50, 52, 56]. Overall, these studies were more likely to address internal validity by describing potential biases and confounders (Supplementary Methods S2). Of the 11 studies judged to be of poor reporting quality, all were conference abstracts [30,31,32, 39,40,41, 46, 48, 53,54,55], most of which did not include descriptions of their statistical methods or strategies to mitigate biases or adjust for confounders. Conference abstracts typically face strict space limitations and do not undergo the same rigorous peer review as journal publications. Nevertheless, they were included given the recent introduction of SVI-based population analyses in the literature and the relative paucity of relevant articles in oncology research.
Patient populations
This review encompassed patients identified as at risk for cancer, diagnosed with cancer, undergoing cancer treatment, or receiving cancer survivorship care. The distribution of included articles by cancer type is summarized in Table 3. Ten studies addressed liver cancer [27, 29, 34, 38, 44, 48, 49, 52, 54, 55], and eight studies addressed colon or colorectal cancer [26, 30, 33, 36, 37, 43, 53, 56]. Other malignancies examined by multiple studies included pancreatic [26, 28, 34, 35, 38, 44], lung [26, 35, 37, 43], rectal [26, 33, 35, 43], and esophageal cancer [26, 35, 43].
Patient data sources
For studies performed across all states, common sources for patient data were the Centers for Medicare & Medicaid Services (CMS) [30] and the Surveillance, Epidemiology, and End Results (SEER) Program [49]. Specific datasets included the Medicare Single Analytic Files [26, 27, 34, 37, 38, 43, 44, 53], Medicare Provider Analysis and Review [36, 56], SEER-21 [32], and the SEER-Medicare linked database [28, 29, 52]. Other specific national data sources included the National Center for Health Statistics [50], the CDC Wide-ranging ONline Data for Epidemiologic Research database [39], the COVID-19 and Cancer Consortium Database [42]. In addition, one study utilized data obtained from a national clinical trials database (ClinicalTrials.gov) [41]. For studies performed in single states, data sources included state-wide health databases [35], senior registry databases [40], and cancer registry databases [40, 47, 51]. In addition, seven studies used de-identified patient data from single institutional electronic medical records [31, 33, 45, 46, 48, 54, 55].
Overall, many of the included studies were population-based cross-sectional studies with minimal risk for selection bias. Many employed retrospective data from national or state registry databases, administrative billing data, or institutional medical records and included all eligible patients (e.g., patients with the diagnosis of interest) in the analytic cohorts.
Use of SVI data
The SVI database provides data at the county or census tract-level [11]. Each residential address in the U.S. has a unique 15-digit geographic identifier (GEOID) [57]. Created by the Census Bureau, each GEOID consists of a 2-digit state code, 3-digit county code, 5-digit census tract code, and/or 4-digit census block code [57]. In the U.S., the relationship between these geographic entities is such that states are subdivided into counties which are further subdivided into census tracts. The GEOID may thus reflect a patient’s county or census tract, and this numeric string can then be used to link patient data with area-level SVI data. In most cases, a patient’s county of residence can be deduced from their ZIP Code™ data, whereas identifying a patient’s census tract of residence typically requires collection of their full postal address data. A majority (67.7%) of studies in this review performed analyses at the county level [26,27,28,29,30, 32, 34,35,36,37,38,39,40,41,42,43, 49, 50, 52, 53, 56]. Seven studies conducted analyses at the census tract-level [31, 33, 45,46,47,48, 51].
The statistical treatment of SVI data also varied across studies. For each variable and subtheme, the SVI database provides percentile rankings ranging from 0 to 100% (least to greatest social disadvantage) [11]. Depending on the specific dataset, counties or census tracts are ranked against each other across a single state or across all states [11]. A patient residence’s SVI value may vary based on the geographic unit of analysis and the comparator group (e.g., all counties in a single state, all census tracts across all states). Some studies analyzed patient outcomes using the overall SVI percentile ranking for the patient residential address [31, 34, 35, 47, 48, 51]. Others used the percentile ranking for subthemes [31, 34, 44], percentile ranking for specific variables [49], median overall SVI [45, 46], and median subtheme SVI [46]. Some studies used 1-unit [41], 10-unit [26, 28], or 20-unit [30] references to calculate odds ratios, and a few treated SVI as a continuous variable [42, 52, 56]. A majority (52.4%) of studies stratified patients’ respective geographic units into SVI quartiles [27,28,29, 32, 33, 35,36,37,38,39, 43, 52,53,54]. While the quartiles did not necessarily align with the overall SVI percentile rankings, they offered insight into the SVI distribution across a patient population. Other studies stratified by tertiles [31, 50], quintiles [40, 56], or deciles [56].
