
Abstract
Diabetic retinopathy, often resulting from conditions like diabetes and hypertension, is a leading cause of blindness globally. With diabetes affecting millions worldwide and anticipated to rise significantly, early detection becomes paramount. The survey scrutinizes existing literature, revealing a noticeable absence of consideration for computational complexity aspects in deep learning models. Notably, most researchers concentrate on employing deep learning models, and there is a lack of comprehensive surveys on the role of vision transformers in enhancing the efficiency of these models for DR detection. This study stands out by presenting a systematic review, exclusively considering 84 papers published in reputable academic journals to ensure a focus on mature research. The distinctive feature of this Systematic Literature Review (SLR) lies in its thorough investigation of computationally efficient approaches and models for DR detection. It sheds light on the incorporation of vision transformers into deep learning models, highlighting their significant contribution to improving accuracy. Moreover, the research outlines clear objectives related to the identified problem, giving rise to specific research questions. Following an assessment of relevant literature, data is extracted from digital archives. Additionally, in light of the results obtained from this SLR, a taxonomy for the detection of diabetic retinopathy has been presented. The study also highlights key research challenges and proposes potential avenues for further investigation in the field of detecting diabetic retinopathy.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Artificial intelligence (AI) has revolutionized a range of fields by incorporating human-like capabilities such as learning, reasoning, and perception into software systems. This technological progression has empowered computers to perform tasks traditionally handled by humans. Boosted by advancements in computing power, the availability of extensive datasets, and the development of cutting-edge AI algorithms, AI applications are now widespread. Notable applications include finger vein recognition (Bilal et al. 2021), diabetic retinopathy detection (Bilal et al. 2024a, b, 2023, 2022, 2021), RNA Engineering (Yu et al. 2024; Feng et al. 2024), cancer detection (Bilal et al. 2024a, b, 2022a, b), biomathematical challenges (Bilal et al. 2021; Bilal and Sun 2020), and smart agriculture (Bilal et al. 2023).
The human eye stands as the paramount sensory organ responsible for detecting light and transmitting signals via the optic nerve to the brain. This process culminates in the formation of images, enabling the profound gift of vision, along with the ability to distinguish colors and perceive depth (Yadav and Singh 2019). Retinopathy, a condition that impacts the human eye’s retina, typically results from various underlying diseases such as diabetes, hypertension, chronic kidney disease, and heart ailments (Fisher et al. 2016).
Diabetic retinopathy (DR) is a consequence of diabetes that causes vision damage and ultimately results in blindness if early diagnosis and treatment are delayed (Bhandari et al. 2023). Common indications of diabetic retinopathy encompass visual blurriness, the presence of floaters and flashes, as well as vision impairment or loss (Akram et al. 2013). For the vast number of diabetic patients, diabetic retinopathy (DR) has emerged as a major global medical problem and is currently the main contributor to blindness in people of working age (Thomas et al. 2019), (Raman et al. 2016; Bilal et al. 2021). Diabetes already affected 537 million people worldwide, according to a report conducted by the International Diabetic Federation in 2021 (Aschner et al. 2021). Globally, it is anticipated that the prevalence of diabetes will increase to 10.2% (578 million) and 10.9% (700 million) by 2030 and 2045 respectively (Saeedi et al. 2019). Additionally, it is predicted that the prevalence of impaired glucose tolerance will increase to 8.0% (454 million) and 8.6% (548 million) by the same time period. Around 75% of these individuals live in below middle-income nations, where almost 33% diabetic patients have DR (Wong and Sabanayagam 2020; Choo et al. 2021).
Hence, early detection of diabetic retinopathy is a pivotal objective, and the development of automated detection methods is imperative to alleviate the strain on the healthcare system caused by manual diagnosis (Bhandari et al. 2023; Dastane 2020). In this context, substantial research endeavors have been dedicated to the automatic detection of diabetic retinopathy, employing a combination of Machine Learning (ML) and image processing techniques (Priya and Aruna 2013). Both fields find applications in various medical contexts, including disease prediction, health risk analysis, and a range of other healthcare-related purposes.
After a thorough examination of the previous survey papers as shown in Table 1, it’s evident that only a limited number of these papers delve into machine-learning methodologies for the detection of diabetic retinopathy. The majority of researchers have reviewed papers published up to the year 2021, with only a limited number of surveys including papers from 2022 in their examinations. Few researchers primarily focus on the segmentation techniques employed for diabetic retinopathy in their publications. However, the majority of the researchers place their emphasis on utilizing deep learning models for diabetic retinopathy detection. To the best of our knowledge, none of the past review papers have explored the computational complexity aspects associated with various deep learning models for diabetic retinopathy detection. There is also a notable absence of a comprehensive survey examining how vision transformers in deep learning models have contributed to improving the efficiency of models for DR detection. In this SLR, those papers are examined that are published in reputable academic journals, excluding workshop publications. This approach was chosen as it allows us to focus on more established and mature research, thus strengthening the rationale for our survey.
This SLR stands out by offering a thorough investigation of computationally efficient approaches and models. It includes an extensive study of how incorporating vision transformers into deep learning models can significantly improve the accuracy of diabetic retinopathy detection. This SLR will assist researchers in developing computationally efficient DL models for real-time Diabetic Retinopathy (DR) detection.
The major contributions of this research work are as follows:
-
1.
A comprehensive, systematic, and in-depth review of computationally efficient deep learning models for diabetic retinopathy detection is performed.
-
2.
The impact of using a vision transformer is analyzed to enhance the accuracy of deep learning models for diabetic retinopathy detection.
-
3.
A detailed analysis and comparison of 13 publicly available datasets are provided.
-
4.
A thematic analysis of the chosen studies is performed to provide a more clearer and comprehensive overview of the current state-of-the-art research for diabetic retinopathy detection.
-
5.
The immediate next steps and two potential research problems are proposed for future exploration in the field of diabetic retinopathy.
The rest of the paper is defined as follows: The literature review is described in Section 2, Research methodology is explained in Section 3, Future recommendations are given in Section 4 and the Conclusion of this SLR is written in Section 5.
2 Literature review
The query string and relevant keyword groups used to extract the list of relevant SLRs are given in Table 3 and 2.
In their comprehensive research detailed in the paper by Das et al. (2022), a thorough exploration is conducted on the topics of Diabetic Retinopathy (DR), DR lesions, structural characteristics, challenges related to identification, and the sequential phases of incidence and progression. The study effectively utilizes DR images to create a chronological narrative. Furthermore, the research involves a comparative analysis of various Deep Learning (DL) models, including hybrid Machine Learning-Deep Learning (ML-DL) models, Deep Convolutional Neural Networks (DCNN), Convolutional Neural Networks (CNN), Transfer Learning (TL) models, ensemble ML/DL models, as well as evolutionary and comprehensive learning algorithms. This comparative analysis sheds light on their respective performances, particularly in the context of early DR detection. However, this review paper lacks a systematic approach, with a notable absence of information regarding the computational complexities of the models under scrutiny. Additionally, the study didn’t mention any research questions. Furthermore, it predominantly draws upon papers published prior to 2021, with only a few exceptions from that year. Notably, the study does not incorporate research papers utilizing vision transformers for diabetic retinopathy detection.
Another study conducted by Nadeem et al. (2022) was carried out in a systematic manner, following the PRISMA approach. To identify the most pertinent published papers, the initial search query in this research paper was simple, containing only two keywords: “Diabetic retinopathy” and "deep learning." The authors of this study performed a thorough evaluation of different deep learning models, structures, and platforms, examining them with regard to their accuracy, the datasets they used, and the kinds of image modalities they applied. However, there is a scarcity of studies that have explored the challenges and consequences associated with deploying deep learning models in clinical environments. In this study, only two papers from the year 2022 were included, while the remaining papers featured in the study were published prior to 2022.
A comprehensive and thorough examination of automated diagnostic techniques for the detection of DR and related eye conditions was conducted by Lalithadevi and Krishnaveni (2022). This study explored various aspects, including the causes of DR, the availability of publicly accessible datasets, image preprocessing, the segmentation of different DR lesions, feature enhancement, an array of deep learning models, and the persistent challenges in ongoing research. Remarkably, among the papers reviewed in this study, only a limited number, approximately 6 to 7, were published in 2021, while the majority were from earlier years. Notably, this research does not delve into the computational complexities of the discussed models. Additionally, this research falls short in providing guidance on which models are well-suited for real-time DR detection.
Tajudin et al. in their paper (Tajudin et al. 2022) provided an overview of 19 research papers published between 2017 and 2022 that utilize CNNs for the detection of five distinct severity levels of Diabetic Retinopathy (DR). The evaluation criteria employed to compare these CNN models encompass accuracy, the area under the receiver operating characteristic curve, specificity, and sensitivity. This review focused only on 19 papers, with two of them published in 2022, while the remaining are from 2017 to 2019 timeframe. The review process does not follow a systematic approach, and the research questions guiding these papers are not explicitly outlined. Furthermore, the scope of this study centers solely on CNN models in the context of DR detection.
A thorough analysis was carried out in another research on various approaches to detect DR, including detection methods and methods for selecting relevant features (Bhandari et al. 2023). The investigation covered a spectrum of computational techniques, such as fuzzy logic, particle swarm optimization, neural networks, and genetic algorithms. Additionally, the study delved into the use of combinations of these computational methods to select relevant features for diabetic retinopathy detection. However, it’s worth noting that this review lacked a systematic approach. Additionally, the discussion of publicly available datasets for diabetic retinopathy detection was relatively limited in this research.
