
Abstract
Hatchery production and fisheries stocking is a widespread and high profile management practice because it allows recreational fisheries to continue in threatened species. Human-mediated transfer of fish across the geographic boundaries of intraspecies lineages or closely related species can cause introgression and occasionally outbreeding depression. Hybridization can be difficult to detect due to limited morphological differences among close lineages and the relatively low power of traditional genetic datasets. Here we showcase the use of genomic techniques to detect admixture of the economically important and threatened golden perch (Macquaria ambigua) in the Murray-Darling Basin, southeast Australia. We detected admixture through a genome-wide dataset of 6,862 single nucleotide polymorphisms (SNPs) across 174 Murray-Darling sourced fish and 15 fish from each of two neighbouring basins: the Lake Eyre and Fitzroy basins. Individuals with partial ancestry from both neighboring basins were detected using genomics throughout the Murray-Darling, suggesting the release of individuals and introgression into the Murray-Darling Basin. Importantly, a traditional microsatellite dataset was unreliable for identifying admixed individuals. The SNP-detected admixed individuals were also found in Murray-Darling impoundments, where fish are solely sourced from government-managed hatcheries, suggesting that some broodstock in hatcheries might have non-endemic ancestry. Stocking programs for golden perch release over one million fingerlings each year, and so could impact the genetic variation in the wild. We advocate for using genomics to check the ancestry of broodstock and for increasing collaboration between managers and academics—as done here—to better integrate the power of genomics into biodiversity management and conservation.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Inland fisheries produce over 10 million tonnes of biomass each year that support livelihoods, the economy and recreation, but are dependent on the maintenance of healthy ecosystems and biodiversity (Welcomme et al. 2010). One of the many factors that can affect this balance is stocking introductions: the release of fish species or populations into areas outside of their native range. Non-native species can be detected based on genetic and morphological differences compared with the native species (Trebitz et al. 2017), and is often a conservation concern (Gozlan et al. 2010). Stocking introductions can result in hybridization, outbreeding depression, genetic swamping of the native population, and greater inbreeding and lower effective population size in the wild from few captive parents contributing to large numbers of released fish (Ward 2006; Todesco et al. 2016; Waples et al. 2016). This can affect evolutionary and ecological processes that are indispensable to maintain biodiversity, functional ecosystems, and associated benefits for humanity (Moritz 2002; Le Cam et al. 2015; Savary et al. 2017). This makes stocking introductions a complex policy problem that should be managed on a case-by-case basis (Allendorf et al. 2001). However, the occurence and impacts of stocking of non-native lineages within a species, or within a complex of closely related species, is much harder to detect than between species and can often receive less attention (Laikre et al. 2010). Detecting non-native, closely-related lineages has become more tractable with advances in DNA sequencing technology, which produce high-resolution data at relatively low cost and without previous genomic resources (Funk et al. 2012).
Genomic technologies are starting to be used in Australia to inform government-managed inland recreational fisheries (e.g. Harrisson et al. 2016; Beheregaray et al. 2017; Attard et al. 2018). Arguably the most economically important inland river system in Australia is the Murray-Darling Basin. It spans more than one million km2 and supplies agricultural and recreational needs, with human impacts from regulation of river flow, water abstraction, habitat degradation, and introduction of non-native taxa (Kingsford et al. 2011). To maintain and enhance recreational fishing within the Murray-Darling Basin, government-managed stocking programs exist for five native fish species across five state and territory jurisdictions (Rowland and Tully 2004; Gilligan et al. 2009; NSW Department of Primary Industries 2010; ACT Environment and Planning Directorate 2015). These ‘harvest stocking’ programs release fingerlings produced from government or private hatcheries to bolster or replace natural recruitment. Stocking is conducted both within connected riverine networks and within hydrologically-isolated impoundments. Stocking approvals consider the endemicity of the lineage of broodfish to the proposed release site, with the level of restrictions dependent on the state or territory government. Outside of stocking programs authorised by the government, private hatcheries market their fingerlings to the public for release into private farm dams.