Other SDOH measures
Eight studies investigated neighborhood characteristics using other SDOH measures in addition to the SVI [32, 37, 45, 47,48,49, 54, 55]. Area-level SDOH based on county or ZIP Code™ data included race and ethnicity [45], foreign-born status [48, 54, 55], median household income [37, 45], educational attainment [45], limited English proficiency [37, 45, 47], employment rate [55], poverty rate [47], insurance status [55], rurality [32, 42, 47], and neighborhood walk score [54, 55]. One study applied multiple county-level metrics such as the Gini coefficient [58], income inequality ratio, and residential segregation in addition to the SVI [32]. Another study integrated county-level variables from the Behavioral Risk Factor Surveillance System such as obesity, tobacco use, and alcohol use [49]. Some studies examined individual-level SDOH beyond race/ethnicity such as educational attainment [40], employment [45], marital status [29, 45, 47], insurance status [35, 50, 53], and rurality [47].
Outcome measures
Many studies in this review addressed multiple components of the cancer care continuum. The distribution of included articles along the cancer care continuum is summarized in Supplementary Table S3. Along the continuum, five studies applied the SVI to examine geographic disparities in potentially cancer-causing exposures (e.g., oncogenic viruses, environmental contaminants or characteristics) [42, 48, 50, 51, 54, 55]; seven to examine disparities in cancer diagnosis (e.g., all-stage, early stage, late stage) [32, 46, 48, 49, 51, 54, 55]; fourteen in cancer treatment (e.g., surgery receipt, chemotherapy receipt, stem cell transplantation, clinical trial access) [27,28,29,30, 34,35,36,37,38, 41,42,43, 47, 53, 56]; nine in treatment recovery (e.g., post-operative complications, readmission rates) [27, 30, 33, 34, 36,37,38, 43, 44]; one in survivorship care [45]; and two in end-of-life care [26, 52]. Fifteen (48.4%) studies also examined disparities in mortality using the SVI [27, 30, 31, 33, 36,37,38,39, 42,43,44, 48, 50, 54, 55]. Studies that examined disparities in secondary prevention (e.g., early detection, screening) were not identified.
Limitations
We assessed the limitations of each study. A large majority of the included studies used a cross-sectional study design in which samples represented a single timepoint. These studies may not capture changes in residence among cancer patients over the course of their disease. For instance, patients may relocate to a different county with a different level of social vulnerability as they seek to live with or near caregivers, improve perceived access to healthcare, receive advanced cancer treatment, or explore a new lifestyle. Thus, the patient residence’s SVI at time of cancer diagnosis may significantly differ from that at time of cancer treatment or end-of-life care.
For the studies that relied on Medicare administrative billing data, a major limitation was low generalizability to younger patient populations since the Medicare population comprises patients aged 65 or older [26, 27, 30, 34, 36,37,38, 43, 44, 53, 56]. The Medicare population also excludes those aged 65 or older without insurance or with private insurance. When compared to the general population, White patients tend to be over-represented in the Medicare dataset, while non-White minority patients are under-represented. Administrative billing data also lacked relevant patient clinical information (e.g., stage at diagnosis, medical comorbidities, referral patterns, refusal of treatment/care) and individual-level SDOH information (e.g., education, income, employment) [29, 35, 47]. In addition, studies based on administrative billing or disease registry data may be subject to information bias from miscoding, incomplete coding, noncoding, or under-ascertainment. Incomplete or inaccurate residential address data could also affect the collection and treatment of area-level SVI data.
For studies that performed analyses at the county level [26,27,28,29,30, 32, 34,35,36,37,38, 41, 43, 49, 52, 54, 55], results may not be applicable to specific census tracts or blocks across the county given potential heterogeneity within the county, especially in urban areas. Similarly, area-level results, whether county- or census tract-level, may not be generalizable to individual patients. Studies that primarily relied on data from a single state [35, 47, 51] or single medical center [45, 48, 54, 55] also had limited generalizability to other states or institutions, respectively.
Discussion
This review seeks to demonstrate the potential utility of the SVI, a composite scale encompassing many different SDOH, as applied to oncology research. Given the variability in reporting quality among the included studies, the diversity of patient populations represented, and the wide range of outcome measures examined, a meta-analysis was precluded in this sutdy. The results of this study rather provide an overview of the wide range of studies related to the SVI that can be found in the indexed oncology literature. As more higher quality studies with rigorous methodologies and analyses are published, future research may apply statistical methods to synthesize findings from studies with similar patient populations and outcome measures.