Dayana and Emmanuel (2023) in their research conducted an extensive and comprehensive analysis of the utilization of deep learning methods in the context of DR detection and grading based on fundus images. This review provided an in-depth exploration of the available fundus image datasets and the preprocessing techniques employed for diabetic retinopathy classification. Furthermore, this study systematically examined and discussed the categorization of diabetic retinopathy, employing transfer learning, ensemble learning, and metaheuristic optimization algorithms. However, the review lacks a systematic evaluation and does not include any research questions. Additionally, the computational complexity of the models is not incorporated into the study.
A systematic review conducted by Vij and Arora (2023) provided an extensive and in-depth analysis of the development of deep learning (DL) methods for the early-stage detection of diabetic retinopathy in retinal fundus images (RFIs). However, this study considered a review of papers related to diabetic retinopathy detection published up until 2021, and the computational complexity of models is also not discussed.
Another study (Uppamma et al. 2023) provided significant contributions in three key aspects. Firstly, it provided a comprehensive foundation on diabetic retinopathy (DR) as a medical condition, along with a thorough exploration of conventional diagnostic methods. Secondly, it offered an extensive survey of various imaging technologies and how deep learning is applied within the domain of DR. Thirdly, practical applications and real-world situations concerning DR detection are explained. However, this study did not follow a systematic approach, and there is an absence of well-defined research questions. Additionally, the study did not include lightweight models for the detection of DR. Similarly, the authors examined various machine learning and deep learning methods for blood vessel segmentation, along with an overview of publicly accessible datasets related to this field in another study (Radha and Karuna 2023). However, this review is not conducted in a systematic manner. Instead, it is specifically concentrated on segmentation techniques and does not cover deep learning models for the automated detection of diabetic retinopathy. A list of available survey and review papers gathered through a search query is given in Table 3.
However, as compared to the previous reviews described above, this systematic literature review (SLR) stands out as this focuses exclusively on publication channels pertaining to Diabetic retinopathy. It takes a deep dive into the computational efficiency of models and identifies approaches that integrate vision transformers for the detection of Diabetic retinopathy. Additionally, this SLR approach is comprehensive and systematic. This study selects papers based on strict criteria described in Sect. 3.
3 Research methodology
The review process is structured into three key stages, as outlined in our research protocol: planning, execution, and data assessment. The search protocol is established after finalizing our research questions, which play a crucial role in guiding the retrieval of relevant review data and ensuring the impartial selection of studies.

Research Strategy

Search Strategy
3.1 Review plan
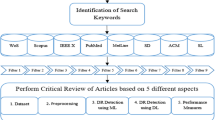
Figures 1 and 2 illustrate the methodology that outlines the research process for establishing the classification scheme, identifying pertinent publications, and defining the criteria for mapping publications. We have employed a comprehensive search strategy to capture all relevant DR data. The approach to study selection is systematically designed to ensure an unbiased process. Throughout this review, a well-structured procedure is followed that encompasses:
-
1.
Defining research objectives
-
2.
Formulating research questions
-
3.
Curating a list of search repositories
-
4.
Meticulously selecting studies
-
5.
Thoroughly screening and evaluating results
-
6.
Extracting essential data
-
7.
Summarizing findings
-
8.
Concluding the review
Creating research questions (RQs) and defining their objectives is a crucial step in conducting a comprehensive investigation of this study. The RQs and their objectives and motives are given in Table 4.
3.2 Review conduct
The review process has been structured into four distinct steps. In the first step, we conducted searches for pertinent primary studies from widely-used digital libraries. The second step involved the selection of studies, employing pre-defined inclusion/exclusion criteria. To enhance the quality of our review, the third step involved the quality assessment criteria. Finally, in the fourth step, we carried out backward snowballing to identify and extract significant candidate papers.
3.3 Automated search in digital libraries
A thorough and systematic research effort has been undertaken to sift through irrelevant studies and gather relevant information. To achieve this, a combination of automatic and manual search methods was employed when investigating the search terms. Throughout this process, numerous digital libraries are explored, opting to focus on repositories that are widely used in systematic literature surveys worldwide. Table 5 represents the digital venues as the primary sources for our automated search are selected, aiming to encompass nearly all pertinent research areas.
3.4 Search query
(Diabetic retinopathy OR DR) AND (Deep Learning OR Deep neural Network OR Vision Transformer OR Machine Learning OR CNN) AND (Computational Complexity OR Computational Time OR Lightweight OR Efficient OR optimization) AND (Detection OR Segmentation OR Identification OR Classification)
Possible arrangements of search string can be seen in Fig. 3 while keyword groups and relative search query are given in Table 6 and in section 3.4. Moreover, the search strategy for digital libraries is given in Table 7.

Keywords used to develop search string
3.5 Inclusion and exclusion criteria
3.5.1 Inclusion criteria
-
1.
The article should have “Diabetic Retinopathy" or “Detection of DR" in its title.
-
2.
The article must be published in a reputable journal or top-tier conference.
-
3.
The publication date of an article should not be prior to 2019.
-
4.
The article uses a dataset that is publicly available.
-
5.
The article addresses one of the research questions.
3.5.2 Exclusion criteria
Articles are excluded from further study on the basis of the following conditions given below:
-
1.
Exclude the articles that do not contain either “Diabetic Retinopathy" or “Detection of DR" in their titles.
-
2.
Exclude articles that are not published in a reputable journal or top-tier conference.
-
3.
The publication date of an article is prior to 2019.
-
4.
The article uses a dataset that is not publicly available.
-
5.
The article doesn’t address one of the research questions.
Table 8 provides an overview of the noteworthy outcomes from the primary search, filtering, and inspection phases across seven digital libraries defined in section 3.3. I have just searched papers from Google Scholar, IEEE Xplore, Springer, Pub Med, ScienceDirect, and wiley Online library and added results in Table 8.
3.6 Quality assessment based selection
Following the application of inclusion and exclusion criteria, articles are subsequently narrowed down based on their quality assessment scores. The quality assessment process stands as a pivotal step in conducting a systematic literature review. The total score is ten (10) and the score is calculated based on the following conditions given below:
-
1.
Assigned a score of two (2) to articles published in journals and a score of one (1) to those published in top conferences.
-
2.
Assigned a score of one (1) to the article if the dataset used in the article is publicly available otherwise assigned a zero (0) score.
-
3.
Assigned a score of three (3) to the article if a vision transformer is used with a deep learning model, a score of two (2) if any deep learning model is used, and a score of one (1) if machine learning model is used.
-
4.
Assigned a score of two (2) if it uses a lightweight model that is computationally efficient, otherwise assigned a score of one (1).
-
5.
Assigned a score of one (1) if future work is given in the article, otherwise assigned a zero (0).
-
6.
Assigned a score of one (1) if the results of the proposed model are compared with other state-of-the-art models, otherwise assigned a zero (0) score.

Year-wise distribution of publications
The quality assessment score of each selected study is given in Table 9. Only those papers are selected for further study whose quality assessment score is 5 or greater than 5.
3.7 Paper selection through snowballing
Following a quality assessment, a backward snowballing technique is used by reviewing the reference lists of each of the finalized studies to identify relevant papers. Only those papers are selected which fulfilled the defined criteria of inclusion and exclusion and their significance is determined based on an initial review of their abstracts and subsequent examination of the full content. After a comprehensive review of the selected papers, an additional three studies (Raiaan et al. 2023; Venkaiahppalaswamy et al. 2023), and Gu et al. (2023) are added to our survey.
3.8 Assessment of RQ1: what are relevant publication channels for DR research?
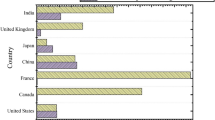
Year-wise distribution and geographic distribution for a total of 86 selected papers are given in Figs. 4 and 5 respectively.

Geographic distribution of publications
The data extracted from each article includes the publication year, the name of the journal in which it was published, the dataset utilized within the article, the accuracy of the model presented in the article, and the model introduced as part of the methodology within the article. Table 10 and 11 shows the extracted information according to the defined criteria.