The largest stocking program in terms of the number of fingerlings, the length of operation, and spatial scale, is the harvest stocking program for the golden perch (Macquaria ambigua) species complex. Golden perch is a medium-large sized, long-lived freshwater fish (length = 35–50 cm; sexual maturity = 2 years males, 4 years females; longevity = 26 years) (Mallen-Cooper and Stuart 2003). This stocking program also represents the greatest risk to the natural genetic variation of the Murray-Darling lineage: the golden perch complex is found in three major hydrologically disconnected drainage basins, each containing a distinct lineage (or cryptic species) with hatchery production occuring for each lineage (Faulks et al. 2010; Beheregaray et al. 2017; Attard et al. 2018). The golden perch complex has hierarchical population structure: there is no more than 0.1 genetic differentiation (FST) among localities within basins (Faulks et al. 2010; Attard et al. 2018) but 0.5 to 0.6 FST among the three basins (Beheregaray et al. 2017). Within the Murray-Darling Basin, fingerlings are produced by numerous government and private hatcheries, and approved releases of fingerlings can be undertaken by government or community groups. Hatchery production programs for golden perch commenced in 1960 (NSW Fisheries 2003), which could have compromised natural genetic variation until 2005 when the first regulation was implemented to regionalize stocking (NSW Department of Primary Industries 2005). The flexibility of ongoing permitted stocking activities, the availability of fingerlings for direct sale from private hatcheries to the public, and the possibility of non-endemic lineages to escape from private dams during floods, also create ample opportunities for stocking introductions of fingerlings across basins. This together with other human activities in the Murray-Darling Basin threaten this native species.
Here we assessed whether there are non-endemic lineages of golden perch from the Lake Eyre or Fitzroy basins in the Murray-Darling Basin. We did so using a genome-wide SNP dataset developed without any previous genomic resources. We also compared the SNP data with microsatellite data to determine whether a genome-wide dataset was needed to conduct an accurate and precise admixture assessment among golden perch in the Murray-Darling Basin. This shows the importance of genomics to detect and mitigate stocking introductions of closely related lineages.
Methods
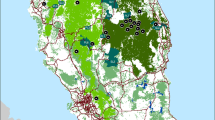
Genomic data from a previous intra-basin study of golden perch in the Murray-Darling Basin (Attard et al. 2018), and a golden perch phylogenomic study that included the Lake Eyre and Fitzroy basins (Beheregaray et al. 2017), were re-purposed to produce a SNP dataset for the current study. In addition, five new samples were added to increase to 15 the sample size at SNPs for the Fitzroy Basin. This resulted in a genomic dataset of 174 fish from 13 localities (including the open river system and impoundments) across the Murray-Darling Basin (Fig. 1) and 15 representative fish from each of the Lake Eyre and Fitzroy basins (Table 1). The Fitzroy Basin samples were all from Nogoa River (to avoid admixed samples from Dawson River (Beheregaray et al. 2017)), and the Lake Eyre Basin samples were six from Diamantina River and three from each of Georgia River, Neales River and Warburton River (to avoid admixed samples from Bulloo Basin (Beheregaray et al. 2017)). The dataset additionally included 15 replicates from across the basins to estimate genotyping error, which was calculated as the average percentage of alleles that differed between replicates.

Map of the Murray-Darling Basin in Australia showing the sampling sites for golden perch. The site code and number of samples are in brackets, and the location of the neighbouring Lake Eyre and Fitzroy basins are shown
Genomic libraries were prepared following the ddRAD protocol of Peterson et al. (2012), with details in Attard et al. (2018) and Beheregaray et al. (2017). Resulting reads were processed using the de novo pipeline of STACKS 1.29 (Catchen et al. 2011; Catchen et al. 2013) to produce the final SNP dataset. This was performed following Attard et al. (2018), except increasing to 12 the number of sampling sites in which a locus needed to be detected in order to keep that locus. This was because of the addition of Lake Eyre and Fitzroy samples.
The genomic dataset was compared to a dataset of eight microsatellites from a landscape genetic study of golden perch (Faulks et al. 2010). Samples with more than two missing microsatellite genotypes were removed from the microsatellite dataset before use in the current study. The microsatellite data was subsampled to 140 fish that were also in the genomic data from the Murray-Darling to allow a direct comparison of individuals, and 15 representative fish from each of the Lake Eyre and Fitzroy basins. The samples from the Lake Eyre and Fitzroy basins were the same between the SNP and microsatellite datasets, except for six samples from the Lake Eyre Basin due to sample availability.
Admixed individuals were detected using multiple methods to ensure robust interpretation of estimates of ancestry. Bayesian clustering methods were implemented for SNPs in FastSTRUCTURE 1.0 (Raj et al. 2014) and ADMIXTURE 1.3.0 (Alexander et al. 2009) using the default parameters. Of these two programs, only FastSTRUCTURE ancestry is presented here as both programs showed almost indistinguishable ancestry estimates. For microsatellites and, for comparison, SNPs, STRUCTURE 2.3.4 (Pritchard et al. 2000) was run using a K of three with the admixture model of ancestry, the independent allele frequency model, not using sampling locations as priors (Hubisz et al. 2009), and with ten independent runs that had reached convergence. A burn-in of 100 000 iterations then 106 iterations were used for the microsatellites and, due to computational time, a burn-in of 10 000 iterations then 105 iterations for the SNPs. The STRUCTURE runs were analysed using CLUMPAK (Kopelman et al. 2015) (Main Pipeline, default parameters) to obtain an estimated membership of each individual to each basin.