To describe the current literature, we employed the cancer care continuum as an evaluation framework. In oncology research, the cancer care continuum helps identify research and policy needs to prevent excess cancer morbidity and mortality. In regard to disparities in cancer treatment, recovery, and survivorship, studies in this review demonstrated that with increasing SVI, cancer patients were less likely to receive neoadjuvant chemotherapy [28], less likely to utilize a high-volume hospital for surgical resection [35, 38], more likely to experience post-operative complications [36, 37], less likely to achieve post-operative textbook outcomes [27, 43], and more likely to encounter fragmented post-operative care [34]. With respect to race and ethnicity, studies in this review showed that minority patients also had a lower likelihood than White patients of receiving neoadjuvant chemotherapy [28] or achieving post-operative textbook outcomes as SVI increased [43]. These studies demonstrate how certain vulnerable populations experience worse outcomes in part due to social factors that could potentially be mitigated with geographically targeted interventions.
A depiction of future opportunities for health disparities research using the SVI can be found in Table 3 and Fig. 2 with respect to cancer types and components of the cancer care continuum, respectively. For example, the SVI could be applied to examine disparities in the socioeconomic and geographic coverage of early detection initiatives such as cancer screening campaigns (e.g., mammograms, Papanicolaou tests, colonoscopies) [59]. To date, many studies related to this topic have been conducted by a surgical oncology research group at The Ohio State University [26,27,28,29,30, 34,35,36,37,38, 43, 52]. This group has demonstrated the value of the SVI as a risk stratification tool in the Medicare cancer patient population, especially among those who had underwent resection surgery. Yet, the SVI could also be applied to analyze outcomes in cancer patients in other settings. All studies identified in this review used a retrospective study design, but the SVI may be utilized as a stratification tool for prospective studies. For instance, the SVI could be applied to measure the equity of patient recruitment for studies/trials in terms of SDOH [60].

Distribution of literature findings (in black) and research opportunities (in green) along the cancer care continuum
In addition, the increased availability of more advanced therapeutic agents (e.g., targeted therapy, immune checkpoint inhibitor therapy) is expected to reduce cancer morbidity and mortality [61]. Yet, vulnerable populations may experience disparities in access to potentially life-saving treatment options. Identification of these vulnerable populations using comprehensive data and objective metrics such as the SVI will facilitate societal efforts to improve access to guideline-concordant care and promote health equity. An example of a localized effort to improve cancer care access within a disadvantaged population can be found in an intervention called the Citywide Colon Cancer Control Coalition [62]. In seeking to promote colorectal cancer awareness and increase colonoscopy screening rates in New York City, this intervention was effective in decreasing overall colorectal cancer incidence, but colorectal cancer incidence and mortality rates remained disproportionally high among non-Hispanic Blacks compared to non-Hispanic Whites, Hispanics, and Asians for over ten years. Furthermore, borough-level analyses revealed that colorectal cancer mortality in the boroughs of Staten Island and the Bronx—boroughs with a higher proportion of Black residents—were significantly higher than those in the boroughs of Queens and Manhattan. Future healthcare policy informed by neighborhood-level characteristics can aid policymaking groups in identifying vulnerable communities from the outset that could benefit from further interventions and resources.
The SVI, which has demonstrated its utility in supporting vulnerable populations during national disaster responses, could therefore be used to guide future endeavors to reduce excess cancer morbidity and mortality in specific communities. In one validation study, Carmichael et al. applied various indices of neighborhood-level disadvantage, namely the Community Needs Index [8], Area Deprivation Index [9], Distressed Communities Index [10], and SVI, to the same dataset and demonstrated that the SVI performs similarly to the other indices [63]. A key advantage to using the SVI is the ability to stratify patient outcomes by specific social variables or subthemes, as listed in Fig. 1 [34, 63]. The SVI can thus be used as a key index not only for research but also for policymaking groups with access to data at the census tract-level. Furthermore, in recognition of innovative applications of the SVI to health disparity research, the CDC has newly developed an extended SVI with two additional subthemes on healthcare access/infrastructure and medical vulnerability [64]. This new tool, called the Minority Health SVI, also enhanced the minority status subtheme by expanding race and ethnicity and language variables. The Minority Health SVI has recently been applied to COVID-19 research, where it has demonstrated a positive association between medical vulnerability and COVID-19 incidence and mortality [16]. Future oncology research could apply the Minority Heath SVI to identify racial and ethnic minority communities with disproportionate vulnerability to adverse outcomes [64].