3.9 Assessment of RQ2: what are the existing approaches and techniques for the automatic detection of DR?
The evaluation of the existing approaches and techniques for the automatic detection of Diabetic Retinopathy (DR) reveals a diverse landscape of methodologies employed across various studies. Based on our examination of the chosen studies detailed in Table 11, it is evident that a variety of deep learning models have been introduced and preferred for the detection of Diabetic Retinopathy (DR). The predominant trend observed among researchers is the widespread utilization of deep learning models in addressing this objective. Khan et al. proposed DR-CCTNet, achieving 90.17% accuracy on datasets APTOS, Messidor2, IDRiD, DDR, and Kaggle Diabetic Retinopathy (Khan et al. 2023). Luo et al. (2023) explored a variety of deep learning models, including DenseNet, VGG, Inception Net, MobileNet V2, ResNext50, ShuffleNet, ViT, and ViG. A Hybrid Convolutional Neural Network, achieving an impressive 96.85% accuracy with the EyePACS dataset is also employed in another study (Ali et al. 2023).The RetNet-10 model demonstrated high accuracy (98.65%) in DR detection using datasets APTOS, Messidor2, and IDRiD introduced by Raiaan et al. (2023). Sau et al. utilized MDNN, a Modified Deep Neural Network (MDNN) that achieved an accuracy of 95.20% using the IDRiD dataset (Sau and Bansal 2022). Bilal et al. (2022) in their study used U-Net, achieving accuracies of 96.60%, 93.95%, and 92.25% with EyePACS-1, Messidor-2, and DIARETDB0 datasets, respectively. Similarly, some other techniques and models e.g. Conv-ViT (Dutta et al. 2023), ADL CNN (Özbay 2023), lightweight DL model based on ColonSegNet (Aurangzeb et al. 2022), Chronological Tunicate Swarm Algorithm (CTSA) (Dayana and Emmanuel 2022), Inception V3 model (Beham and Thanikaiselvan 2023), RCNN-GAN (Krishnamoorthy et al. 2023), SegNet (Elaouaber et al. 2023), Standard Convolutional Neural Network (CNN), and many others have been introduced in the chosen papers for DR detection. Techniques like LSTM-RFO (Pugal Priya et al. 2022), PCNN (Parallel Convolutional Neural Network) (Nahiduzzaman et al. 2023), Shifted windows (Swin) Transformers (Dihin et al. 2022), EDR Net (Aujih et al. 2022), HemNet, Swin Transformer V2 (Li et al. 2023), Hybrid (RCNN-GAN), Tripple cascade convolutional neural network (Jian et al. 2023), and Autoregressive-Henry (Elwin et al. 2022) have also been used for DR detection.
3.10 Assessment of RQ3: what is the impact of using vision transformers in enhancing accuracy in DR detection models?
Vision transformers (ViTs) are emerging as a potent alternative to convolutional neural networks (CNNs) in diabetic retinopathy (DR) detection, addressing limitations inherent in the traditional CNN approach. While CNNs excel at extracting local spatial features from fundus images, they may lack a comprehensive global context, struggle with long-range dependencies, and impose high computational costs. ViTs overcome these challenges by dividing images into patches treated as tokens and leveraging attention mechanisms to capture both local and global information. This offers advantages such as enhanced contextual understanding, increased flexibility in modeling long-range dependencies, and improved scalability. Existing end-to-end DL models are proficient at processing either texture or shape-based information independently, limiting their ability to impart the necessary robustness for classifying various retinal diseases. Addressing this limitation, Dutta et al. (2023) introduced a fusion model named ’Conv-ViT’ specifically designed for detecting retinal diseases from optical coherence tomography (OCT) images. To address both texture and shape-based features comprehensively, the proposed Conv-ViT combines transfer learning-based CNN models, including Inception-V3 and ResNet-50, for processing texture information by calculating pixel correlations. Additionally, they incorporated a vision transformer model to process shape-based features by evaluating pixel correlations over longer distances. This hybrid approach effectively integrates these three models to facilitate shape-based texture feature learning during the classification of retinal diseases.
In another stuudy, Wang et al. (2023) introduced a novel Transformer-based model, termed "VTA + HE," designed specifically for Diabetic Retinopathy (DR) multi-lesion segmentation tasks. This model enhances the original Vision Transformer architecture by integrating a spatial prior module, utilizing convolutional neural networks for image feature extraction. Additionally, the architecture incorporates a spatial feature injector and extractor to boost feature interaction. Their proposed model exhibits superior performance in segmentation on the IDRiD dataset. Hossain et al. (2023) implemented Vision Transformer (ViT) with Dual Shifted Patch tokenization (SPT) and Locality self-attention (LSA) that addresses the inherent location inductive bias (LIB), resulting in enhanced accuracy on relatively smaller datasets compared to traditional Vision Transformer models. To tackle class imbalance, they used StyleGAN2, a generative model, to generate synthetic images for underrepresented classes. A comparative analysis is also conducted by implementing ResNet101, VGG16, and Xception, modifying their layers for improved performance, and providing valuable insights into the effectiveness of different models in the given context.
Using Vision Transformers (ViTs) for diabetic retinopathy detection involves trade-offs between computational complexity and accuracy, resource usage and performance, and implementation complexity and scalability. A study conducted by Mehta and Rastegari (2021) introduced MobileViT, a lightweight, general-purpose vision transformer designed for mobile and resource-constrained environments. The MobileViT model innovatively combines standard convolutional neural networks (CNNs) with lightweight vision transformers, harnessing the strengths of both to form a compact yet powerful architecture. This hybrid structure incorporates mobile-specific optimizations such as depthwise separable convolutions and efficient self-attention mechanisms. To further enhance efficiency, techniques like model pruning, quantization, and parameter sharing are utilized to minimize model size and computational demands, while lightweight transformer blocks ensure the model’s ability to capture long-range dependencies remains intact. MobileViT achieves competitive accuracy on benchmark datasets like ImageNet, maintaining a significantly smaller model size and lower latency compared to traditional ViTs and CNNs. The model excels in computational efficiency, evidenced by reduced inference times and lower memory usage. Despite the optimizations, MobileViT maintained a high accuracy rate of 90%, comparable to traditional ViTs and superior to many CNN models. In another study, Dosovitskiy et al. (2020) introduced Vision Transformers (ViTs) by leveraging the self-attention mechanism to capture global dependencies within retinal images. The study aimed to assess the performance of ViTs in comparison to traditional Convolutional Neural Networks (CNNs). Through optimization techniques such as layer-wise pruning and distillation, the inference time for the ViT was reduced by 30%, making it comparable to optimized CNNs.
Despite promising results, ViTs for DR detection require further research to validate performance across diverse datasets, enhance interpretability, and optimize efficiency for real-time applications, with the potential to revolutionize the diagnosis and management of DR.
3.11 Assessment of RQ4: what are the various approaches and methodologies of deep learning that are computationally efficient for DR detection?
In assessing the approaches and methodologies of deep learning for computationally efficient diabetic retinopathy (DR) detection, several innovative models and techniques were identified. The proposed EDR-Net (Aujih et al. 2022) in the literature addresses the computational inefficiency of the existing DR-Net architecture by introducing a depth-wise separable convolution module. This model achieves comparable predictive performance to state-of-the-art methods in detecting referable diabetic retinopathy (rDR) while significantly reducing computation costs, making it suitable for mobile device-based applications. Another notable approach (Kukkar et al. 2022) involves a Diabetic Retinopathy Classification (DRC) system, leveraging the Internet of Medical Things (IoMT), a deep learning model (RESnet), and a hybrid optimization (HGACO) algorithm. This system shows promise in early detection and classification of DR severity, presenting a potential solution for preventing blindness in diabetic patients. Additionally, the Symmetric Mask Pre-Training Vision Transformer (SMiT) introduces a transformer-based framework for grading pathological images (Zhang et al. 2023). By deviating from traditional convolutional neural network (CNN) models, SMiT achieves superior results in diagnosing colorectal cancer images, demonstrating the effectiveness of visual transformers in medical imaging applications. Furthermore, the Triple-DRNet (Jian et al. 2023) model adopts a triple-cascade network approach to effectively distinguish various DR lesions, enhancing grading performance with high accuracy on the APTOS 2019 Blindness Detection dataset. These approaches collectively showcase advancements in deep learning methodologies that prioritize computational efficiency for DR detection.
Khan et al. (2023) utilized the fine-tuned Compact Convolutional Transformer (CCT) model and introduced the DR-CCTNet model, a modification of the CCT model, for efficient training concerning computational complexity. In another study, Raiaan et al. (2023) proposed the RetNet-10 model for automatic DR detection. They merged three DR datasets (APTOS, Messidor2, IDRiD) to form a dataset of 5,819 images and applied image pre-processing, and data augmentation, and developed a shallow CNN base model. Finally, they experimented with optimized model components and hyperparameters to reduce the computational time. Aurangzeb et al. in their study employed a lightweight DL model based on ColonSegNet for retinal vessel segmentation wih the aim to address the gap of reducing computational complexity in retinal vessel segmentation. The performance of the proposed model was assessed on three datasets (DRIVE, CHASEDB1, STARE) with superior results, making it suitable for low-end hardware devices (Aurangzeb et al. 2022). Another group of researchers introduced a contrast-limited Adaptive Histogram Equalization (CLAHE) pre-processing technique with a Parallel Convolutional Neural Network (PCNN) for feature extraction and an Extreme Learning Machine (ELM) for classification. Fundus images were preprocessed with CLAHE to enhance lesion visibility. They address the problem of reducing parameter complexity and layer complexity as compared to conventional CNN (Nahiduzzaman et al. 2023).
For future research, we suggest several avenues to enhance the performance and applicability of diabetic retinopathy detection models. Improving the performance of specific subnetworks, such as the NPDR-Net, and compressing network parameters will make models more suitable for real-world clinical applications. Lastly, systematic ablation studies to evaluate different design choices for architectures like EDR-Net, along with improvements to modules like the SEC module for better control of channel and spatial dimensions, will be instrumental in advancing the field. Furthermore, implementing different angles of diabetic retinopathy images and employing a patch-wise classification approach with fewer resources could enhance model accuracy and efficiency. Moreover, investigating the application of geometrical deep learning and graph neural networks may offer insights into the progression of diabetic retinopathy.
3.12 Assessment of RQ5: what are the key performance metrics and benchmark datasets commonly used to evaluate the effectiveness and efficiency of deep neural networks for DR detection?