A principal components analysis (PCA), which has no population model assumptions, was conducted for each dataset with ADEGENET 2.0.0 (Jombart 2008) in R. As PCAs require no missing data, SNPs which had complete missing data for at least one basin were removed. The remaining missing data was imputed separately for each basin using GENODIVE 3.0 (Meirmans and van Tienderen 2004) before running the PCA. This would result in admixed individuals in the Murray-Darling Basin having the appearance of greater ancestry to the Murray-Darling than the reality (i.e. it would underestimate admixture), especially in those with more missing data. So the PCAs were used only to explore the power of the SNPs compared with the microsatellites, rather than to accurately estimate individual ancestry.
To help distinguish ‘pure’ and admixed individuals, and to assess the power of the SNPs relative to the microsatellites, we simulated 30 offspring from each of the basins and four admixture classes. Simulations were based on the allele frequencies of individuals with at least 0.99 estimated ancestry to the basin in which they were sampled as estimated by FastSTRUCTURE for SNPs, or at least 0.97 ancestry as estimated by STRUCTURE for microsatellites. The difference in cut-off between datasets is due to the differing power of the datasets (see Results). The simulated admixture classes were F1 Murray-Darling—Lake Eyre hybrids and their backcross to Murray-Darling, and F1 Murray-Darling—Fitzroy hybrids and their backcross to Murray-Darling. The simulations were conducted using the custom Python script of Elliott and Russello (2018), which is based on HYBRIDLAB (Nielsen et al. 2006) but is designed for large SNP datasets, or using HYBRIDLAB 1.0 for the microsatellite data. To examine the impact of missing data on the accuracy of ancestry estimates, we created additional datasets by removing 30% and 80% of the genotypes randomly from the simulated SNP dataset and 30% from the simulated microsatellite dataset using a custom Perl script. We did not simulate 80% missing data for the microsatellites, as this would result in only 1.6 genotyped microsatellites on average per individual. The simulated datasets were then run in FastSTRUCTURE for the SNPs and STRUCTURE for the microsatellites using the same parameters as for the empirical data. As the PCAs were only used to explore the power of the SNPs compared to microsatellites, rather than estimating ancestry and associated impacts of missing data, we only included the simulated datasets with no missing data in the PCAs.
Results
The final genomic dataset consisted of 6,862 SNPs and the genetic dataset consisted of eight microsatellites. The genomic dataset had an estimated genotyping error of 1.6% and had 9% missing data (Table 1). Only 11 samples had more than 30% missing data, with all of these samples from the Murray-Darling Basin. Bayesian analyses produced the expected three genetic clusters that represent the Murray-Darling, Lake Eyre and Fitzroy basins (Fig. 2). All 30 individuals sampled from the Lake Eyre and Fitzroy basins had at least 0.99 ancestry to their basin using SNPs, or at least 0.98 using microsatellites. One hundred and fifty-two of the 174 individuals sampled from the Murray-Darling Basin and analysed using SNPs had at least 0.99 ancestry to that lineage. The remaining 22 consisted of one likely F1 hybrid between the Murray-Darling and Fitzroy basins that was collected in 2005, and individuals with various levels of backcrossed ancestry between the Lake Eyre and Fitzroy basins to the Murray-Darling Basin and that were collected from 2003 to 2015 (Table 2; Fig. 2). The PCA and simulations used 6,023 SNPs when those with missing data in an entire basin were removed, and the PCA produced results that were concordant with the Bayesian clustering analyses (Fig. 3). The microsatellites only detected three of the 15 admixed individuals detected by the SNPs and genotyped in both the microsatellites and the SNPs (Table 2; Fig. 2). The difference in ancestry estimates between the SNPs and microsatellites is unlikely due to the Bayesian analysis used, as the ancestry estimates for the SNPs between FastSTRUCTURE and STRUCTURE were almost indistinguishable (Fig. 2). The simulations revealed the likely explanation that the microsatellites are less powerful than the SNPs, even when the SNPs have 80% missing data (Figs. 3 and 4). Pure individuals simulated using the SNP dataset had at least 99% ancestry to their basin (Fig. 4), even with 80% missing data, which indicates that empirical individuals with less than 99% ancestry based on SNPs are admixed individuals.