Limitations
As with most population-based studies, the inferences drawn at the group, community, or population level may not be applicable at the individual patient level. The reliability of the SVI tool may also require further validation using individual-level SES data. In addition, while this review used a systematic method to search multiple databases and screen results in order to reduce selection bias, relevant articles not yet published, posted, or indexed into the queried databases at the time of the search may have been missed. For articles that used the SVI to examine a patient population not explicitly identified as at risk for cancer or diagnosed with cancer, we reviewed the supplemental materials and all references cited in the methods before deciding whether to include or exclude. Nevertheless, some relevant articles may have been inadvertently excluded during the full-text review stage. This review may be subject to publication bias in which studies with statistically significant findings are more likely to be published or presented. By including gray literature resources such as conference abstracts in the search process, we sought to reduce this bias in order to enhance the comprehensiveness of this review.
Conclusion
In summarizing the current literature as related to the use of SVI in oncology research, this review highlights the SVI as a promising tool for examining health disparities in cancer patients. The results of this study demonstrate the wide-ranging applications of the SVI to examining geographic disparities in potentially cancer-causing exposures, cancer diagnoses, cancer treatments, and cancer mortality as well as in post-operative care, survivorship care, and end-of-life care among cancer patients. Since the SVI dataset is geocoded, it may be linked with other geocoded datasets to generate actionable findings. By highlighting disparities in health-related outcomes and identifying discrete geographic areas with increased risk, the SVI could inform the development and implementation of geographically targeted interventions to decrease cancer morbidity and mortality at the community level. For instance, future research may employ the SVI to investigate disparities in access to cancer screening interventions and diagnostic procedures for early detection. The results from these studies may guide the regional dissemination of public health campaigns and educational programs designed to reduce the burden of cancer.
Data availability
All data compiled in this review have been made available to the reader.
Abbreviations
- SDOH:
-
Social determinants of health
- SES:
-
Socioeconomic status
- SVI:
-
Social vulnerability index
- CDC:
-
Centers for disease control and prevention
- ACS:
-
American Community Survey
- COVID-19:
-
Coronavirus disease 2019
- PRISMA:
-
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
- STROBE:
-
Strengthening the Reporting of Observational Studies in Epidemiology
- CMS:
-
Centers for Medicare and Medicaid Services
- SEER:
-
Surveillance, Epidemiology, and End Results Program
- GEOID:
-
Geographic identifier
References
Smith BD, Smith GL, Hurria A, Hortobagyi GN, Buchholz TA (2009) Future of cancer incidence in the United States: burdens upon an aging, changing nation. J Clin Oncol 27(17):2758–2765. https://doi.org/10.1200/jco.2008.20.8983
Mariotto AB, Enewold L, Zhao J, Zeruto CA, Yabroff KR (2020) Medical care costs associated with cancer survivorship in the United States. Cancer Epidemiol Biomarkers Prev 29(7):1304–1312. https://doi.org/10.1158/1055-9965.Epi-19-1534
Zavala VA, Bracci PM, Carethers JM, Carvajal-Carmona L, Coggins NB, Cruz-Correa MR, Davis M, de Smith AJ, Dutil J, Figueiredo JC, Fox R, Graves KD, Gomez SL, Llera A, Neuhausen SL, Newman L, Nguyen T, Palmer JR, Palmer NR et al (2021) Cancer health disparities in racial/ethnic minorities in the United States. Br J Cancer 124(2):315–332. https://doi.org/10.1038/s41416-020-01038-6