An extensive examination was conducted on 85 carefully selected research papers to identify prevalent evaluation metrics employed in the detection of Diabetic Retinopathy (DR). The findings, as presented in Table 11, primarily focused on reporting the accuracy of each selected paper. However, it is noteworthy that the common evaluation metrics utilized across these studies encompass accuracy, specificity, sensitivity, and, in some papers, the Area Under the Receiver Operating Characteristic (AUC-ROC) curve. These metrics collectively contribute to a comprehensive understanding of the performance of DR detection models.
In addition to evaluating metrics, the study recognized the pivotal role played by datasets in the research process. A thorough analysis of the datasets employed in these studies was conducted, and the dataset characteristics are presented in detail in Table 13. This examination sheds light on the diverse attributes and features of the datasets utilized, providing valuable insights into the foundation upon which the DR detection models were developed and assessed in the respective studies.
3.12.1 Messidor-2
The Messidor-2 dataset serves as a valuable resource for advancing research in computer-assisted diagnoses of diabetic retinopathy. It comprises 1748 macula-centered eye fundus images, including 874 pairs from patients with diabetic retinopathy. The high-resolution PNG format images, each measuring 1440 x 960 pixels, have undergone expert grading to determine the severity of diabetic retinopathy. Additionally, the dataset facilitates the comparison and evaluation of various segmentation algorithms and image database management tools, offering annotations for select images to indicate the presence of lesions such as microaneurysms, hemorrhages, and exudates.
3.12.2 IDRiD
The Indian Diabetic Retinopathy Image Dataset (IDRiD) is a comprehensive resource focused on diabetic retinopathy (DR) and diabetic macular edema (DME), tailored to represent the Indian population. With 516 high-resolution fundus images at 4288 x 2848 pixels and a 50-degree field of view, the dataset includes pixel-level annotations of DR lesions and normal retinal structures, aligning with international standards for disease severity grading. Notably, IDRiD stands out as the sole dataset offering such detailed annotations for an Indian demographic. Captured in authentic clinical settings, it ensures practical applicability and clinical relevance. The dataset’s JPEG format for images and XML format for annotations, along with challenges such as image variability and potential biases, underline its significance in population-specific research.
3.12.3 DDR
The DDR dataset is specifically crafted to support research and development in the realm of diabetic retinopathy (DR) by facilitating detection, classification, and lesion segmentation. Comprising 13,673 fundus images sourced from 147 hospitals spanning 23 provinces in China, the dataset ensures geographic diversity and excludes poor-quality images through meticulous quality control. This dataset proves instrumental for advancing DR-related research, offering a substantial resource for algorithm development and evaluation.
3.12.4 EyePACS
The EyePACS dataset serves a multifaceted purpose, aiming to advance early detection of diabetic retinopathy (DR) and other eye diseases through telemedicine and digital imaging. The dataset comprises over 88,000 high-resolution digital retinal images captured using diverse cameras and imaging protocols. Each image undergoes grading for DR presence and severity by trained human graders, adhering to a standardized protocol. The dataset includes limited patient metadata such as age, gender, and primary care provider information. The images are stored in JPEG format, while grading information is in XML format.
3.12.5 DRIVE
The dataset consists of retinal fundus images captured using a Canon CR5 non-mydriatic 3CCD camera with a \(45^\circ\) field of view, encompassing 40 images, each accompanied by two manually segmented ground truths for blood vessels. The dataset, available in color JPEG format for images and PNG format for ground truth vessel segmentations, bears certain considerations such as its relatively small size, limited diversity in image acquisition devices and patient populations, and the potential for bias in ground truth annotations.
3.12.6 CHASE_DB1
The CHASE_DB1 dataset serves the primary purpose of advancing retinal vessel segmentation algorithms, providing a valuable resource for development and evaluation in this domain. Comprising 28 color fundus images of retinas with a resolution of 999 x 960 pixels, the dataset features images captured from both eyes of 14 children (7 female, 7 male). Derived from the Child Heart and Health Study in England (CHASE), the images were obtained using a Nidek NM-200-D fundus camera with a 30-degree field of view. Despite its relatively small size, which may pose challenges for training complex models, the dataset’s focus on children’s retinas provides a unique perspective, though its generalizability to adult populations should be considered.
3.12.7 STARE
The dataset, primarily geared towards retinal vessel segmentation, encompasses 20 color fundus images with a resolution of 700 x 605 pixels. It provides two sets of ground-truth vessel annotations: Set 1 by Adam Hoover, commonly employed for training and testing, and Set 2 by Valentina Kouznetsova, serving as a human baseline. While the project comprises over 400 raw images, only 20 are publicly available with annotations. Widely utilized in research studies, the dataset is marked by its relatively small size, and limited diversity of images in terms of ethnicity and disease types. Accessible via the STARE project website,
3.12.8 DIARETDB0
The DIARETDB0 dataset is designed for the development and evaluation of algorithms aimed at automated diabetic retinopathy (DR) detection. Comprising 130 color fundus images captured with 50-degree field-of-view digital fundus cameras, the dataset includes 20 normal images and 110 images exhibiting signs of DR. The dataset, labeled as "calibration level 0," suggests potential variability in image quality.
3.12.9 DIARETDB1
The DIARETDB1 dataset serves as a resource for diabetic retinopathy detection and assessment, comprising 89 color fundus images with a resolution of 1500 x 1151 pixels in JPEG format. With a focus on aiding research and algorithm development for diabetic retinopathy, the dataset encompasses images from 89 patients with varying degrees of the condition. It is relatively small size and limited diversity in image characteristics pose challenges to the generalizability of algorithms trained on it.
3.12.10 ORIGA
The ORIGA dataset, standing for Online Retinal Fundus Image Dataset for Glaucoma Analysis and Research, is dedicated to glaucoma detection and analysis. Comprising 650 retinal fundus images with a resolution of 3072 x 2048 pixels, the dataset is distributed between 482 healthy images and 168 glaucomatous images. Annotations include class labels distinguishing healthy from glaucoma cases, as well as detailed contours of the optic disc (OD) and optic cup (OC), along with cup-to-disc ratio (CDR) values.
3.12.11 HRF
The HRF dataset, designed for retinal vessel segmentation and image quality assessment, features high-resolution fundus images with a resolution of 3304 x 2336 pixels. Comprising a segmentation dataset of 45 images and an image quality assessment dataset of 18 image pairs, the dataset includes conditions such as healthy, diabetic retinopathy, and glaucoma. Annotations consist of binary gold standard vessel segmentation masks and field of view (FOV) masks. Organized into 15 subsets, each containing healthy, diabetic retinopathy, and glaucoma images, the dataset is divided into 22 training images and 23 testing images for the segmentation dataset. The image quality assessment dataset comprises 18 pairs of images capturing the same eye under good and poor quality conditions, utilizing a Canon CR-1 fundus camera.
3.12.12 OCTID
The Optical Coherence Tomography Image Retinal Database (OCTID) is an open-source dataset designed for ophthalmology research, comprising over 500 high-resolution retinal images captured using Optical Coherence Tomography (OCT) technology. These images are systematically categorized into five classes, including Normal, Macular Hole, Age-related Macular Degeneration, Central Serous Retinopathy, and Diabetic Retinopathy, encompassing different disease stages. The dataset presents images in JPEG format resized to 500x750 pixels.
3.12.13 APTOS 2019
APTOS 2019, hosted by the Asia Pacific Tele-Ophthalmology Society, held significant importance in 2019 by concentrating on addressing the challenge of diabetic retinopathy (DR), a leading cause of blindness. A pivotal contribution was the release of the APTOS 2019 dataset, featuring over 3,600 fundus images from rural India, expertly classified by DR severity (Albadr et al. 2022).
4 Discussion and future directions
This section provides an overview and analysis of the outcomes pertaining to the systematic literature review.
Integrating advanced computational models like Vision Transformers (ViTs) into clinical practices offers significant potential for enhancing patient outcomes but also presents several challenges that must be addressed for successful implementation in real-world healthcare settings (Parvaiz et al. 2023). These challenges include system integration and interoperability with existing healthcare information systems, ensuring data privacy and security in compliance with regulations, and overcoming the computational resource limitations that may exist in smaller or resource-limited healthcare environments. Additionally, clinical acceptance can be hindered by workflow disruptions and skepticism towards AI-driven decision-making processes, while extensive training and ongoing support for healthcare professionals are necessary to effectively utilize these technologies. Despite the hurdles and difficulties, There are enough benefits, e.g. patient outcomes can be improved significantly using more accurate and timely diagnoses, operational efficiency can be increased by automating the daily tasks, insights can be driven from data to help in clinical decision-making, and the scalability of advanced diagnostic tools to reach underserved areas. Addressing the challenges through careful planning and ensuring model transparency will be key to unlocking the full potential of these technologies in healthcare.
Vision Transformers (ViTs) are helpful in clinical sites for the detection of diabetic retinopathy and their implementation requires cautious consideration of computational load and hardware necessities. For some ViTs like ViT-B/16 requires significant computational sources because it has almost 86 million parameters and a self-attention mechanism requiring \(O(n^2 \cdot d)\) operations. For example, when a 224x224 pixel image is processed using ViT-B/16 requires approximately 1.0 s on GPUs like the NVIDIA RTX 3090. These models can be trained using high-performance GPUs such as NVIDIA A100 with substantial memory requirement of may be more than 20 GB and energy requirement of almost 400 watts per GPU. The deployment of ViTs can become challenging in clinical settings due to the budget limitations and lack of advanced infrastructure in these environments. Therefore, ViTs can be optimized in these clinical environments using techniques such as pruning and quantization. The cost and performance of these ViTs can also be balanced by means of mid-range GPUs or edge devices. In future, the focus should be on the development of proficient ViT structural design or hybrid devices with moderate computational requirements and high accuracy, thus improving the practicality of using these devices in clinical applications.