Bayesian clustering results for golden perch when K is set to three and using (a) genome-wide SNPs in (i) FastSTRUCTURE and (ii) STRUCTURE, or (b) microsatellites in STRUCTURE. Each individual is represented by a column, with the colouring in the column representing the proportion of estimated membership of the individual to each genetic cluster (blue or gray in grayscale, Murray-Darling Basin; yellow or light gray in grayscale, Lake Eyre Basin; red or dark gray in grayscale, Fitzroy Basin). Uncoloured (i.e. white) columns in (b) indicate individuals for which microsatellite data is unavailable. Sampling sites of individuals within the Murray-Darling Basin are indicated by codes defined in Fig. 1; Table 1

PCA of empirical and simulated golden perch individuals using (a) genome-wide SNPs or (b) microsatellites. The percent of variance explained by the first two PCs and, in the inserts, the eigenvalues of the first 10 PCs are shown. Empirical individuals are represented as circles colour-coded according to their sampling basin (blue, Murray-Darling Basin; yellow, Lake Eyre Basin; red, Fitzroy Basin). Simulated individuals overlay the empirical individuals, and are represented as shape outlines according to their simulation category (circle, pure individuals; triangle, F1 hybrids; diamonds, backcrosses)

Bayesian clustering results for simulated golden perch using (a) genome-wide SNPs with (i) no missing data, (ii) 30% missing data and (iii) 80% missing data, and using (b) microsatellites with (i) no missing data and (ii) 30% missing data. Each individual is represented by a column, with the colouring in the column representing the proportion of estimated membership of the individual to each genetic cluster (blue or gray in grayscale, Murray-Darling Basin; yellow or light gray in grayscale, Lake Eyre Basin; red or dark gray in grayscale, Fitzroy Basin)
Discussion
We found using genomics that a proportion of the sampled golden perch in the Murray-Darling Basin have admixed ancestry to the neighbouring Lake Eyre and Fitzroy basins (22/174 samples = ~ 13%). Admixed individuals were distributed widely across the Murray-Darling Basin, and in both the connected river system and impoundments. Fortunately, there was only one likely F1 hybrid, with the remaining admixed individuals representing various levels of backcrosses to the Murray-Darling Basin. This suggests as yet no widespread introgression or complete admixture (as defined by Allendorf et al. (2001)) into the natural Murray-Darling lineage. Non-endemic genetic material in the Murray-Darling Basin may have occurred through one or more human-mediated mechanisms: (i) historical stocking activities that occurred prior to existing fisheries management arrangements, (ii) escape of individuals from private farm dams that were stocked from commercial hatcheries in a different region, (iii) deliberate or careless release of non-endemic lineages, (iv) deliberate, unintentional or careless mixing in hatcheries of broodfish from multiple lineages, (v) or unintended collection and incorporation of admixed broodfish within hatcheries. Unnatural hybridization within the Murray-Darling Basin may lead to ecological and evolutionary consequences (Ward 2006), especially because the golden perch in different basins have diverged to the point that they may be different species (Beheregaray et al. 2017). Our findings serve as a warning that one or more of the human-mediated mechanisms outlined above may need to be managed more effectively than has occurred to date.
The legacy of unregulated stocking programs before 2005 likely includes unnatural admixture in the Murray-Darling Basin, given that the detected introgressed individuals include those sampled before or around 2005 and distant backcrosses. A flow-on effect of the unregulated stocking is that hatcheries may be unintentionally using admixed wild-caught broodstock. Indeed, the impoundment populations sampled here are all stocked from one hatchery run by the state government of New South Wales, and these impoundments contained admixed individuals. Impoundment populations of golden perch have low or no natural local recruitment, and so are reliant on ongoing stocking programs to maintain the recreational fishery (Forbes et al. 2016). Given that government-managed stocking programs collectively produce or facilitate the release of over one million hatchery-bred golden perch fingerlings per year, with the potential to demographically and genetically overwhelm wild-born conspecifics (Crook et al. 2016; Forbes et al. 2016), it is incumbent on those programs to minimise ongoing risks from the admixture already present within the Murray-Darling Basin. We recommend that broodstock at hatcheries undergo genomic interrogation prior to use to ensure they have pure ancestry to the Murray-Darling lineage. A golden perch broodfish can produce tens to hundreds of offspring per year, and so even a small amount of non-native ancestry in one broodfish can spread and introgress into the wild population.