Ward E, Jemal A, Cokkinides V, Singh GK, Cardinez C, Ghafoor A, Thun M (2004) Cancer disparities by race/ethnicity and socioeconomic status. CA Cancer J Clin 54(2):78–93. https://doi.org/10.3322/canjclin.54.2.78
O’Keefe EB, Meltzer JP, Bethea TN (2015) Health disparities and cancer: racial disparities in cancer mortality in the United States, 2000–2010. Front Public Health 3:51. https://doi.org/10.3389/fpubh.2015.00051
Siegel RL, Miller KD, Jemal A (2020) Cancer statistics, 2020. CA Cancer J Clin 70(1):7–30. https://doi.org/10.3322/caac.21590
Grabinski VF, Brawley OW (2022) Disparities in breast cancer. Obstet Gynecol Clin North Am 49(1):149–165. https://doi.org/10.1016/j.ogc.2021.11.010
Roth R, Barsi E (2005) The community need index. A new tool pinpoints health care disparities in communities throughout the nation. Health Prog 86(4):32–38
Kind AJH, Buckingham WR (2018) Making neighborhood-disadvantage metrics accessible—the neighborhood atlas. N Engl J Med 378(26):2456–2458. https://doi.org/10.1056/NEJMp1802313
Economic Innovation Group (2016) The 2016 Distressed Communities Index: an analysis of community well-being across the United States. https://eig.org/wp-content/uploads/2016/02/2016-Distressed-Communities-Index-Report.pdf. Accessed Mar 1, 2022
Centers for Disease Control and Prevention (CDC), & Agency for Toxic Substances and Disease Registry (ATDSDR) (2021) CDC/ATSDR's Social Vulnerability Index (SVI). United States Department of Health & Human Services. https://www.atsdr.cdc.gov/placeandhealth/svi/index.html. Accessed Nov 1, 2021
Yost K, Perkins C, Cohen R, Morris C, Wright W (2001) Socioeconomic status and breast cancer incidence in California for different race/ethnic groups. Cancer Causes Control 12(8):703–711. https://doi.org/10.1023/a:1011240019516
Yang J, Schupp CW, Harrati A, Clarke C, Keegan THM, Gomez SL (2014) Developing an area-based socioeconomic measure from American Community Survey data. https://cancerregistry.ucsf.edu/sites/g/files/tkssra1781/f/wysiwyg/Yang%20et%20al.%202014_CPIC_ACS_SES_Index_Documentation_3-10-2014.pdf
Bakkensen LA, Fox-Lent C, Read LK, Linkov I (2017) Validating resilience and vulnerability indices in the context of natural disasters. Risk Anal 37(5):982–1004. https://doi.org/10.1111/risa.12677
Karmakar M, Lantz PM, Tipirneni R (2021) Association of social and demographic factors with COVID-19 incidence and death rates in the US. JAMA Netw Open 4(1):e2036462. https://doi.org/10.1001/jamanetworkopen.2020.36462
Tipirneni R, Schmidt H, Lantz PM, Karmakar M (2022) Associations of 4 geographic social vulnerability indices with US COVID-19 incidence and mortality. Am J Public Health 112(11):1584–1588. https://doi.org/10.2105/ajph.2022.307018
Freeman HP (2004) Poverty, culture, and social injustice: determinants of cancer disparities. CA Cancer J Clin 54(2):72–77. https://doi.org/10.3322/canjclin.54.2.72
Nekhlyudov L, Ganz PA, Arora NK, Rowland JH (2017) Going beyond being lost in transition: a decade of progress in cancer survivorship. J Clin Oncol 35(18):1978–1981. https://doi.org/10.1200/JCO.2016.72.1373
Bigby J, Holmes MD (2005) Disparities across the breast cancer continuum. Cancer Causes Control 16(1):35–44. https://doi.org/10.1007/s10552-004-1263-1
Saito AM, Landrum MB, Neville BA, Ayanian JZ, Weeks JC, Earle CC (2011) Hospice care and survival among elderly patients with lung cancer. J Palliat Med 14(8):929–939. https://doi.org/10.1089/jpm.2010.0522
Coughlin SS (2019) Social determinants of breast cancer risk, stage, and survival. Breast Cancer Res Treat 177(3):537–548. https://doi.org/10.1007/s10549-019-05340-7
Kurani SS, McCoy RG, Lampman MA, Doubeni CA, Finney Rutten LJ, Inselman JW, Giblon RE, Bunkers KS, Stroebel RJ, Rushlow D, Chawla SS, Shah ND (2020) Association of neighborhood measures of social determinants of health with breast, cervical, and colorectal cancer screening rates in the US Midwest. JAMA Netw Open 3(3):e200618. https://doi.org/10.1001/jamanetworkopen.2020.0618