To ensure the generalizability of computational models for diabetic retinopathy detection, it’s crucial to think and analyze how these models perform and might be translated in various regions, especially considering the available quality of healthcare and how common diabetes is in different regions. The prevalence of diabetes rates can vary a lot on the basis of different factors e.g. lifestyle, genetics, and socioeconomic conditions. In the regions and areas where diabetes is more common (Shera et al. 2007), these models will be needed to consider and handle a big range of disease severity. On the other side, in areas where diabetes patients are less common, the models’ accuracy and reliability can be compromised as models will have less data to learn. The local healthcare system also matters a lot. In developed countries, advanced models can be easily integrated into existing healthcare systems as their healthcare systems are already technology-oriented. However in countries like Pakistan, it will be difficult to integrate these models as they have limited access to high-performance computing and staff is less trained to adopt the technology. Therefore, adapting the models to work in different environments, such as by making them less demanding on technology or creating simpler interfaces, is crucial for ensuring that these technologies can benefit people worldwide. This is essential for making sure the findings are useful and effective across different populations and healthcare systems.
4.1 Thematic analysis
This systematic literature review aimed to assess contemporary lightweight models for the detection of Diabetic Retinopathy. To fulfil this objective, we constructed a taxonomy hierarchy by thoroughly examining and analyzing the chosen studies, as illustrated in Fig. 6. The investigation delved into challenges and advancements across various dimensions, encompassing algorithms and models for DR detection, computationally efficient models, and image processing and enhancement techniques. Furthermore, these dimensions were subdivided into smaller domains to reveal the depth of each aspect contributing to the enhancement of model performance in Diabetic Retinopathy detection.

Taxonomy of diabetic retinopathy
Moreover, a thematic analysis is conducted to extract relevant relationships from the chosen studies, and subsequently, these relationships are coded (Thomas and Harden 2008; Senapati et al. 2024; Schloemer and Schröder-Bäck 2018). The codes are derived from the existing literature review presented in Table 14. Initially, papers employing diverse algorithms and models are selected and coded as VT, DL, TL, and ML. Subsequently, the papers are categorized based on computational complexity, severity classification, and are assigned codes such as LW, OM, CS, SE, and GS. Lastly, papers are selected based on image processing and image enhancement techniques, with codes assigned as IE and IS. The selected studies are thoroughly examined by evaluating and analyzing their objectives, methodologies, areas of discussion, and limitations.
4.2 Future recommendations
Researchers focusing on advancing diabetic retinopathy (DR) detection should immediately prioritize integrating multimodal data for comprehensive early diagnosis systems, developing sophisticated deep learning architectures for multimodal data fusion, and conducting rigorous validation through cross-validation and longitudinal studies to assess both accuracy and long-term treatment outcomes (Bilal et al. 2021, 2022, 2024a, 2021). Concurrently, they should explore semi-supervised learning approaches to mitigate the challenge of limited labeled datasets by leveraging techniques such as self-training and data augmentation to enhance model performance while reducing dependency on expert-labeled data. Evaluating these models against traditional supervised methods and ensuring robustness across diverse datasets will be crucial, with emerging technologies such as federated learning, explainable AI, and using lightweight models or lightweight vision transformers offering transformative potential to accelerate progress in this critical area of medical research (Bilal et al. 2024b, 2024; Sadiq et al. 2021; Hasan et al. 2024).
To improve the efficiency and accuracy of diagnosis systems for DR detection, this study discovered few problems that can be addresses in future.
4.2.1 Problem 1: integrating iultimodal iata for comprehensive early diagnosis systems:
It is observed in the literature that traditional studies, which exclusively rely on imaging data for Diabetic Retinopathy (DR) diagnosis, may overlook crucial factors influencing the development of the disease. An enhanced understanding of a patient’s health profile, including clinical data such as age, blood sugar, and blood pressure, allows for more personalized and nuanced treatment decisions (Kamarudin et al. 2022; Wenhua et al. 2024). However, the majority of current studies focused on early DR diagnosis fail to integrate multimodal data. This research gap limits the comprehensive understanding of patient health, potentially hindering the accuracy and effectiveness of treatment decisions. The incorporation of data from diverse modalities can play a vital role to establish early diagnosis systems that account for the broader health context of individuals. Standard diagnostic metrics like accuracy, sensitivity, and specificity can be used to evaluate the effectiveness of the multimodal data integration strategy. The performance of the multimodal approach can be compared with traditional unimodal methods that solely rely on imaging data. This involves examining the additional value and accuracy improvement attained by integrating patient-specific information. We can conduct cross-validation on diverse patient populations to assess the generalizability of the multimodal approach. It can also be assessed that how well the model performs across different demographic groups, ensuring the robustness and reliability of data integration across various patient profiles. Furthermore, a longitudinal study can be conducted to analyze treatment outcomes based on the comprehensive early diagnosis system. By addressing this research problem and employing the specified evaluation methods, researchers can advance the field of Diabetic Retinopathy diagnosis, creating more inclusive and effective early diagnosis systems. This approach holds the potential to significantly impact patient care and outcomes in the context of Diabetic Retinopathy.
4.2.2 Problem 2: semi-supervised deep learning based model for detection of DR
It has been noted in the existing literature and within selected papers that, despite the existence of public datasets designed for Diabetic Retinopathy (DR) detection, the size of the training and testing image sets within these datasets is limited. The primary challenge is the need for a large number of labeled fundus images and the associated cost of acquiring expert services for this purpose. Hence, there is a need to investigate strategies and methodologies to reduce dependency on expert services for image labeling. This problem is important as it addresses a key bottleneck in the development of supervised deep-learning models for Diabetic Retinopathy detection, making the process more cost-effective and scalable. A subsequent investigation within this domain could be undertaken, focusing on the development of a semi-supervised deep learning model designed for the detection of Diabetic Retinopathy (DR) using minimal labeled data. This is crucial as it offers a potential solution to the scarcity of labeled fundus images, enabling the model to leverage both labeled and unlabeled data for effective learning. The effectiveness of the proposed strategies in reducing dependency on expert services and leveraging limited labeled data can be quantitatively evaluated through metrics such as classification accuracy, precision, recall, and F1-score. This provides a robust assessment of the models’ performance in DR detection. To gauge the impact of the proposed semi-supervised learning approaches, a comparative analysis with traditional supervised methods should be conducted. This involves evaluating the performance of models trained with limited labeled data against models trained with a large fully labeled dataset. This comparison will help to establish the efficacy of the proposed methods. However, it is essential to assess how well the models generalize to unseen data and variations in image characteristics. Generalization and robustness testing involve evaluating model performance on diverse datasets, including those with different resolutions, qualities, and sources. This provides insights into the models’ adaptability to real-world scenarios. Moreover, considering the aim of reducing costs associated with expert services, evaluation methods should include metrics related to resource utilization. This involves assessing the computational efficiency, time, and cost savings achieved through the proposed semi-supervised learning methods compared to traditional approaches. Solving this research problem and applying the defined evaluation methods will contribute to the development of more cost-effective and scalable solutions for Diabetic Retinopathy detection, addressing the challenges associated with the need for a large number of labeled fundus images.
5 Conclusion
This SLR has been conducted to develop a comprehensive understanding of computationally efficient deep-learning models for the detection of diabetic retinopathy (DR). The study adopts a systematic literature review approach to ensure a thorough exploration of challenges and their corresponding solutions. A meticulous search query, comprising a cluster of keywords pertinent to DR detection, is crafted, and the ensuing results are systematically assessed. To refine the scope, proper inclusion–exclusion criteria and rigorous quality assessments are applied, leading to the identification and extraction of 85 relevant articles. The time frame for this extensive search spans from January 2021 to September 2023. This literature review distinguishes itself by not only focusing on prevalent deep learning methods for DR detection but also by incorporating a novel emphasis on the computational aspect of these models. The primary objective is to understand and evaluate computational efficiency, especially pertaining to real-time detection of DR. Seven major digital repositories have been meticulously explored for this search, and papers published in reputable journals only are included in this SLR. In the future, multi-modal data will be integrated for comprehensive diagnosis of DR detection. Moreover, semi-supervised deep learning models will be introduced to learn from minimal labeled data.
Data availibility statement
Since this is a systematic literature review paper so the data used in the paper to report results are explained in section 3.3. The relevant queries and search strategy we used to extract relevant papers from digital libraries are given in table 6.