We have more broadly shown the use of genomics to help manage stocking activities compared to microsatellites. A traditional microsatellite dataset can detect admixture in populations, but cannot differentiate with certainty the ‘pure’ and admixed individuals (Sanz et al. 2009; van Wyk et al. 2017). Instead, SNPs provide two intrinsic advantages for ancestral inferences: first, they have a better genomic resolution with higher density and a more uniform distribution across the genome; second, SNPs have a lower mutation rate than microsatellites, reducing the potential for homoplasy and associated analytical issues. These differences improve the resolution of ancestral inferences, and the biological meaningfulness and usefulness of the results (Morin et al. 2004; Coates et al. 2009; Oliveira et al. 2015). In addition, current SNP protocols do not need standardization across laboratories or detection platforms, as is typically needed for microsatellites (Morin et al. 2004; Coates et al. 2009). The relatively high SNP genotyping error possible from genotyping-by-sequencing can be mitigated by balancing the number of loci and individuals with quality and coverage of sequences, from library preparation to bioinformatic filtering (Fountain et al. 2016). Here, this resulted in a genotyping error rate of only 1.6%. In addition, some data analysis methods—but not those used here—can take into account genotyping error (e.g. Attard et al. 2018). In line with the advantages of SNPs, we showed here that SNPs, but not microsatellites, had the accuracy and precision to reliably detect admixed individuals even with missing data (Figs. 2, 3 and 4). So, SNPs should be used instead of microsatellites to screen individuals when selecting broodstock.
Screening broodstock through genomics expands on its use to inform fisheries management, by identifying stocks, connectivity, functional variation and adaptive capacity under environmental change, structural genomic variants relevant for ecological processes, infectious diseases, and other research questions (e.g. Attard et al. 2018; Jeffery et al. 2018; Munang’andu et al. 2018; Sandoval-Castillo et al. 2018; Grummer et al. 2019; Wellenreuther et al. 2019). Even with this plethora of genomic information, there is often little integration of genetics and genomics into fisheries management (Bernatchez et al. 2017), or to conservation in general (Garner et al. 2016). One way this can be overcome is by simplifying the communication and increasing the collaboration between academics and management agencies (Garner et al. 2016; Bernatchez et al. 2017), as we have done here (see author affiliations). This allows genomic diversity, which is a critical component of biodiversity, to be incorporated into biodiversity management and conservation.
Availability of data and material
Data are available through FigShare: https://doi.org/10.6084/m9.figshare.19372565.
Code Availability
The simulated data were generated using the custom Python script of Elliott and Russello (2018) available from https://github.com/salanova-elliott/recom-sim. Missing data was introduced to the simulated data using a custom Perl script available from https://github.com/CatherineAttard.
References
ACT Environment and Planning Directorate (2015) Fish stocking plan for the Australian Capital Territory 2015–2020. Canberra, Australian Capital Territory (ACT), Australia. Available from https://www.environment.act.gov.au/__data/assets/pdf_file/0009/720873/Fish-stockplan-2015-20.pdf
Alexander DH, Novembre J, Lange K (2009) Fast model-based estimation of ancestry in unrelated individuals. Genome Res 19:1655–1664. https://doi.org/10.1101/gr.094052.109
Allendorf FW, Leary RF, Spruell P, Wenburg JK (2001) The problems with hybrids: setting conservation guidelines. Trends Ecol Evol 16:613–622. https://doi.org/10.1016/S0169-5347(01)02290-X
Attard CRM, Beheregaray LB, Möller LM (2018) Genotyping-by-sequencing for estimating relatedness in nonmodel organisms: avoiding the trap of precise bias. Mol Ecol Resour 18:381–390. https://doi.org/10.1111/1755-0998.12739
Attard CRM, Brauer CJ, Sandoval-Castillo J, Faulks LK, Unmack PJ, Gilligan DM, Beheregaray LB (2018) Ecological disturbance influences adaptive divergence despite high gene flow in golden perch (Macquaria ambigua): implications for management and resilience to climate change. Mol Ecol 27:196–215. https://doi.org/10.1111/mec.14438