Moher D, Liberati A, Tetzlaff J, Altman DG (2009) Preferred reporting items for systematic reviews and meta-analyses: the PRISMA statement. BMJ 339:b2535. https://doi.org/10.1136/bmj.b2535
Adams AD, Benner RS, Riggs TW, Chescheir NC (2018) Use of the STROBE checklist to evaluate the reporting quality of observational research in obstetrics. Obstet Gynecol 132(2):507–512. https://doi.org/10.1097/aog.0000000000002689
von Elm E, Altman DG, Egger M, Pocock SJ, Gøtzsche PC, Vandenbroucke JP (2008) The strengthening the reporting of observational studies in epidemiology (STROBE) statement: guidelines for reporting observational studies. J Clin Epidemiol 61(4):344–349. https://doi.org/10.1016/j.jclinepi.2007.11.008
Abbas A, Madison Hyer J, Pawlik TM (2021) Race/ethnicity and county-level social vulnerability impact hospice utilization among patients undergoing cancer surgery. Ann Surg Oncol 28(4):1918–1926. https://doi.org/10.1245/s10434-020-09227-6
Azap RA, Paredes AZ, Diaz A, Hyer JM, Pawlik TM (2020) The association of neighborhood social vulnerability with surgical textbook outcomes among patients undergoing hepatopancreatic surgery. Surgery 168(5):868–875. https://doi.org/10.1016/j.surg.2020.06.032
Azap RA, Diaz A, Hyer JM, Tsilimigras DI, Mirdad RS, Ejaz A, Pawlik TM (2021) Impact of race/ethnicity and county-level vulnerability on receipt of surgery among older Medicare reneficiaries with the diagnosis of early pancreatic cancer. Ann Surg Oncol 28(11):6309–6316. https://doi.org/10.1245/s10434-021-09911-1
Azap RA, Hyer JM, Diaz A, Paredes AZ, Pawlik TM (2021) Association of county-level vulnerability, patient-level race/ethnicity, and receipt of surgery for early-stage hepatocellular carcinoma. JAMA Surg 156(2):197–199. https://doi.org/10.1001/jamasurg.2020.5554
Barmash E, Diaz A, Paredes A, Pawlik TM (2020) Association of county-level social vulnerability and disparities in emergent vs elective colectomy. J Am Coll Surg 231(4):S133–S134. https://doi.org/10.1016/j.jamcollsurg.2020.07.258
Bhandari R, Teh JB, Nakamura R, Artz AS, Forman SJ, Wong L, Armenian SH (2021) Social vulnerability is a clinically important predictor of outcomes after allogeneic hematopoietic cell transplantation. Blood 138:842. https://doi.org/10.1182/blood-2021-146633
Bowers K, Jensen S, Haithcoat T, Avery E, Shyu C-R, Hammer R (2020) Geospatial analysis of socioeconomic disparity and patterns of leukemia incidence and distribution in the United States (1335). Lab Invest 100:1260. https://doi.org/10.1038/s41374-020-0391-x
Carmichael H, Dyas AR, Bronsert MR, Stearns D, Birnbaum EH, McIntyre RC, Meguid RA, Velopulos CG (2022) Social vulnerability is associated with increased morbidity following colorectal surgery. Am J Surg. https://doi.org/10.1016/j.amjsurg.2022.03.010
Dalmacy DM, Tsilimigras DI, Hyer JM, Paro A, Diaz A, Pawlik TM (2021) Social vulnerability and fragmentation of postoperative surgical care among patients undergoing hepatopancreatic surgery. Surgery. https://doi.org/10.1016/j.surg.2021.08.030
Diaz A, Chavarin D, Paredes AZ, Tsilimigras DI, Pawlik TM (2021) Association of neighborhood characteristics with utilization of high-volume hospitals among patients undergoing high-risk cancer surgery. Ann Surg Oncol 28(2):617–631. https://doi.org/10.1245/s10434-020-08860-5
Diaz A, Barmash E, Azap R, Paredes AZ, Hyer JM, Pawlik TM (2021) Association of county-level social vulnerability with elective versus non-elective colorectal surgery. J Gastrointest Surg 25(3):786–794. https://doi.org/10.1007/s11605-020-04768-3
Diaz A, Dalmacy D, Hyer JM, Tsilimigras D, Pawlik TM (2021) Intersection of social vulnerability and residential diversity: postoperative outcomes following resection of lung and colon cancer. J Surg Oncol 124(5):886–893. https://doi.org/10.1002/jso.26588
Diaz A, Hyer JM, Azap R, Tsilimigras D, Pawlik TM (2021) Association of social vulnerability with the use of high-volume and magnet recognition hospitals for hepatopancreatic cancer surgery. Surgery 170(2):571–578. https://doi.org/10.1016/j.surg.2021.02.038