References
Abbood SH, Hamed HNA, Rahim MSM, Rehman A, Saba T, Bahaj SA (2022) Hybrid retinal image enhancement algorithm for diabetic retinopathy diagnostic using deep learning model. IEEE Access 10:73079–73086
AbdelMaksoud E, Barakat S, Elmogy M (2022) A computer-aided diagnosis system for detecting various diabetic retinopathy grades based on a hybrid deep learning technique. Med Biol Eng Comput 60(7):2015–2038
Abdelmaksoud E, El-Sappagh S, Barakat S, Abuhmed T, Elmogy M (2021) Automatic diabetic retinopathy grading system based on detecting multiple retinal lesions. IEEE Access 9:15939–15960
Abirami A, Kavitha R (2023) A novel automated komodo mlipir optimization-based attention bilstm for early detection of diabetic retinopathy. Signal, Image Video Process 17:1–9
Akram MU, Khalid S, Khan SA (2013) Identification and classification of microaneurysms for early detection of diabetic retinopathy. Pattern Recogn 46(1):107–116
Al-Antary MT, Arafa Y (2021) Multi-scale attention network for diabetic retinopathy classification. IEEE Access 9:54190–54200
Al-Smadi M, Hammad M, Baker QB, Sa’ad A (2021) A transfer learning with deep neural network approach for diabetic retinopathy classification. Int J Electr Comput Eng 11(4):3492
Albadr MAA, Ayob M, Tiun S, Al-Dhief FT, Hasan MK (2022) Gray wolf optimization-extreme learning machine approach for diabetic retinopathy detection. Front Public Health 10:925901
Albahli S, Nazir T, Irtaza A, Javed A (2021) Recognition and detection of diabetic retinopathy using densenet-65 based faster-rcnn. Comput Mater Continua 67(2):1333–1351
Ali G, Dastgir A, Iqbal MW, Anwar M, Faheem M (2023) A hybrid convolutional neural network model for automatic diabetic retinopathy classification from fundus images. IEEE J Trans Eng Health Med 11:341–350
Aschner P, Karuranga S, James S, Simmons D, Basit A, Shaw JE, Wild SH, Ogurtsova K, Saeedi P (2021) The international diabetes federation’s guide for diabetes epidemiological studies. Diabetes research and clinical practice 172
Aujih AB, Shapiai MI, Meriaudeau F, Tang TB (2022) Edr-net: lightweight deep neural network architecture for detecting referable diabetic retinopathy. IEEE Trans Biomed Circuits Syst 16(3):467–478
Aurangzeb K, Alharthi RS, Haider SI, Alhussein M (2022) An efficient and light weight deep learning model for accurate retinal vessels segmentation. IEEE Access 11:23107–23118
Aziz T, Charoenlarpnopparut C, Mahapakulchai S (2023) Deep learning-based hemorrhage detection for diabetic retinopathy screening. Sci Rep 13(1):1479
Bansode BN, Dildar AS, KM B, GS S (2023) Deep cnn-based feature extraction with optimised lstm for enhanced diabetic retinopathy detection. Comput Methods Biomech Biomed Eng: Imaging Visual 11(3):960–975
Beham AR, Thanikaiselvan V (2023) An optimized deep-learning algorithm for the automated detection of diabetic retinopathy. Soft Comput 27:1–11
Bhandari S, Pathak S, Jain SA (2023) A literature review of early-stage diabetic retinopathy detection using deep learning and evolutionary computing techniques. Arch Comput Methods Eng 30(2):799–810
Bhardwaj C, Jain S, Sood M (2021) Transfer learning based robust automatic detection system for diabetic retinopathy grading. Neural Comput Appl 33(20):13999–14019
Bhat P, Anoop B (2023) Improved invasive weed social ski-driver optimization-based deep convolution neural network for diabetic retinopathy classification. Int J Image Gr 3:2550012
Bilal A, Imran A, Baig TI, Liu X, Abouel Nasr E, Long H (2024) Breast cancer diagnosis using support vector machine optimized by improved quantum inspired grey wolf optimization. Sci Rep 14(1):10714
Bilal A, Imran A, Baig TI, Liu X, Long H, Alzahrani A, Shafiq M (2024) Deepsvdnet: A deep learning-based approach for detecting and classifying vision-threatening diabetic retinopathy in retinal fundus images. Comput Syst Sci Eng 48(2):511–528
Bilal A, Imran A, Baig TI, Liu X, Long H, Alzahrani A, Shafiq M (2024) Improved support vector machine based on cnn-svd for vision-threatening diabetic retinopathy detection and classification. PLoS ONE 19(1):0295951
Bilal A, Imran A, Liu X, Liu X, Ahmad Z, Shafiq M, El-Sherbeeny AM, Long H (2024) Bc-qnet: a quantum-infused elm model for breast cancer diagnosis. Comput Biol Med 175:108483
Bilal A, Liu X, Baig TI, Long H, Shafiq M (2023) Edgesvdnet: 5g-enabled detection and classification of vision-threatening diabetic retinopathy in retinal fundus images. Electronics 12(19):4094
Bilal A, Liu X, Long H, Shafiq M, Waqar M (2023) Increasing crop quality and yield with a machine learning-based crop monitoring system. Comput Mater Continua 76(2):2401–2426
Bilal A, Liu X, Shafiq M, Ahmed Z, Long H (2024) Nimeq-sacnet: A novel self-attention precision medicine model for vision-threatening diabetic retinopathy using image data. Comput Biol Med 171:108099
Bilal A, Shafiq M, Fang F, Waqar M, Ullah I, Ghadi YY, Long H, Zeng R (2022) Igwo-ivnet3: Dl-based automatic diagnosis of lung nodules using an improved gray wolf optimization and inceptionnet-v3. Sensors 22(24):9603
Bilal A, Sun G (2020) Neuro-optimized numerical solution of non-linear problem based on flierl-petviashivili equation. SN Applied Sciences 2(7):1166
Bilal A, Sun G, Li Y, Mazhar S, Khan AQ (2021) Diabetic retinopathy detection and classification using mixed models for a disease grading database. IEEE Access 9:23544–23553
Bilal A, Sun G, Li Y, Mazhar S, Latif J (2022) Lung nodules detection using grey wolf optimization by weighted filters and classification using cnn. J Chin Inst Eng 45(2):175–186
Bilal A, Sun G, Mazhar S (2021) Finger-vein recognition using a novel enhancement method with convolutional neural network. J Chin Inst Eng 44(5):407–417
Bilal A, Sun G, Mazhar S (2021) Survey on recent developments in automatic detection of diabetic retinopathy. J Fr Ophtalmol 44(3):420–440
Bilal A, Sun G, Mazhar S, Imran A, Latif J (2022) A transfer learning and u-net-based automatic detection of diabetic retinopathy from fundus images. Comput Methods Biomech Biomed Eng: Imaging Visual 10(6):663–674
Bilal A, Sun G, Mazhar S, Junjie Z (2021) Neuro-optimized numerical treatment of hiv infection model. Int J Biomath 14(05):2150033
Bilal A, Zhu L, Deng A, Lu H, Wu N (2022) Ai-based automatic detection and classification of diabetic retinopathy using u-net and deep learning. Symmetry 14(7):1427
Bilal A, Sun G, Mazhar S, Imran A (2022) Improved grey wolf optimization-based feature selection and classification using cnn for diabetic retinopathy detection. In: Evolutionary Computing and Mobile Sustainable Networks: Proceedings of ICECMSN 2021,pp. 1–14. Springer
Bilal A, Sun G, Mazhar S (2021) Diabetic retinopathy detection using weighted filters and classification using cnn. In: 2021 International Conference on Intelligent Technologies (CONIT), pp. 1–6. IEEE
Bodapati JD, Shaik NS, Naralasetti V (2021) Composite deep neural network with gated-attention mechanism for diabetic retinopathy severity classification. J Ambient Intell Humaniz Comput 12(10):9825–9839
Butt MM, Iskandar DA, Abdelhamid SE, Latif G, Alghazo R (2022) Diabetic retinopathy detection from fundus images of the eye using hybrid deep learning features. Diagnostics 12(7):1607
Choo PP, Din NM, Azmi N, Bastion M-LC (2021) Review of the management of sight-threatening diabetic retinopathy during pregnancy. World J Diabetes 12(9):1386
Dai L, Wu L, Li H, Cai C, Wu Q, Kong H, Liu R, Wang X, Hou X, Liu Y et al (2021) A deep learning system for detecting diabetic retinopathy across the disease spectrum. Nat Commun 12(1):3242
Das D, Biswas SK, Bandyopadhyay S (2022) A critical review on diagnosis of diabetic retinopathy using machine learning and deep learning. Multimed Tools Appl 81(18):25613–25655
Das S, Kharbanda K, Suchetha M, Raman R, Dhas E (2021) Deep learning architecture based on segmented fundus image features for classification of diabetic retinopathy. Biomed Signal Process Control 68:102600
Dastane DO (2020) The impact of technology adoption on organizational productivity. J Ind Distrib Bus 11(4):7–18
Dayana AM, Emmanuel WS (2022) An enhanced swarm optimization-based deep neural network for diabetic retinopathy classification in fundus images. Multimed Tools Appl 81(15):20611–20642
Dayana AM, Emmanuel WS (2022) Deep learning enabled optimized feature selection and classification for grading diabetic retinopathy severity in the fundus image. Neural Comput Appl 34(21):18663–18683
Dayana AM, Emmanuel WS (2023) A comprehensive review of diabetic retinopathy detection and grading based on deep learning and metaheuristic optimization techniques. Arch Comput Methods Eng, 1–35
Dihin RA, Al-Jawher WAM, AlShemmary EN (2022) Diabetic retinopathy image classification using shift window transformer. Int J Innov Comput 13(1–2):23–29