Beheregaray LB, Pfeiffer LV, Attard CRM, Sandoval-Castillo J, Domingos FMCB, Faulks LK, Gilligan DM, Unmack PJ (2017) Genome-wide data delimits multiple climate-determined species ranges in a widespread Australian fish, the golden perch (Macquaria ambigua). Mol Phylogen Evol 111:65–75. https://doi.org/10.1016/j.ympev.2017.03.021
Bernatchez L, Wellenreuther M, Araneda C, Ashton DT, Barth JMI, Beacham TD, Maes GE, Martinsohn JT, Miller KM, Naish KA, Ovenden JR, Primmer CR, Young Suk H, Therkildsen NO, Withler RE (2017) Harnessing the power of genomics to secure the future of seafood. Trends Ecol Evol 32:665–680. https://doi.org/10.1016/j.tree.2017.06.010
Catchen J, Hohenlohe PA, Bassham S, Amores A, Cresko WA (2013) Stacks: an analysis tool set for population genomics. Mol Ecol 22:3124–3140. https://doi.org/10.1111/mec.12354
Catchen JM, Amores A, Hohenlohe P, Cresko W, Postlethwait JH (2011) Stacks: building and genotyping loci de novo from short-read sequences. G3 1:171–81. https://doi.org/10.1534/g3.111.000240
Coates BS, Sumerford DV, Miller NJ, Kim KS, Sappington TW, Siegfried BD, Lewis LC (2009) Comparative performance of single nucleotide polymorphism and microsatellite markers for population genetic analysis. J Hered 100:556–564. https://doi.org/10.1093/jhered/esp028
Crook DA, O’Mahony DJ, Gillanders BM, Munro AR, Sanger AC, Thurstan S, Baumgartner LJ (2016) Contribution of stocked fish to riverine populations of golden perch (Macquaria ambigua) in the Murray–Darling Basin, Australia. Mar Freshwat Res 67:1401–1409. https://doi.org/10.1071/MF15037
Elliott L, Russello MA (2018) SNP panels for differentiating advanced-generation hybrid classes in recently diverged stocks: a sensitivity analysis to inform monitoring of sockeye salmon re-stocking programs. Fisheries Res 208:339–345. https://doi.org/10.1016/j.fishres.2018.09.001
Faulks LK, Gilligan DM, Beheregaray LB (2010) Islands of water in a sea of dry land: hydrological regime predicts genetic diversity and dispersal in a widespread fish from Australia’s arid zone, the golden perch (Macquaria ambigua). Mol Ecol 19:4723–4737. https://doi.org/10.1111/j.1365-294X.2010.04848.x
Forbes J, Watts RJ, Robinson WA, Baumgartner LJ, McGuffie P, Cameron LM, Crook DA (2016) Assessment of stocking effectiveness for Murray cod (Maccullochella peelii) and golden perch (Macquaria ambigua) in rivers and impoundments of south-eastern Australia. Mar Freshwat Res 67:1410–1419. https://doi.org/10.1071/MF15230
Fountain ED, Pauli JN, Reid BN, Palsbøll PJ, Peery MZ (2016) Finding the right coverage: the impact of coverage and sequence quality on single nucleotide polymorphism genotyping error rates. Mol Ecol Resour 16:966–978. https://doi.org/10.1111/1755-0998.12519
Funk WC, McKay JK, Hohenlohe PA, Allendorf FW (2012) Harnessing genomics for delineating conservation units. Trends Ecol Evol 27:489–496. https://doi.org/10.1016/j.tree.2012.05.012
Garner BA, Hand BK, Amish SJ, Bernatchez L, Foster JT, Miller KM, Morin PA, Narum SR, O’Brien SJ, Roffler G, Templin WD, Sunnucks P, Strait J, Warheit KI, Seamons TR, Wenburg J, Olsen J, Luikart G (2016) Genomics in conservation: case studies and bridging the gap between data and application. Trends Ecol Evol 31:81–83. https://doi.org/10.1016/j.tree.2015.10.009
Gilligan D, Beheregaray L, Faulks L, Shaddick K (2009) Recommendations to the NSW Freshwater Fish Stocking—Fishery Management Strategy (FMS) as a result of the project: “Phylogeography, conservation genetics and stocking management of perches and basses”. 15 pages. New South Wales Department of Primary Industries, technical report
Gozlan RE, Britton JR, Cowx I, Copp GH (2010) Current knowledge on non-native freshwater fish introductions. J Fish Biol 76:751–786. https://doi.org/10.1111/j.1095-8649.2010.02566.x
Grummer JA, Beheregaray LB, Bernatchez L, Hand BK, Luikart G, Narum SR, Taylor EB (2019) Aquatic landscape genomics and environmental effects on genetic variation. Trends Ecol Evol 34:641–654. https://doi.org/10.1016/j.tree.2019.02.013
Harrisson KA, Yen JDL, Pavlova A, Rourke ML, Gilligan D, Ingram BA, Lyon J, Tonkin Z, Sunnucks P (2016) Identifying environmental correlates of intraspecific genetic variation. Heredity 117:155–164. https://doi.org/10.1038/hdy.2016.37