Ganatra S, Dani S, Kumar A, Khan SU, Neilan T, Thavendiranathan P, Barac A, Hermann J, Leja M, Deswal AM, Fradley M, Liu J, Ky B, Sadler DB, Asnani A, Baldassarre LA, Gupta D, Yang E, Guha A, Nohria A (2021) Impact of social vulnerability on cardio-oncology mortality in the United States (12757). Circulation 144:A12757
Grant SJ, Deal AM, Heiling HM, Nyrop KA, Muss HB, Rubinstein SM, Lichtman EI, Wildes TM, Tuchman SA (2021) A cross-sectional analysis of county-level social vulnerability and physical frailty among adults with hematological malignancies (906). Blood 138:4130–4132. https://doi.org/10.1182/blood-2021-149742
Grant SJ, Jansen M, Tuchman S, Rubinstein S, Charlot M (2021) Social vulnerability and clinical trial access for older adults with myeloma in North Carolina (e18540). J Clin Oncol. https://doi.org/10.1200/JCO.2021.39.15_suppl.e18540
Hawley JE, Sun T, Chism DD, Duma N, Fu JC, Gatson NTN, Mishra S, Nguyen RH, Reid SA, Serrano OK, Singh SRK, Venepalli NK, Bakouny Z, Bashir B, Bilen MA, Caimi PF, Choueiri TK, Dawsey SJ, Fecher LA et al (2022) Assessment of regional variability in COVID-19 outcomes among patients with cancer in the United States. JAMA Netw Open 5(1):2142046. https://doi.org/10.1001/jamanetworkopen.2021.42046
Hyer JM, Tsilimigras DI, Diaz A, Mirdad RS, Azap RA, Cloyd J, Dillhoff M, Ejaz A, Tsung A, Pawlik TM (2021) High social vulnerability and “textbook outcomes” after cancer operation. J Am Coll Surg 232(4):351–359. https://doi.org/10.1016/j.jamcollsurg.2020.11.024
Labiner HE, Hyer M, Cloyd JM, Tsilimigras DI, Dalmacy D, Paro A, Pawlik TM (2022) Social vulnerability subtheme analysis improves perioperative risk stratification in hepatopancreatic surgery. J Gastrointest Surg. https://doi.org/10.1007/s11605-022-05245-9
McAlarnen LA, Tsaih SW, Aliani R, Simske NM, Hopp EE (2021) Virtual visits among gynecologic oncology patients during the COVID-19 pandemic are accessible across the social vulnerability spectrum. Gynecol Oncol 162(1):4–11. https://doi.org/10.1016/j.ygyno.2021.04.037
McAlarnen LA, Sona M, Tischer K, Small C, Bedi M, Erickson B, Hopp EE (2022) Exploring social vulnerability in locally advanced cervical cancer patients undergoing brachytherapy irradiation (PO-231). Cancer Epidemiol Biomarkers Prev. https://doi.org/10.1158/1538-7755.DISP21-PO-231
Mock J, Meyer C, Mau LW, Nguyen C, Arora P, Heron C, Balkrishnan R, Burns L, Devine S, Ballen K (2021) Barriers to access to hematopoietic cell transplantation among patients with acute myeloid leukemia in Virginia. Transpl Cell Ther 27(10):869.e861-869.e869. https://doi.org/10.1016/j.jtct.2021.06.030
Pan Y, Ying X, Ng C, Sholle E, Rosenblatt R, Fortune BE (2021) Neighborhood-level socioeconomic factors impact clinical outcomes in advanced alcohol-associated liver disease (364). Hepatology 74(1):235A-236A. https://doi.org/10.1002/hep.32188
Papageorge MV, Woods AP, de Geus SWL, Ng SC, Paasche-Orlow MK, Segev D, McAneny D, Kenzik KM, Sachs TE, Tseng JF (2022) Beyond insurance status: the impact of Medicaid expansion on the diagnosis of Hepatocellular Carcinoma. HPB (Oxford). https://doi.org/10.1016/j.hpb.2021.12.020
Parks RM, Benavides J, Anderson GB, Nethery RC, Navas-Acien A, Dominici F, Ezzati M, Kioumourtzoglou MA (2022) Association of tropical cyclones with county-level mortality in the US. JAMA 327(10):946–955. https://doi.org/10.1001/jama.2022.1682
Puvvula J, Bartelt-Hunt SL, Ouattara BS, Kolok AS, Bell JE, Rogan EG (2021) Association between aqueous atrazine and pediatric cancer in Nebraska. Water. https://doi.org/10.3390/w13192727
Rice DR, Hyer JM, Diaz A, Pawlik TM (2021) End-of-life hospice use and medicare expenditures among patients dying of hepatocellular carcinoma. Ann Surg Oncol 28(9):5414–5422. https://doi.org/10.1245/s10434-021-09606-7
Taylor K, Diaz A, Nuliyalu U, Dimick JB, Nathan H (2021) Association of Medicaid eligibility with non-elective surgery outcomes, and costs for colon cancer among Medicare patients (311). Gastroenterology 160(6):883