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, et al. (2020) An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Dutta P, Sathi KA, Hossain MA, Dewan MAA (2023) Conv-vit: a convolution and vision transformer-based hybrid feature extraction method for retinal disease detection. J Imaging 9(7):140
Elaouaber Z, Feroui A, Lazouni M, Messadi M (2023) Blood vessel segmentation using deep learning architectures for aid diagnosis of diabetic retinopathy. Comput Methods Biomech Biomed Eng: Imaging Visual 11(4):1463–1477
Elloumi Y, Abroug N, Bedoui MH (2022) End-to-end mobile system for diabetic retinopathy screening based on lightweight deep neural network. International symposium on intelligent data analysis. Springer, Newyork, pp 66–77
Elloumi Y, Mbarek MB, Boukadida R, Akil M, Bedoui MH (2021) Fast and accurate mobile-aided screening system of moderate diabetic retinopathy. In: Thirteenth International Conference on Machine Vision, vol. 11605, pp. 232–240. SPIE
Elwin JGR, Mandala J, Maram B, Kumar RR (2022) Ar-hgso: autoregressive-henry gas sailfish optimization enabled deep learning model for diabetic retinopathy detection and severity level classification. Biomed Signal Process Control 77:103712
Erciyas A, Barışçı N (2021) An effective method for detecting and classifying diabetic retinopathy lesions based on deep learning. Comput Math Methods Med 2021:1–13
Fan R, Liu Y, Zhang R (2021) Multi-scale feature fusion with adaptive weighting for diabetic retinopathy severity classification. Electronics 10(12):1369
Feng X, Xiu Y-H, Long H-X, Wang Z-T, Bilal A, Yang L-M (2024) Advancing single-cell rna-seq data analysis through the fusion of multi-layer perceptron and graph neural network. Brief Bioinform 25(1):481
Fisher DE, Jonasson F, Klein R, Jonsson PV, Eiriksdottir G, Launer LJ, Gudnason V, Cotch MF (2016) Mortality in older persons with retinopathy and concomitant health conditions: the age, gene/environment susceptibility-reykjavik study. Ophthalmology 123(7):1570–1580
Goel S, Gupta S, Panwar A, Kumar S, Verma M, Bourouis S, Ullah MA (2021) Deep learning approach for stages of severity classification in diabetic retinopathy using color fundus retinal images. Math Probl Eng 2021:1–8
Gu Z, Li Y, Wang Z, Kan J, Shu J, Wang Q et al (2023) Classification of diabetic retinopathy severity in fundus images using the vision transformer and residual attention. Comput Intell Neurosci 2023:1305583
Gunasekaran K, Pitchai R, Chaitanya GK, Selvaraj D, Annie Sheryl S, Almoallim HS, Alharbi SA, Raghavan S, Tesemma BG (2022) A deep learning framework for earlier prediction of diabetic retinopathy from fundus photographs. BioMed Res Int 2022:3163496
Gundluru N, Rajput DS, Lakshmanna K, Kaluri R, Shorfuzzaman M, Uddin M, Rahman Khan MA (2022) Enhancement of detection of diabetic retinopathy using harris hawks optimization with deep learning model. Comput Intell Neurosc 2022:8512469
Gupta S, Thakur S, Gupta A (2022) Optimized hybrid machine learning approach for smartphone based diabetic retinopathy detection. Multimed Tools Appl 81(10):14475–14501
Hasan MK, Habib AA, Islam S, Safie N, Ghazal TM, Khan MA, Alzahrani AI, Alalwan N, Kadry S, Masood A (2024) Federated learning enables 6 g communication technology: requirements, applications, and integrated with intelligence framework. Alex Eng J 91:658–668
Hassan D, Gill HM, Happe M, Bhatwadekar AD, Hajrasouliha AR, Janga SC (2022) Combining transfer learning with retinal lesion features for accurate detection of diabetic retinopathy. Front Med 9:1050436
Hossain S, Chakrabarty A, Alam GR (2023) Diabetic retinopathy classification using visiontransformer architectures and deep learning
Jena PK, Khuntia B, Palai C, Nayak M, Mishra TK, Mohanty SN (2023) A novel approac for diabetic retinopathy screening using asymmetric deep learning features. Big Data Cogn Comput 7(1):25
Jian M, Chen H, Tao C, Li X, Wang G (2023) Triple-drnet: a triple-cascade convolution neural network for diabetic retinopathy grading using fundus images. Comput Biol Med 155:106631
Kadan AB, Subbian PS (2021) Optimized hybrid classifier for diagnosing diabetic retinopathy: iterative blood vessel segmentation process. Int J Imaging Syst Technol 31(2):1009–1033
Kamarudin D, Safie N, Sallehudin H (2022) Electronic personal health record assessment methodology: a review. Int J Adv Comput Sci Appl13(7)
Kanimozhi J, Vasuki P, Roomi SMM (2021) Fundus image lesion detection algorithm for diabetic retinopathy screening. J Ambient Intell Humaniz Comput 12:7407–7416
Khan Z, Khan FG, Khan A, Rehman ZU, Shah S, Qummar S, Ali F, Pack S (2021) Diabetic retinopathy detection using vgg-nin a deep learning architecture. IEEE Access 9:61408–61416
Khan AI, Kshirsagar PR, Manoharan H, Alsolami F, Almalawi A, Abushark YB, Alam M, Chamato FA et al (2022) Computational approach for detection of diabetes from ocular scans. Comput Intell Neurosci 2022:5066147
Khan IU, Raiaan MAK, Fatema K, Azam S, Rashid Ru, Mukta SH, Jonkman M, De Boer F (2023) A computer-aided diagnostic system to identify diabetic retinopathy, utilizing a modified compact convolutional transformer and low-resolution images to reduce computation time. Biomedicines 11(6):1566
Khaparde A, Chapadgaonkar S, Kowdiki M, Deshmukh V (2023) An attention-based swin u-net-based segmentation and hybrid deep learning based diabetic retinopathy classification framework using fundus images. Sens Imaging 24(1):20
Krishnamoorthy S, Weifeng Y, Luo J, Kadry S (2023) Ao-hrcnn: archimedes optimization and hybrid region-based convolutional neural network for detection and classification of diabetic retinopathy. Artifi Intell Rev 56:1–29
Kshirsagar PR, Manoharan H, Meshram P, Alqahtani J, Naveed QN, Islam S, Abebe TG et al (2022) Recognition of diabetic retinopathy with ground truth segmentation using fundus images and neural network algorithm. Comput Intell Neurosci 2022:8356081
Kukkar A, Gupta D, Beram SM, Soni M, Singh NK, Sharma A, Neware R, Shabaz M, Rizwan A (2022) Optimizing deep learning model parameters using socially implemented iomt systems for diabetic retinopathy classification problem. IEEE Trans Comput Soc Syst 4:1654–1665
Lalithadevi B, Krishnaveni S (2022) Detection of diabetic retinopathy and related retinal disorders using fundus images based on deep learning and image processing techniques: a comprehensive review. Concurr Comput: Practice Exp 34(19):7032
Li Z, Han Y, Yang X (2023) Multi-fundus diseases classification using retinal optical coherence tomography images with swin transformer v2. J Imaging 9(10):203
Liu R, Gao S, Zhang H, Wang S, Zhou L, Liu J (2022) Mtnet: a combined diagnosis algorithm of vessel segmentation and diabetic retinopathy for retinal images. PLoS ONE 17(11):0278126
Luo X, Wang W, Xu Y, Lai Z, Jin X, Zhang B, Zhang D (2023) A deep convolutional neural network for diabetic retinopathy detection via mining local and long-range dependence. CAAI Trans Intell Technol 9(1):153–166
Mahmoud MH, Alamery S, Fouad H, Altinawi A, Youssef AE (2021) An automatic detection system of diabetic retinopathy using a hybrid inductive machine learning algorithm. Pers Ubiquitous Comput, 1–15
Mehta S, Rastegari M (2021) Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer. arXiv preprint arXiv:2110.02178
Menaouer B, Dermane Z, El Houda Kebir N, Matta N (2022) Diabetic retinopathy classification using hybrid deep learning approach. SN Comput Sci 3(5):357
Modi P, Kumar Y (2023) Smart detection and diagnosis of diabetic retinopathy using bat based feature selection algorithm and deep forest technique. Comput Indus Eng 182:109364
Murugappan M, Prakash N, Jeya R, Mohanarathinam A, Hemalakshmi G, Mahmud M (2022) A novel few-shot classification framework for diabetic retinopathy detection and grading. Measurement 200:111485
Nadeem MW, Goh HG, Hussain M, Liew S-Y, Andonovic I, Khan MA (2022) Deep learning for diabetic retinopathy analysis: a review, research challenges, and future directions. Sensors 22(18):6780
Nahiduzzaman M, Islam MR, Goni MOF, Anower MS, Ahsan M, Haider J, Kowalski M (2023) Diabetic retinopathy identification using parallel convolutional neural network based feature extractor and elm classifier. Expert Syst Appl 217:119557
Naik S, Kamidi D, Govathoti S, Cheruku R, Mallikarjuna Reddy A (2023) Efficient diabetic retinopathy detection using convolutional neural network and data augmentation. Soft Comput 27:1–12
Nair AT, Muthuvel K (2021) Automated screening of diabetic retinopathy with optimized deep convolutional neural network: enhanced moth flame model. J Mechan Med Biol 21(01):2150005
Narhari BB, Murlidhar BK, Sayyad AD, Sable GS (2021) Automated diagnosis of diabetic retinopathy enabled by optimized thresholding-based blood vessel segmentation and hybrid classifier. Bio-Algorithms Med-Syst 17(1):9–23