Hubisz MJ, Falush D, Stephens M, Pritchard JK (2009) Inferring weak population structure with the assistance of sample group information. Mol Ecol Resour 9:1322–1332. https://doi.org/10.1111/j.1755-0998.2009.02591.x
Jeffery NW, Wringe BF, McBride MC, Hamilton LC, Stanley RRE, Bernatchez L, Kent M, Clément M, Gilbey J, Sheehan TF, Bentzen P, Bradbury IR (2018) Range-wide regional assignment of Atlantic salmon (Salmo salar) using genome wide single-nucleotide polymorphisms. Fisheries Res 206:163–175. https://doi.org/10.1016/j.fishres.2018.05.017
Jombart T (2008) Adegenet: a R package for the multivariate analysis of genetic markers. Bioinformatics 24:1403–1405. https://doi.org/10.1093/bioinformatics/btn129
Kingsford RT, Walker KF, Lester RE, Young WJ, Fairweather PG, Sammut J, Geddes MC (2011) A Ramsar wetland in crisis—the Coorong, Lower Lakes and Murray Mouth. Australia Mar Freshwat Res 62:255–265. https://doi.org/10.1071/MF09315
Kopelman NM, Mayzel J, Jakobsson M, Rosenberg NA, Mayrose I (2015) CLUMPAK: a program for identifying clustering modes and packaging population structure inferences across K. Mol Ecol Resour 15:1179–1191. https://doi.org/10.1111/1755-0998.12387
Laikre L, Schwartz MK, Waples RS, Ryman N (2010) Compromising genetic diversity in the wild: unmonitored large-scale release of plants and animals. Trends Ecol Evol 25:520–529. https://doi.org/10.1016/j.tree.2010.06.013
Le Cam S, Perrier C, Besnard A-L, Bernatchez L, Evanno G (2015) Genetic and phenotypic changes in an Atlantic salmon population supplemented with non-local individuals: a longitudinal study over 21 years. Proc R Soc B 282:20142765. https://doi.org/10.1098/rspb.2014.2765
Mallen-Cooper M, Stuart IG (2003) Age, growth and non-flood recruitment of two potamodromous fishes in a large semi-arid/temperate river system. River Res Appl 19:697–719. https://doi.org/10.1002/rra.714
Meirmans PG, van Tienderen PH (2004) GENOTYPE and GENODIVE: two programs for the analysis of genetic diversity of asexual organisms. Mol Ecol Notes 4:792–794. https://doi.org/10.1111/j.1471-8286.2004.00770.x
Morin PA, Luikart G, Wayne RK, the SNP workshop group (2004) SNPs in ecology, evolution and conservation. Trends Ecol Evol 19:208–216. https://doi.org/10.1016/j.tree.2004.01.009
Moritz C (2002) Strategies to protect biological diversity and the evolutionary processes that sustain it. Syst Biol 51:238–254. https://doi.org/10.1080/10635150252899752
Munang’andu HM, Galindo-Villegas J, David L (2018) Teleosts genomics: progress and prospects in disease prevention and control. Int J Mol Sci 19:1083. https://doi.org/10.3390/ijms19041083
Nielsen EE, Bach LA, Kotlicki P (2006) HYBRIDLAB (version 1.0): a program for generating simulated hybrids from population samples. Mol Ecol Notes 6:971–973. https://doi.org/10.1111/j.1471-8286.2006.01433.x
NSW Department of Primary Industries (2005) The NSW freshwater fish stocking Fishery Management Strategy. Cronulla Fisheries Centre, NSW Department of Primary Industries. Available from https://www.dpi.nsw.gov.au/__data/assets/pdf_file/0020/224291/NSW-Freshwater-Fish-Stocking-FMS-2005.pdf
NSW Hatchery Quality Assurance Scheme (2010) Revision 6 - November 2010. New South Wales Department of Primary Industries, Sydney. Available at: http://www.dpi.nsw.gov.au/fishing/aquaculture/publications/species-freshwater/collecting-finfish-broodstock/info-sheet
NSW Fisheries (2003) Freshwater Fish Stocking in NSW. Environmental Impact Statement—Public Consultation Document. Cronulla Fisheries Centre, New South Wales (NSW) Fisheries, Australia. Available from https://www.dpi.nsw.gov.au/fishing/pests-diseases/animal-health/aquaculture/stocked-fish/fw-stocking/ffs-eis
Oliveira R, Randi E, Mattucci F, Kurushima JD, Lyons LA, Alves PC (2015) Toward a genome-wide approach for detecting hybrids: informative SNPs to detect introgression between domestic cats and European wildcats (Felis silvestris). Heredity 115:195–205. https://doi.org/10.1038/hdy.2015.25
Peterson BK, Weber JN, Kay EH, Fisher HS, Hoekstra HE (2012) Double digest RADseq: an inexpensive method for de novo SNP discovery and genotyping in model and non-model species. PLoS ONE 7:e37135. https://doi.org/10.1371/journal.pone.0037135
Pritchard JK, Stephens M, Donnelly P (2000) Inference of population structure using multilocus genotype data. Genetics 155:945–959