Ying X, Pan Y, Rajan A, Rosenblatt R, Fortune BE (2020) Racial and neighborhood impact on liver cancer and mortality for patients with cirrhosis due to viral hepatitis (674). Hepatology 2(1):407A-408A. https://doi.org/10.1002/hep.31579
Ying X, Pan Y, Ng C, Chua J, Sholle E, Rosenblatt R, Fortune BE (2021) Impact of neighborhood socioeconomic characteristics on advanced liver cancer diagnosis in patients with viral hepatitis and cirrhosis (638). Hepatology 74(1):388A-389A. https://doi.org/10.1002/hep.32188
Zhang Y, Kunnath N, Dimick JB, Scott JW, Diaz A, Ibrahim AM (2022) Social vulnerability and outcomes for access-sensitive surgical conditions among medicare beneficiaries. Health Aff (Millwood) 41(5):671–679. https://doi.org/10.1377/hlthaff.2021.01615
U.S. Census Bureau (2021) Understanding Geographic Identifiers (GEOIDs). U.S. Department of Commerce. https://www.census.gov/programs-surveys/geography/guidance/geo-identifiers.html. Accessed 4 Apr, 2022
Dorfman R (1979) A formula for the gini coefficient. Rev Econ Stat 61(1):146–149. https://doi.org/10.2307/1924845
Manica ST, Drachler Mde L, Teixeira LB, Ferla AA, Gouveia HG, Anschau F, Oliveira DL (2016) Socioeconomic and regional inequalities of Pap smear coverage. Rev Gaucha Enferm 37(1):e52287. https://doi.org/10.1590/1983-1447.2016.01.52287. ((Desigualdades socioeconômicas e regionais na cobertura de exames citopatológicos do colo do útero.))
Notley C, Ward E, Kassianos AP, Kurti A, Muirhead F, Nostikasari D, Payton J, Spears CA (2020) Negotiating cancer preventative health behaviours and adapting to motherhood: the role of technology in supporting positive health behaviours. Int J Qual Stud Health Well-being 15(1):1811533. https://doi.org/10.1080/17482631.2020.1811533
Ribas A, Wolchok JD (2018) Cancer immunotherapy using checkpoint blockade. Science 359(6382):1350–1355. https://doi.org/10.1126/science.aar4060
Brown JJ, Asumeng CK, Greenwald D, Weissman M, Zauber A, Striplin J, Weng O, List JM, Farley SM, Winawer SJ (2021) Decreased colorectal cancer incidence and mortality in a diverse urban population with increased colonoscopy screening. BMC Public Health 21(1):1280. https://doi.org/10.1186/s12889-021-11330-6
Carmichael H, Moore A, Steward L, Velopulos CG (2020) Disparities in emergency versus elective surgery: comparing measures of neighborhood social vulnerability. J Surg Res 256:397–403. https://doi.org/10.1016/j.jss.2020.07.002
Rickless D, Wendt M, Bui J (2021) Minority health social vulnerability index overview. https://www.minorityhealth.hhs.gov/minority-health-svi/assets/downloads/MH%20SVI%20Overview_11.19.2021.pdf
Funding
This study was supported in part by a research grant from the Melanoma Research Foundation. This study was also supported in part by philanthropic contributions from the Lyda Hill Foundation to the University of Texas MD Anderson Cancer Center Moon Shots Program™. The funding sources were not involved in the design or conduct of this study; the collection, management, analysis, or interpretation of the data; the preparation, review, or approval of this manuscript; or the decision to submit this manuscript for publication.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation was performed by all authors. Data collection and analysis were performed by HQD, TT, and MAR. The first draft of the manuscript was written by TT and MAR, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Ethical approval
This is a secondary review of published literature for which ethics approval was not required.
Consent to participate
N/A.
Consent to publish
N/A.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tran, T., Rousseau, M.A., Farris, D.P. et al. The social vulnerability index as a risk stratification tool for health disparity research in cancer patients: a scoping review. Cancer Causes Control 34, 407–420 (2023). https://doi.org/10.1007/s10552-023-01683-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10552-023-01683-1