Nawaz F, Ramzan M, Mehmood K, Khan HU, Khan SH, Bhutta MR (2021) Early detection of diabetic retinopathy using machine intelligence through deep transfer and representational learning. Comput Mater Continua 66(3):1631–1645
Nguyen PT, Huynh VB, Vo KD, Phan PT, Yang E, Joshi GP (2021) An optimal deep learning based computer-aided diagnosis system for diabetic retinopathy. Comput Mater Contin 66(3):2815–2830
Nneji GU, Cai J, Deng J, Monday HN, Hossin MA, Nahar S (2022) Identification of diabetic retinopathy using weighted fusion deep learning based on dual-channel fundus scans. Diagnostics 12(2):540
Ozbay E (2023) An active deep learning method for diabetic retinopathy detection in segmented fundus images using artificial bee colony algorithm. Artif Intell Rev 56(4):3291–3318
Palaniswamy T, Vellingiri M (2023) Internet of things and deep learning enabled diabetic retinopathy diagnosis using retinal fundus images. IEEE Access 11:27590–27601
Parthiban K, Kamarasan M (2023) Diabetic retinopathy detection and grading of retinal fundus images using coyote optimization algorithm with deep learning. Multimed Tools Appl 82(12):18947–18966
Parvaiz A, Khalid MA, Zafar R, Ameer H, Ali M, Fraz MM (2023) Vision transformers in medical computer vision-a contemplative retrospection. Eng Appl Artif Intell 122:106126
Priya R, Aruna P (2013) Diagnosis of diabetic retinopathy using machine learning techniques. ICTACT J Soft Comput 3(4):563–575
Pugal Priya R, Saradadevi Sivarani T, Gnana Saravanan A (2022) Deep long and short term memory based red fox optimization algorithm for diabetic retinopathy detection and classification. Int J Numer Methods Biomed Eng 38(3):3560
Qureshi I, Ma J, Abbas Q (2021) Diabetic retinopathy detection and stage classification in eye fundus images using active deep learning. Multimed Tools Appl 80:11691–11721
Radha K, Karuna Y (2023) Retinal vessel segmentation to diagnose diabetic retinopathy using fundus images: a survey. Int J Imaging Syst Technol 34:e22945
Ragab M, AL-Ghamdi AS, Fakieh B, Choudhry H, Mansour RF (2022) Prediction of diabetes through retinal images using deep neural network. Comput Intell Neurosci 2022:7887908
Raiaan MAK, Fatema K, Khan IU, Azam S, Rashid MR, Mukta MSH, Jonkman M, De Boer F (2023) A lightweight robust deep learning model gained high accuracy in classifying a wide range of diabetic retinopathy images. IEEE Access 11:42361–42388
Raja Sarobin MV, Panjanathan R (2022) Diabetic retinopathy classification using cnn and hybrid deep convolutional neural networks. Symmetry 14(9):1932
Rajamani S, Sasikala S (2023) Artificial intelligence approach for diabetic retinopathy severity detection. Informatica 46(8):195–204
Raman R, Gella L, Srinivasan S, Sharma T (2016) Diabetic retinopathy: an epidemic at home and around the world. Indian J Ophthalmol 64(1):69
Ramasamy LK, Padinjappurathu SG, Kadry S, Damaševičius R (2021) Detection of diabetic retinopathy using a fusion of textural and ridgelet features of retinal images and sequential minimal optimization classifier. PeerJ Comput Sci 7:456
Rayavel P, Murukesh C (2022) Comparative analysis of deep learning classifiers for diabetic retinopathy identification and detection. The Imaging Sci J 70(6):358–370
Sadiq RB, Safie N, Abd Rahman AH, Goudarzi S (2021) Artificial intelligence maturity model: a systematic literature review. PeerJ Comput Sci 7:661
Saeed F, Hussain M, Aboalsamh HA (2021) Automatic diabetic retinopathy diagnosis using adaptive fine-tuned convolutional neural network. IEEE Access 9:41344–41359
Saeedi P, Petersohn I, Salpea P, Malanda B, Karuranga S, Unwin N, Colagiuri S, Guariguata L, Motala AA, Ogurtsova K et al (2019) Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: results from the international diabetes federation diabetes atlas. Diabetes Res Clin Pract 157:107843
Saini M, Susan S (2022) Diabetic retinopathy screening using deep learning for multi-class imbalanced datasets. Comput Biol Med 149:105989
Sau PC, Bansal A (2022) A novel diabetic retinopathy grading using modified deep neural network with segmentation of blood vessels and retinal abnormalities. Multimed Tools Appl 81(27):39605–39633
Schloemer T, Schröder-Bäck P (2018) Criteria for evaluating transferability of health interventions: a systematic review and thematic synthesis. Implement Sci 13:1–17
Senapati A, Tripathy HK, Sharma V, Gandomi AH (2024) Artificial intelligence for diabetic retinopathy detection: a systematic review. Inform Med Unlocked 45:
Shankar K, Perumal E, Elhoseny M, Nguyen PT (2021) An iot-cloud based intelligent computer-aided diagnosis of diabetic retinopathy stage classification using deep learning approach. Comput, Mater Continua 66(2):1665–1680
Shera A, Jawad F, Maqsood A (2007) Prevalence of diabetes in pakistan. Diabetes Res Clin Pract 76(2):219–222
Sungheetha A et al (2021) Design an early detection and classification for diabetic retinopathy by deep feature extraction based convolution neural network. J Trends Comput Sci Smart Technol 3(2):81–94
Tajudin NMA, Kipli K, Mahmood MH, Lim LT, Awang Mat DA, Sapawi R, Sahari SK, Lias K, Jali SK, Hoque ME (2022) Deep learning in the grading of diabetic retinopathy: a review. IET Comput Vision 16(8):667–682
Taranum MPL, Rajashekar JS (2022) Image based edge weighted linked segmentation model using deep learning for detection of diabetic retinopathy. Traitement du Signal 39(1):165–172
Thomas R, Halim S, Gurudas S, Sivaprasad S, Owens D (2019) Idf diabetes atlas: A review of studies utilising retinal photography on the global prevalence of diabetes related retinopathy between 2015 and 2018. Diabetes Res Clin Pract 157:107840
Thomas J, Harden A (2008) Methods for the thematic synthesis of qualitative research in systematic reviews. BMC Med Res Methodol 8:1–10
Uppamma P, Bhattacharya S (2023) Diabetic retinopathy detection: a blockchain and african vulture optimization algorithm-based deep learning framework. Electronics 12(3):742
Uppamma P, Bhattacharya S, et al. (2023) Deep learning and medical image processing techniques for diabetic retinopathy: a survey of applications, challenges, and future trends. J Healthcare Eng2023
Vasireddi HK, K SD, GNV RR (2022) Deep feed forward neural network–based screening system for diabetic retinopathy severity classification using the lion optimization algorithm. Graefe’s Arch Clin Exp Ophthalmol, 1–19
Venkaiahppalaswamy B, Reddy PP, Batha S (2023) Hybrid deep learning approaches for the detection of diabetic retinopathy using optimized wavelet based model. Biomed Signal Process Control 79:104146
Vij R, Arora S (2023) A systematic review on diabetic retinopathy detection using deep learning techniques. Arch Comput Method Eng 30(3):2211–2256
Vinayaki VD, Kalaiselvi R (2022) Multithreshold image segmentation technique using remora optimization algorithm for diabetic retinopathy detection from fundus images. Neural Process Lett 54(3):2363–2384
Wan Z, Wan J, Cheng W, Yu J, Yan Y, Tan H, Wu J (2023) A wireless sensor system for diabetic retinopathy grading using mobilevit-plus and resnet-based hybrid deep learning framework. Appl Sci 13(11):6569
Wang Z, Lu H, Yan H, Kan H, Jin L (2023) Vison transformer adapter-based hyperbolic embeddings for multi-lesion segmentation in diabetic retinopathy. Sci Rep 13(1):11178
Wenhua Z, Hasan MK, Jailani NB, Islam S, Safie N, Albarakati HM, Aljohani A, Khan MA (2024) A lightweight security model for ensuring patient privacy and confidentiality in telehealth applications. Comput Hum Behav 153:108134
Wong TY, Sabanayagam C (2020) Strategies to tackle the global burden of diabetic retinopathy: from epidemiology to artificial intelligence. Ophthalmologica 243(1):9–20
Yadav P, Singh NP (2019) Classification of normal and abnormal retinal images by using feature-based machine learning approach. In: Recent Trends in Communication, Computing, and Electronics: Select Proceedings of IC3E 2018, pp. 387–396. Springer
Yu X, Ren J, Long H, Zeng R, Zhang G, Bilal A, Cui Y (2024) idna-openprompt: openprompt learning model for identifying dna methylation. Front Genet 15:1377285
Zhang Q-m, Luo J, Cengiz K (2021) An optimized deep learning based technique for grading and extraction of diabetic retinopathy severities. Informatica 45(5):659–665
Zhang C, Chen C, Chen C, Lv X (2023) Smit: symmetric mask transformer for disease severity detection. J Cancer Res Clin Oncol, 1–12
Acknowledgements
This research is funded under the research grant number TAP-K021309.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Haq, N.U., Waheed, T., Ishaq, K. et al. Computationally efficient deep learning models for diabetic retinopathy detection: a systematic literature review. Artif Intell Rev 57, 309 (2024). https://doi.org/10.1007/s10462-024-10942-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s10462-024-10942-9