Raj A, Stephens M, Pritchard JK (2014) FastSTRUCTURE: variational inference of population structure in large SNP data sets. Genetics 197:573–589. https://doi.org/10.1534/genetics.114.164350
Rowland S, Tully P (2004) Hatchery Quality Assurance Program. NSW Department of Primary Industries, Grafton, Australia
Sandoval-Castillo J, Robinson NA, Hart AM, Strain LWS, Beheregaray LB (2018) Seascape genomics reveals adaptive divergence in a connected and commercially important mollusc, the greenlip abalone (Haliotis laevigata), along a longitudinal environmental gradient. Mol Ecol 27:1603–1620. https://doi.org/10.1111/mec.14526
Sanz N, Araguas RM, Fernández R, Vera M, García-Marín J-L (2009) Efficiency of markers and methods for detecting hybrids and introgression in stocked populations. Conserv Genet 10:225–236. https://doi.org/10.1007/s10592-008-9550-0
Savary R, Dufresnes C, Champigneulle A, Caudron A, Dubey S, Perrin N, Fumagalli L (2017) Stocking activities for the Arctic charr in Lake Geneva: genetic effects in space and time. Ecol Evol 7:5201–5211. https://doi.org/10.1002/ece3.3073
Todesco M, Pascual MA, Owens GL, Ostevik KL, Moyers BT, Hübner S, Heredia SM, Hahn MA, Caseys C, Bock DG, Rieseberg LH (2016) Hybridization and extinction. Evol Appl 9:892–908. https://doi.org/10.1111/eva.12367
Trebitz AS, Hoffman JC, Darling JA, Pilgrim EM, Kelly JR, Brown EA, Chadderton WL, Egan SP, Grey EK, Hashsham SA, Klymus KE, Mahon AR, Ram JL, Schultz MT, Stepien CA, Schardt JC (2017) Early detection monitoring for aquatic non-indigenous species: optimizing surveillance, incorporating advanced technologies, and identifying research needs. J Environ Manage 202:299–310. https://doi.org/10.1016/j.jenvman.2017.07.045
van Wyk AM, Dalton DL, Hoban S, Bruford MW, Russo I-RM, Birss C, Grobler P, van Vuuren BJ, Kotzé A (2017) Quantitative evaluation of hybridization and the impact on biodiversity conservation. Ecol Evol 7:320–330. https://doi.org/10.1002/ece3.2595
Waples RS, Hindar K, Karlsson S, Hard JJ (2016) Evaluating the Ryman-Laikre effect for marine stock enhancement and aquaculture. Curr Zool 62:617–627. https://doi.org/10.1093/cz/zow060
Ward RD (2006) The importance of identifying spatial population structure in restocking and stock enhancement programmes. Fisheries Res 80:9–18. https://doi.org/10.1016/j.fishres.2006.03.009
Welcomme RL, Cowx IG, Coates D, Béné C, Funge-Smith S, Halls A, Lorenzen K (2010) Inland capture fisheries. Philosophical Transactions of the Royal Society B. Biol Sci 365:2881–2896. https://doi.org/10.1098/rstb.2010.0168
Wellenreuther M, Mérot C, Berdan E, Bernatchez L (2019) Going beyond SNPs: The role of structural genomic variants in adaptive evolution and species diversification. Mol Ecol 28:1203–1209. https://doi.org/10.1111/mec.15066
Acknowledgements
We acknowledge the many researchers that provided samples, aided sample collection, or conducted sample dissection, and the many institutions that provided logistic support (see Beheregaray et al. (2017) and Attard et al. (2018) for details).
Funding
Financial support was provided by an Australian Research Council Future Fellowship (FT130101068) to LBB, and by the associated Flinders University salary component for CRMA.
Open Access funding enabled and organized by CAUL and its Member Institutions
Author information
Authors and Affiliations
Contributions
CRMA and LBB conceived the study. CRMA generated the SNP data and LKF generated the microsatellite data, with contributions from all other authors. CRMA analyzed the data with contributions from JS-C and LBB. CRMA drafted the article. All authors contributed to data interpretation and critically revised the article.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics approval
Collections were obtained under permits from various state fisheries agencies and research under Flinders University Animal Welfare Committee approvals E313 and E342.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Communicated by James Tony Lee.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Attard, C.R.M., Sandoval-Castillo, J., Gilligan, D.M. et al. Genomics outperforms genetics to manage mistakes in fisheries stocking of threatened species. Biodivers Conserv 31, 895–908 (2022). https://doi.org/10.1007/s10531-022-02369-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10531-022-02369-x